2004 EEE
Asia-Pacific Conference on Advanced System Integrated Circuits(AP-ASIC2004)I Aug. 4-5,2004
4-2
A Fast and Power-Saving Self-Timed Manchester Carry-Bypass Adder for
Booth Multiplier-Accumulator Design
*I-Chyn Wey, Hwang-Cherng Chow, You-Gang Chen, and *An-Yeu Wu
*
Graduate Institute of Electronics Engineering, National Taiwan UniversityNo.1, Sec. 4, Rwsevelt Road, Taipei 106, Taiwan Institute of Semiconductor Technology, Chang Gung University
Kwei-Shan, Tao-Yuan 333, Taiwan.
Email: [email protected], [email protected], m9 I2820 1 @stmail.cgu.edu.hv, [email protected]
Abstract
In this paper, a fast and power-saving self-timed Manchester Cany-Bypass Adder (MCBA) is proposed based on the property analysis of the MCBA completion signal. By using a new self-timed approach, the critical path in the summation array of Multiplier-Accumulator (MAC) can be removed without conventional dual MCBA chain circuit. As a result, the speedof the proposed self-timed MCBA can be improved 23.3% and save 56.8% power consumption. Finally, a 16-bit* Ih-bit+40-bit Booth MAC with this new self-timed MCBA is demonstrated at 2.5V. I5OMHz in UMC 0.25um process with 71.28mW power only.
1. Introduction
A digital MAC is one of the main fundamental kernels in digital signal processors (DSP) [ I ] . Developing a high speed MAC is crucial for real-time DSP applications. Moreover, low power design for MAC is more challenging for portable applications, and consumer electronics [2].
To meet the speed constraint of 16-bit*16-bit+40-bit MAC in the DSP applications about IOOMHz, a
glitch-free modified Booth encoding scheme [3] is adopted to reduce the number of additions in multiplication. Besides, the Wallace tree architecture [4] is applied to accelerate the summation speed in the partial product array, and the fast adders are Constructed by MCBA [ 5 ] to accelerate the carry propagation in the adder with two input operands. In the synchronous MAC without pipeline arrangement, the self-timed circuit design technique must be adopted in the design of Manchester carry chain. The self-timed technique is thought to he power saving [6]; however, the generation of completion-signal is very complex, which would lead to the area and power penalty because of the usage of dual-chain design [7,9,10]. Therefore, we will propose a new self-timed design of MCBA without dual chain, which can speed up ahout 23.3% and save 56.8% power. 2. Proposed MAC architecture and circuit design
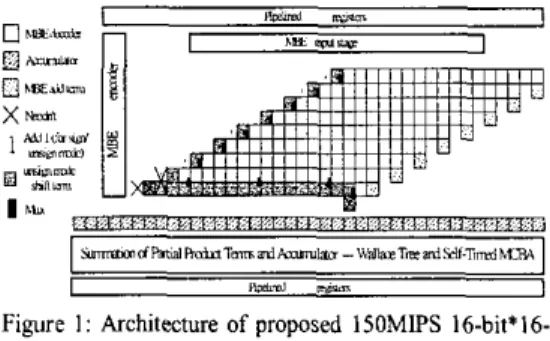
For the design of low power Booth MAC we adopt a high speed, glitch-free MBE recoding scheme [4] in the pan of partial product generation scheme to accelerate the speed and save glitch power dissipation. The parlial
product summation array is constructed by the full adder based Wallace tree architecture as illustrated in Figure 1. By this way, we can accelerate the summation speed by parallel addition and save power by reducing the adder number as compared to the carry-save architecture. The fast adder always lies in the critical path in the synchronous non-pipelined MAC, no matter in the panial product summation m a y , in the final stage adder, or in the accumulator In order to meet the low power demand, the fast adder is constructed by the self-timed MCBA instead of the carrylookahead adder, which can save large power since the parallel styled implementation of fast adder is replaced by serial-chained architecture. All I-bit adder cells are constructed by static mirror adders. The proposed low power MAC is designed without static power loss, and finally all the sub-cells are designed in a fully hierarchical manner.
-
.."axId
I
1
0-7803-8637-X/04/$20.00~2004
IEEE.
50 I I I WdFigure I: Architecture of proposed 150MlPS 16-bi1'16- bitf4O-bit MAC
3. New self-timed Manchester carry-bypass adder In the synchronous MAC without pipeline arrangement, the self-timed circuit design techniques must be adopted in the design of Manchester carry chain. The self-timed techniques is thought to be power saving; however, the speed in the conventional clock-delayed self-timed design [7] is slow. Moreover, the extra MCBA-delayed circuit is needed, which would lead to extra power consumption and extra area penalty. The design of MCBA-delayed circuit can choose simply inverier-based delay buffer or copy of original MCBA circuit to serve
as the MCBA delay. The former choice
can save power and area, while the latter design is more reliable since the delay time in MCBA varies with the process deviation. Another well-known self-timed2004 IEEE
Asia-Pacific Conferenceon
Advanced System Integrated Circuits(AP-ASIC2004)I Aug. 4-5,2004approach icce1eriltcs the , p e d h) urmg thr generation of a zumplr.lion signal [7,Y,IO]. In this case, the clock delay
in w c h mgr. I . n o mors the cntiial MCDA dela). uhich is replaxd with the average of \ICBA dela) Thcrcfure. the spsed in the self-tiinzd .MCBA can be accelerated.
h m w e r , the C ~ I I I C J ~ plrlh IS ,1111 t h s s3mc hlorcoicr. the genrrdtion uf the cornplrtiun signal of Alancherter carq chdin IS ver) complex. uhich uould lead IJ the area and
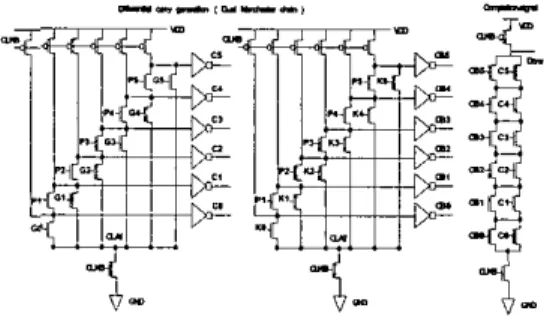
puuer pm3lty lliir I U the w a g e df dual-cham d e w g [7.Y.IU]. The example of 6-hit dudl-ch3in self-tmid \Im:heter adder 1s hhoivn in Figure 2. In I;ipre 2, there
mu51 be one s i p a l i n c v c y CI and C H I p i r s i, ” I ” In the
c ~ a l u ~ t i s ~ n penod: thcreforc, the “Done” signal cdn be
,em out to the next sta&!c tu inform they (tan tu cumpure. This method can be designed with nnl) lmle speed pendty; however. the penalty spent in area. and po\\er is qullc ser1uus.
----I-
-
-la
$-
-i
+-
Figure 2: A 6-bit dual-chain self-timed Manchester adder In this paper, we propose a new self-timed approach in the design of Manchester carry chain to overcome the speed bottleneck in the critical path of summation array and the dual-chain used to generate the completion-signal of Manchester carry chain is no more needed. First, we consider the characteristics of dynamic circuits. In the evaluation period of dynamic circuits, if the function is implemented by the NMOS network, we can tolerate the input signal changing from logic “0” to logic “1”; however, the case of input signal changing from logic “1” to logic “0” is not allowed. In the Manchester carry chain, the sigual in the cany out nodes are either maintained in stable as logical “0” or changed from logic “0” to logic “I”; therefore, the carry out signals io the Manchester cany chain possess the property that can be used to be a completion signal sent to the next dynamic stage. However, in the actual design of Manchester carry bypass adder, the carry out in the present stage does not directly be connected to the NMOS gate
of
dynamic circuit in the next stage. Hence we must further ensure that the signal sent to the next dynamic stage can still maintain the properly of either kept in stable or simply changed from logic “0” to logic “I”. First, we can find the “generate” signal go constructed by the “ A N D gate can also maintain such property since the carry out signals in the Manchester carry chain will arrive in the dynamic gate latter and the carry out signal would never be stable as logical “1” during one clock cycle. And then we can also find that the “propagate” signalpo
doesn’t connect to the dynamic gate. This point demonstrates that we can directly send the carry out signals in the Manchester carrychain to the next stage. And we can use the delay module constructed by the full adder to generate the asynchronous clock as completion signal. The demonstration of operation timing in our proposed self-timed MCBA is illustrated in Figure 3.
I .
Figure 3: The operation timing in our proposed self-timed MCBA
By this way, the critical path in the summation array can be removed, and the dual-chain used to generate completion signal is needn’t. Therefore, the speed can be faster and the power can be greatly saved in the proposed self-timed MCBA. Moreover, since the MCBA doesn’t lie in the critical path of summation array, the size in the self-timed MCBA can be further reduced and the power consumption can be reduced. “he complete proposed %bit self-timed MCBA is presented in Figure 4. By using our proposed self-timed Manchester adder, the critical path in the summation array of MAC lies in the full adder rather than in the fast adder.
I
..._.
Figure 4: The proposed &bit self-timed MCBA 4. Performance comparisons and simulation results
The detailed comparison of various self-timed approaches is illustrated in Figure 5 . In the conventional self-timed approach by using delayed clock, the delay of asynchronous clock is constructed by the worst MCBA delay to guarantee the correct function. Therefore, the speed is quite slow and the delay time of asynchronous clock would vary with the process deviation. Also the power consumption and the area would increase because of the usage of extra MCBA delay circuit.
In
the conventional self-timed approach by using completion signal generation [7,9,10], the asynchronous control2004 IEEE Asia-Pacific Conference on Advanced System Integrated Circuits(AP-ASIC2004)i Aug. 4-5,2004
signal is generated by the MCBA completion signal generation circuit. Consequently, the speed is moderate, which is the average delay time of the MCBA circuit. By using such approach, the power consumption and the area increase greatly because of the usage of dual MCBA chain to generate the completion signal. Moreover, both conventional approaches mentioned above lie in the critical path of summation amy. In the proposed new self-timed approach, the delay time of asynchronous clock is the worst delay in the full adder, which is tolaant to the process deviation. Therefore, the speed is fast and the proposed self-timed MCBA does not lie in the critical path of summation array, while the critical path still exists in the full adder. Moreover, the power consumption and the area can be greatly reduced because the full adder delay is quite small and the MCBA circuit doesn’t lie in the critical path.
I
MCBAI I I I I I I
m,
MCBA
I 1 1 1 1 I I I I I I I I
(C)
Figure 5 : The various self-timed approaches
(a) conventional self-timed MCBA with delayed clock (b) conventional self-timed MCBA with completion signal generation (c) proposed new self-timed approach
Fr-
wllb
Figure 6: The operation timing analysis and comparisons
of various self-timed approaches
The comparison of operation timing between various self-timed approaches is illustrated in Figure 6. In
the proposed self-timed MCBA. the evaluation period in each stage can s m as the output signal of the full adder
is stable. In the conventional completion signal generation self-timed approach, the start of evaluation period is controlled by the MCBA completion signal. In the conventional delayed clock self-timed approach, the evaluation period in each stage can start only as the output signal of the MCBA in the previous stage is stable. As illustration in Figure 6, the speed in our proposed design is the fastest, and the speed in the conventional self-timed approach by using delayed clock i s the slowest.
Transistor level simulation results are performed based on UMC 0.25um process, 2.5V supply voltage, and ISOMHz clock frequency with Ins nieifall time by HSPICE.
Table 1 presents the comparison results of high- speed mux-based CLA [SI, self-timed MCBA by using inverter-based delayed clack [7]; denoted as [7-I], self-timed MCBA by using MCBA-based delayed clock [7]; denoted as [7-21, self-timed MCBA by using completion s i p a l generation [7,9,10]; denoted as [7-31, and the proposed new self-timed MCBA. From Table 1, our new design shows minimal transistor count of only
344, and the speed bottleneck in the partial product
summation array can be removed from the self-timed MCBA with improvement of 13.8%. 21.3%. 29.1%, and 23.3% over [SI, [7-1], [7-2], and [7-31, respectively. And the proposed self-timed MCBA possesses good process deviation tolerance. As for the comparison of power consumption, our proposed design consumes the lowest energy of 1.83mw, with improvement of 73.2%, 30.4%.
60.4%, and 56.8% over [E], [7-I], [7-21, and [7-31,
respectively. Also, the new design has a minimal power delay product value with improvement of 77.1%, 45.5%,
72.1%, and 67.1% over [SI, [7-I], [7-21, and [7-31,
respectively.
Table 1: Comparisons of various 8-bit self-timed fast adders
M*C.P U A C I L A Y*C.II-J,
Figure 7: Performance comparisons of various MAC Designs
2004 IEEE Asia-Pacific Conference on Advanced System Integrated Circuits(AP-ASIC2004)/ Aug. 4-5,2004
Figure 7 illustrates the performance comparisons of various MAC designs, where MAC-P represenu the MAC with proposed self-timed MCBA, MAC-CLA represents the MAC with carry-lookahead adder, and MAC_[7-3] represents the MAC with self-timed MCBA in [7-31. In Figure 7, at nearly the same speed, the MAC with proposed self-timed MCBA consumes the minimal power of only 71.28mw. which saves 51.12mw and 25.98mw with respect to MAC-CLA and MAC-[7-3].
Figure 8: Waveform of the proposed low power Booth MAC at 2.5V, I50MHz
The function of MAC is verified to be correct by using gate-level simulation. The timing is further verified by HSPICE simulation based on UMC 0.25um process and the 40-bit MAC output waveforms, denoted as macpp<O> to macpp<39>, are illustrated in Figure 8.
Table 2: Summary of performance results
Process
I
L'MC 0.25umSuppl) Voltage 2.5V
Transistor count
71.28mw
Finally, Table 2 shows the performance summary of the proposed low power Booth MAC with new self-timed MCBA. In Table 2, we show that total transistor number in the proposed MAC is 10468, and the average power consumption is only 71.28mw as operating at 2.5V. 15OMHz corresponding to the input pattern with 25.78% transition probability.
5. Conclusion
In this paper, a fast and power-saving self-timed MCBA without dual chain is proposed. The new self-timed MCBA is designed based on the analysis of the prapelty of completion signal and input signal of MCBA. By using a new self-timed approach, the critical path in the summation army of MAC can be removed. As a result, in the proposed self-timed MCBA, the delay is only 0.56ns with 23.3% improvement and the power consumption is only 1.83mw with 56.8% improvement as
compared to the self-timed MCBA with completion signal generation. Finally, a 16-bit' 16-bit+40-bit Booth MAC with this new self-timed MCBA is demonstrated at 2.5V. l5OMHz in UMC 0.25um process with 71.28mW power only. Therefore, the proposed self-timed design for Booth MAC is very suitable for low power and fast DSP applications.
References
[I] D. A. Pucknell and K. Eshraghan,"Basic VLSl Design", Prentice Hall, pp. 240-253, 1994.
[2] A. M. Shams, W. M. Badawy, and M. A. Bayoumi, "An Enhanced Low-Power Computational Kernel for a Pipelined Multiplier- Accumulator Unit," Proc. of the 10th International Conference on Microelectronics, pp. 33-36, 1998.
[3]H.C.ChowandI.C. Wey,"A3.3V IGHzhighspeed pipelined Booth multiplier" Proc. IEEE International Symp. on Circuits and Systems, vol. 1 , pp. 457460, 2002.
[4] C. S. Wallace, "A Suggestion for Fast Multiplier," IEEE Trans. on Electronic Computers, Volume EC-13, pp. 14-17, February 1964.
[5] H. C. Chow and 1. C. Wey, "A 3.3V IGHz Low-Latency Pipelined Booth Multiplier with New Manchester CanyBypass Adder" Roc. IEEE International SvmD. on Circuits and Svstems.
. .
vol. 5....
DO.121-124,2003.
161 C. I. IOU and I. Y. Cbuant. " Low-Power Globallv
. .
-
AcynLhronous Locally Synchronous Design U,ing Svif-Timed Circuit Technology" Proc IEEE Intffnitional S) mp. on Circuits and S)ncms. (U]. 3, pp. IhOX-1811, I9Y7.
171 1. M Hrbse). "Digital Integrated Circuits," I'renriie Hall, sccund edition, 2003.
181 K. K. Psrhi, "VLSI Digital Signal Processing S)stcrnc.
I)esign and Implementation,'' Wilcy-litterscience. i 999.
I w k a h a d 3ddcr using inultiple-output DCVSL." Proc ofthc 6th lntmational Conierence on VLSl and
CAD.
[ I O ] G A . Rub, and M.A. Manzano, "Compact 32-hlt
i'\fOS Adder in mbltiple-output DCVS logic for self-tinted circutts," ILI: Proc. Circuits. Devices and System, pp 183-IXX. 1999.
[9] J. II Won and K Choi,"Scif-timed statistical carry
pp. 560.563, I Y P ~ .

![Figure 7 illustrates the performance comparisons of various MAC designs, where MAC-P represenu the MAC with proposed self-timed MCBA, MAC-CLA represents the MAC with carry-lookahead adder, and MAC_[7-3] represents the MAC with sel](https://thumb-ap.123doks.com/thumbv2/9libinfo/8687666.197952/4.918.163.434.258.688/illustrates-performance-comparisons-represenu-proposed-represents-lookahead-represents.webp)
