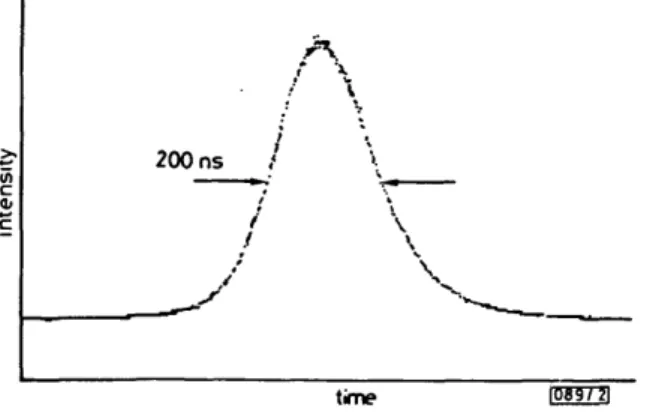
output pulse obtained for a 100 Hz repetition rate and a high Q period of 5 /zs. A peak power of approximately 8-8 W was achieved in a pulse of 200 ns duration. This pulse duration is in good agreement with the calculated value. The fibre laser
A
200 nstime GOZ3 Fig. 2 Profile of 108 (im pulse obtained in Q-switched operation
operated in Q-switched mode for a day or more continuously with negligible long-term variation of the pulse shape.
We also investigated the effect of replacing the modulator in the cavity by an ordinary optical chopper wheel. Remarkably, we found that, in spite of the slow switch-on time of the chopper, which was 10 ^s or a few hundred cavity round-trip times, peak powers approaching half those given by the acousto-optic modulator, whose switch-on time was a few nanoseconds, could be achieved. Fig. 3 shows a typical pulse
450 ns
time |069/3|
Fig. 3 Profile of 108 fim pulse obtained by Q-switching with optical
chopper
of 4 W peak power and 450 ns duration obtained in this way. Multiple subsidiary pulses followed the initial pulse and could not readily be eliminated, but the experimental simplicity of this technique, which has no associated problems of alignment and cavity loss, makes it attractive.
Conclusion: We have demonstrated that Q-switching allows an Nd3+-doped monomode fibre laser to produce high peak powers. If the dye laser pump source was replaced by a semi-conductor diode laser as in Reference 1, then a compact high-power source could be envisaged. The same Q-switching techniques described here should also prove suitable for fibre lasers based on other dopant ions. In particular, the ability to use a simple mechanical chopper, with the advantage of low cost and ease of use, looks encouraging.
Acknowledgments: This work has been supported by a grant from the UK SERC and also in part under a JOERS prog-ramme. The authors are grateful to S. Poole and other members of the Fibre Optics Group in the Department of Electronics & Information Engineering, Southampton Uni-versity, for kindly providing the doped fibre. One of us (I. P. Alcock) acknowledges the support of an SERC studentship.
I. P. ALCOCK A. C. TROPPER A. I. FERGUSON D. C. HANNA Department of Physics • University of Southampton
Southampton SO9 5NH, United Kingdom
12th November 1985
References
1 POOLE, S. B., PAYNE, D. N., and FERMANN, M. E.: 'Fabrication of low-loss optical fibres containing rare-earth ions', Electron. Lett., 1985, 21, pp. 737-738
2 MEARS, R. }., REEKIE, L., POOLE, s. B., PAYNE, D. N.:
'Neodymium-doped silica single-mode fibre lasers', ibid., 1985, 21, pp. 738-740
IMPROVED SYSTOLIC ARRAY FOR LINEAR DISCRIMINANT FUNCTION CLASSIFIER
Indexing term: Signal processing
A word-level systolic array with 100% efficiency is described for the linear discriminant function classifier. When com-pared with two previous word-level linear classifier arrays, it not only saves about C inner product step cells, where C is the number of weighted vectors used, but also simplifies the chip's I/O design.
Introduction: The linear discriminant function classifier is widely used in statistical pattern recognition, such as the Euclidean minimum distance classification1 and voiced/ unvoiced classification2 etc. Let X = \_x1x2 ... xn] be a feature
vector and W{ = [wf wf ... w"w" + 1
~\ be the ith weighted vector, where i = 1, 2, . . . , C. Then the ith class linear dis-criminant function is defined as
g.(X) = = X'WJ x2wf XW'i (1) (2) (3)
where X' = [xlx2 ... x"F] and W\ = [w\w2 ... wf]. Following the method used by Urquhart,3 operations of the linear dis-crimint function classifier can be partitioned into: (i) comput-ing g,{X) for i = 1, 2,..., C, and (ii) findcomput-ing the class label /, for which g,{X) is maximum.
To perform the above operations fast, several linear classi-fier arrays whose computations are based on eqn. 2 have been described in References 3 and 4. Those with contraflow possess only 50% efficiency and those with static weighted vectors possess 100% efficiency. However, updating the weighted vectors is much easier to achieve in the former than in the latter. Besides, using eqn. 2, which is an («+ 1)-dimensional inner product computation, to compute the linear discriminant function is not efficient enough in terms of both hardware and computation time, owing to the fact that the last multiplication operation in eqn. 2 is unnecessary. In this letter an improved word-level systolic array with both contra-flow and 100% efficiency is proposed for the linear discrimi-nant function classifier to remove the redundancy and the tradeoff. Moreover, for ease of both constructing a large array from smaller unit chips and interfacing with memory, a byte-serial grouped I/O scheme is described for the chip.
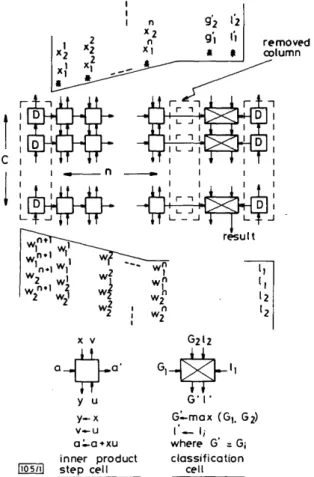
Systolic system: In the proposed array shown in Fig. 1, which is in fact a module for constructing larger arrays, each linear discriminant function is computed from eqn. 3 instead of eqn. 2, i.e. each gt{X) is obtained by performing one
n-dimensional inner product initialised by some proper value. The leftmost column of C delay elements is used to properly provide the initial values. The subarray composed of C x n inner product step cells is used for the computations. The column of C classification cells is used for performing the classification. The rightmost column of C delay elements is used to properly provide the class labels for each current dis-criminant function. When compared with the two word-level arrays in Reference 3, the proposed one requires an additional
2C delay elements, but saves one column of C inner product step cells, as shown by the broken lines in Fig. 1. It is true that the silicon area increased for the former is much less than that decreased for the latter.
In Fig. 1, the augmented feature vector ([xjx? ... x"#}/}]) streams and the modified augmented weighted vector ([_w"+1wl wf ... w"lj) streams move through the array in
1 f y u y - x v—u ai-a+xu inner product step cell • I G ' l ' G^-max (G), C l'— 1; where G' = G classification cell Fig. 1 Proposed linear classifier array module
opposite directions. The former is delayed for C cycle periods (shown by asterisks) to let the 1st feature vector meet the 1st weighted vector at the 1st row. The latter, in which each component occupies two cycle periods, should recirculate con-tinuously in order to process streams of feature vectors. With this arrangement of data flow, it is easy to check that the sequences of weighted vectors in computation with the 1st and the 2nd feature vectors are all 1, 2, ..., C, with the 3rd and the 4th ones all 2, 3, ..., C, 1, and so on. Since all operations are pipelined, the classification results will come out at a rate of one per cycle after some initial delay. Apparently, the pro-posed array module is 100% efficient and its latency is O(C + n) instead of O(C + n + 1).
We can see from Fig. 1 that the weighted vectors can be updated easily and only two symmetrical vector streams are needed to feed in and send out. This is a feature existing in none of the arrays in Reference 3. Hence the chip's I/O design can be greatly simplified. In the following we propose a byte-serial grouped I/O scheme for the system.
The preprocessing circuit shown in Fig. 2, which can be implemented as one additional chip, is used to arrange the
8-bit,
byte -serial/word-parallel shift register
word - parallel /byte-serial shift register
8-bit
Fig. 2 Proposed preprocessing circuit
86
input data flow. Two such circuits are required in the system. One is used for the augmented feature vectors, and the other for the modified augmented weighted vectors. When the byte-serial/word-parallel shift register is filled with consecutive bytes, (n + 2) words are generated and moved down in paral-lel. The delay wedge is used to provide the delay for each word. The function of the word-parallel/byte-serial shift regis-ter is just the inverse of the byte-serial/word-parallel shift register. For the array module, it is easy to understand that two byte-serial/word-parallel and two word-parallel/byte-serial shift registers are enough for the chip's I/O design.
With this I/O scheme, only 32 I/O pins are required in each array chip for any array size, and a complete linear classifier system can be established by cascading one or several array chips (A) and two preprocessing chips (P) together, where the latter is placed at the boundaries (see Fig. 3). Clearly, both
P
A ^ A * ^ Ah
modified I augmented* weighted _^ vectors MEH classification result augmented feature vectorsFig. 3 Complete linear classifier system
chip interconnection and memory interfacing can be achieved easily. However, an extra latching circuit (L) is needed to extract the classification results. As described in Reference 5, two types of timing arrangement can be used for the system: one is that of I/O in parallel with computation, and the other is that of I/O in series with computation.
Conclusions: A word-level linear classifier array with both contraflow and 100% efficiency has been described. When compared with the word-level ones in Reference 3, this array saves about C inner product step cells and has O(C + n) instead of O(C + n + 1) latency, owing to the fact that com-putations are based on eqn. 3 rather than eqn. 2. It also sim-plifies the chip's I/O design, owing to the ease of updating weighted vectors and the symmetry of data flow.
The proposed byte-serial grouped I/O scheme is much easier to implement than the byte-serial grouped scheme described by Chern and Murata,5 owing to the use of byte-serial/word-parallel and word-parallel/byte-serial shift regis-ters rather than demultiplexers, multiplexers and latches to perform the data collection and the data distribution oper-ations. With this I/O scheme, both chip interconnection (for constructing larger arrays) and memory interfacing problems can be solved easily.
CHIN-LIANG WANG CHE-HO WEI SIN-HORNG CHEN*
Institute of Electronics
* Institute of Communication Engineering National Chiao Tung University Hsin-Chu, Taiwan, Republic of China
References
15th November 1985
1 DEVUVER, P. A., and KITTLER, j . : 'Pattern recognition: a statistical approach' (Prentice-Hall Internationak, London, 1982)
2 SIEGEL, L. J.: 'A procedure for using pattern classification tech-niques to obtain a voiced/unvoiced classifier', IEEE Trans., 1979,
ASSP-27, pp. 83-89
3 URQUHART, R. B. : 'VLSI architectures for the linear discriminant function classifier'. Proceedings of IEEE computer society work-shop on computer architectures for pattern analysis and image database management, October 1983, pp. 227-232
4 URQUHART, R. B., and WOOD, D. : 'Systolic matrix and vector multi-plication methods for signal processing', IEE Proc. F, Commun., Radar & Signal Process., 1984,131, pp. 623-631
5 CHERN, M. Y., and MURATA, T.: 'Comparison of various chip-I/O schemes for interconnecting VLSI systolic array processor chips'. Proceedings of IEEE international conference on computer design: VLSI in computers, October 1983, pp. 740-743