具門檻參數之雙變量羅吉斯迴歸的最大概似估計
22
0
0
全文
(2) 220. Ching-Chuan Tsong. area, financial practitioners rely more on direction-of-change forecasts for their investments. For instance, if stock market returns will be higher than the yield of treasury bills, investors should reallocate their funds from the bond market to the stock market to gain more profits. Engel (1994) predicts the direction of change of 18 exchange rates by using the Markov switching model. A challenge that practitioners face is whether or not the event forecasts are accurate. One answer to this issue is to develop an out-of-sample test for evaluating the event forecasts on hand. This financial literature was pioneered by Henricksson and Merton (1981) who proposed the market timing test (henceforth, the HM test). Since then, the HM test has been used in a wide variety of applications. Although the HM test was proposed for this purpose, its use may not be appropriate in time-series situations. Event forecasts-obtained from truncating certain predetermined value of point forecasts generated by estimated econometric models-may be serially correlated. Similarly, event realizations generated by an unknown process are possibly autocorrelated as well. The serial correlation of event forecasts and/or realizations violates the maintained IID assumption for the HM test. In this paper, we first show through a simulation that the IID assumption is crucial for the validity of the HM test. Without this assumption, this test has severe size distortions that can falsely reject the null hypothesis and lead to questionable empirical results. Therefore, a robust test that can account for autocorrelated event forecasts and realizations is extremely important to portfolio managers. However, to our knowledge, the issue has received-and continues to receive-little attention in the financial literature thus far. The conventional HAC robust t-test (e.g., Newey and West, 1987) in a regression framework accommodates serially correlated disturbances, and therefore, it should be a good starting point for getting a robust test. Under the assumption that as the sample size (n) grows, the number (M) of sample autocovariances becomes infinite and the fraction ( M n ) of sample autocovariances for the variance estimator tends to zero, the HAC estimator is consistent for asymptotic variance. Hence, the asymptotics of the HAC robust t-test can be derived as though the variance were known. While the asymptotics follows the standard normal distribution, the HAC robust t-test still has a tendency to over reject the null hypothesis in finite samples (e.g., Andrews, 1991). Therefore, the HAC robust t-test with the standard normal.
(3) Assessing the Accuracy of Event Forecasts. 221. distribution is only a partial solution to the over-sized issue. In practice, however, given a particular data set, a practitioner uses some positive fraction of autocovariances to estimate the asymptotic variance. This implies that M n should be a positive number less than or equal to unity. Based on this fact, Kiefer and Vogelsang (2005) derived a brand-new asymptotic theory for the asymptotic variance estimator under the assumption of M = bn , where b ∈ (0, 1] . While the HAC variance estimator is no longer consistent in this case, its. asymptotic distribution is proportionate to the unknown asymptotic variance and depends on the kernel and b. In addition, the HAC robust t-test has pivotal asymptotics (henceforth, fixed-b asymptotics) that, however, depends on the kernel and b. This differs from the standard normal distribution wherein the effects of kernel and bandwidth are not involved. Derived under the assumption of M = bn , where b ∈ (0, 1] , which reflects the situations in empirical applications, the fixed-b asymptotics is a more accurate approximation to the sampling distribution of the HAC robust t-test than standard normal distribution. Therefore, with the critical value from the fixed-b asymptotics, over-rejections can be reduced remarkably. Bootstrap is an alternative approximation to the sampling distribution of a test statistic. With an appropriate resampling procedure, bootstrap is an effective method to reduce the size distortions of a test statistic (e.g., Davison and Hall, 1993; Lahiri, 1996; Andrew, 2002). Based on this concept, Gonçalves and Vogelsang (2006) proposed the naive block bootstrap, where the formulas used on the bootstrap sample and the original data to compute the test are identical. They showed that the naive block bootstrap has the same large-sample distribution as the fixed-b asymptotics. Most importantly, evidence from our simulation shows that as compared with the fixed-b asymptotics, the empirical distribution obtained from the naive block bootstrap is a more accurate approximation to the sampling distribution of the HAC robust t-test in finite samples. This implies that the naive block bootstrap can deliver a more accurate size than fixed-b asymptotics in small samples even when event forecasts and/or realizations are serially correlated. In this paper, we rely on the naive block bootstrap to deal with the over-rejections of the HAC robust t-test used to assess the accuracy of event forecasts. The remainder of the paper is organized as follows. Section 2 reviews some.
(4) 222. Ching-Chuan Tsong. extant tests and the HAC robust t-test for evaluating the accuracy of event forecasts. Section 3 reports the simulation results showing that the naive block bootstrap is a promising approach to overcome the over-sized problem. In Section 4, we provide an illustrative application. Section 5 summarizes the paper and offers some concluding remarks.. 2. Evaluating Event Forecasts. Suppose that {Yt }tn=1 is a binary stochastic process denoting out-of-sample event. forecasts from a certain econometric model, and { X t }tn=1 is the corresponding stochastic process of event realizations. Under the maintained assumption that both {Yt }tn=1 and { X t }tn=1 are individually IID processes, Henriksson and Merton (1981) test the null hypothesis of no timing ability, that is, H 0 : P(Yt = 0 X t = 0) + P(Yt = 1 X t = 1) = 1 .. (1). This is a test of contemporary independence between {Yt }tn=1 and { X t }tn=1 . Under the null hypothesis, they showed that the test statistic of #{Yt = 0 X t = 0} has a hypergeometric distribution and can be written as P(#{Yt = 0 X t = 0} = k ) =. CkN CmN−k , Cmn 1. 2. (2). where N1 and N 2 denote the number of X t = 0 and X t = 1 , respectively, and m denotes the number of Yt = 0 . Testing the null hypothesis of Eq. (1) is straightforward with the critical value obtained from Eq. (2) in a small sample. For large samples, however, the computation of factorials can be quite tedious. Fortunately, for large samples, the hypergeometric distribution can be accurately approximated by the normal distribution with mean μ. and variance σ 2. described as mN1 and n n N (n − N )(n − m) σ2 = 1 1 2 1 , n (n − 1). μ=. (3) (4). where n1 is the number of Yt = 0 given X t = 0 , and other parameters are defined.
(5) Assessing the Accuracy of Event Forecasts. 223. as above. In the framework of Henriksson and Merton (1981), independence between Yt and X t is tested, regarding IID stochastic processes of {Yt }tn=1 and { X t }tn=1 as the maintained assumption. Under this setting, the conventional chi-square test of independence as well as the t-test in the regression framework can be used to test the null hypothesis. Since Yt can be viewed as a binary dependent variable, the logit and probit models are also appropriate for this problem. Unfortunately,. event. forecasts,. obtained. from. truncating. a. certain. predetermined value of the point forecasts generated by estimated econometric models, may be serially correlated. Similarly, event realizations have a serial correlation as well. Therefore, the IID assumption is violated for all the abovementioned test procedures. As a result, these tests suffer from severe size distortions, falsely rejecting the null hypothesis too often.1 To deal with the over-rejections, the testing procedure should accommodate the autocorrelation of event forecasts and realizations. Three testing procedures, including the HAC robust t-test with the standard normal distribution, the HAC robust t-test with fixed-b asymptotics, and the naive block bootstrap are described briefly below. Breen et al. (1989) pointed out that event forecasts evaluation can be proceeded with a t-test for β = 0 in the linear regression: Yt = α + βX t + ut , t = 1, 2,K, n .. (5). For ease of exposition, rewrite Eq. (5) as yt = xt′γ + ut , t = 1, 2,K, n ,. (6). where yt = Yt , xt = (1, X t )′ and γ = (α , β )′ . Under some regularity conditions, it is straightforward that d n (γˆ − γ ) ⎯ ⎯→ N (0, Q −1ΩQ −1 ) ,. (7). where γˆ is the least squares (LS) estimator for γ , Q = p lim n −1 ∑t =1 xt xt′ and Ω n. denotes the long-run variance of vt = xt ut . Testing hypotheses about γ involves ˆ Qˆ −1 for Q −1ΩQ −1 , following which the getting consistent estimators of Qˆ −1Ω asymptotics free from the nuisance parameters can be constructed by using Eq. (7). 1. Simulation results in the next section will confirm this finding..
(6) 224. Ching-Chuan Tsong. n Clearly, Q can be consistently estimated by Qˆ = n −1 ∑t =1 xt xt′ . A consistent. estimation of Ω , however, is more complicated, since vt may be serially correlated with an unknown pattern. In the literature, a kernel-based consistent estimator for Ω is the most popular. It can be defined as n−1. ˆ = Ω. ∑ k( j. j = − ( n−1). M )Γˆ j ,. (8). with 1 n Γˆ j = ∑ vˆt vˆt′− j for j ≥ 0 , Γˆ j = Γˆ −′ j for j < 0 , n t = j +1. (9). where k ( x) : ℜ → [−1, 1] is an even kernel function satisfying k (0) = 1 , k (x) continuous at x = 0 and. ∫. ∞. −∞. k ( x)dx < ∞ ; vˆt = xt uˆt and uˆt = yt − xt′γˆ . Often, M. denotes the bandwidth as k ( x) = 0 for x > 1 . With the conditions of M → ∞ ˆ is consistent for Ω . Based on Eq. (7) and the and M n → 0 as n → ∞ , Ω argument discussed above, the HAC robust t-test for the evaluation of event forecasts and its asymptotic distribution can be written as t HAC =. n Rγˆ d ⎯ ⎯→ N (0, 1) , −1 ˆ ˆ −1 ˆ RQ ΩQ R′. (10). where R = (0,1) . This result implies that with a suitable choice of bandwidth, the standard normal distribution can be served as an approximation to the sampling distribution of the HAC robust t-test, regardless of which kernel is used. While the conditions of M → ∞ and M n → 0 as n → ∞ are essential to derive the asymptotics of t HAC , they cannot be satisfied in practice. In reality, a practitioner is given a particular data set, and the fraction of sample autocovariances ˆ is always a positive number smaller than unity. Based on this used to compute Ω fact, Kiefer and Vogelsang (2005) derived a brand-new asymptotic theory known as fixed-b asymptotics, for the HAC robust t-test under the condition that the bandwidth is set as a fixed ratio of the sample size. Important differences deserve to ˆ is no longer a consistent estimator for Ω , but be stressed. In this scenario, Ω converges to a random matrix that is proportional to Ω . The HAC robust t-test computed in the usual manner has an asymptotic distribution that depends on the.
(7) Assessing the Accuracy of Event Forecasts. 225. kernel and the bandwidth through b, but is free from any nuisance parameter. Therefore, the critical values can be tabulated and served as the purpose for hypothesis testing. Most importantly, the fixed-b asymptotics can deliver a more accurate approximation than the standard normal distribution, since the value of b is greater than zero and less than or equal to unity in practice. As a result, the HAC robust t-test computed in the usual manner can effectively reduce size distortions with fixed-b asymptotics, as compared to that with its standard normal counterpart. Kiefer and Vogelsang (2002) argued that with the choice of M = n , i.e., b = 1 and the Bartlett kernel, the HAC robust t-test would have a good size and reasonable power performance. Hence, we follow their suggestion in the simulation experiments and empirical study described below. The bootstrap is an alternative to asymptotic approximations. With an appropriate resample scheme, the bootstrap asymptotics can be a more accurate approximation to the sampling distribution of a test (e.g., Lahiri, 1996; Götze and Künsch, 1996; Park, 2003, among others). According to this idea, Gonçalves and Vogelsang (2006) proposed the naive bootstrap where the formula used to compute the test for the bootstrap sample is the same as that used for the original data. The naive bootstrap is briefly stated below. Let wt = ( yt , xt′)′ be the vector that collects dependent and independent variables defined in Eq. (6) for each observation. Further, Bi = ( wi , wi+1 ,K, wi+b−1 ) denotes the block of b consecutive observations starting. from wi , for i = 1, 2,K, n − b + 1 . All the Bi together form n − b + 1 overlapping blocks from the original sample wt . With these n − b + 1 overlapping blocks, the ′ bootstrap sample wt* = ( yt* , xt* )′ can be generated by randomly resampling n b. blocks with replacement and laying them end-to-end in the order in which they are ˆ * denote the bootstrap sampled. Given this bootstrap sample, let γˆ * , Qˆ * , and Ω ˆ , respectively, replacing w with w* . Then, the counterparts for γˆ , Qˆ , and Ω t t. naive block bootstrap HAC robust t-test is defined as t* =. n ( Rγˆ * − r * ) , ˆ *Qˆ *−1 R′ RQˆ *−1Ω. (11). where r * = Rγˆ and R = (0,1) . Repeat the sampling NB times, and the computed NB values of t * can be regarded as an empirical distribution function of the HAC robust t-test. Subsequently, make an inference based on the bootstrap critical value.
(8) 226. Ching-Chuan Tsong. from the empirical distribution function. Gonçalves and Vogelsang (2006) also showed that the naive block bootstrap has the same limiting distribution as the fixed-b asymptotics. Moreover, their simulation results suggest that with the appropriate choice of block length, the naive block bootstrap can deliver a more accurate approximation than the fixed-b asymptotics. This is promising for the naive block bootstrap to deal with the over-rejections of extant tests used to evaluate the accuracy of event forecasts.. 3. Monte Carlo Evidence. 3.1. Experimental Design. In this section, we investigate the finite-sample performance of various test statistics discussed in Section 2. These tests are categorized into two groups by their capability of capturing serial correlations. Conventional test statistics, including the HM test, the chi-square test of independence, the t-tests in linear regression and logit models, fall into the first group.2 The second group includes HAC robust t-test with three types of distributions as an approximation to its sampling distribution, such as the standard normal distribution, fixed-b asymptotics and the empirical distribution obtained from the naive block bootstrap. To generate binary series X t and Yt , let the data-generating process (DGP) be: ⎧1 Xt = ⎨ ⎩0. if u tx > 0 if u tx ≤ 0. ,. (12). and ⎧1 Yt = ⎨ ⎩0. if uty > 0 if uty ≤ 0. ,. (13). where utx = ρ x utx−1 + ε tx. (14). u = ρ yu + ε. (15). y t. 2. y t −1. y t. Since the t-test in the probit model yields similar results as in the logit model, we omit it for brevity..
(9) Assessing the Accuracy of Event Forecasts. 227. with ⎡ε tx ⎤ IID ⎡ ⎢ y ⎥ ~ N ⎢0, ⎢⎣ ⎣ε t ⎦. ρ xy ⎞⎤ ⎛1 ⎜ ⎟⎥ ⎜ρ ⎟⎥ 1 xy ⎝ ⎠⎦. (16). and initials u0x = u0y = 0 . Obviously, if ρ x ≠ 0 , then u tx in Eq. (14) is an autocorrelated series, which leads X t to a serially correlated series. Similarly, if. ρ y ≠ 0 , Yt is autocorrelated. On the other hand, ρ xy in Eq. (16) measures the contemporary correlation between ε tx and ε ty . With the definitions in Eq. (12) and Eq. (13), the value of ρ xy also governs the contemporary correlation between X t and Yt . We consider the sample sizes of n = 50 , 100, 200, and 1000; the contemporary correlation parameters of ρ xy = 0 , 0.2, 0.5, and 0.8; and the autoregressive parameters of ρ x and ρ y each equaling 0, 0.5, 0.8, and 0.9. For all the tests except for the naive block bootstrap, the empirical sizes are computed when ρ xy = 0 ; otherwise, the size-adjusted powers are calculated. For the naive block bootstrap, however, we compute the bootstrap sizes and powers corresponding respectively to ρ xy = 0 and otherwise. Before implementing the naive block bootstrap, the block length must first be determined. Although Politis and White (2004) proposed an automatic method to select the block length for the block bootstrap, our simulation results show that it is futile in dealing with the over-sized problem.3 Instead, we choose b = int(n1 5 ) , where int(.) denotes the integer part, since Hall and Jing (1996) pointed out that the optimal block length should be proportional to n1 5 in this context. All the results are under a nominal size of 5%. We perform 5,000 Monte Carlo replications for the asymptotic tests. For the naive block bootstrap, on the other hand, the number of replications is 1,000 (= NB). Note that computing the HAC robust t-test involves choosing the kernel and bandwidth. As mentioned in Section 2, we choose the Bartlett kernel for the power concern. For the standard normal approximation, bandwidth M is set as int(12(n 100)1 4 ) , while for fixed-b asymptotics, we choose M = n , as Kiefer and. Vogelsang (2002) suggested.. 3. For the sake of concision, these results are omitted. They can be obtained from the author upon request..
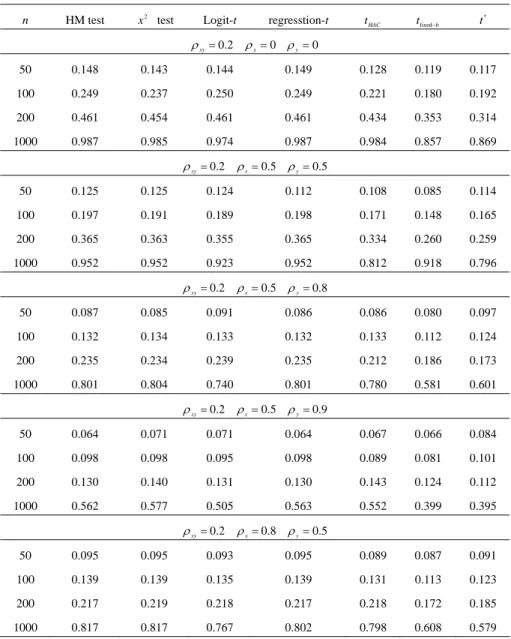
(10) 228. 3.2. Ching-Chuan Tsong. Finite Sample Properties. The simulation results are collected in Tables 1 and 2. The results for the empirical size of various tests are reported in Table 1. As expected, all the tests except for t HAC in the case of n = 50 have an empirical size close to the nominal size when. ρ x = ρ y = 0 . When ρ x and ρ y increase, all the tests in the first group denoted by HM, x 2 , logit-t and regression-t have severe size distortions even in large samples. For example, the size of HM on n = 1000 inflates to 0.402 from 0.047 as both ρ x and ρ y increase to 0.9 from 0. On the other hand, the tests in the second group, including t HAC , t fixed−b , and t * , have a reasonable size performance, except for t HAC when ρ x and ρ y are large. This confirms the finding in Andrew (1991) that t HAC has size distortions in finite samples when data are strongly serially correlated. Besides, the performance of t * is better than that of the t fixed−b and t HAC tests. Moreover, the results of t fixed−b are considerably better than those of t HAC . For instance, they are 0.080, 0.113, and 0.204 for t * , t fixed−b , and t HAC , respectively, when ρ x = ρ y = 0.9 and n = 100 . These facts indicate that the consideration of serial correlation has a positive influence on size performance, as in the tests in the second group. Further, fixed-b asymptotics is a more accurate approximation to the sampling distribution of the HAC robust t-test than the standard normal distribution. Moreover, the naive block bootstrap with the chosen block length can offer a more accurate approximation than fixed-b asymptotics. The results for empirical power are shown in Table 2. The figures for t * are bootstrap power; otherwise, they are size-adjusted power. Undoubtedly, all power increases occur with a larger sample size n. For any given values of ρ x and ρ y , as expected, all the tests have a higher power with a larger value of ρ xy . The power performance would be damaged by the autocorrelation of X t and/or Yt . For example, for the HM test, the power declines to 0.562 from 0.952 when ρ y is up to 0.9 from 0.5, given ρ xy = 0.2 , ρ x = 0.5 , and n = 1000 . Clearly, all the tests except for t fixed−b and t * have comparable power. As compared with t HAC , the power is lower for t fixed−b due to the longer bandwidth. However, the differences can be neglected when the value of ρ xy becomes large. Interestingly, for some cases (e.g.,. ρ x = ρ y = 0.9 ), the t * test shows a power gain over its counterpart of t fixed−b to.
(11) Assessing the Accuracy of Event Forecasts. 229. some extent. An important point must be emphasized here. Generally speaking, the power of t * is lower than the other tests, but it is feasible. In other words, the power reported for the tests except for t * is infeasible because the size-adjusted critical values in finite samples are generally unknown in applications. However, the bootstrap power, in practice, is feasible for any given sample size. Therefore, due to the good size and feasible power properties, t * is a suitable choice for empirical applications. Table 1: Empirical Size Performance of the Tests n. HM test. x 2 test. Logit-t. regresstion-t. t HAC. tfixed−b. t*. ρ xy = 0 ρ x = 0 ρ y = 0 50. 0.050. 0.056. 0.047. 0.062. 0.123. 0.056. 0.042. 100. 0.056. 0.057. 0.057. 0.059. 0.093. 0.059. 0.051. 200. 0.048. 0.050. 0.052. 0.051. 0.066. 0.047. 0.047. 1000. 0.047. 0.047. 0.066. 0.048. 0.054. 0.050. 0.050. ρ xy = 0 ρ x = 0.5 ρ y = 0.5 50. 0.083. 0.088. 0.081. 0.097. 0.143. 0.065. 0.054. 100. 0.089. 0.091. 0.092. 0.097. 0.103. 0.064. 0.045. 200. 0.082. 0.083. 0.088. 0.086. 0.080. 0.056. 0.055. 1000. 0.075. 0.076. 0.105. 0.076. 0.055. 0.045. 0.055. ρ xy = 0 ρ x = 0.5 ρ y = 0.8 50. 0.121. 0.127. 0.110. 0.143. 0.149. 0.065. 0.062. 100. 0.120. 0.123. 0.120. 0.128. 0.115. 0.062. 0.048. 200. 0.122. 0.124. 0.123. 0.126. 0.084. 0.056. 0.045. 1000. 0.124. 0.125. 0.145. 0.125. 0.059. 0.053. 0.062. 50. 0.126. 0.130. 0.108. 0.148. 0.146. 0.057. 0.064. 100. 0.145. 0.145. 0.143. 0.151. 0.115. 0.059. 0.058. 200. 0.130. 0.133. 0.132. 0.135. 0.082. 0.056. 0.044. 1000. 0.140. 0.140. 0.152. 0.141. 0.059. 0.052. 0.062. 0.165. 0.082. 0.060. ρ xy = 0 ρ x = 0.5 ρ y = 0.9. ρ xy = 0 ρ x = 0.8 ρ y = 0.5 50. 0.110. 0.119. 0.099. 0.134. 100. 0.118. 0.121. 0.120. 0.126. 0.111. 0.066. 0.061. 200. 0.116. 0.117. 0.118. 0.122. 0.082. 0.057. 0.071. 1000. 0.116. 0.117. 0.149. 0.117. 0.046. 0.046. 0.045.
(12) 230. Ching-Chuan Tsong. Table 1: Empirical Size Performance of the Tests (continued). n. HM test. x 2 test. Logit-t. regresstion-t. t HAC. tfixed−b. t*. ρ xy = 0 ρ x = 0.8 ρ y = 0.8 50. 0.198. 0.204. 0.174. 0.224. 0.206. 0.099. 0.072. 100. 0.229. 0.232. 0.228. 0.240. 0.148. 0.081. 0.052. 200. 0.227. 0.227. 0.230. 0.231. 0.105. 0.065. 0.065. 1000. 0.237. 0.238. 0.251. 0.239. 0.072. 0.053. 0.055. ρ xy = 0. ρ x = 0.8 ρ y = 0.9. 50. 0.233. 0.235. 0.194. 0.255. 0.205. 0.093. 0.080. 100. 0.282. 0.285. 0.276. 0.293. 0.159. 0.082. 0.055. 200. 0.286. 0.287. 0.287. 0.292. 0.113. 0.067. 0.060. 1000. 0.293. 0.293. 0.304. 0.294. 0.069. 0.054. 0.049. ρ xy = 0 ρ x = 0.9 ρ y = 0.5 50. 0.121. 0.126. 0.104. 0.144. 0.213. 0.125. 0.101. 100. 0.135. 0.137. 0.133. 0.144. 0.128. 0.074. 0.073. 200. 0.145. 0.146. 0.150. 0.152. 0.091. 0.064. 0.066. 1000. 0.142. 0.142. 0.167. 0.144. 0.058. 0.050. 0.056. ρ xy = 0 ρ x = 0.9 ρ y = 0.8 50. 0.220. 0.225. 0.181. 0.249. 0.260. 0.137. 0.104. 100. 0.273. 0.276. 0.266. 0.285. 0.171. 0.097. 0.070. 200. 0.281. 0.283. 0.285. 0.286. 0.117. 0.073. 0.075. 1000. 0.292. 0.293. 0.309. 0.294. 0.071. 0.054. 0.061. 0.137. 0.123. ρ xy = 0. ρ x = 0.9 ρ y = 0.9. 50. 0.271. 0.275. 0.208. 0.299. 0.275. 100. 0.352. 0.355. 0.336. 0.363. 0.204. 0.113. 0.080. 200. 0.363. 0.364. 0.364. 0.371. 0.146. 0.079. 0.078. 1000. 0.402. 0.403. 0.409. 0.403. 0.086. 0.054. 0.064. Notes: The DGP is described from Eq. (12) to Eq. (16). The HM test is the market timing test in Henricksson and Merton (1981). The x 2 test denotes the independence test. Logit-t and regression-t represent the conventional t-test in logit model and regression model, respectively. t HAC , tfixed−b , and t * denote the HAC robust t-test with the standard normal distribution, fixed-b asymptotics, and empirical distribution from the naive block bootstrap, respectively. Refer to Section 2 for further details. The figures reported are the rejection frequencies at the 5% nominal significance level, based on 5,000 replications for the asymptotic tests, and 1,000 for t * with 1,000 re-samples. The asymptotic critical value for the 5% level is 1.96 for all two-sided tests except for tfixed−b . For tfixed−b , the asymptotic critical value is 4.771 obtained from Table 1 in Kiefer and Vogelsang (2002)..
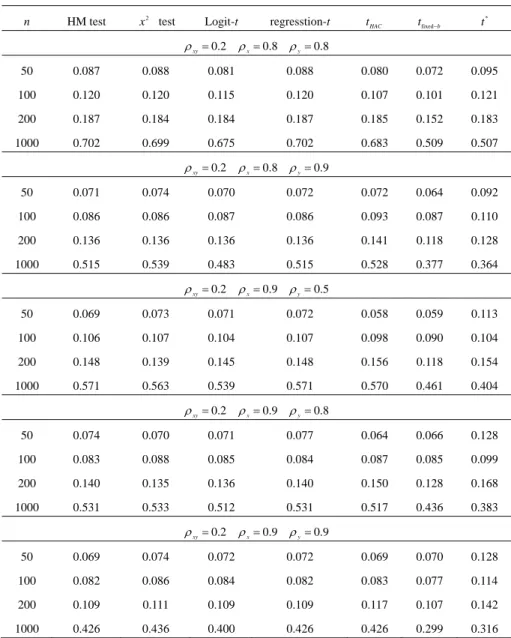
(13) Assessing the Accuracy of Event Forecasts. 231. Table 2: Empirical Power Performance of the Tests. n. HM test. x 2 test. Logit-t. regresstion-t. t HAC. tfixed−b. t*. ρ xy = 0.2 ρ x = 0 ρ y = 0 50. 0.148. 0.143. 0.144. 0.149. 0.128. 0.119. 0.117. 100. 0.249. 0.237. 0.250. 0.249. 0.221. 0.180. 0.192. 200. 0.461. 0.454. 0.461. 0.461. 0.434. 0.353. 0.314. 1000. 0.987. 0.985. 0.974. 0.987. 0.984. 0.857. 0.869. ρ xy = 0.2. ρ x = 0.5 ρ y = 0.5. 50. 0.125. 0.125. 0.124. 0.112. 0.108. 0.085. 0.114. 100. 0.197. 0.191. 0.189. 0.198. 0.171. 0.148. 0.165. 200. 0.365. 0.363. 0.355. 0.365. 0.334. 0.260. 0.259. 1000. 0.952. 0.952. 0.923. 0.952. 0.812. 0.918. 0.796. ρ xy = 0.2. ρ x = 0.5 ρ y = 0.8. 50. 0.087. 0.085. 0.091. 0.086. 0.086. 0.080. 0.097. 100. 0.132. 0.134. 0.133. 0.132. 0.133. 0.112. 0.124. 200. 0.235. 0.234. 0.239. 0.235. 0.212. 0.186. 0.173. 1000. 0.801. 0.804. 0.740. 0.801. 0.780. 0.581. 0.601. ρ xy = 0.2. ρ x = 0.5 ρ y = 0.9. 50. 0.064. 0.071. 0.071. 0.064. 0.067. 0.066. 0.084. 100. 0.098. 0.098. 0.095. 0.098. 0.089. 0.081. 0.101. 200. 0.130. 0.140. 0.131. 0.130. 0.143. 0.124. 0.112. 1000. 0.562. 0.577. 0.505. 0.563. 0.552. 0.399. 0.395. ρ xy = 0.2. ρ x = 0.8 ρ y = 0.5. 50. 0.095. 0.095. 0.093. 0.095. 0.089. 0.087. 0.091. 100. 0.139. 0.139. 0.135. 0.139. 0.131. 0.113. 0.123. 200. 0.217. 0.219. 0.218. 0.217. 0.218. 0.172. 0.185. 1000. 0.817. 0.817. 0.767. 0.802. 0.798. 0.608. 0.579.
(14) 232. Ching-Chuan Tsong. Table 2: Empirical Power Performance of the Tests (continued). n. HM test. x 2 test. Logit-t. ρ xy = 0.2. regresstion-t. t HAC. tfixed−b. t*. ρ x = 0.8 ρ y = 0.8. 50. 0.087. 0.088. 0.081. 0.088. 0.080. 0.072. 0.095. 100. 0.120. 0.120. 0.115. 0.120. 0.107. 0.101. 0.121. 200. 0.187. 0.184. 0.184. 0.187. 0.185. 0.152. 0.183. 1000. 0.702. 0.699. 0.675. 0.702. 0.683. 0.509. 0.507. ρ xy = 0.2. ρ x = 0.8 ρ y = 0.9. 50. 0.071. 0.074. 0.070. 0.072. 0.072. 0.064. 0.092. 100. 0.086. 0.086. 0.087. 0.086. 0.093. 0.087. 0.110. 200. 0.136. 0.136. 0.136. 0.136. 0.141. 0.118. 0.128. 1000. 0.515. 0.539. 0.483. 0.515. 0.528. 0.377. 0.364. ρ xy = 0.2. ρ x = 0.9 ρ y = 0.5. 50. 0.069. 0.073. 0.071. 0.072. 0.058. 0.059. 0.113. 100. 0.106. 0.107. 0.104. 0.107. 0.098. 0.090. 0.104. 200. 0.148. 0.139. 0.145. 0.148. 0.156. 0.118. 0.154. 1000. 0.571. 0.563. 0.539. 0.571. 0.570. 0.461. 0.404. ρ xy = 0.2. ρ x = 0.9 ρ y = 0.8. 50. 0.074. 0.070. 0.071. 0.077. 0.064. 0.066. 0.128. 100. 0.083. 0.088. 0.085. 0.084. 0.087. 0.085. 0.099. 200. 0.140. 0.135. 0.136. 0.140. 0.150. 0.128. 0.168. 1000. 0.531. 0.533. 0.512. 0.531. 0.517. 0.436. 0.383. ρ xy = 0.2. ρ x = 0.9 ρ y = 0.9. 50. 0.069. 0.074. 0.072. 0.072. 0.069. 0.070. 0.128. 100. 0.082. 0.086. 0.084. 0.082. 0.083. 0.077. 0.114. 200. 0.109. 0.111. 0.109. 0.109. 0.117. 0.107. 0.142. 1000. 0.426. 0.436. 0.400. 0.426. 0.426. 0.299. 0.316.
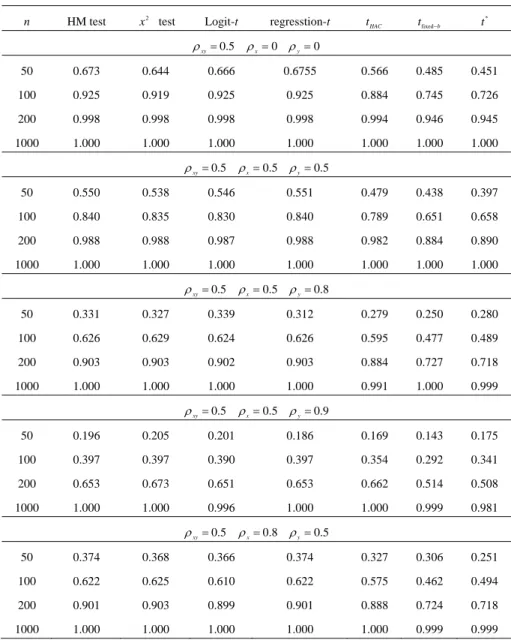
(15) Assessing the Accuracy of Event Forecasts. 233. Table 2: Empirical Power Performance of the Tests (continued). n. HM test. x 2 test. Logit-t. regresstion-t. ρ xy = 0.5. ρx = 0 ρy = 0. t HAC. tfixed−b. t*. 50. 0.673. 0.644. 0.666. 0.6755. 0.566. 0.485. 0.451. 100. 0.925. 0.919. 0.925. 0.925. 0.884. 0.745. 0.726. 200. 0.998. 0.998. 0.998. 0.998. 0.994. 0.946. 0.945. 1000. 1.000. 1.000. 1.000. 1.000. 1.000. 1.000. 1.000. ρ xy = 0.5. ρ x = 0.5 ρ y = 0.5. 50. 0.550. 0.538. 0.546. 0.551. 0.479. 0.438. 0.397. 100. 0.840. 0.835. 0.830. 0.840. 0.789. 0.651. 0.658. 200. 0.988. 0.988. 0.987. 0.988. 0.982. 0.884. 0.890. 1000. 1.000. 1.000. 1.000. 1.000. 1.000. 1.000. 1.000. ρ xy = 0.5. ρ x = 0.5 ρ y = 0.8. 50. 0.331. 0.327. 0.339. 0.312. 0.279. 0.250. 0.280. 100. 0.626. 0.629. 0.624. 0.626. 0.595. 0.477. 0.489. 200. 0.903. 0.903. 0.902. 0.903. 0.884. 0.727. 0.718. 1000. 1.000. 1.000. 1.000. 1.000. 0.991. 1.000. 0.999. ρ xy = 0.5. ρ x = 0.5 ρ y = 0.9. 50. 0.196. 0.205. 0.201. 0.186. 0.169. 0.143. 0.175. 100. 0.397. 0.397. 0.390. 0.397. 0.354. 0.292. 0.341. 200. 0.653. 0.673. 0.651. 0.653. 0.662. 0.514. 0.508. 1000. 1.000. 1.000. 0.996. 1.000. 1.000. 0.999. 0.981. ρ xy = 0.5. ρ x = 0.8 ρ y = 0.5. 50. 0.374. 0.368. 0.366. 0.374. 0.327. 0.306. 0.251. 100. 0.622. 0.625. 0.610. 0.622. 0.575. 0.462. 0.494. 200. 0.901. 0.903. 0.899. 0.901. 0.888. 0.724. 0.718. 1000. 1.000. 1.000. 1.000. 1.000. 1.000. 0.999. 0.999.
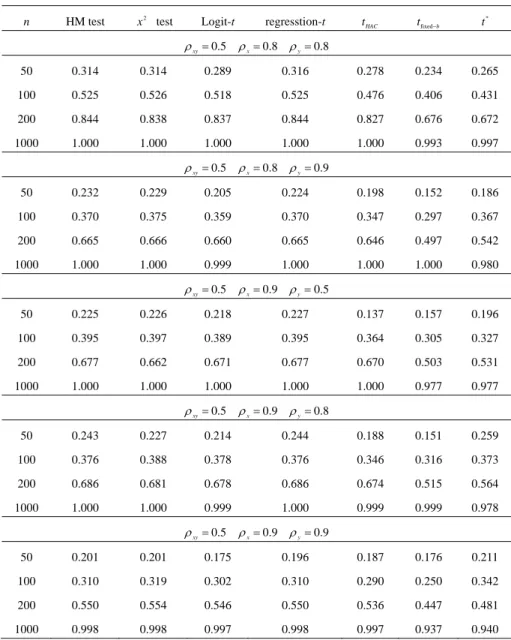
(16) 234. Ching-Chuan Tsong. Table 2: Empirical Power Performance of the Tests (continued). n. HM test. x 2 test. Logit-t. ρ xy = 0.5. regresstion-t. t HAC. tfixed−b. t*. ρ x = 0.8 ρ y = 0.8. 50. 0.314. 0.314. 0.289. 0.316. 0.278. 0.234. 0.265. 100. 0.525. 0.526. 0.518. 0.525. 0.476. 0.406. 0.431. 200. 0.844. 0.838. 0.837. 0.844. 0.827. 0.676. 0.672. 1000. 1.000. 1.000. 1.000. 1.000. 1.000. 0.993. 0.997. ρ xy = 0.5. ρ x = 0.8 ρ y = 0.9. 50. 0.232. 0.229. 0.205. 0.224. 0.198. 0.152. 0.186. 100. 0.370. 0.375. 0.359. 0.370. 0.347. 0.297. 0.367. 200. 0.665. 0.666. 0.660. 0.665. 0.646. 0.497. 0.542. 1000. 1.000. 1.000. 0.999. 1.000. 1.000. 1.000. 0.980. ρ xy = 0.5. ρ x = 0.9 ρ y = 0.5. 50. 0.225. 0.226. 0.218. 0.227. 0.137. 0.157. 0.196. 100. 0.395. 0.397. 0.389. 0.395. 0.364. 0.305. 0.327. 200. 0.677. 0.662. 0.671. 0.677. 0.670. 0.503. 0.531. 1000. 1.000. 1.000. 1.000. 1.000. 1.000. 0.977. 0.977. ρ xy = 0.5. ρ x = 0.9 ρ y = 0.8. 50. 0.243. 0.227. 0.214. 0.244. 0.188. 0.151. 0.259. 100. 0.376. 0.388. 0.378. 0.376. 0.346. 0.316. 0.373. 200. 0.686. 0.681. 0.678. 0.686. 0.674. 0.515. 0.564. 1000. 1.000. 1.000. 0.999. 1.000. 0.999. 0.999. 0.978. ρ xy = 0.5. ρ x = 0.9 ρ y = 0.9. 50. 0.201. 0.201. 0.175. 0.196. 0.187. 0.176. 0.211. 100. 0.310. 0.319. 0.302. 0.310. 0.290. 0.250. 0.342. 200. 0.550. 0.554. 0.546. 0.550. 0.536. 0.447. 0.481. 1000. 0.998. 0.998. 0.997. 0.998. 0.997. 0.937. 0.940.
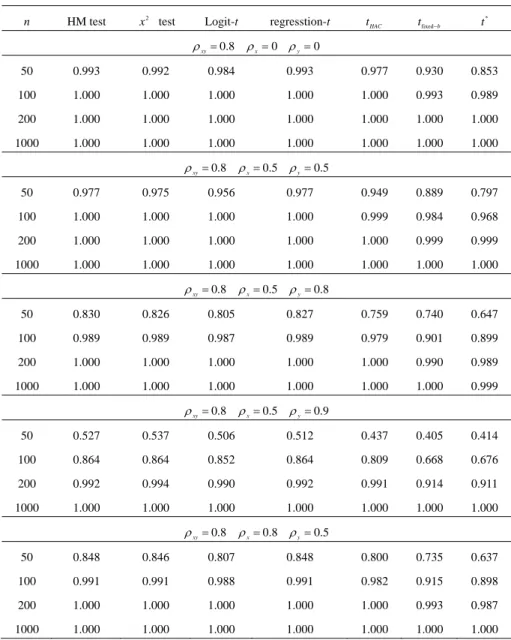
(17) Assessing the Accuracy of Event Forecasts. 235. Table 2: Empirical Power Performance of the Tests (continued). n. HM test. x 2 test. Logit-t. ρ xy = 0.8. regresstion-t. t HAC. tfixed−b. t*. ρx = 0 ρy = 0. 50. 0.993. 0.992. 0.984. 0.993. 0.977. 0.930. 0.853. 100. 1.000. 1.000. 1.000. 1.000. 1.000. 0.993. 0.989. 200. 1.000. 1.000. 1.000. 1.000. 1.000. 1.000. 1.000. 1000. 1.000. 1.000. 1.000. 1.000. 1.000. 1.000. 1.000. ρ xy = 0.8. ρ x = 0.5 ρ y = 0.5. 50. 0.977. 0.975. 0.956. 0.977. 0.949. 0.889. 0.797. 100. 1.000. 1.000. 1.000. 1.000. 0.999. 0.984. 0.968. 200. 1.000. 1.000. 1.000. 1.000. 1.000. 0.999. 0.999. 1000. 1.000. 1.000. 1.000. 1.000. 1.000. 1.000. 1.000. ρ xy = 0.8. ρ x = 0.5 ρ y = 0.8. 50. 0.830. 0.826. 0.805. 0.827. 0.759. 0.740. 0.647. 100. 0.989. 0.989. 0.987. 0.989. 0.979. 0.901. 0.899. 200. 1.000. 1.000. 1.000. 1.000. 1.000. 0.990. 0.989. 1000. 1.000. 1.000. 1.000. 1.000. 1.000. 1.000. 0.999. ρ xy = 0.8. ρ x = 0.5 ρ y = 0.9. 50. 0.527. 0.537. 0.506. 0.512. 0.437. 0.405. 0.414. 100. 0.864. 0.864. 0.852. 0.864. 0.809. 0.668. 0.676. 200. 0.992. 0.994. 0.990. 0.992. 0.991. 0.914. 0.911. 1000. 1.000. 1.000. 1.000. 1.000. 1.000. 1.000. 1.000. ρ xy = 0.8. ρ x = 0.8 ρ y = 0.5. 50. 0.848. 0.846. 0.807. 0.848. 0.800. 0.735. 0.637. 100. 0.991. 0.991. 0.988. 0.991. 0.982. 0.915. 0.898. 200. 1.000. 1.000. 1.000. 1.000. 1.000. 0.993. 0.987. 1000. 1.000. 1.000. 1.000. 1.000. 1.000. 1.000. 1.000.
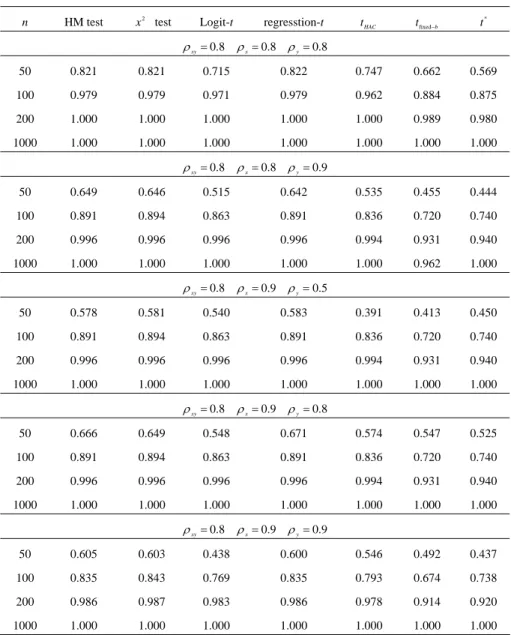
(18) 236. Ching-Chuan Tsong. Table 2: Empirical Power Performance of the Tests (continued). n. HM test. x 2 test. Logit-t. regresstion-t. t HAC. tfixed−b. t*. ρ xy = 0.8 ρ x = 0.8 ρ y = 0.8 50. 0.821. 0.821. 0.715. 0.822. 0.747. 0.662. 0.569. 100. 0.979. 0.979. 0.971. 0.979. 0.962. 0.884. 0.875. 200. 1.000. 1.000. 1.000. 1.000. 1.000. 0.989. 0.980. 1000. 1.000. 1.000. 1.000. 1.000. 1.000. 1.000. 1.000. ρ xy = 0.8 ρ x = 0.8 ρ y = 0.9 50. 0.649. 0.646. 0.515. 0.642. 0.535. 0.455. 0.444. 100. 0.891. 0.894. 0.863. 0.891. 0.836. 0.720. 0.740. 200. 0.996. 0.996. 0.996. 0.996. 0.994. 0.931. 0.940. 1000. 1.000. 1.000. 1.000. 1.000. 1.000. 0.962. 1.000. ρ xy = 0.8. ρ x = 0.9 ρ y = 0.5. 50. 0.578. 0.581. 0.540. 0.583. 0.391. 0.413. 0.450. 100. 0.891. 0.894. 0.863. 0.891. 0.836. 0.720. 0.740. 200. 0.996. 0.996. 0.996. 0.996. 0.994. 0.931. 0.940. 1000. 1.000. 1.000. 1.000. 1.000. 1.000. 1.000. 1.000. ρ xy = 0.8 ρ x = 0.9 ρ y = 0.8 50. 0.666. 0.649. 0.548. 0.671. 0.574. 0.547. 0.525. 100. 0.891. 0.894. 0.863. 0.891. 0.836. 0.720. 0.740. 200. 0.996. 0.996. 0.996. 0.996. 0.994. 0.931. 0.940. 1000. 1.000. 1.000. 1.000. 1.000. 1.000. 1.000. 1.000. ρ xy = 0.8 ρ x = 0.9 ρ y = 0.9 50. 0.605. 0.603. 0.438. 0.600. 0.546. 0.492. 0.437. 100. 0.835. 0.843. 0.769. 0.835. 0.793. 0.674. 0.738. 200. 0.986. 0.987. 0.983. 0.986. 0.978. 0.914. 0.920. 1000. 1.000. 1.000. 1.000. 1.000. 1.000. 1.000. 1.000. Notes: The figures reported are the bootstrap powers for t * and the size-adjusted powers for other tests. The DGP is described from Eq. (12) to Eq. (16). The HM test is the market timing test in Henricksson and Merton (1981). The x 2 test denotes the independence test. Logit-t and regression-t represent the conventional t-test in the logit model and regression model, respectively. t HAC , tfixed−b , and t * denote the HAC robust t-test with the standard normal distribution, fixed-b asymptotics, and empirical distribution from the naive block bootstrap, respectively. Refer to Section 2 for further details. The figures reported are the rejection frequencies at the 5% nominal significance level, based on 5,000 replications for the asymptotic tests, and 1,000 for t * with 1,000 re-samples..
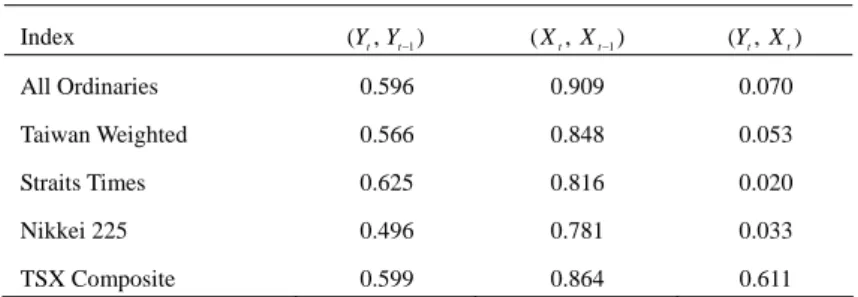
(19) Assessing the Accuracy of Event Forecasts. 4. 237. Empirical Illustrations. In this section, we present a simple empirical example to illustrate that the conventional tests for evaluating event forecast accuracy may be misleading when event forecasts and their corresponding realizations are serially correlated. We stress at the outset that the specification for a forecasting model is not the goal of this empirical study. Instead, we focus on evaluating the accuracy of event forecasts using the tests discussed in Section 2. Hence, an AR(1) forecasting model is sufficient to serve this purpose. Suppose that an AR(1) model rt = α + βrt −1 + ε t is used to forecast one-step-ahead market returns with a rolling scheme.4 Let event forecasts Yt +1 and realizations X t +1 be defined as ⎧⎪1 Yt +1 = ⎨ ⎪⎩0. if αˆ + βˆrt > 0. ,. otherwise. and ⎧1 X t +1 = ⎨ ⎩0. if rt +1 > 0 otherwise. ,. where αˆ and βˆ denote LS estimates for α and β , respectively. We collect monthly observations for five different indices over 1982:01 - 2007:02, including the All Ordinaries Index, Taiwan Weighted Index, Straits Times Index, Nikkei 225 Index, and TSX Composite Index. All the data are retrieved from Info Winner data bank. Let the price data be { pt } . Then, the returns series is generated by {rt } = ln Pt − ln Pt −1 . The total sample of 301 return observations is split into two parts: the first 51 observations are used for estimating the parameters in AR(1) model, and then, the remaining 250 (= n) are used to evaluate a post-sample one-step-ahead prediction. We choose n = 250 to avoid the low power of the tests. The preliminary analysis for event forecasts and realizations is reported in Table 3. Obviously, the sample correlation coefficients indicate that Yt and X t are serially correlated for each index. The maintained IID assumption for the 4 The rolling scheme, which discards the oldest observation when adding the latest one to estimate the parameters in the forecasting model, are more sensible than the fixed and recursive schemes, and is employed in our empirical study..
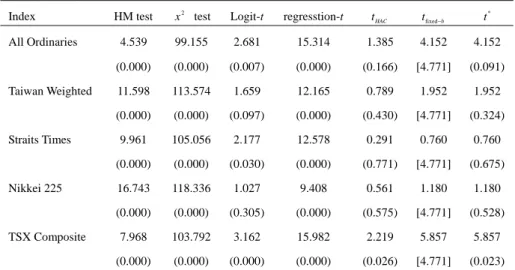
(20) 238. Ching-Chuan Tsong. conventional tests may be violated. This can lead these tests to falsely reject the null hypothesis of no timing ability. In addition, except for the TSX Composite Index, the contemporary correlation between Yt and X t is so weak that the null hypothesis may not be rejected. Table 3: Sample Correlation Coefficients. Index. (Yt , Yt −1 ). ( X t , X t −1 ). (Yt , X t ). All Ordinaries. 0.596. 0.909. 0.070. Taiwan Weighted. 0.566. 0.848. 0.053. Straits Times. 0.625. 0.816. 0.020. Nikkei 225. 0.496. 0.781. 0.033. TSX Composite. 0.599. 0.864. 0.611. The testing results are collated in Table 4. First, consider the All Ordinaries Index and Straits Times Index, the contemporary correlations of which are 0.07 and 0.02, respectively. Given the 5% significance level, the null is rejected by all the tests in the first group. On the contrary, all the tests that possess robust size in the second group do not reject the null. Similar results can be found except for the logit-t with a p-value of 0.305 in Nikkei 225 and with a p-value of 0.097 in Taiwan Weighted. The violation of the maintained IID assumption may be contributing to this contradiction. Although the null is rejected by all the tests for TSX Composite, the result must be interpreted with care. The rejection of the tests in the first group is more likely caused by their severe over-rejections. The testing result of t * , on the other hand, can reflect the strong contemporary correlation between event forecasts and their corresponding realizations due to its robust size and reasonable power.. 5. Conclusions. The conventional tests for assessing the accuracy of event forecasts, such as the HM test or regression t-test, rely on the maintained IID assumption on event forecasts and realizations. In practice, however, event forecasts obtained by truncating the point forecasts generated by estimated econometric models, may be serially correlated. Similarly, event realizations also have serial correlations. According to our simulation evidence, the violation of the maintained assumption contributes to.
(21) Assessing the Accuracy of Event Forecasts. 239. severe size distortions of these tests. Table 4: Tests for the Accuracy of Event Forecasts. Index All Ordinaries. Taiwan Weighted. Straits Times. Nikkei 225. TSX Composite. HM test. x 2 test. Logit-t. regresstion-t. t HAC. tfixed−b. t*. 4.539. 99.155. 2.681. 15.314. 1.385. 4.152. 4.152. (0.000). (0.000). (0.007). (0.000). (0.166). [4.771]. (0.091). 11.598. 113.574. 1.659. 12.165. 0.789. 1.952. 1.952. (0.000). (0.000). (0.097). (0.000). (0.430). [4.771]. (0.324). 9.961. 105.056. 2.177. 12.578. 0.291. 0.760. 0.760. (0.000). (0.000). (0.030). (0.000). (0.771). [4.771]. (0.675). 16.743. 118.336. 1.027. 9.408. 0.561. 1.180. 1.180. (0.000). (0.000). (0.305). (0.000). (0.575). [4.771]. (0.528). 7.968. 103.792. 3.162. 15.982. 2.219. 5.857. 5.857. (0.000). (0.000). (0.000). (0.000). (0.026). [4.771]. (0.023). Notes: All the data are retrieved from Info Winner data bank. Monthly data is available over the period 1982:1-2007:2. All the tests are defined in Section 2. The values of the tests are reported in the first row for each index, and the p-values are in the parentheses. The value in [.] is the asymptotic critical value obtained from Table 1 in Kiefer and Vogelsang (2002) for the two-sided tfixed−b test at the 5% nominal significance level. The replications for the naive block bootstrap is 1,000 (= NB).. On the other hand, the fixed-b asymptotics for the HAC robust t-test offers a more accurate approximation than the standard normal distribution. Furthermore, the naive block bootstrap with an appropriately proper chosen block length can further improve the approximation to the sampling distribution of the HAC robust t-test. Our simulation evidence confirms these results. Therefore, the naive block bootstrap is strongly recommended for empirical applications. We also offer a simple empirical example to illustrate these tests. The testing results using naive block bootstrap are completely different from those with its conventional counterparts. The over-rejections of conventional tests can account for these empirical contradictions.. References Andrew, D. W. K., (1991), “Heteroskedasticity and Autocorrelation Consistent Covariance Matrix Estimation,” Econometrica, 59, 817-858. Andrew, D. W. K., (2002), “Higher-Order Improvements of a Computationally.
(22) 240. Ching-Chuan Tsong. Attractive K-Step Bootstrap for Extremum Estimators,” Econometrica, 70, 119-162. Breen, W., L. R. Glosten, and R. Jagannathan, (1989), “Economic Significance of Predictable Variations in Stock Index Returns,” The Journal of Finance, 44, 1177-1189. Davision, A. C. and P. Hall, (1993), “On Studentizing and Blocking Methods for Implementing the Bootstrap with Dependent Data,” Australian Journal of Statistics, 35, 215-224.. Engel, C., (1994), “Can the Markov Switching Model Forecast Exchange Rates?” Journal of International Economics, 36, 151-165.. Gonçalves, S. and T. J. Vogelsang, (2006), “Block Bootstrap HAC Robust Tests: The Sophistication of the Naive Bootstrap,” Working Paper. Götze, F. and H. R. Künsch, (1996), “Second-Order Correctness of the Blockwise Bootstrap for Stationary Observations,” Annals of Statistics, 24, 1914-1933. Hall, P. and B. Y. Jing, (1996), “On Sample Reuse Methods for Dependent Data,” Journal of Royal Statistical Society Series B, 58, 727-737.. Henriksson, R. D. and R. C. Merton, (1981), “On Market Timing and Investment Performance. II. Statistical Procedures for Evaluating Forecasting Skills,” Journal of Business, 54, 513-533.. Kiefer, N. M. and T. J. Vogelsang, (2002), “Heteroskedasticity-Autocorrelation Robust Testing Using Bandwidth Equal to Sample Size,” Econometric Theory, 18, 1350-1366. Kiefer, N. M. and T. J. Vogelsang, (2005), “A New Asymptotic Theory for Heteroskedasticity-Autocorrelation Robust Tests,” Econometric Theory, 21, 1130-1164. Lahiri, S. N., (1996), “On Edgeworth Expansion and Moving Block Bootstrap for Studentized M-Estimators in Multiple Linear Regression Models,” Journal of Multivariate Analysis, 56, 42-59.. Newey, W. K. and K. D. West, (1987), “A Simple, Positive Semi-Definite, Heteroskedasticity and Autocorrelation Consistent Covariance Matrix,” Econometrica, 55, 703-708.. Park, J. Y., (2003), “Bootstrap Unit Root Tests,” Econometrica, 71, 1845-1895. Politis, D. and H. White, (2004), “Automatic Block-Length Selection for the Dependent Bootstrap,” Econometric Reviews, 23, 53-70..
(23)
數據
+7
相關文件
• Using the remainder estimate for the Integral Test, answer this question (posed at the end of Group Exercise 2 in Section 12.2): If you had started adding up the harmonic series at
Write the following problem on the board: “What is the area of the largest rectangle that can be inscribed in a circle of radius 4?” Have one half of the class try to solve this
3.2 Rolle’s Theorem and the Mean Value Theorem 3.3 Increasing and Decreasing Functions and the First Derivative Test.. 3.4 Concavity and the Second Derivative Test 3.5 Limits
The accuracy of a linear relationship is also explored, and the results in this article examine the effect of test characteristics (e.g., item locations and discrimination) and
volume suppressed mass: (TeV) 2 /M P ∼ 10 −4 eV → mm range can be experimentally tested for any number of extra dimensions - Light U(1) gauge bosons: no derivative couplings. =>
We explicitly saw the dimensional reason for the occurrence of the magnetic catalysis on the basis of the scaling argument. However, the precise form of gap depends
• A language in ZPP has two Monte Carlo algorithms, one with no false positives and the other with no
專案執 行團隊
