行政院國家科學委員會專題研究計畫 成果報告
有限差分近似法在數量性狀基因座定位上最大概似估值變
異矩陣估算上之應用
計畫類別: 個別型計畫
計畫編號: NSC91-2313-B-002-365-
執行期間: 91 年 08 月 01 日至 92 年 07 月 31 日
執行單位: 國立臺灣大學農藝學系暨研究所
計畫主持人: 劉清
報告類型: 精簡報告
處理方式: 本計畫可公開查詢
中 華 民 國 93 年 2 月 6 日
計畫編號: 91-2313-B-002-365
計畫名稱: 有限差分近似法在數量性狀基因座定位上
最大概似估計值變異矩陣估算上之應用
主持人: 劉 清
摘
要
在數量性狀基因座的定位與分析上,混合模式的最大概似估計值可以 EM 法
(Expectation Maximization, Dempster, Laird and Rubin, 1977) 、 ECM 法
(Expectation-Conditional Maximization, Meng and Rubin, 1993)、IRLS 法(Iteratively
Reweighted Least Squares)等方法求出,但最大概似估計值的漸近變異矩陣因為需
要利用概似函數的二次微分式求算,又由於一般混合模式之概似函數的二次微分
式相當複雜不易導出,因此如何計算混合模式之最大概似估計值的漸近變異矩陣
為一相當重要的課題。因為僅有估值卻不知估值的變異,將無法評估根據此估值
所做統計推論的可靠性。本研究提出以數值方法上的有限差分近似法(finite
difference approximation method)來計算概似函數的近似二次微分式及最大概似
估值的漸近變異矩陣。
為證實利用有限差分近似法所算之漸近變異矩陣結果的正確性,特將模擬之
常態分布、二項分布與卜瓦松分布的 F
2子代的數量性狀資料,分別以概似函數
的二次微分式(analytic derivative)與有限差分近似法之近似二次微分式(finite
difference approximation of second order derivative)作計算,並比較兩者之計算結
果。模擬結果證實無論數量性狀資料分布為何,利用概似函數的二次微分式與有
限差分近似法的近似二次微分式,兩者所算出的漸近變異矩陣幾乎完全相同。因
此在數量性狀基因座的定位與分析上,當各類數學模式之概似函數無已知的二次
微分式或不易以解析方法導出時,建議可先以 EM 法、ECM 法、IRLS 法等方法
來計算模式之最大概似估計值。一但求得最大概似估計值的解析解,則可利用數
值方法上的有限差分近似法來計算概似函數的近似二次微分式及最大概似估值
的漸近變異矩陣。
關鍵詞:數量性狀基因座、遺傳標識、簡單區間定位法、綜合區間定位法、有限
ABSTRACT
For mapping and analysis of quantitative trait loci (QTL), the maximum
likelihood (ML) estimates of parameters of mixture model can be calculated via EM,
ECM, IRLS or other methods, whereas the asymptotic dispersion matrix of ML
estimates requires the second order derivative of likelihood function which is
generally complicated and not easily derivable. The calculation of asymptotic matrix
of ML estimates is important in that it enables us to evaluate the plausibility of our
statistical inference based on ML estimates. This study proposes calculating the
asymptotic dispersion matrix of ML estimates by the finite difference approximation
method if the second order derivative of likelihood function is too complicate to
derive.
To verify the correctness of the asymptotic dispersion matrix calculated by the
finite difference approximation method, the asymptotic dispersion matrix of the
simulated normal, binary and Poisson distributed F
2intercross data are calculated by
analytical formula and the finite difference approximation of second order derivative.
Results from the simulated F
2intercross data indicate that the asymptotic dispersion
matrices calculated by the finite difference approximation method are very close to
that of the analytical formula. Therefore, if the second order derivatives of likelihood
functions under various kinds of mathematical model settings are too complicated to
derive, it is suggested to calculate the ML estimates via EM, ECM, IRLS or other
methods which do not require the second order derivative. Once the ML estimates is
available, the asymptotic dispersion matrix of ML estimates can be calculated by
finite difference approximation method.
(SIM), composite interval mapping (CIM), finite difference approximation
method, maximum likelihood estimates, the asymptotic dispersion matrix.
目
錄
中文摘要...i
英文摘要...ii
目錄...iv
圖目錄...vi
表目錄...vii
第一章、前言...1
第二章、數量性狀基因座定位法之簡介...4
第一節、簡單線性迴歸分析...4
第二節、簡單區間定位法...5
第三節、複迴歸分析...7
第四節、綜合區間定位法...8
第三章、研究方法...10
第一節、遺傳模式...10
第二節、廣義線性模式...12
第三節、互換率與分摩...14
第四節、統計模式...16
第五節、概似函數、最大概似估計值與最大概似估計值的
漸近變異矩陣...18
第六節、概似函數之二次微分式的推導...20
I、常態分布...23
II、二項分布...26
III、卜瓦松分布...28
第七節、概似函數之近似二次微分式...30
I、有限差分近似法...30
II、概似函數之有限差分近似二次微分式...31
第四章、資料模擬 ...34
第一節、模擬 F
2子代資料...34
第二節、資料模擬結果...40
I、簡單區間定位法(SIM)之 QTL 效應的計算結果...43
II、綜合區間定位法(CIM)之 QTL 效應的計算結果...47
第三節、模擬結果討論...63
第五章、結果與討論...65
參考書籍與文獻...69
附錄 1、兩基因座間的距離與互換率...71
附錄 2、數量性狀基因座各基因型的出現機率...73
附錄 3、對數概似函數之二次微分式的導出...75
附錄 4、數量性狀基因座各基因型之出現機率函數對交換率的
一次微分式...79
附錄 5、數量性狀基因座各基因型之出現機率函數對交換率的
二次微分式...81
圖
目 錄
圖 3.1 F
2子代示意圖... 11
圖 3.2
累加性效應與顯性效應示意圖... 12
圖 3.3
三個基因座間的互換率關係示意圖... 14
圖 3.4
三個基因座間的分摩關係示意圖... 14
圖 3.5
互換率與分摩之關係圖... 15
圖 3.6
數量性狀基因座與左、右翼標識因子間的相對距離示意
圖... 18
圖 4.1
模擬資料設定之標識因子與 QTL 位置示意圖... 35
圖 4.2
決定第二個標識因子基因型之流程圖... 38
圖 4.3
模擬資料設定之 QTL 位置示意圖(第一條染色體)... 42
圖 A1.1 親代基因型與配子(兩基因座位於不同染色體)... 71
圖 A1.2 親代基因型與配子(兩基因座間發生互換)... 72
表
目 錄
表 4.1
常態分布模擬資料之各染色體上 QTL 的位置、區間及
效應... 36
表 4.2
二項與卜瓦松分布模擬資料之各染色體上 QTL 的位
置、區間及效應... 36
表 4.3
給定一個標識因子的基因型下,另一個標識因子可能
出現之各種基因型的機率... 37
表 4.4
利用 SIM 模式分析常態分布模擬資料之效應的估算
結果(單點分析)... 43
表 4.5
利用 SIM 模式分析常態分布模擬資料之效應的估算
結果(區間分析)... 43
表 4.6
利用 SIM 模式,經由 Logit 連結函數轉換後,分析二
項分布模擬資料之效應的估算結果(單點分析)... 44
表 4.7
利用 SIM 模式,經由 Logit 連結函數轉換後,分析二
項分布模擬資料之效應的估算結果(區間分析)... 44
表 4.8
利用 SIM 模式,經由 Probit 連結函數轉換後,分析二
項分布模擬資料之效應的估算結果(單點分析)... 45
表 4.9
利用 SIM 模式,經由 Probit 連結函數轉換後,分析二
項分布模擬資料之效應的估算結果(區間分析)... 45
表 4.10 利用 SIM 模式,經由對數連結函數轉換後,分析卜瓦
松分布模擬資料之效應的估算結果(單點分析)... 46
表 4.11 利用 SIM 模式,經由對數連結函數轉換後,分析卜瓦
松分布模擬資料之效應的估算結果(區間分析)... 46
表 4.12 利用 CIM 模式分析常態分布模擬資料之效應的估算
表 4.13 利用 CIM 模式分析常態分布模擬資料之效應的估算
結果(區間分析)... 49
表 4.14 利用 CIM 模式,經由 Logit 連結函數轉換後,分析二
項分布模擬資料之效應的估算結果(單點分析)... 52
表 4.15 利用 CIM 模式,經由 Logit 連結函數轉換後,分析二
項分布模擬資料之效應的估算結果(區間分析)... 53
表 4.16 利用 CIM 模式,經由 Probit 連結函數轉換後,分析二
項分布模擬資料之效應的估算結果(單點分析)... 55
表 4.17 利用 CIM 模式,經由 Probit 連結函數轉換後,分析二
項分布模擬資料之效應的估算結果(區間分析)... 56
表 4.18 利用 CIM 模式,經由對數連結函數轉換後,分析卜瓦
松分布模擬資料之效應的估算結果(單點分析)... 58
表 4.19 利用 CIM 模式,經由對數連結函數轉換後,分析卜瓦
松分布模擬資料之效應的估算結果(區間分析)... 60
表 4.20 資料模擬之計算結果整理... 63
表 A2.1 數量性狀基因座各基因型的出現機率... 73
表 A4.1 數量性狀基因座各基因型之出現機率函數(log p
ij)對
互換率(r
1)的一次微分式... 79
表 A5.1 數量性狀基因座各基因型之出現機率函數(log p
ij)對
互換率(r
1)的二次微分式... 81
第 一 章 、 前 言
性狀(character, trait)為生物體可被觀察到的特徵,是由基因與環境相互作用
所形成的,可分為質量性狀(qualitative traits)與數量性狀(quantitative traits)兩種。
質量性狀指個體在表型上可明顯區分為不同類型的性狀,如豌豆花的花色有紫色
或白色、人類耳垂有分離臉頰與緊貼臉頰…等,此類性狀的變異在群體內為不連
續的,也不易受環境的影響,大多由一對或少數幾對的主效基因(major genes)或
寡基因(oligogenes)所控制。數量性狀是指個體在表型上不能明顯劃分為不同類型
的性狀,如作物的產量、倒伏性、抗病性、株高,及人類的身高、體重、智商…
等,此類性狀在群體內以連續性變異(continuous variation)的型態存在,易受環境
的影響,常由數個微效基因(minor genes)或多基因(polygenes)的累積作用所控
制。許多具有重要經濟價值的性狀是以連續性變異的型態存在。早期在育種上是
以族群改良(population improvement)的方式來累積優良及有經濟價值的性狀頻
度,但此法耗時且易受環境的影響。
隨 著 分 子 生 物 學 的 快 速 發 展 , 遺 傳 學 者 開 始 使 用 分 子 標 識 (molecular
markers),如 RFLPs(Restriction Fragment Length Polymorphisms)、microsatellite、
RAPD(Randomly Amplified Polymorphic DNA)、VNTR(Variable Number of Tandem
Repeat)
K等,來定位並分析數量性狀基因座(Quantitative Trait Loci, QTL)的位置
與效應,藉著分子標識大多具有共顯性且又不易受環境影響,將控制同一性狀的
各個數量基因視為獨立,解析為單一基因,可簡化原本複雜的情形,再利用統計
模式分析並找出 QTL 最有可能存在的位置。若能藉此方法辨識出 QTL 的位置,
再利用基因轉殖的技術將具有此一優良數量性狀基因座的染色體片段轉殖回親
代,便可提高優良性狀的頻度,並能改善傳統方法因易受環境影響而存有不確定
性,亦能有效的改進選拔育種的效率。
and Brody, 1976) 。 Lander et al. (1989)提 出 簡單區間 定位法 (Simple Interval
Mapping, SIM),利用 目標區間兩翼 標識因 子(flanking marker)的 資訊來定位
QTL,而將 QTL 的定位與分析由點(point)的概念帶入到區間(interval)的概念。
Jansen (1992)和 Zeng(1993, 1994)結合簡單區間定位法與染色體上其他標識因子
的訊息,提出綜合區間定位法(Composite Interval Mapping, CIM);藉由控制目標
區間外之其他標識因子的遺傳變異殘差,對目標區間進行數量性狀基因座的定位
分析。在遺傳學上,若控制單一性狀的兩個或兩個以上的基因座間有交感作用存
在,則稱此交感作用為上位(epistasis);若一基因座能同時影響多種性狀的表現,
則稱此現象為多效(pleiotropy)。Kao(1995)將綜合區間定位法推廣,進一步的討
論單一性狀且包含上位性效應(epistatic effect)的遺傳模式。Jiang 和 Zeng (1995)
則將綜合區間定位法推廣至單一數量性狀基因座之多效性的遺傳模式。
因上述所有方法之統計模式皆為一種混合模式,沒有封閉式的解(closed
form solution),因此必須以最大概似法,如牛頓法(Newton-Raphson method)求
解。雖牛頓法能同時求得最大概似估計值與最大概似估計值漸近變異矩陣
(asymptotic dispersion matrix),但牛頓法必須利用概似函數的二次微分式計算,
因此若概似函數的二次微分式不易導出或公式太複雜,則只能以其他不需用到概
似函數二次微分式的計算方法,如 EM 法、ECM 法、IRLS 法或其他方法計算,
但最大概似估計值的漸近變異矩陣仍需利用概似函數的二次微分式計算,故以
EM 等方法雖可求算最大概似估計值的解,卻無法再計算最大概似估計值的漸近
變異矩陣(劉, 1997)。大部分討論 QTL 定位法的文獻多忽略了最大概似估計值之
漸近變異矩陣的計算,但僅有估值卻不知估值的變異,則無法評估根據此估值所
做統計推論的可靠性。
本研究提出以數值方法上的有限差分近似法來計算各類數學模式之概似函
數二次微分式與最大概似估計值的漸近變異矩陣。接下來在第二章中,本文將簡
單介紹幾種主要的數量性狀基因座定位法;第三章介紹數量性狀之機率分布為常
態分布、二項分布、卜瓦松分布等指數分布族(exponential family)時,概似函數
二次微分式(analytic derivatives)的推導過程,並說明如何利用有限差分近似法計
算概似函數的近似二次微分式。第四章則將常態分布、二項分布與卜瓦松分布之
F
2子代的數量性狀模擬資料,分別利用所推導之概似函數的二次微分式與有限差
分近似法的近似二次微分式,計算最大概似估計值的漸近變異矩陣,並比較兩者
之計算結果。第五章為本研究之結果與討論。
第 二 章 、 數 量 性 狀 基 因 座 定 位 法 之 簡 介
歷年來數量性狀基因座定位法的演進,基本上是以簡單線性迴歸為基礎,
建立數量性狀表型值(phenotype value)與各標識因子間的統計關係;藉著 RFLP
等標識因子具有共顯性與不受環境因素影響的優點,將控制同一性狀的多個數量
基因解析為單獨的基因,可簡化原本複雜的情形,並建立線性迴歸模式將數量性
狀表型值與標識因子間的關係模式化,以偵側未知基因的位置(盧, 1997)。
第一節、簡單線性迴歸分析
Soller 與 Brody (1976)提出利用簡單線性迴歸分析建立數量性狀基因座的表
現型效應與標識因子基因型間的迴歸模式,以 F
2子代為例,模式如(1),並檢定
模式中有無數量基因存在之差異是否顯著,若檢定結果顯著,則表示有 QTL 與
此標識因子連鎖;若檢定結果為不顯著,則表示無 QTL 與此標識因子連鎖。
0 i i i iy
= +
b
ax
+
dz
+
e
,
i
=
1, 2,...,
n
(1)
其中y 為第 i 個個體的數量性狀基因表型值。 i 0 b 為常數項。 a 為在標識因子上,數量性狀基因座的累加性效應(additive effect)。d
為在標識因子上,數量性狀基因座的顯性效應(dominance effect)。 i x 為累加性效應的指標變數,其值為 0、1、2,分別對應數量性狀基因之基因型為 qq、Qq、QQ。 i z 為顯性效應的指標變數。當數量性狀基因之基因型為為同質型(homozygote, QQ or qq)時,其值為 0;當數量性狀基因之基因型為異質型(heterozygote, Qq)時,其值為 1。( )
2 0, iid i N e:
σ ,為隨機誤差;假設來自平均數 0,變異數σ2的常態分布。 ▅此法最主要貢獻是將數量性狀基因座的定位法以線性模式來估算,但僅使
用迴歸模式分析的方法似乎過於簡單,且有下列的一些缺點(Ott, 1985; Lander
and Botstein, 1989): 1.若數量性狀基因座未位於標識因子上,則數量性狀基因
座的表現型效應將會被嚴重低估,而需較多的子代來估算數量性狀基因座的位置
及效應; 2.當標識因子與數量性狀基因座之間為緊連鎖(互換率小於 0.05)且
表現型效應較小時,或當標識因子與數量性狀基因座之間為鬆連鎖(互換率大於
0.30)且表現型效應較大時,無法定出數量性狀基因座的可能位置; 3.同時檢定
多個標識因子時,錯判率會增加。
第二節、簡單區間定位法
Lander 與 Botstein (1989)提出改進的方法,利用加權迴歸模式發展了簡單區
間定位法,以 F
2子代為例,模式如下(2),利用兩翼標識因子所形成的區間做為
估算的目標區間,在兩翼標識因子為已知的條件下,對目標區間內的任一位置,
若假設此位置有 QTL 存在時,以該位置所有可能出現之 QTL 基因型的機率為加
權值來估算最大概似估計值(Maximum Likelihood Estimate, MLE)與最大概似函
數值。計算目標區間內的每一個位置有 QTL 與沒有 QTL 兩種情形下的最大概似
函數值,兩者相比較求出一個 LOD 值(LOD score)。透過掃描(scan)整個目標區間
所有位置的方法(亦即對目標區間中的每一個位置,皆算出該位置的 LOD 值),
並與 LOD 的臨界值比較是否顯著。最後在所有顯著的 LOD 值中找出局部最大
值,則這些出現局部最大值的位置就是最可能有 QTL 存在的位置。
0 i i i iy
= +
b
a x
∗ ∗+
d z
∗ ∗+
e
,
i
=
1, 2,...,
n
(2)
其中y 為第 i 個個體的數量性狀基因表型值。i x∗為累加性效應的指標變數,其值為 0、1、2,分別對應數量性狀基因之基因型為 qq、Qq、QQ。 i z∗為顯性效應的指標變數。當數量性狀基因之基因型為為同質型(QQ or qq)時,其值 為 0;當數量性狀基因之基因型為異質型(Qq)時,其值為 1。
( )
2 0, iid i N e:
σ ,為隨機誤差;假設來自平均數 0,變異數σ2的常態分布。 ▅以兩翼標識因子計算所有可能出現之 QTL 基因型的條件機率做為加權值,
則加權後的概似函數如(3):
(
2)
( ) ( )
( ) ( )
( ) ( )
0 1,
,
,
0
0
1
1
2
2
n i i i i i i iL b a d
∗ ∗σ
p
f
p
f
p
f
==
∏
+
+
(3)
其中( )
(
(
)
)
2 0 , i i i i f x = Φ y − b +a x∗ +d z∗ σ 為第i
個個體的機率密度函數;(
)
(
)
2 0 , i i i y b a x∗ d z∗ σ Φ − + + 為平均數 0,變異數σ2的常態分布。( )
i p x 為假定兩翼標識因子已知的條件下,所有可能出現之 QTL 基因型的條件機率;( )
0( )
1( )
2 1 i i i p +p +p = 。 ▅與簡單線性迴歸分析法相比較,簡單區間定位法更能確定數量性狀基因座
的正確位置,尤其當目標區間內只有單獨一個數量性狀基因座時,此法所得到的
結果可說是相當精確的,而且用簡單區間定位法所需的子代數目也較少。但簡單
區間定位法仍存在一些問題
(Zeng, 1993)
:
1.
即使目標區間中並無數量性狀基因
座存在,也可能會受到位於鄰近區間之數量性狀基因座的影響,而表現出有數量
性狀基因座存在的結果;
2.
若是區間中有存在有兩個以上的數量性狀基因座,
往往無法區隔其效應,因此所得到的數量性狀基因座的位置與效應都會有所偏
誤;
3.
每次只用兩翼標識因子來做定位分析,而其他標識因子的資訊並沒有運
用到,使得估計與檢定的效率並不高。
第三節、複迴歸分析
針對簡單區間定位法的第
3
點問題,
Cowen(1989)
與
Stam(1991)
等學者將簡
單迴歸分析法推廣成利用複迴歸的方式來定位數量性狀基因座以,
F
2子代為例,
模式如下
(4)
,利用對應於特定標識因子上的偏迴歸係數估計數量基因效應,並
將其他的標識因子視為共變數。
0 1 1 J J i j ij j ij i j jy
b
a x
d z
e
= == +
∑
+
∑
+
,
i
=
1, 2,...,
n
(4)
其中yi為第i個個體的數量性狀基因表型值。 0 b 為常數項。 j a 為給定其他標識因子時,第 j 個標識因子對應於數量性狀值y之累加性效應的偏 迴歸係數。 jd
為給定其他標識因子時,第 j 個標識因子對應於數量性狀值y之顯性效應的偏迴 歸係數。 ij x 為累加性效應的指標變數,其值為 0、1、2,分別對應標識因子之基因型為 qq、 Qq、QQ。 ij z 為顯性效應的指標變數。當標識因子之基因型為為同質型時,其值為 0;當標識因 子之基因型為異質型時,其值為 1。( )
2 0, iid i N e:
σ ,為隨機誤差;假設來自平均數 0,變異數σ2的常態分布。 ▅利用複迴歸分析法建立的定位模式具有四種特性
(Zeng, 1993)
:
1.
假定數量
基因之效應具有累加性,則標識因子上的偏迴歸係數只和相鄰標識因子所形成的
左右區間內之數量性狀基因有關,而與相鄰區間外的數量基因無關;
2.
若將非
連鎖的標識因子視為已知條件,藉著控制遺傳變異,將會降低檢定統計量的抽樣
變異並提高檢定力;
3.
若將連鎖的標識因子視為已知條件,可降低多個
QTL
連
鎖所產生的干擾情形,但可能會產生抽樣變異;
4.
兩個標識因子的偏迴歸係數
第四節、綜合區間定位法
為改進上述之缺點,
Zeng(1993)
結合了簡單區間定位法與複迴歸的觀念,提
出綜合區間定位法,以
F
2子代為例,在給定第
j
個與第
j
+
1
個兩翼標識因子所
形成的目標區間中,若假設目標區間內有
QTL
存在,則模式如下
(5)
。綜合區間
定位法是以簡單區間定位法為基礎,加入目標區間外所有標識因子做為共變數,
對目標區間內的每一個位置,皆計算該位置有
QTL
存在與沒有
QTL
存在之兩種
情形下的最大概似函數值,再利用概似比率檢定
(Likelihood Ratio Test, LRT)
求得
該位置之
LRT
統計量。透過掃描整個目標區間所有位置的方法(亦即對目標區
間中每一個位置,皆算出該位置的
LRT
值),並在所有顯著的
LRT
值中找出局
部最大值,則這些出現局部最大值的位置就是最可能有
QTL
存在的位置。
0 , 1 , 1 i i i k ik k ik i k j j k j jy
b
a x
∗ ∗d z
∗ ∗a x
d z
e
≠ + ≠ += +
+
+
∑
+
∑
+
,
i
=
1, 2,...,
n
(5)
其中yi為第i個個體的數量性狀基因表型值。 0 b 為常數項。 a∗為數量性狀基因座的累加性效應。d
∗為數量性狀基因座的顯性效應。 i x∗為累加性效應的指標變數,其值為 0、1、2,分別對應數量性狀基因之基因型為 qq、Qq、QQ。 i z∗為顯性效應的指標變數。當數量性狀基因之基因型為為同質型(QQ or qq)時,其值 為 0;當數量性狀基因之基因型為異質型(Qq)時,其值為 1。 k a 為第k個標識因子對應於數量性狀值y之累加性效應的偏迴歸係數。 ik x 為第i個個體的第k個標識因子基因型之累加性效應的指標變數,其值為 0、1、2, 分別對應於基因型為 qq、Qq、QQ。 k d 為第k個標識因子對應於數量性狀值y之顯性效應的偏迴歸係數。 ik z 為第i個個體的第k個標識因子基因型之顯性效應的指標變數,其值為 0、1,分 別對應於基因型為同質型、異質型。( )
2 0, iid i N e:
σ ,為隨機誤差;假設來自平均數 0,變異數σ2的常態分布。 ▅若假設目標區間內的某一位置有
QTL
存在,以該位置所有可能出現之
QTL
基因型的條件機率做為加權值,則加權後的概似函數如下
(6)
:
( ) ( )
( ) ( )
( ) ( )
1 10
0
1
1
2
2
n i i i i i i iL
p
f
p
f
p
f
==
∏
+
+
(6)
其中( )
2 0 , 1 , 1 , i i i i k ik k ik k j j k j j f x y b a x∗ ∗ d z∗ ∗ a x d z σ ≠ + ≠ + = Φ − + + + + ∑
∑
為第 i 個個體的 機率密度函數; 2 0 , 1 , 1 , i i i k ik k ik k j j k j j y b a x∗ ∗ d z∗ ∗ a x d z σ ≠ + ≠ + Φ − + + + + ∑
∑
為平均數 0,變異數σ2的常態分布。( )
i p x 為假定兩翼標識因子已知的條件下,不同 QTL 基因型之條件機率;( )
0( )
1( )
2 1 i i i p +p +p = 。 ▅綜合區間定位法的主要優點可歸納為
(Zeng, 1994)
:
1.
一次定位一個區間,
將尋找多個
QTL
的問題由多維
(multiple dimension)
轉為單維
(one dimension)
,且
效應估計值漸近不偏;
2.
在連鎖標識因子已知下,定位準確度提高;
3.
仍保有
如簡單區間定位法用最大概似函數表現數量基因座存在證據強度之優點。但因綜
合區間定位法考慮其他共變數的效應在內,又所有的標識因子效應皆由最大概似
估計法估算所得,故在計算上較簡單區間定位法複雜許多。
近年來數量性狀基因座定位法的發展,陸續有幾位學者考慮到更為複雜的
模式,如單一性狀包含上位性的遺傳模式
(Kao, 1995)
、多性狀不包含上位性的遺
傳模式
(Zeng, 1995)
,及多性狀且包含上位性的遺傳模式等方法,來定位與分析
數量性狀基因座。本研究將引用簡單區間定位法與綜合區間定位法,建立數量性
狀表型值與數量性狀基因型之間的關係,並利用解析方法與有限差分近似法,計
算由簡單區間定位法與綜合區間定位法所建構之對數線性混合模式的概似函數
二次微分式與最大概似估計值的漸近變異矩陣,而不考慮包含多性狀或上位性等
第 三 章 、 研 究 方 法
在數量性狀基因座的定位與分析上,可用於估算混合模式的最大概似估計
值的方法甚多,如
EM
法、
ECM
法、
IRLS
法等計算方法,但最大概似估計值的
漸近變異矩陣因為需要利用概似函數的二次微分式求算,又由於一般混合模式之
概似函數的二次微分式相當複雜而不易導出。本章將以
F
2子代為對象,在不考
慮上位性與多效性的情況下,討論以簡單區間定位法與綜合區間定位法所建構的
混合模式之概似函數二次微分式與最大概似估計值之漸近變異矩陣的計算;說明
數量性狀之機率分布為常態分布、二項分布、卜瓦松分布等指數分布族時,各類
分布之概似函數二次微分式的推導過程,並介紹本研究將如何應用數值方法上的
有限差分近似法,計算概似函數之近似二次微分式,進而求出最大概似估值的漸
近變異矩陣。
第一節、遺傳模式
本研究以來自於兩自交系雜交之
F
2子代為研究對象。若
與
分別代表
雙親之數量性狀基因座的基因型,則
F
1子代之基因型為
,
F
1子代自交後,可
產生基因型為
、
或
的
F
2子代(如下圖
3.1
)。
A
(QQ)
╳
B
(qq)
F
1(Qq)
╳
F
1(Qq)
F
2(QQ,
or qq)
圖
3.1 F
2子代示意圖
假設有一大小為
n
之樣品,來自於兩自交系雜交而來之
F
2子代。樣品中之
每個個體除紀錄有數量性狀表型值外,亦紀錄一些具有共顯性的遺傳標識。
F
2子代的任一數量性狀基因座
(QTL)
所可能出現的基因型有
、
與
三種,
而三種基因型出現的基因頻度分別為
1 4、
12及
14,而
QTL
效應之遺傳模式
(genetic model)
可以下式表示:
0G
=
m
1G
= + +
m
a
d
22
G
= +
m
a
若 QTL 基因型為 qq 若 QTL 基因型為 Qq(7)
若 QTL 基因型為 QQ 其中G ,j j=0,1, 2之下標(subscript)分別代表 QTL 基因型中所含 Q 的個數 m 代表模式的平均值 a 代表累加性效應(additive effect) d 代表顯性效應(dominance effect) ▅在
F
2子代中,所有可能出現之數量性狀基因型有
、
與
三種,而
其對性狀值的貢獻可分為累加性效應與顯性效應,各基因型與不同效應之關係可
以下圖(圖
3.2
)表示
(
盧
, 1997)
:
d
a a
0
圖
3.2 累加性效應與顯性效應示意圖
在圖
3.2
中,
u
為基因型
之數量基因效應與基因型
之數量基因效應
兩者之中間值。累加性效應
a
即為中間值
u
與同質型數量基因
、
qq)
間用一
定尺度所測量之增量,而顯性效應
d
則為自中間值起向任一方向之增量,其值可
為正、負,亦可為零;當
d=0
時,代表無顯性效應;當
d>a
時,代表有超顯性
(overdominance)
的現象發生。若設基因型
之數量基因效應為
0
,則基因型
之數量基因效應便為
a+d
,而基因型
之數量基因效應便為
2
a
。
第二節、廣義線性模式
在數量性狀基因座定位與分析研究上,數量性狀的觀測值並非皆為連續性
的分布,有時因受觀測儀器、技術或研究目的的限制下,而無法觀測到連續性的
資料,如研究植株的倒伏性時,研究者通常很難將每一植株的倒伏角度測量出
來,必須藉著設立門檻
(threshold)
的方式將觀測資料加以分組,而將原本應為連
續性分布的數量性狀,觀測成間斷性的多項分布性狀
(
江
, 1998
;張
, 2000)
,還有
一些蒐集到的性狀資料,是以比率
(rate)
的方式表示,如白米率
(mill rice)
、稔實
率
(fertility)
、榖種指數
(index of grain yield)
等
(
陳
, 1998)
。若數量性狀的觀測值非
連續性資料,而為二項、多項,或卜瓦松分布或其他指數分布族,則需利用廣義
線性模式
(Generalized Linear Model, GLIM)
來建立
QTL
定位的統計模式。廣義線
性模式包括三個部分:
(1)
隨 機 成 份
(random component) , 指 具 有 指 數 族 型 式 的 獨 立 反 應 變 項
[
Y Y1, 2,...,Yn]
′ = Y,每一個反應變項觀測值
Yi的機率分布為
(
i;
i) ( ) ( )
i iexp
i( )
if y
θ
=
a
θ
b y
y Q
⋅
θ
其中 θi為反應變項觀測值Y 之機率分布參數。 i( )
i a θ 為僅包含θi的函數。( )
i b y 為僅包含反應變項觀測值Y 的函數。 i( )
i Q θ 稱為分布的自然參數(natural parameter)。 ▅(2)
系統成份
(systematic component),為連結線性估計元
η
′ =
(
η η
1,
2,...,
η
n)
與解
釋變數
X 間的線性模式。
=
η Xβ
其中X
為n
×
p
階矩陣;β
為p
×
1
階之模式參數向量。 ▅(3)
連結函數
(link function)
,用來建立系統成份與隨機成份期望值之間的關係
函數。若
η η µi=( )
i為將連續型數量性狀
µi轉換成線性估算元
(linear predictor)
的連結函數
(link function)
;
µi =Exp y( )
i為第
i
個個體的數量性狀期望(平均)
值,則
( )
i j ij jx
η µ
=
∑
β
, 1, 2,...,
i
=
n
(代表個體)
1, 2,...,
j
=
J
(代表模式參數)
第三節、互換率與分摩
當細胞進行減數分裂
(meiosis)
時,染色體間的遺傳物質可能會發生互換的現
象,因為互換發生的機率大小與兩基因座間的距離遠近成正比,所以可利用互換
率
(recombination frequency, recombination fraction)
來估計兩基因座間距離,而分
摩
(centi-Morgan, cM)
是計算兩基因座間遺傳距離
(genetic distance)
的單位。
A B C
圖
3.3 三個基因座間的互換率關係示意圖
以 互 換 率 為 單 位 所 表 示 之 基 因 座 與 基 因 座 間 的 距 離 是 不 可 累 加 的
(non-additive)
,如圖
3.3
,若基因座
A
與
B
的互換率為
0.2
,基因座
B
與
C
的互
換率為
0.2
,則基因座
A
與
C
的互換率
r = r
1(1-r
2)+r
2(1-r
1) = r
1+r
2-2r
1r
2= 0.32
,
並非基因座
A
與
C
的互換率和基因座
A
與
B
的互換率直接相加之值。
A B C
圖
3.4 三個基因座間的分摩關係示意圖
以 分 摩 為 單 位 所 表 示 之 基 因 座 與 基 因 座 間 的 遺 傳 距 離 是 可 累 加 的
(additive)
,如圖
3.4
,若基因座
A
與
B
的距離為
20 cM
,基因座
B
與
C
的距離為
20 cM
,則基因座
A
與
C
的距離是基因座
A
與
B
的距離再加上基因座
B
與
C
的
x
2= 20 cM
x = x
1+x
2= 40 cM
r
1= 0.2
r
2= 0.2
r = r
1(1-r
2)+r
2(1-r
1) = r
1+r
2-2r
1r
2= 0.32
x
1= 20 cM
距離:
x = x
1+x
2= 40 cM
。
基因座與基因座間的互換率與遺傳距離的關係,可利用
Haldane
基因定位函
數
(Haldane’s map function)
做一轉換:
(
2)
1
2
xe
r
−−
=
或
ln 1 2
(
)
2
r
x
=
−
−
(8)
其中
x
的單位是摩
(Morgan, M)
,而互換率
r
則是機率的單位。
510 20 30 40 50 100 150 200 0 5 10 20 30 40 50 centi-Morgan (cM) re c o mb in ati o n f ra cti o n ( % )圖
3.5 互換率與分摩之關係圖
由圖
3.5
可看出,當兩基因座間的距離小於
10 cM
時,互換率與分摩之值相
當接近,但若兩基因座間的距離大於
10 cM
時,互換率與分摩的關係就需要透過
定位函數來轉換。當兩基因座間的互換率相當接近或等於
0.5
時,則視兩基因座
分別位於不同的染色體上(請見附錄
1
說明)。
第四節、統計模式
根據上述之遺傳模式,則樣品資料之簡單區間定位法
(SIM)
與綜合區間定位
法
(CIM)
的統計模式如下:
(SIM):
η η µ
i=
( )
i= +
m
a x
∗ ∗i+
d z
∗ ∗i,
i
=
1, 2,...,
n
(9)
(CIM):
η η µ
i=
( )
i= +
m
a x
∗ ∗i+
d z
∗ ∗i+
b x ,
′
ii
=
1, 2,...,
n
(10)
其中ηi為將連續型數量性狀µi轉換成線性估算元的連結函數。 m 為常數項。 a∗為數量性狀基因座的累加性效應。 i x∗為累加性效應的指標變數。當 QTL 基因型為 qq、Qq、QQ 時,其值分別為 0、1、 2。 d∗為數量性狀基因座的顯性效應。 i z∗為顯性效應的指標變數。當 QTL 基因型為同質型(QQ or qq)時,其值為 0;當 QTL 基因型為異質型(Qq)時,其值為 1。 i x 為除了兩翼標識因子外的所有標識因子之各項效應指標變數向量,包含累加性效 應與顯性效應。 b 為除了兩翼標識因子外的所有標識因子之各項效應指標變數的偏迴歸係數向量。 ▅觀察
(9)
、
(10)
之簡單區間定位法
(SIM)
與綜合區間定位法
(CIM)
的統計模式,
由於兩種區間定位法的概念皆相同,差別只在於綜合區間定位法
(CIM)
中多加入
了目標區間外所有標識因子的資訊,也就是模式中的
b x
′
i,故在不失一般性的原
則下,僅詳述利用綜合區間定位法
(CIM)
估算
QTL
效應之理論推導,而簡單區間
定位法
(SIM)
在計算上與綜合區間定位法
(CIM)
相似,只需令
b 0
=
即可。
若
µ
i0、
µ
i1、
µ
i2為分別代表第
i
個個體之
QTL
基因型為
、
、
時,
數量性狀期望(平均)值。令
β′ =m a∗ d∗ b,且
0 1 2
1 0
0
1 1
1
1 2
0
i i i i i i′
′
′
=
′
′
′
x
x
x
x
x
x
則
η µ
( )
i0=
x β ,
i′
2η µ
( )
i1=
x β ,
i′
1η µ
( )
i2=
x β 。
′
i2令
f y
( )
θ
=
f
為數量性狀
y
之機率密度函數,
f
代表常態、二項、卜瓦松分
布或其他指數分布族的機率密度函數,
θ
代表由模式中所有的參數所構成的向
量,包括了數量性狀
y
分布的參數及
QTL
與兩翼標識因子間的互換率。因為
F
2子代的
QTL
基因型有
、
及
三種可能,以三種基因型可能出現之機率
(請見附錄
2
)為權重,則數量性狀
y
i(第
i
個個體的數量性狀)的機率密度函
數為三個分布給定權重後,相加而得的混合模式
(mixture model)
,模式如下:
( )
i i0( )
i0( )
i i1( )
i1( )
i i2( )
i2( )
ig y
θ
=
p
θ
f
y
θ
+
p
θ
f
y
θ
+
p
θ
f
y
θ
( )
( )
2 0 ij ij i jp
f
y
==
∑
θ
θ ,
i
=
1, 2,...,
n
(11)
在
(11)
式中,
p
i0、
p
i1、
p
i2是在給定目標區間之兩翼標識因子基因型的條件
下,出現各種
QTL
基因型的條件機率,可視為三種基因型(
、
及
)的
事前機率
(prior probability)
。在實際應用上,通常可透過連續測驗目標區間內的
多個位置的方式,如區間內每
2cM
的位置做一次測驗,對每一個測驗位置皆分
析該位置若有
QTL
存在的可能性,再比較所有測驗位置的分析結果,則可找出
目標區間內最可能有
QTL
存在的位置。由於上述方法對每一個測驗位置而言,
QTL
與兩翼標識因子間的距離都是固定的(即互換率之值為已知)
,故不需將互
換率當成模式的參數,但真實的
QTL
卻可能存在於兩個測驗位置之間,因此若
能將互換率也當成未知的參數加入模式中,則可直接估計區間內最可能有
QTL
存在的位置。不過直接估計區間內
QTL
最可能存在的位置,並無法像連續測驗
缺點,最好能都使用。
left marker
QTL
right marker圖
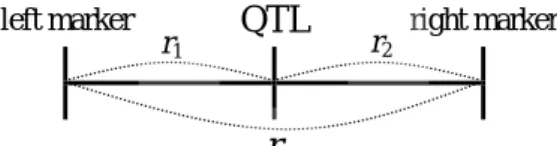
3.6 數量性狀基因座與左、右翼標識因子間的相對距離示意圖
如圖
3.6
,通常兩翼標識因子間的互換率
r
若非已知,也可由連鎖分析的方
式估計得到,因此只需估計
QTL
與左翼標識因子之間的互換率
r
1即可,至於
QTL
與右翼標識因子之間的互換率
r
2則可利用
r
和
r
1計算:
(
1)
2 11 2
r
r
r
r
−
=
−
。
第五節、概似函數、最大概似估計值與最大概似估計
值的漸近變異矩陣
所有觀測值之混合模式的概似函數
(likelihood function)
如下:
(
)
( )
2( )
( )
1 2 1 1 0,
,...,
n n n i ij ij i i i jL
y y
y
g y
p
f
y
= = =
=
=
∏
∏
∑
θ
θ
θ
θ
(12)
取對數後的對數概似函數
(log likelihood function)
為
( )
( )
2( )
( )
1 1 0
log
log
log
n n i ij ij i i i j
L
g y
p
f
y
= = =
=
=
∑
∑
∑
θ
θ
θ
θ
(13)
欲求出參數
θ
的估計值 ˆ
θ,可使概似函數的值達到極大,則等同於求出可使
對數概似函數一次微分式等於
0
的解:
r1 r2r
( )
log L
∂
=
∂
θ
0
θ
(14)
在
(14)
式中,向量
∂log L∂( )
θθ
稱為
gradient
向量或
score function
。因為混合
模式沒有封閉式的解,所以必須以數值方法來求解。若可導出對數概似函數的二
次微分式,則可利用牛頓法
(Newton-Raphson method)
遞迴
(iterative)
求解:
設
ˆθ 為起始值,則
0( )
( )
2 1 1 ˆ ˆlog
log
ˆ
ˆ
k k k kL
L
− + = =
∂
∂
=
−
∂ ∂
′
⋅
∂
θ θ
θ θθ
θ
θ
θ
θ θ
θ
(15)
將
(15)
反覆遞迴計算,直到符合收斂條件
( ) ( )
ˆk 1 ˆk L θ+ −L θ <ε為止(
ε為給定之
可容許誤差值)
,而此時所得到之參數估值即為最大概似估計值。
若牛頓法無法收歛或混合模式之概似函數的二次微分式相當複雜而不易導
出時,則可利用其他不需要用到概似函數二次微分式的計算法,如
EM
法、
ECM
法、
IRLS
法等方法,計算概似函數的最大概似估計值。牛頓法和
EM
法等各種
不同的計算方法或許在計算方式的導出與計算效率上相差極大,但最後卻大多能
收斂到相同的解。
至於最大概似估計值的漸近變異矩陣則可利用
(16)
求出:
( )
2( )
1 ˆlog
ˆ
ˆ
L
V
− =
∂
= −
′
∂ ∂
θ θ
θ
θ
θ θ
(16)
的負值(或
information
矩陣的逆矩陣)
。利用牛頓法
(15)
來求解最大概似估計值
的優點,就是可在參數收斂的同時,又能順道求出收斂參數(即最大概似估計值)
的漸近變異矩陣
(16)
。但若混合模式之概似函數的二次微分式相當複雜或不易導
出時,雖可利用其他不需要用到概似函數二次微分式的方法,如
EM
法,計算概
似函數的最大概似估計值,但最大概似估計值的漸近變異矩陣卻仍需要利用概似
函數的二次微分式計算。由於在
QTL
的定位分析上,可用於估算混合模式的最
大概似估計值的方法甚多,故本研究僅討論最大概似估計值之漸近變異矩陣的求
算。
第六節、概似函數之二次微分式的推導
本節將整理
(
劉
, 1998)
數量性狀之機率分布為常態分布、二項分布、卜瓦松
分布等指數分布族時,各類分布之概似函數的二次微分式。
欲求出
(16)
最大概似估計值的漸近變異矩陣,必須先導出對數概似函數的二
次微分式。令
θ
1與
θ
2為參數向量
θ
的兩個部分集合
(subset)
,並將
(11)
改寫為
( )
i i0 i0 i1 i1 i2 i2g y
=
p f
+
p f
+
p f
2 0 ij ij jp f
==
∑
,
i
=
1,...,
n
(17)
將
(13)
中取對數的混合模式對參數向量
θ
的部分集合
θ
1做一次微分:
因為
1 1 log ij ij ij f f f ∂ ∂ = ∂θ ∂θ,
1 1 log ij ij ij p p p ∂ ∂ = ∂θ ∂θ,
所以
( )
2 1 1 0 log log i ij ij j g y p f = ∂ = ∂ ∂ ∂ ∑
θ θ( )
1 2 1 0 ij ij i j p f g y − = ∂ = ∂∑
θ( )
1 2 1 1 0 ij ij i ij ij j f p g y − p f = ∂ ∂ = ∂ + ∂ ∑
θ θ( )
1 2 1 1 0 log ij log ij i ij ij ij ij j f p g y − p f p f = ∂ ∂ = ∂ + ∂ ∑
θ θ 2 1 1 0 log ij log ij ij j f p q = ∂ ∂ = ∂ + ∂ ∑
θ θ其中
2 0 ij ij j ij ij ij p f p f q = =∑
(18)
(18)
式之
q
i0、
q
i1與
q
i2可視為三種基因型(
、
及
)的事後機率
(posterior probability)
。
將
(18)
再次微分,則可導出對數混合模式
logg y( )
i之二次微分式:
( )
2 2 2 1 1 0 1 1 1 1 1 1log log log log log
log i ij ij ij ij ij ij j f f f p f g y q = ∂ ∂ ∂ ∂ ∂ ∂ = + ⋅ + ⋅ ∂ ∂ ′ ′ ′ ′ ∂ ∂θ θ
∑
∂ ∂θ θ θ ∂θ θ ∂θ 2 1 1 1 1 1 1
logpij logpij logpij logfij logpij
∂ ∂ ∂ ∂ ∂ + + ⋅ + ⋅ ∂ ∂ ′ ′ ′ ∂ ∂ ∂ ∂ θ θ θ θ θ θ
2 2 1 1 1 1 0 0
log ij log ij log ij log ij
ij ij j j f p f p q q = = ∂ ∂ ∂ ∂ − + ′ + ′ ∂ ∂ ∂ ∂
∑
θ θ ∑
θ θ (19)
( )
2 2 2 1 1 0 1 2 1 2 2 2log log log log log
log i ij ij ij ij ij ij j f f f p f g y q = ∂ ∂ ∂ ∂ ∂ ∂ = + ⋅ + ⋅ ∂ ∂ ′ ′ ′ ′ ∂ ∂θ θ
∑
∂ ∂θ θ θ ∂θ θ ∂θ 2 2
1 1 2 2
0 0
log ij log ij log ij log ij
ij ij j j f p f p q q = = ∂ ∂ ∂ ∂ − + ′ + ′ ∂ ∂ ∂ ∂
∑
θ θ ∑
θ θ (20)
(詳細推導過程請見附錄
3
)
因此對數概似函數的一次與二次微分式可寫成
( )
( )
2 1 1 0 1 1 1 1log
log
log
nlog
n ij ij i ij i i jf
p
L
g y
q
= = =
∂
∂
∂
∂
=
=
+
∂
∑
∂
∑ ∑
∂
∂
θ
θ
θ
θ
θ
(21)
( )
( )
2 2 1 1 1 1 1log
nlog
i iL
g y
=∂
∂
=
′
′
∂ ∂
∑
∂ ∂
θ
θ θ
θ θ
2 2 1 1 1 0 1 1 1 1log log log log log
n ij ij ij ij ij ij i j f f f p f q = = ∂ ∂ ∂ ∂ ∂ = + ⋅ + ⋅ ∂ ∂ ′ ′ ′ ∂ ∂ ∂ ∂
∑ ∑
θ θ θ θ θ θ 2 1 1 1 1 1 1logpij logpij logpij logfij logpij
∂ ∂ ∂ ∂ ∂ + + ⋅ + ⋅ ∂ ∂ ′ ′ ′ ∂ ∂ ∂ ∂ θ θ θ θ θ θ 2 2 1 1 1 1 0 0
log ij log ij log ij log ij
ij ij j j f p f p q q = = ∂ ∂ ∂ ∂ − ∂ + ∂ ∂ ′ + ∂ ′
∑
θ θ ∑
θ θ (22)
( )
( )
2 2 1 1 2 1 2log
nlog
i iL
g y
=∂
∂
=
′
′
∂ ∂
∑
∂ ∂
θ
θ θ
θ θ
2 2 1 1 1 0 1 2 2 2log log log log log
n ij ij ij ij ij ij i j f f f p f q = = ∂ ∂ ∂ ∂ ∂ = + ⋅ + ⋅ ∂ ∂ ′ ′ ′ ∂ ∂ ∂ ∂
∑ ∑
θ θ θ θ θ θ 2 1 1 1 2 2 2logpij logpij logpij logfij logpij
∂ ∂ ∂ ∂ ∂ + + ⋅ + ⋅ ∂ ∂ ′ ′ ′ ∂ ∂ ∂ ∂ θ θ θ θ θ θ 2 2 1 1 2 2 0 0
log ij log ij log ij log ij
ij ij j j f p f p q q = = ∂ ∂ ∂ ∂ − ∂ + ∂ ∂ ′ + ∂ ′
∑
θ θ ∑
θ θ (23)
若令
θ1′ =r1(
QTL
與左翼標示因子之互換率)
,
θ′2= =β′ m a∗ d∗ b′;因
p
ij與分布的參數無關,而
f
ij則與互換率無關,所以
( )
( )
2 1 1 1 1 0 1 log log n log i n ij ij i i j p L g y q r = r = = r ∂ ∂ ∂ = = ∂∑
∂∑ ∑
∂ θ(24)
( )
( )
2 1 1 0 log log n log i n ij ij i i j f L g y q = = = ∂ ∂ ∂ = = ∂∑
∂∑ ∑
∂ θ β β β(25)
( )
( )
2 2 2 2 1 1 1 log n log i i L g y r = r ∂ ∂ = ∂∑
∂ θ 2 2 2 2 2 2 1 1 1 1 0 0log log log
n ij ij ij ij ij i j j p p p q q r r r = = = ∂ ∂ ∂ = + + ∂ ∂ ∂
∑ ∑
∑
(26)
( )
( )
2 2 1 1 1 log n log i i L g y r = r ∂ ∂ = ∂ ∂∑
∂ ∂ θ β β 2 2 2 1 1 1 0 0 0log log log log
n ij ij ij ij ij ij ij i j j j p f p f q q q r r = = = = ∂ ∂ ∂ ∂ = ∂ ∂ − ∂ ∂
∑ ∑
β∑
∑
β(27)
( )
( )
2 2 1 log n log i i L g y = ∂ ∂ = ′ ′ ∂ ∂∑
∂ ∂ θ β β β β 2 2 1 0log log log
n ij ij ij ij i j f f f q = = ∂ ∂ ∂ = ′ + ′ ∂ ∂ ∂ ∂