Content-based Video Retrieval via Motion Trajectories
Man-Kwan Shan* and Suh-Yin Lee
Institute of Computer Science and Information Engineering
National Chiao lung University, HsinChu, Taiwan, ROC
ABSTRACT
Motion is one of the most prominent features of video. For content-based video retrieval, motion trajectory is the intuitive
specification of motion features. In this paper, approaches for video retrieval via single motion trajectory and multiple motion trajectories are addressed. For the retrieval via single motion trajectory, the trajectory is modeled as a sequence of
segments and each segment is represented as the slope. Two quantitative similarity measures and corresponding algorithms based on the sequence similarity are presented. For the retrieval via multiple motion trajectories, the trajectories of the video are modeled as a sequence of symbolic pictures. Four quantitative similarity measures and algorithms, which are also based
on the sequence similarity, are proposed. All the proposed algorithms are developed based on the dynamic programming
approach.
Keywords: content-based retrieval, video retrieval, motion trajectory, similarity measures, sequence similarity
1. INTRODUCTION
Video access is one of the important design issues in the development of multimedia information system,
video-on-demand and digital library. Video can be accessed by attributes oftraditional database techniques, by semantic descriptions oftraditional information retrieval technique, by visual features and by browsing. Access by attributes ofdatabase technique
and access by semantic descriptions of information retrieval technique are insufficient for video access owing to the numerous interpretation of visual data. Besides, the automatic extraction of semantic information from general video programs is outside the capability ofthe current technologies ofnichine vision.
Access by visual features retrieves video clips on the basis of content features. Research on content-based video retrieval classifies visual features into spatial and temporal features. The approach of spatial features selects a set of representative key frames from each shot. Image retrieval techniques are then applied on the extracted key frames. Similarity between two shots is derived by comparing visual features of the most similar key frames between them.
Temporal features include statistical visual features over all frames in a shot, statistical motion features derived from optical flows, camera work and object motion trajectory.
Among all, object motion trajectory is the most intuitive specification of motion features for human beings. The object may be a recognized object, a region or a collection of regions exhibiting consistency across several video frames.2 Users can access video clips by specifying objects and associated motion trajectories or just sketching the motion trajectory. Two
distinguished features of retrieval via motion trajectories lie in the matching and approximate matching.9 For
sub-matching, users query is the subpart ofthe trajectory ofaccessed video. For approximate sub-matching, it is impossible for users to specify the query trajectory precisely.
Previous approaches modeled the trajectory matching problem as the pattern matching 8, 9, 10 Theresponse to the query only returns the qualified video sequences, not relevant video sequences along with degrees of relevance.
In this paper, quantitative similarity retrieval via single motion trajectory and multiple trajectories are addressed. For
the retrieval via single motion trajectory, the trajectory is modeled as a sequence of segments while each segment is represented as the slope. Two quantitative similarity measures 0CM and OCMR are proposed for approximate matching
between query and video trajectory.
For the retrieval via multiple motion trajectories, the simple approach is the intersection of results of individual query
motion trajectory. However, this simple approach considers neither the spatial nor the temporal relationships between the
query motion trajectories. We follow the approach as suggested by Chang et al.2 Multiple motion trajectories are modeled as
a sequence of symbolic pictures while each symbolic picture is represented as a 2D string. Four quantitative similarity
measures based on sequence similarity are proposed.
This paper is organized as follows. In the next section, some work related to the motion trajectory matching is reviewed.
In section 3, two proposed similarity measures and algorithms for retrieval via single motion trajectory are presented. In
section 4, we discuss the retrieval via multiple motion trajectories and defme four quantitative video similarity measures and To whom all correspondence to be sent. E-mail: shancc.nctu.edu.tw.
algorithms. Section 5 describes the normalization of the proposed similarity measures. Conclusions and future work are
described in section 6.
2. RELATED WORK
ql
P5Lr/
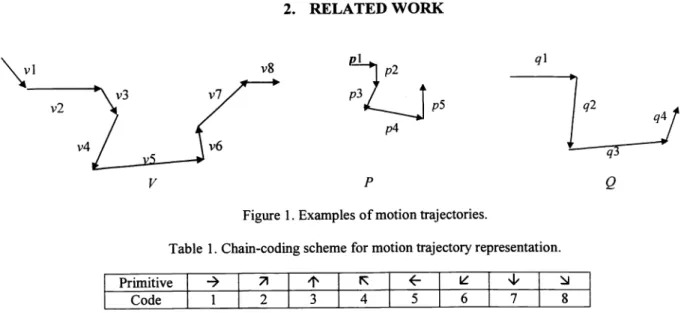
Figure 1. Examples of motion trajectories.Table 1. Chain-coding scheme for motion trajectory representation. I Primitive
I
I
'
- I
V4'
ICode I 1 I 2 I 3 I 4 I 5 6 I 7 8
Dimitrova and Golshani presented several mechanisms for representation of motion trajectory.4'5 These mechanisms
include B-spline curve representation, chain-coding, differential chain-coding. For example, using the chain-coding scheme illustrated in Table 1, the video motion trajectory V in Figure 1 is represented as (81862421). The query motion trajectory P
is represented as (17683). Matching functions used for motion retrieval depend on the method employed for trajectory representation. For the example of chain-coding scheme, the problem of trajectory matching is translated to the pattern
matching problem. However, the matching methods are not discussed.
Notice that exact substring matching algorithms are not suitable for matching of chain-coding scheme. For example in Figure 1 , intuitively, given the query trajectory P, the video trajectory V is somewhat relevant. Using exact substring matching algorithm, P represented as (17683) is not the substring of V represented as (81862421). Therefore, it is necessary to employ the approximate substring matching algorithms.
Yoshitaka et al. proposed a motion trajectory method based on the index of chain coding scheme.'° An exhaustive search is applied to map the index motion trajectory to the query curve. However, the exhaustive mapping of the motion
trajectory is inefficient.
800,.1800
1
16 1
°i2- :::;i5
1098
00 Figure2. Peak orientation and angle primitives.
Wai and Chen modeled the motion trajectory and the query curve as a combination of peaks.9 The motion trajectory query processing problem is converted into the string matching problem. Each peak is represented as a triplet, (or, a,,, t,),
where
o, a, t,
representthe orientation, angle and time of the peak p, respectively. The orientation of the peak is defined asthe orientation of the angle bisector and is coded according to the primitives shown in Figure 2. The angle of the peak is
defmed as the angle expanded by the two edges of the peak and is coded by dividing -180°-S 1800 into 16 partitions shown in Figure 2. In order to quantify the similarity for approximate trajectory matching in the peak model, the similarity model is
vl v2 v3 v8 v7 v6 V p4
P
2 3 14
built on the combination code of the angle and the orientation of the peak. Moreover, to deal with the case where, for
example, two angles ofpeak a, aq equal 1 and 16 respectively, the difference, d(a, aq), between ap, aq 5 defmed as follows,
If (a < aq) then d(a, aq) (a1, -
aq)mod 16else d(a, aq) [16 (ag,- aa)]
mod16.Wai and Chen proposed a new finite automata based matching algorithm for string matching which is shown to be
superior to UNIX built-in utility grep. For example, in Figure 1 ,thetrajectory V is represented as [(1 ,15), (2, 14), (4, 14), (1, 7), (3, 5), (4, 15), (3, 15)], while query trajectory P is represented as [(1, 12), (4, 3), (1, 6), (3,6)]. It can be seenthat peaks of
P (1 ,2),(4, 3), (1, 6), (3, 6) match with peaks of V (2, 14), (4, 14), (1, 7), (3, 4) respectively. However, given the query Q modeledas [(1
,
12),(1 ,5),(3, 3)], it can be seen that, using the string matching method proposed by Wai and Chen, the trajectory V is not relevant to the query trajectory Q.Whenthe query contains multiple motion trajectories, Wei and Chen stored all the query trajectories in the same finite automata.9 However, this considers neither the spatial nor the temporal relationships between the query motion trajectories. In VideoQ, Chang et al.2 suggested imposing spatial/temporal constraints on the query result by using the idea of 2D string. 2D string preserves the spatial knowledge of a symbolic picture.3 Based on the 2D string approach, Shearer et al. proposed the spatial indexing for video sequences and defined three types of video matching.8 However, in this approach, either the video sequence is qualified or unqualified to the query sequence. The response to the query only returns the qualified video sequences, not relevant video sequences along with degrees of relevance.
3. RETRIEVAL VIA SINGLE MOTION TRAJECTORY
In the proposed approach, the motion trajectory is modeled as a sequence of segments, instead of peaks. Each segment is represented by the angle. The angle is defmed as the slope ofthe segment. For example, the video motion trajectory V in Figure 1 is represented as (3 100, 00 3 100, 2400, 5° 950450 00).The query motion trajectory P is represented as (00, 270°,
260°, 0°, 90°) while Qisrepresented as (00, 265°, 5°, 70°). Moreover, there exist two values for the difference, d(v,, q1),
between two angles of segments v,, q• For example, if v, equals 30° while q equals -30°, then d(v,, q) equals either 60° or 300°. Therefore, the difference, d(v,, q3), is defmed as follows.
If v, -qt> 1 80° then d(v1, q) (360° -Iv, - qI)
else d(v1, q)= I(v,-
q.
We first define the quantitative substring matching Optimal Consecutive Mapping (0CM) in the following. The algorithm is listed in Algorithm 0CM.
Definition 1 Given the query shot Q =(q1,q2,. .., q,),the video shot V =(v1,v2,. .. , vN),M _<N, a consecutive mapping
between them is a one-to-one relation RCMfrom { 1 ,2,.. . , M}to { 1 ,2, .. . , N},suchthat
(I) for each i, 1
i M, there exists onej, 1 j N, such that (i ,f) E R
(2) for any two ordered pairs (i 'f), (k, 1) in RCM, [(I -1)=
1]if and only if {(i k) =1J.Definition 2 Given the query shot Q= (q1, q2,. .
., q),
the video shot V= (v1, v2,.. .,vN),and d(q1, vi), V1,1i <M, Vj, I
j N, the distance between Q and Vfor a given consecutive mapping R, D 'JcJ(Q' V S defmed as
DRCM(Q,V)=
d(q1,v).
V(i,j)ERCM
Definition 3 Given the query shot Q= (q1, q2,. .
., q)
and the video shot V= (v1, v2,. .., VN),the distance between Q and V forOptimal Consecutive Mapping is defmed as
DOCM(Q,V)= mm {DR (Q,V)}.
VRCM CM
Algorithm Optimal Consecutive Mapping (0CM)
forj =
0
to N-Mdo D[0,j] =0;
forj 0 to N-Mdo
fori1 toM-i do
D[i, i+jJ =D[i—1,i+j-1}+d(q1, v.+); D[M, M] =D[M-1,M-l]+d(q, vM);
forjM+ 1 toNdo
D[M,j] =min(D[M-1,j-1]+d(q,v), D[M,j-1}); return D[M, NJ
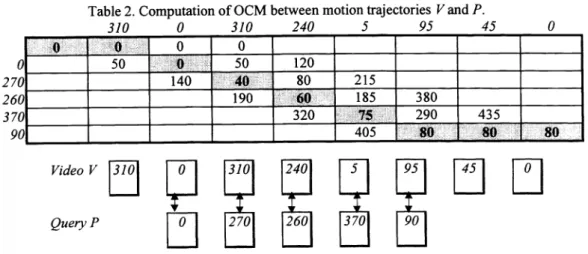
Given the example in Figure 1, the computation of the quantitative similarity 0CM between the video trajectory V and query trajectory P is listed in Table 2. Figure 3 describes the mapping relation between segments of V and P.
Table 2. Computation of 0CM between motion trajectories V and P. 310
0
310240
5 95 450
O
00
500
50 120 140 40 80 215 190 60 185 380 320IS
290 435 405 80 80 80 Video V 310 240 5 95 Query P 270 260 37090
Figure 3. Mapping between segments of V and P using 0CM.
0CM measures the similarity for one-to-one segment mapping between trajectories. However, in Figure 1 ,givenquery
trajectory Q, represented as (0°, 265°, 5°, 70°), video trajectory V is not relevant using 0CM. The reason comes from that
intuitively the segment q2 of Q is mapped with the segments v3 and v4 of V. Therefore, we extend the defmition of Optimal
Consecutive Mapping to Optimal Consecutive Mapping with Replication (OCMR). In OCMR, each segment of query trajectory is permitted to map with more than one segments of video trajectory. In addition, the same as 0CM, the mapped
segments must be consecutive.
Definition 4 Given the query video shot Q (q1, q2,. .. , q),the video shot V (v1, v2,. .. , VN),M <N, a consecutive mapping
with replication between them is a one-to-many relation RCMR from { I , 2,.. . , M}to { 1 ,2, .. . , N} ,such
that
(1) for each i, 1
i M, there exists at least onej, 1 j N, such that (i 'f) e RCMR
(2) let Pmax() be max{j I(1,J) E RCMR} ,Prnin(Obe min{j I
(i,
f) E RCMR} ,foreach j, pm,(l) j Pmax(M),
thereexistsone i, 1 j M, such that (i J)
(3) for any two ordered pairs (i f) (k, 1) in RR, if(i < k) then (j < 1),
(4) any two ordered pairs (i 'f)' (k, 1) in RCMR, if[(j -1)
=
1]then either [(i k) 1] or [(1 -k)=
0
}.Definition 5 Given the query video shot Q (q1, q2,. . ., q), the video shot V (v1, v2,. . ., VN) and d(q,, v3),V i, I
i M, Vj,
I j N, the distance between Q and Vfor a given consecutive mapping RR, D RcMR(Q V, is defmed as
DRCMR(Q,V) d(q,v1).
V(i,J)ERCMR
Definition 6 Given the query shot Q (q1, q2,. . ., q) and the video shot V (v1, v2,. . ., vN), the distance betweenQ and V for Optimal Consecutive Mapping with Replication is defmed as
DOCMR(Q,V)= mm {DR (Q,V)}.
VR
CMRThesolution of OCMR can be obtained as follows. First, if a mapping R is an OCMR, then the first segment q1 must be mapped with only one segment of video sequence, so does the last segment qM• Otherwise, suppose that q1 is mapped with segments Va,. . . v,1, v, q S mapped with v, vji . . . , vb. We can derive a mapping with less distanceby removing the mapping pairs between q1 and va,. . . v,1, and those between q and v . . ., vb. Therefore the behaviors ofq1 and q arethe same as that of segment in 0CM.
Next, without loss of generality, we assume that q1 is mapped with va, q is mapped with vb. Let D[i, j} be the minimum cost of mapping with replication between (Va +1, v +2' • • , v1) and (q2 , q3
,
.. . , qM-i). There are two possible relations betweenD[m, n] and D[i,jII for some combinations ofsmaller is andjs.:
p: the segment v is mapped with the segment Urn, D[m, n] Dm-1, n-I] + d(Urn, va).
replicatev: the segment v is replicated to mapped with the segment Urn, D[m, nI D[m-1, n} + d(Urn, va). Figure 4 illustrates the relation. Combining these two cases, 'we get the following recurrence relation.
. ID[rn
— 1, n — 1] + d(Umv)
D[mn]=mm
t
D[m—1,n]+d(um,vn)withD[0,0]0,D[0,j]0,forallj,1 j N-M,andD[i,i-1]°°,foral1i,1 iM
0 270 260 370 90Algorithm OCMR lists the procedure.
vn_1 vn
q-1 D[m-1, n-i] D[m-1, nJ
m[m,n1] rep
D[m,n]Figure 4. Relation ofOCMR between D[m, n] and D[i,j] for some combinations ofsmaller is andjs. Algorithm Optimal Consecutive Mapping with Replication (OCMR)
forj =
0to N-Mdo D[O,j] =0; For i =1 to M-l do D[i, i-i] =co;forj
0 to N-Mdofori= ltoM-l do
D[i, i+j] =min(D[i-1,i+j-1]+d(q,, v.+), D[i, i+j- l]+d(q1, v,+1) ); D[M, M] = D[M-1,M-l}+d(q, vM);
forjM+ 1 toNdo
D[M,J] =
min(D[M-l,j-1]+d(q,
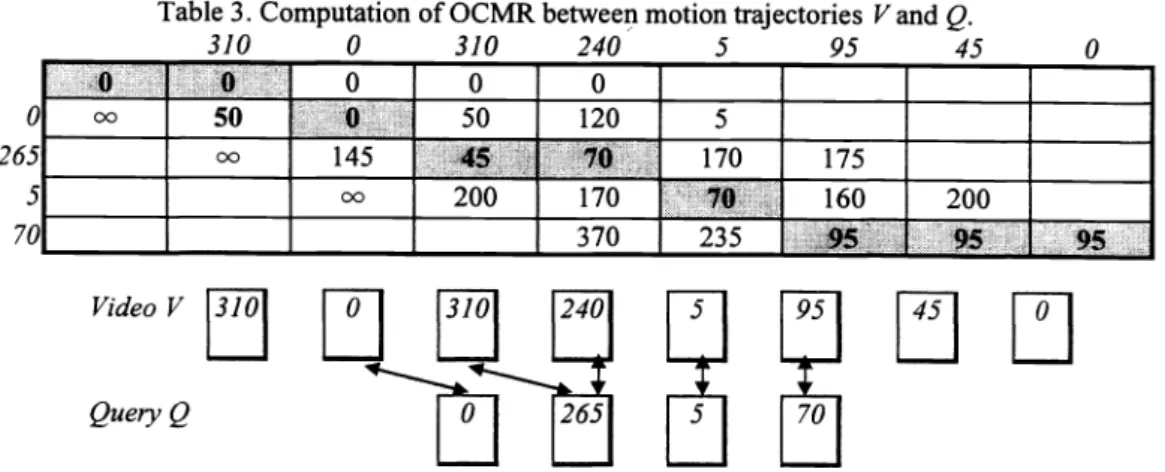
v), D[M,j-1]); return D[M,IV]Table3 .Computationof OCMR between motion trajectories V and Q.
310 0 310 240 5 95 45 0
0
000
50 00 00
145 0 5045
0 12010
5 170 175 00 200 170 70 160 200 370 2355
95 QueryQ'1i
265 5 70Figure5. Mapping between segments of V and QusingOCMR.
Using the similarity OCMR, Table 3 describes the computation of the similarity between the video trajectory V and
query trajectory Q.
In
Figure 5, it can be seen that the segment q2 is mapped with v3 and v4.4. RETRIEVAL
VIA MULTIPLE
MOTION TRAJECTORIES
When the query contains multiple motion trajectories, the result is simply an intersection of results of individual query
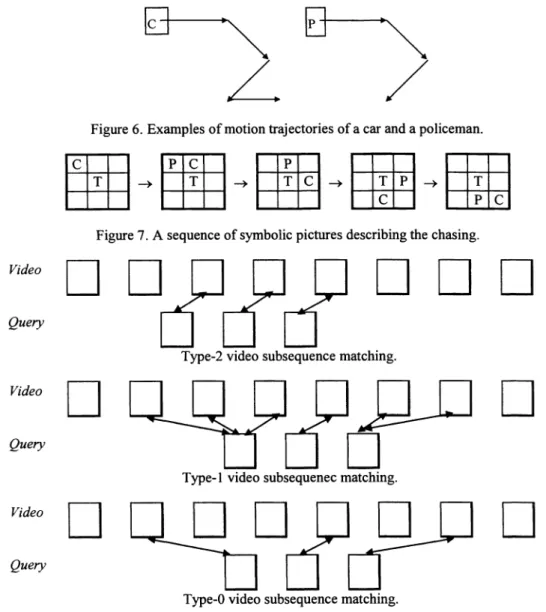
motion trajectory. However, this simple approach considers neither the spatial nor the temporal relationships between the query motion trajectories. For example, a video shot, in which the policeman runs after a car, consists of two motion
trajectories shown in Figure 6. From these two trajectories, no information is available about the spatial/temporal
relationships indicating the action of chasing.To impose the spatial/temporal constraint, multiple trajectories can be modeled as a sequence of symbolic pictures. Figure 7 shows a sequence of symbolic pictures. In these pictures, the symbols "C", "P" and "T" denote the car, the
policeman and the tree respectively. From this sequence of pictures, the action of chasing can be derived. Spatial
information of the symbolic picture can be represented by the spatial data structure, 2D string.3 For the sequence of
symbolic pictures, 2D strings can be extended to a sequence of 2D strings or a 2D string followed by a sequence of change Shearer et al. defmed three types of video matching.8 Type-2 video matching displays a picture for picture equivalence between the two compared video sequences. Picture matching is the same as the original type-0, 1, 2 subpicture matching.
C
26
.5Type-I video matching relaxes type-2 video matching by allowing repetitions of matching pictures. Type-O video matching relaxes type- 1 matching that the matching pictures need not to be consecutive pictures. Figure 8 describes these three types of video matching.
EJ—ØN\\\
7
/
Figure6. Examples ofmotion trajectories ofa car and a policeman.
C
PC
P
____ ____
T
—I
TCI_)
TP -
T____
____
I
CPC
Figure 7. A sequence of symbolic pictures describing the chasing.
Type-2 video subsequence matching.
::
LI
Ll?LlLjEJ
LI
Type-ivideo subsequenec matching.
::
LI
LJLILIIJ1
LI
Type-Ovideo subsequence matching.
Figure 8. Three types of video subsequence matching.6
However, in this approach, either the video sequence is qualified or unqualified to the query sequence. The response to
the query only return the qualified video sequences, not relevant video sequences along with degrees of relevance. We
propose the similarity algorithms to measure the similarity between sequences of symbolic pictures, as long as the distance
between symbolic pictures are available. A few approaches for computation of similarity (or distance) between symbolic
pictures have been tu67
In the previous section, we have described the definitions and algorithms 0CM and OCMR. It can be seen that the defmition of 0CM is the quantitative similarity matching corresponding to type-2 subsequence matching. Defmition of OCMR is somewhat correspondent with type-i video matching. Both OCMR and type-i matching allow repetitions of matching frames with the exception that, in OCMR, only one image frame is allowed to mapped for the first and the last
image frame. For example, given the distance between the symbolic pictures of video sequence V and Q (Table 4), the computation of type-2, type-i video similarity between V and Q are presented in Table 5 and Table 6. Figure 9 and Figure
Table 4. Distance between symbolic pictures of Q and V. V1 V2 V3 V4 V5 V6 V7 0.3 0.1 0.2 0.4 0.1 0.5 0.1 --- 0.1 0.3 0.4 0.2 0.3 0.7 0.1 q3 0.6 0.2 0.1 0.7 0.2 0.2 0.4 q4 0.2 0.2 0.3 0.3 0.2 0.6 0
Table 5. Computation oftype-2 video similarity between Q and V.
V1 V, V3 V4 V5 V6 V7 0 0 0 0 03 01 02 fl4 0.5 0.7 0.4 1.2 1.0 0.6
07
0.6 1.0 0.9 1.0 0.9:
Figure 9. Mapping oftype-2 video similarity between Q and V. Table 6. Computation ofType-1 video similarity between Q and V.
V1 V3 V4 V5 V6 V7
0
0 0 03 00 01 06 00 0.Z 0507
04 12 10 0706
1008
10 0508
Q
Figure 10. Mapping oftype-1 video similarity between Q and V.
For the quantitative similarity matching corresponding to type-0 subsequence matching, we defme Optimal
Subsequence Mapping (OSM) and present the corresponding algorithm as follows.Definition 7 Given the query shot Q= ( q1, q2,. .
., q)
and the video shot V (v1, v2,. .., VN),M <N, a subsequence mappingbetween them is a one-to-one relation R from { 1 ,2,.. . , M}to { 1 ,2, .. . , N}, such that
(1) for each i, 1
i M, there exists onej, 1 j N, such that (i 'J) E
R
(2) forany two ordered pairs (i 'f)' (k, 1) in R, (j <1)if and only if(i <k).Definition 8 Given the query shot Q ( q1, q2,. .
., q),
the video shot V (V1, v2,. .., VN),and the distance d(q1, i),V
i,1i
M, Vj,
1 j N,
the distance between QandVfor a given subsequence mapping R, D '(Q, V), is defmed asD RsM(QY)
d(q1,v).
V(i,J)ERSM
Definition 9 Given the query shot Q ( q1, q2,. .
., q)
and the video shot V (V1, V2,. .., vN),the distance between Q and V forOptimal Subsequence Mapping is defmed as
qlI q21 q1 q-)
q
q1 q2 q3 q4DOSM(Q,V)= mm {DR (Q,V)}.
VRSM SM
Algorithm Optimal Subsequence Mapping (OSM)
fori= 1 toMdoD[i, i-i] =
oo;for]
=
0to N-Mdo D[O,j] =0; for i 1 to Mdofor] I to I +N-Mdo
D[i,j]=min( D[i—1,j-1]+d(q,, vi), D[i,j-1] );
return D[M,
N]
Table7. Computation oftype-0 video similarity between Q and V.
V1 V-, V1 V4 V V6 V7 q1 q2 q3 q4
0
0
0
0
0003
00 0.106
0°01
05
07
01
03
07
03
05
05
oo_
10
09
09
05
Figure 1 1. Mapping oftype-0 video similarity between Q and V.
Table 7 is the computation oftype-0 video similarity measure. The mapping result is shown in Figure 1 1 .Sometimes,
it
is possible that the trajectory of query Q is very similar to that of video V, except that few pictures are very dissimilar. Usingthe similarity measures mentioned previously, these dissimilar pairs of pictures produce large distance. Therefore, in the
following defmitions, the mapping is constrained by a threshold 6.
Definition 10 Given the query shot Q (q1, q2,. .. , q), the video shot V (v1, v2,. .. , VN),the frame distance tolerance 6 and
the distance d(q1, v1), V i, I I M, Vj, 1 ij N, a distance-constrained subsequence mapping between them is a
one-to-one relation RDfrom {1, 2, ...,M}to {1,2, ...,N},such that (1) for each order pair (i,j) in RD, d(u1, v3) 6,
(2) for each i, 1
i M, there exists onej, 1 j N, such that (1 ,j) RD
(3) for any two ordered pairs (1 ,j), (k, 1) in RDM, (I < 1) ifand only if(i < k).
Definition 1 1 Given the query shot Q (q1, q2,. .. , q4),the video shot V (V1, V2,. .., VN),the frame distance constraint 6, and
the distance d(q1, vi), V i, 1 I M, Vj, 1 ij N, the distance between Q and Vfor a given mapping RD, D RDSM(QV6), is defined as
DRDSM(Q,V,S)= . .
d(q,,Vf).
V(1,J)ERDSM
Definition 12 Given the query shot Q' ( q1, q2,. .
., q)
and the video shot V =(v1,l'2,. . ., VN),the distance between Q and Vfor Distance- constrained Optimal Subsequence Mapping(DOSM) is defined as DDOSM(Q, V,8) = mm {DR
(Q, V,8)).
VRDSM DSM
Ifthere is no such mapping, the distance DDO(Q, V, 6) is set to oo
AlgorithmDistance-constrained Optimal Subsequence Mapping (DOSM)
fori= 1 toMdoD[i,
i-1}= 00;for]
=
0toN-Mdo
D[0,j] =0;fori 1 toMdo
for] i to i +N-Mdo
if d(q1, v) <8 thenV
Q
D[i,j]—min( D[i-1,j-1] +d(q1,vi), D[i,j-1])
else
D[i,j]= D[i,j—1];
return D[M, N]
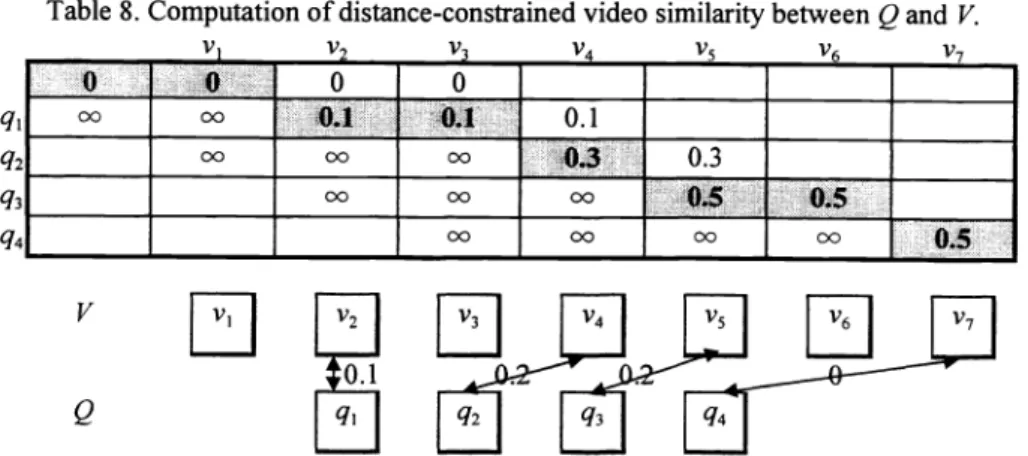
For example, given the distances in Table 4, the computation of video similarity between V and QusingDOSM are presented in Table 8. In this table, the distance constraint is set to 0.3. Figure 12 shows the mapping result.
Table 8. Computation ofdistance-constrained video similarity between QandV.
V1 V2 V3 V4 V6 V; V.
0
0
0 0 00 00 00 0:1 00 0001
00 0001
O3
0003
5
00 00 00 005
5. NORMALIZATION OF SIMILAITY MEASURES
Concerning the normalization of similarity measures between sequence of frames, it is unfair for video with more
number of frames to be measured by the algorithms allowing replications. For example, considering two video sequence V, V2 and the query sequence Qshownin Figure 13, the distances ROCMR(Q, V1) and ROCMR(Q, V2) both equal 80. However,
intuitively, V1 is more similar to Q,thoughthere are more number of mapping in V1 .To deal with this unfairness, we
normalize the distance by the cardinality of relation ROCMR. In this example, the normalized ROCMR(Q, l/) becomes 80/6 while the normalized ROCMR(Q, V2) becomes 80/2.
l3J
120 160Figure 13. ROCMR(Q, V1) and ROCMR(Q, V2).
6. CONCLUSIONS
Content-based video retrieval is an important issue in applications of multimedia information systems. Motion
trajectory is one ofthe most prominent features of video. Two distinguished features of motion trajectory matching are sub-matching and approximate sub-matching.
In this paper, we propose quantitative similarity approaches for video retrieval via single motion trajectory and multiple motion trajectories. For the retrieval via single motion trajectory, the trajectory is modeled as a sequence of segments and each segment is represented as the slope. Two quantitative similarity measures and corresponding algorithms based on the sequence similarity are presented. For the retrieval via multiple motion trajectories, the trajectories ofthe video are modeled
as a sequence of symbolic pictures. Four quantitative similarity measures and algorithms, which are also based on the
sequence similarity, are proposed. Evaluating the performance of the proposed similarity measures is left as future work.
q1 q2 q3 q4
Q
Figure 12. Mapping of distance-constraint video similarity between QandV(6=0.3).
V1
ro
Q
7. REFERENCE
1 . T.Arndt and S. K. Chang, "Image Sequence Compression By Iconic Indexing," In Proceedings oJIEEE Workshop on
Visual Languages, Los Alamitos, CA, pp. 177-182, 1989.
2. S. F. Chang, W. Chen, H. J. Meng, H. Sundaram and D. Zhong, "VideoQ: An Automated Content Based Video Search
System Using Visual Cues," In Proceedings ofACMMultimedia '97, Seattle, WA, pp. 313-324, 1997.
3. S. K. Chang, Q. Y. Shi and C. W. Yang C. W., "Iconic Indexing by 2-D Strings," IEEE Transactions on Pattern
Analysis andMachine Intelligence, Vol. PAMI-9, No. 3, pp. 413-428, 1987.
4. N. Dimitrova and F. Goishani, "Rx for Semantic Video Database Retrieval," In Proceedings oJACM Multimedia '94,
San Francisco, CA, pp. 219-226, 1994.
5. N. Dimitrova and F. Golshani, "Motion Recovery for Video Content Classification," ACM Transactions on Information Systems, Vol. 13, No. 4, pp. 408-439, 1995.
6. V. N. Gudivada and V. V. Raghavan, "Design and Evaluation of algorithms for Image retrieval by Spatial Similarity,"
ACM Transactions on Information Systems, Vol. 13, No. 2, pp. 114-144, 1995.
7. Suh-Yin Lee, Man-Kwan Shan and Wei-Pang Yang, "Similarity Retrieval of Iconic Image Database," Pattern
Recognition, Vol. 22, No. 6, pp. 675-682, 1989.8. K. Shearer, S. Venkatesh and D. Kieronska, "Spatial Indexing for Video Databases," Journal of Visual Communication
and Image Representation, Vol. 7, No.4, pp. 325-335, 1996.
9. T. 1. Y. Wai and A. L. P. Chen, "Retrieving Video Data via Motion Tracks of Content Symbols," In Proceedings of ACM International Conference on Information and Knowledge Management CIKM'97, Las Vegas, NV, pp. 105-112,
1997.
10. A. Yoshitaka, M. Yoshimitsu, M. Hirakawa and T. Ichikawa, "V-QBE: Video Database Retrieval by Means of