國
立
交
通
大
學
資訊管理研究所
碩
士
論
文
在病毒行銷中尋找有影響力的節點
Discovering Influential Nodes for Viral Marketing
研 究 生:林嘉豪
指導教授:李永銘 博士
在病毒行銷中尋找有影響力的節點
Discovering Influential Nodes for Viral Marketing
研 究 生:林嘉豪 Student:Chia-Hao Lin
指導教授:李永銘 Advisor:Yung-Ming Li
國 立 交 通 大 學
資 訊 管 理 研 究 所
碩 士 論 文
A ThesisSubmitted to Institute of Information Management College of Management
National Chiao Tung University in Partial Fulfillment of the Requirements
for the Degree of Master
in
Institute of Information Management
June 2008
Hsinchu, Taiwan, Republic of China
中華民國九十七年六月
i
在病毒行銷中尋找有影響力的節點
學生:林嘉豪
指導教授:李永銘 博士
國立交通大學資訊管理研究所碩士班
摘 要
在傳統的行銷行為中,高昂的成本和效果的不確定性是常見的問題。我們發現 對於一般人來說,由顧客所撰寫的線上產品使用心得通常比廠商的廣告更可信,尤其 當這些心得是由他們的朋友們所寫的時候。社群網路的力量也使得這些產品形象就像 真實的病毒一樣以驚人的速度傳播。發現那些撰寫有價值的產品評論、並且擁有廣泛 人際關係的特定評論者們會是一個解決行銷上不確定性問題的好方法。 在本研究中,我們使用兩個方式來衡量每位評論者的行銷價值:改良的 PMI 和 RFM。PMI 可以量化每篇評論探勘的結果,RFM 則被用來把每位評論者的寫作情況納入 影響力分數計算之中。人工智慧技術中的類神經網路被使用來為我們的模型訓練合適 的網路架構。影響力的指標:信任機制被使用在模型的評估上。它包含了真實世界中 數以萬計的人際關係網路。實驗結果顯示我們的模型在選擇具有影響力的評論者上比 「人氣作者」和「評論分數」的排序方法有更佳的效果。本研究能指出哪些評論者在 產品資訊的傳遞上是有效的,這份結果也對欲進行行銷活動的廠商具有參考的價值。ii
Discovering Influential Nodes for Viral Marketing
Student: Chia-Hao Lin
Advisor: Dr. Yung-Ming Li
Institute of Information Management
National Chiao Tung University
ABSTRACT
High cost and uncertain effects are main problems of traditional marketing behaviors. We discover online product reviews, which are written by customers are usually more trustworthy than firms’ advertisements for people, especially those written by their friends. The power of social network also makes these product impressions spread in amazing speed as real viruses. To discover influential reviewers who write valuable product reviews and have wide human relationships is a good way to solve the problem of marketing behaviors.
In this research, we propose two methods to measure the marketing value of each reviewer: revised PMI and RFM. The modified PMI quantifies each review mining result and the RFM concept is used to take each reviewer’s writing status into consideration of influence calculating. The artificial neural network (ANN) is adopted to train an appropriate network structure for our model. The influence power indicator: trust is applied in the evaluation of our model and it considers thousands of human relationships among the real world. Experiment result shows that our model outperforms “popular author” and “review rating” methods in selecting influential reviewers. This research can point out which reviewers are really effective in product information spreading and the results will be valuable for companies to refer.
iii
誌 謝
兩年的研究生活很快的過去了。在這段時間中,經歷了許多充滿挑戰的難關, 以及與研究室夥伴們的共同回憶。過程中不論是喜悅、悲傷、無奈抑或是憤怒,這本 論文終究在許多人的協助與支持下一步步的完成了。在這裡,我要感謝許多曾經對這 本論文的誕生付出心力的師長、同學及好友們。沒有你們,這本論文無法完成,而我 也無法因為這些歷練而有所成長。 首先我要感謝我的指導教授李永銘博士。老師對於研究有著非常高的熱忱,在 這兩年之中,有了老師的諄諄教誨,才能一步步地磨練出我對於研究能力的基本功, 本論文以及其他眾多的研究才能順利完成。兩年的研究生涯老師引領我進入學術的領 域,也帶給我許多終身受用的研究成果。此外,在為人處事上,我也從老師的身上學 習到許多待人接物的道理,相信未來在社會上也能夠學以致用,真的是非常感謝您。 口試委員林福仁教授、劉敦仁教授以及簡宏宇教授的指教也對論文的缺失與改善提供 了非常寶貴的意見,這篇論文才得以產生更大的價值。非常感謝諸位老師的協助。 研究室的夥伴們對這篇論文的完成也有著莫大的貢獻。有了建邦,這篇論文的 許多想法才能成形,實驗的進行才能夠順利。建邦也常常和我一起討論許多課業以外 的問題,相信不只是我,研究室的每一位成員或多或少都是因為你的協助,才能解決 許多人生與課業上的問題。在最後的半年,我們又很湊巧的成為室友,在和你相處這 麼長的時間之中,真是獲益匪淺,希望能早日接到你的喜訊。在這裡我要毫不吝嗇的 感謝並讚揚你對整間研究室的貢獻,謝謝你。海王子敬文是我們這屆的另一個戰友, 跟你講話最大的好處就是完全沒壓力,而且你獨特的說話方式真的非常的幽默,我和 建邦常常被你逗得大笑;感謝你為我的論文所提供的許多好點子,以及大家在一起時 所提供的歡笑,還有宜蘭真的很好玩!相信就算幾十年後,我依然會記得管二樓下那塊 我們三個放鬆和討論各種想法的地方。 這兩年的生活中,學長和學弟妹們也對我提供了極大的幫助。我們所遭遇的各 種困難,易霖學長總能一派輕鬆的解答,不愧是有歷練又優秀的好學長。無尾熊是個 懂得享受生活又風趣的學長,和你在一起總是非常愉快。我一定會記得和你大吃大喝 和卡丁車的日子,祝你快快畢業,未來成為一位好教授。還有 Denny,在論文最緊要的iv 關頭提供了我最大的幫助,真的非常感謝你;恭喜你順利爭取到交換學生的資格,但 是卡丁車還要再練練唷。涵文、連乃、子鳳、宗穎、正乾,謝謝你們為我們所付出的 心力,我會一直記得那段和你們在研究室同甘共苦的日子。馬上就要碩二了,壓力一 定很大,相信你們明年一定也能有好的成果,快快樂樂的畢業;也祝正乾在台大有新 的生活、新的體驗、新的收穫。 除了自己研究室以外,和我們關係最密切的就是最佳化研究室的同學們了。賢 慧的亞梅學姊總是能把研究室整理的井然有序,在我們煩惱時,也提供了最有力的協 助。筱嵐學姊是我日劇的同好之一,祝妳在香港一切順利,能有好的研究成果。怡菱 學姊是個有趣的人,謝謝妳常在我們忙到深夜時適時出現,帶給我們輕鬆愉快的氣 氛。葵棠和昱劭的智慧,幫助我們度過許多艱難的課程,非常感謝你們。還有盈佑和 總機小姐,謝謝你們總是幫大家解決民生問題。 另外還有鵝蛋,你雖然不是研究室的同學,但是論文的完成你功不可沒。在最 後的一刻,你在最短的時間幫助我迅速的修改好論文,對於壓迫到你的休息時間至今 我仍深感抱歉;能有你這位責任心重、可靠又有義氣的好朋友,相信會是我一生的資 產;真的非常非常感謝你。 最後,我要由衷感謝家人對我的支持與栽培。有了父母的關心、慰問與支持, 我才能夠度過每一個難關與困境;才能夠沒有後顧之憂的傾注全部的心力在研究上。 在研究進行到最後的一段日子裡,我沒有辦法常常在身邊陪伴你們,真的非常抱歉。 謝謝你們對我永遠的寬容和體諒。 這兩年的研究生活對我來說,論文不只是唯一的紀念。在這段日子裡,我得到 了更高深的學識、具備了初步的研究能力、有了一些成果、得到了許多摯友,還培養 了良好的適應性與抗壓性。相信在未來的日子裡,這些寶藏會讓我終身受用無窮,感 謝在這段時間裡幫助我的所有人。
林嘉豪
2008 年六月 謹誌於 新竹 國立交通大學光復校區v
TABLE OF CONTENTS
摘 要 ... I ABSTRACT ... II 誌 謝 ... III CHAPTER 1 INTRODUCTION ... 1 1.1 RESEARCH BACKGROUND ... 1 1.2 RESEARCH PROBLEM ... 4 1.3 RESEARCH OBJECTIVES ... 6 1.4 RESEARCH OUTLINE ... 7CHAPTER 2 LITERATURE REVIEW ... 8
2.1 VIRAL MARKETING ... 8
2.2 OPINION MINING ... 10
2.3 RFMMEASURE ... 11
2.4 TRUST MECHANISM ... 12
2.5 ARTIFICIAL NEURAL NETWORK... 13
CHAPTER 3 THE MODEL ... 16
3.1 REVIEW MINING ... 18
3.1.1 Word Set Expanding ... 18
3.1.2 PMI Strength Level Approach ... 21
3.2 RFMVALUE ... 23
3.2.1 Recency Model ... 23
3.2.2 Frequency Model ... 24
3.3 TRUST NETWORK VALUE CALCULATION ... 24
CHAPTER 4 EXPERIMENTS ... 28 4.1 THE DATA ... 28 4.1.1 Data Source ... 28 4.1.2 Data Descriptions ... 29 4.2 WORD SET EXPANSION ... 32 4.3 WORD MATCHING ... 34 4.4 RFMSCORE ... 35 4.5 TRUST SCORE ... 36
4.6 ARTIFICIAL NEURAL NETWORK TRAINING ... 38
CHAPTER 5 RESULTS AND EVALUATION ... 41
5.1 CHOOSE WORD SET EXPANDING LEVEL ... 41
5.2 INFLUENTIAL RANKING RESULT AND EVALUATION DESIGN ... 42
5.3 EVALUATION AND DISCUSSION ... 44
CHAPTER 6 CONCLUSIONS AND FUTURE WORK ... 48
6.1 CONCLUSIONS ... 48
6.2 LIMITATION OF THIS RESEARCH ... 49
vi
vii
LIST OF TABLES
TABLE 4.1 THE DISTRIBUTION OF REVIEWS IN DIFFERENT CATEGORY ... 30
TABLE 4.2 THE DISTRIBUTION OF AUTHORS IN DIFFERENT CATEGORY ... 31
TABLE 4.3 WORD SET EXPANSION RESULTS ... 34
TABLE 4.4RECENCY VALUE OF TESTING REVIEWERS ... 35
TABLE 4.5 FREQUENCY VALUE OF TESTING REVIEWERS ... 36
TABLE 4.6 SCN OF TESTING REVIEWERS... 38
TABLE 4.7PARAMETERS FOR NEURAL NETWORK TRAINING ... 39
TABLE 5.1 MAPE VALUE IN DIFFERENT WORD SET EXPANDING LEVEL ... 41
TABLE 5.2INFLUENTIAL RANKING ... 42
TABLE 5.3RANKINGS AND MAPE VALUE IN DIFFERENT METHODS ... 44
LIST OF FIGURES
FIGURE 2.1 A NEURAL NETWORK ... 14FIGURE 3.1SYSTEM CONCEPT AND ARCHITECTURE ... 17
FIGURE 3.2TRUST NAME LIST EXPANDING RELATIONS ... 26
FIGURE 4.1 EPINIONS.COM WEBSITE ... 28
FIGURE 4.2 THE DISTRIBUTION OF REVIEWS IN DIFFERENT CATEGORY ... 30
FIGURE 4.3 THE DISTRIBUTION OF AUTHORS IN DIFFERENT CATEGORY ... 32
1
CHAPTER 1
INTRODUCTION
1.1
Research Background
Marketing is the key of commercial activities. Viral marketing is a new marketing method which spreads product information based on people’s word-of-mouth. The effect of it grows in incredible speed in the Internet era. How to integrate viral marketing correctly into overall marketing strategy is very important for firms if they want to save significant marketing cost and create more business chances.
We have known that outstanding marketing strategies usually bring future revenues to enterprises because they add extra values to products (include physical, virtual products or services) and firms themselves. Future revenues not only mean current sales but also represent some business chances which are hard to predict and valuable for future business growing. As a result, marketing behaviors are absolutely needed by firms to maintain and create more profits. In facts, lots of scholars have done so many researches about marketing which cover various perspectives and domains. For example, organizational issues relevant to marketing strategy (e.g. branding, competitive behavior, positioning, and segmentation), organizational issues that span functions (e.g. quality management), the interface between marketing and business strategy, organization level phenomena that impact marketing strategy (e.g. market orientation, corporate culture), and outcomes of marketing strategy (e.g. market share, customer satisfaction) [53].
We know the purpose of marketing is getting high growing in sales, market share, and gross margin in the marketplace and the ultimate goal is enhancing the shareholder returns [46]. However, while the technological advancement reduces the manufacturing and managerial costs, the marketing cost rises rapidly [56]. The implementation of Just-in-Time
2
strategy and flexible manufacturing systems had reduced the manufacturing cost efficiently. Managerial costs (e.g., finance, accounting, human resource, R & D) also declined as a fraction of total corporate costs due to the adoption of new managerial and IT tools. In the cost structure of firms, only the marketing costs (include expenses such as product development, selling, distribution, advertising, sales promotion, public relations, customer service, outbound logistics, and order fulfillment) raised a lot in recent 50 years [43]. In addition, the returns on marketing are usually unpredictable, especially in advertisement. For example, firms can design delicate advertisements and spread them through various media but it is very hard to predict how many people will be attracted by the advertisements and how much revenues will be generated. The investment may be a huge success due to some special ideas in the advertisement or a catastrophic failure after spending a huge budget. These marketing behaviors are undoubtedly risky for a firm’s finance, especially for business of small scale. High cost and uncertain characteristics make enterprises have to spend more and more money on marketing, but the revenues cannot be guaranteed so firms are reluctant to invest too much on marketing plans. This strategy saves some resource and cost temporarily but blocks the future growing because appropriate marketing plans are definitely needed for sustainable management in every business. Firms may also lose some profitable business chances due to conservative strategy in marketing plans.
High cost and uncertainty problems exist in the long business history of humanity no matter how excellent and cost-cutting technologies are invented in manufacturing. The marketing cost problems are still the killer for gross profits. However, the invention of the Internet changes the world and also creates new chances to traditional marketing. After 1990, the Internet brings new methods for transactions into the traditional marketplace. We can find many new business models which are born due to the Internet such as online shopping or online banking. The whole business environment also produced new transaction and
3
advertisement models. In the Internet era, to run a business does not need grand scale or capital. Even individuals have the ability to do business with others rapidly and accurately. By adopting simple business models, sometimes they even have better performance than traditional business models. C2C, virtual marketplace, auction brokers, and social network marketing are all outputs under this environment [38].
In the e-commerce world, information about traditional products can now be exchanged in more convenient ways now. Many kinds of new products which are different than traditional ones are also emerged because they are ideal to deliver directly in the Internet era. For example, many knowledge-based products which can be stored in digital format like movies, music, and e-books are all common in our daily life. The characteristics of the Internet make it is the most appropriate platform for knowledge-based product delivery. From the marketing’s point of view, or the advertising part in specific, firm’s purpose is to spread the positive impressions of products to their customers and to attract them to buy their products. Not only advertisements but also the aforementioned knowledge-based products have similar characteristics in transmitting due to their “non-physical” form. In other words, advertising is one kind of “information spreading” procedure and the Internet is the best way to achieve it. With lower cost, higher speed, and higher external effects, marketing on the Internet has more advantages than on traditional media no matter the target products are physical products or knowledge-based virtual ones.
The effects of viral marketing become larger in this scenario. Originally, viral marketing is the “word -of-mouth” action. People tell their friends about their using experience and spread the product information accidentally. The result is amplified due to the characteristics of the Internet and firms start to pay their attentions to taking advantages of viral marketing. In fact, viral marketing is not only one kind of information spreading method
4
but also the inclusion of the influence of friends. The information is filtered by our friends and is more trustworthy than general advertisements. If the spreading of information can be controlled, it will be a good solution for marketing problems.
1.2
Research Problem
Although marketing on the Internet has lower cost and higher influence than traditional ways, it could be the solution to only half of the problems we stated. The Internet technology definitely lowers the cost of enterprises to advertise products but cannot ensure the effects to be really achieved. In other words, online advertisements are viewed as useless message by most of the Internet users. For example, e-mail is one of the most common channels for general advertising on the web but statistics shows that more than 95% of the emails are junk mails [55]. The high garbage rate would make most people pay less attention to handle these junks and lower the effects of advertising at the same time. In addition, over-advertising even make the customers have bad impressions to firms. No matter how low the cost of advertising is on the Internet, the resources are wasted definitely. These resources may be bandwidth, server computing power, electricity or more infrastructures in order to maintaining a large scale marketing behaviors. After all, the convenience of the Internet may also lead to negative impacts on the visibility of the information we want to spread.
Lots of researches provide many methods to solve the problem. The developing of recommendation system is an important milestone. In short, the recommendation mechanisms filter most information and only send the product information the customers may be interested in. It is one kind of one-to-one marketing and achieved complete personalization. The quality of recommendations relies on the techniques used. Generally, the purchase history and personal preference will be considered as basic materials for system input by data mining techniques such as collaborative filtering, association rules, and content-based filtering [10]
5
[26] [59].
Effective algorithms provide product information which only the customers may want. They are also applied in many online shopping websites now. However, the Internet environment currently creates a new chance for a new type of marketing. The advancement of IT infrastructure empowers almost everyone to contribute or to share information on the Internet. The sharing behaviors on the web are so called “Web 2.0” [36]. In Web 2.0 environment, information is no longer only sent from traditional firms to customers or organizations to individuals but also passed between every node on the Internet. Individuals can share their creations with everyone in any place, anytime. In other words, information flow is not purely as client / server structure which sends and receives data in single direction but like the peer to peer architecture (P2P) which every node in the framework can play the client or server role at the same time. The concepts of peer production [5] and social network [4] are also constructed by the power of Web 2.0.
In lots of Web 2.0 community and discussion groups, people contribute their comments after using products and find comments about products they need or want to buy. More importantly, these comments may be provided by their friends. Consumers can reach the real comments of their friends more easily than ever before, and the firms can no longer control the scattered information source about their products. It makes more sense to believe the using experience provided by someone we trust rather than to buy the firms’ advertisements. In such information spreading model, the impressions of products are decided by online users’ comments and human connections, not the advertisements. It is doubtless that people now have other channels for product information with higher credibility. They are reliable, trustworthy, close to our real using habits, and the most important is: drawbacks will no longer be hidden by fancy advertisements of manufacturers. Current Internet environment
6
provides us another bright path to solve the uncertainty problem of marketing.
1.3
Research Objectives
The objective of this research is to solve the uncertainty problem of marketing. We have known that viral marketing is incubated based on Web 2.0 environment since it provides new chances for everyone to express their opinions. Research have shown that social networks affect the adoption of individual innovations and products [41] [47] and the power of social network spreads information in breathtaking speed [22]. In fact, people are usually affected by the purchasing decision of their friends in daily life, especially when they need to buy something expensive. From the perspective of firms, we expected only by marketing to a few people who has the ability to spread product impressions and affect their friends efficiently can accelerate business. This strategy not only saves money but also lowers the probability of consumers’ complains due to annoying advertisements. By leveraging the power of social network, enterprise can achieve amazing results in lower cost and higher accuracy by marketing to fewer potential customers (or nodes). These nodes should have plenty of purchasing experiences, contribute their using experiences often, and equip with wide social networks.
In this research, we hope to find an easy way to discover influential nodes with potentials to achieve the effects of viral marketing. How to measure the influence of each node is a very important topic because it determines which nodes are appropriate to market. Among the key factors we mentioned in last paragraph which affect people to make buying decisions in current Internet market, we consider the using experience, contributing status of opinions, and social connection are the main elements to shape the influence of each node. In addition, we found that the online product review wrote by users is an excellent source to acquire these elements. The contents and basic attributes of each review can satisfy our needs
7
of data. As a result, we start from analyze online product reviews and RFM indexes about individuals on the professional product review website: Epinions.com. Text mining techniques, artificial intelligence model, and trust mechanisms will also be applied. By quantifying the value of each review and author, the commercial value of online users can also be identified. Enterprises can use the information to make a good marketing strategy and budget plans in order to achieve the best effects of infection. They will know who are their valuable targets and pay more attentions to these potential nodes. The results and evaluations show that our framework for finding potential nodes is effective and better than traditional “popular author” and “review rating” mechanisms.
1.4
Research Outline
The remaining part of this paper is divided into the following sections: In section 2, we survey existed literatures about our research topic. In section 3, we propose the whole system architecture and methodologies applied in this work. Next, the procedures and materials about experiments will be stated in detail in section 4. The results and evaluations will be displayed in section 5. Finally, we have a discussion and conclusion.
8
CHAPTER 2
LITERATURE REVIEW
This chapter reviews literatures related to our research, including viral marketing, opinion mining, RFM, trust, and artificial neural network. These concepts and methodologies will be applied in our model’s construction, experiment, and evaluation design.
2.1
Viral Marketing
Viral marketing is a new marketing method which is not based on the advertising budget of firms. It uses electronic communication channels (Ex: e-mail) to propagate brand messages throughout a widespread network of buyers [15]. In fact, this new marketing way spreads the brand impressions with no partiality no matter its brand reputation. Dobele et al. [15] realized this fact and tried to find out an appropriate approach for successful marketing. They considered viral marketing a good chance for new startup firm but most firms are lack in “control” of this power. They studied several real marketing cases and analyzed why they need viral marketing, how to apply technology in it, and how to use it successfully.
Dobele et al. [14] also identified the key points about the success or failure of message passing in viral marketing. They collected and categorized many cases about the message passing behaviors in several different products. They realized that “emotion” and “the expectation of recipient” play important roles in the successful message passing. The result shows that emotional expression during message passing is important. In addition, the authors also stated that marketing to several influential people will perform better than sending message to everyone and that is what we want to achieve.
Moore [31] did a research about the branding influence based on viral marketing environment. For example, Microsoft’s hotmail member increases with high speed due to its involvement with many contacts of each user. This is a famous example in viral marketing
9
because Microsoft spend only $50,000 on traditional marketing channel but the members of hotmail grew from zero to 12 million in 18 months [22]. In mid-2000, Hotmail owned over 66 million members and 270 thousand of new accounts are created on a daily basis. These users send their personal messages and the “Hotmail” brand at the same time are spread. In other words, Hotmail has provided a place to allow users fulfill their needs of communication and, in exchange, it is gained its reputation in cyberspace. For business operators like Microsoft, one of the most important outcomes is chances to generate profits. Thus, treating this as an opportunity, Microsoft attaches advertisement to mails. Although the advertisements every member receives are not filtered, ads do function well to spread through links among people and achieve practical effects.
Leskovec et al. [25] analyzed information about product recommendation and discovered the relationship of social network. They proposed a model to explain user behaviors in a large community where people recommend products to others in different strength according to their social network in this community. In addition, the growth and the effectiveness of the social network are identified. Richardson and Domingos [40] used probabilistic models and data from knowledge-sharing sites to design a viral marketing plan. They also tried to optimize the amount of investment for each customer and to lower the computational cost.
We can find several works about viral marketing which is based on social networks. However, most works focus on the observation of business condition or the calculation of social network spreading. In an Internet context, the effects of viral marketing become attractive for commercial application. We focus on creating a practical model which can be applied easily on business strategy making. Our works will pay much attention on applications of information technologies to help enterprise find a good solution of marketing
10
strategy in viral marketing. The model is constructed on the platform of Web 2.0 environment--a place where real using experiences of online users to achieve an effective marketing behavior take place.
2.2
Opinion Mining
We have known that people can get useful information about products which they want to buy in many online communities. They read product reviews which are written by other experienced users for reference to make a decision. In other words, these reviews equipped with some influencing power to the readers’ decisions and the purpose of opinion mining is measuring the influencing level of them. For example, Zhan et al. [58] emphasize the important role of writing and referring product reviews in Internet environment. These product reviews are both influential for consumers’ decision and firms’ customer service department to do product improvement.
Empirically, there are already some social datasets distributed on the web [49] and it is helpful in simplifying the data collecting process for opinion mining. In the case of the methodologies to implement opinion mining, many scholars focus on the identification of author’s attitude such as positive or negative [13] [18] [19] [37]. The semantic tendency of an article is usually decided by some specific keywords which are clear and hard to be misinterpreted. The semantic identification is helpful for review tendency judging automatically.
In this research, we intend to apply these techniques to do a detailed scoring for the value of each review. Since modified- and multi-dimensional scoring mechanisms are relevant to our problems, in this research, we focus on identifying the critical review with subjective semantics. By identifying these reviews, they are useful in understanding consumers’ behavior.
11
2.3
RFM Measure
Hughes [20] proposed RFM analytical model in 1994. RFM stands for Recency, Frequency, and Monetary. It is a way to measure the values of customers for enterprises. For every customer, enterprises can get the three elements from his / her purchase history [39]:
Recency: What time is the last purchase of this customer or how long from last purchase to
now?
Frequency: How many times of purchase happened during a specific time period?
Monetary: How much the customer spends on each purchase?
By RFM analysis, firms can understand the potential of customers easily by observing their past behaviors. Newell [35] also stated that RFM method is very effective in customer segmentation. So, the simple and direct this measure has been used in direct marketing for a decade [3]. It intends to find customers who recently purchase (Recency), the number of times they purchase (Frequency), and by how much they spend (Monetary) [30].
There are many researches based on the concept of RFM analysis. Drozdenko and Drake [16] applied the hard coding techniques on RFM weighting. They assigned weights to three variables in RFM analysis and acquired the weighted score of each person in database. This technique is also called as “judgment based RFM” due to the procedures are functions of judgments of marketers. Chan [7] presented a novel approach that combines customer targeting and customer segmentation for campaign strategies. RFM and customer life time value (LTV) are included in his model to identify and evaluate customer behaviors. Liu and Shih [28] proposed two hybrid methods which take advantage of weighted-RFM (WRFM) method and preference-based CF method to improve the accuracy of recommendations. Although RFM is not an innovative method to identify values of customers, the extensive applications have proved its importance in academic ground.
12
In this research, RFM will be used to derive partial values of online reviewers. Modifications will be made to accommodate data. In the end, RFM will be used to measure the potential value of customers by their past behaviors. Moreover, online product reviewers also have similar characteristics. According to the records of their writings, we can understand that these reviewers are currently active or not. Lastly, the application of RFM can be realized as the way to choose a good reviewer but what it cannot do is to create new information people need.
2.4
Trust Mechanism
Trust is a relationship of reliance [48] and is also a willingness to rely on an exchange partner in whom one has confidence [32]. Erikson [17] defines trust as “general belief in the goodness of others”; Rotter [42] describes trust as “an expectancy held by an individual or a group that the word, promise, verbal, or written statement of another individual or group can be relied upon”. In brief, trust is an expectancy that the behaviors of people (or objects of trust evaluation) will follow a predetermined manner [1] and this manner is the behaviors of others they trust.
Trust can also be used to indicate the strength level of relationships among people without doing detailed investigation of intention [44]. The strength level of trust can be viewed as an indicator that the probability people will follow the behaviors of someone they trust or not. Due to the characteristics of trust, it is often used to create better working efficiency in organizations. Munns [34] stated that trust is a relation from personal to individual, arising from the experiences of and influences on that individual. Strong trust level of someone will shape a strong influence making others trust him / her. Some researches have indicated the effectiveness of trust mechanism and its implications in different academic subjects.
13
Trust has been described as "central to all transactions" between individual or organizational actors in economics [12]. It strengthens the motivations of people to do transactions and the benefits of each transacting target can be evaluated accordingly. Morgan and Hunt [33] theorized, modeled, and tested the success of relationship marketing and found that commitment and trust are key factors. The study of Cook and Wall [11] classifies trust between peers and trust between peers and management. They found that trust is based on "faith in intentions" and "confidence in ability". Smith and Barclay [45] studied the relationships between buyers and sellers. Their results show that trust is based on character / motives / intentions and role competence / judgment. Trust value of a supplier also influences a buyer’s future interacting will with the supplier.
The concept of trust and related algorithms clarifies the intimate level between nodes or organizations. Dasgupta [12] stated that trust is helpful in the condition involving uncertainty about the actions that will be undertaken by others. Stated differently, trust mechanism is an important and effective factor for customers to make purchase decisions even customers may not be familiar with the product. There must be a higher probability to follow the recommendation from people with high trust score than the advertisements of firms. Due to this fact, the calculation of trust score of potential nodes is clearly justified. We will use this concept as the evaluation indicators to reflect the effects of our model.
2.5
Artificial Neural Network
Artificial neural network (ANN) is an interconnected group of artificial neurons that uses a mathematical or computational model for information processing based on a connectionistic approach to computation [2]. The purpose of ANN is to construct an artificial model which can learn and think with a mode similar to the brain of human. ANN is appropriate for solving complex problems which includes many variables. A simple structure
14
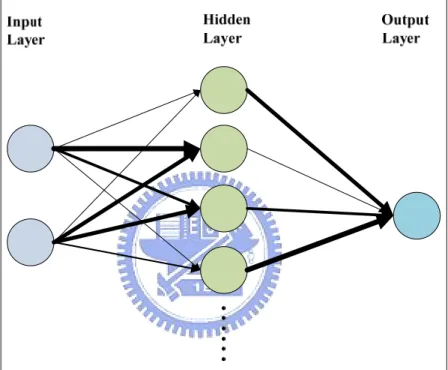
of ANN is similar to Figure 2.1. By continuous lots of times of “training” and “learning”, a well-trained ANN will change its structure according to external and internal information that flows through the network. So, ANN is an adaptive and intelligent system which can vary to fit the users’ needs according to the characteristics of training data. A well-developed ANN is also expected to generate usable results from input data by following existed learning rules. Therefore, ANN is of great importance to predicate in many research areas.
Figure 2.1 A neural network
ANN technique has been used for solving business problems extensively and can be judged as an element of business intelligence. Kuo and Chen [24] used fuzzy neural network to learn rules produced from order selection questionnaires in electronic commerce. A feed-forward ANN with error back-propagation learning algorithm is also employed to integrate different scores. Cao and Schniederjans [6] created an ANN model for a reputation agent to evaluate capabilities for selecting products and services in an e-tourism environment. Chiang et al. [9] developed an ANN model to predict and explain consumer’s choice between web and physical stores. Tsaih et al. [50] combined rule-based systems and ANN to predict the
15
direction of daily price changes in S&P 500 stock index futures. Li et al. [27] used ANN model and other statistical methods to forecast the final price of online auction items.
The existing works have proven the effects of ANN in solving various complex problems. In our research, we need to acquire the predicted influence score from several factors such as text mining, Recency, and Frequency. The relationships among these factors are complex and many human behaviors cannot be indicated by linear models. These kinds of complex materials are appropriate to be constructed by massive data training and learning in ANN.
16
CHAPTER 3
THE MODEL
In this research, we analyzed the after-use reviews provided by online users and RFM values in each author’s activity recorded to identify which authors are influential. While the influential reviews represent the influence of their authors, the RFM value indicates the infective ability of each reviewer by time segmentation.
An influence ranking list of authors is generated to identify potential nodes and it is expected to construct a well-learned model in order to calculate each reviewer’s mixed-score of two elements above. Data which contained complete review content and RFM attributes are needed for well-structured model training. Artificial neural network technique is then applied to achieve the training procedure for better weight measurement among these elements. The well-trained network model will be fed with selected testing nodes and the output ranking list will be compared with two existing common methods for selecting influential authors.
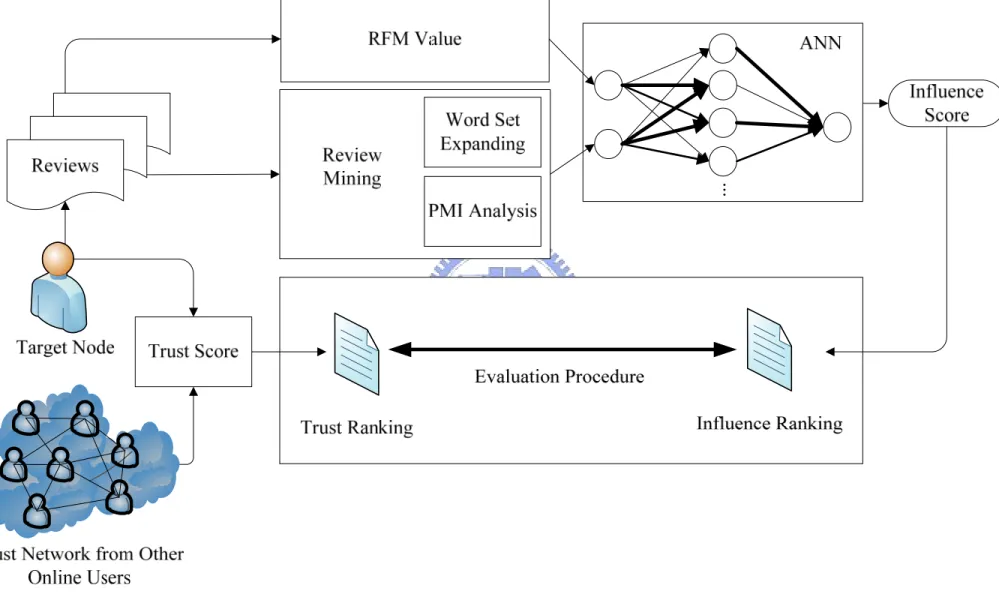
From enterprises’ perspective, these high-ranking authors are valuable targets for their marketing behaviors. They are expected to spread products’ reviews. And the impact is profound. Firms can have set up strategies to take advantage of these potential reviewers. They can provide free trial version of their newest products or special discounts to these targets in order to induce the consumption, which entails influential review. It is hoped that the behavior of spreading of product behaves as a virus. Figure 3.1 displays this concept and its architectures:
17
...
18
Our target nodes are chosen from an online social network environment. Online discussion platform provides users to write product reviews of any kinds. What we try to do is to assign scores to these reviewers and to decide which reviewers are the most infective to the market. Note that the infective ability is decided by two factors: reviews and RFM value.
The reviews written by each reviewer will be analyzed by text mining techniques based on their scores. The results of analysis will be quantified by our modified PMI model in six different degrees. In addition, we can also acquire the “RFM value” of each node by recording attributes of each review (i.e. time, date, and category). The both scores will be weighted by artificial neural network as the final virus score to decide the value of the reviewer. It will learn the most appropriate structure of network to reflect the effects of each element by massive data training. Our mechanism can consider both text mining methodologies and the effectiveness of each node’s writings. It tries to discover the hidden value in each review and consider verifying the effect of it at the same time. We do a detail statement about each unit in this architecture in the following subsections.
3.1
Review Mining
3.1.1 Word Set Expanding
In existing research, the semantics of single article are usually classified in four categories: positive, negative, objective, and subjective. Since the reviews are not evaluated based on these classification, thus, we will not follow previous work. Instead, we focus on general attitude from reviewers and they are the nodes we want to be discovered. However, previous work indicates that reviewers who write at extreme values (e.g. all positive (hyper spam) or all negative (defaming spam) comments) are hard to be trusted [21]. In addition, objective perspectives are usually descriptions about products without additional reference value are not considered important because they are lack of “emotions,” which has higher
19
possibility to affect the purchasing decisions of others [14]. Thus, in this study, the subjective factors are considered.
Turney and Littman [51] defined two sets of words which represent positive and negative sentiments, respectively:
{
}
{
}
= good, nice, excellent, positive, fortunate, correct, superior bad, nasty, poor, negative, unfortunate, wrong, inferior p
n S S =
The two sets are decided due to their lack of sensitivity to context. It means that in most situations, articles with these words represent the original meaning no matter how the structure of these articles was. Our model was analyzed based on these two sets.
We expand Sp n+ in order to make a subjective word base. In order to consider the
subjective reviews, both word sets will be included in our model. We define:
n p n
p
S
S
S
+=
+
The composite word set Sp n+ is the combination of the two above sets so it covers
both positive and negative semantics. We believe that the ingredients of Sp n+ will carry a
complete meaning of “subjective words” which can reach our expectations. Although reviewers can express their emotion completely through subjective comments, which are valuable for other online users, firms would hope not to see any negative comments spreading on the Internet. Nevertheless, a trustable reviewer should always express their thinking fairly. A reviewer who only write positive reviews is possible to be viewed as an employee of the firm and his / her reviews will not be trusted by others. In order to achieve effective information spreading, it is necessary to select trustable reviewers. Firms should try doing the right things to please these influential reviewers who write negative comments instead
20
ignoring them. Any negative comments will hurt the reputations of firms, especially in the Internet world. Firms should promptly respond to negative comments, contact those reviewers, and find out what can be done to improve the products or services. This will not only remove the sources of bad reputations but also increase positive reputations of firms.
We hope to check if these words of Sp n+ exist in each review to decide the subjective
level of each review, but the number of words in the set is too few to do an accurate check. It may ends up with none being discovered. The problem can be solved by expanding original
p n
S
+ set. Some online semantic lexicon such as WordNet [57] would be helpful. We plan toextract synonyms of Sp n+ from WordNet to achieve different level of Sp n+ . We have known
that the synonyms can be traced from Sp n+ recursively, so the size of word set could be
different according to the iteration times.
We mark the word set Skp n+ which denotes kth expansion times. For example, k=1
equals to original 14 items in 1 n p
S + and k =2equals to 14 items in 2 n p
S + . The sets will grow
rapidly according to k value and the number of matches will also increase due to larger word
set Skp n+ . Clearly, different value of k will lead to different matching pairs between Skp n+ and
test reviews. In our experiment, six degrees of word set expansion will be executed to observe a better expanding level. As k value becomes larger, the system will consume more resource in word matching and the whole system becomes inefficient. The six levels of word matching will be recorded and quantified in the following PMI method. The scores are used to calculate the strength of subjective of these reviews.
21
3.1.2 PMI Strength Level Approach
In this subsection, we use PMI (Pointwise Mutual Information) as a tool to calculate the score of strength of each review as the basis for the results of review analysis. Turney and Littman [51] define PMI in the following equation:
( )
2( ) ( )
( )
Pr , , log Pr Pr c i i r w i t t PMI t t t t =∑
This equation can measure the semantic association between the matched term
t
in areview and
t
iin word setk p n
S + by calculating the emerging probability in the whole article.
The key point of PMI calculation is the value of Prc
( )
t t , , i Prr( )
t , and Prw( )
ti . We define each of them as follows:( )
( )
( )
(
i)
Pr 1 PrPr , 1 i.e. term t and t are the same word. tr r r w i s c i n t N t N t t = = =
Term
n
tr stands for the number of termt
(i.e. number of matches) in target’s review and N stands for the number of all words in this review. rN
s represents the number of wordsin the word set while
t
i was collected into it. In fact,t
andt
i are the same due to the matching mechanism. Thus, the association between these two words is not our real purpose. The real effect of PMI is that it considers the number of matched words in the whole article before it reflects the subjective strength level of the target. In addition, PMI also takes the word appearance probability in each review and decreases the errors due to unequal number22
of words in each review. In order to simplify the calculation and retrieve appropriate value for processing, we modify PMI in the following form:
( )
, i log2 Prr( ) ( )
Prw iPMI t t = ⎡⎣ t t ⎤⎦
The PMI score of each review is calculated by the adaptive PMI equation above. It is based on the viewpoint of each review. Every time the model processes the score of one
review, PMI ,
( )
t ti considers all matches in it, meaning that every review in our data set will have its PMI score and it comes from the sum of its all matches. It is obvious that this equation will produce a negative score and it is inconvenient for continued processing. Because of the negative characteristic of each PMI value, we will standardize every PMI score from every review before combining with other character values:min _ max min i i std
PMI
PMI
PMI
PMI
PMI
−
=
−
The modified and standardized PMI equation can help acquire the strength score of each review. Then, we can acquire the target node’s score by:
_ 1 n i std i Avg
PMI
PMI
n
==
∑
This equation sums and averages all reviews’ PMI score of every author. This step is necessary to construct a comparative standard for all authors. After the processing, every author’s text results in our data set can be identified, recorded, and ranked.
23
Now, we have shown how to calculate reviewers’ score of the target node. The review analysis scores of these target nodes are important elements when considering their influence. They will be combined and processed with other scores by later weighting mechanisms.
3.2
RFM Value
In this research, we accommodated original RFM concepts into our experimental situation. Recency and Frequency indexes are adopted in our RFM analysis only due to the characteristics of online product reviews. Monetary value is excluded because of its only inappropriateness and difficulty to measure. In the Web 2.0 environment, information contributors provide knowledge to the Internet voluntarily and their efforts have no direct relationships to pecuniary revenues.
3.2.1 Recency Model
The original concept of “Recency” is the days between the purchased date and the presence. In our work, we explain “Recency” as the time range γ between current date and the latest wrote date of each node. It is measured by days. The benchmark date (i.e. current date) is set at May 20th, 2008 due to the experimental duration.
i i =C−l
γ
While l is the last written date of node i , i Cis the current date. Initial values of Recency are measured by days. They are needed to be standardized in order to combine other index values later. Recency standardization is different from general standardization procedures because higher values indicate lower market values. In order to display real meaning of Recency, the following formula to standardize Recency value:
i i i i xi Std γ γ γ γ min max max − − =
24
The absolute value between γi and maxγi indicate the strength of lower Recency with higher standardized value.
3.2.2 Frequency Model
Frequency represents the purchasing times in a specific time range. Similar definition is applied in our work. It indicates the number of writings in a specific time range of each author. To segment the time range is the first step to record frequency. We set three time points as the separation:
90
90-365
365
: The number of writings made within 90 days
: The number of writings made between 90 and 365 days : The number of writings made over 365 days
θ θ θ
<
>
The three-time points are calculated. In addition, most data are electronic products and the product life cycles are shorter than general products. Divided the time range by quarter and one year at most will be appropriate Each author’s writing records will be classified into the three categories and they are still in need to be standardized by the same method. However, we do not combine scores of these three categories into single Frequency score. It is apparent that writing reviews in different time range represent different level of importance and it will be reflected on the influence score of each reviewer. We put them into the ANN model for weighting because linear or static weighting of these three scores cannot represent real scenarios in life. The effects of ANN will learn appropriate distribution among the three scores automatically and the pre-combination can be ignored.
3.3
Trust Network Value Calculation
Although trust is effective in influencing the purchasing decision of others, we do not adopt it directly as an element of our model. One reason is most of the online product comment communities do not consider trust mechanisms in their website design thus make it
25
difficult to apply a trust-embedded system for firms to identify influential nodes. The other reason is that even online product websites do equipped with complete trust scoring mechanism, they are only useful for experienced nodes because these nodes have wider social networks for trust measuring. In order to increase the effectiveness of our model, we have added RFM measure as the factor to judge the active status of each node, and the characteristics of trust may filter some new but potential nodes out. However, many literatures indicate that the relationships between trust and influence are very tight. If nodes discovered by our model also have high trust value, the effectiveness of our model can be acceptable.
Due to the characteristics of trust, in this research, trust value will be applied in evaluation procedure. The spirit of viral marketing is to leverage the elements of social network. Thus, the output of our model must have similar effects to social networks: the power of spreading. Equipped with this character, trust value evaluation will reflect the human relationships of social network, and the effects of our model can be verified. We believe that the trust relationships among these reviewers can add more benefits to product information spreading. This architecture design of our model can make our results have strong influence, which is verified by trust, and solve bias problem for new reviewers.
We have found that many online discussion forums assign impression scores to others. Every online user can establish his / her personal friend list and black list. This procedure indicates each user’s trust level which may be different among users. We will use these lists to consider the propagating ability of each user.
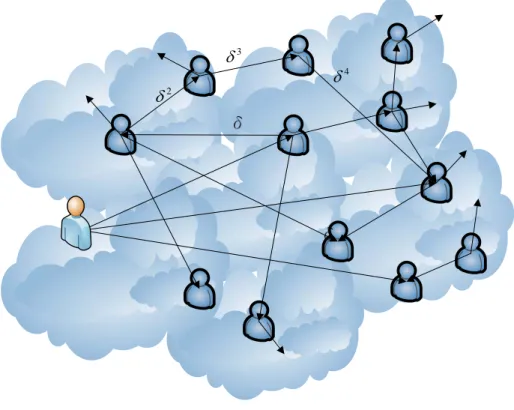
26 2 δ 3 δ 4 δ
Figure 3.2 Trust name list expanding relations
Figure 3.2 displays the trust relationships among online users. For example, the target node (reviewer) is trusted by three people and his name exists in the three people’s friend lists. The names of the three people would also exist in other friends’ lists. The relationship can be traced more according to our need. By iterated tracing actions, we can observe everyone’s social connections within the online community. The social connections represent the influencing range of each node. We call it “SCN (Social Connection Number)”. If we do review mining to discover the influencing strength of a reviewer, we can measure the influential range. In brief, the tracing of social connection of each target node is our primary task and it can be formulated by the following equation:
i
i i j tr j
27
i
SCN
starts from any revieweri
in our data set.n
i is the function that counts thenumber of people denoted as trust node
i
.tr
i is the set of nodes who trust nodei
. We knowthe strength of connection would decrease as the tracing level increases. δ is added to represent the decay rate of SCN. Note that the repeated connections would happen in different tracing level because we may connect to our friends via different path. Redundant connection numbers are erased if the nodes already exist in previous tracing procedures.
Figure 3.2 shows that the tracing of SCN is a large recursive process. Friend nodes will increase at a fast speed. In order to reduce computing time and to keep the process efficient, the setting of tracing level becomes a critical topic. We explain this part in CHAPTER 4.
28
CHAPTER 4
EXPERIMENTS
4.1
The Data
4.1.1 Data Source
We use real data from the Internet in this experiment. In order to acquire objective results, we need to find an open platform where online users can write reviews to various products. Epinions.com (Figure 4.1) is a good platform which can satisfy our need. It not only it has a variety of product reviews but also provides a complete set of writing, rating, ranking, and trust mechanism for members to identify the effect of reviewers. The characteristics of Epinions.com are appropriate for us to retrieve related data, especially for our trust value retrieval. In addition, lots of researches have used Epinions.com as their experimenting data source [8] [29] [52] [54] so the stability and objectivity of data would not bias.
29
In order to acquire sufficient data for neural network training and testing, we need to prepare two independent data sources. The retrieval date of these reviews is on May 14, 2008. 2952 reviews are randomly selected from seven sub-categories under classification Electronics. They are “Home Audio”, “Video”, “Communications”, “Car Audio”, “Optics”, “Outdoor Electronics”, and “PDA & Handhelds”. The authors of these reviews all have SCN value larger than zero. The only remaining sub-category under Electronics is “Cameras and Accessories” and we will extract the testing data from it.
The selection of testing data goes through several steps. We need to have a data set which started form the reviewers’ angle due to our ranking purpose. We picked up the product “Canon PowerShot S5 IS Digital Camera” from “Cameras and Accessories” sub-category, and it has 69 different consumer reviews. All reviews wrote by the 69 reviewers are retrieved but only the latest 100 reviews of each reviewer are reserved. In addition, if the reviewers are not trusted by anyone, they are erased from our data set because we need the trust value of them to evaluate our system.
4.1.2 Data Descriptions
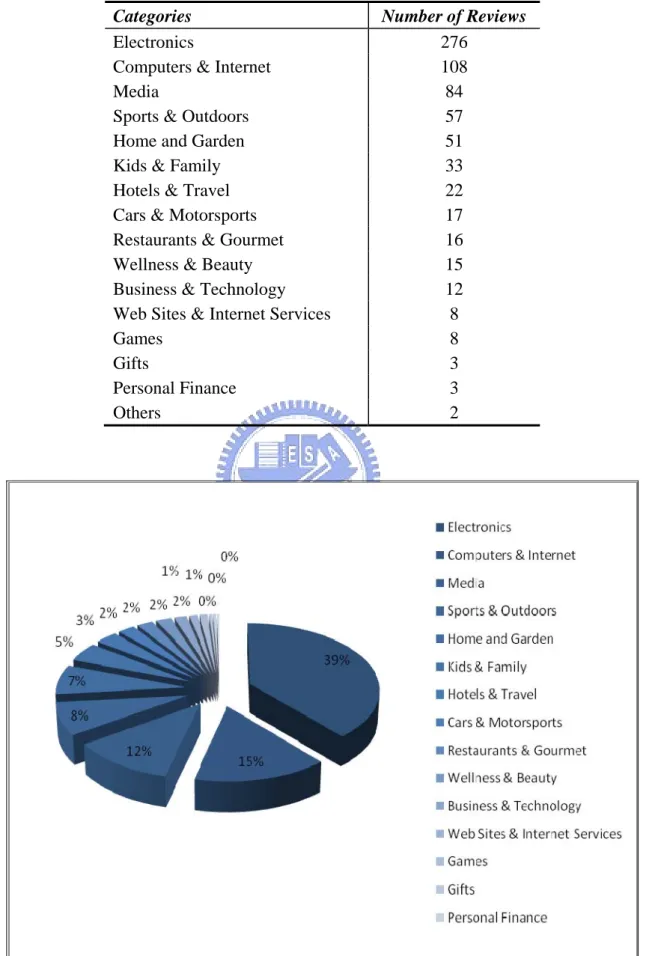
In above section, 941 reviews wrote by 69 reviewers are retrieved but only 16 people are reserved due to the consideration of trust. We find that 715 out of the 941 reviews are written by the 16 people. In other words, 23.19% reviewers create 75.98% reviews and they all have some level of trust. This situation can reflect the Pareto principle (or 80 / 20 principle) and prove trust is really a significant indicator of the influencing power again. The 715 reviews wrote by 16 reviewers are the confirmed testing data in our experiment. They are all wrote between December 28th, 1999 and April 30th, 2008. These reviews are classified into 16 categories and the distributions are displayed in Table 4.1, Table 4.2, Figure 4.2, and Figure 4.3.
30
Table 4.1 The distribution of reviews in different category
Categories Number of Reviews
Electronics 276 Computers & Internet 108
Media 84 Sports & Outdoors 57
Home and Garden 51
Kids & Family 33
Hotels & Travel 22 Cars & Motorsports 17 Restaurants & Gourmet 16 Wellness & Beauty 15 Business & Technology 12 Web Sites & Internet Services 8
Games 8 Gifts 3
Personal Finance 3
Others 2
31
As Table 4.1 and Figure 4.2 shows, the testing reviews are centralized in “Electronics”, “Computer & Internet”, and “Media”. These three parts represent two-thirds of all reviews. We think the situation is due to our starting point in collecting data. In other words, the online platform for writing product reviews is constructed by computer and networks. It is reasonable that most users are familiar with products related to electronics and information technology. The centralized data distribution also has some advantages. It makes the main character of data can be identified easily and the applying range of our model is also cleared.
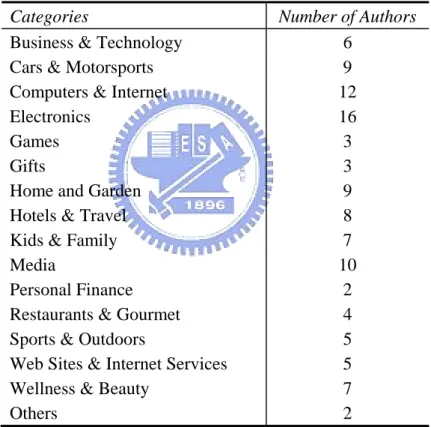
Table 4.2 The distribution of authors in different category
Categories Number of Authors
Business & Technology 6 Cars & Motorsports 9 Computers & Internet 12
Electronics 16 Games 3 Gifts 3
Home and Garden 9
Hotels & Travel 8
Kids & Family 7
Media 10
Personal Finance 2
Restaurants & Gourmet 4 Sports & Outdoors 5 Web Sites & Internet Services 5 Wellness & Beauty 7
32
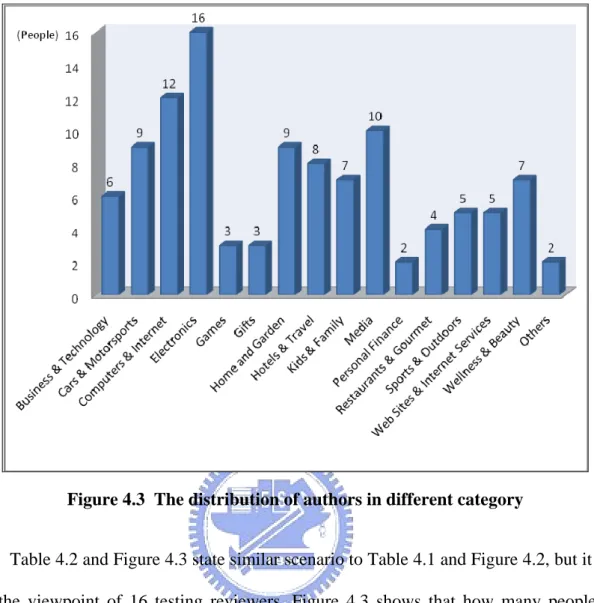
Figure 4.3 The distribution of authors in different category
Table 4.2 and Figure 4.3 state similar scenario to Table 4.1 and Figure 4.2, but it starts from the viewpoint of 16 testing reviewers. Figure 4.3 shows that how many people ever wrote reviews in each category. We can still observe that most of our 16 reviewers wrote reviews in several main categories similar to Figure 4.2. The above two figures indicates the tendency of our data set. Analysis shows that the characteristic of our reviews and reviewers are skilled mainly in electronics, computers, and media. Our experiment results are also expected to have related value for these categories.
4.2
Word Set Expansion
Training and testing reviews retrieved from Epinions.com are expected to be matched
with the word set Spk+n. In order to carry out subjective word matching in different level, we
33
out the synonyms of original word set. WordNet has defined all related subjective words and listed their synonyms clearly. Many opened Application Programming Interfaces (APIs) of WordNet are helpful for simplifying this step. JWordnet interface [23] is chosen for the implementation of our synonyms retrieval.
First, our target is the adjective classification in WordNet because the contents of 1
n p
S + are full of adjectives and it is the most appropriate category to indicate the tendency or
semantics of a review author. Next, the JWordnet API will help us extract all synonyms of 1
n p
S + from WordNet word base and add these words into S1p+n to generateSp2+n. Of course,
duplicate words will be ignored. The pseudo codes are listed as Figure 4.4:
We construct six word set expansion levels for later word matching (i.e. Set
k
from 1to 6). We plan to compare the PMI result of the six level word sets to decide which level is appropriate for our experiment. The expansion results are listed in Table 4.3.
Set S = S1p+n;
Synset [] Wordset = new Synset; for (S.next) {
//Feed each word in S1p+n into the loop
String word = dictionary.lookupIndexWord(ADJ, S.i);
/*look up the adjective synonyms of each input word from dictionary*/
if (S.content != word && Wordset.content != word){ Wordset.add(word);
/*if the word is not duplicate, add the synonyms into a temporary array.*/
} }
S.add(Wordset[j]);
//Add synonym array into S1p+n to generate Sp2+n.
34
Table 4.3 Word set expansion results
k
value 1 2 3 4 5 6Number of words in Skp+n 14 142 578 1241 2148 3223
It is obvious that the growing of synonyms becomes smooth gradually. The main
reason is the number of duplicate words also grows larger as the
k
value increasing. Whilek
becomes larger, most synonyms are erased because they already exist in Skp+n.4.3
Word Matching
Word set expanding level (or
k
value) is the key control factor in this process. In this experiment, 920,137 words of the 715 reviews are processed. All reviews will have sixdifferent matching results, but they will be compared under the same
k
value only to maintain the accuracy of experiment. The executing procedures are listed in the following:(1) Keep original word set.
(2) Execute key words matching to all words in the word set with all reviews in our data source.
(3) Recording matching counts and calculated the PMI strength score according to the model in section 3.1.2.
(4) The review score of each reviewer will be averaged and recorded in a data set.
(5) Increase
k
value and repeat step(2)-(4) again to acquire scores of different levels. (6) The best score set under specifick
value will pick up for upcoming process.It is noticeable that the scoring mechanism transferred the ranking angle from “articles” to “reviewers” in step (4). This processing is necessary for our experimenting purpose because an influencing ranking list of reviewers is expected in the end.
35
4.4
RFM Score
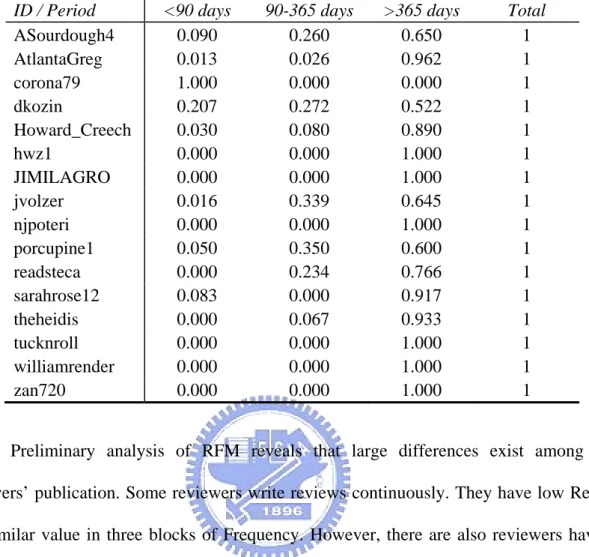
Time attribute of each review is needed for the calculation of Recency and Frequency value. It is convenient that the two indicators are both based on the reviewer’s viewpoint originally. The standardized Recency and Frequency value are displayed in Table 4.4 and Table 4.5.
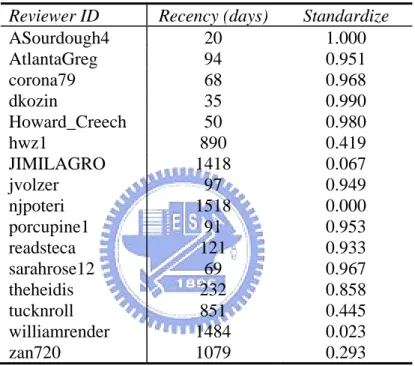
Table 4.4 Recency value of testing reviewers
Reviewer ID Recency (days) Standardize
ASourdough4 20 1.000 AtlantaGreg 94 0.951 corona79 68 0.968 dkozin 35 0.990 Howard_Creech 50 0.980 hwz1 890 0.419 JIMILAGRO 1418 0.067 jvolzer 97 0.949 njpoteri 1518 0.000 porcupine1 91 0.953 readsteca 121 0.933 sarahrose12 69 0.967 theheidis 232 0.858 tucknroll 851 0.445 williamrender 1484 0.023 zan720 1079 0.293
36
Table 4.5 Frequency value of testing reviewers
ID / Period <90 days 90-365 days >365 days Total
ASourdough4 0.090 0.260 0.650 1 AtlantaGreg 0.013 0.026 0.962 1 corona79 1.000 0.000 0.000 1 dkozin 0.207 0.272 0.522 1 Howard_Creech 0.030 0.080 0.890 1 hwz1 0.000 0.000 1.000 1 JIMILAGRO 0.000 0.000 1.000 1 jvolzer 0.016 0.339 0.645 1 njpoteri 0.000 0.000 1.000 1 porcupine1 0.050 0.350 0.600 1 readsteca 0.000 0.234 0.766 1 sarahrose12 0.083 0.000 0.917 1 theheidis 0.000 0.067 0.933 1 tucknroll 0.000 0.000 1.000 1 williamrender 0.000 0.000 1.000 1 zan720 0.000 0.000 1.000 1
Preliminary analysis of RFM reveals that large differences exist among these reviewers’ publication. Some reviewers write reviews continuously. They have low Recency and similar value in three blocks of Frequency. However, there are also reviewers have not been writing for a long time and all publications are centralized in number of years ago. We think these characteristics would be helpful for identifying influential nodes in later processing because there are fewer vague scenarios in their behaviors
4.5
Trust Score
We have found that Epinions.com has equipped with a complete trust scoring mechanism for their users. Users can create their friend and black list to show whether they trust someone or not. In addition, this information is opened for everyone to query. By checking users’ profile, we can know specifically whom the user trusts and who trusts this user. These data are helpful for our trust score computation.
37
Our purpose is to discover how large the influential range of each reviewer is, and this is a fair indicator to determine his / her influence. In other words, we want to know these reviewers are trusted by how many people. The whole Social Connection Number (SCN) of a reviewer can be constructed be recursive tracing. The pseudo codes for recursive SCN computation is showed in Figure 4.5:
After retrieving each node’s social relationships of friends of friends, we found the growing of social networks is really amazing. In this experiment, we set the decay rate
0.8
δ = . While k =1, SCN just indicates each node’s number of friends, and there are only
about two thousand relationships among the nodes. However, while k =2, the number of relationships grows to about 40 thousand. Even nodes have lower SCN in level 1 exceed higher ones in level 2. We use k =2 as the SCN expanding level to acquire the trust ranking of testing reviewers because we focus on the relative rankings of these reviewers. As Table
int k; //The tracing depth
long rec(long Nk){ //The target node is trusted by N people in level k if (k<2 || Nk==0){
return dup(Nk);
/*If no one trusts the node or the relationship ends in level 1, return the number of people trust the target node in level 1. Redundant connections are ignored by dup().
*/ }
else{
return δk−1*dup(Nk)+ rec(Nk−1);
//Return cumulative SCN and erase redundant connections. }
}