A World-Wide Web Server
on
a
Multicomputer System *
Chun-Hsing Wu, Chun-Chao Yeh, and Jie-Yong Juang
Dept.
of Computer Science and Information Engineering
National Taiwan University
Taipei, Taiwan, 10617
Fax:
8 8 6- 2-
3
6
28 16
7
Email: [email protected]
Abstract
A s the number of people browsing the world-wide web increases explosively, workload of popular web servers also increases rapidly. A multicomputer sys-
tem, that was designed f o r 1/0 intensisve applications has been found to be quite suitable for serving as a web server. T h e s y s t e m i s composed of multiple clusters of
multiprocessors interconnected by a n interconnection network. T h e interconnection network is a n ATM- like cell-based switching network which can be restructured
so that the s y s t e m can be scaled u p to meet the i n - creasing demands of web service. It is also found that the multicomputer s y s t e m can support video streams eflectiuely. Design of the s y s t e m as well as porting of web servers o n to it will be discussed in this paper.
1
Introduction
Since the initial World-Wide Web prototype was developed in 1990, it grows rapidly and becomes the most popular system on the Internet in recent years [2]. According to the Internet Domain Survey con- ducted in January 1996, about 76,000 s y s t e m now
have the registered domain name www. up from only
600 in July, 1994 [9]. Due to the increasing demands
of web requests, it becomes a critical issue for a web
server of a popular site to offer high performance and guarantee high availability. A web server must be able to serve multiple simultaneous requests promptly even in its peak time. Besides, from the informa- tion providers’ point of view, the provided information
of each server will accumulate as the time passes by.
Therefore, it is desirable for a web server to be scal-
able and t o support better information searching ca- pability. In the near future, supporting video streams
will also become a basic requirement for a web server.
Accordingly, highly-available, scalable machine with
strong 1/0 capability will be necessary to run a web
server.
To address these issues, we are developing a world- wide web server on top of a multicomputer machine designed and implemented in our laboratory. The ma-
chine uses a multistage switching network to connect
multiple clusters of multiprocessors. Each processor *This work was partially supported by t h e National Science Council under grants NSC84-2221-E-002-004, and NSC85-2221- E-002-029.
can either be a simple CPU module, or with individ-
ual storage devices and/or network adapters attached
depending on the needs of applications. As a result,
multiple 1/0 devices can be accessed concurrently to
provide higher
110
bandwidth than single-bus ma-chines. An ATM-like cell-based interconnection net- work is designed to support more predictable and more efficient inter-processor communication. In addition, its restructurable architecture also makes the machine scalable. The web server on the machine will identify different kinds of requests and assign them to the pro- cessors optimized to handle the type of requests. The
web server can also work well as a proxy web server.
Furthermore, with our multicomputer, a simple repli-
cation strategy can be applied with little overhead to achieve high availability.
In the following sections, we will describe the char- acteristics of existing W W W systems and the avail- ability issues first. Some related works are also dis- cussed. Then, we present our multicomputer platform
in Section 3. In Section 4, a general software struc-
ture of a web server proposed for multicomputers like ours is depicted. An implementation of the server is
discussed in Section 5. Section 6 draws conclusions.
2
Issues
of
WWW
Servers
In World-Wide Web, user agents use the
application-level stateless Hypertext Transfer Proto-
col (HTTP) [3] to request documents or other kinds
of objects from web servers (or from proxies/gateways
to other Internet servers). In practice, a browser es-
tablishes a T C P connection t o a web server before
requesting a document. After fetching a document,
it disconnects the connection immediately. The web server will feed the browser the document or just redi-
rect it to contact other servers. A document may be
a text file, either in plain format, in HTML, an im-
age, or a motion-picture file. It also may be a virtual
document, actual d a t a of which is generated on-the-
fly. Most servers support Common Gateway Interface (CGI) for virtual documents. Database queries and search requests can be implemented by this mecha- nism. There is also an extension to H T T P called
server-push t o handle dynamic documents consisting
of multiple parts. Server-push allows implementation of simple animation, nevertheless it may occupy a con-
nection for a longer time.
To reduce the network traffic, a browser may con-
tact a local proxy server ( or caching server) for remote
documents. The proxy server fetches remote docu-
ments for the browsers and then keeps a copy in its
local disk. Next time if some request wants the same document, it may directly feed the browser with the
local copy [SI.
According to several trace analysis studies [4, 1, 51,
small documents are accessed more frequently than
large documents. This observation is consisteriit with
the general web page design rule to $eep the front page small. Most documents are read-only or not modified frequently comparing with ordinary files. For those virtual documents generated by database access, they usually invoke search queries which niay involvle large volume of read-only files. In summary, small files are accessed in most simple connections, and read-only file access contributes t o most disk activities. The phenomena yields another opportunity for optimizing
a web server.
In a web server, disk write access is performed mainly in log operation, and in caching remote doc-
uments in local disks in case of a proxy server.
Disk write in these cases is usually write-once, arid the cached remote documents are always discardable. These features make the traditional weak consistency
model of network file systems suitable for a web server
and alleviate the consistency overhead in replicating
files. Besides these, the link inform.ation in a hyper-
text document may give a hint t1ia.t indicates which
files will be requested soon. The link: information rnay
be used to design a more effective b’uffer replacement
algorithm than that in a general file system.
Many browsers are multi-threaded. They are able to simultaneously send multiple requests for in-lined
images within a HTML document. It can increase
the concurrency of a web server, but it also reduces
the nuniber of users that a web server can serve dur-
ing peak time. Besides, a request .may occupy T C P
connection for a long period of time if it’s request-
ing for a large file or is connected from a low-speed
network. For a proxy server, it will need more connec-
tion capability t o serve local proxy clients and fetch remote documents while no cached file is available.
However, there is limitation on the available connec-
tions of a server due to the shortage of operating sys- tem resources such as limited T C P ports, mbuf, pro- cess table, etc. Fine-tuning the system will solve the problem, but will not solve it definitely.
Existing rsedirection mechanism in H T T P p-rotocol can be adopted to improve the availability and scala-
bility [3]. Requests received by a central web nrachine
can be redirected to a pool of web machines. This
approach alleviates the workload of the central web machine, but it incurs network and. connectiori over- head in redirection. In addition, t h e central web ma- chine may still be the hot-spot of the machine groups. Furthermore, the same document returned by two dif- ferent machines in the groups will be considered by
clients or proxy servers as two different copies. It
makes the global caching scheme ineffective.
In the design of NCSA’s scalable web server [6], a
Round-Robin DNS approach is designed for distribut-
ing requests among a cluster of web servers, which
share the same alias host name. The authoritative DNS server in the cluster acts as avirtual router to dis- tribute requests by rotating through the web servers that are alternately mapped to the shared alias name. This design eliminates the single point of failure, and it can dynamically increases the capacity of the vir- tual server. However, result of the name resolving
will be cached in
a
client’s local name server for aperiod of time. Any further resolving request to the same local name server, even from different clients, will reuse it before the mapping is expired. This may make the load distribution among the server cluster uneven. One method proposed to alleviate this effect is to shorten the time-to-live value for each resolv- ing result, and then the name servers of clients will query again soon, but the DNS queries will increase the global traffic.
In the design of our proposed web server, it dis- tributes the requests transparently and more evenly
among several clusters of multiprocessors. It also can
tolerate single point of failures. Before describing the design of the web server, we present the multicomputer architecture first.
3 The
NTU
Cost-effective Multicom-
puter Clusters
In this section we present a cost-effective rnulticom-
puter architecture, called SIGMA (System-Integrated
Growable Multicomputer Architecture)
,
developed a tNational Taiwan University. The goal of the project was to develop a clustered machines to offer better cost-performance ratio than conventional supercom- puters. In stead of using expensive custom design ap- proach, the NTU SIGMA machine is developed with off-the-shelf components. It leverages the latest micro- processor technologies, and integrate computing com-
ponents together with a proprietary interconnection
network.
3.1
Architecture overview
Figure 1 shows an example of SIGMA multicom-
puter architecture with 64-node connection. The sys- tem consists of two major entities: computing nodes and network subsystem. The computing node can be
as simple as a CPU module, or can be a complete com-
puter with proper 1/0 capabilities. The network sub-
system is a multistage interconnection network(M1N).
For instance, in Figure 1, the MIN is a three-stage
Clos networ%[7], in which each stage consists of six- teen four-by-four switching elements. Each comput-
ing node contains a SIGMA Network Interface(SN1)
to connect its bus interface to a port of the MIN.
3.2
SIGMA computing nodes
Ehch computing node consists of a CPU module
and some optional 1/0 modules. Connection between
modules is via a standard 1/0 bus, arid thus a vast
array of commodity I/O adapters can be used in the node[lO]. Each node is physically separated from each others. Communication between nodes is achieved by
SIGMA cell-communication networkiSCCN1
SIGMA-nodes
r I
I
6 4 x 6 4 M I NI
Figure 1: The SIGMA multicomputer architecture -
A 64-node example
message passing through the internal network subsys- tern. Messages can also be delivered through conven- tional LANrLocal Area Network) facility if LAN de- vices are plugged into the nodes. The distributed na- ture of the architecture allows the system to survive device failures. All nodes are not necessary to be the same. Heterogeneous nodes can be in the system. Al- though most of system devices are separated located, system resources can be shared effectively through the
communication facilities, the MIN or the plugged-in
LANs.
3.3
SIGMA cell communication network
T h e network subsystem, SIGMA Cell Communi-
cation Network(SCCN), consists of two major parts:
SIGMA network interface(SNI), and a cell switching
network. A message is chopped into small fixed-sized d a t a entities(cells), before it goes into the switching network, and the cells are reassembled a t the desti-
nation nodes. The SNI take charges of 1. network
protocol conversion (data partition/reassembling), 2.
d a t a buffering, 3. cell header checking/generating, 4.
network link serialization/de-serialization, 5 . cell re-
transmission and link level flow control. In case of transmitting, packets are irijected into SNI through the bus interface. Then, they are converted into cells and stored in cell trarisrriitting buffer. As soon as cells
go into the buffer, they will be fetched out and serial-
ized for sending through the network immediately, cell
by cell, whenever the requested channels are available. Upon receiving, similar operation steps in reverse di- rection will be performed on the cells. To overlay computing (protocol processing) and communication
(cell sending/receiving), we use dual port RAM as cell
buffer in the SNI. Also, we allow transmitting buffer and receiving buffer be rrianipulated concurrently. In
addition, SCCN is a self-routing network based on
(external) . : . :
.
. /
.
. : . :.
. j.
((;;hi
7
1
,,i.”’
9
j S I G - n o d e s : .______._._..______..______ i/netowk SIGMA c e l l ( S C C N ) communication
: S C C N - L ~ ,
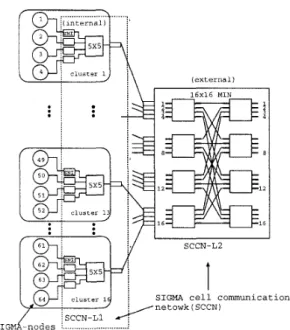
Figure 2: A configuration of SIGMA multicomputer
system with 64 nodes
the destination information carried in the cell header. Cells in the network can therefore be routed individ- ually.
3.4
Cluster-based multicomputer system
The SIGMA multicomputer system is designed not only for parallel computing, but also for interactive
computing. Therefore, each node occupies larger
spaces than that in MPP(Massive1y Parallel Proces- sor) systems. It is hard t o put too many nodes all
together in a P C B board. One common solution is to
partition nodes into several clusters. In SIGMA multi- computer system, each cluster consists of several pro-
cessor nodes and a on-board interconnection network
with an architecture similar to t h a t shown in Figure 1
but with fewer stages. Figure 2 shows an example of
partitioning a system of sixty-four nodes network into
sixteen clusters, with four nodes in each cluster.
3.5
Features of SIGMA multicomputer
Some features of the SIGMA multicomputer make
SIGMA machine feasible to run a web server, although
it can be applied t o other applications as well. First,
the system is expansible (scalable). To meet huge sys-
tem resource demands of large scale web servers, size
of a SIGMA machine is allowed to be incrementally
increased. Upgrading of SIGMA system can be made
on module-by-module basis. For instance, one can
simply insert one CPU module t o enhance comput-
ing power, instead of adding a whole computer(1ike
PC/Workstation) to the system as it is needed in the case of PC/workstation clusters with conven- tional LAN interconnection. Besides, customized in-
terconnection network of the SIGMA machine pro- vides higher bandwidth and better system resource
sharing. Second, the system allows concurrent 1/0
operations. Different from scientific computing, Web service is more I/O-oriented, especially in disk 1/O and
networking. The SIGMA machine is a share-nothing
architecture. Each node of it would be attached to
disk modules and network modules. Consequently, it provides not only large aggregated computing power
and system memory, but also large bandwidth of disk
and network I/O. In addition, design of the SIGMA interconnection network also providles efficient com- munications to facilitate concurrent I/O.
3.5.1 hardware flow control
Flow-control supported at the hardware level con-
tribute to the fast message-passing communication
in SIGMA. It prevents data loss due to receiving
buffer overflow (in hubs or in destination nodes). For
a connection-oriented communication, any d a t a loss
would require re-transmission of the packet. This would waste bandwidth and cause significant commu- nication delay. Although higher level flow-control pro- tocols such as T C P / I P window-based flow-control can also alleviate the problems, it incurs larger overhead, and moreover it "avoids" the d a t a loss problem, but not guarantees t o "prevent" the problem from hap- pening.
3.5.2 cell-swit ching communication
Another important feature is the cell-switching. Cell
size in SIGMA is fixed at 64 bytes lasng. Four blytes of
the cell is designated as cell header:, two of them are hardware hea.der, and the other two are cell adaption
layer header. Sixty bytes of d a t a pa,yload can carry a
complete ATM cell (53 bytes) or a minimum length of
IP packet over Ethernet(6O bytes) which covers large
portion of small control packets(e.g., ICMP, ARP,
RARP packets) used in T C P / I P protocols. Sixty- byte packet fits one SIGMA cell without any waste,
while it woulld need two ATM cells to carry such a
packet. Also', we support multicasting in the hard- ware. Current version of SIGMA cell-switching net-
work can achieve multicasting within a cluster (four
nodes), and broadcasting(t0 all nodles) in the system. To respond to a urgent packet quickly, an emergency bit in the cell header can be set and will be identi- fied by the hardware for immediate :processing. Other
benefits from cell switching versus packet switching
are summariaed as follows:
0 simple architecture: Comparing with variable
length(packet-based) architecture, cell-based ar- chitecture is simpler. Simplicity of the architec- ture results in better performance. It not only simplifies control logics but also eases the man- agement of random access buffers.
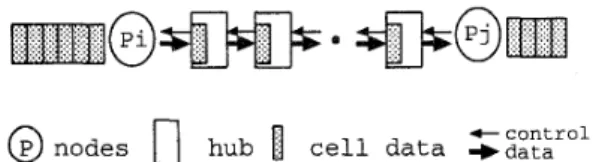
0 latency improvement: Small packet can interleave
with large packets. As an example shown in Fig-
ure 4, small packets like p 2 and p 5 can be sent out
+control
E)
nodes0
hub[
cell data +dataFigure 3: Worm-hole effects of transmitting a packet
across multiple switching hubs
quickly by interleaving with other large packets. These packets may be blocked by the large pack- ets in case of packet-switched communication. in case of pack. Furthermore, transmission of large packets can benefit from worm-hole effects of the network as shown in Figure 3.
0 more predictable transmitting time: Characteris-
tics of cell-interleaving(Figure 4) in SIGMA net-
work subsystem make it more like a TDMA (Time
Division Multiple Access) network where network
bandwidth is divided into a set of time slots. Con-
sequently, the time t o transmit a S-byte packet
can be limited to N * S / B , where N is the number
of nodes, and B is network bandwidth. Bounded
transmitting time is important for real-time ap- plications such as providing real-time video/audio streams in Web servers.
3.5.3 Cell pre-sink
To reduce communication latency, a cell pre-sink scheme was applied, which asks all nodes in a clus- ter receive(sink) all cells transmitted to t h e cluster in advance before the cells are determined which nodes they should go to exactly by the routing logics. Once the routing tags of the cells are resolved, all nodes in the clusters will be notified if they are the right desti-
nations. If yes, it continues to receive the rest of the
data, segments of the cells; if not, it just flushes the pre-sink data of the cells and gets ready for next cells.
As a result, data can be sent at a full speed without
any delay due to routing tag processing.
4 Software Configuration
of the Web
Server
onSIGMA
Since the SIGMA multicomputer is flexible in 1/0
device arrangement, it allows a large variety of soft-
ware configurations for a web server. We propose a
configuration based on the world-wide web's run-time
behavior to take advantages of SIGMA architecture.
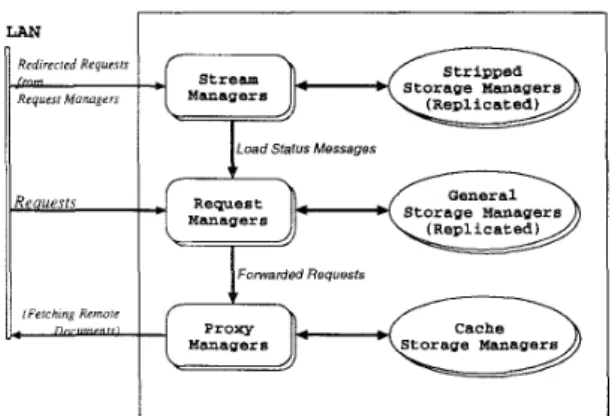
The proposed software configuration of our web
server is shown in Fig. 5 . It is composed of several
manager groups, each of which consists of several com- puting nodes. Number of nodes in each group depends on the workload of the web server and can be scaled up
or down when it is necessary. Note that a computing
node may run more than one kind of mangers at the
9 9
P I P 2 P3 P 4 P5
an example of packets transmission (five nodes, each with a packet o f s i z e pi1
T D ~ T D Z TD3 TD4 TD5
o
- t i m e
case (a) : packet-switching
TD 2 TD5 TD3 TD4 TD1
0
- 2 8 12 time
case (b) : cell-switching
Tpi: completion time f o r packet i
Figure 4: Cell interleaving
via the SIGMA SCCN switching network. However.
request managers, stream managers and proxy man-
agers, may also have connection to external LANs.
Caching can be done more effectively with this archi-
tecture since each computing node is assigned with a
specific task (or tasks) and it is easier to design ef-
fective caching schemes based on locality properties of individual tasks.
4.1 Load sharing among request man-
While
a
request arrives a t the server, it is receivedby a request manager. Instead of using a single request
manager, multiple request managers are asked to re-
ceive requests simultaneously. A distributed decision
method is used to distribute workload evenly among
them. In our design, all request managers share the
s a n e IF’ address. When a request packet arrives a t a
computing node where a request manager is running, the low-level network module will peek off its source
IP address, a n d then apply a distributed decision al-
gorithm to determine whether to receive the packet or
not. It will be accepted directly by one of them and re- jected by others. The distributed decision algorithm is
implemented in the driver. So when an HTTP request
is forwarded up to the high-level request manager, it’s
destined. Only one request manager will receive the request, others will not even see the request. This method reduces the overhead of the computing nodes.
Note that, in the connection with broadcast networks
agers
LAN
I
I
ILoad Sfafus MassagesI/
# Storage Managers Reouesrs Request Managers I I JFomarded RequestsFigure 5 : Software configuration of a world-wide web
server on SIGMA multicomputer
such as Ethernet, the computing nodes sharing the same I P will also share the same physical network ad- dress.
4.2 Load redistribution
Three load redistribution strategies are used in our design to improve the web server performance. The first one is for the request manager to directly serve the request locally, the second is to redirect the re- quest to another one, and the last is asking another computing node for help. These three strategies are
applied to three different kinds of requests of differ-
ent natures. Requests for small documents are bet-
ter be served directly because the documents are of-
ten cached in the request manager’s memory buffers. Requests for large files such as video streams usually take longer time t,o process, and processing of some re-
quests will need to generate a virtual document such
as database query results. Request managers will redi- rect the client sending these kinds of requests to some stream manager for help. This approach will alleviate the workload of request managers and improve the
availability. The third strategy is good for proxy re-
quests. Most current browsers are not able to redi-
rect proxy requests. Moreover, it’s difficult to trans-
parently create another TCP connection between the
client and another node to replace the existing C Q ~ - nection (between the client and the request manager).
Thus, a request manager must handle all proxy re-
quests (requests to remote sites) by itself. This is fine if the requested documents are cached. If not, the re-
quest manager will create a n e x t r a TCP connection to the remote server t o fetch the document. Usually, these two connections may stay for a long time. T C P
connections are valuable resources in a web server, and
should be used more effectively. To solve this prob-
lem, a request manager will route the request to a
proxy manager if a local copy is not available. If, for-
tunately, the requested remote document is cached in the proxy manager, it will directly return the docu- ment to the request manager. Otherwise, it is the
proxy manager’s duty to fetch the remote document.
The remote IP address is used as the hash key so that
all proxy requests to the same remote site are handled by the same proxy manager. Furthermore, the proxy
manager can prefetch or clean the cached documents
from the hyperlink information of the documents for
optimization. By carefully applying these three strate- gies, the machine’s performance and availability could be enhanced optimistically.
4.3
Video stream service
If all requests l o the same video are served by
the same stream manager, it will haxe better locality.
However, this may cause a problem. when a popu-
lar video program solicits a large number of requests
in the same ]period. The load will not be distributed
evenly among the stream manager groups. So, the
hashing algorithm in a request manager will first redi-
rect all requests for the same videlo program t o the same stream manager, and each stream manager will periodically broadcast its loading status to the request
managers. Once the number of requests to a stream
manager is larger than a threshold, request managers
will then take the source IP address into considera-
tion to choose a second stream manager. In addi-
tion to supporting load distribution, a status message
can also act as a probe message t o check whether a
request manager or a stream manager is still alive.
Status broadcasting can be implemented by the low- level multicast mechanism of the !3IGMA switching network.
In SIGMA, accessing remote memories is faster than accessing local disks. To improve the perfor-
mance of video stream service, a large file is parti-
tioned into pieces and stored in a set of stripped stor-
age managers. While a video file is requested, all of the stripped storage managers will access their local disks concurrently and then return the video program to
the agent via a single stream manager. Each stripped
storage manager simply keeps pieces of the file and
they can access disks concurrently. So the total time
to request a whole video file can be reduced.
4.4
Storage managers
There are three kinds of storage managers in the system, namely cache storage managers, general stor- age managers, and stripped storage managers. They work together with proxy managers, request man- agers, and stream managers respectively, and main- tain remote documents, local files, and video files cor-
respondingly.
A
SIGMA computing node running oneof these managers should have locall disks attached. Except for cached remote documents, local docu-
ments and video files are replicated so that serving
requests can continue even when disk failures occur. Some of the reasons not t o replicate remote documents are:
1. Remote documents can be fetched again later after the cache storage manager recovers from crashes.
2. Leaving more disk spaces for caching other remote
documents results in better cache hit rate.
Figure 6: An implementation of the proposed world- wide web server on an eight-node SIGMA multicom- puter
3. Replicating files dynamically incurs some over-
At present, replicating local files and video files is done
by ii simple file duplication scheme since web files are
rarely modified by requests and inconsistency during the period of file transfer can be tolerated.
5 Implementation
I n this section we present an implementation of the proposed world-wide web server on an eight- node SIGMA multicomputer. The server is composed
of t,wo mirrored clusters as shown in Fig. 6. Re-
quest managers, proxy managers and stream managers run in association with corresponding general storage managers, cache storage managers, and stripped stor- age managers. There are two stripped storage man- agers in each cluster so t h a t a large file can be seg- mented into two stripes. Local files are replicated in different clusters. Currently we are porting the reference library and the H T T P server released by the World-Wide Web Consortium onto our eight-node SIGMA prototype. Each node runs FreeBSD Unix. All nodes are also connected to an Ethernet LAN ex- cept for the ones dedicated to stripped storage man- agers.
Since the nodes running Request Manager A and
Request Manager B have the same IP address and
physical Ethernet address, all incoming packets des-
tined to the shared IP address will reach both Ether-
net drivers. The drivers have been hacked to support distributed decision method. In the current imple- mentation, they only accept the packets with the least
significant bits of the IP address match their unique
node ID. The number of bits t o be checked depends on the number of request managers in the system. In this way, all incoming requests are dispatched to Request
Manager A and Request Manager B intrinsically.
A
request is routed to one of three manager groups,and there are two managers in each group that can ac- cept and serve requests concurrently. A video request, on the other hand, will be served by two stripped storage managers concurrently. This arrangement can achieve high degree of load sharing and improve the system availability.
In addition to serving requests concurrently and accessing disks in parallel, request managers are de- signed to utilize time locality. Small general docu- ments are requested more frequently, and they tend to be cached in the memories of request managers. Large files or video streanis won’t be cached by request man-
agers; they are redirected to stream managers. Stream
managers with replicated stripped storage managers are designed to explore space locality. Large disk block, sequential block placement and prefetching disk blocks for read are implemented in the file system of stripped storage managers.
The system can be scaled up in different ways to adopt the change of request distribution. If the total number of requests increases, more computing nodes
can be added to run as request managers. If proxy
service becomes heavy, we should add more comput- ing nodes to run proxy managers and cache storage
managers. If demands for video stream service in-
crease, more computing nodes for stream managers
arid stripped storage managers are required. On the
other hand, the system can also be scaled down grace-
fully when a manager or a cluster of‘ nodes fails to
work. The system will be able to continue to work with degraded performance.
6
Summary and
Conclusions
In this paper we demonstrate that Internet com-
puting is a suitable application of a multicomputer
system. T h e proposed web server is composed of sev-
eral groups of different managers. Each manager is ar-
ranged to run on one node of the multiprocessor clus-
ters. Using a distributed decision method and hash-
ing algorithms for dispatching request and redistribut- ing workload, computing nodes can share workload, concurrently handle requests, tolerate single point of
failure, and act as a virtual server transparently to
clients. By optimizing the processing of the three kinds of requests independently, performance of the web server can also be improved significantly, even for video streams and caching remote documents. Thus,
we believe that a scalable multicomputer like ours is
suitable for serving as a web server.
References
[l] M. Abrams, C. R. Standridge, G. Abdulla, S.
Williams, and E. A. Fox, “Caching Proxies:
Limitations and Potentials,” Fourth International World Wide Web Conference, 1995.
T. Berners-Lee, R. Cailliau, J. Groff’, and B. Poller-
mann, “World-Wide Web: The Information Uni-
verse,” Electronic Networking: Research, Applica-
tions, and Policy, Vol. 1, No.2, 1992.
T. Berners-Lee, R. Fielding, and H. Frystyk, ”Hy-
pertext Transfer Protocol - HTTP/l.O,” Internet
Draft, Nov. 1995.
H. Braun, and K. Claffy, “Web Traffic characteri- zation: an assessment of the impact of caching doc-
uments from NCSA’s web server,’: Second World
Wide Web Conference, Oct. 1994.
R.J. Clark, and M.H. Ammar, “Providing Scalable
Web Service Using Multicast Delivery,” Second I n -
ternational Workshop on Services i n Distributed
and Networked Environments, 1995.
E.D. Katz, M. Butler, and R. McGrath, ”A Scal-
able H T T P Server: The NCSA Prototype,” Com-
puter Networks and I S D N Systems, Vol. 27, No. 2, 1994.
Y. J. Lin, J . M. Ho, C. C. Yeh, and J. Y. Juang,
“Design of a Switching Module for Large-scale
ATM Switch,” International Conference o n Paral-
lel and Distributed Systems, Taiwan, pp. 399-408, 1993.
A. Luotonen, and Kevin Altis, “World-Wide Web
Proxies,” First International World Wide Web
Conference, 1994.
Network Wizards, “Internet Domain Survey,”
UR L:http://www. nw. com/zone/ W W W / t o p . html, January 1996.
[lo] C. C. Yeh, J. T. Lin, W. C. Kao, C. H. Wu,
and J. Y. Juang, ” A Multicomputer Server for
I/O-Intensive Applications,” 12th I A S T E D Inter-
national Conference on Applied Informatics, Aus- tria, 1995.