行政院國家科學委員會專題研究計畫 期中進度報告
子計畫一:可重置式低功率處理器核心之指令集定義與對應
工具研發(1/3)
計畫類別: 整合型計畫 計畫編號: NSC93-2213-E-110-049- 執行期間: 93 年 08 月 01 日至 94 年 07 月 31 日 執行單位: 國立中山大學資訊工程學系(所) 計畫主持人: 鄺獻榮 計畫參與人員: 王俊評、江忠霖、莊淵智、羅美薇 報告類型: 精簡報告 報告附件: 出席國際會議研究心得報告及發表論文 處理方式: 本計畫可公開查詢中 華 民 國 94 年 5 月 24 日
用於嵌入式多媒體並行處理之低功率可重置式處理器矽核之研製
-
子計畫一:
可重置式低功率處理器核心之指令集定義與對應工具研發(1/3)
Instruction Set Definition and Mapping Tool Development for Lower Power ReconfigurableProcessor Cores 計畫編號:NSC 93-2213-E-110-049 執行期間:93 年 8 月 1 日 至 94 年 7 月 31 日 主持人:鄺獻榮 國立中山大學資訊工程學系 一、中文摘要 以平台為基礎的設計流程與方法是目前 有效解決系統單晶片 高度設計複雜度的 方案 之一。本子計畫要在三年內發展可重置式平行 處理核心中使用的低功率可重置式處理器之 指令集架構與應用介面,以及對應工具與編譯 器,並協助低功率可重置式處理器的設計與製 作。本年度(第一年)著重於可重置式處理器 指令集架構與應用介面之研究與制定,以及適 用於此可重置式低功率處理器核心之對應工 具規劃與初步實現。 英文摘要
Platform-based design is an efficient method to conquer the design complexity of system-on-chip (SoC). The subproject will research and develop the instruction set architecture, the application interface, the mapping tool and compiler for the low power reconfigurable processor core, and assist to design and implement the hardware architecture of the low power reconfigurable processor core within three years. In the first year, this subproject focused on developing the instruction set architecture and application interface of the reconfigurable processor core. In addition, a mapping tool, which is feasible to be used in the
reconfigurable parallel processing platform, has also developed and implemented.
二、研究目的 各式 SoC 產品在功能與效能方面經常有 許多不同的要求,為了顧及適應性,系統單晶 片平台經常需要包含可重置式單元,藉由可重 置式單元的可重新組態之特性,達到廣泛的可 應用性,也藉由可重置式單元的潛在運算平行 度之利用,達到所需要的系統效能 [1~4]。此 外,為了達到高運算量,系統單晶片平台經常 需要具備平行處理的能力,我們將這種兼具可 重置性與平行處理能力的系統單晶片平台稱 為 可 重 置 式 平 行 處 理 平 台 (reconfigurable parallel processing platform)。
近年來有許多可重置式設計平台發展計 畫,可重置式處理器方面的研究更是不勝枚 舉,而這類計畫經常需要搭配編譯器或是對應 工具的發展計畫,例如[1 , 2]以及[5]的論文中 不但強調可重置式計算架構或平台,同時也突 顯編譯器與對應工具支援的重要性,其中[1] 討論可重置式架構平台上嵌入式控制應用的 軟硬體分割(hardware/software partitioning)與 執行碼的產生(code generation),[5]則是研究 可變指令集架構與它的編譯器支援。也有一些 論文單獨強調對應工具與編譯器的方法與技 術,例如[6]指出嵌入式系統編譯技術的新方
向,[7]介紹多媒體應用的嵌入式編譯。其他也 有諸多論文討論在進行應用程式的對應與編 譯時,如何將功率消耗納入考量,以編譯出消 耗能量較低的執行碼。由以上的諸多文獻中可 以看出可重置式架構或處理器,以及相對的對 應工具與編譯器在 SoC 設計中的重要性。 事實上,不論那一類型的可重置式處理器 架構,它們都需要對應工具或是編譯器的協助 才得以形成完整的系統,因為可重置式處理器 與可重置式通訊介面必須使用對應工具以進 行應用程式的分析與評估之後,才能產生相對 的資料作為重置的依據。再者,透過對應工具 將應用程式對應到可重置式平行處理核心上 的各個可重置式處理器上,應用程式將得以在 平行處理核心 上進行時間與空間多工運作的 平行處理。 而對應工具的設計與效能也將重大地影 響可重置式處理器的效能表現、硬體成本、以 及功率消耗。對應工具的設計必須與處理器架 構與重置方式以及通訊元件架構與重置方式 密切配合,同時在進行對應時必須同時考慮到 效能與功率消耗的問題,如此才能與處理器相 輔相成,獲得最佳的整體表現。而可重置式低 功率處理器對應工具與編譯器的設計正是本 子計畫(子計畫一)所要研發的重點。 三、研究方法 對應工具與編譯器必須完全瞭解並掌握 可重置式處理器與可重置式通訊介面的硬體 架構與特性,如此才能產生低功率可執行程式 以及最佳的重置資料。可重置式低功率處理器 與可重置式通訊介面硬體架構主要由子計畫 二、三共同完成之。故本子計畫(子計畫一) 今年度即參與可重置式處理器指令集架構與 硬體架構的制定,以期能夠發展出適當的對應 工具及編譯器,與可重置式處理器相輔相成, 獲取最佳的效能。本計畫可重置式處理器指令 集架構與應用介面主要參考 ARM 處理器的指 令集架構與應用介面制定之。可重置式處理器 指令集架構與處理器硬體架構請參見子計畫 二,通訊介面硬體架構請參見子計畫三。 本子計畫第一年主要發展一套通用型的 對應工具。此對應工具依據系統規格與要求將 高階語言撰寫的應用程式切割並對應到 可重 置式低功率平行處理核心上的各個可重置式 處理器或是特殊用途硬體元件上,其中主要的 對應工作包含軟硬體分割以及排程。在進行軟 硬體分割以及排程時必須考慮通訊架構以及 通訊時間,否則所得到的最佳化合成結果將與 實際的情形產生極大差距,甚至造成整個系統 不 能 正 確 運 作 或 是 無 法 滿 足 系 統 規 格 及 需 求。此外,可重置式低功率平行處理核心經常 用於實現多媒體單晶片系統,而多媒體系統常 常具有資料連續輸入的特性,因此必須進行管 線化排程以提昇系統效能。基於以上的考量, 本子計畫發展一套整數線性規劃(ILP)方法, 制定適當的目標函數以及條件不等式,在考慮 通訊時間的情況下,同時處理軟硬體分割與管 線化排程問題,以獲得最佳的軟硬體分割與管 線化排程結果。 我們的軟硬體分割與管線化排程系統的 輸入是多媒體系統規格與限制條件。多媒體系 統規格首先經過 SUIF 編譯系統檢查、分析之 後轉換成 Task Graph。Task Graph 具有兩種節 點,計算節點對應到多媒體系統規格的一個計 算工作(副程式),通訊節點對應到多媒體系 統規格的資料傳輸,記錄需要傳送的資料量以 及傳送者與接收者等資訊。然後根據軟體資料 庫、硬體資料庫以及通訊資料庫進行計算節點 與通訊節點的軟體、硬體以及通訊評估,以決 定計算節點以可重置式處理器實現或是特殊 用途硬體元件實現時所需之執行時間或硬體 面積、成本等資訊,以及通訊節點以匯流排實
現時所需之傳輸時間或成本等資訊。之後根據 系統限制條件及資料相依性進行 Task Graph 的軟硬體對應以及管線化排程,找出適當的軟 硬體分割結果,以決定可重置式處理器、特殊 用途硬體元件以及通訊架構的規格。 假 設 Task Graph G(V, E) 中 包 含 |V| 個 functionality nodes 以 及 |E| 個 communication edges。每個 functionality nodes 以 Fi表示,其 中 1 ≤ i ≤ |V|。每個 communication edge 則以 Cj(Fi1, Fi2)表示, 其中 1 ≤ j ≤ |E|。Fi1與 Fi2分別 為 communication edge Cj 的 source functionality node 以及 destination functionality node。Functionality node Fi可以使用不同類型 的元件(例如處理器或是特殊用途硬體)來執 行其功能。若 functionality node Fi 可以使用 component type Mj 執行其功能,則以 Fi ⊂ Mj 表示之。以下是我們的 ILP model 需要使用到 的符號:
• MLib: the set of all components available to perform the functionality nodes of task graph.
• MLi: the set of components available to perform the functionality node Fi.
• MNj: the number of components available for type Mj.
• MAreaj: the area of a component of type Mj. • FTimei,j: execution time of functionality node
Fi performed by component of type Mj. • CTimej: communication time of
communication edge Cj.
• StageT: the throughput constraint (the delay of a pipeline stage in the design).
• S: the pipeline stage constraint (the maximal pipeline stage available in the design).
以下是我們的 ILP model 用到的決定變數:
• MDj: an integer variable which denotes the number of component of type Mj used.
• PS: the largest pipeline stage number of the final pipelined scheduling.
• s
i
t and e i
t : start time and end time of
functionality node Fi or communication edge
Ci. • s i pt and e i pt : if functionality node Fi or communication edge Ci is scheduled in pipeline stage p (p ≥ 1), s
i
pt and e i
pt denote start time and end time of Fi or Ci in pipeline stage p. That is, s
i pt = s i t − (p−1)×StageT and e i pt = e i t − (p−1)×StageT.
• xi,j,k: a 0−1 integer variable associated with functio nality node Fi ∈ V. xi,j,k = 1 if Fi is performed by the kth instance of component type Mj; otherwise, xi,j,k = 0.
• yj: a 0−1 integer variable associated with communication edge Cj(Fi1, Fi2) ∈ E. yj = 1 if the source and destination functionality nodes Fi1 and Fi2 of Cj executed on the different component instance; otherwise, yj = 0. • zi,p: a 0−1 integer variable associated with
functionality node Fi ∈ V or communication edge Ci∈ E. zi,p = 1 if Fi or Ci is scheduled at pipeline stage p; otherwise, zi,p = 0.
此 ILP model 必 須 滿 足 以 下 的 限 制 (constraints)以獲得最佳的軟硬體分割與管線 化排程結果,這些 constraints 包含 General Constraint 、 Resource Constraint 、 Data Dependency Constraint、Pipelined Schedule 以 及 Sharing,分別說明如下:
General Constraint:
每個 functional node 只能在 target architecture 中的某一個 component instance 上執行其功 能,因此
∑
∑
∈ i ≤ ≤ j ML j M k MN k j, i, x 1 = 1, ∀ Fi ∈ V (1)Resource Constraint: 最後使用的 component type Mj 的實體數目 (instance number)MDj必須小於等於可以使 用的實體數目 MNj,因此 MDj≥
∑
≤ ≤k MNj ⋅ 1 k j, i, x k , ∀ Fi⊂ Mj (2) MDj≤ MNj, Mj∈ MLib (3)Data Dependency Constraint:
對於每一個 G(V, E)中的 communication edge Ci而言,其 source functionality node 的 end time 必須大於等於 Ci的 start time。此外,Ci的 end time 必須大於等於其 destination functionality node 的 end time 以保證不違反資料相依性。 Functionality node Fi與 communication edge Ci 的 start time s i t 與 end time e i t 可以使用以下 的公式計算之 e i t = s i t +
∑
∑
∈ i ≤ ≤ ⋅ j ML j M k MN k j, i, j i, x , FTime 1 ∀ Fi ∈ V (4) e i t = s i t + CTimei⋅yi, ∀ Ci ∈ E (5) 因此,以下的限制條件必須被滿足: s i t −tns≥CTimen⋅yn, ∀ F i ∈ V and itsincoming communication edge Cn (6) s n t − s i t ≥
∑
∑
≤ ≤ ∈ i j ⋅ j k MN k j, i, j i, ML M x FTime 1 , ∀Cn∈Eand its source functionality node Fi (7) 令 MLi12 = MLi1 ∩ MLi2,相關於 communication edge Cn(Fi1, Fi2) 的 變 數 yn 使 用 以 下 的 constraints 決定之
yn≥ xi1,j,k−xi2,j,k, ∀Mj∈MLi12 and 1≤k ≤MNj (8)
yn≥ xi2,j,k −xi1,j,k, ∀Mj∈MLi12 and 1≤k ≤MNj (9)
yn≥xi1,j1,k, ∀Mj1∈MLi1, Mj1∉MLi12, 1≤k ≤MNj1 (10)
yn≥ xi2,j2,k, ∀Mj2∈MLi2, Mj2∉MLi12, 1≤k ≤MNj2 (11)
Pipelined Schedule:
對 於 每 一 個 functionality node Fi 或 是 communication edge Ci而言,它們的 start time
s i t 和 end time e i t 必 須 在 相 同 的 pipeline stage,這個限制暗含 Fi的執行時間或是 Ci的 通訊時間必須小於等於 StageT,因此
∑
≤ ≤p S = p i, z 1 1, ∀ Fi ∈ V and Ci ∈ E (12) s i t ≥ z p StageT S p p i, × − ⋅∑
≤ ≤ 1 1 , ∀Fi∈V and Ci∈E (13) e i t ≥ z p StageT S p p i, × − ⋅∑
≤ ≤ 1 1 , ∀Fi∈V and Ci∈E (14) s i t ≤ z p StageT S p p i, × ⋅∑
≤ ≤ 1 , ∀Fi∈V and Ci∈E (15) e i t ≤ z p StageT S p p i, × ⋅∑
≤ ≤ 1 , ∀Fi∈V and Ci∈E (16)而 the largest pipeline stage number PS 必須滿 足以下的限制條件 PS ≥ p ⋅zi,p, ∀ Fi ∈ V and Ci ∈ E (17) Sharing: 假如多個 functionality nodes (例如 Fi1 以及 Fi2) 使 用 相 同 component type j 的 同 一 個 instance k 來執行其功能,則 Fi1的執行時間(亦 即[ s i pt1, e i pt1])必須與 Fi2 的執行時間(亦即 [ptis2, e i pt2])錯開,因此
T×(1−xi1,j,k)+T×(1−xi2,j,k)+T×(1−wi1,i2)+pti2s ≥ pt (18) i1e
T×(1−xi1,j,k)+T×(1−xi2,j,k)+T×wi1,i2+pti1s ≥ pt i2e (19)
T 是一個夠大的自然數(可將 T 設為 StageT), 而 wi1,i2則是一個輔助的 binary variable。當 xi1,j,k =0 或 xi2,j,k =0 時,(18)與(19)式必定成立。當
xi1,j,k = xi2,j,k =1 時,pt is2 ≥ pt (wie1 i1,i2 = 1) 或
是 s 1 i pt ≥ e 2 i pt (wi1,i2 = 0) 兩者之一必定成 立,使得 Fi1 的執行時間與 Fi2 的執行時間錯
開。另一方面,若多個 communication edges
(例如 Ci1以及 Ci2)使用相同的通訊通道,則
Ci1 以及 Ci2 也必須滿足類似於(18)與(19)式的 限制條件。
我們的 ILP model 目標函式(objective function)主要是要極小化以下兩個項目:the total area 以 及 the largest pipelined stage number,此目標函式可以表示為 Minimize j j MLib M MArea MD j ⋅
∑
∈ +PS+C∑
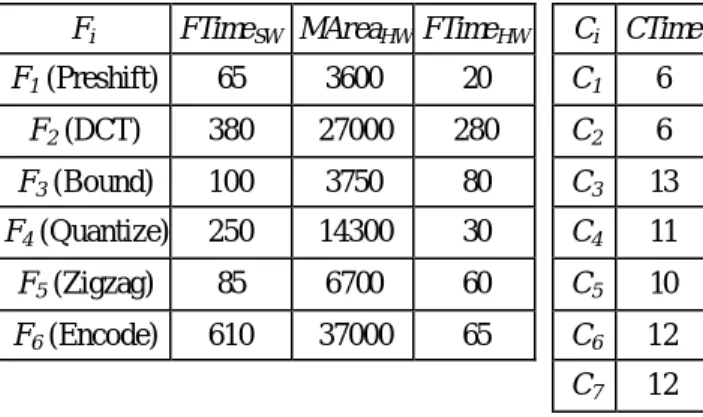
∈E n n y (20) 四、結果與討論 本子計畫已經發展以整數線性規劃方法 為 基 礎 的 軟 硬 體 分 割 與 管 線 化 排 程 對 應 工 具。我們制定適當的目標函數以及條件不等 式,在考慮通訊時間的情況下,同時處理軟硬 體分割與管線化排程問題,以獲得最佳的軟硬 體分割與管線化排程結果,將多媒體系統規格 對應到可重置式低功率平行處理核心上。這個 對應工具已經被用來設計 JPEG encoder 以及 MP3 decoder 等多媒體系統的系統架構。表一 是 JPEG encoder 的 Task Graph 中 的 functionality nodes 與 communication edges 的 評 估 結 果 。 接 著 , 我 們 設 定 不 同 的 系 統 throughput constraints(亦即 StageT),並且假 設最多可以使用 3 個處理器(每個處理器面積 設為 45000)來進行運算,則系統架構設計結 果表二所示。在表二之中,Total Area 表示系 統所需要的全部 component area,Dsw代表系統 所使用的處理器個數,PS 表示 largest pipeline stage,CPU time 則是我們的 ILP model 獲得解 所需要的時間(單位為 second)。當 throughput constraint 設得很大時(2000),所獲得的系統 架構是 non-pipelined(PS = 1)。當 throughput constraint 設得很小時(≤ 700),所獲得的系統 架構是 pipelined 而且沒有使用運算速度較慢 的處理器。我們對 MP3 decoder 進行相同的實驗。MP3 decoder 的 Task Graph 包含 9 個 functionality nodes 以 及 11 communication edges,其設計結果如表三所示。這些實驗結果 顯 示 我 們 的 ILP model 可 以 在 不 同 的 throughput constraints 之下,獲得最少 total compone nt area 的最佳 pipelined 架構。
Table 1. Estimation results of the JPEG example.
Fi FTimeSW MAreaHW FTimeHW Ci CTime
F1 (Preshift) 65 3600 20 C1 6 F2 (DCT) 380 27000 280 C2 6 F3 (Bound) 100 3750 80 C3 13 F4 (Quantize) 250 14300 30 C4 11 F5 (Zigzag) 85 6700 60 C5 10 F6 (Encode) 610 37000 65 C6 12 C7 12
Table 2. Design results of JPEG example.
StageT Total Area DSW PS CPU Time
300 92350 0 3 1 500 92350 0 2 1 800 88700 1 2 14 1000 79350 1 2 10 2000 45000 1 1 1
Table 3. Design results of MP3 example.
StageT Total Area DSW PS CPU Time
2000 267944 1 4 1 6000 236547 1 2 6 8000 205544 1 2 5 10000 205544 1 1 9 20000 197544 1 1 4 未來我們將針對子計畫二所提出的可重 置式處理器以及子計畫三所提出的通訊介面 硬體架構,修改並加強軟體評估、硬體評估、 通訊評估的方法以及效率,以迅速獲得更確實 的評估資訊,作為軟硬體分割與管線化排程工 具進行分割與排程的依據。此外,對應工具在
進行對應與編譯時,除了面積與速度的考量之 外,另一個重要的考量因素是功率消耗。本子 計畫第二年預計發展系統功率評估方法,並制 定適當的限制條件,將功率消耗納入整數線性 規劃目標函數之中。此外,低功率編譯器的實 作也將於第二年開始。 五、參考文獻
[1] M. Baleani, F. Gennari, Yunjian Jiang, Y. Patel,
R.K. Brayton, and A. Sangiovanni-Vincentelli, “HW/SW partitioning and code generation of embedded control applications on a
reconfigurable architecture platform,” 10th
International Symposium on Hardware/Software Codesign, pp. 151-156, 2002.
[2] J. M. P. Cardoso and M. Weinhardt, “Fast and guaranteed C compilation onto the PACT-XPP/spl trade/ reconfigurable computing platform,” 10th
Annual IEEE Symposium on Field-Programmable Custom Computing Machines, pp. 291-292, 2002.
[3] S. Guccione, E. Verkest, and I. Bolsens, “Design technology for networked reconfigurable FPGA platforms,” Design, Automation and Test in
Europe Conference and Exhibition, pp. 994-997,
2002.
[4] J. Becker, and M. Vorbach, “Architecture, memory and interface technology integration of an industrial/academic configurable system-on-chip (CSoC),” IEEE Computer Society
Annual Symposium on VLSI, pp. 107-112, 2003.
[5] J. Liu, F. Chow, T. Kong, and R. Roy, “Variable instruction set architecture and its compiler support,” IEEE Transactions on Computers, Vol. 52, No. 7, pp. 881-895, 2003.
[6] N. Dutt, A. Nicolau, H. Tomiyama, and A. Halambi, “New directions in compiler technology for embedded systems,” Proceedings of the
ASP-DAC, pp.409-414, 2001.
[7] N. Daw, S. Goldstein, and D. Strelow, “Embedded compilation for multimedia applications ,” IEEE
Symposium on Field -Programmable Custom Computing Machines, pp. 315-316, 2000.
[8] Shiann-Rong Kuang, Chin-Yang Chen and Ren-Zheng Liao, “Partitioning and Pipelined Scheduling of Embedded System Using Integer
Linear Programming,” The IEEE/IFIP
International Workshop on Parallel and
Distributed Embedded Systems, July 2005.
[9] Jiun-Ping Wang and Shiann-Rong Kuang, “Design of Parallelized Controllers for High-performance Controller-Datapath System”
The 9th IEEE International Workshop on Cellular Neural Networks and their Applications, May
2005. 六、計畫成果自評 本子計畫第一年已經參與子計畫二的可 重置式處理器指令集架構與硬體架構制定,並 且發展以整數線性規劃方法為基礎的軟硬體 分割與管線化排程對應工具,在考慮通訊時間 的情況下,將多媒體系統規格對應到可重置式 低功率平行處理核心上。本子計畫進度與預定 目標大致相符,目前已有兩篇會議論文發表[8, 9],其中[9]提出的高效能平行化控制器設計方 法,在納入低功率的考量之後,未來可用於設 計可重置式處理器與通訊介面的控制電路。