影像處理與電腦視覺技術應用於複雜文件影像分析、夜間駕駛輔助、以及視訊監控系統之研究
195
0
0
全文
(2) 影像處理與電腦視覺技術應用於複雜文件影像分析、夜間駕駛輔助、 以及視訊監控系統之研究 A Study of Image Processing and Computer Vision Techniques for Complex Document Image Analysis, Nighttime Driver Assistance, and Video Surveillance Systems. 研 究 生:陳彥霖. Student:Yen-Lin Chen. 指導教授:吳炳飛 教授. Advisor:Prof. Bing-Fei Wu. 國 立 交 通 大 學 電機與控制工程學系 博 士 論 文. A Dissertation Submitted to Department of Electrical and Control Engineering College of Electrical Engineering National Chiao Tung University in partial Fulfillment of the Requirements for the Degree of Doctor of Philosophy in. Electrical and Control Engineering December 2006 Hsinchu, Taiwan, Republic of China. 中華民國九十五年十二月.
(3) 影像處理與電腦視覺技術應用於複雜文件影像分析、夜間 駕駛輔助、以及視訊監控系統之研究. 研究生:陳彥霖. 指導教授:吳炳飛 教授. 國立交通大學電機與控制工程學系博士班. 中文摘要 影像處理與電腦視覺技術的發展,近十年來在各種應用領域的期刊文獻上,發表了 許多針對不同目的所開發之系統,用於靜態影像切割、文件分析與辨識、智慧型運輸系 統、視訊監控等許多應用上。本論文將針對這些應用需求,發展一系列以影像處理與電 腦視覺技術為基礎的研究方法與應用系統。本論文主要分為六個章節,第一章我們對於 影像處理與電腦視覺在各領域的應用作一簡要介紹。而第二章至第五章,則分別探討簡 介本論文所提出之各個以影像處理與電腦視覺為基礎的研究方法與應用系統。 在第二章中,我們提出了一個快速且具高度可靠性的多重門檻值選擇機制,以針對 含有多個物件的灰階影像,加以將其中內含之物件分離,以利於後續之處理與分析。這 個機制包含了一個最佳化的分離度量測法則,可以確保所得之切割影像,具有統計特性 上的最大分離度,以此獲得最佳的切割效果。目前現有的門檻值選取演算法,多是為了 二值化切割而設計,少數具有多門檻值選取技術,其大多需要消耗相當多的運算能量, 以及多是設計於在具有某些特定特性的影像上才具有較高可靠度。而這個研究提出了一 個最佳化的分離度量測判定準則,據此所開發之自動多重門檻值選擇技術,可在多種不 同特性的影像上,皆可以極低的運算時間,判定影像上的物件個數,並決定門檻值加以 切割分離之,並經過多種實驗測試證明其高效率與可靠性。這個技術可應用於電腦與機 器視覺相關之系統開發,以此技術將具意義之物件加以從影像分離後,以利其後續之分 i.
(4) 析與辨識處理,如在文件影像分析與辨識、ITS 智慧型運輸系統之電腦視覺處理上之整 合運用,皆需要將有意義之物件從影像中擷取出,以利進行進一步的分析處理工作。 我們在第三章則提出了一套多平面影像切割演算法,以將文字從彩色圖文交疊的複 雜文件影像中完整萃取。由於在現今生活中常見的文件,因印刷排版技術的發展,使得 多媒體複合文件的大量出現,此類文件之文字大多印刷在複雜的背景內涵下。將文字從 文件影像中抽離是文件分析研究的重要一環,目前已經有許多學者在這個領域提出相關 文字切割技術。然而,先前的技術大多無法解決複雜文件影像抽離文字的困難。這個技 術可以解決許多由於文件影像背景日益複雜所衍生的相關問題。在實驗分析中,我們使 用了書本封面、平面廣告和雜誌等進行處理,實驗結果證明本論文所提出的方法,能夠 成功的將這些文件影像中的中英文文字字串加以成功萃取。這個研究的主要目的,是開 發一套以區域性切割演算法為基礎的文件影像切割技術,針對彩色圖文交疊的複雜文件 影像,將其中所包含的前景物件與背景物件分別分離,並再以一套文字萃取演算法,使 其中之文字資訊能夠完整的加以萃取,即使他們都被印刷在緩慢變化或快速變化的高度 複雜背景圖形中。 在第四章中,我們則提出了一個針對夜間行車駕駛輔助與車輛自動化駕駛需求的智 慧型高速夜間車輛偵測與辨識系統。該系統透過 CCD 影像擷取設備,結合電腦視覺處 理技術,以實現夜間車輛偵測、相對位置與距離判定、車輛標定與追蹤,並以此輔助駕 駛獲得前方之交通狀況資訊。以此可以提供一個有效的機制,以自動操控車上的相關裝 置設備,如運用於車輛頭燈的遠近光燈控制上,可以在偵測判斷前方車道的交通狀況 時,自動將車輛頭燈之遠光燈與近光燈調整至最佳狀態,防止炫光而影響前方來車駕駛 視線,避免因為遠光燈近距離照射造成目眩所困擾而導致之車禍危險性。並可以基於所 偵測獲得之本車前方交通狀況,如本車與前方道路上所出現車輛之相對運動關係,以提 供作為自動駕駛與自動巡航速度的上層控制機制。 第五章我們提出一個智慧型多通道錄影視訊監視控制系統,其對於影像壓縮速度的 提升,在於達成多通道錄影即時視迅壓縮編碼的高標準要求,同時又能保持極高的壓縮 影像品質與壓縮效率,加以為了達成現今軟體工程的主流,系統開發以實作微軟所提出 之 ActiveX 系統元件模型完成,以利於多媒體應用、網際網路應用與快速應用軟體程式 開發。再加上結合了網路伺服程式、影像擷取卡與 CCD 攝影機,發展成為一高效率的 多錄影通道智慧型監控系統,並擁有高效能、低成本與功能強大的特質。最後,在第六 章的部分,我們整理了本篇論文的結論與未來的研究展望。 ii.
(5) A Study of Image Processing and Computer Vision Techniques for Complex Document Image Analysis, Nighttime Driver Assistance, and Video Surveillance Systems. Student:Yen-Lin Chen. Advisor:Prof. Bing-Fei Wu. Department of Electrical and Control Engineering National Chiao Tung University. Abstract Image processing and computer vision are the studies of how computers can perceive and understand the interesting information about the world surrounding human beings by automatically extracting and analyzing observed images, image sets, or video sequences using theoretical and algorithmic computations. Object extraction and analysis is one of the important applications of image processing and computer vision. Among the applications of object extraction and analysis, document image analysis (DIA) is the one that provides many valuable applications in document analysis and understanding, such as optical character recognition, document retrieval, and compression. Vision-based techniques of driver assistance and autonomous vehicle navigation systems are emerging practical applications as well. It aims at detecting and recognition the vehicular objects in the road environment for driver assistance and autonomous vehicle guidance. As well as the security issues in modern life, digital video monitoring is also a promising application. In this dissertation, we will present several algorithmic, practical, and integrated methods and systems for the above-mentioned applications based on image processing and computer vision techniques.. iii.
(6) Firstly, Chapter 2 presents an efficient automatic multilevel thresholding method for image segmentation. An effective criterion for measuring the separability of the homogenous objects in the image, based on discriminant analysis, has been introduced to automatically determine the number of thresholding levels to be performed. Then, by applying this discriminant criterion, the object regions with homogeneous illuminations in the image can be recursively and automatically thresholded into separate segmented images. This proposed method is fast and effective in analyzing and thresholding the histogram of the image. In order to conduct an equitable comparative performance evaluation of the proposed method with other thresholding methods, a combinatorial scheme is also introduced to properly reduce the computational complexity of performing multilevel thresholding. In Chapter 3, we propose a new method, namely the multi-plane segmentation approach, for segmenting and extracting textual objects from various real-life complex document images. The proposed multi-plane segmentation approach first decomposes the document image into distinct object planes to extract and separate homogeneous objects including textual regions of interest, non-text objects such as graphics and pictures, and background textures. This proposed approach processes document images regionally and adaptively according to their respective local features. Hence detailed characteristics of the extracted textual objects, particularly small characters with thin strokes, as well as gradational illuminations of characters, can be well-preserved. Moreover, this way also allows background objects with uneven, gradational, and sharp variations in contrast, illumination, and texture to be handled easily and well. Next, an effective method for detecting vehicles in front of the camera-assisted car during nighttime driving is presented in Chapter 4. This proposed method detects vehicles based on detecting and locating vehicle headlights and taillights by using techniques of image segmentation and pattern analysis. First, to effectively extract bright objects of interest, a fast bright object segmentation process based on automatic multilevel histogram thresholding is applied on the grabbed nighttime road-scene images. This automatic multilevel thresholding approach can provide robustness and adaptability for the detection system to be operated well iv.
(7) on various illuminated conditions at night. Then the extracted bright objects are processed by a rule-based connected-component analysis procedure, to identify the vehicles by locating and analyzing their vehicle light patterns, and estimate the distance between the detected vehicles and the camera-assisted car. In Chapter 5, we present a wavelet-based approach to compressing video, with high speed, high image quality and high compression ratio. Using the sequential characteristics of surveillance images, this method applies the low-complexity zero-tree coding, which costs low memory, to develop an algorithm for encoding and decoding video, which significantly improves the speeds of compression and decompression and maintains images of high quality. Based on this low-complexity and low-memory-cost wavelet-based coding scheme and motion compression strategy, the proposed video codec achieves high vision quality, high compression speed and high compression ratio. Then the ActiveX COM component technique is also implemented and integrated with the proposed video codec to realize multimedia, internet applications and many other video-intensive applications. Furthermore, an intelligent surveillance system, which integrates the proposed wavelet-based video codec, computer peripherals and mobile communication, is also presented in this chapter. Finally, we give a brief conclusion and future works in Chapter 6.. v.
(8) 誌. 謝. 回首這些年來的博士班研究過程,學生首先要誠摯的感謝恩師 吳炳飛教授。打從 大三修習教授的線性控制系統課程,就深深為老師上課所展露的獨特風采與孜孜不倦的 精神所吸引,從而加入了 CSSP 實驗室這個大家庭,展開了人生中最重要的一段學術研 究訓練。因得力於恩師所給予我這樣的一個兼具深度與廣度、理論與實務的研究方向, 使我得以一窺影像處理與電腦視覺研究領域的堂奧,給了我在這些年來的研究與學習的 歷練中獲益匪淺。 感謝口試委員 蔡文祥校長、王聖智教授、曾定章教授、張志永教授與陸儀斌教授, 給予了我在研究論文上許多相當寶貴的意見,從而讓本論文能夠更完整而嚴謹。此外, 更讓我也瞭解到自己在進行研究時,常因過於著重於解決問題,以致過於著重 How, 而時而忽略了對於研究課題本身的 Why 的思考的缺失,從而使我在對於自己往後所從 事的研究,有了更深刻的了悟。此外,也很感謝 林源倍教授與黃有評教授,給予了我 許許多多課業上與研究上的寶貴諮詢與幫助。 這些年來,相當的感謝重甫、忠哥、旭哥、暐哥學長們在我研究的過程中的提攜 與照顧,也感謝從碩士班直到現在的嘴泡好哥們子偉同學,以及曾與我一起合作研究過 的堯俊、元馨、至明學弟妹,這段一起在 CSSP 實驗室並肩打拼的日子是我最好的回憶。 也要感謝所有與我一起在實驗室合作與相處的實驗室所有學長、同學、和學弟妹們,在 這六年多的日子裡,和大家一起在實驗室裡共同的生活點滴、 研究上的討論、嘴泡、 與豪洨,組隊「團戰」的革命情感,還有因為睡過頭而偷偷低著頭閃進 Group Meeting… 等,這些酸甜苦辣的經驗,是我一生最難忘的回憶。 另外,也要感謝中華扶輪教育基金會在我博士修業期間所提供的豐厚獎學金,使 我能夠毫無後顧之憂的專心完成我的研究。 最後,要感謝爸爸和媽媽一路上對我的支持與鼓勵,還有對我要「所費」時總是 有求必應,使我的研究過程一直無後顧之憂的一往無前,而順利的完成學業。 謹以此文感謝這段期間許許多多曾經幫助提攜過我的人,謝謝你們。. 陳彥霖. 於交通大學電機與控制工程學係 CSSP 實驗室 2007/01/17. vi.
(9) Table of Contents. Chapter 1. Introduction......................................................................................................1 1.1 Motivation..............................................................................................................1 1.2 The Proposed Approaches......................................................................................6 1.2.1 Multi-level thresholding approaches for image segmentation...................6 1.2.2 A multi-plane segmentation approach for text extraction in complex document images .......................................................................................................7 1.2.3 Vision-based nighttime vehicle detection for driver assistance.................8 1.2.4 Real-time wavelet-based video compression approach for video surveillance ................................................................................................................9 1.3 Organization.........................................................................................................10 Chapter 2. Multi-level Thresholding Approaches for Image Segmentation................ 11 2.1 Introduction.......................................................................................................... 11 2.2 Review of Conventional Image Thresholding Criterion Functions .....................16 2.2.1 The between-class variance thresholding criterion..................................16 2.2.2 The maximum entropy thresholding criterion .........................................19 2.2.3 The minimum error thresholding criterion ..............................................20 2.3 The Proposed Fast Combinatorial Scheme for Efficient Selection of Multiple Thresholds........................................................................................................................21 2.3.1 The Combinatorial Search Scheme of Optimal Threshold Set Selection 21 2.3.2 Fast Implementation of Criterion Functions for Multilevel Thresholding Methods 27 2.4 The Proposed Automatic Multilevel Thresholding Method ................................33 2.5 Experimental Results ...........................................................................................38 Chapter 3. Multi-plane Segmentation Approach for Complex Document Images .....53 3.1 Introduction..........................................................................................................54 3.2 Localized Histogram Multilevel Thresholding ....................................................61 3.3 Multi-plane Region Matching and Assembling Process......................................71 3.3.1 Initial Plane Selection Phase....................................................................72 3.3.2 Matching Phase........................................................................................74 3.3.3 Plane Construction Phase.........................................................................81 3.3.4 Overall Process ........................................................................................85 3.4 Text Extraction.....................................................................................................88 3.5 Experimental Results ...........................................................................................97 Chapter 4.. Nighttime Vehicle Detection for Driver Assistance ................................... 114 vii.
(10) 4.1 4.2 4.3 4.4 4.5 4.6 4.7. Introduction........................................................................................................ 114 Bright Object Extraction ....................................................................................118 Spatial Clustering Process for Bright Objects ...................................................121 Rule-Based Vehicle Identification .....................................................................126 Vehicle Distance and Position Estimation .........................................................127 Vehicle Tracking Process ...................................................................................131 Experimental Results .........................................................................................134 4.7.1 Implementation ......................................................................................134 4.7.2 Performance Evaluation.........................................................................135. Chapter 5.. Real-Time Wavelet-Based Video Compression Approach to Video. Surveillance Systems............................................................................................................139 5.1 Introduction........................................................................................................139 5.2 The Proposed Fast Wavelet-Based Video Compression Technique...................142 5.2.1 Forward/Inverse Component Transform................................................144 5.2.2 Forward/Inverse DWT ...........................................................................145 5.2.3 Quantization/De-quantization ................................................................147 5.2.4 Low-Complexity and Low-Memory Zero-tree Entropy Coder (LLZC Encoder/Decoder) ..................................................................................................147 5.2.5 Inter-Frame Difference Extraction / Difference Compensation and Bidirectional Frame Interpolation..........................................................................151 5.3 Experimental Results .........................................................................................153 5.4 5.5. Video Codec Software Component....................................................................159 Implementation of an Intelligent Video Surveillance System ...........................162. Chapter 6. Conclusions and Future Works ..................................................................165 6.1 Multi-level thresholding approaches for image segmentation...........................165 6.2 A multi-plane segmentation approach for text extraction in complex document images 166 6.3 Vision-based nighttime vehicle detection for driver assistance.........................168 6.4 Real-time wavelet-based video compression approach for video surveillance .169 References .............................................................................................................................170. viii.
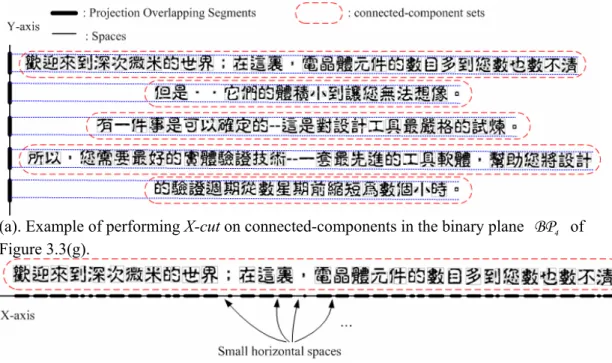
(11) List of Figures. Figure 2.1. Conventional search procedure of optimal. ψ (T ) ................................................22. Figure 2.2. The pseudo code of the Twiddle procedure ...........................................................26 Figure 2.3. Improved search procedure of optimal. ψ (T ) using the combinatorial scheme ..26. Figure 2.4. Result of segmenting the test image 1, “Road” (image size=720×480)................42 Figure 2.5. Result of segmenting the test image 2, “Lena” (image size=512×512) ................46 Figure 2.6. Result of segmenting the test image 3, “Advertisement”......................................51 Figure 3.1. Block diagram of the proposed multi-plane segmentation approach ....................60 Figure 3.2. Example of the results by the localized multilevel thresholding procedure..........70 Figure 3.3. An example of the test image, “Calibre”, and the object planes obtained by the multi-plane segmentation (image size = 1929 x 1019)..........................................87 Figure 3.4. Examples of the text location and extraction process ...........................................96 Figure 3.5. Representative color images of Figure 3.3(a) after performing Jain and Yu's method....................................................................................................................97 Figure 3.6. Text extraction results of Fig. 3(a) by Jain and Yu’s method and Pietikainen and Okun’s method. ......................................................................................................98 Figure 3.7. Original images of the test images 2 and 3..........................................................100 Figure 3.8. Decomposed object planes of Figure 3.7(a) after performing the proposed multi-plane segmentation.....................................................................................101 Figure 3.9. Representative color images of Figure 3.7(a) after performing Jain and Yu's method..................................................................................................................102 Figure 3.10. Text extraction results of Figure 3.7(a) by the proposed approach, Jain and Yu’s method, and Pietikainen and Okun’s method. .....................................................103 Figure 3.11. Decomposed object planes of Figure 3.7(b) after performing the proposed multi-plane segmentation.....................................................................................104 Figure 3.12. Representative color images of Figure 3.7(b) after performing Jain and Yu's method..................................................................................................................105 Figure 3.13. Text extraction results of Figure 3.7(b) by the proposed approach, Jain and Yu’s method, and Pietikainen and Okun’s method. .....................................................106 ix.
(12) Figure 3.14. Original images of the test images 4 - 6 ............................................................106 Figure 3.15. Text extraction results of Figure 3.14(a) by the proposed approach, Jain and Yu’s method, and Pietikainen and Okun’s method. .....................................................108 Figure 3.16. Text extraction results of Figure 3.14(b) by the proposed approach, Jain and Yu’s method, and Pietikainen and Okun’s method. .....................................................108 Figure 3.17. Text extraction results of Figure 3.14(c) by the proposed approach, Jain and Yu’s method, and Pietikainen and Okun’s method. .....................................................109 Figure 3.18. Results of test image 7 (size: 1829 × 2330) ...................................................... 111 Figure 3.19. Results of test image 8 (size: 3147 × 4536) ...................................................... 111 Figure 3.20. Results of test image 9 (size: 1859 × 2437) ...................................................... 111 Figure 3.21. Results of test image 10 (size: 1344 × 1792) .................................................... 112 Figure 3.22. Results of test image 11 (size: 2309 × 2829)..................................................... 112 Figure 3.23. Results of test image 12 (size: 2469 × 3535) .................................................... 112 Figure 4.1. Block diagram of the proposed method............................................................... 117 Figure 4.2. An example of nighttime road environment........................................................ 119 Figure 4.3. Bright object plane extracted from Figure 4.2 after performing the bright object segmentation process ...........................................................................................120 Figure 4.4. The processing area determined by the virtual horizon and the bright components of interest .............................................................................................................123 Figure 4.5. The spatial clustering process of bright components ..........................................125 Figure 4.6. The illustration of the lateral positions of the detected vehicle bodies in the image coordinates ...........................................................................................................130 Figure 4.7. The experimental camera-assisted car – TAIWAN iTS-1 ...................................134 Figure 4.8. The vision system mounted in the experimental car ...........................................135 Figure 4.9. Result of vehicle detection on the nighttime road scene with one oncoming vehicle ..................................................................................................................136 Figure 4.10. Result of vehicle detection on the nighttime road scene with both oncoming and preceding vehicles................................................................................................136 Figure 4.11. Result of vehicle detection on the nighttime road scene comprised of vehicles and many other non-vehicle lights.......................................................................137 Figure 5.1. Structure of the coding and decoding flow of the proposed method...................143 x.
(13) Figure 5.2. Illustration of the 4:2:0 sampling process ...........................................................144 Figure 5.3. Examples of Wavelet Transform .........................................................................147 Figure 5.4. Tree structure of the distribution of wavelet coefficients ....................................149 Figure 5.5. Coding procedure of LLZC .................................................................................149 Figure 5.6. Frame sequence encoding in Fast Mode .............................................................152 Figure 5.7. Frame sequence encoding in Turbo Mode...........................................................152 Figure 5.8. Comparative results of JPEG and the proposed method .....................................154 Figure 5.9. Results of compressing the standard testing clip – “Akiyo” (CIF format, 352*288) ..............................................................................................................................156 Figure 5.10. Results of compressing the standard testing clip – “Foreman” (QCIF format, 176*144) ..............................................................................................................157 Figure 5.11. Comparison of compression speeds between MPEG-4 method and the proposed method..................................................................................................................159 Figure 5.12. Video codec component and its applications.....................................................160 Figure 5.13. Visual Basic environment for developing surveillance applications.................161 Figure 5.14. Example of web-surveillance application .........................................................161 Figure 5.15. Implementation of Intelligent surveillance system............................................163 Figure 5.16. Mobile carrier with a CCD camcorder ..............................................................164 Figure 5.17. The controlling interface of the monitoring user...............................................164. xi.
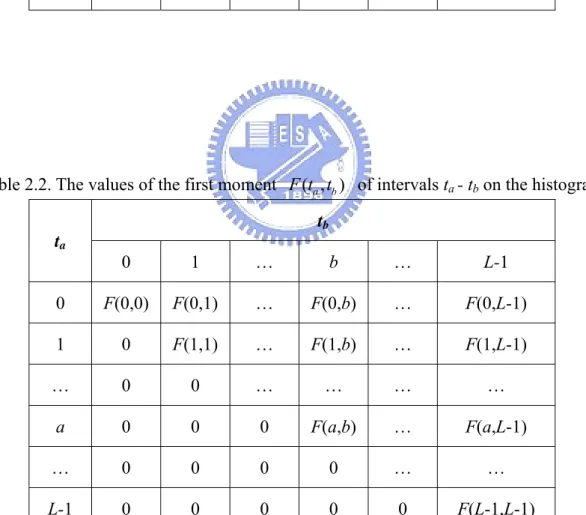
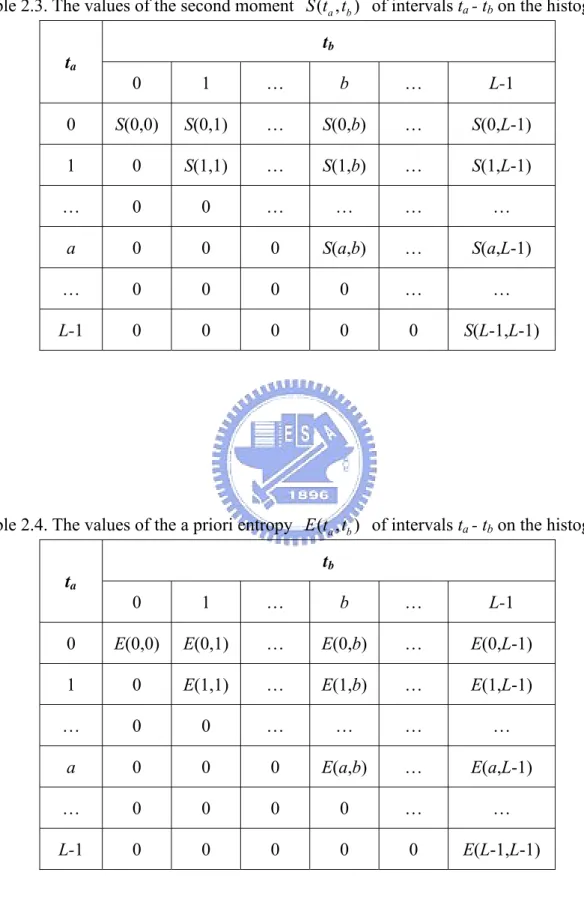
(14) List of Tables. Table 2.1. The values of the zeroth moment Z (ta , tb ) of intervals ta - tb on the histogram ...30 Table 2.2. The values of the first moment F (ta , tb ) of intervals ta - tb on the histogram.......30 Table 2.3. The values of the second moment S (ta , tb ) of intervals ta - tb on the histogram...31 Table 2.4. The values of the a priori entropy E (ta , tb ) of intervals ta - tb on the histogram...31 Table 2.5. Experimental data of performing thresholding on Figure 2.4(a), “Road”, by our proposed automatic multilevel thresholding method (AMT), Between-class variance method (BCV), Entropy method (ENT) and Minimum Error method (ME) ................................................................................................................................40 Table 2.6. Experimental data of performing thresholding on Figure 2.5(a), “Lena”, by our automatic multilevel thresholding method (AMT), Between-class variance method (BCV), Entropy method (ENT), and Minimum Error method (ME) ....................44 Table 2.7. Experimental data of performing thresholding on Figure 2.6(a), “Advertisement”, by our automatic multilevel thresholding method (AMT), Between-class variance method (BCV), Entropy method (ENT), and Minimum Error method (ME) .......48 Table 3.1. Experimental data of Jain and Yu’s method and our proposed approach..............109 Table 5.1. Classes of coefficients...........................................................................................151 Table 5.2. Comparisons of the need of storage space between the JPEG-Based system and the proposed method under similar visual quality (QVGA format, 320*240) ..........155 Table 5.3. Comparisons of performance between proposed method and MPEG-4 (Akiyo, CIF format, 352*288)..................................................................................................158 Table 5.4. Comparisons of performance between proposed method and MPEG-4 (Foreman, QCIF format, 176*144) .......................................................................................158. xii.
(15) Chapter 1.. INTRODUCTION. Image processing and computer vision are the studies of how computers can perceive and understand the interesting information about the world surrounding human beings by automatically extracting and analyzing observed images, image sets, or video sequences using theoretical and algorithmic computations [1]-[3]. Object extraction and analysis is one of the important applications of image processing and computer vision. Among the applications of object extraction and analysis, document image analysis (DIA) is the one that provides many valuable applications in document analysis and understanding, such as optical character recognition, document retrieval, and compression [4][5]. Vision-based techniques of driver assistance and autonomous vehicle navigation systems are emerging practical applications as well. It aims at detecting and recognition the vehicular objects in the road environment for driver assistance and autonomous vehicle guidance [6]-[9]. As well as the security issues in modern life, digital video monitoring is also a promising application. In this dissertation, we will present several algorithmic, practical, and integrated methods and systems for the above-mentioned applications based on image processing and computer vision techniques.. 1.1. Motivation Extraction of objects from observed images using image thresholding techniques is. useful for in the early processing stages of a vision system [10][11]. To-date, many researchers have developed valuable thresholding techniques [12]-[26] for applications that include image segmentation, pattern recognition and document analysis, among others. The conventional concept of most of these methods is that the thresholding is carried out as a 1.
(16) simple classification procedure that the pixels of the image are assigned to two classes, foreground object pixels and background pixels. Hence most of them were developed for effectively adoption on bi-level thresholding process. The surveys and comparative performance testing studies of these methods was presented in the remarkable works of Sahoo et al. [10] and Lee et al. [11]. Besides, in Trier and Jain’s work [27][28], a goal-directed evaluation methodology has been proposed for performance testing on the thresholding methods based on judgment of the recognition performance of conducting OCR process on the binarization results obtained by these methods. The conventional thresholding techniques are all based on finding the threshold value which achieves the optimal condition of the criterion functions. Indeed, they are effective in bi-level thresholding. However, when the number of desired thresholds increases, the computation needed to obtain the optimal threshold values is substantially increased and the search to achieve the optimal value of the criterion functions is particularly exhaustive. Another problem associated with the conventional methods is that the number of segments, into which the image should be segmented, cannot be suitably and automatically determined. Thus, we intend to develop a computationally fast and effective automatic multilevel thresholding approach to overcome the above-mentioned image segmentation issues associated with the conventional methods. For document image analysis, the interesting objects in a document image are textual objects. Extracting textual objects from document images provides many useful applications in document analysis and understanding, such as optical character recognition, document retrieval, and compression [4][5]. To-date, many techniques were presented for extracting textual objects from monochromatic document images [29]-[32]. In recent years, owing to advances in multimedia publishing and printing technology have led to an increasing number of real-life documents in which stylistic character strings are printed with pictorial, textured, and decorated objects and colorful, varied background components. However, most of 2.
(17) conventional approaches cannot work well for extracting textual objects from real-life complex document images. Compared to monochromatic document images, text extraction in complex document images brings many difficulties associated with the complexity of background images, variety and shading of character illuminations, superimposing characters with illustrations and pictures, as well as other decorated background components. As a result, there is an increasing demand for a system that is able to read and extract the textual information printed on pictorial and textured regions in both colored images as well as monochromatic main text regions. Since most textual objects show sharp and distinctive edge features, methods based on edge information [33]-[36] have been developed. Such methods utilize an edge detection operator to extract the edge features of textual objects, and then use these features to extract characters from document images. Such edge-based methods are capable of extracting textual objects in different homogeneous illuminations from graphic backgrounds. However, when the characters are adjoined or touched with graphical objects, texture patterns, or backgrounds with sharply varying contours, edge-feature vectors of non-text objects with similar characteristics may also be identified as text, and thus the characters in extracted textual. regions. are. blurred. by. those. non-text. objects.. Several. conventional. color-segmentation-based methods for text extraction from color document images have been proposed [37]-[41]. These methods utilize color clustering or quantization approaches for determining the prototype colors of documents so as to facilitate the detection of textual objects in these separated color planes. However, most of these methods have difficulties in extracting characters which are embedded in complex backgrounds or that touch other graphical objects. This is because the prototype colors are determined in a global view, so that appropriate prototype colors cannot be easily selected for distinguishing textual objects from those touched graphical objects and complex backgrounds without sufficient contrast. 3.
(18) For vision-based systems for driver assistance and autonomous vehicle guidance, many researchers have also developed valuable techniques for recognizing interesting vehicles and obstacles from images of road environments outside the car [6]-[9], to facilitate applications on the camera-assisted system that assists drivers in understanding possible hazards on the road, and automatically controlling the apparatus of vehicles, such as headlights, windshield wipers, etc. A vision-based vehicle and obstacle detection system is aiming at identification of vehicles, obstacles, traffic signs and other patterns on the road from grabbed image sequences by means of image processing and pattern recognition techniques. Until recently, researchers in this field still open new questions and concepts [42][43]. By adopting different concepts and definitions on interesting objects on the road, different techniques are applied on the grabbed image sequences to detect them as vehicles or obstacles. For locating vehicles in an image sequence, the task can be carried out by searching for specific patterns on the images based on typical features of vehicles, such as shape, symmetrization, or their surrounding bounding boxes [44]-[46]. Until recently, most of the conventional works focused on detecting vehicles under daytime road environments. However, under bad-illuminated conditions in nighttime road environments, those obvious features of vehicles which are effective for detecting vehicles in daytime become invalid in nighttime road environments. Thus, most of the above-mentioned conventional techniques cannot work well under such nighttime road environments. At night, as well as under dark illuminated condition in general, the only visual features of vehicles are their headlights and taillights. Headlights and taillights are visible if a vehicle lies in the visible range of the CCD camera mounted on a camera-assisted car. However, there are also many other illuminant sources coexisted with the vehicle lights in nighttime road environments, such as street lamps, traffic lights, and road reflector plates on ground. These non-vehicle illuminant sources cause many difficulties for detecting actual vehicles in 4.
(19) nighttime road scenes. As for the applications on video surveillance systems, it is an emerging application of video compression and communication for security issues in modern life. However, conventional monitoring systems are mostly analog systems, which exploit many tapes and human effort, to replace the tapes frequently. The recording time and image quality of systems cannot compete with those of digital monitoring systems. In digital monitoring systems, transform coding techniques are the most popular for video recording applications. At the beginning of the development of this field, DCT-based (Discrete Cosine Transform) coding techniques were commonly used, and have since become an element of the JPEG image compression standard. Accordingly, its application can be seen in many electronic devices today. Over recent years, researchers have demonstrated that DWT-based (Discrete Wavelet Transform) transform coding ([47]-[50]) outperforms DCT-based methods. Hence, newly emerging image compression methods such as the video compression method standard MPEG-4 [51][52] and the still image compression standard JPEG2000 are using DWT-based methods [53][54]. Since multiple CCD camera systems are continuously heavily loaded with sequences of images, so the speed of image compression is critical in such systems. Presently, DWT-based compression techniques suffer from high computational complexity, and so cannot support multi-channel video recording with a high frame rate. A new, highly efficient DWT-based technique, which yields images of high visual quality, is a significant demand for such application.. 5.
(20) 1.2. The Proposed Approaches In this dissertation, we will present several algorithmic, practical, or integrated methods. and systems based on image processing and computer vision techniques to deal with the above-mentioned issues, including multilevel thresholding techniques for low-level image segmentation, text extraction for complex document image analysis, nighttime vehicle detection for driver assistance, and multi-channel video surveillance. They are briefly introduced in the following sub-sections.. 1.2.1. Multi-level thresholding approaches for image segmentation For segmenting objects from a given image, different objects with homogeneous. illuminations must be separated into different segmented images. However, most of the conventional thresholding techniques [12]-[26] were developed for effectively applying on bi-level thresholding cases, and when the number of desired thresholds increases, the computation costs needed to obtain the optimal threshold values is substantially increased. Another problem associated with these conventional methods is that the number of segments, into which the image should be segmented, cannot be suitably and automatically determined. For this purpose, the discriminant criterion, for measuring separability among the segmented images with different objects, is described in this section. By evaluating the separability criterion, the number of objects, into which the image should be segmented, can be automatically determined. Hence, an automatic multilevel thresholding method, based on this criterion, will be presented in this dissertation. The concept of using discriminant analysis for classification problems was first introduced by Fisher [55] and was applied on image thresholding by Otsu [12]. It is attractive for the simplicity in computation, with which it measures the separability among segmented 6.
(21) images. In Chapter 2, we will analyze the properties of discriminant analysis and then propose an automatic multilevel thresholding method [56]. The proposed method applies the discriminant criterion for analyzing the separability among the gray levels in the image to automatically determine the optimal number of thresholded classes that the gray levels should be partitioned. A fast recursive selection strategy is also introduced for determining the optimal thresholds to segment objects of interest in complex images into separate thresholded images in a computationally fast way. Each threshold determined by this recursive selection strategy is ensured to achieve the maximum separation on the resultant thresholded images, and hence satisfactory thresholded results can be accomplished by means of the smallest number of thresholding levels. To conduct an equitable performance evaluation of the proposed method, when compared to other criterion-based methods (i.e. the between-class variance method [12], the entropy method [13] and the minimum error method [14]), we also will introduce a efficient combinatorial scheme [57] to properly reduce the computation complexity of performing multilevel thresholding by these methods.. 1.2.2. A multi-plane segmentation approach for text extraction in complex document images For extracting textual objects from complex document images involves several. difficulties. These difficulties arise from the following properties of complex documents: 1) Character strings in complex document images may have different illuminations, sizes, and font styles, and are overlapped with various background objects with uneven, gradational, and sharp variations in contrast, illumination, and texture, such as illustrations, photographs, pictures or other background textures. 2) These documents may comprise small characters with very thin strokes as well as large characters with thick strokes, and may be influenced by image shading. 7.
(22) Hence, we will propose effective region-based approaches for extracting textual objects from these complex document images [58]-[62], and resolving the above issues associated with the complexity of their backgrounds. The document image is processed by the proposed multi-plane segmentation technique to decompose it into separate object planes. The proposed multi-plane segmentation technique comprises two stages: automatic localized histogram multilevel thresholding, and multi-plane region matching and assembling processing. After the multi-plane segmentation technique has been carried out, homogeneous objects including textual blocks, other non-text objects, and background textures are separated into individual object planes. The text extraction process is then performed on the resultant planes to detect and extract textual objects with different characteristics in the respective planes. The document image is processed regionally and adaptively according to local features by the proposed method. This allows detailed characteristics of the extracted textual objects to be well-preserved, especially the small characters with thin strokes, as well as the gradational illuminations of characters. This also allows for characters adjoined or touched with graphical objects and backgrounds with uneven, gradational, and sharp variations in contrast, illumination, and texture to be handled easily and well.. 1.2.3. Vision-based nighttime vehicle detection for driver assistance. For the issues of nighttime driver assistance and the development of autonomous camera-assisted vehicles, an efficient technique for effectively detection and recognition of moving vehicles in nighttime road-scene image sequences is practically a necessary demand. Besides, this way provides beneficial information for the driver to perceive surrounding traffic conditions outside the vehicle during nighttime driving, and can also be applied to a versatile control scheme for the apparatus of vehicles. For example, the use of high-beam and low-beam states of headlights can be intelligently controlled according to the detection results 8.
(23) of presence of oncoming and preceding vehicles, and thus many hazards during nighttime driving, such as headlight dazzler, can be efficiently prevented. Therefore, we will present an effective nighttime vehicle detection method [63]-[65] for identifying vehicles by locating and analyzing their headlights and taillights. This proposed method comprises of the following processing stages. First, a fast bright object segmentation process based on automatic multilevel histogram thresholding is performed to extract pixels of the bright objects from the grabbed image sequences of nighttime road scenes. The advantage of this automatic multilevel thresholding approach is its robustness and adaptability for dealing with various illuminated conditions at night. Then a connected-component analysis procedure is applied on the bright pixels obtained by the previous bright object segmentation stage, to locate the connected-components of these bright objects. These bright components are then grouped by a projection-based spatial clustering process to obtain potential pairing headlights of oncoming vehicles, and taillights of preceding vehicles. Accordingly, a set of identification rules are applied on each group of bright objects to determine whether it represents an actual vehicle. Finally, the distance between each of the detected vehicles and the camera-assisted car can be estimated and reported.. 1.2.4. Real-time wavelet-based video compression approach for video surveillance For the purpose of developing a digital surveillance system fulfilling the requirements of. real-time multi-channel video compression, and ensuring the high quality of restored images and the efficiency of compression and decompression of images, we will present a real-time wavelet-based video compression technique and an intelligent multi-channel surveillance system [66]. Based on the low-complexity and low-memory-cost wavelet-based coding 9.
(24) scheme and motion compression strategy, the proposed video codec achieves high vision quality, high compression speed and high compression ratio. Then the ActiveX COM component technique is also implemented and integrated with the proposed video codec to realize multimedia, internet applications and many other video-intensive applications. Furthermore, an intelligent surveillance system, which integrates the proposed wavelet-based video codec, computer peripherals and mobile communication, is also developed in this study. Therefore, the future e-Home with controlled home electronics, managed video/audio systems and home security will be realized.. 1.3. Organization The rest of this dissertation is organized as follows. Chapter 2 presents an automatic. multilevel thresholding method for image segmentation. A region-based segmentation approach for text extraction from complex document images will be proposed in Chapter 3. In Chapter 4, we will propose a vision system to detect and recognize of vehicles for nighttime driver assistance. A real-time wavelet-based video codec for intelligent multi-channel monitoring system will be presented in Chapter 5. Finally, some conclusions and future research perspectives will be stated in Chapter 6.. 10.
(25) Chapter 2.. MULTI-LEVEL THRESHOLDING APPROACHES FOR. IMAGE SEGMENTATION. In this chapter, we will present a combinatorial scheme for reducing the computation timings of fixed-level multilevel thresholding process, and an efficient automatic multilevel thresholding method for image segmentation. As for fixed-level multilevel thresholding, by applying the proposed combinatorial scheme on conventional criterion-based multilevel thresholding, not only the redundant evaluation of threshold sets can be effectively avoided, but the computation cost for each evaluation of each potential threshold set can also be substantially suppressed, and thereby the computation timings for obtaining the optimal set of thresholds can be significantly reduced. Besides, this proposed combinatorial scheme can also achieve the parameterization of the desired number of thresholds. For automatic multilevel thresholding, an effective criterion for measuring the separability of the homogenous objects in the image, based on discriminant analysis, has been introduced to automatically determine the number of thresholding levels to be performed. Then, by applying this discriminant criterion, the object regions with homogeneous illuminations in the image can be recursively and automatically thresholded into separate segmented images. Both the two proposed multilevel approaches are fast and effective in analyzing and thresholding the histogram of the image.. 2.1. Introduction In image processing, objects must usually be segmented from an image in order to. facilitate further processing. Accordingly, many researchers have developed valuable thresholding techniques [12]-[26] for applications that include image segmentation, pattern 11.
(26) recognition and document analysis, among others. The conventional concept of most of these methods is that the thresholding is carried out as a simple classification procedure that the pixels of the image are assigned to two classes, foreground pixels and background pixels. Hence most of them were developed for effectively adoption on bi-level thresholding process. Most of these methods were developed for adoption on bi-level thresholding. The surveys and comparative performance testing studies of these methods was presented in the remarkable works of Sahoo et al. [10] and Lee et al. [11]. Besides, in Trier and Jain’s work [27][28], a goal-directed evaluation methodology has been proposed for performance testing on the thresholding methods based on judgment of the recognition performance of conducting OCR process on the binarization results obtained by these methods. The concept of using discriminant analysis for classification problems was first introduced by Fisher [55] and was firstly applied on the gray-level histogram distributions for image thresholding by Otsu [12]. This method is carried out by maximizing the separability of the resultant thresholded classes using the between-class variance criterion associated with them. It is attractive for the simplicity in computation, with which it measures the separability among segmented images. Besides, from the alternative viewpoint of gray-level histogram distributions, Kittler and Illingworth [14] developed an approach that based on the assumption that the probability distributions of gray levels of objects in an image (i.e. foreground object and background) are Gaussianly distributed. Hence they proposed the minimum error thresholding method to determine the optimal threshold which minimizes the error rate of the resultant thresholded classes with the desired mixtures of Gaussian distributions. Selecting the optimal threshold using the information theoretic concept is another master stream of thresholding methods. Kapur et al. [13] developed a method using the concept of the maximum entropy principle of a histogram in order to determine a suitable threshold. This method is performed by separating the histogram of gray level probabilities 12.
(27) into two distributions, where one is associated with the foreground, and the other one with the background of the image. The entropy of the two distributions is then combined, and the gray value with the maximal combined entropy is selected as the threshold value. In the maximum entropic correlation method proposed by Chang et al. [15], the distributions of the object and background classes are formulated by a entropic correlation criterion function, and the optimal threshold is determined by maximizing the entropic correlation criterion between the two distributions. This method can provide relatively simplifier computation cost than that of Kapur et al.’s maximum entropy method. Similar to the concept of the above-mentioned two entropic methods, Sahoo et al. [16] proposed a threshold selection method using an alternative formulated entropic criterion function using Renyi’s entropy. This entropic criterion function gives a generalization formulation form including the maximum entropy criterion and the maximum entropic correlation criterion, and can yield a more effective threshold for the image. However, this criterion function costs much more computation timing for determining the optimal threshold than those of the above-mentioned two entropic criterion functions. Recently, based on the concept of the fuzzy set theory integrated with the maximum entropy principle, several fuzzy entropic thresholding methods are developed [17]-[19]. They are performed by selecting the optimal threshold which maximizes the fuzzy entropy of the distributions of the object and background classes. Cheng et al. [18] applied the concept of fuzzy set theory into the principle of maximizing the objective entropy function for determining the optimal threshold. Besides, a unified formulation for the criterion functions used in the methods of Otsu [12], Kittler and Illingworth [14], and Huang and Wang [17] was introduced in Yan’s work [20]. Most of these above-mentioned criterion-based thresholding methods are mostly based on finding the threshold value which achieves the optimal condition of the criterion functions. Indeed, they are effective in bi-level thresholding. 13.
(28) However, when the number of desired thresholds increases, the computation needed to obtain the optimal threshold values is substantially increased, and the search for achieving the optimal value of the criterion functions becomes particularly exhaustive. To perform multilevel thresholding in a more computationally frugal way, Tsai [21] developed a method using moment-preserving to threshold an image into a specific number of object images. This approach is fast and convincing when the number of thresholds is less than or equal to four. However, some complex numerical methods may be required when the number of thresholds exceeds four. In Reddi et al.’s work [22], an efficient implementation scheme for performing multilevel thresholding of the between-class variance criterion in a more computationally frugal way was presented. However, this method can be adequately performed only on exactly three or fewer thresholding levels. For segmenting dark characters in document images with multiple illuminated objects, Chereit et al. [23] extended Otsu’s approach by repeatedly performing bi-level thresholding to segment the bright object away at each recursion, and leaving the darkest character-like objects in the given resultant image. This method is effective on extracting dark characters from document images with bright homogeneous background, especially for bank checks. Tsai [24] presented a method using Gaussian kernel smoothing to repeatedly perform on the histogram of the image until the histogram being divided into desired number of classes. When the desired number of classes is much lower than the number of peaks in the original histogram, the computation time to find the solutions of threshold values is expensive. Fleury et al. [26] proposed a running entropic method that can reduce the computation cost for performing multilevel thresholding of the maximum entropy criterion [13]. This method has also been implemented in a parallelization computation form on a parallel workstation. However, this method cannot adapt to the changes of different desired number of thresholds, that is, once the number of desired thresholds is changed, its computational implementation must be re-programmed for 14.
(29) performing on the new desired number of thresholding levels. Besides, the main problem associated with the aforementioned methods is that the number of segments, into which the gray-level image should be segmented, cannot be automatically determined. In this study, we propose two approaches for fast and automatic implementation of multi-level thresholding process. First, we present a combinatorial scheme to reduce the computation cost of determining the optimal threshold values in multilevel thresholding. This proposed scheme comprises of two elements – a combinatorial search scheme for efficiently and sequentially producing sets of potential threshold values to be evaluated, as well as a fast implementation scheme of the criterion functions for speedy evaluation of the potential threshold sets. This scheme effectively avoids evaluating redundant threshold sets, substantially suppresses the computation cost for each evaluation of each potential threshold set, and thereby significantly reduces the computation timings of obtaining the optimal set of threshold values. Moreover, the proposed scheme also provides the parameterization for the number of desired thresholds, and hence the implementation of the proposed scheme can provide adaptation to be performed on any different number of thresholding levels. We will apply the proposed scheme on multilevel thresholding using the criterion functions of the three most well-known methods - Otsu’s between-class variance criterion [12], Kapur et al’s maximum entropy criterion [13], and the Kittler and Illingworth’s minimum error thresholding criterion [14]. Furthermore, based on the extension of this concept, we analyze the properties of discriminant analysis and then propose an automatic multilevel thresholding method. This proposed method applies the discriminant criterion for analyzing the separability among the gray levels in the image to automatically determine the optimal number of thresholded classes that the gray levels should be partitioned. A fast recursive selection strategy is also introduced for determining the optimal thresholds to segment objects of interest in complex 15.
(30) images into separate thresholded images in a computationally fast way. Each threshold determined by this recursive selection strategy is ensured to achieve the maximum separation on the resultant thresholded images, and hence satisfactory thresholded results can be accomplished by means of the smallest number of thresholding levels. To conduct an equitable performance evaluation of the proposed method, when compared to other criterion-based methods which are improved by the combinatorial scheme as mentioned before. The results of these three modified criterion-based methods with combinatorial scheme, and this proposed method are compared using several images with different characteristics and complexity. The experimental results demonstrate the feasibility and computational efficiency of these two proposed methods on multilevel thresholding.. 2.2. Review of Conventional Image Thresholding Criterion Functions In this section, we describe three well-known criterion functions utilized in the. thresholding methods - the between-class variance criterion [12], the maximum entropy criterion [13], and the minimum error criterion [14]. The multilevel thresholding computation forms of these criterion functions are also in turn described.. 2.2.1. The between-class variance thresholding criterion The classical method of discriminant analysis, to classify two class cases, was first. introduced by Fisher [27], and extended to multiple class cases by Rao [67]. This method sought the set of variables which maximized the ratio of the between-class variance and within-class variance of the resultant classes. These discriminant criteria, used by image thresholding, to extract foreground objects from the background, were presented by Otsu [12]. In his work, three possible discriminant criterion functions, based on within-class, 16.
(31) between-class and total variance ratios were presented, all of which were equivalent, for evaluation of an optimal thresholding process. Among the above three criterion functions, the between-class variance is the simplest one to compute. This method is performed by finding an optimal threshold, for which the between-class variance between dark and bright regions of the image is maximized. Let fi denote the observed occurrence frequencies (histogram) of pixels in a given image I, with a given gray level i, and N denotes the total amount of pixels in the image I, and can be given by N = f0+f1+…+fL-1, where L is the number of gray values in the histogram. Hence, the normalized probability Pi of one pixel having a given gray level i can be denoted as,. Pi =. where Pi ≥ 0 ,. fi , N. (2.1). L −1. ∑ P =1 i =0. (2.2). i. For the bi-level thresholding process, an image I is classified into two classes, C0 and C1 (e.g. foreground and background) using an optimal gray-level threshold t, where C0 = and C1 =. {t , t + 1,..., L − 1} .. {0,1,..., t − 1}. This method finds the optimal threshold for which the. between-class variance is maximized. The between-class variance, denoted by vbc, is an effective criterion for evaluating the separability of the two classes, and is defined as,. vbc (t ) = w0 ( μ0 − μT ) 2 + w1 ( μ1 − μT ) 2 = w0 w1 ( μ1 − μ0 ) 2. (2.3). The within-class variance, denoted by vwc , of all segmented classes of pixels is computed as,. vwc (t ) = w0σ 0 2 + w1σ 12. (2.4). where w0 and w1 denotes the cumulative probability mass function of the classes C0 and C1, 17.
(32) respectively; μ0, μ1, σ 0 , and σ 1 denotes the mean and the standard deviation of pixels in class C0 and C1, respectively. They are defined as t −1. L −1. i =0. i =t. w0 = ∑ Pi , and w1 = ∑ Pi = 1 − w0 L −1. t −1. ∑ iP. μ0 =. i =0. i. w0. t1. σ 02 =. , and μ1 =. ∑ P (i − μ ) i =0. 0. i. w0. (2.5). ∑ iP i. i =t. (2.6). w1 L −1. 2. , and σ 12 =. ∑ P (i − μ ) i =t. i. 2. 1. (2.7). 1 − w0. And the total variance vT and the overall mean μT of pixels in the image I are computed as, L −1. L −1. i =0. i =0. vT = ∑ (i − μT ) 2 Pi , and μT = ∑ iPi. (2.8). The criterion function used to select the optimal threshold for providing the best separability between the classes C0 and C1 is:. ψ BCV (t ) =. vbc (t ) vT. (2.9). The determination of the optimal threshold ( tBCV ) for achieving maximal separability between two classes, can be performed by maximizing the criterion function,. t BCV = Arg Maxψ BCV (t ) .. (2.10). 0≤t < L. We then extend this procedure to a multilevel thresholding case. For multilevel thresholding with k thresholds to partition the image into k+1 classes, pixels of the image I are segmented by applying a threshold set T, which is composed of k thresholds, where T = {t1,..., tn,…, tk} . These classes are represented by C0 =. {0,1,...,t1}. ,…, Cn=. {tn + 1, tn + 2,..., tn+1} ,…, Ck = {tk + 1, tk + 2,..., L − 1} . First, the between-class variance can be 18.
(33) derived from Eq. (2.3) and is computed as,. vBC (T ) = w0 ( μ0 − μT ) 2 + ... + wn ( μ n − μT ) 2 + ... + wk ( μ k − μT ) 2. (2.11). Then the within-class variance for multilevel thresholding can also be derived from Eq. (2.4) and is computed as,. vWC (T ) = w0σ 0 2 + ... + wnσ n 2 + ... + wkσ k 2. (2.12). where k is the number of selected thresholds to segment pixels into k+1 classes; wn is the cumulative probability mass function of class Cn; μn and σ n represent the mean and the standard deviation of pixels in class Cn, respectively. They are defined as, tn+1. t1. w0 = ∑ Pi ,…, wn = i =0. ∑ P , …,. i = tn +1. tn+1. t1. ∑ iP. μ0 =. i =0. w0. t1. σ 02 =. ∑ P (i − μ ) i =0. 0. i. w0. i. ,…, μ n =. ∑. i = tn +1. , …, σ n2 =. ∑. i = tn +1. wk =. L −1. ∑P. i =tk +1. (2.13). i. L −1. iPi. , …, μ k =. wn tn+1. 2. i. ∑ iP i. i = tk +1. ,. wk. L −1. Pi (i − μn ) 2 wn. (2.14). , …, σ k2 =. ∑ P (i − μ ). i =tk +1. i. 2. k. wk. (2.15). where a dummy threshold t0 = 0 is utilized for simplifying the expression of equation terms. Thus, the optimal threshold set ( TBCV ) can be determined by maximizing the following extended discriminant criterion function:. TBCV = Arg Maxψ BCV (T ) , 0 ≤T < L. 2.2.2. ψ. BCV. (T ) =. vBC (T ) vT. (2.16). The maximum entropy thresholding criterion. In entropy-based thresholding, the optimal threshold is obtained by applying information 19.
(34) theory. As derived from Kapur et al.’s work [13], the original gray level distribution of the image is divided into a number of classes of probability distributions in the multilevel thresholding case. Then the entropies associated with these distributions are computed as, tn +1 −1. H n = − ∑ ( Pi wn ) log ( Pi wn ). (2.17). i = tn. where n = 0, 1, …, k; and the threshold set T, and their corresponding probability mass functions wn are computed similar to the ones utilized in the computation of the between-class variance criterion as described in the previous subsection. Then the optimal threshold set ( TEnt ) is the threshold set which maximizes the entropy criterion, and is computed as,. TEnt = Arg Maxψ Ent (T ) , 0 ≤T < L. (2.18). k. where. ψ Ent (T ) = ∑ H n. (2.19). n =0. 2.2.3. The minimum error thresholding criterion. In the concept of minimum error thresholding [14], the gray level histogram of the image is thought of as an estimate of the probability density function p(i) of the mixture distribution, comprising the gray levels of several classes (i.e. objects and background). It is assumed that each of these class distributions p(i | n) of the mixture follows a normal distribution, with a class standard deviation of σ n , a class mean of μn and an a priori. probability of wn; hence, the histogram can be approximated as, k. 2 wn e− (( i − μn ) n = 0 σ n 2π. p (i ) = ∑. 20. 2σ n2 ). (2.20).
(35) After re-arranging the nature log of both sides, the optimal threshold ( TME ) can be determined by solving the resultant quadratic equation with respect to i: (i − μ0 ) 2. σ 02. ... =. + 2 log(σ 0 ) − 2 log( w0 ) = ... =. (i − μk ) 2. σ k2. (i − μn ) 2. σ n2. + 2 log(σ n ) − 2 log( wn ). (2.21). + 2 log(σ k ) − 2 log( wk ). However, the parameters wn, μn, and σ n of the mixture density function p(i ) associated with the image are unknown. In order to overcome the difficulties of estimating the unknown parameters, Kittler and Illingworth [14] presented a criterion function ψ ME (T ) , which is given by,. ψ. k. ME (T ) = 1 + 2∑ wn [ log(σ n ) + log( wn ) ] ,. (2.22). n =0. And wn, μn and σ n are respectively obtained as Eqs. (2.13), (2.14), and (2.15) which are similar to those in the computation of the between-class variance criterion. Hence, the optimal threshold set ( TME ) can be determined by minimizing the criterion function ψ ME (T ) :. TME = Arg Minψ ME (T ) 0 ≤T < L. 2.3. (2.23). The Proposed Fast Combinatorial Scheme for Efficient Selection of Multiple Thresholds. 2.3.1. The Combinatorial Search Scheme of Optimal Threshold Set Selection. To obtain the optimal threshold set T = {t1,..., tn,…, tk}, it is necessary to evaluate all the possible threshold sets to optimize the aforementioned criterion functions. ψ (T ) .. Traditionally, one can obtain the optimal threshold set by a simple and iterative, but exhaustive search procedure. The values of all thresholds in T are iteratively incremented and 21.
(36) evaluated till the maximum or minimum. ψ (T ). is obtained, and is performed as the pseudo. code procedure presented in Figure 2.1.. ( Min _ ψ ← ∞ ; for using the Minimum Error criterion). Max _ψ ← 0 ;. Optiaml _ T ← 0. for (t1 = 0 to L-1) do { . . for (tk = k-1 to L-1) do {. ψ (T ) ; (of ψ BCV (T ) , ψ Ent (T ) or ψ ME (T ) ψ (T ) > Max _ψ then (using ψ (T ) < Min _ψ. Evaluate If. ) when using the Minimum Error. criterion) { Max _ ψ ← ψ (T ) ; ( Min _ ψ ← ψ (T ) when using the Minimum Error criterion) Optiaml _ T ← T ;. } } … }. Figure 2.1. Conventional search procedure of optimal. ψ (T ). It is obvious that the exhaustive search for finding the optimal consuming.. In. order. to. obtain. L × ( L − 1) × ( L − 2)... × ( L − k + 1) =. the. optimal. threshold. set. ψ (T ) with. k. is very time thresholds,. L! possible threshold sets must be evaluated! Thus, ( L − k )!. for example, when the number of thresholds is k = 3, and the number of gray levels L = 256, the number of potential threshold sets for which the criterion function. ψ (T ). must be. evaluated is 16581120. This is because many equivalent threshold sets are repeatedly evaluated. In addition, this implementation is not scalable and parameterizable for variable amount of thresholds in multilevel thresholding, that is, the thresholding procedure cannot be 22.
(37) adapted to the changing of the number of desired thresholds k. To overcome these above mentioned drawbacks which arise from extending bi-level thresholding to multilevel thresholding cases, we introduce a combinatorial scheme to suppress the computation complexity, and to accomplish the parameterization of a desired threshold number k. The iterative procedure of evaluating all potential threshold sets for determining the optimal threshold set can be viewed as a combinatorial problem [69]. So we implement an efficient combinatorial generation procedure to obtain all potential threshold sets T. This combinatorial scheme avoids duplicate evaluation of equivalent threshold sets, and significantly reduces the amount of computation required. Looking at it as a combinatorial problem, the multilevel thresholding for selecting a set with k thresholds can be regarded as an “L choose k” problem, i.e.. ( kL ) . The combination of. a potential threshold set is denoted as a k-subset of the set of L gray levels. There are. ( kL ) = k !(LL−! k )!. k-subsets possible in L gray levels. The task now of the multilevel. thresholding is to find all these possible threshold combinations and determine the appropriate threshold set which achieves the optimal condition of the criterion function. In this study, we employ the Twiddle algorithm [70] to obtain all candidate combinations of thresholds. The Twiddle algorithm is a simple and efficient method for generating a threshold set. It has several features: 1) at each stage, only one element of the combination, i.e. C[z] as mentioned below, is altered for generating a new successive combination of numbers (threshold values), 2) this algorithm is order preserving in the sense that the elements of each threshold combination generated in each stage are strictly increasing with respect to the order of the set of L gray levels. We implement this algorithm using the C++ programming language, including several 23.
(38) necessary modifications for utilization in the C++ environment. Let the array G[0…L-1] store all elements of the set of L gray levels; and let the successive combinations be stored in the array C[0…k-1]. Consequently, one consecutive k-subset of combinations of thresholds is stored in this array in each stage of performing the Twiddle,. Then the auxiliary integer array p[0…L+1] is utilized to store the states of the Twiddle procedure. The auxiliary array p is initialized as follows: p[0] is set equal to L+1; p[1] through p[L-k] are set equal to 0; p[L-k+1] through p[L] are set equal to 1 through k, respectively, and p[L+1] is set equal to -2. When the Twiddle procedure is performed, three indexing numbers x, y, z are utilized to alter the states of the auxiliary array p and produce new successive combinations. A Boolean variable “finish” is employed as a return value of the Twiddle procedure to reflect if there are still new successive combination that can be produced. Initially, the “finish” is set equal to false, and the elements of the first combination C[0] through C[k-1] are set equal to G[L-k]. through G[L-1], respectively. Hence the Twiddle procedure is called upon, and is performed repeatedly to produce consecutive combinations by setting C[z] equal to G[x], until the “finish” is toggled to be true. The pseudo code procedure of the Twiddle is presented in Figure 2.2.. procedure Twiddle(x, y, z, p, finish): {. i ← 0, j ← 0, and k ← 0; while ( p[ j ] ≤ 0 ) do {. j ← j + 1; } If ( p[ j − 1] = 0 ) then { For ( i ← j − 1 step -1 until i = 1 ) do { p[i ] ← −1 ;. } p[ j ] ← 0 ;. 24.
(39) x ← 0 , z ← 0 and y ← j − 1 ; p[1] ← 1 ;. } Else then { If (j > 1) then { p[ j − 1] ← 0 ;. } While ( p[ j ] > 0 ) do {. j ← j + 1; }. k ← j – 1, and i ← j ; while ( p[i ] = 0 ) do { p[i ] ← −1 , then i ← i + 1;. } If ( p[i ] = −1 ) then { p[i ] ← p[k ] ; z ← p[k ] − 1 ; x ← i − 1 , and y ← k − 1 ; p[k ] ← −1 ;. } Else then { If ( i = p[0] ) then {. finish ←true; (All combinations have been produced. Then the Twiddle procedure should be terminated by toggling “finish”) Return (finish = true); } Else then { p[ j ] ← p[i ] ; z ← p[i ] − 1 ; p[i ] ← 0 ; x ← j − 1 , and y ← i − 1 ;. } } }. finish ←false; (there are still more successive combinations to be produced.) 25.
數據


+7




Outline
Motivation
The Proposed Approaches
The Combinatorial Search Scheme of Optimal Threshold Set Selection 21
Experimental Results
Localized Histogram Multilevel Thresholding
Matching Phase
Plane Construction Phase
Inter-Frame Difference Extraction / Difference Compensation and
Real-time wavelet-based video compression approach for video surveillance .169
相關文件
• It is a plus if you have background knowledge on computer vision, image processing and computer graphics.. • It is a plus if you have access to digital cameras
• It is a plus if you have background knowledge on computer vision, image processing and computer graphics.. • It is a plus if you have access to digital cameras
• It is a plus if you have background knowledge on computer vision, image processing and computer graphics.. • It is a plus if you have access to digital cameras
The stereo matching techniques developed in the computer vision community along with ima ge-based rendering (view interpolation) tech niques from graphics are both essential
Mehrotra, “Content-based image retrieval with relevance feedback in MARS,” In Proceedings of IEEE International Conference on Image Processing ’97. Chakrabarti, “Query
隨著影像壓縮技術之進步、半導體科技之快速發展、無線通訊技術與數位傳送輸技術
Mutual information is a good method widely used in image registration, so that we use the mutual information to register images.. Single-threaded program would cost
Umezaki,B., Tamaki and Takahashi,S., "Automatic Stress Analysis of Photoelastic Experiment by Use of Image Processing", Experimental Techniques, Vol.30 , P22-27,
