Elsevier Editorial System(tm) for Expert Systems With Applications Manuscript Draft
Manuscript Number:
Title: A Practical Extension of Web Usage Mining with Intentional Browsing Data toward Usage Article Type: Full Length Article
Keywords: Web usage mining; Intentional browsing data; Web log file, Browsing behaviour; Knowledge Discovery
Corresponding Author: Dr. Yu-Hui Tao,
Corresponding Author's Institution: National University of Kaohsiung First Author: Yu-Hui Tao
A Practical Extension of Web Usage Mining with Intentional
Browsing Data toward Usage
Abstract
Intentional browsing data is a new data component for improving Web usage mining that uses Web log files as the primary data source. Previously, the Web transaction mining algorithm was used in e-commerce applications to demonstrate how it could be enhanced by intentional browsing data on pages with item purchase and complemented by intentional browsing data on pages without item purchase. Although these two intention-based algorithms satisfactorily illustrated the benefits of intentional browsing data on the original Web transaction mining algorithm, three potential issues remain: Why is there a need to separate the source data into purchased-item and not-purchased-item segments to be processed by two intention-based algorithms? Moreover, can the algorithms contain more than one browsing data types? Finally, can the numeric intention-based data counts be more user friendly for decision-making practices? To address these three issues, we propose a unified intention-based Web transaction mining algorithm that can efficiently process the whole data set simultaneously with multiple intentional browsing data types as well as transform the intentional browsing data counts into easily understood linguistic items using the fuzzy set concept. Comparisons and implications for e-commerce are also discussed. Instead of addressing the technical innovation in this extension study, the revised intention-based Web usage mining algorithm should make its applications much easier and more useful in practice.
1. Introduction
Web mining can be defined simply as the application of data mining techniques to Web data [1]. The Web poses new challenges to Web mining due to its size, the complexity of Web pages, its dynamic nature, the broad diversity of user
communities, and the low relevance of useful information [2]. Cooley et al. classified Web mining into three categories, namely, Web structure mining that identifies authoritative Web pages, Web content mining that classifies Web documents automatically or constructs a multi-layered Web information base, and Web usage mining (WUM) that discovers users’ access patterns of Web pages [3]. From the data-source perspective, both Web structure and Web content mining target the Web content, while WUM targets the Web access logs that typically include the host name or IP address, remote user name, login name, date stamp, retrieval method, HTTP
completion code, and number of bytes in a file retrieved
(http://www.w3.org/TR/WD-logfile). The log file content has been shown to be valuable in many WUM studies [4-13] or data mining studies [14-16]; however, it does not include all the user interactions that the WUM algorithm can utilise.
As a result, intentional browsing data (IBD) [17], such as the scroll-bar, select, or save-as user interactions, was formally defined as a new data ingredient to be used in WUM. The benefits of IBD has been shown to improve the estimation of Web browsing time [18] and is used in illustrating Web transaction mining (WTM) algorithms [19] that explore the role of traversal and purchasing behaviour in e-commerce applications. Specifically in the case of WTM, IBD was used to enhance the intention-based WTM (IWTM) algorithm which focused on the purchased items
(IWTMp) and complemented the potential benefits of the not-purchased items not
considered before (IWTMnp). These modified algorithms meet their intended purpose
satisfactorily. However, the following practical question begs to be asked: Why is there a need to separate the data sources into purchased and not-purchased segments for two algorithms? It would be more efficient in practice to have one unified IWTM algorithm (IWTMu) to process the whole data set at one time. Furthermore, one IBD
seems to be less flexible in real-world applications. It would thus be good to allow multiple IBD types (IWTMum) such that different screens could address the most
appropriate IBD types for better usage mining effects. Moreover, according to the idea of fuzzy logic which is “to approximate human decision making using natural language terms instead of quantitative terms” [20], IBD counts seem to be not user-friendly in practice. Consequently, this paper addresses these three practical issues by proposing a unified IWTMu with fuzzy treatment on IBD (IWTMumf) and
discusses the comparative implications among IWTMp, IWTMnp, IWTMu, IWTMum,
and IWTMumf. The organisation of the paper is as follows. The IWTMpand IWTMnp
algorithms are described in Section 2, the unified IWTMumf algorithm is defined in
Section 3, an example of IWTMumf is illustrated in Section 4, a simulation experiment
presented in Section 5, and finally, the conclusions and implications of the study are discussed in Section 6.
2. Preliminaries
The original WTM algorithm assumed one merchandise item on one Web page, which was represented as B{i1}, meaning a Web page B with item i1. The purpose of
IWTMp is to show that an average user’s interest level on an item can be represented
as the occurrence of a certain IBD, which can then enhance the predictive power of the original WTM association rules [17]. For example, an IWTMp association rule on
the browsing path of Web pages A-B-F-G, that is, <ABFG: B{i1, b14}. G{i6, b61}>,
indicates additional information on Web page B with 4 occurrences of b1-type IBD,
and on Web page G with 1 occurrence of b6-type IBD. One implication is that among
users who have purchased i1 on page B, the one with a higher b1-type IBD is more
likely to purchase i6 on page G, especially if it is accompanied by any b6-type IBD.
Therefore, more resources and promotion strategies can be applied to those users with higher occurrences of corresponding b1 and b6.
On the other hand, IWTMnp was used to probe those Web pages without any
purchase by IBDs, which was not possible in the original WTM algorithm without the IBD data [17]. For example, <ABFG: F{0, b55}.G{0, b61}> implies that an average
user with browsing path A-B-F-G may not purchase anything on Web pages F and G, but has a strong potential interest on page F with 5 occurrences of b5-type IBD and
some interest on page G with 1 occurrence of b6-type IBD. Therefore, a proper
promotion effort may stimulate a user who has purchased neither on page F nor on G but with higher occurrences of corresponding b6 and b7.
The way to use IWTMp and IWTMnp in actual practice is to separately feed the
purchase data into IWTMp and then the non-purchase data into IWTMnpfor mining
results. In the domain of Web mining where speed is sometimes one of the critical performance criteria [13, 21], this unnecessary waste of time in splitting the data for two algorithms needs to be resolved. Accordingly, a unified and enhanced IWTM algorithm with fuzzy IBD linguistic terms is introduced in the next section.
3. The Unified IWTM Algorithm with Fuzzy IBDs (IWTMumf)
From a practical viewpoint, the purpose of a unified IWTMu algorithm is to
process the whole intended data set at once using only one algorithm, while IWTMum
further removes the restriction of one IBD on one Web page. Finally, IWTMumf is
meant to add fuzzy treatment on IBDs to IWTMum. We modify and enhance the
original notations, definitions, and implication rules of IWTM [17] as follows. Let N = {n1, n2, ..., np-1, np} be a set of Web pages of a Web site; I = {i1, i2, ..., im-1, im} be the
merchandise items listed in the Web site assuming one Web page can have only one merchandise item for sale; and BT = {b1o ,b1 2o ,..., b2 t-1o , bt1 to } be the IBD t-tuple t assuming each Web page has up to BT IBDs associated with corresponding
occurrences ot, where p, m, and t are none-zero positive integers and need not be the same values.
Figure 1 illustrates a Web transaction tree with associated IBDs, where A, B, ..., L represent the Web page names, and A is the entry page that usually contains no merchandise items.
Definition 1: Let {s1, s2, ..., sy} be a path sequence, where {s1, s2, ..., sy} N y
.
Definition 2: Let z be the number of fuzzy regions for IBD counts, im I for 1
m x, and b BT. A transaction pattern is represented as <s1, s2, ..., sy: n1{i1,
b1r , b1 2r ,…, b2 trz}, n2{i2, b1r , b1 2r ,…, b2 trz}, …, nx{ix, b1r , b1 2r ,…, b2 trz}>,
where rf is the fuzzy region of the f-th IBD with 1 f z, and {n1, n2, ..., nx} {s1,
s2, ..., sx} N y
.
Definition 3: Let <sy : X Y> be an association rule, where X and Y are both
subsets of (I, BT) and X∩Y =ψ.
The detailed definitions and notations of fuzzy treatment can be referred to in the work of Wang et al. [22]. Similar to either IWTMp or IWTMnp, the unified IWTMumf
in which the IBD counts are transformed into fuzzy regions for linguistic terms by a given membership function. The procedure for IWTMuf is first summarised here, and
an example is given in the next section:
Step 1: Sort all transaction records in ascending order of IDs.
Step 2: Generate a set of 1-transaction candidate patterns C1 from Step 1 with multiple fuzzy IBDs.
Step 2-1: First, calculate the occurrences of purchased items in each Web page without repetition. For each user, count only one for repeated purchases of the same items, but these should be exact occurrences of IBDs. In the case of one user having the same IBDs in different patterns, take the minimum value as a conservative estimate since the IBD potential has yet to be realised. Then take the maximum value among all users having the same IBD occurrences. Repeat the same procedure for counterpart Web pages without item purchases.
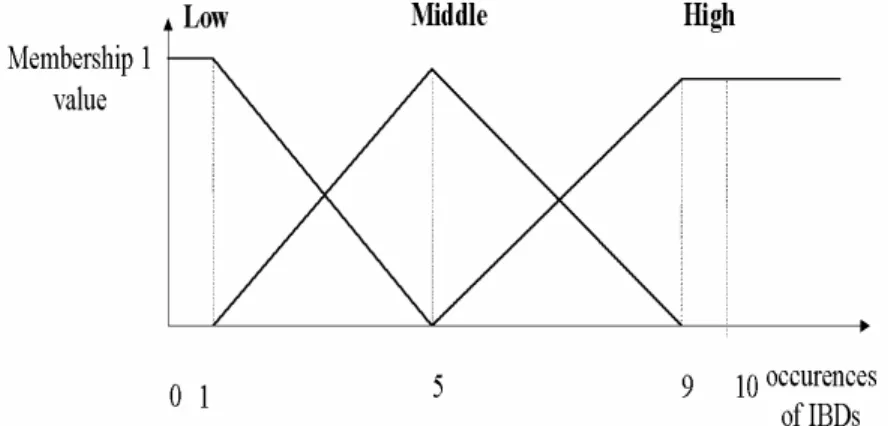
Step 2-2: For each item in C1, convert the occurrence values of multiple IBDs for each Web page into the membership values in all of the fuzzy regions according to the given membership function. An example of a membership function is shown in Figure 2.
Step 2-3: The scalar cardinality of each fuzzy region in all users is calculated as the count value.
Step 2-4: The fuzzy region with the highest IBD count among all of the possible regions for each Web page is selected. A set of 1-transaction candidate patterns C1 is then completed with the semantic information of IBDs.
Step 3: Set two minimum support values, one for the patterns with item purchases and the other for those without purchases. Save all C1 items whose sums of occurrences are greater than or equal to the minimum support value into large 1-transaction patterns T1, which represents possible browsing paths for purchasing or not purchasing an item over a hurdle value.
Step 4: Generate a set of candidate 2-transaction patterns C2 by joining items in T1.
Step 4-1: According to the Web browsing sequential paths, generate a set of candidate 2-transaction patterns C2 by joining items in T1.
Step 4-2: Calculate the fuzzy membership values of all C2 patterns for all user IDs. For each C2 pattern, first take the minimum value of pattern components within the same user ID as a conservative estimate similar to Step 2-1, and then sum them up across user IDs. Repeat the same process for all C2 patterns.
Step 5: Set the minimum support values and save all C2 items whose sums of occurrences are greater than or equal to the minimum support value into large 2-transaction patterns T2.
Step 6: Repeat Steps 4 and 5 until no large k-transaction sets can be generated. IWTMumf differs from IWTMp or IWTMnp mainly in three aspects. First, all
records enter into IWTMu in Step 1 and are processed differently in Step 2 for records
with purchases and without purchases as they are in IWTMp and IWTMnp,
respectively. Second, items with purchases and without purchases are joined in a mixed way after Step 3. Therefore, minimum support values can be set differently as in IWTMp and IWTMnp in Steps 3 and 5 so that IWTMu is guaranteed to cover
whatever outcomes IWTMp and IWTMnp have. Third, the multiple IBD counts, which
are different in IWTMp and IWTMnp, are transformed into a linguistic representation
in IWTMumf so that the association rules are much user friendly during business
implementation or actual practice.
4. An Example of IWTMumf
In order to easily demonstrate how the algorithm works, we only considered three IBDs, that is, BT (b1, b2, b3), on all Web pages. We illustrate IWTMumf using the
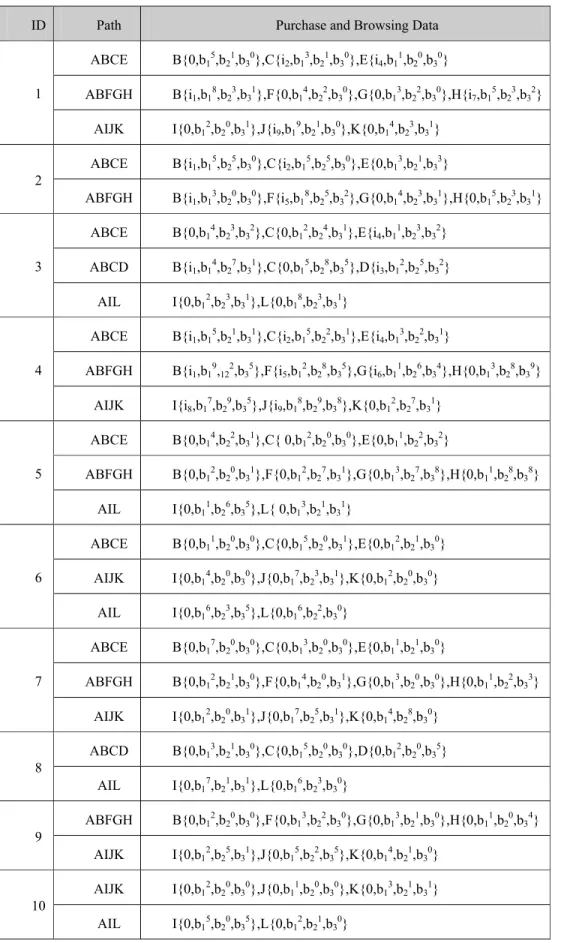
Step 1: Order user Web browsing transaction records in the ascending order of IDs. Table 1 lists the user IDs, Web sequential browsing paths, and sets of (item, BT)
which represent purchase states and corresponding IBD occurrences of b1, b2, and b3.
Notice that every path contains both items with purchases and without purchases such as B{0,b15,b21,b30}, C{i2,b13,b21,b30}, and E{i4,b11,b20,b30} which exist in the path of
ABCE path for user ID 1, where item zero represents no purchase.
Step 2: Generate the candidate set C1 from all the pages with or without item purchases.
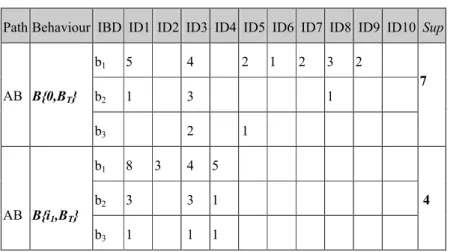
Step 2-1: For the with-purchase illustration, user ID 2 in Table 1 has purchased i1
on page B twice, namely, B{i1,b15,b25,b30} and B{i1,b13,b20,b30}, which are counted
only once. Among the 10 users of IDs 1-10, only users 1-4 had purchased i1 on page
B, which leads to a support value of 4 for i1 purchase on page B, as seen in the last
column of Table 2. A similar process is applied to the IBD. The frequency of b1 is
calculated first as the minimum value for each user. For the with-purchase illustration, user ID 2 in Table 1 has purchased i1 on page B twice, namely, B{i1,b15,b25,b30} and
B{i1,b13,b20,b30}, which are calculated as min(b15, b13) = b13, min(b25, b20) = b20, and
min(b30, b30) = b30. This means that the IBD occurrence tuple is (3,0,0) for user ID 2
on page B with purchase. On the other hand, B{0, BT} of path AB, which is the
b12, b11 , b12, b13, b12}= b15 from IDs 1, 3, 5, 6, 7, 8, and 9. This calculation is
repeated for all users with purchase items and without purchase items as seen in Table 2. Due to the length of the tabulation, only partial results are listed in Table 2.
Step 2-2: The occurrence values of IBDs for each user on the Web page from Table 2 are converted into the fuzzy sets by the given membership function in Figure 2. For instance, the IBD value of B{0, BT} for user ID 3 is 4, which is converted into
the fuzzy set (0.25/Low+0.75/middle +0/High). The complete result of items in Table 2 can be seen in Table 3, in which each item has its values in the regions of Low, Middle, and High. Again, only partial results are listed in Table 3.
Step 2-3: In Table 3, the scalar cardinality of each fuzzy region in all users is calculated as the count value. Taking the Low fuzzy region of b1 for Web page B
without purchase B{0,BT} as an example, its scalar cardinality equals
(0.0+0.0+0.25+0.0+0.75+1.0+0.75+0.5+0.75 +0.0)=4 as indicated in the last column of Table 3. This step is repeated for all other regions and for all behaviour items.
Step 2-4: The fuzzy region with the highest count among the three possible regions for each Web page is selected. Taking the IBD of b1 in B{0,BT} as an
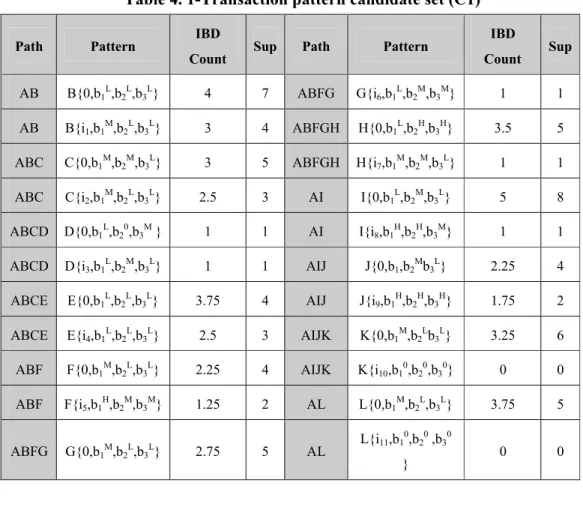
example, its counts are 4 for Low (L), 3 for Middle (M), and 0 for High(H). Since the count for Low is the highest among the three counts, the region Low is thus used to represent the occurrences of b1L for pattern B{0,BT} in later mining processes as
shown in the first path AB by B{0, BT} with support value (Sup) 7 in Table 4. Notice
that Sup is calculated in Step 2-1 as explained earlier. This step is repeated for all other IBDs. Steps 2-2 to 2-4 complete the fuzzy treatment of IBD counts and thus the complete C1 is shown in Table 4.
Step 3: Assume that the minimum support value for item purchase is 2 and for no item purchase, 6. The rationale for the different minimum support values is that among all the records, a practical Web site would have more no-purchased transactions than purchased transactions. Therefore, a higher initial minimum support value on no-purchase transactions will quickly filter out a large portion of insignificant no-purchase items. Save the transaction patterns with purchases whose support values are greater than or equal to 2 in the large 1-transaction pattern set T1. Similarly, save the transaction patterns without purchase whose support values are greater than or equal to 6 in the large 1-transaction pattern set T1 as seen in Table 5.
Step 4: Generate a set of candidate 2-transaction patterns C2 by joining items in T1.
Step 4-1: According to the Web sequential browsing paths, generate the 2-transaction pattern candidate set C2 from T1 by joining items in T1 as shown in Table 6. Notice that the Sup value is determined by the occurrence counts of the
behaviour items found in Table 1. If the count is 0, then the 2-transaction pattern is not shown in Table 6.
Step 4-2: For each user ID, the fuzzy membership values of each 2-transaction pattern in candidate set C2 is calculated. For example, when calculating B{i1,b1,b2,b3
} of ID1 as seen in Table 3, the fuzzy region value of (0.25/b1M+0.5/b2L+1/b3L) is
calculated as max(0.25,0.5,1)=1, that is, the fuzzy value of B{i1,b1M,b2L , b3L } is 1.
Repeat the fuzzy-value calculation of all patterns for each user. The minimum operator is used for the intersection. Taking <ABC: B{i1,b1M,b2L,b3L }, C{i2,b1M,b2L,
b3L}> as an example, its membership value for ID 1 in Table 3 is calculated as
min(1.0, 1.0) = 1.0. The overall membership value for <ABC: B{i1,b1M,b2L, b3L },
C{i2,b1M,b2L, b3L}> is 2.5, which is calculated by adding up the membership values of
IDs 1-10 as shown in Table 7.
Step 4-3: The scalar cardinality (count) of each candidate 2-item set in C2 is
calculated as seen in Table 8.
Step 5: Assuming both minimum support values are set to 2, only those patterns whose support values are greater than or equal to 2 are kept in the large 2-transaction pattern set T2 as seen in Table 9.
Step 6: According to the Web sequential browsing paths, generate 3-transaction pattern candidate set C3 by joining the item sets from T2 as seen in Table 10. Since
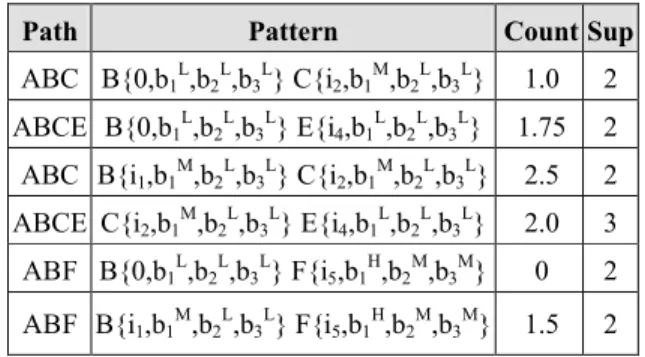
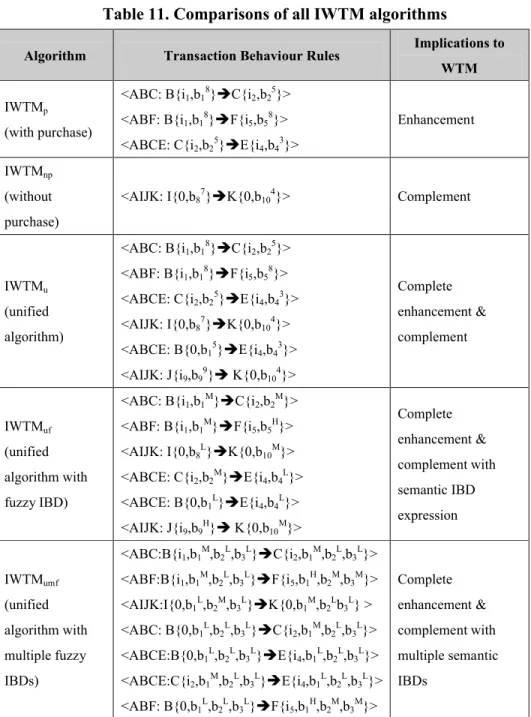
all the support values are less than the minimum support value 2, this algorithm ends here. Accordingly, the final results generate six association fuzzy rules as suggested by T2 in Table 9, which can be seen in Table 11 under Section 5.
The derived rules from IWTMumf are listed together with the ones from IWTMp,
IWTMnp, IWTMu, and IWTMfu in Table 11. As we can see, the unified IWTMu
algorithm not only covers all the (first four) rules derived from both IWTMp and
IWTMnp, but also generates two new rules by rejoining the split data sets. In other
words, IWTMu can efficiently obtain the same results as IWTMp and IWTMnpdo while
simultaneously enriching the rule base of previous IWTM algorithms. For instance, the new rule <ABCE: B{0,b15}E{i4,b43}> implies that an average user who did not
purchase on page B but with a high interest level of b15-type IBD may purchase items
on Web pages E with high levels of b15-type or b43-type IBDs, respectively. In
practice, we can allocate more resources to promote any user who has presented a high occurrence of b1-type IBD on page B for potential purchase on page E.
Furthermore, more dedicated strategies can be deployed based on the interest levels of b15 so that more accurate customer targeting and marketing performance may be
achieved.
On the other hand, the rules derived from IWTMuf and IWTMu are identical except
As a result, the IBD is expressed in a more natural and understandable way for decision makers to apply the association rules in practice as suggested in [20]. Finally, IWTMumf has evolved into an integral version that preserves all the intended
characteristics while removing the restriction of one IBD per page. Therefore, the derived rules are identical to the ones from either IWTMufor IWTMu,except that more
IBDs are included as extra clues for decision making. From the view of WTM evolution, the IWTMumf algorithm has been demonstrated to present a highly
integrated view on IBD.
5. A Simulation Experiment
The merits of the integrated IWTMumf and some extra benefits have been clearly
demonstrated through the examples in the above section. In this section, a simulation experiment was used to further illustrate and explore how this unified algorithm could be useful to a decision maker by another example, that of a Web toy store. The scenario is that the daily volumes of browsing and sales in this Web toy store are stable but are significantly increased during holidays such as Halloween and Christmas. Therefore, the management of this Web toy store is interested in knowing what toy items are more attractive to buyers in order to appropriately allocate the
marketing budget in online promotion for a typical business day as well as for a national holiday.
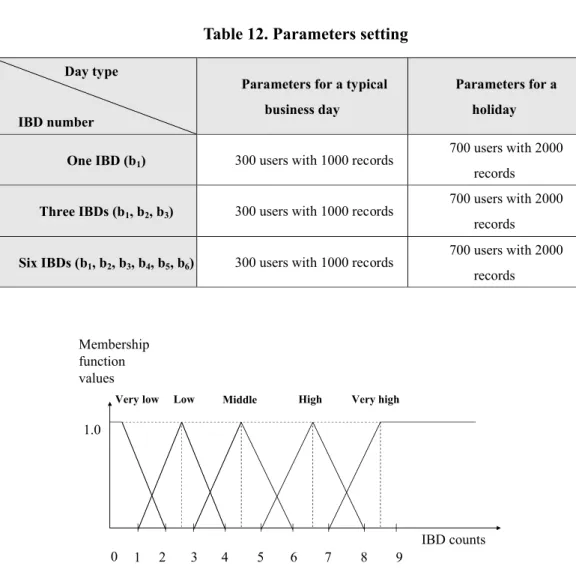
Assume there were 22 different items as shown in Figure 3. One typical business day and one national holiday were simulated assuming an average of 300 users with 1000 records for a typical business day and 700 users with 2000 records for a holiday. In order to explore the impact of the number of IBDs, the simulation runs were conducted with one IBD, three IBDs, and six IBDs, respectively. The experimental matrix of IBD number versus day type is listed in Table 12. The six IBDs are rolling the scroll bar (b1), clicking a hyperlink (b2), hitting the back hyperlink (b3), selecting a
range of context (b4), printing a page (b5), and copying texts (b6). The first three IBDs
belonged to page manipulation behaviors, while the last three belonged to data retrieval behaviors.
In order to appropriately present the fuzzy semantic for IBD information in this case, the membership function has been modified to become a five-layer hierarchical area as shown in Figure 4 with the semantic of Very Low (S), Low (L), Middle (M), High (H), and Very High (X). A simple program was implemented using Borland’s C++ Builder using text files as the input and output files. The program interface for executing IWTMufm is shown in Figure 5, which sets up mining data sources,
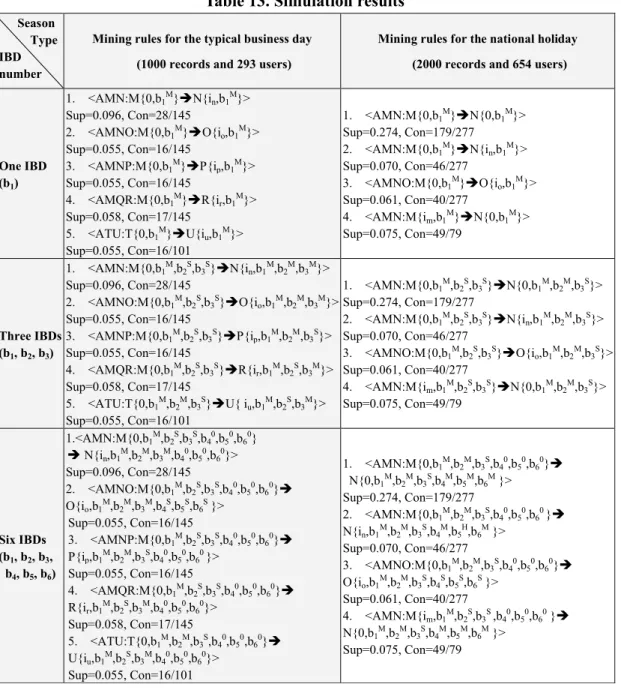
merchandises in area A, path structure in area B, and algorithm execution procedures in area C. Using the same random number seeds for the three simulation runs, five rules were mined out for the typical business day and four for the national holiday under one, three, and six IBDs as seen in Table 13.
To avoid describing the lengthy analytical process, only important observations from Table 13 with practical implications for decision making are included as follows:
First, the major strength of IWTMumf is that it can mine additional rules with all
merchandise items and even including those without any purchases. Take the first four mined rules from the typical business day under the one IBD case for example. Although there was no purchase of merchandise item im in page M, certain IBD
activities in page M still imply consequent purchases on merchandise items in in page
N, io in page O, ip in page P, or ir in page R. Similar examples can be found in the
mined rules for the holiday and for three and six IBD cases. Therefore, this simulation experiment confirmed again the integrated mining convenience of IWTMumf over
IWTMp and IWTMnp.
There are four new observations that can be concluded from this simulation experiment. First, applying IWTMumf to different typical days was necessary. Mined
Rules 4 and 5 for the typical business day were not shown for the typical holiday. This implies that different scenarios need to be identified when applying IWTMumf for
better adoption effectiveness. Second, the higher number of users and transaction records did not generate more mined rules. There were five mined rules for the typical business day, while there were only four for the national holiday. Therefore, this implies that IWTMumf can be quickly adopted without a large data set, which makes it
a low-entry hurdle algorithm in practice. Third, more IBDs in the mined rules provide a better fine-tuning capability to effectively allocate resources for executing marketing strategies. For example, in the first mined rule for the typical business day, if only one IBD (b1) was recorded when two users browsed page M with the same M
level of interest on b1, the same marketing strategy applies to both users. However, in
the same situation, if six IBDs were recorded, then when any one of the remaining five IBDs was captured differently, a different marketing strategy can be deployed. This implies that multiple IBDs are preferred in practical applications of IWTMumf.
Finally, contrary to the above observation, too many IBDs may degrade the usability of the mined rules. In the six-IBD case, mapping the large number of IBD semantic combinations (56) to marketing strategies becomes complicated. Even for the three-IBD case, there are already 125 (53) combinations. Therefore, it is recommended that only critical and representative IBDs should be included in IWTMumf for the purpose of increasing its usability in practical applications.
6. Conclusions and Future Work
This paper focused on practical improvements that were not addressed in the illustrative work [17] regarding how potential benefits could be brought into the traditional WTM algorithm for e-commerce applications. We have successfully shown how an integrated IWTMumf algorithm could capture the same outcomes as
IWTMp and IWTMnp algorithms do while deriving additional association rules and
accommodating multiple IBD types. Moreover, IBD counts in derived association rules were converted to a more readable expression of linguistic terms via the fuzzy set concept to heed the suggestion of Bih [20]. In other words, IWTMumf is indeed an
efficient replacement of IWTMp and IWTMnp algorithms and an effective
improvement of the volume of useful association rules in practical business applications.
Accordingly, the major contribution of this study as an extension work is that any electronic-commerce Web site can now more effectively and efficiently utilise IWTMumf to make recommendations to their customers based on their intentions as no
other WUM algorithm has ever done before. This was due to the newly defined IBD source, which was analytically demonstrated in the sample example in Section 4 and which was partially illustrated by the toy-store simulation experiment in Section 5. Nevertheless, establishing the capability of collecting IDBs from Web users is not
trivial; thus, one immediate future work may be to seek the cooperation of an electronic-commerce Web site for experimenting IWTMnp in real-world operations
based on the work of Tao et al. [17]. Another future technical work is to relieve the constraint of one merchandise item per Web page in IWTMumf, as posed by the
original WTM algorithm [19], the purpose of which is to make IWTMumf an
empirically validated method in practical applications.
7. References
[1] Oren, E. (1996). The World Wide Web: quagmire or gold mine, Communications of the ACM, 39, 65-68.
[2] Han, J. and Kamber, M. (2001) .Data Mining: Concepts and Techniques, Academic Press.
[3] Cooley, R. Mobasher, B. and Srivastava, J. (1999). Data preparation for mining World Wide Web browsing patterns, Journal of Knowledge and Information Systems, 1(1), 5-32.
[4] Chen, M. S. Park, J. S. and Yu, P. S. (1998). Efficient data mining for path traversal patterns, IEEE Transaction on Knowledge and Data Engineering, 10(2), 209-221.
[5] Perkowitz M. and Etzioni, O. (2000). Towards adaptive Web sites: conceptual framework and case study, Artificial Intelligence, 118(1-2), 245-275.
[6] Spiliopoulou, M. (2000). Web usage mining for Web site evaluation, Communications of the ACM, 43(8), 127 – 134.
[7] Bonchi, F. Giannotti, F. Gozzi, C. Manco, G. Nanni, M. Pedreschi, D. Renso, C. and Ruggieri, S. (2001). Web log data warehousing and mining for intelligent web caching, Data and Knowledge Engineering, 39(2), 165-189.
[8] Zhang, D. and Dong, Y. (2002). A novel Web usage mining approach for search engines, Computer Networks, 39(3), 303-310.
[9] Cooley, R. (2003). The use of web structure and content to identify subjectively interesting web usage patterns, ACM Transactions on Internet Technology, 3(2), 93-116.
[10] Bae, S. M., Park, S. C. and Ha, S. H. (2003). Fuzzy Web ad selector based on Web usage mining, IEEE Intelligent Systems, 18(6), 62-69.
[11] Tanasa, D. and Trousse, B. (2004). Advanced data preprocessing for intersites Web usage mining, IEEE Intelligent Systems, 19(2), 59-65.
[12] Girardi, R. Marinho, L. B. and de Oliveira, I. R. (2005). A system of agent-based software patterns for user modelling based on usage mining, Interacting with Computers, 17(5), 567-591.
[13] Huang, Y.-M. Kuo, Y.-H. Chen, J.-N. and Jeng, Y.-L. (2006). NP-miner: A real-time recommendation algorithm by using web usage mining,
Knowledge-Based Systems, 19(4), 272-286.
[14] Thelwall, M. (2001). A Web crawler design for data mining, Journal of Information Science, 27(5), 319-325.
[15] Chang, J. H. and Lee, W. S. (2005). Efficient mining method for retrieving sequential patterns over online data streams, Journal of Information Science, 31(5), 420-432.
[16] Liao, S. S., He, J.W. and Tang, T. H. (2004). A framework for context information management, Journal of Information Science, 30(6), 528-539. [17] Tao, Y. H. Su, Y. M. and Hong, T. P. (2008).Web usage mining algorithm with
intentional browsing data, Expert System with Applications, 35(4). [18] Tao, Y. H., Hong, T.P. and Su, Y.M. (2006). Improving browsing time
estimation with intentional behaviour data, International Journal of Computer Science and Network Security, 6(12), 35-39.
[19] Yun, C.H. and Chen, M. S. (2000).Using pattern-join and purchase-combination for mining transaction patterns in an electronic commerce environment, The 24th Annual International Conference on Computer Software and Applications
Taiwan, R.O.C., 99-104.
[20] Bih, J. (2006), Paradigm shift - an introduction to fuzzy logic, IEEE Potentials, 25(1), 6-21.
[21] Song, Q. and Shepperd, M. (2006). Mining Web browsing patterns for e-commerce, Computers in Industry, 57, 622-630.
[22] Wang, S. L., Lo, W. S. and Hong, T. P. (2002). Discovery of fuzzy multiple-level Web browsing patterns, in Proceedings of the International Conference on Fuzzy Systems and Knowledge Discovery, Singapore.
b10 i10 K b11 i11 L b9 i9 J b8 i8 I b7 i7 H b6 i6 G b5 i5 F b4 i4 E b3 i3 D b2 i2 C b1 i1 B -A IB D Item s N o de (B ) A B C D E F G H I J K L (A )
Figure 1. A Web transaction tree and corresponding transaction data
Table 1. The list of general transaction patterns by user ID
ID Path Purchase and Browsing Data
ABCE B{0,b15,b21,b30},C{i2,b13,b21,b30},E{i4,b11,b20,b30}
ABFGH B{i1,b18,b23,b31},F{0,b14,b22,b30},G{0,b13,b22,b30},H{i7,b15,b23,b32}
1
AIJK I{0,b12,b20,b31},J{i9,b19,b21,b30},K{0,b14,b23,b31}
ABCE B{i1,b15,b25,b30},C{i2,b15,b25,b30},E{0,b13,b21,b33}
2
ABFGH B{i1,b13,b20,b30},F{i5,b18,b25,b32},G{0,b14,b23,b31},H{0,b15,b23,b31}
ABCE B{0,b14,b23,b32},C{0,b12,b24,b31},E{i4,b11,b23,b32}
ABCD B{i1,b14,b27,b31},C{0,b15,b28,b35},D{i3,b12,b25,b32}
3
AIL I{0,b12,b23,b31},L{0,b18,b23,b31}
ABCE B{i1,b15,b21,b31},C{i2,b15,b22,b31},E{i4,b13,b22,b31}
ABFGH B{i1,b19,122,b35},F{i5,b12,b28,b35},G{i6,b11,b26,b34},H{0,b13,b28,b39}
4
AIJK I{i8,b17,b29,b35},J{i9,b18,b29,b38},K{0,b12,b27,b31}
ABCE B{0,b14,b22,b31},C{ 0,b12,b20,b30},E{0,b11,b22,b32} ABFGH B{0,b12,b20,b31},F{0,b12,b27,b31},G{0,b13,b27,b38},H{0,b11,b28,b38} 5 AIL I{0,b11,b26,b35},L{ 0,b13,b21,b31} ABCE B{0,b11,b20,b30},C{0,b15,b20,b31},E{0,b12,b21,b30} AIJK I{0,b14,b20,b30},J{0,b17,b23,b31},K{0,b12,b20,b30} 6 AIL I{0,b16,b23,b35},L{0,b16,b22,b30} ABCE B{0,b17,b20,b30},C{0,b13,b20,b30},E{0,b11,b21,b30} ABFGH B{0,b12,b21,b30},F{0,b14,b20,b31},G{0,b13,b20,b30},H{0,b11,b22,b33} 7 AIJK I{0,b12,b20,b31},J{0,b17,b25,b31},K{0,b14,b28,b30} ABCD B{0,b13,b21,b30},C{0,b15,b20,b30},D{0,b12,b20,b35} 8 AIL I{0,b17,b21,b31},L{0,b16,b23,b30} ABFGH B{0,b12,b20,b30},F{0,b13,b22,b30},G{0,b13,b21,b30},H{0,b11,b20,b34} 9 AIJK I{0,b12,b25,b31},J{0,b15,b22,b35},K{0,b14,b21,b30} AIJK I{0,b12,b20,b30},J{0,b11,b20,b30},K{0,b13,b21,b31} 10 AIL I{0,b15,b20,b35},L{0,b12,b21,b30}
Table 2. The occurrence values of IBD for all user IDs
Path Behaviour IBD ID1 ID2 ID3 ID4 ID5 ID6 ID7 ID8 ID9 ID10 Sup
b1 5 4 2 1 2 3 2 b2 1 3 1 AB B{0,BT} b3 2 1 7 b1 8 3 4 5 b2 3 3 1 AB B{i1,BT} b3 1 1 1 4
Table 3. The counts of fuzzy regions for candidate sets C1
Path Behaviour IBD Region ID1 ID2 ID3 ID4 ID5 ID6 ID7 ID8 ID9 ID10 Count Sup
Low 0.25 0.75 1 0.75 0.5 0.75 4 Middle 1 0.75 0.25 0.25 0.5 0.25 3.0 b1 High 0 Low 1 0.5 1 2.5 Middle 0.5 0.5 b2 High 0 Low 0.75 1 1.75 Middle 0.25 0.25 AB B{0,BT} b3 High 0 7 Low 0.5 0.25 0.75 Middle 0.25 0.5 0.75 1 2.5 b1 High 0.75 0.75 Low 0.5 0.5 1 2 Middle 0.5 0.5 1 b2 High 0 Low 1 1 1 3 Middle 0 AB B{i1,BT} b3 High 0 4
Table 4. 1-Transaction pattern candidate set (C1)
Path Pattern IBD
Count Sup Path Pattern
IBD
Count Sup
AB B{0,b1L,b2L,b3L} 4 7 ABFG G{i6,b1L,b2M,b3M} 1 1
AB B{i1,b1M,b2L,b3L} 3 4 ABFGH H{0,b1L,b2H,b3H} 3.5 5
ABC C{0,b1M,b2M,b3L} 3 5 ABFGH H{i7,b1M,b2M,b3L} 1 1
ABC C{i2,b1M,b2L,b3L} 2.5 3 AI I{0,b1L,b2M,b3L} 5 8
ABCD D{0,b1L,b20,b3M } 1 1 AI I{i8,b1H,b2H,b3M} 1 1
ABCD D{i3,b1L,b2M,b3L} 1 1 AIJ J{0,b1,b2Mb3L} 2.25 4
ABCE E{0,b1L,b2L,b3L} 3.75 4 AIJ J{i9,b1H,b2H,b3H} 1.75 2
ABCE E{i4,b1L,b2L,b3L} 2.5 3 AIJK K{0,b1M,b2Lb3L} 3.25 6
ABF F{0,b1M,b2L,b3L} 2.25 4 AIJK K{i10,b10,b20,b30} 0 0
ABF F{i5,b1H,b2M,b3M} 1.25 2 AL L{0,b1M,b2L,b3L} 3.75 5
ABFG G{0,b1M,b2L,b3L} 2.75 5 AL
L{i11,b10,b20 ,b30
} 0 0
Table 5. Large 1-Transaction Pattern Set (T1)
Path Pattern Sup Path Pattern Sup
AB B{0,b1L,b2L,b3L} 7 ABF F{i5,b1H,b2M,b3M} 2
AB B{i1,b1M,b2L,b3L} 4 AI I{0,b1L,b2M,b3L} 8
ABC C{i2,b1M,b2L,b3L} 3 AIJ J{i9,b1H,b2H,b3H} 2
ABCE E{i4,b1L,b2L,b3L} 3 AIJK K{0,b1M,b2Lb3L} 6
Table 6. 2-Transaction Pattern Candidate Set (C2)
Path Pattern Sup Path Pattern Sup
ABC B{0,b1L,b2L,b3L} C{i2,b1M,b2L,b3L} 2 ABF B{0,b1L,b2L,b3L} 2
ABC B{i1,b1M,b2L,b3L} C{i2,b1M,b2L,b3L} 2 AIJ B{i1,b1M,b2L,b3L} 2
ABCE B{0,b1L,b2L,b3L} E{i4,b1L,b2L,b3L} 2 AIJK I{0,b1L,b2M,b3L} 1
ABCE B{i1,b1M,b2L,b3L } E{i4,b1L,b2L,b3L} 1 AIJK I{0,b1L,b2M,b3L} 5
Table 7. The membership values for <B{i1,b1M} C{i2,b2M}> of all users.
ID B{i1,b1M,b2L,b3L } C{i2,b1M,b2L,b3L} B{i1,b1M,b2L,b3L } C{i2,b1M,b2L,b3L}
1 1.0 1.0 1.0 2 0.5 1.0 0.5 3 0.75 0 0 4 1.0 1.0 1.0 5 0 0 0 6 0 0 0 7 0 0 0 8 0 0 0 9 0 0 0 10 0 0 0 Total 2.5
Table 8. 2-transaction pattern candidate set with fuzzy counts
Path Pattern ID1 ID2 ID3 ID4 ID5 ID6 ID7 ID8 ID9 ID10 Count Sup ABC B{0,b1L,b2L,b3L} C{i2,b1M,b2L,b3L} 1.0 1.0 2
ABCE B{0,b1L,b2L,b3L} E{i4,b1L,b2L,b3L} 1.0 0.75 1.75 2
ABC B{i1,b1M,b2L,b3L} C{i2,b1M,b2L,b3L} 1.0 0.5 1.0 2.5 2
ABCE B{i1,b1M,b2L,b3L } E{i4,b1L,b2L,b3L} 1.0 1.0 1.0 3.0 1
ABCE C{i2,b1M,b2L,b3L} E{i4,b1L,b2L,b3L} 1.0 1.0 2.0 3
ABF B{0,b1L,b2L,b3L} F{i5,b1H,b2M,b3M} 0 2
ABF B{i1,b1M,b2L,b3L} F{i5,b1H,b2M,b3M} 0.5 1.0 1.5 2
AIJ I{0,b1L,b2M,b3L} J{i9,b1H,b2H,b3H} 1.0 1.0 1
AIJK I{0,b1L,b2M,b3L} 1.0 0.25 0.75 1.0 0.75 3.75 5
Table 9. Large 2-transaction pattern set (T2)
Path Pattern Count Sup
ABC B{0,b1L,b2L,b3L} C{i2,b1M,b2L,b3L} 1.0 2
ABCE B{0,b1L,b2L,b3L} E{i4,b1L,b2L,b3L} 1.75 2
ABC B{i1,b1M,b2L,b3L} C{i2,b1M,b2L,b3L} 2.5 2
ABCE C{i2,b1M,b2L,b3L} E{i4,b1L,b2L,b3L} 2.0 3
ABF B{0,b1L,b2L,b3L} F{i5,b1H,b2M,b3M} 0 2
Table 10. 3-transaction pattern candidate set (C3)
Path Behaviour Sup
ABCE B{0,b1L,b2L,b3L} C{i2,b1M,b2L,b3L} E{i4,b1L,b2L,b3L} 1
ABCE B{i1,b1M,b2L,b3L} C{i2,b1M,b2L,b3L} E{i4,b1L,b2L,b3L} 1
Table 11. Comparisons of all IWTM algorithms
Algorithm Transaction Behaviour Rules Implications to
WTM
IWTMp
(with purchase)
<ABC: B{i1,b18}C{i2,b25}>
<ABF: B{i1,b18}F{i5,b58}>
<ABCE: C{i2,b25}E{i4,b43}>
Enhancement
IWTMnp
(without purchase)
<AIJK: I{0,b87}K{0,b104}> Complement
IWTMu
(unified algorithm)
<ABC: B{i1,b18}C{i2,b25}>
<ABF: B{i1,b18}F{i5,b58}>
<ABCE: C{i2,b25}E{i4,b43}>
<AIJK: I{0,b87}K{0,b104}> <ABCE: B{0,b15}E{i4,b43}> <AIJK: J{i9,b99} K{0,b104}> Complete enhancement & complement IWTMuf (unified algorithm with fuzzy IBD)
<ABC: B{i1,b1M}C{i2,b2M}>
<ABF: B{i1,b1M}F{i5,b5H}>
<AIJK: I{0,b8L}K{0,b10M}>
<ABCE: C{i2,b2M}E{i4,b4L}>
<ABCE: B{0,b1L}E{i4,b4L}> <AIJK: J{i9,b9H} K{0,b10M}> Complete enhancement & complement with semantic IBD expression IWTMumf (unified algorithm with multiple fuzzy IBDs) <ABC:B{i1,b1M,b2L,b3L}C{i2,b1M,b2L,b3L}> <ABF:B{i1,b1M,b2L,b3L}F{i5,b1H,b2M,b3M}> <AIJK:I{0,b1L,b2M,b3L}K{0,b1M,b2Lb3L} > <ABC: B{0,b1L,b2L,b3L}C{i2,b1M,b2L,b3L}> <ABCE:B{0,b1L,b2L,b3L}E{i4,b1L,b2L,b3L}> <ABCE:C{i2,b1M,b2L,b3L}E{i4,b1L,b2L,b3L}> <ABF: B{0,b1L,b2L,b3L}F{i5,b1H,b2M,b3M}> Complete enhancement & complement with multiple semantic IBDs
A B C D E F G H I J K L M N O P Q R S T U V W
Figure 3. Item tree for the Web toy store Table 12. Parameters setting
1 5 9 0 Membership function values IBD counts
Very low Middle Very high
2 3 4 6 7 8
Low High
1.0
Figure 4. Modified membership functions for the IBD
Day type IBD number
Parameters for a typical business day
Parameters for a holiday One IBD (b1) 300 users with 1000 records
700 users with 2000 records
Three IBDs (b1, b2, b3) 300 users with 1000 records
700 users with 2000 records
Six IBDs (b1, b2, b3, b4, b5, b6) 300 users with 1000 records
700 users with 2000 records
Table 13. Simulation results
Season Type IBD number
Mining rules for the typical business day (1000 records and 293 users)
Mining rules for the national holiday (2000 records and 654 users)
One IBD (b1) 1. <AMN:M{0,b1M}N{in,b1M}> Sup=0.096, Con=28/145 2. <AMNO:M{0,b1M}O{io,b1M}> Sup=0.055, Con=16/145 3. <AMNP:M{0,b1M}P{ip,b1M}> Sup=0.055, Con=16/145 4. <AMQR:M{0,b1M}R{ir,b1M}> Sup=0.058, Con=17/145 5. <ATU:T{0,b1M}U{iu,b1M}> Sup=0.055, Con=16/101 1. <AMN:M{0,b1M}N{0,b1M}> Sup=0.274, Con=179/277 2. <AMN:M{0,b1M}N{in,b1M}> Sup=0.070, Con=46/277 3. <AMNO:M{0,b1M}O{io,b1M}> Sup=0.061, Con=40/277 4. <AMN:M{im,b1M}N{0,b1M}> Sup=0.075, Con=49/79 Three IBDs (b1, b2, b3) 1. <AMN:M{0,b1M,b2S,b3S}N{in,b1M,b2M,b3M}> Sup=0.096, Con=28/145 2. <AMNO:M{0,b1M,b2S,b3S}O{io,b1M,b2M,b3M}> Sup=0.055, Con=16/145 3. <AMNP:M{0,b1M,b2S,b3S}P{ip,b1M,b2M,b3S}> Sup=0.055, Con=16/145 4. <AMQR:M{0,b1M,b2S,b3S}R{ir,b1M,b2S,b3M}> Sup=0.058, Con=17/145 5. <ATU:T{0,b1M,b2M,b3S}U{ iu,b1M,b2S,b3M}> Sup=0.055, Con=16/101 1. <AMN:M{0,b1M,b2S,b3S}N{0,b1M,b2M,b3S}> Sup=0.274, Con=179/277 2. <AMN:M{0,b1M,b2S,b3S}N{in,b1M,b2M,b3S}> Sup=0.070, Con=46/277 3. <AMNO:M{0,b1M,b2S,b3S}O{io,b1M,b2M,b3S}> Sup=0.061, Con=40/277 4. <AMN:M{im,b1M,b2S,b3S}N{0,b1M,b2M,b3S}> Sup=0.075, Con=49/79 Six IBDs (b1, b2, b3, b4, b5, b6) 1.<AMN:M{0,b1M,b2S,b3S,b40,b50,b60} N{in,b1M,b2M,b3M,b40,b50,b60}> Sup=0.096, Con=28/145 2. <AMNO:M{0,b1M,b2S,b3S,b40,b50,b60} O{io,b1M,b2M,b3M,b4S,b5S,b6S }> Sup=0.055, Con=16/145 3. <AMNP:M{0,b1M,b2S,b3S,b40,b50,b60} P{ip,b1M,b2M,b3S,b40,b50,b60 }> Sup=0.055, Con=16/145 4. <AMQR:M{0,b1M,b2S,b3S,b40,b50,b60} R{ir,b1M,b2S,b3M,b40,b50,b60}> Sup=0.058, Con=17/145 5. <ATU:T{0,b1M,b2M,b3S,b40,b50,b60} U{iu,b1M,b2S,b3M,b40,b50,b60}> Sup=0.055, Con=16/101 1. <AMN:M{0,b1M,b2M,b3S,b40,b50,b60} N{0,b1M,b2M,b3S,b4M,b5M,b6M }> Sup=0.274, Con=179/277 2. <AMN:M{0,b1M,b2M,b3S,b40,b50,b60 } N{in,b1M,b2M,b3S,b4M,b5H,b6M }> Sup=0.070, Con=46/277 3. <AMNO:M{0,b1M,b2M,b3S,b40,b50,b60} O{io,b1M,b2M,b3S,b4S,b5S,b6S }> Sup=0.061, Con=40/277 4. <AMN:M{im,b1M,b2S,b3S ,b40,b50,b60 } N{0,b1M,b2M,b3S,b4M,b5M,b6M }> Sup=0.075, Con=49/79