基於增長層級式SOM之自動影像註解方法
59
0
0
全文
(2) 致謝 碩士班兩年的光陰轉瞬即逝,看著撰寫完成的論文心中有無限感謝,回憶起這兩年 所經歷與相識的人事物,心中有著滿滿的不捨與感謝,人生中無不散的宴席,在碩士班 兩年的淬煉下,相信當我踏出校門,我將會是自信昂揚的面對未來挑戰。. 從踏入碩士班開始,在楊新章教授在研究上對我總是耐心教導,孜孜不倦的指引我 研究方向,也教導我正確的研究態度與做事方法,並且在研究遇到挫折與困難的同時伸 出援手,更感謝在我面臨實習與研究兩難的同時給予我最大的支持與鼓勵,我真的衷心 的感謝。. 感謝王學亮教授在課堂上細心的教導,並在我的研究生活中提供了許多自身的建議 與想法,讓我可以承襲其經驗而避免許多錯誤;蕭漢威教授對我關心有加,不論是學業 或是研究上總是給我最大的協助;丁一賢教授對於我的研究亦提供了許多建議,並在予 其多次討論中獲得了更多不同的想法;也感謝一同走過七百多個日子的朋友,特別是昱 仁(旺伯)學長對我的教導以及為我研究所需要的技術奠下了基礎,還有宗儒、思揚、軍 達、祐寧、齊祥、東健與恆慈,我的生活因為有了你們而變得更加璀燦,這兩年來共同 努力的回憶我將永遠記在心底。感謝碩一的坤裕(大卜)、慶鴻、國隆、裕晟、偉鈞和信 慧等學弟妹,你們對我的付出與幫忙都讓我很感動,我不會忘記你們的。. 感謝我的父母,因為他們默默的付出讓我可以無後顧之憂的努力,更在我面對挫折 與打擊的時候給予我最大的依靠,讓我知道我要更努力去戰勝自己。至此,我心中只有 滿滿的感謝,對於所有幫助過我的家人、老師與朋友們,真的,謝謝你們,這篇論文獻 給你們。 莊智翔. 謹致於 國立高雄大學 資訊管理學系(碩士班) 中華民國九十八年七月. II.
(3) 摘要 隨著數位影像科技發展,數位影像資料量快速成長,自動影像檢索技術的發展與應 用逐漸成為重要之研究課題。為能有效檢索影像,影像語意之淬取與表達為重要之步驟。 傳統上影像語意之淬取與表達大致上分為直接以影像視覺特徵表達與以文字註解表達兩 類。然而使用視覺特徵具有不易淬取與語意混淆之缺點。反之,文字註解之語意明確, 且容易進行檢索。但對大量影像進行註解為一十分花費時間與人力之工作。本研究重點 在於發展一適用於影像文件上之自動影像註解方法。在本研究中將採用增長層級式自我 組織圖(The Growing Hierarchical Self-Organizing Map,GHSOM)來協助發掘影像文件與 註解文件之間隱含之關聯,並使用此關聯進行影像註解。我們將先使用 GHSOM 分別對 影像與註解進行分群與階層產生,並提出一階層比對方法以發掘影像群集與註解群集間 之關聯。新進之影像即可利用此關聯進行註解。本文以一參考資料庫進行實驗,實驗結 果證明本方法在進行自動影像註解上頗為可行。. 關鍵字:自動影像註解、類神經網路、文件分群、增長層級式自我組織圖. III.
(4) Abstract With the improvement of digital image technology and increasing amount of digital image data, the issue of automatic image annotation technology and applications becomes more and more important. In order to retrieval image efficiently, it is important to extract and represent the semantics of images. Traditional image semantics extraction and representation schemes were commonly divided into two categories, namely visual features and text annotations. However, visual feature scheme are difficult to extract and are often semantically inconsistent. On the other hand, the image semantics can be well represented by text annotations. It is also easier to retrieve images according to their annotations. The problem is annotating images are always time-consuming and requiring lots of human effort. In this thesis, we try to develop an automatic image annotation method. We adopted the Growing Hierarchical Self-Organizing Map (GHSOM) to help us discover the concealed relations between image data and annotation data, and annotate image according to such relations. We first applied GHSOM to cluster and generate hierarchies for images and annotations individually. We then proposed a hierarchical mapping method to discover the relations between image clusters and annotation clusters. New images can be annotated according to such relations. We conducted experiments using the proposed method on an image dataset and obtained promising result, which showed that our method could be plausible.. Keyword:Automatic Image Annotation、Neural Networks、Text Clustering、Growing Hierarchical Self-Organizing Map. IV.
(5) 目錄 摘要........................................................................................................................................... II Abstract .................................................................................................................................... IV 目錄........................................................................................................................................... V 圖目錄.....................................................................................................................................VII 表目錄................................................................................................................................... VIII 第一章 緒論.............................................................................................................................. 1 1.1 研究背景................................................................................................................ 1 1.2 研究動機................................................................................................................ 6 1.3 研究目的................................................................................................................ 7 1.4 論文架構................................................................................................................ 8 1.5 研究限制................................................................................................................ 8 第二章 文獻探討...................................................................................................................... 9 2.1 自動影像註解........................................................................................................ 9 2.2 文件關聯方式...................................................................................................... 10 2.3 階層式架構.......................................................................................................... 11 第三章 研究方法與步驟........................................................................................................ 14 3.1 資料前置處理....................................................................................................... 15 3.1.1 影像特徵向量擷取................................................................................... 15 3.1.2 註解特徵向量擷取................................................................................... 17 3.2 GHSOM訓練 ....................................................................................................... 19 3.2.1 SOM ......................................................................................................... 19 3.2.2 GHSOM ................................................................................................... 20 3.3 影像與註解關聯對應........................................................................................... 24 3.3.1 資料筆數法............................................................................................... 24 3.3.2 群集距離法............................................................................................... 27 V.
(6) 3.3.3 同分處理................................................................................................... 30 3.3.3.1 深度優先法............................................................................... 30 3.3.3.2 歐基里德距離法....................................................................... 32 3.4 新進影像註解過程.............................................................................................. 35 第四章 實驗結果與評估........................................................................................................ 36 4.1 實驗步驟............................................................................................................... 36 4.1.1 前置處理................................................................................................... 36 4.1.2 資料分群................................................................................................... 39 4.1.3 影像與註解關聯對應............................................................................... 40 4.1.4 新進影像註解........................................................................................... 41 4.2 實驗評估.............................................................................................................. 42 第五章 結論與討論................................................................................................................ 46 參考文獻.................................................................................................................................. 48. VI.
(7) 圖目錄 圖 3-1 自動註解方法流程圖.................................................................................................. 14 圖 3-1-1 影像之色彩分佈特徵向量…………………...…………………………………….16 圖 3-1-2 影像註解文件特徵向量 .......................................................................................... 19 圖 3-2-1 GHSOM階層架構圖................................................................................................ 20 圖 3-3-1 影像與註解樹狀階層 .............................................................................................. 25 圖 3-3-2 資料筆數法說明實例 .............................................................................................. 26 圖 3-3-3 群集距離關聯示意圖 .............................................................................................. 27 圖 3-3-4 群集距離法說明實例 .............................................................................................. 28 圖 3-3-3-2 深度優先法實例說明........................................................................................... 31 圖 3-3-3-3 歐基里德距離法實例........................................................................................... 33 圖 4-1-1 測試australia1 影像資料.......................................................................................... 37 圖 4-1-2 測試影像australia1 之能量頻譜圖.......................................................................... 37 圖 4-1-3 測試影像australia1 特徵向量.................................................................................. 38 圖 4-1-8 影像階層關係示意圖 .............................................................................................. 41 圖 4-2-2 系統評估示意圖 ...................................................................................................... 44. VII.
(8) 表目錄 表 3-3-1 實例計算結果 .......................................................................................................... 27 表 3-3-2 群集距離法範例計算過程 ...................................................................................... 29 表 3-3-3 圖 3-3-3-2 依資料筆數法計算結果 ........................................................................ 31 表 3-3-4 圖 3-3-3-2 資料權重法計算結果 ............................................................................ 31 表 3-3-5 圖 3.3.3.3 依資料筆數法計算結果 ......................................................................... 33 表 3-3-6 圖 3.3.3.3 依資料權重法計算結果 ......................................................................... 33 表 3-3-7 影像原始註解之特徵向量 ...................................................................................... 34 表 3-3-8 註解群集特徵向量平均 .......................................................................................... 34 表 3-3-9 註解群集計算結果 .................................................................................................. 34 表 4-2 檢索評估關鍵字.......................................................................................................... 43 表 4-3 關鍵字精確率與召回率.............................................................................................. 45. VIII.
(9) 第一章 緒論 現今網路的發達與資訊科技的日新月益,數位影像設備日趨普及,如數位照相手 機、數位攝影機、掃描器,使得數位影像資料不論是質與量均不斷蓬勃成長,大量未經 過有效整理,且持續快速成長之影像資料亦逐漸雜亂的充斥於網路與生活中,如何有效 且正確的從雜亂且大量的資料中取出所需便成為當前熱門研究議題。數位影像資料內容 常有附註相關說明,即所謂註解(annotation),使用者便可依此進行數位影像資料檢索。 事實上,目前影像檢索方式多為針對影像註解加以檢索。各大著名影像搜尋引擎,例如 Google 與 Yahoo 所提供之影像檢索服務亦採取使用者輸入之查詢關鍵字與影像註解進 行比對方式加以檢索。然此種檢索方式需透過人工或自動方式對資料加上註解後以進行 檢索。使用傳統人工註解方式容易產生註解不一致、人工註解成本過高以及部分影像內 容無法以文字完整表達三大缺點。因此,發展一個自動化方法以自動產生影像註解,並 透過這些註解,令使用者可以更有效率的對影像資料進行資料檢索方法之研究便逐漸受 到重視。. 1.1. 研究背景. 在網路盛行之前,影像檢索在發展上未受重視有兩大主因:影像檢索技術難以克服 與數位影像尚未普及,因此數位資料大多僅於特定領域中被使用,例如生物科技或是國 防相關、太空研究、醫療影像等。然隨著近年來資訊科技快速進步,網路快速普及,影 像處理技術與成本及速度亦大幅改善,數位影像應用快速從特定領域擴展至各方面及多 樣化領域。例如 Google 網站已蒐集了超過十億張影像,而對於典藏機構而言,上千萬 張影像之儲存量亦頗為普遍,對於個人使用者而言,亦可能擁有數以千計之影像。面對 影像相關技術演進與發展,傳統以人工方式進行檢索勢不可行,因此影像檢索技術之需 求應運而生。影像檢索技術之目標為快速且精確的自大量影像中獲取符合使用者需求影 像,亦即符合使用者意圖之影像。使用者之意圖對應於影像之意涵,在此可以語意 1.
(10) (semantics)統稱之。當使用者表達其意圖時,影像檢索系統必須判斷影像之語意並與之 比對,再依其相似程度呈現於使用者,然而影像之語意頗難判定。目前已有許多影像檢 索方法已被發展出來,依照不同方式可以將其概分為三大類。 第一類為基於關鍵字之影像檢索(keyword-based image retrieval)。這類技術基本上為 自傳統以文字為主之資訊檢索技術所延伸出來。在資料庫中的每一張影像,除了影像內 容之外,另外還附加了一串列的關鍵字以描述影像的內容,稱為註解(annotation)。使用 者在檢索影像時所發出之詢問句,也是以關鍵字的方式表達,詢問句與影像間之比對, 也是以傳統文字檢索之技術為主。因此這類方式仰賴的是正確的影像註解,而這工作通 常得由專家以手動方式為之,成本十分高昂且費時,因此這類方式並不適用於大量的資 料庫之檢索上。然其註解所包含之語意通常十分正確,在特定應用上仍有其價值。使用 者之詢問句查詢方式與文字檢索方式類似,對於使用者而言十分方便。目前許多商用搜 尋引擎採取這種方式進行影像檢索。 第二類稱為基於內容之影像檢索(content-based image retrieval)。這類方式是直接以 影像內容進行檢索,而不用透過人為之註解。其主要方法為淬取出影像中之特徵並以此 特徵來表示影像。使用者可以影像特徵或範例影像來描述其資訊需求,並據以進行影像 特徵間之相似度比對。由於這樣的方式不需專門人員進行影像註解,其特徵淬取以至比 對皆可自動完成,因此較適合儲存大量影像之資料庫使用。在此所採用之影像特徵,多 為人類視覺所能感測之特徵,例如色彩(color)、形狀(shape)、紋理(texture)、輪廓(Contour) 以及這些特徵間之結構資訊等等。由於其高度自動化的特性,以內容為主之影像檢索為 目前影像檢索研究之主流,大部份的影像檢索系統也是由這類技術所促成,例如 QBIC[8],Virage[3],Photobook[22],VisualSEEK[30]等等。然而以內容為主之影像檢索 技術具有下列缺點: 1.. 影像之特徵通常僅能描述影像之部分意涵,甚或根本與影像之意涵無關。例如 色彩,30%的白色和 70%的藍色可能同時表示一張海景影像或一張藍白相間之 車輛影像,兩張完全不同意涵的影像。同樣的,包含圓形的影像可能是棒球, 也可能是一個盤子。因此使用者在詢問時所得到的結果常與其期望相差甚大。 2.
(11) 使用者很難將其意圖完整的表達。例如若使用者想要檢索有關蝴蝶的影像,在. 2.. 以色彩為主的影像檢索系統中是很難表達他的需求的。即使是在使用以範例查 詢(query by example)的系統時,使用者仍然會發現要找到可以完全描述其需求 之範例影像是一件不容易的事。 因此基於內容之影像檢索技術雖為目前之主流,但其效果並非十分良好,即使在某 一特定領域影像有突出的表現,也無法廣泛的應用在一般的影像檢索上。究其原因,在 於使用者所想要查詢的影像,通常並不是具備某些特徵,或和某張影像相似的影像,而 是符合某種概念的影像,例如「蝴蝶」就是一種很明確的概念。雖然人類可以明瞭「蝴 蝶」這個概念所代表的影像應為何,但不同色彩,不同形狀,不同姿態,不同環境下之 所有蝴蝶影像實難以簡單的特徵來完整描述。因此不論如何表示詢問句,即或以範例影 像進行查詢,所得到的結果均無法完整涵蓋完整影像,且所擷取出之影像中也僅有一小 部份是正確的。由於人類所認知之影像視覺特徵與使用者透過文字進行檢索之語意 (semantics)間無法直接建立關聯,造成影像內容與影像語意(或意涵)間具有所謂的語 意鴻溝(semantic gap)障礙。這道鴻溝使得以內容為主之影像檢索並不能完全滿足使用者 的期望。 目前之以內容為主之影像檢索,多只能以影像之基本特徵(primitive features),例如 色彩、形狀、紋理或輪廓等進行查詢,即所謂之第一階查詢(level 1 query)。事實上,查 詢之方式還有更高階的方式,即所謂的第二階(level 2)與第三階(level 3)查詢。第二階查 詢是以衍生特徵(derived features)為主的查詢。衍生特徵包含了影像中物件的某種程度的 邏輯推論,例如:“找出總統府的影像",這類詢問必須包含對特定概念(例:總統府) 的瞭解。第三階的查詢所包含的是以更高層的抽象意涵所進行的查詢。例如:“找出所 有表達快樂的影像"。我們可以知道要進行第二階與第三階查詢是十分困難的事。目前 在第一階與第二階間存在最顯著的鴻溝,因此我們將存在於第一階與第二、三階查詢間 之鴻溝稱為語意鴻溝。如何跨越此一鴻溝便成了近年來熱門的研究課題。基於語意之影 像檢索(semantic-based image retrieval)(或稱語意影像檢索)相關研究便因運而生,試圖 解決語意鴻溝之問題。基於語意之影像檢索便是我們所歸類之第三類影像檢索方法。 3.
(12) 語意影像檢索為一十分困難的問題。主要的困難在於如何淬取出影像中所包含之語 意(或意涵)。目前的作法多將影像中的視覺特徵與人工定義之語意相連結以定義影像 之語意。隨後再以結合視覺特徵比對及語意相關度比對之方式進行檢索。這些方法最主 要的問題在於語意之定義大多須以人工方式事先定義或以關聯回饋(relevance feedback) 方式加入影像之描述中,造成其應用範圍受限或須花費過多之時間與成本。 影像檢索之目標,如同其他資訊檢索工作之目標一般,無非是要滿足使用者之需 求。當使用者表達其意圖時,影像檢索系統必須判斷影像之語意並與之比對,再依其相 似程度呈現於使用者。因此事實上,上述的三類影像檢索方法廣義上皆是以語意來進行 檢索,只是語意之表達與淬取方式不同。因此我們可以將關鍵字與視覺特徵視為使用者 詢問之方式,影像檢索系統再藉由分析這些詢問以獲取語意,俾以進行語意比對並據以 檢索。若以此觀點視之,我們可以將影像檢索分為兩個步驟,即語意淬取(semantics extraction)與語意比對(semantics matching)。在語意淬取部份,基於關鍵字之影像檢索技 術藉由分析存在於影像所附屬之註解(annotation)、影像標題(caption)或影像周圍之文字 (surrounding text)以獲取語意。基於內容之影像檢索技術則直接根據影像之視覺特徵,如 色彩、形狀、紋理等以獲取語意。然而這類內容特徵之分析直至目前尚未能有效的提供 一解決方案來獲取語意,且自文字中獲取語意之方法在計算語言學、資訊檢索等領域已 有多年的研究,並獲得良好的結果,而且以文字來表達語意對於語意之相似度比對較為 容易,這方面已有深入的研究[27]。相關的研究並已成功應用於數位圖書館、搜尋引擎 等案例上。事實上,目前之影像搜尋引擎大多也是使用文字作為比對之依據。總體而言, 使用文字來表達影像之語意應是較為便利且準確的。使用文字來表達使用者意圖或影像 語意時通常都是以關鍵字為基礎。使用者以若干關鍵字來描述其所欲影像之意涵,影像 資料庫中亦以關鍵字來表達所儲存影像之意涵。 綜合以上所言,以關鍵字為基礎進行影像檢索是於目前為較可行之方案。然而此類 方法之成功取決於一個關鍵要素,即影像語意之正確描述。目前影像語意大都以影像註 解之方式來表達,即在影像附加一段文字或若干關鍵字以描述影像意涵。影像註解之附 加傳統上以人力為之,即由專家審視影像後,再將其意涵以文字描述後附加於影像文件 4.
(13) 之上。人工方式雖可獲得較佳的語意,但費時費力,僅可應用於小型影像資料庫上,對 於大型資料庫而言實用性不高。自動影像註解(automatic image annotation)則可有效的解 決人工註解的困難。自動影像註解乃是藉由分析影像之意涵,淬取其語意,轉化為註解 型式附加於影像。其優點為無需或僅需少量人力介入,可迅速處理大量影像,並可即時 處理新進影像。 自動影像註解技術雖有諸多優點,但其難度頗高。主要的難處在於影像語意之淬取 為一高階認知過程(high-level cognitive process),一般人雖可輕易的藉由觀察影像而得知 其意涵,但此一過程要以自動化之過程完成之卻頗為困難。一張影像內包含有各式資 訊,以傳統影像內容分析觀點視之,可分為色彩、形狀、紋理與輪廓等主要影像特徵。 雖然我們可以有效的自影像中淬取出上述的特徵,但仍、需克服兩個問題。其一為此特 徵是否可以有效的表達影像之全部語意。其二為如何將此特徵對應至以文字形式所描述 之影像語意。第一個問題其實與第二個問題相關,因不論所採用之影像特徵為何,其後 之文字對應方式若能完善,均可獲致較佳的效果。但如前所言,此對應方式為一高階認 知過程,頗難克服,也成為自動影像註解中最為關鍵之步驟。 將影像之內容對應至符合其語意之文字註解的過程,在此稱之為影像語意發掘 (image semantics discovery)過程。影像語意發掘技術已被研究許久,主要可分為兩個方 向。其一為根據內容直接發掘語意,其二為根據環境間接的發掘語意。第一種方法直接 自影像內容萃取出影像視覺特徵後,再與相關文字對應以產生具語意性的註解。這種方 式的優點為影像語意為內容直接分析而得,較為直接且合理。其缺點為較難設計出有效 的對應方式。第二種方式不直接分析影像的內容,而以其周邊的文字資訊為主要分析對 象。其優點為語意取得容易,缺點為周邊文字不易精確的獲取甚至完全缺乏。目前大部 份的影像註解相關研究都採取第一個方向,因周邊文字之不一致性較高,因此很難精確 的取得。. 5.
(14) 1.2. 研究動機 影像檢索在數位資訊檢索中扮演重要角色,目前又以數位典藏應用最為受到廣泛使. 用,但因愈來愈多文件包含影像資料,甚至文件本身即為一完整資料。例如博物館在進 行數位典藏時,影像資料將占其大宗。另一方面,全球資訊網中之影像檢索需求亦有遞 增的趨勢。舉例而言,個人部落格(blog)或網頁相簿之使用與日俱增,因此其中之影像 管理成為該類網站一個重要的課題。在這些應用中,如何有效的進行影像檢索將左右應 用的成功與否。傳統將影像檢索技術分成三個層次,其一為基於關鍵字之影像檢索 (keyword-based image retrieval) , 其 二 為 基 於 內 容 之 影 像 檢 索 (content-based image retrieval),其三為基於語意之影像檢索(semantic-based image retrieval)。後兩者因為都是 直接以影像內涵進行檢索,較符合以影像進行檢索之要求,但卻面臨影像意涵難以取得 的困難。前者可提供使用者最簡便之檢索方式,但卻有文字註解不易建立之缺點。自動 影像註解技術便可調合兩者之優劣:另一方面,使用者可以利用關鍵字或影像進行查 詢,另一方面,藉由影像內容分析,可避免人工建立註解之困難。但自動影像註解主要 的難處在於影像內容意涵萃取與轉化為人類認知之高階語意過程,一般使用者雖可藉由 觀察影像而得知其意涵,但此一過程要以自動化過程加以完成卻頗為困難。目前自動影 像註解多藉由分析影像內容,包含影像色彩、紋理以及輪廓等內容特徵,藉以獲得影像 內容,而後再透過分群方式將影像分群。使用者輸入欲查詢之影像,藉由比對查詢影像 與影像群集之間內容相似度後,再自動給予其適當註解。自動影像註解之目的在於無需 或只需少量的人力即可處理大量未被註解之影像,降低人工註解建立之困難程度,且使 用者僅須利用文字作為關鍵字即可進行檢索,因此一般使用者對於以關鍵字做為查詢方 式仍舊較能接受。 要進行以關鍵字為基礎之影像檢索,正確的影像註解可謂是其中關鍵之因素。要能 自動對影像進行註解,取決於如何自影像中萃取出影像之語意,此方面之研究與文字語 意之萃取頗為相關。自文字中獲取語意之方法在資訊檢索與計算機語言學等領域已有多 年的研究,透過文字進行影像內涵之比對於技術實現上亦較為可行[27]。相關的研究並 已成功應用於數位圖書館、搜尋引擎等案例上。語意發掘之技術頗多,其中部份技術屬 6.
(15) 於文本探勘(text mining)之範疇。芬蘭學者Kohonen再1996年提出自我組織圖 (Self Organizing Map ,SOM)方法,該方法透過將大量多維度資料投射於二維圖形上,使用者 可快速觀察出資料所屬之分群特性。後有學者接續研究發現在分群資料中仍具有部分隱 含之關聯,例如,資料分群中,假若有一群分類為交通工具,若該群中應仍具有各式交 通工具,例如汽車、火車、飛機等等,而汽車又應具有不同的廠牌與型號等等,SOM指 可有效表達出資料分群結果,但卻無法表現出隱含於資料與資料之間關係,且SOM亦具 有拓樸結構大小需事先設定之缺點。因此Rauber等學者提出改良SOM缺點之增長層級式 自我組織圖(Growing Hierarchical Self-Organizing Map,GHSOM),目的在於解決SOM 對於群集資料中隱含之資料關聯與SOM圖形大小固定之缺失。Jeon等學者將影像註解問 題視為跨語言資訊檢索問題[10],跨語言資訊檢索是將兩種不同語言進行互相對應與參 考以達到檢索目的,若將影像與註解各自視為一符號集,則其間之關聯則可視為發掘兩 符號集之關聯,此類看法與多語言文本探勘(multilingual text mining)具有異曲同工之 妙。本研究將基於此類比,嘗試以多語言文本探勘技術應用於影像語意發掘,並進行自 動影像註解,嘗試提供一個有效解決方法。. 1.3. 研究目的. 目前自動影像註解之註解結果於影像自動註解完整度與自動註解之正確性方面皆 仍需改善,造成此問題之主要的困難點在於影像之語意與發掘不易。若能成功克服這個 問題,則可有效解決影像檢索之兩大問題,即影像比對問題與使用者介面設計,並進一 步對於數位圖書館,全球資訊網影像資訊檢索及數位典藏應用提供可靠之解決方案。本 論文將以多語言文本探勘技術為基礎發展自動影像註解方法,本研究所採用之方法屬於 尚未被嘗試之方向,且對於這方面的研究將極有助益。本研究目的為以多語言文本探勘 技術為基礎之影像意涵淬取技術,並結合關鍵字檢索方法,發展可解決目前自動影像註 解發展瓶頸之自動影像註解方法,可在少量人力之情形下即可處理大量影像註解,自動 給予新進影像適當之註解,並提升自動註解之正確性,對於提升影像檢索效率相關研究 將有頗大的助益 。 7.
(16) 1.4. 論文架構. 本論文共有五章,各章節安排如下:第一章為『緒論』,此部分說明本研究之研究 背景、動機以及研究目的,並說明本研究之論文架構與研究限制。第二章為『文獻探討』, 說明自動影像註解與GHSOM相關研究之發展過程與現況。第三章為『研究方法』說明 本研究完整研究所實行之實驗步驟與過程,並說明整個資料收集,特徵分析、轉換與擷 取,進行訓練,實際測試過程及結果。第四章為『實驗結果』此章節將說明本研究之實 際特徵擷取,訓練測試資料並經由本研究之方法給予其相關註解並評估其正確率。第五 章為『結論與討論』為本研究之總結。說明本研究方法之研究結果,並探討研究結果, 發掘問題點並找出需改進之處與建議作為未來發展。. 1.5. 研究限制 本研究所遭遇到之限制主要包含已驗證之註解資料來源數量與影像特徵萃取方式. 兩部分,對於本研究而言,具有正確可信資料之數量與研究之結果呈現正向相關,但囿 於研究過程中,影像資料過多或影像註解準確性需加以驗證,因此已驗證之正確資料量 即為本研究限制之一;此外,影像特徵除常見色彩、紋理與輪廓外,尚有多種可表達影 像之影像特徵,每種特徵對於影像內容亦有不同程度之表達能力。而在影像檢索方法 中,影像之影像特徵選取是否適合與研究驗證之成效亦呈現正向相關,但何種特徵對於 本研究所提之方法為最佳,或者是多種特徵結合是否可有效提升研究正確性則有待實 證。因此該選取何種影像特徵代表影像便成為本研究之限制因素。. 8.
(17) 第二章 文獻探討 2.1. 自動影像註解. 自動影像註解最早之相關研究由 Mori 等學者 [19]在 1999 年所提出之報告開始,他 們透過將影像進行切割成為方型區塊,透過將影像低階特徵及相關字詞的共現模型 (co-occurrence model)來產生影像註解。他們利用共現模型透過計算影像相關字詞與影像 之間共同出現次數做為預測影像可能之相關註解字詞作為影像註解。在此研究之後,自 動影像註解便分別朝向兩個不同方向進行發展 ,其一為使用影像切割演算法,透過將 影像依內容切割為不規則之區域,並以其作為註解基礎進行註解;另一則為場景導(scene) 向模式,透過將每份影像資料視為單一場景,場景中的所有的物件均有其對應標籤 (tag),透過以標籤做為註解基礎進行註解。 首先,利用影像切割演算法索切割之每一區塊稱為 blob,許多研究者以此為基礎進 行後續研究,Duygulu 等學者[6]在 2002 年便為影像中所有的區塊(blob)群集建立了一種 離散型態之字彙集合(vocabulary),並將這些集合視為一種視覺語言(visual language),所 謂視覺語言可借用符號學中對言辭符號之概念,將視覺符號的組成也視為一種語言,並 認為這些視覺符號透過人類肉眼觀察即可洞悉其涵意;之後再透過機器翻譯(machine translation)模型將這些不規則區塊翻譯成為註解,機器翻譯模型。將預估翻譯成功之機 率以收集共現模型相關資訊。Jeon 等學者[10]他們結合資訊檢索概念,將影像與註解視 為兩種不同之文件資料,並預期可透過資料檢索概念建立影像與註解之間關聯,他們使 用跨媒體關連模型(cross-media relevance model)來發掘影像與註解之間關聯,進而對影 像進行註解與檢索,研究結果證明在檢索的效能上優於 Duygulu 等學者所提出的機器翻 譯模型。接著 Lavrenko 等學者[13]在 2003 年採用 Jeon 等學者[10]所提出之跨模體關聯 模型,結合連續機率密度函數來描述產生不規則影像區域的過程,他們希望降低因量化 程序(quantization process)所造成的資訊損失,之後再透過與 Jeon 研究相同之資料集進行 驗證,在結果上得到顯著的改善效果。而 Metzler 與 Manmatha 等學者[17]在 2004 年採 用相同方式,先將影像依內容切割成不規則區域後,再使用推論網路(inference network) 方式來連結影像以及註解。首先他們所提出的新進影像之註解方法先以影像切割演算法 9.
(18) 索切割出不規則區域影像,並以此影像啟動推論網路,並於網路中傳遞信任度(believe) 用來代表某區域之字詞之節點產生註解。之後 Feng 等學者[7]在 2004 年提出將不規則影 像區域(blob)轉變成為方型區塊,結合多重伯努力分配(multiple Bernoulli distribution)方 式來建立關鍵字模型,目的在於改善 Lavrenko et al.與 Metzler et al. 之實驗缺陷與結果, 而研究結果亦證實其所提之方法的確可得到較前兩者更佳之結果。Blei 等學者在 2003 年提出將 Latent Dirichlet Allocation(LDA)[5]模型加以擴充,LDA 屬於一完整之生成模 型,此模型將每一份資料之機率視為潛藏於各主題中隨機字詞之混和模型,並進而求得 資料出現之機率值,Blei 等學者所提出之模型將一組潛在因素(latent factors)混合產生字 詞語不規則影像之特徵[4],並利用該模式將字詞指定予不規則影像。 第二個方向則是較簡單的場景(scene)導向方式,由 Oliva 與 Torralba 等學者[20][21] 在 2001 年所提出,其認為影像是由多個不同之影像內容物件所組成,並將影像內容物 加以區隔做為場景標籤,根據其研究結果顯示影像可藉由影像內容相關之低階全域特徵 結合影像內場景標籤來描述,如建築物、公路等具有明顯低階特徵一致性之物件。 Torralba 等學者[31]在 2003 年更進一步以此種場景導向方式結合影像統計資訊以推論出 場景內之物件是否存在。Yavlinsky 等學者[35]在 2005 提出遵循上述之場景導向方式, 探討全域特徵在自動影像註解上之可行性之研究。他們的研究顯示在此架構下即使僅利 用簡單之權域特徵,如全域之色彩統計等,亦能夠有效的進行自動影像註解之目的。. 2.2. 文件關聯方式 隨著科技發展,各式各類的資料也呈現爆炸性成長,因此資料分群 (data clustering). 相關概念與技術日漸受到重視且已經廣泛應用於不同領域中,例如決策支援與市場預 測、圖像辨識與處理、資料探勘、機器學習、資訊檢索等。一般研究人員面臨到大量資 料時,首先所採取的步驟即為對資料進行簡化及分類與分類,而分群的目的是為了能夠 使得在某些特性上相似或是具有關聯性之事物,並依照特性或關聯程度將其劃分成幾個 群集,同一集群所包含之資料彼此間具有極高之同質性,而群集與群集間分別所包含之 資料則具有極高之異質性。當處理大量多維資料時,如何判定資料群聚關係是十分重要 10.
(19) 的課題,Merk 與 Kohonen 等人分別運用所提出之 SOM(self-organizing map, SOM)將資 料進行視覺化二維的方式呈現。SOM 是由學者 Kohonen 於 1982 年所提出[11],可將多 維資料映射至二維空間,並藉由其可視覺化判斷之特性來呈現資料群聚特性 [12][14], 在將多維資料映射至二維平面後,資料群集兼具有相鄰群集具有相似的特性之關係,故 此方法屬於分群技術之一。但是 SOM 具有兩大缺點,分別是圖形之拓撲結構固定且需 在資料進行訓練前設定完成,因此不易找到最適大小,另外是以二維平面方式呈現大量 多維資料容易過度簡化資料與群集間複雜關係,在大量的文件資料中可能包含有多階層 的關係,僅以簡化之二維方式來表示資料群集關係無法充分表達出資料間隱含之關係。 學者 Miikkulainen 提出此 Hierarchical Feature Map[18] 之改良方法,其可將資料訓練結 果透過階層方式加以表示,但此種方法僅可產生具有固定與對稱架構之 SOM,且每一 階層之拓樸結構均相同,如此依舊無法充份表示出資料群集之關聯階層。而 Growing SOM[2]雖可依據資料之關聯程度於二維空間上自行擴展圖型拓鋪結構,但此種方法卻 無法產生階層架構。因此以 Rauber 等學者便於 2002 年提出了 GHSOM[25]來克服 SOM 之兩大限制。GHSOM 屬於一種動態演算法,大量且多為資料經由其訓練後可依照資料 群集關聯程度呈現階層樹狀結構,各層級之樹狀節點皆為一獨立之 SOM。且每一 SOM 之的拓撲結構大小均依據資料所需而增長。 GHSOM 應用於各領域均有極佳之成效,Rauber 等學者利用 GHSOM 對俄、英、德、 法等三種語言進行探勘工作[17],實驗結果表示該方法具有相當準確的分群品質。Yeh 和 Chau 利用 Fuzzy 概念將中文與英文兩種詞彙產生隸屬程度關係,再經由 SOM 進行文 件分類之動作,在 19,257 篇文章中,有 17,136 篇被正確的分類,接近 89%的效能[36]。 GHSOM 亦被應用於新聞文件的分群 [25]、文件的典藏 [25]及法律文件的分類 [28]以 及多語言文本探勘[34]、金融詐欺發掘[32]、以及行銷專家系統開發[30]等,此方法逐漸 各領域學者廣泛重視。. 2.3. 階層式架構. 階層式架構是由階層式分群法概念所構成,階層式分群[26]是透過訂定訓練終止條 11.
(20) 件,當滿足終止條件後便停止訓練之分群方法。終止條件通常為群與群之間在經過資料 分群以及群集合併之後,藉由判斷群與群之間相似程度是否達到終止訓練之門檻值作為 判斷依據,階層式分群法之演算法架構類似樹狀結構,而其分群法可大略分為下列聚合式 (agglomerative)與分割式(divisive)兩種[9],所謂聚合式分群法屬於一種由下而上之分群 方式,所有訓練資料於初始過程均各自歸類為一群,接著透過計算資料相似度判斷資料 是否有相似資料需要合併,再計算各群集間相似程度是否大於既定之臨界值,若大於門 檻值則將群集合併,直到所有的資料分別歸屬於各自群集且不再變動,或是符合終止條 件方才停止分群;而分列式分群法則屬於一種由上到下的分群方式,資料於訓練初期均 屬於同一群集,再經過資料相似度計算後將其分別依照相似程度加以分割成為較小子 群,直到所有資料均有其所對應之群集,或是符合終止條件方才停止分群。以此類方法 所產生的分群結果可以是一個樹狀結構的形態,較鄰近的節點就是較相似的資料,資料 間相似關係亦可由群集聚合與分割的結果能表現出來。 本研究所採用之 GHSOM[25]屬於階層式分群法,為根基於 SOM[11],且為改善 SOM 之缺點所發展出來。SOM 可將大量資料映射至二維平面上以利分析,但其拓撲結構須 在資料開始訓練前加以設定,並且拓樸結構大小於訓練過程中均固定無法更改,拓樸結 構大小是否適合須依據分群結果方可判定,因此不易設定適當之拓樸結構大小。透過二 維的方式呈現大量與高維度資料亦容易造成過於簡化資料之間的複雜關係,在大量且可 能具有階層關係的資料中,只以二維方式呈現資料結構有時無法充分表達文件的概念。 為改善此問題,強化 SOM 對於辨認群集之間與群集內的關係,U-Matrix[33]和 Cluster Connections[15]等測量方法便被提出,藉由分析拓樸結構中,各鄰近單元之間的距離, 藉以判斷 SOM 之群集間相似程度。另外,SOM 具有將大量多維資料視覺化呈現之能力, 但受限於其無法自動調整拓樸結構所需之最佳大小,因此便有學者提出 LabelSOM[16][23],其可以找出具代表性的特徵屬性,將分群結果的各個群集標記出主 要的特徵屬性。藉由以上方法,即可測量出 SOM 之各群集於分群後的關係。由於大量 的文件資料中可能存在階層的關係,而 SOM 容易造成將資料結構簡化之缺點,因此學 者 Miikkulainen 便提出 Hierarchical Feature Map[18]方法,該方法可將訓練結果透過階層 12.
(21) 方式表示,但此種方法僅產生固定與對稱架構之拓樸結構,拓樸大小每一階層都一樣, 因此無法充份顯示出資料集的階層與資料之間所隱含之關係。因此,學者 Alahakoon 便 提出 Growing SOM[2]加以解決此問題,Growing SOM 可以在二維空間上,根據資料訓 練過程所需自行擴展地圖大小,不過此種方法無法產生階層架構。所以 Rauber 等學者 提出了 GHSOM[25]來克服 SOM 的兩個限制。GHSOM 屬於動態演算法,此方法結合 Hierarchical Feature Map 以及 Growing SOM 之優點,對於大量且多維度資料可依據其資 料訓練所需而對拓樸結構大小進行自動增長已達到最佳拓樸結構大小,每一層均為一獨 立之 SOM,若資料在分群過程中未達到終止條件,表示資料間尚有隱含之關聯,因此 將再進行訓練直到所有資料均分配至最適合之群集,且各群集亦得到最佳之拓樸結構大 小便停止訓練。. 13.
(22) 第三章 研究方法與步驟 本研究之自動影像註解方法包含影像訓練與影像註解兩階段,本研究所採用之實驗 影像資料集為一具有正確人工註解之影像資料集,每一份實驗影像均有其對應之人工註 解。在訓練階段我們對影像註解與影像內容分別進行前置處理與特徵向量擷取,接著將 特徵向量透過 GHSOM 之訓練演算法進行資料訓練。訓練結果可得到資料已分群完成之 分群結果,而分群結果包含影像註解與影像內容,分群結果依據資料彼此關連性而呈現 樹狀階層拓樸架構。接著進行影像內容與影像註解之間的對應,在此採用本研究所提出 之註解與影像資料對應演算法建立註解與影像對應關係。最後進行自動影像註解階段, 本研究將訓練資料部分選取作為測試影像,經過和訓練階段相同之處理過程後,訓練影 像將依據其影像特徵向量分別標記至適當之影像群集當中。由於影像階層與註解階層經 過先前資料關聯對應之演算法處理,影像與註解群集彼此均已具有對應關聯,因此測試 影像在標記至對應之影像群集後,依循對應關聯可得到適當之註解群集並自動給予其正 確相關之註解。本研究之研究方法與流程如圖 3-1 所示:. 圖 3-1 自動註解方法流程圖 14.
(23) 3.1. 資料前置處理. 本研究實驗資料包含影像內容與影像註解資料,資料前置處理目的為取出資料內容 中重要且可代表資料之特徵並用以代表原始影像。以下將說明本實驗前置處理部分,本 章節包含影像特徵向量與註解特徵向量之擷取過程。. 3.1.1 影像特徵向量擷取 由於本研究需要將影像轉換為特徵向量以供後續資料訓練使用,因此在選取影像特 徵表示法時將以可轉換為固定長度向量之表示法為主。目前於影像相關研究中,最為常 見之影像特徵分別為影像色彩(color)、形狀(shape)、紋理(Texture)以及輪廓(Contour),但此 些常見之影像特徵各有其優缺點。然色彩資訊在自然物體中較為穩定,對於任何影像而 言,色彩亦為最基本之組成元素,對於影像內容具有良好之表達能力,除此之外,色彩 資訊萃取也較易達成,且透過色彩資訊可有效率的將影像內容轉換成固定長度之影像特 徵向量,因此本研究採用之影像特徵為影像色彩分佈直方圖(color histogram)作為代表影 像內容之影像特徵。在進行影像特徵向量轉換之前,本研究將對影像之彩色資訊進行對 應之色彩還原過程,將影像像素值還原為灰階值(Grey Level)以降低資訊量,進而提升處 理效率,但此步驟將損失部分影像色彩及內容資訊。為提升影像特徵對影像之表達能 力,本研究另外採用影像之頻率資訊作為其特徵以統計影像中之平緩程度,其作法為將 影像轉換為可表達影像變換頻率之影像能量分佈頻譜(power spectrum)以獲得更多影像 相關資訊。採用色彩分佈直方圖之目的在於擷取影像內容當中的色彩特徵,且色彩分佈 直方圖所花費之計算與處理速度較快且成本較低。採用影像能量頻譜之目的在於取得影 像內容在空間表現上之特徵,同時亦希望取得影像內容變動之頻率特徵作為代表該影像 之影像特徵。 在萃取色彩特徵時,首先須將影像進行RGB三原色之像素還原,並進行影像色彩分 佈直方圖之特徵向量擷取步驟。還原過程是將彩色像素(Pixel)轉成0至255之灰階值,透 過下式(1)可得到,其中I為影像像素轉換後之灰階像素值。. I = 0.299R + 0.587G + 0.114B. 15. (1).
(24) 其中R、G、B分別代表該像素之紅、綠、藍色之值。並加以統計與計算所得到之影像色 彩分佈直方圖結果。再將色彩分佈直方圖正規化(normalize)至相同區間,本研究將其正 規化至 0 與 1 之區間,如此可得到長度為 256 ,且資料大小介於 0 到 1 之間之向量,該 向量即為該影像之影像色彩分佈特徵向量HI。圖3-1-1 為正規化後之色彩分佈直方圖之部 分向量檔,每一列為單一獨立影像,最前面為影像之檔名,其後為長度為 256 之色彩分 佈直方圖向量。. 圖 3-1-1 影像之色彩分佈特徵向量. 本研究所採用之另一影像特徵向量,即能量分佈頻譜,是將影像利用離散傅立葉轉 換(discrete Fourier transform,DFT)進行轉換所得到。DFT 通常被用在做頻譜分析與濾波 器之設計上,對於一個 n×n 的方塊,二維正 DFT 之定義為. F (u, v ) =. 1 n2. ⎧ 2πi (uj + vk ) ⎫ ⎬ n ⎭. n −1 n −1. ∑∑ f ( j, k )exp⎨⎩− j =0 k = 0. (2). 二維逆 DFT 定義為. n −1 n −1 ⎧ 2πi (uj + vk ) ⎫ f ( j , k ) = ∑∑ F (u , v )exp ⎨ ⎬ n ⎩ ⎭ u =0 v =0. 其中 i = −1 ,f 為原始影像訊號,F 為轉換後之結果。. 16. (3).
(25) 另 DFT 轉換的二維核心(kernel)是可分開的,即. exp{. 2π i (uj + vk ) 2π iul 2π ivk } = exp{ } • exp{ } n n n. (4). 影像資料經過 DFT 轉換後,再將所得之頻率係數轉換為能量頻譜值。. P(u, v ) =. 1 2 F (u, v ) 2 n. (5). 再依所有像素之頻譜值範圍進行統計,可得影像能量分佈頻譜。我們將頻譜值範圍量化 固定長度之向量,如此可得該影像之特徵向量PI,其長度為 256。整張影像之特徵向量 FI即為HI與PI連結而成,其長度為 512。. 3.1.2 註解特徵向量擷取 本研究之註解文件前置處理則採用學者 Salton 等人於 1968 提出之 (vector space. model,VSM)[29]做為註解文件表示法。向量空間模型目前廣泛受到資訊檢索領域之研 究者所採納,但本研究之影像註解部分僅需進行二元判斷,由於文件來源為影像之註解, 屬於簡單關鍵字集合,因此本研究簡化其演算法,並未針對其資料權重調整進行計算, 僅將資料權重依其出現與否轉換為以二元值方式表示。每一影像所對應註解均視為一註 解文件,註解文件由多個關鍵字所組成,但各影像所對應之註解關鍵字具有重複出現情 況,因此首先便需將具有重複出現之註解關鍵字進行過濾處理以得到一個包含所有註解 關鍵字且不重複之集合,過濾方法為將所有註解關鍵字進行聯集運算,所得之結果稱之 為字彙集(vocabulary)。本研究將每一註解文件依其所包含之關鍵字與字彙集進行運算, 運算結果即為各影像註解之特徵向量。 首先每一文件可表達為其所包含之關鍵字所構成之集合,如下式:. 17.
(26) Di = { ki1,ki2,ki3,…………..,……,kini}. (6). 其中Di表示第i份影像註解文件,1≤i≤N,N 表示影像註解之文件總數,kij表示第i份影像 註解文件中第j個註解關鍵字,1≤j≤ni,ni表示第i份影像註解文件中之關鍵字個數。其後 將所有的註解關鍵字之集合以聯集方式運算即得到本研究之註解字彙集,以V表示,如 下式:. V = { D1∪D2∪D3∪………DN} = {kj|1≤j≤T}. (7). 其中T表示所有註解關鍵字總數。接續將各影像註解文件與註解字彙集A作比較,若V中 之關鍵字出現於比較文件中則將該關鍵字所對應之元素設為一,若無出現則設定為零, 如此可得一個二元向量,如下式所示:. ⎧1 if f k j i > 0 wk j i = ⎨ ⎩0 otherwise. (8). 其中wkji表示關鍵字kj在文件Di當中對應之設定值,fkji為註解關鍵字kj在文件Di中所出現的 次數,轉換後之向量則以vi表示,如下式所示:. {. v i = wk j i | 1 ≤ j ≤ T. }. (9). vi表示第i份影像註解文件經由前述方式轉換後得到之向量,其維度為T,此向量即為該影 像之註解向量(annotation vector)。影像註解文件特徵向量如圖 3-1-2 所示。其中 0 代表該 向量成份所對應之關鍵字並不是此影像之註解關鍵字;反之若為 1 則代表此關鍵字出現 在此影像之註解中。例如字彙集中之第 15 號關鍵字便出現在影像arborgreenImage01 之 註解中。 18.
(27) 圖 3-1-2 影像註解文件特徵向量. 3.2. GHSOM 訓練 影像與註解之特徵向量分別經由上述步驟進行計算完成,本節將說明影像及註解資. 料之訓練與分群過程。影像資料數量龐大,如何資料之分群效率與易於辨識程度變成為 資料分群法之選擇重點。目前採用各式分群對應方法中,以類神經網路之 SOM[11]最可 達到需求。SOM 之目的是希望將任意維度資料透過群聚與分群方式,映射至一維或二 維之拓樸結構上,並將資料彼此之拓樸關係映射於特徵圖上,如此便可取得資料所屬之 分群特性。後有學者接續研究發現資料之間應還存在有一些階層性的關聯,SOM 只可 將資料以二維拓樸結構方式呈現,卻無法呈現出資料與資料間隱含之階層性的關係,且 其各群集之大小固定,往往無法得到最適當之分群拓樸與結果,因此 Rauber 等學者便 提出改良 SOM 之 GHSOM[17],其目的在於解決 SOM 無法展現內容間階層性的關係以 及分群大小固定之缺失,本研究亦採用其做為資料分群方法,以下將分別針對 SOM 與. GHSOM 進行說明。. 3.2.1 SOM SOM 主要由下列三項元素所組成[1]: 輸入層:用以表示網路的輸入變數,即訓練範例的輸入向量,或稱特徵向量,其處理單 元數目依問題而定。 輸出層:用以表現網路的輸出變數,即訓練範例的群集,其處理單元數目依問題而定。 19.
(28) 網路連結:每個輸出單元與輸入層處理相連結的加權值所構成的向量。當網路學習完畢 後,其輸出處理單元相鄰近者會具有相似的連結加權值。 資料經由SOM訓練過後可得到一個以二維結構呈現之輸出結果,內容為資料分佈狀 況,輸入之資料則將憑藉資料間相關程度與分佈情形而自行聚集成為相關聯之群集與分 佈,亦即將自動調整輸出層各資料間鄰近關係。資料間之相鄰關係是指輸出層中各資料 相互連結之情形,資料在學習與訓練過程中會依據各自資料特性與輸入之資料特性調整 其鄰近距離,而使得輸出拓樸得以反映輸入資料之特徵。SOM對於大量且高維度資料具 有良好處理能力,可將高維度資料結合空間概念投影於二維平面上,便於使用者觀察資 料間相關性與群集等特性。SOM之輸出層拓樸大小須事先固定,且在訓練前不易得知最 佳資料群集數。同時SOM利用二維平面方式呈現資料有著資料之間關聯過度簡化之缺 點。. 3.2.2 GHSOM 在大量資料中,資料間往往存在著多重關聯性,若可發現此中關聯,對於資料利可 有更好的利用率,並可有更深入的研究,因此Rauber等學者[17]提出了GHSOM來克服. SOM固定架構且無法表達層級組織的限制,其架構地圖類似樹狀階層架構,如下圖3-2-1 所示:. 圖 3-2-1 GHSOM 的階層架構圖. 主要參數有學習速率(learning rate)、鄰近距離(neighborhood)與地圖大小(map size)。學習 20.
(29) 速率是用來控制權重調整的參數,鄰近距離指的是最贏向量影響範圍,地圖大小可以自 動調整。. GHSOM 為根基於 SOM 進行發展之一種類神經網路模式,GHSOM 中各階層中之 輸出拓樸結構均為單一 SOM,而每一拓樸架構當中的每個單元均視其輸入向量分群狀 況,決定是否繼續分群並產生另一 SOM,除了可將大量資料以二維空間方式呈現,並 且針對資料與資料間隱含之關聯進行資料分析與探索之外,GHSOM 除了可根據資料內 容與資料群聚程度動態決定資料階層生長,若群集中資料已然十分相似,則該群集便停 止訓練,若群集中尚存在有不同關聯的群集,則在進行進一步之訓練,直到各群集中資 料均為最相似方才停止,透過此方式,GHSOM 可反應資料內含彼此間階層關聯與架 構,並且透過其發展原則讓資料以階層式的方式呈現,GHSOM 可克服 SOM 之輸出拓 樸結構須事先設定與非階層式階層地圖之問題,依據資料內容進行地圖發展與階層架構 生長。. GHSOM 藉由量化誤差(quantization error)來引導整個訓練過程。它利用平均量化誤 差(mean quantization error, mqe)衡量輸入向量與神經元之間的相異性,並且控制整個成 長過程。因此對於單元 i,其 mqe 計算方式如下式:. (10). 其中d代表輸入向量x之樣本數,wi表示神經元之權重值向量,而後續SOM是否繼續成長 之終止生長條件如下式(11):. (11). 其中mqe0代表第 0 層之平均量化誤差,τ2代表輸入資料品質之控制參數,任意階層之輸 出神經元之mqe 均必須小於上一層之mqe。由於GHSOM的各階層均由數個獨立的SOM 21.
(30) 所組成,因此訓練過程與SOM的演算法相同,但是第一層的拓樸大小初始值不能設太 大。對於所有未達整體終止準則的神經元而言,需要將更細部的資料表示,也就是需要 再擴張到下一層。在其成長過程需針對每一層級計算MQE如下式:. (12). 其中μ代表地圖 m 階層中,獨立之 SOM 之數量。獨立之 SOM 成長的終止計算方式如下 式:. (13). 其中τ1代表控制GHSOM成長之參數。. GHSOM 演算法其學習過程中包括拓樸大小與階層成長兩個部份,其步驟如下: 1. 初始化設定 在訓練前,第 0 層只包含一個單元,以所有輸入向量的平均值初始化這個 單元的權重向量(w0),並計算其平均量化誤差(mean quantization error, mqe0)。處 理單元i的mqei為其權重向量(wi)與所有對應至該單元的輸入向量們(xi)之間的平 均歐氏距離(Euclidean distance)。. 2. 地圖的成長過程 在第 0 層之下建立一個 2x3 的 SOM 地圖(即第 1 層) ,第 1 層的地圖依據 前述的 SOM 演算法發展,在固定λ次訓練回合後,分析所有單元的 mqe 值, 高的 mqe 值表示輸入空間沒有被正確地分群,因此,需要加入新的單元,以增 進分群呈現的品質,擁有最高 mqe 值的單元,被選為誤差單元 e,一個新的列 或欄將被插入這個誤差單元和與它最不相似鄰居之間,新處理單元的權重向量 被初始化為與其鄰居的平均值。拓樸大小成長步驟如下: 步驟 1:計算第 0 層的平均量化誤差 22.
(31) 1 mqe = × w − xi 0 n x∑ 0 ∈ I I i. (14). 其中nI表示輸入向量xi樣本數、wi表示權值向量。 步驟 2:執行一次 SOM 學習。 步驟 3:找出錯誤單元(error unit) e 與最不相似鄰居(dissimilar neighbor unit) d。 步驟 4:在 e 與 d 之間插入新的一列或一行,如圖 3-2-2 所示。新的單元權重根. 據其鄰近單元的平均權重。. MQEm =. 1. μ. × ∑ mqei i ,MQEm代表這個拓. 樸中新插入單元的權重。. e Insert a row. e d. d Insert a column e. d. e. d. 圖 3-2-2 GHSOM 地圖成長方式. 步驟 5:重覆 Step 2 至 Step 4,直到 MQEm < τ1 × mqe0 。. 3. 階層結構的呈現 當地圖訓練完成後,每個單元必須被檢測是否需進一步擴展,即發展下一 層地圖,這表示某一群集內含有性質太分散之內容,因此將需創造次一層的新 地圖,此擴展決策的門檻值由第二個參數τ2所決定,不像前述水平地圖(horizontal. map)的停止成長準則(stopping criterion)是由上一層的單元所決定,對於所有地 圖 上 的 每 個 單 元 , 這 第 二 個 準 則 僅 根 據 於 mqe0 , 亦 即 第 0 層 的 mqe 。 若. mqei > τ × mqe ,則需在下一層中展開一個新的小地圖,反之,則不需進一 2 0 步展開。階層式成長步驟如下: 23.
(32) 步驟 1:檢查拓樸中每個單元的mqei值,如果 mqei > τ 2 × mqe0 ,將會在該單 元底下拓展一個新的SOM地圖。 步驟 2:在新增加的子階層中,進行 SOM 的學習。 經由 GHSOM 訓練後,影像內容與註解文件將分別被分群與標記至具階層關聯之群 集中。透過將影像或註解特徵向量標記於 SOM 上,內容相似的註解或影像會藉由訓練 過程逐漸群聚在一起,藉此可以推論被分在同一群的文件具有某種程度上之相關性,此 時可得到已分群完成之影像內容與註解文件之兩個樹狀階層。. 3.3. 影像與註解關聯對應. 影像與註解之向量資料經由 GHSOM 之步驟訓練後,所產生之資料群集彼此間呈現 樹狀階層關係,且各資料群集內所屬資料具有極高之相關程度,群集之間距離亦與資料 相似程度具正比關係,因此本研究提出兩種影像與註解之間關聯發掘之演算法,一種為 資料筆數法,另一則為資料權重法,此兩種方法皆以投票式權重增長概念為基礎,當資 料符合條件時,權重值便增長一分,每一影像與註解群集於計算後均可得到各自所對應 之權重,但群集權重於資料具有相同權重時則會產生無法判定最佳結果之困境,因此本 研究亦提出兩種解決此一困境之同分處理演算法,分別稱為深度優先法與群集距離法。. 3.3.1 資料筆數法 影像資料經由訓練後,相似之影像將被歸類至同一群集,所有影像均分別成為各影 像群集之內容,若某註解群集相較於其他群集受到較多份影像資料對應,則該影像群集 與對應之註解群集有極高之相關聯性,因此該註解群集即為影像群集所對應之最佳註解 群集。. 24.
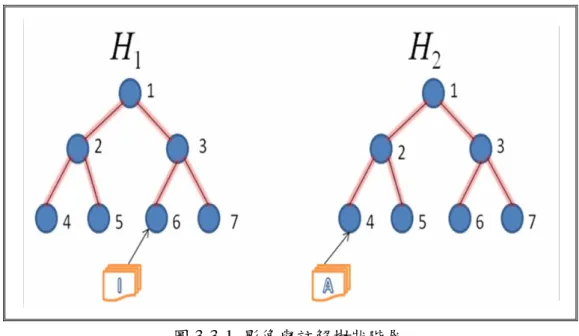
(33) 圖 3-3-1 影像與註解樹狀階層 圖 3-3-1 為經由GHSOM訓練後之樹狀階層示意圖,影像階層以H1表示,而H2則為註解 階層。其中I為H1所包含之一影像群集,A為H2之一註解群集,本研究所採用之影像資料 均有其各自對應之註解。若任一影像群集內容中,任一影像所對應之註解於任一註解群 集中出現之頻率較高,則可稱此二群集(影像與註解群集各一)為相關的。某一影像群 集I之對應註解群集A*可由下式獲得:. A* = arg max ∑ S (i, A) A. (15). i∈I. 其中當影像i之註解位於註解群集A時,S(I,A) = 1,否則為 0。以下圖 3-3-2 為例,影像階 層(H1)之群集 6 包含有影像I1、I2、I3、I4、以及I5等分群結果共五份影像資料,而各影像 階層所對應之註解階層(H2)之群集 4 包含有影像I1、I2、I4對應之註解A1、A2、A4,而群 集 8 與群集 9 則分別包含有影像I3、 I5分別所對應之註解A3與 A5,本方法之影像對應, 本方法之影像與註解關聯對應是根基投票式權重增長之概念來進行對應,其方法之演算 步驟如下: 步驟 1:假設影像群集階層中任意群集 I 包含 n 份影像資料。設定所有註解群集之 權重為零。 步驟 2:找出 I 中某一影像對應註解所在之註解群集,將此註解群集之權重值增加 25.
(34) 一分。 步驟 3:重複步驟 2,直到 I 中所有影像所對應註解均已計算完成。 步驟 4:找出分數最高之註解群集A*為優勝群集。此群集即為I之關聯對應群集。. 以下圖為例進行說明。. 圖 3-3-2 資料筆數法說明實例 影像樹狀群集(H1)之群集 6 包含有影像I1、I2、I3、I4、以及I5,而該些影像原本之註 解對應於註解樹狀群集(H2)分別有影像I1、I2、I4對應至註解群集 4,而影像I3對應至註解 群 8 之A3,影像I5對應至註解群集 9 之A5。由於影像群集 6 共有五份文件,因此共需進 行 5 次權重增長步驟。首先進行I1,I1所對應之註解群集均於註解群集 4,因此註解群集. 4 便獲得一分,接著I2之註解屬於註解群集 4,因此再給予註解群集 4 一分,此時可知註 解群集 4 共有二分,完整計算過程如下表 3-3-1 所示。. 26.
(35) 表3-3-1 實例計算結果 影像. 註解群集 4 註解群集 8 註解群集 9 分數 分數 分數. I1. 1. 0. 0. I2. 1+1=2. 0. 0. I3. 2. 1. 0. I4. 2+1=3. 1. 0. I5. 3. 1. 1. 根據上表可得知群集 4 權重分數最高,表示該註解群集所包含之內容與影像群集 6 所包含之影像最為相關,因此便將該註解群集所包含之註解與對應之影像群集所包含之 影像作關聯對應與連結。而其他影像群集亦可用相同方式得到其所關連對應之註解群集。. 3.3.2 群集距離法 影像與註解之特徵象輛經過 GHSOM 訓練過後,在所呈現之樹狀階層關係中,群集 與群集之間距離亦代表其群集與群集彼此間的關聯程度,在此所提之距離即為某群集走 訪至另一群集所走訪之路徑數,且基於 GHSOM 之分群概念,若任兩資料群集若彼此距 離十分相近,則兩群集所包含之內容應亦有一定程度之相似性,因此可認定為兩群集之 距離與兩群集之內容相似程度呈現反比關係,如下圖 3-3-3 所示:. 圖 3-3-3 群集距離關聯示意圖 27.
(36) 群集I2至群集I3之最短距離小於群集I1至群集I3之距離,則群集I2與群集I3之關聯性應大於 群集I1與群集I3,因此本研究認為兩群集間所走訪經過之群集亦具備相同特性,故提出此 群集距離法,以下圖 3-3-4 為例:. 圖 3-3-4 群集距離法說明實例. 上圖H1為影像階層群集,H2為註解階層群集,H1之群集 6 包含四份影像資料影像分別為. I1、I2、I3與 I4,個影像原始對應之註解分別位於H2之註解群集 4、5 以及群集 7。本研究 之影像標記與註解對應方式基於投票式權重增長之概念為基礎,並結合分群之群集距離 關係以決定關聯對應結果,方法其詳細演算步驟如下: 步驟 1:令影像階層中任一群集包含 n 份影像資料。針對其中任兩影像進行步驟 2-3。 共需進行 C n2 次計算過程。 步驟 2:找出該兩影像對應註解所在之註解群集,給予此二註解群集權重值各 1 分。 步驟 3:針對步驟 2 所選擇之二註解群集,找出兩群集最短路徑,給予此路徑途之 所有節點. 1 分。 兩群集相連最短路徑節 點數 - 1. 步驟 4:當該群集中每一影像對均已被處理,找出分數最高之註解群集為優勝群集。 此群集即為 I 之對應群集。. 以上圖 3-3-4 為例,假設欲找尋上圖 3-3-4 中,影像階層(H1)之群集 6 之最佳註解, 28.
(37) H1 之節點 6 包含四張影像I1、I2、I3與I4,分別對應之註解為A1、A2與A3。根據上述演算 規則得知共需 C 42 次給分步驟。計算過程分別兩兩影像進行計算,總計算步驟分別為. (I1,I2)、(I1,I3)、(I1,I4)、(I2,I3)、(I2,I4)、(I3,I4),首先計算(I1,I2),其I1與I2所對應之註解皆位 於H2之群集 4,故群集 4 獲得 1+1=2 分,而其他節點則未獲得分數。第二次使用(I1,I3),. I1與I2分別原始註解分位於H2之註解群集 4 與註解群集 5,故此二群集分別獲得 1 分。另 兩點間之最短路徑途經群集為群集 2, 群集 1, 群集 3 與群集 6,亦各獲得 1/(3–1) = 0.5 分,下表 3-3-2 將列出完整計算與給分過程: 表3-3-2 群集距離法範例計算過程 影像群集 (A,B). 註解群集 4 得分. 註解群集 5 得分. 註解群集 7 得分. 最短路徑群集及其得分 (結 點:分數). (I1,I2). 1+1=2. 0. 0. 無. (I1,I3)、. 2+1=3. 1. 0. 2:(1/3-1)=1/2 2:1/2+(1/5-1)=3/4. (I1,I4). 3+1=4. 1. 1. 1: (1/5-1)=1/4 3: (1/5-1)1/4. (I2,I3). 4+1=5. 1+1=2. 1. 2:3/4+(1/3-1)=5/4 2:5/4+(1/5-1)=6/4. (I2,I4). 5+1=6. 2. 1+1=2. 1:1/4+(1/5-1)=2/4 3:1/4+(1/5-1)=2/4 2:6/4+(1/5-1)=7/4. (I3,I4). 6. 2+1=3. 2+1=3. 1:2/4+(1/5-1)=3/4 3:2/4+(1/5-1)=3/4. 最後計算各節點之總分,經由整理上表可得到群集 4 得到 6 分,群集 5 與 7 得到 3 分,而各群集相連最短路徑所經過之群集 2、1、3 則分別得到 7/4、3/4 及 3/4 分,群集. 4 為最高分,因此影像群集 6 所對應之註解群集即為註解群集 4。而其他影像群集亦可用 相同方式得到其所對應之註解群集。 29.
(38) 3.3.3 同分處理 若前述之方法發生群集權重同分之困境,則無法判定與影像群集最佳之註解群集關 聯對應,關聯無法建立便無法完成後續自動影像註解之目的。由於 GHSOM 具有可有效 將資料進行訓練與分群,且可依據資料關聯性而動態增長以達到最佳分群結果之特性, 因此本研究據此提出深度優先法與群集距離法兩種方法做為同分處理方法。. 3.3.3.1. 深度優先法. 根據 GHSOM 之特性,資料在訓練過程中將不斷針對資料相關程度進行計算與比 較,相同或相似者歸類至相同群集,若分群結果尚未到達最佳分群狀態,則再進行訓練 直到最佳分群狀態完成,如下圖所示:. 資料. 是. GHSOM. 最佳群集. 往下伸展. 輸出結果. 否. 圖 3-3-3-1GHSOM 訓練流程示意圖 因此可認定階層較深之群集相較於階層較淺之群集內容應更為細膩與精確,故當有 多個群集之分數相同時,本研究以階層數最高者優先選擇做為影像群集之關聯對應。以 下圖為例:. 30.
(39) 圖 3-3-3-2 深度優先法實例說明. 上圖 3-3-3-2 在經過資料筆數法與資料權重法計算後將得到兩種不同之計算結果,將計算 所得知結果表列如下表 3-3-3 與表 3-3-4: 表3-3-3 圖 3-3-3-2 依資料筆數法計算結果 影像群集. 註解群集 4. 註解群集 6. 註解群集 3. I1. 1. 0. 0. I2. 1. 1. 0. I3. 1. 1. 1. 表3-3-4 圖 3-3-3-2 資料權重法計算結果 影像群集(A,B). 註解群集 4. 註解群集 6. 註解群集 3. (I1,I2). 1. 1. 0. (I1,I3). 2. 1. 1. 最短路徑途經 群集. 2:1/3 5:1/3 2: 2/3 1:1/3 5:2/3 (I2,I3). 2. 2. 2. 2: 11/12 1:7/12. 31.
(40) 由上表可得知採用資料筆數法與資料權重法之分數均為註解群集 3、群集 4 與群集 6 為最高,此時根據上圖得知群集 6 為三個群集資料中具有階層深度最深者,所分群之註 解資料相較階層較淺之群集註解更為精確,因此影像群集 6 所對應之註解群集即為註解 群集 6。. 3.3.3.2. 歐基里德距離法. 根據前述,當資料群集出現同分狀況時,可先根據階層深度關係加以判定何群集為 較適合之影像對應註解群集,但若發生任兩群集在經由前述演算法計算後得到相同權 重,且註解群集之階層深度亦相同,此時便無法利用深度優先法進行判斷。由於 GHSOM 之訓練結果中,同一群集之內容十分相關,影像所對應之註解應亦為十分相關,且訓練 結果可得到一有效分群之分群結果,因此將各影像群集內容所對應之註解均視為十分相 關。若在同分且相同階層深度之情況下,由於 GHSOM 之特性,本研究提出一方法稱之 為歐基里德距離法來解決深度優先法無法解決之困境。歐基里德距離法之概念為註解與 註解所在群集越相似則表示該群集與正確註解之相似性越高。一般而言,資料分群後, 可利用群集中心點作為該群集之代表,因此選擇與註解所在群集最為相似之註解群集作 為影像群集所關聯之註解。其演算步驟如下: 步驟 1:計算影像群集中,影像原始註解所有文件之向量平均以求得群集中心點。 步驟 2:計算各影像所對應之註解特徵向量與註解所屬群集中心點之歐基里德距離。 步驟 3:重複步驟 1-2 直到所有影像對應之註解文件均計算完成。 步驟 4:比較所有影像所對應之註解與註解所屬之群集中心之歐基里德距離,並取 距離最小之群集為影像群集所對應之最佳註解群集。. 以下圖 3-3-3-3 為例:. 32.
(41) 圖 3-3-3-3 歐基里德距離法實例. 根據資料筆數法與資料權重法計算結果如下表 3-3-5 (a)與表 3-3-6 表3-3-5 圖 3.3.3.3 依資料筆數法計算結果 影像群集. 註解群集 4. 註解群集 3. 註解群集 5. I1. 1. 0. 0. I2. 1. 0. 1. (I2,I3). 1. 1. 1. 表3-3-6 圖 3.3.3.3 依資料權重法計算結果 影像群集(A,B). 註解群集 4. 註解群集 3. 註解群集 5. 最短路徑途經群集. (I1,I2). 1. 1. 0. 2:1/(3-1)=1/2. (I1,I3). 1+1=2. 1. 1. 2:(1/2)+(1/(4-1))=5/6 1:1/(4-1)=1/3. (I2,I3). 2. 1+1=2. 1+1=2. 2:(5/6)+(1/(4-1))=7/6 1:(1/3)+1/(4-1)=2/3. 由上列資料筆數法與資料權重法計算結果可知註解群集 3、4 與 5 所得分數為所有群 集中最高且同分,此時根據本研究所提之深度優先法可取得群集 4、5 可能為最佳註解群 集,但此時無法決定最佳註解群集,因此利用歐基里德距離法以解決此一現況。現假設 33.
(42) 影像I1、I2、各自對應之註解A1、A2註解特徵向量與各群集之特徵向量平均值分別如下表. 3-3-7 與表 3-3-8,其中A1 Group平均值為將該群集中所有註解特徵向量相加並加以平均 所得。 表3-3-7 影像原始註解之特徵向量 註解階層群集 6. 影像對應之註解特徵向量. 包含文件. A1. 110001011001011101011000010000000001. A2. 000000000110110001010011000000000000 表3-3-8 註解群集特徵向量平均. 對應之註解階層. 註解群集特徵向量平均. 群集 6. A1 Group. 000001001110000000001011011100000000. A2 Group. 111001001000000000000000000000000001. 此時分別計算註解A1與所屬A1 Group平均值之歐基里德距離,與A2及A3之歐基里德 距離得到如下表 3-3-9 表3-3-9 註解群集計算結果 註解文件. 計算結果. A1. 4. A2. 3. 由上表可得知註解A2與其所屬群集中心之歐基里德距離為最小,表示註解A2與其所屬群 集最為相似,該群集所包含之註解正確性相較於A1為佳,因此A2群集所屬之註解即為影 像群集 6 之最佳註解,因此可得到影像群集 6 與註解階層之關聯對應。 34.
數據



+4



相關文件
In this section we define a general model that will encompass both register and variable automata and study its query evaluation problem over graphs. The model is essentially a
Promote project learning, mathematical modeling, and problem-based learning to strengthen the ability to integrate and apply knowledge and skills, and make. calculated
• Is the school able to make reference to different sources of assessment data and provide timely and effective feedback to students according to their performance in order
The closing inventory value calculated under the Absorption Costing method is higher than Marginal Costing, as fixed production costs are treated as product and costs will be carried
• To achieve small expected risk, that is good generalization performance ⇒ both the empirical risk and the ratio between VC dimension and the number of data points have to be small..
Our main goal is to give a much simpler and completely self-contained proof of the decidability of satisfiability of the two-variable logic over data words.. We do it for the case
We try to explore category and association rules of customer questions by applying customer analysis and the combination of data mining and rough set theory.. We use customer
Step 5: Receive the mining item list from control processor, then according to the mining item list and PFP-Tree’s method to exchange data to each CPs. Step 6: According the
