國
立
交
通
大
學
資訊科學與工程研究所
博
士
論
文
摘錄式多文件自動化摘要方法之研究
A Study on Extraction-based
Multidocument Summarization
研 究 生:葉鎮源
指導教授:楊維邦 博士
柯皓仁 博士
中 華 民 國 九 十 七 年 三 月
摘錄式多文件自動化摘要方法之研究
A Study on Extraction-based
Multidocument Summarization
研 究 生:葉鎮源
Student:
Jen-Yuan
Yeh
指導教授:楊維邦 博士
柯皓仁 博士
Advisors: Dr. Wei-Pang Yang
Dr. Hao-Ren Ke
國 立 交 通 大 學
資 訊 科 學 與 工 程 研 究 所
博 士 論 文
A Thesis
Submitted to Institute of Computer Science and Engineering College of Computer Science
National Chiao Tung University in partial Fulfillment of the Requirements
for the Degree of Doctor of Philosophy
in
Computer Science and Engineering March 2008
Hsinchu, Taiwan, Republic of China
中華民國九十七年三月
摘錄式多文件自動化摘要方法之研究
研究生: 葉鎮源 指導教授: 楊維邦 博士 柯皓仁 博士 國立交通大學 資訊科學與工程研究所摘 要
隨著資訊科技的快速發展,線上資訊的量及其可得性已大幅地增長。資訊爆 炸導致產生資訊超載的現象,如何有效率地取得且有效地利用所需的資訊,已儼 然成為人們生活中必須面對的迫切問題。文件自動化摘要(Text Summarization) 技術由電腦分析文件內容,擷取出重要的資訊,並以摘要的形式呈現。此技術可 以幫助人們處理資訊,於短時間內了解文件的內容,以作為決策的參考。 本論文探討多文件自動化摘要的方法,研究主題包含:(1) 多文件摘要(Multidocument Summarization)與(2) 以查詢為導向之多文件摘要(Query-focused Multidocument Summarization)。多文件摘要乃是從多篇主題相關的文件中產生單 篇摘要;以查詢為導向之多文件摘要則是從多篇主題相關的文件中擷取與使用者 興趣相關的內容,並依此產生單篇摘要。本論文採用語句摘錄(Sentence Extraction) 的方法,判別語句的重要性,並逐字摘錄重要的語句以產生摘錄式摘要。其中, 本論文的重點為語句重要性的計量及語句排序方法的研究。 針 對 多 文 件 摘 要 , 本 論 文 提 出 一 套 以 圖 形 為 基 礎 的 語 句 排 序(Sentence Ranking) 方 法 : iSpreadRank 。 此 方 法 建 構 語 句 關 係 網 路 (Sentence Similarity Network)作為分析多文件的模型,並採用擴散激發理論(Spreading Activation)推導 語句的重要性作為排序的依據。接著,依序挑選重要的語句以形成摘要;挑選語 句時,以與先前被挑選的語句具較低資訊重複者為優先。實驗中,將此摘要方法
應用於DUC 2004 的資料集。評估結果顯示,相較於 DUC 2004 當年度競賽的系
統,本論文所提出的方法於ROUGE 基準上有良好的表現。
針對以查詢為導向之多文件摘要,本論文結合:(1) 語句與查詢主題的相似 度與(2) 語句的資訊代表性,提出一套語句重要性的計量方法。其中,利用潛在 語意分析(Latent Semantic Analysis),以計算語句與查詢主題於語意空間的相似 度;並採用傳統摘要方法中探討語句代表性的特徵(Surface-level Features),以評
量語句的資訊代表性。本論文亦基於Maximum Marginal Relevance 技術,考量資
訊的重複性,提出一個適用於以查詢為導向之多文件摘要的語句摘錄方法。實驗
中,將此摘要方法應用於DUC 2005 的資料集。評估結果顯示,相較於 DUC 2005
當年度競賽的系統,本論文所提出的方法於ROUGE 基準上有良好的表現。
關鍵詞:多文件摘要;一般性摘要;以查詢為導向之摘要;語句排序;語句摘錄; 重複性資訊過濾;
A Study on Extraction-based
Multidocument Summarization
Student: Jen-Yuan Yeh Advisors: Dr. Wei-Pang Yang
Dr. Hao-Ren Ke
Institute of Computer Science and Engineering, National Chiao Tung University
ABSTRACT
The rapid development of information technology over the past decades has dramatically increased the amount and the availability of online information. The explosion of information has led to information overload, implying that finding and using the information that people really need efficiently and effectively has become a pressing practical problem in people’s daily life. Text summarization, which can automatically digest information content from document(s) while preserving the underlying main points, is one obvious technique to help people interact with information.
This thesis discusses work on summarization, including: (1) multidocument summarization, and (2) query-focused multidocument summarization. The first is to produce a generic summary of a set of topically-related documents. The second, a particular task of the first, is to generate a query-focused summary, which reflects particular points that are relevant to the user’s desired topic(s) of interest. Both tasks are addressed using the most common technique for summarization, namely sentence extraction: important sentences are identified and extracted verbatim from documents and composed into an extractive summary. The first step towards sentence extraction is obviously to score and rank sentences in order of importance, which is the major focus of this thesis.
In the first task, a novel graph-based sentence ranking method, iSpreadRank, is proposed to rank sentences according to their likelihood of being part of the summary. The input documents are modeled as a sentence similarity network. iSpreadRank practically applies spreading activation to reason the relative importance of sentences based on the network structure. It then iteratively extracts one sentence at a time into the summary, which not only has high importance but also has low redundancy with the sentences extracted prior to it. The proposed summarization method is evaluated using the DUC 2004 data set and found to perform well in various ROUGE measures. Experimental results show that the proposed method is competitive to the top systems at DUC 2004.
In the second task, a new scoring method, which combines (1) the degree of relevance of a sentence to the query, and (2) the informativeness of a sentence, is proposed to measure the likelihood of sentences of being part in the summary. While the degree of query relevance of a sentence is assessed as the similarity between the sentence and the query computed in a latent semantic space, the informativeness of a sentence is estimated using surface-level features. Moreover, a novel sentence extraction method, inspired by maximal marginal relevance (MMR), is developed to iteratively extract one sentence at a time into the summary, if it is not too similar to any sentences already extracted. The proposed summarization method is evaluated using the DUC 2005 data set and found to perform well in various ROUGE measures. Experimental results show that the proposed method is competitive to the top systems at DUC 2005.
Keywords: multidocument summarization; generic summary; query-focused
Contents
摘 要 ... I
ABSTRACT... III Contents ... V List of Figures... VIII List of Tables... XI
致 謝 ...XII
Chapter 1 Introduction...1
1.1 Background...3
1.1.1 History of text summarization ...4
1.1.2 Summarization factors ...6
1.1.3 Summarization techniques ...8
1.1.4 Summary Evaluation...12
1.2 Tasks and Challenges...13
1.2.1 Multidocument summarization ...13
1.2.2 Query-focused multidocument summarization...17
1.3 Guide to Remaining Chapters...20
Chapter 2 Literature Survey...21
2.1 Multidocument Summarization ...21
2.2 Query-focused Multidocument Summarization...25
2.3 Related Research Projects...28
2.3.1 PERSIVAL...28
2.3.3 MEAD...29
2.3.4 GLEANS...30
2.3.5 NeATS...30
2.3.6 GISTexter...31
Chapter 3 Multidocument Summarization...32
3.1 Design ...34
3.2 Algorithm...37
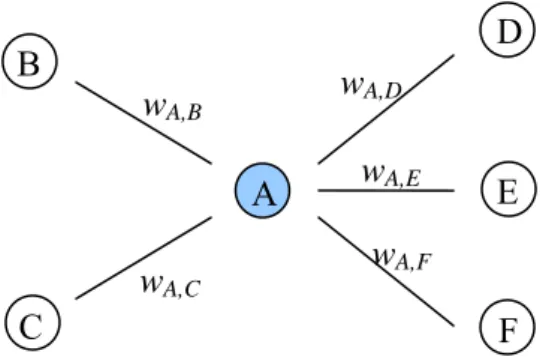
3.2.1 Text as a graph: sentence similarity network...37
3.2.2 Feature extraction...39
3.2.3 Ranking the importance of sentences ...41
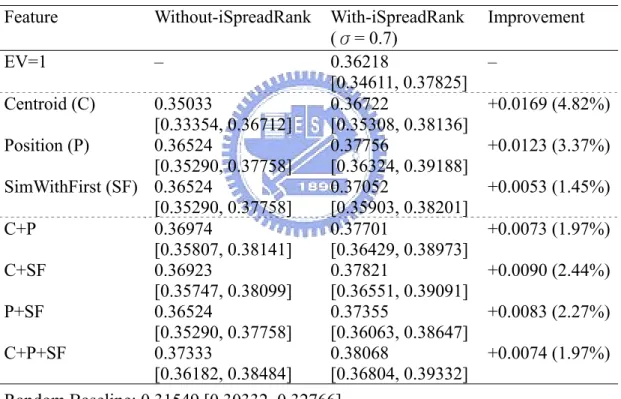
3.2.4 Sentence extraction ...49
3.2.5 Sentence ordering...50
3.3 Evaluation ...51
3.3.1 Data set and experimental setup ...51
3.3.2 Evaluation method and metric ...51
3.3.3 Results...53
3.3.4 Example output ...58
3.4 Discussion...63
3.4.1 Sentence similarity network...63
3.4.2 The use of sentence-specific features ...63
3.4.3 iSpreadRank...64
3.4.4 The proposed summarization approach ...66
Chapter 4 Query-focused Multidocument Summarization...68
4.1 Design ...70
4.2.1 Relevance between a sentence and the query ...74 4.2.2 Feature extraction...78 4.2.3 Sentence scoring ...81 4.2.4 Sentence extraction ...83 4.2.5 Sentence ordering...84 4.3 Evaluation ...85
4.3.1 Date set and experimental setup ...85
4.3.2 Evaluation method and metric ...85
4.3.3 Results...87
4.3.4 Example output ...90
4.4 Discussion...109
4.4.1 Query relevance analysis by latent semantic analysis ...109
4.4.2 The use of sentence-specific features ...110
4.4.3 MMR vs. Modified MMR...110
4.4.4 The proposed summarization method... 111
Chapter 5 Conclusions... 112
5.1 Multidocument Summarization Framework ...112
5.2 Contributions...114
5.3 Future Work ...117
List of Figures
1.1. Overview of the summarization process...3
3.1. The proposed multidocument summarization approach ...34
3.2. A sentence similarity network...38
3.3. The collection and the spread of activations for node A in one iteration...45
3.4. An example to explain how iSpreadRank works ...48
3.5. The computation of X(1)...48
3.6. The algorithm of sentence extraction...49
3.7. The algorithm of sentence ordering ...50
3.8. ROUGE-1 scores of system and human peers at DUC 2004...56
3.9. ROUGE-2 scores of system and human peers at DUC 2004...56
3.10. ROUGE-3 scores of system and human peers at DUC 2004...57
3.11. ROUGE-4 scores of system and human peers at DUC 2004...57
3.12. ROUGE-L scores of system and human peers at DUC 2004 ...58
3.13. ROUGE-W-1.2 scores of system and human peers at DUC 2004...58
3.14. ROUGE-1 scores of With-iSpreadRank (C+P+SF) for 50 clusters...59
3.15. System summary for d30045t ...59
3.16. Model summary, created by B, for d30045t ...60
3.17. Model summary, created by C, for d30045t ...60
3.18. Model summary, created by E, for d30045t...60
3.19. Model summary, created by F, for d30045t ...61
3.20. System summary for d30027t ...61
3.21. Model summary, created by A, for d30027t ...62
3.22. Model summary, created by C, for d30027t ...62
3.24. Model summary, created by G, for d30027t...63
4.1. The proposed query-focused multidocument summarization approach ...70
4.2. The process of sentence extraction using MMR...83
4.3. ROUGE-2 scores of system and human peers at DUC 2005...90
4.4. ROUGE-SU4 scores of system and human peers at DUC 2005 ...90
4.5. ROUGE-2 scores of M4 for 50 clusters...91
4.6. ROUGE-SU4 scores of M4 for 50 clusters...91
4.7. Query statement for d357i ...92
4.8. System summary for d357i ...93
4.9. Model summary, created by D, for d357i ...93
4.10. Model summary, created by E, for d357i...94
4.11. Model summary, created by F, for d357i ...94
4.12. Model summary, created by I, for d357i...95
4.13. Query statement for d694j ...96
4.14. System summary for d694j ...96
4.15. Model summary, created by G, for d694j...97
4.16. Model summary, created by H, for d694j ...97
4.17. Model summary, created by I, for d694j...98
4.18. Model summary, created by J, for d694j...98
4.19. Query statement for d376e...99
4.20. System summary for d376e ...100
4.21. Model summary, created by A, for d376e...100
4.22. Model summary, created by B, for d376e...101
4.23. Model summary, created by C, for d376e...101
4.24. Model summary, created by D, for d376e...102
4.26. Model summary, created by G, for d376e ...103
4.27. Model summary, created by H, for d376e...103
4.28. Model summary, created by I, for d376e ...104
4.29. Model summary, created by J, for d376e...104
4.30. Query statement for d436j ...105
4.31. System summary for d436j ...106
4.32. Model summary, created by G, for d436j...106
4.33. Model summary, created by H, for d436j ...107
4.34. Model summary, created by I, for d436j...108
4.35. Model summary, created by J, for d436j...108
List of Tables
1.1. Examples that employ extractive techniques...11
1.2. Examples that employ abstractive techniques ...11
1.3. Query statement for set d357i...18
1.4. Query statement for set d376e ...18
3.1. The sentence-specific feature set ...40
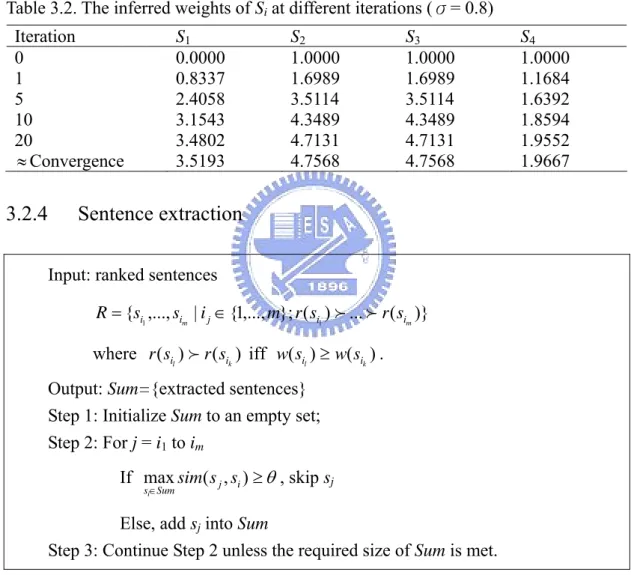
3.2. The inferred weights of Si at different iterations...49
3.3. ROUGE runtime arguments for DUC 2004...52
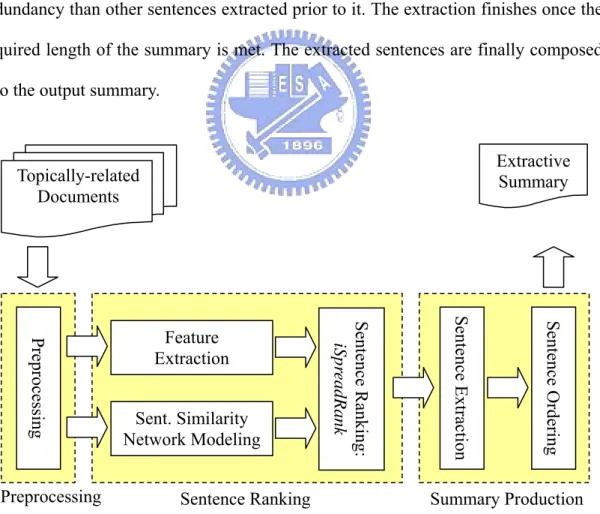
3.4. ROUGE-1 scores obtained in different experimental settings...54
3.5. Part of the official ROUGE-1 scores of Task 2 at DUC 2004 ...55
4.1. ROUGE runtime arguments for DUC 2005...86
4.2. Settings of different models ...87
4.3. ROUGE-2 scores obtained in different experimental settings...87
4.4. ROUGE-SU4 scores obtained in different experimental settings...87
4.5. Part of the official ROUGE-2 scores at DUC 2005...89
致 謝
本論文得以順利完成,首先要感謝指導教授楊維邦博士及柯皓仁博士。兩位 教授於我的求學過程,歷經碩士及博士兩個階段,多年來一直悉心且不辭辛勞地 引領、指導與鼓勵。恩師們的教導,啟發我對研究的興趣,使我得以一窺高深學 術的殿堂,並走上研究之路。亦是恩師們的支持,我才能夠申請到出國訪問研究 的機會。於國外學習的經驗,不僅開闊我的視野,也使得我的人生經歷更加豐富。 此外,恩師們的學者風範以及待人處世的態度,日後將是我努力追隨的模範。 感謝本校孫春在教授、袁賢銘教授、梁婷教授,以及台灣大學項潔教授、清 華大學金陽和教授與唐傳義教授、成功大學曾新穆教授。你們的不吝指教,給予 我在研究方向及論文內容的諸多寶貴建議與指正。同時,感謝Columbia University的Kathleen R. McKeown 教授與 Owen Rambow 博士,謝謝你們於我在美國進行
訪問研究時的照顧與指導。 感謝實驗室的夥伴們,由於你們對我的關懷與照顧,讓我的研究生活不感孤 單。每次的討論與腦力激盪,每每提供我不同的意見,使我獲得許多新的想法。 同時,也由衷地感激過去所有曾經陪伴、幫助與鼓勵我的朋友們。 最後,感謝我親愛的父母與家人們。謝謝你們長久以來100%的支持與鼓勵, 使我能專心致力於研究工作,並且堅持下去完成學業。僅以此論文獻予你們,同 時致上我最真摯的愛與祝福。 鎮源 于 新竹 2008.03
Chapter 1
Introduction
The rapid development of information technology over the past decades has brought human beings into the Information Age. With the advent of new technologies, the amount and the availability of online information have dramatically increased. There has been a large amount of information produced in the last decade. However, the process of information production never ends and is even going on at an extremely rapid growth rate. For example, the Internet Archive1, an archive of snapshots of the Web, has collected almost 2 petabytes of data and is currently growing at a rate of 20 terabytes per month. The explosion of information has led to information overload (i.e., a state of having too much information to make a decision or remain informed about a topic), implying that finding and using the information that people really need efficiently and effectively has become a pressing practical problem in people’s daily life.
An information retrieval (IR) system, (e.g., search engines, such as Google2, Microsoft Live Search3, and Yahoo! Search4) can greatly facilitate the discovery of information by retrieving documents, which seem to be relevant to a user query. However, hundreds or even thousands of hits might be returned for a search, by which the user is often overwhelmed. Hence, it is still desirable to have other kinds of applications (e.g., document clustering, text categorization, question answering, and topic detection and tracking) to help people interact with information.
1 http://www.archive.org/ 2 http://www.google.com.tw/ 3 http://www.live.com/ 4 http://search.yahoo.com/
Text summarization (TS), which can automatically digest information content from document(s) while preserving the underlying main points, is obviously one such application. This technique can potentially reduce the amount of text that people need to read, since, instead of a full document (or a set of related documents), only a brief summary needs to be read. For instance, by providing snippets of text for each match returned in a query, search engines can significantly help users identify the most relevant documents in a short time. The following gives other scenarios, mentioned in [57], where text summarization might be beneficial: (1) put a book on the scanner, turn the dial to ‘2 pages’, and read the result, (2) download 1,000 documents from the Web, send them to the summarizer, and select the best ones by reading the summaries of the clusters, and (3) forward the Japanese email to the summarizer, select ‘1 par’, and skim the translated summary. In general, text search and summarization are the two essential technologies that complete each other [45]: while text search engines serve as information filters to sift out an initial set of relevant documents, text summarizers play the role of information spotters to help users spot a final set of desired documents.
In this thesis, we present work on multidocument summarization, a task of producing a single summary of multiple documents on the same (or related) topic. In the following, Section 1.1 first gives a general background on text summarization, presenting an overview of the summarization process, discussing summarization factors, and sketching briefly the history of research in summarization, as well as the categorization of summarization techniques. Section 1.2 introduces the tasks and the challenges that are addressed in this thesis. Finally, Section 1.3 provides a guide to the remaining chapters.
1.1 Background
Text summarization is the creation of a shorten version of a text (or texts), while still preserving the underlying main points of the original text(s). By definition, text summarization is:
(a) the process of distilling the most important information from a source (or sources) to produce an abridged version for a particular user (or users) and task (or tasks) [87]; or
(b) the process of taking a textual document, extracting content from it and presenting the most important content to the user in a condensed form and in a manner sensitive to the user’s or application’s needs [85].
Audience Function Fluency
Generic
User-focused IndicativeInformative
Evaluative Fragments Connected-text
An
aly
sis
Tr
ans
form
ation
Sy
nthesis
Documents
Summaries
Compression
Audience Function Fluency
Generic
User-focused IndicativeInformative
Evaluative Fragments Connected-text
An
aly
sis
Tr
ans
form
ation
Sy
nthesis
Documents
Summaries
Compression
Fig. 1.1. Overview of the summarization process [87]
In general, the main challenge in text summarization is to identify the informative segments at the expense of the rest [110]. Fig. 1.1 illustrates a high-level overview of the process of text summarization. The input could be a single document or multiple related documents. The output summary may be an extract of the source(s) or an abstract. The summarization process, as mentioned in [87], can be decomposed
into three phases: (1) analysis, (2) transformation, and (3) synthesis. The analysis phase analyzes the input text and interprets it into a source representation. The transformation phase transforms the analysis results into a summary representation. Finally, the synthesis phase takes the summary representation as input, and produces an appropriate summary corresponding to the user’s need.
In the whole process, factors, such as audience, function, and fluency, will lead to different types of the desired output summaries. This is further discussed in Section 1.1.2. As also shown in Fig. 1.1, another important factor in summarization is the compression rate, which is the ratio of the length of the summary to that of the original text(s). While the compression rate decreases, the length of summary gets shorter, indicating that more information is lost. The length of summary, on the other hand, becomes longer as the compression rate increases. However, in such a case, it tends to include more insignificant or redundant information in the summary. Traditionally, a compression rate ranging from 1% to 30% will produce a good summary [87]. See also [44], [48], [66] for more discussion.
1.1.1
History of text summarization
Text summarization has its first inception in the late 1950s, for the hope to automatically create abstracts from scientific articles. Due to the lack of powerful computers and the difficulties in nature language processing (NLP), early works were only based on the use of heuristics, such as term frequency (e.g., [82], [113]), lexical cues (e.g., [36]), and location (e.g., [36]), to determine which information units (e.g., words, phrases, sentences, or paragraphs) should be included into the summary. The principal shortcoming of this kind of approaches is that they depend very much on the particular format and style of writing [55], which limits these approaches only in
special domains.
In the late 1970s and the 1980s, research works turned to complex text processing, where techniques developed in artificial intelligence (AI) were exploited; for instance, the use of logic and production rules (e.g., [42]), scripts (e.g., [33], [69]), and semantic networks (e.g., [115]). See also [114]. The intuition behind these studies is to model text entities in knowledge representations (e.g., frames and templates) and to extract relationships between entities by inference. While these approaches have proven successful to a degree, the major drawback is that limitedly-defined knowledge representations may result in incomplete analysis of entities and their relationships.
Since the 1990s, dominant approaches turned to finding characteristic text units using statistical methods, techniques developed in information retrieval (IR), as well as hybrid approaches. See [7], [20], [29], [45], [55], [103], [119]. Early works mainly focused on analysis and representation in symbolic level (or word level), and did not take into account semantics, such as synonymy, polysemy, and term dependency [55]. Fortunately, from the mid-90s, the issue of semantics has been gradually addressed because more reliable natural language processing tools, such as for information extraction (IE) and sentence parsing, become available [127].
In recent years, supervised learning-based methods play an important role in text summarization. For example, [66], [76], [90], [128]. With the application of machine learning (ML), classification rules from documents and their corresponding summaries can be learned to determine whether a text unit should be included in the summary. The process of supervised summarization mainly consists of two phases: (1) training, and (2) test. While the training phase extracts appropriate features from the
training data set, and employs a learning algorithm to generate pattern rules, the test phase applies the rules on new documents to produce summaries. The advantage is that supervised learning-based methods can deliver effective systems without the effort of summarization model analysis [127].
Started from the late-90s, numerous large-scale evaluation programs (e.g., SUMMAC5, DUC6, and NTCIR-TSC7) and workshops have been run to measure the performance of summarization systems. Many standard collections for training and test on evaluation of summarization methods have been established recently, which leads to the great encouragement of the summarization work. For instance, since 2001, DUC (Document Understanding Conferences), sponsored by the National Institute of Standards and Technology (NIST), has held several evaluation competitions in single-document summarization, multidocument summarization, cross-lingual summarization, and query-focused summarization.
1.1.2
Summarization factors
The design and evaluation of a summarization system usually depend on several factors (e.g., the type of input documents, the purpose that the final summary should serve, and the ways of presenting a summary) that it takes into account during the development. The following factors, as outlined in [55], [107], are traditionally considered to yield the main categorization of research in text summarization. See also [16], [26], [126] for more discussion.
(1) Format: extract and abstract
5 http://www-nlpir.nist.gov/related_projects/tipster_summac/. 6 http://duc.nist.gov/.
A summary can be in the form of an extract of the source(s) or an abstract. An extract is usually created by the selection and verbatim inclusion of text units (e.g, sentences, paragraphs, and even phrases) from the original text(s). In contrast, an abstract involves the fusion of information content and the presentation of information in novel phrasings by natural language generation. (2) Context: generic and query-focused
A summary can either be generic or query-focused (i.e., “user-focused” in Fig. 1.1). A generic summary reflects the author’s point of view and mainly concerns “what” described in the text(s). A query-focused summary, on the other hand, is customized to satisfy the user’s information need and to reflect particular points that are relevant to the user’s desired topic(s) of interest.
(3) Genre: indicative, informative, and evaluative
A summary can be indicative, only to suggest what a particular subject of the source(s) is about, without conveying any specific content. As an example, a list of keywords is an indicative summary. An informative summary conveys information pertinent to the source(s) and attempts to stand in place of the source(s) as a surrogate. A summary, such as a book review, is evaluative (or critical) to offer a critique of the source(s) [125].
(4) Dimension : single-document and multidocument
There are single-document and multidocument summarization, with respect to the number of input documents. While the input of single-document summarization (SDS) comprises only one document, multidocument
summarization (MDS) takes as input a set of topically-related documents, such as news articles on the same event. It would be much beneficial to create a summary of multiple documents. However, the need to identify important similarities and differences across documents makes multidocument summarization more challenging than single-document summarization [110]. (5) Linguality: monolingual, multilingual, and cross-lingual
The linguistic property is usually related to multidocument summarization. Monolingual summarization deals with documents, which are written in only one language. Multilingual summarization tries to determine the relevance of text portions and to generate multilingual texts based on information in different source languages. See [21], [70], [112]. As for cross-lingual summarization, the output summary is translated into another language different from the input one.
1.1.3
Summarization techniques
Nowadays, text summarization has reached a relatively mature stage [95]. Many summarization techniques have been developed and evaluated in the past decades. There are several ways to characterize the various summarization techniques. Based on the level of text processing, [87] categorized summarization techniques as approaching the problem at the surface, entity, or discourse levels. Surface-level approaches represent information using shallow features (e.g., term frequency, location, cue word, etc.) and combine these features to yield a salience function to measure the significance of information. For example, [54], [66], [76], [84], [90], [91], [103], [111], [128], [137]. Entity-level approaches model text entities and their relationships (e.g., co-occurrence, co-reference, syntactic relations, logical relations, etc.) and determine salient information based on text-entity models. See [6], [7], [33],
[51], [62], [69], [97], [135]. Discourse-level approaches model the global structure of the text (e.g., document format, rhetorical structure, etc.) and its relation to communicative goals. For instance, [17], [89].
[48], instead, classified summarization techniques into knowledge-poor or knowledge-rich, according to how much domain knowledge is involved in the summarization process. Knowledge-poor approaches do not consider any knowledge pertaining to the domain to which text summarization is applied. Therefore, they can be easily applied to any domains. For example, [45], [54], [55], [78], [91], [98], [119]. The principle behind knowledge-rich approaches is that the understanding of the meaning of a text can benefit the generation of a good summary. These approaches rely on a knowledge base of rules, which must be acquired, maintained, and then adapted to different domains. See [7], [49], [51], [62], [97], [116], [135]. In general, surface-level approaches are known as knowledge-poor approaches, while entity-level and discourse-level approaches are recognized as knowledge-rich approaches.
The following provides some examples of summarization techniques. [76] exploited a selection function for extraction, and used machine-learning to automatically learn an appropriate function to combine different heuristics. [5], [66], [90] regarded the task as a classification problem, and employed Bayesian classifier to determine which sentence should be included in the summary. [7] created summaries by finding lexical chains, relying on word distribution and lexical links among them to approximate content, and providing a representation of the lexical cohesive structure of the text. [6] used co-reference chains to model the structure of a document and to indicate sentences for inclusion in a summary. [45] proposed two methods: one used relevance measure to rank sentence relevance, and the other used latent semantic analysis to identify semantically important sentences. [55] attempted to create a robust
summarization system, based on the hypothesis: summarization = topic identification + interpretation + generation. The identification stage is to filter the input and retain the most important topics. In the interpretation stage, two or more extracted topics are fused into one or more unifying concept(s). The generation stage reformulates the extracted and fused concepts and then generates an appropriate summary.
1.1.3.1 Extraction vs. abstraction
The most common way to differentiate summarization techniques is the format of the summary being produced. Based on this, current summarization techniques can be characterized as extraction or abstraction. Today, most summarization systems, in fact, follow a broadly-used summarization model, namely sentence extraction, to produce extractive summaries. The paradigm identifies and extracts key sentences verbatim from the input source(s) based on a variety of different criteria and then concatenates them together to form a summary. [1] recognized two main categories of extractive techniques: (1) each sentence is assigned a weight based on various surface-level features, and is ranked in relation to the other sentences, so that the top-n ranked sentences could be extracted, and (2) machine learning and language processing techniques are employed to detect important sentences based on a graph representation of the input document(s). For a study discussing the potential and limitations of sentence extraction, please refer to [80].
Table 1.1 gives some examples that employ extractive techniques. The input field indicates the number of input documents and in what language that they are written. The purpose field concerns whether the summary is indicative, informative, or evaluative, generic or user-oriented. The output field means the “material” to create a summary. Finally, the method field outlines the specific methods used in the
summarization process.
Table 1.1. Examples that employ extractive techniques (excerpted from [1])
Input Purpose Output Method
[21] Multidocument, Multilingual (English, Chinese) Generic, Domain-specific (news)
Sentences Use of keywords
[36] Single-document, English Generic, Domain-specific (scientific articles) Sentences Statistics (surface-level features), Use of thematic keywords [82] Single-document, English Generic, Domain-specific (technical papers) Sentences Statistics (surface-level features) [86] Multidocument, English User-oriented, General purpose
Text regions Graph-based, Use of cohesion relations [89] Single-document, English Generic, Domain-specific (scientific articles) Sentences Tree-based, RST [119] Single-document, English Generic, General purpose Paragraphs Graph-based, Statistics (similarity) Table 1.2. Examples that employ abstractive techniques (excerpted from [1])
Input Purpose Output Method
[7] Single-document, English Generic, Domain-specific (news) Clusters Syntactic processing [33] Single-document, English Informative, User-oriented, Domain-specific
Scripts Script activation
[97] Multidocument, English Informative, User-oriented, Domain-specific Templates Information Extraction [117] Single-document,
English Informative, User-oriented, Domain-specific
Ontology-based
representation Syntactic processing, Ontology-based Annotation
While the pre-dominant techniques are extractive, some summarization systems adopt abstractive techniques, in which the most important information is encoded and
fed into a natural language generation system to generate a summary in novel phrasings. [1] distinguished abstractive techniques into two categories: (1) the most important information is identified using prior knowledge about the structure of information, which is represented by cognitive schemas (e.g., scripts and templates), and (2) the most important is identified based on a semantic representation (e.g., noun phrases and their relations) of the document(s). Table 1.2 gives some examples that employ abstractive techniques.
1.1.4
Summary Evaluation
Evaluation is a critical issue in summarization. However, it has been proven as a difficult problem to evaluate the quality of a summary, principally because there is no obvious “ideal” summary due to the subjective aspect of summarization [110]. Therefore, the summarization community has practically used multiple model summaries for system evaluation to help alleviate this problem.
In general, the existing methods for evaluating text summarization approaches can be broadly classified into: (1) extrinsic evaluation, and (2) intrinsic evaluation (see [87]). The first judges the quality of a summary based on how it affects the completion of other tasks. For example, [21] proposed an evaluation model using question-answering: both the original text and its summary are processed by a question-answering system to extract answers for questions and the precisions and the recalls on the retrieved answer sets are compared. The second, on the other hand, judges the quality of summary based on coverage between the summary and model summaries, user judgments of informativeness, etc. For instance, SEE (Summary Evaluation Environment) [122] supports human evaluation, where an interface is provided for assessors to judge the quality of summaries in grammatically, cohesion,
and coherence. Automatic evaluation methods, such as ROUGE [79] and Pyramid [52], which measure the coverage, also fall in this category.
1.2 Tasks and Challenges
There are two research tasks discussed in this thesis: (1) multidocument summarization, and (2) query-focused multidocument summarization. The first focuses on producing a generic summary of a set of topically-related documents, while the second focuses on, given a user query, generating a query-focused summary of a set of topically-related documents to reflect particular points that are relevant to the user’s desired topic(s) of interest. Both tasks are addressed in this thesis using the most common technique for summarization, namely sentence extraction: important sentences are identified and extracted verbatim from documents and composed into an extractive summary. The first step towards sentence extraction is obviously to score and rank sentences in order of importance, which is the major focus of this thesis.
1.2.1
Multidocument summarization
Early works on text summarization dealt with single-document summarization. Since the late-90s, the rapid increase and the availability of online texts have made multidocument summarization a worth problem to be solved. Given a collection of documents on the same (or related) topic (e.g., news articles on the same event from several newswires), summaries that deliver the majority of information content among documents and emphasize the differences would be significantly helpful to a reader. However, it is much harder towards multidocument summarization than towards single-document summarization, since several unique issues, such as anti-redundancy and content ordering, need to be addressed. In general, the major challenge of
multidocument summarization is to discover similarities across documents, as well as to identify distinct significant aspects from each one.
By the definition given in [110], multidocument summarization is the process of producing a single summary of a set of related documents, where three major issues need to be addressed: (1) identifying important similarities and differences among documents, (2) recognizing and coping with redundancy, and (3) ensuring summary coherence. Previous works have investigated various methods for solving these issues. For instance, sentence clustering to identifying similarities (e.g., [29], [44], [53], [96]), information extraction to facilitating the identification of similarities and differences (e.g., [97]), maximum marginal relevance (MMR) [20] and cross-sentence informational subsumption (CSIS) [111] to removing redundancy, and information fusion (e.g., [9]) and sentence ordering (e.g., [8]) to generating coherent summaries. For a general overview of the current state of the art, please refer to Chapter 2.
While many approaches to single-document summarization have been extended to deal with multidocument summarization (e.g., [22], [49], [77], [84]), there are still a number of new issues, as briefed below, needed to be addressed. See also [44]. (1) Lower compression rate:
Traditionally, a compression rate ranging from 1% to 30% is suitable for single-document summarization [87]. However, for multidocument summarization, the degree of compression rate is typically much low. For example, [44] found that a compression to the 1% or 0.1% level is required for summarizing 200 documents.
The degree of redundancy in information contained in a group of related documents is usually high, due to the reason that each document in the group is apt to describe the main points as well as necessary shared background [44]. Therefore, it is necessary to minimize redundancy in the summary of multiple documents (i.e., to avoid including similar or redundant information into the summary).
(3) Information fusion:
One problem of the selection of a subset of similar passages in extraction-based approaches is the production of a summary biased towards some sources. Information fusion, which synthesizes common information, such as repetitive phrases, in the set of related passages into the summary, can alleviate this problem by the use of reformulation rules.
(4) Content ordering:
Content ordering is the organization of information from different sources to ensure the coherence of the summary. In single-document summarization, content ordering could be decided, based on the precedence orders in the original document. In multidocument summarization, instead, no single document can provide a global ordering of information in the summary.
In this study, we focus on extraction-based multidocument summarization to produce an extractive generic summary for a set of related news articles on the same event. In the approach that we propose in Chapter 3, the multidocument summarization task is divided into three sub-tasks: (1) ranking sentences according to their likelihood of being part of the summary, (2) eliminating redundancy while
extracting the most important sentences, and (3) organizing extracted sentences into a summary.
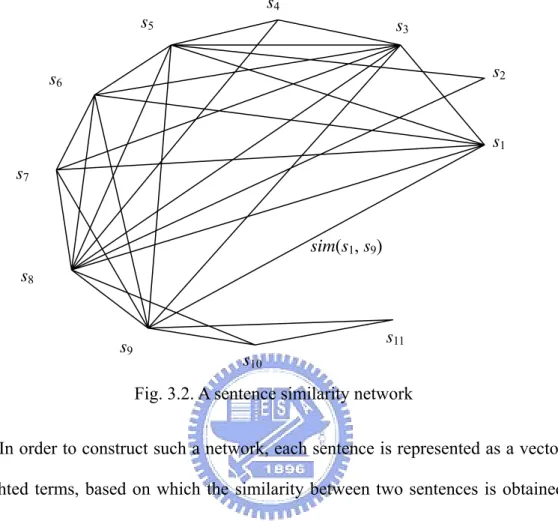
The focus of the proposed approach is a novel sentence ranking method to perform the first sub-task. The idea of modeling a single document into a text relationship map [119] is extended to model a set of topically-related documents into a sentence similarity network (i.e., a network of sentences, with a node referring to a sentence and an edge indicating that the corresponding sentences are related to each other), based on which a graph-based sentence ranking algorithm, iSpreadRank, is proposed.
iSpreadRank hypothesizes that the importance of a sentence in the network is related to the following factors: (1) the number of sentences to which it connects, (2) the importance of its connected sentences, and (3) the strength of relationships between it and its connected sentences. In other words, iSpreadRank supposes that a sentence, which connects to many of the other important sentences, is itself likely to be important. To realize this hypothesis, iSpreadRank practically applies spreading activation [106] to iteratively re-weight the importance of sentences by spreading their sentence-specific feature scores throughout the network to adjust the importance of other sentences. Consequently, a ranking of sentences indicating the relative importance of sentences is reasoned.
Given a ranking of sentences, in the second sub-task, a strategy of redundancy filtering, based on cross-sentence informational subsumption [111], is utilized to iteratively extract one sentence at a time into the summary, if it is not too similar to any sentences already included in the summary. In practice, this strategy only extracts high-scoring sentences with less redundant information than others. Finally, in the
third sub-task, a sentence ordering policy, which considers together topical relatedness and chronological order between sentences, is employed to organize extracted sentences into a coherent summary.
The proposed summarization method is evaluated using the DUC 2004 data set, and found to perform well. Experimental results show that the proposed method obtained a ROUGE-1 score of 0.38068, which is competitive to that of the 1st-ranked system at DUC 2004.
1.2.2
Query-focused multidocument summarization
Query-focused multidocument summarization is a particular task of multidocument summarization. Given a cluster of documents relevant to a specific topic, a query statement consisted of a set of related questions, and a user profile, the task is to create a brief, well-organized, fluent summary which either answers the need for information expressed in the query statement or explains the query, at the level of granularity specified in the user profile. Table 1.3 and Table 1.4 give examples of the query statements. The level of granularity, here, can be either specific or general: while a general summary prefers a high-level generalized description biased to the query, a specific summary should describe and name specific instances of events, people, places, etc.
As stated in [3], this task can be seen as topic-oriented, informative multidocument summarization, where the goal is to produce a single text as a compressed version of a set of documents with a minimum loss of relevant information. This suggests that a good summary for query-focused multidocument summarization should not only best satisfy the need for information expressed in the query statement but also need to cover as much of the important information as
possible across documents [136].
Table 1.3. Query statement for set d357i with granularity specified as “specific” <topic>
<num> d357i </num>
<title> Boundary disputes involving oil </title> <narr>
What countries are or have been involved in land or water boundary disputes with each other over oil resources or exploration? How have disputes been resolved, or towards what kind of resolution are the countries moving? What other factors affect the disputes?
</narr>
<granularity> specific </granularity> </topic>
Table 1.4. Query statement for set d376e with granularity specified as “general” <topic>
<num> d376e </num> <title> World Court </title> <narr>
What is the World Court? What types of cases does the World Court hear? </narr>
<granularity> general </granularity> </topic>
In general, the challenges of query-focused multidocument summarization are twofold. The first one is to identify important similarities and differences among documents, which is a common issue of multidocument summarization. The second one is the need to take into account query-biased characteristics during the summarization process.
In this study, we focus on extraction-based query-focused multidocument summarization to produce an extractive query-focused summary, which reflects particular points relevant to user’s interests, for a set of related news articles on the same event. In the approach that we propose in Chapter 4, the query-focused multidocument summarization task is divided into four sub-tasks: (1) examining the degree of relevance between each sentence and the query statement, (2) ranking
sentences according to their degree of relevance to the query and their likelihood of being part of the summary, (3) eliminating redundancy while extracting the most important sentences, and (4) organizing extracted sentences into a summary.
The first sub-task is addressed as a query-biased sentence retrieval task. For each sentence s, given a query q, the degree of relevance between s and q is measured as the degree of similarity between them, i.e., sim(s, q). Three similarity measures are proposed to assess sim(s, q). The first is computed as the dot production of the vectors of s and q in the vector space model. The second exploits latent semantic analysis (LSA) [32] to fold s and q into a reduced semantic space and computes their similarity based on the transformed vectors of s and q in the semantic space. Finally, with the idea of model averaging, the third combines the similarities obtained from the first and the second in a linear manner.
In the second sub-task, several surface-level features are extracted to measure how representative a sentence is with respect to the whole document cluster. The feature scores, acting as the strength of representative power (i.e., the informativeness) of each sentence, are combined with the degree of relevance between the sentence and the query to score all sentences. As for the third sub-task, a novel sentence extraction method, inspired by maximal marginal relevance (MMR) [20] for redundancy filtering, is utilized to iteratively extract one sentence at a time into the summary, if it is not too similar to any sentences already included in the summary. In one iteration, all the remaining unselected sentences are re-scored and ranked using a modified MMR function, so as to extract the sentence with the highest score. Finally, in the fourth sub-task, all extracted sentences are simply ordered chronologically to form a coherent summary.
The proposed summarization method is evaluated using the DUC 2005 data set, and found to perform well. Experimental results show that the proposed method obtained a ROUGE-2 score of 0.07265 and a ROUGE-SU4 score of 0.12568, which are competitive to those of the 1st-ranked and 2nd-ranked systems at DUC 2005.
1.3 Guide to Remaining Chapters
The remainder of this thesis is organized as follows: Chapter 2 provides a survey of the current state of the art in multidocument summarization and query-focused multidocument summarization. While Chapter 3 introduces the proposed approach to multidocument summarization that is based on a graph-based sentence ranking algorithm, Chapter 4 presents the proposed approach to query-focused multidocument summarization in which the combination of query-biased characteristics and surface-level features is studied. Finally, Chapter 5 concludes this thesis and provides possible directions for future work.
Chapter 2
Literature Survey
In this chapter, Section 2.1 and Section 2.2 provide a sketch of the current of the art of multidocument summarization, and of query-focused multidocument summarization, respectively. Section 2.3 introduces some example research projects in the field.
2.1 Multidocument Summarization
[97] pioneered work on multidocument summarization. They established relationships between news stories by aggregating similar extracted templates using logical relationships, such as agreement and contradiction. The summary was constructed by a sentence generator based on the facts and their relationships in the templates. These template-based methods are still of interests recently (see [51], [135]). However, manual efforts are required to define domain-specific templates, while poorly-defined templates may lead to incomplete extraction of facts.
Most recent studies have adopted clustering to identify themes8 (i.e., clusters of common information) (e.g., [9], [14], [29], [44], [53], [96], [101]). These approaches are founded on an observation that multiple documents concerning a particular topic tend to contain redundant information, as well as information unique to each [29]. Once themes have been recognized, a representative passage in each theme is selected and included in the summary; alternatively, repeated phrases in clusters are exploited to generate an abstract-like summary by information fusion [110].
Typical research on theme clustering is briefed as follows. [9] and [96]
8 A theme, also viewed as a sub-topic, is defined as a group of passages (such as sentences and
discovered common themes using graph-based clustering based on features, such as word co-occurrence, noun phrase matching, synonymy matching, and verb semantic matching. Similar phrases in the identified themes were synthesized into a summary by information fusion using natural language generation. [44] grouped paragraphs into clusters and collected, into the summary, from each group a significant passage with large coverage and low redundancy, measured by maximal marginal relevance (MMR) [20]. This strategy aimed at high relevance to the query and keeping redundancy low in the summary. [29] evaluated several policies for choosing indicative sentences from sentence clusters and concluded that the best policy is to extract sentences with the highest sum of relevance scores for each cluster. [101] clustered sentences as topical regions. Seed paragraphs, each having the maximum total similarity with others in the same topical region, are considered as the representative passages.
Other studies have applied information retrieval and statistical methods to find salient concepts, as well as informative words and phrases in multiple documents (e.g., [43], [49], [65], [77], [111]). For instance, [111] detected a set of statistically important words as the topic centroid of a document cluster, which is treated as a feature and considered together with other heuristics to extract sentences. [77] recognized key concepts by calculating log-likelihood ratios of unigrams, bigrams and trigrams of terms, and then clustered these concept-bearing terms to detect sub-topics. Each sentence in the document set was ranked using key concepts in order to produce an extractive summary. [49] discussed different strategies to create signatures of topic themes and evaluated methods to use them in summarization.
Surface-level features extended from the well-developed single-document summarization methods have also been exploited (e.g., [54], [84], [91], [111]).
Heuristics-based approaches selectively combine features to yield a scoring function for the discrimination of salient text units. Commonly used features include sentence position, sum of TF-IDF in a sentence, similarity with headline, sentence cluster similarity, etc. Alternatively, there are approaches that apply machine learning to automatically combine surface-level features from a corpus of documents and their summaries. For instance, [54] used support vector machines (SVM) [132] to learn a sentence ranking model.
Techniques depending on a thorough analysis of the discourse structure of the text have been explored (e.g., [11], [15], [22], [62], [139]). [139] developed a cross-document structure theory (CST) to define the cross-document rhetorical relationships between sentences across documents. The cohesion of extractive summaries is found to be meliorated by the CST relationships. [15] and [22] built lexical chains to identify topics in the input texts. Sentences are ranked according to the number of word co-occurrences in the chains and sentences. [11] constructed noun phrase co-reference chains across documents based on a set of predefined word-level fuzzy relations. The most important noun phrases in important chains are selected to score sentences.
Researchers have also investigated graph-based approaches. [86] modeled term occurrences as a graph using cohesion relationships (e.g., synonymy, and co-reference) among text units. The similarities and differences in documents are successfully pinpointed by applying spreading activation [106] and graph matching. Sentences are extracted based on a scoring function which measures term weights in the activated graph. [124] constructed a graph using the similarity relations between sentences. The summary is generated by traversing sentences along a shortest path of the minimum cost from the first to the last sentence. [138] presented a bipartite graph of texts where
spectral graph clustering is applied to partition sentences into topical groups.
Some graph-based methods employ the concept of centrality in social network analysis. [119] first attempted such an approach for single-document summarization. They proposed a text relationship map to represent the structure of a document, and utilized the degree-based centrality to measure the importance of sentences. Later works following the idea of graph-based document models employed distinct ranking algorithms to determine the centralities of sentences. [39] recognized the most significant sentences by a sentence ranking algorithm, LexRank, which performs PageRank [18] on a sentence-based network according to the hypothesis that sentences similar to many other sentences are central to the topic. [38], [133] examined biased PageRank to extract the topic-sensitive structure beyond the text graph for question-focused summarization. [98] examined several graph ranking methods originally proposed to analyze webpage prestige, including PageRank and HITS [64], for single-document summarization. [100] extended the algorithm of [98] for multiple documents. A meta-summary of documents is produced from a set of single-document summaries in an iterative manner. [140] proposed a cue-based hub-authority approach that brings surface-level features into a hub/authority framework. HITS is used in their work to rank sentences.
Last but not least, other graph-based works build a dependency graph with a word as a node and a syntactical relation as a link. One good example is [130] for event-focused news summarization, which employed PageRank to identify word entities participating in important events or relationships among all documents.
2.2 Query-focused Multidocument Summarization
The major difference of query-focused multidocument summarization, compared to multidocument summarization, is the need to measure the relevance of a sentence to the user query. Hence, most research works have regarded query-biased sentence retrieval as the first step towards query-focused multidocument summarization. For example, [31] employed a Bayesian language model to estimate the relevance between a sentence and the query. They found that the Bayesian model consistently works well even when there is significantly less information in the query. [47] presented a system which measures relevance and redundancy of sentences using a latent semantic space, constructed over a very large corpus. [59] combined multiple strategies, including relevance-based language modeling [68], latent semantic indexing [32], and word overlap, to identify query-relevant sentences. [136] proposed concept links to compute the similarity between a sentence and the query in semantic level. They showed that concept links outperforms similarity measures based on word co-occurrence since semantically-related words are highlighted. [121] investigated a tree matching algorithm to obtain a similarity between a sentence and the query based on their dependency parsing trees.
Other studies have applied statistical methods to detect query-related words, based on which the relevance of a sentence to the query is assessed. Typical examples are given as follows. [46] compared two weighting schemes for estimating word importance: (1) raw word frequency, and (2) log-likelihood ratio (LLR). They concluded that LLR is more suitable for query-focused summarization since it is more sensitive to query relevance. [131] computed the importance of each word as a linear combination of the unigram probabilities derived from the query and those from the
documents. Sentences, which have more words with the highest importance, are extracted to produce a summary. [27] exploited key-phrase extraction to identify relevant terms and used machine learning to select significant key-phrases. Summaries are generated according to the coverage of query-relevant phrases contained in the sentences.
Methods have also been explored to combine query-dependent and query-independent (i.e., surface-level) features for the assessment of the importance of a sentence. For instance, [72] and [73] exploited various features to judge whether a sentence is appropriate to be included in the summary. The features that they used include word-based features (e.g., word overlap, and cosine similarity), entity-based features (e.g., named entity), semantic-based features (e.g., WordNet-based similarity), and global features (e.g., sentence length, and position). [60] calculated the relevance of a sentence to the query based on relevance-based language models [68] along with semantic representation of words in HAL semantics spaces [83]. The relevance of a sentence is combined with the informativeness of a sentence, which is measured using a unigram-based language model trained on the Web.
The application of machine learning has been tried to automatically combine features from a corpus of documents and their summaries to learn a sentence ranking model. [24] introduced an “oracle” score, based on the probability distribution of unigrams trained from human summaries. Each sentence is scored as the average of the probabilities of words that it contains. [40] combined two models to obtain a global sentence ranking model for extraction: (1) query-neutral ranking trained using a perceptron-baesd ranking model [25], and (2) query-focused ranking learned based on raw term frequency. [129] presented a trainable extractive summarization system that learns a log-linear sentence ranking model by maximizing three metrics of
sentence goodness, based on ROUGE [79] and Pyramid [52] scores against model summaries. [41] and [74] employed support vector machines (SVM) [132] to automatically combine various features to generate a scoring function for extraction.
Some approaches depend on deep discourse analysis to extract query-relevant sentences. [142] utilized lexical chains and document index graphs to score sentences. [75] built, for each document, a set of lexical chains, and merged chains into a global representation of the document cluster. [62] represented documents as a composite topic tree, in which each node stands for one topic identified from documents. Using the topic tree, nodes containing query-related information are extracted to form a summary. [56] proposed a method based on basic elements. A basic element, defined as a head-modifier-relation representation, is regarded as a basic unit to determine the salience of a sentence.
Researchers have also investigated graph-based approaches. [86] used a document graph to formulize relations between words inside a document. Spreading activation [106] and graph matching are applied to perform query-biased summarization. [17] created a graph representation for a document based on the rhetorical structure theory (RST) [88]. Given the graph model, a graph search algorithm is exploited to identify relevant sentences. [38] and [133] examined biased PageRank [18] to extract the topic-sensitive structure beyond the text graph. [134] employed manifold-ranking [141] to rank sentences based on the biased information richness of a sentence.
Last but not least, [123] proposed a summarizer that focuses on subjectivity analysis. The summarizer generates summaries to reflect information need based on subjectivity clues. [10] introduced a statistical model for query-relevant
summarization. The statistical information is learned with a collection of FAQs using maximum-likelihood estimation. [12] created a system to produce summaries for definitional and biographical question-answering. [67] presented a framework for question-directed summarization, which uses multiple question decomposition and summarization strategies to create a single responsive summary-length answer for a complex question.
2.3 Related Research Projects
This section offers a brief introduction of example research projects in the field.
2.3.1
PERSIVAL
PERSIVAL (PErsonalized Retrieval and Summarization of Image, Video, And Language)9 [94] is designed to provide personalized access to a distributed patient care digital library. The system consists of: (1) a query component that uses clinical context to help formulate user queries, (2) a search component that uses machine learning to find relevant sources and patient information, and (3) a personalized presentation component that uses patient information and domain knowledge to summarize related multimedia resources. A multidocument summarization system, CENTRIFUSER [61] (see also [37], [62], [63]), is integrated in PERSIVAL to support personalized summarization. CENTRIFUSER models all the input documents into a composite topic tree, with a node standing for one topic (e.g., disease, symptom, etc.) extracted from documents. Using the topic tree, CENTRIFUSER determines which parts of the tree are relevant to the query and the patient information, and then extracts related parts to create a summary.
2.3.2
NewsBlaster
NewsBlaster10 [92], [93] is an on-line news summarization system, which supports topic detection, tracking, and summarization for daily browsing of news. The core summarization module, Columbia Summarizer, is composed of: (1) router, (2) MultiGen [96], and DEMS [120]. The router determines which type an input event cluster is and forwards the cluster to a suitable summarization module. The type, here, can be single-event, multi-event, biography, and other. MultiGen generates a concise summary based on the detection of similarities and differences across documents. Machine learning and statistical techniques are exploited to identify groups of similar passages (i.e., themes), followed by information fusion [9] to synthesize common information into an abstractive summary using natural language generation. While MultiGen is designed to cope with topically-related documents, DEMS is more general for loosely-related documents. DEMS combines features for new information detection and uses heuristics to extract important sentences into a summary.
2.3.3
MEAD
MEAD11 [111] is an essentially statistical summarizer in public domain, developed to produce extractive summaries for either single- or multi-document summarization by sentence extraction. MEAD consists of: (1) feature extractor, (2) sentence scorer, and (3) sentence re-ranker. The feature extractor extracts summarization-related features from sentences, such as position, centroid, cosine with query, and length. The sentence scorer combines various features to measure the salience of a sentence. Finally, the sentence re-ranker iteratively selects candidate summary sentences while redundant sentences are avoided by checking similarity against prior selected ones.
10 http://newsblaster.cs.columbia.edu/ 11 http://www.summarization.com/mead/
NewsInEssence12 [108] and WebInEssence [109] are two practical applications of MEAD. Given the user’s interest, NewsInEssence retrieves related news articles from different online newswires and produces an extractive summary according to the user-specified parameters. WebInEssence, instead, is integrated into a general-purpose Web search engine to summarize the returned search results.
2.3.4
GLEANS
GLEANS [30] is a multidocument summarization system. The system classifies document clusters into a category, in which the content is about single person, single event, multiple events, or natural disaster. For each category, GLEANS maintains a set of predefined templates. Text entities and their logical relations are first identified, and mapped into canonical, database-like representations. Then, sentences, which conform to predefined coherence constraints, are extracted to form the final summary.
2.3.5
NeATS
NeATS [77], [78] is an extractive summarizer for multidocument summarization. The system is composed of: (1) content selection, (2) content filtering, and (3) content presentation. The content selection module recognizes key concepts by calculating likelihood ratios of unigrams, bigrams, and trigrams of terms. The content filtering module extracts sentences based on term frequency, sentence position, stigma words, and maximum marginal relevance [20]. Finally, the content presentation module exploits term clustering and explicit time annotation to organize important sentences into a coherent summary.
iNeATS [71] is a derivative of NeATS. The system allows users to dynamically
control over the summarization process. Furthermore, it supports the linking from the summary to the original documents, as well as the visualization of the spatial information, indicated in the summary, on a geographical map.
2.3.6
GISTexter
GISTexter [51] is designed to produce both extracts and abstracts for single- and multi-document summarization. The core of GISTexter is an information extraction (IE) system, CICERO [50], which identifies entities and fills relevant information, such as text snippets and co-reference information, into predefined IE-style templates using pattern rules. To generate summaries, GISTexter chooses representative templates and extracts source sentences for the template snippets.
Chapter 3
Multidocument Summarization
Multidocument summarization refers to the process of producing a single summary of a set of topically-related documents (i.e., a set of documents on the same or related, but unspecified topic). In this chapter, we deal with multidocument summarization using an extraction-based approach to create an extractive generic summary of multiple documents.
The proposed approach follows the most common technique for summarization, namely sentence extraction: important sentences are identified and extracted verbatim from documents and are composed into a summary. In the proposed approach, the multidocument summarization task is divided into three sub-tasks:
(1) Ranking sentences according to their likelihood of being part of the summary;
(2) Eliminating redundancy while extracting the most important sentences; (3) Organizing extracted sentences into a summary.
The focus of the proposed approach is a novel sentence ranking method to perform the first sub-task. The idea of modeling a single document into a text relationship map [119] is extended to model a set of topically-related documents into a sentence similarity network (i.e., a network of sentences, with a node referring to a sentence and an edge indicating that the corresponding sentences are related to each other), based on which a graph-based sentence ranking algorithm, iSpreadRank, is proposed.
![Fig. 1.1. Overview of the summarization process [87]](https://thumb-ap.123doks.com/thumbv2/9libinfo/8495272.184900/17.892.169.727.534.898/fig-overview-summarization-process.webp)
![Table 1.1. Examples that employ extractive techniques (excerpted from [1])](https://thumb-ap.123doks.com/thumbv2/9libinfo/8495272.184900/25.892.136.758.189.714/table-examples-employ-extractive-techniques-excerpted.webp)

![Table 3.1. The sentence-specific feature set (excerpted from [111]) Feature name Feature value](https://thumb-ap.123doks.com/thumbv2/9libinfo/8495272.184900/54.892.151.748.477.868/table-sentence-specific-feature-excerpted-feature-feature-value.webp)