國
立
交
通
大
學
資訊科學系
碩
士
論
文
一個以規則為基礎之非集中式資料
共享安全機制
A Rule-Based, Decentralized Approach to
Secure Information Sharing
研 究 生:徐嘉宏
指導教授:陳俊穎 博士
一個以規則為基礎之非集中式資料共享安全機制
A Rule-Based, Decentralized Approach to
Secure Information Sharing
研 究 生:徐嘉宏 Student:Cha-Hun Hsu
指導教授:陳俊穎 Advisor:Jing-Ying Chen
國 立 交 通 大 學
資 訊 科 學 系
碩 士 論 文
A ThesisSubmitted to Institute of Computer and Information Science College of Electrical Engineering and Computer Science
National Chiao Tung University in partial Fulfillment of the Requirements
for the Degree of Master
in
Computer and Information Science July 2005
Hsinchu, Taiwan, Republic of China
一 個 以 規 則 為 基 礎 之 非 集 中 式 資 料 共 享 安 全 機 制
學生:徐嘉宏
指導教授
:陳俊穎博士
國立交通大學資訊科學系
摘要
隨著網際網路的普及而成為大眾資訊交流的媒介,資訊共享的安全與隱 私權保護的課題益發重要。保護機制不完善的資料共享系統可能會導致機密 的資料洩漏。為了減低這樣的風險,已有許多不同資訊安全的機制與技術被 提出。而這些方法大多採用以標籤為基礎的存取控制機制。進一步地說,這 些安全機制為系統所管理的資料及使用者貼上適當的標籤,並根據這些標籤 來制定及執行不同的安全政策。然而,為了讓安全政策可以正確的運行,這 些方法需要複雜且冗長的管理。另一方面,大多數的方法主要是針對資料的 存取,而對於處理資料的工具本身並沒有進一步的控制。由於判定一個的工 具能否存取某筆資料取決於使用此工具的使用者,使得安全管理的正確性不 易控制。在本篇論文中,我們提出一個資料分享的模型,能提供一個有彈性 且非集中式的方法來控制資訊流動,而不須仰賴集中式的管理。此模型中, 每個使用者可以指定其個人的存取等級,並根據此存取等級對資料及工具貼 上標籤。並且,藉由非集中式的工具降級設定,每個使用者可以個別地增強 或減弱某工具所能存取的資料等級,進而達到更方便且安全的政策制定。最 後,為了減少對每筆資料貼上標籤的麻煩,我們的模型使用了一個以規則為 基礎的標籤機制來處理不同等級的資料。總結來說,我們的模型利用靈活的 政策管理,統合且改進了現存的模型,能作為未來網際網路資訊共享安全機 制的核心。A Rule-Based, Decentralized Approach to Secure Information Sharing
student:Cha-Hun Hsu
Advisors:Dr. Jing-Ying Chen
Department of Computer and Information Science
National Chiao Tung University
Abstract
As the Internet becomes a ubiquitous environment where people with different background and purposes can share their information, information security and privacy have become an increasingly critical issue. With poor protection, informa-tion systems may leak sensitive informainforma-tion to the open public. To reduce such risks, there have been many security mechanisms and technologies proposed and developed. Most of these approaches rely on a mixture of label-based access con-trol and information flow mechanisms. Specifically, they enforce various security policies by attaching suitable labels to information as well as users and grant data access based on these labels. However, many labeling approaches often require complicated managerial efforts in order to set up and enforce security policies correctly. In addition, they focus primarily on labeling data without paying too much attention to sharing tools that process these data. As a result, whether a given tool can access a piece of data depends on who is invoking the tool, making correct security management more challenging. In this thesis, we propose an in-formation sharing model that permits controlling inin-formation flow in a flexible, decentralized manner, where each user can specify his/her own access hierarchy instead of relying on centralized security management. Based on the access hier-archy, each user can label both data and tools in a consistent manner, and can real-ize data declassification by restricting or relaxing the access level of individual tools. Finally, to reduce the overhead associated with individual data labeling, we introduce a rule-based labeling mechanism to associate data with their access lev-els correspondingly. In summary, we believe our model is a unification of and
improvement over existing access control mechanisms, and can contribute to se-cure information sharing over the Internet.
致謝
這篇論文的完成,我想要感謝的人很多很多。首先是要感謝實驗室的同學、學 弟、以及已經畢業的學長們。林建宏學長、郭訓宏學長、張舜禹學長、劉許吉學 長,在我的研究生涯中總是不吝給我指導與協助。和我有革命情感的同學們,詹 亦秋、林君翰、莊景棠、鄧嘉源,陪我一同度過充實研究生涯。 我也要感謝給我的口試委員曾文貴教授以及王伯堯研究員,在口試的時候給 我許多有用的看法以及建議,讓我的論文能夠更加完整。 此外,我要感謝我的爸爸、媽媽、哥哥,他們是我的精神支柱,總是在我背 後默默支持我,讓我有走完這兩年研究生涯的動力。我也要感謝我的女朋友淑 如,在我困頓落寞的時候,總是給我適時的鼓勵,讓我有勇氣與自信能夠完成這 篇論文。 最後,我想要感謝我的指導教授陳俊穎老師,在這兩年的日子總是耐心的給 我勉勵與指導,除了學習到的專業知識,我想我在研究生涯中最讓感到充實的, 就是學習何謂作研究應有的態度。我想,對於傳授我這些知識與觀念的指導教 授,言語以及文字的感謝已經太膚淺了。List of Contents
摘要... i
Abstract... ii
致謝... iv
List of Contents ... vi
List of Figures... vii
Chapter 1 Introduction... 1
Chapter 2 Background... 6
2.1 Internet as an Information Sharing Environment ... 6
2.2 Security and Access Control Mechanisms ... 7
2.3 Information Flow Mechanisms... 8
2.4 Role-Based Access Control... 11
2.5 Decentralized Information Flow Control ... 12
2.6 Declassification ... 13
2.7 Security Policies and Policy Standards ... 13
Chapter 3 Motivation and Objective ... 15
3.1 A Medical Data Analysis Example ... 15
3.2 A Bank Example... 17
Chapter 4 A Rule-Based Decentralized Information Flow Approach... 20
4.1 Overview ... 20
4.2 Object and Principal Labeling ... 21
4.3 A Rule-Based Labeling Approach... 23
4.4 Tool Sharing and Declassification... 24
Chapter 5 Type Systems Approach to Information Flow... 27
5.1 The Volpano Approach ... 27
5.2 Type System of Our Model ... 32
Chapter 6 Comparisons with the ML Model... 37
Chapter 7 System Design and Implementation ... 43
Chapter 8 Related Work ... 47
List of Figures
Figure 1. Illustration of a general information sharing system ... 2
Figure 2. Access control mechanisms restrict rights for a subject to access object ... 7
Figure 3. Illustration of an access control matrix, where the row represents subjects, the column objects, and each cell corresponds to the privileges that subject has over the object. ... 8
Figure 4. Information flows from data object A to data object B and from data object A to data object C... 9
Figure 5. Lattice-based information flow policies. ... 10
Figure 6. Definition of the can-flows relation from L1 to L2... 12
Figure 7. Definition the join operator L1 ∪ L2... 12
Figure 8. A medical data analysis scenario where statistical analysis is conducted on patient records... 16
Figure 9. The bank example where each customer keeps asset information private from other customers and the bank wants to keep its total asset private... 18
Figure 10. Overview of our information sharing model, that consists of a set of principals, data, and tools... 20
Figure 11. An object label contains sub-labels each indicating the security level of the object from each principal’s perspective. ... 22
Figure 12. Definition of the label structure... 22
Figure 13. Definition of the can-flows relation... 22
Figure 14. Definition of the join operator among labels... 23
Figure 15. Our model allows a principal to attach individual labels on data in the realm... 24
Figure 16. Each user can specify declassification on each tool. ... 25
Figure 17. Typing rules for the Volpano model... 30
Figure 18. Evaluation rules for the Volpano model... 31
Figure 19. Language syntax definition... 32
Figure 20. Typing rules for our model ... 33
Figure 21. Flow declaration and un-declaration for typing rule (letvar) ... 34
Figure 22. Evaluation rules in our model... 36
Figure 23. Checking password example which is a procedure to check whether the username and password is correct... 37
Figure 24. Constraints of the password checking example presented by decentralized label model... 38
Figure 25. The constraint solution of password checking example... 38
Figure 26. Checking password example performed by our model. ... 39
Figure 27. Type inference and constraints generation of tool password checker using type inference algorithm... 40
Figure 28. Type inference and constraints generation of tool string matcher using our type inference algorithm. ... 40
Figure 29. Overview of our system implementation... 43
Figure 30. The flow path of data processing... 45
Figure 31. The flow path of policy specification. ... 45
Chapter 1 Introduction
Today, people rely extensively on the Internet for information exchange, professionally or socially. Many Internet applications such as WWW, e-mail, and instant messengers all provide people with different means to exchange information and collaborate with each other. As a result, the issue of security and privacy protection is becoming more critical. For example, if an information sharing system contains spyware, information may be stolen or destructed in an undesired way. The Center for Democracy Technol-ogy [CDT], a non-profit organization dedicated to promoting civil liberties values on the Internet, also summarizes potential security risks resulting from inadvertent sharing of sensitive personal information via spyware or adware. [Dav 03] also list some poten-tial security risks.
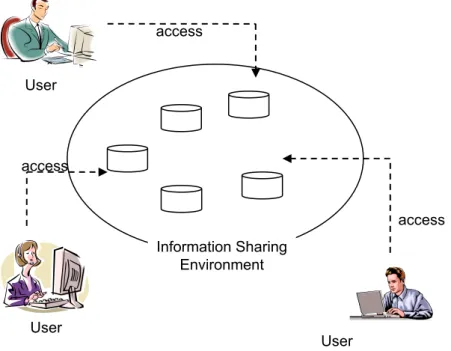
To simplify discussion, in this thesis we are concerned with information sharing sys-tems in general. As depicted in Figure 1, an information sharing system consists of data elements, tools that create and operate on these data, and users that establish connec-tions with the system to gain access to the data and tools inside. Information sharing is achieved when data created by one user can be accessed by another. Note that informa-tion sharing systems need not maintain data or tools in a centralized place. Many impor-tant Internet applications can be regarded as information sharing systems. For example, the most popular and successful one, i.e. WWW, conceptually forms a global informa-tion space that contains numerous Web pages interconnected through hyperlinks, and people use Web browsers to access Web pages created by others behind Web servers.
access
Figure 1. Illustration of a general information sharing system
Information security concerns the control of use and dissemination of information within an information sharing system. Privacy protection is the ability of a user to con-trol the availability of information about oneself, and is becoming an important topic of information security nowadays. Security policies are security and/or privacy require-ments that an information system needs to enforce. Some systems allow administrators or individual users to define security policies in terms of rules about different conditions under which certain data can be access by a particular user. Policy management is a general term that includes policy specification, deployment, and reason over policies, updating and maintain policies and enforcement. For example, Internet Explorer allows user to configure security and privacy settings. Security setting is done through config-uring the degree of trust for various web sites in terms of download permissions and execution permissions such as blocking advertisements from specific sites. Privacy pro-tection is done through setting the permissions for particular web sites to obtain sensi-tive information about the use through cookies.
Enforcing security policies within a complex system to prevent careless information leakage is nontrivial. There has been numerous security mechanisms developed over the last decades to address this challenge. Common security mechanisms include
authenti-User User access User Information Sharing Environment access
cation, authorization, discretionary access control, and information flow. Authentication is the process of verifying whether a person is really someone he/she claims to be, while authorization is the process of checking whether that person is permitted to access a given system or resource. Further introduction to authentication and authorization is beyond the scope of this thesis.
Discretionary access control (DAC) is a kind of security mechanisms that prevents
destruction of information by defining or restricting the rights of subjects (users, some-times also called principals) as well as processes that act for them to access a particular data object. One main objective of DAC is to protect information from accident or un-desired destruction. The mechanism provided byInternet Explorer as described above is an example of DAC. In general, DAC-based systems grant access rights based on data and subject labeling. For example, most operating systems provide DAC mechanisms that allow users to specify the access rights for individual directories and files they own, such as read, write, and execute operations, for different classes of users within the sys-tem. However, most DAC based systems support labeling an inefficient way, especially when the volume of data is large. Consider, for example, the strategies and amount of work needed to properly set access rights for all the files a user own in an operating system, to make sure no accidental leak of information occurs from time to time.
A more serious problem of DAC is that it does not control the dissemination of in-formation, that is, how a user uses the data objects after he/she gains access to them, including improper propagation of the information to other people. To prevent such information leakage, information flows, also called mandatory access control (MAC), is an approach to preventing unauthorized propagation of information. With data objects properly classified, MAC mechanisms ensure that high level information can not flow to low level user, and users are greatly relieved from otherwise tedious policy manage-ment.
Despite the advantage of MAC over DAC where information flow can be controlled more rigorously, such restriction also prevents user from releasing part of his/her infor-mation to other users or tools for further analysis – an important requirement for many information systems. To remedy this problem, certain declassification mechanisms are proposed to “breach” security requirements in an acceptable degree. For example, the "acts-for" relation proposed in [Mye97] allows one principle to grant all access right to
subject A acts for subject B, subject A can get all information that principal B can get, even to change principal B's policy temporarily to facilitate certain data processing tasks principal A needs. However, as with most DAC mechanisms, the acts-for ap-proach to declassification relies heavily on mutual trust among principals, thus careful design and management of the acts-for relations are required.
Take a medical information system as an example, where a doctor may own certain diagnosis information that a statistician wants for further statistical analysis. To achieve this goal, the doctor can declassify such sensitive data by permitting the statistician to act for him, assuming certain agreement or mutual understanding has been established between the two, so that the statistician can get access to the diagnosis data. Obviously, once the act-for permission is granted, the doctor has no explicit control about how the statistician can evaluate the data. Moreover, even if the statistician has no bad intention, he may leak some sensitive information by accident, or when he/she under security at-tack unknowingly.
The discussion above about permitting one subject to act on behave of another, either through the acts-for mechanisms in [Mye97] or through other comparable mechanisms, brings up the issue of controlling privacy policies. Many systems, including both DAC and MAC-based systems, often rely on centralized security administration governing the protection and closure about private data. Individuals often have limited options about how their personal data can be protected and used. To deal with this problem, [Mye97] also proposes decentralized information flow model, so that different users can specify their own policies, respectively, yet the overall information flow is under con-trol.
When the complexity of policy management is concerned, MAC also faces the prob-lem of correctly managing security policies. It is easy to prevent improper dissemina-tion of informadissemina-tion in small systems. In large system, however, controlling informadissemina-tion flow is difficult, especially when the data, tools, and users involved are diverse and the relations among them become complicated.
In this thesis we propose a decentralized information flow model that attempts to ad-dress security and privacy issues highlighted above. Following Myers and Liskov’s work, we focus on mechanisms supporting decentralized policy management in a gen-eral information sharing environment. Specifically, in our model, users define their own information flow lattice structures, respectively, and associate data with security levels
drawn from such lattice structures using user-defined rules. Tools that process and gen-erate data are also an integral part of the model, to enable true secure information shar-ing.
Normally, tools respect the information flow jointly defined by the users. When de-classification is needed, our model does not rely on the acts-for relation. Instead, tools are labeled individually in a decentralized manner similar to data labeling, but with downgrading specification describing the tolerable range for each user using the same user-defined lattice. With this approach, users can grant different tools with different capacities based on their understanding of the input-output characteristics of the tools, thereby eliminating the dependency on mutual trust among users. To further reduce po-tential security risks, we also define a simple yet flexible programming language such that for tools written in the language, automated analysis and verification can be per-formed to give users definite security guarantee about these tools.
We have developed a prototype system implementing our ideas using Prolog, and de-scribed the system using type theoretical approach. Specifically, our system accepts a user query or processing request only when no security breach can happen. The rest of this thesis is organized as follows. In chapter 2, we first present some important back-ground on security mechanisms such as access control and information flow models, and the decentralized approach to information flows pioneered by Myers and Liskov. In chapter 3, we use two information sharing examples to help present the motivation be-hind our research. In chapter 4, we describe our decentralized information flow model in detail, followed by some analysis of the model using type systems in chapter 5. In chapter 6, we differentiate our model from the work by Myers and Liskov and explain how to achieve similar information sharing policies using our model. Finally we give some discussion about related work and conclude with some future research directions.
Chapter 2 Background
2.1 Internet as an Information Sharing Environment
As the Internet rose during mid-1990, new forms of digital information exchange such as e-mail, FTP, and WWW emerged and gradually transform how people work and col-laborate with each other ([Jap00, Gaw03, Xu04]). A typical information worker spends over one and half an hour on e-mails each day in average - 20% of the working hours. Employees get 50% to 75% of their relevant information directly from other people, and more than 80% of enterprises reside in hard drives. Thus we can see that information sharing plays an important role in modern human life.
However, using public media such as the Internet for information exchange and shar-ing among people also created many problems and pose challenges for companies. Among the most important issues is security and privacy protection. As pointed out by the Center for Democracy and Technology ([CDT]), potential security risks include − Inadvertent sharing of sensitive personal information – users may leak sensitive
per-sonal information by inadvertent mistake.
− Spyware and adware – software may collect user's personal information to third party without user's knowledge.
− Security concern – information exchange also introduces the risks similar to those faced by Internet users generally, where people should be careful to only execute tools whose source they trust, and they should safeguard their computers when online. To ensure security and privacy of information, one needs to prevent sensitive informa-tion from leaking out inadvertently. Privacy and security are inextricably linked; both are need to establish a complete protection mechanism for an information sharing sys-tem, since one can not ensure privacy without suitable security control.
2.2 Security and Access Control Mechanisms
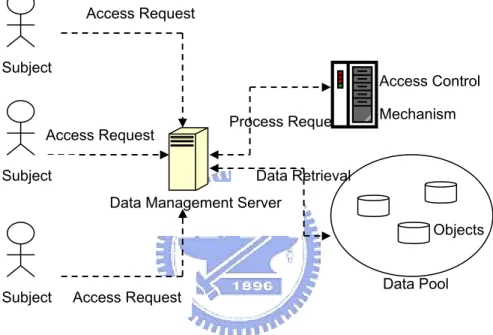
Information security concerns the protection of data against unauthorized access. In-formation security mechanisms are ways to deal with the particular access requests, which contain authentication, authorization, and access control (Figure 2). Authentica-tion is the process of checking whether a person or software agent is permitted to access a particular resource. Typical authentication involves password checking, although other methods such as fingerprinting or other biometrics are also common nowadays.
Access Request
Figure 2. Access control mechanisms restrict rights for a subject to access object
Authentication is part of the more general access control topic that concerns the protec-tion of computer resources against undesired access. Basic access control concepts in-clude objects, subjects and access rights. Objects are a general concept that refers to any computer resources providing information, ranging from files, to memory and other IO devices, to complete network accessible systems. Subjects include both users and tools that access objects on behave of the users who use them. Access rights describe which operations (e.g. read, write, and execute operations) are permitted for a subject to perform on a given object. Since early 1960s, access control has been a major research topic for information systems such as database management systems and operation sys-tems. Modern access control systems can grant or deny access requests from a particular
Data Retrieval Process Requests
Access Control Mechanism
Data Management Server
Access Request Access Request Subject Subject Objects Data Pool Subject
subject according a wide variety of criteria, such as time, current location, or domain of the subject.
Popular access control mechanisms include discretionary access control (DAC) and
mandatory access control (MAC). DAC was originated from the academic area. In a
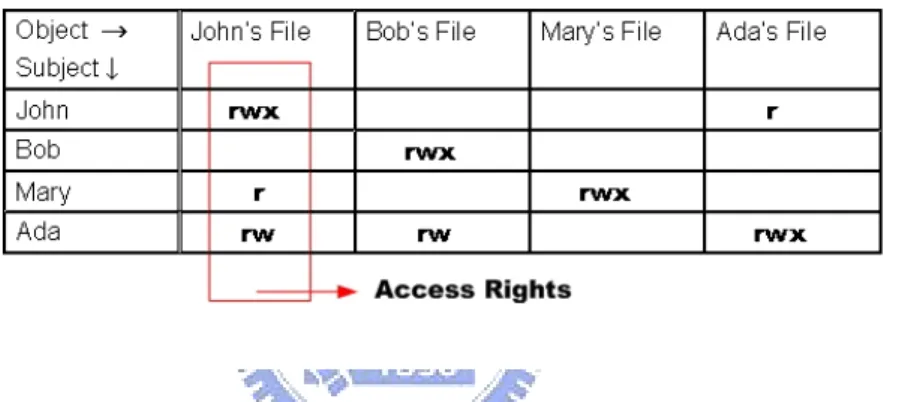
DAC model, each object belongs to an owner, who can restrict or grant the access re-quest from other users. One of the most commonly used approaches to DAC is access control matrices [San92]. Figure 3 shows an example of access control matrix in which each row represents a subject and each column represents an object. Each cell in the matrix contains the privileges the corresponding subject has over the corresponding object. The access control matrix may change when modification to the subjects, objects, and/or privileges in each cells are made.
Figure 3. Illustration of an access control matrix, where the row represents subjects,
the column objects, and each cell corresponds to the privileges that subject has over the object.
DAC mechanisms are commonly used in multi-user operating systems. However, ac-cess control mechanisms control immediate acac-cess request without taking into account information flow path implied by a given, outstanding collection of access rights [Den76]. Thus they can not prevent dissemination of objects [Li03] [Mye97] [Zan04]. Also, DAC lacks a theoretical base to ascertain that objects are protected without any mistakes made by users, and careful specification and management of policies is needed.
2.3 Information Flow Mechanisms
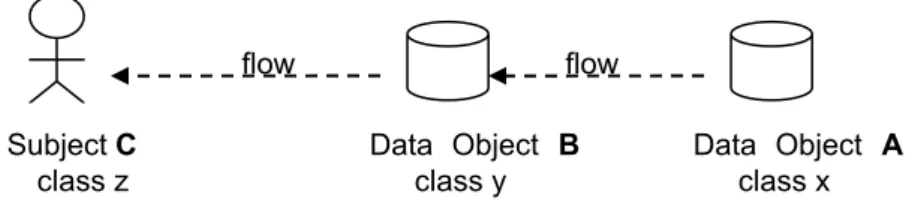
MAC mechanisms, also called information flow models, are another approach to infor-mation security, with the objective to prevent unauthorized inforinfor-mation flow among
objects and subjects. As shown in Figure 4, information is said to flow from object A to object B whenever information associated with object A affects the content of which associated with B. Information also flows between objects and subjects (e.g. from B to C in the figure). Information flow is transitive, thus in Figure 4 an information flow also occurs from object A to subject C.
Figure 4. Information flows from data object A to data object B and from data object
A to data object C.
Secure information flow is usually achieved by assigning each object and subject a
se-curity class, or sese-curity label, where possible sese-curity classes are drawn from an access
hierarchy, or more generally, a lattice structure. Since security classes have ordering relations among each other reflecting their relative sensitiveness or secrecy, MAC mechanisms ensure that information cannot flow from higher security classes to lower ones. As also shown in Figure 4, object A, B and subject C are assigned security classes x, y, and z, respectively, and the information flow among A, B, and C implies that x, y, and z are in an ascending order. Note that it is usually assumed that labels on data ob-jects and subob-jects would not change, and the assumption is known as tranquility [San93].
The most widely known information flow models are the Bell-LaPadula model [Blp75] which deals with information confidentiality, and the Biba model [Bib77] that deals with information integrity. Confidentiality is concerned with disclosure of infor-mation, i.e. preventing information from flowing downwards from higher security label to lower one. Information integrity, on the other hand, is concerned with the modifica-tion of informamodifica-tion. For example, in a bank informamodifica-tion system, confidentiality is con-cerned with preventing clients from finding other clients’ cash balances, while integrity is concerned with preventing the clients from changing the balances.
The Bell-LaPadula model defines two properties: the simple security property and the
star property. The simple security property prescribes the so-called no-read up
princi-flow flow Data Object A class x Subject C class z Data Object B class y
ple, that is, a subject can not read an object higher than its own security class. The star property prescribes the no-write down principle, that is, a subject can not write to an object lower than its own security level. The basic idea of the Biba model is similar to Bell-LaPadula model, which also defines two similar properties from the integrity per-spective: the simple integrity property and the integrity star property. The simple integ-rity defines no-write up, that is, a subject can not write to an object higher than its own integrity level. The integrity stat property defines no read down, that is, a subject can not read an object higher than its own integrity level.
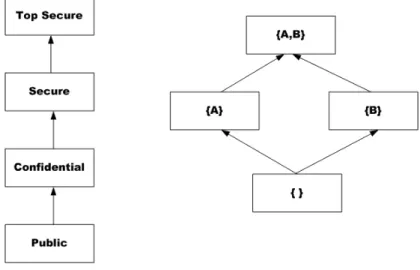
Formally, an information flow model is defined as a set of security classes, a binary relation between security classes, and join operator on security classes. For example, the information flow model by Denning [Den76] is defined as a triple < SC, →, ♁>, where SC is a set of security classes, → ⊆ SC × SC is a binary relation (denoted as "can flow" relation) on SC, and ♁: SC × SC → SC is a binary class-combining or join operator on SC. Under the assumptions below, the information flow model forms a lattice structure:
1. The set of security classes SC is finite
2. The can-flow relation → is a partial order on SC. 3. SC has a lower bound with respect to →.
4. The join operator ♁ is totally defined least upper bound operator.
Figure 5 shows an example lattice-based information flow policy that says information can only flow from low level objects to high level objects, but not the other way around.
Information flow models provide more precise control of information than DAC models. In DAC, an object becomes accessible to some subject when appropriate permission is specified in the access control matrix. But once the subject gets access to the object, it can propagate the content of the object in an arbitrary way. Information flow models realizes the so called non-interference [Gog82] property, which states that low level output should not be affected by high level input. This assures that a low level agent cannot get information about the high level inputs. With non-interference property, in-formation sharing system can prevent low level subjects to observe change of high level subjects.
2.4 Role-Based Access Control
One problem DAC-based systems encounter in practice is when access control policies change frequently. As stated in [Clk87], earlier access control models could not satisfy the practical requirements needed by commercial organizations. It is realized that large voluminous data in organization are not owned by individual users but the organization itself. In addition, individual users may have various access rights under different cir-cumstances. These considerations inspired the so called Role-Based Access Control (RBAC) proposed in 1988, when Lochovsky and Woo defined roles and organized them into a hierarchy [LW88].
The basic idea of role-based access control is to define roles as the entities and au-thorize them rather than auau-thorize subjects directly. In real environments, a user can play different roles under different contexts. Instead of granting access to an object of a subject, the authorization is represented as a role’s access to an object, and the subjects can be assigned to different roles. RBAC models often form relation of roles as a hier-archy reflecting different positions in an enterprise, and support more dynamic policy changing and relax the otherwise rigid constraints.
Although role-based access control supports more flexibility than DAC, there are some scenarios can not be supports well by role-based access control. An example is that a team has a goal and member work collaboratively. It is hard to express real world policy by role manipulations [Bel04]. More importantly, information flow addressed by MAC is also not addressed by RBAC.
2.5 Decentralized Information Flow Control
Traditional information flow models form a multi-level security system, which is useful for centralized administration. For example, the Biba model and the Bell-LaPadula model originated from a centralized, military setting. However, these models are not suitable for commercial environment where each user has his/her own security policy on information sharing.
Myers and Liskov [Mye97] developed a decentralized information flow model, which we refer to as the ML model from here on, permits setting information flow policy in a decentralized manner. In the ML model, a label of an object contains an owner set, whereas each owner in the owner set maintains a set of readers. The set of valid readers to the object is defined as the intersection of all the reader sets. For example, a label L can be described as {O1: R1, R2; O2: R2, R3} where O1, O2, R1, R2, R3 are subjects. The
owner set of L, denoted as owners(L), is {O1 , O2}. The reader set of O1 in L, denoted as
readers(L, O1), is {R1, R2} and the reader set of O2 in L is {R1, R2}. The valid readers
of L is defined as the intersection of {R1, R2} and {R2, R3}, namely, {R2}. The
can-flows relation between to labels L1 to L2, i.e. whether L1 can flow to L2, is shown in
Figure 6, which indicates that L1 should contain fewer owner and more readers than L2.
owners (L1) ⊆ owners(L2),
∀ O ∈owners(L1), readers(L1, O) ⊇ readers(L2, O).
Figure 6. Definition of the can-flows relation from L1 to L2
The join operator of two values Label of L1∪L2, as shown in Figure 7, is defined as the
join of readers and union of owners. The upper bound is data which is owned by every principals and no reader allowed, and the lower bound corresponds to data can flow anywhere. We can see that information can flow from more readers and fewer owners to fewer readers and more owners, and a global lattice is formed.
owners (L1∪L2) = owners (L1) owners (L∪ 2),
readers (L1∪L2, O) = readers (L1, O) ∩ readers (L2, O).
In addition to the definition of the lattice structure, another important component of the decentralized model is the constraint that a subject has the right to modify his/her own reader set in the label for a given object without influencing other users’ policies. This decentralized policy specification, compared with centralized downgrading approaches, are more suitable for secure information sharing in a complex, distributed environment.
2.6 Declassification
During information processing in mandatory information flow models, the resulting object labels become increasingly restrictive and make the information less available for subjects. Sometimes, the security levels of the objects need to be relaxed so that other parties can read it. This kind of label relaxation is called declassification. From the per-spective of information flow control, declassification allows high level entities to flow to low level entities.
The ML model described in the previous section also introduces the acts-for relation indicating whether a subject subsumes all privileges of another subject. That is, if the subject A gets the right to act for the subject B, then A has all the access rights B pos-sesses. The acts-for relation facilitates declassification due to the fact that once subject A acts for subject B, subject A can temporally modify subject B’s reader sets of the la-bels for all involving objects.
As [Sam00] states, however, the acts-for mechanism is powerful but dangerous, and users must be careful to allow only trusted principals to act on their behalf.
2.7 Security Policies and Policy Standards
Information security policy defines a set of rules for information availability within an information sharing system. How to specify and enforce security policy precisely is a long standing problem because managing policies involving sharing tools among sub-jects with diverse goals, which can involve complicated declassification management.
There are currently many standards supporting information security and privacy ([Appel], [PHI], [ASS], [XACML]). For example, HIPAA (The Health Insurance Port-ability and AccountPort-ability Act, [HIPAA]) established rules such as those in [PHI], [ASS] to protect the confidentiality and other personal health information. Another example is
Appel (A P3P Preference Exchange Language, [Appel]) for website privacy defined by P3P ([P3P]). P3P specifies an architecture comprising user agents, privacy reference files, and privacy policies. Appel allows webmasters to specify a standard set of multi-ple-choice questions, which result in tags embedded in the web site's home page. On the other hand, P3P-enabled Web browsers allow users also define their own privacy re-quirements, such as stating whether they allow their names disclosed to third parties. Together, P3P and Appel help Web sites announce their privacy practices while letting users automate their accepting and rejecting decisions. Note that P3P does not attempt to enforce or ensure privacy through technology—for example, by cryptographic or anonymization techniques. Instead, it relies on social and legal pressures to compel or-ganizations to comply with their stated policies
XACML (eXtensible Access Control Markup Language, [XACML]) is a policy lan-guage standard developed by OASIS (Organization for the Advancement of Structured Information Standards, [OASIS]), which aims at protecting content during enterprise data exchange by defining flexible way to express and enforce access control policies in a variety of environments. XACML also ratify the e-business standards.
Chapter 3 Motivation and Objective
Our goal is to develop an information sharing system that permits decentralized specifi-cation and management of information flow policies for individual users, yet reduces the burden of policy management as well as the risks of accidental information leakage. Earlier models do not meet these requirements, and several common problems still re-main. They either handle declassification in an inefficient way, or fail to manage large volume of data properly, mainly due to the cost of manual data labeling.
In a medical data analysis system, for example, patients may want to share their own information with researchers to help advance medical research, yet they want to control the exposure of their private information according to their own policies, respectively, such as permitting the access to his diagnosis record only for certain statistical analyses. To better illustrate the decentralized policy specification and management problem, in this section we describe two motivating information sharing examples adopted from [Mye97]. These examples will be used later to help describing our model and compar-ing it with other related work.
3.1 A Medical Data Analysis Example
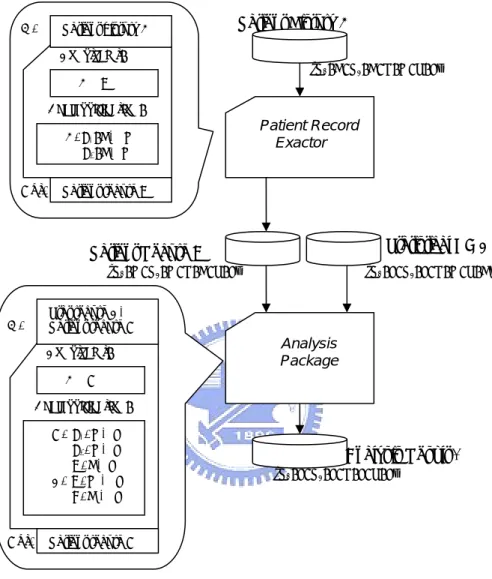
Consider a medical data analysis system illustrated in Figure 8. The purpose of the medical system is to permit statistical analysis on a large number of patient records. While patients would like to keep their own patient information private, they may allow their own patient history to be accessed by statisticians and researchers, provided that they perform statistical research without exposing personal information to public.
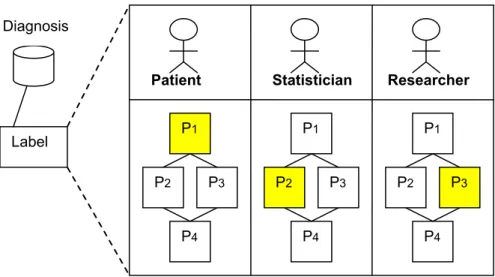
In Figure 8, there are four important principals: patient P1 and P2, researcher R, and
statistician S. There are also two kinds of tools: patient record exactor (PRE) and analy-sis package (AP), whose purpose are to make a brief summary of and to produce a sta-tistical report based on patient records, respectively.
The label structure has the form: {P1: L1, P2: L2, P3: L3 …}, meaning the subject Pi
classifies the labeled object as level Li according to his/her own judgment. Since the
from both P1 and P2 perspective since both label the object as H (High). Likewise, the
analysis result is labeled {P1: L, P2: L, R: L, S: L}. In such a setting, information can
not flow from patient records to analysis report.
Patient History H
Figure 8. A medical data analysis scenario where statistical analysis is conducted on
patient records.
In this model, a label of a tool contains a parameter set, a constraint set for parameters, and a declassification specification. For example, the utility tool PRE exacts informa-tion from patient histories and summarizes them as patient records. PRE is labeled for each of its parameters: the input patient history is labeled H and the output summary is labeled R. The constraint set states that R should be more restrictive than H, whereas the declassification specification declares that the input with label R can be dropped to M temporarily, for both P1 and P2, provided that the actual output has label the same or
Patient Record Exactor Analysis Package {P1: H; P2: H; R: M; S: L} {P1: M; P2: M; R: H; S: L} {P1: L; P2: L; R: M; S: H} {P1: L; P2: L; R: L; S: L}
In: Patient history H
Constraint: H ≤ R Declassification:
H: P1: H↓ M
P2: H↓M
Out: Patient record R
Statistical DB C Patient Record R
Stat record C,
In: Patient record O
Constraint: H ≤ O Declassification: O: P1: M↓L P2: M↓L Analysis Result A R: H↓L C: R: M ↓ L S: H ↓ L
more restrictive than M. Similarly, the results of the statistical study are made public for all users with patient records kept private, with the understanding that AP would not leak private information through its output. In this way statistic record and patient re-cord can flow to analysis result when AP is invoked. Note that users declassify tools individually, and changing the declassification specification of one tool does not affect the specifications of other tools. However, since a tool may invoke other tools during its own computation, automated analysis of the chain of tool invocations is needed to de-termine whether information flow is violated in the presence of declassification.
The example above shows that it is possible to sharing private information with other users without giving all privileges to them.
3.2 A Bank Example
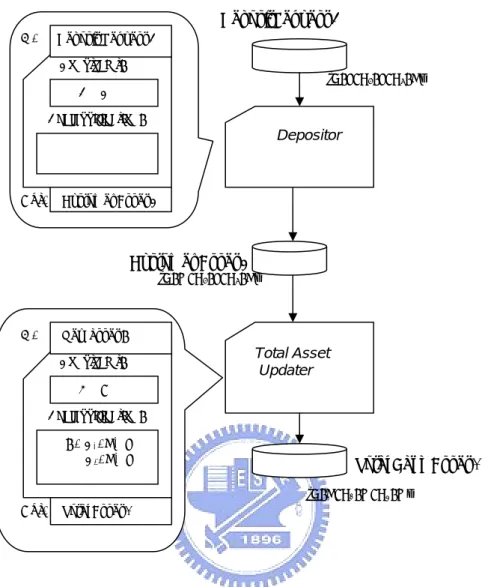
Consider another bank example, as shown in Figure 9, where the bank serves many cus-tomers and both the bank and the cuscus-tomers would like to keep their assets private. The bank would like to keep its own total asset safe from all customers and the customers would like to keep their own asset safe from other customers.
This example contains three subjects: bank B and customers C1 and C2. One
require-ment of this example is that depositing money into personal account and updating the total bank deposit are done without leaking individual account information to unex-pected customers and non-customers. There are also two tools in this example: the asset depositor (AD) and total asset updater (TAU), which take account information and de-posit money into individual asset, and updates the total bank asset, respectively. A cus-tomer can make deposit request through these tools.
The object DepositRequest of C2 is labeled {B: L, C1: L, C2: H} because that the
de-posit is requested by principal C2. C2 can always use the tool AD to deposit money into
his account. The deposit request should contain information about his account, or the invoking of depositor would fail.
Since the functionality of AD is to deposit money into a personal account, the con-straint of AD is that the resulting asset should be more restrictive than the deposit. Now asset is labeled as {B: M; C1: L; C2: H} which is more restrictive than the deposit,
Figure 9. The bank example where each customer keeps asset information private
from other customers and the bank wants to keep its total asset private.
After completing deposit transactions for individual customers, the bank needed to up-date its total asset, which is done by TAU. However, the constraint set of TAU states that the label of the total bank asset must be more restrictive than the label of individual asset, which goes against the object labeling where the total bank asset is labeled {B: H; C1: M; C2: M} and is less restrictive than the label of asset C2 with label {B: M; C1: L;
C2: H}.
The conflict can be solved by proper declassification, by the customers, such that the customer asset can be dropped to level L if it has level H originally. Thus the total asset of bank can be updated when customers can control propagation of their own account and asset information.
DepositRequest D Depositor Total Asset Updater {B: L; C1: L; C2: H} {B: M; C1: L; C2: H} {B: H; C1: M; C2: M}
In: Deposit Request D
Constraint: D ≤ C Declassification:
Out: Customer Asset C
Customer Asset C
In: New asset N
Constraint: H ≤ O Declassification:
N: C1: H↓L
C2: H↓L Total Bank Asset A
This scenario shows a bank example making processing normally and also keeping each principal’s information private without any rigid constraints. Customers can keep their own personal account information and asset private from other customers and non-customers.
Chapter 4 A Rule-Based Decentralized Information Flow
Approach
In this section we define a decentralized model fulfilling the objective discussed in the previous section, by allowing individual principals to specify their own policies based on user-defined lattice structures. This model handles declassification in a selective way, through tool declassification, rather than by giving all access rights to other principals. As a result, policy management becomes easier to handle with our model.
Figure 10. Overview of our information sharing model, that consists of a set of
prin-cipals, data, and tools.
4.1 Overview
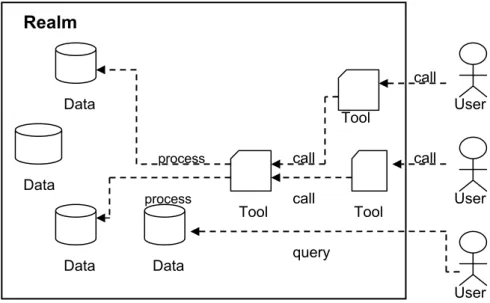
Figure 10 depicts our overall secure information sharing model, which is basically a
realm of secure environment that contains a set of (data) objects, a set of tools, and a set
of principals representing users. Within the realm, objects are created and manipulated only through tools, whereas tools are created by principals only. Specifically, principals do not access objects directly but through tools instead. Technically, to access tools, each user needs to first establish a communication channel with the realm, during the
call call User User User Realm Tool Data Tool Tool Data Data call call query process process Data
process the channel is bound with the corresponding principal and assumes the identity and associated privileges of that principal.
Each object inside the realm is attached with a label that is further divided into multi-ple sub-labels each corresponding to a principal. In other words, each principal assigns a sub-label to each object representing the security level of the object from the princi-pal’s perspective, and the total sub-labels to the object constitute the actual label.
Tools are considered an integral part in our model. Informally, each tool is associated with certain documentation indicating what the tool do and the information flow it in-duces when invoked. A tool can be invoked only when its execution will not violate the information flow requirement, i.e. causing information flowing from high-level objects to low-level ones.
In our model, data are imported into the realm through tools. The label of the im-ported data is decided according to the setting of declassification. For example, a doctor can specify declassification on the tool which is used for importing new data by statisti-cians about the output values imported from the tool can rise to level M. This approach is similar to importing data through channels in decentralized label model.
4.2 Object and Principal Labeling
As mentioned, security labels represent the security levels of the objects they denote from the perspective of all participating principals, respectively. Different from other models, we view principals as a special kind of objects which information may flow from and into. Whether a principal can read or modify the content of an object is subject to the same information flow constraint. Furthermore, a principal can assign security labels to other principals in exactly the same way he/she labels objects.
Our model excludes the concept of ownership – objects are considered shared and administrated by all principals “collectively.” As illustrate in the Figure 11, the label of a diagnosis record contains sub-labels P1, P2, and P3 which represents security level of
Figure 11. An object label contains sub-labels each indicating the security level of
the object from each principal’s perspective.
Figure 12 illustrate the general lattice structure of object labels. It is assumed that the sub-labels coming from the same principal are drawn from a lattice defined by that prin-cipal so that the can-flows relations among labels can be defined, as shown in Figure 13. The rule from L to L’ must be restriction which implies each sub-label of L should be more restrictive than L’. This rule for information flow is more precise because the la-bel is formed as Cartesian product of sub-lala-bels of all principals.
Figure 12. Definition of the label structure.
Figure 13. Definition of the can-flows relation
Definition of the can-flows relation from L to L’:
L = (p1:l1; p2:l2; …) ≤ L’ = (p1:l1’; p2:l2’; …) iff li ≤ li’ ∀i
Definition of the label structure:
L = { p1:l1; p2: l2 ; p3: l3 ; … }
where pi represents a principal and li ∈ Li a sub-label
drawn from the lattice Li associated with pi.
Label
Patient Statistician Researcher
P1 P3 P2 P4 P1 P2 P3 P4 P1 P2 P3 P4 Diagnosis
When the content of an object is derived from the contents from other objects, such derivation should respect the information flow constraint. For example, consider a com-putation x = y + z where x would contain information about y and z, the label of x should be more restrictive than y and z. More generally, if an object labeled L contains information derived from the objects labeled L1 and L2, respectively, L should be more
restrictive than both L1 and L2. The least restrictive label that is more restrictive than L1
and L2, denoted L1∩ L2, is defined as follows:
Definition of the join operator L ∩ L’:
L∩ L’ = (p1:l1∩l1’; p2: l2∩l2’; …)
where L = (p1:l1; p2:l2; …) , L’ = (p1:l1’; p2:l2’; …)
and li ∩ li’ the join of li and li’ defined in Li
Figure 14. Definition of the join operator among labels
It is easy to see that the labels in our model form a lattice, since the can-flows relation is a partial order relation, with the least restrictive label denoted as ⊥, and the most re-strictive label denote as ┬ well defined.
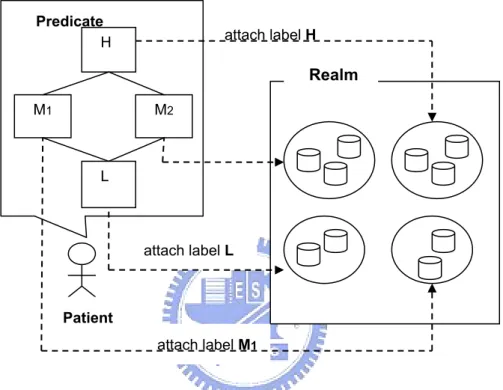
4.3 A Rule-Based Labeling Approach
In our model, instead of labeling objects individually, a principal associates labels with objects through user-defined predicates. A predicate is a rule-based assignment of a sub-label to a subset of objects within the realm. Specifically, the subset is defined through a set of user-defined rules. Using the example in Figure 11 for illustration, the patient may define a predicate stating that (from the patient’s perspective) “all diagnosis information is P1,” then all diagnosis information of the patient in the realm would be
attached P1. The situation is similar for the statistician and the researcher, with
diagno-sis attached P2 and P3, respectively. In this thesis, we leave concrete definition of such
rules open, although we have implemented some rule-based labeling mechanisms using Prolog. However, we do require that any such rule-based predicate mechanism should partition the objects statically, such that once an object is attached a label, such
assign-object identities without relying on assign-object contents or other external (dynamic) envi-ronmental conditions. For example, assuming all medical data are stored in a file system, a predicate by a doctor may prescribe that all records in the directory storing diagnoses are all labeled private. In this example, the directory is part of the object identities for all the diagnoses, and the predicate even asserts that “future” diagnosis records to be placed in the directory will have the same security level from the doctor’s perspective.
Figure 15. Our model allows a principal to attach individual labels on data in the
realm.
4.4 Tool Sharing and Declassification
A tool executes by processing data from its input parameters (or channels) and gener-ates output into its output parameters. Therefore, a tool should contain explicit
docu-ment about the information flow it may cause among its input/output parameters. For
“system” tools, possible written in system programming languages, the system adminis-trator is responsible of ensuring that these tools do not cause information flow exceed-ing what they claim in their documents. Therefore, system tools are outside the control of principals and used as is. However, principals can still create tools using the pro-gramming languages allowed by the system, as long as the system can analyze and
Predicate Realm H M2 M1 L Patient attach label M1 attach label H attach label L
erate correct documents for these tools automatically. We will describe a simple pro-gramming language for tool definition in the next chapter.
specifies declassification
H: H↓ M
Figure 16. Each user can specify declassification on each tool.
An example of information flow documents is shown in Figure 16, where the constraint set of the tool PRE indicates that information would flow from patient history to patient record. That is, the label of patient record should be more restrictive than patient history; otherwise, the invocation of the tool would be denied by the system. The signature of tools helps user recognize the constraints for what flow would happen after using the tool and also help users for specify declassification.
The purpose of declassification is to relax the constraints of tools so as to enable more useful data analysis. Declassification refers to the permission of information flow from higher-level objects to lower-level ones. In earlier systems for controlling informa-tion flow, declassificainforma-tion relies on the trust relainforma-tion outside the model. In our model, on the other hand, declassification comes with tools. For example, in Figure 16, a patient may specify declassification such that the output data patient record can raise level from M to H temporally. Originally, information flow from patient history to patient record is denied because that input parameter corresponding to patient record is lower than M in the patient's part. After specifying declassification by patient, the constraint of the tool
User P2
User P1
specifies declassification:
In: Patient history H
Constraint: H ≤ R Declassification: Patient Record Exactor H: P1: H↓ M P2: H↓M Out: Patient record R
is relaxed such that information can flow from patient history which labeled level L patient record which labeled level M in processing of the tool patient record extractor.
In summary, our model represents a flexible approach to sharing and protection of in-formation in a decentralized manner. We use consistent labeling approach base on lat-tice to specify policies on data and other user. Unlike existing models focus on who can share and declassify information, our model focuses on how to share and declassify. Without giving all access rights to another parties, our model deal declassification in a safer way. Moreover, the use of predicates also reduces the complexity of managing policies for large volume of data.
Chapter 5 Type Systems Approach to Information Flow
In this chapter we present a program certification mechanism by defining a program-ming language for tools and developing a verifier for the language. There are three main advantages of program certification mechanisms over run-time enforcement mecha-nisms [Den76]. First, to prevent purposely security violations, the program execution is guaranteed to be secure before it executes. Second, a certification mechanism would not blemish the speed of program execution since all security checks are performed before the program execution. Third, to be comprehended and corrected conveniently, the cer-tification mechanism can be specified in terms of higher level languages rather than low level hardware instruction. We present our program certification framework via type theoretical approach following Volpano’s method. In particular, we define the syntax and operational semantics of a simple programming language and augment it with de-classification specification..
5.1 The Volpano Approach
Volpano [Vop96, Vop97] adopts a type system approach to information flow analysis. A type system for a procedural language guarantees that well-typed programs do not cause undefined value conversions during execution. In the context of information flows, the type system approach is adapted so that well-typed programs do not cause information flow from high-level objects to low-level ones, which are often termed non-interference property. In short, a system has the nonnon-interference property if no matter how high-level data object change during computation, low-level data objects remain the same. Using the following procedure contains two parameters as an example,
proc p( in x: high , out y: low )
where x and y are variables with high and low security levels, respectively. Now two calls p(a: high, b: low) and p(c: high, b: low) end with final values a, b, and c. If the procedure p is noninterference, then a and c may change and the final value of b would remain the same in both cases no matter how a and c change.
(Phrase) p ::= e | c
(Expr) e ::= x | n | l | e + e' | e - e' | e = e' | e < e' |
c | letvar x := e in c | proc (in x1,inout x2,out x3)c
(comm) c ::= e := e' | c; ' | e(ec 1, e2, e3) |
do
if e then c else c' | when e
letproc x(in x1, inout x2, out x3) c in c’
eta-variable x ranges over identifiers,
where m l ranges
its security level. For example, ea
n ranges over integer literals and
over external storage locations which can be used for input and output in the language. The initial values of external locations represent inputs to a program and final values of external locations represent the output of the program.
Variables in a program should be labeled to denote
ch variable x, y has a security class denoted as x, y, respectively. Information flow from x to y is permitted if and only if x ≤ y. The type definition of core language in the Volpano model is shown below,
eta-variable s ranges over a set of security levels which is partial ordered by
τ := s π := τ |
ρ := π | τ var | τ acc τ proc (τ1, τ2 var, τ3 acc) | τ cmd
where m ≤.
fe
nd give e' τ var then the com-The typing of variables, i.e. assignment of labels to variables, is done through type in-rence. Consider the assignment x: = y. If the identifier typing γ give x low and give y high, that is, x ≤ y, then the assignment is rejected by the typing rule since the content in variable y would affect the final value of x. Thus a typing rule is introduced to cover assignment:
The rule says that if the identifier typing γ give e τ var a
mand e: = e' is typed as τ cmd. As another example, suppose that we try to copy x to y indirectly as follows: while ( x > 0 ) do y = y + 1; x = x - 1 end λ; γ├ e : τ var λ γ├ cmd ; e': τ λ; γ├ e := e': τ
The final value of y is affected by x. This is so-called implicitly information flow from x to y. Thus it is needed to insist while statement such that the guard and the body should be typed a y level:
erence. Security type in-ference attem
straints which are in t variables must sat-isfy for the program to b he Volpano model are given
) to any identifier x' other than x. Meta-variable λ ranges over location ty
typing rule for the t the same securit λ; γ├ e : τ
λ; γ├ c : τ cmd
λ; γ├ while e then c : τ cmd
It is possible check a program is well type by security type inf
pted to use type variables to presents unknown types and collect con-he form of type inequalities such that tcon-he type
e well typed. The typing rules of t in Figure 17.
In the typing rule λ;γ ├ p : ρ, meta-variable γ ranges over identifier typing. An identi-fier typing is a finite function mapping identiidenti-fiers to types of the form τ; γ(x) is the type assigned to x by γ, and γ[x: ρ] is a modified identifier typing assigning type ρ to x and assigning γ(x'
(letvar) λ; γ├ e : τ λ; γ [x: τ var]├ c : τ' cmd λ; γ├ letvar x := e in c : τ' cmd (if) λ; γ├e : τ λ; γ├c : τ cmd λ; γ├c' : τ cmd λ; γ├ if e then c else c' : τ cmd (while) λ; γ├ e : τ λ; γ├ c : τ cmd λ; γ├ while e then c : τ cmd
(procedure) λ; γ [x1 :τ1, x2: τ2 var, x3: τ3 acc] ├ c: τ cmd
λ; γ├ proc (in x1, inout x2, out x3) c :
τ proc(τ1, τ2 var, τ3 acc )
(apply) λ; γ├ e : τ proc (τ1, τ2 var, τ3 acc)
λ; γ├ e1: τ1 ; λ; γ ├ e2 : τ2 var ; λ; γ├ e3 : τ3 acc
λ; γ├ e (e1, e2, e3) : τ cmd
(letproc) λ; γ├ proc (in x1, inout x2, out x3) c : π
λ; γ├ [proc (in x1, inout x2, out x3) c/x ] c' : τ cmd
λ; γ├ letproc x(in x1, inout x2, out x3)c in c': τ cmd
Figure 17. Typing rules for the Volpano model
The evaluation rules for the Volpano model are shown in the Figure 18, in which a closed phrase is evaluated relative to a memory µ. An evaluation is a finite function mapping from location to integers. The semantics uses µ├ e ⇒ n for the expression evaluation and µ├ c ⇒ µ' for the command evaluation. The content of a location l∈
dom(µ) is the integer µ(l), and µ[l := n] denotes that memory assigns n to location l and
assigns µ( l') to location l' other than l. They write [e'/x] to denote the capture-avoiding substitution of e' for all free occurrences of x in c.
(val) µ├ n ⇒ n' (contents) µ├ l ⇒ µ(l) l ∈ dom(µ) (add) µ├ e ⇒ n µ├ e ⇒ n' µ├ e + e' ⇒ n + n' (sequence) µ├ c ⇒ µ' µ'├ c' ⇒ µ'' µ├ c; c' ⇒ µ'' (branch) µ├ e ⇒ 1 µ├ c ⇒ µ' µ├ if e then c else c' ⇒ µ' µ├ e ⇒ 0 µ├ c' ⇒ µ' µ├ if e then c else c' ⇒ µ' (update) µ├ e ⇒ n l ∈ dom(µ) µ├ l:=e ⇒ µ'[l := n] (update) µ├ e ⇒ n l ∈ dom(µ) µ├ l:=e ⇒ µ'[l := n] (loop) µ├ e ⇒ 0 µ├ while e do c ⇒ µ µ├ e ⇒ 1 µ├ c ⇒ µ' µ'├ while e do c ⇒ µ'' µ├ while e do c ⇒ µ''
5.2 Type System of Our Model
In this section we follow Volpano’s approach and describe our model by defining a type system. The syntax definition of our language is given below:
(phrase) ρ ::= e | c (expression) e ::= x | l | n
(commands) c ::= e := e' | c; c' | e(e1, e2) |
if e then c else c' | when e do c | letvar x = e in c | lettool x(in x1, inout x2) c in c'
Figure 19. Language syntax definition
In the definition, meta-variable x ranges over identifiers, n ranges over integer literals, and l ranges over external locations (such as files). Like in the Volpano model, the ini-tial contents of the externals locations represent inputs and final values of external re-sources represent the output. For simplicity, we assume that each tool has two parame-ters: the parameters of type in cannot be assigned values to while the parameters of type
inout can. Therefore, inout parameters accept only locations but not literal values.
The typing rules of our model are shown in Figure 20. In a typing rule θ├ e : θ ',
meta-variable θ ranges over contexts. A context contains information about the total security level of the “environment” under which e is evaluated, and contains a set of bound variables in actuality. That is, intuitively, all expressions or commands under a context can see the contents of all the variables in that context. In the typing rule φ ;θ ├
c : φ ', meta-variable φ ranges over flow constraints. A flow constraint is a finite set of dependencies among variables, which is defined (informally) below.
Definition 5.2.1 (Flow Declaration): for a flow constraint φ and a variable x, φ[x] is a
flow constraint extended with the declaration of x (Figure 21b). Intuitively, declaration introduces a fresh variable x shadowing those in φ, so that it captures the occurrences of
(assign) θ├ e : θ ' φ ;θ ├ x:=e : φ [x⇐θ '] (compose) φ ;θ ├ c : φ ' φ '; θ├ c' : φ '' φ ;θ├ c;c' : φ '' (if) θ ├ e : θ ' φ ;θ ' ├ c1 : φ ' φ ';θ ' ├ c2 : φ '' φ ;θ├ if(e, c1, , c2) : φ '' (while) θ ├ e : θ ' φ ;θ ' ├ c : φ '' φ ; θ├ while(e, c): φ '' (letvar) θ ├ e : θ ' φ [x][x⇐θ '];θ '├ c : φ '' φ ;θ├ let x = e in c : φ ''<x> (call) θ ├ e: θ ' θ ├ l: θ '' {}[x1][x2]; {}├ c : φ ' φ '' = φ [x1][x2][φ '[θ '/x1][θ ''/x2]] <x2><x1> φ ; θ├ (tool (in x1, inout x2) c)(e, l): φ ''
Figure 20. Typing rules for our model
Definition 5.2.2 (Flow Constraints): for a flow constraint φ, a context θ, and a variable
x , φ[x⇐θ] is a flow constraint with additional flow dependencies from θ to x, that is,
from all variables in θ to x (Figure 21c)
Definition 5.2.3 (Flow Un-declaration): for a flow constraint φ and a variable x declared
in φ, φ<x> is a flow constraint by removing the declaration of x and “redirect” all flow dependencies into x in φ to all the other variables in φ that depends on x (Figure 21d).