THE ARBITRARILY SHAPED TRANSFORM OF SEGMENTED MOTION FIELD
FOR A PSEUDO OBJECT-ORIENTED VERY L O W BIT-RATE VIDEO CODING
SYSTEM
Chung- W e i K u , Y o u - M i n g Chiu, Liang-Gee C h e n , and Y u n g - P i n Lee D S P / I C Design Lab., Department of Electrical Engineering
National Taiwan University, Taipei, Taiwan, R.O.C. Email: {william,lgchen}@video.ee.ntu.edu.tw
URL: http://video.ee.ntu.edu.tw/william
ABSTRACT
T h e arbitrarily shaped transform (AST) of the segmented motion field generated by modified optical flow algorithm (MOFA) is suggested i n this paper. Because the transform kernels are dependent on the shape of the coded region, in- formation about t h e contours of the objects must be trans- mitted. To achieve d a t a compression, coefficient selection function (CSF) is defined for A S T coefficients reduction. Since shape information costs lots of d a t a amount, a rect- angle approximation method is also developed. According t o the simulation results, t h e proposed coding method is efficient and i t s performance is much better t h a n the tra- ditional block matching algorithm no matter in terms of P S N R or bit-rate. I n addition, t h e proposed algorithms are integrated together to build a very low bit-rate video cod- ing system. From some primary simulations of t h e system, t h e proposed method can guarantee 34 d B P S N R for most cases a t around 1 0 Kbps; Furthermore, the segmentation of objects is potential for object scalability.
1. INTRODUCTION
Although H.261 has defined a standard for videophone or videoconferencing with p x 6 4 Kbps, lower bit-rate is expect- ed in order t o utilize current general switched telephone net- work (GSTN). According t o the standard of modern modem (V.34), transmission rate is defined as 28.8 Kbps. To meet t h e above requirements, as early as May 1 9 9 1 t h e “Moving Picture Expert Group” ( M P E G ) raised the issue of audio- visual standard targeted a t t h e bit-rate of 4.8-64 Kbps, with t h e motivation being t h e limited channel bandwidth and limited storage capacity. These efforts was approved in Ju- ly 1 9 9 3 with t h e MPEG-4 nickname and the title “Very Low Bit-Rate Coding of Moving Pictures and Associated Audio” [l]. Recently, I T U - T also announced a draft about “Video Coding for Low Bit-Rate Communication” or H.263 [2], which is an extension of H.261 standard for very low
bit-rate visual telephone. I t is still a block based algorithm basically with some MPEG-1 optimizations. However, s- ince the goal of MPEG-4 is t o integrate telecommunication, computer, and multimedia applications, some quite differ- ent approaches about MPEG-4 are also developed rapidly. For example, model-based coding [3] and object-oriented coding algorithms [4]. W e developed a modified optical flow based motion estimation algorithm t o generate a homoge- neous and meaningful motion field [7]. In order t o encode these motion vectors efficiently and build a prototype of a very low bit-rate video coding system, arbitrarily shaped transform and coutour description are proposed and ap- plied t o t h e segmented motion field i n this paper. Besides,
0-7803-3073-0/96/$5 .OO ‘1996
IEEE
a pseudo object-oriented very low bit-rate video coding sys- tem which is based upon the above techniques is presented. T h e simulation results reveal the proposed system is very suitable for very low bit-rate video coding applications, or even content-based applications.
2 . ARBITRARILY SHAPED TRANSFORM
T h e general form of the two dimensional unitary transform i s
X , Y and its inverse transform is
1,3
f ( z , y ) indicates t h e image d a t a in spatial domain and
F ( z , j ) indicates t h e coefficients i n frequency domain.
k
is the kernel function of t h e transformation. z, y are spatial indices and i , j are frequency indices. T o meet t h e unitary restriction, IC must satisfy the following property:IC(;,
j , z , y ) k ( m , n , z I y) = 0, f o r i#
m O T j#
n“IY
~ ~ ( i , j , 2 , y ) ~ ~ ( i , j , z, y) = 1, f o r i = m a n d j = n. “ I Y
In most developed standards such as H.261, MPEG-1 and MPEG-2, D C T plays an important role for spatial redun- dancy reduction. However, if there are edges in the trans- formed block, the performance of D C T degrades obviously. To avoid the above drawbacks, an object-oriented UTbZtrUT- zly shaped t r a n s f o r m (AST) is suggested in literature [6]. It can be used for any shape of homogeneous regions rather than the square block for general D C T . D a t a compression is achieved by transmitting the coefficients in frequency do- main. O n the other hand, since the input d a t a distribute in arbitrary shape, t h e kernel functions of the transform are dependent on the distribution. In this paper, polynomial based functions are selected in our system for t h e feasibil- ity of programming. Because the basis should satisfy t h e orthonormal requirements for arbitrarily shaped condition- s ) an orthonormalization process for those polynomial basis must be executed, such as Gram-Schmidt process; more details can be found in [6]. I n brief, t h e procedures for arbitrarily shaped transform includes:
1. For the region which will be transformed, find its cir- cumscribed rectangle.
2 . According to the shape of the region, orthonormalize the polynormal basis.
3 . Apply t h e transformation t o the input region according t o the orthonormalized basis t o obtain the coefficients. T h e basis to be orthogonalized are {1,r, y, r y , z 2 , y 2 . . .}. I t should be noticed t h a t the basis are orthonormalized in both encoder and decoder. In addition, the shape informa- tion must be transmitted because the kernels are orthonor- malized according t o the shape of the coded region; the decoder can recover t h e kernels from t h e shape information then apply inverse arbitrarily shaped transform (IAST) to those coefficients t o reconstruct the original input.
For t h e reason of d a t a compression, only parts of the low-ordered transformation coefficients are computed and transmitted. Besides, as the sizes and shapes of different regions vary widely, i t is unfair t o calculate a fixed number of coefficients for any kinds of regions. T h a t is, some regions need more coefficients while some others need less. Our approach is to determine how many and which coefficients are necessary before applying forward transform. Generally speaking, the number of critical coefficients is dependent on the size and homogeneity of t h e region. If the region is considerably homogeneous, we assume two heuristic rules to select t h e coefficients. T h e first is: “For large regions, more coefficients are needed t o reach the same performance as t h a t for small regions”. I t is a reasonable assumption because large regions contain more information t h a n small regions statistically. T h e second rule is: “The increasing of necessary coefficients in the first rule should be fewer than the increasing of region size”. To interpret i t , consider the case of D C T . Suppose block A is four times as large as block B. When the homogeneities in both blocks are comparable, the number of critical coefficients for block A should be less t h a n four times of t h a t for block B. This phenomenon also can be observed in t h e case of AST. Figure 1 shows the realization of t h e coefficient selection scheme. As Figure 1 (a) shows, given the region we can find its circumscribed rectangle with width p and height q. T h e frequency domain after A S T is shown in Figure 1 (b). We compute only the effective coefficients i n t h e shaded area which is with two sides, f(p) and f(q). According t o the above two heuristics, the coefficient selection function (CSF)
f
should satisfy t h e following properties:1.
f
is a n increasing function.2. T h e deviation o f f (f‘) is a decreasing function. In our system, f ( r ) =
6
is selected as the CSF, which sat- isfies t h e above properties and its complexity is acceptable.3. SEGMENTATION FOR AST
Before applying AST, the motion field is segmented into several homogeneous regions. In fact, the operation of seg- mentation is equivalent t o clustering similar motion vectors around. T h e similarity of t h e neighboring pixels can be evaluated from some local informations. T h a t is, if the dif- ference between a motion vector and one of i t s neighbor is large, the two vectors should be segmented into different re- gions; otherwise they will be grouped into the same region. I t is analogous t h a t a drop of color ink drips down the can- vas and floods over the region with similar texture, where the similarity is defined as the gradient of the segmented field. Since there are two components in a motion vector (i.e. z-component and y-component), both the gradients in I and y field are considered for t h e segmentation. If both
of the gradients are larger than a threshold, the considered vectors will not be grouped together. T h e above segmen- tation method is very suitable for later AST operation be- cause each segmented motion field keeps i t s homogeneity. In addition, the number of regions are quite few for real conversation applications because there are only one or t- wo persons on screen in general. An example explaining the above ideas is shown is Figure 2. Since the kernels are dependent on t h e shape information, it is unnecessary t o transmit the d a t a about kernels; instead, the shape of the coded region is used. In most cases, there is only one out- er boundary enclosing the region. However, if one region covers part of another, as shown in Figure 3 region A has both inner and outer boundaries, i t is redundant t o encode the common boundary between A and B twice. Instead, we regard A as a hollow-free region. As long as A is decod- ed before E , where region B locates will be reconstructed consequently. Since region A is encoded like those regions without holes, the pixels in the hole ( t h e region enclosed by dashed curve in Figure 3 ) must be filled with some value. I t is reasonable to give t h e m the mean value of the object. Suppose there are m pixels in A and R. pixels i n t h e hole, then the mean value of A is
Ei.
If we insert t h e hole with this value, the new mean is the same:m m m
-(zE;+n(---E,))=
1 1-E&.
1m
n + m i = l i= 1 ,=1
Therefore, the first coefficient after A S T for the new hollow- free object will be equal t o t h a t for original A.
T h e encoding of region contour will be inefficient if error- free coding scheme is applied, such as chain code. It causes t h a t large amount of t h e encoded d a t a is about contour. Instead, the shape is approximated by some description- s before appling AST. There are many methods for curve approximations, and they must be able to resolve t h e sit- uations of overlaps and ”no-mans-land’’ holes. Fortunate- ly, since the error is not noticeable for h u m a n eyes, it is not really a serious problem. In addition, the possibility of the above phenomenon is quite few in general conver- sation applications. In our system, the shape description is approximated by rectangle. A heuristic algorithm is de- veloped t o find those knot points. These knot points are linked as a rectangle t o approximate the region as Figure 4 displays. T h e segmented and approximated motion field is then applied with AST. Because t h e motion vectors vary little in spatial domain, A S T can be executed in “grid unit” instead of “pixel unit”. T h a t is, the segmented regions is determined in subsampled motion field. In o u r experiments, the subsampling factor is 4 for both x-axis and y-axis; the computation complexity is reduced greatly while the perfor- mance remains excellent. Before appling A S T in t h e sub- sampled motion field, b o t h z and y fields are with the same shape described by the rectangle knot points. T h e polyno- mial based kernels of AST is orthonormalized according t o the approximated shape. Two sets of AST coefficients are computed and transmitted to the channel/storage resource. Since the information about motion and shape are both p- reserved, the proposed methods are very suitable for very low bit-rate coding or motion recognition.
4. EXPERIMENTAL RESULTS
T h e performance of the proposed AST and rectangle de- scription for motion field is evaluated by several monochro- matic head and shoulders sequences, which are with Q C I F
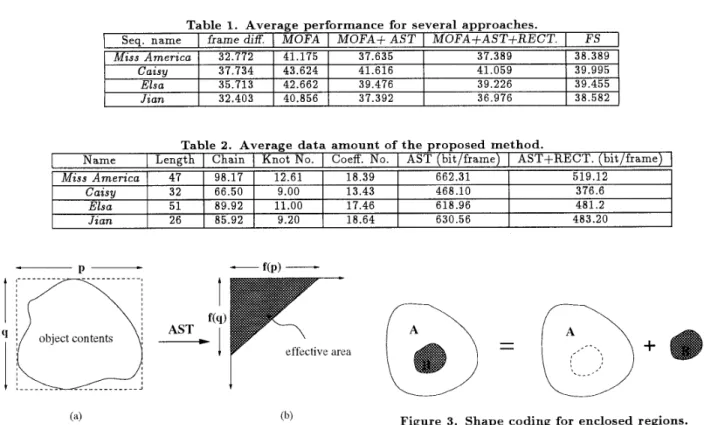
format and 1 0 frames/sec frame rate. I n order to simplify t h e evaluation, t h e residual error will not propagate to the later frames i n our simulation. If t h e d a t a of two successive frames are subtracted directly without any motion com- pensation method, the P S N R would be t h e lower bound with respect t o motion estimation/motion compensation. T h e bit-rate of frame difference is zero because nothing is transmitted. O n t h e other h a n d , if the the motion vec- tors generated by MOFA is used for motion compensation directly, its P S N R would be the upper bound with respec- t t o AST of t h e motion field. However, t h e bit-rate will be very high because t h e motion vector of each pixel must be transmitted. T h e result of the proposed AST coding is between t h e two bounds because of t h e loss by encod- ing motion vectors. T h e simulation results reveal t h a t the proposed A S T coding of the motion field can guarantee 35 dB P S N R picture quality a t least. In addition, the rectan- gle description method works pretty well with almost ne- glectable loss in performance. To make a clear comparison, the average performance of several sequences is listed in Table 1. In this table, FSindicates full-search block match- ing algorithm with block size 8 x 8 and search range -4 t o $4. Remember t h a t M O F A is t h e upper bound while f r a m e
dzg.
is t h e lower bound. For the sequence “Cazsyll and “Elsa”, the proposed method outperforms F S . For “ M Z S SAmerzca” and “Jzan”, the performance is about 1 d B low- er t h a n FS. I t is obvious the performance of the proposed AST with rectangle description is almost equal t o full-search block matching algorithm, b u t the d a t a amount is reduced. T h e d a t a amount analysis is displayed in Table 2. T h e av- erage chain code length and AST coefficient numbers are all listed. T h e full-search block matching algorithm need- s 6 bits for each motion vector (-4 to +4), and there are
-
= 396 blocks in each frame. T h e total data for one frame is 396 x 6 = 2376 bits. On the other hand, the proposed method needs t o transmit one shape information a n d two sets of A S T coefficients. For chain code descrip- tion each chain costs 3 bits; t h e AST coefficients are with 1 0 bits word length in our system. Therefore the average d a t a amount for one frame is about one quarter of the amoun- t of F S with comparable performance. In addition, if the rectangle description scheme is applied, the d a t a amount is reduced further more. In our simulation, the z and y parts of t h e knot points are coded with 6 bits (-32 t o $32) each. As a result, extra 20% saving of AST d a t a is obtained b u t the performance is still preserved. All the materials are variable length coded t o remove t h e statistical redundancy. T o decode the bitstream, In inter mode, a motion field is generated b y inverse arbitrarily shaped transform (IAST) from the shape (i.e. t h e orthonormal kernels are generat- ed from t h e shape), t h e n current picture is reconstructed by motion compensation with the preceding decoded frame and the motion field. According t o some primary simula- tion results of our system, the proposed methods are very useful for very low bit-rate video coding applications. In general, 1 0 Kbps bit-rate can be expected.5 . CONCLUSION
We proposed a modified optical flow based motion estima- tion algorithm (MOFA) [7]. Compared with other motion estimation algorithms, i t s performance is the best for both subjective view a n d PSNR. In order t o transmit the motion field efficiently, an arbitrarily shaped transform (AST) pro- cess is designed i n this paper. T o achieve the goal of d a t a compression, coefficient selection function (CSF) is careful-
ly defined and rectangle approximation of shape is devel- oped in our system. According t o the simulation results, AST of the motion field is efficient and t h e performance is much better t h a n the traditional block matching algorithm no matter in terms of P S N R or bit-rate.
In the proposed pseudo object-oriented system, motion estimation algorithm is executed by MOFA t o remove the temporal redundancy in video sequence. T h e generated mo- tion field is subsampled and segmented into regions; these regions are applied with AST t o remove t h e spatial redun- dancy in motion field. For conversation application, usually there is only single object on screen and most of t h e contents on screen are well compensated b y the above combination; this “pseudo object” is called motion compensated object ( M C O ) . T h e coding of motion off object ( M F O ) is under development. Since the patterns appear on screen is less restricted in our system, we believe the proposed system is very suitable and practical for videophone or videoconfer- encing.
To optimize the system, t h e investigation about fast A S T is studied because i t is t h e most time-consuming part in our system. Currently the encoding time is the most serious problem and t h e real-time software decoder is under pro- gramming. Besides, for some detail operations of eyes and mouth, several fine compensation methods will be append- ed to advance the acceptance of picture [8]. I n addition t o very low bit-rate applications, the object scalability is im- plied in our region segmentation and more efforts will be spent on this topic.
REFERENCES
[l] ISO/IEC J T C I / S C 2 9 / W G 1 1 M P E G 92/699, Project D e s c r i p t i o n f o r v e r y Low Bitrate A / V Coding, 5, 1992.
[2] I T U - T Study Group 15, Working P a r t y 15/1, “Draft ITU-T Recommendation H.263 - Video coding for low bitrate communication”, D o c u m e n t - L B C - 9 5 - 2 5 1 , Jul. 1995.
[3] K. Aizawa, H. Harashima and T . Saito, “Model-based analysis-synthesis image coding (MBASIC) system for a person’s face”, Signal Processing: I m a g e C o m m u n i - cation, vol. 1, pp. 139-152, 1989.
[4] H. Shiller and M . Hotter, “Investigations on color cod- ing in an object-oriented analysis-synthesis coder”, Sig- nal Processing: I m a g e C o m m u n i c a t i o n , vol. 5, pp. 319- 326, 1993.
[5] N. Ahmed and K.R. Rao, Orthogonal T r a n s f o r m f o r Digital Signal Processing, New York: Springer-Verlag, 1975.
[6] M. Gilge, “Coding of arbitrarily shaped image seg- ments based on a generalized orthogonal transform”, Signal Processing: Image C o m m u n i c a t i o n , vol 1, pp.
153-180, 1989.
[7] C.-W. K u , Y.-M. Chiu, L.-G. Chen, and Y.-P. Lee, “Building a pseudo object-oriented very low bit-rate video coding system from a modified optical flow mo- tion estimation algorithm”
,
t o appear in Proc. ICAS-S P ’96, Atlanta.
[8] C.-W. K u , L.-G. Chen, Y.-M. Chiu, and Y.-P. Lee, “A pseudo object-oriented very low bit-rate video cod- ing system with cache V Q for detail compensation”, submitted to I E E E International Conference o n Image Processzng, Laussane, Sep. 1996.
Table 1. Average performance for several approaches.
I
Seq. nameI
framediff.I
MOFAI
M O F A + A S TI
MOFA+AST+RECT.I
F S1
I ~~ Miss A m e r i c a ~~ I 32.772 I 41.175 I 37.635 I 37.389 I 38.389I
Caisy Elsa J i a n 37.734 43.624 41.616 41.059 39.995 35.713 42.662 39.476 39.226 39.455 32.403 40.856 37.392 36.976 38.582Name Length Chain Knot No. Coeff. No. AST (bit/frame)
M i s s A m e r i c a 47 98.17 12.61 18.39 662.31
C a i s y 32 66.50 9.00 13.43 468.10
Elsa 5 1 89.92 11.00 17.46 618.96
J i a n 26 85.92 9.20 18.64 630.56
Figure 3. Shape coding for enclosed regions.
(a) (h)
Figure 1. Coefficient selection scheme: (a) spatial domain, (b) frequency domain.
A S T S R E C T . (bit/frame) 519.12 376.6 481.2 483.20 'orlglnal' 6 approximated -t- 0 t**'
Figure 4. Rectangle description for shape approxi- mation.
Figure 2. An example: (a) previous frame, (b) cur- rent frame, (c) motion field, and (d) segmented re- gions.