Proceedings of 2005 International Symposium on Intelligent Signal Processing and Communication Systems
Hardware
Oriented
Content-Adaptive
Fast
Algorithm
for Variable
Block-Size Integer
Motion
Estimation
in
1.264
Yu-Han Chen, Tung-Chien Chen, and Liang-Gee Chen
DSP/IC Design Lab, Graduate Institute of Electronics Engineering and Department of Electrical Engineering, National Taiwan University, Taipei, Taiwan
Email:{doliamo, djchen, lgchen}(video.ee.ntu.edu.tw
Abstract- Motion estimation can reduce temporal redundancy and achieve high compression capability in video coding
stan-dards.InH.264, the coding gain is further improved by variable block-size motion estimation (VBSME). In order to reduce the complexity, many fast algorithms have been proposed. Though previous works can reduce a large amount of computation, most of them are not suitable for hardware implementation and not robust for complex motion videos. A content-adaptive fast algorithm for variable block-size integer motion estimation (VBSIME) is proposed in this paper. Motion activity is exploited to improve the coding efficiency. Because of the good data
reuse scheme and simple control flow, the proposed algorithm is applicable to hardware implementation. According to the simulation results, about 98% searching candidates and 86% encoding time are reduced with at most 0.05dB quality drop in average compared with full search even for complex motion videos.
I. INTRODUCTION
H.264 is an advanced video coding standard co-developed
by ITU-TVideo CodingExperts Group andISO/IEC Moving
Picture Experts Group [1]. This standard provides superior
codingtoolstoupgradethecoding efficiencyand videoquality
when compared with previous standards. Due to its high compression capability, H.264 is potential to be adopted in manyemerging applications.
Motion estimation is thecoretechniqueto remove temporal
redundancy and to achieve high compression ratio in video
coding standards. VBSME largely enhances the ME
perfor-mance in H.264. For coding a macroblock (MB), 7 kinds
of block-sizes (16x16, 16x8, 8x16, 8x8, 8x4, 4x8, and
4x4) are allowed. In reference software [2], matching costs
of different block-sizes are calculated individually. Without
good data reuse, 7 times of computational resources are required. To solve this problem, all SAD (Sum of Absolute
Difference) costs of the smallest 4x4 blocks are computed
first. Next, other costs of larger block-sizes are generated
from the 4x4 costs. Finally, full search is applied to all kinds
of partitions by means of the pre-computed costs. Though computation is greatly reduced, alarge amount of memory is
requiredto store all SAD data. For hardware consideration, it
is infeasible. In[3], afull searchalgorithmand its architecture
for VBSME has been proposed. Unlike the sequential flow
in reference software, all costs of different block-sizes are
computedinparallel, andgooddatareuseis attained. However,
(a) Fig. 1.
frame.
(b)
Complex motion scene. (a) The current frame; (b) The previous
in resource-constrained systems such as mobile devices, fast
search algorithmis a must. Therefore, a fast searchalgorithm
witha gooddata reuse scheme is required.
VBSME is useful for videos with complex motion. An
example is depicted in Fig. 1. Inthis scene, the moonis still
but the cloud is moving. We can't get good matching block
for whole 16x16 MB inthe centerunless the 16x8 partition
is used. Traditional fast algorithms are developed for single
block-size and easy to be trappedin local minimum. That is
to say, they can'tprovide robust coding efficiency especially
in complex motion videos. For VBSME, motion activity in theneighboring area should beexploitedwell. Inthecomplex
motion area, morecomputationis needed to search for the best
matching candidate. On the other hand, less computation is
consumed while the motion is simple. A motion-adaptive fast
algorithm for VBSME is beneficial to computation reduction andquality maintenance.
In this paper, a hardware oriented content-adaptive fast
al-gorithm for VBSME isproposed. Motionactivityis exploited well to improve the coding efficiency. Because of the good
data reuse scheme and simple control flow, it is suitable for
hardware implementation. The rest of this paper is organized
asfollows.For astart,problem analysisis illustrated in section
II. Then,theproposedfastalgorithmfollowedbythe hardware
architecture is introduced in section III. The performance is
shown in section IV. Finally, we will give a conclusion in
section V.
II. ANALYSIS
Though VBSME contributes high coding efficiency, it also
occupiesamajor partofcomputationalload in H.264 encoder.
0-7803-9266-3/05/$20.00 C2005IEEE.
December13-16,2005 Hong Kong
-According to the run time profile, about60% computation time is spent in integer motion estimation (IME) when the searching range (SR) is set to 16. With SR larger than 32, IME will dominate whole encoding system (more than 90%). In order to reduce the complexity and meet the real-time constraint, a
fast search algorithm for VBSIME is needed.
Conventional fast block matching algorithm (BMA), such
asfour step search (4SS) [4] and diamond search (DS) [5] are
developed for previous standards with single block size. If we directly adopt them for VBSME with the sequential procedure
in reference software, computation reduction is limited. The
SAD reuse scheme in reference software is not suitable here
because pre-computing all SAD costs is too expensive for fast
search algorithms. Without good data reuse, the computation
will increase proportional to the number of block-sizes. For
example, the minimum number of searching candidates for
DS is 13 in previous standards but91(13 x 7) in H.264. That
is to say, a fast search algorithm with good data reuse scheme is important.
Several fast algorithms for VBSME have been proposed.
In [6], authors propose a top-down procedure to process the
largest 16x16block first. In [7], a bottom-up approach starting
from the smallest 4x4 blocks is suggested. By combining the
above twoideas, amerge-and-splitscheme isproposedin [8].
Inthese algorithms, motion estimation for different block-sizes
areperformed sequentiallyindefinedcriteria,andcomputation
is reducedby earlytermination scheme. However, the control
is complex ,and the sequential flow still leads to poor data
reuse.
In [9], a data-adaptive motion estimation algorithm is
proposed. According to the motion activity, the proposed
algorithm adjusts the size of searching window to reduce
unnecessarycomputation. Becausefull search isappliedwithin
theadaptive window, it can achieve good data reuse. However,
in complex motion areas, the SR should be large enough
to maintain video quality which leads to a large amount of
computation.
According to these considerations, a fast search algorithm with a good data reuse scheme and a simple control flow
is required. Besides, motion activity needs to be exploited
well to improve the coding efficiency especially in complex
motion areas. Inthefollowing section, our proposed algorithm
satisfying all the requirements above will be introduced.
III. PROPOSEDCONTENT-ADAPTIVEFASTALGORITHM
A. Concepts
Asmentionedbefore,agooddata reuse scheme isimportant
for fast search algorithms. In fact, ifwe compute all
corre-sponding 4x4 SAD costs for a search point, all other costs
of larger block-sizes can be directly merged from them. In
this way, the SAD costs can be reused well without additional
memory usage. This scheme seems similar to that in reference
software, but they are different in several points. First, our
scheme reuse the SAD costs immediately for one searching
candidate. We don't need to store them in the memory and
it's very efficient for hardware consideration. Secondly,all the
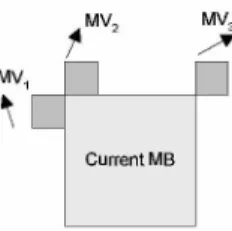
MV2 MV3 MV1
Fig. 2. Neighboring predicted motion vectors.
Fig. 3. The proposed moving window fast search algorithm.
costs of different block-sizes are generated simultaneously.
Unlike the sequential flow in reference software, motion
estimation for different block-sizes needs to be processed in
parallel for this scheme. However, this parallel flow leads to inaccurate motion vector (MV) costs which will induce some
qualityloss in low bit-rate condition. We will show thequality degradationinsection IV.
Using MV predictors is the general idea to exploit the
spatial correlation between neighboring MBs. Conventional
video coding standards use the median MV ofleft, up, and
up-right MBs (as depicted in Fig. 2) as the MV predictor of
the current MB. But in acomplex motion area, the predictor is
not accurate. If we only search the area around the predictor,
coding efficiencymaydrop severely. Tosolve thisproblem, a
moving window fast algorithm is proposed (as depicted in Fig. 3). First, the adaptive moving window is generated according
to the neighboring motion vectors ,and motion activity is
predicted accurately. Secondly, fast search is applied to not
onlythepredictorbut also the vertices of themovingwindow.
It can catch the complex motion better and contribute high
coding efficiency.
Motion vectors in a simple motion region have a strong
correlation with thepredictor. Besides,MBsinthezeromotion
background usually have motion vectors around the origin.
Hence, an adaptive algorithmis needed to search more initial
candidates incomplexmotion videos and less in simpleones.
That is to say, the searchingeffort should beadaptedtomotion
activity.
B. Procedures
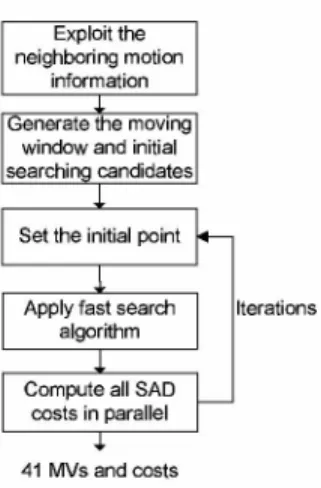
The flow of the proposed algorithm is shown in Fig. 4.
At first, motion activity is exploited to generate the moving
window and the initial searching candidates. Then, the fast
search is applied from the initial candidates, and all the costs
of different block-sizesarecomputedinparallel.After several
passes of iterations, the 41 best integer MVs and costs are
generated.
-Exploit the neighboring motion
information Generate the moving
window and initial searching candidates
Set the initialpoint
Apply fast search Iterations algorithm
Compute all SAD costsinparallel
41 MVs andcosts
Fig.4. The flow of theproposed content-adaptive algorithm.
Fourboundaries of the moving window are generated from
neighboring MVs(MV1, MV2, andMV3 inFig. 2) as follows.
Boundup
=max(MVYi,
MVY2,
MVy3)
Bounddow,
=min(MVyl,
MVY2, MVy3)
Boundleft
=min(MVx1,
MVx2,
MVx3)
Boundright=
max(MVxl,
MVx2,
MVx3)
Next, the number of the initial searching candidates should
be adjusted by the motion information. If the horizontal
components of motion vectors MV1, MV2, and MV3 (in
Fig. 2) are all the same, it means horizontal motion is well
predicted in this area. We can shrink the moving window in
the horizontal direction to save unnecessary computation. For
the vertical direction, it's in the same manner. The conditions
are shownas follows.
If
(MVxl
=MVx2
=MVx3)
Then Shrink horizontal
moving
windowIf
(MVyl
=MVy2
=MVy3)
Then Shrink vertical
moving
windowIn Table I, we show the number ofsearching passes and the
states of moving window for different conditions. Because background with zero motion may usually occur, we always
need to add the originas another initial candidate. At last, 2,
4, or 6 passes of fast search will be applied according to the
motion activityin the video content.
C. Hardware Architecture
Due to the good data reuse scheme and simple control
flow, the proposed algorithm is suitable for hardware
imple-mentation. The hardware architecture is shown inFig. 5. The
searchingwindow SRAMs areusedto stored all the reference
pixels inside SR. The data are loaded fromexternal SDRAM
through the system bus. In order to compute all costs in
parallel, we need to generate the 16x16 absolute difference
values simultaneously. Therefore, 16x16 registers are used as
thecurrent MBbuffer, and 16x16shiftregisterarrayis needed
to store the reference pixels. The reference data are shifted
TABLE I
LIST OF THE NUMBER OF INITIALCANDIDATESAND THE STATES OF MOVINGWINDOW EXPANSION.
Fig. 5. The hardware architecture of theproposed algorithm.
according to the movement (upwards, downwards, leftwards,
and rightwards) of the searching candidate. Because all data
needed are stored inregisters,we cancompute all the absolute
difference values simultaneously and accumulate themto the
41 SAD costs. After these SAD costs are added by the MV
costs, the final costs are comparedto the previous best costs
and stored into buffer if the current results are better. A
control unit is needed here.Itloads the motion information and
generates the initial searching candidates at the start. During
block matching process, it generates the control signals for
reading the required data from searching window SRAMs,
shifting the reference register array in the proper direction,
andgenerating the MV costs.
IV. SIMULATIONRESULTS
The proposed content-adaptive algorithm is embedded into
reference software JM8.2 encoder. Wehave tested 1 QCIF and
5 CIF sequences withlow,medium, andhighmotion activity.
FSS is chosen as the fast search algorithm in our proposed
algorithm. Because its square searchpattern is similarto full
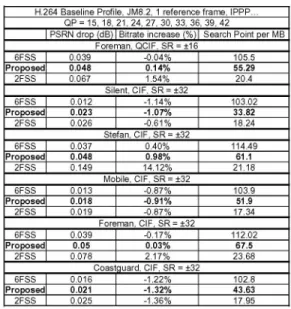
search and suitable for hardware implementation. Table II
shows the PSNR drop, bitrate increasing, and the number
of search points per MB. The performance of6FSS, 2FSS,
and the proposed content-adaptive algorithm are compared
with full search in JM8.2. 6FSS algorithm fixes 6 passes
of iterations for the fast search algorithm (the origin, the
predictor, and the four vertices of the moving window). 2FSS
-343 -Horizontal Shrink
Expand
Shrink19
.y
VirticalExpand
TABLEII
LIST OF PSNR DROP, BITRATE INCREASING, AND SEARCH POINTS PER
MBFOR6FSS, 2FSS,AND THE PROPOSED CONTENT-ADAPTIVE ALGORITHM COMPARED TO FULL SEARCH IN REFERENCE SOFTWARE.
R-D Curve(Stefan,CIF, SR=32, 1 ref frame, IPPP.)
-ProposedAlgorithmX
---2FSS
- - -JM8.2 FullSearchX
Fig. 6. R-Dcurve ofStefansequence. Run Time (Stefan, CIF, SR=32, 1 refframe,IPPP...)
15 20 25 30
QP
algorithm uses only 2 initial candidates (the origin and the
predictor) without expanding the moving window. FromTable
II, our proposed content-adaptive algorithm finds a good
trade-off between quality and computation. For low motion
sequences (like "Silent"), most computation is saved. On the other hand, more search points are consumed to maintain
coding efficiency in highmotion videos. For example, bitrate
increasealotin2FSSbut lessintheproposed content-adaptive
algorithm for
Stef
an and Foreman sequences. The R-Dcurve of Stefan sequences is shown in Fig. 6. The coding
efficiency of theproposed algorithm is closeto that of JM8.2.
A little performance degradation in low bitrate range is due
to inaccurate motionvector cost. However, the averagePSNR
drop is less than 0.05dB as shown in Table II. Inaddition, the
performance is much better than 2FSS algorithm. Thismeans
our proposed algorithm withmoving window expansion can
accurately catch the complex motion in Stefan.
Fig.7is theruntime data ofStefansequence.Itshowsour
proposed content-adaptive fast algorithm can greatly reduce
the complexity of integer motion estimation and contributeto
respectively 86%and43%runtime reduction comparedtofull
search and fast search algorithm inreference software JM8.2. V. CONCLUSIONS
We propose a content-adaptive fast algorithm for variable
block-size integermotion estimation in H.264. Ouralgorithm
canadjustthesearchingeffortaccordingtothe motionactivity,
and find a good trade-off between quality and computation.
About 98% searching candidates and 86% encoding time are
reduced withat most0.05dBquality dropinaveragecompared
with full search even for complex motion videos. Because
of the good data reuse scheme and simple control flow, the
Fig. 7. Run time of Stefan sequencefor whole H.264 encoder. proposed algorithm is suitable for hardware implementation.
REFERENCES
[1] Joint Video Team of ITU-T and ISO/IEC JTC 1, "Draft ITU-T Rec-ommendation and Final Draft International Standard of Joint Video Specification (ITU-T Rec. H.264 ISO/IEC 14496-10 AVC)," Mar. 2003.
[2] "H.264/AVC reference sofware JM8.2," July 2004.
[3] Y.-W. Huang, T.-C. Wang, B.-Y. Hsieh, and L.-G. Chen, "Hardware architecturedesign for variable block size motion estimationinMPEG-4 AVC/JVT/ITU-T H.264," Proc. IEEE Int'l Symposium on Circuits and
Systems, vol. 2, pp.796-799, 2003.
[4] L.-M. Po and W.-C. Ma, "A novel four-step search algorithm for fast block motion estimation," IEEE Transactions on Circuits and Systems
for Video Technology, vol. 6, no.3,pp. 313-317, June 1996.
[5] J. Y. Tham, S. Ranganath, M. Ranganath, and A. A. Kassim, "A novel
unrestricted center-biased diamond search algorithm for block motion
estimation,"IEEETransactionson Circuits andSystems for Video
Tech-nology,vol. 8,no. 4,pp.369-377, Aug. 1998.
[6] M. Chan, Y. Yu, and A. Constantinides,"Variable size blockmatching motioncompensation with applicatoins to videocoding," Proc. IEEon
Communications, Speech and Vision, vol. 137,no.4,pp.205-212, Aug.
1990.
[7] I.Rhee, G. R. Martin, S. Muthukrishnan, and R. A. Packwood,
"Quadtree-structured variable-sizeblock-matchingmotion estimation with minimal
error,"IEEETransactionson Circuits andSystems for Video Technology,
vol. 10,no. 1,pp.42-50, Feb. 2000.
[8] Z.Zhou,M.-T.Sun,andY.-F.Hsu,"Fast variable block-size motion
esti-mationalgorithm basedonmergeand slitprocedures for H.264/MPEG-4
AVC," Proc. IEEE Int'l SymposiumonCircuits andSystems, vol. 3,pp.
725-728, 2004.
[9] S. Saponaraand L.Fanucci, "Data-adaptivemotion estimationalgorithm
and VLSI architecture designforlow-powervideo systems,"Proc. IEE
onComputers and Digital Techniques, vol. 151,pp. 51-59, 2004.
-344
-H.264 BaselineProfile, JM8.2,1referenceframe,IPPP...
QP=15, 18, 21, 24, 27, 30, 33, 36, 39,42
PSRN drop(dB) Bitrate increase(7/%)7S-earchPoint per MB Foreman,QCIF,SR =±16 6FSS 0.039 -0.04% 105.5 Proposed 0.048 0.14% 55.29 2FSS 0.067 1.54% 20.4 Silent, CIF, SR = ±32 6FSS 0.012 -1.14% 103.02 Proposed 0.023 -1.07% 33.82 2FSS 0.026 -0.61% 18.24 Stefan,CIF, SR = ±32 6FSS 0.037 0.40% 114.49 Proposed 0.048 0.98% 61.1 2FSS 0.149 14.12% 21.18 Mobile,CIF, SR = ±32 6FSS 0.013 -0.87% 103.9 Proposed 0.018 -0.91% 51.9 2FSS 0.019 -0.87% 17.34 Foreman,CIF,SR=±32 6FSS 0.039 -0.17% 112.02 Proposed 0.05 0.03% 67.5 2FSS 0.078 2.17% 23.68
Coastguard,CIF,SR=±32
6FSS 0.016 -1.22% 102.8 Proposed 0.021 -1.32% 43.63 2FSS 0.025 -1.36% 17.95 500 --JM8.2(Full Search) O400C=---JM8.2(Fast Search) 300 - ProposedAlgorithm 200