國 立 台 中 師 範 學 院 數 學 教 育 研 究 所 碩 士 論 文
指 導 教 授 : 劉 湘 川 博 士
電腦適性測驗題目曝光率
之模擬研究
研 究 生 : 謝 友 詩 撰
中 華 民 國 九 十 四 年 一 月
摘要
電腦適性測驗在實際實施後,最受注目的議題便是題目的過度曝光, 題目的過度曝光表示大部分的受測者施測過此題目。當受測者重新施測, 則容易施測到相同的題目使得測驗的安全性與公平性產生危機。 本研究採用五種選題方法,分別為最接近偏移難度法、區間式最大訊 息法、KL 訊息法、鄰近法、與考慮 b 參數的 a 分層法,分別討論在不同 題庫樣式下對於曝光率均勻度與能力估計誤差的表現。結果發現,各適性 選題法依曝光率均勻度與能力估計精準度的表現上可分為三大類:1.有較 高估計精準度的區間式最大訊息法與 KL 訊息法;2.是有較均勻題目曝光 的最接近偏移難度法與考慮 b 參數的 a 分層法;3.是對均勻題目曝光率與 估計精準度較折衷的鄰近法。 關鍵字 關鍵字關鍵字 關鍵字::::電腦電腦電腦適性測驗電腦適性測驗適性測驗、適性測驗、、、題目曝光率題目曝光率、題目曝光率題目曝光率、、、題目反應理論題目反應理論題目反應理論、題目反應理論、、選題法、選題法選題法選題法The simulating study of the item exposure rate
in computerized adaptive tests
Abstract
For operational computerized adaptive tests, the most important issue is the overexposure item rates. The item having overexposure rate means most of the examinees tested it. When the examinees retest, they tend to test the same items, which leads to serious test security and equity risks.
In this study, discuss the effects of the five item selection criterions – minimum offset difficulty, maximum interval information, KL information, NN criterion, and STR-B – were compared with respect to the precision of the trait estimation and the effect of the item usage at the same item banks. In the result, by the exposure rate and the precision the selection criterions could separate to three groups: maximum interval information and KL information criterions which having more precision of estimation; minimum offset difficulty criterion and STR-B which having more uniform exposure rates; NN criterion which balancing the estimation precision and effective item usage.
Keywords: terms: computerized adaptive testing, item exposure rate, item response theory, selection criterion.
目
目
目
目 錄
錄
錄
錄
第一章
第一章
第一章
第一章 緒論
緒論
緒論
緒論---
1 第一節 研究動機--- 1 第二節 研究目的--- 2 第三節 名詞釋義--- 2第二章
第二章
第二章
第二章 文獻探討
文獻探討
文獻探討
文獻探討---
4 第一節 題目作答反應--- 4 第二節 電腦化適性測驗--- 8 第三節 題目曝光率議題--- 17 第四節 評估準則--- 18第三章
第三章
第三章
第三章 研究方法
研究方法
研究方法
研究方法---
20 第一節 研究架構--- 20 第二節 研究工具--- 21 第三節 適性測驗流程設計--- 21第四章
第四章
第四章
第四章 研究結果
研究結果
研究結果
研究結果與分析
與分析
與分析
與分析---
25 第一節 題庫大小對電腦化適性測驗的影響--- 25 第二節 測驗長度對電腦化適性測驗的影響--- 31 第三節 受測人數對電腦化適性測驗的影響--- 35第五章
第五章
第五章
第五章 結論與建議
結論與建議
結論與建議
結論與建議---
37 第一節 結論--- 37 第二節 建議--- 38參考文獻
參考文獻
參考文獻
參考文獻--- 39
中文部份--- 39 英文部份--- 39表
表
表
表 次
次
次
次
表 2-1 對數模式與題目訊息量對應關係--- 8 表 3-1 能力樣式說明--- 22 表 3-2 文獻資料之參數範圍--- 22 表 3-3 模擬題庫樣式--- 23 表 4-1 題庫樣式 PX1 之均方根差--- 25 表 4-2 題庫樣式 PX1 之最大題目曝光率--- 26 表 4-3 題庫樣式 PX1 之題目曝光率低於 0.05 題目數--- 27 表 4-4 題庫樣式 PX3 之均方根差--- 28 表 4-5 題庫樣式 PX3 之最大題目曝光率--- 28 表 4-6 題庫樣式 PX3 之曝光率低於 0.05 題目數--- 29 表 4-7 題庫樣式 PX6 之均方根差--- 29 表 4-8 題庫樣式 PX6 之最大題目曝光率--- 30 表 4-9 題庫樣式 PX6 之題目曝光率低於 0.05 題目數--- 30 表 4-10 題庫樣式 PX6_tx 之能力均方根差--- 32 表 4-11 題庫樣式 PX6_tx 之題目曝光率低於 0.05 題目數--- 33 表 4-12 題庫樣式 PX6_tx 之題目重複率--- 34 表 4-13 模擬樣式 SAX_PX6 之均方根差--- 35 表 4-14 模擬樣式 SAX_PX6 之卡方值--- 36 附表 1 SA1_PA1_t2 的能力均方根差和曝光率統計表--- 43 附表 2 SA1_PA3_t2 的能力均方根差和曝光率統計表--- 44 附表 3 SA1_PA6_t2 的能力均方根差和曝光率統計表--- 45 附表 4 SA3_PA6_t2 的能力均方根差和曝光率統計表--- 46 附表 5 SA1_PA6_t4 的能力均方根差和曝光率統計表--- 47 附表 6 SA1_PB1_t2 的能力均方根差和曝光率統計表--- 48 附表 7 SA1_PB3_t2 的能力均方根差和曝光率統計表--- 49 附表 8 SA1_PB6_t2 的能力均方根差和曝光率統計表--- 50 附表 9 SA3_PB6_t2 的能力均方根差和曝光率統計表--- 51 附表 10 SA1_PB6_t4 的能力均方根差和曝光率統計表--- 52 附表 11 SA1_PC1_t2 的能力均方根差和曝光率統計表--- 53 附表 12 SA1_PC3_t2 的能力均方根差和曝光率統計表--- 54 附表 13 SA1_PC6_t2 的能力均方根差和曝光率統計表--- 55 附表 14 SA3_PC6_t2 的能力均方根差和曝光率統計表--- 56附表 15 SA1_PC6_t4 的能力均方根差和曝光率統計表--- 57 附表 16 SA1_PD1_t2 的能力均方根差和曝光率統計表--- 58 附表 17 SA1_PD3_t2 的能力均方根差和曝光率統計表--- 59 附表 18 SA1_PD6_t2 的能力均方根差和曝光率統計表--- 60 附表 19 SA3_PD6_t2 的能力均方根差和曝光率統計表--- 61 附表 20 SA1_PD6_t4 的能力均方根差和曝光率統計表--- 62 附表 21 SA1_PE1_t2 的能力均方根差和曝光率統計表--- 63 附表 22 SA1_PE3_t2 的能力均方根差和曝光率統計表--- 64 附表 23 SA1_PE6_t2 的能力均方根差和曝光率統計表--- 65 附表 24 SA3_PE6_t2 的能力均方根差和曝光率統計表--- 66 附表 25 SA1_PE6_t4 的能力均方根差和曝光率統計表--- 67 附表 26 SA1_PF1_t2 的能力均方根差和曝光率統計表--- 68 附表 27 SA1_PF3_t2 的能力均方根差和曝光率統計表--- 69 附表 28 SA1_PF6_t2 的能力均方根差和曝光率統計表--- 70 附表 29 SA3_PF6_t2 的能力均方根差和曝光率統計表--- 71 附表 30 SA1_PF6_t4 的能力均方根差和曝光率統計表--- 72
圖
圖
圖
圖 次
次
次
次
圖 3-1 研究架構圖--- 20 圖 3-2 實施流程圖--- 21 附圖 1 SA1_PA1_t2 的題目曝光率圖--- 43 附圖 2 SA1_PA3_t2 的題目曝光率圖--- 44 附圖 3 SA1_PA6_t2 的題目曝光率圖--- 45 附圖 4 SA3_PA6_t2 的題目曝光率圖--- 46 附圖 5 SA1_PA6_t4 的題目曝光率圖--- 47 附圖 6 SA1_PB1_t2 的題目曝光率圖--- 48 附圖 7 SA1_PB3_t2 的題目曝光率圖--- 49 附圖 8 SA1_PB6_t2 的題目曝光率圖--- 50 附圖 9 SA3_PB6_t2 的題目曝光率圖--- 51 附圖 10 SA1_PB6_t4 的題目曝光率圖--- 52 附圖 11 SA1_PC1_t2 的題目曝光率圖--- 53 附圖 12 SA1_PC3_t2 的題目曝光率圖--- 54 附圖 13 SA1_PC6_t2 的題目曝光率圖--- 55 附圖 14 SA3_PC6_t2 的題目曝光率圖--- 56 附圖 15 SA1_PC6_t4 的題目曝光率圖--- 57 附圖 16 SA1_PD1_t2 的題目曝光率圖--- 58 附圖 17 SA1_PD3_t2 的題目曝光率圖--- 59 附圖 18 SA1_PD6_t2 的題目曝光率圖--- 60 附圖 19 SA3_PD6_t2 的題目曝光率圖--- 61 附圖 20 SA1_PD6_t4 的題目曝光率圖--- 62 附圖 21 SA1_PE1_t2 的題目曝光率圖--- 63 附圖 22 SA1_PE3_t2 的題目曝光率圖--- 64 附圖 23 SA1_PE6_t2 的題目曝光率圖--- 65 附圖 24 SA3_PE6_t2 的題目曝光率圖--- 66 附圖 25 SA1_PE6_t4 的題目曝光率圖--- 67 附圖 26 SA1_PF1_t2 的題目曝光率圖--- 68 附圖 27 SA1_PF3_t2 的題目曝光率圖--- 69 附圖 28 SA1_PF6_t2 的題目曝光率圖--- 70 附圖 29 SA3_PF6_t2 的題目曝光率圖--- 71 附圖 30 SA1_PF6_t4 的題目曝光率圖--- 72第一章
第一章
第一章
第一章 緒論
緒論
緒論
緒論
本研究主要目的在於探討電腦化適性測驗中,影響能力值估計誤差與 題目曝光率的因素,以提供在建置題庫,發展適性測驗時,能控制能力估 計的誤差,也能保障題庫的安全性。本章第一節為研究此問題之動機,第 二節為本研究的目的,第三節針對本研究之名詞作概括性的探討。第一節
第一節
第一節
第一節 研究動機
研究動機
研究動機
研究動機
近年來由於電腦的蓬勃發展與逐漸普及,使得電腦適性測驗突破繁瑣 的計算過程與設備不足的窘境,成為日漸普及的測驗形式,而有逐漸取代 傳統紙筆測驗的趨勢。在傳統的紙筆測驗中,受試者必須將一份試卷,從 頭至尾全部作答;電腦適性測驗則針對不同的受試者給予適當的題目,不 但能避免程度低的學生面對困難題目產生挫折、盲目猜題或產生作弊行 為,也能避免程度高的學生面對簡單題目而覺得考試很無聊、不具挑戰性 或粗心大意等行為。目前許多大型測驗如 GRE(Graduate Record Examinations)、TOFEL(Test
of English as a Foreign Language)、GMAT(Graduate Management Admission Test)等已改變為電腦化的適性測驗,而電腦適性測驗在測驗實施前必須先 建立題庫,當受試者進入測驗時,便從題庫中選出題目測驗,而一般的選 題方法著重於估計能力值的效率,從題庫中選擇最適合受試者的題目,以 利於提昇估計的精準度,因此某些具有良好特性的題目常被使用,這也表 示受試者容易施測到相同的題目,且這些題目的曝光率過高。 以往的電腦適性測驗並不重視題目曝光率的問題,但題庫題目的過度 曝光卻會使得測驗不公平、不客觀。而題庫建製需要花費大量的成本,性 質良好的題目設計不易,為使測驗具有公平性、題庫可長久使用,題目曝 光率的議題便顯得特別重要。
第二節
第二節
第二節
第二節 研究
研究
研究
研究目的
目的
目的
目的
本研究主要目的如下: 一、 分析不同分佈題目參數題庫,對能力估計與曝光率的影響。 二、 分析不同大小題庫,對能力估計與曝光率的影響。 三、 比較不同選題方法,對能力估計與曝光率的影響。 四、 比較不同受試人數,對能力估計與曝光率的影響。第三節
第三節
第三節
第三節 名詞釋義
名詞釋義
名詞釋義
名詞釋義
一
一
一
一、
、
、
、
題目
題目
題目
題目反應理論
反應理論
反應理論
反應理論
題目反應理論(item response theory, IRT)是依據受試者的測驗表現結
果,經數學模式的運算,評估受試者能力和測驗反應間之關係,也就是以 機率的概念來解釋受試者能力和題目反應間之關係,此數學模式稱之為題
目特徵函數(item characteristic function, ICF)。
二
二
二
二、
、
、
、
題目
題目
題目
題目訊息函數
訊息函數
訊息函數
訊息函數
題目訊息函數(item information function)可作為題目優劣的一個判定函
數。在某能力值的題目訊息,代表題目所能提供某能力值的貢獻量,題目 訊息越高,其提供的貢獻量越大,相對的能力值估計誤差越小。
三
三
三
三、
、
、
、
偏移難度
偏移難度
偏移難度
偏移難度
在單參數或二參數對數模式時,題目的最大訊息量發生於能力值為難 度的點上;若為三參數對數模式,即猜測度不為零時,則題目的最大訊息 量發生點會產生偏移,故稱此最大值發生點為偏移難度。四
四
四
四、
、
、
、
題庫
題庫
題庫
題庫
題庫(item pool)並非是一堆題目的集合而已,它是經過電腦化且統計過的題目組合。對教學者或出題者而言,題目的數量越多越好,題目所提供 的題目參數或指標;如難度、鑑別度等,越詳細越好。但是要建立一個數 量足夠且品質兼顧的題庫,則需花費的時間、人力成本是相當龐大的。而 且不足量的題庫拿來使用是相當危險的,受測者容易有背誦、猜題的舉 動。還有除了足量且高品質的題庫之外,還要能不斷充實題庫,才能確保 題庫的實用性。
五
五
五
五、
、
、
、
題目曝光率
題目曝光率
題目曝光率
題目曝光率
題目曝光率(item exposure rate)為測驗長度中,每題被使用的相對次 數。題庫中設計良好的題目通常具有較高的受試者訊息。若經常使用這些
題目,則測驗的效率高且精準度高,但易使這些題目產生過高的題目曝光 率,導致電腦化適性測驗之安全性與公平性受到質疑,所以在實際的電腦
第二章
第二章
第二章
第二章 文獻探討
文獻探討
文獻探討
文獻探討
第一節
第一節
第一節
第一節 題目
題目
題目
題目作答理論
作答理論
作答理論
作答理論
一
一
一
一、
、
、
、
題目
題目
題目
題目反應理論
反應理論
反應理論
反應理論
題目反應理論(item response theory, IRT)是現代測驗理論中重要的基
礎。Lord(1968)認為題目反應理論是在定義人類特質後,依據這些特質, 估計個體的能力,並以獲得之數值,在相關情境下預測或解釋個體的表 現。也就是說,IRT 是在建立受試者能力與測驗反應間之模式後,觀測受 試者的測驗反應結果,再經由數學模式的運算,估計受試者的能力(ability) 或潛在特質(latent traits)。 一、基本假定
題目反應理論是建立在三個基本假定上(Hambleton & Swaminathan,
1985;余民寧, 1992): (一)單向度(unidimensionality):指測驗中每個題目都能測量到同一種 共同能力或潛在特質。在實際的測驗情境中,受試者在測驗上的表現很少 是純粹受到一種因素的影響,故只要該測驗具有能夠影響測驗結果的一個 主要成分或因素,便算符合單向度假定的基本要求,此主要成分或因素所 指的即是該測驗所測量的單一能力或潛在特質。 (二)局部獨立性(local independence):即各題目之間無相關存在,也 就是一個題目不能提供另一個題目線索。這意謂著涵蓋在題目反應模式裡 的單一能力或潛在特質,才是唯一影響考生在測驗題目上做反應的因素。
(三)非速度測驗(non speeded tests):題目反應理論認為受試者對測驗 為完全作答,是因受試者的能力問題所致,而不是由於作答時間不夠所致。
基於此三個基本假設,以下針對有關題目反應理論重要的課題做一概 述,包括題目特徵函數、能力參數估計方法及題目訊息函數。
二
二
二
二、
、
、
、
題目
題目
題目
題目特徵函數
特徵函數
特徵函數
特徵函數
受試者在測驗上表現結果與受試者能力間的函數關係,也就是題目答 對機率對受試者能力的迴歸線,此數學模式稱之為題目特徵函數(item
characteristic function, ICF),若將函數以圖形表示則稱為題目特徵曲線 (item characteristic curve, ICC),曲線之 X 軸表示受試者能力值,Y 軸表示 答題機率。題目特徵曲線顯示受試者答對題目的可能性,題目的答對機率 隨受試者能力變大而緩慢上升,上升的幅度可用函數表示,函數的數學式 隨題目反應理論基礎不同而有差異,不論如何表示,函數必須滿足遞增的 原則,若以ui代表受試者在第i題的作答反應,若受試者答對第i題則ui=1, 答錯則ui=0;θ 表示第s s位受試者的能力參數,則常用的參數型題目反應 理論模式介紹如下: (一)單參數對數模式 又稱Rasch 模式(Rasch, 1960),此模式關於題目特性的描述僅有題目難
度參數(bi),故稱為單參數對數模式(one-parameter logistic model),其
數學式可表示如下: 1.7( ) 1 ( 1| ) 1 exp θ θ − − = = + s i i s b P u (2.1) (二)二參數對數模式 由學者 A. Birnbaum(1968)修改 F.M. Lord 的原始雙參數肩型模式,將 模式增加題目鑑別度參數(ai)。二參數對數模式(two-parameter logistic model)的數學式可表示如下: 1.7 ( ) 1 ( 1| ) 1 exp θ θ − − = = + i s i i s a b P u (2.2) (三)三參數對數模式 因選擇題形式的題目易產生受試者猜測作答的情況,此模式增加題目 猜測參數(ci)。三參數對數模式(three-parameter logistic model, Birnbaum,
1968)的數學式可表示如下: 1.7 ( ) 1 ( 1| ) 1 exp θ θ −− − = = + + i s i i i s i a b c P u c (2.3)
三
三
三
三、
、
、
、參數
參數
參數
參數估計方法
估計方法
估計方法
估計方法
由於 IRT 是描述受試者能力、題目參數(難度、鑑別度、猜測度等)與 作答反應機率三者之間的函數關係式(Hambleton & Swaminathan, 1985)。為了解題目的特性,必須根據受試者答題反應進行參數估計,參數估計主要 可分為題目參數與能力參數都未知的同時估計法,與題目參數或能力參數
僅 有 其 中 一 項 未 知 的 估 計 方 法 , 而 估 計 法 主 要 分 為 最 大 概 似 估 計 法
(maximum likelihood estimation, MLE)與貝氏估計法(Bayesian estimation)兩 類(Bejar & Weiss, 1979)。
貝氏估計法先假設參數的先驗分配(prior distribution)後再進行估計,能 提供能力完整的估計,即使受試者的反應為全對或全錯,也能估計,但有 向平均數迴歸的現象,尤其是在較短的測驗中,這種迴歸的影響頗大。當 測驗長度夠長,最大概似法的能力估計值為近似不偏估計,但受試者在答 題中必須有答對也有答錯才能進行估計。 假設受試者已測驗n個題目,則概似函數(likelihood function)可表示為 1 1 2 1 ( , ,..., | ) i i n u u n i i i L u u u θ P Q− = =
∏
(2.4) 其中ui為在題目i受試者作答狀況,若受試者答對此題,則 i u =1;反之, 答錯此題,則ui=0, ( )= ( 1 | ) i i i P = P θ P u = θ 為受試者在題目i的答對機 率,Qi = Qi( )=1θ − Pi為答錯機率。而最大概似估計法即將不同的能力值θ 帶入對數函數中,而能使受試者的概似函數最大的能力值定義為受試者的 能力值θ之最大概似估計值(MLE)。四
四
四
四、
、
、
、題目訊息函數
題目訊息函數
題目訊息函數
題目訊息函數
IRT 提出一個能夠用來描述題目或測驗、挑選測驗題目、以及比較測 驗 的 相 對 效 能 的 實 用 方 法 , 該 方 法 即 需 要 使 用 題 目 訊 息 函 數 ( item information function),作為建立、分析、與診斷測驗的主要參考依據。題 目訊息函數為能力值的最大概似估計值(MLE)的變異數倒數,表示在不同 能力點上的測驗精準度,當題目訊息量越高表示題目對該能力點的測量精 確度越高,其計算公式如下 ) ( ) ( )] ( [ ) ( 2 ' θ θ θ θ i i i i Q P P I = i=1,2,..,n (2.5) 其中Ii(θ)表示題目i在能力值θ上所提供的訊息,而Pi'(θ)為在θ點上 的Pi(θ)的導數。以三參數對數反應模式為例,(2.5)可簡化為(Birnbaum, 1968; Lord, 1980): ] 1 ][ [ ) 1 ( ) ( 1.7 ( ) 1.7 ( ) 2 i i i i b a b a i i i i e e c c a I − − − + + − = θ θ θ ,i=1,2,..,n (2.6) 從公式 2.6 中,我們很容易便可推知 a、b 和 c 參數在題目訊息函數中 所扮演的角色:(1)當 b 值愈接近 θ 時,訊息量較大;反之,b 值愈遠 離 θ 時,訊息量則較小;(2)當 a 參數較高時,訊息量也會較大;(3) 當 c 參數接近 0 時,訊息量則會增加(陳俊宏, 2004)。可見題目訊息函數受 到題目參數的影響,王寶墉(1995)指出,某個題目所提供的最大訊息量, 剛好出現在能力參數為θmax上,表 2-1 即為對數模式中,使用題目訊息最 大的θmax與其對應之題目訊息量Imax,其中 D 為 1.7。表2-1 對數模式與題目訊息量對應關係 模式 θmax Imax 單參數 bi 2 4 1 D 雙參數 bi 2 2 4 1 i a D 三參數 1 / 2 1 (1 8 ) 1 {ln[ ]} 2 i i i c b Da + + + [1 20 8 (1 8 ) ] ) 1 ( 8 2 / 3 2 2 2 2 i i i i i c c c c a D + + − − − 測驗訊息函數最重要的一個特性就是測驗中每一題目對測驗訊息量的 貢獻是彼此互相獨立的,也就是說每個題目對整份測驗的訊息量是可累加
性的,故一份測驗在某一個θ值上的測驗訊息函數(test information function) 為在θ 值上的題目訊息函數之總和,即此測驗可提供θ 的訊息量,記作 ) (θ T I ,其表示方式如下
∑
= = n i i T I I 1 ) ( ) (θ θ (2.7) 因此當測驗的題數越多,測驗訊息函數也就越大,也表示受試者能力 的最大概似估計值之變異數越小,能力值估計愈準確。 由於題目反應理論具有可大幅縮短測驗時間與長度的高效率,與可精 確計算出受試者的能力值的高精確度,一直都是最常被研究者提及的適性 測驗模式,使得題目反應理論幾乎成為適性測驗的同義詞。第二節
第二節
第二節
第二節 電腦適性化測驗
電腦適性化測驗
電腦適性化測驗
電腦適性化測驗
電腦的快速發展與普及,配合題目反應理論,導致電腦適性測驗(computerized adaptive testing, CAT)的發展。電腦適性測驗是利用電腦來實 施測驗,處理選題、計分、能力估計等問題的一種測驗方式。也就是,在
電腦適性測驗實施時,依據受試者之答題的對錯,重新估計受試者能力 值,再依更新過的能力估計值,選擇適當的題目進行測驗,若答對,則選
測驗。因此,電腦適性測驗比傳統測驗需要施測較少的題目,就能有效估 計能力值。 以下針對電腦適性測驗的要素與重要議題—初始值設定、題庫、選題 法與終止條件作一簡介與探討:
一
一
一
一、
、
、
、
初始值設定
初始值設定
初始值設定
初始值設定
電腦適性測驗的基本原則是依受試者能力提供適當的題目呈現給受試 者施測,但在測驗之始,受試者之能力高低未能得知,因此,必須決定測 驗的起始點,以選擇第一個題目提供受試者施測。常用於起始題的決定方 式,有以下幾種(王寶墉, 1995;陳麗如, 1998): (一)、 中等難度題目:即假設受試者為中等能力,在題庫中挑選難度適中 的題目作為施測的起始題;中等難度題目開始,因題目有限,若每 位受試者都使用相同的題目開始,其保密性需要考量。 (二)、 由受試者之基本資料(年齡、學習、經驗或其他測驗結果)估算受 試者能力初始值,以決定測驗起始點。 (三)、 自由選題:由受試者在接受測驗的時候,自行判定自己的程度,以 決定施測的起始題。 (四)、 隨機選題:由電腦隨機選題,但一般限定題目難度參數 b 介於-0.5 至 0.5 間為選取範圍。二
二
二
二、
、
、
、題庫
題庫
題庫
題庫
電腦適性測驗與傳統紙筆測驗的差異在於必須建立一個含有題目反應 理論測驗題目參數的題庫,題庫中之參數必須以共同量尺來表示,才能有 一致的單位。適性測驗之效度與效率,與選題題庫大小具有密切關係(李茂 能, 2000)。若要使電腦適性測驗與傳統紙筆測驗具有相同的測驗水準,假 如電腦適性測驗採固定長度約為傳統紙筆測驗的一半時,選題題庫大小最 好為傳統紙筆測驗的 6 至 8 倍長(Stocking, 1994)。當選題題庫長度為 3 倍以上,精確度與作答效率才有顯著差異(Hung, 1988)。
三
三
三
三、
、
、
、選題法
選題法
選題法
選題法
選題方法乃電腦適性測驗中重要的要素之ㄧ,根據不同的選題方法會 導致不同的測驗效率,在此介紹常用的選題法如下: (一)、 最接近難度法 選擇題目難度bj最接近受測者能力估計值θ)的題目,作為下一階段施測的題目(Reckase, 1973; Urry, 1970; Weiss, 1974);此種方法在計算上比較
簡單,其選題函數定義為(2.8),選題時選擇尚未施測且Fj最小的題目。 | ˆ | ) ˆ ( j j b F θ =θ − (2.8) (二)、 最接近偏移難度法 若猜測度cj ≠0時,題目訊息最大值不會發生在難度bj,會產生偏移至 j m ,最接近偏移難度法為選擇題目偏移難度最接近受試者能力估計值θ)的 題目,作為下一階段施測的題目。定義偏移難度mj(Birnbaum, 1968)為 1 1 8 1 log( ) D. 2 j j j j c m b a + + = + (2.9) 則選題時選擇尚未施測且選題函數Fj(2.10)最小的題目。 | ˆ | ) ˆ ( j j m F θ =θ − (2.10) (三)、 單點式最大訊息法 單點式最大訊息法是選擇對受試者目前能力能提供最豐富訊息的題目 來施測,也就是選擇訊息函數(2.5)最大的題目,在此即選擇尚未施測且公 式 2.11 中Fj最大的題目,作為適性測驗下一階段施測題目。此種選題法可 使訊息量達到最大,由於訊息量與估計誤差呈負相關(Lord, 1980),這種選
題方式可使每一位受試者的能力值估計誤差降到最低。 ) ˆ ( ). ˆ ( )] ˆ ( ' [ ) ˆ ( 2 θ θ θ θ j j j j Q P P F = (2.11) (四)、 區間式最大訊息法 區間式最大訊息法使用區間能力值的題目訊息總值,來取代在某點能 力值的題目訊息量(Veerkamp & Berger, 1997)。區間式最大訊息法是選擇訊 息函數在信賴區間內的面積,選擇最大的訊息面積,作為適性測驗下一階 段施測題目,故選題時選取尚未施測且選題函數(2.12)最大者。 θ θ θ θ θ d F u l
∫
= ˆ ˆ j j( ) I ( ) (2.12) 其中 ) ) ˆ ( I 1.96 ˆ , ) ˆ ( I 1.96 -ˆ ( ) ˆ , ˆ ( T T θ θ θ θ θ θl u = + (五)、KL 訊息法 1. 定義 KL 訊息 為定義真實能力值θ0與任意能力值θ 間的距離(discrepancy),以改進 CAT 的估計誤差精準度 Cover & Thomas(1991)與 Kullback(1959)提出 KL 訊息(Kullback-Leibler information; KL information),KL 訊息在真實能力值θ0
距離θ越遠時,KL 值越大;反之,KL 值小。而當θ0=θ時,KL 訊息為 0; 且對各題目的總訊息有加法性。若作答反應為Ui,第i題的 KL 訊息定義 為 ≡ ) ; ( ) ; ( log ) || ( 0 0 0 i i i i i U L U L E K θ θ θ θ θ (2.13) 其中 0 θ E 為對θ0的期望值, (θ; ) i(θ) 1 Ui(θ) i U i i i U P Q L = − 為第i題的最大概似函 數,故 KL 訊息亦可改寫為
− − − + = ) ( 1 ) ( 1 log )] ( 1 [ ) ( ) ( log ) ( ) || ( 0 0 0 0 0 θ θ θ θ θ θ θ θ i i i i i i i P P P P P P K (2.14) 2. 定義平均 KL 訊息指標 Chang 與 Ying 在 1996 年利用 KL 訊息的特性定義第i題的平均 KL 訊
息指標(average KL information index)為
θ θ θ θ θ δ δ θ K d K n n n n n i n i
∫
+ − = ˆ ˆ ) ˆ || ( ) ˆ ( (2.15) 其中θˆn為施測n題後的能力估計值,δn為平均值的計算區間大小。 此指標表示 KL 訊息在θˆn − δn與θˆn + δn間的區域面積,若δn值小,則 指標(2.15)受Ki(θ ||θˆn)在θˆn上的曲度(curvature)影響;若δn值大,則指標易 受 Ki(θ ||θˆn)尾端 值 影 響 。 故δn應 隨 施 測 階 段 n 遞減 到 0 , 並 且 區 間 (θˆn − δn,θˆn + δn)應包含θ0,又因θ0的最大概似估計θˆn為平均數為θ0,變異 數為1 (n)(θ0) I 的近似常態分佈,故將區間設為 (θˆn- 1 ( )n ( )ˆ 2 n c Iθ
, n θˆ + 1 ( )n( )
ˆ
2 nc
I
θ
) 其中常數 c 依據收斂機率選擇。因I(n)為 n 階,故可設 n δ 為 n c n = δ (2.16) 即第i題的平均 KL 訊息指標為 θ θ θ θ θ θ K d K c n n c i n n i n n∫
−+ = ˆ ˆ ) ˆ || ( ) ˆ ( (2.17) KL 訊息法以此平均 KL 訊息指標選出最大訊息者,作為適性測驗的下 一階段施測的題目。 最大訊息法與 KL 訊息法最大的差異在於使用函數不同,最大訊息法 使用題目訊息函數(2.11),而 KL 訊息法採用 KL 訊息(2.17),而題目訊息函 數為真實能力值θ0的函數,KL 訊息為真實能力值θ0與任意能力值θ 的函數,因 KL 訊息考量真實與任意兩能力值,計算較複雜且費時,當θ0=θ時, KL 訊息函數的曲度即為題目訊息函數,兩訊息法相同有訊息的加法性, 可計算測驗的總訊息量。
(六)、 鄰近法
鄰近法(Nearest-Neighbors criterion, NN criterion; Cheng & Liou, 2003)
為考慮題目曝光率與能力估計精準度兩目標的折衷選題法,結合有較均勻 曝光率的最接近偏移難度法與高估計精準度的單點式最大訊息法,其實施 步驟如下: 步驟一:計算每題在對數模式時題目訊息最大值發生點偏移難度mj, 與其最大題目訊息Mj,其公式如下: + + + = 2 8 1 1 log 7 . 1 1 j j j j c a b m (2.18)
[
]
[
2 2/3]
2 2 ) 8 1 ( 8 20 1 ) 1 ( 8 ) 7 . 1 ( ) ( j j j j j j c c c c a I Max M − − + + − = ≡ θ θ (2.19) 步驟二:設定非遞增整數 (k) n k=1,2,…,L 步驟三:初始化能力值估計值 ˆ(k) θ 步驟四:找新題 (k) n 個,其題目偏移難度mj最接近θˆ(k) 步驟五:選 (k) n 個題目中,有最大Mj的作為下一題施測題目,重新估 計能力值為 ˆ(k+1) θ ,回到步驟三,直到停止條件成立。 其中 L 為施測題目數。當施測題目越多,能力估計值變動越小,估計 越接近真實能力值,但為降低其誤差,故在鄰近能力估計值能力值間選擇 最大訊息的題目,此表示當施測題目越多,估計越精準,則題目是否為最 大訊息的題目漸不重要,故非遞減整數 (k) n 可設為L,L-1,…,1,表示當施測題數越多,則鄰近選題法越接近偏移難度選題法。 (七)、a 分層法 Chang 與 Ying 於 1999 年提出以鑑別度將題庫分層,以降低高鑑別度 題目的曝光率,並增加低鑑別度題目的曝光,稱之為 a 分層法(a-stratified method, STR-A),其實施步驟如下: 步驟一:將題庫依題目鑑別度分為K層; 步驟二:將測驗分入此K層; 步驟三:由第k個階層中選出nk個與能力估計值最接近難度的題目, 並施測之(n1+n2 +...+nk=L); 步驟四:k由 1,2,...,到K,重複步驟三。 影響分層數K的因素為在層中鑑別度的變異、難度的範圍可對應到真 實能力值的程度、測驗長度與題庫大小。若題庫夠大,K可為測驗長度。 而各層的可施測題目數nk,一般而言應該是各層被施測的題目數比例,以 確保在不同層的題目曝光率相似。或者除第一層外,各層使用相同的題目 數,因為第一層的題目必須夠多才能確保能力估計值夠好。因此,若L為 測驗長度,各層的施測題數應接近L/K。 a 分層法在測驗初始階段使用鑑別度小的題目,當已測驗的題目個數 逐步增加時,鑑別度亦逐步增加,鑑別度最大的題目放在測驗的最後階段 使用。這種方法實質上是一種鑑別度遞增法。這種演算法不僅保證了開始 估計的穩定性,而且比較平均地使用到鑑別度高、中、低的題目(王茜娟, 丁 樹良, 譚淵, 2004)。 (八)、 考慮 b 參數的 a 分層法
考慮b參數的 a 分層法(a-stratified with b-stratification approach, STR-B;
Yi & Chang, 2003)結合 a 分層法與 Weiss(1973)的 b 分層法,將題庫分層兩 次,第一次依難度參數分層,第二次再依鑑別度參數分層,其分層方式與
實施步驟如下: 步驟一:將題庫中所有題目依難度參數遞增排列分塊,每塊 R 題; 步驟二:將每一塊試題依鑑別度遞增排列,將每一塊的第一題放入第 一層中,第二題放入第二層,依次放入各層,則共有 R 層; 步驟三:將每層各集中為一個子題庫,由第 r 個子題庫選出nr個與能 力估計值最接近難度的題目,並施測之(n1+n2 +...+nr=L); 步驟四:r 由 1,2,...,到 R,重複步驟三。 STR-B 分層後題庫的特性有二:一為每層中之難度參數分配與題庫之 難度分配相似;一為每層中之平均鑑別度依層而遞增。此法之選題過程似 STR-A,但加入 b 分層的概念,當難度參數與鑑別度參數無關時,STR-B 的題庫與 STR-A 相似(Chang et al.,2001)。
電腦適性測驗的選題方法為依照現今受試者的能力估計值選出最適合
其能力的題目,而依不同的標準制定出不同的選題方法,在過往的研究 中,Chen 等人(2000)比較單點式最大訊息法、區間式最大訊息法、後驗最
大訊息法、KL 訊息法與貝氏 KL 訊息法的估計精準度,以區間式最大訊息 法與 KL 訊息法在初始階段有較佳的估計精準度,但並未比較曝光率。
Cheng& Liou(2003) 使 用 1990 年 美 國 國 家 教 育 進 展 評 量 (National Assessment of Education Progress, NAEP)數學測驗 622 題與 1992 年閱讀測 驗 203 題的題庫資料,針對兩題庫各別依不同選題法選題與模擬 1000 名 受試者的作答情況,以 20 題與 40 題為停止條件,以均方差評估估計精準 度,以卡方值評估題目曝光率的均勻程度,比較不同選題方法的估計精準 度與題目曝光率,以單點式最大訊息法與區間式最大訊息法精準度較高但 曝光率較不均勻;以最接近偏移難度估計精準度較低但曝光率較均勻;以 鄰近法的估計精準度與曝光率均勻度介於兩者之間,是較折衷的選題法, 並顯示選題方法不能兼顧估計精準度與曝光率均勻度。 Yi & Chang(2003)在考慮內容平衡下,比較加入 SH 曝光控制的單點式
最大訊息法比 a 分層法、考慮 b 參數的 a 分層法與考慮內容平衡的 a 分層 法的估計精準度與題目曝光率,顯示加入 SH 曝光控制的單點式最大訊息 法估計精準度較高,以卡方值與題目重複率評判曝光率均勻程度,以考慮 內容平衡的 a 分層法曝光率較均勻。 陳俊宏(2004)比較最接近難度法、最接近偏移難度法、單點式最大訊 息法與區間式最大訊息法在能力估計的精準度,顯示在題庫為單參數對數 模式時,四種選題方法相同;二參數對數模式時,選題法可歸為難度法與 訊息法兩類,以訊息法較好;三參數對數模式時,區間式最大訊息法較好。
四
四
四
四、
、
、
、終止條件
終止條件
終止條件
終止條件
電腦化適性測驗施測題目與題數因人而異,而依測驗的目的與性質, 測驗終止的標準一般有下列方式(陳麗如, 1998;陳新豐, 1999): (一)、 設定固定施測題數。當所有受試者答題數達到預設之題數限制時, 即終止測驗,一般以二十至三十題之間為原則。此法常用於模擬研 究,其優點是易於設計開發,題目使用率可較精確地預測,但可能 使受試者能力估計的精確度具變動性。 (二)、 當受試者的能力估計標準差低於預設標準時,測驗即終止。此即能 力估計的精確度已達預定標準,使用此種終止標準通常是以貝氏選 題法為選題策略。 (三)、 當題庫中未使用的題目,再也無法獲得更多的測驗訊息時,即終止 測驗。換言之,能力的估計已穩定,再做題目已經沒有幫助,採用 此終止標準時,通常以最大訊息選題法為選題策略。第三節
第三節
第三節
第三節 題目曝光率議題
題目曝光率議題
題目曝光率議題
題目曝光率議題
傳統的紙筆測驗中通常讓大量的受試者在同一時間測驗,且測驗相同 或複本的題目,所以沒有題目曝光率的問題。而電腦適性測驗與傳統的紙 筆測驗最大的不同點在於電腦適性測驗能針對不同受試者的能力給予不同 的題目,電腦適性測驗為了能縮短測驗題目數與估計的精準度,給予適合 受試者難度且鑑別度大的題目,因此有些鑑別度高的題目過度被使用,而 過度的曝光率使得題目的保密性受到威脅,有一些人可能事先知道題目與 答案而比較容易答對該題目,造成對受試者能力的誤判,也導致題庫的安 全性與測驗的公平性遭受危機。 在此,將題目曝光率定義測驗長度中每題使用的相對次數(如,Chang &Ying, 1999;Sympson & Hetter, 1985),如下
i er=(第i題被使用的次數)/N (2.20) 其中N為受試者人數,若題目曝光率為 0.2,則表示 100 名受試者中就 有 20 位受試者測驗過此題目。若 L 為平均的測驗長度或固定的測驗長度, 則平均曝光率為 n L er = / (2.21) 為顧及題目曝光率的均勻度,使題庫內的題目皆能被施測,期望題庫 內每題曝光率應接近於平均曝光率。 最理想控制曝光率與題目重複率的方法是不經由選題方法選擇題目, 對每一位受試者從題庫中隨機選題,但這並不符合適性測驗的原則。若每 次選題都給予題庫中最佳的題目,則能增進測驗效能,但易造成最佳題目 的濫用,使測驗遭到質疑,故當發展測驗系統時,必須同時考量「估計精 準度」與「均勻題目曝光率」。
第四節
第四節
第四節
第四節 評估
評估
評估準則
評估
準則
準則
準則
分別針對能力值的估計誤差與題目曝光率的表現進行評估。ㄧ
ㄧ
ㄧ
ㄧ、
、
、
、誤差評估
誤差評估
誤差評估
誤差評估:
:
:
:
利用真實能力值θ 與估計能力值θˆ的均方根差(root mean squared error,
RMSE),評估電腦適性測驗系統對受試者能力估計的準確度。 2 1 1 ˆ ( ) N i i i RMSE N = θ θ =
∑
− (2.22)二
二
二
二、
、
、題庫效能評估
、
題庫效能評估
題庫效能評估
題庫效能評估:
:
:
:
(ㄧ)、題目曝光率的均勻度 為量化曝光率,需要一個目標分配,因所有題目應有相同的曝光率, 故假設曝光率為均勻分配。則表示每題之曝光率的期望值為平均曝光率, 故利用 Pearson 的卡方檢定,檢定題目曝光率是否呈現均勻分配,其檢定 統計量為∑
= − = n i i er er er 1 2 2 / ) ( χ (2.23) 表示平均曝光率與觀測的題目曝光率的變異程度,並將題庫使用的效 率量化,若χ 值小,則題目曝光率為均勻分配,表示題目被充分的使用,2 故題庫使用有效率。 為了比較兩種不同選題方法的曝光率,即比較他們的卡方檢定統計 量,假設選題方法一的卡方檢定統計量為 2 1 χ ,選題方法二為 2 2 χ ,比較的 方法定義為: 2 2 2 1 / F =χ χ (2.24)若F <1,則選題方法一在題目曝光率的平衡上比方法二好(Yi & Chang,
(二)、題目重複率
Way(1997)將題目重複率(test overlap rate)定義為題目被兩位受試者施 測,所有成對比較平均的比例,即表示區塊或成對的題目,在不同測驗同 時讓受試者施測的程度,簡單的計算方式可為兩個隨機選出的受試者施測 的重複題目數,除上測驗長度。所以若 N 為受試者人數,題目重複率的計 算步驟為: (1)計算N(N−1)/2對受試者重複題目數; (2)加總此N(N −1)/2個數; (3)將此總數除以LN(N−1)/2。 若測驗的題目重複率越高,表示受試者測驗相同題目的比例越高,所 以,理想上,任一對受試者重複題目數應該被最小化。
第三章
第三章
第三章
第三章 研究方法
研究方法
研究方法
研究方法
透過前兩章所參閱的相關理論與提出之研究目的進行研究設計,本章 分為研究架構、研究工具與適性化測驗流程設計。第一節
第一節
第一節
第一節 研究架構
研究架構
研究架構
研究架構
本研究利用電腦模擬資料的方式,藉以比較不同選題法在不同條件下 對於估計精準度與題目曝光率之效果,圖 3-1 乃依據本研究之研究動機、 研究目的、研究背景以及參考相關文獻後設計之研究架構圖。 擬定研究主題 學習 MATLAB 程式語言 相關文獻探討 電腦模擬 估算能力參數 撰寫報告 精準度分析 與 曝光率分析 圖 3-1 研究架構圖第二節
第二節
第二節
第二節 研究工具
研究工具
研究工具
研究工具
本研究所使用的主要軟體工具為 MATLAB,而選擇 MATLAB 的原因 為其有功能強大的計算能力與高階但簡單的程式環境,可使用簡單的指令 呼叫函數的方式,數值計算、模擬與繪圖等。故採用此軟體作為模擬題庫 題目參數、模擬電腦適性測驗與繪製統計圖。第
第
第
第三
三
三
三節
節
節
節 適性測驗流程設計
適性測驗流程設計
適性測驗流程設計
適性測驗流程設計
不成立 成立 設定測驗模式 模擬受試者能力值 設定初始值 模擬資料: 設定人數、題目數以及 參數範圍及樣式 能力估計 選題方法 作答反應 誤差與題庫效能 評估 模擬題目各參數 圖 3-2 實施流程圖 資 料 模 擬 階 段 電 腦 適 性 測 驗 階 段 終止條件ㄧ
ㄧ
ㄧ
ㄧ、
、
、
、模擬受試者能力值
模擬受試者能力值
模擬受試者能力值
模擬受試者能力值
一般測驗受試者在測驗中所表現出的分數,大多符合常態分佈,尤其 是在大型考試中,更能顯現出此現象,又根據文獻參考資料的能力參數範 圍(表 3-2),因此模擬受試者能力為標準常態分配,能力值範圍介於-3 到 3 之間,樣式說明如表 3-1。為清楚解釋,以下將 N(m, v)定義為平均數 m 及 變異數 v 之常態分配,U(a, b)定義為介於 a 與 b 間的均勻分配。 表 3-1:能力樣式說明 能力樣式 能力 SA N(0,1) 以能力樣式配合受試者人數 1000 人與 3000 人,其能力代號為 SAm, SA 為能力樣式,m 為人數之千位數。二
二
二
二、
、
、
、模擬題庫
模擬題庫
模擬題庫
模擬題庫
為了瞭解題庫特性對題目曝光率表現的影響,根據文獻參考資料的參 數範圍(表 3-2)與 Urry(1977)建議進行 CAT 時題庫最少在 100 題以上,並在 鑑別度參數設定上參考 Patz 與 Junker(1999)的研究,考慮鑑別度參數為 lognormal(0,1)的情況,考慮六種不同的題庫參數樣式,如表 3-3 所示,並 將題庫大小設為 160、300 與 600 題,以題庫樣式配合 3 種題庫大小作組 合,其題庫代號為 PXm,其中 PX 為題庫樣式,m 為題庫題數之百位數。 表 3-2 文獻資料之參數範圍 作者(年代) 能力 參數 難度 參數 鑑別度 參數 猜測度 參數 Stone (1992) -4~4 -2.18~2.43 0.716~3 0 Baker (1990) -2.4~2.4 -1.8~1.2 0.35~2 0 Drasgow (1989) -3~3 -1.5~2.5 0.4~1.4 0 Mislevy & Stocking (1989) -3.5~3.5 -2~2 0~1.5 0~0.4 Skaggs & Stevenson (1989) -3~3 -2~2 0.4~1.2 0.1~0.3表 3-3 模擬題庫樣式
題庫樣式 難度 鑑別度 猜測度
PA U(-2.8,2.8) U(0.5,2) 0
PB N(0,1) U(0.5,2) 0
PC N(0,1) lognormal(0,1) 0
PD U(-2.8,2.8) U(0.5,2) U(0,0.25)
PE N(0,1) U(0.5,2) U(0,0.25) PF N(0,1) lognormal(0,1) U(0,0.25)
三
三
三
三、
、
、
、模擬受試者作答反應資料
模擬受試者作答反應資料
模擬受試者作答反應資料
模擬受試者作答反應資料
本研究所使用的受試者作答反應是根據 Birnbaum(1968)的三參數對數 模式產生,假設受試者人數為 N 人,題庫題數 n 題,模擬受試者作答反應 資料的步驟: (1)設定受試者能力參數,與題庫題目參數。 (2)依(1)之設定,產生受試者答題機率Pi(θ),i=1,2,...,n。 (3)以隨機方式產生 n 個介於 0 至 1 的亂數ui,i=1,2,...,n。 (4)比較Pi(θ)與ui,若Pi(θ)>ui,則受試者答對此題,反之則表示答錯。四
四
四
四、
、
、初始值設定
、
初始值設定
初始值設定
初始值設定
由於 CAT 施測題目會隨受試者的答題反應調整施測題目的難度,Lord(1977)發現不同起始點對於測驗標準誤(standard error of measurement) 並沒有很大差別。所以偏差的起始題應不致於影響測量結果,但較正確的
起始題,的確有助於縮短施測題數,而使能力估計提早完成。若從難易適 中的題目開始施測,經過多次使用後必然增加洩題的可能,基於保密性的
第一個題目。但是,隨機選取的方式並不能保證找到最佳起始點,同時也 不符合適性測驗的精神。故本研究起始題以隨機選取中難度的題目,使題 目對受試者不至於太難或太簡單,且避免產生過高的題目曝光率。
五
五
五
五、
、
、
、選題方法
選題方法
選題方法
選題方法
在以往的文獻中並未研究 KL 訊息法的曝光率,且未比較鄰近法與考 慮 b 參數的 a 分層法,故本研究針對最接近偏移難度法、區間式最大訊息 法、KL 訊息法、鄰近法與考慮 b 參數的 a 分層法等五種選題法進行估計 誤差與曝光率的評估。六
六
六
六、
、
、
、終止條件
終止條件
終止條件
終止條件
測 驗 終 止 條 件 可 分 為 固 定 測 驗 長 度 (fixed-length) 與 變 動 測 驗 長 度 (variable-length)兩種。固定測驗長度法常用於施測目的為瞭解受試者能力 之測驗,例如成就測驗;變動測驗長度法則是通常用於電腦化精熟測驗, 此種測驗只關心受試者是否達到通過標準,例如證照測驗(Wang, 1997)。 因採用固定測驗長度能透過預定每個內容領域要施測的題目數目,能 更直接控制施測內容,並且較符合一般受試者對測驗的預期,目前大多數 電腦化適性測驗採用固定測驗長度,故本研究使用之停止條件為固定測驗 長度為 20 題與 40 題,設定其停止條件的代號各為 t2 與 t4。第四章
第四章
第四章
第四章 研究結果與分析
研究結果與分析
研究結果與分析
研究結果與分析
本章主要分析不同的題庫類型、題庫大小、測驗長度與受測人數在各 選題方法中,對電腦適性測驗受測者能力估計與對題庫中題目曝光率的影 響,並做成分析圖表說明其結果。題目曝光率圖為各選題方法之題目曝光 率由小而大排序後的散佈圖,為了能比較曝光率間的關係,散佈圖將縱軸 設定在 0 到 0.7 之間;能力均方根差和曝光率統計表是由能力值的均方根 差、曝光率的描述性統計量、題目重複率與卡方統計量所組成的統計表, 其中 RMSE 表示能力值的均方根差、χ 表示曝光率的卡方統計量、#(exp2 >0.2)與#(exp<0.05)分別為表示曝光率大於 0.2 與小於 0.05 的題目數。第一節
第一節
第一節
第一節 題庫大小對適性測驗的影響
題庫大小對適性測驗的影響
題庫大小對適性測驗的影響
題庫大小對適性測驗的影響
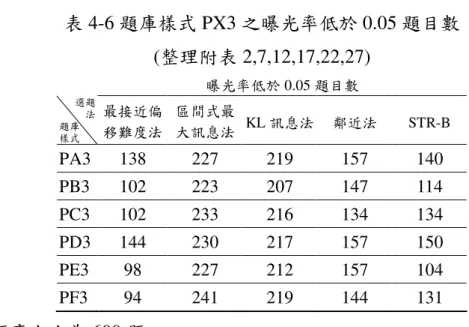
一、題庫大小 160 題 在受試能力為 SA1(1000 人)、題庫樣式為 PX1(160 題)、測驗長度為 20 題,各選題法的均方根差於表 4-1,以 PA1 為例,以 KL 訊息法(0.1940) 與區間式最大訊息法(0.1940)較小,鄰近法(0.2031)次之,最接近偏移難度 法(0.2261)與考慮 b 參數的 a 分層法(0.2414)較大;PB1、PC1、PD1、PE1、 PF1 也有此順序關係。以 PF1 的最接近偏移難度法(0.3457)、考慮 b 參數的 a 分層法(0.3494)和 PC1 的考慮 b 參數的 a 分層法(0.3053)均方根差大於 0.3。 表 4-1 題庫樣式 PX1 之均方根差(整理附表 1,6,11,16,21,26) 能力均方根差 選題 法 題庫 樣式 最接近偏 移難度法 區間式最 大訊息法 KL訊息法 鄰近法 STR-B PA1 0.2261 0.1940 0.1904 0.2031 0.2414 PB1 0.2307 0.2018 0.2036 0.2154 0.2360 PC1 0.2977 0.1921 0.1936 0.2365 0.3053 PD1 0.2845 0.2266 0.2277 0.2455 0.2968 PE1 0.2693 0.2047 0.2090 0.2342 0.2680 PF1 0.3457 0.2157 0.2124 0.2566 0.3494在受測能力為 SA1(1000 人)、題庫樣式為 PA1、PB1、PC1、PD1、PE1、 PF1(160 題)、測驗長度為 20 題,各選題法的題目最大曝光率由表 4-2 可知 最接近偏移難度法的最大曝光率介於 0.2220 至 0.4180,區間式最大訊息法 的最大曝光率介於 0.7010 至 0.9070,KL 訊息法的最大曝光率介於 0.5360 至 0.6760,鄰近法的最大曝光率介於 0.3920 至 0.5780,考慮 b 參數的 a 分 層法的最大曝光率介於 0.2920 至 0.4460。 在各題庫樣式與選題法中,最大曝光率以區間式最大訊息法為 0.9070 最大,而曝光率為 0.9070 表示每 100 名受試者就有 90.7 位施測過此題目, 也就是受試者中有 90.7%的受試者施測過此題,顯示題目有過高的曝光率。 表 4-2 題庫樣式 PX1 之最大題目曝光率(整理附表 1,6,11,16,21,26) 最大題目曝光率 選題 法 題庫 樣式 最接近偏 移難度法 區間式最 大訊息法 KL訊息法 鄰近法 STR-B PA1 0.4180 0.7850 0.6470 0.5780 0.4010 PB1 0.2660 0.7010 0.5360 0.3920 0.3460 PC1 0.2570 0.8270 0.6030 0.4150 0.2920 PD1 0.3750 0.7990 0.6760 0.5530 0.4460 PE1 0.2220 0.7770 0.6210 0.4090 0.3740 PF1 0.2510 0.9070 0.6480 0.4630 0.3520 在受測能力為 SA1(1000 人)、題庫樣式為 PX1(160 題)、測驗長度為 20 題,各選題法之題目曝光率低於 0.05 的題目數(表 4-3),在題庫樣式為 PA1 時,最接近偏移難度法為 63 題,佔題庫的 39.375%;區間式最大訊息 法為 97 題,佔題庫的 60.625%;KL 訊息法為 87 題,佔題庫的 54.375%; 鄰近法為 70 題,佔題庫的 43.75%;考慮 b 參數的 a 分層法為 56 題,佔題 庫的 35%。 在題庫樣式為 PB1、PC1、PD1、PE1、PF1,其題目曝光率低於 0.05 的題目數在選題法為區間式最大訊息法和 KL 訊息法與 PA1 差異不大;對 其他選題法,以 PA1 題目數最多、PD1 次之,其他題庫則較少,以 PB1 為例,最接近偏移難度法為 10 題,佔題庫的 6.25%;考慮 b 參數的 a 分層
法為 13 題,佔題庫的 8.125%;鄰近法為 25 題,佔題庫的 15.625%,由 PA1 與 PD1 之附圖(附圖 1、16)與其他題庫樣式相比可看出 PA1 與 PD1 之圖形 最接近偏移難度法、考慮 b 參數的 a 分層法與鄰近法較其他題庫樣式陡峭, 而 PA 與 PD 相同都是難度與鑑別度為均勻分配,表示當小樣本時,題庫樣 式是難度與鑑別度為均勻分配時,最接近偏移難度法、考慮 b 參數的 a 分 層法與鄰近法曝光率較其他題庫樣式不均勻。 表 4-3 題庫樣式 PX1 之題目曝光率低於 0.05 題目數 (整理附表 1,6,11,16,21,26) 題目曝光率低於 0.05 題目數 選題 法 題庫 樣式 最接近偏 移難度法 區間式最 大訊息法 KL訊息法 鄰近法 STR-B PA1 63 97 87 70 56 PB1 10 98 80 25 13 PC1 5 109 97 13 14 PD1 42 101 88 57 43 PE1 2 97 77 24 17 PF1 8 110 94 15 22 二、題庫大小為 300 題 在受試能力為 SA1(1000 人)、題庫樣式為 PX3(300 題)、測驗長度為 20 題,各題庫樣式的均方根差列表於表 4-4,以題庫樣式 PA3 為例 KL 訊 息法(0.1807)與區間式最大訊息法(0.1842)較小,鄰近法(0.1986)次之,最接 近偏移難度法(0.2452)與考慮 b 參數的 a 分層法(0.2486)較大;在題庫樣式 為 PB3、PC3、PD3、PE3、PF3 與 PA3 有相同的順序關係,除 PF3 的最接 近偏移難度法(0.4123)、考慮 b 參數的 a 分層法(0.3766)均方根差大於 0.3。
在受測能力為 SA1(1000 人)、題庫樣式為 PA3、PB3、PC3、PD3、PE3
與PF3(300 題)、測驗長度為 20 題,各題庫樣式的題目最大曝光率由表 4-5、 可知最接近偏移難度法的最大曝光率介於 0.1690 至 0.2770,區間式最大訊 息法的最大曝光率介於 0.5800 至 0.9070,KL 訊息法的最大曝光率介於
的 a 分層法的最大曝光率介於 0.2120 至 0.3310。 表 4-4 題庫樣式 PX3 之均方根差(整理附表 2,7,12,17,22,27) 能力均方根差 選題 法 題庫 樣式 最接近偏 移難度法 區間式最 大訊息法 KL訊息法 鄰近法 STR-B PA3 0.2452 0.1842 0.1807 0.1986 0.2486 PB3 0.2300 0.1799 0.1737 0.1920 0.2384 PC3 0.2429 0.1427 0.1392 0.1729 0.2543 PD3 0.2819 0.2106 0.2111 0.2375 0.2822 PE3 0.2686 0.1958 0.1943 0.2233 0.2736 PF3 0.4123 0.1940 0.1923 0.2681 0.3766 表 4-5 題庫樣式 PX3 之最大題目曝光率(整理附表 2,7,12,17,22,27) 最大題目曝光率 選題 法 題庫 樣式 最接近偏 移難度法 區間式最 大訊息法 KL訊息法 鄰近法 STR-B PA3 0.2390 0.6600 0.5860 0.4280 0.3310 PB3 0.1840 0.5800 0.4550 0.3470 0.2280 PC3 0.1980 0.7310 0.4950 0.3250 0.2120 PD3 0.2770 0.7880 0.6470 0.4150 0.2870 PE3 0.1690 0.7130 0.5200 0.3350 0.2650 PF3 0.1760 0.9070 0.6840 0.3370 0.2710 在受測能力為 SA1(1000 人)、題庫樣式為 PA3(300 題)、測驗長度為 20 題,比較各選題法題目曝光率低於 0.05 的題目數(表 4-6),最接近偏移 難度法為 138 題,佔題庫的 46%;區間式最大訊息法為 227 題,佔題庫的 75.67%;KL 訊息法為 219 題,佔題庫的 73%;鄰近法為 157 題,佔題庫 的 52.33%;考慮 b 參數的 a 分層法為 140 題,佔題庫的 46.67%。 在題庫樣式為 PB3、PC3、PD3、PE3、PF3,其題目曝光率低於 0.05 的題目數與 PA3 略有差異,各選題法以區間式最大訊息法最多,較少的是 最接近偏移難度法與考慮 b 參數的 a 分層法。
表 4-6 題庫樣式 PX3 之曝光率低於 0.05 題目數 (整理附表 2,7,12,17,22,27) 曝光率低於 0.05 題目數 選題 法 題庫 樣式 最接近偏 移難度法 區間式最 大訊息法 KL訊息法 鄰近法 STR-B PA3 138 227 219 157 140 PB3 102 223 207 147 114 PC3 102 233 216 134 134 PD3 144 230 217 157 150 PE3 98 227 212 157 104 PF3 94 241 219 144 131 三、題庫大小為 600 題 在受試能力為 SA1(1000 人)、題庫樣式為 PX6(600 題)、測驗長度為 20 題,各題庫樣式的均方根差於表 4-7,以題庫樣式 PA6 為例 KL 訊息法 (0.1644)與區間式最大訊息法(0.1679)較小,鄰近法(0.1776)次之,最接近偏 移難度法(0.2294)與考慮 b 參數的 a 分層法(0.2325)較大;在題庫樣式為 PB6、PC6、PD6、PE6、PF6 與 PA6 有相同的順序關係,而 PF6 的最接近 偏移難度法(0.3345)、考慮 b 參數的 a 分層法(0.3283)均方根差大於 0.3。 表 4-7 題庫樣式 PX6 之均方根差(整理附表 3,8,13,18,23,28) 能力均方根差 選題 法 題庫 樣式 最接近偏 移難度法 區間式最 大訊息法 KL訊息法 鄰近法 STR-B PA6 0.2294 0.1679 0.1644 0.1776 0.2325 PB6 0.2333 0.1701 0.1724 0.1897 0.2389 PC6 0.2489 0.1198 0.1185 0.1550 0.2409 PD6 0.2817 0.1864 0.1891 0.2054 0.2760 PE6 0.2819 0.1860 0.1897 0.2039 0.2760 PF6 0.3514 0.1387 0.1421 0.1914 0.3318
在受測能力為 SA1(1000 人)、題庫樣式為 PA6、PB6、PC6、PD6、PE6
與PF6(600 題)、測驗長度為 20 題,對各選題法的題目最大曝光率由表 4-8 可知最接近偏移難度法的最大曝光率介於 0.0920 至 0.1740,區間式最大訊
0.4030 至 0.5610,鄰近法的最大曝光率介於 0.2280 至 0.3530,考慮 b 參數 的 a 分層法的最大曝光率介於 0.1210 至 0.2120。 表 4-8 題庫樣式 PX6 之最大題目曝光率(整理附表 3,8,13,18,23,28) 最大題目曝光率 選題 法 題庫 樣式 最接近偏 移難度法 區間式最 大訊息法 KL訊息法 鄰近法 STR-B PA6 0.1740 0.5090 0.4080 0.3150 0.1730 PB6 0.0920 0.5290 0.4030 0.2470 0.1210 PC6 0.1580 0.7540 0.5500 0.2280 0.1500 PD6 0.1590 0.6740 0.5090 0.3530 0.1560 PE6 0.1200 0.6240 0.4940 0.2600 0.1430 PF6 0.1470 0.8420 0.5610 0.2440 0.2120 在受測能力為 SA1(1000 人)、題庫樣式為 PX6(600 題)、測驗長度為 20 題,比較各選題法之題目曝光率低於 0.05 的題目數(表 4-9),在題庫為 PA6 時,最接近偏移難度法為 453 題,佔題庫的 75.5%;區間式最大訊息 法為 510 題,佔題庫的 85%;KL 訊息法為 499 題,佔題庫的 83.167%; 鄰近法為 473 題,佔題庫的 78.83%;考慮 b 參數的 a 分層法為 461 題,佔 題庫的 76.83%。 在題庫樣式為 PB6、PC6、PD6、PE6、PF6,其題目曝光率低於 0.05 的題目數與 PA6 略有差異,各選題法以區間式最大訊息法最多,較少的是 最接近偏移難度法與考慮 b 參數的 a 分層法。 表 4-9 題庫樣式 PX6 之題目曝光率低於 0.05 題目數 (整理附表 3,8,13,18,23,28) 題目曝光率低於 0.05 題目數 選題 法 題庫 樣式 最接近偏 移難度法 區間式最 大訊息法 KL訊息法 鄰近法 STR-B PA6 453 510 499 473 461 PB6 474 511 490 480 489 PC6 492 522 500 501 487 PD6 442 523 508 477 458 PE6 482 516 494 473 499 PF6 499 526 506 486 501
大體上,對各題庫樣式均方誤以區間式最大訊息法與 KL 訊息法最 小,次之為鄰近法,以考慮 b 參數的 a 分層法與最接近偏移難度法最大; 而題目最大曝光率以區間式最大訊息法最大,次之為 KL 訊息法、鄰近法, 以考慮 b 參數的 a 分層法與最接近偏移難度法較低,且題目最大曝光率會 隨題庫越大而下降。 對於不同題庫大小,各選題法在曝光率低於 0.05 的題目數以區間式 最大訊息法最多,且隨題庫題數越多,其題目數佔整個題庫的比例越高, 顯示當題庫題數增加時,區間式最大訊息法選題仍然易集中於某些題目, 使得大部分的題目曝光率低於 0.05,而其圖形也反映出此特點而呈現出陡 峭的題目曝光率圖形,而相對於最接近偏移難度法曝光率低於 0.05 的題目 數較少,其圖形也較平緩。
第二節
第二節
第二節
第二節 測
測
測
測驗長度對適性測驗的影響
驗長度對適性測驗的影響
驗長度對適性測驗的影響
驗長度對適性測驗的影響
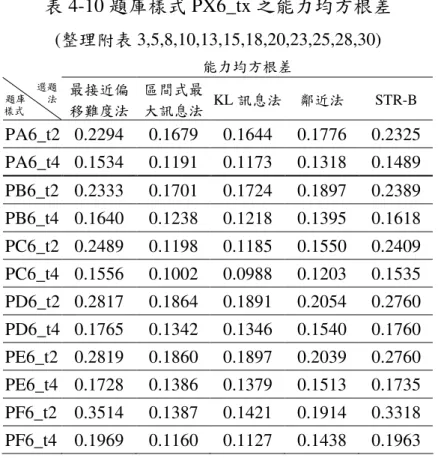
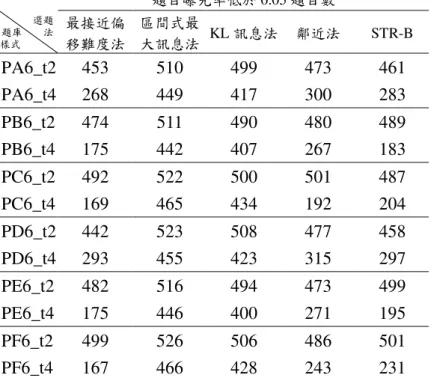
在受測能力為 SA1(1000 人)、題庫樣式為 PX6(600 題)、測驗長度為 20 題與 40 題,對各題庫的均方根差整理於表 4-10,以能力均方根差比較 測驗長度對能力估計效率與精準度的影響,以題庫樣式 PA6 為例可發現當 測 驗 長 度 增 長 時 , 區 間 式 最 大 訊 息 法 (0.1679—0.1191) 、 KL 訊 息 法 (0.1644—0.1173)與鄰近法(0.1776—0.1318)的估計誤差有微幅的下降,相對 於 最 接 近 偏 移 難 度 法 (0.2294—0.1534) 與 考 慮 b 參 數 的 a 分 層 法 (0.2325—0.1489)下降較為明顯。 若停止條件設為變動測驗長度,以均方根差達 0.18 為停止條件,則 區間式最大訊息法、KL 訊息法與鄰近法在受試者平均施測 20 題內可達到 此停止條件,相對於最接近偏移難度法與考慮 b 參數的 a 分層法必須測驗 20 題以上、40 題以內才能達到此估計精準度。表 4-10 題庫樣式 PX6_tx 之能力均方根差 (整理附表 3,5,8,10,13,15,18,20,23,25,28,30) 能力均方根差 選題 題庫 法 樣式 最接近偏 移難度法 區間式最 大訊息法 KL訊息法 鄰近法 STR-B PA6_t2 0.2294 0.1679 0.1644 0.1776 0.2325 PA6_t4 0.1534 0.1191 0.1173 0.1318 0.1489 PB6_t2 0.2333 0.1701 0.1724 0.1897 0.2389 PB6_t4 0.1640 0.1238 0.1218 0.1395 0.1618 PC6_t2 0.2489 0.1198 0.1185 0.1550 0.2409 PC6_t4 0.1556 0.1002 0.0988 0.1203 0.1535 PD6_t2 0.2817 0.1864 0.1891 0.2054 0.2760 PD6_t4 0.1765 0.1342 0.1346 0.1540 0.1760 PE6_t2 0.2819 0.1860 0.1897 0.2039 0.2760 PE6_t4 0.1728 0.1386 0.1379 0.1513 0.1735 PF6_t2 0.3514 0.1387 0.1421 0.1914 0.3318 PF6_t4 0.1969 0.1160 0.1127 0.1438 0.1963 在受測能力為 SA1(1000 人)、題庫樣式為 PX6(600 題)、測驗長度為 20 與 40 題,各選題題庫的曝光率低於 0.05 題目數整理於表 4-11,以 PA 為例,比較兩種測驗長度對曝光率低於 0.05 題目數的影響,可發現最接近 偏 移 難 度 法 (453—268) 、 區 間 式 最 大 訊 息 法 (510—449) 、 KL 訊 息 法 (499—417)、鄰近法(473—300)與考慮 b 參數的 a 分層法(461—283)在測驗 長度增長時對曝光率低於 0.05 題目數減少的趨勢。 在題庫樣式為 PB6、PC6、PD6、PE6、PF6,測驗長度為 20 題與 40 題,其能力估計均方根差與 PA6 略有差異,仍是以最接近偏移難度法與考 慮 b 參數的 a 分層法下降較明顯。而其曝光率低於 0.05 題目數在各選題方 法有隨測驗長度增長而減少的趨勢,表示測驗長度增長使得不常被選到的 題目被施測的機會增加,而以最接近偏移難度法與考慮 b 參數的 a 分層法 減少較明顯,顯示當測驗長度增加時,最接近偏移難度法與考慮 b 參數的 a 分層法使估計更精準,且能使用到曝光率低於 0.05 的題目。
表 4-11 題庫樣式 PX6_tx 之題目曝光率低於 0.05 題目數 (整理附表 3,5,8,10,13,15,18,20,23,25,28,30) 題目曝光率低於 0.05 題目數 選題 題庫 法 樣式 最接近偏 移難度法 區間式最 大訊息法 KL訊息法 鄰近法 STR-B PA6_t2 453 510 499 473 461 PA6_t4 268 449 417 300 283 PB6_t2 474 511 490 480 489 PB6_t4 175 442 407 267 183 PC6_t2 492 522 500 501 487 PC6_t4 169 465 434 192 204 PD6_t2 442 523 508 477 458 PD6_t4 293 455 423 315 297 PE6_t2 482 516 494 473 499 PE6_t4 175 446 400 271 195 PF6_t2 499 526 506 486 501 PF6_t4 167 466 428 243 231 在受測能力為 SA1(1000 人)、題庫樣式為 PA6(600 題)、測驗長度為 20 題與 40 題,對各選題方法的題目重複率於表 4-12,可知當測驗長度增 長 時 , 最 接 近 偏 移 難 度 法 (0.0589—0.1016) 、 區 間 式 最 大 訊 息 法 (0.2350—0.3063)、KL 訊息法(0.1908—0.2452)、鄰近法(0.1007—0.1268)、 考慮 b 參數的 a 分層法(0.0622—0.1085)的題目重複率有微幅的上升,顯示 測驗長度增長對於受試者的題目重複率有增加的現象。而各選題法的題目 重複率排序由大到小為區間式最大訊息法、KL 訊息法、鄰近法、考慮 b 參數的 a 分層法與最接近偏移難度法。 在題庫樣式為 PA6、PB6、PC6、PD6、PE6、PF6,測驗長度為 20 題 與 40 題,其題目重複率與 PA6 略有差異,仍顯示出微幅的上升現象,且 各選題法的題目重複率排序以區間式最大訊息法與 KL 訊息法較大,在測 驗長度為 20 題時,區間式最大訊息法的題目重複率介於 0.2184 與 0.2912 之間、KL 訊息法介於 0.1742 與 0.2095 之間,而題目重複率為 0.2912 表示
受試者在測驗 20 題中,平均有 5.8(20*0.2912)題與其他受試者相同;在測 驗長度為 40 題時,最接近偏移難度法的題目重複率介於 0.0757 與 0.1074 之間、考慮 b 參數的 a 分層法介於 0.0795 與 0.1085 之間、鄰近法介於 0.0920 與 0.1375 之間,表示受試者在測驗 40 題中,最接近偏移難度法與考慮 b 參數的 a 分層法平均約有 3 到 4 題與其他受試者相同,鄰近法平均約有 4 到 6 題與其他受試者相同,顯示出區間式最大訊息法與 KL 訊息法在測驗 長度為 20 題時,題目重複率仍高於測驗長度為 40 題的最接近偏移難度 法、考慮 b 參數的 a 分層法與鄰近法。 表 4-12 題庫樣式 PX6_tx 之題目重複率 (整理附表 3,5,8,10,13,15,18,20,23,25,28,30) 題目重複率 選題 題庫 法 樣式 最接近偏 移難度法 區間式最 大訊息法 KL訊息法 鄰近法 STR-B PA6_t2 0.0589 0.2350 0.1908 0.1007 0.0622 PA6_t4 0.1016 0.3063 0.2452 0.1268 0.1085 PB6_t2 0.0435 0.2184 0.1742 0.0838 0.0456 PB6_t4 0.0762 0.2757 0.2163 0.1046 0.0795 PC6_t2 0.0449 0.2650 0.2017 0.0745 0.0475 PC6_t4 0.0770 0.3346 0.2572 0.0920 0.0835 PD6_t2 0.0631 0.2778 0.2175 0.1111 0.0615 PD6_t4 0.1074 0.3283 0.2523 0.1375 0.1074 PE6_t2 0.0427 0.2464 0.1922 0.0893 0.0472 PE6_t4 0.0757 0.3034 0.2239 0.1098 0.0798 PF6_t2 0.0448 0.2912 0.2095 0.0804 0.0557 PF6_t4 0.0775 0.3324 0.2525 0.0972 0.0866