A Method for Multilingual Text
Mining and Retrieval Using Growing
Hierarchical Self-Organizing Maps
Hsin-Chang Yang1
Department of Information Management, National University of Kaohsiung, Kaohsiung, Taiwan
Chung-Hong Lee
Department of Electrical Engineering, National Kaohsiung University of Applied Sciences, Kaohsiung, Taiwan
Ding-Wen Chen
Department of Information Management, Chang Jung Christian University, Tainan, Taiwan
Abstract
With the increasing amount of multilingual texts in the Internet, multilingual text retrieval techniques have become an important research issue. However, the discovery of relationships between different languages remains an open problem. In this paper we propose a method, which applied the growing hierarchical self-organizing map (GHSOM) model, to discover knowledge from multilingual text documents. Multilingual parallel corpora were trained by the GHSOM to generate hierarchical feature maps. A discovery process is then applied on these maps to discovery the relationships between documents of different languages. The relationships between keywords of different languages are also revealed. We conducted experiments on a set of Chinese-English bilingual parallel corpora to discover the relationships between documents of these languages. We also use such relationships to perform multilingual information retrieval tasks. The experimental results show that our multilingual text mining approach may capture conceptual relationships among documents as well as keywords written in different languages.
Keywords: multilingual text mining, multilingual information retrieval, growing hierarchical self-organizing maps
1
Correspondence to: Hsin-Chang Yang, Department of Information Management, National University of Kaohsiung, Kaohsiung, 811, Taiwan, email: [email protected].
1.
Introduction
The storage and retrieval of documents have become important research topics in last decades [1]. The rapid spread of network access and growth of web-based documents have augmented such need. Nowadays most of the research efforts of information retrieval are spent on monolingual documents, especially English documents. However, users that have non-English native languages increase rapidly in recent years. According to the Ethnologue catalogue published in 2005 [2], there are more than 870 million Chinese-speaking people. There are also more than 300 million people speaking Indian and Spanish, respectively. English-speaking people occupy another 300 millions. As a result, more and more non-English documents appear in the Web today. According to Internet World Stats [3], 31.7% of Internet users use English as their major language, which is the top 1 language in the Web. Chinese and Spanish-language users occupy another 14.3% and 8.8% of Internet users, respectively. It should be noted that Chinese Internet users grow 413.9% in the last 7 years, while English users grow only 157.7% in the same interval. This circumstance suggests that non-English Web documents will increase significantly in the future.
Most of the Internet users use some search engines to find documents they want in the Web. Unfortunately, most of the search engines provide only monolingual search interface, i.e. the queries and target documents are written in the same language, mostly English. There are increasing needs for searching documents written in a different language other than that of queries. The users must translate their queries into another language to meet the limitation of traditional search engines. However, the translations are always ambiguous and imprecise, especially for untrained users. It would be convenient for these users to express their queries in familiar language and search documents in other languages. Cross-lingual or multilingual information retrieval (MLIR) techniques meet such need.
The task of multilingual information retrieval intends to break the language barrier between the queries and the target documents. A user can express her need with one language and search documents of another language. However, this task is not easy to conquer since we have to relate one language to the other. One straightforward way is to translate one language into the other through some machine translation schemes. Unfortunately, there is still no well recognized scheme to provide precise translation between two languages. A different approach is to match queries and documents directly without a priori translation. This approach is also difficult since we need some kind of measurements to measure the semantic relatedness between queries and documents. Such semantic measurements are generally not able to be explicitly defined, even with human intervention. Thus we need a kind of automated process to discover the relationships between different languages. Such process is often called multilingual text mining (MLTM).
Generally, text mining refers to the process of discovering implicit knowledge from a set of unstructured or semi-structured text documents. Techniques such as natural language processing, machine learning, and information retrieval are often used in a text mining process. The knowledge to be mined has no well accepted recognition. In fact, any implicit pattern could be the knowledge that to be mined. However, we prefer knowledge that could be represented for easy comprehension by human beings. Research work related to applying text mining methods to a monolingual corpus such as English text collections has been well established by several research teams [4][5]. However, little attention has been paid to applying the techniques to handle the documents in Asian languages such as Chinese, and further extend the mining algorithms to support the aspects of multilingual text documents. One major reason is associated with the nature of language used in the texts. Therefore, translation of queries (or documents) from one language into another seems to be reasonable approach to tackle the language barrier in multilingual text mining. In general, there are three types of possible techniques employed to deal with the issue: (1) Using a machine translation system; (2) Using a bilingual dictionary or terminology base; (3) Using a statistical/probabilistic model based on parallel texts. In the first category, the machine translation system seems to be the sensible tool for multilingual text mining. However, it should be emphasized that with their distinctive natures, machine translation and text mining have widely divergent concerns. Most machine translation systems tend to spend lots of effort trying to produce syntactically correct sentences. This effort has little, if any, application in current text mining approaches which are often based on single words. In the second category, one can use either an ordinary general-purpose dictionary or a technical terminology database for query translation. It is worth mentioning that in any sizable dictionary most words
receive many translations that correspond to different meanings. Although much research effort has attempted to disambiguate word meanings, it is still very difficult to determine the correct meaning thus translation, of a word in a query. In the third type of approach, a corpus of parallel texts (that is, a corpus made up of source texts and their translations) is employed as a basis for automatically determining equivalence of translation. Parallel texts have been applied in several studies on MLIR. Although the principle of using parallel texts in MLIR is similar, the approaches used may be very different.
In this work, we will develop a MLTM technique and apply it to MLIR. Our method applies GHSOM to cluster and structure a set of parallel texts. The reason we adopt GHSOM is that it could effectively construct a hierarchical structure of the documents. We could then develop algorithms to discover the relationships between different languages based on such hierarchical structure. The major contribution of this work is the discovery algorithm that could find the relationships between multilingual text documents as well as multilingual linguistic terms. We perform experiments on a set of Chinese-English parallel texts. Evaluation results suggest that our approach should be plausible in tackling MLIR tasks.
The remaining of the article is organized as follow. Sec. 2 reviews some related work. We then introduce the GHSOM algorithm and the processing of documents in Sec. 3. The discovery algorithms are described in Sec. 4. In Sec. 5, the experiment results are shown. Finally we give some conclusions in the last section.
2. Related Work
We will briefly review some articles in two related fields. In Sec. 2.1 we review works in MLIR/MLTM. Later in Sec. 2.2 we will discuss works of self-organizing maps (SOM), especially GHSOM.
2.1. Related work in multilingual information retrieval and multilingual text mining
The aim of MLIR is to provide users a way to search documents written in a different language from the query. Query translation thus plays a central role in MLIR research. Three different strategies for query translation were used [6], namely dictionary-based [7], thesaurus-based [8], and corpus-based methods. We will briefly described these methods in following subsections.
2.1.1 Dictionary-based MLIR
Most of the early MLIR works are based on machine translation [9][10]. Two schemes could be applied in translation [11], namely query translation and document translation. Document translation scheme translates every document in the corpus into multiple languages. This enables the users to query multilingual documents in any language. The drawback of this scheme is the cost for such translation is high, making it unsuitable for large or real-time datasets such as the Web. Query translation scheme converts a query to another language using a dictionary. The converted query is then used to find the target documents. Both schemes suffer from the low precision of the retrieval result. Hull and Grefenstette [12] performed experiments using dictionary-based approach without ambiguity analysis. The experiments showed that the precisions are 0.393 and 0.235 for retrieving monolingual and multilingual texts, respectively. They, especially the multilingual case, are not adequate in most retrieval tasks. In another experiment, Davis [13] reported precisions of 0.2895 and 0.1422 for monolingual and multilingual retrieval, respectively. The performance of multilingual retrieval is only half of the monolingual case. These experiments suggest that word polysemy and ambiguity deteriorate the performance of dictionary-based approach. This was proved by Ballesteros and Croft [14], which showed that correct translation has positive affect on the retrieval quality. However, resolving word ambiguity in machine translation is still difficult until now.
Another problem comes from the proper nouns. Thompson and Dozier [15] found that 67.8%, 83.4%, and 38.8% of queries to the Wall Street Journal, the Los Angeles Times, and the Washington Post corpora,
respectively, contain proper nouns. Proper nouns, as well as uncollected words, are still open problems in dictionary-based translation.
2.1.2 Thesaurus-based MLIR
A thesaurus is a list of words together with their related words. It is commonly used in information retrieval and document indexing. Peters and Picchi [16] indicated that MLIR could be achieved through precise mapping between thesauri of different languages. Salton [17] also suggested that the performance of MLIR systems could resemble those monolingual ones provided a correct multilingual thesaurus is established. However, the difficulties of thesaurus-based approach come from the construction of the thesaurus, which needs much human effort and time cost. Moreover, a precise and complete thesaurus is difficult to construct. Furthermore, the mapping between different thesauri is not obvious and needs thorough investigation. Chen et al. [18] used Chinese and English thesauri to generate news summaries in both languages. They found the high occurrences of proper nouns and uncollected words in the news articles significantly deteriorate the quality of the result.
2.1.3 Corpus-based MLIR and MLTM
Corpus-based approach uses knowledge acquisition techniques to discover cross-language relationships and applies them to MLIR. We may divide this approach into three categories, namely word alignment, sentence alignment, and document alignment, based on the granularity of alignment. Word alignment can generate the finest bilingual corpora, which the relationships between words in different languages have been clearly defined automatically or manually. Brown [19] used this kind of technique to construct a translation table for query translation. Chen et al. [20] stated that the precision of alignment will affect the quality of query translation. Good alignment methods should be developed to ensure the quality of corpus-based MLIR. For sentence alignment, an example is the work of Davis and Dunning [21]. Both word alignment and sentence alignment suffer from the fact that such alignments are not easy to achieve. On the other hand, document alignment is much easier. There are two types of corpora that could be used in document alignment, namely parallel corpora and comparable corpora. The former contains documents in multiple translations. The latter contains categories of multi-language documents that have the same topics. Comparable corpora are common since the multi-language copies of a topic are easier to obtain. An example is the work by Sheridan and Ballerini [22]. They aligned German and Italian news articles and constructed a translation dictionary. This dictionary is then used to generate target query.
Many multilingual text mining techniques, especially for machine learning approaches, are based on comparable or parallel corpora. Chau and Yeh [23] generated fuzzy membership scores between Chinese and English terms and clustered them to perform MLIR. Lee and Yang [24] also used SOM to train a set of Chinese-English parallel corpora and generate two feature maps. The relationships between bilingual documents and terms are then discovered. Rauber et al. [25] applied GHSOM to cluster multilingual corpora which contain Russian, English, German, and French documents. However, they translated all documents into one language first before training. Thus they actually performed monolingual text mining.
2.2. Related work on SOM and GHSOM for document clustering
The self-organizing map model was first proposed by Teuvo Kohonen and has been applied to many fields such as data visualization, clustering, classification, control, telecommunications, etc. [26] Here we should focus on its applications on document clustering and text mining. Most of these works used SOM to visualize a set of documents in 2D map for document analysis and retrieval. For example, two important works are Merk [27] and Kohonen et al. [28]. However, these works apply SOM of fixed topology that needs to be designated before training. Besides, the 2D map may over simplify the relations existed among the documents. To tackle these deficiencies, variants of basic SOM have been proposed. For example, growing SOM [29] can extend the map when necessary. Hierarchical feature maps [30] use SOMs organized in hierarchical manner to train the data. But the maps in each layer have fixed sizes. Therefore, Rauber et al. proposed GHSOM [25] that could expand the map and develop hierarchical structure dynamically. GHSOM will expand the SOMs if current map could not learn the data well. When a cluster contains too much incoherent data, it could also expand another layer to further divide data into finer cluster. The depth of hierarchical and the size of each SOM are determined dynamically.
These properties make it a good choice for document clustering and exploration. GHSOM have been applied to various fields such as expertise management [31], failure detection [32], etc. The application on MLIR has only been done by the GHSOM team. However, as mentioned in Sec. 2.1.3, what they did is actually monolingual text mining that applies to MLIR. In this work, we will develop a MLTM method based on GHSOM and apply the method on MLIR.
3. Document processing and clustering by GHSOM
In this section we will describe how we process multilingual documents and cluster them with GHSOM. First in Sec. 3.1 we will brief describe the entire architecture of the proposed method. The processing steps of converting documents into proper form will be discussed in Sec. 3.2. Finally in Sec. 3.3 we describe GHSOM and the way we apply it to cluster multilingual documents.
3.1. System architecture
Figure 1 depicts the processing steps of our method. A set of parallel corpora are used to train the GHSOM. In this work we used Chinese-English parallel corpora. However, parallel corpora of any languages are suitable for our method since we use only separated keywords rather than sentences as features for the documents. Both corpora are preprocessed to convert each document to a feature vector. The preprocessing step will be described in Sec. 3.2. These feature vectors are then fed to the GHSOM to generate hierarchical feature maps. This process will be described in Sec. 3.3. The associations between bilingual documents as well as bilingual terms will be discovered through an association discovery process, which will be described in Sec. 4. Three kinds of associations, namely document associations, keyword associations, and document/keyword associations, will be revealed after the process. The associations are depicted as bidirectional arrows in the figure. We use dashed lines to emphasize document/keyword associations. These associations are then used to perform the MLIR tasks. The query is preprocessed in the same manner as documents to extract a set of query keywords. These keywords are then used to retrieve bilingual documents according to the discovered associations. The MLIR process is also discussed in Sec. 4.
3.2. Preprocessing and encoding of bilingual documents
A document should be converted to proper form before GHSOM training. Here the proper form is a vector that catches essential (semantic) meaning of the document. In this work we adopt bilingual corpora that contain Chinese and English documents. The encoding of English documents into vectors has been well addressed [33]. Processing steps such as word segmentation, stopword elimination, stemming, and keyword selection are often used in extracting representative keywords from a document. In this work, we first used a common segmentation program to segment possible keywords. A part-of-speech tagger is also applied to these keywords so that only nouns are selected. These selected keywords may contain stopwords that have trivial meanings. These stopwords will be removed to reduce the number of keywords. Stemming process will be also applied to convert each keyword to its stem (root). This will further reduce the number of keywords. After these processing steps, we will obtain a set of keywords that should be representative to this document. All keywords of all documents are collected to build a vocabulary for English keywords. This vocabulary is denoted as VE. A document is encoded
into a vector according to those keywords that occurred in it. When a keyword occurs in this document, the corresponding element of the vector will have a value greater than 0; otherwise, the element will have value 0. In practice, the value is just the traditional tf⋅idf (term frequency times inverse document frequency) value, where tf counts the frequency of the keyword in this document and idf measures the frequency of the keyword occurs across all documents. With this scheme, a document Ej will be encoded into a vector Ej. The size (number of
Chinese documents English documents Parallel corpora preprocessing Chinese document vectors English document vectors Train by GHSOM Hierarchy of monolingual documents Hierarchy of bilingual documents Association discovery Document associations Keyword associations Document/Keyword associations query Retrieval result MLTM process MLIR process Figure 1. System architecture
The processing of Chinese documents differs significantly from their English counterparts in several points. First, a Chinese sentence contains a list of consecutive Chinese letters. A Chinese letter, however, carries little meaning individually. Several letters are often combined to give specific meaning and are basic constituents of a sentence. Here we will mention such combined letters as a word for consistency with English words. The segmentation of Chinese words is more difficult than English words because we have to separate these consecutive letters into a set of words. There are several segmentation schemes for Chinese words. We adopt the segmentation program developed by the CKIP team of Academia Sinica to segment words [34]. Another difference between Chinese and English text processing is the need for stemming. Chinese words require no stemming in general. Stopword elimination could be applied to Chinese words as in English. However, unlike English stopwords, there is no standard stopword list available. In this work, we omit this process since we select only nouns as keywords. As in English case, the selected keywords are collected to build Chinese vocabulary VC.
Each Chinese document Cj is encoded into a vector Cj in the same manner as English. The size of Cj is just the
size of the vocabulary VC, i.e. |VC|.
3.3. GHSOM training
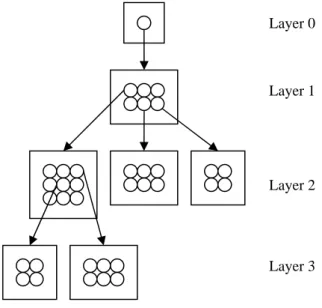
GHSOM is a neural network model modified from basic SOM. The major advantage of GHSOM is its hierarchical structure of expandable maps. A map could expand its size during training to achieve better result. Any neuron in the map could even expand to a lower level map when necessary. A schematic drawing of the
structure of a typical GHSOM is depicted in Figure 2. Layer 0 contains a single neuron which controls the development of the layers. This neuron expands to a new layer, layer 1, which contains 6 neurons in 2×3 format. The upper-right, lower-center, and lower-left neurons in layer 1 are further expanded to 3×3, 2×3, and 2×2 maps in layer 2, respectively. The expansion could proceed to lower layers.
Layer 0
Layer 1
Layer 2
Layer 3
Figure 2. A typical structure of GHSOM We briefly summarize the GHSOM training algorithm in the following.
Step 1. (Initialization step) Layer 0 contains a single neuron. The synaptic weight of this neuron, w0, is
initialized to the average value of the input vectors:
, 1 1 0
∑
≤ ≤ = N i i N x w (1)where xi is the ith training vector and N is the number of training vector. The mean quantization
error mqe0 is calculated as follow:
. 1 1 0 0
∑
≤ ≤ − = N i i N mqe x w (2)Step 2. (Map growing step) Construct a small SOM m, e.g. containing 2×3 neurons, below layer 0. This is layer 1. Train this layer by SOM algorithm in λ steps. Find the neuron which each training vector is labelled to. A training vector is labelled to a neuron if the synaptic weight of this neuron is closest to this vector. Calculate the mean quantization error of neuron n as follow:
, 1
∑
∈ − = n X i n i n n X mqe x w (3)where Xn is the set of training vectors that label to neuron n and wn is the synaptic weight vector of
neuron n. The mean quantization error of this map, denoted by MQEm, is the average of the mean quantization error of every neuron in this map. If MQEm exceeds a fixed percentage of mqe0, i.e.
MQEm ≥ τm×mqe0, a new row or a new column of neurons will be inserted to this SOM. This new
row or column is added in the neighbour of the error neuron e with the highest mqee. Whether a row
or a column is added is guided by the location of the most dissimilar neurons to e. The insertion of neurons is depicted in Figure 3. In this figure, a new row is added below error neuron e since its most dissimilar neuron, d, lies below it. The insertion process proceeds until MQEm < τm×mqe0.
e d
e
d before insertion after insertion
Figure 3. The insertion of neurons
Step 3. (Hierarchy expansion step) All neurons in the maps of a layer are examined to determine if they need further expansion to new maps in next layer. A neuron with large mean quantization error, i.e. an error greater than a percentage of mqe0, will expand to a new SOM in next layer. The percentage is
denoted by τu. When neuron i is selected to be expanded, the expanded SOM is trained using those
vectors labelled to i. Each new SOM could grow in the way described in Step 2. Step 4. Repeat Step 3 until no neuron in all maps of a layer needs expansion.
GHSOM complies with LabelSOM [35] technique to label each neuron with some important keywords. These keywords are used to identify the topic of those input vectors labelled to this neuron. Thus, a neuron in the hierarchy will be labelled by a set of keywords as well as a set of documents.
In this work, two kinds of training will be performed by GHSOM. The first kind, namely bilingual vector training, concatenates the vector of a Chinese document with the vector of its English counterpart to form the training vectors. That is, the encoded vectors for Ej and its counterpart Cj, which are Ej and Cj respectively, are
combined to form the bilingual vector BBj. Thus the size of BjB is the sum of those of Ej and Cj. A training document
for this kind of training, in effect, concatenates two parallel documents, which contains a Chinese document and its direct English translation. The other kind of training uses Ej and Cj individually to train GHSOM. We call such
training monolingual vector training. Two hierarchies will be constructed after monolingual vector training. On the other hand, only one hierarchy will be constructed by bilingual vector training.
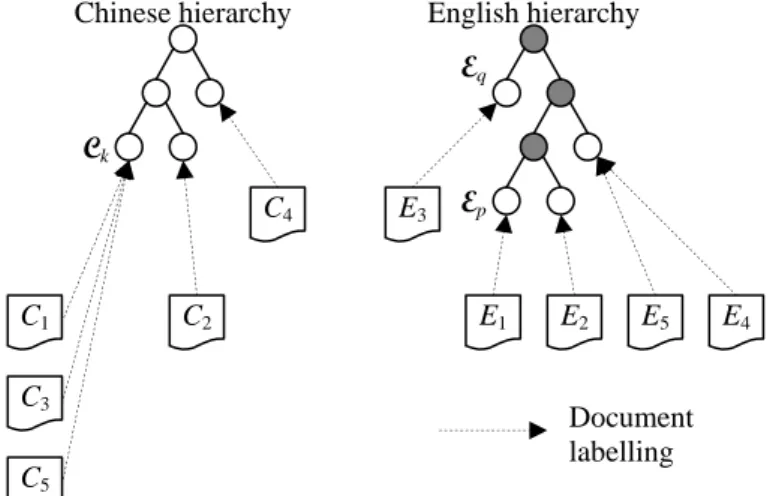
We introduce a measure to evaluate the quality of the constructed bilingual hierarchies. Let Ci be a Chinese
document and Ei be the English translation of Ci. We also define Ck and Ek be the document cluster associated with
neuron k in the Chinese hierarchy and English hierarchy, respectively. We calculate the mean inter-document path length between each pair of documents in Ck or Ek:
(
)
, 2 , dist 1 ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ = ≤∑
≤≤ k j i j i k k C C P C C (4)where function dist(Ci,Cj) returns the shortest path length between Ei and Ej, which are the translations of Ci and Cj, in the English hierarchy. An example is depicted in Figure 4. In the figure, Ck contains Chinese documents C1,
C3, and C5. Therefore, Pk is the average of dist(C1,C3), dist(C1,C5), and dist(C3,C5), which are the path lengths
between E1 and E3, E1 and E5, and E3 and E5, respectively. In this case, Pk = (4+3+3)/3 = 3.33. Note that although
we show two hierarchies in this figure, which are the results of monolingual vector training, the same approach can be applied to single hierarchy produced by bilingual vector training. The quality of the bilingual hierarchies can then be measured by the average of all Pk, denoted by Pk , over entire hierarchy. A small Pk means better
quality since it shows that the English translations of some related Chinese documents are also related. Note that the calculation of Pk could also be done in bilingual vector training, where only one hierarchy will be created. This
single hierarchy will be treated as both Chinese and English hierarchies whenever applicable.
k
P could also be used to align the monolingual hierarchies. Since GHSOM, as well as other SOM-based algorithm, uses random initial weights, the result could be varied for each training. To ensure that Chinese and English hierarchies have comparable result, we may generate Chinese hierarchy first and repeatedly generate
English hierarchies. The Pk between the Chinese hierarchy and the newly-created English hierarchy is then measured. We stop GHSOM training for English vectors as soon as Pk is lower than some threshold. When there is no English hierarchy could yield Pk that is lower than this threshold, the one with the lowest Pk should be
selected. Although this scheme will spend additional time in generating English hierarchy, we should apply it to ensure that both hierarchies are comparable and the discovered associations are accurate.
C1 C3 C5 C2 C4 E1 E2 E3 E4 E5 Ck Document labelling
Chinese hierarchy English hierarchy
Ep
Eq
Figure 4. An example of the bilingual hierarchies
4. Association discovery
As we have described in Sec. 3, hierarchies of bilingual corpora could be constructed by GHSOM training. In this section we will develop methods to discover various types of associations from these hierarchies. The methods for bilingual vector training and monolingual vector training will be discussed in Sec. 4.1 and 4.2, respectively. In Sec. 4.3 we will introduce the way we use these associations in MLIR.
4.1. Association discovery for bilingual vector training
A single hierarchy will be constructed when bilingual vector training is used. In this hierarchy, the labelled keywords for each neuron consist of both Chinese and English keywords. Likewise, the labelled documents of a neuron contain both Chinese and English documents. Three types of associations could be discovered, as will be described in the following.
4.1.1 Keyword associations
The association between keywords, no matter Chinese or English ones, could be derived directly from the labelled keywords of the same neuron. Since the labelled keywords of a neuron are considered representative for the themes of those documents labelled to this neuron, these keywords should be semantically related. We call these keywords a keyword cluster. Thus we may associate each keyword with every other keyword, no matter Chinese or English, in this keyword cluster and create bilingual keyword associations. We may also create weaker associations by allowing close clusters being related. For example, all cluster that have the same parent in the hierarchy could be considered related. Such associations should be weaker than those of the same cluster.
4.1.2 Document associations
Document associations could be discovered in the same manner as for the keyword associations. The documents labelled to the same neuron are considered related. Document associations will be created between each pair of documents within these documents. Weaker associations could also be created as for the keyword associations described in Sec. 4.1.1.
4.1.3 Document-keyword associations
The association between a document Dj and a keyword Ki could be easily defined by the locations of their
corresponding neurons in the hierarchy. Dj is associated with Ki (and vice versa) if they are labelled to the same
neuron in the hierarchy. Note that both Dj and Ki could be Chinese or English. Weaker associations could also be
created when Dj and Ki associate with nearby neurons, which, for example, are parent and children nodes in the
hierarchy.
4.2. Association discovery for monolingual vector training
When we use monolingual vector training for GHSOM, two hierarchies should be constructed, one for Chinese and one for English documents. These hierarchies reveal document and keyword associations for one language, which associations could be found in the same way described in Sec. 4.1. However, associations between documents or keywords of different languages are much difficult to find because there is no direct mapping between these hierarchies. In this section, we will develop methods to discover associations for multilingual documents and keywords.
4.2.1 Document and Keyword associations
To find the associations between keywords of different languages, we should map a neuron in one hierarchy to some neuron(s) in another hierarchy. Since the GHSOM, together with LabelSOM, will label a set of keywords on a neuron, this neuron forms a keyword cluster as mentioned above. Therefore, what we need is a way to associate a Chinese keyword cluster to an English keyword cluster. Actually, this problem is a kind of general problem of ontology alignment [36][37]. A simple solution is to translate these Chinese keywords into English and obtain their association. This is implausible here since we may not use any dictionary or thesaurus in all stages. What we should rely on are the trained hierarchies. A Chinese keyword cluster is considered to be related to an English one if they represent the same theme. Meanwhile, the theme of a keyword cluster could be determined by the documents labelled to the same neuron as it. Thus we could associate two clusters according to their corresponding document clusters. Since we use parallel corpora to train the GHSOM, the correspondence between a Chinese document and an English document is known a priori. We should use such correspondences to associate document clusters of different languages. To associate Ck with some English cluster El, we use a voting
scheme to calculate the likelihood of such association. For each pair of Chinese documents Ci and Cj in Ck, we
should find the neuron clusters which their English counterpart Ei and Ej are labelled to in the English hierarchy.
Let these clusters be Ep and Eq, respectively. The shortest path between them in the English hierarchy is also found.
A score of 1 is added to both Ep and Eq. A score of (dist( 1, )−1)
j iC
C is added to all other clusters on this path. The same
scheme is applied to all pairs of documents in Ck and the overall scores for all clusters in the English hierarchy are
calculated. We associate Ck with El when it has the highest score. When there is a tie in scores, we should
accumulate the largest score of their adjacent clusters to break the tie. If a tie still happens, arbitrary selection could be made. A possible choice is to select the cluster in the same or nearest layer of Ck since it may has similar
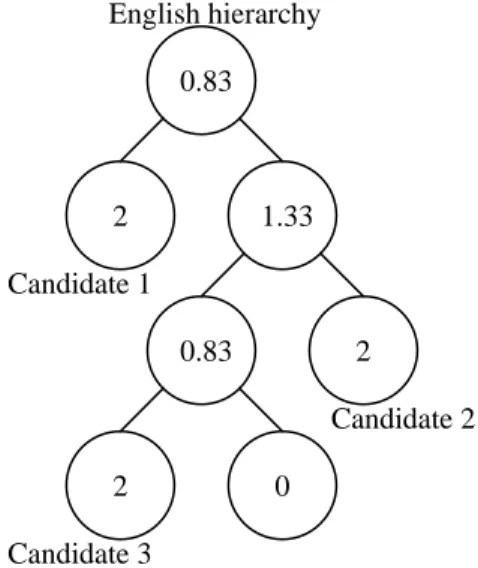
coverage of themes. We use Figure 4 as an example. The corresponding neuron clusters of C1 and C3 in the
English hierarchy are Ep and Eq, respectively. Thus the score of Ep is increased by 1. This is also true for Eq. The
other three clusters, which are shown in grey dots, are increased by 31. We also apply this scoring scheme for pairs (C1, C5) and (C3, C5). The final scores for every cluster are shown in Figure 5. According to the result, there
are three clusters having the highest score 2. To break the tie, the score of a candidate cluster is added by the score of its adjacent cluster. For example, the score of candidate 1 will increase by 0.83 and result in a total score of
2.83. The scores of candidate 2 and 3 will be 3.33 and 2.33, respectively. Therefore candidate 2 will be selected as the cluster associated with Ck in Figure 4.
The associations between documents can then be defined by such cluster associations. Chinese document Ci is
associated with English document Ej if their corresponding clusters are associated. For example, C1, C3, and C5 in
Figure 4 are associated with E4 and E5 since these two clusters are found to be related. In this example E1 and E3
are not associated with C1 and C3, which may betray common realization. This is because we intentionally
separate them in the English hierarchy for demonstration purpose. In real applications, however, these documents should be assembled nearby so associations between them should tend to be created. Likewise, the keyword associations are created according to the found cluster associations. A Chinese keyword labelled to neuron k in the Chinese hierarchy will be associated with an English keyword labelled to neuron l in the English hierarchy if Ck
and El is associated. Both document and keyword associations could be extended to include weaker associations as
described in Sec. 4.1. 0.83 2 1.33 2 2 0 0.83 English hierarchy Candidate 1 Candidate 3 Candidate 2
Figure 5. The scores of clusters in the English hierarchy in Figure 4 4.2.2 Document-Keyword associations
When cluster associations have been found as mentioned above, associations between documents and keywords, no matter in either language, could be easily defined. When Ck is associated with El, all documents and
keywords labelled to these two neurons are associated. This includes the association between a Chinese document and a Chinese keyword, association between an English document and an English keyword, association between a Chinese document and an English keyword, and association between an English document and a Chinese keyword.
4.3. MLIR applications
When a query is submitted, it is first preprocessed to a set of keywords Q as described in Sec. 3. The documents associated with query keyword q ∈ Q are retrieved according to the document-keyword associations found in Sec. 4.2. Both Chinese and English documents will be retrieved. We may also retrieve documents in each language when necessary. We will discuss the ranking mechanisms of both types of training in the following subsections.
4.3.1 MLIR using bilingual vector training
In bilingual vector training, a training vector contains elements for both Chinese and English keywords. Thus, an element of a neuron’s synaptic weight vector corresponds to a Chinese or an English keyword. For a query keyword q, its corresponding element in the synaptic weight vector is first obtained. The value of this element will then be used to calculate the ranking scores of documents. The ranking score of a document Dj is composed of two
components. The first is the cluster score, SC(q, Dj), which measures the importance of the cluster that Dj belongs
to. The other is the keyword score, SK(q, Dj), which measures the importance of q in document Dj. SC(q, Dj) is
defined as:
(
)
1 ) , ( 1 , + Δ = j D q j C q D S C C , (5)where Cq is the cluster that q is associated with, CDj is the cluster that Dj is associated with, and Δ
(
C ,q CDj)
measures the shortest path length between Cq and CDj. Note that if there are multiple clusters containing q, the
cluster Cq that is closest to CDj is used. SC(q, Dj) have a value of 1 if q and Dj both associate with the same cluster.
The value of SC(q, Dj) decreases when q and Dj associate with distant clusters in the hierarchy. SK(q, Dj) is simply
the value of the element corresponding to q in the document vector of Dj. Thus the ranking score of Dj in
responding to q is defined as:
SR(q, Dj) = SC(q, Dj) SK(q, Dj). (6)
A larger score means that the document should better meet the query. Basically, the documents in the cluster which is close to the one q is associated with will be ranked higher. For those in the same cluster, SK(q, Dj) allows
us to differentiate each document. Thus we perform coarse ranking and fine ranking with the help of SC(q, Dj) and SK(q, Dj), respectively.
4.3.2 MLIR using monolingual vector training
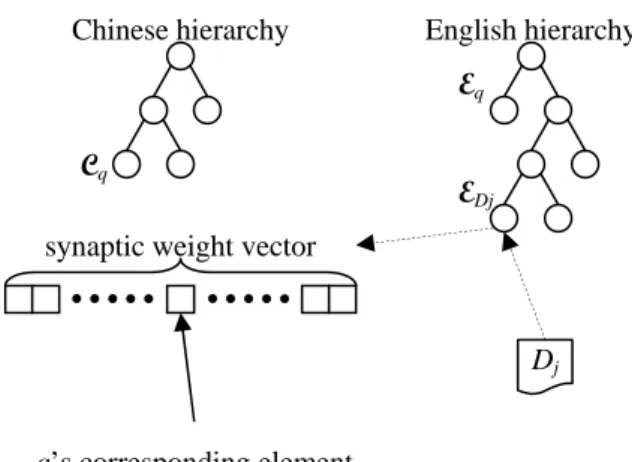
Two monolingual hierarchies are constructed for monolingual vector training. Monolingual information retrieval can be achieved by the same way described in Sec. 4.3.1. When query and target documents are in different languages, we should use the associations found in Sec. 4.2. Let Cq be the document cluster that a
Chinese query keyword q is associated with in the Chinese hierarchy. We also let Eq be the document cluster
which is associated with Cq in the English hierarchy. The ranking score of an English document Dj in responding
to q could also be defined by Eq. 6. However, SC(q, Dj) here is defined as:
(
)
1 ) , ( 1 , + Δ = j D q j C q D S E E , (7)where EDj is the document cluster associated with Dj in the English hierarchy. SK(q, Dj) is defined as the value of
the component corresponding to q in the synaptic weight vector of EDj. The ranking score of a Chinese document
in responding to an English query keyword is also calculated in the same way by exchanging the languages of the query and document. Figure 6 depicts the calculation of SC(q, Dj) and SK(q, Dj). In this figure, SC(q, Dj) will be 0.2
since the length between Eq and EDj is 4. SK(q, Dj) will be equal to the value of q’s corresponding element in the
Dj
Cq
Chinese hierarchy English hierarchy
EDj
Eq
q’s corresponding element synaptic weight vector
Figure 6. The calculation of ranking score in monolingual vector training
5. Experimental Result
5.1. Document collection and processing
We constructed the parallel corpora by collecting parallel documents from Sinorama corpus. The corpus contains segments of bilingual articles of Sinorama magazine. An example article is shown in Figure 7. An advantage of this corpus is that each Chinese article was faithfully translated into English. We collected two sets of parallel documents in our experiments. Each document is a segment of an article. The first set, denoted as Corpus-1, contains 976 parallel documents. The other set, denoted as Corpus-2, contains 10672 parallel documents. Each Chinese document had been segmented into a set of keywords though the segmentation program developed by the CKIP team of Academia Sinica. The program is also a part-of-speech tagger. We selected only nouns and discarded stopwords. As a result, we have vocabularies of size 3436 and 12941 for Corpus-1 and Corpus-2, respectively. For English documents, common segmentation program and part-of-speech tagger are used to convert them into keywords. Stopwords were also removed. Furthermore, Porter’s stemming algorithm [38] was used to obtain stems of English keywords. Finally, we obtained two English vocabularies of size 3711 and 13723 for Corpus-1 and Corpus-2, respectively. These vocabularies were then used to convert each document into a vector, as described in Sec. 3.2. Both bilingual vectors and monolingual vectors were constructed.
Figure 7. An example bilingual document in the Sinorama corpus
5.2. GHSOM training
5.2.1 Bilingual vector training
We used the GHSOM program developed by Rauber’s team2 to train the bilingual vectors. The GHSOM initially contains a 2×2 map in layer 1. Parameters τm and τu are set to 0.18 and 0.02, respectively. For
demonstration purpose, we will only depict the result of using Corpus-1 for training in the following examples. Figure 8(a) depicts the result of the layer 1. The map had grown to a 3×2 map. It is clear that GHSOM could label similar keywords together. For example, the upper-left neuron contains keywords related to Taiwan, mainland China, Dongguan (a city in southern China), and business. The lower-left neuron contains only two keywords, which are Macau and its Chinese translation, ‘澳門’. The lower-right neuron contains keywords about art. This neuron is further explored to layer 2, which is shown in Figure 8(b). We should observe that all 6 neurons in Figure 8(b) have the same theme, which is art of their parent neuron. We linked a Chinese keyword to its direct English translation if available. We can see that many direct translations, as well as other related keywords, could be found in the same cluster.
The quality of the constructed bilingual hierarchy is evaluated by the average of mean inter-document path length defined in Sec. 3.3. In our experiment, Pk= 1.17, which means that most pairs of the parallel documents locate close in the hierarchy. We also conducted an experiment to observe the distribution of P . We performed k
2
100 trainings for Corpus1 and Corpus-2, respectively, and obtained an average value of 1.82 and 2.54 for P , k
respectively. We believe that these experiments exhibit the capability of GHSOM in creating multilingual hierarchies.
(a) (b)
Figure 8. (a) The layer 1 map of bilingual vector training for Corpus-1 (b) The layer 2 map extended from the lower-right neuron of (a)
5.2.2 Monolingual vector training
The same GHSOM parameters as Sec. 5.2.1 are used to train monolingual vectors. We also use the Pk control scheme described in Sec. 3.3 to ensure the generated Chinese and English hierarchies are comparable. The
threshold value was set to 1.5.
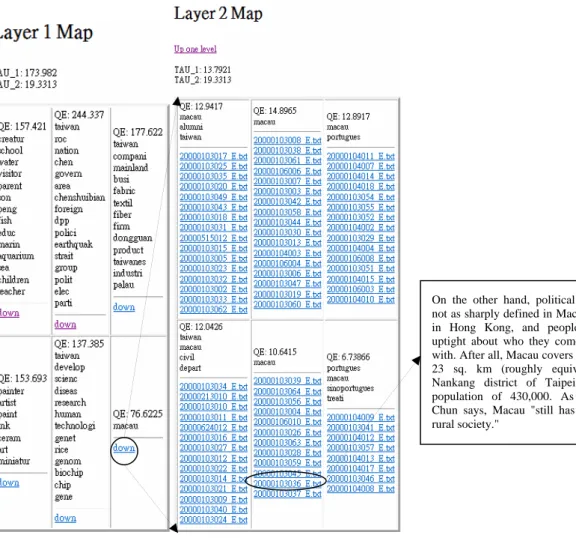
Figure 9 and Figure 10 depict parts of the Chinese and English hierarchies, respectively. For demonstration purpose, we trace links in these hierarchies in these figures to demonstrate the capability of GHSOM in organizing documents. We traced links with topic ‘Macau’, which Chinese translation is ‘澳門’, in both hierarchies. The traced links are circled and expanded to maps in the next layer. We also show the contents of two corresponding documents, namely ‘20000106004_C.txt’ and ‘20000106004_E.txt’. The filename convention makes it easier to correlate a Chinese document to its English counterpart. The Pk value for these hierarchies is 1.45, which is
higher than that in bilingual vector training. However, we could reduce Pk value by choosing a smaller threshold, which may cost much time. As in Sec. 5.1.1, we also computed the average value of P over 100 trainings for k
Corpus-1 and Corpus-2, respectively. We obtained a value of 2.39 and 3.65, respectively, without setting any threshold. 但 話 說 回 來 , 總 面 積 二 十 三 平 方 公 里 (相當於台北南港區大)、人口四十三 萬 的 澳 門 , 「 還 保 有 著 農 業 社 會 的 味 道」,梁金泉說,人與人之間的關係沒 那麼緊張,左中右派的分界也不像香港 這麼明顯。
On the other hand, political divisions are not as sharply defined in Macau as they are in Hong Kong, and people are not so uptight about who they come into contact with. After all, Macau covers an area of just 23 sq. km (roughly equivalent to the Nankang district of Taipei) and has a population of 430,000. As Leong Kam Chun says, Macau "still has the feel of a rural society."
Figure 10. A part of English hierarchy
5.3. MLIR experiments
We developed a simple search engine to evaluate the performance of our method in MLIR. To evaluate the effectiveness of the proposed method in MLIR, classic recall and precision measures [1] were used. We used 31 query keywords, including 19 Chinese and 12 English keywords, in the experiments. Each query keyword was sent to the search engine to perform multilingual retrieval tasks for both corpora. The results for two kinds of training are shown in the following subsections.
5.3.1 MLIR using bilingual vector training
The calculations of recall and precision require the definition of ‘correct answers’, i.e. truly relevant documents, for each query. Many approaches have been devised to determine such correct answers. One of the main approaches is to use human experts to have the decisions. However, this approach requires much cost and prohibits its use on large data set. In this work, we use a simple rule to determine the correct answers. All documents in the clusters of a hierarchy with this query keyword as a label are considered as relevant documents. We limit the clusters under consideration to those of leaf nodes in the hierarchy. For example, all documents in layer 2 in Figure 10 are relevant documents to keyword ‘macau’ since all 6 clusters have label ‘macau’ and are leaf nodes. The precision versus recall curves for all sample queries using Corpus-1 and Corpus-2 are depicted in Figure 11 and Figure 12, respectively. The thick lines depict the average of all curves. Both figures show good
results. The result for Corpus-1 is better since the documents are much coherent than those in Corpus-2 and are likely to create better hierarchies.
Precision versus recall curve for Corpus-1
0 10 20 30 40 50 60 70 80 90 100 0 10 20 30 40 50 60 70 80 90 100 Recall P reci si on 纖維 south africa 東莞 紡織業 成衣 palau 水稻 gene disease 生物 晶片 aquarium earthquake children 老師 九份 紀念碑 human right 兩岸 garbage president 選舉 邦交 外交 macau museum 達文西 陶瓷 美術 印象派 水墨畫 Average Figure 11. The precision versus recall curves of all queries for Corpus-1
Precision versus recall curve for Corpus-2
0 10 20 30 40 50 60 70 80 90 100 0 10 20 30 40 50 60 70 80 90 100 Recall Pr ec is io n 纖維 south africa 東莞 紡織業 成衣 palau 水稻 gene disease 生物 晶片 aquarium earthquake children 老師 九份 紀念碑 human right 兩岸 garbage president 選舉 邦交 外交 macau museum 達文西 陶瓷 美術 印象派 水墨畫 Average Figure 12. The precision versus recall curves of all queries for Corpus-2
5.3.2 MLIR using monolingual vector training
As described in Sec. 5.3.1, we should first define the correct answer to a query. Let Cq be the document cluster
is associated with Cq in the English hierarchy. The correct answers corresponding to q are those documents
labelled to either Cq or Eq. Such definition is also applied to English queries as we change the roles of Cq and Eq.
The precision versus recall curves for Corpus 1 and Corpus 2 are depicted in Figure 13 and Figure 14, respectively. These figures show that monolingual vector training outperforms the bilingual vector training.
Precision versus recall curve for Corpus-1
0 10 20 30 40 50 60 70 80 90 100 0 10 20 30 40 50 60 70 80 90 100 Recall P reci si on 纖維 south africa 東莞 紡織業 成衣 palau 水稻 gene disease 生物 晶片 aquarium earthquake children 老師 九份 紀念碑 human right 兩岸 garbage president 選舉 邦交 外交 macau museum 達文西 陶瓷 美術 印象派 水墨畫 Average Figure 13. The precision versus recall curves for Corpus 1
Precision versus recall curve for Corpus-2
0 10 20 30 40 50 60 70 80 90 100 0 10 20 30 40 50 60 70 80 90 100 Recall P reci si on 纖維 south africa 東莞 紡織業 成衣 palau 水稻 gene disease 生物 晶片 aquarium earthquake children 老師 九份 紀念碑 human right 兩岸 garbage president 選舉 邦交 外交 macau museum 達文西 陶瓷 美術 印象派 水墨畫 Average Figure 14. The precision versus recall curves for Corpus 2
6. Conclusions
In this work we proposed a text mining method to extract associations between multilingual texts and use them in multilingual information retrieval. Documents written in different languages were first clustered and organized into hierarchies using growing hierarchical self-organizing map model. Bilingual documents from parallel corpora are either concatenated or separated to train the maps. Two discovery processes are then applied on the training results to mine the associations between bilingual keywords as well as documents. We used these associations to perform multilingual information retrieval tasks and obtained acceptable result.
The major contribution of this work is the development of multilingual association mining techniques. Since the associations between elements of different languages are difficult to automatically discovered, our full automatic approach may greatly reduce the effort of human beings in translating documents into one language to perform multilingual information retrieval and make it plausible for modern information resources such as the Web. In fact, what we proposed is a method that can be used to find the associations between two sets of elements that have been organized into hierarchies. We will explore this method further for various hierarchy generation methods as well as different types of elements other than texts, for example, images.
A limitation of our method in MLIR is that we can only use those labels in the hierarchies as queries. Since the GHSOM only labels important keywords on the generated hierarchies, we can only use these keywords to find the associations and retrieve documents. Two approaches could be adopted to remedy this insufficiency. The first is to adjust the parameters in GHSOM training to allow more labelled keywords. However, this may reduce the representability of the labelled themes and the clarity of the hierarchies. The other approach is to use some kinds of thesaurus to expand the queries. We believe that the latter approach should be better to overcome such deficiency.
Another limitation of our method comes from the need of parallel corpora. We need the knowledge of the correspondences between different language documents to discover the associations. When parallel corpora are not available, comparable corpora could also be used as long as the correspondence between documents could be defined. When both parallel and comparable corpora are unavailable, we may also apply another correspondence discovery process to find such correspondence prior to our method. However, this is beyond the scope of this work as we will not go further here.
7. References
[1] R. R. Korfhage, Information Storage and Retrieval (Wiley Computer Publishing, New York, 1997).
[2] R. G. Gordon, Jr. (eds), Ethnologue: Languages of the World, Fifteenth edition (SIL International, Dallas, 2005).
[3] Internet World Stats, Top Ten Languages Used in the Web (2007). Available at:
http://www.internetworldstats.com/stats7.htm (accessed 30 July 2007).
[4] R. Feldman, I. Dagan, and H. Hirsh, Mining text using keyword distributions, Journal of Intelligent Information Systems 10 (1998) 281-300.
[5] S. Kaski, T. Honkela, K. Lagus, and T. Kohonen, WEBSOM-self-organizing maps of document collections, Neurocomputing, 21 (1998) 101–117.
[6] D. W. Oard and B. J. Dorr, A Survey of Multilingual Text Retrieval, Technical Report UMIACS-TR-96-19, (University of Maryland, Institute for Advanced Computer Studies, 1996).
[7] L. Ballesteros and W. B. Croft, Dictionary-based methods for cross-lingual information retrieval, Proceedings of the 7th International DEXA Conference on Database and Expert Systems Applications, (1996) 791-801.
[8] H. H. Chen, C. C. Lin, and W. C. Lin, Construction of a Chinese-English WordNet and its application to CLIR, Proceedings of 5th International Workshop on Information Retrieval with Asian Languages, (Hong Kong, 2000) 189-196.
[9] C. Fluhr, Survey of the state of the art in human language technology, (Center for Spoken Language Understanding, Oregon Graduate Institute, 1995) 291-305.
[10] M. Tallving and P. Nelson, A question of international accessibility to Japanese databases, In: D. I. Raitt (ed.), 14th International Online Information Meeting Proceedings, (Oxford, Learned Information, 1990) 423-437.
[11] J. S. McCarley, Should we translate the documents or the queries in cross-language information retrieval?, In: Proceedings of the 37th Annual Meeting of the Association for Computation Linguistics, (1999) 208-214. [12] D. A. Hull and G. Grefenstette, Querying across languages: a dictionary-based approach to multilingual
information retrieval, In: Proceedings of the 19th International Conference on Research and Development in Information Retrieval, (1996) 49-57.
[13] M. W. Davis, New experiments in cross-language text retrieval at NMSU’s Computing Research Lab, In: Proceedings of TREC 5, (1997) 447-454.
[14] L. Ballesteros and W. B. Croft, Phrasal translation and query expansion techniques for cross-language information retrieval, Working Notes of AAAI-97 Spring Symposiums on Cross-Language Text and Speech Retrieval, (1997) 1-8.
[15] P. Thompson and C. Dozier, Name searching and information retrieval, In: C. Cardie and R. Weischedel (eds.) Proceedings of Second Conference on Empirical Methods in Natural Language Processing, (Association for Computational Linguistics, Somerset, New Jersey, 1997) 134-140.
[16] C. Peters and E. Picchi, Across languages, across cultures: Issues in multilinguality and digital libraries, D-Lib Magazine (1997). Available at: http://www.dlib.org/dlib/may97/peters/05peters.html (accessed 31 July 2007)
[17] G. Salton, Automatic processing of foreign language documents, Journal of the American Society for Information Science, (1970) 187-194.
[18] H. H. Chen, J. J. Kuo, and T. C. Su, Clustering and visualization in a multi-lingual multi-document summarization system, In: Proceedings of 25th European Conference on Information Retrieval Research, Lecture Notes in Computer Science, LNCS 2633, (Pisa, Italy, 2003) 266-280.
[19] R. D. Brown, Example-based machine translation in the Pangloss system, In: Proceedings of the 16th International Conference on Computational Linguistics (Copenhagen, Denmark, 1996) 169-174.
[20] K. H. Chen and H. H. Chen, A part-of-speech-based alignment algorithm, In: Proceedings of 15th International Conference on Computational Linguistics, (Kyoto, Japan, 1994) 166-171.
[21] M. W. Davis and T. Dunning, A TREC evaluation of query translation methods for multi-lingual text retrieval, In: D. K. Harmon (ed), Proceedings of TREC-4. (Gaithesburg, MD, 1996) 483-497.
[22] P. Sheridan and J. P. Ballerini, Experiments in multilingual information retrieval using the SPIDER system, In: Proceedings of the 19th ACM SIGIR Conference on Research and Development in Information Retrieval, (1996) 58-65.
[23] R. Chau and C. H. Yeh, A multilingual text mining approach to web cross-lingual text retrieval, Knowledge-Based Systems 17(5-6) (2004) 219-227.
[24] C. H. Lee and H. C. Yang, A multilingual text mining approach based on self-organizing maps, Applied Intelligence 18(3) (2003) 295-310.
[25] A. Rauber, D. Merkl, and M. Dittenbach, The growing hierarchical self-organizing map: exploratory analysis of high-dimensional data, IEEE Transactions on Neural Networks 13 (2002) 1331-1341.
[26] T. Kohonen, Self-Organizing Maps (Springer, Berlin, 2001).
[27] D. Merk, Text classification with self-organizing maps: some lessons learned, Neurocomputing 21(1-3) (1998) 61-77.
[28] T. Kohonen, S. Kaski, K. Lagus, J. Salojärvi, J. Honkela, V. Paatero, and A. Saarela, Self organization of a massive document collection, IEEE Transactions on Neural Network 11(3) (2000) 574-585.
[29] D. Alahakoon, S. K. Halgamuge, and B. Srinivasan, Dynamic self-organizing maps with controlled growth for knowledge discovery, IEEE Transactions on Neural Networks 11(3) (2000) 601-614.
[30] R. Miikkulainen, Script recognition with hierarchical feature maps, Connection Science 2 (1990) 83-101. [31] J. Y. Shih, A study of applying ghsom on expertise management, In: Proceedings of the 10th Joint
Conference on Information Sciences, (Salt Lake City, Utah, 2007) 621-627.
[32] G. L. Liao, T. L. Shi, and Z. R. Tang, Gearbox failure detection using growing hierarchical self-organizing map, In: Proceedings of International Conference on Fracture and Damage Mechanics VI, (Madeira, Portugal, 2007) 177-180.
[33] G. Salton, Automatic Text Processing: the Transformation, Analysis, and Retrieval of Information by Computer, (Addison-Wesley, Reading, 1989).
[34] K. J. Chen, M. H. Bai, Unknown word detection for Chinese by a corpus-based learning method, International Journal of Computational linguistics and Chinese Language Processing 3(1) (1998) 27-44. [35] A. Rauber, LabelSOM: On the labeling of self-organizing maps, In: Proceedings of the International Joint
Conference on Neural Networks, (Washington, DC, 1999) 3527-3532.
[36] M. Ehrig, J. Euzenat, State of the Art on Ontology Alignment, (Knowledge Web Deliverable 2.2.3, University of Karlsruhe, 2004).
[37] A. V. Zhdanova, J. de Bruijn, K. Zimmermann, and F. Scharffe, Ontology Alignment Solution D14 v2.0, (Institute of Computer Science, University of Innsbruck, 2004).