應用遺傳程式規劃之影像自動分類系統
8
0
0
全文
(2) Simultaneous Autoregressive (MSAR) 模型與 Shift-Invariant DCT 的係數來得出不同的特 徵向量,進而使用 k-nearest neighbor 等分類 演算法進行影像分類。其它方法如例用 Probabilistic Reasoning [9] 與 Sequential Resolution Nearest Neighbor (SRNN) [8]等。 在本篇論文㆗,我們針對不特定範圍 (domain)的㆒般影像特徵向量設計㆒具學習 能力的分類函數學習系統,對於任何不同影 像擷取演算法所擷取出來之影像物件特徵向 量,皆能有效㆞自動學習出最適當的分類函 數並準碓㆞進行分類,而不必擔心如何計算 特徵向量間相似度的問題。我們主要所使用 的學習方法為遺傳程式規劃演算法(Genetic Programming),遺傳程式規劃是㆒種自動調 整的演算法,能夠動態㆞依照不同的密合度 (fitness)來找尋最符合需求的函數,因此, 利用遺傳程式規劃演算法的特性,當影像物 件經由特徵的擷取並以多維度特徵向量來表 示之後,我們即可利用遺傳程式規劃演算法 來學習並產生出對應於每個影像類別的分類 函數,而經由這些分類函數,可以使我們的 系統達成高分類準確率的目標。 本篇論文的結構如㆘:第㆓節㆗將簡單 介紹遺傳程式規劃的基本步驟與方法,第㆔ 節介紹我們所用以展示的影像資料集合、影 像分類系統架構與分類函數之動態訓練法, 第㆕節說明分類實驗與所得到的結果,最後 則是結論與未來的研究方向。. 2. 遺傳程式規劃演算法 將遺傳的操作方式帶入資訊工程應用的 是遺傳演算法(Genetic algorithm),遺傳演 算法是將參數做編碼的動作,然後將編碼後 的碼代入函數做運算,目的是求出更佳的函 數值;經由對編碼後的參數做複製 (Reproduction)、交配(Crossover)與突變 (Mutation)的動作,可以將參數做進化,於 是在淘汰掉某些表現不佳的參數後,代入有 最佳表現的參數後,即可得出最佳的解。 遺傳程式規劃(Genetic programming, 或稱遺傳規劃)是由 J. R. Koza 在 1989 年所 提出的㆒種自動函數產生方法,它能由給定 的參數,自動的找出能符合這些參數的函 數。和遺傳演算法㆒樣,遺傳程式規劃利用 了遺傳演化的概念,包含了複製、交配與突 變等操作方法。而經由演化的方式,可以逐 次得到最佳的函數。然而遺傳程式規劃與遺 傳演算法所適用的問題不同,遺傳演算法所 求的是最佳解(Optimum solution),但是遺 傳 程 式 規 劃 所 求 的 是 最 佳 函 數 ( Fitness function)。相對於對參數做改變的遺傳演算. 法,遺傳程式規劃的參數是固定的,然後對 函數的多項式做演化運算,將函數的部份多 項式保留或淘汰,使得經由進化的動作,找 到能夠符合我們給定的參數的函數。 遺傳程式規劃的輸出為㆒函數運算式 (Functional expression) ,它將我們所輸入的 資料屬性加以運算成為㆒個數值,函數㆗可 以使用各種不同的運算元,例如:+、-、 × 與÷ ,甚至 IF、ELSE 與 OR 等邏輯判斷與 Sine、Cosine 等㆔角函數。然後以㆓元樹的 資料結構來表示運算式,㆒棵㆓元樹即為㆒ 個函數個體(Individual) ,使用者可以決定這 棵樹的深度,樹葉的內容為資料屬性或常數 運算元。許多㆓元樹將形成㆒個族群 (Population),同樣的,使用者可以決定族 群的數目。遺傳程式規劃的進化準則在於合 適度(Fitness)的設定,亦即以個體的表現 如何來決定個體是否需要進化,所以遺傳程 式規劃最重要的㆒個環節就是設計合適度的 判斷方式與程序。 遺傳程式規劃的初始化是隨機產生足夠 的㆓元樹族群,這些族群㆗的㆓元樹將會經 由複製(Reproduction) 、交配(Crossover) 與突變(Mutation)等過程來演化出更符合 要求的㆘㆒代函數,遺傳程式規劃的主要流 程如圖 1 所示。主要演化㆘㆒代新個體的方 法說明如㆘: 複製:是選擇具有較優良表現的個體給予保 留,然後複製同樣的個體到新的族群。 交配:為選擇㆓個個體後,隨機產生㆒個交 配點(Crossover point) ,將這兩個個體 從交配點後的子樹做交換,於是產生 ㆓個新的個體,如圖 2 所示,運算式 (5+X)+X 與(X+X)-2 經由交配後得到 兩個新的運算式:(X+X)+X 與(5+X)-2。 突變:有兩種主要的做法,㆒種是單點突變, 即直接對某㆒節點以新的內容取代, 如圖 3,運算式(5+X)+X 經由突變後得 出新運算式:(5-X)+X。另㆒種是子樹 突變,則是將個體的某個節點的子樹 以㆒棵新的、隨機產生的子樹取代。 突變可以產生新的個體,以避免區域 最佳值(Local optimum)的產生,如 圖 4,運算式(5+X)+X 突變後為(7+X)。 遺傳程式規劃可以經由增加或減少㆓元 樹節點或樹末終端的方法來去除不必要的資 料屬性,例如:假設我們輸入的資料屬性數 目為 19,則在遺傳程式規劃輸出的運算式 裡,可能只出現 8 個特徵向量,亦即有 11 個 資料屬性的值是無意義或是不重要的,並不 能做為分類的判斷,在影像物件特徵向量維 度較高的時候,這種選擇重要特徵的優點將 能使分類函數處理在運算時,處理較少的特.
(3) 徵,進而快速㆞得出分類結果。. 世代數 Gen=0. 結束. 隨機建立初始族群 是. 顯示結果. 滿足停止條件? 否 變數 I 初始為 0. Gen=Gen+1. 是. 計算族群個體的合適度. I 等於族群數? 否. 依機率選擇不同遺傳運算. Pm. Pr. Pc. 隨機選擇㆒個個體. 依 Fitness 選擇㆒個個體. 依 Fitness 選擇兩個個體. 選定突變點. 執行複製. I 加1. 依突變類型執行突變運算. 複製到新的族群. 執行交配. I加1. 插入兩個個體到新族群. 插入新個體到新族群. 圖 1: 遺傳程式規劃流程圖. 圖 2: 交配運算. 圖 4: 子樹突變. 3. 影像自動分類系統 本節㆗首先我們將提出㆒個影像分類系 統架構,並詳述如何使用遺傳規劃演算法應 用在影像分類。. 圖 3: 突變運算. 3.1 影像分類之系統架構 在這㆒節,我們將對我們所提出之影像 分類系統架構做㆒說明。對於㆒已知類別的 影像物件,我們將其稱為樣本影像物件,經 過影像特徵擷取(Feature extract)的處理之.
(4) 後,樣本影像物件將以多維向量表示。對於 所有影像所擷取出之特徵向量,我們建立㆒ 資料庫,將所有特徵向量向量儲存在特徵資 料庫(Feature DB)㆗,而將樣本影像物件儲 存於媒體資料庫(Media DB) ,而樣本影像物 件的類別與檔名等資訊則儲存在資訊資料庫 (Information DB)。 然後,所有在特徵資料庫㆗的影像特徵 向量將被視為訓練資料(Training Data),而 訓練資料將應用在遺傳程式規劃㆗以得出對 應於各類別之分類函數。在利用遺傳程式規 劃並得到每個類別的函數之後,我們建立㆒ 資料庫稱為函數資料庫(Function DB) ,並將 分類函數儲存於函數資料庫㆗,以便於分類 時取出使用。 我們的系統流程介紹如㆘。於使用者介 面㆗,在使用者輸入㆒個未知類別的影像物 件之後,經過特徵擷取演算法處理,將得到 影像物件之特徵向量,然後將各分類函數由 函數資料庫㆗取出,對此特徵向量進行運 算,經過各分類函數的運算與判斷之後,此 影像物件的類別將被決定,於是可以此影像 物件分類至適當類別,並將此影像物件儲存 於媒體資料庫㆗,特徵向量與其它資料則分 別儲存於特徵資料庫與資訊資料庫。最後系 統將會顯示分類結果於使用者介面。 在媒體資料庫的影像增加之後,分類函 數可能發生分類率㆘降的問題,此時可經由 系統的函數資料庫與特徵資料庫,對所有分 類函數再次進行遺傳程式規劃,使得各類別 之分類函數能保持高度的分類準確率。. 首先我們定義影像的類別共有 K 類,每 張影像物件可表示為 n 維特徵向量,而 K 個 類別則可表示成集合 C C = {C1, C2, …, CK}, 其㆗ C1, C2, …, CK 分別代表第 K 類的影像物 件。對於用來代表影像物件的影像特徵向 量,在擷取後則表示為: xjt = (vj1, vj2, …, vjt, …vjn) 其㆗ 1 ≤ t ≤ n,vjt ∈ R 代表影像物件 xj 之特徵 向量的第 t 個特徵。 將已知類別的影像物件,即樣本影像物 件,稱之為訓練資料(training data),以 TR 表示,而欲分類之未知類別的影像物件,稱 為測試資料(testing data)。假設 TR 的資料 個數|TR| = m,TR ㆗的每㆒個影像物件 xj 均 對應到已知類別其㆗的㆒類。我們將其表示 為 <xj, cj>, 1 ≤ j ≤ m, cj ∈ C TR 則可表示為 TR = {<xj, cj>| xjt=(vj1, …vjn), 1≤ j ≤m,cj∈C} 然後我們可以定義分類函數 fi 為對應類 別 Ci 且由 Rn 對映至 R 的函數: fi : Rn → R 對於給定的常數 a 與訓練集合㆗影像特 徵向量<xj, cj>,分類函數 fi 必須能滿足以㆘ 條件:. f i ( x j ) ≥ a, if c j = ci ,1 ≤ i ≤ k ,1 ≤ j ≤ m f i ( x j ) < a, if c j ≠ ci. 圖 5: 影像自動分類系統架構. 3.2 問題定義 在這㆒節,我們將分類問題與我們所使 用的符號做正式的定義。. 也就是說,以給定之常數 a 做為判斷之 準則,若對於 cj = Ci 之影像特徵向量 xj,分 類函數 fi 能夠將此影像特徵向量對映至㆒個 大於 a 之實數,則我們說分類函數 fi 分類正 確;若 cj ≠ Ci,則分類函數 fi 應該能正確㆞得 出㆒小於 a 的實數。對於所有的分類函數, 我們定義㆒個分類函數集合 F,並將其表示 為 F = {fi | fi : Rn → R, 1 ≤ i ≤ K}. 3.3 分類函數之動態遞增訓練法 我們在遺傳程式規劃對訓練資料作訓練 的過程,並非㆒次即將全部的資料給予訓 練,而是採用漸進式遞增資料的訓練。首先,.
(5) 我們定義動態遞增訓練法所需要的變數 g, m’, p, w 與 r;g 是㆒整數,為每次動態遞增訓練 法所進行的世代數,p 為㆒實數且 0 < p < 1, w 是㆒個實數,用以判斷分類函數的密合度 (Fitness)優劣,最後定義 r 是㆒個整數,用以 調整動態遞增訓練法所增加的訓練資料筆 數。在初始階段,我們設定 m’=0,r=1,然 後初始的訓練資料項目數,將其設定為 m’×p×r,在遺傳程式規劃每經過 g 個世代之 後,我們判斷所得出的分類函數之密合度是 否優於 w,若是,則將 r 的值增加。然後, 我 們 將 參 與演 化 的 訓 練資 料 筆 數 m’加 ㆖ m’×p×r,重覆以㆖步驟直到訓練資料全部訓 練完為止。詳細的動態遞增訓練法之步驟整 理如㆘: 步驟㆒: 設定 g, p, w 之初始值, 令 r = 1 且 m’ = 0。 步驟㆓: 設 m’ = m×p×r + m’,若 m’ ≥ m,則 m’ = m。 步驟㆔: 進行遺傳程式規劃,世代數為 g。 在 g 個世代結束之後,我們將得到 ㆒個分類函數。 步驟㆕: 若 m’=m,則所得到的分類函數為 最後結果,輸出此函數並停止動態 遞增訓練法。否則執行步驟五。 步驟五: 利用密合度函數計算所得到之分 類函數的密合度,若此分類函數的 密合度優於設定的 w,則增加 r 的 大小。否則 r 為 1。回步驟㆓。 在挑選訓練資料時,通常必須包含正例 與負例,才能達到訓練目的,對於正例資料 必須能正確㆞辦認(Recognize),而對於負 例資料,必須要能正確㆞排除(Discard) 。我 們將正負例之定義如㆘:對於㆒個影像物件 <xj, cj> ∈ TR,1 ≤ j ≤ m,對於某㆒類別 Ci, 若 cj = Ci,則我們稱影像物件<xj, cj>為類別 Ci 之正例,反之,若 cj ≠ Ci,則此影像物件 稱為類別 Ci 之負例。 3.4 密合度的判斷 在遺傳程式規劃㆗,㆒個分類函數是族 群㆗的㆒個個體,而對於個體的密合度,是 以㆒密合度函數來計算,在本論文㆗,我們 所設計的密合度函數是基於誤差度量的方式 的完成。考慮類別 Ci 之分類函數 fi,依 3.2 節所述,若影像物件<xj, cj>是正例,則我們 期望 fi(xj) ≥ a,而若<xj, cj>屬於負例資料,則 希望 fi(xj) < a。為達成此要求,我們另外設定 了兩數α與β,令α > a,β < a,且α + β = 2a。 對於正例資料,定義密合度誤差 Dpositive 為: If cj = Ci and fi(xj) ≥ a, Dpositive = 0, If cj = Ci and fi(xj) < a, Dpositive = [α- fi(xj)]2.. 對於負例資料,定義密合度誤差 Dnegative 為: If cj ≠ Ci and fi(xj) ≥ a, Dnegative = [ fi(xj)- β]2, If cj ≠ Ci and fi(xj) < a, Dnegative = 0. 然後,個體的密合度定義為 Fitness,為 正例密合度誤差與負例密合度誤差的總合。 Fitness = -Dpositive+Dnegative 由以㆖的密合度誤差,我們即可判斷在 所有族群當㆗,何者表現較好,何者表現較 差,在進行遺傳運算的交配運算、突變運算 與複製等演化動作時,給予誤差小、表現好 的個體較大的被選擇機率,而對於誤差大、 表現不好的個體,則給予較低的被選擇機 率,於是較佳的個體較有可能被演化,進而 在新㆒代的族群產生較佳的新個體,然後進 行㆘㆒次的評估,最後即可得到密合度最佳 的個體,而此個體即為我們所需要的分類函 數。. 4. 實驗 為了展示自動化影像分類系統,我們使 用 UCI 影像資料集 Image Segment[1] 來做為 我們系統的測試與展示。Image Segment 資料 分為兩個資料集合,第㆒個資料集合是訓練 資料,用以得出合適的分類函數,而第㆓個 資料集合則是供分類函數測試其分類準確率 之測試資料。Image Segmentation Data 共有 7 個類別,分別是 brickface、sky、foliage、 cement、window、path 與 grass,在訓練資料 集合㆗,各類別之影像物件數目為 30 筆,共 210 筆,而測試資料集合㆗各類別含 300 筆, 共 2100 筆。每㆒筆影像萃取出 19 個特性形 成特徵向量來表示。各特徵的萃取方法及所 代表的意義如列於表㆒之說明。 我們使用 GP Quick 2.1[10]來做為實驗 的工具,並修改部份程式碼內容以符合實驗 ㆖的需求,使用的參數如表 2 所示,而資料 項目的 19 個屬性值以 F1、F2、…F19 來表 示。在密合度函數㆗,使用的參數定義為:α = 100,β = -100,a = 0,在動態遞增訓練法㆗, 參數設定為 g = 500,p = 0.1, r = {1, 2},w = 0。實驗流程如圖 6 所示。 為了評估分類函數的分類準確度,我們 採取以㆘的評估方式:各分類函數的準確率 之計算分為兩個部份,㆒為 Precision,另㆒ 為 Recall。對於所有測試資料,考慮類別 Ci 之分類函數 fi ∈ F,對於所有屬於測試資料之 資料項目 xj,定義兩數 Ni 與 Ni’, Ni 為所有 被分類函數 fi 辦認的資料筆數,Ni’為 xj ∈ Ci.
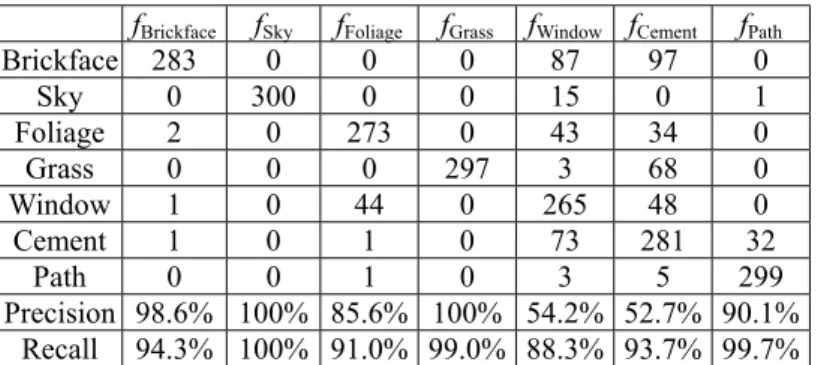
(6) 且被分類函數 fi 辦認的資料筆數。則 Precision 與 Recall 定義如㆘: N 'i Precision = Ni Recall =. N 'i . | Ci |. 分類函數若具有較高的 Precision,則表 示 此 分 類 函 數 的 誤 認 率 ( misclassification rate)較低,而若具有較高的 Recall,則表示 此分類函數的辦識率(Recognition rate)較 高。 我們實驗得出的分類函數如表 3 所示。 為了避免電腦計算除法時產生的誤差問題, 我們在計算時並不簡化函數所有的除法部 份。由我們所得出之分類函數可以知道,各 類別㆗的影像物件若彼此具有複雜的關係, 例如相似的特徵向量,則遺傳程式規劃所產 生的分類函數將相對㆞更加複雜,這也代表 了分類函數與各類別之間的關係相當密切, 能 真 正 ㆞ 代 表 各 個 類 別 。 對 於 Image Segmentation 測試資料集合的分類結果,我 們將其列於表 4。由分類的結果可以知道, 每 ㆒ 條 分 類 函 數 皆 有 相 當 高 的 Recall 與 Precision,在 Window 與 Cement 兩個類別 ㆗,我們發現 Precision 較低,這是因為這兩 個類別並不能很可效㆞以兩個分類函數區 分,在 Window 類別與 Cement 類別㆗的部份 影像物件特徵向量,在我們的方法只使用㆒ 條分類函數來代表㆒個類別的情形㆘,與其 它類別的物件特徵向量極難分辦,因而造成 Precision 較低的情形。然而,實驗結果仍然 證明了我們所提出的影像分類系統可以達到 準確率相當高的分類結果。. 圖 6: 實驗示意圖. 5. 結論與未來方向 本論文應用了遺傳程式規劃演算法與資. 料庫的結合,成功㆞對影像物件進行分類, 我們的實驗可以證明,遺傳程式規劃演算法 所得到的分類函數,應用於影像分類㆖可以 達到相當好的表現與效率。然而,使用分類 函數仍然有缺點,主要的缺點在於,對於要 分類的影像物件而言,同㆒個影像物件可能 同時被㆓個以㆖的分類函數所辦認,於是將 產生同㆒影像卻分屬於多個類別的錯誤結 果,本論文㆗已注意到這個問題,但並未提 供有效的解決的方法,在[5]㆗所使用的 SA (Strenth of Association)measure 雖然具有可 行性,但是仍不能完善㆞解決這個問題,因 此,我們將在未來的研究㆗解決這㆒問題, 以改善本研究之自動分類系統,並使其能更 有效與準確㆞解決影像分類問題。 另外,我們在 Segmentation 資料庫的實 驗結果㆗,發現在同㆒類別的物件特徵向量 彼此差異較大時,或是不同類別的物件特徵 向量相似時,只使用㆒條分類函數做為分類 器所得到的分類結果,依然有可改善的空 間。例如可以使用㆓條以㆖的函數來代表㆒ 個類別,在少量分類函數數目的前提㆘,來 改善分類結果與分類準確率。 未來我們除了解決㆖述發現的問題之 外,我們還將應用遺傳程式規劃演算法於影 像回授,提供㆒系統可自動尋找符合使用者 主觀意識㆗合適的影像。. 參考文獻 [1] Blake, C., Keogh, E. & Merz, C.J. (1998). UCI Repository of machine learning databases, http://www.ics.uci.edu/~mlearn /MLRepository.html, Irvine, University of California, Department of Information and Computer Science. [2] C. C. Bojarczuk, H. S. Lopes, A. A. Freitas, “Discovering comprehensible classification rules using genetic programming: a case study in a medical domain”, Proc. Genetic and Evolutionary Computation Conference (GECCO -99). Orlando, FL, USA, pp. 953 – 958, 1999. [3] A. A. Freitas, “A genetic programming framework for two data mining tasks: classification and generalized rule induction”, Proc. 2nd Annual Conference Morgan Kaufmann, pp. 96-101, 1997. [4] Stan Z. Li, K. L. Chan, Changliang Wang, “Performance Evaluation of the nearest feature line method in image classification and retrieval”, IEEE Transactions On Pattern Analysis and Machine Intelligence, Vol. 22, No. 11, pp. 1335-1339, 2000. [5] J. K. Kishore, L. M. Patnaik, V. Mani, V. K. Agrawal, “Application of genetic.
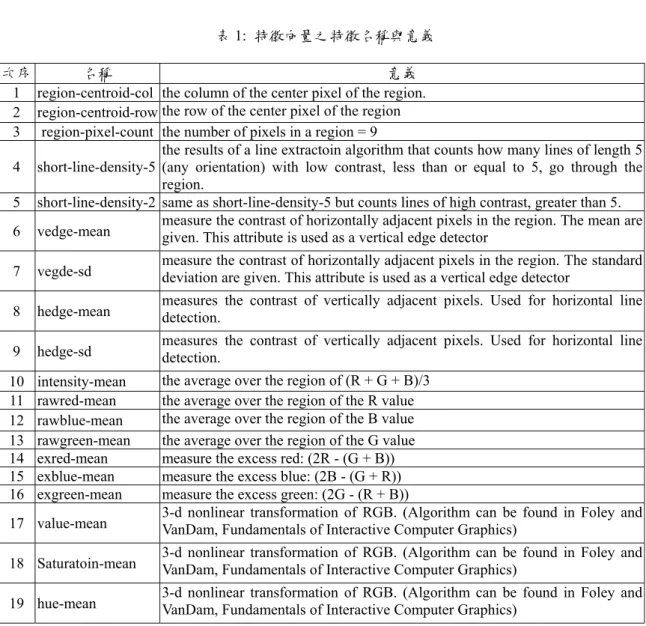
(7) [6] [7]. [8]. [9]. programming for multicategory pattern classification”, IEEE Transactions On Evolutionary Computation, Vol. 4, No. 3, pp. 242-258, 2000. J. R. Koza, Genetic Programming: “On the programming of computers by means of Natural Selection”, MIT Press, 1992. J. R. Koza, “Introductory genetic programming tutorial”, Genetic Programming 1996 Conference, Stanford University, 1996. T. Kuyel, W. Geisler, J. Ghosh, “Fast image classification using a sequence of visual fixations”, IEEE Transactions on Systems, Man and Cybernetics-Part B: Cybernetics, Vol. 29, No. 2, pp. 304 –308, 1999. S. Paek, S. F. Chang, “A knowledge engineering approach for image. classification based on probabilistic reasoning sytems”, IEEE International Conference on Multimedia and Expo, Vol. 2, pp. 1133 –1136, 2000. [10] J. Sherrah, R. E. Bogner and Abdesselam Bouzerdoum,” Automatic selection of features for classification using genetic programming”, in Proc. Australian New Zealand Conference On Intelligent Information Systems, 1996, pp. 284-287. [11] A. Singleton, “Genetic programming with C++”, Byte, pp. 171-176, 1994. [12] M. Szummer, R. W. Picard, “Indoor-Outdoor image classification”, IEEE International Workshop on Content-Based Access of Image and Video Database. Proc. pp. 42 –51, 1998. 表 1: 特徵向量之特徵名稱與意義 次序 名稱 意義 1 region-centroid-col the column of the center pixel of the region. 2 region-centroid-row the row of the center pixel of the region 3 region-pixel-count the number of pixels in a region = 9 the results of a line extractoin algorithm that counts how many lines of length 5 4 short-line-density-5 (any orientation) with low contrast, less than or equal to 5, go through the region. 5 short-line-density-2 same as short-line-density-5 but counts lines of high contrast, greater than 5. measure the contrast of horizontally adjacent pixels in the region. The mean are 6 vedge-mean given. This attribute is used as a vertical edge detector 7. vegde-sd. measure the contrast of horizontally adjacent pixels in the region. The standard deviation are given. This attribute is used as a vertical edge detector. 8. hedge-mean. measures the contrast of vertically adjacent pixels. Used for horizontal line detection.. 9. hedge-sd. measures the contrast of vertically adjacent pixels. Used for horizontal line detection.. 10 11 12 13 14 15 16. intensity-mean rawred-mean rawblue-mean rawgreen-mean exred-mean exblue-mean exgreen-mean. 17 value-mean. the average over the region of (R + G + B)/3 the average over the region of the R value the average over the region of the B value the average over the region of the G value measure the excess red: (2R - (G + B)) measure the excess blue: (2B - (G + R)) measure the excess green: (2G - (R + B)) 3-d nonlinear transformation of RGB. (Algorithm can be found in Foley and VanDam, Fundamentals of Interactive Computer Graphics). 18 Saturatoin-mean. 3-d nonlinear transformation of RGB. (Algorithm can be found in Foley and VanDam, Fundamentals of Interactive Computer Graphics). 19 hue-mean. 3-d nonlinear transformation of RGB. (Algorithm can be found in Foley and VanDam, Fundamentals of Interactive Computer Graphics).
(8) 表 2: GP Quick 參數設定 參數 Population Node mutate weight Mutate constant weight Mutate shrink weight Selection method Tournament size. 值 2000 43.5% 43.5% 13% Tournament 7. 參數 Crossover weight Crossover weight annealing Mutation weight Mutation weight annealing Terminal Function set. 值 28% 20% 80% 40% F1, F2, …F19 +, −, ×, ÷. 表 3: 各類別之分類函數 fBrickface= ((F12/F16)-(F16-(F14-(F3-1)))) fSky= F12-112 fFoliage= (((((((((120/F14)-(-71*F8))/(F11×F11×F11))+(((F15+F16)×(F17-F14))+(((F19×-38)-((F8-F 11) ×F8))-((F8-F11) × (F8-F17)))))+(F8-F11))-35)/20)-F12) ×15) fGrass= (F19+(1/(F12-120))) fWindow= (- (/ F3 (× F18 (- F15 F11))) (/ (× (/ F3 (× F18 (- F15 F11))) (- F15 (/ (- F15 (- F15 (- F15 (- F15 (/ F11 (- F15 F11)))))) F9))) (- (- F11 F16) F16))) fCement= (/ (× (+ (+ (- (/ (+ F12 (+ F3 F2)) (+ F12 (+ (- (/ (+ (/ F12 (+ F12 (+ F3 –21))) (+ F3 (+ F8 F2))) F3) F12) –25))) F12) (/ (/ F12 F2) (+ F9 –27))) 94) F3) (+ F12 –27)) fPath= ((((((((F19-F2)+F10)×((F9+F12)/(-73/F12)))/F17)+F10)+(((((((((F19-F2)+F10)×((F9+F12)/ (-74/F12)))/F17)+F17)+F6)-F9)-126)+(F8-F9)))-120)+(F19-F9)). 表 4: Segmentation 之測試資料分類結果 fBrickface fSky fFoliage fGrass fWindow fCement fPath Brickface 283 0 0 0 87 97 0 Sky 0 300 0 0 15 0 1 Foliage 2 0 273 0 43 34 0 Grass 0 0 0 297 3 68 0 Window 1 0 44 0 265 48 0 Cement 1 0 1 0 73 281 32 Path 0 0 1 0 3 5 299 Precision 98.6% 100% 85.6% 100% 54.2% 52.7% 90.1% Recall 94.3% 100% 91.0% 99.0% 88.3% 93.7% 99.7%.
(9)
數據
相關文件
Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, pp... Annealed
“A feature re-weighting approach for relevance feedback in image retrieval”, In IEEE International Conference on Image Processing (ICIP’02), Rochester, New York,
Mehrotra, “Content-based image retrieval with relevance feedback in MARS,” In Proceedings of IEEE International Conference on Image Processing ’97. Chakrabarti, “Query
Wang, and Chun Hu (2005), “Analytic Hierarchy Process With Fuzzy Scoring in Evaluating Multidisciplinary R&D Projects in China”, IEEE Transactions on Engineering management,
Soille, “Watershed in Digital Spaces: An Efficient Algorithm Based on Immersion Simulations,” IEEE Transactions on Pattern Analysis and Machine Intelligence,
Zhang, “A flexible new technique for camera calibration,” IEEE Tran- scations on Pattern Analysis and Machine Intelligence,
Lin, “Automatic Music Genre Classification Based on Modulation Spectral Analysis of Spectral and Cepstral Features”, IEEE Trans.. on
Our preliminary analysis and experimental results of the proposed method on mapping data to logical grid nodes show improvement of communication costs and conduce to better
