An E±cient Protocol for Disseminating Data with Multi-dimensional Index on Multiple Broadcasting Channels
6
0
0
全文
(2) Int. Computer Symposium, Dec. 15-17, 2004, Taipei, Taiwan.. dimensional index tree results in not only a single path traversal from the root to a leaf (one-path search) but also partially traversing the index tree (multi-path search). Multi-path search is more general than one-path search and more practical for real world applications. We assume that all the clients have enough memory to execute their own queries. We observe that, in order to have less latency, the broadcast schedule on multiple channels should satisfy the following properties, ancestor property and switch property. We say that the generated broadcast schedule satisfies the ancestor property if when a node v is broadcast for the first time in a cycle, the parent of v has been broadcast earlier in the same cycle. Let u and v be two nodes, with u being the parent of v. Assume u and v are assigned to channels cu and cv , respectively. A switch occurs between u and v when cu is not equal to cv . We say a broadcast schedule satisfies the switch property if for each switch between u and v we have cu < cv . The switch property ensures that any root-to-leaf path in a tree experiences at most c − 1 switches, if there are c channels. This leads to a fewer number of switches between channels; thus, reduces the power consumption. Our schedule is indeed optimal for some kinds of queries. We assumes that each node in the tree is broadcast only once in a cycle. In a multiple channel environment, a mobile client can only select one channel to tune into at each time instance; hence, conflicts arise when a mobile client needs to access nodes placed in the same position at some time instance. We refer to such a conflict as read-conflict. The readconflicts will impact the performance of the query processing. For more details about the read-conflict, please refer to [4]. Since it is not easy to control such conflicts, our server broadcast schedule does not consider the read-conflicts too much in this paper. Our schedule will have the ancestor property and switch property as well as minimizes the cycle length. On the client side, we provide a query processing corresponding to the broadcast schedule which minimizes the latency.. 4. the number of nodes in subtree) of their corresponding subtrees, (b) assigns the root r to position 1, and (c) sets the capacity of each channel (i.e., the number of nodes still to be assigned). The second step corresponds to a call to Algorithm AssignChannels and it is the heart of Algorithm c-MinCycle: every node is assigned to a channel, but not to a position in the channel. The channel assignments made result in selected nodes being marked as filler-nodes or root-nodes. Filler-nodes guarantee that the generated schedule satisfies the ancestor property. Rootnodes terminate the assignment process: When a node u is marked as a root-node, the nodes in the subtree rooted at u are (i) assigned to the same channel with node u and (ii) they do not get marked. The distribution of filler- and root-nodes is such that for a root-node u, all nodes on the path from the root r to u’s parent are filler-nodes. The third step of Algorithm c-MinCycle assigns every node to a position in the assigned channel. Filler- and root-nodes are used to determine the positions of nodes within their assigned channel. We now turn to Algorithm AssignChannels whose description is given in Figure 2. AssignChannels is invoked with four parameters: (1)a filler-node u which is the root of a subtree T 0 , (2)an integer β representing the number of channels used, (3) a parameter offset, and (4) a list L containing β target channel capacities. Algorithm c-MinCycle Input: n-node tree T with root r Output: a c-channel broadcast schedule with cycle e+1 length d n−1 c (1) (a) arrange the children of every node by non-increasing subtree sizes (b) assign root r to channel 1 and mark r as a filler-node (c) set the capacity of each channel (2) AssignChannels(r, c, 0, L) (3) for channel i, 1 ≤ i ≤ c, do (a) starting with position 2, contiguously place the filler-nodes assigned to channel i in order of increasing levels; (b) consider the root-nodes assigned to channel i by increasing level in T ; root-nodes on the same level are considered from right to left; starting with the next position in channel i, place the nodes in the subtrees rooted at each root-nodes in preorder in consecutive channel locations End c-MinCycle. Broadcasting Protocol. This section introduces our data disseminating protocol which consists of the broadcast scheduling on the server side and the query processing on the client side. We start our discussion with the broadcast scheduling.. 4.1. Server scheduling. This section presents our algorithm for scheduling the broadcast for an n-node multi-dimensional index tree on c channels, c > 1. We assume that the degree of the index tree must have the following property: whenever the algorithm considers a subtree rooted at r0 on c0 channels, node r0 must have at least c0 children. Thus, initially, the root r must have at least c children. Furthermore, the schedule can be generated in O(n) time. We refer to the algorithm generating the broadcast schedule as Algorithm c-MinCycle shown in Figure 1. The first step (a) arranges the children of every node of input tree T by non-increasing sizes (i.e.,. Figure 1: Generating a c-channel broadcast schedule of minimum cycle length satisfying the ancestor and switch properties. The nodes from tree T 0 - excluding node u, which is already assigned - are assigned to channels offset+1, . . . , offset+β. Alternatively, we will say node u is associated with channels offset+1, . . . , offset+β. Every channel is assigned the number specified in its corresponding target capacity. Suppose the channels associated with node u are channels 1, · · · , β,. 88.
(3) Int. Computer Symposium, Dec. 15-17, 2004, Taipei, Taiwan.. Algorithm AssignChannels(u, β, offset, L) (0) let v1 , . . . , vl be the children of u with β ≤ l set i = l; k = β (1) Root-Oriented Step: while (k ≤ i and i 6= 0) do (1.1) if si < tk then assign vi as a root-node in channel offset+k; tk = tk − si else if si = tk then assign vi as a root-node in channel offset+k; tk = 0; k = k − 1 else /* invoke a 2-channel problem on vi */ assign vi as a filler-node in channel offset+k − 1; make a list L0 = ((si − 1) − tk , tk ); k = k − 1; AssignChannels(vi , 2, offset+k − 2, L0 ); tk = 0; tk−1 = tk−1 − (si − tk ); k = k − 1 (1.2) i = i − 1 endwhile (2) if i = 0 then /* all children have been handled*/ return (3) Filler-Oriented Step: (3.1) mark v1 , · · · , vi as filler-nodes for channels offset+1, · · ·, offset+i and target channel capacities update (3.2) r0 = 1 (3.3) for j = 1 to i do • determine rj such that P rj −1 tm < (sj − 1) and j−1 Prm=r j t ≥ (sj − 1) m=rj−1 m • if rj = rj−1 then assign all children of vj as root-nodes to channel offset+rj ; trj = trj − (sj − 1) • if rj > rj−1 then Prj −1 trj = trj − (sj − m=r tm − 1);. Pr. −1. j−1. β > 1. Let tk be the target capacity of channel k, 1 ≤ k ≤ β. Let v1 , · · · , vl be the children of node u. We have β ≤ l. This holds for all calls to AssignChannels since (i) initially every non-leaf node has at least β children and (ii) removing children from future calls results in a corresponding reduction in the number of channels to be filled. Algorithm AssignChannels starts assigning nodes to channels in the Root-Oriented Step and then in the Filler-Oriented Step. The Root-Oriented Step considers the children of u from right to left. This corresponds to starting with the subtree of smallest size. One iteration assigns either one subtree rooted at a child of node u to one channel or it partitions one subtree among two channels. The Root-Oriented Step operates as long as the number of children of u not assigned to a channel is larger or equal to the number of channels still to be assigned nodes. This is the condition enforcing the ancestor property of the generated schedule. In figure 3, the Root-Oriented Step processes nodes a6 , a5 , a4 , and a3 and the root-nodes are a6 , a5 , and a3 . Node a4 is a filler-node.. r a1 b1. b2. b3. b4. a2. a3. a4. b5. b7. b9. b6. b8. b10. c1 c2 c3 c4 c5 c6 c7 c8 c9 c10 c11 c12 c13 c14. Position Channel 1 Channel 2 Channel 3 Channel 4. 1. r. 2. 3. 4. 5. 6. a1 b3 b2 c4 c5 a2 b5 b4 c8 c9 a4 b9 a3 b7 c14 a6 b13 b14 a5 b11. 7. a5. c15. 8. a6. b11 b12 b13 b14 c16. 9. 10. b1 c1 c2 c3 c10 c11 c7 c6 b8 b6 c13 c12 c16 b12 b10 c15. Figure 3: An index tree of size 37 to be scheduled on four broadcast channels with optimal cycle length 10; filler-nodes (bold lines) are a1 , a2 , a4 , b3 , b5 , and b9 . When the number of children of u, i, which have not been processed is less than the number of channels, k, which need nodes to fill in, the algorithm switches to the Filler-Oriented Step. Note that this does not happen when the Root-Oriented Step terminates when all of the children have been explored (since channel assignments are complete). The Filler-Oriented Step assigns nodes v1 , · · · , vi to channels 1, · · ·, k−1, respectively, and marks them as filler-nodes (done in Step (3.1)). The remaining children of u are then considered from left to right. Assume we are currently at child vj , 1 ≤ j ≤ i. Entries rj (resp. rj−1 ) represents the largest (resp. smallest) channel index being assigned a node in the subtree tooted at vj . We refer to Step (3.3) for the exact computation of these indices. Then, when rj = rj−1 , all children of node vj are made root-nodes for channel rj . Note that node vj remains labeled a fillernode. It is not a root-node, since it is not assigned to channel rj , but to a smaller indexed channel. When rj > rj−1 , we invoke a channel broadcast problem. j t0rj = (sj − m=r tm − 1); j−1 0 make a list L of target capacities: L0 = (trj−1 , . . . , trj ); AssignChannels(vj , rj − rj−1 + 1, offset+rj−1 − 1, L0 ); trj = trj − t0rj ; endfor End AssignChannels. Figure 2: Assigning the nodes in the subtree rooted at node u to β channels.. 89.
(4) Int. Computer Symposium, Dec. 15-17, 2004, Taipei, Taiwan.. on vj using rj − rj−1 + 1 < k channels, as detailed in Step (3.3) of Algorithm AssignChannels. In the figure 3, the Filler-Oriented Step processes nodes a1 and a2 and assigns these two nodes as filler-nodes. To show that Algorithm c-MinCycle satisfies the ancestor property, we first state a number of properties following from the way nodes are assigned to channels and channel positions.. in all channels. Hence, the generated schedule satisfies the ancestor property. The O(n) time for generating the schedule follows immediately from known algorithms for tree computations and tree traversals. 2. Property 1 If a filler-node u is assigned to channel k and a descendant of u is assigned to channel k0 , then k ≤ k0 .. This section discusses the query processing on the client side. We assume that the query processing starts at beginning of a broadcast cycle. For onepath search, the query processing is straightforward. Having the broadcast scheduled satisfy the ancestor property and achieve the minimum cycle length, onepath search can always be done in O( nc ) time in a c-channel environment. For a multi-path search, after exploring an internal node, one can have each child’s position and channel number assigned to it and know which child(ren) should be explored later. We therefore must store the information of these relevant children. We discuss two different methods for multipath search on the client side.. 4.2. For the following properties assume u is a filler-node associated with channels γ + 1, · · · , γ + β, β > 1. Property 2 The subtree rooted at u contains no filler-node assigned to channel γ + β. Property 3 Let u0 and u00 be two filler-node children of u with u0 to the left of u00 . Assume γ 0 + 1, · · · , γ 0 + β 0 are the channels associated with u0 and γ 00 + 1, · · · , γ 00 + β 00 are the channels associated with u00 , where β 0 and β 00 > 1. Then, γ + 1 ≤ γ 0 + 1 < γ 0 + β 0 ≤ γ 00 + 1 < γ 00 + β 00 ≤ γ + β.. 4.2.1. Property 4 Let u0 be a filler-node associated with channels γ 0 + 1, · · · , γ 0 + β 0 . Assume u0 is on level i, i ≥ 2. Then, for any channel k with γ 0 + 1 ≤ k < γ 0 + β 0 , u0 or a right sibling of u0 is a filler-node assigned to channel k. In addition, level i of tree T contains exactly one filler-node assigned to channel k.. Client processing. Method 1: Using a stack (SM). The first method for multi-path search is straightforward and we use it to compare our method discussed in the following subsection. This simple method uses a stack to store the children information the client has received. Due to the FILO property of a stack, we need to push the child assigned to a large channel number first. If there is a tie, we push the child having large position first. After pushing all the relevant children into the stack, the one popped out from the stack is the next node to be explored. However, this methods may still result in a long latency. This will be explained later in Section 5.. The following two lemmas show that the broadcast schedule generated by Algorithm c-MinCycle satisfies the ancestor property. We first use the above properties to show that the ancestor property is satisfied for the filler-nodes. Then, we argue that the ancestor property holds for remaining nodes by first showing that all nodes assigned to channel c satisfy the ancestor property. The argument used for channel c is then applied to the remaining channels. Due to the space limit, we omit the detail of the proofs. Following these two lemmas, we conclude this section with a theorem.. 4.2.2. Method 2: Two dictionary structures (TDSM). In a multiple channel environment, nodes to be explored may have the same position but be on different channels. The client uses a p-element to hold the nodes to be explored which have the same position. Therefore, a p-element consists of a position and a set of channel indices. It maintains two dictionary structures, Tact and Tnext , which are built on p-elements with p-element’s position as the key. The client uses Tact to determine the next node to explore. It first uses the operation Extract-Min on Tact to get the p-element, e, having the closest (smallest) position. It then decides the next node to explore by selecting the smallest channel index from the channel index set of e. If the channel index set of e is not empty after removing the smallest channel index, the client inserts e into Tnext for the query processing to extract e in the next cycle. Consider a client has determined the next node to explore from Tact , say node u. If u is a productive node, let v1 , · · · , vl be the children of u to be explored. Nodes v1 , · · · , vl are then inserted into Tact . When inserting a node vi , i = 1, · · · , l, into Tact , the client first checks whether the position of vi is already in Tact . If it finds a p-element having the position of vi as the key in Tact , it inserts the. Lemma 1 Let P be any path from the root r to some filler-node u with P = < p1 = r, · · · , pe = u >. Then, pos(pi ) = i, 1 ≤ i ≤ e. Lemma 2 Let v be a node assigned to position pos(v) in channel c. If u is v’s parent, then pos(u) < pos(v). Theorem 3 The schedule generated by Algorithm c-MinCycle satisfies the ancestor and the switch property. The schedule can be generated in O(n) time. Proof: The switch property follows from Property 1. From Lemma 2 we know that the ancestor property holds for all nodes assigned to channel c. Remove from the generated schedule and from the tree all nodes assigned to channel c. Then, mark every filler-node assigned to channel c − 1 as a rootnode for channel c − 1 and apply the argument given in Lemma 2. A repeated application of this process shows that the ancestor property holds for all nodes. 90.
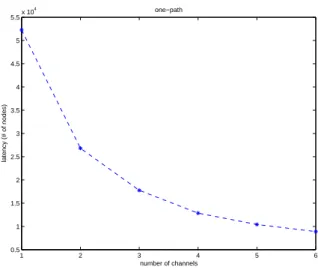
(5) Int. Computer Symposium, Dec. 15-17, 2004, Taipei, Taiwan.. channel index of vi into the channel index set. Otherwise, the client creates a p-element from node vi and inserts this p-element into Tact . After the exploration of a productive node u, the next node to be explored can be found in Tact as discussed above since Tact is not empty. After the exploration of an unproductive node, one of the following situations may occur.. 4. 5.5. one−path. x 10. 5. 4.5. latency (# of nodes). 4. (1) Tact is not empty. The next node to be explored can be found in Tact as discussed above. (2) Tact is empty but Tnext is not empty. When this happens, the query processing moves to the next broadcast cycle. Tnext contains all the information used in the following cycle. The client exchanges Tact and Tnext and continues the query processing.. 3.5. 3. 2.5. 2. 1.5. 1. 0.5. (3) Tact and Tnext both are empty. The query processing stops since there is no more node to be explored.. 1. 2. 3 4 number of channels. 5. Figure 4: The average latency for a one-path search. One way to implement Tact and Tnext is using a binary search tree. The operations on them include Extract-Min, Search, Insert, and Delete. Since the maximum number of p-elements in Tact or Tnext e + 1, each operation on Tact or Tnext can is d n−1 c e) time. Moreover, one can be done in O(logd n−1 c maintain the channel index set of a p-element by a heap. It will takes O(log c) time to obtain the smallest channel index from the channel index set. Therefore, the client needs O(log n) time to find the next node to explore in Tact . A partial traversal of the index tree results in traversing many paths which start at the root and end at internal nodes or leaves. We consider two kinds of paths in a partial traversal of the index tree. One is the path ending at a root-node and the other is the path ending at a filler-node. Because the nodes in the subtree rooted at a root-node are arranged in preorder in the same channel, two (or more) different paths having a common ancestor which is a root-node can be traversed in the same cycle. We hence consider the paths ending at rootnodes. On the other hand, a search path may end at a filler-node u. In such a case, none of u’s children is relevant to the query. We refer to a query processing as an m-search if the query processing results in a partial traversal which has m paths ending at a root-node and a filler-node as discussed. In the rest of this section, we discuss the performance of the query processing in terms of number of cycles. We will show that a multi-dimensional query resulting in an m-search can be executed within at most min{m, c} broadcast cycles. We first claim the following lemma.. on an R*-tree of size 105,721 and having 100,000 leaves as well as degree 10.. a multi-dimensional query resulting in an m-search with m < c can be executed within at most m cycles. We therefore have the following theorem: Theorem 5 A multi-dimensional query resulting in an m-search can be executed within at most min{m, c} broadcast cycles, where c is the number of channels.. 5. Experimental Results. In this section, we provide our simulation work. The multi-dimensional index tree considered here is an R*-tree. We point out that our protocol can be applied to any kind of multi-dimensional index tree, not only R- or R*-trees. We also assume that the clients always have enough memory to hold all the information during the execution of query. The power efficiency can be achieved using the index. We therefore focus on the latency in single- and multichannel environments. We consider synthetic data of rectangles for the time being. All the rectangles are generated using a uniform distribution with the unit square. For random rectangles, the centers of the rectangles are generated uniformly in the unit square and the sides of the rectangles are generated with a uniform distribution between 10−5 to 10−2 . Having the rectangle data set, we can build an R*-tree where the data are stored in the leaves. In our experiments, we consider the R*-trees which have 10,000 or 100,000 leaves, respectively. For each R*-tree, we generate the broadcast schedule on c channels where c is from 2 to 6. For the 1-channel broadcast protocol, we refer to [4] and compare the performance on latency with our multi-channel broadcast protocol. We use the number of nodes (packets) as our measurement. To measure the latency, we run 100(1000) different queries on the R*-tree with 10,000 (100,000) leaves and then take the average. We first show the result of one-path search and then the result of multi-path search. All the experiments show similar trends.. Lemma 4 Any multi-dimensional query can be executed within c broadcast cycles. Proof: Due to the space constraint, please refer to [6] for more details. 2 The performance for an m-search is better when m < c. Consider a path ending at a root-node v. The nodes on the path from the root to v and in the subtree rooted at v can be traversed in one cycle by the ancestor property. The result also holds for the path ending at a filler-node. Therefore, at lease one path can be traversed in one cycle. Hence,. 91. 6.
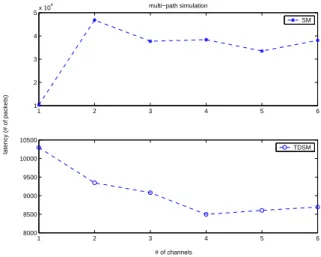
(6) Int. Computer Symposium, Dec. 15-17, 2004, Taipei, Taiwan.. 4. 5. Our protocol not only achieves the optimum latency for a one-path search but also leads to a shorter latency for a multi-path search.. multi−path simulation. x 10. SM 4. 3. REFERENCES. latency (# of packets). 2. 1. 1. 2. 3. 4. 5. 6. [1] S. Acharya, M. Franklin, and S. Zdonik. Balancing push and pull for data broadcasts. In Proceedings of the 1997 ACM SIGMOD International Conference on Management of Data, pages 183–194, May 1997.. 10500 TDSM 10000 9500 9000. [2] N. Beckmann, H. Kriegel, R. Schneider, and B. Seeger. The R*-tree: An efficient and robust access method for points and rectangles. In Proceedings of ACM SIGMOD Conference on Management of Data, pages 322–331, May 23-25 1990.. 8500 8000. 1. 2. 3. 4. 5. 6. # of channels. Figure 5: The average latency for a multi-path. [3] M.-S. Chen, P.S. Yu, and K.-L. Wu. Indexed sequential data broadcasting in wireless mobile computing. In Proceedings of the 17th International Conference on Distributed Computing Systems. IEEE Computer Society Press, May 1997.. search using SM and TDSM respectively on an R*tree of size 11,025 and having 10,000 leaves as well as degree 6.. Figure 4 shows the average latency for a onepath search on an R*-tree of size 105,721 and having 100,000 leaves. The degree of the R*-tree is at least 10. In the plot, the average latency decreases as the number of channels increases. Furthermore, the average latency is reduced with a factor of 1c . We now discuss the average latency for a multipath search using SM and TDSM respectively on an R*-tree. Although our multi-channel broadcast schedule satisfies the ancestor and switch properties as well as achieves the minimum cycle length, the resulting average latency for SM is not as good as the one in a 1-channel environment as shown in fig. 5. Using a stack will skip some nodes closer to the current explored node. This leads to finish the execution of query in more than c cycles. On the other hand, TDSM makes the result better. In all our experiments, TDSM has a better latency compared to a 1-channel environment.. 6. [4] S. Hambrusch, C.-M. Liu, W. Aref, and S. Prahakar. Query processing in broadcasted spatial index trees. In Advances in Spatial and Temporal Databases - 7th International Symposium (SSTD 2001), Lecture Notes in Computer Science 2121, pages 502–521. Springer-Verlag, July 2001. nski, S. Viswanathan, and B. R. Badri[5] T. Imieli´ nath. Data on air: Organization and access. IEEE Transactions on Knowledge and Data Engineering, 9(3):353–372, May/June 1997. [6] C.-M. Liu. Broadcasting and blocking large data sets with an index tree. PhD thesis, Purdue University, 2002. [7] S.-C. Lo and A.L.P. Chen. Optimal index and data allocation in multiple broadcast channels. In Proceedings of 2000 IEEE International Conference on Data Engineering, pages 293– 304, February 2000.. Conclusions. [8] N. Shivakumar and S. Venkatasubramanian. Efficient indexing for broadcast based wireless systems. Mobile Networks and Applications, 1(4):433–446, May/June 1996.. We consider to generate the schedule by directly mapping the index tree into channels without considering the read-conflicts. Our schedule consists of two steps, channel assignment and node placement. For the channel assignment, the procedure focuses on which channel a node should belong. The node placement will place the node into the right position in the assigned channel to keep ancestor property. In order to make the algorithm easy to keep the ancestor and switch properties, the index tree should be rearranged by the subtree sizes. We show that our schedule satisfies the ancestor and switch properties by counting. Besides, we provide the corresponding algorithms for executing query on the client side to integrate the broadcasting schedule and query process into a proper protocol. Having the protocol, we implement it and compare the performance with the protocols in a one channel environment in terms of latency.. [9] K.-L. Tan and J. X. Yu. Generating broadcast programs that support range queries. IEEE Transactions on Knowledge and Data Engineering, 10(4):668–672, July/August 1998. [10] K.L. Tan, J. X. Yu, and P.K. Eng. Supporting range queries in a wireless environment with nonuniform broadcast. Data Knowledge Engineering, 29(2):201–221, 1999. [11] W.G. Yee, S. B. Navathe, E. Omiecinski, and C. Jermaine. Efficient data allocation over multiple channels as broadcast servers. IEEE Transactions on Computers, 51(10):1231–1236, 2002.. 92.
(7)
數據

相關文件
Let us consider the numbers of sectors read and written over flash memory when n records are inserted: Because BFTL adopts the node translation table to collect index units of a
Agent: Okay, I will issue 2 tickets for you, tomorrow 9:00 pm at AMC pacific place 11 theater, Seattle, movie ‘Deadpool’. User:
共同業務 教師成長 C/Q/S E/R/A 專業發展 C/Q/S E/R/A 實驗研究組 科學活動 C/Q/S E/R/A 研究發展 C/Q/S E/R/A 資料出版組 出版刊物 C/Q/S E/R/A 國際教育 C/Q/S
We would like to point out that unlike the pure potential case considered in [RW19], here, in order to guarantee the bulk decay of ˜u, we also need the boundary decay of ∇u due to
(A) The PC has the TCP/IP protocol stack correctly installed (B) The PC has connectivity with a local host (C) The Pc has a default gateway correctly configured (D) The Pc
The Liouville CFT on C g,n describes the UV region of the gauge theory, and the Seiberg-Witten (Gaiotto) curve C SW is obtained as a ramified double cover of C g,n ... ...
We compare the results of analytical and numerical studies of lattice 2D quantum gravity, where the internal quantum metric is described by random (dynamical)
• Consider an algorithm that runs C for time kT (n) and rejects the input if C does not stop within the time bound.. • By Markov’s inequality, this new algorithm runs in time kT (n)
