Efficient Hiding of Collaborative Recommendation Association Rules with
Updates
Shyue-Liang Wang
1, Ting-Zheng Lai
3, Tzung-Pei Hong
2, Yu-Lung Wu
3 1Department of Information Management
2
Department of Electrical Engineering
National University of Kaohsiung
Kaohsiung, Taiwan 81148
3
Institute of Information Management
I-Shou University
Kaohsiung, Taiwan 84001
{[email protected], [email protected]}
{[email protected]
,
[email protected]}
Abstract
We propose here an efficient data mining algorithm to hide collaborative recommendation association rules when the database is updated, i.e., when a new data set is added to the original database. For a given predicted item, a collaborative recommendation association rule set [17] is the smallest association rule set that makes the same recommendation as the entire association rule set by confidence priority. Several approaches to hide collaborative recommendation association rules from static databases have been proposed [17, 18]. However, frequent updates to the database may require repeated sanitizations of original database and added data sets. The efforts of previous sanitization are not utilized in these approaches. In this work, we propose using pattern inversion tree to store the added data set in one database scan. It is then sanitized and merged to the original sanitized database. Numerical experiments show that the proposed approach out performs the direct sanitization approach on original and added data sets, with similar side effects.
1. Introduction
Privacy-preserving data mining, is a novel research direction in data mining and statistical databases, where data mining algorithms are analyzed for the side effects they incur in data privacy. There have been two types of privacy concerning data mining. The first type of privacy, called output privacy, is that the data is minimally altered so that the mining result will not disclose certain privacy. Many techniques have been proposed for the output privacy [1, 5, 11, 13]. For example, perturbation, blocking, aggregation or merging, swapping, and sampling are some alternation methods that have recently been proposed. The second type of privacy, input privacy, is that the data is manipulated so that the mining result is not affected or
minimally affected [6, 9, 14]. For example, the reconstruction-based technique and the cryptography-based techniques are some recently proposed techniques for input privacy.
In output privacy, given specific rules or patterns to be hidden, many data altering techniques for hiding association, classification and clustering rules have been proposed. For association rules hiding, three basic approaches have been proposed. The first approach [13, 16] hides pre-selected rules one rule at a time. It first selects transactions that containing items in a pre-selected rule. It then tries to modify transaction by transaction until the confidence or support of the pre-selected rule fall below minimum confidence or minimum support. The modification is done by either removing items from the transaction or inserting new items to the transactions. The second approach deals with groups of pre-selected restricted patterns or association rules [10, 11]. It first selects the transactions that contain the intersecting patterns of a group of pre-selected restricted patterns. Depending on the disclosure threshold given by users, it sanitizes a percentage of the selected transactions in order to hide the restricted patterns. The third approach [17] deals with hiding certain constrained classes of association rules. Once the proposed hiding items are given, the approach integrates the rule selection process into the hiding process. It hides one rule at a time by calculating the number of transactions required to sanitize and modify them accordingly.
However, databases may be updated frequently. It is non-trivial to maintain the hidden association rules when the database is updated. New rules and/or already hidden rules may arise and need to be hidden again. In this work, we are interested in improving the efficiency of hiding collaborative recommendation association rules when the transaction database is updated, i.e., when a transaction data set is added to the original database. This problem is
referred to as the maintenance of hiding collaborative recommendation association rules.
One possible approach to the maintenance problem is to re-run the hiding algorithms on the whole updated database. However, this approach has some obvious disadvantage. All the computation done initially at sanitizing the original database is wasted and has to be computed again from scratch. Therefore, more efficient algorithms for hiding collaborative recommendation association rules, utilizing the information from the old sanitization process, are quite desirable.
In this work, we propose using pattern inversion tree to store the added data set in one database scan. It is then sanitized and merged to the original sanitized database. Numerical experiments and running time analyses show that the proposed approach out performs the direct sanitization on original and added data sets, with similar side effects.
The rest of the paper is organized as follows. Section 2 presents the statement of the problem and the notation used in the paper. Section 3 presents the proposed algorithm for the maintenance of sanitizing collaborative recommendation association rule sets that contain the specified predicting items. Section 4 shows an example for the proposed algorithm. Section 5 shows the experimental results of the performance and various side effects of the proposed algorithm compared with direct sanitization approach. Concluding remarks and future works are described in section 6.
2. Problem Statement
The problem of mining association rules was
introduced in [2]. Let
I
{
i
1,
i
2,
,
i
m}
be a set ofliterals, called items. Given a set of transactions D, where each transaction T in D is a set of items such that
T
I
, an association rule is an expressionX
Y
whereI
X
,Y
I
, andX
Y
. The X and Y hereare called respectively the body (left hand side) and head (right hand side) of the rule. The confidence is calculated
as
X
Y
X
, whereX
is the number of transactions containing X andX
Y
is the number of transactions containing both X and Y. The support of the rule is the percentage of transactions that contain both Xand Y, which is calculated as
X
Y
N
, where N is the number of transactions in D. In other words, the confidence of a rule measures the degree of the correlation between itemsets, while the support of a rule measures the significance of the correlation between itemsets. The problem of mining association rules is to find all rules thatare greater than the user-specified minimum support and minimum confidence.
As an example, for a given database in Table 1, a minimum support of 33% and a minimum confidence of 70%, nine association rules can be found as follows: B=>A (66%, 100%) C=>A (66%, 100%), B=>C (50%, 75%), C=>B (50%, 75%), AB=>C (50%, 75%), AC=>B (50%, 75%), BC=>A(50%, 100%), C=>AB(50%, 75%), B=>AC(50%, 75%), where the percentages inside the parentheses are supports and confidences respectively.
Table 1: Database D before and after sanitization
TID D D’ T1 ABC AB T2 ABC ABC T3 ABC ABC T4 AB AB T5 A A T6 AC AC
However, mining association rules usually generates a large number of rules, most of which are unnecessary for the purpose of collaborative recommendation. For example, to recommend a target item {C} to a customer, the collaborative recommendation association rule set that contains only two rules, B=>C (50%, 60%), AB=>C (50%, 60%), will generate the same recommendations as the entire nine association rules found from Table 1. This means that if the new customer has shown interests in purchasing item {B} or items {AB}, then the collaborative recommender will recommend the new customer to purchase target item {C}. Therefore, a collaborative recommendation association rule set can be informally defined as the smallest association rule set that makes the same recommendation as the entire association rule set by confidence priority.
Formally, given an association rule set R and a predicting itemset P, we say that the collaborative recommendation for P from R is a sequence of items Q. Using the rules in R in descending order of confidence generates the sequence of Q. For each rule r that matches P (i.e., for each rule whose antecedent is a subset of P), each consequent of r is added to Q. After adding a consequence to Q, all rules whose consequences are in Q are removed from R.
The objective of data mining is to extract hidden or potentially unknown and interesting rules or patterns from databases. However, the objective of privacy preserving data mining is to hide certain sensitive information so that they cannot be discovered through data mining techniques [1, 4-6]. In this work, we are particularly interested in
improving the efficiency of hiding collaborative recommendation association rules when the transaction database is updated, i.e., when a new transaction data set is added to the original database. Assuming new added data set is given; we propose an algorithm to maintain the sanitization of collaborative recommendation association rules (MSCR). More specifically, given a transaction database D, a minimum support, a minimum confidence and a set of recommended items Y, a sanitized transaction database
D
, and a new data set
, the objective is to minimally and efficiently modify the updated database ( D+ = D +
) such that no collaborative recommendation association rules containing Y on the right hand side of the rule will be discovered.As an example, for a given database D in Table 1, a minimum support of 33%, a minimum confidence of 70%, and a hidden item Y = {C}, applying the DCBS algorithm proposed in [18] on D, if transaction T1 is modified from
ABC to AB, then the following rules that contain item C on the right hand side will be hidden: B=>C (33%, 50%), AB=>C (33%, 50%). However, four rules are lost, C=>B (33%, 60%), AC=>B (33%, 66%), C=>AB (33%, 66%), B=>AC (33%, 50%), and no new rule is generated are the side effects. The sanitized database is D’ shown in Table 1.
When a new data set
= {T7:BC, T8:B, T9: ABC} isadded to the database D, there are direct and indirect sanitization approaches. For the direct approach, applying the DCBS algorithm proposed in [18] on D+ = D +
directly, the transaction T6 is sanitized from AC to Cand T7 is sanitized from BC to C. The sanitized database
'
D
is shown in Table 2 asD
'(DCBS). The following rule containing item C on the right hand side will be hidden: A=>C (44%, 57%), B=>C (44%, 57%). One new rule is generated C=>AB (44%, 100%) and hiding failure is generated AB=>C (44%, 80%) as side effects. There is no lost rule. However, this approach requires re-processing of the old data set D. For the indirect approach, the new data set
is processed or sanitized first. The old sanitized database will be sanitized only when hiding failure persists and/or side effects get worse. Using the proposed MSCR algorithm described in the next section, the old sanitized databaseD
is not processed. Only the added data set is sanitized and the resulting sanitized database is shown in Table 2 asD
'(MSCR). It is our objective here to minimally and efficiently modify theupdated database (D+ = D +
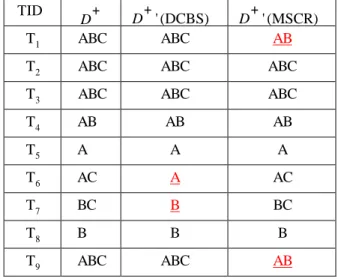
) such that no collaborative recommendation association rules containing predicted item Y on the right hand side of the rule will be discovered.Table 2: Updated Databases before and after sanitization TID
D + D+ ' (DCBS) D+ ' (MSCR)
T1 ABC ABC AB
T2 ABC ABC ABC
T3 ABC ABC ABC
T4 AB AB AB T5 A A A T6 AC A AC T7 BC B BC T8 B B B T9 ABC ABC AB
3. Proposed Algorithm
In order to hide an association rule, X=>Y, we can
either decrease its supports, (
X
N
orX
Y
N
), to be smaller than pre-specified minimum support ordecrease its confidence (
X
Y
X
) to be smaller than pre-specified minimum confidence. To decrease the confidence of a rule, two strategies can be considered. The first strategy is to increase the support count of X, i.e., the left hand side of the rule, but not support count ofY
X
. The second strategy is to decrease the support count of the itemsetX
Y
. For the second strategy, there are in fact two options. One option is to lower the support count of the itemsetX
Y
so that it is smaller than pre-defined minimum support count. The other option is to lower the support count of the itemsetY
X
so thatX
Y
X
is smaller than pre-defined minimum confidence. To decrease support count of an item, we will remove one item at a time in a selected transaction by changing from 1 to 0. We will adopt the second strategy of decreasing the support count of the itemsetX
Y
, i.e., sanitize the transactions that contain the itemsetX
Y
.To reduce the number of database scanning in generating large or frequent itemsets in association rule mining, a one-scan of database method was proposed in [8]. The basic idea is to construct a tree structure, called Pattern tree (P-tree) and a frequency list which contains the frequency counts of each item in one database scan. The pattern tree is then restructured to a compact Frequent-Pattern tree (FP-tree) proposed by [7], which is
an extended prefix-tree structure for storing compressed, crucial information about frequent patterns in less space. A FP-tree based pattern growth method (FP-growth) is used to find all the large itemsets from the FP-tree.
In [18], we proposed a Pattern-Inversion tree (PI-tree) based on the pattern tree to sanitize collaborative recommendation association rules with one database scan. A PI-tree is similar to a P-tree except the following. Each node in a PI-tree contains three fields: item name (or item number), number of transactions containing the items on the path from the root to current node, and list of transaction ID that contains all the items on the path from the root to current node. For example, the PI-tree for the six transactions in Table 1 is shown in Figure 1. The frequency list is L = < (A:6), (B:4), (C:4)>.
Figure 1 Pattern Inversion Tree for Database in Table 1 To sanitize the collaborative recommendation association rules of updated database D+, there are two possible approaches as mentioned in section 2. One approach is that we can re-run any hiding algorithm on the updated database D+ directly. The second approach is to process the newly added data set
incrementally and combined it with the sanitized result of original databaseD’. For the second approach, a collaborative recommendation association rule in D does not have to be a collaborative recommendation association rule in
orD+, and vice versa. However, if all collaborative recommendation association rules in D and in
are sanitized, then all collaborative recommendation association rules are sanitized in the updated database D+. We will adopt this strategy to sanitize the collaborative recommendation association rules in his work.Based on the strategies described above, we propose a data-mining algorithm called MSCR for the maintenance of sanitizing collaborative recommendation association
rules. The basic steps of the algorithm are described as follow.
Algorithm MSCR
Input: (1) a sanitized database
D
(or pattern inversion treePI
'
, and frequency listL
' )(2) min_support (3) min_confidence (4) a set of hidden items Y (5) added data set
Output: a sanitized database
D
'
, D+ = D +
, where rules containing items of Y on RHS will be hidden1. Build the Pattern Inversion Tree
PI
for
according toL
' and new items in
2. Sort frequency list
L
for
in descending order 3. Sanitize all collaborative recommendation associationrules of the form: U:
x
y
in
according to
L
, to obtain ' PI
and ' L
4. Build frequency list
L
'
forD
'
, by adding ' L
to 'L
5. Merge PI-trees ' PI
andPI
'
to obtainPI
' 6. RestructurePI
' according toL
'
7. Output sanitized database
D
'
4. Example
Using the same example database D and sanitized database
D
with minimum support of 33% and minimum confidence of 70% in Table 2, when the data set
= {T7:011, T8:010, T9:111} is added, the result ofrunning proposed MSCR algorithm is as follows.
In step one, the pattern inversion tree '
PI
for
has two branches, root – B:2:[T8] – C:1:[T7], root – A:1 –B:1 – C:1: [T9]. In step two, the sorted frequency list
L
= <(B:3),(C:2),(A:1)> is built. In step 3, to hide A=>C (33%, 100%), transaction T9 is sanitized from ABC
to C. The sanitized '
PI
tree has two branches, root – B:2:[T8] – C:1:[T7], root – A:1 – B:1:[T9]. In step 4, the
updated frequency list for D+ is
L
'
= <(A:7),(B:7),(C:4)>. In step 5, the mergedPI
'
tree has 3 branches, root – A:7:[T5] – B:5:[T1,T4,T9] – C:2[T2,T3], and root –step 6, the restructured
PI
'
tree according toL
'
remains unchanged.The sanitized database
D
'
is shown in Table 2 as'
D
(MSCR). It hides collaborative recommendation association rule A=>C (0%, 0%), There are no new rules generated, no hiding failure and three rules are lost, A=>BC (0%, 0%), AB=>C (0%, 0%), AC=>B (0%, 0%), as side effects.5. Numerical Experiments
In order to better understand the characteristics of the proposed MSCR algorithm numerically, we perform a series of experiments to measure various effects and compare with the direct sanitization DCBS algorithm proposed in [18]. The following effects are considered: time effects, side effects, and database effects. For time effects, we measure the running time required to hide one and two predicting items, i.e., one and two collaborative recommendation association rule sets respectively. For side effects, we measure the hiding failure; new rules generated and lost rules. The hiding failure side effect measures the number of collaborative recommendation association rules that cannot be hidden. The new rule side effect measures the number of new rules appeared in the transformed database but is not in the original database. The lost rule side effect measures the number of rules that are in the original database but not in the transformed database. The database effects measure the percentage of altered transactions in the database.
The experiments are performed on a PC with AMD 1.99 GHz processor and 1 GB RAM running on Windows XP operating system. The data sets used are generated from IBM synthetic data generator. The sizes of the data sets range from 5K to 25K transactions with average transaction length, |ATL| = 5, and total number of items, |I| = 50. For each data set, various sets of association rules are generated under various minimum supports and minimum confidences. The minimum support range is from 3% to 10%. The minimum confidence range is from 20% to 40%. Total number of association rules is from 6 to 178. The number of hidden rules ranges from 3 to 16, which in percentage over total association rules is from 9% to 66%. The number of predicting items considered here is one and two items.
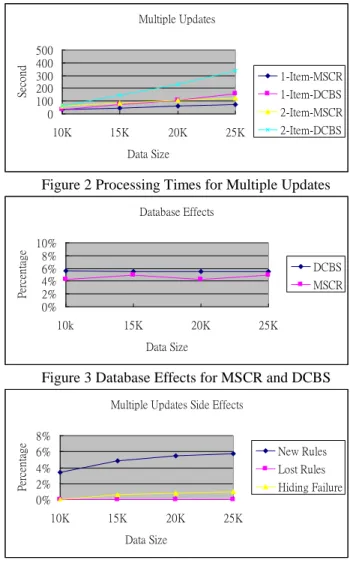
Figure 2 shows the processing times required to maintain the sanitized collaborative recommendation association rules under multiple updates. Multiple updates mean more than one data set is added to the original database in sequence. For example, in Figure 3, the original database has data size |D| = 10k, | ∆+ | = 5k, and ∆+ is added to the D three times in sequence. The
processing time required to sanitize 10k is 31.82 seconds to hide one item and 63.82 seconds to hide two items. Adding the first 5k data set, MSCR algorithm requires 45.42 and 84.54 seconds and DCBS algorithm requires 71.88 and 143.51 seconds for hiding one item and two items respectively. The 20k data size refers to adding second 5k data set to the previously sanitized 15k data set.
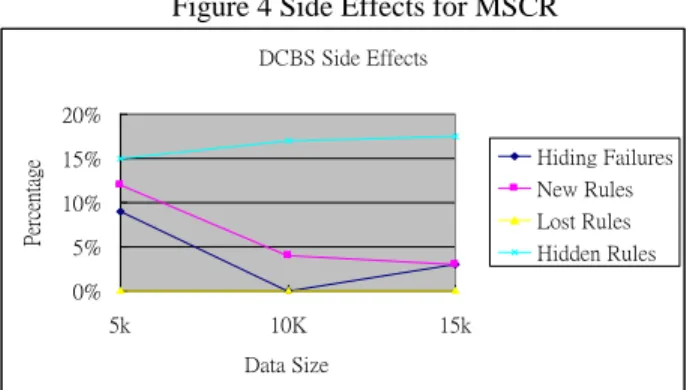
Figure 3 shows the percentage of transactions altered using MSCR and DCBS algorithms. Even for different database sizes, the percentages of altered transactions remain almost constant, about 4.5% for MSCR and 5.5% for DCBS with one predicting item. This indicates that the processing time should increase proportionally as the size of dataset increases. Figures 4 and 5 show the various side effects of MSCR and DCBS algorithms hiding two predicting item. There are about the same percentage of rules to be hidden for both algorithms. There is no lost using MSCR or DCBS algorithm. There are about 6% of new rules generated for each 5k data set and about 1.13% of association rules are hiding failures for each 5k data set for MSCR algorithm. The DCBS algorithm shows some hiding failure (9%, 0%, 3%), few new rules (11%, 3%, 3%), and no lost rules for two recommended items.
Multiple Updates 0 100 200 300 400 500 10K 15K 20K 25K Data Size Se co nd 1-Item-MSCR 1-Item-DCBS 2-Item-MSCR 2-Item-DCBS
Figure 2 Processing Times for Multiple Updates
Database Effects 0% 2% 4% 6% 8% 10% 10k 15K 20K 25K Data Size Pe rc en ta ge DCBS MSCR
Figure 3 Database Effects for MSCR and DCBS
Multiple Updates Side Effects
0% 2% 4% 6% 8% 10K 15K 20K 25K Data Size Pe rc en ta ge New Rules Lost Rules Hiding Failure
Figure 4 Side Effects for MSCR DCBS Side Effects 0% 5% 10% 15% 20% 5k 10K 15k Data Size Per ce nt ag e Hiding Failures New Rules Lost Rules Hidden Rules
Figure 5 Side Effects for DCBS
6. Conclusion
In this work, we have studied the database privacy problems caused by data mining technology and proposed an efficient data-mining algorithm MSCR to maintain sanitized collaborative recommendation association rule sets. The proposed algorithm incrementally sanitized the added data set and merged with the previously sanitized database with one database scanning using pattern-inversion trees. Example illustrating the proposed algorithm is given. Numerical experiments are performed to show the time effects, database effects, and side effects of the algorithm and compared with direct database sanitization algorithm. In addition, running time analysis of the proposed algorithm is presented. It can be seen that the proposed MSCR algorithm out performs the direct sanitization algorithm DCBS in processing time with similar side effects. In the future, we will consider the problem of efficient maintenance of privacy for other types of rules and patterns when databases are updated. In addition, the issue of how side effects affect the level of privacy will be studied.
7. References
[1] D. Agrawal and C. C. Aggarwal, “On the design and quantification of privacy preserving data mining algorithms”, In Proceedings of the 20th Symposium on Principles of Database Systems, Santa Barbara, California, USA, May 2001.
[2] R. Agrawal, T. Imielinski, and A. Swami, “Mining Association Rules between Sets of Items in Large Databases”, In Proceedings of ACM SIGMOD International
[3] Conference on Management of Data, Washington DC, May 1993.
[4] R. Agrawal and R. Srikant, ”Privacy preserving data mining”, In ACM SIGMOD Conference on Management of Data, pages 439–450, Dallas, Texas, May 2000.
[5] L. Brankovic and V. Estivill-Castro, “Privacy Issues in Knowledge Discovery and Data Mining”, Australian Institute of Computer Ethics Conference, July, 1999, Lilydale.
[6] C. Clifton, M. Kantarcioglu, X.D. Lin and M. Y. Zhu, “Tools for Privacy Preserving Distributed Data Mining”, SIGKDD Explorations, 4(2), 1-7, Dec. 2002.
[7] A. Evfimievski, J. Gehrke and R. Srikant, “Limiting Privacy Breaches in Privacy Preserving Data Mining”, PODS 2003, June 9-12, 2003, San Diego, CA.
[8] J. Han, J. Pei, and Y. Yin, “Mining Frequent Patterns without Candidate Generation”, Proceedings of ACM International Conference on Management of Data (SIGMOD), 2002, 1-12.
[9] H. Huang, X. Wu, and R. Relue, “Association Analysis with One Scan of Databases”, Proceedings of IEEE International Conference on Data Mining, Maebashi City, Japan, December, 2002, 629-632.
[10] M. Kantarcioglu and C. Clifton, “Privacy-preserving distributed mining of association rules on horizontally partitioned data”, In ACM SIGMOD Workshop on Research Issues on Data Mining and Knowledge Discovery, June 2002. [11] S. Oliveira, O. Zaiane, “Privacy Preserving Frequent Itemset Mining”, Proceedings of IEEE International Conference on Data Mining, November 2002, 43-54.
[12] S. Oliveira, O. Zaiane, “An Efficient On-Scan Sanitization for Improving the Balance Between Privacy and Knowledge Discovery”, Technical Report TR 03-15, Department of Computing Science, University of Alberta, Canada, June 2003. [13] S. J. Rizvi and J. R. Haritsa, “Privacy-preserving association rule mining”, In Proc. of the 28th Int’l Conference on Very Large Databases, August 2002.
[14] Y. Saygin, V. Verykios, and C. Clifton, “Using Unknowns to Prevent Discovery of Association Rules”, SIGMOND Record 30(4): 45-54, December 2001.
[15] J. Vaidya and C.W. Clifton. “Privacy preserving association rule mining in vertically partitioned data”, In Proc. of the 8th ACM SIGKDD Int’l Conference on Knowledge Discovery and Data Mining, Edmonton, Canada, July 2002. [16] V. Verykios, A. Elmagarmid, E. Bertino, Y. Saygin, and E. Dasseni, “Association Rules Hiding”, IEEE Transactions on Knowledge and Data Engineering, Vol. 16, No. 4, 434-447, April 2004.
[17] S.L. Wang, D. Patel, A. Jafari, and T.P. Hong, “Hiding Collaborative Recommendation Association Rules”, Applied Intelligence, Volume 27 (1), August 2007, 67-77.
[18] S.L. Wang, and T.P. Hong, “One-Scan Sanitization of Collaborative Recommendation Association Rules”, Proceedings of National Computer Symposium, November, 2007, Taichun, Taiwan.