Automatic Detection of Social Tag Spams Using a
Text Mining Approach
Hsin-Chang Yang
Department of Information Management National University of Kaohsiung
Kaohsiung, 811 Taiwan Email: [email protected]
Chung-Hong Lee
Department of Electrical Engineering National Kaohsiung University of Applied Sciences
Kaohsiung, Taiwan
Email: [email protected]
Abstract—Social tags are annotations for Web pages
collabo-ratively added by users. It will be much easier to understand the meaning of Web pages and classify them according to their tags. The precision in retrieving Web pages may also increase using such tags. Nowadays social tags are mostly annotated manually by users via social bookmarking Web sites. Such manual annotation process may produce diverse, redundant, and inconsistent tags. Besides, many tags which are inconsistent with their annotated Web pages exist and deteriorate the feasibility of social tags. In this work we will develop an automatic scheme to discover the associations between Web pages and social tags and apply such associations on applications of social tag spam detection. We applied a text mining approach based on self-organizing maps to find the relationships between Web pages and social tags. The disadvantages of manual annotation will be remedied through such relationships. The discovered associations were then used to identify social tag spams. Preliminary exper-iments show that the quality and usability of social tags were improved through this method.
I. INTRODUCTION
Social Web sites have been one of the widely used services in the World Wide Web (WWW, or the Web). Various types of social Web sites exist to provide services like friends-making, audio/video sharing, and Web pages bookmarking, etc. The major characteristic of these Web sites is user collaboration, in which users of a social Web site contribute, share, manage, and annotate its content. Social bookmarking Web sites provide platforms for users to contribute interesting Web pages as well as their annotations. People may annotate a Web page according to its content with a set of keywords which are called social tags. The annotating process is collaborative, i.e. a user can add, delete, or update the tags of any pages he interested, no matter who contributed them. The social bookmarking/tagging service is also known as folksonomy [1] since it is collaborative and provides a taxonomy for Web pages. There are several benefits of social tags. First, the effort of Web page annotation is alleviated. Since it is rather difficult to understand the content of a Web page automati-cally, we often rely on the annotations of the Web page to capture its major semantics. Such annotations were generally added manually by human experts or semi-automatically using machine learning or natural language processing techniques. However, such schemes can only annotate a small amount of pages, which are impractical for real world applications. Social
tagging allows users annotate Web pages collaboratively and should significantly improve the quality and amount of Web page annotations. Second, the precision of Web page retrieval could be improved. Traditional information retrieval systems relied on the analysis of the content of Web pages to retrieve Web pages. However, it is rather difficult to understand the content automatically. Social tags provide a convenient way to obtain the semantics of the Web pages and thus should result in better retrieval performance. Third, automatic Web page categorization is possible. The social tags naturally form classes that can be used to categorize the Web pages. These classes should faithfully reveal the semantics of the Web pages. Therefore, accurate categorization of Web pages may be achieved by means of using such tags.
Beyond the benefits described above, the value of social tags could be depreciated by improper manipulation of them. Social tag spams are, like email spams, tags which are unrelated or improperly related to their annotating Web pages. The relatedness is generally defined by the semantic correlation between tags and Web pages. For example, a Web page describing artist ’Michael Jackson’ may be annotated by some company’s name to promote the visibility of this company. Some users may also manipulate the ranking of some tags through multiple registrations. Tag spams may deteriorate the quality of tags and cause misapprehension of the content of Web pages and imprecision of categorization. Therefore, tag spam detection should be performed to eliminate unwanted tags. Through tag spam detection, social tags could effec-tively reflect the relatedness between their annotated Web pages and them. Three major approaches were adopted to detect tag spams, namely detection-based, prevention-based, and demotion-based schemes [2]. In detection-based schemes, likely spams are identified first manually or automatically. These spams are then deleted or highlighted by the systems. Detection of spams, however, is not easy. We can classify the detection schemes into two categories, namely behavior-based and content-behavior-based approaches. Hybrid approach is also possible. In behavior-based approaches, we try to identify spams according to the user’s individual or collaborative behavior such as the frequency of posting tags, the tag counts, and ranges of login IP, etc. Basically, behavior-based approaches would not rely on the content of the Web pages to
detect spams. In contrast, content-based approaches analyze the relatedness between the content of Web pages and the tags. A tag is identified as spam if the relatedness is too low. The analysis often involved techniques from machine learning, natural language processing, and statistics fields. Various mea-surements of semantic correlation have been proposed, such as latent semantic analysis [3], pointwise mutual information [4], WordNet [5], and Google distance [6], etc.
In this work we will describe a scheme to detect social tag spams using a text mining approach. In the first phase of the scheme we apply the self-organizing map (SOM) model [7] to cluster Web pages as well as tags. An association discovery process is then applied to discover the relationships between Web pages and tags. The relatedness between a Web page and a tag can then be calculated according to such relationships. A tag will be identified as spam if the relatedness between its annotated page and itself is too low. Our approach can automatically discover the semantic relatedness between Web pages and tags and detect tag spams accordingly. It can also be applied to other social tagging applications such as tag suggestion.
The remaining article is divided into five sections. In Sec. II we discussed some works related to our research. Sec. III describes the method of applying SOM to cluster Web pages and tags. The association discovery process is also described. We then show the way to detect tag spams in Sec. IV. In Sec. sec:experiment we show the experimental result of the proposed method. Finally we give some conclusions and discussions in the last section.
II. RELATEDWORK
The research on tag spam detection arisen from the detection on blog spams and comment spams on the Wikipedia [8], [9], [10]. The earliest research on spam message detection in social bookmarking Web sites was conducted by Cattuto et al. [11]. Heymann et al. are the first to work on the detection of social tag spams [2], [12]. Krause et al. proposed a machine learning approach to detect tag spams based on the tag contributors, tag semantics, and user behavior [13].
Most tag spam detection methods were based on the the analysis of tag annotators, tag content, and user connections. For annotator-based methods, white lists or black lists are often used to filter possible spams, such as those used in TrustRank [14]. In content-based approaches, Bayesian clas-sifiers were often used to analyze the keywords [15]. Writing style analysis was also used to detect spams [8], [16].
III. ASSOCIATION DISCOVERY BYSOM
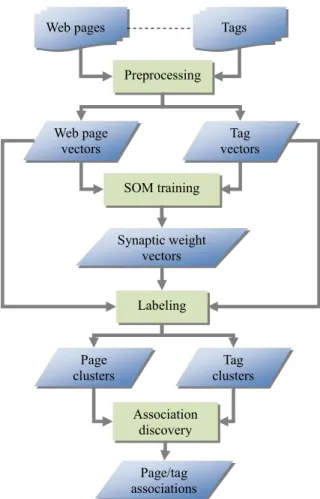
In this section we will describe the method to discover associations between Web pages and tags. Figure 1 depicts the flowchart of the proposed method. We will describe the details in the following subsections.
A. Preprocessing
We used a set of training Web pages as well as their tags to train the SOM. Each Web page in the training corpus
Web pages Tags
Page/tag associations Association discovery Preprocessing Web page vectors Tag vectors SOM training Page clusters Tag clusters Synaptic weight vectors Labeling
Fig. 1. The flowchart of association discovery.
is annotated with some tags. These tags are all clean, i.e. they are not spams. We ignored syntactic keywords of Web languages and used only the normal text contained in the Web pages. The remaining text were then segmented into a set of words. These words, however, often consists of useless words such pronouns, articles, and conjunctions, etc. which are collectively called stopwords. Therefore, we should discard such stopwords to reduce the number of keywords. Besides, not all parts of speech are equally important. For example, nouns generally carry more semantic meaning of a sentence than other parts of speech such as adjectives and adverbs. Therefore, we actually discarded terms which are not nouns. Moreover, stemming process was applied on the remaining keywords to obtain word stems. It is much easier to process tags since they are generally segmented. Some systems allow users to annotate with phrases, which contains multiple words in a tag. Segmentation is needed for such tags. Stopword elimination, noun selection, and stemming should also be applied on these tags to conform with the keywords from Web page. We then collected all these keywords, from both Web pages and tags, and obtained the vocabulary of the Web pages. Let V = {kj|1 ≤ j ≤ N} be the vocabulary of the corpus,
where kj denote the jth keyword and N is the number of
pi ={pij|1 ≤ j ≤ N} resemble to the classic vector space model [17] as follows: pij = { 1 if kj appears in Pi, 0 otherwise. (1)
Unlike traditional vector space model, we ignore the term weightings since the tags often appears once for single Web page. Similarly, the set of tags for Pi, collectively known as the
tag list of Pi and denoted by Ti, is transformed into a binary
vector ti = {tij|1 ≤ j ≤ N} in the same way described in
equation 1.
B. SOM training
All Web page vectors pi and tag vector tiwere then trained
respectively by two SOMs, which are called page SOM and tag SOM hereafter. Standard SOM training algorithm [7] is used, which is described as follows:
Step 1 Randomly select a training vector xifrom the corpus.
xi could be either pi or ti upon the training map.
Step 2 Find the neuron j with synaptic weight vector wj
which is the closest to xi, i.e.
||xi− wj|| = min
1≤k≤J||xk− wj||, (2) where J is the number of neurons in the SOM. Step 3 For each neuron l in the neighborhood of neuron j,
update its synaptic weights by
wnewl = woldl + α(t)(xi− woldl ), (3)
where α(t) is the training gain at time stamp t. Step 4 Increase time stamp t. If t reaches the preset
max-imum training time T , halt the training process; otherwise decrease α(t) and the neighborhood size, goto Step 1.
C. Labeling
After training, we can label each Web page as well as tag list to a neuron on the page SOM and tag SOM, respectively. The labeling process is simple. A page Piis labeled to the jth
neuron on the page SOM if equation 2 holds. Similarly, a tag list Tiis labeled to the jth neuron on the tag SOM if equation 2
holds. After the labeling process, we should obtain two feature maps, namely the page cluster map (PCM) and the tag cluster map (TCM). In PCM, similar pages will be clustered together on the same neuron or nearby neurons. Therefore a neuron forms a cluster of similar pages. Moreover, the geometric distance between two neurons reveals the semantic similarity between the pages belonged to these clusters. The same properties hold for TCM.
D. Association discovery
The PCM and TCM reveal the the association among Web pages and tags, respectively. However, we need another kind of associations, i.e. associations between pages and tags, to detect tag spams. Obviously, we can obtain an inherent association between a Web page and its tag list. Besides such simple associations, we try to find the associations between
page clusters and tag clusters. The association between two clusters in different SOMs can be obtained by the inherent association between each Web page and its tag list. Let a cluster CkP CM = {Wkl} in the PCM contain a set of Web
pages. We used a voting scheme to find its associated cluster in the TCM. For each Wkl in CkP CM, we find the cluster in
TCM to which Tkl, the tag list of Wkl, labels. The cluster, says
CT CM
p , will have a score increased by 1. The same process
will be applied to every page in CkP CM. After the voting, we simply associate CP CM
k with the cluster in TCM with the
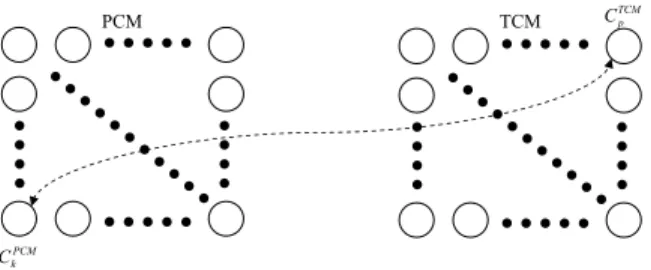
highest score. Figure 2 depicts the voting process.
PCM TCM CTCMp
PCM k C
Fig. 2. The voting process in finding associations between CP CM
k . The score of CT CM
p will increase by 1 since it contains a tag list which is associated with a page in CP CM
k .
When there is a tie after the vote, the cluster with less number of tag lists will be selected since these tag lists should be more consistent. If still there is a tie, arbitrary cluster could be selected. Each cluster in the PCM will associate with a cluster in the TCM. We can also reverse the roles of the PCM and TCM, i.e. find the associated clusters in PCM of a cluster in TCM. In either way we can establish the associations between page clusters and tag clusters. We may represent the associations by a correlation matrix A with size JP CM× JT CM defined as follows:
A = [aij]JP CM×JT CM, (4) aij = { 1 if CP CM i associates with CjT CM 0 otherwise , (5)
where JP CM and JT CM are the number of neurons in the
PCM and TCM, respectively.
IV. TAG SPAM DETECTION
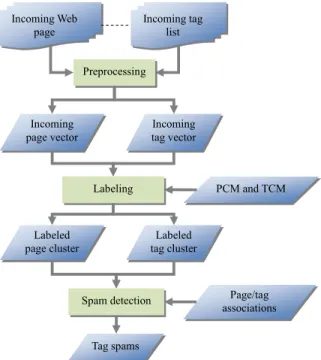
In this section we will show the way to use the result of the association discovery process for tag spam detection. The processing steps for spam detection is depicted in Figure 3. We will describe the steps in the following subsections.
A. Preprocessing and labeling
When a user annotated a Web page with some tags (a tag list), we should first preprocess them into vectors, as described in Section III-A. Note that stopwords, which are rather common in tags, will be removed in this phase. We then label these page vector and tag vector on the trained maps as described in Section III-C. The incoming page as well as its tag list should be labeled to a page cluster in the PCM and a tag cluster in the TCM, respectively.
Incoming Web page Incoming tag list Page/tag associations Preprocessing Incoming page vector Incoming tag vector Labeling Labeled page cluster Labeled tag cluster Spam detection Tag spams PCM and TCM
Fig. 3. The flowchart of spam detection process.
B. Spam detection
When an incoming page PI and its tag list TI are labeled to
a page cluster CP CM
p and a tag cluster CqT CM, respectively,
we can decide if TI contains tag spams according to the
asso-ciation between these clusters. Two levels of spam detection were allowed, namely document-scope detection and tag-scope detection. In document-scope detection, the entire tag list will be identified as spams. On the other hand, tag-scope detection can identify individual spam tags.
Document-scope detection can be achieved by using the page/tag associations discovered in Section III-D. The incom-ing tag list TI is identified as spam if its tag cluster CqT CM is
not related to CP CM
p to which its annotated page PI labels.
The relatedness is defined by the page/tag associations. It is obvious that CpP CM is related to CqT CM if apq = 1, as
defined in equation 4. However, such relationships are binary, i.e. a page cluster is either related to a tag cluster or not. It will help if we can differentiate the degree of relatedness. By virtue of the SOM, similar clusters will locate closely on the map. Moreover, the geometric distance between two clusters reflects their relatedness. Therefore, we can incorporate such proximity into the relatedness calculation. Here we define the relatedness between CP CM p and CqT CM as: S(CpP CM, CqT CM) = 1 |Q| ∑ CT CM k ∈Q apk D(CT CM k , CqT CM) + 1 , (6) where Q is the set of neighboring clusters of CqT CM and
D(CkT CM, CqT CM) is the geometric distance between the two clusters. The neighborhood Q is generally a rectangular area around CqT CM. For example, Q can include the 8-neighbors of
CT CM
q along with itself. The contributions of the neighboring
clusters are weighted by their geometric distance to CqT CM.
That is, clusters which close to CT CM
q will contribute more
to the degree of relatedness between CP CM
p and CqT CM than
those distant clusters. Incoming tag list TI will be identified
as spam if S(CP CM
p , CqT CM) < τ , where τ is a predefined
threshold.
Tag-scope detection tries to identify individual tag as spams rather than entire tag list. We achieve tag-scope detection by checking the semantic coherence between a tag and its annotated page. Two approaches are possible in measuring such coherence. The first approach compares the semantic similarity between the tag and the content of its annotated pages. Many methods have been devised to measure the semantic similarity [17]. A common and simple scheme is to count the occurrences of the tag within the page. If the tag did not appear in the page, this tag can be identified as a spam. This scheme suffers from cases such as use of abbreviations, translations, dialects, and aliases. Thus we devise another scheme to relieve the requirement of word occurrence. The second approach compare the tag with other tags in the same tag cluster. We define a tag to be a spam if it is inconsistent to other tags in the same tag cluster. A tag is inconsistent to its labeled cluster when it did not appear in any other tag lists in this cluster. We could also include neighboring clusters in checking the inconsistency.
V. EXPERIMENTAL RESULT
We performed experiments on a corpus of Web pages as well as their tag lists. The corpus contains 1500 pairs of Web page and its tag list which were collected from Delicious 1 Web site. Two thirds of the pairs in the corpus are used for training and the other one third are used for testing. These Web pages and tag lists were preprocessed as described in Section III-A. These tag lists were then screened by hands to find spam tags. When spam tags were found in a tag list, we should label both the list and the individual tags as spams. There are total 362 spam tag lists and 786 spam tags found in the corpus, among all 5157 tags. The vocabulary of the Web pages contains 13437 keywords after preprocessing. We then trained the Web page vectors and the tag list vectors separately by two SOMs using 1000 pairs of Web pages and tag lists. The training parameters used in the experiments are shown in Table I. These parameters were determined by selecting the ones which achieved better result. The labeling and association discovery processes were applied on the trained maps to discover the associations between Web page clusters and tag list clusters.
We measured the performance of the spam detection method by applying the test data set on the PCM and the TCM. For document-scope detection we calculated the relatedness between a Web page and its tag list using equation 6. The threshold was set to 0.7, which is determined experimentally. The confusion matrix of the test result is shown in Table. II.
TABLE I
THE PARAMETERS OF THE TRAINING PROCESS
Web pages Tag lists
Map sizes 10× 10 10× 10
Max training epoch 400 200 Initial training gain 0.4 0.4 Number of training vectors 1000 1000 Sizes of vocabulary 13437 5157
TABLE II
THE CONFUSION MATRIX OF DOCUMENT-SCOPE DETECTION Actual result Spam Not spam Predicted result Spam 118 65
Not spam 44 273
The accuracy of the detection result is then (118+273)/500 = 78.2%.
VI. CONCLUSIONS
In this work we proposed a method for tag spam detection in social Web sites. The proposed method is inspired by a text mining approach which could discover the relationships between Web pages as well as tags. We first clustered the Web pages and their tags respectively by self-organizing map algorithm. A labeling process was then applied on the trained map to discover the relationships between Web pages and between tags. The detection of tag spams could then be achieved by examining the semantic relatedness between a tag and its tagged Web page. We conducted experiments on a set of Web pages collected from the social Web site Delicious and obtained promising result.
REFERENCES
[1] T. Vander Wal, “Folksonomy,” http://vanderwal.net/folksonomy.html, 2007, [Online; accessed 10-April-2010].
[2] P. Heymann, G. Koutrika, and H. Garcia-Molina, “Fighting spam on social web sites: A survey of approaches and future challenges,” IEEE
Internet Computing, vol. 11, no. 6, pp. 36–45, 2007.
[3] S. Deerwester, S. Dumais, G. Furnas, and K. Landauer, “Indexing by latent semantic analysis,” Journal of the American Society for
Information Science, vol. 40, no. 6, pp. 391–407, 1990.
[4] K. Church and P. Hanks, “Word association norms, mutual information, and lexicography,” Computational Linguistics, vol. 16, no. 1, pp. 22–29, 1990.
[5] C. Fellbaum, WordNet: An Electronic Lexical Database. Cambridge, MA: MIT Press, 1998.
[6] R. Cilibrasi and P. Vitanyi, “The Google similarity distance,” IEEE
Trans. Knowledge and Data Engineering, vol. 19, no. 3, pp. 370–383,
2007.
[7] T. Kohonen, Self-Organizing Maps. Berlin: Springer-Verlag, 1997. [8] G. Mishne, D. Carmel, and R. Lempel, “Blocking blog spam with
language model disagreement,” in Proceedings of the 1st International
Workshop on Adversarial Information Retrieval on the Web (AIRWeb ’05), Chiba, Japan, 2005.
[9] P. Kolari, T. Finin, and A. Joshi, “SVMs for the blogosphere: Blog identification and splog detection,” in AAAI Spring Symposium on
Computational Approaches to Analysing Weblogs, Computer Science
and Electrical Engineering. University of Maryland, Baltimore County, March 2006, also available as technical report TR-CS-05-13.
[10] P. Kolari, A. Java, T. Finin, T. Oates, and A. Joshi, “Detecting spam blogs: A machine learning approach,” in Proceedings of the 21st
National Conference on Artificial Intelligence (AAAI 2006), Computer
Science and Electrical Engineering. University of Maryland, Baltimore County, July 2006.
[11] C. Cattuto, C. Schmitz, A. Baldassarri, V. D. P. Servedio, V. Loreto, A. Hotho, M. Grahl, and G. Stumme, “Network properties of folk-sonomies,” AI Communications, vol. 20, no. 4, pp. 245–262, 2007. [12] G. Koutrika, F. A. Effendi, Z. Gy¨ongyi, P. Heymann, and H.
Garcia-Molina, “Combating spam in tagging systems,” in Proceedings of the
3rd International Workshop on Adversarial Information Retrieval on the Web (AIRWeb ’07), Banff, Canada, 2007, pp. 57–64.
[13] B. Krause, C. Schmitz, A. Hotho, and G. Stumme, “The anti-social tagger - detecting spam in social bookmarking systems,” in Proceedings
of the 4th International Workshop on Adversarial Information Retrieval on the Web (AIRWeb ’08), Beijing, China, 2008, pp. 61–68.
[14] Z. Gy¨ongyi, H. Garcia-Molina, and J. Pedersen, “Combating Web spam with TrustRank,” in Proc. 30th Very Large Databases Conference, Toronto, Canada, 2004, pp. 576–587.
[15] C. Kim and K.-B. Hwang, “Naive Bayes classifier learning with feature selection for spam detection in social bookmarking,” in Proc. Europ.
Conf. on Machine Learning and Principles and Practice of Knowledge Discovery in Databases (ECML/PKDD), Antwerp, Belgium, 2008.
[16] T. Urvoy, T. Lavergne, and P. Filoche, “Tracking Web spam with hidden style similarity,” in Proceedings of the 2nd International Workshop on
Adversarial Information Retrieval on the Web (AIRWeb ’06), Seattle,
WA, 2006, pp. 25–31.
[17] G. Salton and M. J. McGill, Introduction to Modern Information