國立臺中教育大學教育測驗統計研究所
教學碩士學位暑期在職專班碩士論文
指導教授:郭伯臣 博士
不同次級量尺估計法之水平及
垂直等化效果比較
研究生:唐嘉謚 撰
謝 辭
就讀研究所期間,充實良多,也遇到許多挫折與感傷,但都一一克服,所以 這本論文之所以能夠完成,非常由衷感謝許多陪伴在我週邊的人—家人、老師與 學長、姐的幫助! 首先要感謝我的指導教授郭伯臣老師,謝謝您從我暑碩二時期,教導我們做 學問的態度,讓我謹慎地面對我的研究,您提供我許多資源,讓我可以順利地完 成學業。在我最徬徨時,給予一劑強心針,讓我得以完成碩士學位—一個曾經想 要放棄的目標,謝謝您!感謝我的兩位口試委員施淑娟老師與黃孝雲老師,謝謝 三位老師們在論文口試時給我的建議及提醒,讓我的論文更趨完備。 在進行模擬實驗研究的過程中,感謝暄博學長不厭其煩地與我共同討論,因 為我老是在狀況外,我一定讓你相當失望,但你還是耐心地給予我許多參考建 議,在我觀念模糊時,給予適當提醒並釐清觀念;也感謝佳穎學姊與宛婷學姊給 我的指點與協助,幾次遇上問題幫我解說程式,細心地找出問題原因所在;還有 感謝研究室裡的典佑、智為、育隆等諸位學長,在我碩班這三年裡曾經給予我的 幫助。 感謝我的爸、媽,這三十多年來總是對我有著最深切的期望,求學路上的不 順遂你們最知道,總在我遇到瓶頸時,給予最大的支持與陪伴。最後,我想將這 份成果獻給我最愛的老婆,謝謝妳在去年不辭辛勞生下我們可愛的軒,軒的呱呱 落地帶給我更多的責任,他是支撐我熬過這段期間的最大動力,讓我擁有更大的 力量—往前邁進! 本論文部分成果為國科會計畫:不同次級量尺估計法之水平及垂直等化效果 比較(99-2410-H-656-005-)之研發成果。摘要
本研究主要是使用平衡不完全區塊設計(balanced incomplete block, BIB)之 等化設計,以模擬實驗方式於水平與垂直等化設計的情境中,探討不同次級量尺 分數(subscale score)估計方法於測驗分數之估計效果,其中,水平等化設計考 慮三種因素:施測人數、題本次級量尺比例及次級量尺相關程度;在垂直等化設 計中,考慮五種因素:施測人數、題本次級量尺比例、次級量尺相關程度、題本 定錨比例及高低年級能力分布。 本研究結果發現: 1. 水平與垂直等化設計中,對於本研究設計之施測人數而言,次級量尺分數估 計誤差沒有明顯的差異; 2. 水平與垂直等化設計中,次級量尺分數估計誤差隨著次級量尺相關程度增加 而減少;然而,次級量尺分數估計誤差隨著題本次級量尺比例懸殊程度增加 而變大; 3. 垂直等化設計中,在不同定錨比例中的情境下,次級量尺分數估計誤差以定 錨比例為20%有較佳的估計效果;高低年級能力分布以N(2,1) vs. N(0,1)時效 果最佳。 關鍵字:水平等化設計、垂直等化設計、次級量尺分數估計方法、次級量尺
Abstract
The purpose of this paper is to compare subscale scores estimation in two equating design situations, horizontal and vertical equating design. Using simulation data, this study investigates the accuracy of subscale scores estimation for different methods of estimating subscale scores.
In horizontal equating design and vertical equating design, using the design method, balanced incomplete block (BIB), factors that horizontal equating design are taken into consideration include the following: percentage of subscales, correlation between subscales, and sample sizes. In vertical equating design, factors taken into consideration include the following: sample sizes, percentage of subscales, correlation between subscales, the percentage of anchor items, the distributions of high and low abilities, and sample sizes.
The results show that:
1. In horizontal and vertical equating design, the estimation errors have no difference as the sample sizes change in this study.
2. In horizontal and vertical equating design, the estimation errors decrease as correlation between subscales increases; however, the estimation error increases as percentage of subscale increases.
3. In vertical equating testing design, the result shows that the best decision of the percentage of anchor items and the distributions of high and low abilities are 20 percentage and the distributions of high and low abilities are N(2,1) vs. N(0,1).
Keywords: horizontal equating design, vertical equating design, subscale scores estimation, subscale
目錄
摘要 ... I 目錄 ...III 表目錄 ... IV 圖目錄 ...V 第一章 緒論 ...1 第一節 研究背景與動機 ...1 第二節 研究目的 ...3 第三節 待答問題 ...4 第四節 名詞釋義 ...5 第二章 文獻探討 ...6 第一節 試題反應理論 ...6 第二節 次級量尺分數估計方法 ...15 第三節 測驗等化的意義、種類與等化設計 ...18 第三章 研究方法 ...21 第一節 研究流程 ...21 第二節 研究變項設定 ...22 第三節 實驗設計 ...26 第四節 估計精準度 ...32 第五節 研究工具 ...32 第四章 研究結果 ...33 第一節 水平等化設計之估計結果 ...33 第二節 垂直等化設計之估計結果 ...36 第五章 結論與未來研究建議 ...43 第一節 結論 ...43 第二節 未來研究建議 ...45 參考文獻 ...46 中文部分...46 英文部分...47 附錄一 水平等化設計之誤差 RMSE ...53 附錄二 垂直等化設計之誤差 RMSE ...54 附錄三 垂直等化設計之題本配置比例 RMSE ...81表目錄
表 3-1 水平等化設計變項設定...22 表 3-2 垂直等化設計變項設定...24 表 3-3 BIB 設計表 ...27 表 3-4 不同年級間 BIB 等化設計(垂直等化)模式...28 表 3-5 不同年級間 BIB 等化設計(垂直等化)模式之 10%定錨試題 ...29 表 3-6 不同年級間定錨試題數與總試題數對照表 ...29圖目錄
圖 2-1 題間多向度測驗模式...14 圖 2-2 題內多向度測驗模式...14 圖 3-1 研究流程圖...21 圖 4-1 水平等化設計下之不同測施人數之 RMSE...33 圖 4-2 水平等化設計下不同題本次級量尺比例之 RMSE...34 圖 4-3 水平等化設計下不同次級量尺相關程度之 RMSE...35 圖 4-4 垂直等化設計下之不同測施人數之 RMSE...36 圖 4-5 垂直等化設計下不同題本次級量尺比例之 RMSE...37 圖 4-6 垂直等化設計下不同次級量尺相關程度之 RMSE...37 圖 4-7 垂直等化設計下不同年級受試者群在題本配置比例之 RMSE...38 圖 4-8 垂直等化設計下不同次級量尺相關程度之 RMSE...39 圖 4-9 垂直等化設計下不同年級受試者群在次級量尺相關之 RMSE...39 圖 4-10 垂直等化設計下不同試題定錨比例之 RMSE...40 圖 4-11 垂直等化設計下不同年級受試者群在不同試題定錨比例之 RMSE...41 圖 4-12 垂直等化設計下不同高低年級能力分布之 RMSE...41 圖 4-13 垂直等化設計下不同年級受試者群在不同能力分布之 RMSE...42第一章
第一章
第一章
第一章
緒論
緒論
緒論
緒論
本研究根據試題反應理論(item response theory, IRT)中單參數 Rasch 模式 (one-parameter logistic model, 1PL)與多向度試題反應理論(multidimensional item response theory, MIRT)中多向度隨機係數多項 logit 模式(multidimensional random coefficients multinomial logit model, MRCMLM),以模擬實驗方式探討不 同次級量尺分數估計方法於水平與垂直等化設計的情境中,次級量尺分數估計之 效果。本章將針對研究背景與動機、研究目的、待答問題與名詞釋義進行闡述。
第一節 研究背景與動機
郭 伯 臣 、 王 暄 博 、 吳 慧 珉 、 張 宛 婷 (2010) 指 出 大 型 測 驗 ( large-scale assessments)大致可分為兩種類型,一為具有篩選功能之大型測驗,目的在於測 量學生的學科能力,以提供學生高中入學或大學入學之參考或依據,例如:台灣 的國中基本學力測驗(The Basic Competence Test for Junior High School Students) 與美國的大學入學測驗(American College Test, ACT)等;另一種為建立教育資 料庫之大型測驗,目的在建置一套客觀且完善的學生學習成就資料庫,藉由測驗 結果以追蹤學生的學習成果與分析其學習變遷趨勢,例如:臺灣學生學習成就評 量資料庫(Taiwan Assessment of Student Achievement, TASA)、國家教育進展評 量(National Assessment of Educational Progress, NAEP)、國際學生評量計畫 (Program for International Student Assessment, PISA)等。若是以建立教育資料庫為目的之大型測驗,由於必須考慮施測不同年級與不 同學科之情況,例如:TASA施測年級包含國小四年級、六年級、國中二年級、
試者群學生的量尺分數統一,才能對受試者的分數進行比較,所以水平等化 (horizontal equating)與垂直等化(vertical equating)是必須要同時進行的,除 了有助於建立相同年級及不同年級之量尺外,並可藉由量尺分數分析來比較學生 在各學科及不同年級之學習表現。
測驗之整體分數可以知道個人在全體之等級,而測驗之次級量尺分數通常有 助於教師評斷學生的優勢及劣勢(Yen, 1987;Wainer, Vevea, Camacho, Reeve, Rosa, Nelson, Swygert, & Thissen, 2000)。這兩種分數提供受試者對不同重要訊息之解 釋,然而若能直接測量學生各領域的能力,會比由學生整體成績來預測學生在此 領域表現程度有較好的效果(Bock, Thissen, & Zimowski, 1997)。因此,精準的估 計次級量尺分數,可以有效提供受試者更多訊息,所以次級量尺分數的報告亦為 許多大型測驗(large-scale assessments)所感興趣的問題(Kahraman & Kamata, 2004)。舉例來說,TIMSS 2007八年級數學能力測驗,測驗內容包含數(number)、
代數(algebra)、幾何(geometry)及資料與機率(data and chance)等四個次級量尺, 由測驗的整體分數不但能了解學生的整體表現,且藉由次級量尺分數的測驗報告 則能呈現學生在數、代數、幾何與資料與機率等多面向的優缺點(TIMSS 2007),
也可檢視目前國家數學教育政策與體制是否完備。
目前 已有 許多 國 內 外文 獻比 較不 同 次 級量 尺分 數估 計 之 方法 ,例 如: Gessaroli(2004)、Tate(2004)及 Yao 與 Boughton(2007)皆以多向度試題反應 理論估計次級分數(subscore)。郭伯臣、王暄博、吳慧珉、張宛婷(2010) 曾探 討次級量尺分數估計方法之單一測驗設計與等化測驗設計之估計效果。謝佳穎 (2009)曾探討在多向度試題反應理論用於次級量尺分數估計之模擬研究,主要 比較不同等化設計之次級量尺分數估計效果加入 MIRT 次級量尺分數估計方法, 以比較不同方法之次級量尺分數估計效果,研究結果亦指出 MIRT 之方法有不錯 之估計效果;然而,並沒有任何文獻探討次級量尺估計方法的不同對水平與垂直 等化設計之影響,因此,本研究延續謝佳穎(2009)之研究,探討不同次級量尺
分數在水平及垂直等化之研究。
根據過去的研究顯示,現今許多大型測驗接使用試題反應理論進行資料分析 以建立共同量尺,其採用之測驗題本連結設計為 BIB 設計與定錨不等組設計 (nonequivalent groups with anchor test design, NEAT)等兩種等化設計,惟 NEAT 與 BIB 兩種等化設計在各實驗情境中,各次級量尺分數估計方法之估計精準度幾 乎無差異(謝佳穎,2009),因此,本研究連結設計擬以 BIB 等化設計作為測驗 題本之連結設計。因此,本研究擬採用 IRT 中的 Rasch 模式(Rasch, 1960)與 MRCMLM,以探討在 BIB 設計中水平與垂直等化測驗對次級量尺分數估計之效 果。
第二節 研究目的
根據前述的研究背景與動機,在水平等化情境下除了延續先前所做之研究, 本研究將探討在垂直等化同年級受試者群間能力差異,以及定錨試題在次級量尺 間所佔比例不同等情況,於不同次級量尺估計方法之次級量尺分數估計效果。 根據上述的研究之成果,本研究以模擬實驗方式探討不同等化設計對於次級 量尺分數估計之影響。且在次級量尺分數估計方法上,並討論各估計方法之效果。 綜合上述,茲將本研究計畫目的擬定如下: 一、 不同次級量尺分數估計方法於不同受試者人數、題本次級量尺比例、次級 量尺間之相關程度下水平等化效果。 二、 不同次級量尺分數估計方法於不同受試者人數、題本次級量尺比例、次級 量尺間之相關程度、題本定錨試題比例、高低年級受試者能力分布下垂直 等化效果。第三節 待答問題
依據上述之研究目的,擬於水平等化設計與垂直等化設計的情境中,分別提 出下列幾項問題:壹、 水平等化設計
一、 不同施測人數是否影響次級量尺分數估計之效果? 二、 不同題本次級量尺比例是否影響次級量尺分數估計之效果? 三、 不同次級量尺間相關程度是否影響次級量尺分數估計之效果?貳、 垂直等化設計
一、 不同施測人數是否影響次級量尺分數估計之效果? 二、 不同題本次級量尺比例是否影響次級量尺分數估計之效果? 三、 不同次級量尺間相關程度是否影響次級量尺分數估計之效果? 四、 不同題本定錨比例是否影響次級量尺分數估計之效果? 五、 不同高低年級受試者能力分布是否影響次級量尺分數估計之效果?第四節
名詞釋義
壹、次級量尺分數
次級量尺分數係指學生在學習目標(learning objectives)、子測驗(subtests) 或學習標準(learning standards)之表現(Meyers, Shin, & Nichols, 2008)。如數 學學科成就測驗包含數、代數、幾何及資料與機率等面向即為次級量尺。
貳、定錨試題
在不同測驗中作為測驗連結等化之用的共同試題稱為定錨試題(anchor item)。在本研究中,從低年級試題庫中挑選難度較高之試題至高年級試題庫中 當作定錨試題。參、水平等化
水平等化係指利用測驗分數等化之技術,將兩個或兩個以上測量相同特質、 相同能力的測驗,且其受試者能力分佈及試題難度相似,其原始分數轉換之過 程,本研究中水平等化是指同年級不同測驗間之等化。肆、垂直等化
垂直等化係指利用測驗分數等化之技術,將兩個或兩個以上測量相同特質、 相同能力的測驗,且其受試者能力分佈及試題難度不相同,其原始分數轉換之過 程,本研究中垂直等化是指不同年級之間不同測驗間之等化。第二章
文獻探討
本研究目的在探討不同次級量尺分數估計方法用於水平等化設計與垂直等 化設計情境下,對測驗分數估計之效果。因此,本章將針對次級量尺估計方法、 測驗等化的意義、測驗等化設計等相關研究進行分析整理。本章共分為三節,第 一節為試題反應理論(item response theory, IRT);第二節為次級量尺分數估計方 法;第三節為測驗等化的意義、種類與等化設計,詳述如下。
第一節 試題反應理論
測驗理論是一種解釋資料實證關係理論學說(余民寧,1992a,1992b) , 分成兩大派:一為古典測驗理論(classical test theory, CTT)主要是以真實分數模 式為架構,其數學模式相當簡單,計分容易而廣被採用,卻有非線性與受試者依 賴、試題依賴的缺點,影響了測驗的品質;另一為當代測驗理論(modern test theory),主要是以試題反應理論為架構,由於加入許多不同參數型試題反應理 論,使得測驗有線性與客觀性,獲得比較好的品質。另外大樣本的測驗資料較容 易符合參數模式的假設,所以 IRT 比起 CTT 較適合大樣本的分析,所以本研究 施測人數而言,符合 IRT 之參數模式特性,以下將介紹 IRT: 試題反應理論根據強勢假設(strong assumption)而來,認為受試者對試題反 應的正確性之期望值可用下式表示: ) , ( ) (X = f I A ξ (2-1) 其中, X 為試題反應的正確性; I 為試題參數向量; A 為能力參數向量。 X 的期 望值是由試題參數和能力參數之函數所決定的。 然而,使用 IRT 進行測驗資料之分析時,IRT 模式必須符合四項基本假設 ( Weiss & Yoes, 1991 ), 才 能 用 來 分 析 所 有 的 測 驗 資 料 。 亦 即 單 向 性 (unidimensionality);局部獨立(local independence)非速度性(nonspeedness)
及「知道-正確」假設(“know-correct” assumption)。 一、單向性: 是指某一份測驗只針對受試者一種能力或潛在特質(latent traits)進行 測量。 二、局部獨立: 受試者在測驗不同試題時,其作答情形彼此互相獨立,除了受試 者本身的能力之外,不受其它試題的影響。 三、非速度性:受試者的測驗得分是受本身能力高低所影響,不因測驗時間限制而 影響其表現。 四、「知道-正確」:受試者知道試題的正確答案,就一定會答對該試題,無人為因 素的錯誤填答情形。
常見使用之試題反應理論為單向度反應理論(unidimensional item response theory, UIRT),只能針對單向性的測驗,也就是測驗中所有的試題都測量一種能 力或一個潛在特質;然而,有許多測驗情境經常包含多種能力或潛在特質同時運 作的多個分測驗,例如心理測驗、綜合能力測驗等,不僅僅只有測量單一能力或 單一潛在特質,因此以目前的 UIRT 無法適用於上述的測驗情境。況且 UIRT 個別進 行測驗的分析,所得到的測驗的信度都不高,故實際應用上 UIRT 出現兩種缺點, 第一,無法利用向度之間的關連,來增加各向度的測量精準度;第二,無法同時分析多 向度的試題,也就是多種潛在特質的試題,所以單向度模式延伸至多向度模式是 必然的趨勢,因而學者們提出多向度試題反應理論模式(multidimensional item response theory,MIRT)(Adams, Wilson & Wang, 1997; Bock & Aitkin, 1981; Fraser, 1988; McDonald, 1967; Mckinley & Reckase, 1983; Sympson, 1978; Whitely, 1980),以解決測驗實際應用上的問題(Rasch 測量理論與其在教育和心理之應 用,2004;測驗專業工作坊,2006)。
因此,本節將分別針對單向度試題反應理論及多向度試題反應理論進行模式 之介紹。
壹、單向度試題反應理論
UIRT 模 式 有 三 種 , 以 不 同 的 參 數 作 為 命 名 , 分 別 為 單 參 數 對 數 模 式 (one-parameter logistic model, 1PL)、二參數對數模式(two-parameter logistic model, 2PL)及三參數對數模式(three-parameter logistic model, 3PL),分述如下。 一、 單參數對數模式 單參數對數模式即是 Rasch 模式,每個題目有一個試題參數以表示該題的難 度(Rasch, 1960),假設受試者 j 之能力為θ ,其作答試題 i 通過的機率如下: j ) (
exp
1
1
)
,
|
1
(
i j b D i j ijb
X
P
− −+
=
=
θ
θ (2-2) 其中,X 為受試者 j 在試題 i 的作答反應,ij Xij=0 或 1,答對記為 1,答錯記 為 0;b 為試題 i 之試題難度參數(i item difficulty parameter),−∞<bi <∞; D 為一個量尺因素(scaling factor),通常D=1.702。 二、 二參數對數模式
在IRT的1PL模式下,再增加一個斜率參數(slope parameter),此參數也可 稱為鑑別度參數,即Rasch模式被擴展為二參數對數模式(two-parameterlogistic model, 2PL; Birnbaum, 1968),假設受試者 j 之能力為θ ,其答對試題 i 的機率如j 下: ) ( *
exp
1
1
)
,
,
|
1
(
i j i b a D i i j ija
b
X
P
− −+
=
=
θ
θ (2-3) 其中,X 為受試者 j 在試題 i 的作答反應,ij Xij=0 或 1,答對時記為 1,答錯 時記 為 0 ;a 為 試 題 i 之 試 題 鑑 別 度 參 數 (i item discrimination parameter ),∞ < < ∞ − ai ;b 為試題 i 之試題難度參數,i −∞<bi <∞;D 是一個量尺因素(scaling factor),通常D=1.702。 三、 三參數對數模式
在 IRT 的 2PL 模式下,再增加一個漸近線參數(asymptotic parameter),有 學者稱此參數為猜測參數(pseudo-guessing parameter),形成三參數對數模式 (3-paramter logistic model, 3PL; Birnbaum, 1968),假定測驗會發生猜題之現象, 假設受試者 j 之能力為θ ,其答對試題 i 的機率如下(Birnbaum, 1968;Lord, j 1980): ) ( *
exp
1
)
1
(
)
,
,
,
|
1
(
i j i b a D i i i i i j ijc
c
c
b
a
X
P
− −+
−
+
=
=
θ
θ (2-4) 其中,X 為受試者 j 在試題 i 的作答反應,ij Xij=0 或 1,答對時記為 1,答錯 時記為 0;a 為試題 i 之試題鑑別度參數,i −∞<ai <∞;b 為試題 i 之試題難度參i數,−∞<bi <∞;c 為試題 i 之試題猜測度參數(i item guessing parameter),
1 0≤ci < ; D 是一個量尺因素(scaling factor),通常D=1.702。 在上述這些模式中, θ 不是一個向量,只是個純量,表示只有一種潛在特質 影響作答反應,因此稱為單向度模式。
貳、多向度試題反應理論
一、 多向度試題反應理論模式
MIRT模式目前大多是UIRT模式的衍生模式,為了表示多種受試者潛在特質(一) 多向度二參數模式
多向度二參數模式(multidimensional two parameters model, M2PL)為二參數 logistic 模式(2PL)所衍生的模式(Mckinley & Reckase, 1983; Reckase & Mckinley, 1991),以公式(2-6)表示: )] ( 7 . 1 exp[ 1 1 ) , , | 1 ( i j i j i i ij i d d x P − ′ − + = = θ a θ a (2-6) 其中x 為受試者反應型態,ij xij = 0或1,1 表示答對該試題,0 表示答錯該 試題。ai為試題鑑別度向量, i d 為試題難度,θ 為受試者能力向量。這個模式與j 二參數 IRT 的差別是將原受試者能力值 θ 與試題鑑別度 a 擴展為向量θ 及j ai,藉 由向量可將多向度的能力表現在此模式中,答對機率會受到多向度能力的考驗。 另外試題鑑別度向量ai包含多個向度的鑑別度,無法完整表示個別試題的鑑
別度,因此 Reckase & McKinley(1991)定義出兩個多向度指標,一個是第i題
的多向度鑑別度參數(multidimensional discrimination parameter, MDISC )i :
∑
= = m k ik i a MDISC 1 2 1 2 ) ( (2-7) 其中, m 為能力向度數目。另一個是第i題的多向度難度參數(multidimensional difficulty parameter,
i MDIFF ): i i i MDISC d MDIFF = − (2-8) 除了能具體觀察試題的向度結構,以顯示個別向度鑑別度a 與多向度鑑別度ik 參數MDISC 之間的關係,Ackerman(1996)定義試題所要測量的能力方向與各i 能力向度間的夾角,如下: i ik ik MDISC a = α cos ,k =1,...,m (2-9) 其中,α 為試題 i 的在能力向度ik k的夾角。 由MDISC 、i MDIFF 和i α 可把多向度試題依據受試者能力向度圖形化為能ik
力空間(ability space),這個試題反應曲面(Item Response Surface , Bolt & Lall, 2003)會經過設定的不同受試者能力原點−3。
(二) 多向度三參數模式
多向度三參數模式(multidimensional three parameters model, M3PL)為三參 數洛基模式(3PL)改良而得,將模式中的能力參數與鑑別度參數改成向量的型 式(Hattie, 1981; Sympson, 1978),其模式如公式(2-10)所示: )] ( 7 . 1 exp[ 1 1 ) , , , | 1 ( 1 θ a θ a b c c c b U P j i i i j i i i i i − ′ − + − + = = (2-10) 其中,U 為第i i題反應型態;θ 為受試者能力向量;j c 為試題的猜測參數;i ai 為試題鑑別度向量;而為了使試題的難度成為向量用以與能力向量相減,故將難 度參數 b 與向量 1 相乘。 另外由 Reckase(1997)提出的多向度三參數洛基模式(multidimensional three-parameter logistic model, M-3PL):假設有N個受試者,標示為i=1,...,N;有
J 個試題,標示為 j=0,1,...J。用矩陣表示受試者 i 在試題 j 的作答反應X ={Xij}, ) ,..., , ( i1 i2 iJ i X X X Xr = ,受試者所有能力 T N) ,..., , (θ1 θ2 θ θ = r r ,依公式(2-11)所示, 能力為θi r 的受試者,在二元計分試題 j的答對機率為: ) ( 3 3 1 1 2 1 1 ) , | 1 ( j T i j β β j j j i ij ij e β β β θ x P P + θ Θ − + − + = = = r r r r (2-11) 其中,x 為受試者ij i在試題 j的作答反應,xij = 0或1,1 表示答對該試題, 0 表示答錯該試題;β2j =(β2j1,...,β2jD) r 為D個向度的試題鑑別度參數向量;β1j為 試題難度參數;β3j為試題猜測參數; Θ =
∑
= D l jl il T i j θ β θ β2 1 2 r r ;第 j 題的試題參數為 ) , , ( 2j 1j 3j j β β β β r r = 。 (三) 多向度隨機係數多項洛基模式個受到試題參數 ξ 與受試者的潛在特質變數影響混合模式(mixed co-efficients model),PISA 數學能力之測量模式即是使用 MRCMLM 模式。 假設有N 個試題,標示為i=1,...,N;每個試題有Ki +1個反應類別,標示為 i K k =0,1,... 。用向量表示隨機變數Xi的值為 i i i iK T i X X X , ,..., ) ( X = 1 2 ,其中, = 其他 個反應類別 作答第 如果試題 , 0 , 1 i k ik X 以 指 出 試 題 i 的 Ki +1個 可 能 反 應 。 Xik 也 可 以 收 集 成 一 個 單 向 量 ) ' ,..., ' , ' ( ' X 1 2 i iK i i ik = X X X ,稱為反應向量或反應組型。 當作答反應類別0時,即表示零向量,其有效地使0類別成為一個參照類別, 以此作為參照類別是強制性的,這樣的條件對於模式鑑定是必要且不影響模式的 主要部分。這個計分方程式可用以說明每一個試題的分數或每一個試題的每一個 可能反應類別,若反應在0類別的分數為0分,但是其他反應也有可能計為0分。 MRCMLM之多向度型式假定受試者反應之下有 D 個潛在特質所組成,這 D 個潛在特質可定義為一個 D -向度的潛在空間。向量 T D ) ,..., , (θ1 θ2 θ θ = 表示一 個在 D -向度的潛在空間中的位置。試題參數是由未知的參數 ξ 所描述,而受試者 的潛在變數 θ ,是一個隨機變項。 p 個參數的試題由向量ξ (ξ1,ξ2,...,ξp) T = 描述 之。這些線性組合被用在反應機率模式中描述每一個試題的反應類別的經驗上的 特徵。 D 個向度之設計向量(design vector)為aik(i=1,...,N;k =1,...,Ki),向量長 度 皆 為 p , 可 集 合 成 一 個 設 計 矩 陣 ( design matrix ) ) ,..., ,..., , ,..., , ( 11 12 1 21 2 1 2 1 K KN K T a a a a a a A = ,故設計向量定義 ξ 各元素的線性組合。 若在試題 i 、向度 D 之反應為類別 k ,則其反應分數為bikd,橫跨 D 個向度並
集合成一個行向量 T ikD ik ik ik (b 1,b 2,...,b ) b = ,而後對試題 i 集合成一個計分子矩陣 (scoring submatrix) T iD i i i (b1,b2,...,b ) B = ,最後對整份測驗再集合成一個計分矩 陣(scoring matrix) T ) ,..., , (B1T BT2 BTN B = 。 因此,試題 i 反應在類別k機率的模式如公式(2-12)所示:
∑
= ′ + ′ ′ + ′ = = i 1 ) exp( ) exp( ) , , ; 1 ( K k ik ik ik ik ik | P ξ a θ b ξ a θ b θ ξ B A X (2-12) 其中X 為受試者反應型態,ik K 為第 i 題的反應類別數,i bik′ 為第i題在第k個反應 類別上的計分向量;θ 為受試者能力向量;aik′ 為第i題中第k個反應類別的設計向 量; ξ 為試題參數向量。另外當 θ 變為純量,b就會變為純量,此時MRCMLM就 變成RCMLM。二、多向度測驗的種類
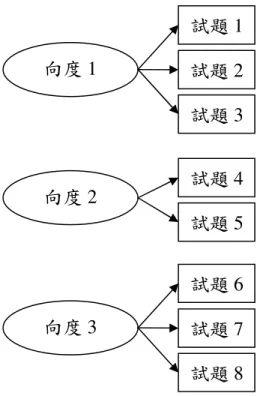
多向度測驗可以分為兩種(Adams, Wilson & Wang, 1997; Wang, Wilson & Adams, 1997)。一種是題間多向度測驗(between-item multidimensional test),這 種測驗裡的每個題目只能測單一種能力,即單向度試題,所以整份測驗會包含許 多單向度的試題。諮商心理學家常常使用的田納西自我概念量表即屬於題間多向 度測驗的一種,每個試題只測量單一種能力(如個人生理、心理、家庭、社會和 道德倫理等),而整份量表則包含了這些單向度試題。又如現行學測的考試科目 中的社會科包含歷史、地理、公民與社會;自然科包含物理、化學、生物、地球 科學/地球與環境等學科能力。社會與自然考科結合不同學科的設計,有測量考
圖 圖圖
圖 2-1 題間多向度測驗模式
另一種是題內多向度測驗(within-item multidimensional test),這種測驗裡的每個 題目所測量的能力,可能不只一種,因為題目本身就具有多向度的潛在特質。例 如:全民英檢測驗裡的看圖寫作即為題內多向度測驗,以文字描述呈現,受試者 必須先瞭解圖意,運用閱讀能力將圖之故事情境加以分析,並把所了解的以個人 寫作能力呈現,所以看圖寫作不僅僅測量了語文閱讀能力,而且還有寫作能力。 此類型的測驗如圖2-2所示。 圖 圖 圖 圖 2-2 題內多向度測驗模式 試題 1 試題 2 試題 3 試題 4 試題 5 試題 6 試題 7 試題 8 向度 1 向度 2 向度 3 試題 1 試題 2 試題 3 向度 1 試題 4 向度 2
第二節 次級量尺分數估計方法
次級量尺分數估計之方法相關研究論文中,可精確估計觀察分數(observed score)且可信賴之估計方法(Bock, Thissen, & Zimowski, 1997;Gessaroli, 2004; Kahraman & Kamata, 2004;Pommerich, Nicewander, & Hanson, 1999;Shin, 2007; Shin, Ansley, Tsai, & Mao, 2005;Tate, 2004;Wainer, Vevea, Camacho, Reeve, Rosa, Nelson, Swygert, & Thissen, 2000;Yen, 1987;Yen, Sykes, Ito, & Julian, 1997),這 些方法藉由測驗分數在不同次級量尺間的附屬訊息,進而產生次級量尺分數估計 值。本研究延續謝佳穎(2009)研究結果,因此,僅比較多向度試題反應理論方 法(MIRT method)、Bock 方法(Bock method)、W-Bock 方法(W-Bock method) 等三種次級量尺分數估計方法,本節將針對這些方法做介紹,詳述如下。
壹、MIRT 方法
MIRT 方法是以多向度試題反應理論來估計次級量尺分數,利用受試者於測 驗中之 MIRT 量尺分數轉換成次級量尺分數。本研究所採用之 MIRT 方法是根據 MIRT 中的 MRCMLM 來估計次級量尺分數,PISA 數學能力之測量模式即是使用 MRCMLM 模式。研究者將 MIRT 方法次級量尺 j之分數定義為MIRT Tj,若X 為j次 級 量 尺 j 中 觀 察 答 對 試 題 分 數 ( observed number-correct score ), 則 定 義 ) n / X ( E
Tj ≡ j j ,其估計如公式(2-13)所示(Adams, Wilson, & Wang, 1997):
∑
= ′ + ′ ′ + ′ = i 1 ) exp( ) exp( K k ik ik ik ik j T MIRT ξ a θ b ξ a θ b (2-13) 其中,K 為第 i 題的反應類別數;i bik′ 為第i題在第k個反應類別上的計分向量;θ 為受試者能力向量;a′ 為第ik i題中第k個反應類別的設計向量;ξ 為試題參數向量。貳、BOCK 方法
BOCK 方法是以 IRT 模式下估計次級量尺分數,利用受試者於測驗中之 IRT 量尺分數轉換成次級量尺分數。研究者將 BOCK 方法次級量尺 j之分數定義為
j
T
IRT ,其估計如公式(2-14)所示(Bock, Thissen, & Zimowski, 1997;Shin, 2007; 郭伯臣、王暄博、吳慧珉、張宛婷,2010):
∑
= = j I i ij j j n T IRT 1 ) ˆ ( 1 θ ε (2-14) 其中, i 為試題; j 為次級量尺;I 為次級量尺 j 中的試題數;j n 為次級量尺 j 中j 最大可能分數,且∑
= − = i I i i j m n 1 ) 1 ( ,m 為試題 i 之所有類別數;i θˆ 為受試者能力估 計值;εij(θˆ)為受試者能力估計值為 θˆ 時,次級量尺 j 在試題 i 之答對率。 若測驗試題為選擇題的試題,則次級量尺 j 在試題 i 之答對率εij(θˆ)即為 IRT 中該題之通過機率,由公式(2-15)所示: ) ˆ ( ) ˆ (θ ij θ ij P ε = (2-15) 因此,以本研究使用 IRT 的 1PL 模式時,則 )] ( exp[ 1 1 ) ˆ ( ) ˆ ( i j ij ij b P ε − θ − + = θ = θ (2-16) 其中, b 為試題難度參數。ij參、W-BOCK 方法
W-BOCK 方法是以 Bock 方法為基礎,引入「權重」概念之估計方法,亦即 將題本 v 之 IRT 量尺分數信度ρ 之比重視為權重。而 W-BOCK 方法次級量尺 j 之v 分數定義為WIRTTj,其估計如下式所示(郭伯臣、王暄博、吳慧珉、張宛婷,2010): j j v j v j n x ρ T ρ T WIRT = ˆ +(1− ) (2-19) 其中, j 為次級量尺;Tˆ 為答對率分數;j n 為次級量尺 j 中最大可能分數;j xj 為次級量尺 j 的總分;xj /nj為觀察答對率分數,由公式(2-19)可得;ρ 為題本v v 之信度。 信度的概念是由 Green、Bock、Humphrey、Linn 與 Reckase(1984)提出,計 算公式(2-20)所示 2 2 2 ) ( ) ( θ e θ σ θ σ σ ρ θ = − (2-20) 其 中 , 2 θ σ 為 能 力 估 計 值 的 變 異 數 , 2( ) θ σe 為 能 力值 測 量 誤 差 變 異 數
第三節 測驗等化的意義、種類與等化設計
在許多大型測驗中,例如:TASA、NAEP 及 PISA 等,經常透過測驗等化來 比較施測不同測驗題本之受試者的能力特質。然而,文獻之中尚無針對次級量尺 做垂直等化之探討,且鑑於多種測驗等化設計之中,尤以 BIB 此種設計最常使用 於這些大型測驗之中,本節將對測驗等化的意義、種類以及本研究所使用之 BIB 等化設計、水平等化及垂直等化做說明。分述如下。壹
、測驗等化的意義
測驗等化(test equating)是使用統計方法將受試者在某一測驗的分數轉換至 另一測驗分數量尺,即兩測驗分數在同一量尺比較的過程(Kolen & Brennan, 1995)。等化進行必須滿足以下條件(Hambleton & Swaminathan, 1985;Lord, 1980):一、對稱性(symmetry property):等化的轉換是可逆的,即由 X 測驗等化至 Y 測驗的結果,與 Y 測驗等化至 X 測驗的結果必須相同。
二、相等性(equity properties):即受試者不論接受 X 測驗或 Y 測驗的施測,所 測得結果並無差異。
三、團體不變性(group invariance property):即等化過程中受試者不論來自何種 團體,轉換出來的結果也要相同。
四、單向度(unidimensionality of the tests): 其測驗內容進行等化時須測量同 一能力特質。
貳
、測驗等化的種類
Hambleton 與 Swaminathan(1985)認為測驗等化可分為水平等化與垂直等化 兩種,茲介紹如下:
水平等化是指當兩個或兩個以上欲測量同一能力或同一特質測驗間之原始 測驗分數可在共同的量尺上進行轉換過程,且接受測驗的受試者的能力分布與試 題難度是相似的群體,這些測驗題本為維持公平性,編制成不同形式但內容及難 度極為相似的複本測驗。例如:大型測驗中的托福、GRE的考試就有多種複本測 驗,可以在一年有多次考試機會。 二、 垂直等化 垂直等化是指當兩個或兩個以上測驗測量同一能力或同一特質測驗間之原 始測驗分數可在共同的量尺上進行轉換過程,但接受測驗的受試者的能力分布與 試題難度是不相等的群體。這些測驗題本會包括許多不同形式、不同難度水準之 題本,此類型等化適用於比較不同年齡或不同年級受試者。如美國的加州成就測 驗(California Achievement Tests)、愛奧華基本技能測驗(Iowa Test of Basic Skills) 等。
參
、測驗等化設計
測驗等化設計指收集資料之方式以進行等化,等化設計的選擇會影響等化的 誤差,茲介紹本研究所採用的 BIB 設計: Yates(1963)提出 BIB 設計,將題庫中的試題分成數個試題區塊,區塊間 與區塊內的試題皆不重複。若設計幾個題本(booklet)則受試者可分為幾群,每 群受試者只需接受某些試題區塊的試題,不同受試者可以接受完全相同、部分相 同、或完全不同的試題區塊。最後,將所有受試者的作答反應資料堆疊進行等化 分析,以達到能力估計的目的。 此設計在無作答時間(response time)之限制情形下,必須滿足以下限制式: S s k x t ,..., 1 , = =∑
(2-20)t j i z S s ijs , 1,..., 1 = < ≥
∑
= λ (2-22) S s t j i z x xis + js ≥2 ijs, < =1,..., , =1,..., (2-23) 其中: t 指試題區塊數; s 指題本代號,s=1,...,S; k:每個題本配置的試題區塊數; r:試題區塊在所有題本中出現的次數; i:題庫中個別區塊代號,i =1,...t; j:題庫中成對區塊中第二個區塊代號, j =1,...,t; λ:成對試題區塊在所有題本中出現的次數; is x :試題區塊與題本的配置組型,xis ∈{ }
0,1 ,i = 1,..., t,s = 1,..., S ; ijs z :成對試題區塊與題本的配置組型,zijs∈{ }
0,1 ,i< j=1,...,t,s =1,...,S 。 公式(2-20)代表每一個題本配置的試題區塊數目;公式(2-21)代表每一 個試題區塊在所有題本中出現的次數;公式(2-22)代表成對試題區塊在所有題 本中出現的次數;公式(2-23)代表成對試題區塊與組型的一致性。BIB 設計須 符合公式(2-20)至(2-23)的要求,求出符合的最佳解。 BIB 設計的優點為試題區塊與題本之配置方式乃是採用螺旋(spiral)式排 列方式,其可使每一個試題區塊的施測次數相同(Nemhauser & Wolsey, 1999;van der Linden, Veldkamp & Carlson, 2004)。另外BIB 設計有三項基本限制:(一) 每一個題本內的試題區塊數要相同; (二) 試題區塊作結合以求出最小題本數;
第三章 研究方法
本章共分為五節,第一節為研究流程;第二節為研究變項設定,說明研究中 的共同變項設定與參數設定;第三節為實驗設計,說明研究中水平與垂直等化設 計;第四節為估計精準度,說明本研究用來比較不同方法估計誤差之指標;第五 節介紹研究工具;詳述如下。第一節 研究流程
根據文獻探討,MIRT 方法、Bock 方法、W-Bock 方法,皆可用於次級量尺 分數之計算,因此,本模擬研究欲探討不同方法於不同等化情境中,計算次級量 尺分數之精準度。 設定研究主題 文獻蒐集與探討 設定實驗情境 水平等化 垂直等化 產生模擬資料 採用 Acer ConQuest 2.0 軟體進行估計 使用不同估計方法 計算次級量尺分數 計算不同次級量尺分數估計方法之估計精準度
第二節 研究變項設定
本研究欲探討不同次級量尺分數計算方法在水平與垂直等化設計測驗情境 下,對測驗分數估計之精準度。本節將分別就水平與垂直等化設計中之共同變項 設定與研究中之參數設定做說明。詳述如下。壹、模擬實驗之變項設計
一一一一、水平等化設計水平等化設計水平等化設計水平等化設計變項設定變項設定變項設定變項設定 本研究中模擬水平等化設計,欲比較不同估計方法對於次級量尺分數之估 算,茲將本研究的變項設定整理如表 3-1。 表 表表 表3-1 水平等化設計變項設定 研究變項 研究變項 研究變項 研究變項 變項設定變項設定 變項設定變項設定 試題長度 每個題本施測題數 60 題 題本包含之次級量尺個數 4 個 次級量尺在各試題區塊之比例 25%、25%、25%、25%; 30%、30%、20%、20%; 40%、40%、10%、10% 次級量尺相關程度 0.2、0.5、0.8 受試人數 3570 及 7560 人 每一種情形模擬次數 100 次 在水平等化設計中設定五種不同變項,如表 3-1 所示。依照各情境變項產生 模擬資料,五種研究變項敘述如下: 1. 在測驗題本長度的設定,BIB 設計下每個題本配置之試題區塊個數有 3 個, 模擬每個測驗題本長度為 60 題。 2. 在題本次級量尺個數的設定,模擬題本次級量尺個數為 4 個。 3. 在次級量尺在各試題區塊之比例設定,在題本次級量尺比例的設定,本研究 欲探討在每個試題區塊內,次級量尺題數的比例對於次級量尺分數估計的影 響,故模擬兩種題本次級量尺比例,四個次級量尺間題數的比例分別為25%、25%、25%、25%,30%、30%、20%、20%及 40%、40%、10%、10% 三種比例。其中 30%、30%、20%、20%之比例為研究者參考許多國內外大 型測驗技術報告中,數學科測驗之次級量尺比例,如 PISA 2003 數學科及 TIMSS 2007 八年級數學科所包含四個內容領域之比例即為 30%、30%、 20%、20%(PISA 2003;TIMSS 2007);另一比例參考謝佳穎( 2009 )為探討 次級量尺比例懸殊較大時之次級量尺分數估計精準度,而定下 40%、40%、 10%、10%之比例;另一比例則為研究者為探討次級量尺比例較平均時之次 級量尺分數估計精準度,而定下 25%、25%、25%、25%之比例。 4. 在次級量尺相關程度的設定,本研究探討國內外文獻中,如: Yao, L., & Boughton, K. A. (2007). 探討相關程度中選用 0.1、0.3、0.5、0.7、0.9;David Shin. ( 2007 ) 探討相關程度中選用 0.5、0.8、1.0;張宛婷(2008)探討相關 程度中選用 0.2、0.5、0.8、1;謝佳穎(2009)探討相關程度中選用 0.2、0.5、 0.8。故本研究為延續之前謝佳穎(2009)之研究,故設定受試者次級量尺能 力值 θ 之間的相關係數(correlation coefficients)在低相關為 0.2、在中等相 關為 0.5、在高相關為 0.8,模擬受試者之能力值 θ 服從標準多變量常態分佈 (standardized multivariate normal distribution),並假設能力值之間的相關係 數為 0.2、0.5 及 0.8 三種相關程度。
5. 在施測人數的設定上,本研究根據 NAEP 1998 年的技術性報告中,每一試 題施測需要 500 個測試樣本(Allen, Donoghue & Schoeps, 2001),藉由 BIB 設 計,本研究受試者人數有510×7=3570人及1080×7=7560人兩種人數。 6. 次級量尺估計方法中,僅比較三種估計方法(BOCK 方法、W-BOCK 方法、
MIRT 方法)的估計效果。
表 表表 表3-2 垂直等化設計變項設定 研究變項 研究變項 研究變項 研究變項 變項設定變項設定 變項設定變項設定 試題長度 每個題本施測題數 60 題 題本包含之次級量尺個數 4 個 高低年級受試者群能力分佈 L 年級:N ( 0, 1),範圍-3 ~ 3 H 年級:N ( 0.5, 1),範圍-2.5 ~ 3.5 N ( 1, 1),範圍-2 ~ 4 N ( 2, 1),範圍-1 ~ 5 次級量尺在各試題區塊之比例 25%、25%、25%、25% 30%、30%、20%、20% 40%、40%、10%、10% 次級量尺相關程度 0.2、0.5、0.8 每個題本定錨比例 10%、20%、30% 受試人數 3570 及 7560 人 每一種情形模擬次數 100 次 在垂直等化設計中設定七種不同變項,如表 3-2 所示。依照各情境變項產生 模擬資料,七種研究變項敘述如下: 1. 在測驗題本長度的設定,BIB 設計下每個題本配置之試題區塊個數有 3 個, 模擬每個測驗題本長度為 60 題。 2. 在題本次級量尺個數的設定,模擬題本次級量尺個數為 4 個。 3. 在高低年級受試者群能力分佈的設定,L 年級:N (0, 1),範圍-3 ~ 3; H 年級:N (0.5, 1),範圍-2.5 ~ 3.5;N (1, 1),範圍-2 ~ 4;N (2, 1),範圍-1 ~ 5。所以有 N (0.5, 1) vs. N (0, 1) 、N (1,1) vs. N (0, 1) 及 N (2,1) vs. N (0, 1)三 種能力分佈設定 4. 如同水平等化設計,在產生模擬資料時,亦考慮了次級量尺在各試題區塊 之比例設定、次級量尺相關程度及受試者人數的設定。次級量尺相關程度 有 0.2、0.5 及 0.8 三種相關;受試者人數有 3570 人及 7560 人兩種人數。 5. 次級量尺估計方法中,僅比較三種估計方法(BOCK 方法、W-BOCK 方法、 MIRT 方法)的估計效果。
因此,根據模擬實驗之各變項設定,本研究在等化測驗設計中,共探討 162 2 3 3 3 3× × × × = 種配置情形。
貳、參數設定
一、水平等化之參數設定 (一)受試者能力參數設定 模擬不同次級量尺水平等化之受試者能力分布,服從多變量分布。並參考自 Woods & Lin (2009)的研究中的能力參數分布之設計來作為模擬研究之能力參 數產生資料之基礎:以常態分布為例,假設θ =(θ1,...,θj)服從多變量常態分布,記為MN(µ,Σ),其中,
j
θ
θ1,..., 分 別 為 截 尾 常 態 分 布 ( truncated normal distribution ), 即 ) 1 , 0 ( ~ ),..., 1 , 0 ( ~ 1 N θj N θ ,平均數為0,標準差為1,範圍界定於−3~3,相關為0.2、 0.5與0.8。 (二) 試題參數設定 模擬難度參數分布為截尾常態分布N(0,1),範圍−3~3。 二、垂直等化之參數設定 (一)受試者能力參數設定 本研究將垂直等化之受試者能力分為 H 年級與 L 年級兩群,H 年級代表年級 較高之受試者,L 年級代表年級較低之受試者,進行不同年級間量尺之垂直等化。 其中,L 年級受試者取自水平等化設計之受試者。本研究共有三組垂直等化設計, 參考自 Woods & Lin (2009)的研究中的能力參數分布之設計來作為模擬研究之 能力參數產生資料之基礎,再依據不同年級受試者來模擬受試者能力分布。以 H
實驗一︰θ1 ~N(0.5,1),...,θj ~N(0.5,1),平均數為 0.5,標準差為 1,範圍界定 於−2.5~3.5,相關為 0.2、0.5 與 0.8。 實驗二︰θ1~N(1,1),...,θj ~N(1,1),平均數為 1,標準差為 1,範圍界定於 4 ~ 2 − ,相關為 0.2、0.5 與 0.8。 實驗三︰θ1 ~N(2,1),...,θj ~N(2,1),平均數為 2,標準差為 1,範圍界定於 5 ~ 1 − ,相關為 0.2、0.5 與 0.8。 L 年級︰ ,平均數為 0,標準差為 1,範圍界定於−3~3, 相關為 0.2、0.5 與 0.8。 (二)試題參數設定 模擬難度參數分布為截尾常態分布,依不同年級而區分成,H 年級為 ) 1 , 5 . 0 ( N 、N(1,1)與N(2,1),範圍分別為−2.5~3.5、−2~4與−1~5,以及 L 年級為N(0,1),範圍分別為−3~3。
第三節 實驗設計
本研究撰寫程式模擬水平等化與垂直等化設計之測驗題庫,其設定每個 試題區塊內皆含有四個次級量尺的試題。此兩種等化設計的題本測驗長度為 60 題,每個試題區塊有 20 題,在題本次級量尺比例為 25%、25%、25%、25%的設 計中,每個試題區塊內之四個次級量尺的題數分別為 5 題、5 題、5 題、5 題;在 題本次級量尺比例為 30%、30%、20%、20%的設計中,每個試題區塊內之四個 次級量尺的題數分別為 6 題、6 題、4 題、4 題;在題本次級量尺比例為 40%、40%、 10%、10%的設計中,每個試題區塊內之四個次級量尺的題數分別為 8 題、8 題、 2 題、2 題。因此,因每個試題區塊有 20 題,模擬產生 140 題(20×7=140)水 平等化 MC 試題題庫。施測人數為 3570 及 7560 人,模擬產生受試者人數 7560 ) 1 , 0 ( ~ ),..., 1 , 0 ( ~ 1 N θj N θ人,以探討不同人數之等化後次級量尺分數精準度時,再隨機抽取所需之人數。 另外垂直等化設計有比較三種定錨試題比例在三組垂直等化設計中不同次 級量尺對於次級量尺分數估計誤差之影響,而垂直等化所需之試題數,以每個題 本定錨試題所佔比例為 10%為例,同年級不同群體間水平等化,各群體所需試題 數為 140 題,垂直等化時,扣除由水平等化題庫中抽取之定錨試題 14 題,模擬 不同年級之試題數題,組合成垂直等化所需之題庫試題數為 266 題。施測人數為 7140 及 15120 人,故模擬產生 H 年級及 L 年級受試者人數各 7560 人,以探討不 同人數之垂直等化後次級量尺分數精準度時,再隨機抽取所需之人數。 表3-1將介紹本研究等化測驗設計所採用之等化設計,表3-2為垂直等化設計 時,試題分配情形。
壹、等化測驗設計
一 一 一 一、BIB等化設計 本研究使用之BIB等化設計如表3-3所示。 表 表 表 表3-3 BIB設計表 題本序號 區塊(k1) 區塊(k2) 區塊(k3) S1 M1 M2 M4 S2 M2 M3 M5 S3 M3 M4 M6 S4 M4 M5 M7 S5 M5 M6 M1 S6 M6 M7 M2 S7 M7 M1 M3 本研究之BIB等化設計係依據王暄博(2006)所設計之BIB設計,由表3-2可 知,即7個試題區塊、7個測驗題本之設計,每個題本包含3個試題區塊、每一試二 二 二 二、、、、BIB垂直等化設計 表3-3為本研究在垂直等化之BIB 設計,利用不同年級間之定錨試題做等化 連結,等化設計排列的格式如下: 表 表 表 表 3-4 不同年級間 BIB 等化設計(垂直等化)模式 L 年級 H 年級 1 M L− H−M1 包含 L−M1−1~L−M1−g 2 M L− H−M2 包含 L−M2−1~L−M2 −g 3 M L− H−M3 包含 L−M3−1~L−M3−g 4 M L− H−M4 包含 L−M4−1~L−M4 −g 5 M L− H−M5 包含 L−M5−1~L−M5 −g 6 M L− H−M6 包含 L−M6 −1~L−M6−g 7 M L− H −M7 包含 L−M7 −1~L−M7−g 其中,每個試題區塊(M)各抽取g題為定錨試題,本研究探討g=2、4、6之 效果。 表3-2為不同年級之BIB垂直等化設計模式,以下介紹幾個研究自訂之代號︰ 7 1~ M M 為 試 題 區 塊代 號 ,H−M1 ~H−M7 代 表 H 年 級 所 包 含 之 試 題 區 塊 , 7 1~ L M M L− − 代表L年級之試題區塊,L− M1−1代表L年級試題區塊1的第1題。 BIB 垂直等化設計中,不同年級的試題排列均依照 BIB 等化設計排列,在定 錨試題部份是將 H 年級中每個試題區塊,放入 L 年級對應試題區塊中難度較難的 試題。如表 3-2,H 年級的試題區塊 1(H−M1)中,包含 L 年級試題區塊 1 內試 題難度較難的g題(L−M1−1~L−M1−g)定錨試題。 表 3-4 為本研究在定錨試題比例 10%之垂直等化設模式,設定不同年級間各 試題區塊之定錨試題為 2 題,即探討不同年級間題本總定錨試題數為 14 題之等 化效果,相對於高年級試題區塊為 18 題,高年級的試題題庫共有18×7=126題。
表 表 表 表 3-5 不同年級間 BIB 等化設計(垂直等化)模式之定錨試題 10% 題本 序號 L - M1 L - M2 L - M3 L - M4 L - M5 L - M6 L - M7 H - M1 H - M2 H - M3 H - M4 H - M5 H - M6 H - M7 S1 20 20 20 S2 20 20 20 S3 20 20 20 S4 20 20 20 S5 20 20 20 S6 20 20 20 S7 20 20 20 S8 2 2 2 18 18 18 S9 2 2 2 18 18 18 S10 2 2 2 18 18 18 S11 2 2 2 18 18 18 S12 2 2 2 18 18 18 S13 2 2 2 18 18 18 S14 2 2 2 18 18 18 本研究討論每個試題區塊中定錨試題佔每個題本試題比例為 10%、20%、30% 之效果。即探討不同年級間每個題本定錨試題數為 14、28、42 題之等化效果, 相對於高年級的試題題庫則為 126、112、98 題。本研究不同年級間定錨試題數 與總試題數整理成表 3-5: 表 表 表 表 3-6 不同年級間定錨試題數與總試題數對照表 定錨比例 不同年級等錨試題數 各年級試題數 兩年級試題數 10% 14 140 266 20% 28 140 252 30% 42 140 238
貳、模擬實驗步驟
一、水平等化設計之模擬實驗步驟 (一) 試題難度參數服從截尾常態分佈,建立試題題庫,並從題庫中挑選試題並 依照題本次級量尺比例,挑選試題至各次級量尺組成題本; (二) 模擬各次級量尺之受試者能力服從標準多變量常態分布,並假設次級量尺 間的相關約為 0.8、0.5 與 0.2; (三) 使用 Rasch 模式計算各次級量尺之Pij(θ),其中,i為試題、j為次級量尺; (四) 使用步驟三之Pij(θ)計算每個次級量尺之真實分數。以題本次級量尺比例 為 25%、25%、25%、25%之情境為例來說,第一個次級量尺有 35 題 (5題 × 7個試題區塊 = 35題),此次級量尺之真實分數為試題 1 到試題 5、 試題 21 到試題 25、試題 41 到試題 45、試題 61 到試題 65、試題 81 到試 題 85、試題 101 到試題 105 及試題 121 到試題 125 之Pij(θ)的總和,第二、 三、四個次級量尺之真實分數依此計算方法依此類推。研究中假設此為真 實分數,用來作為比較不同次級量尺分數計算方法之基準; (五) 使用步驟(三)之Pij(θ)產生作答反應(response)X ; ij (六) 使用步驟(五)之作答反應X 及 Acer ConQuest 2.0 軟體進行參數估計; ij (七) 分別用 BOCK、W-BOCK 及 MIRT 等三種方法估計次級量尺分數; (八) 將上述之步驟(一)到步驟(七)重複進行 100 次,比較不同方法之次級 量尺分數的 RMSE。 二、垂直等化設計之模擬實驗步驟 (一) 試題難度參數服從截尾常態分佈,建立試題題庫,並從題庫中挑選試題至 各次級量尺組成不同年級之題本;從 L 年級試題庫中挑選難度較高之試題 至 H 年級試題庫中當作定錨試題;
(二) 模擬不同次級量尺之受試者能力分布,服從標準多變量常態分布,並假設 相關為 0.2、0.5、0.8; (三) 利用 Rasch 模式計算各次級量尺之Pij(θ),其中,i為試題、 j為次級量尺; (四) 使用步驟三之Pij(θ)計算每個次級量尺之真實分數。以題本次級量尺比例 為 25%、25%、25%、25%與定錨試題比例 10%之情境為例來說,第一個 次級量尺有 63 題(5題 × 7個試題區塊 +4題 × 7個試題區塊 = 63題),此次 級量尺之真實分數為試題 1 到試題 5、試題 21 到試題 25、試題 41 到試題 45、試題 61 到試題 65、試題 81 到試題 85、試題 101 到試題 105 及試題 121 到試題 125、試題 141 到試題 144、試題 159 到試題 162、試題 177 到 試題 180、試題 195 到試題 198、試題 213 到試題 216、試題 231 到試題 234 及試題 249 到試題 252 之Pij(θ)的總和,第二、三、四個次級量尺之 真實分數依此計算方法依此類推。研究中假設此為真實分數,用來作為比 較不同次級量尺分數計算方法之基準; (五) 使用步驟(三)之Pij(θ)產生作答反應(response)X ; ij (六) 使用步驟(五)之作答反應X 及 Acer ConQuest 2.0 軟體進行參數估計; ij (七) 分別用 BOCK、W-BOCK 及 MIRT 等三種方法估計次級量尺分數; (八) 將上述之步驟(一)到步驟(七)重複進行 100 次,比較不同方法之次級 量尺分數的 RMSE。
第四節 估計精準度
估計精準度指估計誤差的大小,估計風險值(value at risk)越小,則代表估 計越準確。本研究使用次級量尺分數之RMSE作為估計分數的準確指數,計算公 式如下: N RMSE N i ij ij j j∑
= ξ − ξ = ξ ξ 1 2 ) ˆ ( ) ˆ , ( (3.1) 其中,j為第j個次級量尺; N代表受試者人數; ξ =(ξ1j,ξ2j,ξ3j,...,ξNj)為次級量尺之真實分數; ξˆ=(ξˆ1j,ξˆ2j,ξˆ3j,...,ξˆNj)為次級量尺之估計分數。第五節 研究工具
壹、MATLAB
MATLAB 常被應用於科學與工程領域,它結合了數值分析、矩陣運算、分 析與模擬及繪圖等功能,語法簡單且操作簡易,擁有功能強大的函數庫,提供矩 陣運算指令。因此,本研究使用此軟體來產生模擬資料及撰寫次級量尺分數計算 之程式,並次級量尺估計方法之精準度。貳、ConQuest
電腦套裝軟體ConQuest適用於試題反應模式及潛在回歸模式。在試題反應模 式提供分析。ConQuest在多向度試題反應模式、潛在回歸模式且可用於多向度IRT 之估計。它提供完整的試題反應和迴歸分析。第四章 研究結果
本章分為兩節,第一節為水平等化設計之估計結果;第二節為垂直等化設計 之估計結果。本章將以折線圖方式呈現各次級量尺估計方法於各實驗情境中之比 較結果,次級量尺分數估計之RMSE則於附錄一及附錄二呈現。垂直等化設計之 題本次級量尺比例與次級量尺相關程度之RMSE於附錄三及附錄四呈現。第一節 水平等化設計之估計結果
本研究之測驗設計探討三種次級量尺分數估計方法在各實驗情境中之估計 精準度。本節將說明 MIRT 方法、BOCK 方法及 W-BOCK 方法於不同施測人數、 不同題本次級量尺比例及不同次級量尺相關程度等三種實驗情境下之估計結果。壹、 不同施測人數之估計結果
根據本研究模擬實驗之結果,將 BIB 兩種等化設計之不同次級量尺分數估計 方法依施測人數分類,可得其於施測人數為 3570 人及 7560 人之估計結果。圖 4-1 為水平等化設計之施測人數平均誤差結果。 0.08 0.09 0.1 0.11 0.12 0.13 3570 7560 受試總人數 R M S E MIRT BOCK W-BOCK方法之估計誤差並無明顯差異,顯示次級量尺分數之估計較不受施測大樣本人數 影響。無論施測人數為3570人或7560人,MIRT方法之估計效果仍明顯優於其他 次級量尺分數估計方法。以BIB等化設計下,三種次級量尺分數估計方法,無論 在施測人數為3570人或7560人之情境下,估計精準度幾乎無差異,兩種施測人數 情境之RMSE由大到小皆依次為BOCK、W-BOCK、MIRT。整體而言,MIRT方 法之估計效果較其他方法精確。
貳、 不同題本次級量尺比例之估計結果
根據本研究模擬實驗之結果,將 BIB 等化設計之不同次級量尺分數估計方法 依題本次級量尺比例分類,可得其於題本次級量尺比例為 25%-25%-25%-25%、 30%-30%-20%-20%及 40%-40%-10%-10%之估計結果。圖 4-2 為水平等化設計之 題本次級量尺比例平均誤差結果。 受試人數3570人 0.08 0.09 0.1 0.11 0.12 0.13 0.14 25%-25%-25%-25% 30%-30%-20%-20% 40%-40%-10%-10% 次級量尺配置比例 R M S EMIRT BOCK W-BOCK
圖 圖 圖 圖 4-2 水平等化設計下不同題本次級量尺比例之 RMSE 由圖 4-2 可知,在三種題本次級量尺比例中,不同次級量尺分數估計方法之 估計誤差皆隨著題本次級量尺比例懸殊程度增加而變大,誤差以 BOCK 法最高, MIRT 法最低。在題本次級量尺比例為 40%-40%-10%-10%之小比例次級量尺中, 受試人數7560人 0.08 0.09 0.1 0.11 0.12 0.13 0.14 25%-25%-25%-25% 30%-30%-20%-20% 40%-40%-10%-10% 次級量尺配置比例
估 計 誤 差 明 顯驟 增 , 藉 由 謝 佳 穎 ( 2009 ) 中 所 論 述 的 建 議 , 本 研 究 增 加 25%-25%-25%-25%來比較,發現誤差是三種配置比例最小的,所以題本次級量尺 比例以平均分配最好。整體而言,MIRT 方法之估計效果較其他方法精確。
參、 不同次級量尺相關程度之估計結果
根據本研究模擬實驗之結果,將 BIB 等化設計之不同次級量尺分數估計方法 依次級量尺相關程度分類,圖 4-3 為水平等化設計之次級量尺相關程度平均誤差 結果。 受試人數3570人 0.06 0.08 0.10 0.12 0.14 0.16 0.2 0.5 0.8 次級量尺相關程度 R M S EMIRT BOCK W-BOCK
圖 圖圖 圖 4-3 水平等化設計下不同次級量尺相關程度之 RMSE 在三種次級量尺相關程度中,其餘不同次級量尺分數估計方法之估計誤差皆 隨著次級量尺相關增加而降低,其中以 BOCK 方法最為明顯。整體而言,小比例 次級量尺之估計誤差隨著次級量尺間相關程度增加而變大,與其他估計方法大致 一樣,然而 MIRT 方法之估計效果較其他方法精確。 受試人數7560人 0.06 0.08 0.10 0.12 0.14 0.16 0.2 0.5 0.8 次級量尺相關程度
第二節 垂直等化設計之估計結果
本研究之等化測驗實驗探討水平與垂直兩種測驗等化設計,於不同研究變項 中,使用 MIRT 方法、BOCK 方法及 W-BOCK 方法的次級量尺分數估計方法, 其中,研究變項包含不同題本次級量尺比例、不同次級量尺相關程度、不同定錨 試題比例及不同施測人數。將其估計誤差以圖表表示,其中橫軸表示各種垂直等 化設計情境,代號為 N_M_A,N 為受試者人數( N = 7140、15120 ) ,N=T 時 L=N/2,H=N/2,換句話說 T=L+H,總受試人數等於低年級人數加高年級人數。 M 為受試者能力分布( M = 0.5、1、2 ) ,A 為每個題本定錨試題比例(A = 1、2、 3 ),以 1 代表 10 %、2 代表 20 %、3 代表 30%,詳細結果將在附錄二至附錄四 呈現。
壹
、不同次級量尺方法估計結果
一、不同施測人數比較 0.09 0.1 0.11 0.12 0.13 7140 15120 受試總人數 R M S E MIRT BOCK WBOCK 圖 圖圖 圖 4-4 垂直等化設計下不同受測人數之RMSE比較 由圖 4-4 可知,在兩種施測人數中,隨著施測人數增加,不同次級量尺分數 估計方法之估計誤差並無明顯差異,顯示次級量尺分數之估計在本研究中所使用 的施測人數而言,較不受施測人數影響。無論施測人數為低年級人數加高年級人 數,亦是3570×2=7140或7560×2=15120人,MIRT 方法之估計效果仍明顯優於其他次級量尺分數估計方法。 0.09 0.1 0.11 0.12 0.13 L H T 不同受試者群比較 R M S E MIRT BOCK WBOCK 圖 圖 圖 圖 4-5 垂直等化設計下不同年級受試者群之 RMSE 由圖 4-5 可知,三種次級量尺分數估計方法,無論在施測人數為 7140 人或 15120 人之情境下,L 年級與 H 年級與總人數做比較,估計誤差沒有差異,兩種 施 測 人 數 情 境和 不 同 年 級 受 測 人 數 之 RMSE 由 大 到 小 皆 依 次 為 BOCK 、 W-BOCK、MIRT。整體而言,MIRT 方法之估計效果較其他方法精確。 二、題本配置比例比較 0.09 0.10 0.11 0.12 0.13 25-25-25-25(%) 30-30-20-20(%) 40-40-10-10(%) R M S E MIRT BOCK WBOCK
估計誤差皆隨著題本次級量尺比例懸殊程度增加而變大,誤差以 BOCK 法最高, MIRT 法最低。在題本次級量尺比例 40%-40%-10%-10%之小比例次級量尺中,估 計 誤 差 明 顯驟 增 , 藉 由 謝 佳 穎 ( 2009 ) 中 所 論 述 的 建 議 , 本 研 究 增 加 25%-25%-25%-25%來比較,發現誤差是三種配置比例最小的,所以題本次級量尺 比例以平均分配最好。整體而言,MIRT 方法之估計效果較其他方法精確。 0.1 0.11 0.12 L H T 不同年級受試者群 RM SE 25-25-25-25(%)30-30-20-20(%) 40-40-10-10(%) 圖 圖 圖 圖 4-7 垂直等化設計下不同年級受試者群在不同題本配置比例之 RMSE 由圖 4-7 可知,不同年級受試者群在不同題本次級量尺比例之 RMSE 與上述 不同次級量尺方法在三種題本次級量尺比例之 RMSE,皆以題本次級量尺比例 25%-25%-25%-25%效果最佳,題本次級量尺比例 30%-30%-20%-20%次佳,而題 本次級量尺比例 40%-40%-10%-10%估計誤差較高,可見題本次級量尺比例愈平 均愈好。 三、次級量尺相關程度比較
0.08 0.09 0.1 0.11 0.12 0.13 0.14 0.15 0.2 0.5 0.8 次級量尺相關程度 RMSE MIRT BOCK WBOCK 圖 圖 圖 圖 4-8 垂直等化設計下次級量尺相關程度之RMSE 由圖 4-8 可知,在三種次級量尺相關程度中,不同次級量尺分數估計方法之 估計誤差皆隨著次級量尺相關增加而降低,其中以 BOCK 方法最為明顯。在 BIB 垂直等化設計下,三種次級量尺分數估計方法,在次級量尺相關為 0.2 時,RMSE 由大到小皆依次為 BOCK、W-BOCK、MIRT;在次級量尺相關為 0.5 時,RMSE 由大到小皆依次為 BOCK、W-BOCK、MIRT;在次級量尺相關為 0.8 時,RMSE 由大到小皆依次為 BOCK、W-BOCK、MIRT。整體而言,MIRT 方法之估計效果 比其它方法較佳。 0.08 0.09 0.1 0.11 0.12 0.13 0.14 L H T