基於特定區域紋理特徵之人臉表情辨識
51
0
0
全文
(2) 基於特定區域紋理特徵之人臉表情辨識 指導教授:賴智錦 博士 國立高雄大學電機工程學系. 研究生:謝鴻瑲 國立高雄大學電機工程學系碩士班. 摘要. 近年來,自動化地人臉表情辨識在建構人機互動系統上已獲得了極大的關注。 從影像中擷取重要並具辨識能力的特徵是人臉表情辨識中最重要的一環。本論文 提出一個以特定區域進行特徵擷取之人臉表情辨識方法。我們先將人臉表情影像 透過加速穩健特徵計算出特徵點,並根據特徵點分布選出特定區域,接著使用結 合中心對稱區域三元圖樣及區域符號方向圖樣之特徵擷取方法擷取出這些特定區 域內之特徵,最後將這些特徵以支持向量機分類器進行表情辨識。實驗結果證實, 我們提出的方法在 Cohn-Kanade、Extended Cohn-Kanade、TFEID 及 JAFFE 表情資 料庫中,都能提取出表情影像中較具有鑑別度的特徵,進而得到良好的辨識效果。. 關鍵字:人臉表情辨識、加速穩健特徵、中心對稱區域三元圖樣、區域符號方向 圖樣、支持向量機. i.
(3) Facial Expression Recognition Based on Salient Local Texture-based Features Advisor: Dr. Chih-Chin Lai Department of Electrical Engineering National University of Kaohsiung. Student: Hung-Chiang Hsieh Department of Electrical Engineering National University of Kaohsiung. ABSTRACT Automatic facial expression recognition has gained an increasing interest in recent years in building natural human-computer interaction systems. Extracting the discriminative features from facial images is the most important part of facial expression recognition. In this paper, we propose a facial expression recognition approach based on salient local texture-based features. We use Speeded Up Robust Features to find interest points and to generate salient regions from facial images, and then the associated features based on Center-Symmetric Local Ternary Pattern and Local Sign Directional Pattern in these regions are extracted. These features are classified by using the Support Vector Machine. Experimental results show that our approach can achieve higher recognition rate on the Cohn-Kanade, Extended Cohn-Kanade, TFEID, and JAFFE facial expression databases. Keywords: Facial expression recognition, Speeded up robust features, Center-symmetric local ternary pattern, Local sign directional pattern, Support vector machine. ii.
(4) 誌謝 首先感謝我的指導教授賴智錦老師,在課業、研究與論文撰寫上的指導。另 外,感謝口試委員陳榮銘老師、吳志宏老師與潘欣泰老師針對論文內容提供的寶 貴意見,使本論文內容更加完整豐富。 兩年研究所生涯,慶幸自己遇到了好老師,感謝賴智錦老師這兩年來的指導, 不僅課業、研究上的幫助,更重要的是在您身上學到了待人處事的道理與面對各 種問題應有的態度,態度正確,問題處理上自然事半功倍。感謝柯柯學長在研究 上提供寶貴經驗,讓我更加順利地找到研究方向。感謝建璋、士弼,這兩年一起 修課、互相勉勵,有你們的幫助與陪伴使我的研究生活更加多采多姿。感謝學弟 彥均幫忙實驗室大小事務,讓我能更加專注於自己的研究當中。在此祝福各位未 來都能有很好的發展,一切順遂、平安。 最後感謝我最親愛的家人,感謝父母給予我生活上的支持與關懷,使我能無 後顧之憂地專注在我的研究上。感謝我的女友玉潔,謝謝你這些年的鼓勵與陪伴, 讓我順利考上研究所並完成它。僅以此論文獻給我最親愛的家人們!謝謝!. iii.
(5) 目錄 摘要 ...................................................................................................................................i ABSTRACT ..................................................................................................................... ii 誌謝 ................................................................................................................................ iii 目錄 .................................................................................................................................iv 圖目錄 .............................................................................................................................vi 表目錄 ........................................................................................................................... vii 第一章 導論 .................................................................................................................... 1 1.1 研究動機與目的 ............................................................................................... 1 1.2 研究方法與架構 ............................................................................................... 2 第二章 文獻探討 ............................................................................................................ 3 2.1 基於幾何特徵之人臉表情辨識 ....................................................................... 3 2.2 基於外觀特徵之人臉表情辨識 ....................................................................... 3 2.3 特定區域之特徵資訊擷取 ............................................................................... 5 第三章 研究方法 ............................................................................................................ 6 3.1 表情辨識系統 ................................................................................................... 6 3.2 特定區域之擷取方法 ....................................................................................... 8 3.3 區域紋理特徵 ................................................................................................. 10 3.3.1 區域二元圖樣 ...................................................................................... 11 3.3.2 中心對稱區域三元圖樣 ...................................................................... 11 3.3.3 區域符號方向圖樣 .............................................................................. 13 3.4 支持向量機 ..................................................................................................... 16 第四章 實驗結果 .......................................................................................................... 18 4.1 實驗環境 ......................................................................................................... 18 4.2 表情資料庫 ..................................................................................................... 18 4.3 實驗分析 ......................................................................................................... 22 4.3.1 實驗一 .................................................................................................. 23 4.3.2 實驗二 .................................................................................................. 24 4.3.3 實驗三 .................................................................................................. 26 4.3.4 實驗四 .................................................................................................. 27 4.3.5 實驗五 .................................................................................................. 35 iv.
(6) 4.3.6 實驗六 .................................................................................................. 35 4.3.7 實驗七 .................................................................................................. 35 第五章 結論與未來工作 .............................................................................................. 38 參考文獻 ........................................................................................................................ 40. v.
(7) 圖目錄 圖 3.1:臉部影像擷取 ..................................................................................................... 6 圖 3.2:系統流程圖 ........................................................................................................ 7 圖 3.3:各類表情特徵點位置示意圖。左上至右下依序為:無表情、憤怒、恐懼、 厭惡、高興、悲傷、與驚訝 ............................................................................. 8 圖 3.4:特定區域紋理特徵擷取方法 ............................................................................. 9 圖 3.5:不同的半徑 R 及相鄰點數目 N[49] ................................................................ 10 圖 3.6:不同紋理特徵之 LBP[49] ................................................................................ 11 圖 3.7:CS-LTP 特徵直方圖 ........................................................................................ 13 圖 3.8:8 種不同方向的 Kirsch mask 示意圖 .............................................................. 13 圖 3.9:8 個方向響應位置與 LDP 位元位置............................................................... 14 圖 3.10:影像中某像素點及其八鄰點之像素值 ........................................................ 14 圖 3.11:LSDP 特徵直方圖 ......................................................................................... 16 圖 3.12:最大間隔超平面 ............................................................................................. 17 圖 4.1:CK 之序列影像,順序為左上至右下 ............................................................ 19 圖 4.2:CK 同一人之七類表情,左上至右下依序為:無表情、憤怒、恐懼、厭惡、 高興、悲傷、與驚訝 ....................................................................................... 19 圖 4.3:部分 CK+新增之影像 ...................................................................................... 20 圖 4.4:JAFFE 同一人之七類表情,左上至右下依序為:無表情、憤怒、恐懼、厭 惡、高興、悲傷、與驚訝 .............................................................................. 21 圖 4.5:TFEID 同一人之七類表情,左上至右下依序為:無表情、憤怒、恐懼、厭 惡、高興、悲傷、與驚訝 ............................................................................... 21 圖 4.6:十次交叉驗證示意圖 ....................................................................................... 22 圖 4.7:不同的 CS-LTP 門檻值對於辨識率的影響 .................................................... 23 圖 4.8:CK 資料庫在不同 區塊大小與所取區塊比例設定之辨識率 ....................... 24 圖 4.9:CK 資料庫在不同區塊大小與所取區塊比例設定之訓練時間 .................... 25 圖 4.10:JAFFE 中部份較難分辨所屬表情之影像 .................................................... 28 圖 4.11:各個資料庫之六類表情辨識結果 ................................................................ 32 圖 4.12:各個資料庫之七類表情辨識結果 ................................................................ 33 圖 4.13:JAFFE 資料庫在不同區塊大小與所取區塊比例設定之辨識率 ................. 34 圖 4.14:遮蔽位置示意圖,由上至下依序為 CK、CK+、JAFFE 與 TFEID .......... 36 vi.
(8) 表目錄 表 3.1:以 k = 3 為例之 LDP 編碼 ............................................................................... 15 表 3.2:LSDP 編碼範例 ................................................................................................ 16 表 4.1:所提方法與其他方法之辨識率比較 ............................................................... 26 表 4.2:所提方法對於不同資料庫之辨識率 .............................................................. 27 表 4.3:CK 資料庫之六類表情混淆矩陣(%) ........................................................... 28 表 4.4:CK 資料庫之七類表情混淆矩陣(%) .............................................................. 29 表 4.5:CK+資料庫之六類表情混淆矩陣(%) ............................................................. 29 表 4.6:CK+資料庫之七類表情混淆矩陣(%) ............................................................. 30 表 4.7:JAFFE 資料庫之六類表情混淆矩陣(%) ........................................................ 30 表 4.8:JAFFE 資料庫之七類表情混淆矩陣(%) ........................................................ 31 表 4.9:TFEID 資料庫之六類表情混淆矩陣(%) ........................................................ 31 表 4.10:TFEID 資料庫之七類表情混淆矩陣(%) ................................................... 32 表 4.11:CK 資料庫不同樣本數之辨識率 .................................................................. 35 表 4.12:CK+資料庫不同樣本數之辨識率................................................................. 35 表 4.13:各資料庫不同遮蔽情形之辨識率(%) .......................................................... 37. vii.
(9) 第一章 導論. 1.1 研究動機與目的 近年來,智慧型產品的蓬勃發展,日常生活當中也逐漸導入智慧型態的服務, 使得人機互動(Human-Computer Interaction)的相關研究成為學術界的熱門議題。為 了使機器使用起來更加友善、親切,讓機器具有人類獨特的觀察、詮釋、辨識能 力,如何創造一個更好的互動系統成了非常重要的課題。在日常生活中,人們通 常是透過言語敘述表達自己內心的感受,並且以臉部表情或肢體動作強化自己心 中情緒的傳達。臉部表情是相較於其他表達方式中,最不受性別、年紀、文化背 景差異所限制的表達方式之一,甚至不需要經過學習就能夠以臉部五官及複雜的 肌肉變化來表達心理情緒的狀態。因此,為了增進機器與人類間的互動,讓機器 也能具備如人一般的辨識能力,人臉表情辨識就成為相當重要的研究之一。 人臉表情辨識系統之應用相當廣泛,例如:透過監視器拍攝病患臉部表情, 以其表情變化作為警訊依據,進而達到即時照護的目的,同時也可以彌補醫療人 力不足的問題。此外,更有學者將人臉表情辨識作為憂鬱症的研究分析[1],協助 病患了解自己情緒變化及憂鬱症程度,並提供家屬該病情的參考依據。在娛樂方 面,例如:智慧型寵物,藉由判斷使用者臉部表情做出適當的回應,在其互動當 中達到娛樂的目的。或是透過相機鏡頭觀察拍攝對象之表情,尋找最佳拍攝時機 的微笑快門。因此,人臉表情辨識系統不僅是學術界上的研究,亦具有相當大的 商業價值。 自動化的人臉表情分析是一項極具挑戰性的研究問題,人臉表情雖然千變萬 化,但大多數並不具有實質意義。1971 年,Ekman 與 Friesen[3-4]的研究提出,人 類有六種主要情緒,分別是高興(Happiness)、悲傷(Sadness)、憤怒(Anger)、驚訝 (Surprise)、厭惡(Disgust)和恐懼(Fear),就算是不同背景文化的人都能將這些情緒 1.
(10) 正確配對至其所對應的臉部表情,亦表示此六種情緒所對應的表情對於人類而言 是很基本、理所當然的;因此,目前以電腦視覺為基礎之表情辨識的研究,多以 此六種情緒的辨別為主[5-16]。如何使機器能準確判斷這六種情緒之表情,進而提 高其應用效率,則成為本論文主要的研究動機。. 1.2 研究方法與架構 人臉表情辨識系統是以多種技術結合而成,一般可分為為三個主要程序:先 以人臉偵測開始,將影像中的臉部區域擷取出來,接著針對臉部區域的影像進行 特徵資訊的計算,最後將這些特徵資訊經由分類器分類,進而得出該影像之人臉 屬於何種表情。其中,對於最後辨識結果最具影響的程序為特徵資訊的計算,以 何種方式、何種方法才能夠計算出較具有辨識力的特徵資訊變得格外重要。本論 文提出一種方法,先將人臉影像透過加速強健特徵(Speeded Up Robust Features, SURF)[17] 找 出 較 具 辨 識 力 的 區 域 , 再 使 用 中 心 對 稱 區 域 三 元 圖 樣 (Center-Symmetric Local Ternary Pattern, CS-LTP)[18]與區域符號方向圖樣(Local Sign Directional Pattern, LSDP)[19]等區域紋理特徵擷取方法,擷取適合人臉表情辨 識之用的臉部特徵,最後交由支持向量機(Support Vector Machine, SVM)[20]進行表 情的分類。我們使用 Cohn-Kanade(CK)[21]、Extended Cohn-Kanade(CK+)[22]、 TFEID[23]及 JAFFE[24]表情資料庫進行系統效能驗證,實驗結果顯示,使用本論 文所提之方法,能得到更準確的辨識效果。 本論文共分成五個章節,第一章介紹研究動機與目的並概述本論文的架構。 第二章為所用技術之相關文獻探討。第三章說明本論文所提出的特定區域選取方 式與區域紋理特徵擷取影像資訊的方法。第四章為測試本論文方法的效能,並與 其他方法的實驗比較數據。第五章總結本論文,以及討論未來可研究及改良的方 向。. 2.
(11) 第二章 文獻探討 人臉表情辨識的方法是透過人臉影像進行特徵提取,再根據這些特徵以分類 器分類,進而判斷出人臉所顯現出何種表情,過去有許多學者提出許多方法,在 特徵資訊擷取上大致可分為兩大類:基於幾何特徵與基於外觀特徵[25]。. 2.1 基於幾何特徵之人臉表情辨識 由於人類的各種表情在臉部肌肉的形狀、線條表現上都不完全相同,因此, 基於幾何特徵的方法是利用眼睛、鼻子、嘴巴等形狀、位移的變化進行分析。人 臉動作編碼系統[26]是以各種表情牽動人臉肌肉的狀況,定義出 46 種動作單元 (Action Unit, AU),透過 AU 的組合進行表情辨識。以幾何特徵的位移變化進行分 析的方法[27],是將無表情人臉影像放置網格節點,觀察各個表情所產生不同節點 位移的變化進行分析的方法。Valstar 等人[28]以 AU 作為基準點直接計算與何種表 情最相近或加上以 Adaboost 演算法偵測這些動作單元的位置[29],提高其辨識效 果。黃彥強[2]以眉毛、眼睛以及嘴巴的位置擷取出 16 個臉部特徵點,在各個特徵 點間定義出 17 個特徵距離並結合臉部邊緣特徵作為特徵資訊,將此特徵資訊透過 半徑基底函數(Radial Basis Function, RBF)類神經網路進行分類辨識。Su 等人[30] 則是根據兩眼以及嘴巴三個區域在無表情時的位置訂出 84 個特徵點,以各個表情 的特徵點位移作為特徵資訊。Zhang 等人[31]則直接以五官的區域變化作為特徵資 訊進行辨識,雖在擷取五官位置上需要較多的計算,但所擷取出之特徵維度較少 則相對節省了訓練辨識模組的時間。. 2.2 基於外觀特徵之人臉表情辨識 基於外觀特徵的方法主要依據表情的紋理及像素值上的差異進行分析,早期 的研究中有使用主成分分析(Principal Component Analysis, PCA)、獨立成分分析 3.
(12) (Independent Component Analysis, ICA)、區域特徵分析(Local Feature Analysis, LFA)、 線性判別分析(Linear Discriminant Analysis, LDA)、與 Gabor 小波表示法作為特徵 的擷取方法,這些都是屬於基於外觀特徵的擷取方式,Tian[32]也驗證了在真實的 環境中,Gabor 小波表示法比使用幾何特徵的方法效果更佳。Gritti 等人[16]則將對 陰影和光照變化具有穩定性的方向梯度直方圖(Histogram of Oriented Gradient, HOG)用於特徵資訊的計算上。為了解決 Gabor 小波表示法在計算上需要花費許多 時間及儲存空間的問題,區域二元圖樣(Local Binary Patterns, LBP)逐漸被使用在影 像資訊的表達上[33]。Viola 等人[34]證實 LBP 對於光線的變化及低解析度影像有 較高的強韌性,其辨識效果更優於 Gabor 小波表示法。 由於 LBP 的計算簡單,能降低許多計算時間及儲存空間的需求,有越來越多 的學者以此作為人臉表情辨識研究的主要方法[35-37],之後也陸續出現許多以 LBP 為基礎所延伸出來的方法。 Tan 等人[38]提出區域三元圖樣(Local Ternary Patterns, LTP)應用於臉部偵測上, LTP 將 LBP 的二元編碼概念擴展成三個位元,使之更能有效的表達影像中的像素 值變化。 由於 LBP 與 LTP 僅考慮兩個像素點之間的灰階變化,可能會產生多種不同像 素值分布情況皆計算出相同特徵值的問題。Hossain 等人[14]提出 Compound Local Binary Pattern (CLBP)方法,其編碼方式是鄰點與中心點以及區域平均值做比較, 編碼也從 LBP 的 1 bit 改為 2 bit 表示,得到一個 16 bit 的二元編碼,再將其拆解成 兩個 8 bit 的二元編碼,實驗結果雖較 LBP 及 LTP 佳,但其維度為 LBP 的兩倍, 也增加了辨識所需的時間。 為 了 降 低 特 徵 維 度 , Heikkilä 等 人 [39] 提 出 中 心 對 稱 區 域 二 元 圖 樣 (Center-Symmetric Local Binary Pattern, CS-LBP)。CS-LBP 是改變 LBP 以鄰點與中 心點一一比較的編碼方式,改以中心點相對稱的兩點作比較,依照此編碼方式, 編碼長度由 8 bit 降為 4 bit。Zeng 等人[18]則依據 CS-LBP 的概念,將 LTP 擴展成. 4.
(13) 中心對稱區域三元圖樣(Center-Symmetric Local Ternary Pattern, CS-LTP),亦大大降 低了 LTP 維度過大的問題。 LBP 僅將影像中某個像素點周圍的灰階梯度大小變化進行編碼,並沒有將該 像素自身的灰階梯度大小變化或方向性考慮進去。Jabid 等人[12]提出透過八個方 向的 Kirsch mask 計算邊在八個方向的響應值,並將其編碼成區域方向圖樣(Local Directional Pattern, LDP)。藉由計算不同方向的邊緣響應(Edge response),對每個像 素點進行方向屬性的編碼,並以 Adaboost 及 PCA 降低特徵直方圖維度進行人臉表 情辨識。由於 LDP 透過遮罩計算後,會有正負號不同卻對應到相同編碼的情形, 且對於光線變化強韌性較低,針對這些缺點,Castillo 等人[19]改良 LDP 的觀念而 提出區域符號方向圖樣(Local Sign Directional Pattern, LSDP),以最大正數與最小負 數的位置作為編碼。但由於 LDP 與 LSDP 需要透過遮罩運算,相較於 LBP 在特徵 值計算上,需要花費更多的時間。. 2.3 特定區域之特徵資訊擷取 在特徵資訊計算的區域上,Gritti 等人[16]提出將臉部影像分割成數個子區塊, 分割方式又分為重疊與不重疊,再針對各個子區塊進行特徵擷取與直方圖運算, 最後將各個子區塊的直方圖串接在一起,形成單一且代表該張臉部表情影像的特 徵直方圖。實驗結果顯示若以重疊的方式分割區塊,整體辨識效果會比不重疊的 分割方式提升約 2%。 由於整張表情影像具有辨識能力的部份主要分布於五官及其四周,其他部份 則 較 不 具 辨 識 能 力 。 Khandait 等 人 [40] 提 出 以 Smallest Univalue Segment Assimilating Nucleus 演算法將人臉影像進行邊緣偵測,之後根據邊緣資訊找出眉毛、 眼睛、鼻子與嘴巴區域計算特徵資訊。Nagi 等人[41]則是以 Haar Feature-based Cascade Classifier 找出眼睛、鼻子與嘴巴所組成之三個區塊,再以 LBP 進行特徵 資訊擷取。. 5.
(14) 第三章 研究方法 表情辨識系統效能的好壞,通常與臉部影像中的光線變化、影像解析度等有 非常直接的關係。從文獻探討中我們得知,相較於幾何特徵方法,以外觀特徵為 基礎的方法對於這些影響有較高的容忍度,亦能得到較好的辨識效果。光線照射 在影像的表達上會造成整體像素值偏高,而光線照射的另一側則造成像素值偏低 的情形。由於區域二元圖樣和以它為基礎之變形的區域紋理特徵擷取方法,都是 以像素點及其鄰點的像素值差異進行分析、計算,所以較能適應光線的變化及解 析度的影響,而且運算簡單、快速。基於此原因,本論文採用結合中心對稱區域 三元圖樣與區域符號方向圖樣的區域紋理特徵擷取方法,並以加速穩健特徵選取 出特定區域進行特徵資訊的擷取。本章節將依序介紹相關技術,及本論文所提方 法。. 3.1 表情辨識系統 本論文所提出的表情辨識系統係結合人臉偵測及 SVM 分類器[20]。在表情影 像前處理部分,我們使用 OpenCV[42]中的人臉偵測函式進行臉部擷取,如圖 3.1 所示。OpenCV 中的人臉偵測函式是使用 Viola 等人[34]所提出的方法,此方法運 算時間快速,能將影像快速的轉換為任何大小的 Haar-like 特徵,並以 Adaboost 分 類器在大量的特徵中進行篩選,快速篩選掉不要的背景區域。首先,我們以此方 法對表情影像進行前處理,取出大小為 150×120 的臉部表情影像。. 圖 3.1:臉部影像擷取 6.
(15) 為了擷取出較具有辨識能力的特徵,我們先將所有影像以 SURF 找出各張影 像的特徵點,再根據所有影像的特徵點分布進行特定區域的選取,以此方式找出 較具有辨識能力的區塊進行特徵擷取。 特徵資訊的擷取方式,我們採用結合 CS-LTP 與 LSDP 的特徵。先將影像依前 述特定區域選取方式選出來的各個區塊進行 CS-LTP 運算並統計特徵直方圖,將各 區塊的特徵直方圖串接在一起,形成單一且代表該張臉部表情影像的特徵直方圖。 再以同樣方式進行 LSDP 運算後,將 LSDP 特徵直方圖串接於 CS-LTP 所產生的特 徵直方圖之後,形成一個混合特徵直方圖,最後以此特徵直方圖作為臉部表情影 像的表情特徵進行辨識。 表情辨識系統的最後階段是將特徵資訊輸入 SVM 進行分類辨識,此階段分為 訓練與測試兩個部份。訓練部份,將每張訓練影像透過前述特徵擷取方式所產生 之特徵直方圖作為特徵向量,透過 SVM 以各類表情的訓練樣本進行分類訓練,得 到各類表情的 SVM 模型。測試部分,將測試影像透過前述特徵擷取方式取得特徵 向量,輸入訓練好的 SVM 模型,進行分類並得到最終辨識結果。圖 3.2 為本論文 所提的系統流程,在後續的小節中,我們將詳細介紹系統所使用到的各個方法與 技術。. 圖 3.2:系統流程圖. 7.
(16) 3.2 特定區域之擷取方法 為了找出人臉影像中較具辨識能力之區域,本論文提出一特定區域選取方式, 先透過加速穩健特徵(Speeded Up Robust Features, SURF)進行特徵點擷取,再依據 這些特徵點選取特定區域作為特徵資訊計算的區塊。 加速穩健特徵(Speeded Up Robust Features, SURF)是由 Bay 等人[17]於 2008 年 所提出,常被運用於計算機視覺上,例如:物件識別[43]、3D 重構[44]等;由於其 具有旋轉不變性,也常被應用於影像匹配技術中[45-46]。Huang 與 Tai[47]直接將 其視為特徵資訊計算進行人臉表情辨識。 SURF 主要分為兩部分:以改良尺度不變特徵轉換(Scale Invariant Feature Transform, SIFT)之方法結合積分影像的計算方式進行特徵點擷取,以及透過 Haar 小波濾波器計算出各個特徵點之特徵向量。我們將不同表情的臉部影像透過 SURF 進行運算,找出特徵點並觀察特徵點的分布情形,如圖 3.3 所示。我們發現在不同 表情影像當中所找出來的特徵點位置大部分都是落在眼睛、鼻子、與嘴巴等五官 位置周圍;由於不同表情的變化主要是透過五官的變化來表達,因此我們可以透 過這些特徵點,找出適當的特徵擷取區塊。. 圖 3.3:各類表情特徵點位置示意圖。左上至右下依序為:無表情、憤怒、恐懼、 厭惡、高興、悲傷、與驚訝 8.
(17) 由於表情辨識是透過影像所計算出的特徵資訊進行辨識,我們期望能夠找出 在各種表情影像中都能計算出有效特徵資訊的區域,再進行特徵資訊計算;因此, 我們是以資料庫中七種表情的所有影像進行特定區域的擷取。本論文採用 SURF 對資料庫中的每張表情影像進行特徵點計算,我們將所有影像計算出的特徵點位 置標示於一個 150×120 的區塊當中,再以 N × N 大小的子區塊從左上角至右下角對 整個區塊範圍進行劃分。為了提高有效辨識區域的擷取率,相鄰兩個子區塊會有. 2 三分之一的區域重疊,意即子區塊位置每次往右平移 N 的距離,若平移至區塊邊 3 2 界則往下平移 N 後,再平移至區塊最左側開始往右繼續劃分。針對各個劃分出來 3 的子區塊統計出區塊內的特徵點數,再根據各個子區塊內的特徵點數量,取特徵 點數量較多的前 K%的子區塊,依序進行特徵資訊計算,再將各個子區塊的直方圖 依序串接起來,程序如圖 3.4 所示。. 圖 3.4:特定區域紋理特徵擷取方法. 9.
(18) 3.3 區域紋理特徵 由於不同的表情,是以各種不同的臉部區域紋理變化所組成,例如:眼尾、 嘴角、嘴型等;因此,本論文採用結合兩種不同的區域紋理特徵的特徵描述方法, 二者都是以 LBP 為基礎的變形方法,對於影像的紋理變化能更有效的表達。. 3.3.1 區域二元圖樣 區域二元圖樣最早由 Ojala 等人[48]提出,其原理是將彩色影像轉為灰階影像 後,對各個像素點與其八個鄰點的灰階值進行差值比較並編碼。若周圍鄰點的灰 階值大於或等於中心點灰階值,則該點編碼設為 1,反之設為 0;以此方式可將八 鄰點表示為一組二位元編碼,再將此二位元編碼乘上相對應之權重值,加總後即 為該點之 LBP 值。LBP 運算規則如公式(1)與(2): N −1. LBPR , N = ∑ s (ni − nc )2 i ,. (1). 1, x ≥ 0 s ( x) = . 0, x < 0. (2). i =0. 其中,R 為相鄰點與中心點的距離,N 為相鄰點個數,n i 為鄰點的灰階值,n c 為中 心點的灰階值。由於 R 與 N 並沒有限制,因此從原始的 LBP 衍生出多種不同半徑 R 與相鄰點數目 N 的組合,如圖 3.5 所示。若所考慮之鄰點位置並未剛好落在某像 素點,則以相鄰像素點的灰階值透過內插法求得的值與中心點灰階值比較。. (a) N = 8 , R = 1. (b) N = 16 , R = 2. (c) N = 8 , R = 2. 圖 3.5:不同的半徑 R 及相鄰點數目 N [49] 10.
(19) 區域二元圖樣原本被使用在描述影像中紋理的特徵,故透過 LBP 二位元編碼 可歸納出相對應之紋理特徵。如圖 3.6 所示,白點代表 0(比中心點較暗),黑點代 表 1(比中心點較亮),當影像為一點(spot)時,中心點灰階值遠低於或遠高於周圍鄰 點,則二元編碼為全部為 0 或全部為 1;由於影像當中一般情況之紋理分布情形通 常具有連續性,故獨立點的出現通常被視為雜訊。若為線段端點(line end),則黑點 較少且集中;若是紋理之邊緣(edge),則黑白點會平均分布於中心點兩側;若為紋 理之轉角(corner),則黑白點會呈現角錐狀分布。. 圖 3.6:不同紋理特徵之 LBP [49]. 3.3.2 中心對稱區域三元圖樣 區域三元圖樣(Local Ternary Pattern, LTP)為 LBP 的一種延伸方法[50],其原理 為將灰階影像的各個像素點與其八個鄰點的灰階值進行差值與門檻值比較並編碼。 首先設定一個門檻值,若周圍鄰點的灰階值與中心點灰階值之差大於或等於門檻 值,則該點編碼設為 2;若介於正負門檻值之間,則設為 1;若小於或等於負的門 檻值,則設為 0。與 LBP 不同的地方是將原本的二位元編碼擴展成三個位元,使 之更能有效的表達影像中的像素變化。LTP 的運算規則定義如公式(3)與(4): N −1. LTPR , N = ∑ s (ni − nc )3i ,. (3). 2, x ≥ T s ( x) = 1, − T < x < T . 0, x ≤ −T . (4). i =0. 11.
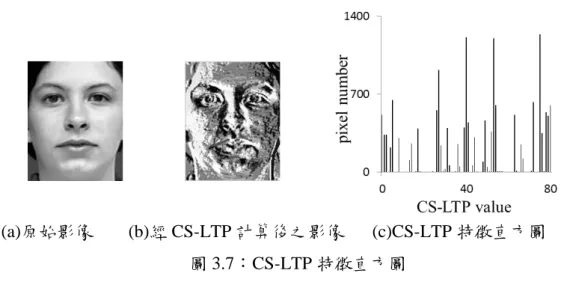
(20) 其中,R 為相鄰點與中心點的距離,N 為相鄰點個數,n i 為鄰點的灰階值,n c 為中 心點的灰階值,T 為門檻值。由於 LTP 為三元編碼,相較於 LBP 的二元編碼能更 詳細的描述影像中紋理變化;但是由於編碼上的位元增加,造成其特徵資訊表示 維度的增加,使得運算上需要花費更多的時間。 由於 LTP 的維度過大造成運算量增加,Zeng 等人[18]則依據 CS-LBP[39]的觀 念,將 LTP 擴展成中心對稱區域三元圖樣(Center-Symmetric Local Ternary Pattern, CS-LTP)。如此,能夠在一定程度上降低特徵資訊的維度,相較於 LTP 也能得到較 佳的辨識效果。CS-LTP 是一種透過區域紋理模式顯示影像區域灰階變化的特徵擷 取方法,其原理加入中心對稱的比較方式對影像進行編碼,定義出新的灰階值間 的比較規則。LTP 是以八鄰點和中心點之差與門檻值比對後得到其三位元編碼, CS-LTP 則改以中心點對稱的兩個鄰點之差與門檻值進行比較,其運算規則定義如 公式(5)與(6): N −1 2. CS − LTPR , N = ∑ s (ni − ni + N )3i ,. (5). 2, x ≥ T s ( x) = 1, − T < x < T . 0, x ≤ −T . (6). i =0. 2. 其中,R 為相鄰點與中心點的距離,N 為相鄰點個數,n i 與 ni+N/2 表示在等間隔分 佈在以中心點為圓心、R 為半徑的圓上之 N 個相鄰點中,相對於中心點對稱的兩 個像素點的灰階值,T 為門檻值。利用上述方法得到的 CS-LTP 特徵值維度為 34, 大幅降低了 LTP 的特徵維度(38)。 將影像上每一個像素點經過 CS-LTP 方法運算後,依據不同的特徵值進行統計, 即可得出該張影像的特徵直方圖,此特徵直方圖即為代表該張影像之紋理特徵。 過程如圖 3.7 所示。. 12.
(21) (a)原始影像. (b)經 CS-LTP 計算後之影像. (c)CS-LTP 特徵直方圖. 圖 3.7:CS-LTP 特徵直方圖. 3.3.3 區域符號方向圖樣 LBP 僅將影像中某個像素點周圍的灰階梯度大小變化進行編碼,Jabid 等人[12] 提出一種方法,將像素點自身的灰階梯度大小變化及方向性考慮進去,針對各個 像素點 計算其邊緣 在 不同方 向的響應值,並將其 編碼成區域方向圖樣(Local Directional Pattern, LDP)。藉由計算不同方向上的邊緣響應(Edge response),對每個 像素點進行方向屬性的編碼,以該像素點右邊方向為位置 0,依逆時針方向依序編 號至位置 7。圖 3.8 是八種不同方向的 Kirsch mask,將所要計算之像素點周圍的八 個鄰點,依序代入八種 mask,即可計算出八個方向的邊緣響應值。圖 3.9 為 mask 響應位置及 LDP 位元位置。. 圖 3.8:8 種不同方向的 Kirsch mask 示意圖. 13.
(22) m3. m2. m1. b3. b2. b1. m4. X. m0. b4. X. b0. m5. m6. m7. b5. b6. b7. 圖 3.9:8 個方向響應位置與 LDP 位元位置 透過 M 0 至 M 7 遮罩計算後可得相對應之響應值 m 0 到 m 7,此特徵擷取方法中, 需要找出將響應值取絕對值後前 k 大的值作為主要的方向,再將這 k 個方向的編碼 設為 1,其餘(8−k)個設為 0,最後依照相對應之位元位置排列後,即可得出該像素 點之 LDP 值,其運算規則定義如公式(7)與(8): 7. LDPk = ∑ bi (mi − mk )2i ,. (7). 1, a ≥ 0 bi (a) = . 0, a < 0. (8). i =0. 其中,m k 為計算完響應值取絕對值後的第 k 大的值。以圖 3.10 作為影像上某像素 點及其八個鄰點的像素值為例,進行 Kirsch masks 的運算,可得到八個不同方向的 邊緣響應值。若以 k = 3 為例,將響應值取絕對值後取前 3 個將編碼設為 1,其餘 設為 0,即得此像素點的 LDP 值為 38,詳細過程如表 3.1 所示。. 46. 68. 88. 34. 47. 65. 60. 36. 44. 圖 3.10:影像中某像素點及其八鄰點之像素值. 14.
(23) 表 3.1:以 k = 3 為例之 LDP 編碼 遮罩方向. M7. M6. M5. M4. M3. M2. M1. M0. 響應值. -163. -203. -283. -203. -139. 293. 445. 253. 排序. 7. 6. 3. 5. 8. 2. 1. 4. LDP 編碼. 0. 0. 1. 0. 0. 1. 1. 0. 由於 LDP 較易產生雜訊,且對於光線變化強韌性較低,針對這些缺點,Castillo 等人[19]則改良 LDP 的觀念進而提出區域符號方向圖樣(Local Sign Directional Pattern, LSDP)描述方法。此方法是將影像的每一個像素點轉換為一組六位元的二 進制編碼,以此方式擷取出影像區域紋理特徵。LSDP 主要是藉由計算不同方向上 的邊緣響應,對每個像素點進行方向屬性的編碼,以像素點右邊方向為位置 0,依 逆時針方向依序編號至位置 7。使用的 Kirsch mask 與 LDP 相同,用於計算出八個 方向的邊緣響應值,找出邊緣響應值最大正數與最小負數出現的位置編號,以位 置編號透過 LSDP 值運算規則,即可得此像素點之 LSDP 值,運算規則如公式(9) 所示:. LSDP = 8i + j .. (9). 其中,i 為響應值出現最大正數的對應位置編號,j 為響應值出現最小負數的對應 位置編號。 以圖 3.10 之影像像素值為例,以 Kirsch mask 的八種遮罩進行運算,可得到八 個不同方向的邊緣響應值,取出其最大正數(445)與最小負數(-283)所對應之位置編 碼 1 與 5,代入 LSDP 運算規則,即得此像素點的 LSDP 值為 13。詳細過程如表 3.2 所示。. 15.
(24) 表 3.2:LSDP 編碼範例 遮罩方向 響應值. M7. M6. M5. M4. M3. -163 -203 -283 -203 -139. M2. M1. M0. 293. 445. 253. 最大正數 最小負數. X X LSDP code: 001 101. 以上述方法將影像中所有像素點計算,並統計特徵直方圖,此特徵直方圖即 為代表該張影像之紋理特徵,如圖 3.11 所示。. (a)原始影像. (b)經 LSDP 計算後之影像. (c)LSDP 特徵直方圖. 圖 3.11:LSDP 特徵直方圖. 3.4 支持向量機 在實驗當中,我們選擇支持向量機(SVM)[20]作為分類器進行效能的測試。 SVM 是一種監督式學習的方法,被廣泛地應用於統計分類以及迴歸分析,透訓練 資料之學習建立模型,再以此模型對未知的測試資料進行分類。 SVM 是將所輸入之特徵向量映射至更高維的空間,在此空間中所屬不同類別 的兩類特徵向量之間找出最大間隔超平面,將此兩類別的特徵向量分開,並以此 超平面作為區分這兩類別的依據,如圖 3.12 所示。. 16.
(25) 圖 3.12:最大間隔超平面 SVM 主要在求得兩類別資料間的最大間隔超平面,若要處理兩類以上的分類 問題則需延伸至多元分類,其可歸納成兩種方法:(1)一對多(one-against-all, OAA), 以及(2)一對一(one-against-one, OAO)[51]。一對多的方法是將 k 類問題分解成 k 個 兩類問題進行處理,因此會產生 k 個 SVM,第 i 個 SVM 能分出 i 以及非 i 兩種類 別(i=1, 2, …, k)。一對一的方法則是每兩個類別就有一個 SVM 進行分類,若有 k 種類別資料就需要有 k(k-1)/2 個 SVM 來處理,將資料輸入所有 SVM 進行分類, 最後以所有 SVM 判斷的結果進行投票,票數最多的類別,即為該資料所屬類別。 本論文之實驗,以 LIBSVM[52]作為測試系統效能之工具,此函式庫是以一對 一的方式實現多元分類,並具有線性、多項式、輻狀基底等核心函數可供實驗進 行上的選擇。我們將訓練影像透過 CS-LTP 以及 LSDP 方法取得之特徵向量以 LIBSVM 進行訓練,在訓練階段會針對所有訓練資料找出一組最佳的參數,並以 此組參數設定產生出分類模型,再將測試影像以相同特徵擷取方法取得之特徵向 量輸入分類模型當中分類,即可從分類結果中得出我們所提方法之整體辨識效 果。 由於 SVM 大部分的時間花費在訓練階段上,LIBSVM 作者依原始版本以 CPU 進行運算的方式予以改良;將其改以 GPU 進行運算的方式,如此大幅減少訓練階 段所需的時間,因此本論文所有實驗皆以 GPU 版本的 LIBSVM 進行[52]。 17.
(26) 第四章 實驗結果 本章節將依據本論文所提出之人臉表情辨識方法進行一系列實驗測試,以及 和其他特徵擷取方法進行比較與分析。我們使用 Cohn-Kanade (CK)[21]、Extended Cohn-Kanade (CK+)[22]、TFEID[23]與 JAFFE[24]表情資料庫驗證所提系統之效能。 另外,再對資料庫中所有影像施以局部遮蔽處理後,進行特徵擷取與辨識,測試 所提方法對於部分區域隱藏影像之辨識能力。. 4.1 實驗環境 本論文所進行實驗之環境為一台四核心電腦,CPU 型號為 Intel® Core™ i5-2500 @ 3.3GHz,記憶體大小為 8GB,作業系統為 Windows 7,程式語言為 C++, 並搭配 OpenCV[42]與 LIBSVM[52]函式庫進行程式撰寫及結果辨識。. 4.2 表情資料庫 本論文所提之方法的參數設定實驗,主要以 CK[21]資料庫進行,之後亦使用 CK+[22]、JAFFE[23]和 TFEID[24]對所提方法進行效能測試,並針對各個資料庫與 其他文獻進行效能比較。 Cohn-Kanade Facial Expression Database(CK)目前已被廣泛使用於表情辨識的 研究領域。此資料庫分為兩個部分,我們使用的第一部分包含 486 組序列影像, 由 97 位大學生所拍攝而成,年齡分布於 18 至 30 歲之間;其中有 65%為女性、35% 為男性;當中更包含 15%的非裔美籍以及 3%的亞裔或拉丁裔人士。每個人都有二 到七種不同的表情(自然表情、憤怒、厭惡、恐懼、高興、悲傷、驚訝等)。如圖 4.1 所示,每段序列中包含一系列大小為 640× 490 的灰階影像,皆是以自然表情(或稱 無表情)開始,以某一種表情結束。. 18.
(27) 圖 4.1:CK 之序列影像,順序為左上至右下 由於有部分序列影像在完成各種表情前即結束,無法得到最終表情影像,因 此我們從資料庫 486 組序列影像中,選取其中包含 93 人的 1 至 6 種表情,共 320 組完整的序列影像。再將每一段影像中的第一張影像作為無表情影像、最後三張 作為表情影像,以此方式選出七種表情共 1280 張影像,其中各類表情之樣本數分 別為:320 張無表情、108 張憤怒、120 張厭惡、99 張恐懼、282 張高興、126 張 悲傷以及 225 張驚訝。圖 4.2 為 CK 資料庫中,某人之七類表情影像。. 圖 4.2:CK 中同一人之七類表情。左上至右下依序為:無表情、憤怒、恐懼、厭 惡、高興、悲傷、與驚訝. 19.
(28) Lucey 等人[22]於 2010 年將原始 CK 資料庫進行擴增,建置了 Extended Cohn-Kanade Facial Expression Database (CK+)。我們使用 CK+資料庫中的表情影像 部份,是由 123 位不同的人所拍攝之 593 組序列影像所組成,年齡介於 20 到 45 歲,所有序列影像皆是由無表情開始,並以某一種表情結束。由於有部分序列影 像同 CK 資料庫一樣有不完整之情形,因此我們從 593 組序列影像中選出 395 組完 整的序列影像,將每段序列影像的第一張影像作為無表情、最後三張作為某類表 情影像,最後選出 159 張憤怒、156 張厭惡、174 張恐懼、267 張高興、183 張悲 傷、246 張驚訝以及 395 張無表情,共 1580 張臉部影像作為實驗之用。圖 4.3 為 部分 CK+資料庫新增之表情影像。. 圖 4.3:部分 CK+新增之影像 由 10 位日本女性所拍攝而成的 Japanese Female Facial Expression Database (JAFFE),每一位皆以憤怒、厭惡、恐懼、高興、悲傷、驚訝以及無表情這七種表 情各拍攝 2 至 4 張表情影像,所有影像包含 30 張憤怒、29 張厭惡、32 張恐懼、 31 張高興、31 張悲傷、30 張驚訝以及 30 張無表情,共 213 張臉部表情影像。圖 4.4 為 JAFFE 資料庫中,同一人之七類表情影像。. 20.
(29) 圖 4.4:JAFFE 中同一人之七類表情。左上至右下依序為:無表情、憤怒、恐懼、 厭惡、高興、悲傷、與驚訝 由國立陽明大學 Brain Mapping 研究室與台北榮民總醫院整合性腦功能研究室 共同建立而成的 Taiwanese Facial Expression Image Database (TFEID),其中包括由 40 位台灣人所拍攝的七種不同表情影像。與其他資料庫最大不同處在於,各類表 情影像中每一位拍攝者只會有一張該類別表情影像,共 268 張。各類表情樣本數 分別為:34 張憤怒、40 張厭惡、40 張恐懼、40 張高興、39 張悲傷、36 張驚訝以 及 39 張無表情。. 圖 4.5:TFEID 中同一人之七類表情,左上至右下依序為:無表情、憤怒、恐懼、 厭惡、高興、悲傷、與驚訝 21.
(30) 4.3 實驗分析 本節將依序介紹我們所進行的實驗,以驗證我們所提方法之效能。實驗一與 實驗二是為得到最佳辨識效果,進行所提方法系統之參數調整;實驗三是將其他 文獻所提方法套用我們所提之特定區域選取概念進行實驗並與我們所提方法比較; 實驗四將我們所提之方法以不同表情資料庫進行實驗並分析;實驗五則是針對實 驗四辨識結果不佳的 JAFFE 資料庫進行參數調整;實驗六是將樣本數較多的 CK 與 CK+資料庫減少其樣本數量,觀察實驗樣本數量多寡對辨識率的影響;實驗七 則是將各個資料庫中的表情影像,以部分遮蔽的方式進行實驗,觀察其對於辨識 率之影響。 為了得到更精確的實驗結果,我們採用十次交叉驗證(10-fold cross validation) 之架構進行各項實驗,其觀念如圖 4.6 所示。將資料集平均分成 10 等分,每次選 擇當中的某 1 等分作為測試資料(Testing data),其餘 9 等分作為訓練資料(Training data),以此方式將每個子資料集依序作為測試資料,共進行 10 次,再將 10 次得 到的結果取平均,以此平均值作為最終的實驗結果。. 圖 4.6:十次交叉驗證示意圖 在分類器的相關設定上,我們參考其他文獻在 SVM 的核心函數實驗中,皆是 以輻狀基底函數的辨識效果較佳,因此後續的實驗皆以此作為核心函數進行 SVM 模組的訓練。. 22.
(31) 4.3.1 實驗一 我們所提之方法中,CS-LTP 的門檻值不同,對於所擷取出之特徵會有所影響, 進而影響最後的辨識效果。本實驗以 CK 表情資料庫進行,將 CS-LTP 的門檻值設 定為 1 到 10,藉由不同門檻值所擷取出之特徵直方圖進行辨識,找出能得到最佳 辨識率的設定值,實驗結果如圖 4.7 所示。 100.0. Recognition rate(%). 99.5. 99.0. 98.5. 98.0. 97.5. 97.0 T=1. T=2. T=3. T=4. T=5. T=6. T=7. T=8. T=9. T=10. Threshold value 圖 4.7:不同的 CS-LTP 門檻值對於辨識率的影響 不同的門檻值設定,所擷取出之特徵資訊不盡相同。從實驗結果顯示,門檻 值設定過小,可能導致特徵資訊包含過多無用的雜訊;反之,門檻值設定過大, 將造成影像中重要資訊喪失,無法清楚表示其特徵,進而導致辨識率隨著門檻值 增加而下降。由圖 4.7 可得知,當門檻值設定為 5 時,可得到最佳的辨識率。因此, 選擇適當的門檻值,確實有助於提升整體辨識準確度。 進行此 CS-LTP 門檻值設定之實驗時,我們首先將 N × N 區塊大小與所取區塊 比例 K%分別設定為 N = 18 pixels 以及 K = 60,得到最佳的門檻值設定為 5。以 5 23.
(32) 作為門檻值設定進行實驗二,找出最佳的區塊大小與所取區塊比例之設定為 N = 24 pixels、K = 60,以此組參數重新再進行一次實驗一,最後以 N = 24 pixels、K = 60 之實驗作為本實驗的結果。. 4.3.2 實驗二 我們所提的方法為了找出較具鑑別度之區域進行特徵擷取,運用 SURF 計算 影像當中的特徵點,再根據特徵點分布取得影像中之特定區塊進行特徵擷取,其 中影像區域是以 N × N 大小的區塊劃分,依照劃分出之各個子區塊統計出區塊中特 徵點數目後取數量較多的前 K%的區塊進行特徵值計算。本實驗將測試不同區塊大 小與不同比例區塊數目對於系統辨識效能的影響,進而得到最佳的參數設定,實 驗以 CK 資料庫進行,結果如圖 4.8 所示。. 100.0. Recognition rate(%). 99.5. 99.0 18 pixels 24 pixels. 98.5. 30 pixels 36 pixels. 98.0. 42 pixels 97.5. 97.0 40. 50. 60. 70. 80. 90. Number of blocks(%) 圖 4.8:CK 資料庫在不同區塊大小與所取區塊比例設定之辨識率 由於所取區塊增加,擷取出的辨識特徵亦隨之增加,就能更準確地辨別該張 影像屬於哪類表情。從圖 4.8 結果可得知,當各大小區塊在所取區塊比例 40%至 24.
(33) 60%之間時,辨識率都有隨著所取區塊數量的增加而提升,且在 60%時,劃分區塊 之邊長 N 為 24 pixels 時,能得到較好的辨識率。然而,當比例增加至 70%、80% 和 90%時,辨識率開始出現不規則升降,探討其可能原因為:用於擷取特徵資訊 之區塊的選取,是先以 SURF 對所有影像進行特徵點計算並依各區塊劃分之區域 內之特徵點數量多寡,作為選取的優先順序。因此選取至 60%的部份區塊,當中 都具有高辨識能力的特徵。至於選取至 70%、80%甚至 90%的部份區塊時,可能 因此將不具辨識能力、甚至包含過多雜訊之區域進行特徵擷取,進而造成辨識率 產生不規則升降的情況。 此外,我們還測試不同區塊大小所需之訓練時間,結果如圖 4.9 所示。 3,000. 2,500. Training time (sec). 2,000 18 pixels 24 pixels 30 pixels 36 pixels 42 pixels. 1,500. 1,000. 500. 0 40. 50. 60. 70. 80. 90. Number of blocks(%) 圖 4.9:不同區塊大小與所取區塊比例設定之訓練時間 從結果顯示,隨著所取區塊比例增加,將需要花更多的時間進行模組的訓練。 為避免雜訊對於實驗可靠度的影響以及訓練時間的考量,所取區塊比例之參數我 們將它設定為 60%,並以此設定進行後續之實驗。 25.
(34) 4.3.3 實驗三 在本實驗中,我們將其他文獻所提之特徵擷取方法與本論文所提方法進行比 較,為了排除實驗環境設置不同的情形,亦將其他方法結合特定區域選取的概念 再擷取其特徵。由於多數文獻都是使用 CK 資料庫進行實驗設計,我們亦採用 CK 資料庫進行結果的比較,方法之參數以實驗一與實驗二所得之最佳參數:門檻值 為 5、區塊大小為 24 pixels × 24 pixels、所取區塊比例為 60%,作為本實驗之參數 設定,實驗數據如表 4.1 所示。 表 4.1:所提方法與其他方法之辨識率比較 以整張影像進行區塊式. 選擇特定區域進行特. 特徵擷取之辨識率(%). 徵擷取之辨識率(%). LBP[33]. 88.9 ± 3.5. 97.0 ± 1.4. CS-LBP. 96.0 ± 1.7. 98.8 ± 0.9. CS-LTP. 93.3 ± 3.6. 98.9 ± 1.0. LSDP[19]. 94.8 ± 3.1. 98.0 ± 1.6. Ours. 98.8 ± 0.9. 99.3 ± 0.5. 方法. 從表 4.1 得知,相較於用整張表情影像進行區塊式特徵擷取,以 SURF 選擇出 較具有辨識能力的區域進行特徵擷取之方式,在各個特徵擷取方法上確實都能得 到較好的辨識效果。CS-LTP 為 LBP 擴展為三位元後加入中心對稱概念之方法, LSDP 則是以 LBP 結合邊際與方向資訊的觀念,進行臉部特徵的擷取;從表 4.1 比 較結果可得知,兩者的辨識效果相較於 LBP 已有大幅提升。由於我們的方法是結 合 CS-LTP 與 LSDP,期望能將兩方法在特徵擷取上之優勢突顯出來,因此亦將兩 種方法單獨使用之效果予以比較,結果顯示將兩方法結合之作法,確實能得到較 好的辨識效果。此外,在十次交叉驗證所計算出之標準差僅 0.5,亦顯示此方法相 較於單獨使用能有更好的穩定度。. 26.
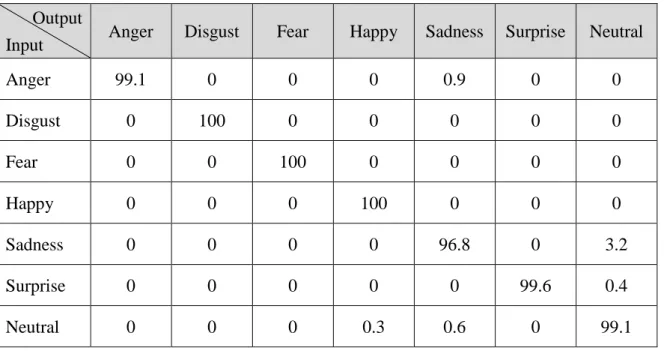
(35) 4.3.4 實驗四 受到光照方向、拍攝角度等因素影響,拍攝出來的影像也會有所不同。由於 各個表情影像資料庫的影像建立環境不太一致,產生出來之表情影像亦會有所差 異,為了測試我們的方法,是否也適用於其他資料庫的表情之辨識,實驗四我們 將針對四個表情資料庫進行辨識率的測試,以我們所提的方法分別對 CK、CK+、 JAFFE 以及 TFEID 資料庫進行辨識準確率的實驗,特徵擷取方法以實驗一與實驗 二所得之最佳參數:門檻值為 5、區塊大小為 24 pixels × 24 pixels、所取區塊比例 為 60%,作為本實驗之參數設定,結果如表 4.2 所示。 表 4.2:所提方法對於不同資料庫之辨識率 資料庫. 6-class 辨識率(%). 7-class 辨識率(%). CK. 99.7 ±0.7. 99.3 ±0.5. CK+. 99.4 ±0.8. 98.8 ±1.0. JAFFE. 86.1 ±3.5. 83.2 ±5.8. TFEID. 94.3 ±3.4. 93.7 ±4.1. 相較於 CK 與 CK+的辨識率,在七類表情的辨識結果,TFEID 的辨識率下降 至 93.7%。我們探討其可能原因為:由於 TFEID 資料庫各類表情影像中,每一位 拍攝者只會有一張該類別表情影像,排除了 CK、CK+與 JAFFE 都可能發生訓練資 料集與測試資料集同時擁有同一名拍攝者之同一類別表情影像之情形,辨識難度 提升,進而造成辨識率降低。相較於其他三個資料庫的辨識結果,JAFFE 資料庫 的辨識結果則降至 83.2%,造成此辨識率的大幅落差,探究其可能原因為:JAFFE 資料庫中某些表情之五官變化不太明顯,甚至以人工方式進行表情的辨別,亦難 將其所屬表情分辨出來,如圖 4.10 所示。如此將導致不同類別影像卻擷取出相似 的特徵,進而影響 SVM 所訓練出來的模型,最後造成測試影像被分類錯誤的情形。. 27.
(36) (a)無表情. (b)厭惡. (c)悲傷. 圖 4.10:JAFFE 中部份較難分辨所屬表情之影像 為了檢視各類表情辨識的情形,我們將各個資料庫之六類及七類辨識結果建 立成混淆矩陣。混淆矩陣主要用於觀察方法對於各類表情的分類效果,以測試資 料對建構出之 SVM 模型進行驗證。表 4.3、表 4.4 為 CK 資料庫之六類與七類表情 之混淆矩陣,表 4.5、表 4.6 為 CK+資料庫之六類與七類表情之混淆矩陣,表 4.7、 表 4.8 為 JAFFE 資料庫之六類與七類表情之混淆矩陣,表 4.9、表 4.10 為 TFEID 資料庫之六類與七類表情之混淆矩陣。 表 4.3:CK 資料庫之六類表情混淆矩陣(%) Output Input. Anger. Disgust. Fear. Happy. Sadness. Surprise. Anger. 99.1. 0. 0. 0. 0.9. 0. Disgust. 0. 100. 0. 0. 0. 0. Fear. 0. 0. 100. 0. 0. 0. Happy. 0. 0. 0. 100. 0. 0. Sadness. 0.8. 0. 0. 0. 99.2. 0. Surprise. 0. 0. 0.4. 0. 0. 99.6. 28.
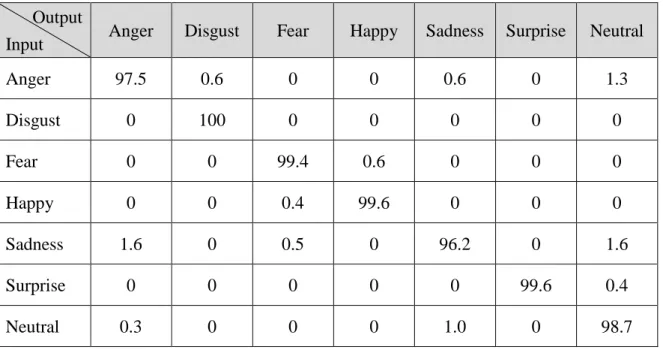
(37) 表 4.4:CK 資料庫之七類表情混淆矩陣(%) Output Input. Anger. Disgust. Fear. Happy. Sadness. Surprise. Neutral. Anger. 99.1. 0. 0. 0. 0.9. 0. 0. Disgust. 0. 100. 0. 0. 0. 0. 0. Fear. 0. 0. 100. 0. 0. 0. 0. Happy. 0. 0. 0. 100. 0. 0. 0. Sadness. 0. 0. 0. 0. 96.8. 0. 3.2. Surprise. 0. 0. 0. 0. 0. 99.6. 0.4. Neutral. 0. 0. 0. 0.3. 0.6. 0. 99.1. 透過表 4.3 與表 4.4 可得知,CK 表情資料庫在憤怒以及悲傷兩類表情上是較 容易造成判斷錯誤的,甚至在七類表情辨識中,悲傷的表情也有 3.2%會被判定為 無表情。 表 4.5:CK+資料庫之六類表情混淆矩陣(%) Output Input. Anger. Disgust. Fear. Happy. Sadness. Surprise. Anger. 98.1. 1.9. 0. 0. 0. 0. Disgust. 0. 100. 0. 0. 0. 0. Fear. 0. 0. 100. 0. 0. 0. Happy. 0. 0. 0. 100. 0. 0. Sadness. 1.1. 0. 0.5. 0. 98.4. 0. Surprise. 0. 0. 0. 0. 0.4. 99.6. 29.
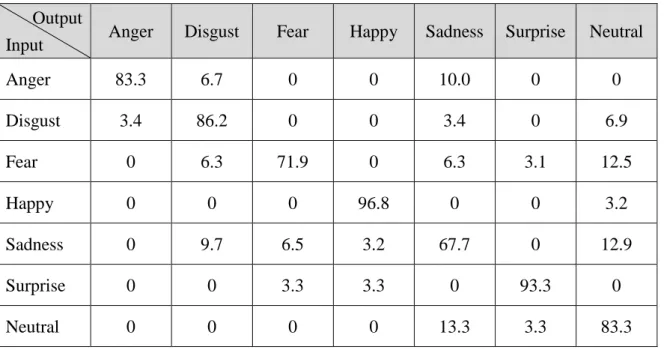
(38) 表 4.6:CK+資料庫之七類表情混淆矩陣(%) Output Input. Anger. Disgust. Fear. Happy. Sadness. Surprise. Neutral. Anger. 97.5. 0.6. 0. 0. 0.6. 0. 1.3. Disgust. 0. 100. 0. 0. 0. 0. 0. Fear. 0. 0. 99.4. 0.6. 0. 0. 0. Happy. 0. 0. 0.4. 99.6. 0. 0. 0. Sadness. 1.6. 0. 0.5. 0. 96.2. 0. 1.6. Surprise. 0. 0. 0. 0. 0. 99.6. 0.4. Neutral. 0.3. 0. 0. 0. 1.0. 0. 98.7. 從表 4.5 與表 4.6 可觀察出,CK+資料庫在六類表情中容易判斷錯誤的表情為 憤怒與悲傷。而無表情的加入,也使得憤怒與悲傷的誤判率更加提升,無表情本 身也容易與憤怒和悲傷表情混淆。 表 4.7:JAFFE 資料庫之六類表情混淆矩陣(%) Output Input. Anger. Disgust. Fear. Happy. Sadness. Surprise. Anger. 86.7. 10.0. 0. 0. 3.3. 0. Disgust. 10.3. 89.7. 0. 0. 0. 0. Fear. 0. 9.4. 81.3. 0. 6.3. 3.1. Happy. 0. 0. 0. 96.8. 3.2. 0. Sadness. 3.2. 9.7. 6.5. 3.2. 77.4. 0. Surprise. 0. 0. 0. 3.3. 0. 96.7. 30.
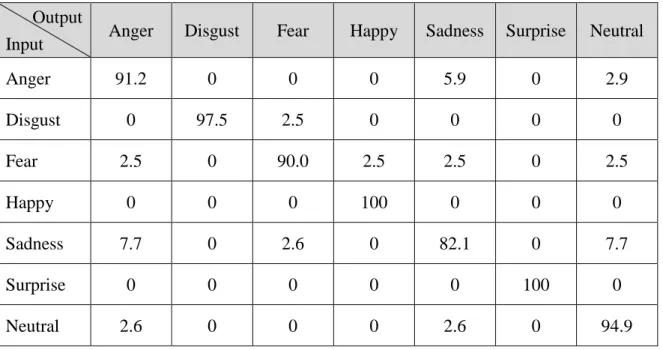
(39) 表 4.8:JAFFE 資料庫之七類表情混淆矩陣(%) Output Input. Anger. Disgust. Fear. Happy. Sadness. Surprise. Neutral. Anger. 83.3. 6.7. 0. 0. 10.0. 0. 0. Disgust. 3.4. 86.2. 0. 0. 3.4. 0. 6.9. Fear. 0. 6.3. 71.9. 0. 6.3. 3.1. 12.5. Happy. 0. 0. 0. 96.8. 0. 0. 3.2. Sadness. 0. 9.7. 6.5. 3.2. 67.7. 0. 12.9. Surprise. 0. 0. 3.3. 3.3. 0. 93.3. 0. Neutral. 0. 0. 0. 0. 13.3. 3.3. 83.3. 觀察 JAFFE 資料庫之辨識結果所產生之混淆矩陣表 4.7 與表 4.8 可以清楚看出, 悲傷表情是最不容易辨別的表情,而七類表情當中僅有 83.3%的憤怒與無表情以及 71.9%的恐懼表情能被正確判定,悲傷甚至只有 67.7%被正確的辨識出來,這也說 明了 JAFFE 資料庫的各類表情影像之間過於相似,造成辨識率偏低的情形。 表 4.9:TFEID 資料庫之六類表情混淆矩陣(%) Output Input. Anger. Disgust. Fear. Happy. Sadness. Surprise. Anger. 94.1. 0. 0. 0. 5.9. 0. Disgust. 0. 97.5. 2.5. 0. 0. 0. Fear. 0. 0. 85.0. 5.0. 10.0. 0. Happy. 0. 0. 0. 100. 0. 0. Sadness. 10.3. 0. 0. 0. 89.7. 0. Surprise. 0. 0. 0. 0. 0. 100. 31.
(40) 表 4.10:TFEID 資料庫之七類表情混淆矩陣(%) Output Input. Anger. Disgust. Fear. Happy. Sadness. Surprise. Neutral. Anger. 91.2. 0. 0. 0. 5.9. 0. 2.9. Disgust. 0. 97.5. 2.5. 0. 0. 0. 0. 2.5. 0. 90.0. 2.5. 2.5. 0. 2.5. Happy. 0. 0. 0. 100. 0. 0. 0. Sadness. 7.7. 0. 2.6. 0. 82.1. 0. 7.7. Surprise. 0. 0. 0. 0. 0. 100. 0. Neutral. 2.6. 0. 0. 0. 2.6. 0. 94.9. Fear. 從表 4.9 與 4.10 可得知,TFEID 資料庫之六類表情辨識中,悲傷表情只有 89.7% 被正確分類,而恐懼表情則只有 85.0%。在七類表情辨識中也是悲傷和恐懼這兩類 表情最容易造成誤判,而憤怒表情則有部分會被錯誤分類到悲傷與無表情中。 透過四種不同的資料庫觀察各類表情所辨識出之結果,圖 4.11 是各個資料庫 之六類表情的各類辨識結果,圖 4.12 則是七類表情的各類辨識結果。 100.0. Recognition rate(%). 95.0 90.0 85.0. CK CK+. 80.0. JAFFE TFEID. 75.0 70.0 65.0. Anger. Disgust. Fear. Happy. Sadness. Surprise. Facial expression 圖 4.11:各個資料庫之六類表情辨識結果 32.
(41) Recognition rate(%). 100.0 95.0 90.0 CK. 85.0. CK+. 80.0. JAFFE. 75.0. TFEID. 70.0 65.0. Anger. Disgust. Fear. Happy. Sadness Surprise Neutral. Facial expression 圖 4.12:各個資料庫之七類表情辨識結果 在六種表情當中,相較於厭惡、高興以及驚訝表情的五官變化較大,憤怒、 恐懼和悲傷這三種表情在五官上的變化是相對較小的;因此,當我們以人眼分辨 這三種表情的難度上會比厭惡、高興以及驚訝來的高。從六類以及七類的各類表 情辨識結果都可以發現,在憤怒、恐懼和悲傷這三種表情的辨識率上都是相對低 的,這部分的結果與日常生活中以人眼分辨各類表情的情況是相當類似的。 從圖 4.11 與圖 4.12 也可以得知 JAFFE 與 TFEID 資料庫在各類表情的辨識效 果上差異較大,我們推測可能造成的原因為:CK 與 CK+資料庫各類表情影像的樣 本數量差異較大,CK 資料庫樣本數最少與最多差了 221 張,CK+資料庫最少與最 多則差了 239 張。JAFFE 與 TFEID 資料庫的各類表情樣本數各有 29 至 32 張,以 及 34 至 40 張,由於各類樣本數過於平均,但不同表情的辨識難易程度不相同, 進而對整體辨識效果造成影響。. 4.3.5 實驗五 由於以 CK 資料庫進行實驗找出來的參數設定,在 JAFFE 資料庫上的表現並 不理想;因此,本實驗針對 JAFFE 資料庫再次進行區塊大小與所取區塊比例設定. 33.
(42) 的實驗,期望能找出不一樣的參數設定使得 JAFFE 資料庫的辨識效果得到提升, 結果如圖 4.13 所示。 90.0. Recognition rate(%). 85.0. 80.0 18 pixels 24 pixels. 75.0. 30 pixels 36 pixels. 70.0. 42 pixels. 65.0. 60.0 40. 50. 60. 70. 80. 90. Number of blocks(%) 圖 4.13:JAFFE 資料庫在不同區塊大小與所取區塊比例設定之辨識率 從圖 4.13 得知,與 CK 資料庫的實驗結果相同的是,區塊大小為 24 pixels 時 能得到最好的辨識率為 88.2%;而不同的地方是,所取區塊比例要取至 80%時在各 大小區塊才能得到一個較佳的辨識結果。推測其可能原因為:由於 JAFFE 資料庫 的表情影像較易混淆,需要多一些區塊進行特徵擷取,才能將它們區隔出來,但 若對過多的區塊進行特徵擷取,會因為擷取出較不具辨識能力的特徵進而影響最 後的辨識結果。. 4.3.6 實驗六 CK 資料庫的各類表情樣本數最少的是恐懼表情有 99 張,最多則是無表情有 320 張,CK+資料庫最少的是厭惡表情有 156 張,最多的是無表情有 395 張,相較. 34.
(43) 之下 JAFFE 與 TFEID 資料庫的各類表情樣本數較平均但數量偏少。為了得知樣本 數對於辨識結果是否有所影響,以及資料庫當中各類表情樣本數不平均對於整體 辨識效能的影響,本實驗將 CK 資料庫隨機挑選出不同表情影像各 30 張、60 張與 90 張,以及 CK+資料庫各 30 張、60 張、90 張、120 張與 150 張,比較不同表情 樣本數下的辨識效果,結果如表 4.11 與表 4.12 所示。 表 4.11:CK 資料庫不同樣本數之辨識率 各類表情樣本數. 30. 60. 90. 辨識率(%). 81.4 ± 5.4. 94.8 ± 3.3. 96.8 ± 2.7. 表 4.12:CK+資料庫不同樣本數之辨識率 各類表情樣本數. 30. 60. 90. 120. 150. 辨識率(%). 79.5 ± 5.2. 87.9 ± 3.8. 94.3 ± 2.9. 95.1 ± 3.2. 97.1 ± 1.6. 觀察表 4.11 與表 4.12 可得知,不管是 CK 或 CK+資料庫,辨識率都隨著樣本 數增加而提升,但在各類表情取相同數量的前提下,CK 資料庫各類表情樣本數取 至 90 張以及 CK+資料庫取至 150 張時的辨識率也都無法達到以所有表情影像進行 的辨識效果。由此,我們得到以下兩點結論: 1.. 以越多的訓練樣本訓練出的模型,效果也會越好。樣本數增加確實能夠 訓練出更有辨識能力的模型進行辨識。. 2.. 由於不同表情有不同的辨識難易程度,不平均的樣本數量加強了某些表 情的辨識能力,彌補了上述的情形,使得最終能夠訓練出一個更好的模 型,進而得到較好的辨識效果。. 4.3.7 實驗七 由於實際環境中人臉可能會有遮蔽的情形,例如:頭髮、鬍子等,又或在某 些情形下,人們會在臉上配戴物品,例如:眼鏡、口罩等。基於臉部表情辨識系 35.
(44) 統之適應性,實驗七將對人臉影像當中的某部分進行遮蔽,觀察各個資料庫在各 種遮蔽方式下對於辨識率的影響。本實驗以 CK、CK+、JAFFE、與 TFEID 等資料 庫進行,在 CK、CK+與 TFEID 三個資料庫上之參數設定是以實驗一與實驗二所得 之最佳參數:門檻值為 5、區塊大小為 24 pixels × 24 pixels、所取區塊比例為 60%, 在 JAFFE 資料庫上之參數設定則是以實驗一與實驗五所得之最佳參數:門檻值為 5、區塊大小為 24 pixels × 24 pixels、所取區塊比例為 80%作為本實驗之參數設定。 由於實驗是以相同大小之人臉表情影像擷取特徵資訊,因此亦採固定大小區域的 方式遮蔽每張影像。遮蔽位置示意圖如圖 4.14 所示。. (a)原圖. (b)眼睛遮蔽. (c)鼻子遮蔽. (d)嘴巴遮蔽. 圖 4.14:遮蔽位置示意圖,由上至下依序為 CK、CK+、JAFFE 與 TFEID 透過遮蔽不同位置之各類表情影像,進行特徵擷取與辨識,比較各種遮蔽方 式對辨識率之影響,結果如表 4.13 所示。. 36.
(45) 表 4.13:各資料庫不同遮蔽情形之辨識率(%) 遮蔽部位 資料庫. 未遮蔽. 眼睛. 鼻子. 嘴巴. CK. 99.3 ± 0.5. 98.4 ± 1.1. 98.6 ± 0.7. 98.0 ± 0.8. CK+. 98.8 ± 1.0. 98.7 ± 1.3. 98.8 ± 0.8. 98.6 ± 1.4. JAFFE. 88.2 ± 5.3. 71.5 ± 10.9. 84.1 ± 9.2. 79.8 ± 6.5. TFEID. 93.7 ± 4.1. 84.7 ± 6.3. 89.1 ± 5.6. 88.8 ± 4.8. 從表 4.13 結果得知,遮蔽對於四個表情資料庫之辨識率有一定的影響。比較 三種遮蔽方式,由於人臉在各個表情的五官變化,相對於眼睛和嘴巴部分,鼻子 部份是屬於變化較少的,因此在四個表情資料庫中,遮蔽鼻子的辨識效果相對其 他兩種遮蔽情形都有較高的辨識率。. 37.
(46) 第五章 結論與未來工作 對於人臉表情辨識系統,擷取影像特徵是造成整個系統好壞最重要的關鍵。 本論文提出一個方法,將表情影像以 SURF 進行特徵點計算,進而找出較具有辨 識效果的區域進行特徵擷取。擷取方法是透過 CS-LTP 與 LSDP 分別計算出區域內 各個像素點的特徵值後將其統計成特徵直方圖,再將兩特徵直方圖進行串接,形 成一個混合特徵直方圖,以此作為該張表情之特徵資訊;比起個別單獨使用 CS-LTP 或 LSDP 的方法,更能提升整體的辨識效能。 針對本論文所提之方法,主要研究結論有二: 1.. 特定區域選取:由於人臉影像包含太多資訊,如何選出有利於辨識的區 域進行特徵擷取,是影響人臉表情辨識系統的關鍵。本論文所提之特定 區域選取方法,以具有高度穩健性及計算速度快等優點的 SURF 進行特 徵點計算,再根據這些特徵點選取出特徵擷取區塊。實驗結果顯示以此 方式所擷取出之區塊,具有一定程度的辨識能力,若搭配不同的特徵擷 取方法,都能使整體辨識效能得到提升。. 2.. 特徵擷取方法之結合:特徵擷取方法經過許多學者不斷創新、改良,已 產生出許多類型的擷取方式,每一種方式都有其優缺點。如何將某方法 之優勢突顯出來?或要以何種方式,進行不同方法的結合?本論文提供 了一種可行的方式,從實驗結果顯示,相較於單獨執行個別方法,確實 能得到更好的辨識效果。. 因為特徵擷取之方法不斷推陳出新,未來可以嘗試以更好的擷取方法做結合, 或是以更好的演算法找出人臉影像的重要區域進行特徵擷取。為了使人臉表情辨 識系統更具有適用性,也可以更多表情資料庫進行方法的測試,亦可針對使用的 環境不同選擇特定表情資料庫進行開發,例如:憂鬱症患者表情資料庫、嬰幼兒. 38.
(47) 表情資料庫等。隨著科技進步,智慧型手持裝置越來越普及,若能將人臉表情辨 識系統結合至手持裝置當中,將可大幅提高其實用性。. 39.
(48) 參考文獻 [1] [2] [3] [4] [5]. [6]. [7]. [8]. [9]. [10]. [11]. [12] [13]. 謝明宏,使用臉部表情辨識作為憂鬱症分析之研究。逢甲大學資訊工程學系 碩士班碩士論文,100 年 7 月。 黃彥強,應用於自然環境中的個人化人臉表情辨識。國立雲林科技大學資訊 工程研究所碩士班碩士論文,98 年 6 月。 P. Ekamn and W. V. Friesen, “Constants across cultures in the face and emotion,” Journal of Personality and Social Psychology, vol. 17, pp. 124-129, 1971. P. Ekamn and W. V. Friesen, Unmasking the Face, Malor Books, Los Altos, 2003. W. Liu, Y. Wang, and S. Li, “LBP feature extraction for facial expression recognition,” Journal of Information & Computational Science, vol. 8, no. 3, pp. 412-421, 2011. C. Shan, S. Gong, and P. W. McOwan, “Conditional mutual information based boosting for facial expression recognition,” in Proc. British Machine Vision Conference, Sep. 2005, vol. 1, pp. 399-408. C. Shan and T. Gritti, “Learning discriminative LBP-histogram bins for facial expression recognition,” in Proc. British Machine Vision Conference, 2008, pp. 2-12. C. Shan, S. Gong, and P. W. McOwan, “Facial expression recognition based on local binary patterns: A comprehensive study,” Image and Vision Computing, vol. 27, no. 6, pp. 803-816, 2009. Y. Tian, L. Brown, A. Hampapur, S. Pankanti, A. Senior, and R. Bolle, “Real world real-time automatic recognition of facial expression,” in Proc. IEEE Workshop on Performance Evaluation of Tracking and Surveillance, 2003, pp. 2-5. Y. Tian, “Evaluation of face resolution for expression analysis,” in Proc. Computer Vision and Pattern Recognition Workshop on Face Processing in Video, 2004, pp. 82-88. S. Liao, W. Fan, C. S. Chung, and D. Y. Yeung, “Facial expression recognition using advanced local binary patterns, tsallis entropies and global appearance features,” in Proc. IEEE International Conference on Image Processing, 2006, pp. 665-668. T. Jabid, M. H. Kabir, and O. Chae, “Robust facial expression recognition based on local directional pattern,” ETRI Journal, vol. 32, no. 5, pp. 784-794, 2010. X. Tan and B. Triggs, “Enhanced local texture feature sets for face recognition under difficult lighting conditions,” IEEE Trans. on Image Processing, vol. 19, no. 6, pp. 1635-1650, 2010. 40.
(49) [14] B. Hossain, A. Faisal, and H. Emam, “Person-independent facial expression recognition based on compound local binary pattern (CLBP),” The International Arab Journal of Information Technology First Online Publication, vol. 11, no. 2, pp. 195-203, 2012. [15] M. Kabir, T. Jabid, and O Chae, “Local directional pattern variance (LDPv) : A robust feature descriptor for facial expression recognition,” The International Arab Journal of Information Technology, vol. 9, no. 4, pp. 382-391, 2012. [16] T. Gritti, C. Shan, V. Jeanne, and R. Braspenning, “Local features based facial expression recognition with face registration errors,” in Proc. IEEE International Conference on Automatic Face and Gesture Recognition, 2008, pp. 1-8. [17] H. Bay, T. Tuytelaars, and L. V. Gool, “SURF: Speeded up robust features,” in Proc. European Conference on Computer Vision, Berlin, Heidelberg, 2006, pp. 404-417. [18] H. Zeng, Z. C. Mu, and X. Q. Wang, “A robust method for local image feature region description,” Acta Automatica Sinica, vol. 37, no. 6, pp. 658-664, 2011. [19] J. A. R. Castillo, A. R. Rivera, and O. Chae, “Facial expression recognition based on local sign directional pattern,” in Proc. IEEE International Conference on Image Processing, 2012, pp. 2613-2616. [20] C. Cortes and V. Vapnik, “Support-vector networks,” International Journal of Machine Learning, vol. 20, no. 3, pp. 273-297, 1995. [21] T. Kanade, J. F. Cohn, and Y. Tian, “Comprehensive database for facial expression analysis,” in Proc. IEEE International Conference on Automatic Face and Gesture Recognition, Grenoble, France, 2000, pp. 46-53. [22] P. Lucey, J. F. Cohn, T. Kanade, J. Saragih, Z. Ambadar, and I. Matthews, “The extended Cohn-Kanade dataset (CK+): A complete facial expression dataset for action unit and emotion-specified expression,” in Proc. IEEE Conference on Computer Vision and Pattern Recognition Workshops, 2010, pp. 94-101. [23] L. F. Chen, Y. S. Yen, TFEID: Taiwanese facial expression image database, Nov. 2011, http://bml.ym.edu.tw/tfeid. [24] F. Y. Shih and C. F. Chuang, “Performance comparisons of facial expression recognition in JAFFE database,” International Journal of Pattern Recognition and Artificial Intelligence, vol. 22, no. 3, pp. 445-459, 2008. [25] Y. Tian, T. Kanade, and J. F. Cohn, Handbook of Face Recognition, 2nd Ed., Springer, 2005, pp. 487-520. [26] P. Ekman and W. V. Friesen, Facial Action Coding System: A Technique for the Measurement of Facial Movement, Consulting Psychologists Press, 1978. [27] I. Kotsia and I. Pitas, “Using geometric deformation features and support vector machines,” IEEE Trans. on Image Processing, vol. 16, no. 1, pp. 172-187, Jan. 41.
(50) [28]. [29]. [30]. [31]. [32] [33]. [34] [35]. [36]. [37]. [38]. [39]. [40]. 2007. M. Valstar, I. Patras, and M. Pantic, “Facial action unit detection using probabilistic actively learned support vector machines on tracked facial point data,” in Proc. IEEE Conference on Computer Vision and Pattern Recognition, 2005, vol. 3, pp. 76-84. M. Valstar and M. Pantic, “Fully automatic facial action unit detection and temporal analysis,” in Proc. IEEE Conference on Computer Vision and Pattern Recognition, 2006, pp. 149-156. M. C. Su, Y. J. Hsieh, and D. Y Huang, “A simple approach to facial expression recognition,” in Proc. The 2007 annual Conference on International Conference on Computer Engineering and Applications, 2007, pp. 456-461. L. Zhang and D. Tjondronegoro, “Facial expression recognition using facial movement features,” IEEE Trans. on Affective Computing, vol. 2, no. 4, pp. 219-229, 2011. Y. Tian, “Evaluation of face resolution for expression analysis,” in Proc. CVPR Workshop on Face Processing in Video, 2004, pp. 82-88. C. Shan, S. Gong, and P. W. McOwan, “Robust facial expression recognition using local binary patterns,” in Proc. IEEE International Conference on Image Processing, Sep. 2005, vol. 2, pp. 370-373. P. Viola and M. J. Jones, “Robust real-time face detection,” International Journal of Computer Vision, vol. 57, no. 2, pp. 137-154, 2004. X. Feng, M. Pietikainen, and A. Hadid, “Facial expression recognition with local binary patterns and linear programming,” Pattern Recognition and Image Analysis, vol. 15, no. 2, pp. 546-548, 2005. X. Feng and M. Pietikäinen, “A coarse-to-fine classification scheme for facial expression recognition,” in Proc. International Conference on Image Analysis and Recognition, 2004, pp. 668-675. S. M. Lajevardi and Z. M. Hussain, “Facial expression recognition using Log-Gabor filters and local binary pattern operators,” in Proc. International Conference on Communication, Computer and Power, Feb. 2009, pp. 15-18. X. Tan and B. Triggs, “Enhanced local texture feature sets for face recognition under difficult lighting conditions,” IEEE Trans. on Image Processing, vol. 19, no. 6, pp. 1635-1650, 2010. M. Heikkilä, M. Pietikäinen, and C. Schmid, “Description of interest regions with center-symmetric local binary patterns,” in Proc. 5th Indian Conference on Computer Vision, Graphics and Image Processing, 2006, pp. 58-69. S. P. Khandait, R. C. Thool, and P. D. Khandait, “Automatic facial feature extraction and expression recognition based on neural network,” International 42.
數據
![表 3.1:以 k = 3 為例之 LDP 編碼 遮罩方向 M 7 M 6 M 5 M 4 M 3 M 2 M 1 M 0 響應值 -163 -203 -283 -203 -139 293 445 253 排序 7 6 3 5 8 2 1 4 LDP 編碼 0 0 1 0 0 1 1 0 由於 LDP 較易產生雜訊,且對於光線變化強韌性較低,針對這些缺點,Castillo 等人[19]則改良 LDP 的觀念進而提出區域符號方向圖樣(L](https://thumb-ap.123doks.com/thumbv2/9libinfo/8794177.221257/23.892.187.710.140.341/M響應值產生雜訊且對於光線變化強韌性較低針對這些缺點Castillo等人L.webp)
![圖 3.12:最大間隔超平面 SVM 主要在求得兩類別資料間的最大間隔超平面,若要處理兩類以上的分類 問題則需延伸至多元分類,其可歸納成兩種方法:(1)一對多(one-against-all, OAA), 以及(2)一對一(one-against-one, OAO)[51]。一對多的方法是將 k 類問題分解成 k 個 兩類問題進行處理,因此會產生 k 個 SVM,第 i 個 SVM 能分出 i 以及非 i 兩種類 別(i=1, 2, …, k)。一對一的方法則是每兩個類別就有一個 SVM 進行分類,若有](https://thumb-ap.123doks.com/thumbv2/9libinfo/8794177.221257/25.892.311.582.131.425/資料間類以上成兩種方以及是將以及兩種一對一的方法則是有一個.webp)
+7
相關文件
Keywords: pattern classification, FRBCS, fuzzy GBML, fuzzy model, genetic algorithm... 第一章
Tekalp, “Frontal-View Face Detection and Facial Feature Extraction Using Color, Shape and Symmetry Based Cost Functions,” Pattern Recognition Letters, vol.. Fujibayashi,
Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, pp... Annealed
In this thesis, we propose a novel image-based facial expression recognition method called “expression transition” to identify six kinds of facial expressions (anger, fear,
The purpose of this paper is to achieve the recognition of guide routes by the neural network, which integrates the approaches of color space conversion, image binary,
Zhang, “A flexible new technique for camera calibration,” IEEE Tran- scations on Pattern Analysis and Machine Intelligence,
Jones, "Rapid Object Detection Using a Boosted Cascade of Simple Features," IEEE Computer Society Conference on Computer Vision and Pattern Recognition,
Tseng (1997), “Invariant handwritten Chinese character recognition using fuzzy min-max neural network,” Pattern Recognition Letter, Vol.18, pp.481-491.. Salzo (1997), “A
