Transcriptional Analysis of the DNA Polymerase Gene of Shrimp White Spot Syndrome Virus
Li-Li Chen,*,1Han-Ching Wang,‡,1Chiu-Jung Huang,* Shao-En Peng,* Yen-Gu Chen,* Shin-Jen Lin,* Wei-Yu Chen,* Chang-Feng Dai,‡ Hon-Tsen Yu,* Chung-Hsiung Wang,† Chu-Fang Lo,*,2 and Guang-Hsiung Kou*
*Department of Zoology, †Department of Entomology, and ‡Institute of Oceanography, National Taiwan University, Taipei, Taiwan, Republic of China
Received January 22, 2002; returned to author for revision April 22, 2002; accepted April 25, 2002
The white spot syndrome virus DNA polymerase (DNA pol) gene (WSSV dnapol) has already been tentatively identified based on the presence of highly conserved motifs, but it shows low overall homology with other DNA pols and is also much larger (2351 amino acid residues vs 913-1244 aa). In the present study we perform a transcriptional analysis of the WSSV
dnapol gene using the total RNA isolated from WSSV-infected shrimp at different times after infection. Northern blot analysis
with a WSSV dnapol-specific riboprobe found a major transcript of 7.5 kb. 5⬘-RACE revealed that the major transcription start point is located 27 nucleotides downstream of the TATA box, at the nucleotide residue A within a CAGT motif, one of the initiator (Inr) motifs of arthropods. In a temporal expression analysis using differential RT-PCR, WSSV dnapol transcripts were detected at low levels at 2–4 h.p.i., increased at 6 h.p.i., and remained fairly constant thereafter. This is similar to the previously reported transcription patterns for genes encoding the key enzyme of nucleotide metabolism, ribonucleotide reductase. Phylogenetic analysis showed that the DNA pols from three different WSSV isolates form an extremely tight cluster. In addition, similar to an earlier phylogenetic analysis of WSSV protein kinase, the phylogenetic tree of viral DNA pols further supports the suggestion that WSSV is a distinct virus (likely at the family level) that does not belong to any of the virus families that are currently recognized. © 2002 Elsevier Science (USA)
Key Words: Penaeus monodon; white spot syndrome virus; WSSV Taiwan isolate; WSSV dnapol gene; transcription analysis.
INTRODUCTION
White spot syndrome virus (WSSV) is the causative agent of a disease that has led to severe mortalities of cultured shrimps all over the world (Inouye et al., 1994; Takahashi et al., 1994; Chou et al., 1995; Flegel, 1997). WSSV is an enveloped, ellipsoid, large, double-stranded DNA virus (Wang et al., 1995; Wongteerasupaya et al., 1995; Lo et al., 1996b) and ithas a wide hostrange among crustaceans (Lo et al., 1996a; Flegel, 1997, Lo and Kou, 1998). The virus is transmitted both horizontally (Chang et al., 1996; Chou et al., 1998) and vertically (Lo et
al., 1997). Even while the molecular data were still
lim-ited, the uniqueness of this virus was highlighted by the preliminary WSSV-DNA sequence analysis (Lo et al., 1997), the morphological characteristics, and the general biological properties of the virus (Wongteerasupaya et
al., 1995; Lo et al., 1996a). Recent data, including studies
on individual genes and analysis of the complete ge-nome sequence, suggestthatWSSV is a member of a new virus family (Tsai et al., 2000b; Yang et al., 2001; van Hulten et al., 2001a; Liu et al., 2001).
The size of the WSSV genome has been differently
reported for different isolates: 305,107 bp (GenBank Ac-cession No. AF332093), 292,967 bp (GenBank AcAc-cession No. AF369029), and 307,287 bp (GenBank Accession No. AF440570) for viruses isolated from China, Thailand, and Taiwan, respectively. The size differences are mostly due to several small insertions and one large (⬃12 kb) dele-tion (Chen et al., 2002). The genome organizadele-tion and the overall sequences show little variation across these three isolates, reinforcing the early tentative conclusion that there is little genetic variation among WSSV isolates from around the world (Lo et al., 1999; Chang et al., 2001). For the China and Thailand isolates, the analysis of the complete WSSV genome has been published (Yang et al., 2001; van Hulten et al., 2001a). To date, although much of the sequence of the WSSV genome is already known, and the predicted sequences for many genes have al-ready been published, most of the putative WSSV genes have been subjected to sequence analysis only. The few genes that have been studied further are those encoding the ribonucleotide reductase large (RR1) and small (RR2) subunits (Tsai et al., 2000a), two structural proteins (van Hulten et al., 2000, 2001b), a novel chimeric polypeptide of cellular-type thymidine kinase and thymidylate kinase (Tsai et al., 2000b), a basic peptide (Zhang et al., 2001), a protein kinase (Liu et al., 2001), and a nucleocapsid protein with nuclear targeting behavior (Chen et al., 2002). Many genes that are important for the completion of WSSV’s infection cycle still remain to be studied. One
1These authors contributed equally to this work.
2To whom correspondence and reprintrequests should be
ad-dressed at Department of Zoology, National Taiwan University, Taipei 107, Taiwan R.O.C. Fax: 886-2-23638179. E-mail: [email protected]. edu.tw.
doi:10.1006/viro.2002.1536
0042-6822/02 $35.00
© 2002 Elsevier Science (USA) All rights reserved.
of the most important of these is the DNA polymerase (DNA pol) gene.
Based on the presence of highly conserved motifs, a WSSV gene that codes DNA pol, has already been ten-tatively identified (Yang et al., 2001; van Hulten et al., 2001a). However, the size of the putative WSSV DNA pol was differently reported in these two studies (2195 and 2351 amino acid residues, respectively), and in addition to showing low overall homology with other DNA pols, the putative WSSV DNA pol is also much larger (2351 amino acid residues vs 913-1244 aa). Since no other information beyond these sequence data has hitherto been provided, here we conduct a transcriptional analy-sis of the WSSV dnapol gene, determine the 5⬘ and 3⬘ terminus of the WSSV dnapol transcript, and provide evidence that transcription may be mediated by RNA polymerase II from the host. We also locate the con-served motifs and show that the unusually large size of WSSV DNA pol is due to the extra-large spacer regions between these consensus domains.
RESULTS AND DISCUSSION Location and structure of the WSSV dnapol gene
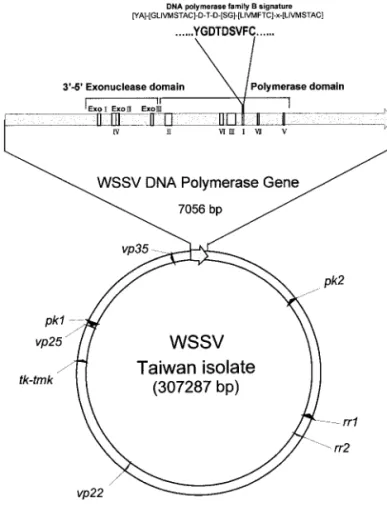
The virus used in this study was isolated from a batch of WSSV-infected Penaeus monodon collected in Taiwan in 1994 (Wang et al., 1995), which is now known as WSSV Taiwan isolate (Lo et al., 1999). From this virus, several plasmid libraries were constructed (Wang et al., 1995; Tsai et al., 2000a; Liu et al., 2001) for sequencing the WSSV genome. From a 28,325 bp contig (pms147, pmshP1, and pmh182), a 7056-ntopen reading frame (ORF) was found. When the deduced amino acid se-quence of this 7056-nt ORF was compared with other sequences in GenBank by using the BLAST network service (Atschul et al., 1997), it was found to contain the three conserved regions of the exonuclease domain (Exo I, Exo II, and Exo III) and the seven conserved regions of the polymerase domain (Regions IV, II, VI, III, I, VII, and V; Region IV is adjacentto Exo II, as in mostcases of
dnapol) (Fig. 1).
Transcriptional analysis of WSSV dnapol
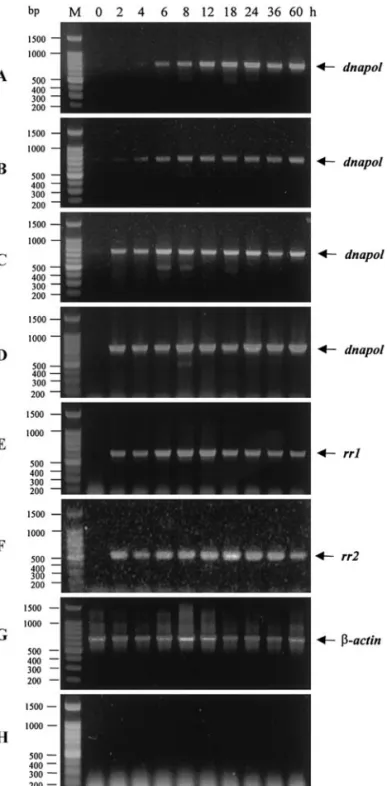
To determine when the dnapol mRNA is transcribed in the viral life cycle, and which mRNA is transcribed, we performed a transcriptional analysis of dnapol using RT-PCR and Northern blot analysis. RT-RT-PCR analysis was used to detect the dnapol-specific transcript in DNase-treated total RNA from shrimp specimens before infec-tion (0 h) and at 2, 4, 6, 8, 12, 18, 24, 36, and 60 h after WSSV infection by intramuscular injection. Primer sets specific to WSSV genes rr1 and rr2 were used for tran-scriptional comparison and a -actin primer setwas selected for template control. After 20 cycles of amplifi-cation, the dnapol transcript was first detected by
RT-PCR at 6 h.p.i. and continued to be found through to 60 h.p.i. (Fig. 2A). As the number of amplification cycles was increased, the dnapol transcript was detectable sooner (at 2 h.p.i; Figs. 2B, 2C, and 2D) and the intensity of the bands increased, but from 6 h.p.i. (Figs. 2A and 2B) and 2 h.p.i. (Figs. 2C and 2D) the intensity of the dnapol RT-PCR productbands remained fairly constantthrough to 60 h.p.i. The overall transcriptional pattern of dnapol was similar to the patterns of rr1 and rr2 (Figs. 2E and 2F), and unlike that of the structural protein gene vp25 (Liu et al., 2001). Positive and genomic DNA contamina-tion controls both gave the expected results (Figs. 2G and 2H), thus confirming RNA template quality and that no viral genomic DNA was leftin the prepared RNA.
A DIG-labeled RNA probe derived from the WSSV
dnapol gene (⫹2356 to ⫹3111 nt relative to the putative
translation initiation codon) was generated by in vitro transcription for the detection of the WSSV dnapol gene transcript in total RNA extracted from WSSV-infected shrimp. Northern blot analysis with this WSSV dnapol gene-specific riboprobe first detected one major tran-scriptof approximately 7.5 kb at6 h.p.i. (Fig. 3), which is
FIG. 1. The relative position of the WSSV dnapol gene on the entire WSSV genome. Other published genes [rr genes (Tsai et al., 2000a);
tk-tmk (Tsai et al., 2000b); vp22, vp25 and pk1 (Liu et al., 2001); vp35
(Chen et al., 2002)] are shown for reference. A protein kinase gene (pk2) that is distantly related to the published protein kinase (pk1) is also indicated.
consistent with the differential RT-PCR result shown in Fig. 2A. Likewise in both differential RT-PCR (Fig. 2A) and Northern blotting (Fig. 3), the transcript was present through to the end of the 60 h experiment. The size of the transcript matched the predicted size of the dnapol mRNA after allowing for the presumed dnapol coding
region (7056 nt) plus a stretch of 5⬘/3⬘-nontranslated regions (5⬘/3⬘-NTRs) (see below) and a poly(A) tail. Mapping 5⬘ end of the dnapol transcript
The 5⬘ region of the dnapol transcript was obtained by rapid amplification of the cDNA 5⬘ end (5⬘-RACE) (Forh-man et al., 1988) using the 5⬘/3⬘-RACE kit(Roche) in which oligo(dT)-anchor primer, anchor primer, and other key reagents were included. The RNA samples used in this study were isolated from the shrimp 24 h after WSSV infection and then treated with RNase-free DNase. The locations of the primers are shown in Fig. 4. For the first step of 5⬘-RACE, the appropriate gene-specific primer (pol-5⬘-RACE-sp1 primer; Fig. 4B) was used for first-strand cDNA synthesis from the total RNA by using an avian myeloblastosis virus (AMV) reverse transcriptase. After adding the poly(A) head to the cDNA products, these cDNAs were used as templates for PCR amplifi-cation with the pol-5⬘-RACE-sp2/oligo(dT)-anchor primer set. The PCR products formed a single band in an aga-rose gel atabout630 bp (Fig. 4B). Analysis of 5⬘-RACE products cloned in pGEM-T Easy vector revealed that the 5⬘-termini of 9 of the first 10 randomly picked clones were located 24 to 26 nt upstream of the predicted ATG initi-ation codon (Fig. 4A). The sequence of these three most likely transcriptional start points (boldfaced) and sur-rounding nucleotides is CACAGTC. Further, the 5 ⬘-termi-nus of six of these nine clones was at the second A (Fig. 4A), which suggests that this is the major start point for this 60-p.i. RNA sample. In the upstream (⬃25 nt) of the transcriptional initiation sites, a putative TATA box was found atnt⫺52 to nt ⫺57 relative to the ATG transla-tional start. The sequences surrounding the putative translation initiation codon (GAGATGA) conform reason-ably well to the eukaryotic translation consensus se-quence (Kozak, 1987, 1997).
FIG. 3. Northern blot temporal transcription analysis of total RNA isolated from WSSV-infected P. monodon using WSSV dnapol-specific riboprobes. The transcript is approximately 7.5 kb. The size standards were determined by RNA marker (Gibco-BRL). Lane headings show hours p.i.
FIG. 2. Temporal transcription analysis of WSSV dnapol gene by differential RT-PCR. Differential RT-PCR with WSSV dnapol-specific primers after (A) 20 cycles, (B) 25 cycles, (C) 30 cycles, and (D) 40 cycles. RT-PCR (40 cycles) with (E) rr1-specific primers and (F) rr2-specific primers. Internal controls: total RNA treated with DNase and amplified for 40 cycles with (G) actin-specific primers and (H) intergenic primers. The products were resolved in 1% agarose gel containing 0.5 g/ml ethidium bromide. Lane M is a 100-bp DNA ladder (Promega), and the other lane headings show hours p.i.
Mostpromoters for RNA polymerase II usually have the TATA box located⬃25 bp upstream of the transcrip-tion start point (Young, 1991; Nikolov and Burley, 1997). No extensive sequence homology has been reported for the start point, but there is a tendency for the first base of the mRNA to be A, flanked on either side by
pyrimi-dines. This region is called the initiator (Inr), and together with the TATA box, these two components are the basal elements of the RNA polymerase II promoter. The start point itself is thus identified by the Inr and/or by the TATA box close by (Martins et al., 1994; Nikolov and Burley, 1997). Whether a functional TATA box is presentor not,
FIG. 4. Mapping the 5⬘ end of the WSSV dnapol transcript. (A) The primers used for 5⬘-RACE (pol-5⬘-RACE-sp1, pol-5⬘-RACE-sp2) are underlined. The bent arrows indicate the 5⬘ termini (transcriptional start points) revealed by sequencing nine 5⬘-RACE clones. The predicted TATA box is shaded. (B) Agarose gel analysis of the 5⬘-RACE product. Lane M is a 100-bp DNA marker ladder (Promega). (C) Comparison of the tentative basal elements for RNA polymerase II of WSSV dnapol, rr1, and rr2 genes. TATA boxes are shaded, and the transcription start sites identified by 5⬘-RACE are indicated with bent arrows.
many insect baculovirus early promoters feature the same conserved transcription initiation sequences, ei-ther CAGT or ACGT, at or near the transcription start site (Friesen, 1997). Although WSSV is a shrimp virus rather than an insect virus, the WSSV dnapol transcript also matches this pattern in having an Inr (CACAGTC) with a CAGT motif located⬃25 bp downstream of the TATA box (Fig. 4C). The structure of the WSSV dnapol promoter therefore seems to mimic that of the promoters normally responsive to RNA polymerase II of arthropods (Cherbas and Cherbas, 1993). Furthermore, as noted above, it is the A within this CAGT motif that appears to be the major transcriptional start point. It therefore seems likely that, similar to most of the insect baculovirus early genes that have one or both of these basal elements, WSSV dnapol transcription may also be mediated by host RNA poly-merase II.
In passing, as Fig. 4C shows, we note that the tran-scription start sites for WSSV dnapol, rr1, and rr2 are all from 25 to 27 nucleotides downstream of the TATA box. The dnapol Inr consensus sequence (CAGT) does not exactly match the consensus sequence for the WSSV rr1 and rr2 transcription initiation sites, which has previously been tentatively identified as TCAc/tTC (Tsai et al., 2000a), but a provisional, modified a/tCAc/g/tT consen-sus can be built from these three Inrs. These a/t/CAc/ g/tT motifs closely match the a/c/t/CAg/tT Inr motifs of arthropods (Cherbas and Cherbas, 1993), in which the CA dinucleotide is the most influential in maintaining levels of CAGT transcriptional initiation (Pullen and Friesen, 1995). The fact that the distance between the TATA box and the start pointis almostthe same for all three of these genes also suggests that all three may use the same basal transcription factors/cofactors. These speculations still remain to be tested experimentally, but the data shown in Fig. 4C are provocative.
Mapping the 3⬘ end of the WSSV dnapol transcript To determine the 3⬘-terminus of the major WSSV
dnapol transcript, 3⬘-RACE was performed. The
first-strand cDNA was synthesized using the oligo(dT)-anchor
primer and AMV reverse transcriptase. Amplification of the 3⬘ region of the resulting cDNA was carried out by PCR using the pol-3⬘RACE-sp1/anchor primer set(Fig. 5) and yielded a PCR productof about370 bp. Sequence analysis of the cloned 3⬘-RACE products revealed that poly(A) was added at a site 17 nt downstream of the AATAAA polyadenylation signal (nt 7065 to nt 7070), which was found eight nucleotides downstream of the translation stop codon (Fig. 5).
Amino acid sequence alignment of WSSV DNA pol When the deduced amino acid sequence of the WSSV DNA pol 7056-nt ORF was compared with other se-quences in GenBank, the N-terminal domain was found to contain the three conserved regions of the exonucle-ase domain (Exo I, Exo II, and Exo III; Bernad et al., 1989) and the seven conserved regions of the polymerase domain (IV, II, VI, III, I, VII, and V; Larder et al., 1987) (Fig. 1). Although WSSV DNA pol is much larger than the other known viral DNA pols, this is due to the expanded spacer regions surrounding the conserved motifs (Fig. 6), while the motifs themselves are still conserved (Figs. 7 and 8). WSSV DNA pol thus has the characteristics of the eu-karyotic-type family B DNA pols (Wong et al., 1988; Ito and Braithwaite, 1991).
Phylogenetic analysis
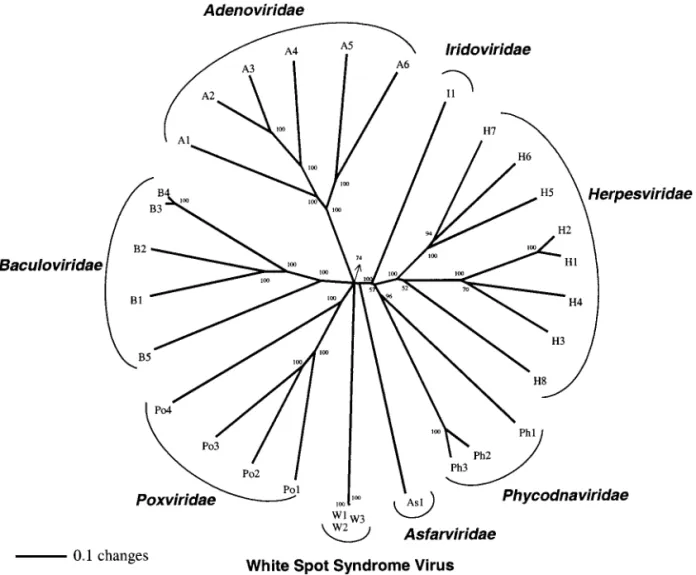
A total of 31 viral DNA pols (family B DNA pols; Table 1) were used to construct phylogenetic trees. Since both the neighbor-joining (NJ) and the parsimony trees gen-erated similar results, and since the NJ tree also re-vealed finer structures within major phylogenetic clades, only the NJ tree (Saitou and Nei, 1987) is shown here. On the tree, the viral DNA pols reflect their current phyloge-netic grouping (Fig. 9). A similar result was found for a WSSV protein kinase (PK1; Liu et al., 2001). However, the phylogenetic tree of the DNA pols appears to offer better resolution, placing WSSV, the Adenoviridae,
Baculoviri-dae, and Poxviridae in one clade and in the next, the Iridaviridae, Herpesviridae, and Phycodnaviridae in
an-FIG. 5. Mapping the 3⬘ end of the WSSV dnapol transcript. The primer used for 3⬘-RACE (pol-3⬘-RACE-sp1) is underlined. The polyadenylation signal (AATAAA) is boldfaced. The poly(A) addition site is indicated by the bent arrow.
other, while at the next level up, the two clades and
Asfarviridae form an unresolved polytomy.
As Fig. 9 also shows, the DNA pols from the three sequenced WSSV isolates form an extremely tight cluster, which reflects the closeness of their relationship. The dif-ferences among these three isolates are summarized in Table 2. First, it should be noted that while the overall genome size of the China WSSV isolate (Yang et al., 2001) is close to that of the Taiwan WSSV isolate (Chen et al., 2002), i.e., 305,107 bp vs 307,287 bp, the polypeptide en-coded by its putative DNA pol ORF (WSV514) is shorter by 246 amino acids (Table 2). Comparison of the two genes shows that a nucleotide (A) addition occurs at⫹460 relative to the translation initiation codon of the Taiwan isolate. The location of this nucleotide between the 5th and 6th M (ATG) means that the WSV514 ORF uses the 6th M as the trans-lation initiation codon and thus accounts for the 246 aa discrepancy. Second, we note that although the DNA pols of the Taiwan and Thailand isolates are closely related (Fig. 9), with just three differences over 2351 aa (Table 2), the large deletion region (⬃12 kb; a region including vp35 shown in Fig. 1) in the genome of the Thailand isolate is
FIG. 6. Protein map indicating proportional lengths of DNA pol (black lines) and relative locations of the seven conserved polymerase regions.
FIG. 7. Alignment of the amino acid sequences of the three exonu-clease domains of the DNA polymerase proteins. Gaps, introduced to optimize the alignment, are indicated by dots. Shading is used to indicate the occurrence (black 100%, gray with white letters 80%, and gray with black letters 60%) of identical amino acids. Abbreviations are as for the viruses listed in Table 1.
located not far from the dnapol gene. In this region, there are at least 10 genes including a nuclear targeting protein, WSSV VP35 (Chen et al., 2002), and several candidate genes for transcription factors which would normally be actively expressed in the infected shrimp (G. H. Kou and C. F. Lo, unpublished data). To date, the functional relation-ship between WSSV dnapol and the genes in the deletion region have notbeen elucidated, nor is itknown whatroles these genes might play in WSSV pathogenesis. Clearly, however, it would be worth investigating other isolates— especially those from Thailand—to see in how many this deletion occurs.
MATERIALS AND METHODS Virus and genomic plasmid libraries
WSSV collected in 1994 from Taiwan from infected P.
monodon (Wang et al., 1995) was used to construct
WSSV genomic libraries (Lo et al., 1996b; Tsai et al., 2000a; Liu et al., 2001). This virus source has been maintained in our laboratory since 1994 and has the GenBank Accession No. AF440570. Ithas previously been known simply as the WSSV Taiwan isolate (Lo et
al., 1999), but to distinguish it from other WSSV Taiwan
isolates, it will henceforth be referred to as the WSSV
FIG. 8. Alignment of the amino acid sequences of the seven polymerase domains of the DNA polymerase proteins. Gaps, introduced to optimize the alignment, are indicated by dots. Shading is used to indicate the occurrence (black 100%, gray with white letters 80%, and gray with black letters 60%) of identical amino acids. Abbreviations are as for the viruses listed in Table 1.
Taiwan-1 strain (WSSV T-1 strain). The WSSV T-1 strain was used as the basis for all of the WSSV genome sequence work done in the present study.
Localization and structure of the WSSV dnapol gene Plasmid DNA for sequencing was purified using the QIAprep Miniprep System (Qiagen, Germany) and was sequenced by primer walking on both strands. The nu-cleotide and the predicted protein sequences were an-alyzed using GeneWorks 2.5.1 (Oxford Molecular Group, Inc., Campbell, CA). The DNA and the deduced amino acid sequences were compared with GenBank/EMBL, SWISSPORT, and PIR databases using the programs FASTA (Pearson and Lipman, 1988) and BLAST (Altschul
et al., 1997). Alignments of amino acid sequences were
made in CLUSTAL X (Thompson et al., 1997) and edited in GeneDoc (Nicholas et al., 1997).
Mapping of the 5⬘ end of the dnapol transcript
The 5⬘region of the dnapol transcript was determined by rapid amplification of the cDNA 5⬘ end (5⬘-RACE)
(Forhman et al., 1988) using a commercial 5⬘/3⬘-RACE kit (Roche, Germany) according to the instructions provided by the manufacturer. The locations of the primers used in this study are shown in Fig. 4A. Total RNA was isolated from WSSV-infected P. monodon as described previously (Tsai et al., 2000a; Liu et al., 2001). The appropriate gene-specific primers (pol-5⬘-RACE-sp1; Fig. 4A) were then used for cDNA synthesis. Before being subjected to PCR, a poly(A) “head” with terminal transferase was added to the cDNA products in the presence of dATP. The PCR for pol was performed using the primer pol-5 ⬘-RACE-sp2 and an oligo(dT)-anchor primer. The final products were characterized by subcloning and se-quencing, and the resulting sequences were compared with the genomic sequences.
Mapping of the 3⬘ end of the dnapol transcript
The 5⬘/3⬘ region of the dnapol transcript was deter-mined by 3⬘-RACE using a commercial 3⬘-RACE kit (Roche) according to the instructions provided by the manufacturer. First-strand cDNA was synthesized using
TABLE 1
Viral DNA Polymerase Used in the Sequence Alignment and Phylogenetic Construction
Viral DNA polymerase
Virus
Accession No. Reference
Species Family
1. As1 Africa swine fever virus Asfarviridae P43139 Martins et al. (1994)
2. Po1 Fowlpox virus Poxviridae DJVZFP Binns et al. (1987)
3. Po2 Orf virus Poxviridae AAB19092 Mercer et al. (1996)
4. Po3 Vaccinia virus Poxviridae A24878 Earl et al. (1986)
5. Po4 Choristoneura biennis entomopoxvirus Poxviridae S25855 Mustafa and Yuen (1991) 6. B1 Helicoverpa zea nuclear polyhedrosis virus Baculoviridae AAA58700 Cowan et al. (1994) 7. B2 Lymantria dispar nuclear polyhedrosis virus Baculoviridae JQ1920 Bjornson et al. (1992) 8. B3 Autographa californica nuclear polyhedrosis virus Baculoviridae DJNVCP Tomalski et al. (1988) 9. B4 Bombyx mori nuclear polyhedrosis virus Baculoviridae BAA03756 Chaeychomsri et al. (1995) 10. B5 Xestia c-nigrum granulovirus Baculoviridae AAC06350 Goto et al. (1998)
11. A1 Duck adenovirus Adenoviridae NP_044702 Hess et al. (1997)
12. A2 Human adenovirus type 40 Adenoviridae NP_040853 Ishino et al. (1987) 13. A3 Human adenovirus type 12 Adenoviridae NP_040915 Kimura et al. (1981) 14. A4 Canine adenovirus type 2 Adenoviridae NP_044409 Shibata et al. (1989) 15. A5 Frog adenovirus 1 Adenoviridae NP_062435 Davison et al. (2000) 16. A6 Turkey adenovirus 3 Adenoviridae NP_047384 Pitcovski et al. (1998) 17. I1 Lymphocystis disease virus Iridiviridae NP_078724 Schnitzler et al. (1987) 18. H1 Herpes simplex virus 2 Herpesviridae P07918 Tsurumi et al. (1987) 19. H2 Herpes simplex virus 1 Herpesviridae P09854 Larder et al. (1987) 20. H3 Pseudorabies virus Herpesviridae AAA74383 Berthomme et al. (1995) 21. H4 Varicella-zoster virus Herpesviridae P09252 Davison and Scott (1986) 22. H5 Guinea pig cytomegalovirus Herpesviridae AAA43832 Schleiss (1994)
23. H6 Murine cytomegalovirus Herpesviridae P27172 Elliott et al. (1991) 24. H7 Human cytomegalovirus Herpesviridae P08546 Kouzarides et al. (1987) 25. H8 Epstein-Barr virus Herpesviridae P03198 Bankier et al. (1983) 26. Ph1 Feldmannia sp. virus Phycodnaviridae AAB67116 Lee et al. (1998) 27. Ph2 Paramecium bursaria Chlorella virus PBCV-1 Phycodnaviridae A42543 Grabherr et al. (1992) 28. Ph3 Paramecium bursaria Chlorella virus NY2A Phycodnaviridae AAA88827 Grabherr et al. (1992) 29. W1 White spot syndrome virus (Taiwan-1 strain) AF440570 Present paper
30. W2 White spot syndrome virus (Thailand isolate) AF369029 van Hulten et al. (2001a) 31. W3 White spot syndrome virus (China isolate) AF332093 Yang et al. (2001)
oligo(dT)-anchor primer. The resulting cDNA was ampli-fied with the anchor and the appropriate primer (pol-3 ⬘-RACE-sp1; Fig. 5). The final products were characterized by subcloning and sequencing, and the resulting se-quences were compared with the genomic sese-quences. WSSV dnapol transcriptional analysis
Since to date no WSSV-susceptible shrimp cell lines have become available, all the RNA for the
transcrip-tional analysis was taken from WSSV-infected shrimp at different times after infection using procedures de-scribed in Chen et al. (2002). Total RNA was isolated as described previously (Tsai et al., 2000a; Liu et al., 2001). Temporal analysis of WSSV dnapol transcription by RT-PCR
The procedure for cDNA synthesis followed the pro-cedure outlined by Chen et al. (2002). The cDNA reaction
FIG. 9. Unrooted neighbor-joining phylogenetic tree of the WSSV DNA pol. Numbers at branch nodes indicate percent bootstrap support for that node based on 1000 replications. Abbreviations refer to the viruses listed in Table 1. W1, WSSV Taiwan-1 strain; W2, WSSV Thailand isolate; W3, WSSV China isolate.
TABLE 2
The Comparison of the WSSV DNA Polymerase from the Three Different Sources
Virus source (isolate) Putative DNA pol length (aa)
Differences in amino acid residues (aaa)
Reference aa 833–836 aa 1386 aa 1680 aa 2069
Taiwan 2351 GGGG G S L Presentstudy
Thailand 2351 GGGG D N F van Hulten et al., 2001a
China 2195 GGGGG D N L Yang et al., 2001
products were subjected to PCR with the primer set pol-RTF/pol-RTR (AGTGGGTGGAACAATGTAGC/TCTACA-GATTGCTCCTTCTC) for the dnapol gene. A-actin tran-script was amplified with the actin-F1/actin-R1 primer set (5 ⬘-GAYGAYATGGAGAAGATCTGG-3⬘/5⬘-CCRGGGTACAT-GGTGGTRCC-3⬘) and used as an internal control for RNA quality and amplification efficiency. A WSSV genomic DNA-specific primer setIC-F2/IC-R3 (5
⬘-CAGACTATTAA-TGTACAAGTGCG-3
⬘/5⬘-GAATGATTGTTGCTGGTTAGAA-CC-3⬘) derived from an intergenic region of the WSSV genome was used to confirm that the RNA was not contaminated by any viral DNA.
Detection of WSSV dnapol transcripts in WSSV-infected shrimp by Northern blot hybridization analysis with a dnapol gene-specific riboprobe
A WSSV dnapol-specific DIG-labeled riboprobe was used for Northern blot analysis. To generate the riboprobe, the RNA polymerase promoter addition kit Lig’nScribe (Ambion, Austin, TX) was used in accordance with the manufacturer’s instructions to produce templates from WSSV dnapol-specific PCR products for the in vitro tran-scription. Briefly, the WSSV dnapol-specific fragmentwas amplified from WSSV genomic DNA by PCR with the primer setpol-RTF/pol-RTR. An aliquot(25 ng) of the WSSV dnapol-specific PCR product was then ligated with T7 promoter adapter (supplied with the kit) using T4 DNA ligase. To generate WSSV dnapol-specific fragments that contained the T7 RNA polymerase promoter, an aliquot (2 l) of the reaction mixture (10 l) was used as a template in PCR with a primer set consisting of the PCR adapter primer 1 (5⬘-GCTTCCGGCTCGTATGTTGTGTGG-3⬘, sup-plied with the kit) and pol-RTF. An aliquot (3.6l) of PCR product(50 l) was then used to generate the WSSV
dnapol-specific DIG-labeled riboprobe by in vitro
tran-scription (Sambrook et al., 1989) in a 20-l reaction mixture containing 40 U T7 RNA polymerase (Roche) and 1 mM NTP labeling mix (Roche) for 2 h at 37°C. The reaction mixture was then treated with 200 U RNase-free DNase I for 30 min at room temperature, terminated at 68°C for 15 min, and filtered through a Sephadex G50 column.
Total RNA (5g) was separated on 1% formaldehyde-agarose gel and transferred onto a Hybond-N⫹ mem-brane (Amersham Pharmacia Biotech, Inc., Piscataway, NJ) (Sambrook et al., 1989). The membrane was prehy-bridized for 1 h at 68°C in a prehybridization buffer (Roche) and then hybridized with a specific DIG-labeled riboprobe that was added to the buffer. After hybridiza-tion for 16 h at 65°C, the membrane was washed for 5 min with wash buffer I (2⫻ SSC and 0.1% SDS) atroom temperature, and 30 min with wash buffer II (0.1⫻ SSC and 0.1% SDS) at 68°C. DIG-labeled nucleotides in the blots were detected as described previously (Lo et al., 1999). The membrane was then exposed to Kodak BioMax
MR film via an intensifying screen for several days at ⫺70°C and the film was then developed.
Amino acid sequence comparison and phylogenetic construction
Thirty-one full-length DNA family B pols from GenBank were used in the alignment and phylogenetic analysis. The multiple sequence alignments were done by the multiple sequence alignment program CLUSTAL X (Thompson et al., 1997) and edited in GeneDoc (Nicholas
et al., 1997). Phylogenetic analysis based on the
full-length DNA pol sequences was performed using neigh-bor-joining and parsimony methods with the PAUP 4.0b1 program (Swofford, 1998), using CLUSTAL X to produce input files of aligned protein sequences. One thousand bootstrap replicates were generated to test the robust-ness of the trees.
ACKNOWLEDGMENTS
This work was supported by the National Council Grants NSC90-2317-B-002-011 and NSC90-2611-B-002-003, and Ministry of Education Grant 89-B-FA01-1-4. We are indebted to Paul Barlow and Yu-Tsan Lin for helpful criticism of the manuscript.
REFERENCES
Altschul, S. F., Madden, T. L., Schaffer, A. A., Zhang, J., Zhang, Z., Miller, W., and Lipman, D. J. (1997). Gapped BLAST and PSI-BLAST: A new generation of protein database search programs. Nucleic Acids Res. 25, 3389–3402.
Bankier, A. T., Deininger, P. L., Farrell, P. J., and Barrell, B. G. (1983). Sequence analysis of the 17166 base-pair EcoRI fragmentC of B95–8 Epstein-Barr virus. Mol. Biol. Med. 1, 21–45.
Bernad, A., Blanco, L., Lazaro, J. M., Martin, G, and Salas, M. (1989). A conserved 3⬘-5⬘ exonuclease active site in prokaryotic and eukary-otic DNA polymerases. Cell 59, 219–228.
Berthomme, H., Monahan, S. J., Parris, D. S., Jacquemont, B., and Epstein, A. L. (1995). Cloning, sequencing, and functional character-ization of the two subunits of the pseudorabies virus DNA polymer-ase holoenzyme: Evidence for specificity of interaction. J. Virol. 69, 2811–2818.
Binns, M. M., Stenzler, L., Tomley, F. M., Campbell, J., and Boursnell, M. E. (1987). Identification by a random sequencing strategy of the fowlpoxvirus DNA polymerase gene, its nucleotide sequence and comparison with other viral DNA polymerases. Nucleic Acids Res. 15, 6563–6573.
Bjornson, R. M., Glocker, B., and Rohrmann, G. F. (1992). Characteriza-tion of the nucleotide sequence of the Lymantria dispar nuclear polyhedrosis virus DNA polymerase gene region. J. Gen. Virol. 73, 3177–3183.
Chaeychomsri, S., Ikeda, M., and Kobayashi, M. (1995). Nucleotide sequence and transcriptional analysis of the DNA polymerase gene of Bombyx mori nuclear polyhedrosis virus. Virology 206, 435–447. Chang, P. S., Lo, C. F., Wang, Y. C., and Kou, G. H. (1996). Identification
of white spot syndrome associated baculovirus (WSBV) target organs in the shrimp Penaeus monodon by in situ hybridization. Dis. Aquat.
Org. 27, 131–139.
Chang, Y. S., Peng, S. E., Wang, H. C., Hsu, H. C., Ho, C. H., Wang, C. H., Wang, S. Y., Lo, C. F., and Kou, G. H. (2001). Sequencing and ARFLP analysis of ribonucleotide reductase large subunit gene of the white spotsyndrome virus found in Blue Crab Callinectes sapidus col-lected from American coastal waters. Mar. Biotechnol. 3, 163–171.
Chen, L. L., Leu, J. H., Huang, C. J., Chou, C. M., Chen, S. M., Wang, C. H., Lo, C. F., and Kou, G. H. (2002). Identification of a nucleocapsid protein (VP35) gene of shrimp white spot syndrome virus and char-acterization of the motif important for targeting vp35 to the nuclei of transfected insect cells. Virology 293, 44–53. doi:10.1006/ viro.2001.1273.
Cherbas, L., and Cherbas, P. (1993). The arthropod initiator: The capsite consensus plays an important role in transcription. Insect Biochem.
Mol. Biol. 23, 81–90.
Chou, H. Y., Huang, C. Y., Lo, C. F., and Kou, G. H. (1998). Studies on transmission of white spot syndrome associated baculovirus (WSBV) in Penaeus monodon and P. japonicus via waterborne contact and oral ingestion. Aquaculture 164, 263–276.
Chou, H. Y., Huang, C. Y., Wang, C. H., Chiang, H. C., and Lo, C. F. (1995). Pathogenicity of a baculovirus infection causing white spot syn-drome in cultured penaeid shrimp in Taiwan. Dis. Aquat. Org. 23, 165–173.
Cowan, P., Bulach, D., Goodge, K., Robertson, A., and Tribe, D. E. (1994). Nucleotide sequence of the polyhedrin gene region of the
Helico-verpa zea single nucleocapsid nuclear polyhedrosis virus:
Place-ment of the virus in lepidopteran nuclear polyhedrosis virus group II.
J. Gen. Virol. 75, 3211–3218.
Davison, A. J., and Scott, J. E. (1986). The complete DNA sequence of varicella-zoster virus. J. Gen. Virol. 67, 1759–1816.
Davison, A. J., Wright, K. M., and Harrach, B. (2000). DNA sequence of frog adenovirus. J. Gen. Virol. 81, 2431–2439.
Earl, P. L., Jones, E. V., and Moss, B. (1986). Homology between DNA polymerases of poxviruses, herpesviruses, and adenoviruses: Nu-cleotide sequence of the vaccinia virus DNA polymerase gene. Proc.
Natl. Acad. Sci. USA 83, 3659–3663.
Elliott, R., Clark, C., Jaquish, D., and Spector, D. H. (1991). Transcription analysis and sequence of the putative murine cytomegalovirus DNA polymerase gene. Virology 185, 169–186.
Flegel, T. W. (1997). Special topic review: Major viral diseases of the black tiger prawn (Penaeus monodon) in Thailand. World J. Microbiol.
Biotechniques 13, 422–433.
Forhman, M. A., Dush, M. K., and Martin, G. R. (1988). Rapid production of full-length cDNAs from rare transcripts: Amplification using a single gene-specific oligonucleotide primer. Proc. Natl. Acad. Sci.
USA 85, 8998–9002.
Friesen, P. D. (1997). Regulation of baculovirus early gene expression.
In “The Baculoviruses” (L. K. Miller, Ed.), pp. 141–170. Plenum Press,
New York.
Goto, C., Hayakawa, T., and Maeda, S. (1998). Genome organization of Xestia c-nigrum granulovirus. Virus Genes 16, 199–210.
Grabherr, R., Strasser, P., and Van Etten, J. L. (1992). The DNA polymer-ase gene from chlorella viruses PBCV-1 and NY-2A contains an intron with nuclear splicing sequences. J. Virol. 188, 721–731. Hess, M., Blocker, H., and Brandt, P. (1997). The complete nucleotide
sequence of the egg drop syndrome virus: An intermediate between mastadenoviruses and aviadenoviruses. Virology 238, 145–156, doi: 10.1006/viro.1997.8815.
Inouye, K., Miwa, S., Oseko, N., Nakano, H., and Kimura. T. (1994). Mass mortalities of evidence of cultured kuruma shrimp, Penaeus
japoni-cus, in Japan in 1993: Electron microscopic evidence of the causative
virus. Fish Pathol. 29, 149–158. [in Japanese]
Ishino, M., Sawada, Y., Yaegashi, T., Demura, M., and Fujinaga, K. (1987). Nucleotide sequence of the adenovirus type 40 inverted terminal repeat: Close relation to that of adenovirus type 5. Virology 156, 414–416.
Ito, J., and Braithwaite, D. K. (1991). Compilation and alignment of DNA polymerase sequences. Nucleic Acids Res. 19, 4045–4057. Kimura, T., Sawada, Y., Shinawawa, M., Shimizu, Y., Shiroki, K., Shimojo,
H., Sugisaki, H., Takanami, M., Uemizu, Y., and Fujinaga, K. (1981). Nucleotide sequence of the transforming early region E1b of adeno-virus type 12 DNA: Structure and gene organization, and comparison
with those of adenovirus type 5 DNA. Nucleic Acids Res. 9, 6571– 6589.
Kouzarides, T., Bankier, A. T., Satchwell, S. C., Weston, K., Tomlinson, P., and Barrell, B. G. (1987). Sequence and transcription analysis of the human cytomegalovirus DNA polymerase gene. J. Virol. 61, 125–133. Kozak, M. (1987). At least six nucleotides preceding the AUG initiator codon enhance translation in mammalian cells. J. Mol. Biol. 196, 947–950.
Kozak, M. (1997). Recognition of AUG and alternative initiator codons is augmented by G in position⫹4 butis notgenerally affected by the nucleotides in positions⫹5 and ⫹6. EMBO J. 16, 2482–2492. Larder, B. A., Kemp, S. D., and Darby, G. (1987). Related functional
domains in virus DNA polymerases. EMBO J. 6, 169–175.
Lee, A. M., Ivey, R. G., and Meints, R. H. (1998). Repetitive DNA insertion in a protein kinase ORF of a latent FSV (Feldmannia sp. virus) genome. Virology 248, 35–45, doi:10.1006/viro.1998.9245.
Liu, W. J., Yu, H. T., Peng, S. E., Chang, Y. S., Pien, H. W., Lin, C. J., Huang, C. J., Tsai, M. F., Huang, C. J., Wang, C. H., Lin, J. Y., Lo, C. F., and Kou, G. H. (2001). Cloning, characterization and phylogenetic analysis of a shrimp white spot syndrome virus (WSSV) gene that encodes a protein kinase. Virology 289, 362–377, doi:10.1006/viro.2001.1091. Lo, C. F., Ho, C. H., Chen, C. H., Liu, K. F., Chiu, Y. L., Yeh, P. Y., Peng,
S. E., Hsu, H. C., Liu, H. C., Chang, C. F., Su, M. S., Wang, C. H., and Kou, G. H. (1997). Detection and tissue tropism of white spot syn-drome baculovirus (WSBV) in captured brooders of Penaeus
mon-odon with a special emphasis on reproductive organs. Dis. Aquat. Org. 30, 53–72.
Lo, C. F., Ho, C. H., Peng, S. E., Chen, C. H., Hsu, H. C., Chiu, Y. L., Chang, C. F., Liu, K. F., Su, M. S., Wang, C. H., and Kou, G. H. (1996a). White spot syndrome baculovirus (WSBV) detected in culture and captured shrimp, crabs and other arthropods. Dis. Aquat. Org. 27, 215–225.
Lo, C. F., Hsu, H. C., Tsai, M. F., Ho, C. H., Peng, S. E., Kou, G. H., and Lightner, D. V. (1999). Specific genomic fragment analysis of different geographical clinical samples of shrimp white spot syndrome virus.
Dis. Aquat. Org. 35, 175–185.
Lo, C. F., and Kou, G. H. (1998). Virus associated white spot syndrome of shrimp in Taiwan: A review. Fish Pathol. 33, 365–371.
Lo, C. F., Leu, J. H., Ho, C. H., Chen, C. H., Peng, S. E., Chen, Y. T., Chou, C. M., Yeh, P. Y., Huang, C. J., Chou, H. Y., Wang, C. H., and Kou, G. H. (1996b). Detection of baculovirus associated with white spot syn-drome (WSBV) in penaeid shrimps using polymerase chain reaction.
Dis. Aquat. Org. 25, 133–141.
Martins, A., Ribeiro, G., Marques, M. I., and Costa, J. V. (1994). Genetic identification and nucleotide sequence of the DNA polymerase gene of African swine fever virus. Nucleic Acids Res. 22, 208–213. Mercer, A. A., Green, G., Sullivan, J. T., Robinson, A. J., and Drillien, R.
(1996). Location, DNA sequence and transcriptional analysis of the DNA polymerase gene of orf virus. J. Gen. Virol. 77, 1563–1568. Mustafa, A., and Yuen, L. (1991). Identification and sequencing of the
Choristoneura biennis entomopoxvirus DNA polymerase gene. DNA Seq. 2, 39–45.
Nicholas, K. B., Nicholas, H. B. Jr., and Deerfield D. W. II. (1997). GeneDoc: Analysis and visualization of genetic variation. EMBNEW.
NEWS 4, 14.
Nikolov, D. B., and Burley, S. K. (1997). RNA polymerase II transcription initiation: A structural view. Proc. Natl. Acad. Sci. USA 94, 15–22. Pearson, W. R., and Lipman, D. J. (1988). Improved tools for biological
sequence analysis. Proc. Natl. Acad. Sci. USA 85, 2444–2448. Pitcovski, J., Mualem, M., Rei-Koren, Z., Krispel, S., Shmueli, E., Peretz,
Y., Gutter, B., Gallili, G. E., Michael, A., and Goldberg, D. (1998). The complete DNA sequence and genome organization of the avian adenovirus, hemorrhagic enteritis virus. Virology 249, 307–315, doi: 10.1006/viro.1998.9336.
Pullen, S. S., and Friesen, P. D. (1995). The CAGT motif functions as an initiator element during early transcription of the baculovirus trans-regulator ie-1. J. Virol. 69, 3575–3583.
Saitou, N., and Nei, M. (1987). The neighbor-joining method: A new method for reconstructing phylogenetic trees. Mol. Biol. Evol. 4, 406–425.
Sambrook, J., Fritsch, E. F., and Maniatis, T. (1989). “Molecular Cloning: A Laboratory Manual,” 2nd ed., Cold Spring Harbor Laboratory Press, Cold Spring Harbor, NY.
Schleiss, M. R. (1994). Cloning and characterization of the guinea pig cytomegalovirus glycoprotein B gene. Virology 202, 173–185, doi: 10.1006/viro.1994.1333.
Schnitzler, P., Delius, H., Scholz, J., Touray, M., Orth, E., and Darai, G. (1987). Identification and nucleotide sequence analysis of the repet-itive DNA element in the genome of fish lymphocystis disease virus.
Virology 161, 570–578.
Shibata, R., Shinagawa, M., Iida, Y., and Tsukiyama, T. (1989). Nucleo-tide sequence of E1 region of canine adenovirus type 2. Virology 172, 460–467.
Swofford, D. L. (1998). PAUP*. Phylogenetic analysis using parsimony (*and other methods). Version 4. Sinauer, Sunderland, MA. Takahashi, Y., Itami, T., Kondo, M., Maeda, M., Fujii, R., Tomonaga, S.,
Supamattaya, K., and Boonyaratpalin, S. (1994). Electron microscopic evidence of bacilliform virus infection in Kuruma shrimp (Penaeus
japonicus). Fish Pathol. 29, 121–125.
Tomalski, M. D., Wu, J. G., and Miller, L. K. (1988). The location, se-quence, transcription, and regulation of a baculovirus DNA polymer-ase gene. Virology 167, 591–600.
Thompson, J. D., Gibson, T. J., Plewniak, F., Jeanmougin, F., and Higgins, D. G. (1997). The CLUSTAL X windows interface: Flexible strategies for multiple sequence alignment aided by quality analysis tools.
Nucleic Acids Res. 25, 4876–4882.
Tsai, M. F., Lo, C. F., van Hulten, M. C. W., Tzeng, H. F., Chou, C. M., Huang, C. J., Wang, C. H., Lin, J. Y., Vlak, J. M., and Kou, G. H. (2000a). Transcriptional analysis of the ribonucleotide reductase genes of shrimp white spot syndrome virus. Virology 277, 92–99, doi:10.1006/ viro.2000.0596.
Tsai, M. F., Yu, H. T., Tzeng, H. F., Leu, J. H., Chou, C. M., Huang, C. J., Wang, C. H., Lin, J. Y., Kou, G. H., and Lo, C. F. (2000b). Identification and characterization of a shrimp white spot syndrome virus (WSSV) gene that encodes a novel chimeric polypeptide of cellular-type thymidine kinase and thymidylate kinase. Virology 277, 100–110, doi:10.1006/viro.2000.0597.
Tsurumi, T., Maeno, K., and Nishiyama, Y. (1987). Nucleotide sequence of the DNA polymerase gene of herpes simplex virus type 2 and comparison with the type 1 counterpart. Gene 52, 129–137. van Hulten, M. C. W., Westenberg, M., Goodall, S. D., and Vlak, J. M.
(2000). Identification of two major virion protein genes of white spot syndrome virus of shrimp. Virology 266, 227–236, doi:10.1006/ viro.1999.0088.
van Hulten, M. C. W., Witteveldt, J., Peters, S., Kloosterboer, N., Tarchini, R., Fiers, M., Sandbrink, H., Lankhorst, R. K., and Vlak, J. M. (2001a). The white spot syndrome virus DNA genome sequence. Virology 286, 7–22, doi:10.1006/viro.2001.1002.
van Hulten, M. C. W., Witteveldt, J., Snippe, M., and Vlak, J. M. (2001b). White spot syndrome virus envelope protein VP28 is involved in the systemic infection of shrimp. Virology 285, 228–233, doi:10.1006/ viro.2001.0928.
Wang, C. H., Lo, C. F., Leu, J. H., Chou, C. M., Yeh, P. Y., Chou, H. Y., Tung, M. C., Chang, C. F., Su, M. S., and Kou, G. H. (1995). Purification and genomic analysis of baculovirus associated with white spot syndrome (WSBV) of Penaeus monodon. Dis. Aquat. Org. 23, 239– 242.
Wong, S. W., Wahl, A. F., Yuan, P., Arai, N., Pearson, B. E., Arai, K., Korn, D., Hunkapiller, M. W., and Wang, T. S. (1988). Human DNA polymer-ase␣ gene expression is cell proliferation dependent and its primary structure is similar to both prokaryotic and eukaryotic replicative DNA polymerase. EMBO J. 7, 37–47.
Wongteerasupaya, C., Vickers, J. E., Sriurairatana, S., Nash, G. L., Akarajamorn, A., Boonsaeng, V., Panyim, S., Tassankajon, A., With-yanchumnarnkul, B., and Flegel, T. W. (1995). A non-occluded, sys-temic baculovirus that occurs in cells of ectodermal and mesodermal origin and causes high mortality in black tiger prawn Penaeus
mon-odon. Dis. Aquat. Org. 21, 69–77.
Yang, F., He, J., Lin, X., Li, Q., Pan, D., Zhang, X., and Xu, X. (2001). Complete genome sequence of the shrimp white spot bacilliform virus. J. Virol. 75, 11811–11820.
Young, R. A. (1991). RNA polymerase II. Annu. Rev. Biochem. 60, 689– 715.
Zhang, X., Xu, X., and Hew, C. L. (2001). The structure and function of a gene encoding a basic peptide from prawn white spot syndrome virus. Virus Res. 79, 137–144.