An Incremental Mining Algorithm for High Average-Utility Itemsets
Tzung-Pei Hong
Dept. of Computer Science andInformation Engineering National University of Kaohsiung
Kaohsiung, Taiwan [email protected]
Cho-Han Lee
Institute of Electrical Engineering National University of Kaohsiung
Kaohsiung, Taiwan [email protected]
Shyue-Liang Wang
Dept. of Information Management National University of KaohsiungKaohsiung, Taiwan [email protected]
Abstract—The average utility measure reveals a better utility effect of combining several items than the original utility measure. In this paper, we propose a two-phase average-utility mining algorithm that can incrementally maintain the high average-utility itemsets as a database grows. Based on the concept of the FUP algorithm, the proposed algorithm combines the previously mined information from the original database and the new mined results from the newly inserted transactions to speed up the mining process. Experimental results also show the effectiveness and efficiency of the proposed algorithm.
Keywords - utility mining; average-utility; two-phase mining; incremental mining.
I. INTRODUCTION
Utility mining may be thought of as an extension of frequent-itemset mining [1, 2]. In the past, many algorithms [2-8] were proposed to find the high utilities itemsets from transactions. Traditionally, the utility of an itemset is the summation of the utilities of the itemset in all the transactions regardless of its length. Thus, the utility of an itemset in a transaction will increase along with the increase of its length. In order to alleviate the effect of the length of itemsets and identify really good utility itemsets, the average utility measure was applied to reveal a better utility effect of combining several items than the original utility measure. It is defined as the total utility of an itemset divided by its number of items within it. The average utility of an itemset is then compared with a threshold to decide whether it is a high average-utility itemset.
Most of the above approaches assumed that the database was static and focused on batch mining. However, in real-world applications, the database varies with newly added records (or transactions). When new records are added into the database, some of the originally frequent or high utility itemsets may become invalid, or some new implicitly frequent or high utility itemsets may appear in the whole updated database [9-12].
In this paper, we proposed an incremental algorithm based on the FUP [9] concept to mine the high average-utility itemsets in the database varying with constantly inserted records. The algorithm adopts the Apriori strategy to search for high average-utility itemsets level by level. The “downward closure” property of itemsets, which is the basic principle of the Apriori-like strategy, is used to reduce the search space by pruning low utility itemsets early. With the
“downward closure” property, the number of candidate itemsets generated at each level is greatly reduced in a two-phase way. Besides, in order to handle the database varying with new inserted records, the concept of the FUP algorithm is adopted to reduce the time to re-process the whole updated database.
The rest of this paper is organized as follows. Some related works are reviewed in Section 2. The proposed incremental mining algorithm for high average-utility itemsets is described in Section 3. An example to illustrate the proposed algorithm is shown in Section 4. The experimental results are presented in Section 5. Conclusion and discussion are given in Section 6.
II. REVIEW OF RELATED WORKS
A. Apriori principle
Agrawal and Srikant proposed the Apriori algorithm [13] to mine association rules from a set of transactions in a level-wise way. In each pass, Apriori employs the downward-closure (anti-monotone) property to prune impossible candidates, thus improving the efficiency of identifying frequent itemsets.
B. Utility mining
The utility of an item in a transaction is defined as the product of its quantity (local transaction utility) multiplied by its profit (external utility) [1]. The utility of an itemset in a transaction is thus the sum of the utilities of all the items in the transaction. If the sum of the utilities of an itemset in all the transactions is larger than the predefined utility threshold, then the itemset is called a high utility itemset.
In utility mining, the downward-closure property no long exists since the utility of an itemset will grow monotonically and the frequency of an itemset will reduce monotonically along with the number of items in an itemset. The two different monotonic properties make the downward-closure property invalid in utility mining.
In the past, several mining approaches were proposed for fining high utility itemsets. For example, Barber and Hamilton proposed the approaches of Zero pruning (ZP) and Zero subset pruning (ZSP) to exhaustively search for all high utility itemsets in a database [3, 4]. Li et al. proposed the FSM, the ShFSM and the DCG methods [5, 7, 8] to discover all high utility itemsets by taking advantage of the level-closure property. Yao then proposed a framework for mining high utility itemsets based on mathematical properties of
utility constraints [14]. Liu et al. then presented a two-phase algorithm for fast discovering all high utility itemsets [2, 6]. Hong et al proposed the high average-utility itemsets to reduce the size of candidates in order to decrease the time to scan a database.
C. The FUP algorithm
Cheung et al. proposed the FUP [9] algorithm to incrementally maintain the mined results of association rules when new transactions were inserted. In FUP, large itemsets with their counts in preceding runs were recorded for later use in maintenance. As new transactions were added, FUP first scanned them to generate candidate 1-itemsets, and then compared these itemsets with the previous ones to decide which case the itemset belonged to. The corresponding process was thus executed according to the four cases, respectively as follows.
Case 1: An itemset was large in the original database and in the newly inserted transactions.
Case 2: An itemset was large in the original database, but was not large in the newly inserted transactions. Case 3: An itemset was not large in the original database,
but was large in the newly inserted transactions. Case 4: An itemset was not large in the original database
and in the newly inserted transactions.
III. THE PROPOSED INCREMENTAL AVERAGE-UTILITY
MINING ALGORITHM
The proposed incremental average-utility mining algorithm was based on the concept of the four cases in FUP but for average-utility itemsets. There are two phases in the proposed incremental average-utility mining algorithm. In the first phase, the average-utility upper bound is used to overestimate the itemsets. The average-utility upper bound is an overestimated utility value instead of actual utility value. The average-utility upper bound can ensure the anti-monotone property which is used to decrease the number of itemsets to be scanned level by level.
In the second phase, the actual average-utility values of the high upper-bound average-utility itemsets are calculated. Also, these itemsets are checked against the minimum average-utility threshold to determine whether they are actually high or not. All the actual high average-utility itemsets can thus be found.
Our incremental utility mining algorithm can reduce the time to re-process the whole updated database when compared with conventional batch utility mining algorithms. The details of the proposed incremental average-utility mining algorithm are described below.
The proposed incremental two-phase average-utility mining algorithm:
INPUT: The profit values of the items, the minimum average-utility ratio , an original database D with its minimum average-utility threshold αD (= total utility*), high upper-bound average-utility itemsets (HUD) and high average-utility itemsets
(HD), and a set of new transactions N = {T1, T2, …, Tn}.
OUTPUT: A set of high average-utility itemsets (HU) for the updated database U (= D∪N).
STEP 1: Calculate the minimum average-utility thresholds (αN and αU) respectively for the new transactions N and for the updated database U as follows:
D N n d and ( ) D U d n d ,
where αD is the minimum average-utility threshold for the original database, d is the number of transactions in the original database, and n is the number of new transactions.
STEP 2: Calculate the utility value ujk of each item Ij in each new transaction Tk as ujk = qjk * pj, where qjk is the quantity of Ij in Tk, pj is the profit value of Ij, j = 1 to m and k = 1 to n.
STEP 3: Find the maximal item-utility value muk in each new transaction Tk as muk = max{u1k, u2k, …, umk}, k = 1 to n.
STEP 4: Set k = 1, where k records the number of items in the itemsets currently being processed.
STEP 5: Generate the candidate k-itemsets and calculate their average-utility upper bounds from the new transactions. The average-utility upper bound ubs of each candidate k-itemset s is set as the summation of the maximal item-utilities of the transactions which include s. That is:
k s k s T ub mu
.STEP 6: Check whether the average-utility upper bound of each candidate k-itemset s from the new transactions is larger than or equal to N. If s satisfies the above condition, put it in the set of high upper-bound average-utility k-itemsets for the new transactions, N
k
HU .
STEP 7: For each k-itemset s in the set of high upper-bound average-utility itemsets (HU ) from the kD original database, if it appears in the set of high upper-bound average-utility k-itemsets (HU ) in kN the new transactions, do the following substeps. Substep 7-1: Set the newly updated average-utility upper
bounds of itemset s as:
ubU(s) = ubD(s) + ubN(s).
Substep 7-2: Put s in the set of updated high upper-bound average-utility k-itemsets, U
k
HU .
STEP 8: For each k-itemset s in the set of high upper-bound average-utility itemsets ( D
k
HU ) from the original database, if it does not appear in the set of high upper-bound average-utility k-itemsets
( N k
HU ) in the new transactions, do the following substeps.
Substep 8-1: Set the updated average-utility upper bound of itemset s as :
ubU(s) = ubD(s) + ubN(s).
Substep 8-2: Check whether the average-utility upper bound of itemset s is larger than or equal to
U. If it satisfies the above condition, put it in the set of updated high upper-bound average-utility k-itemsets, U
k
HU .
STEP 9: For each k-itemset s in the set of high upper-bound average-utility itemsets (HU ) in the new kN transactions, if it does not appear in the set of high upper-bound average-utility k-itemsets ( D
k
HU ) in the original database, do the following substeps. Substep 9-1: Rescan the original database to determine
the average-utility upper bound (ubD(s)) of itemset s.
Substep 9-2: Set the updated average-utility upper bound of itemset s as:
ubU(s) = ubD(s) + ubN(s).
Substep 9-3: Check whether the average-utility upper bound of itemset s is larger than or equal to
U. If it satisfies the above condition, put it in the set of updated high upper-bound average-utility k-itemsets, HU . kU
STEP 10: Generate the candidate (k+1)-itemsets from the set of high upper-bound average-utility k-itemsets
( N
k
HU ) in the new transactions; If any k-sub-itemsets of a candidate (k+1)-k-sub-itemsets is not contained in the set of updated high upper-bound average-utility k-itemsets (HU ), remove it from kU the candidate set.
STEP 11: Set k = k+1.
STEP 12: Repeat STEPs 5 to 11 until no new candidate itemsets are generated.
STEP 13: For each high upper-bound average-utility itemset s in HUU of the updated database, if it appears in the set of high upper-bound average-utility itemsets (HUD) of the original database, do the following substeps.
Substep 13-1: Calculate the actual average-utility value of each itemset s for the new transactions as:
( ) | | k j jk s T i s N u au s s
,where ujk is the utility value of each item Ij in transaction Tk and |s| is the number of items in s.
Substep 13-2: Set the new actual average-utility value of s in the updated database as:
auU(s) = auD(s) + auN(s).
Substep 13-3: Check whether the actual average-utility value of itemset s is larger than or equal to αU. If it satisfies the above condition, put it in the set of updated high average-utility itemsets, HU.
STEP 14: For each high upper-bound average-utility itemset s in HUU of the updated database, if it does not appears in the set of high upper-bound average-utility itemsets (HUD) of the original database, do the following substeps.
Substep 14-1: Calculate the actual average-utility value of each itemset s for the new transactions as:
( ) | | k j jk s T i s N u au s s
,where ujk is the utility value of each item Ij in transaction Tk and |s| is the number of items in s.
Substep 14-2: Rescan the original database to determine the actual average-utility value auD(s) in HUD.
Substep 14-3: Set the new actual average-utility value of s in the updated database as:
auU(s) = auD(s) + auN(s).
Substep 14-4: Check whether the actual average-utility value of itemset s is larger than or equal to αU. If it satisfies the above condition, put it in the set of updated high average-utility itemsets, HU.
After Step 14, the final updated high average-utility itemsets for the updated database can then be found.
IV. AN EXAMPLE FOR INCREMENTAL TWO-PHASE
AVERAGE-UTILITY MINING ALGORITHM
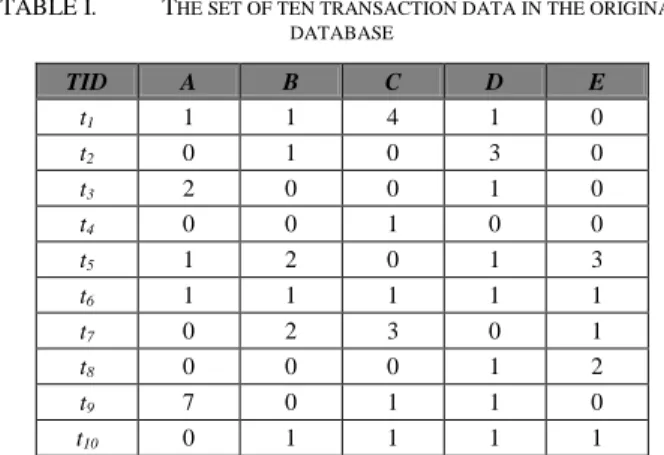
In this section, an example is given to demonstrate the proposed incremental average-utility mining algorithm. Assume the original database includes 10 transactions, shown in Table 1. Each transaction consists of its transaction identification (TID) and items purchased. The numbers represents the quantities purchased.
TABLE I. THE SET OF TEN TRANSACTION DATA IN THE ORIGINAL DATABASE TID A B C D E t1 1 1 4 1 0 t2 0 1 0 3 0 t3 2 0 0 1 0 t4 0 0 1 0 0 t5 1 2 0 1 3 t6 1 1 1 1 1 t7 0 2 3 0 1 t8 0 0 0 1 2 t9 7 0 1 1 0 t10 0 1 1 1 1
Also assume that the profit value of each item is defined in Table 2.
TABLE II. THE PREDEFINED PROFIT VALUES OF THE ITEMS Item Profit A 3 B 10 C 1 D 6 E 5
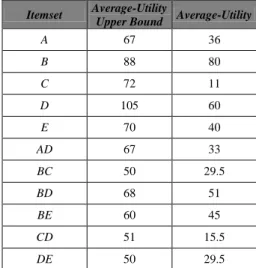
Suppose the minimum average-utility ratio is set at 20%. Thus, the minimum average-utility threshold is calculated as the total utility value multiplied by 20%, which is 45.4. Using the batch mining algorithm for the original database, the set of high upper-bound average-utility itemsets generated in Phase 1 are shown in Table 3. The average-utility upper bound and the actual average-average-utility value of each high upper-bound average-utility itemset are also recorded in Table 3.
TABLE III. THE AVERAGE-UTILITY UPPER BOUNDS AND THE ACTUAL AVERAGE-UTILITY VALUES OF THE HIGH UPPER-BOUND AVERAGE-UTILITY
ITEMSETS FROM THE ORIGINAL DATABASE Itemset Average-Utility Upper Bound Average-Utility
A 67 36 B 88 80 C 72 11 D 105 60 E 70 40 AD 67 33 BC 50 29.5 BD 68 51 BE 60 45 CD 51 15.5 DE 50 29.5
Assume the three new transactions shown in Table 4 are inserted after the initial data set is processed. The proposed incremental average-utility mining algorithm proceeds as follows.
TABLE IV. THE THREE NEWLY INSERTED TRANSACTIONS
TID A B C D E
t11 1 1 1 2 0
t12 0 3 4 1 0
t13 2 0 2 0 1
The utility value of each item occurring in each newly inserted transaction is calculated. The utility values of the
items in a transaction are compared and the maximal utility value in the transaction is found. The average-utility upper bounds of the 1-itemsets in the newly inserted transactions are first calculated. The upper-bound values of all the items in the new transactions are shown in Table 5.
TABLE V. THE AVERAGE-UTILITY UPPER BOUNDS OF THE 1-ITEMSETS IN THE NEW TRANSACTIONS
1-Itemset Average-Utility Upper Bound A 18 B 42 C 48 D 42 E 6
In this example, after Phase 1, the set of all the updated high upper-bound average-utility itemsets are shown in Table 6.
TABLE VI. THE SET OF ALL THE UPDATED HIGH UPPER-BOUND AVERAGE-UTILITY ITEMSETS, HUU Itemset Average-Utility Upper Bound A 85 B 130 C 120 D 147 E 76 AD 79 BC 92 BD 110 BE 60 CD 93 BCD 72
The actual average-utility value of each itemset s for the new transactions is calculated. All the high average-utility itemsets for the updated database can then be found as shown in Table 7.
TABLE VII. ALL THE HIGH AVERAGE-UTILITY ITEMSETS FOR THE UPDATED DATABASE, HU High Average-Utility Itemset Average-Utility B 120 D 78 BD 80 V. EXPERIMENTAL RESULTS
Experiments were made to show the performance of the proposed approach. All the experiments were performed on
an Intel Core 2 Duo E6550 (2.33GHz) PC with 2 GB main memory, running the Windows XP Professional operating systems. The proposed algorithm was implemented in Visual C# 9.0 and applied to a real data set, which was from a major grocery chain store in America. There were 21,556 transactions and 1,559 distinct items in the database. Each transaction consisted of the products sold and their quantities. The average transaction length was 4.03. The total utility of the dataset was $104,450,739.
The proposed incremental two-phase average-utility mining algorithm (ITPAU) was then compared to the two-phase average-utility mining algorithm (TPAU), which was a batch utility mining algorithm. The high upper-bound average-utility itemsets and the high average-utility itemsets of original database were recorded for incremental mining. The number of new inserted transactions was set as 100 each time. The numbers of the original transactions were respectively set as 1000, 5000, 10000, 15000 and 20000 to show the effects on different numbers of transactions. The same transactions datasets but with inserted data were executed by the batch utility mining algorithm (TPAU) as well. The original minimum average-utility thresholds were set respectively at 0.01% (Low), 0.05% (Medium) and 0.09% (High) of the total utility to show the effects on different minimum average-utility thresholds.
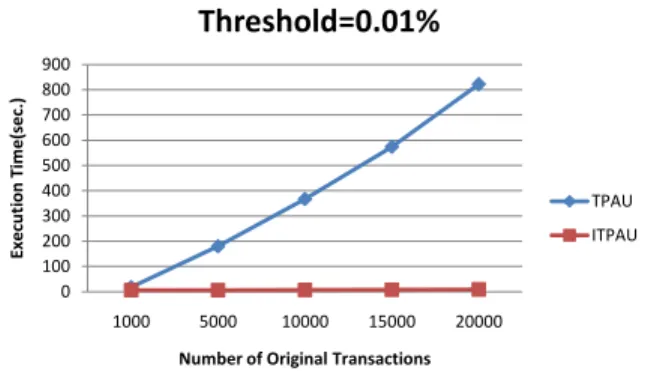
Figure 1 shows the execution time of ITPAU vs. TPAU on different numbers of transactions, with the threshold set at 0.01% of the total utility. The results for 0.05% (Medium) and 0.09% (High) are also similar.
0 100 200 300 400 500 600 700 800 900 1000 5000 10000 15000 20000 Execu ti on Ti m e(sec .)
Number of Original Transactions
Threshold=0.01%
TPAU ITPAU
Figure 1. The execution time of ITPAU vs. TPAU on different numbers of transactions (threshold=0.01%).
From the three figures, we could observe that when the number of original transactions was small, the execution time of ITPAU was close to that of TPAU. But with the number of original transactions increases, the execution time of TPAU increased considerably, and the execution time of ITPAU increased only a little. The difference between the execution time of ITPAU and TPAU became apparent with the number of original transactions increased. The execution time of ITPAU was less than that of TPAU on different numbers of transactions and on different minimum average-utility thresholds. The reason was that the mined results from original transactions were recorded. Since the most execution time of the algorithm ITPAU was spent on updating the
upper-bound values of high upper-bound average-utility itemsets and checking against the minimum threshold, the time to scan the database could thus was substantially reduced in this way. Thus, the total execution time of ITPAU was less than that of TPAU for the updated database.
VI. CONCLUSIONS
In order to handle the database varying with newly inserted records, we propose an algorithm to incrementally mine the high average-utility itemsets from the updated database. This algorithm adopts the concept of the FUP algorithm to reduce the time to re-process the original database. The proposed algorithm searches for high utility itemsets level by level and maintains the “downward-closure” property of itemsets. With the “downward-“downward-closure” property, the number of candidate itemsets generated at each level can be greatly reduced. Besides, this paper also uses the new measure called average-utility to calculate the utility value of itemsets. The experiments show that our algorithm is effective to process the incremental transactions dataset for high average-utility itemsets.
REFERENCES
[1] H. Yao, H. Hamilton, and C. Butz, "A foundational approach to mining itemset utilities from databases," in Proc. of the 4 th
SIAM International Conference on Data Mining, 2004, pp.
211-225.
[2] Y. Liu, W. Liao, and A. Choudhary, "A fast high utility itemsets mining algorithm," in Proceedings of the 1st international
workshop on Utility-based data mining, 2005, pp. 90-99.
[3] B. Barber and H. J. Hamilton, "Algorithms for Mining Share Frequent Itemsets Containing Infrequent Subsets," in
Proceedings of the 4th European Conference on Principles of Data Mining and Knowledge Discovery: Springer-Verlag, 2000.
[4] B. Barber and H. Hamilton, "Extracting share frequent itemsets with infrequent subsets," Data Mining and Knowledge Discovery, vol. 7, pp. 153-185, 2003.
[5] Y. Li, J. Yeh, and C. Chang, "A fast algorithm for mining share-frequent itemsets," in Proceedings of the 7th Asia Pacific Web
Conference, Springer-Verlag, Germany, 2005, pp. 417-428.
[6] Y. Liu, W. Liao, and A. Choudhary, "A Two-Phase Algorithm for Fast Discovery of High Utility Itemsets," in Proceedings of
the Pacific-Asia Conference on Knowledge Discovery and Data Mining (PAKDD), 2005.
[7] Y. Li, J. Yeh, and C. Chang, "Efficient algorithms for mining share-frequent itemsets," in Fuzzy Logic, Soft Computing and
Computational Intelligence-11th World Congress of International Fuzzy Systems Association (IFSA 2005), 2005, pp.
534–539.
[8] Y. Li, J. Yeh, and C. Chang, "Direct candidates generation: a novel algorithm for discovering complete share-frequent itemsets," Lecture notes in computer science, vol. 3614, p. 551, 2005.
[9] D. Cheung, J. Han, V. Ng, and C. Wong, "Maintenance of discovered association rules in large databases: An incremental updating approach," in The twelfth IEEE international
conference on data engineering, 1996, pp. 106-114.
[10] D. Cheung, S. Lee, and B. Kao, "A general incremental technique for maintaining discovered association rules," in In
Proceedings of the Fifth International Conference On Database Systems For Advanced Applications, 1997.
[11] M. Lin and S. Lee, "Incremental update on sequential patterns in large databases," in Tenth IEEE International Conference on
Tools with Artificial Intelligence, 1998. Proceedings, 1998, pp.
24-31.
[12] N. Sarda and N. Srinivas, "An adaptive algorithm for incremental mining of association rules," in Proceedings of the 9th
International Workshop on Database and Expert Systems Applications: IEEE Computer Society Washington, DC, USA,
1998, p. 240.
[13] R. Agrawal and R. Srikant, "Fast Algorithms for Mining Association Rules in Large Databases," in Proceedings of the
20th International Conference on Very Large Data Bases:
Morgan Kaufmann Publishers Inc., 1994.
[14] H. Yao and H. Hamilton, "Mining itemset utilities from transaction databases," Data & Knowledge Engineering, vol. 59, pp. 603-626, 2006.