國 立 交 通 大 學
資訊管理研究所
博士論文
以知識流探勘與文件推薦提供知識支援
Knowledge Flow Mining and Document
Recommendation for Knowledge Support
研 究 生: 賴 錦 慧
指導教授: 劉 敦 仁 博士
以知識流探勘與文件推薦提供知識支援
Knowledge Flow Mining and Document Recommendation for
Knowledge Support
研 究 生:賴錦慧 Student: Chin-Hui Lai
指導教授:劉敦仁 Advisor: Dr. Duen-Ren Liu
國立交通大學 資訊管理研究所
博士論文
A Dissertation
Submitted to Institute of Information Management College of Management
National Chiao Tung University in Partial Fulfillment of the Requirements
for the Degree of
Doctor of Philosophy in Information Management December 2009
Hsinchu, Taiwan, the Republic of China
ii
以知識流探勘與文件推薦提供知識支援
研究生: 賴錦慧 指導教授: 劉敦仁 博士 國立交通大學資訊管理研究所摘要
知識是獲得與維持組織競爭優勢的重要來源。在不斷變動的商業環境中,組織必須 使用有效的方法來保留知識、分享知識和知識再利用,以協助知識工作者尋找工作相關 的資訊。因此,要如何從工作者過去的工作記錄中,發掘與建構知識流(Knowledge Flow) 是一個重要的議題。建立知識流模型的目的是在於,了解知識工作者的工作需求與參考 知識的方式,進而提供適性化的知識支援。此外,組織中的知識是透過知識流的遞送與 累積,而且知識工作者具備不同領域的知識,他們會參與以工作為基礎的群體,並進行 合作,以滿足工作的需求。 本研究首先提出以知識流模型為基礎之混合式推薦方法,其整合知識流探勘、序列 規則探勘,以及協同式過濾技術來推薦工作知識。這些以知識流為基礎的推薦方法包含 二個階段:知識流探勘階段與知識流推薦階段。知識流探勘階段能藉由分析工作者的知 識參考行為(資訊需求),以發掘工作者的知識流;而知識流推薦階段則利用所提出的 混合式推薦方法,主動地提供相關知識給工作者。因此,根據工作者對於知識文件的喜 好與知識參考行為,本研究方法能預測工作者感興趣的主題,進而推薦工作相關的知識 文件給工作者。在實驗中,我們利用某研究單位實驗室的真實資料,來評估本研究之混 合式方法的推薦效果,並與傳統的協同式過濾方法做比較。最後,實驗結果顯示,工作 者對於知識文件的偏好與知識參考行為,可以有效地改善推薦品質並促進組織內的知識 分享。 此外,為了協助群體學習與分享工作相關知識,針對以工作任務為基礎之群體,我 們提出整合資訊檢索與資料探勘技術之演算法,發掘與建構群體知識流(Group-based Knowledge Flow)。群體知識流可利用有向性之知識圖來表示,藉此呈現一群工作需求 相近工作者的知識參考行為(或知識流),而從知識圖中所發現的頻繁知識參考路徑, 可以代表群體使用者的頻繁知識流。為了驗證方法的效能,我們實作一個群體知識流探 勘之雛型系統。在一個重視協同合作與團隊合作的環境中,透過群體知識流探勘的方法 與系統,可以加強組織學習,以及知識的管理、分享與再利用。 關鍵字: 知識流、知識流探勘、知識分享、文件推薦、協同式過濾、序列規則探勘、推 薦系統、群體知識流、知識圖、資料探勘、資訊檢索.Knowledge Flow Mining and Document Recommendation
For Knowledge Support
Student: Chin-Hui Lai Advisor: Dr. Duen-Ren Liu
Institute of Information Management National Chiao Tung University
Abstract
Knowledge is a critical resource that organizations use to gain and maintain competitive advantages. In the constantly changing business environment, organizations must exploit effective and efficient methods of preserving, sharing and reusing knowledge in order to help knowledge workers find task-relevant information. Hence, an important issue is how to discover and model the knowledge flow (KF) of workers from their historical work records. The objectives of a knowledge flow model are to understand knowledge workers’ task-needs and the ways they reference documents, and then provide adaptive knowledge support. Additionally, knowledge is circulated and accumulated by knowledge flows (KFs) in the organization to support workers’ task needs. Because workers accumulate knowledge of different domains, they may cooperate and participate in several task-based groups to satisfy their needs.
This work first proposes hybrid recommendation methods based on the knowledge flow model, which integrates KF mining, sequential rule mining and collaborative filtering techniques to recommend codified knowledge. These KF-based recommendation methods involve two phases: a KF mining phase and a KF-based recommendation phase. The KF mining phase identifies each worker’s knowledge flow by analyzing his/her knowledge referencing behavior (information needs), while the KF-based recommendation phase utilizes the proposed hybrid methods to proactively provide relevant codified knowledge for the worker. Therefore, the proposed methods use workers’ preferences for codified knowledge as well as their knowledge referencing behavior to predict their topics of interest and recommend task-related knowledge. Using data collected from a research institute laboratory, experiments are conducted to evaluate the performance of the proposed hybrid methods and compare them
iv
with the traditional CF method. Finally, the results of experiments demonstrate that utilizing the document preferences and knowledge referencing behavior of workers can effectively improve the quality of recommendations and facilitate efficient knowledge sharing.
Moreover, to support group-based learning and share task-related knowledge, we propose an algorithm that integrates information retrieval and data mining techniques to mine and construct group-based KFs (GKFs) for task-based groups. A GKF is expressed as a directed knowledge graph which represents the knowledge referencing behavior, or knowledge flow, of a group of workers with similar task needs. The frequent knowledge referencing path is identified from the knowledge graph to indicate the frequent knowledge flow of the workers. To demonstrate the efficacy of the proposed method, we implement a prototype of the GKF mining system. Our GKF mining method and system can enhance organizational learning and facilitate knowledge management, sharing, and reuse in an environment where collaboration and teamwork are essential.
Keywords: Knowledge Flow, Knowledge Flow Mining, Knowledge Sharing, Document
Recommendation, Collaborative Filtering, Sequential Rule Mining, Recommender System, Group-based Knowledge Flow, Knowledge Graph, Data Mining, Information Retrieval.
致 謝
論文即將完成,也代表著即將完成現階段的任務,揮別漫長的博士班生涯,並邁向 人生的另一個旅程、另一個開始。在過去的日子裡,一直很期盼能快快完成學業,然而 在此刻來臨時,心中卻開始覺得依依不捨了。雖然還有許多夢想與目標尚未達成,未來 的我仍會秉持自己的信念與堅持,繼續努力與成長。 在博士班期間,非常感謝指導教授劉敦仁老師,他是一位個性好相處、時時關懷與 體貼學生、做研究認真的好老師。感謝劉老師對錦慧論文的細心指導,也教導我做研究 的方法與態度,並培養我獨立思考與做研究的能力。在忙碌的研究之餘,老師也常會帶 我們出去踏青、辦生日party、並和我們一起唱歌一起同樂,讓我們舒解研究上的壓力, 也讓研究室無時無刻充滿歡樂的氣氛。能夠順利畢業,還要感謝口試委員羅濟群老師、 李永銘老師、李瑞庭老師與許秉瑜老師,在論文審查口試期間,給與許多寶貴的建議與 指正,讓論文能更加完善。 感謝所有交大資管所老師的教導,讓我學習不同領域的知識。感謝實驗室的學長姐, 在研究上與生活上的協助與指導;感謝可愛的學弟妹們,常常與你們一起玩樂,讓實驗 室總是充滿快樂與歡笑,也謝謝你們幫忙我分擔許多雜務;感謝博士班的同儕,一起分 享研究上的心得與經驗,舒解研究上的壓力;謝謝所有交大朋友們對我的照顧、關心與 協助,並大方地與我分享生活哲學和有趣的事情,讓我的生活變得多采多姿。 最後,感謝我最摯愛的家人與親戚長輩們,謝謝你們不斷地鼓勵與支持,得以讓我 無後顧之憂順利完成學位,也讓我有無限的力量與勇氣,去迎接人生的下一階段,去面 對未來更多的困難與挑戰,真的很謝謝你們,我永遠愛你們。 賴錦慧 于新竹-交通大學 2009/12/08vi
Contents
中文摘要……. ... ii
Abstract…… ... iii
Contents…… ... vi
List of Figures ... viii
List of Tables ... ix
Chapter 1. Introduction ... 1
1.1 Research Background and Motivation ... 1
1.2 Research Objectives ... 3
1.3 The Approaches Based on Knowledge Flow ... 4
1.4 Organization of the proposal ... 5
Chapter 2. Related Work ... 6
2.1 Knowledge Flow ... 6
2.2 Information Retrieval and Task-based Knowledge Support ... 6
2.3 Document Clustering Methods ... 7
2.3.1 The CLIQUE Clustering Method ... 8
2.3.2 Clustering Quality ... 8
2.4 Dynamic Programming Algorithm for Sequence Alignment ... 9
2.5 Rule-based Recommendations ... 10
2.6 Collaborative Filtering Recommendation ... 11
2.7 Process Mining ... 12
Chapter 3. The Overview of Knowledge Flow-Based Research ... 14
3.1 Knowledge Flow Model ... 14
3.2 The Framework of Knowledge Flow-based Approaches... 16
3.3 Knowledge Flow Mining Phase ... 17
3.3.1 Document Profiling and Document Clustering ... 17
3.3.2 Knowledge Flow Extraction ... 18
Chapter 4. Knowledge Flow-based Recommendation Framework ... 20
4.1 Knowledge Flow-based Recommendation Phase ... 21
4.2 Identifying Similar Workers Based on their Knowledge Flows ... 22
4.2.1 KF Alignment Similarity ... 23
4.2.2 Aggregated Profile Similarity ... 24
4.3.1 Mining Knowledge Referencing Behavior ... 26
4.3.2 Identifying the Knowledge Referencing Behavior of the Target Worker ... 26
4.3.3 Document Recommendation ... 28
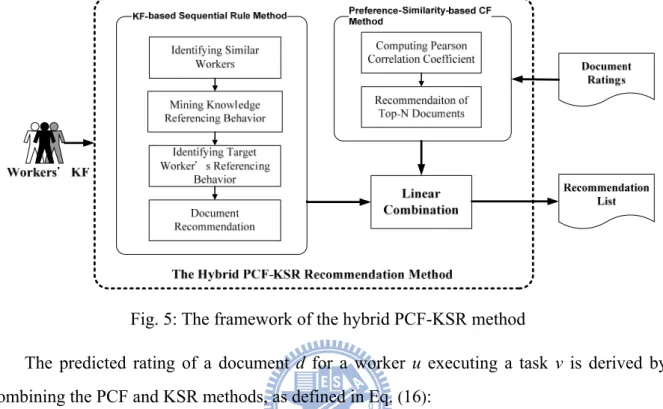
4.4 The Hybrid PCF-KSR Method ... 30
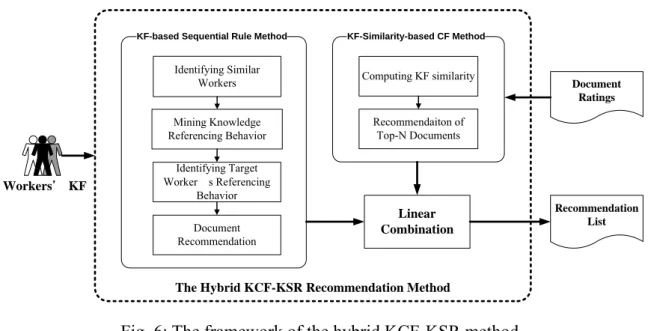
4.5 The Hybrid KCF-KSR Method ... 32
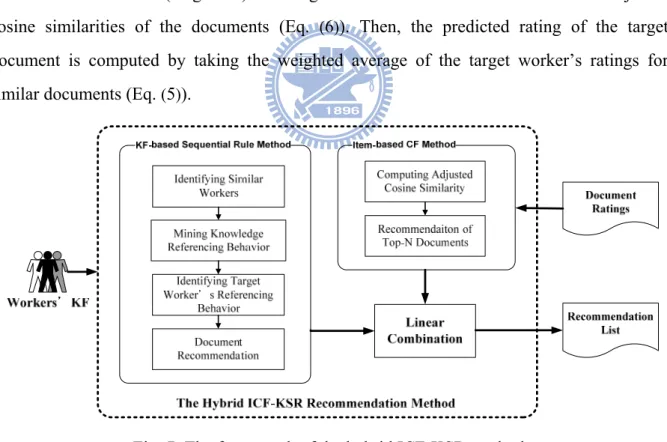
4.6 The Hybrid ICF-KSR Method ... 33
4.7 Experiment Setup ... 34
4.8 Experiment Results ... 36
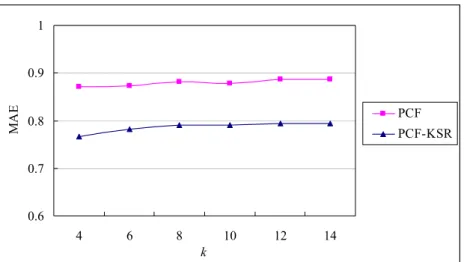
4.8.1 Evaluation of the hybrid PCF-KSR Method ... 36
4.8.2 Evaluation of the hybrid KCF-KSR Method ... 38
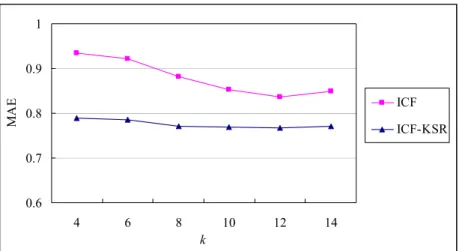
4.8.3 Evaluation of the hybrid ICF-KSR Method ... 39
4.8.4 Comparison of All Methods ... 40
4.9 Discussion ... 41
Chapter 5. Group-based Knowledge Flow Mining Methods ... 44
5.1 The group-based knowledge flow mining process ... 45
5.2 Clustering Similar Workers Based on their Knowledge Flows ... 46
5.3 Definition of Group-based Knowledge Flows ... 46
5.4 GKF Mining Algorithm (without considering duplicate topics) ... 49
5.4.1 Topic Relation Identification ... 53
5.4.2 Measuring the Importance of an Edge ... 58
5.4.3 Graph Transformation ... 59
5.4.4 Topological Sorting ... 60
5.4.5 Using the Edge Deletion Procedure to Remove Infrequent Edges ... 61
5.5 The GKF Mining Algorithm for Dealing with Topic Loops ... 64
5.5.1 Applying the GKF Mining Algorithm for Dealing with Topic loops ... 66
5.6 Identifying Knowledge Referencing Paths in a GKF Graph ... 68
5.7 The Prototype System for Mining Group-based Knowledge Flows ... 68
5.7.1 Dataset ... 69
5.7.2 System Implementation ... 69
5.7.3 Discussion ... 72
Chapter 6. Conclusions and Future works ... 74
6.1 Summary ... 74
6.2 Future Works ... 75
viii
List of Figures
Fig. 1: The two levels of a knowledge flow ... 14
Fig. 2: The overview of knowledge flow-based research ... 16
Fig. 3: Document recommendation based on knowledge flows ... 20
Fig. 4: An overview of the KSR method ... 25
Fig. 5: The framework of the hybrid PCF-KSR method ... 31
Fig. 6: The framework of the hybrid KCF-KSR method ... 32
Fig. 7: The framework of the hybrid ICF-KSR method ... 33
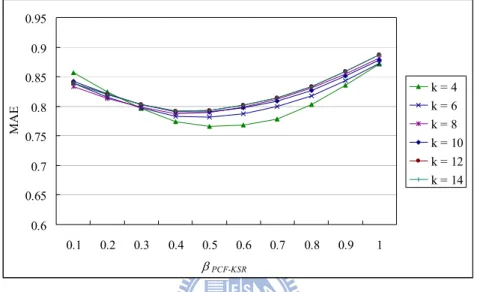
Fig. 8: The performance of the hybrid PCF-KSR method with various k and βPCF-KSR values 37 Fig. 9: Comparison of the hybrid PCF-KSR and PCF methods under different k ... 38
Fig. 10: Comparison of the hybrid KCF-KSR and KF methods under different k ... 38
Fig. 11: Comparison of the hybrid ICF-KSR and KF methods under different k ... 39
Fig. 12: The performances of the compared methods under different k ... 40
Fig. 13: An overview of mining group-based knowledge flows ... 44
Fig. 14: The procedure of the proposed GKF mining method ... 45
Fig. 15: An example of a directed graph ... 47
Fig. 16: The algorithm for mining a GKF when TKFs do not contain duplicate topics ... 50
Fig. 17: The initial graph of the GKF model ... 52
Fig. 18: The topic relation identification procedure ... 54
Fig. 19: A parallel relation in a GKF graph ... 56
Fig. 20: A sequential relation in a GKF graph ... 58
Fig. 21: The edge weights in a GKF graph ... 58
Fig. 22: The result of graph transformation ... 59
Fig. 23: The edge deletion procedure ... 61
Fig. 24: The final graph GN of the GKF model ... 62
Fig. 25: The initial graph of the GKF model with topic loops ... 67
Fig. 26: The graph of the GKF model with topic loops ... 67
Fig. 27: The final GKF graph, which considers the duplicate topics in each worker’s TKF ... 68
Fig. 28: The main frame of the KF mining system ... 70
Fig. 29: The CLIQUE clustering module ... 71
List of Tables
Table 1: The t-test results for various recommendation methods with k = 8 ... 41
Table 2: The differences of all methods ... 42
Table 3: Five workers and their TKFs ... 52
Table 4: The TKFs of seven knowledge workers ... 57
1
Chapter 1. Introduction
1.1 Research Background and Motivation
Organizational knowledge can be used to create core competitive advantages and achieve commercial success in a constantly changing business environment. Hence, organizations need to adopt appropriate strategies to preserve, share and reuse such a valuable asset, as well as to support knowledge workers effectively [42, 44]. Knowledge and expertise are generally codified in textual documents, e.g., papers, manuals and reports, and preserved in a knowledge database. This codified knowledge is then circulated in an organization to support workers engaged in management and operational activities [12]. Because most of these activities are knowledge-intensive tasks, the effectiveness of knowledge management depends on providing task-relevant documents to meet the information needs of knowledge workers.
In task-based business environments, knowledge management systems (KMSs) can facilitate the preservation, reuse and sharing of knowledge. Moreover, workers may need to obtain task-relevant knowledge to complete a knowledge-intensive task by referencing codified knowledge (documents); For example, based on a task’s specifications and the process-context of the task, the KnowMore system [1] provides context-aware knowledge retrieval and delivery to support workers’ procedural activities. The task-based K-support system [39, 58] adaptively provides knowledge support to meet a worker’s dynamic information needs by analyzing his/her access behavior or relevance feedback on documents. To help knowledge workers complete multiple tasks, TaskTracer [19] was developed to monitor workers’ activities and help them rapidly locate and reuse processes employed previously. However, previous research on task-based knowledge support did not analyze and utilize the flow of knowledge among various types of codified knowledge (documents) to provide effective recommendations about task-relevant documents.
Knowledge flow (KF) research focuses on how KF can transmit, share, and accumulate knowledge when it passes from one team member/process to another. In a workflow situation, work knowledge may flow among workers in an organization, while process knowledge may flow among various tasks [61-62, 64]. Thus, KF reflects the level of knowledge cooperation
between workers or processes and influences the effectiveness of teamwork/workflow. Zhuge [61] proposed a management mechanism for realizing ordered knowledge sharing, and integrated the knowledge flow with the workflow to assist people working in a complex and knowledge intensive environment. Also, KF plays an important role in academic research, as researchers often devise novel concepts based on previous research reported in the literature [63]. However, to the best of our knowledge, there is no systematic method that can flexibly identify KF in order to understand the information needs of workers. Furthermore, conventional KF approaches do not analyze knowledge flow from the perspective of information needs and recommend relevant documents based on the discovered KF.
Knowledge workers normally have various task needs over time. Moreover, they may need to obtain task-relevant knowledge to complete a task by referencing several types of codified knowledge (documents); and the knowledge in one document may prompt a worker to reference another related document. Based on a worker’s referencing behavior, KF can be used to describe the evolution of information needs, preferences, and knowledge accumulated for a specific task. From the perspective of information needs, some knowledge in a KF may have a higher priority for accomplishing a task. For example, before taking a Data Mining course, a student must take courses in Statistics and Database Systems, which represent the fundamental knowledge of Data Mining. Thus, these two courses are significant and have a high priority for the student. Additionally, academic knowledge may flow between different courses and thereby help students accumulate more knowledge. Similarly, the codified knowledge for a task also has different referencing priorities and ordering based on its perceived importance. In other words, important basic knowledge about a task should be referenced first. Therefore, KF can be utilized to provide effective recommendations about task-relevant knowledge to suit workers’ information needs for tasks. This issue has not been addressed by previous research.
In task-based business environments, large amounts of such codified knowledge are circulated and accumulated in an organization to support knowledge workers engaged in diverse tasks and activities. Knowledge workers may cooperate with each other to accomplish a specific task. During the collaboration phase, task knowledge can be transmitted, shared and accumulated from one team member/process to another. Knowledge flows (KFs) can be used
3
to represent the long-term evolution of workers’ information needs [36]. Based on those needs, the knowledge flow-based document recommendation method proactively delivers task-relevant topics and documents to the workers.
To work more efficiently, workers who have task-related knowledge, expertise and experience may join a task-based group and collaborate to perform a task. The workers can share task-related knowledge delivered by their knowledge flows (KF) during the collaboration. In addition, workers in the same group may have similar referencing behavior and techniques for learning knowledge. Each group may require knowledge of different topic domains to accomplish its tasks and goals. Because the information needs of workers or groups may change over time, modeling the knowledge referencing behavior of a group of workers is difficult. Obviously, recognizing those needs, delivering knowledge during the collaboration, and facilitating knowledge sharing/reuse are important issues that must be addressed in a knowledge intensive organization. However, to the best of our knowledge, there is no appropriate approach for analyzing and constructing KFs from the perspective of a group’s information needs; and very little research effort has been expended on KF mining for task-based groups.
1.2 Research Objectives
According to the research motivation, the major research objectives are listed below.
z Mining the knowledge flow for each knowledge worker and a group of workers; z Identifying and analyzing topics of interest, major referencing behavior patterns,
and the long-term evolution of workers’ information needs;
z Providing knowledge support adaptively based on the referencing behavior of workers;
z Effectively recommending task-relevant knowledge to suit workers’ information needs for tasks;
z Enhancing organizational learning and task collaboration;
z Facilitating knowledge dissemination, sharing and reusing among workers in the context of collaboration and teamwork;
1.3 The Approaches Based on Knowledge Flow
In an attempt to resolve the limitations of previous research, we first propose KF-based recommendation methods for recommending task-related codified knowledge. To adaptively provide relevant knowledge, collaborative filtering (CF), the most frequently used method, predicts a target worker’s preference(s) based on the opinions of similar workers. However, the target worker’s referencing behavior may change over the period of the task’s execution, because his/her information needs may vary. Traditional CF methods only consider workers’ preferences for codified knowledge. They neglect the effect of the time factor, i.e., workers’ referencing behavior for knowledge over time. To fill this research gap, we propose a KF-based sequential rule method (KSR) that recommends codified knowledge by utilizing the KF-based sequential rules. However, the method is based on the target worker’s referencing behavior without considering the opinions of his/her neighbors who may have similar preference for documents. Therefore, to take advantage of the merits of typical CF and KSR methods, we propose hybrid recommendation methods that combine CF and KSR methods to enhance the quality of document recommendation. The hybrid methods consider workers’ preferences for codified knowledge, as well as their knowledge referencing behavior, in order to predict topics of interest and recommend task-related knowledge.
The proposed hybrid methods consist of two phases: a KF mining phase and a KF-based recommendation phase. To determine a knowledge worker’s referencing behavior, the KF mining phase analyzes his/her historical work records to identify the knowledge flow, i.e., the target worker’s information needs. Then, the KF-based recommendation phase selects and recommends documents based on the document preferences and KF-based sequential rules derived from the target worker’s neighbors. In other words, the proposed methods trace a worker’s information needs by analyzing his/her knowledge referencing behavior for a task over time, and also proactively provide relevant codified knowledge for the worker based on the KFs of the worker’s neighbors.
According to the KF mining approach [36], we extend it and propose algorithms that integrate information retrieval and data mining techniques for mining and constructing the group-based knowledge flows (GKFs). Specifically, we discover a group’s KF from the KFs of the participating workers. First, based on the workers’ logs, we analyze each worker’s
5
referencing behavior when acquiring task-related knowledge, and then construct his/her KF. Workers who have similar KFs are clustered into the same group by a clustering method, and the resulting group is regarded as a working group. Because workers in the same group may adopt different behavior when referencing task-related knowledge, we design GKF mining algorithms to discover the frequent referencing behavior of a group of workers. Second, we apply the concepts of graph theory to visualize the GKF as a knowledge graph in which a vertex and an edge indicate, respectively, a topic domain and a direct flow relation between two topic domains. From the knowledge graph, frequent knowledge paths (patterns) can be identified based on the edge frequencies in the graph. The paths represent the worker’s frequent knowledge referencing behavior and important knowledge flows in the group. Finally, to demonstrate the efficacy of our proposed method, we implement a prototype system for mining the GKF of a group of workers. The system provides useful functions that allow users to simplify the complexity of KF mining and visualize KFs graphically.
1.4 Organization of the proposal
The remainder of this proposal is organized as follows. Chapter 2 provides a brief overview of related works. In Chapter 3, we describe the knowledge flow model, the overview of knowledge flow-based research and the knowledge flow mining phase. The knowledge flow-based recommendation framework is illustrated in Chapter 4. The group-based knowledge flow mining methods are illustrated in Chapter 5. According to these methods, we propose a prototype system for mining the group-based knowledge flow. Finally, in Chapter 6, we summarize our conclusions and consider future research directions.
Chapter 2. Related Work
In this chapter, we discuss the background of our research, including knowledge flow, information retrieval and task-based knowledge support, document clustering methods, dynamic programming algorithm, rule-based recommendations, collaborative filtering and process mining.
2.1 Knowledge Flow
Knowledge can flow among people and processes to facilitate knowledge sharing and reuse. The concept of knowledge flow has been applied in various domains, e.g., scientific research, communities of practice, teamwork, industry, and organizations [33, 63]. Scholarly articles represent the major medium for disseminating knowledge among scientists to inspire new ideas [8, 63]. A citation implies that there is knowledge flow between the citing article and the cited article. Such citations form a knowledge flow network that enables knowledge to flow between different scientific projects to promote interdisciplinary research and scientific development.
KM enhances the effectiveness of teamwork by accumulating and sharing knowledge among team members to facilitate peer-to-peer knowledge sharing [61]. To improve the efficiency of teamwork, Zhuge [62] proposed a pattern-based approach that combines codification and personalization strategies to design an effective knowledge flow network. Kim et al. [33] proposed a knowledge flow model combined with a process-oriented approach to capture, store, and transfer knowledge. KF in weblogs (blogs) is a communication pattern where the post of one blogger links to that of another blogger to exchange knowledge [8]. Similarly, knowledge flow in communities of practice helps members share their knowledge and experience about a specific domain to complete their tasks [46].
2.2 Information Retrieval and Task-based Knowledge Support
Information retrieval (IR) facilitates access to specific items of information [10, 21]. The vector space model [48] is typically used to represent documents as vectors of index terms, where the weights of the terms are measured by the tf-idf approach. tf denotes the occurrence frequency of a particular term in the document, while idf denotes the inverse document
7
frequency of the term. Terms with higher tf-idf weights are used as discriminating terms to filter out common terms. The weight of a term i in a document j, denoted by wi,j, is expressed
as follows: ) 1 (log2 , , , = × = × + n N tf idf tf wi j i j i i j , (1)
where tfi,j is the frequency of term i in document j, idfi is measured by (log2 N/n) + 1, N is
the total number of documents in the collection, and n is the number of documents in which term i occurs at least once.
Information retrieval techniques coupled with workflow management systems (WfMS) have been used to support proactive delivery of task-specific knowledge based on the context of tasks within a process [2]. For example, the KnowMore system [1] provides context-aware delivery of task-specific knowledge. The Kabiria system assists knowledge workers with knowledge-based document retrieval by considering the operational context of task-associated procedures [9].
Information filtering with a similarity-based approach is often used to locate knowledge items relevant to the task-at-hand. The discriminating terms of a task are usually extracted from a knowledge item/task to form a task profile, which is used to model a worker’s information needs. Holz et al. [27] proposed a similarity-based approach to organize desktop documents and proactively deliver task-specific information. Liu et al. [39] proposed a
K-Support system to provide effective task support for a task-based working environment.
2.3 Document Clustering Methods
Document clustering or unsupervised document classification methods are used in many applications. Most methods apply pre-processing steps to the document set and represent each document as a vector of index terms. To cluster similar documents, the similarity between documents is usually measured by the cosine measure [10, 57], which computes the cosine of the angle between their corresponding feature vectors. Two documents are considered similar if the cosine similarity value is high. The cosine similarity of two documents, X and Y, is
simcos(X, Y)= Y X Y X K K K K
Documents within a cluster are very similar, while documents in different clusters are very dissimilar.
Agglomerative hierarchical clustering [30, 32] is a popular document clustering method. In this work, we use the single-link clustering method [20, 29] to cluster codified knowledge (documents). Initially, each document is regarded as a cluster. Next, the single-link method computes the similarity between two clusters, which is equal to the greatest similarity between any document in one cluster and any document in the other cluster. Then, based on the similarity measurement, the two most similar clusters are merged to form a new cluster. The merging process continues until all documents have been merged into one cluster at the top of a hierarchy, or a pre-specified threshold is satisfied [29].
2.3.1 The CLIQUE Clustering Method
We also apply the CLIQUE clustering method [6, 29] to derive worker groups. CLIQUE starts with the definition of a unit-elementary rectangular cell in a subspace and uses a bottom-up approach to find units whose densities exceed a threshold. The algorithm has four key steps. First, 1-dimensional units are determined by dividing intervals into equal-width bins (a grid). Next, candidate k-dimensional units are generated from (k-1)-dimensional dense units, which involves self-joining of k-1 units that have common k-2 dimensions (Apriori-reasoning). Finally, all the subspaces are sorted by their coverage and those with less coverage are pruned. Therefore, a cluster is defined as a maximal set of connected dense units.
2.3.2 Clustering Quality
A good clustering method generates clusters that are cohesive and isolated from other clusters. For this reason, the measurement of clustering quality takes both inter-cluster similarity and intra-cluster similarity into account [16]. Let C be a set of clusters. The inter-cluster similarity between two clusters Ci and Cj, similarityA(Ci, Cj), is defined as the
average of all pairwise similarities between the documents in Ci and Cj; and the intra-cluster
similarity within a cluster Ci, similarityA(Ci, Ci), is defined as the average of all pairwise
similarities between documents in Ci. On the basis of the cohesion and isolation of C, the
9
∑
∈ = C C A i i i i A i similarity C C C C similarity C 1 CQ(C) ) , ( ) , ( , where Ci =∪i≠jCj. (2) Note that the smaller the value of CQ(C), the better the quality of the derived set of clusters, C, will be.2.4 Dynamic Programming Algorithm for Sequence Alignment
In this work, each worker’s knowledge flow is represented as a sequence. We use sequence alignment techniques to analyze the similarity of workers’ knowledge flows, which corresponds to a sequence alignment problem. Such techniques are used to compare or align strings in many application domains, such as biology, speech recognition, and web session clustering. A number of methods can be used for sequence alignment, e.g., the sequence alignment method (SAM) [14, 24] and dynamic programming. SAM, also called the string edit distance method [35], considers the sequential order of elements in a sequence and then measures the similarity/dissimilarity of sequences. The measurements reflect the operations necessary to equalize the sequences by computing the costs of deleting and inserting unique elements as well as the costs of reordering common elements [24, 41]. In addition, Charter et
al. [14] proposed a dynamic programming algorithm that solves the sequence alignment
problem efficiently.
The algorithm consists of three steps: initialization, FindScore and FindPath [14, 43]. The first step creates a dynamic programming matrix with N+1 columns and M+1 rows, where N and M correspond to the sizes of the sequences to be aligned. One sequence is placed at the top of the matrix and the other is placed on the left-hand side of the matrix. There is a gap at the end of each sequence to allow calculation of the alignment score. The FindScore step calculates the two-dimensional alignment score of sequences. If two aligned sequences have an identical matching in the same column, the column is given a positive score s (e.g., +1 or +2); but if the values in a column are mismatches, the score s is zero or negative (e.g., 0, -1 or -2). In addition, if a column contains a gap, it is given a penalty score w (e.g., 0, -1 or -2). Therefore, starting from the bottom right-hand corner, each position in the dynamic programming matrix is given the maximal score Mij. For each position in the matrix, Mij is
(
) (
) (
)
{
M s M w M w}
Maximum
Mij = i−1,j−1+ ij , i,j−1+ , i−1,j+ , (3)
where i is the row number, j is the column number, sij is the match/mismatch score, and
w is the penalty score. The third step, FindPath, determines the actual KF alignment that
derives the maximal score. It traverses the matrix from the destination point (top left-hand corner) to the starting point (bottom right-hand corner) to find an optimal alignment path in order to determine the maximal alignment score δ. We calculate the flow similarity based on the maximal alignment score. The details are given in Section 4.2.
2.5 Rule-based Recommendations
Association rule mining [3-4, 59] is a widely used data mining technique that generates recommendations in recommender systems. An association rule describes the relationships between items, such as products, documents, or movies, based on patterns of co-occurrence across transactions. The Apriori algorithm [3-4] is usually employed to identify such rules. Two measures, support and confidence, are used to indicate the quality of an association rule [3]. The discovered rules should satisfy two user-defined requirements, namely minimum support and minimum confidence.
To improve the quality of traditional CF, Cho et al. [15] proposed a sequential rule-based recommendation method that considers the evolution of customers’ purchase sequences. Transactions are clustered into a set of q transaction clusters, C={C1,C2,…,Cq}, where each Cj
is a subset of transactions. Each customer’s transactions over l periods are then transformed into transaction clusters as a behavior locus, Li =<Ci,T-l-1,…Ci,T-1, Ci,T>, where Ci,T-k ∈ C,
k=1,2,…,l-1, l≧2. Finally, sequential purchase patterns are extracted from the behavior locus
of customers by time-based association rule mining to keep track of customers’ preferences during l periods, with T as the current (latest) period. A sequential rule is expressed in the form CT-l+1, …, CT-1 ⇒ CT, where CT represents the customers’ purchase behavior in period T.
If a target customer’s purchase behavior prior to period T was similar to the conditional part of the rule, then it is predicted that his/her purchase behavior in period T will be CT.
11
2.6 Collaborative Filtering Recommendation
Collaborative filtering (CF) is a well-known approach for recommender systems: GroupLens [34], Ringo [51], Siteseer [47], and Knowledge Pump [22]. CF recommends items, e.g., products, movies, and documents, based on the preferences of people who have the same or similar interests to those of the target user [11, 38, 40]. The CF approach involves two steps: neighborhood formation and prediction. The neighborhood of a target user is selected according to his/her similarity to other users, and is computed by Pearson correlation coefficient or the cosine measure. Either the k-NN (nearest neighbor) approach or a threshold-based approach is used to choose n users that are most similar to the target user. Here, we use the k-NN approach. In the prediction step, the predicted rating is calculated from the aggregated weights of the selected n nearest neighbors’ ratings, as shown in Eq. (4):
(
)
∑
∑
= = − + = n i n i i j i u j u i u w r r i u w r P 1 1 , , ) , ( ) , ( , (4)where Pu,j denotes the prediction rating of item j for the target user u; ruand ri are the
average ratings of user u and user i, respectively; w(u,i) is the similarity between target user u and user i; ri,j is the rating of user i for item j; and n is the number of users in the
neighborhood.
Similar to the PCF method, the item-based collaborative filtering (ICF) algorithm [37, 40, 50] analyzes the relationships between items (e.g., documents) first, rather than the relationships between users. Then, the item relationships are used to compute recommendations for workers indirectly by finding items that are similar to other items the worker has accessed previously. Thus, the prediction for an item j for a user u is calculated by the weighted sum of the ratings given by the user for items similar to j and weighted by the item similarity, as shown in Eq. (5).
∑
∑
= = × = n m n m jm j u m j w r m j w p 1 1 , , ) , ( ) , ( , (5)where pu,j represents the predicted rating of item j for user u; w(j,m) is the similarity
methods can be used to determine the similarity between items e.g., the cosine-based similarity, correlation-based similarity, and adjusted cosine similarity methods. Since the adjusted cosine similarity method performs better than the others [50], we use it as the similarity measure for the ICF method. The adjusted cosine similarity between two items i and j is given by Eq. (6).
∑
∑
∑
∈ ∈ ∈ − − − − = U u ui u u U u j u U u ui u u j u r r r r r r r r j i sim 2 , 2 , , , ) ( ) ( ) )( ( ) , ( , (6)where ru,i / ru,j is the rating of item i/j given by user u; and ru is the average item rating
of user u.
2.7 Process Mining
In a workflow system, a process mining technique is used to extract the description of a structural process from a set of real process executions [54]. It then infers the relations between the tasks/activities and generates a process model from event-based data (log data) automatically [7, 53, 55-56]. The relations between processes (tasks/activities) are defined as casual relations and parallel relations, and are modeled by a directed graph [7, 23] or an instance graph [56]. Because a workflow log contains information about workflow processes, a loop may occur in a process. Most process mining algorithms assume that loops do not exist [23, 56]. However, some algorithms have been proposed to handle the problem of process loops [18, 54]. For example, Agrawal, et al.’s algorithm [7] builds a general directed graph with cycles for mining process models from the logs of executed processes. The algorithm labels multiple instances of the same activity with different identifies to differentiate them in the workflow graph. Vertices with different instances of the same activity form an equivalent set and can be merged to form one vertex. A directed edge is added if there is an edge between two vertices of different equivalent sets.
Process mining is used in various applications. Discovering frequently occurring temporal patterns in process instances facilitates intelligent and automatic extraction of useful knowledge to support business decision-making [7, 28]. Similarly, data mining techniques are exploited in workflow management contexts to mine frequent workflow execution patterns [23]. The frequent patterns represent blocks of activities that have been scheduled together
13
more frequently during the execution of a process. The sequence of activities within a process, the time required to complete it, the execution cost and the reliability of the process can be predicted by using the process path mining technique [13]. Based on the process patterns and process paths, unexpected and useful knowledge about the process is extracted to help the user make appropriate decisions. In addition, combining the concepts of process mining and social network analysis is useful for mining social networks from event logs [52].
Another benefit of process mining is that it is useful for discovering how people and/or procedures work [54]. In this work, we use process mining to analyze the relations between knowledge topics in a knowledge flow and model the referencing behavior of a group of workers. We design algorithms for mining the group-based knowledge flow (GKF) and construct a GKF as a directed knowledge graph. In such graphs, frequent knowledge paths can be derived to represent the most common referencing behavior of the group.
Chapter 3. The Overview of Knowledge Flow-Based Research
3.1 Knowledge Flow Model
In a knowledge-intensive and task-based environment, workers may need to access a large number of documents (codified knowledge) to accomplish a task. From the perspective of information needs, a worker’s knowledge flow (KF) represents the evolution of his/her information needs and preferences during a task’s execution. Workers’ KFs are identified by analyzing their knowledge referencing behavior based on their historical work logs, which contain information about previously executed tasks, task-related documents and when the documents were accessed.
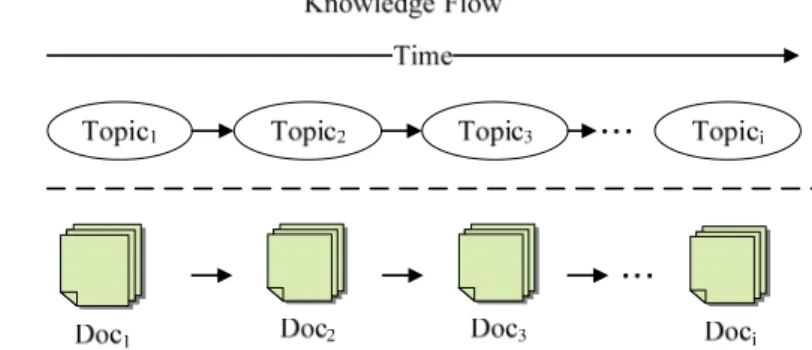
A KF consists of two levels: a codified level and a topic level, as shown in Fig. 1. The knowledge in the codified-level indicates the knowledge flow between documents based on the access time. In most situations, the knowledge obtained from one document prompts a knowledge worker to access the next relevant document (codified knowledge). Hence, the task-related documents are sorted by their access time to obtain a document sequence as the codified-level KF.
Documents with similar concepts can be grouped together automatically to form a topic-level abstraction of knowledge. Note that each topic may contain several task-related documents. The codified-level KF can be abstracted to form a topic-level KF, which represents the transitions between various topics. Since the task knowledge in the topic level may flow among topics, it could prompt the worker(s) to retrieve knowledge from the next related topic. Formally, we define knowledge flow as follows.
15
Definition 1: Knowledge Flow (KF)
Let a worker’s knowledge flow be { , v} w v w v w TKF CKF low KF = , where v w TKF is the
topic-level KF of the worker w for a task v, and v w
CKF is his/her codified-level KF for the task
v.
Definition 2: Codified-Level KF
A codified-level KF is a time-ordered sequence arranged according to the access times of the documents it contains. Thus, it is defined as =< tf >
w t w t w v w d d d CKF 1, 2, , , " and t1<t2<"<tf, where tj w
d denotes the document that the worker w accessed at time tj for a specific task v.
Each document can be represented by a document profile, which is an n-dimensional vector
containing weighted terms that indicate the key content of the document.
Definition 3: Topic-Level KF
A topic-level KF is a time-ordered topic sequence derived by mapping documents in the codified-level KF to corresponding topics. Thus, it is defined as =< tf >
w t w t w v w TP TP TP TKF 1, 2,", , f t t t1< 2<"< , where tj w
TP denotes the corresponding topic of the document that worker w
accessed at time tj for a specific task v. Each topic is represented by a topic profile, which is
3.2 The Framework of Knowledge Flow-based Approaches
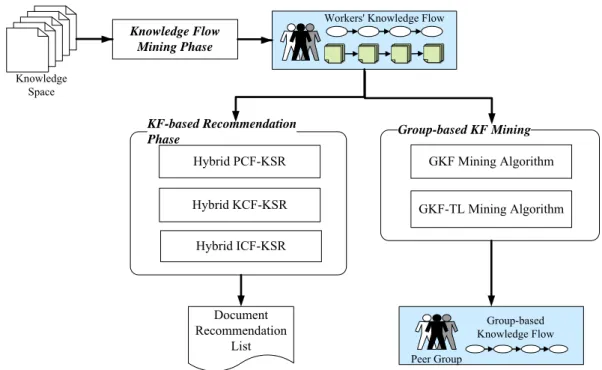
Fig. 2: The overview of knowledge flow-based research
Fig. 2 illustrates the overview of our research which is knowledge flow-based approaches for providing knowledge support. According to the definition of knowledge flow, the knowledge flow mining is used to identify both topic-level and codified-level KF of each knowledge worker based on their log data which consists of the access behavior of task-related documents. Then, based on the discovered KF, our research is divided into two parts: KF-based recommendation phase and group-based KF mining methods.
The KF-based recommendation phase selects and recommends documents based on document preferences and knowledge flows derived from the target worker’s neighbors. In other words, the proposed recommendation methods trace a worker’s information needs by analyzing his/her knowledge referencing behavior for a task over time, and also proactively provide relevant codified knowledge for the worker based on the KFs of the worker’s neighbors.
According to the KF mining approach [36], we propose the group-based KF mining algorithms that integrate information retrieval and data mining techniques for mining and constructing the group-based knowledge flows (GKFs). Specifically, we discover a group’s KF from the KFs of the participating workers and identify the frequent referencing behavior
Peer Group
Group-based Knowledge Flow Workers' Knowledge Flow
Knowledge Flow Mining Phase KF-based Recommendation Phase Hybrid KCF-KSR Hybrid PCF-KSR Hybrid ICF-KSR Document Recommendation List Knowledge Space Group-based KF Mining GKF-TL Mining Algorithm GKF Mining Algorithm
17
of a group of workers. Then, the concepts of graph theory are applied to visualize the GKF as a knowledge graph. The paths on such graph represent the workers’ frequent knowledge referencing behavior and important knowledge flows in the group. Section 3.3 describes the details of knowledge flow mining first. Then, the two parts of our research are based on the mining results and are illustrated in Chapter 4 and Chapter 5.
3.3 Knowledge Flow Mining Phase
The objective of the knowledge flow (KF) mining phase is to identify the KF of each knowledge worker. In this Section, we describe how the KF mining method identifies KFs from workers’ log. This phase consists of three steps: document profiling, document clustering and KF extraction. In the first step, each document is represented as a document profile, which is an n-dimensional vector comprised of significant terms and their weights.
Then, based on the document profiles, documents with higher similarity measures are grouped in clusters by the hierarchical clustering method. In the third step, topic-level and codified-level KFs are generated from the document clustering results. A topic-level KF is expressed as a sequence of topics referenced by a worker, while a codified-level KF is represented as a sequence of codified knowledge accessed by a worker. Further details are given in the following subsections.
3.3.1 Document Profiling and Document Clustering
Two profiles, a document profile and a topic profile, are used to represent a worker’s KF. A document profile can be represented as an n-dimensional vector composed of terms and
their respective weights derived by the normalized tf-idf approach based on Eq. (1). Based on
the term weights, terms with higher values are selected as discriminative terms to describe the characteristics of a document. The document profile of dj is comprised of these discriminative
terms. Let the document profile beDPj =<dt1j:dtw1j,dt2j:dtw2j,",dtnj:dtwnj >, where dtij is the
term i in dj and dtwij is the degree of importance of a term i to the document dj, which is
derived by the normalized tf-idf approach. The document profiles are used to measure the
similarity of the documents.
similar profiles into clusters by using the cosine measure to calculate the similarity between the profiles of two documents. The single-link method computes the cluster similarity between two clusters Cr and Ct by
{
(
)
}
, ,
i r j t i j
d C d C∈max simcos d d∈ [60], and then merges the two most
similar clusters into a single cluster. The similarity computation and cluster combination steps are repeated until the similarity of the most similar pair of clusters is no greater than a pre-specified threshold value. Different clustering results can be obtained by setting different threshold values. We adjust the threshold value systematically and use the quality measure described in Section 2.3.2 to evaluate each clustering result. Then, we take the one with the best quality measure as our clustering result. Note that a cluster represents a topic set and has a topic profile (derived from the document cluster) that describes the features of the topic.
Topic Profile
Documents in the same cluster contain similar content and form a topic set. The key features of the cluster are described by a topic profile, which is derived from the profiles of documents that belong to the cluster. Let TPx =<tt1x:ttw1x,tt2x:ttw2x,",ttnx:dtwnx> be the profile of a topic (cluster) x, where ttixis a topic term and ttwixis the weight of the topic term.
In addition, let Dx be the set of documents in cluster x. The weight of a topic term is
determined by Eq. (7) as follows:
x D j ij ix D dtw ttw x
∑
∈ = , (7)where dtwij is the weight of term i in document j, and |Dx| is the number of documents in
cluster x. The weight of a topic term is obtained from the average weight of the terms in the
document set.
3.3.2 Knowledge Flow Extraction
In this section, we describe the method used to extract a worker’s KF from his/her data log when performing a task. We define a task as a unit of work, which denotes either a previously executed (i.e., historical) task or the current task. When performing a task in a knowledge-intensive and task-based environment, a worker usually requires a large amount of task-related knowledge to accomplish the task. By analyzing a worker’s referencing behavior for a specific task, the corresponding knowledge flow of the task is derived by the knowledge
19
flow extraction method. Note that if a worker performs more than one task, more than one knowledge flow will be extracted. For a specific task, the method derives two kinds of KF,
codified-level KF and topic-level KF, to represent the worker’s information needs for the task.
Codified-Level Knowledge Flow
The codified-level KF is extracted from the documents recorded in the worker’s work log. In most situations, workers are motivated to access a document about a specific task because of knowledge derived from other documents. The documents are arranged according to the times they were accessed, and a document sequence, i.e., a codified-level KF, is obtained. The order of documents in the sequence is subjective, since it is determined by the worker. In other words, each worker has his/her own codified-level KF, which represents his/her knowledge accumulation process for a specific task at the codified level.
Topic-Level Knowledge Flow
The topic-level KF is derived by mapping documents in the codified-level KF of a specific task into corresponding clusters and is represented by a topic sequence. In the previous step, documents with similar content were grouped into clusters. We use the document clustering results to map the documents in the codified-level KF into topics (clusters) in order to compile the topic-level KF. Since the codified-level KF is the basis of the topic-level KF, the knowledge in the latter is an abstraction of the former, and indicates how knowledge flows among various topics. A topic in the topic-level KF may be duplicated because the worker may read about the same topic frequently to obtain essential knowledge while executing a task.
Chapter 4. Knowledge Flow-based Recommendation Framework
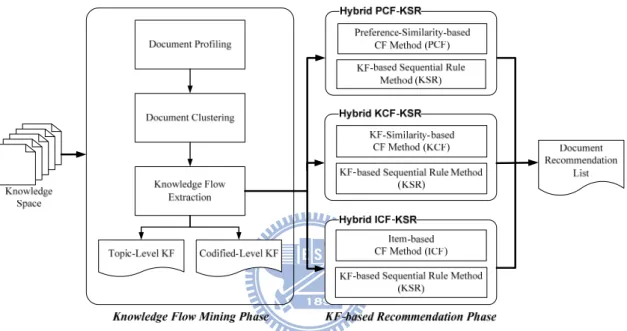
The proposed recommendation methods are illustrated in Fig. 3. Our methods consist of two phases, a knowledge flow mining phase and a KF-based recommendation phase. The first phase identifies the worker’s knowledge flow from the large amount of knowledge in the worker’s log. Then, the second phase recommends codified knowledge to the target worker by using the proposed recommendation methods.
Fig. 3: Document recommendation based on knowledge flows
In the knowledge flow mining phase, KFs are identified from the task requirements and the referencing behavior of workers recorded in their logs. As tasks are performed at various times, each knowledge worker requires different kinds of knowledge to achieve a goal or complete a task. Further details about this phase are given in Section 3.3.
The proposed hybrid recommendation methods combine a KF-based sequential rule (KSR) method with a user-based/item-based collaborative filtering (CF). The KSR method is regarded as the core process of the proposed hybrid methods. In the KSR method, workers with similar KFs to that of the target worker are deemed neighbors of the target worker and their knowledge referencing behavior patterns are identified by a sequential rule mining method. Based on the discovered sequential rules and the neighbors’ KFs, relevant topics and codified knowledge are recommended to the target worker to support the task-at-hand. Moreover, by considering workers’ preferences for codified knowledge, the CF method
21
makes recommendations to the target worker based on the opinions of similar workers. Three approaches are used to find similar workers to the target worker. The preference-similarity-based CF method (PCF) chooses workers with similar preferences, while the KF-similarity-based CF method (KCF) chooses workers with similar KFs. Different from these two user-based methods, the item-based CF method predicts a document rating based on its similar documents that have been rated by a target user. To adaptively and proactively recommend codified knowledge, we consider workers’ referencing behavior as well as their preferences for codified knowledge. Therefore, three hybrid recommendation methods are used in the KF-based recommendation phase: 1) a hybrid of PCF and KSR (PCF-KSR), 2) a hybrid of KCF and KSR (KCF-KSR) and 3) a hybrid of ICF and KSR (ICF-KSR). Further details are given in the following subsections.
4.1 Knowledge Flow-based Recommendation Phase
In this work, we propose three hybrid recommendation methods based on knowledge flow (KF), which is a sequence of codified knowledge (documents) or topics referenced by a worker during a task’s execution. KF represents a worker’s information needs and the evolution of knowledge requirements, and is identified by analyzing a worker’s work log. To support workers effectively, our methods consider workers’ preferences as well as their referencing behavior in order to recommend task-related knowledge. During the recommendation phase, the user-based collaborative filtering (CF) is used to predict a target worker’s preferences based on the opinions of similar workers, while the item-based collaborative filtering [50] is used to predict a document based on the targets worker’s interests on its similar items (documents). However, the limitation of these traditional CF methods is that they only consider workers’ preferences for codified knowledge and neglect workers’ referencing behavior. A worker’s referencing behavior may change during the task’s execution to suit his/her current information needs. To address this issue, we propose a KF-based sequential rule method that improves the recommendation quality by tracking workers’ referencing behavior based on sequential rules. However, this method does not consider the opinions of the target worker’s neighbors who have similar preferences for documents. To overcome the limitations of CF and KF-based sequential rule methods, we combine the advantages of the two approaches and propose three hybrid recommendation
methods that integrate KF mining, KF-based sequential rule mining and CF techniques to enhance the quality of recommendations.
The KF-based recommendation phase consists of three hybrid recommendation methods: 1) PCF and KSR (PCF-KSR), 2) KCF and KSR (KCF-KSR) and 3) ICF and KSR (ICF-KSR), as shown in Fig. 3. We note that PCF denotes the preference-similarity based CF method; KCF denotes the KF-similarity based CF method; ICF denotes the item-based CF method; and KSR denotes the KF-based sequential rule method. To adaptively recommend documents, both the PCF method and the KCF method select neighbors based on the similarity of preferences, while the ICF method chooses similar documents for a document based on their preferences given by a target user. The three methods differ in the way they compute the similarity between workers’ preferences to select the target worker’s neighbors. The PCF method (traditional CF) uses preference ratings to compute the similarity, while the KCF method uses workers’ KFs to derive the similarity. The ICF method applies similarity measure to evaluate the similarity between two items (i.e., documents), rather than the similarity between two workers. The proposed KSR method traces workers’ knowledge referencing behavior by using the KF-based sequential rules. The proposed hybrid recommendation methods take advantage of the merits of the KSR, PCF, KCF and ICF methods.
4.2 Identifying Similar Workers Based on their Knowledge Flows
To find a target worker’s neighbors, his/her topic-level KF is compared with those of other workers to compute the similarity of their KFs. The resulting similarity measure indicates whether the KF referencing behavior of two workers is similar. In this work, we regard each knowledge flow as a sequence. Since comparing knowledge flows is very similar to aligning sequences, the sequence alignment method (SAM) [24] and the dynamic programming approach [14, 43] can be used to measure the similarity of two KF sequences.
To determine which of the two methods would be more appropriate for comparing workers’ knowledge flows, we applied both methods in our experiments and found that dynamic programming is better than SAM. Therefore, we employ the dynamic programming algorithm [14, 43] to measure the similarity of workers’ knowledge flows.
23
Unlike the sequence alignment problem, a worker’s KF contains task-related documents. Thus, we have to consider the sequential order of topics in a knowledge flow, as well as the worker’s aggregated profile, which accumulates the task-related documents based on the times they were accessed during the task’s execution. We propose a hybrid similarity measure, comprised of the KF alignment similarity and the aggregated profile similarity, to evaluate the similarity of two workers’ KFs, as shown in Eq. (8).
) , ( ) 1 ( ) , ( ) , ( l j v i P l j v i a l j v i TKF sim TKF TKF sim AP AP TKF sim =α× + −α × , (8) where ( , l) j v i a TKF TKF
sim represents the KF alignment similarity between worker i and worker j who execute task v and task l respectivel v
i
TKF / l
j
TKF is the topic-level KF of worker i/j for task v/l; ( , l)
j v i
p AP AP
sim represents the aggregated profile similarity of two workers’ KF v
i
AP l j
AP is the aggregated profile of worker i/j for task v/l; and α is a parameter used to adjust the relative importance of the two types of similarity.
The KF alignment similarity is based on the topic sequence and topic coverage, while the aggregated profile similarity is based on the aggregated profiles derived from the profiles of referenced documents in the KFs. Note that the KF alignment similarity considers the topic sequence in the KF without considering the content of workers’ profiles; while the aggregated profile similarity considers the content of profiles without considering the topic sequence in the KF. By linearly combining these two similarities, we can balance the tradeoff between KF alignment and the aggregated profile. We discuss the rationale behind these two similarity measures next.
4.2.1 KF Alignment Similarity
The KF alignment similarity is comprised of two parts: the KF alignment score, which measures the topics in sequence; and the join coefficient, which estimates the topic’s coverage in two compared topic-level KFs. We modify the sequence alignment method [14] to derive the KF alignment score. In addition to computing the sequence alignment score, we estimate the overlap of the topics in two compared topic-level KFs by using the join coefficient. The rationale is that if the topic overlap is high, the KF alignment similarity of the two compared KFs will also be high. In other words, the two compared KFs will be very similar. The KF
alignment similarity, ( , l) j v i
a TKF TKF
sim , is defined as follows:
where v i
TKF / l
j
TKF denotes the topic-level KF of worker i/ worker j for task v/ task l; η is the KF alignment score; Norm is a normalization function used to transform the value of η
into a number between 0 and 1; v i
TPS and l j
TPS are the sets of topics in v i TKF and TKFjl respectively; l j v i TPS
TPS ∩ is the intersection of topics common to v i TKF and l j TKF ; and v i TPS and l j
TPS represent the number of topics in v i
TKF and l
j
TKF respectively. The KF alignment score, which is based on the sequence alignment method [43], is defined in Eq. (10):
where δ is the maximal alignment score derived by the dynamic programming approach,
ms is the identical matching score (+2), and ξ is the length of the aligned KF. To obtain the
maximal alignment score δ, we set the matching score ms, the mismatching score md and the
gap penalty score mg to +2, -1 and -2 respectively in the dynamic programming approach [14]
discussed in Section 2.4. The maximum value of η is 1 if the two compared KFs are exactly the same. On the other hand, the value of η is negative if most of topics in the two compared KFs do not match. Thus, the value of η may range from a negative value to 1. To alter the range of the KF alignment score, the value of η is transformed into a value in the range [0, 1]
by the normalization function. The normalized KF alignment score Norm(η) is then used to calculate the KF alignment similarity.
4.2.2 Aggregated Profile Similarity
The aggregated profile similarity, defined as ( , l) j v i p AP AP
sim , computes the similarity of two workers’ KFs based on their aggregated profiles, which are derived from the profiles of documents they have referenced; v
i
AP and l j
AP are the respective vectors of the aggregated
profiles of workers i/ j for task v/ l. We use the cosine formula to calculate the similarity
between two aggregated profiles. The value of the similarity score ranges from 0 to 1. The
l j v i l j v i l j v i a TPS TPS TPS TPS Norm TKF TKF sim + ∩ × × = ( ) 2 ) , ( η , (9) ξ δ η × = s m , (10)
25
aggregated profile of a worker i for task v is defined as
∑
= × = T t v t T t v i tw DP AP 1 , , (11)where twt,T is the time weight of the document referenced at time t in the KF; T is the
index of the times the worker accessed the most recent documents in his KF; and v t
DP is the
profile of the document referenced by worker i at time t for task v. The aggregation process
considers the time decay effect of the documents. Each document profile is assigned a time weight according to the time it was referenced. Thus, higher time weights are given to documents referenced in the recent past. The time weight of each document profile is defined as St T St t twtT − − =
, , where St is the start time of the worker’s KF.
4.3 KF-based Sequential Rule Method
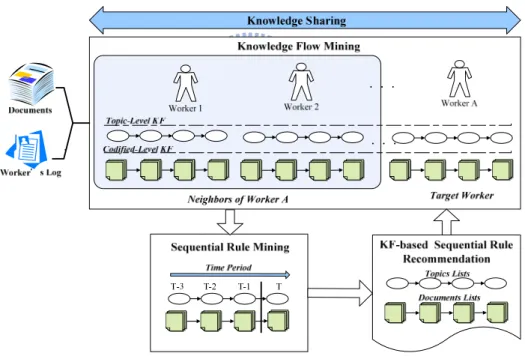
Fig. 4: An overview of the KSR method
The KF-based sequential rule method (KSR) considers the referencing behavior of neighbors whose KFs were very similar before time T, and then recommends documents at
time T for the target worker. Fig. 4 provides an overview of the KSR method. To determine
the similarity of various topic-level KFs, the target worker’s KF is compared with those of other workers by measuring their KF similarity, as discussed in Section 4.2. Workers with similar KFs to that of the target worker are regarded as the latter’s neighbors and their
. . .