2003 IEEE XI1 Workshop on
Neural Networks for Signal Processing
T R A I N I N G ALGORITHMS FOR F U Z Z Y
S U P P O R T VECTOR M A C H I N E S WITH N O I S Y
DATA
Chun-fu Lin and SIieng.de Wang Department of Electrical Engineering, National Taiwan University, Taipei, Taiwan 106 E-mail: genelinOhpc.ee.ntu.edu.tw, sdwangOcc.ee.ntu.edu.tw
A b s t r a c t . F u z z y s u p p o r t vector machines (FSVMs) provide a inethod to classify data with noises or outliers. E a c h data point is associated w i t h a fuzzy m e m b e r s h i p that c a n reflect their rela- t i v e d e g r e e s as m e a n i n g f u l data. I n t h i s paper, we investigate and c o m p a r e t w o s t r a t e g i e s of a u t o m a t i c a l l y setting the fuzzy member- s h i p s of data points. It makes the usage of FSVMs easier in t h e a p p l i c a t i o n of r e d u c i n g t h e effects of noises o r outliers. The exper-
i m e n t s s h o w that the generalization error of FSVMs is c o m p a r a b l e to other methods o n b e n c h m a r k datasets.
INTRODUCTION
The theory of support vector machines (SVMs), that is based on the idea of structural risk minimization (SRM), is a new classification technique and has drawn much attention on this topic in recent years [3][4][9][10]. The good
generalization ability of SVMs is achieved by finding a large mwgin between two classes [1][8]. In many applications, the thcory of SVMs has been shown to provide higher performance than traditional learning machines [3] and has been introduced as powerful tools for solving classification problems.
Since the optimal hyperplane obtained by the SVM depends on only a small part of the data points, it may become sensitive to noises or outliers in the training set [2][13]. To solve this problem, one approach is to do some preprocessing on training data to remove noises or outliers, and then use the remaining set to learn the dccision function. This method is hard to implement if we do not have enough knowledge about noises or outlicrs. In many real world applications, we are given a set of training data without knowledge about noises or outliers. There are some risks to remove the meaningful data points as noises or outliers.
There are many discussions in this topic and some of them show good performance. The theory of Leave-One-Out SVMs [ll] (LOO-SVMs) is a
modified version of SVMs. This approach differs from classical SVMs in that it is based on the maximization of the margin, hut minimizes the expression given by the bound in an attempt to minimize the leave-one-out error. No free parameter makes this algorithm easy to use, but it lacks the flexibility of tuning the relative degree of outliers as meaningful data points. Its gen- eralization, the theory of Adaptive Margin SVMs (AM-SVMs) [12], uses a parameter X t o adjust the margin for a given learning problem. It improves the flexibility of LOO-SVMs and shows better performance. The experiments in both of them show the robustness against outliers.
FSVn4s solve this kind of problems by introducing the fuzzy memberships of data points. The main advantage of FSVMs is that we can associate a fuzzy membership to each data point such t h a t different data points can have different effects in the learning of the separating hyperplane. We can treat the noises or outliers as less importance and let these points have lower fuzzy membership. It is also based on the maximization of the margin like the classical SVMs, but uses fuzzy memberships t o prevent some points from making narrower margin. This equips FSVMs with the ability to train data with noises or outliers by setting lower fuzzy memberships to the data points that are considered as noises or outliers with higher probability.
The previous work of FSVMs [6] did not address the issue of automati- cally setting t h e fuzzy membership from the d a t a set. We need to assume a noise model of the training data points, and then try and tune the fuzzy membership of each data point in the training. Without any knowledge of the distribution of data points, it is hard to associate the fuzzy membership t o the data point.
In this paper. we propose two strategies to estimate the probability that the data point is considered as noisy information and use this probability to tune the fuzzy membership in FSVMs. This simplifies the use of FSVMs in the training of data points with noises or outliers. The experiments show that the generalization error of FSVMs is comparable to other methods on benchmark datasets.
FUZZY SUPPORT VECTOR MACHINES
Suppose we are given a set S of labeled training points with associated fuzzy memberships
Each training point
x,
ERN
is given a label yz E {-1,1} and a fuzzy membership UI
s,I
1 with z = 1. . . , 1 , and sufficient small U>
0, since the data point with st = 0 means nothing and can be just removed from training set without affecting the result of optimization. Let z = p(x) denote the corresponding feature space vector with a mapping ~p fromRN
to a feature space 2.Since the fuzzy membership s, is the attitude of t h e corresponding point
x. toward one class and the parameter
6
can be viewed as a measure of error (Yl,Xl,Sl),..
. >
(YI,Xl>~l). (1)in the SVM, the term siti is then a measnre of error with differeh weighting. The optimal hyperplane problem is then regraded as the solution to
1 minimize - w . w + ~ C s i < i , 1 i = l 2 subject to yi(w. zi
+
b ) 2 1- t i ,
i = 1:. . . , 1 , 1ti
2 0 , i = l ,...,
l ,where C is a constant. I t is noted that a smaller si reduces theleffect of the parameter ti in problem (2) such that the corresponding point x, is treated as less important.
The problem (2) can be transformed into
maximize
subject t o yiac = 0
i = l
0
5
ai5
sic, 2 = 1,. . . , l . and the Kuhn-Tucker conditions are defined asa ; ( y i ( w . Z i + b ) - 1 + f i ) = 0 , i = l ,
...,
1> I (4)(sic-a;)Fi
= 0 , 2 = I , . . . , 1 . (5) The only free parameter C in SVMs controls the tradeoff between the maximization of margin and the amount of misclassifications.. A larger Cmakes the training of SVMs less misclassifications and narrower margin. The decrease of C makes SVMs ignore more training points and'get a wider margin.
In FSVhfs, we can set C to be a sufficient large value. It is'the same as SVMs that the system will get narrower margin and allow less miscalssifi- cations if we set all si = 1. With different value of s i , we can control the trade-off of the respective training point xi in the system. A smaller value of si makes the corresponding point xi less important in the training. There is only one free parameter in SVMs while the number of free parameters in FSVMs is equivalent to the number of training points.
TRAINING PROCEDURES
There are many methods t o training data using FSVMs, depending on how much information contains in the data set. If the data points are already associated with the fuzzy memberships, we can just use this information in training FSVMs. If it is given a noise distribution model of the data set, we
can set the fuzzy membership as the probability of the data point that is not a noise, or as a function of it. Let pi be the probability of the data point zi that is not a noise. If there exists this kind of information in the training data, we can just assign the value si = pi or si = fp(pi) as the fuzzy membership of each data point. Since almost all applications lack this information, we need some other methods to predict this probability. In order to reduce the effects of noisy data when using FSVMs in this kind of problem, we propose the following training procedure.
1. Use the original algorithm of SVMs t o get the optimal kernel parameters and the regularization parameter C.
2. Use some strategies to set the fuzzy memberships of data points and find the modified hyperplane by FSVMs in the same kernel space.
As for steps, we propose two strategies: one is based on kernel-target alignment and the other is using k-NN.
Strategy of U s i n g K e r n e l - T a r g e t A l i g n m e n t
The idea of kernel-target alignment is introduced in [5]. Let f K ( x i r y i ) =
E:.=,
yiyjK(xi,xj). The kernel-target alignment is defined as(6)
Et=,
fK(Xi.Yi)A K T =
14-
This definition provides a method for selecting kernel parameters and the experimental results show that adapting the kernel to improve alignment on the training d a t a enhances the alignment on the test data, thus improved classification accuracy.
In order to discover some relation between t h e fuzzy membership and the data point, we simply focus on the value f~(xi,y,). Suppose K ( x i , x i ) is
a kind of distance measure between data points xi and xj in feature space
3. For example, by using the RBF kernel
K(xi,x,)
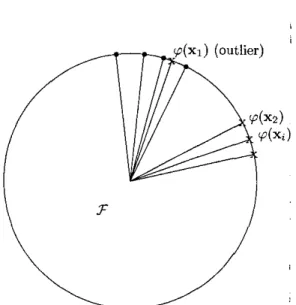
= e-711xi-x~112, the data points live on the surface of a hypersphere in feature space 7 as shown in Figure 1. ThenK(xi,x3)
= xi). ~p(xj) is the cosine of the angle between p(x;) and p(xj). For the outlier ip(x1) and the representative ~ ( x x ) , we havefK(X1,YI) = K(Xl,Xi) - K(Xl,Xi)
fK(XZIY2) = K(xz,xd - K(X2,Xi).
(7) Y i = Y 1 Y i i Y l
Y i = Y 2 Y,#Y2
Figure 1: The value f K ( x 1 ; y l ) is Ion-er than fK(xz3yzj in the RBF kernel such that the value f ~ ( x 1 : y l ) is lower than f~(x2,yz).
We observe this situation and assume that t h e data point xi with lower value of f ~ ( x < , y ~ ) can be considered as outlier and should make less con- tribution of the classification accuracy. For this assumption, we can build a relationship between the fuzzy membership si and the value of f ~ ( x { , yi)
that is defined as
iffK(xi,yi)
>
fg”
si = if f d x i r y i )
<
fkB
(9)U + (1 - U)(f^.(xt,Yi)-f:B)d otherwise
r
f : E - fis
where
fgB
andf,$”
are the parameters that control the mapping region between si and f ~ ( x i , y i ) , and d is the parameter that controls the degree of mapping function as shown in Figure 2.The training points are divided into three regions by the parameters
fg”
andfk”.
The d a t a points in the region with f ~ ( x i , yi)>
fgB
can be viewed as valid examples and the fuzzy membership is equalto
1. The data points in the region with f ~ ( x , , y < )<
fk”
can be highly thought as noisy data and the fuzzy membership is assigned to U. The data points in rest regionare considered as noise with different probabilities and can make different distributions in the training process.
Strategy of Using k-NN
For each data point x i , we can find a set Sf that consists of
k
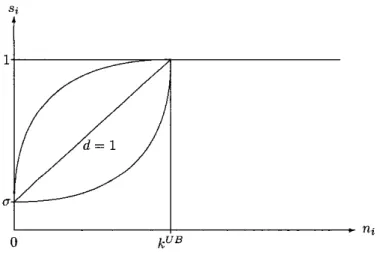
nearest neigh- bors of x i . Let ni be the number of data points in the set Sf that the class label is the same as the class label of data point x i . It is reasonab;le to assume that the data point with lower value of ni is more probable as noiFy data. But for the data points that are near the margin of two classes, the value n, ofFigure 2: The mapping between t h e fuzzy membership s, and f K ( x , , y , ) these points may be lower. It will get poor performance if we set these data points with lower fuzzy memberships. In order t o avoid this situation, we introduce a parameter kUB that controls the threshold of which data point needs to reduce its fuzzy membership.
For this assumption, we can build a relationship between the fuzzy mem- bership s. and the value of n, that is defined as
if ni
>
k u BU
+
(1 ~ otherwisesi =
where d is the parameter that controls the degree of mapping function as shown in Figure 3.
1-
U-
-
ni0 kuB
EXPERIMENTS
In these simulations, we use the RBF kernel as
(11) K ( x i , x . ) - e-’IIx’-xll12
3
-We conducted computer simulations of SVMs and FSVMs using the same data sets as in [7]. Each data set is split into 100 sample sets of training and test sets’. For each data set, we train and test the first 5 sample sets iteratively to find the parameters of the best average test error. Then we use these parameters to train and test the whole sample sets iteratively and get the average test error. Since there are more parameters than the original al- gorithm of SVMs, we use two procedures to find the parameters as described in the previous section. In the first procedure, we search the kernel parame- ters and C using the original algorithm of SVMs. In the second procedure, we fix the kernel parameters and C that are found in the first stage, and search the parameters of the fuzzy membership mapping function.
To find the parameters of strategy using kernel-target alignment, we first fix
fg”
= maxifK(xt,yi) andfi”
= minifx(xi,yi), and perform a two- dimensional search of parameters a and d. The value of a is chosen from 0.1 to 0.9 step by 0.1. For some case, we also compare the result of U = 0.01.The value of d is chosen from 2T8 to 2’ multiply by 2. Then, we fix U and
d, and perform a two-dimensional search of parameters
”
:
f
andA”.
The value of f;” is chosen such that 0%, lo%, 20%, 30%, 40%, and;50% of datapoints have the value of fuzzy membership as 1. The value of
fi”
is chosen such that 0%,lo%,
20%, 30%, 40%, and 50% of data points have the value of fuzzy membership as U .To find the parameters of strategy using k-NN, we just perform a two- dimensional search of parameters U and k . We fix the value kuB = k / 2 and d = 1 since we don’t find much improvement when we choose other values of these two parameters such that we skip searching for saving time. The value of U is chosen from 0.1 to 0.9 stepped by 0.1. For some case, we also compare
the result of U = 0.01. The value of k is chosen from 2’ to 2’ multiplied by 2. Table 1 lists the parameters after our optimization in the’simulations. For some data sets, we cannot find any parameters that can ‘improve the performance of SVMs such that we left blank in this table.
Table 2 shows the results of our simulations. For comparison’with SVMs, FSVMs with kernel-target alignment perform hetter in 9 data sets, and FSVMs with k-NN perform better in 5 data sets. By checking the aver- age training error of SVMs in each data set, we find that FSVh4s perform well in the d a t a set when the average training error is high. These results show that our algorithm can improve the performance of SVMs when the data set contains noisy data.
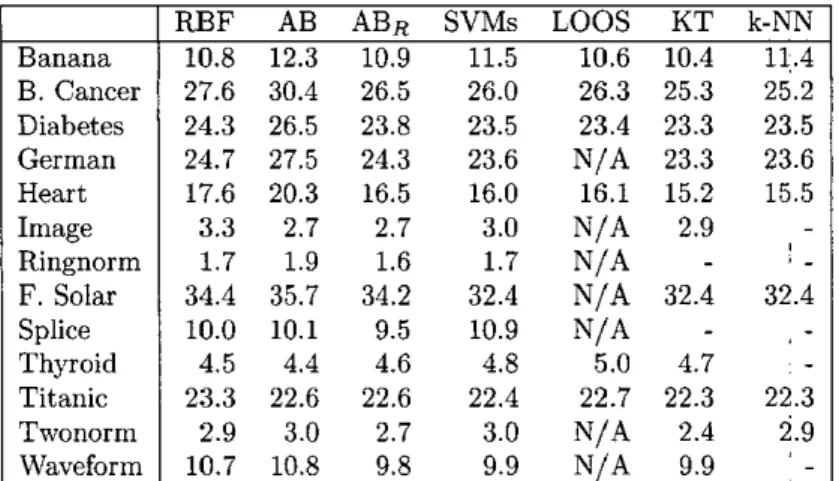
We also list in Table 3 the other results for single RBF classifier (RBF), AdaBoost (AB), and regularized AdaBoost (ABR), that are obtained from
TABLE 1: THE PARAMETERS USED IN S V h ' I S , FSVhIs USING STRATEGY OF KERNEL- T A R G E T ALIGNMENT ( K T ) , AND FSVh'h USING STRATEGY OF K-NN (K-NN) ON 13 DATASETS. Banana
B.
Cancersm4s
K T k-NNc
y o d U B L B Uk
316.2 1 0.01 64 10% 0% 0.1 32 15.19 0.02 0.5 8 20% 0% 0.01 64 Diabetes Heart Image F. Solar Splice Thyroid Twonorm Waveform German Ringnorm Titanic 1 0.05 0.7 8 10% 0% 0.6 4 3.162 0.00833 0.3 16 30% 30% 0.2 32 le+9 0.1 1.023 0.03333 0.5 T4 20% 0% 0.3 256 1000 0.14286-
3.162 o.ni818 0.6 8 20% 30% 0.8 4 500 0.03333 0.3 T3 10% 0% - 10 0.33333 0.7 2-6 0% 0% 100000 0.5 0.5 32 30% 0% 0.2 12s 3.162 0.025 0.01 128 10% 0% 0.01 128 1 0.05 0.01 2-* 50% 0% Banana B. Cancer Diabetes German Heart Image RingnormF.
Solar Splice Thyroid Titanic Twonorm Waveform T R SVMs K T k-NN 6.7 11.5 10.4 11.4 18.3 26.0 25.3 25.2 19.4 23.5 23.3 23.5 16.2 23.6 23.3 23.6 12.8 16.0 15.2 15.5 1.3 3.0 2.9 0.0 1.7 0.0 10.9 0.4 4.8 4.7 19.6 22.4 22.3 22.3 0.4 3.0 2.4 2.9 3.5 9.9 9.9 32.6 32.4 32.4 32.4TABLE 3: COMPARISON OF T E S T ERROR OF S I N G L E RBF CLASSIFIER, ADABOOST (AB), REGLAREED AD.4BOOST (ABn), SVhIS, LOO-SVMS (LOOS), FSVRIS
USING STRATEGY OF KERNEL-TARGET ALIGNMENT (KT). AND FSVhlS USING STRATEGY OF K-NN ( K - N N ) ON 13 DATASETS.
I
RBF AB ABB SVMsLOOS
KT k-NN Banana1
10.8 12.3 10.9 11.5 10.6 10.4 11.4 B. Cancer Diabetes German Heart Image RingnormF.
Solar Splice Thyroid Titanic Twonorm Waveform 27.6 30.4 26.5 24.3 26.5 23.8 24.7 27.5 24.3 17.6 20.3 16.5 3.3 2.7 2.7 1.7 1.9 1.6 34.4 35.7 34.2 10.0 10.1 9.5 4.5 4.4 4.6 23.3 22.6 22.6 2.9 3.0 2.7 10.7 10.8 9.8 26.0 23.5 23.6 16.0 3.0 1.7 32.4 10.9 4.8 22.4 3.0 26.3 25.3 25.2 23.4 23.3 23.5 N/A 23.3 23.6 16.1 15.2 15.5 N/A 2.9N/A
32.4 32.4 N/A-
5.0 4.7 22.7 22.3 22.3 N/A 2.4 2.9 N/A-
I _ 9.9 N/A 9.9 ' -experiments show that the performance is better in the applications with the noisy data.
We also compare the two strategies for setting the fuzzy membership in FSVMs. T h e usage of FSVMs with kernel-target alignment is more com- plicated since there exist many parameters. It costs much time t o find the optimal parameters in the training process but the performance is better. T h e usage of FSVMs using k-NN is much simple to use and the results are close to the previous strategy.
REFERENCES
111 P. Bartlett and J. Shawe-Taylor, ',Generalization Performance of,Support Vec- tor Machines and Ot.her Patt,ern Classifiers," in B. Scholkopf, C. Burges and A. Smola (eds.), Advances in Kernel Methods: Support Vector Learn- ing, Cambridge, MA: MIT Press, pp. 43-54, 1998.
(21 B. E. Boser, I. Guyon and V. Vapnik, "A Training Algorithm for Optimal Margin Classifiers," in Computational Learing Theory, 1992, pp. 144-
152.
[3] C. J. C. Burges, "A tutorial on support vector machines for pa!tern recogni- tion," Data Mining and Knowledge Discovery, vol. 2, no. 2, pp. 121-167, 1998.
[4] C. Cortes and V. Vapnik, "Support Vector Networks," Machine Learning, vol. 20, pp. 273-297, 1995.
[5] N. Cristianini, J. ShaweTaylor, A. Elisseeff and J. Kandola, "On Kernel- Target Alignment," in T. G. Dietterich, S. Becker and Z. Ghahiamani ( e d s . ) ,
Advances in Neural Information Processing Systems 14, MIT Press, 2002, pp. 367-373.
[6] C:F. Lin and S.-D. Wang, “Fuzzy support vector machines,” IEEE Trans- actions o n Neural Networks, vol. 13, no. 2, pp. 464471, 2002.
[7] G. Riitsch, T. Onoda and K.-R. Miller, “Soft Margins for AdaBoost,“ Ma- chine Learning, vol. 42, no. 3, pp. 287-320, 2001.
[8] J. Shawe-Taylor and P. L. Bartlett, “Structural risk minimization over data- dependent hierarchies,” IEEE Transactions on Information Theory, vol. 44, no. 5 , pp. 1926-1940, 1998.
[9] V. Vapnik, The Nature of Statistical Learning Theory, New York: Springer, 1995.
[lo] V. Vapnik, Statistical Learning Theory, New York: Wiley, 1998.
[I11 J. Weston, “Leave-One-Out Support Vector Machines,” in T. Dean (ed.), Pro- ceedings of t h e Sixteenth International Joint Conference on Artifi- cial Intelligence, IJCAI 99, Morgan Kaufrnann, 1999, pp. 727-733. [I21 J. Weston and R. Herbrich, “Adaptive margin support vector machines,” in
A. Smola, P. Bartlett, B. Scholkopf and D. Schuurmans (eds.), Advances i n Large Margin Classifiers, Cambridge, MA: MIT Press, pp. 281-295, 2000. 1131 X. Zhang, “Using ClassCenter Vectors to Build Support Vector Machines,”