國立交通大學
資訊科學與工程研究所
博士論文
利用物件修補之數位內容還原與修改技術
Video Content Recovery and Modification
by Object Inpainting
研 究 生:
凌誌鴻
指導教授:
廖弘源 教授
陳永昇 教授
中華民國 一百零一 年 六 月
利用物件修補之數位內容還原與修改技術
Video Content Recovery and Modification by Object Inpainting
研 究 生: 凌誌鴻 Student: Chih-Hung Ling
指導教授: 廖弘源 Advisor: Hong-Yuan Mark Liao
陳永昇 Yong-Sheng Chen
國 立 交 通 大 學
資 訊 科 學 與 工 程 研 究 所 博 士 論 文
A Thesis
Submitted to Institute of Computer Science and Engineering College of Computer Science
National Chiao Tung University in partial Fulfillment of the Requirements
for the Degree of Doctor of Philosophy
in
Computer and Information Science
June 2012
Hsinchu, Taiwan, Republic of China
利用物件修補之數位內容還原與修改技術
學生:凌誌鴻 指導教授:廖弘源 博士 陳永昇 博士 國立交通大學資訊科學與工程研究所博士班 摘 要 隨著數位攝影機的普及化,人們開始利用影像或影片記錄生活的 點滴;因此,數位內容的還原及修改逐漸成為一個重要的研究議題。 針對數位內容的還原,影片修補技術(video inpainting)可以自動地 修補影片中內容缺失的部分,由於現存的影片修補技術對於影片中移 動物體的修補成效不彰,因此在本論文中,我們提出兩種物件修補技 術來修補影片中移動的物體;針對數位內容的修改,影片超解析度技 術(video super-resolution)可以自動地增加影片在空間軸及時間 軸上的解析度,由於現存的影片超解析度技術對於擴充影片中移動物 體在時間軸上的解析度成效不彰,因此在本論文中,我們提出一種視 訊內容擴充技術用來增加影片的畫面數同時擴充移動物體的動作內 容。在第一項研究中,我們先利用維度轉換將單張畫面上的物體資訊 轉換成時空切片(spatio-temporal slice)上的物體軌跡資訊,每條軌跡 紀錄物體某個部位沿著時間軸的變化趨勢,接著我們利用影像修補技 術來修補時空切片上軌跡缺失的區域,最後經過維度反轉換,在單張 畫面上我們重建被遮蔽物體可能的輪廓及位置。在下個步驟,根據重 建的物體輪廓,我們從可用的物體姿態(posture)中選取適合的姿態 並利用它取代畫面中被遮蔽的物體;當無可用的姿態時,我們提出一 種姿態合成技術合成所需的姿態。第一種方法的效率容易受物體運動 方向影響,因此我們在第二個方法中提出一種不受限於物體運動方向 的物件修補技術。 在第二項研究中,我們先利用流形學習(manifold learning) 將 影片中物體運動的資訊轉換成在流形空間(manifold space) 中運動 軌跡的資訊;根據軌跡在流行空間中的分佈情況,我們描述動作連續 的特性並定義兩種動作預測策略,利用定義的策略,我們可以預測被 遮蔽物體可能的姿態。接著我們結合提出的預測策略及雙向預測方 法,對於每個被遮蔽的物體選出一些可能的姿態,最後利用馬可夫隨 機場(Markov random field)來選來最適當的姿態。
在第三項研究中,針對畫面數較低的影片,我們提出一種視訊內 容擴充技術。我們先利用流形學習將影片中物體運動的資訊換換成在
流形空間中運動軌跡的資訊。在步驟二中,我們先利用提出的運動資 料對齊方法將不同的運動資訊對齊並排列至張量(tensor)中,接著利 用張量分解(tensor decomposition)從訓練的影片中抽取動作的資 訊,並結合原始影片的人物資訊重建原始影片在高畫面數情況下動作 軌跡在流形空間中分佈的情形,最後利用接著利用研究二中提出的方 法選出適當的姿態並插入影片中適當的位置。
Video Content Recovery and Modification by
Object Inpainting
Student:Chih-Hung Ling Advisors: Dr. Hong-Yuan Mark Liao
Dr. Yong-Sheng Chen Institute of Computer Science and Engineering
National Chiao Tung University Abstract
With the popularization of digital cameras, people use image or video to record some snapshots of daily life. Hence, video content recovery and modification has become a popular research field in recent years. For video content recovery, video inpainting is considered as one of the most important techniques that can be used to automatically recover the missing regions of videos. However, most video inpainting algorithms generate artifacts if the object to be inpainted is seriously occluded or its motion is not complicated. To avoid generating such artifacts, we propose two different kinds of object-based video inpainting schemes that can solve the above-mentioned spatial inconsistency problem and the temporal continuity problem simultaneously in this dissertation. As to video content modification, video super-resolution is considered as one of
important techniques that can be used to automatically increase spatial and temporal resolution of videos. However, existing super-resolution methods may fail to produce realistic and smooth results while dealing with sequences of human motion. Hence, we propose a learning-based approach which can increase the frame rate of video and also enrich the motion content of human motion.
In our first work, we present a novel framework for object completion in a video. We transform object in frames into object trajectory in spatio-temporal slices, and complete the partially damaged object trajectories in the 2-D slices. The completed slices are then combined to obtain a sequence of virtual contours of the damaged object. Next, a posture sequence retrieval technique is applied to retrieve the most similar sequence of object postures based on virtual contours. Finally, a synthetic posture generation scheme is proposed to reduce the effect of insufficient postures.
In our second work, we propose a human object inpainting scheme that divides the whole process into three steps: human posture synthesis, graphical model construction, and posture sequence estimation. Human posture synthesis is used to enrich the number of postures. Then, all
postures are projected into manifold space to build a graphical model of human motion. We also introduce two constraints to confine the local motion continuity property. Finally, we perform both forward and backward prediction to derive local optimal solutions and then apply the Markov Random Field model to compute an overall best solution.
In our third work, we propose a learning-based approach to increase the temporal resolution of human motion sequences. We summarize the proposed framework in the following steps: graphical model construction, motion trajectory reconstruction and posture sequence estimation. In the first step, each motion sequence is projected into manifold space and represented as a motion trajectory. Then, we apply tensor decomposition to decompose motion trajectories into orthogonal factors. After that, we combine the motion factor from training sequences with the person factor from the input sequence to reconstruct the motion trajectory for the input sequence. Finally, we use the reconstructed motion trajectory combined with object inpainting technique to generate the final result.
誌 謝 漫長的求學階段終於畫上句點,這段期間受到許多人的幫忙及照 顧,在此向曾經幫助我的師長、家人以及朋友獻上我的最誠摯的感謝。 首先要先感謝廖弘源老師,感謝老師提供了一個很好的研究環 境,讓學生可以無憂無慮的作研究,並同時以身作則教導我們做研究 及做人做事的道理,少了老師的教導,學生是無法完成這篇博士論 文。同時也要感謝林嘉文老師,感謝老師九年來的教導,老師不僅在 研究上給我許多指導,在學期間也給我許多的鼓勵及建議,讓學生在 遇到挫折時仍能堅持完成學業。感謝陳永昇老師在系上事務上給予的 許多幫忙及建議。感謝許秋婷老師在忙碌的生活中能願意撥空指導我 論文的內容及寫作的方法。在此並感謝百忙之中抽空指導我口試的蔡 文祥老師、莊仁輝老師、孫永年老師、范國清老師、柳金章老師及賴 尚宏老師,對於本論文的指導以及建議。 感謝在中研院的學長(志文、祐銘,敦裕、士韋、易聰、明昉、 家棟、立威、育駿)、同學(殷盈、興源)、學弟妹(堯麟、俊緯)及助 理(amy、亦雲),謝謝你們多年來的幫忙,這些年有了你們,讓枯燥 的研究生活變得更為有趣,讓徬徨無助的研究生活中多了盞明燈。 最感謝我的父母,這麼多年來的支持,也感謝我的妹妹這幾年來
幫我擔負著照顧父母的責任,讓我可以完成我的學業,僅以此篇論文 來表達我對家人的萬分感謝。
Table of Contents
摘 要 ... I Abstract ... IV 誌 謝 ... VII Table of Contents ... IX List of Table ... XII List of Figure... XIII
1 Introduction ... 1
1.1 Motivation ... 1
1.2 Related Work ... 4
1.3 Overview of the Proposed Methods ... 7
1.4 Dissertation Organization ... 11
2 Virtual Contour Guided Video Object Inpainting Using Posture Mapping and Retrieval... 12
2.1 Introduction ... 12
2.2 Occluded Object Completion Using Posture Sequence Matching ... 14
2.2.1 Overview ... 14
2.2.2 The Shape Context Descriptor ... 18
2.2.3 Virtual Contour Construction Using Spatio-Temporal Slices ... 20
2.2.4 Key Posture-based Posture Sequence Matching ... 28
2.2.5 Synthetic Posture Generation ... 32
2.4 Summary ... 47
3 Human Object Inpainting Using Manifold Learning-Based Posture Sequence Estimation ... 49
3.1 Introduction ... 49
3.2 Human Object Inpainting Using Posture Sequence Estimation ... 53
3.2.1 Human Posture Synthesis ... 53
3.2.2 Graphical Model Construction ... 53
3.2.3 Posture Sequence Estimation ... 56
3.3 Experimental Results ... 65
3.4 Summary ... 75
4 Object Posture Temporal Super-Resolution Using Tensor Decomposition-Based Manifold Learning ... 76
4.1 Introduction ... 76
4.2 Object Posture Temporal Super-Resolution... 79
4.2.1 Overview of the Proposed Method ... 79
4.2.2 Graphical Representation of Object Motion ... 83
4.2.3 Temporal Super-Resolution Using Tensor Decomposition–Based Manifold Learning ... 83
4.2.4 Posture Selection ... 89
4.3 Experimental Results ... 90
4.4 Summary ... 102
5 Conclusions and Future Work ... 103
5.1 Conclusions ... 103
5.2 Future Work ... 106
List of Table
2.1 Run-time analysis of key operations in the proposed method ... 46
3.1. Detailed information derived during the forward-backward
prediction process ... 61
3.2 Comparison of the ground-truth postures and the
reconstructed missing postures (The parts in black, red and gray represent the ground-truth postures, reconstructed
postures, and perfectly matched portions, respectively) ... 69
3.3 Comparison of the ground-truth postures and the
reconstructed missing postures (The parts in black, red and gray represent the ground-truth postures, reconstructed
postures, and perfectly matched portions, respectively) ... 74
4.1 Comparison of the ground-truth postures and the up-sampled
postures obtained by different methods for test sequence #1 ... 93
4.2 Comparison of the ground-truth postures and the up-sampled
postures obtained by different methods for test sequence #2 ... 95
4.3 Comparison of the ground-truth postures and the up-sampled
List of Figure
2.1 Simplified flowchart of the proposed video inpainting
scheme.……….. ... 15
2.2 Flowchart of the proposed object completion scheme. ... 17
2.3 Extracting the local context of a posture: (a) the object’s
original posture; (b) the object’s silhouette described by a set of feature points; (c) the local histogram of a significant feature point, (d) extracting significant feature points of the object’s silhouette using a convex hull surrounding the silhouette; and (e) the resultant significant feature points of the object’s silhouette. ... 19
2.4 Sampling a 3-D video volume comprised of several
consecutive frames: (a) the original frame; (b) the object trajectory on a sampled XT plane s, indicated by the green lines in (a); (c) the original frame; (d) the object’s trajectory on a sampled YT plane, indicated by the red lines in (c); (e) 2-D spatio-temporal slices sampled on a video shot, where the object’s size varies due to non-pure horizontal motion; and (f) the removed occluded object trajectories on the XT plane sampled on the 2-D plane. ... 24
2.5 The notations used for the data and confidence terms in
patch-based image inpainting [14]. ... 25
2.6 Virtual contours constructed by combining 2-D
method proposed in [14]. The left-hand side shows the virtual contours obtained by combining completed spatio-temproal slices without corrections, and the right-hand side shows the virtual contours with corrections. ... 27
2.7 The process for converting available postures and virtual
contours into a sequence of key posture labels. The blue frames and numbers indicate the frames with available postures and their corresponding key-posture labels. The orange frames and numbers indicate the frames with constructed virtual contours and their corresponding key-posture labels. ... 32
2.8 Examples of using substring matching to solve the posture
mapping problem. The length of the substring is 4. The blue numbers indicate the key-posture labels of available postures; the brown numbers indicate the labels of virtual contours; and the red numbers indicate the labels of available postures used to replace the occluded objects. In the first posture mapping, the available postures in frames 5, 6, n–5 and n–4 are deemed the best matches to replace the damaged objects in frames i,
i+1, j–1 and j respectively. In the second mapping, however, a
good match cannot be found for the damaged object in frame
i+2 (with the virtual contour labeled “V”). ... 32
2.9 Synthesizing a new posture using available postures. The new
posture is comprised of three components (the head, body, and legs) taken from different postures. ... 34
process.……….. ... 35
2.11 The constituent components of a posture are partitioned based
on local variance extraction. The dashed lines which separate postures into constituent components are determined based on the distribution of local variance shown on the right-hand side……… ... 36
2.12 Test sequence #1 containing a single pedestrian: (a) some
snapshots of the original video (ground-truths); (b) the virtual contours (on the left), which are constructed by combining the completed spatio-temporal slices and their corresponding best-match ostures (on the right); (c) the corresponding completed frames; (d) comparison of the completed objects
(on the left) and the ground-truths (on the right) ... 40
2.13 Test sequence #2 with two people walking toward each other:
(a) original video frames; (b) the virtual contours (on the left), which are constructed by combining the completed spatio-temporal slices and the corresponding best-match postures (on the right); (c) the completed frames (on the left) using the original key-postures and the additional synthetic postures and the corresponding frames composed from the completed 2-D slices (on the right). ... 42
2.14 Test sequence #3 containing two people walking toward each
other (with a long occlusion period): (a) original video frames; (b) the virtual contours (on the left) and the corresponding best-match postures (on the right) without including synthetic postures; (c) the virtual contours (on the left) and the
corresponding best-match postures (on the right) with the additional synthetic key-postures; and (d) the completed frames (on the left) using the original key-postures and the additional synthetic postures and the corresponding frames
composed from the completed 2-D slices (on the right). ... 44
2.15 Test sequence #4: (a) some snapshots of the original video; (b) the corresponding best-match postures; and (c) the result derived by the proposed method. ... 46
3.1 A graphical model of an object’s motion in a low-dimension manifold. The blue points represent the feature points of the postures, and the red lines connect two feature points whose corresponding postures appear in adjacent frames. In this example, occlusion occurs between frames i and j, so we try to find a motion path with l internal points that can be used to link points xi and xj. ... 54
3.2 The neighborhood constraint. ... 57
3.3 The motion tendency constraint. ... 58
3.4 Some snapshots extracted from test sequence #1. ... 60
3.5 (a)−(b) some forward prediction steps, (c)−(d) some backward prediction steps, and (e) the combined results of two-way prediction at time t. ... 61
3.6 An example of the MRF process. ... 64
3.7 The experiments on test sequence #1: (a) partial sequence of
test sequence #1 in which the red rectangle indicates missing frames; (b) frames reconstructed by Ding et al.’s approach; (c) frames reconstructed by Xu et al.’s approach; (d) frames
reconstructed by the proposed approach; and (e) the corresponding trajectory information of predicted object motion generated by the three approaches. ... 69
3.8 The experiments on test sequence #2: (a) some snapshots of
the occluded object in the test sequence; (b) frames reconstructed by Ding et al.’s approach; (c) frames reconstructed by Xu et al.’s approach; (d) frames reconstructed by the proposed approach; and (e) the inpainting result derived by our approach. ... 71
3.9 The experiments on test sequence #3: (a) partial sequence of
the test sequence in which the red rectangle indicates the 7 missing frames; (b) the frames reconstructed by Ding et al.’s approach; (c) the frames reconstructed by Xu et al.’s approach; (d) the frames reconstructed by the proposed approach; and (e) the corresponding trajectory information of predicted object
motion generated by the compared approaches…… ... 74
4.1 Flowchart of the proposed posture super-resolution scheme ... 82
4.2 Illustration of tensor decomposition and arrangement: (a) a
tensor data is decomposed into the product of core tensor and orthogonal factors, and (b) a tensor is flattened in two
different ways to obtain flattened matrices. ... 85
4.3 Illustration of the low-dimensional manifolds of two different
posture sequences and the corresponding postures at the crests and troughs of the manifold. ... 86
4.4 (a) The coordinates of the k postures of the LR input sequence.
along the mean motion curve of all the HR learning sequences. The index of the k reference points indicates the suitable position in tensor of the input sequence postures. ... 88
4.5 Our scheme of arranging training postures into tensor data,
where the green rectangles represent unknown object postures in the tensor. In tensor decomposition, we extract the motion factor only from the training sequences as indicated by the red rectangles and the person factor from the columns with
complete postures as indicated by the blue rectangles. ... 89
4.6 Comparison of reconstruction accuracies with respect to the
ground-truth sequence with nine subsampling rates for test sequence #1. The five compared methods include Xu et al’s approach [39], Ding et al’s approach [10], Makihara et al’s approach [59], object inpainting [60] and the proposed temporal SR approach. ... 101
Chapter 1
Introduction
1.1 Motivation
With the popularization of digital cameras, video content recovery and modification has become a popular research field in recent years. For video content recovery, video inpainting [1]-[11] has attracted a great deal of attention in recent years because of its powerful ability to fix/restore damaged videos and the flexibility it provides for editing home videos. It also ensures visual privacy in security applications [12]. More specifically, inpainting techniques have been used extensively for fixing/restoring damaged digital images [13]-[18]. Depending on how they restore damaged images, the techniques can be categorized into three groups:
texture synthesis-based methods [13][14], partial difference
equation-based (PDE-based) methods [15], and patch-based methods [16].The concept of texture synthesis is borrowed from computer graphics. Its main purpose is to insert a chosen input texture into a damaged/missing region. In contrast, PDE-based approaches propagate information from the boundary of a missing region toward the center of
that region. They are suitable for completing a damaged image in which thin regions are missing. Texture synthesis and PDE-based propagation cannot handle cases of general image inpainting because the former does not consider structural information and the latter frequently introduces blurring artifacts. A patch-based approach [16], on the other hand, is much more suitable for image inpainting because it can produce high-quality visual effects and maintain the consistency of local structures. Because of the success of patch-based image inpainting, researchers have applied a similar concept in video inpainting; however, the issues that need to be addressed in video inpainting are much more challenging. Although video inpainting is a relatively new research area, a number of methods have been proposed in recent years. Generally, the methods can be classified into two types: patch-based methods [1]-[6], and object-based methods [7][8]. Patch-based methods often have difficulty handling spatial consistency and temporal continuity problems. In addition, patch-based approaches often generate inpainting errors in the foreground. As a result, many researchers have focused on object-based approaches, which usually generate high-quality visual results. Even so, some difficult issues still need to be addressed; for example, the artifacts
generated by inpainting completely occluded object or inpainting occluded object with non-periodic motion. Hence, in this dissertation, we propose two different kinds of object-based video inpainting schemes that can solve the spatial inconsistency problem and the temporal continuity problem simultaneously.
As to video content modification, super resolution-based (SR-based) methods have attracted much attention for their ability in enhancing the spatial or temporal resolution of low-resolution (LR) images/videos [48]−[54]. While dealing with sequences of human motion, existing SR-based methods may fail to produce realistic and smooth results if no special efforts are taken to handle the non-rigid human motion. Since human motion usually contains repeated postures, one may insert interpolated postures into the LR input sequence to increase the temporal resolution. In order to generate postures and animate animal/human motion, Xu et al. [39] proposed to animate motions by minimizing a predefined energy function. Since the energy minimization process did not include a human motion model, the performance is unstable and very sensitive to the selected parameters. Therefore, some existing methods [10] [59] develop their approach under the constraint of periodic motion.
To overcome the above mentioned drawbacks, we propose the use of learning-based approach to extract motion tendency from a set of learning sequences and then synthesize human motion using the learned motion tendency as the prior information.
1.2 Related Work
Conventional video inpainting methods can be roughly classified into two types: the first type is patch-based [1]-[6] and the other type is template-based [7][8]. In [1], Patwardhan et al. proposed a video inpainting technique that makes use of motion information and image inpainting technique together. Motion information is adopted to help find the most suitable patch. In [2], the space-time volume is sliced up into motion manifolds to perform video completion. The proposed manifolds are composed of two-dimensional patches (one for the spatial dimension and the other for the temporal dimension). These patches cover the entire trajectory of pixels, and the method in [2] applies Sun et al.’s approach [17] to inpaint those missing regions. However, these approaches would cause spatial or temporal structure inconsistency artifacts. In [4], Wexler
value of a missing pixel is estimated by a set of constituent patches and a multiscale solution is used to speed up the process. In [5], Cheung et al. introduced a probabilistic patch model for video inpainting. They use a video epitome method to compress an original video by learning, after that the epitome is used to synthesize data for the damaged areas of a video.
In the template-based video inpainting category, Cheung et al. [7] proposed a technique to deal with the problem of missing objects in videos captured by a stationary camera. All available object templates are used to inpaint the foreground. Then, for each missing object, a fixed-size sliding window that covers the missing object and its neighboring templates is used to find the most similar object template. Although the sliding window can help find similar object templates, the inpainting result may be unsatisfactory if the number of postures is insufficient. Furthermore, a good filling position is crucial for an object inpainting process because an inappropriate position may cause visually annoying artifacts. In [8], Jia et al. proposed a user-assisted video layer segmentation technique that decomposes an input video into color and illumination videos. A tensor voting technique is then used to address the
pertinent spatio-temporal issues in background and foreground. Image repairing is used for background inpainting and occluded objects are reconstructed by synthesizing other available objects. However, a synthesized object created under this approach does not have a real trajectory, so the approach is only suitable for objects with periodic motion.
As to human motion animation, Ding et al. [10] proposed a rank minimization approach to model and synthesize human motion for video inpainting. They first projected the observed data into a low-dimension manifold and then organized the embedded features to form a Hankel matrix. The missing features in the Hankel matrix are determined by minimizing the rank of Hankel matrix. Finally, they applied the Radial Basis Function (RBF) to inversely transform the embedded features back to the observation domain. This rank minimization approach would usually produce good results as far as the object’s motion is periodic. Makihara et al. [59] proposed a reconstruction-based method to synthesize periodic human motion with high frame rate from a single periodic motion sequence. The human motion data are first transformed into embedded features in a low-dimension manifold. Then, they
iteratively conducted phase registration and motion trajectory reconstruction within an energy minimization process. Under the constraint of periodic motion, their method could also produce good experiment results.
1.3 Overview of the Proposed Methods
Our literature survey shows that most video inpainting algorithms generate artifacts if the object to be inpainted is completely occluded or its motion is not periodic. To void generating such artifacts, a posture sequence estimation process of good accuracy is required for object inpainting. In this dissertation, we propose two different kinds of object-based video inpainting schemes that can solve the spatial inconsistency problem and the temporal continuity problem simultaneously. As to human motion animation, some kinds of method [10] [59] have performance limitation of periodic motion. Therefore, in this dissertation, we propose to extract motion tendency form a set of learning sequences as prior information and then synthesize human motion using the extracted motion tendency.
Virtual Contour Guided Video Object Inpainting Using Posture Mapping and Retrieval
In this work, we present a novel framework for object completion in a video. To complete an occluded object, our method first samples a 3-D volume of the video into directional spatio-temporal slices, and performs patch-based image inpainting to complete the partially damaged object trajectories in the 2-D slices. The completed slices are then combined to obtain a sequence of virtual contours of the damaged object. Next, a posture sequence retrieval technique is applied to the virtual contours to retrieve the most similar sequence of object postures in the available non-occluded postures. Key-posture selection and indexing are used to reduce the complexity of posture sequence retrieval. We also propose a synthetic posture generation scheme that enriches the collection of postures so as to reduce the effect of insufficient postures. The experiment results demonstrate that the proposed method can maintain the spatial consistency and temporal motion continuity of an object simultaneously.
Sequence Estimation
In this work, we propose a human object inpainting scheme that divides the process into three steps: human posture synthesis, graphical model construction, and posture sequence estimation. Human posture synthesis is used to enrich the number of postures in the database, after which all the postures are used to build a graphical model that can estimate the motion tendency of an object. We also introduce two constraints to confine the motion continuity property. The first constraint limits the maximum search distance if a trajectory in the graphical model is discontinuous; and the second confines the search direction in order to maintain the tendency of an object’s motion. We perform both forward and backward prediction to derive local optimal solutions. Then, to compute an overall best solution, we apply the Markov Random Field model and take the potential trajectory with the maximum total probability as the final result. The proposed posture sequence estimation model can help identify a set of suitable postures from the posture database to restore damaged/missing postures. It can also make a reconstructed motion sequence look continuous.
Object Posture Super-Resolution Using Tensor Decomposition-Based Manifold Learning
In this work, we propose a learning-based approach to increase the temporal resolutions of human motion sequences. Given a set of high resolution motion sequences, our idea is first to learn the motion tendency from this learning dataset and then synthesize new postures for the low-resolution sequence according to the learned motion tendency. To ensure the synthesized motion should preserve the learned motion tendency as well as its personal characteristic, we propose using tensor decomposition to decompose motion data into two orthogonal factors. We summarize the proposed framework in the following steps: (1) Each motion sequence is first projected into a low-dimension manifold space, where the local distance between postures could be better preserved. We then represent each of the projected motion sequences as a motion trajectory, and conduct tensor decomposition on the motion trajectories to extract the two orthogonal factors: motion and person. (2) We combine the motion factor from training sequences with the person factor from the input sequence to reconstruct the motion trajectory for the input sequence. (3) We use the reconstructed motion trajectory combined with object
inpainting technique to generate the final result. Our experimental results demonstrate the effectiveness of the proposed method, and also show its outperformance over two existing approaches.
1.4 Dissertation Organization
The remainder of this dissertation is organized as follows. In Chapter 2, the proposed framework for virtual contour guided video object inpainting using posture mapping and retrieval is described in detail. In Chapter 3, the proposed framework for human object inpainting using manifold learning-based posture sequence estimation is described in detail. In Chapter 4, the proposed object posture super-resolution using tensor decomposition-based manifold learning is described in detail. Finally, in Chapter 5, we draw our conclusions and future work.
Chapter 2
Virtual Contour Guided Video Object Inpainting Using
Posture Mapping and Retrieval
In this Chapter, we describe the proposed framework for virtual contour guided video object inpainting using posture mapping and retrieval. First, we give an introduction about this research topic. The proposed approach is then described. Next, we detail the experiment results. Finally, we present our conclusions.
2.1 Introduction
Video inpainting [1]-[11] has been a very popular research topic recently due to its powerful ability to fix/restore damaged videos and the flexibility it provides for editing home videos. Researchers working in this field divide video inpainting methods into patch-based methods [1]-[6] and object-based methods [7][8]. A patch-based method often has difficulty handling spatial consistency and temporal continuity problems. As a result, many researchers have focused on object-based approaches, which usually generate high-quality visual results. Even so, some difficult issues still need to be addressed; for example, the unrealistic trajectory
problem and the inaccurate representation problem caused by an insufficient number of postures in the database. In order to solve these problems, we propose an object-based video inpainting scheme. The scheme is comprised of three steps: virtual contour construction, key-posture selection and mapping, and synthetic posture generation. The contribution of this work is three-fold. First, we propose a scheme that is able to derive the virtual contour of an occluded object. The contour provides a fairly precise initial estimate of the posture and filling location of the occluded object, even if the object is completely occluded. Therefore, the virtual contour is suitable for finding a good replacement for the occluded object from the available postures in the input video. Second, we propose a key posture-based mapping scheme that converts the posture sequence retrieval problem into a substring matching problem, thereby reducing the computational complexity significantly, while maintaining the matching accuracy. Since the occluded objects are completed for a whole sub-sequence rather than for individual frames, the temporal continuity of object motion is maintained as well. Third, for a sequence in which we cannot find a sufficiently rich set of available postures for completing occluded postures, our proposed synthetic
posture generation scheme can effectively enrich the database of postures by combining the constituent parts of different available postures. As a result, improved inpainting performance is achieved.
2.2 Occluded Object Completion Using Posture Sequence Matching
2.2.1 Overview
The proposed object-based video inpainting scheme can maintain the spatial consistency and temporal motion continuity of an object simultaneously. The scheme can also handle the problem of insufficiency of available postures. Figure 2.1 shows a block diagram of the proposed scheme. Initially, we assume that the objects to be removed and the occluded objects to be restored have been extracted by an automatic object segmentation scheme [19], or by an interactive extraction scheme [20]-[22]. After object extraction, the occluded objects and the background are completed separately. We also assume that the trajectory of each occluded object can be approximated by a linear line segment during the period of occlusion. This assumption is reasonable for many practical applications because the duration of an occlusion is typically short, and an object does not usually perform complex motions during
such a short period.
Building background
mosaic Background inpainting Virtual contour
construction by spatio-temporal slice sampling
and inpainting
Posture mapping
Replacing a damaged object with a synthetic
posture Replacing a damaged object with an available
posture Result Object extraction Input video Object inpainting
Figure 2.1 Simplified flowchart of the proposed video inpainting scheme.
Our primary goal is to solve the problem of completing partially or totally occluded objects in a video. Figure 2.2 shows the flowchart of the proposed object completion scheme which is comprised of three steps: virtual contour construction, key posture-based posture sequence matching, and synthetic key posture generation. The first step of object inpainting involves sampling a 3-D volume of video into directional spatio-temporal slices. Then a patch-based (exemplar-based) image inpainting [16] operation is performed to complete the partially damaged object trajectories in the 2-D spatio-temporal slices. The objective is to maintain the trajectories’ temporal continuity. The completed
spatio-temporal slices are then combined to form a sequence of virtual contours of the target object to infer the missing part of the object’s posture [29]. Next, the derived virtual contours and a posture sequence matching technique are used to retrieve the most similar sequence of object postures from among the available non-occluded postures. The available postures are collected from the non-occluded part of the input video. We perform key posture selection, indexing, and coding operations to convert the posture sequence retrieval problem into a substring search problem, which can be solved efficiently by existing substring-matching algorithms [23]. If a virtual contour cannot find a good match in the database of available postures, we construct synthetic postures by combining the constituent components of key postures to enrich the posture database. This process mitigates the problem of insufficient available postures. After retrieving the most similar posture sequence, the occluded objects are completed by replacing the damaged objects with the retrieved ones.
For background inpainting, we follow the background mosaics method proposed in [1]. The method first constructs a background mosaic for each video shot based on global motion estimation (GME), and then
finds the corresponding available data in the background mosaic for each pixel in a missing region. The data is used to fill the missing regions and thereby achieve spatio-temporal consistency in the completed background. Since background inpainting is not the focus of this work we do not consider its implementation in detail.
Input Video Posture extraction Spatio-temporal slice sampling Patch-based image inpainting Correction of completed slices Virtual contour construction Keyposture selection
Mapping available postures and virtual contours to key posture indices
AABC...CV…GG…FGGB
Replace damaged objects with synthetic postures
Replace damaged objects with available postures
Result
Synthetic posture creation
Substring matching
Posture alignment & normalization
2.2.2 The Shape Context Descriptor
Before discussing the proposed method in detail, we describe the shape context descriptor in [23][24], which we use for posture alignment/normalization and key posture selection. The descriptor is invariant to translation, scaling, and rotation; and it is even robust against small amounts of geometrical distortion, occlusion and outliers. As shown in Figure 2.3, given an object image (Figure 2.3 (a)), the descriptor selects a set of feature points to describe the object’s silhouette (Figure 2.3 (b)). The object’s local shape context is described by the local histograms of the regions centered at the feature points. Under this method, for each feature point, a circle with radius r (Figure 2.3 (c)) is
used to find the local histogram. The circle is then divided into Nbin
partitions and the number of feature points in each partition is calculated,
resulting in a histogram with Nbin bins. The value of Nbin is
empirically set to be 60 for all sequences. The cost of matching two different sampled points which belong to two different postures can be defined as follows: bin 2 1 ( ) ( ) 1 ( , ) 2 ( ) ( ) i j i j N a c i j k a c h k h k F a c h k h k = − = +
∑
, (2.1) where ( ) i a h k and ( ) j cai and cj, respectively. The value of Nbin is empirically set to be 60 for
all sequences, and the value of r is determined by an algorithm described in [24]. The best match between two different postures can be accomplished by minimizing the following total matching cost:
(
( ))
( ) j, j j
H π =
∑
F a cπ , (2.2)where π is a permutation of 1, 2, …, n. Because of the one-to-one
matching requirement, shape matching can be considered as an assignment problem that can be solved by a bipartite graph matching method. Therefore, the shape context distance between two shapes A and
C can be computed by ( ) ( ) 1 1 ( , ) ( , ) ( , ) sc i i j j i j A C F A C F a c F a c N π N π =
∑
+∑
, (2.3)where NA and NC are the numbers of sample points on the shape A and C,
respectively.
(a) (b) (c) (d) (e)
posture; (b) the object’s silhouette described by a set of feature points; (c) the local histogram of a significant feature point, (d) extracting significant feature points of the object’s silhouette using a convex hull surrounding the silhouette; and (e) the resultant significant feature points of the object’s silhouette.
2.2.3 Virtual Contour Construction Using Spatio-Temporal Slices The main difficulty in completing a damaged video object is that the information left in a badly damaged object is usually insufficient to reconstruct the object properly by using spatio-temporal clues. Furthermore, completing an object frame-by-frame often causes temporal discontinuity in the object’s appearance and motion, since a frame-wise completion process does not consider an object’s temporal dependency in consecutive frames. Such temporal discontinuity results in visually annoying artifacts like flickering and jerkiness. To ensure that a completed object is visually pleasing, it is important to extract a set of features from a damaged object in a number of consecutive frames. As a result, the features not only represent the object’s characteristics (e.g., motion, appearance, and posture), but also take its temporal continuity into account.
Manifold learning based methods [10][25] have been proposed to recover the damaged/missing poses of an occluded object. Although the
consecutive poses of an object with regular and cyclic motion can be well represented by a low-dimensional manifold embedded in a high-dimensional visual space, poses with non-regular motions (e.g., transitions in two types of motions) are usually not the case. As a result, mapping reconstructing a high-dimensional video object with irregular or non-cyclic motion from the object’s low-dimensional manifold approximation usually leads to annoying artifacts (e.g., ghost images).
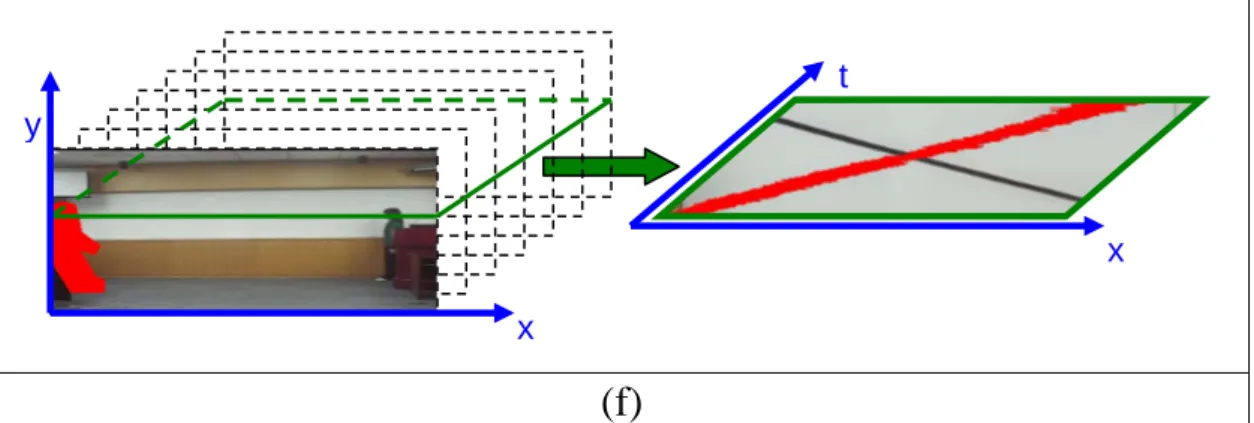
As mentioned earlier, we use spatio-temporal slices of a video to derive virtual object contours, which are then used as features to infer the occluded object poses. More specifically, after object extraction and removal, we sample a 3-D video volume comprised of several consecutive frames to obtain a set of directional 2-D spatio-temporal slices, as shown in Figure 2.4. For example, if a 3-D video volume (Figure 2.4 (a)) is sampled at different Y values (Figure 2.4 (b)), each resulting XT slice represents the horizontal trajectory of an object over time. The trajectory can fully capture an object’s motion if it only has horizontal motions. Other directional sampling schemes can be used to deal with objects that have different motion directions. Note that a non-pure horizontal motion will cause an object’s size to vary over time
due to the zoom-in/zoom-out effect, as shown in Figure 2.4(c). In this case, posture alignment and normalization can be used to avoid the inference of different posture scales. Without loss of generality, we use the largest posture of an object as a reference for aligning and normalizing the other postures. First, we establish the correspondence between the contour points of every two adjacent postures by shape matching [23][24]. The affine transformation parameters between the largest posture and the others can then be estimated from the corresponding points using the least squares optimization method. As a result, all postures are aligned and normalized with the largest posture via the affine transformations. As shown in Figure 2.4(d), after removing the foreground object and posture alignment, after removing the foreground object and posture alignment, object occlusion results in incomplete trajectories of the object in the spatio-temporal slices. The missing regions of object trajectories in the 2-D spatio-temporal slices must be completed using an image inpainting method before composing a virtual contour. Because an object’s occlusion period is usually short, we assume that the occluded part of a motion trajectory in a 2-D slice can be approximated by a line. Based on this assumption, the occluded part in
each directionally sampled slice can be inpainted well. Since the trajectory of an object on each 2-D slice records the locations of the same part of object over time, as long as the missing regions of trajectories are completed properly, the reconstructed trajectories will be continuous, thereby preserving the temporal continuity of an object.
(a) (b) (c) (d) (e) x y X t Y Y X Y X t
(f)
Figure 2.4 Sampling a 3-D video volume comprised of several consecutive frames: (a) the original frame;(b) the object trajectory on a sampled XT plane s, indicated by the green lines in (a); (c) the original frame; (d) the object’s trajectory on a sampled YT plane, indicated by the red lines in (c); (e) 2-D spatio-temporal slices sampled on a video shot, where the object’s size varies due to non-pure horizontal motion; and (f) the removed occluded object trajectories on the XT plane sampled on the 2-D plane.
To obtain continuous object trajectories, we use the patch-based image inpainting scheme proposed in [16] to complete missing regions in the spatio-temporal slices. The method first determines the filling order of the missing regions based on the confidence term and data term as follows:
( ) ( ) ( )
P p =C p ⋅D p , (2.4)
where P(p) represents the priority of a missing regionp; and C(p) and
D(p) denote the confidence term and the data term expressed in (2.5) and
(2.6) respectively. ( ) ( ) ( ) q p p C q C p = ∈Ψ ∩ Ι−Ω Ψ
∑
, (2.5) x y x t( ) Ip np D p α ⊥ ∇ ⋅ = , (2.6)
where Ψ represents the area of region p Ψ , p α is a normalization
factor, n denotes the unit vector orthogonal to the front p δΩ at point
p , and ⊥ stands for the orthogonal operator, as illustrated in Figure 2.5.
Figure 2.5 The notations used for the data and confidence terms in patch-based image inpainting [14].
Based on the filling order, a missing region is filled with the most similar neighboring patches (measured by the sum of squared differences). After completing each spatio-temporal slice of a video frame, we use the Sobel edge detector to find the boundary of the object’s trajectory in the slice. Then, the completed spatio-temporal slices are combined to construct a virtual contour, which is used to guide the subsequent posture mapping and retrieval process.
Sometimes, image inpainting errors lead to imprecise virtual contours, making it difficult to retrieve correct postures for object inpainting. To resolve this problem, we use the object tracking scheme proposed in [27] to correct image inpainting errors. To inpaint an occluded object, our method tracks the object in the non-occlusion period to obtain their positions. Accordingly, each spatio-temporal slice is then divided into two regions, the background region and the foreground trajectory, which allows us to apply image inpainting to the regions separately and thereby avoid inpainting errors. That is, available foreground information will only be used to infill the missing region of foreground region, and vice versa. Figure 2.6 shows that the tracking-based correction technique significantly reduces the distortion of a virtual contour caused by inpainting errors.
Figure 2.6 Virtual contours constructed by combining 2-D spatio-temporal slices derived via the patch-based inpainting method proposed in [14]. The left-hand side shows the virtual contours obtained by combining completed spatio-temproal slices without corrections, and the right-hand side shows the virtual contours with corrections.
The rationale behind the proposed virtual contour construction method is that if the continuity of object trajectories can be maintained in individually completed spatio-temporal slices, then the motion continuity of an object reconstructed by combining all the inpainted slices will also be maintained. Thus, so long as the linear line motion assumption holds during the occlusion period, a virtual contour can provide fairly precise information about the posture and filling location of an occluded object,
even if the object is badly damaged.
2.2.4 Key Posture-based Posture Sequence Matching
After composing a sequence of consecutive virtual contours, we use them to match the most similar posture sequence in the set of available postures to complete the occluded objects. To simplify the posture sequence matching process, we use the key posture selection method proposed in [24] to select the most representative postures from among the available postures. The method uses also uses the shape context descriptor in [24] to measure the similarity between two postures. As illustrated in Figure 2.3, given an object’s posture (Figure 2.3 (a)), a set of feature points are selected to describe the object’s silhouette (Figure 2.3 (b)). To reduce the complexity of posture matching without sacrificing the matching accuracy significantly, a convex hull bounding the silhouette (Figure 2.3 (d)) is used to select a subset of key feature points (Figure 2.3 (e)) to describe the shape context of the object. The similarity between two postures is evaluated by matching the two corresponding posture silhouettes by (2.3). A posture is deemed a key posture if its degree of similarity to all key postures exceeds a predefined threshold, THposture,
that is empirically set to be 0.08. The key-posture selection algorithm is summarized below.
Algorithm: Key Posture Selection
The set of key-postures Q = {q1, q2,…, qn}
The available posture database B = {b1, b2,…, bn}
For i = 1 to n { If ( Q = φ) Q = Q ∪bt else if (H b q( ,i j)>THposture,∀ ) qj Q = Q ∪bt }
After the key posture selection process, each key posture is labeled with a unique number. The virtual contour of each available posture is then matched with the key posture that has the most similar context, as defined in (2.3). If a virtual contour cannot be matched in this way, it is given a special label. As a result, a sequence of contiguous available postures and virtual contours can be converted into a string of key-posture labels based on the temporal order, as shown in Figure 2.7.
After the encoding process, the problem of retrieving the most similar sequence of postures for a sequence of virtual contours becomes a substring matching problem [26] that, given an input segment of codes, searches for the most similar substring in a long string of codes. The occluded objects are then replaced with the retrieved sequence of available postures. Figure 2.8 shows two examples of using substring matching to solve the posture mapping problem. During the occlusion period, a string of labels in a fixed-size sliding window (the size is 4 in the example) is matched to the substring of labels in the normal periods. We use two sliding windows that respectively start from the two ends of the occlusion period and move toward the center of the period. Each sliding window overlaps with the neighboring normal period by half a window. As a result, half of the labels in the initial string are derived from available postures and the remaining labels are obtained from the virtual contours. As illustrated in the first example of Figure 2.8, the left sliding window initially consists of four postures encoded as “BBCC” including two available postures (the “BB” part) in frames i–2, i–1 and two virtual contours (the “CC” part) in frames i, i+1. The right sliding window initially contains four postures encoded as “EFGG” where “EF”
represents the two virtual contours in frame j–1 and j. and “GG” represents the two available postures in frames j+1, and j+2, respectively. In this example, the available postures in frames 5, 6, n–5 and n–4 of the two initial sliding windows are deemed the best-match sequence to replace the damaged objects in frames i, i+1, j–1 and j. In the second matching, however, a good match cannot be found for the damaged object in frame i+2 (with virtual contour label “V”) after substring matching. Our method handles such situations by constructing synthetic key-postures, as will be discussed later.
Using the proposed key-posture selection and mapping method to encode a sequence of virtual contours and available postures with a compact representation of key-posture labels has two advantages. First, since there are many efficient substring matching algorithms, converting the posture sequence retrieval problem into a substring matching problem reduces the computational complexity substantially. Second, as the occluded objects are completed for a whole sub-sequence rather than for individual frames, the temporal continuity of object motion is maintained.
1, 2, 3, 4,…….…. i, i+1,i+2,…….. j-1, j,…………. n-2, n-1, n Key posture selection Key posture database Similarity measure
AABBCCDEFGGA……BBCCE…EEFGG……AFFEEFGGDBA
Figure 2.7 The process for converting available postures and virtual contours into a sequence of key posture labels. The blue frames and numbers indicate the frames with available postures and their corresponding key-posture labels. The orange frames and numbers indicate the frames with constructed virtual contours and their corresponding key-posture labels.
1, 2, 3, 4,…….…. ……… i, i+1, i+2,……. j-1, j,………. n-2, n-1, n Posture mapping 1 B B C C B B C C B B C C E F G G E F G G E F G G Posture mapping 2 A A B B C C E F…B B C CV …G E FG G…F G E F G G D B A A B B C C E F…B B C C V …G E F G G…F G E F G G D B C CV ? C CV ? ………....………..C CV ?
Can not find same substring => no similar posture for virtual contour V
………..…………E F G G
Figure 2.8 Examples of using substring matching to solve the posture mapping problem. The length of the substring is 4. The blue numbers indicate the key-posture labels of available postures; the brown numbers indicate the labels of virtual contours; and the red numbers indicate the labels of available postures used to replace the occluded objects. In the first posture mapping, the available postures in frames 5, 6,
n–5 and n–4 are deemed the best matches to replace the damaged objects in frames i, i+1, j–1 and j respectively. In the second mapping, however, a good match cannot be
found for the damaged object in frame i+2 (with the virtual contour labeled “V”).
The occlusion problem occurs in real-world applications all the time; hence, a virtual contour generated from an occlusion event may not find a good match among the selected key postures due to the lack of available non-occluded object postures. The problem of insufficient postures usually arises when the occlusion period for a to-be-completed object is long, resulting in many reconstructed virtual contours, or when the object’s non-occlusion period is too short to collect a sufficiently rich set of non-occluded postures. Using a poorly matched posture to complete an occluded object can result in visually annoying artifacts. To resolve the problem where a virtual contour cannot find a good-match in the available key-posture database, we synthesize more postures by combining the constituent components of the available postures to enrich the content of the database. Figure 2.9 shows how a new posture is synthesized by using three constituent components (the head, torso, and legs) from different available postures selected by a skeleton matching process.
The flowchart of the proposed synthetic posture generation process is shown in Figure 2.10. First, the skeleton of a virtual contour that cannot find a good match in the posture database is extracted using the scheme
proposed in [28], which is also used to extract the skeletons of all available postures. Then, the constituent components of each selected key-posture are decomposed based on the distribution of the variance in alignment errors between every two aligned key-postures. The component decomposition result of key postures is used to help segment the extracted skeletons into their constituent components. We use the segmented skeleton components of a virtual contour to retrieve similar posture components, which are then used to synthesize new postures.
Figure 2.9 Synthesizing a new posture using available postures. The new posture is comprised of three components (the head, body, and legs) taken from different postures.
Extract the skeleton of the virtual contour
Divide the skeleton into its constituent
components
Extract the skeletons of
available postures
Divide the skeletons into their constituent
components Calculate the local
variance between two key postures Calculate the distribution of local variance Calculate the distribution of local variance Segment constituent components Virtual contour
Find the most similar components and combine them to obtain a synthetic
posture ...
Key-postures
... Available postures
Figure 2.10 Flowchart of the proposed synthetic posture generation process.
All of the above-mentioned constituent components are derived from the components of existing database postures. To use these components, we need to perform segmentation on the key-postures in advance, as shown in Figure 2.11. After aligning the postures, we compute the difference between every two consecutive key postures. From the distribution of the variance, it is possible to identify the components that move more frequently. Then, we label the “frequently moving” components as the constituent components of the posture synthesis process.
Figure 2.11 The constituent components of a posture are partitioned based on local variance extraction. The dashed lines which separate postures into constituent components are determined based on the distribution of local variance shown on the right-hand side.
We use the skeletons of objects to retrieve similar posture components, which are then used to synthesize new postures. To extract object skeletons, we employ the method proposed in [28]. It defines candidate skeleton points as the centers of the maximal disks located inside the planar shape. Then, a Euclidean distance map is used to determine whether or not a candidate skeleton point is a genuine skeleton point. A candidate skeleton point is deemed a real skeleton point if any one of its eight neighbors satisfies the connectivity criterion:
2 2 2 2 1 1 and max( , ) r r D x y ρ − ≤ ≥ , (2.7)
where x= x2 − and x1 y = y2 − y , in which 1 ( ,x y1 1)and( ,x y2 2)denote,
respectively, the coordinates of the two nearest contour points e1 and e2;
1
r and r2 represent, respectively, the shortest and longest distances
the distance between the two nearest contour points; and ρ is a pre-determined threshold.
We use the following relevance metric, K, to measure the contribution of an arc to the shape of a contour in order to determine whether the arc is a redundant branch of the skeleton:
1 2 1 2 1 2 1 2 ( , ) ( ) ( ) ( , ) ( ) ( ) l l l l l l K l l l l l l β = + , (2.8)
where l1 and l2 represent, respectively, two line segments of the object’s
contour; β( , )l l1 2 is the turn angle at the common vertex of segments ls1
and ls2; and l(·) denotes the length function.
The relevance metric allows us to select and remove arcs that only make a small contribution to an object’s shape. This operation reduces the shape’s contour, which is then used to remove unimportant skeleton points. We use the thresholds derived in the posture classification step to separate the skeletons of virtual contours and those of the available postures. After aligning the parts of a skeleton in the virtual contours with the corresponding parts in the available postures, the best-matched skeleton components of the available postures can be identified based on the following similarity metric:
( , ) ( , ) , , ( , ) ( , ) x y x y x y x y t T s S S T S w t s ∈ ∩ ∈ =
∑
, (2.9)where T an S denote, respectively, the skeleton component of a virtual contour and the corresponding part in an available posture; and
, ,
( x y, x y)
w t s represents the matching score of the corresponding skeleton
points, tx y, and sx y, , of the virtual contour and the available posture,
defined as follows:
1 , ,
, , 2 , ,
, if and belong to the skeleton region
( , ) , if and belong to the foreground region
0, otherwise x y x y x y x y x y x y score t s w t s score t s = , (2.10)
Here, the two score constants, score1 and score2, are set empirically as 3
and 1 respectively.
Finally, a new posture can be synthesized by combining all the best-matched constituent components of the available postures selected by the component-wise skeleton retrieval process.
2.3 Experimental Results
We used six test sequences to evaluate the efficacy of our method. Five sequences were captured by a commercial digital camcorder with a frame rate of 30 fps, and a resolution of 352×240 (SIF). The remaining one was taken from [1]. In the experiments, we first removed unwanted objects and occluded objects completely, and then used the proposed inpainting method to reconstruct the occluded objects.
Figure 2.12(a) shows some snapshots of test sequence #1, which contains a pedestrian. In this experiment, we intentionally removed the person from 20 consecutive frames, and then used the proposed method to restore the missing person. This test case simulates a real-world situation in which objects in a number of consecutive frames are damaged due to packet loss during transmission of the video (e.g., the loss of several video-object-planes of an MPEG-4 stream), or due to a damaged hardware component (e.g., a hard disk or an optical disk). Since we have the ground-truth of the missing object in this case, we can evaluate the performance of our object completion method based on the ground-truth. First, we observe that the virtual contours of the missing objects, constructed by combining the completed spatio-temporal slices (shown in Figure 2.12(b)), retain most of the objects’ posture information. This verifies that the virtual contour of a missing object provides a fairly good initial estimate for finding the best-matched available posture to complete the missing object. Figure 2.12 (c) shows that the objects completed frame-by-frame by the proposed posture mapping scheme conform to the ground-truths very well. Moreover, the scheme maintains the temporal continuity of object motion even if the object is lost completely in several
consecutive frames.
(a)
(b)
(c)
Figure 2.12 Test sequence #1 containing a single pedestrian: (a) some snapshots of the original video (ground-truths); (b) the virtual contours (on the left), which are constructed by combining the completed spatio-temporal slices and their corresponding best-match postures (on the right); (c) the corresponding completed frames; (d) comparison of the completed objects (on the left) and the ground-truths (on the right)
Test sequence #2, shown in Figure 2.13 (a), simulates a common real-life situation that occurs in home videos, i.e., two people walking
toward each other. In this scenario, one person is occluded by the other, which is not desirable. This case is similar to the situation where a moving object is occluded by a stationary object. After removing the unwanted object, we use the proposed method to restore the partially/completely occluded object. Figure 2.13 (b) shows, once again, that the virtual contours of damaged objects provide reasonably good estimates of the objects’ postures. We do not have a ground-truth for this test sequence. However, Figure 2.13 (c) shows that the restored person moves with rather natural and continuous postures. Besides, our method maintains the temporal motion continuity of the object well. Note, the occluded girl turns her body a bit (i.e., the pose angle is changed) during the occlusion period. Since the pose angles of available postures are slightly different from the actual ones, the occluded objects are replaced with the available postures with similar silhouette information but different pose angles, leading to some artifact during the transition of pose angle (see the video in [30]). Such pose angle change problem has not yet been addressed in this work.
(a)
(b)
(c)
Figure 2.13 Test sequence #2 with two people walking toward each other: (a) original video frames; (b) the virtual contours (on the left), which are constructed by combining the completed spatio-temporal slices and the corresponding best-match postures (on the right); (c) the completed frames (on the left) using the original key-postures and the additional synthetic postures and the corresponding frames composed from the completed 2-D slices (on the right).
Test sequence #3 (Figure 2.14 (a)) is similar to test sequence #2, except that the person is occluded for a significantly longer period than in sequence #2. The longer occlusion period made it difficult to complete the occluded object because only a small number of available
non-occluded postures were available in the sequence. In other words, the key-postures selected from the available postures were not sufficiently comprehensive, so we could not find a good match among the key-postures for the occluded object. Figure 2.14 (b) shows the virtual contours of the occluded object and its corresponding matched postures. The postures matched with the set of insufficient available postures appear to be incorrect in the hands and legs, leading to visually unpleasant artifacts in the completed video. Recall that our scheme minimizes the effect of insufficient available postures by adding synthetic postures to the available posture database to enrich the choice of postures, as shown in Figure 2.14 (c) and Figure 2.14 (d).


![Figure 2.5 The notations used for the data and confidence terms in patch-based image inpainting [14]](https://thumb-ap.123doks.com/thumbv2/9libinfo/8249104.171620/45.892.137.757.361.897/figure-notations-confidence-terms-patch-based-image-inpainting.webp)






