A New Method for Fuzzy Information Retrieval Based on Geometric-Mean Averaging Operators
24
0
0
全文
(2) A New Method for Fuzzy Information Retrieval Based on Geometric-Mean Averaging Operators Shi-Jay Chen and Shyi-Ming Chen Department of Computer Science and Information Engineering National Taiwan University of Science and Technology, Taipei, Taiwan, R. O. C. Abstract In this paper, we present a new method for fuzzy information retrieval based on geometric-mean averaging (GMA) operators. We use some examples to compare the proposed GMA operators with the existing averaging operators. We also prove some properties of the proposed GMA operators. The proposed GMA operators can deal with fuzzy information retrieval in a more flexible and more intelligent manner. Keywords: Fuzzy Information Retrieval, Fuzzy Query, Geometric Mean, GMA Operators, T-Operators. 1. Introduction From [17], we can see that fuzzy sets [25] are very useful in information retrieval (IR). In [3]-[5], [8], [10], [11], [13], [15]-[20] and [24], they all used the T-operators [6], namely T-norms and T-conorms, to deal with the AND and OR operations for fuzzy information retrieval, respectively. However, in [9], Kim et al. pointed out that the existing T-operators are not well model human’s behavior for document ranking. In [9], [12] and [14], Lee et al. pointed out that there are three averaging operators (i.e., P-Norm operators [21], Infinite-One operators [23], and Waller-Kraft operators [24]), which are suitable for achieving high retrieval effectiveness in information retrieval systems. According to [12], the three averaging operators have the following common characteristics: (1) The resulting values of the three averaging operators are controlled by an associated parameter, respectively. For instance, the resulting values of the P-Norm operators are controlled by a parameter p, where 1 ≤ p ≤ ∞; the resulting values of the Infinite-One operators are controlled by a parameter γ, where 0 ≤ γ ≤ 1; the resulting values of the Waller-Kraft operators are controlled by a parameter γ, where 0 ≤ γ ≤ 1. (2) The resulting values of the three averaging operators are always in the range between “Min” and “Max”. However, the three averaging operators still have some drawbacks. 1.
(3) when we use them to deal with fuzzy information retrieval. That is, sometime they will get unreasonable retrieval results in fuzzy information retrieval. Thus, it is important to develop new averaging operators to overcome the drawbacks of the existing averaging operators for fuzzy information retrieval. In this paper, we present a new method for fuzzy information retrieval based on geometric-mean averaging (GMA) operators. We use some examples to compare the proposed GMA operators with the existing averaging operators. We also prove some properties of the proposed GMA operators. The proposed GMA operators can deal with fuzzy information retrieval in a more flexible and more intelligent manner. The rest of this paper is organized as follows. In Section 2, we briefly review the definitions of information retrieval based on the conventional fuzzy set model from [9]. We also briefly review T-operators [6], [12], three existing averaging operators [21], [23], [24], and some analytic results of the T-operators and the averaging operators [9], [12], [14]. In Section 3, we point out the drawbacks of the three existing averaging operators (i.e., the P-Norm operators, the Infinite-One operators, and the Waller-Kraft operators). In Section 4, we present new averaging operators, called the GMA operators, based on the geometric mean for handling the AND and OR operations in fuzzy information retrieval. We use some examples to compare the proposed GMA operators with the existing averaging operators. Furthermore, we also prove some properties of the proposed GMA operators. In Section 5, we extend the proposed GMA operators to deal with weighted fuzzy queries in fuzzy information retrieval. The conclusions are discussed in Section 6. 2. Preliminary In this section, we briefly review the definitions of information retrieval based on the conventional fuzzy set model [10]. We also briefly review T-operators [6], [12], three existing averaging operators [21], [23], [24], and some analytic results of the T-operators and the averaging operators [9], [12], [14]. 2.1 Information Retrieval Based on the Conventional Fuzzy Set Model In [9], Kim et al. pointed out that an information retrieval system based on the conventional fuzzy set model is defined by a quadruple <T, Q, D, F>, where (1) T is a set of index terms, T={t1, t2, …, tm}. The index terms are used to represent queries and documents.. 2.
(4) (2) Q is a set of queries. Each query q ∈ Q is a Boolean expression composed of index terms tj, where 1 ≤ j ≤ m, and logical operators “AND”, “OR” and “NOT”. (3) D is a set of documents, D ={d1, d2, …, dn}. Each document di ∈ D is represented by ((t1, ei1), (t2, ei2), …, (tm, ei m)), where eij denote the weight (i.e., the degree of strength) of term tj in document di, eij ∈ [0, 1], 1 ≤ i ≤ n, and 1 ≤ j ≤ m. (4) F is a retrieval function, F: D × Q → [0, 1],. (1). where F(di, q) denotes the degree of satisfaction of document di with respect to the query q, F(di, q) ∈ [0, 1], and 1 ≤ i ≤ n. 2.2 A Review of T-Operators The T-operators [6] (i.e., T-norms and T-conorms) are very useful for handling the decision-making problems and they usually used the AND and OR operations to deal with fuzzy information retrieval [3]-[5], [8], [10], [11], [13], [15]-[20], [24]. In [1] and [7], Alsina and Höhle et al. introduced the operators of the T-norms (∧) and the T-conorms (∨) of fuzzy sets. Let T be a T-norm and let S be a T-conorm, where T: [0, 1] × [0, 1] → [0, 1] and S: [0, 1] × [0, 1] → [0, 1]. In [12], Lee et al. summarized some T-norms and T-conorms as shown in Table 1. Table 1. Some T-norms and T-conorms [12] T-Norms T-Conorms Min(x, y), Logical Product Max(x, y), Logical Sum x × y, Algebraic Product x + y – x × y, Algebraic Sum xy x + y − 2 xy , , Hamacher Product Hamacher Sum x + y − xy 1 − xy x if y = 1 y if x = 1 0 otherwise Max(x + y - 1, 0),. Drastic Product. x if y = 0 y if x = 0 1 otherwise . Drastic Sum. Bounded Product. Min(x + y, 1),. Bounded Sum. Based on [6], we can see that the T-operators can be used in conventional Boolean retrieval systems when the evaluating values eij of index terms tj in documents di are either 0 or 1, where 1 ≤ i ≤ n and 1 ≤ j ≤ m. 2.3 A Review of Averaging Operators In the following, we briefly review three averaging operators from [21], [23] and [24] shown as follows:. 3.
(5) (1) P-Norm Operators [21]: F (d i , q AND ) = F (d i , t1 AND t 2 ANDL AND t m ) m ∑ (1 − eij ) p j =1 = 1− m . 1. p , . (2). F (d i , qOR ) = F (d i , t1 OR t 2 OR L OR t m ) m p ∑ eij j =1 = m . 1. p , . (3). where 1 ≤ p ≤ ∞ and 1 ≤ i ≤ n. If p = 1, then F (d i , q AND ) = F (d i , q OR ) and they are the same as the arithmetic mean. If p = ∞, then formula (2) became F (d i , q AND ) = F (d i , t1 AND t 2 ANDL AND t m ) = 1 − Max[(1 − ei1 ), (1 − ei 2 ),L , (1 − eim )]. (4). = Min[ei1 , ei 2 , L , eim ], and formula (3) became F (d i , q OR ) = F (d i , t1 OR t 2 OR L OR t m ). (5). = Max (ei1 , ei 2 ,L , eim ). (2) Infinite-One Operators [23]: F (d i , q AND ) = F (d i , t1 AND t 2 ANDL AND t m ) m. = γ × Min(ei1 , ei 2 ,L , eim ) + (1 − γ ) ×. ∑e j =1. (6). ij. ,. m. F (d i , q OR ) = F (d i , t1 OR t 2 OR L OR t m ) m. = γ × Max(ei1 , ei 2 , L , eim ) + (1 − γ ) ×. ∑e j =1. m. (7). ij. ,. where 0 ≤ γ ≤ 1 and 1 ≤ i ≤ n. If γ = 0, then F (d i , q AND ) = F (d i , q OR ) and they are the same as the arithmetic mean. If γ = 1, then formula (6) became the operator of logical product, and formula (3) became the operator of logical sum. (3) Waller-Kraft Operators [24]:. 4.
(6) F (d i , q AND ) = F (d i , t1 AND t 2 AND L AND t m ). = (1 − γ ) × Min( ei1 , ei 2 , L , eim ) + γ × Max(ei1 , ei 2 , L , eim ),. (8). where 0 ≤ γ ≤ 0.5 and 1 ≤ i ≤ n, F (d i , q OR ) = F (d i , t1 OR t 2 OR L OR t m ). = (1 − γ ) × Min( ei1 , ei 2 , L , eim ) + γ × Max(ei1 , ei 2 , L , eim ),. (9). where 0.5 ≤ γ ≤ 1 and 1 ≤ i ≤ n. If γ = 0.5, then F (d i , q AND ) = F (d i , q OR ) = Min(ei1 , ei 2 ,L, eim ) + Max(ei1 , ei 2 ,L, eim ) . 2. If γ = 0, then formula (8) became the operator of. logical product. If γ = 1, then formula (9) became the operator of logical sum. 2.4. Some Analytic Results of the T-Operators and the Averaging Operators In [9], Lee et al. defined the following three properties for evaluating the T-operators and the averaging operators: Definition 2.1 An operator θ is “single operand dependency” if θ (x, y) is either x or y, where x ∈ [0, 1] and y ∈ [0, 1], and this type of operator is called the “single operand dependency” operator. Definition 2.2 An operator θ is “negatively compensatory” if θ (x, y) is less than Min (x, y) or greater than Max (x, y) for all x, y ∈ [0, 1], and this type of operator is called the “negatively compensatory” operator. Definition 2.3 An operator θ is “positively compensatory” if θ (x, y) is greater than Min (x, y) and less than Max (x, y) for all x, y ∈ [0, 1], and this type of operator is called the “positively compensatory” operator. In [9], [12] and [14], Lee et al. pointed out that the operators of logical product (i.e., Min(x, y)) and logical sum (i.e., Max(x, y)) shown in Table 1 are inappropriate for handling fuzzy information retrieval because these two operators have the “single operand dependency” property. In the following, we use two examples to explain why these two operators are inappropriate to deal with fuzzy information retrieval. Example 2.1: Assume that there are two documents d1 and d2, and assume that there is a query q1 shown as follows: d1 = {(Information, 0.5), (System, 0.5)}, d2 = {(Information, 0.9), (System, 0.4)}, q1 = Information AND System.. 5.
(7) If the operator of logical product is used for the AND operations, then the degrees of satisfaction of the documents d1 and d2 with respect to the query q1 can be evaluated and are equal to 0.5 (i.e., Min(0.5, 0.5) = 0.5) and 0.4 (i.e., Min(0.9, 0.4) = 0.4), respectively, and the system will retrieve the document d1. However, intuitively, the document d2 is more suitable than the document d1 with respect to the query q1. Example 2.2. Assume that there are two documents d3 and d4, and assume that there are two queries q2 and q3 shown as follows: d3 = {( t1, 0), ( t2, 0.8), ( t3, 1), …, ( t99, 1), ( t100, 1)}, d4 = {( t1, 0), ( t2, 0.1), ( t3, 0.1), …, ( t99, 0.1), ( t100, 1)}, q2 = t1 AND t2 AND t3 AND … AND t99 AND t100, q3 = t2 OR t100. If the operator of logical product is used for the AND operations, then the degrees of satisfaction of the documents d3 and d4 with respect to the query q2 are the same (i.e., Min(0, 0.8, 1, …, 1, 1) = Min(0, 0.1, 0.1, …, 0.1, 1) = 0). However, intuitively, the document d3 is more suitable than the document d4 with respect to the query q2. If the operator of logical sum is used for the OR operation, the degrees of satisfaction of the documents d3 and d4 with respect to the query q3 are the same and are equal to 1, respectively (i.e., Max(0.8, 1) = Max(0.1, 1) = 1). However, intuitively, the document d3 is more suitable than the document d4 with respect to the query q3. From [9], [12] and [14], we can see that the remaining T-operators except the operators of logical product and logical sum shown in Table 1 are still inappropriate for handling fuzzy information retrieval due to the fact that they have the “partially single operand dependency” and “negatively compensatory” properties. In [9], Kim et al. pointed out that the “partially single operand dependency” operator can avoid the problem described in Example 2.1, but it still have the same problem described in Example 2.2. The “negatively compensatory” property can cause the problem illustrated in the following example. Example 2.3. Assume that there is a document d5 and assume that there are two queries q4 and q5 shown as follows: d5 = {(Information, 0.5), (System, 0.5), (Management, 0.5)}, q4 = Information AND System, q5 = Management.. 6.
(8) If we use the operator of algebraic product (i.e., x × y) for the AND operations, then the degrees of satisfaction of the document d5 with respect to the queries q4 and q5 can be evaluated and are equal to 0.25 (i.e., 0.5 × 0.5 = 0.5) and 0.5, respectively. However, it is unreasonable that the degree of satisfaction of the document d5 with respect to the query q4 is less than that of the document d5 with respect to the query q5. From the above three examples, we can see that the Min and Max operators suffer from the problem of “single operand dependency”. Other T-operators (i.e., “Algebraic product and Algebraic sum”, “Hamacher product and Hamacher sum”, “Drastic product and Drastic sum”, and “Bounded product and Bounded sum”) shown in Table 1 have the problems of not only “partially single operand dependency”, but also “negative compensatory”. Because the T-operators have these problems, some averaging operators are proposed to overcome these problems [21], [23], [24]. In [9], Kim et al. pointed out that P-Norm operators [21] (i.e., formulas (2) and (3)), Infinite-One operators [23] (i.e., formulas (6) and (7)), and Waller-Kraft operators [24] (i.e., formulas (8) and (9)) have the “positively compensatory” property. From [9], we can see that “positively compensatory” operators are neither “partially single operand dependency” nor “negatively compensatory”, they can avoid all the problems described previously if the fuzzy information retrieval system using the “positively compensatory” operators as the evaluating formulas for the AND and OR operations. Thus, in [9], kim et al. pointed out that the three averaging operators (i.e., P-Norm operators, Infinite-One operators, and Waller-Kraft operators) are suitable to achieve high retrieval effectiveness for fuzzy information retrieval. 3. Analysis of the Existing Averaging Operators From [9], we can see that P-Norm operators [21], Infinite-One operators [23], and Waller-Kraft operators [24] are appropriate to deal with the AND and OR operations for fuzzy information retrieval respectively. However, according to our research, the three averaging operators still have the following drawbacks: (1) From [21], we can see that the resulting value of P-Norm operators is controlled by a parameter p, and the values of the parameter p is between 1 and ∞. From [23] and [24], we can see that the resulting values of the Infinite-One operators and Waller-Kraft operators are controlled by a parameter γ, and the values of the parameter γ is between 0 and 1. However, it is very subjective and very hard to determine an appropriate value of the parameter γ between 0 and 1 and to determine. 7.
(9) the appropriate parameter p between 1 and ∞ for fuzzy information retrieval. (2) According to the Infinite-One operators (i.e., formulas (6) and (7)), if γ = 1, then formula (6) became the operator of logical product (i.e., Min(x, y)) for the AND operations and formula (7) became the operator of logical sum (i.e., Max(x, y)) for the OR operations. However, from Section 2, we can see that the operators of logical product and logical sum have the “single operand dependency” property, and from Example 2.1 and Example 2.2, we can see that the Infinite-One operators are inappropriate for fuzzy information retrieval if the parameter γ = 1. In the same way, if we use P-Norm operators (i.e., formulas (2) and (3)) to deal with fuzzy information retrieval, it will has the same drawback describe above if the parameter p = ∞; if we use Waller-Kraft operators (i.e., formulas (8) and (9)) to deal with fuzzy information retrieval, it will has the same drawback describe above if the parameter γ = 0 in formula (8) and the parameter γ = 1 in formula (9). (3) According to Infinite-One operators (i.e., formulas (6) and (7)), if γ = 0, then the two operators are the same as the arithmetic mean, and the resulting values of the AND and OR operations are the same. That is, the system can not distinguish the degrees of satisfaction of the documents with respect to the queries for the AND and OR operations. Example 3.1. Assume that there is a document d6, and assume that there are two queries q6 and q7 shown as follows: d6 = {(Information, 0.2), (System, 0.6)}, q6 = Information AND System, q7 = Information OR System. If formula (6) is used for the AND operation and formula (7) is used for the OR operation and if γ = 0, then the degrees of satisfaction F(d6, q6) and F(d6, q7) of the document d6 with respect to the queries q6 and q7, respectively, can be evaluated as follows: F (d 6 , q 6 ) = F (d 6 , Information AND Systems) 0.2 + 0.6 2 = 0.4, =. 8.
(10) F (d 6 , q 7 ) = F (d 6 , Information OR Systems) 0.2 + 0.6 2 = 0.4. =. In this situation, the system can not distinguish the degrees of satisfaction of the document d6 with respect to the queries q6 and q7, respectively. In the same way, if we use the P-Norm operators (i.e., formulas (2) and (3)) to deal with fuzzy information retrieval, it will have the same drawback if the parameter p = 1; if we use the Waller-Kraft operators (i.e., formulas (8) and (9)) to deal with fuzzy information retrieval, it will have the same drawback if the parameter γ = 0.5. (4) According to the Infinite-One operators (i.e., formulas (6) and (7)), if γ = 0.5, then the system can distinguish the degrees of satisfaction of the documents with respect to the queries for the AND and OR operations [9]. However, it still has a drawback illustrated as follows. Example 3.2. Assume that there are two documents d7 and d8, and assume that there is a query q8 shown as follows: d7 = {(Information, 0.2), (System, 0.7), (Management, 0.9)}, d8 = {(Information, 0.3), (System, 0.4), (Management, 0.8)}, q8 = Information AND System AND Management. If formula (6) is used for the AND operation and if γ = 0.5, then the degrees of satisfaction F(d7, q8) and F(d8, q8) of the documents d7 and d8 with respect to the query q8, respectively, can be evaluated as follows:. F (d 7 , q8 ) = F (d 7 , Information AND System AND Management ) = 0.5 × Min(0.2, 0.7, 0.9) + 0.5 ×. 0.2 + 0.7 + 0.9 3. = 0.5 × 0.2 + 0.5 × 0.6 = 0.4, F (d 8 , q8 ) = F (d 8 , Information AND System AND Management ) = 0.5 × Min(0.3, 0.4, 0.8) + 0.5 ×. 0.3 + 0.4 + 0.8 3. = 0.5 × 0.3 + 0.5 × 0.5 = 0.4. In this situation, the system can not distinguish the degrees of satisfaction of the document d7 and the document d8 with respect to the query q8, respectively. However, 9.
(11) intuitively, the document d7 is more suitable than the document d8 with respect to the query q8. (5) If we use Waller-Kraft operators (i.e., formulas (8) and (9)) to deal with fuzzy information retrieval, the operators have a drawback illustrated in the following example. Example 3.3. Assume that there are two documents d9 and d10, and assume that there is a query q9 shown as follows: d9 = {(Information, 0.1), (System, 0.2), (Management, 0.9)}, d10 = {(Information, 0.1), (System, 0.8), (Management, 0.9)}, q9 = Information AND System AND Management. If formula (8) is used for the AND operations, then the degrees of satisfaction F(d9, q9) and F(d10, q9) of the documents d9 and d10 with respect to the query q9 can be evaluated as follows: F (d 9 , q9 ) = F (d 9 , Informatio n AND System AND Management ) = (1 − γ ) × Min(0.1, 0.2, 0.9) + γ × Max(0.1, 0.2, 0.9) = (1 − γ ) × 0.1 + γ × 0.9, F (d10 , q9 ) = F (d 10 , Informatio n AND System AND Management ) = (1 − γ ) × Min(0.1, 0.8, 0.9) + γ × Max(0.1, 0.8, 0.9) = (1 − γ ) × 0.1 + γ × 0.9,. where 0 ≤ γ ≤ 0.5. That is, F(d9, q9) = F(d10, q9). However, intuitively, the document d10 is more suitable than the document d9 with respect to the query q9. Thus, if we want to use the averaging operators for the AND and OR operations in fuzzy information retrieval, it is important to develop new averaging operators to overcome the drawbacks of the above three averaging operators. 4. Fuzzy Information Retrieval Based on the Proposed Geometric-Mean Averaging Operators In the following, we present the new averaging operators, called the Geometric-Mean Averaging (GMA) operators, for fuzzy information retrieval shown as follows: F (d i , q AND ) = F (d i , t1 AND t 2 AND L AND t m ) 1. m m = ∏ (α + eij ) − α , j =1 . 10. (10).
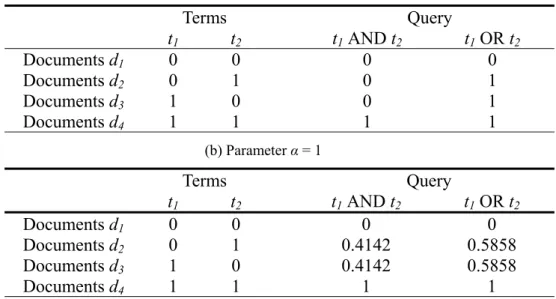
(12) F (d i , q OR ) = F (d i , t1 OR t 2 OR L OR t m ) 1. m m = (α + 1) − ∏ (α + 1 − eij ) , j =1 . (11). where α ∈ {0, 1}, 1 ≤ i ≤ n, 1 ≤ j ≤ m, F(di, qAND) ∈ [0, 1] and F(di, qOR) ∈ [0, 1]. The values of F(di, qAND) and F(di, qOR) of the proposed GMA operators are controlled by a parameter α, where α is either 0 or 1. If the evaluating values eij of terms tj in documents di are either 0 or 1, where 1 ≤ i ≤ 4 and 1 ≤ j ≤ 2, then the example shown in Table 2 indicates that the proposed GMA operators are compatible with the traditional Boolean operators (i.e., Table 2(a)) if the parameter α is 0 and are compatible with the extended Boolean operators [21] (i.e., Table 2(b)) if the parameter α is 1. For example, let’s consider the document d2 shown in Table 2(a) and formulas (10) and (11). If t1 = 0, t2 = 1 and the parameter α = 0, then we can get F (d 2 , q AND ) = F (d 2 , t1 AND t 2 ) 1. = [0 × 1]2 = 0, F (d 2 , q OR ) = F (d 2 , t1 OR t 2 ) 1. = 1 − [(1 − 0) × (1 − 1)]2 = 1.. Furthermore, let’s consider the document d2 shown in Table 2(b) and formulas (10) and (11). If t1 = 0, t2 = 1 and the parameter α = 1, then we can get F (d 2 , q AND ) = F (d 2 , t1 AND t 2 ) 1. = [1 × 2]2 − 1 = 0.4142, F (d 2 , q OR ) = F (d 2 , t1 OR t 2 ) 1. = 2 − [(2 − 0) × (2 − 1)]2 = 0.5858.. From Table 2(a), we can see that when α = 0, the proposed GMA operators can be used in the traditional Boolean information retrieval environment.. 11.
(13) Table 2. Applying the Proposed GMA Operators for Information Retrieval (a) Parameter α = 0. Terms Documents d1 Documents d2 Documents d3 Documents d4. t1 0 0 1 1. Query t1 AND t2 0 0 0 1. t2 0 1 0 1. t1 OR t2 0 1 1 1. (b) Parameter α = 1. Terms Documents d1 Documents d2 Documents d3 Documents d4. t1 0 0 1 1. Query t1 AND t2 0 0.4142 0.4142 1. t2 0 1 0 1. t1 OR t2 0 0.5858 0.5858 1. In the following, we analyze the proposed GMA operators in different situations, i.e., the parameter α is 0 and the parameter α is 1. Situation 1: If the parameter α is 0, then the proposed GMA operators (i.e., formulas (10) and (11)) became F (d i , q AND ) = F (d i , t1 AND L AND t m ) 1. (12). m m = ∏ eij , j =1 F (d i , q OR ) = F (d i , t1 OR L OR t m ) 1. m m = 1 − ∏ (1 − eij ) . j =1 . (13). In this situation, the proposed GMA operators (i.e., formulas (12) and (13)) have the “partially single operand dependency” property. From Section 2, we can evaluate that this property can overcome the problem of Example 2.1. Furthermore, formulas (12) and (13) do not have the “negative compensatory” property. Thus, it can avoid the problem of Example 2.3. In the following, we use formula (12) to deal with Example 2.1 and Example 2.3, respectively. (1) If we use formula (12) to deal with Example 2.1, we can evaluate the degree of satisfaction F (d1 , q1 ) of the document d1 with respect to the query q1 shown as follows:. 12.
(14) F ( d 1 , q1 ) = F ( d 1 , Informatio n AND System ) 1. = [0.5 × 0.5]2 = 0 .5 .. In the same way, we can obtain the degree of satisfaction F (d 2 , q1 ) of the document d2 with respect to the query q1, where F (d 2 , q1 ) = 0.6, and the system will retrieve the document d2, and it coincides the viewpoint of the human’s intuition. (2) If we use formula (12) to deal with Example 2.3, we can evaluate the degree of satisfaction F (d 5 , q 4 ) of the document d5 with respect to the query q4 shown as follows:. F (d 5 , q 4 ) = F (d 5 , Information AND System AND Management) 1. = [0.5 × 0.5 × 0.5]3 = 0.5. In the same way, we can evaluate the degree of satisfaction F (d 5 , q5 ) of the document d5 with respect to query q5, where F (d 5 , q5 ) = 0.5. In this situation, we can evaluate the same degrees of satisfaction of the document d5 with respect to the queries q4 and q5, respectively, and it coincides the viewpoint of the human’s intuition. Furthermore, the proposed GMA operators can overcome the drawbacks of Example 3.1, Example 3.3 and Example 3.3. In the following, we use formulas (12) and (13) to deal with Example 3.1, Example 3.2 and Example 3.3, respectively. (1) If we use formulas (12) and (13) to deal with Example 3.1, we can evaluate the degrees of satisfaction of the document d6 with respect to the queries q6 and q7, respectively, shown as follows: F (d 6 , q 6 ) = F (d 6 , Information AND System) 1. = [0.2 × 0.6]2 = 0.3464, F (d 6 , q 7 ) = F (d 6 , Information OR System) 1. = 1 − [(1 − 0.2) × (1 − 0.6)]2 = 0.4343.. According to the values of F (d 6 , q6 ) and F (d 6 , q 7 ) , the system can distinguish the degrees of satisfaction of the document d6 with respect to the queries q6 and q7,. 13.
(15) respectively. (2) If we use formula (12) to deal with Example 3.2, we can evaluate the degree of satisfaction F (d 7 , q8 ) of the document d7 with respect to the query q8 shown as follows: F (d 7 , q8 ) = F (d 7 , Information AND System AND Management ) 1. = [0.2 × 0.7 × 0.9]3 = 0.5013. In the same way, we can evaluate the degree of satisfaction F (d 8 , q8 ) of the document d8 with respect to query q8, where F (d 8 , q8 ) = 0.4579. The system will retrieve the document d7, and it coincides the viewpoint of the human’s intuition. (3) If we use formula (12) to deal with Example 3.3, we can evaluate the degree of satisfaction F (d 9 , q9 ) of the document d9 with respect to the query q9 shown as follows: F (d 9 , q9 ) = F (d 9 , Information AND System AND Management ) 1. = [0.1 × 0.2 × 0.9]3 = 0.2621. In the same way, we can evaluate the degree of satisfaction F (d10 , q9 ) of the document d10 with respect to query q9, where F (d10 , q9 ) = 0.416. The system will retrieve the document d10, and it coincides the viewpoint of the human’s intuition. From the previously discussions, we can see that when the parameter α is 0, the proposed GMA operators are very useful to deal with fuzzy information retrieval. However, it still have the same problem of Example 2.2, i.e., the degrees of satisfaction F (d 3 , q 2 ) and F (d 4 , q 2 ) are all evaluated as 0, and the degrees of satisfaction F (d 3 , q3 ) and F (d 4 , q3 ) are all evaluated as 1. In this situation, we can use the proposed GMA operators and set the parameter α to 1 to overcome this problem. Let us consider the following situation. Situation 2: If the parameter α is 1, then the proposed GMA operators (i.e., formulas (10) and (11)) became. 14.
(16) F (d i , q AND ) = F (d i , t1 AND L AND t m ) 1. (14). m m = ∏ (1 + eij ) − 1, j =1 F (d i , q OR ) = F (d i , t1 OR L OR t m ) 1. (15). m m = 2 − ∏ (2 − eij ) . j =1 . In this situation, the proposed GMA operators have the “positively compensatory” property if the parameter α is 1. In [14], Lee pointed out that the “positively compensatory” operators are functions of the form p: [0, 1]×[0, 1]→[0, 1]. They must satisfy the follow two properties: Property 1: p(x, x) = x; i.e., p is idempotent. Property 2: Min(x, y) < p(x, y) < Max(x, y), where x ≠ y. In the following, we prove the properties of the proposed GMA operators when the parameter α is 1. Property 1: F (d , x AND x) = x and F (d , x OR x) = x; i.e., F (d , x AND x) and F (d , x OR x) are idempotent. Proof: 1. F (d , x AND x) = [(1 + x) × (1 + x)]2 − 1 = (1 + x) − 1 = x, 1. F (d , x OR x) = 2 − [(2 − x) × (2 − x)]2 = 2 − (2 − x) = x.. Thus, we can see that the proposed GMA operators are idempotent when the parameter α is 1. Property 2: Min(x, y) < F (d , x AND y) < F (d , x OR y) < Max(x, y), where x ≠ y. Proof: If x = 0 and y = 1, then we can see that Min(x, y) = 0 and Max(x, y) = 1. If we use formulas (14) and (15), we can get. 15.
(17) 1. F (d , x AND y ) = [(1 + x) × (1 + y )]2 − 1 1. = [(1 + 0) × (1 + 1)]2 − 1 = 0.4142, 1. F (d , x OR y ) = 2 − [(2 − 0) × (2 − 1)]2 = 2 − ( 2). 1 2. = 0.5858.. In the same way, we can evaluate the same results if x = 1 and y = 0 shown as follows 1. F (d , x AND y ) = [(1 + x) × (1 + y )]2 − 1 1. = [(1 + 1) × (1 + 0)]2 − 1 = 0.4142, 1. F (d , x OR y ) = 2 − [(2 − 1) × (2 − 0)]2 1. = 2 − ( 2) 2 = 0.5858.. In summary, we can see that Min(x, y) < F (d , x AND y) < F (d , x OR y) < Max(x, y), where x ≠ y. According to above properties, we can see that the proposed GMA operators have the “positively compensatory” property when the parameter α is 1. From [9], [12] and [14], we can see that the “positively compensatory” operators do not have either the “single operand dependency” property or the “negatively compensatory” property. Therefore, the fuzzy information retrieval using “positively compensatory” operators can avoid the “single operand dependency” and “negative compensatory” problems of Example 2.1 to Example 2.3. In the following, we use formulas (14) and (15) to deal with Example 2.1, Example 2.2 and Example 2.3, respectively. (1) If we use formula (14) to deal with Example 2.1, we can evaluate the degree of satisfaction F (d1 , q1 ) of the document d1 with respect to the query q1 shown as follows:. 16.
(18) F (d1 , q1 ) = F (d1 , Information AND System) 1. = [(1 + 0.5) × (1 + 0.5)]2 − 1 1. = [1.5 × 1.5]2 − 1 = 0.5. In the same way, we can evaluate the degree of satisfaction F (d 2 , q1 ) of the document d2 with respect to the query q1, where F (d 2 , q1 ) = 0.631. The system will retrieve the document d2, and it coincides the viewpoint of the human’s intuition. (2) If we use formula (14) to deal with Example 2.2, we can evaluate the degree of satisfaction F (d 3 , q 2 ) of the document d3 with respect to the query q2 shown as follows: F ( d 3 , q 2 ) = F ( d 3 , t1 AND t 2 AND L AND t100 ) 1. = [(1 + 0) × L × (1 + 1) ]100 − 1. = 1.9841 − 1 = 0.9841 .. In the same way, we can evaluate the degree of satisfaction F (d 4 , q 2 ) of the document d4 with respect to the query q2, where F (d 4 , q 2 ) = 0.1055. The system will retrieve the document d3, and it coincides the viewpoint of the human’s intuition. Then, we use formula (15) to evaluate the degree of satisfaction F (d 3 , q3 ) of the document d3 with respect to the query q3 shown as follows: F ( d 3 , q 3 ) = F ( d 3 , t 2 OR t100 ) 1. = 2 − [( 2 − 0.8) × ( 2 − 1) ]2 = 2 − 1.0954 = 0.9046 .. In the same way, we can evaluate the degree of satisfaction F (d 4 , q3 ) of the document d4 with respect to the query q3, where F (d 4 , q3 ) = 0.6216. The system will retrieve the document d3, and it coincides the viewpoint of the human’s intuition. (3) If we use formula (12) to deal with Example 2.3, we can evaluate the degree of satisfaction F (d 5 , q 4 ) of the document d5 with respect to the query q4 shown as follows:. 17.
(19) F ( d 5 , q 4 ) = F ( d 5 , Informatio n AND System AND Management ) 1. = [(1 + 0 .5) × (1 + 0 .5) × (1 + 0 .5) ]3 − 1 1. = [1 .5 × 1 .5 × 1 .5]3 − 1 = 0 .5 .. Then, we can evaluate the degree of satisfaction F (d 5 , q5 ) of the document d5 with respect to query q5, F (d 5 , q5 ) = 0.5. In this situation, we can obtain the same evaluating results of the document d5 for the queries q4 and q5, respectively, and it coincides the viewpoint of the human’s intuition. Furthermore, the proposed GMA operators can overcome the drawbacks of the existing averaging operators of Example 3.1, Example 3.2 and Example 3.3. In the following, we use formulas (14) and (15) to deal with Example 3.1, Example 3.2 and Example 3.3, respectively. (1) If we use formulas (14) and (15) to deal with Example 3.1, we can evaluate the degrees of satisfaction of the document d6 with respect to the queries q6 and q7 shown as follows: F (d 6 , q 6 ) = F (d 6 , Information AND System) 1. = [(1 + 0.2) × (1 + 0.6)]2 − 1 1. = [1.2 × 1.6]2 − 1 = 0.3856, F (d 6 , q 7 ) = F (d 6 , Information OR System) 1. = 2 − [(2 − 0.2) × (2 − 0.6)]2 = 0.4125.. According to the values of F (d 6 , q6 ) and F (d 6 , q 7 ) , the system can distinguish the degrees of satisfaction of the document d6 with respect to the queries q6 and q7, respectively. (2) If we use formula (14) to deal with Example 3.2, we can evaluate the degree of satisfaction F (d 7 , q8 ) of the document d7 with respect to the query q8 shown as follows:. 18.
(20) F (d 7 , q8 ) = F (d 7 , Information AND System AND Management ) 1. = [(1 + 0.2) × (1 + 0.7) × (1 + 0.9)]3 − 1 1. = [1.2 × 1.7 × 1.9]3 − 1 = 0.5708. In the same way, we can evaluate the degree of satisfaction F (d 8 , q8 ) of document d8 with respect to query q8, where F (d 8 , q8 ) = 0.4852. The system will retrieve the document d7, and it coincides the viewpoint of the human’s intuition. (3) If we use formula (14) to deal with Example 3.3, we can evaluate the degree of satisfaction F (d 9 , q9 ) of the document d9 with respect to the query q9 shown as follows: F (d 9 , q9 ) = F (d 9 , Information AND System AND Management ) 1. = [(1 + 0.1) × (1 + 0.2) × (1 + 0.9)]3 − 1 1. = [1.1 × 1.2 × 1.9]3 − 1 = 0.3587. In the same way, we can evaluate the degree of satisfaction F (d10 , q9 ) of the document d10 with respect to query q9, where F (d10 , q 9 ) = 0.5553. The system will retrieve the document d10, and it coincides the viewpoint of the human’s intuition. 5. Weighted Fuzzy Query Based on the Extended Geometric-Mean Averaging Operators In Section 4, we only considered non-weighted fuzzy queries for fuzzy information retrieval. In [14], Lee pointed out that the retrieval effectiveness could be improved by assigning importance factors or weights to the terms and clauses in the queries. From [2], [14], [21] and [22], we can see that weighted queries are very useful in fuzzy information retrieval. Let us consider an example of weighted Boolean query q shown as follows [14]: q = (((t1, wq1) OR (t2, wq2)), wq1 OR q2) AND (t3, wq3), where wqj denotes the weight of the term tj in the query q, 1 ≤ j ≤ 2, and wq1. OR q2. denotes. the weight of the clause “(t1, wq1) OR (t2, wq2)” in the query q, where wqj ∈ [0, 1] and wq1 OR q2. ∈ [0, 1]. In the following, we extend the proposed GMA operators of formulas (10) and (11) to 19.
(21) formulas shown as follows: F (d i , q AND ) = F (d i , (t1 , wq1 ) AND (t 2 , wq2 ) ANDL AND (t m , wqm )) wq. j. (16). m. ∑ wq j. m. = ∏ (α + eij ) j =1. −α,. j =1. F (d i , q OR ) = F (d i , (t1 , wq1 ) OR (t 2 , wq2 ) OR L OR (t m , wqm )) wq. j. (17). m. m. = (α + 1) − ∏ (α + 1 − eij ). ∑. wq. j =1. j. ,. j =1. where F(di, qAND) ∈ [0, 1], F(di, qOR) ∈ [0, 1] , wqj ∈ [0, 1], α ∈ {0, 1}, 1 ≤ i ≤ n, and 1 ≤ j ≤ m. The weight wqj of the term tj in the query q in formulas (16) and (17) is a relative weight. In [14], Lee pointed out that users submit a query with “relative query weights” will be easier than with “absolute query weights”. In the following, we use an example to illustrate how to use formulas (16) and (17) to deal with weighted fuzzy queries for fuzzy information retrieval. Example 5.1. Assume that there is a document d11 and assume that there are two queries q10 and q11 shown as follows: d11 = {(Information, 0.2), (System, 0.6), (Management, 0.7)}, q10 = (Information, 0.7) AND (System, 1), q11 = (q10, 0.6) OR (Management, 0.9). If we use formula (16) to deal with the AND operation and the parameter α is 1, then the degree of satisfaction F(d11, q10) of the document d11 with respect to the query q10 can be evaluated as follows: F (d11 , q10 ) = F (d11 , ( Informtion, 0.7) AND ( System, 1)) 0.7. 1. = [(1 + 0.2) 0.7 +1 × (1 + 0.6) 0.7 +1 ] − 1 = [(1.2) 0.4118 × (1.6) 0.5882 ] − 1 = 0.4212. That is, the degree of satisfaction F(d11, q10) of the document d11 with respect to the query q10 is 0.4212. In the same way, if we use formula (17) to deal with the OR operation and the parameter α is 1, then the degree of satisfaction F(d11, q11) of the document d11 with respect to the query q11 can be evaluated as follows:. 20.
(22) F (d 11 , q11 ) = F (d 11 , (q10 , 0.6) OR ( Management , 0.9)) = 2 − [(2 − 0.4212) = 2 − [(1.5788). 0.4. 0.6 0.6 + 0.9. × ( 2 − 0 .7 ). 0.9 0.6 + 0.9. ]. × (1.3) ] 0.6. = 0.5949.. That is, the degree of satisfaction F(d11, q11) of the document d11 with respect to the query q11 is 0.5949. 6. Conclusions In this paper, we have presented a new method for fuzzy information retrieval based on geometric-mean averaging (GMA) operators. We use some examples to compare the proposed GMA operators with the existing averaging operators. We also prove some properties of the proposed GMA operators. The proposed GMA operators can deal with fuzzy information retrieval in a more flexible and more intelligent manner. References [1] C. Alsina, E. Trillas, and L. Valverde, “On some logical connectives for fuzzy set theory,” Journal of Mathematical Analysis and Application, vol. 93, no. 1, pp. 15-26, 1983. [2] A. Bookstein, “Fuzzy requests: an approach to weighted Boolean searches,” Journal of the American Society for Information Science, vol. 31, no. 4, pp. 240-247, 1980. [3] D. A. Buell and D. H. Kraft, “Threshold values and Boolean retrieval systems,” Information Processing and Management, vol. 17, no. 3, pp. 127-136, 1981. [4] D. A. Buell, “A problem in information retrieval with fuzzy sets,” Journal of the American Society for Information Science, vol. 36, no. 6, pp. 398-401, 1985. [5] R. Fagin, “Combining fuzzy information from multiple systems,” Journal of Computer and System Sciences, vol. 58, no. 1, pp. 83-99, 1999. [6] M. M. Gupta and J. Qi, “Theory of T-norms and fuzzy inference methods,” Fuzzy Sets and Systems, vol. 40, no. 3, pp. 431-450, 1991. [7] U. Höhle, “Probabilistic uniformization of fuzzy topologies,” Fuzzy Sets and Systems, vol. 1, no. 1, pp. 311-332, 1978. [8] C. M. Kim and Y. G. Kim, “An improvement of Bandler-Kohout fuzzy information retrieval model using reduced set,” Proceedings of the 1999 IEEE International Fuzzy Systems Conference, Seoul, Korea, pp. 22-25, 1999. [9] M. H. Kim, J. H. Lee, and Y. J. Lee, “Analysis of fuzzy operators for high quality information retrieval,” Information Processing Letters, vol. 46, no. 5, pp. 251-256, 1993. 21.
(23) [10] D. H. Kraft and D. A. Buell, “Fuzzy sets and generalized Boolean retrieval systems,” International Journal of Man-Machine Studies, vol. 19, no. 1, 45-56, 1983. [11] D. H. Kraft and D. A. Buell, “An extended fuzzy linguistic approach to generalize Boolean information retrieval,” Information Sciences, vol. 2, no. 3, 119-134, 1994. [12] J. H. Lee, W. Y. Kim, M. H. Kim, and Y. J. Lee, “On the evaluation of Boolean operators in the extended Boolean retrieval framework,” Proceedings of the Sixteenth Annual ACM Conference on Research and Development in Information Retrieval, pp. 291-297, Pittsburgh, Pennsylvania, U. S. A., 1993. [13] J. H. Lee, M. H. Kim, and Y. J. Lee, “Ranking Documents in thesaurus-based Boolean retrieval systems,” Information Processing and Management, vol. 30, no. 1, pp. 79-91, 1994. [14] J. H. Lee, “Properties of extended Boolean models in information retrieval,” Proceedings of the Seventeenth Annual ACM Conference on Research and Development in Information Retrieval, pp. 182-190, Dublin, Ireland, 1994. [15] D. Lucarella and R. Morara, “FIRST: fuzzy information retrieval system,” Journal of Information Science, vol. 17, no. 2, pp. 81-91, 1991. [16] R. L. Mántaras, U. Cortés, J. Manero, and E. Plaza, “Knowledge engineering for a document retrieval system,” Fuzzy Sets and Systems, vol. 38, no. 2, pp. 223-240, 1990. [17] S. Miyamoto, Fuzzy Sets in Information Retrieval and Cluster Analysis. Kluwer, Dordrecht, 1990. [18] G. Pasi and R. A. M. Pereira, “A decision making approach to relevance feedback in information retrieval: a model based on soft consensus dynamics,” International Journal of Intelligent Systems, vol. 14, no. 1, pp. 105-122. 1999. [19] S. E. Robertson, “On the nature of fuzz: a diatribe,” Journal of the American Society for Information Science, vol. 29, no. 4, pp. 304-307, 1978. [20] W. M. Sachs, “An approach to associative retrieval through the theory of fuzzy sets,” Journal of the American Society for Information Science, vol. 27, no. 1, pp. 85-87, 1976. [21] G. Salton, E. A. Fox, and H. Wu, “Extended Boolean information retrieval,” Communications of the ACM, vol. 26, no. 12, pp. 1022-1036, 1983. [22] G. Salton, “A simple blueprint for automatic Boolean query processing,” Information Processing and Management, vol. 24, no. 3, pp. 269-280, 1988. [23] M. E. Smith, Aspects of the P-Norm Model of Information Retrieval: Syntactic Query Generation, Efficiency, and Theoretical Properties, Ph.D. Thesis, Cornell University, 1990. 22.
(24) [24] W. G. Waller and D. H. Kraft, “A mathematical model of a weighted Boolean retrieval system,” Information Processing and Management, vol. 15, no. 5, pp. 235-245, 1979. [25] L. A. Zadeh, “Fuzzy sets,” Information and Control, vol. 8, no. 3, pp. 338-353, 1965. [26] H. J. Zimmermann, Fuzzy Set Theory and Its Applications. Boston: Kluwer Academic Publishers, 1991. [27] H. J. Zimmermann and P. Zysno, “Latent connectives in human decision making,” Fuzzy Sets and Systems, vol. 4, no. 1, pp. 37-51, 1980.. 23.
(25)
數據
![Table 1. Some T-norms and T-conorms [12]](https://thumb-ap.123doks.com/thumbv2/9libinfo/8912039.260336/4.892.143.756.649.896/table-t-norms-t-conorms.webp)
相關文件
• If the same monthly prepayment speed s is maintained since the issuance of the pool, the remaining principal balance at month i will be RB i × (1 − s/100) i. • It goes without
• If the same monthly prepayment speed s is maintained since the issuance of the pool, the remaining principal balance at month i will be RB i × (1 − s/100) i.. • It goes
(c) If the minimum energy required to ionize a hydrogen atom in the ground state is E, express the minimum momentum p of a photon for ionizing such a hydrogen atom in terms of E
Keywords: Requesting Song, Information Retrieval, Knowledge Base, Fuzzy Inference, Adaptation Recommendation System... 致
Particularly, combining the numerical results of the two papers, we may obtain such a conclusion that the merit function method based on ϕ p has a better a global convergence and
Corollary 13.3. For, if C is simple and lies in D, the function f is analytic at each point interior to and on C; so we apply the Cauchy-Goursat theorem directly. On the other hand,
Corollary 13.3. For, if C is simple and lies in D, the function f is analytic at each point interior to and on C; so we apply the Cauchy-Goursat theorem directly. On the other hand,
2-1 註冊為會員後您便有了個別的”my iF”帳戶。完成註冊後請點選左方 Register entry (直接登入 my iF 則直接進入下方畫面),即可選擇目前開放可供參賽的獎項,找到iF STUDENT
