災難事件下新媒體資訊傳播方式分析與自動化分類設計 ─ 以八八風災為例 - 政大學術集成
88
0
0
全文
(2) 致謝 終於到了寫致謝的時候,也代表回到學校的生活將要告一個段落了。當初在教育 系博士班許博士嘉家的鼓勵之下,大膽的由醫學院公共衛生的領域踏入理學院資 訊科學的挑戰中,為了全心接受這跨領域的考驗,無畏的辭掉工作離開職場當一 個全職的學生,在家人親友的支持、同學的相互砥礪下,通過了這人生中重要的 轉捩試煉,心中有太多的感謝。 在學業的路上,最感謝指導教授李蔡彥老師,除了學業上的教導,老師以身. 政 治 大 是我們所謹記的,致力於激發我們內在的學習動機,即使再忙也不放棄任何與學 立. 教給了旭峰這一輩子最好的學習,寬容看待事情的態度與圓融的待人處事原則都. 生們的互動機會。也感謝水火計畫中的陳百齡老師和鄭宇君老師,與您們的研究. ‧ 國. 學. 討論和想法上激盪,增加了許多研究的深度與視野上的廣度,同時也感謝兩位老. ‧. 師對我資訊領域想法上的重視和信任,讓旭峰更能了解跨領域合作上的方法與禮. y. Nat. 節。另外,感謝台灣師範大學科學教育中心的任宗浩老師,回到學生生涯在生活. er. io. sit. 上的種種支持和研究方法上的指導,能遇見您是我一生中珍惜的貴人。 最後感謝我最親愛的家人,謝謝你們在我老大不小的年紀時,仍然全心全意. al. n. v i n 的支持我去完成追尋我的目標,忙不過來時仍然給我堅定和堅持的鼓勵。還有, Ch engchi U. 謝謝 IMLab 大家庭中的學長姐和學弟妹。ㄌㄎㄒ帶我的心境去看世界,頓頓、阿 衝、胖達、少女與張小泰在學業程式上的幫助,見識 MOK 博班大學長的威嚴、小 COW 的商業智慧、Helen 的文學氣質和 IR 小天使、宅配貼心的聆聽與建議、芳茄 療癒系超可愛風格插畫、原原和橘子為實驗室帶來熱鬧的氣氛、搖旗的現代文青 氣息等等。我的同班同學小顧,一起熬夜寫 CODE、準備考試、吃好料、唱歌踏 青…,為大家大來不一樣歡樂氛圍,相信在這樣的記憶發酵,我們會是一輩子最 好的朋友。.
(3) 摘要 災難事件發生時,災難資訊的分析和傳遞需具有即時性,才能讓資訊運用達 到防災與救災的目的。網路基礎設施普及後,災難資訊的提供者加入廣大的網路 公眾媒體,單獨透過搜尋引擎檢索無法即時的反應災難目前狀態;而像災難應變 中心這類傳統頻道的災難通報管道有限,經常無法負荷突然爆發的資訊。這些因 災難爆發的瞬間巨量資料,已無法完全使用人力蒐集、過濾與處理,需要發展新 的工具能夠快速的自動化分類新媒體頻道資訊,提供救災防災體系應變或政府決. 政 治 大 本研究收集莫拉克颱風八八水災期間五個頻道資料,經過文字處理與專家分 立. 策時參考。. ‧ 國. 學. 類後,由頻率分布、分類結構組成與詞彙共現網絡,觀察不同頻道資料集之性質 的異同。在未考慮詞性與文法的狀況下,使用向量空間模型訓練 OAO-SVM 分. ‧. 類器模型,評估自動化分類方式的績效。. sit. y. Nat. 根據分析結果我們發現災難發生後,網路上的資訊隨著時序存在著階段性的. al. er. io. 期程,能夠由各個頻道瞭解災難的進程。透過詞彙共現網絡,瞭解救難專家書寫. v. n. 相較於俗民書寫使用的詞彙少重複且異質性較高。使用 OAO-SVM 訓練分類器. Ch. engchi. i n U. 結果,救難專家書寫的頻道分類績效優於俗民書寫。分類器交叉比較後,對於同 性質頻道的內容具有較好的分類績效。透過合併相同屬性資料集訓練,我們發現 當訓練資料的品質夠好時,分類器能夠有不錯的分類績效。品質不夠時,可以經 由增加訓練資料的數量來提升分類的績效。本研究的歸納,以及所發展出來的分 類方式與資訊探索技術,未來可以用於開發更有效率且精確的社群感知器。.
(4) Abstract When disaster events occur, information diffusion and transmission need to be in real-time in order to exploit the information in disaster prevention and recovery. With the establishment of network infrastructure, mass media also joins the role of information providers of disaster events on the internet. However retrieved information through search engines often cannot reflect the status of a progressing disaster. Traditional channels such as disaster reaction centers also have difficulty handling the inpour of disaster information, and which is usually beyond the ability of human processing. Thus there is a need to develop new tools to quickly automate classification of information from new media, to provide reliable information to disaster reaction centers, and assist policy decision-making. In this study, we use the data during typhoon Morakot collected from five different channels. After word processing and content classification by experts, we observe the difference between these datasets by the frequency distribution, classification structures and word co-occurrence network. We use the vector space model to train the OAO-SVM classification model without considering speech and grammar, and evaluate the performance of automated classification. From the results, we found that the chronology of internet data can identify a number of stages throughout the progression of disasters, allowing us to oversee the. 立. 政 治 大. ‧. ‧ 國. 學. sit. y. Nat. n. al. er. io. development of the disaster through each channel. Through word relation in word co-occurrence network, experts use fewer repeating words and high heterogeneity than amateur writing channels. The training results of classifier from the OAO-SVM model indicate that channels maintained by experts perform better than amateur writing. The cross compare classifier has better performance for channels with the same properties. When we merge the same property channel dataset to train classifier, we found that when the training data quality is good enough, the classifier can have a good performance. If the data quality is not enough, you can increase amount of training data to improve classification performance. As a contribution of this research, we believe the techniques developed and results of the analysis can be used to design more efficient and accurate social sensors in the future. Ch. engchi. i n U. v.
(5) 目錄 摘要 Abstract 目錄................................................................................................................................ 1 圖目錄............................................................................................................................ 3 表目錄............................................................................................................................ 4 第一章 導論............................................................................................................5 1.1.. 研究動機....................................................................................................5. 1.2. 1.3. 1.4. 第二章. 問題描述....................................................................................................9 研究目的..................................................................................................10 預期貢獻..................................................................................................10 相關研究..................................................................................................11. 2.1. 2.2. 2.3. 2.4. 2.5. 第三章 3.1.. 災難期間的傳播活動.................................................................................. 11 災難發生後資訊傳達問題(瞬間巨量).................................................. 12 備援頻道和浮現型頻道..............................................................................12 網際網路在災難中的角色..........................................................................13 過去文字訊息分類...................................................................................... 13 系統架構與研究方法..............................................................................15 資料來源..................................................................................................16. 立. 政 治 大. ‧. ‧ 國. 學. sit. y. Nat. 4.3. 4.4. 4.5. 第五章 5.1. 5.2.. 移除停用字.............................................................................................. 40 專家分類使用者介面設計......................................................................41 機器學習與分類器.................................................................................. 44 實驗結果與分析...................................................................................... 48 頻率分析..................................................................................................48 詞彙網絡分析.......................................................................................... 52. n. al. er. 系統設計與概觀...................................................................................... 17 資料收集與儲存資料集..........................................................................19 資料前處理.............................................................................................. 20 中文斷詞處理.......................................................................................... 21 移除停用字.............................................................................................. 21 專家文本分類.......................................................................................... 21 機器學習.............................................................................................. 23 系統實作..................................................................................................33 各資料來源前處理.................................................................................. 33 中文斷詞處理.......................................................................................... 38. io. 3.2. 3.3. 3.4. 3.5. 3.6. 3.7. 3.8. 第四章 4.1. 4.2.. Ch. engchi. 1. i n U. v.
(6) 5.3.. 機器學習比較.......................................................................................... 58. 第六章 結論與未來研究...................................................................................... 67 參考文獻...................................................................................................................... 70 附件一、專家文本分類編碼表.................................................................................. 73 附件二、中央研究院平衡語料庫詞頻統計.............................................................. 79. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. 2. i n U. v.
(7) 圖目錄 圖 1、自動分類系統概觀 ........................................................................................ 16 圖 圖 圖 圖 圖 圖 圖. 2、系統概觀與流程 ............................................................................................ 18 3、向量空間示意圖 ............................................................................................ 25 4、K 折交叉驗證示意圖 .................................................................................... 30 5、資料處理流程 ................................................................................................ 33 6、Twitter’s Taylor Singletary 宣布結束支援 XML .......................................... 34 7、JSON Object 結構圖 ..................................................................................... 34 8、JSON value 型態 ........................................................................................... 35. 圖 圖 圖 圖. 9、Twitter Response JSON format data .............................................................. 35 10、挑選災難詞彙應用程式介面 ...................................................................... 40 11、專家分類使用者介面(未選取) .............................................................. 43 12、專家分類使用者介面(已選取) .............................................................. 43. 圖 圖 圖 圖 圖 圖. 13、機器學習流程 .............................................................................................. 45 14、每日發佈頻率 .............................................................................................. 48 15、各資料集每日發佈百分比分佈 .................................................................. 49 16、各資料集專家文本分類統計 ...................................................................... 50 17、專家文本分類逐日分佈 .............................................................................. 51 18、Ricks 與 Xdite 資料集專家分類逐日分佈圖 .......................................... 52. 立. 政 治 大. ‧. ‧ 國. 學. sit. y. Nat. n. al. er. io. 圖 19、TFIDF 詞彙共現網絡圖 .............................................................................. 55 圖 20、平均卡方值特徵詞彙共現網絡 .................................................................. 56 圖 21、最大卡方值特徵詞彙共現網絡 .................................................................. 57. Ch. engchi. 3. i n U. v.
(8) 表目錄 表 1、MySQL Table Schema .................................................................................... 36 表 表 表 表 表 表 表. 2、卡方特徵詞彙共現網絡結構 ........................................................................ 53 3、TFIDF 詞彙共現網絡結構 ............................................................................ 54 4、特徵詞彙數量與閾值 .................................................................................... 59 5、不同平均卡方值特徵詞彙數量與資料集結果 ............................................ 59 6、不同最大卡方值特徵詞彙數量與資料集結果 ............................................ 59 7、各資料集機器學習結果 ................................................................................ 60 8、交叉比對資料集分類器績效(平均卡方特徵詞彙) ................................ 62. 表 表 表 表. 9、交叉比對資料集分類器績效(最大卡方特徵詞彙) ................................ 62 10、合併同質頻道訓練分類器績效(平均卡方特徵詞彙) .......................... 63 11、合併同質頻道訓練分類器績效(最大卡方特徵詞彙) .......................... 63 12、合併資料集訓練分類器績效 ...................................................................... 64. 立. 政 治 大. ‧. ‧ 國. 學. 表 13、分類器模組與專家編碼員間相互同意度(平均卡方特徵詞彙) .......... 65 表 14、分類器模組與專家編碼員間相互同意度(最大卡方特徵詞彙) .......... 65. n. er. io. sit. y. Nat. al. Ch. engchi. 4. i n U. v.
(9) 第一章 導論 1.1. 研究動機 災難是一種自然發生或是人為帶來的危害。近年來,各式各樣的災難在全球不斷 的發生,1999 年我國中部的 921 大地震;2001 年發生於美國的 911 恐怖攻擊事. 政 治 大 年南亞大海嘯、禽流感疫情爆發,2005 年卡翠那(Katrina)颶風造成美國紐奧 立. 件;2003 年全球性的 SARS(Severe Acute Respiratory Syndrome)疫情事件;2004. ‧ 國. 學. 良嚴重風災;2009 年全球 H1N1 新流感疫情、我國莫拉克颱風造成的八八水災、 美國北達科他州(North Dakota)融雪造成紅河水災;2010 墨西哥漏油事件、俄. ‧. 羅斯森林大火、海地大地震;2011 年日本東北近海 311 大海嘯事件等等。無論. sit. y. Nat. 是人為策畫或是自然帶來的災難,這些災情的規模和所造成的損害讓我們仍記憶. io. er. 猶新。而隨著國際關係的變化及全球環境的變遷,新型態的災難仍可能不斷的出. al. 現。除了災難預測科技的發明,災難發生時的資訊傳遞相關議題研究也逐漸受到. n. v i n Ch 重視。基於現今網際網路技術的突發猛進和資訊基礎建設的高密集性,日常生活 engchi U. 中,人們利用網際網路傳遞資訊的方式已漸多於信件、電話等傳統資訊傳播方式。 由於網際網路的特性,使得網路在近年災難中扮演著災害訊息傳遞的重要角色。 以下我們進一步分析災難及網路的特性:. 1.1.1.. 災難的特性. 災難有許多共同的特徵: (1)災難發生時狹帶高度的風險,將可能導致人命 的威脅和財產的重大損失;(2)災難可以被預期但很難事前被預知 (unpredictable) ,即使今日科技發達,預警系統仍無法精確的掌握其發生的 5.
(10) 時間和地點; (3)將造成社會機構的功能失靈,災難發生集中於一段時間和 一個地區,社會機構因工作負荷超載或權威秩序瓦解,導致溝通管道失靈和 防災計畫無法發揮效果; (4)災難具有時間緊迫性,人於災難發生時常會措 手不及,發生後有效的應變時間也非常的有限,所以為當下社會帶來嚴重的 焦慮和挫折[1]。 陳百齡等人[2]於文章中補充了三點當代災難的觀察:(1)災難事件的 全球化,當代的災難事件規模擴大,受到衝擊的對象不再只是單一地區或團 體。 (2)當代災難的社會參與成員有極大變化,以往救災工作唯一角色是政. 政 治 大. 府和專業組織;隨著當代社會第三部門的崛起和興盛,災難應急不再是公部. 立. 門和專家的禁臠。 (3)當代災難訊息,較以往更不受到時空的羈絆,一旦經. ‧ 國. 網際網路的特性. ‧. 1.1.2.. 學. 過媒體報導,往往引發全球其他場域人們更多的傳播活動。. sit. y. Nat. 不易全面癱瘓. n. al. er. io. 1950 年代美蘇冷戰時期,美國國防先進研究計畫局(DARPA,Defense. i n U. v. Advanced Research Projects Agency)為了考慮戰爭在造成許多毀損之後,仍. Ch. engchi. 具備可以信賴的工具來指揮動員部隊,便提出了一個計畫。計畫內容為由成 千上萬的自主性設備,組成一個無法單由任何中心控制的架構,在各個電子 障礙中,能以無數節點的方式相互連接,形成一個網絡結構型態。而這個計 畫成為最早的 ARPANET,也就是現在網際網路最早的雛形。發展出的工具 將不會因為一處的毀損造成整體的癱瘓而無法運作。 無時間性雙向傳遞 由方向性來看,傳統的大眾傳媒為單向傳遞,必須在其他媒體的輔助下才能 構成資訊雙向傳遞。如電視節目與電話叩應(Call-in)、報紙與讀者回函。 6.
(11) 而由時間性來看,傳統媒介同樣需要借助其他的工具輔佐,才能達到非同步 的接收訊息,如廣播節目與錄音機,電視節目與錄影機。 相對於傳統大眾傳媒,網際網路的基礎結構(Infrastructure)是連接許 多計算機的網路,透過相同的通訊傳輸協定規範,提供了一個同步 (Synchronous)或非同步(Asynchronous)的資訊雙向(Double way)傳遞 流通環境。 多元溝通模式. 政 治 大 大眾傳媒的傳播模式僅止於一對多(one-to-many)的方式,網際網路除了 立. 若由溝通的面相來觀察,網際網路較傳統大眾傳媒更具有高傳播效能。傳統. ‧ 國. 學. 一對多還具有一對一(one-to-one)、多對一(many-to-one)、多對多 (many-to-many)的傳播模式[3] 。加上前述可選擇同步與非同步的時間性,. ‧. 相較於傳統大眾傳媒,網際網路是一個互動性高、時空限制性低,允許多元. sit. y. Nat. 溝通模式的「互動媒體」。. n. al. er. io. 共同的資訊空間. i n U. v. 網際網路是無數計算機網絡的連結,所有網絡中的節點都可能成為儲存資訊. Ch. engchi. 的載體,我們很難得知資料確切的儲存位置,形成一個無限寬廣的資訊儲存 空間。網際網路興起時,人們習慣用一朵雲來表示其寬廣和深不可知,所以 近年我們稱這樣的網際網路儲存環境為「雲端儲存(Cloud storage)」。無論 是文字文件、影像、聲音、影片等,在雲端上的資料容許有很多種的儲存格 式,而且其資訊承載量相較傳統大眾傳媒,更不受形式、版面和節目時間的 限制。以資訊整體性考量,網際網路上的資訊是一個不受時間或空間切割, 可以累積和整合又可以將多元呈現的方式彙集於「一個共同的資訊空間」裡 的方式[4]。. 7.
(12) 個人化大眾媒體 網際網路發展至今,各種商業交易、行銷傳播、遊戲娛樂、社群討論、文章 寫作甚至人對人的即時溝通,都可以在網路上進行,其使用的方式日趨大眾 化和個人化,有些傳播學者稱之為「個人化大眾媒體」(Personalized mass medium) 。2005 年 O'Reilly Media 總裁 Tim O'Reilly 提出了 Web2.0 的概念[5]。 雖然 Web 2.0 至目前仍尚未有明確的定義,其主要概念則為網路即平台 (Network as platform) ,並有下面幾項特點: (1)以 Web 作為平台; (2)匯 聚集體智慧;(3)資訊內容將成為重點;(4)羽量化的程式設計模式;(5). 政 治 大 媒介讓使用者不再只是接受資訊,而是以人為中心出發點的網際網路世界, 立. 超越單一設備層次的軟體; (6)更豐富的使用者體驗。具有 Web 2.0 的網路. ‧ 國. 學. 成為人人可用且隨手可得的傳播管道。. 網際網路基於上述的幾項特性,在災難發生的時候,不會因部分地區硬體建. ‧. 設毀損造成整體無法使用,無時間上的限制,隨時都能進行雙向一對一、一對多、. y. Nat. sit. 多對一或多對多的溝通,在網際網路的環境中分享災情的文字訊息、照片或拍攝. n. al. er. io. 的影片。加上近年來各種網站系統的成熟和社群網絡的高使用率,個人化媒體發. i n U. v. 展亦漸趨完備,網際網路已成為災難來臨的一個重要資訊傳遞途徑和媒介。. 1.1.3.. Ch. 災難和網際網路的關係. engchi. 網際網路是一種新式的大眾傳媒,災難發生後所能發揮的角色,最早在 1995 年 的日本阪神大地震事件中就可以發現其功能。在災變第二天市政府就成立網站直 接以日文和英文報導震災消息和圖片,排除一般媒體負面和情緒性文字,提供客 觀和正確性的報導和最即時的數據,包含電力、瓦斯、電話通訊和傷亡及倖存者 名單[6]。除了官方的網站公布的資訊,在當時還透過其他的網際網路工具傳遞 災情消息,如:電子郵件、BBS(電子佈告欄)、討論群組和 IRC 頻道(Internet Relay Chat) 。網際網路發揮了不同的資訊傳遞方式,集散了來自不同地方的消息, 8.
(13) 具有發聲與訊息交換的功能。此後,同年在美國奧克拉荷馬市炸彈攻擊,事件發 生後馬上就有網站和 IRC 頻道因應緊急災難成立,發揮網際網路於災難中的特 質。 同樣,最早在國內的 921 集集大地震時,網際網路即發揮了他的作用。在震 後三天網路上即有「親友協尋」和「傷亡名單」設置,後有網路業者提供地震專 區,彙集許多救援、賑災、重建資訊和防災知識提供查詢。隨著網路技術和行動 設備的發展,即使至 2009 年的莫拉克八八風災,可以發現災難發生後,仍透過 不同的網路工具和平台來溝通和傳播災難的資訊。因此,網際網路在災難中,具. 政 治 大. 有提高能見度、增加互動性和匯集資訊等功用。. 立. ‧ 國. 學. 1.2. 問題描述. ‧. 隨著網路內容供應平台及行動通訊設備的普及,災難資訊提供的角色已不僅是傳. Nat. sit. y. 統專業媒體提供者,更加入廣大的網路公眾媒體。傳統媒體與公眾媒體最大的不. n. al. er. io. 同是傳統媒體使用的是先篩選後報導的機制,而公眾媒體則是先報導再透過網路. i n U. v. 技術或機制將內容篩選[1]。因現今網路基礎建設普及而公眾媒體內容平台眾多,. Ch. engchi. 所以資訊內容與流通的速度迅速增加,傳統廣播式媒介已經無法負荷,訊息數量 已經遠超過媒介載具所能負載的頻寬,而發生資訊過載(Information Overload) 的情形[2]。 災難當下若發生資訊過載問題,將會觸發人們對於媒體的創用行為。於災難 的危機情境下,人們透過資訊科技協力來緊急應變,使用網路上各種新興科技頻 道,從事社會的各種緊急聚合現象,包括有搜尋親友資訊、調度救災資源、從事 頻道言論管理等。然而,由這些新興媒體上收集資訊和分析的方式,已經和過去 大不相同,這些存在於網路上的資料集(Dataset)龐大且複雜,無法單純透過人 9.
(14) 力來擷取蒐集、過濾、管理、收藏以及做進一步的處理,這樣的資料被稱為「巨 量資料(Bid Data)」,每一個環節對於研究者來說都是極大的挑戰。. 1.3. 研究目的 在網路時代中,僅透過電話媒介做訊息通報是不夠周全的方式,尚有許多以 新興媒體平台溝通與資訊交換的方法,然而,有鑑於人力能夠處理訊息之數量的 限制性,在本研究中,希望透過觀察 2009 年莫拉克八八風災期間於網路和救災 應變中心收集的資料,發展工具比較與分析災難事件中不同性質來源資料集間的. 政 治 大 類模組,探索自動化分類災難資訊的可能性,以期能初步過濾資料為不同類別, 立. 異同與特性。並針對各資料集內容抽取特徵資訊,以機器學習的方式建立各項分. ‧ 國. 學. 輔助人力上的不足,協助進行資訊過濾和處理,未來能將自動化工具使用於發展 社群新媒體平台感測器。. ‧ sit. y. Nat. 1.4. 預期貢獻. n. al. er. io. 政府機構防救災體系應變政策之決定,需要事先得到足夠的防救災必要資訊. i n U. v. 才能做出判斷,發揮協調、聯繫、指揮調度和搶救的機能,而利用人力蒐集建立. Ch. engchi. 救災資料的方式,已經無法負荷今日的防救災勤務即時反應的功能[7]。存在網 路上的災情資訊和政府的防救災體系沒有足夠的連結,以致現階段防災救災應變 中心只能處理 119 急救專線建立的訊息,無法處理新興媒體上即時的資訊內容。 若發展自動化訊息分類,便能將網路上的資訊初步以機器過濾,減少人力資源並 解決資訊過多無法負荷的窘境。. 10.
(15) 第二章 相關研究 2.1. 災難期間的傳播活動 人們在災難期間的傳播活動具體而言可以分為四點 [2]: (1) 資訊蒐集和傳播. 政 治 大 人們透過媒體尋求近況,聯繫親人朋友,特別在通訊管道中斷之際,行動電 立. ‧ 國. 學. 話和網際網路等個人媒體發揮了聯繫作用。 (2) 物資徵集和流向. ‧ sit. y. Nat. 人們利用新媒體向社會大眾徵集物資,或透過線上討論平台,調整救災物資. io. n. al. er. 流向和數量,確保物資能用在正確的地方不致於產生救災資源的落差。 (3) 組織人力和任務派遣. Ch. engchi. i n U. v. 重大災難發生的時候,往往產稱新的團體或組織參與救災行動,透過媒體協 調和指揮救災志工,進行策略編組和調度派遣。 (4) 抒發心情與表達支持 危機事件下,人們需要情感撫慰的資訊以消弭焦慮或恐慌,透過新媒體平台 抒發慰問之情或表達救災看法和見解。. 11.
(16) 2.2. 災難發生後資訊傳達問題(瞬間巨量) 災難發生後社會內部通常會發生重大失序,人們需要相關資訊以確認自己或是親 友的安危,此時卻也是資訊最匱乏的狀態。由於能源中斷、設施毀損或指揮結構 失靈等因素,使得相關訊息無法正常的被傳送,人們因而設法透過其他管道來發 佈訊息,訊息經過重複的傳遞在短時間內造成龐大的訊息數量,使得原本負載過 重的系統因此而癱瘓[8]。 災難時期訊息的瞬間巨量成長、資訊匱乏和資訊過載,讓平時主要的資訊流. 政 治 大 路新媒體平台,形成無法處理的資訊數量是,災難的危機處理便轉化成為資訊的 立 通傳播媒介面臨極大的挑戰,當巨量的災情訊息湧入防救災單位、新聞機構和網. ‧ 國. 學. 危機處理。. ‧. 2.3. 備援頻道和浮現型頻道. y. Nat. io. sit. 備援頻道(Backchannels)是用來描述災難發生當下,人們使用網路上各種新興. n. al. er. 科技頻道從事緊急應變的現象,在頻道中的使用者同時具有發言和傾聽的參與。. i n U. v. 在南加州大火的社群媒體使用研究[9]中發現,雖然官方在大火發生時不認同社. Ch. engchi. 群媒體(Social Media)分享的資訊內容,視備援頻道上的內容為錯誤資訊或是 謠言。但在災難中,社群媒體卻是促成大規模群眾參與的重要關鍵,人們藉由線 上論壇、即時通訊、部落格、為網誌或線上共筆系統進行聯繫和傳遞訊息。 浮現型頻道(Emergence Channels)為災難中才浮出抬面的媒體頻道,這類 媒體在災難前並不存在,災難事件發生後,既有的媒體未能適時地提供足夠的資 訊,為因應資訊流通的情境需要而浮現出來,和備援頻道相對照。此類頻道使用 的媒體技術形式,足夠支持災難資訊傳播使用,參與者多半是自發性動員而來。 當危機狀況解除以後,這類頻道即回復原先的角色或是淡出而消失。 12.
(17) 2.4. 網際網路在災難中的角色 近年來引起大眾注意的許多災難事件中,網際網路都扮演過去其他傳統媒體沒有 的功能,人們利用各種新興網路技術的新媒體頻道來傳遞龐大災難資訊。在顧佳 欣的文章[10]中指出:網際網路本身在莫拉克八八風災中扮演資訊傳達、資源募 集調配的重要角色。如何以資訊傳播科技使資訊暢通,是災害發生時的關鍵。網 際網路的「互動性」和「資訊空間」可以讓偵測環境的功能更為接近民眾的個人 資訊需求[11]。線上社群網路和社交媒體的特點之一是他們對於信息傳播的潛力。 他們在訊息擴散的技術創新,已被有經驗的社會學家研究多年[12]。. 政 治 大 網路現已成為平民化的傳播工具,任何的組織不需要昂貴的器材和專業的製 立. ‧ 國. 學. 作團隊,就可以上網發布訊息及傳遞聲音影像,而且握有較多的內容掌控權,發 布新聞訊息時也不必耽心被媒體簡化或曲解。透過網路,受到災情影響的人們,. ‧. 也可以簡單地將他們的經驗與需要放到網站上,和其他地方的受害者一起分享他. sit. y. Nat. 們的想法,甚至是和救援單位溝通。過去幾年中,社群訊息網路工具(如:Twitter). n. al. er. io. 已經在災難時期被用來作為一種溝通工具,這類工具可以跨越國家、時區和文化. v. 讓人們分享訊息和知識,參與者可以找尋資料和驗證事件資訊,分享災區和失蹤. Ch. 人口等有關的詳細資訊[13]。. engchi. i n U. 2.5. 過去文字訊息分類 在這個知識爆炸的時代,整個世界處處都充滿了「文字」。巨大的文字數量人類 已無法有效的去解析這些內容。而這問題也已經引起自然語言處理(Natural Language Processing)和機器學習(Machine Learning)這些領域的研究人員注意。 過去有從簡短的文字訊息學習分類的問題,曾經有研究利用各種機器學習的演算 法(像是 Naive Bayes、SVM、Logistic Regression 和 Decision Trees),來解決識 別簡短訊息的垃圾訊息問題[14],或是針對一些線上問題的對話內容(如 Yahoo 13.
(18) Answers 或 Google Answers)進行分類比對[15]。亦有利用部落格的文本內容, 自動抽取關鍵字和階層式分類改善文章註解的方式[16],或是對醫療方面的文字 訊息分類,協助非洲偏遠地區的醫療問題[17]。 近年來網路和簡易手持行動運算設備的日趨成熟,簡化了人們對於事件的參 與並增加對事件內容討論的可近性。因此也提高了學者對於災難發生時,人們在 網際網路上所發佈傳遞的文字訊息分析的興趣,Cornelia 在其文章中提出了 EMERSE(Enhanced Messaging for the Emergency Response SEctor)架構系統, EMERSE 系統包含了四個元素: (1)自動的訊息分類(2)一個 iPhone 的應用程. 政 治 大. 式(3)撈取 Twitter 資料元件(4)機器翻譯,收集 Twitter 上的資料在經過機器. 立. 的語言翻譯後來分類災難發生時 Twitter 上的資訊[18]。. ‧ 國. 學. 過去的訊息分類研究中,雖有針對簡訊或網路訊息分類,但缺乏災難事件下. ‧. 針對未翻譯的原生語言,同時具有跨不同性質資料集比較的經驗。這次我們的研. io. n. al. er. 資訊內容,進行跨性質的資料集分析與訊息分類實驗。. sit. y. Nat. 究,則在單一莫拉克颱風八八水災事件下,收集了三種頻道來源共五個資料集的. Ch. engchi. 14. i n U. v.
(19) 第三章 系統架構與研究方法. 過去對於災難事件發生時的收集和分析,著重於和身分有關的資料比對,協助有 關災難中發生事故傷亡或是失蹤失聯的受難者身分確認。香港政府的重大事件災 難支援系統即是一個例子,此系統主要協助警務單位調查複雜罪案及在災難的支 援行動中協助傷亡查詢。該系統的資料收集方式,由警務處提供的資料,在第二. 政 治 大. 代系統中是以手動輸入資料,而第三代開始,主要透過內部迴路與警務單位和衛. 立. 生單位以電子形式交換數據資料[19]。這種固定的數據交換格式,將使得系統中. ‧ 國. 學. 的資料更容易被規劃與分析,而本研究中資料集的來源方式則有別於此種固定格 式資料獲得的方式。. ‧. sit. y. Nat. 本研究中所使用的資料集,除了來自緊急救難單位,大部分資料收集來自於. io. er. 網路的不同型別頻道。網路獨特的交流和傳播方式,並非所有使用者都接受過專 業的文字書寫訓練,使得收集得到的資訊相對的增添更多的干擾因素。因此在本. al. n. v i n Ch 研究中,除了各資料集的基本分析,在進行文本分析前,我們設計一些格式統整 engchi U. 以及去除干擾因素的方法,進行資料內容的前處理程序。最後,我們以機器學習 的方式訓練各個不同頻道類別的訊息自動分類器。本研究的訊息自動分類系統設 計,是希望透過目前收集到既有的五個資料庫內容,初步經過資料內容處理、文 章特徵值抽取,機器學習建立分類模組、驗證分類結果最後比較各個資料戶的異 同及評估驗證這些分類器的效果。期盼將來能夠利用分類器,對災難的資訊進行 自動化處理,將即時訊息在最短的時間內作初步過濾,提供給各類訊息相對應的 單位團體利用(如下圖 1)。 Collection Historical Data. Xdite Ricks. Analysis. Application. 15 Model. Research.
(20) 圖 1、自動分類系統概觀. 3.1. 資料來源. 立. 政 治 大. 莫拉克(Morakot)為 2009 年太平洋第 8 號颱風,是一個中度颱風,本身的颱風. ‧ 國. 學. 強度並不強大,但在 8 月 9 日至 8 月 11 日三日期間內帶來了罕見的驚人雨量, 符合了極端氣候的特性,單高雄市山區即帶來超過 2,500 毫米的雨量,如此雨量. ‧. 等同於三日內降下一年的雨量。莫拉克在短時間內狹帶超量雨水集中於台灣南部. Nat. er. io. sit. y. 地區,形成大規模水災重創南部地區,也帶來少見的資訊洪流。 水患的災民與其親友於此次水災中,在無法得知足夠資訊的恐慌焦慮下,只. al. n. v i n 能四處求援,因而癱瘓了部分應變中心的通訊系統。在既有管道壅塞的情形下引 Ch engchi U 發資訊氾濫,這現象引起一些網路使用者與技術人員的注意,在相互引導下組織 動員,自發性成立災情資訊頻道,提供莫拉克災情相關的資訊內容張貼和討論。. 如本文開頭第一章導論中第一節網際網路的特性所述,網路是一個共同的資 訊空間,資料可能會存放在網際網路某個儲存節點上,所以資訊可以累積與整合 不容易流失,但災難發生時,網路上爆發的瞬間巨量資料,可能使得原本不存在 的浮現型頻道因應情境誕生。通常此類頻道在災難結束後,會隨之恢復為原來的 角色或淡出網路消失。所以蒐集此類頻道的資料具有時效性,當災難結束後,我 們就不容易蒐集到較完整的資料,僅能透過搜尋方式找到部分已被封存在搜尋引 16.
(21) 擎資料庫的內容。 本研究中所選擇使用的資料,即為 2009 年發生在南台灣地區的莫拉克八八 風災的頻道資料,經主事者同意授權下,利用程式將既有頻道(屏東及台南縣市 119 報案電話記錄)和網路上備援頻道(ADCT 數位文化 Twitter 資料)及浮現頻 道(XDite、Ricks)等五個資料來源,整理儲存在資料庫中,以做為本次研究的 基本資料集。. 3.2. 系統設計與概觀. 治 政 圖 2 為本研究的系統設計概觀與流程,包括撈取網路社群資料、文字辨識、文字 大 立 轉碼等資料前處理步驟,並將資料儲存至資料庫中保存。而後進行專家文本分類、 ‧ 國. 學. 移除干擾符號、中文斷詞處理和去除停用詞(Stop Words)等資料前處理。在進. ‧. 行機器學習前,我們抽取更具意義的特徵資料,作為建立向量空間模型的維度, 以 TFIDF 向量模型來做為分類器的訓練,在訓練時期設計交叉驗證(Cross. y. Nat. n. al. er. io. sit. Validation)的方法,對訓練後的各個分類模組進行驗證及比對。. Ch. engchi. 17. i n U. v.
(22) Scan Image. Original Data. Twitter tweets. OCR. Format Convert. Data Crawl. Encoding Convert. Database. 治 政 Remove Noise 大. Word Segmentation. 立. ‧ 國. 學. Remove Stop Words. ‧. TFIDF Calculation. Expert Classification. er. io. sit. y. Nat. Database. Feature Selection. n. al. Ch. TFIDF Vector. engchi. i n U. v. 10-Fold. Training. Model. Vector Space Model. Testing. Cross-Validation. Result. Calculate Index. 圖 2、系統概觀與流程 18.
(23) 3.3. 資料收集與儲存資料集 本研究中的資料包含了莫拉克颱風八八風災期間三種頻道(既有頻道、備援頻道、 浮現頻道)內容,這些資料雖於事後收集完成但皆為發生災難當下資料。以圖形 文字辨識、文件格式轉換、資料擷取過濾匯入等方式,統一儲存至關聯式資料庫。 不同來源的資料因屬性相異,我們儲存至不同的資料表中,每一筆資料給予一個 不重複且獨立的編碼,方便後續的文章分析時辨識使用,這些資料系統中我們稱 為「歷史性資料(Historical Data)」。. 政 治 大 轉換,可能有亂碼出或缺漏出現在文章內容中。為求較好的文字品質以減低文字 立. 歷史性資料來自不同單位和平台,有部分儲存前已經過文字辨識或資料編碼. ‧ 國. 學. 分析時的錯誤率,在完成儲存後先做資料清查(Data Cleaning)的動作,以人力 將所有經過文字辨識(Ricks)、檔案轉換(屏東及台南縣市 119 報案電話記錄). ‧. 的資料內容進行校正。. y. Nat. io. sit. 我們收集的歷史性資料有屏東及台南縣市 119 報案電話記錄、Ricks、Xdite. n. al. er. 與 ADCT 的 Twitter 發文內容,屏東及台南縣市 119 報案電話記錄為既有頻道,. Ch. i n U. v. Ricks 和 Xdite 為浮現頻道,ADCT 為備援頻道。收集資料經過掃描與轉檔後,. engchi. 統一儲存至關聯式資料庫 MySQL,詳細的方法如下所述: Tainan119、Pingtung119 報案電話記錄:由於報案電話記錄屬敏感性資料無 法直接獲得電子檔案,我們在主事單位同意下取得紙本記錄資料。經過掃描成圖 檔再透過機器文字辨識與人工校對後,將資料儲存為逗號分隔文字檔(.csv) ,再 編碼轉換後存入資料庫。兩個 119 資料集的欄位有:獲報時間、鄉鎮別、災害地 點、災情類別、災害狀況、處理情形。總共取得資料筆數有 Tainan119 資料集 2436 筆、Pingtung119 資料集 512 筆。. Ricks:為網友自行架設的網站,我們於莫拉克風災發生期間,透過人力擷 19.
(24) 取「莫拉克颱風災情資料表」網站上的資料,儲存為 Excel 檔案格式(.xls) 。Ricks 的資料欄位有:發生時間、推文與否、鄉鎮市、詳細地址、聯絡方式、發生災情、 需要協助內容、最新狀態。Ricks 資料集總共取得 4193 筆資料。. Xdite:同樣為網友自發性動員架設的網站,為一種論壇形式的網站。我們 取得為資料庫檔案(.sql) ,檔案中包含許多資料表,主要發文和回文內容資料表 的資料欄位有:文章標題、文章內容、發文時間、更新時間、垃圾訊息標示。 Xdite 資料集總共取得 9499 筆資料。. 政 治 大 是透過協會官方的 Twitter 帳號(@adctnpo)統一將收集整理的資訊發布至 Twitter 立 ADCT:台灣數位文化協會(Association of Digital Culture, Taiwan)資料集. 上。我們使用 Twitter API 將 2009 年 8 月 9 日至 2009 年 10 月 6 日期間 ADCT Twitter. ‧ 國. 學. 的發布內容擷取下來,共取得資料 2,099 筆資料。Twitter API 是一種 RESTful. ‧. (Represental State Transfer)API,目前許多網路應用服務皆採用這種結合了. sit. y. Nat. HTTP 與 URL 兩種協定的網路軟體設計架構,高效率且高靈活性。Twitter API. io. er. 回傳的資料為 JSON(Javascript Object Notation)格式,JSON 為一種輕量級的資 料交換語言,是獨立於語言之外的文本格式。Twitter JSON 資料中包含許多 tweets. al. n. v i n Ch 和 User 的基本資料,轉換後我們僅保留了幾個欄位內容儲存,分別是 Tweet 編 engchi U. 號(id) 、tweet 內文(text) 、發文時間(created_at) 、發文者名稱(screen_name)、. 轉載次數(retweet_count)。. 3.4. 資料前處理 除了屏東與台南 119 報案電話紀錄,其餘已儲存的歷史性資料皆來自於網路,網 路上大部分的使用者沒有受過撰文的訓練,網路發言的內容可能有較多口語化表 達和語氣詞,文章結構比較隨興不夠嚴謹可能也會有文字表情符號等內容。所以 進行文字分析前,對於來源為網路的資料,進行資料內容的前置處理與移除干擾 20.
(25) 值,處理內容的方法將在下一章節中介紹。. 3.5. 中文斷詞處理 在完成資料前處理後,對這些儲存的歷史性資料內容進行下一步中文斷詞處理。 詞彙(Word)是最小且有意義的語言單位,任何語言處理的系統都必須要先能 夠分辨文本中的詞才能夠進行更進一步的處理,所以在做文本處理時斷詞便成為 不可或缺的技術。在英文的文本中我們可以透過空白取得文本中的每個詞彙,但 是中文的文本中句子裡沒有分隔符號,所以我們沒有辦法直接取出中文詞彙,必. 政 治 大. 須依靠中文斷詞系統將可能的詞彙先行處理。. 立. ‧ 國. 學. 3.6. 移除停用字. 文件中常包含語助詞、副詞和連接詞等經常出現的慣用字詞,尤其是發表於網路. ‧. 的一般文章中,這類詞彙的頻率相當高,但是這些詞彙對於文件的分析較不具有. y. Nat. io. sit. 意義,在資料探勘的領域中稱這些詞彙為停用字(Stop Words)。在分析前,將. n. al. er. 符合停用字集合的詞彙,由斷詞後的文件中移除,避免停用字影響後續分析的結 果。. Ch. engchi. i n U. v. 3.7. 專家文本分類 除了文本的中文斷詞處理,另外抽取每個歷史性資料中不同資料庫的內容,請災 難傳播學者進行專家文本分類編碼員訓練,訓練後計算不同編碼員間的信度與效 度,達到信度標準後再進行分類。最後,儲存分類結果作為機器學習之用。. 3.7.1.. 專家分類項目. 經過專家學者抽取瀏覽部分歷史性資料,對於收集來的資料內容歸納建議,根據 21.
(26) 災難時會發生的一些資訊特性,將收集的頻道資訊分為四個群組共九個類別,分 別如下: (1)資訊:請求協尋(2)資訊:提供情境資訊(3)資訊:轉貼傳媒或 公告(4)行動:請求救援(5)行動:志工物資(6)表達:討論反應(7)表達: 自律(8)其他:公關行銷(9)其他:資訊不完整無法分類。. 3.7.2.. 時間隨機抽樣分類. 為避免時間排序後的分類母群,可能會與分類項目產生時間性干擾偏差,先將每 個資料庫內容依照發布的時間由先而後排序,並以等距抽樣的方式,抽取十分之 一的內容筆數作為分類用的母群資料。並設計程式由母群中隨機抽取尚未分類的. 政 治 大. 內容,提供給編碼人員進行分類編碼,並於顯示內容時隱藏時間資料。. 立. 編碼員信度分析. 學. ‧ 國. 3.7.3.. 針對專家建議的類別,定義九個類別的分類原則,製作成編碼參考表(Coding. ‧. Table)以訓練分類編碼人員。當編碼人員超過一人我們必須檢測不同編碼人員. sit. y. Nat. 的一致性(Consistency)求取信度(Reliability)的可靠性,確保資料分類編碼. io. 致性也可以確認分類編碼內容的可信度。. n. al. Ch. engchi. er. 的過程中不會受到人、事或工具的影響而產生變化。信度代表分類編碼結果的一. i n U. v. 在此研究中,隨機抽取五十分之一的資料筆數,一式多份給不同的編碼人員 進行編碼後計算其信度。信度參考王石番(1991)傳播內容分析法中公式,此為 依據 Holsti(1969)提出的內容分析相互同意度及複合信度公式。. Intercoder Agreement (IA) =. Composite Reliability (CR) =. 2×𝑀 𝑁1 + 𝑁2. 𝑁 × (𝐴𝑣𝑒𝑟𝑎𝑔𝑒 𝑜𝑓 𝐼𝐴) 1 + [(𝑁 − 1) × (𝐴𝑣𝑒𝑟𝑎𝑔𝑒 𝑜𝑓 𝐼𝐴)]. M:編碼完全相同數量,N:參與編碼的人員數 N1:第一位編碼人員,N2:第二位編碼人員 22.
(27) 據王石番(1991)書中內容,信度檢定需達到 0.80 以上信度係數標準。. 3.8. 機器學習 過去在文字訊息機器自動分類的應用上,大都運用於垃圾郵件和垃圾訊息的過濾 機制上,對於訊息多類別分類的運用則在少數。而災難發生時對於資訊的需求具 有較大的急迫性,網路上傳遞的文字訊息卻過於龐大遠超出人力所及之上,難於 有效的時間內提供足夠決策或參考的資訊,在這樣的矛盾下,若能透過機器學習 的方式建立自動分類模式,簡化災難時的巨量文字訊息為可用的資訊,提供救災 防災單位進一步的運用。. 立. 政 治 大. 機器學習(Machine Learning)所關注的是電腦程式所能達到的學習,如何. ‧ 國. 學. 透過結合統計、機率等方法將經驗累積達到自動學習的效果。只要給定問題的範 圍和訓練資料(Training Data),由資料中選擇特徵資訊(Feature Selection),然. ‧. 後建構資料的模型(Model Selection) ,把模型當做學習的成果,我們可以將之用. Nat. sit er. al. n. TFIDF. io. 3.8.1.. y. 來預測未知資料內容(如類別)。. Ch. engchi. i n U. v. 在一般情形下,一個詞彙出現在文件中的次數越高,代表這個詞彙在文章中越重 要,但並不是所有詞頻(Term Frequency)較高的詞彙,都具有好的文章代表性。 因此我們也會注意詞彙在整個文件集中,出現的篇數有多少來看詞彙的重要性。 詞彙在文件集合中出現的篇數越少,表示越可以被用來區隔文件,反之,出現篇 數越多時表示詞彙狠普遍不具有代表性。詞彙出現的文件頻率和其重要性具有反 比關係,所以,衍生出逆向文件頻率(Inverse Document Frequency)作為詞彙普 遍重要性的度量。 綜合上述兩個要素,Salton 提出 TF-IDF(Term Frequency - Inverse Document 23.
(28) Frequency)這種統計方法[20],在資訊檢索(Information Retrieval)領域中,常 用來評估一個詞彙對於一個文件集的重要程度。其算式如下所示:. tf(𝑡, 𝑑) =. f(𝑡, 𝑑) ∑{f(𝑤, 𝑑): 𝑤 ∈ 𝑑}. t:詞彙,d:文章(資料集中的發文). f(t.d):該詞彙在文章中出現的次數. ∑{f(𝑤, 𝑑): 𝑤 ∈ 𝑑}:該文章的詞彙總數. 政 治 大 詞頻(Term Frequency,TF)是指一個詞彙於文件中出現的頻率,為了避免 立. |𝐷| |{𝑑 ∈ 𝐷: 𝑡 ∈ 𝑑}|. n. al. er. io. t:詞彙,D:資料集,d:文章. sit. Nat. idf(𝑡, 𝐷) = log. y. 文件),除以文章中的詞彙總數來標準化數值。. ‧. ‧ 國. 學. 單純使用詞彙次數會出現的偏差(在一份長文字文件裡出現的次數會高於短文字. i n C |D|:資料集中的文章總數 hengchi U. v. |{𝑑 ∈ 𝐷: 𝑡 ∈ 𝑑}|:出現該詞彙的文章數 逆向文件頻率(Inverse Document Frequency,IDF)是用來表示一個詞彙在 整個文件庫中的普遍重要程度。如果包含某個詞彙的文件越多,代表這詞彙在文 件庫中較不具有分辨的重要性,IDF 的數值就較低。 結合詞頻與逆向文件頻率的想法,可以得到 TF-IDF = tf × idf 的計算式。 若一個詞彙在文件中具有高的詞頻,而在整個文件庫中有較低的文件頻率,會有 高的 TFIDF 權重數值。這個 TFIDF 的方式會傾向於會傾向於過濾掉太常見的詞彙, 24.
(29) 保留較重要的詞彙。. 3.8.2.. 向量空間模型. 向量空間模型(Vector Space Model)的概念最早由 Salton 於 1975 年提出[21], 是一個應用於資訊擷取與過濾、索引文件和評估相關性的一個代數模型。向量空 間模型中,將每個文件的重要詞彙作為代表文件的屬性,聯集所有的屬性表示為 高維向量空間中的的獨立維度,形成文件的屬性向量。每個維度為文件中的關鍵 詞彙,給予每個詞彙一個權重數值,代表詞彙在文件中的重要性,即能表示文件. 政 治 大 ,計算出每個詞彙的權重數值就可以決定文件在. 在高維空間中的情形。如下圖 3 的向量空間示意圖,每一個文件由三個詞彙權重. 立. 組成了一個向量. ‧. ‧ 國. 學. 空間中的位置。. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. v. 圖 3、向量空間示意圖 在本研究中,我們先將每篇發文的內容視為一個文件,挑選出具有代表性的 詞彙作為維度,把每個文件表示成一條向量內容。向量中的每一個維度是一個獨 立的詞彙內容,如下式子所示: 25.
(30) 再計算每篇文件中這些詞彙的 TF-IDF(Term Frequency - Inverse Document Frequency)權重數值,代入上式中詞彙所屬的維度位置,便可以得到每篇文件 的屬性向量。. 3.8.3.. 文件特徵選取. 特徵選取(Feature Selection)又被稱為子集選取,依據特定的評估指標,從原有 的特徵集合中挑選出具有鑑別能力的有效特徵,產生最佳的特徵子集合,使得績. 治 政 效評估指標可以到達最佳化。也就是說,特徵選取是在我們訓練分類器模型時, 大 立 在無損機器學習演算法的效能的情形下,過濾掉沒有效用、不具關鍵影響力和具 ‧ 國. 學. 有類似鑑別能力的雜訊特徵,僅保留下真正對效能指標有影響的特徵資料,來達. ‧. 到降低特徵空間維度的目的。對於文件分類的特徵選取就是刪除對於分類準確沒 有影響的詞彙特徵。. sit. y. Nat. n. al. er. io. 文件分類時特徵選取的方法,常被使用的統計指標有資訊量增益比例. i n U. v. (Information Gain) 、共同資訊量(Mutual Information)和卡方分析(CHI-Square. Ch. engchi. Test),利用上述統計方法計算每個詞彙指標值,排序後以特定閾值(threshold) 過濾的方式,挑選出有影響力的特徵詞彙子集合。在先前 Yiming Yang 對文件分 類時特徵選取方法的研究[22]中發現,卡方分析(CHI-Square Test)和資訊量增 益比例(Information Gain)的效果優於共同資訊量(Mutual Information)。在我 們的研究中選擇卡方分析作為特徵選取的統計方法。 卡方分析(χ2 Statistic measure, CHI-Square Test)的方法又稱為獨立性檢定, 是用來確定兩個組別的獨立性,使用在文件分類的特徵選取上,即表示用來觀察 詞彙與類別之間的獨立性,越高的數值代表詞彙與類別的相關性越高。. 26.
(31) 卡方分析的數值計算方式如下公式: 詞彙 類 別. 是. 否. 是. A. C. 否. B. D. t:詞彙. c:類別. 政 治 大 B:出現指定詞彙但是不在類別中的數量 立. A:同時出現指定詞彙與類別的數量. ‧ 國. 學. C:類別中其他非指定詞彙的數量 D:不在類別中也非指定詞彙的數量. ‧. 計算每個詞彙與類別的數量,我們每個詞彙取得兩個卡方值,一個為平均卡. sit. y. Nat. ),一個為最大卡方值(. io. n. al. ),如下式子:. er. 方值(. Ch. engchi. i n U. v. 平均卡方值代表的是詞彙與所有類別的平均關係,一般來說數值越高代表詞 彙與大部分類別有較好的相關性。最大卡方值代表詞彙與某類別特別高相關性, 或許對所有類別並非都具有好的相關性,但是對某個類別特別有高相關,可能具 有好的鑑別力。. 27.
(32) 3.8.4.. 支持向量機(Support Vector Machine). 在我們的研究中所使用的機器學習方法,是一種監督式學習(Supervised Learning) 法。監督式學習是由有標示的訓練資料中學習建立一個模型,在利用模型來預測 其他資料的標示,前項敘述中的專家文件分類,即為監督式學習的標示。 常用於文件分類的監督式學習方法有單純貝氏分類(Naïve Bayes)和支持向 量機(Support Vector Machine, SVM) 。單純貝氏分類是一種基於統計機率所發展 的分類法,當樣本越大時越能夠得到好的預測績效。機率構成的分類模型雖然有. 政 治 大 因此,在本研究中採用 SVM 作為分類的演算法。 立. 簡單快速,但是真實世界的資料,或許無法總是滿足其屬性資料完全獨立的假設。. ‧ 國. 學. SVM 是以統計為基礎的機器學習演算法,是一種處理二元分類(Binary Classification)的方法,在高維度的空間中尋找一個超平面(Hyperplane)將兩. ‧. 個類別分隔開。這樣的超平面可能有很多個,SVM 的目的在找出最佳的超平面,. Nat. er. io. sit. y. 使兩個類別的邊界(Margin)幅度最大話,能夠明顯區分兩個類別。 對於多類別(Multi-Class)分類問題,單獨使用一個 SVM 分類器是不足的,. al. n. v i n Ch 因此對於多類別分類常用的方法有一對多(One-Against-All, OAA-SVM)、一對 engchi U 一(One-Against-One, OAO-SVM)和有向非循環圖(Directed Acyclic Graph,. DAG-SVM)三種,根據 Duan[23]利用五個不同資料集對於 OAA-SVM、OAO-SVM 與 DAG-SVM 三種方法進行測試,整體而言, 1000 筆以下的的資料集以 OAO-SVM 與 DAG-SVM 的錯誤率較低。在本研究中,資料集中已完成專家分類 的筆數最多為 1,056 筆,所以我們選擇使用 OAO-SVM 作為機器學習建立分類器 模組的方法。. 28.
(33) 3.8.5.. 交叉驗證(Cross Validation). 在實際的應用上我們通常只能取樣一部分的資料,因此模組的績效評估目的,則 在於求得與資料母體間的最小誤差。為了確定模組的效度問題,研究者通常會使 用折半樣本(Holdput Method Sample),以隨機的方式將樣本分成兩半,以其中一 半的樣本來建立最佳模組,並以此模組來預測另一半樣本,看看預測誤差的變異 數是否達顯著水準,判定模組的預測效度。折半樣本法的缺點,是如果只切割一 組的訓練與測試資料,一旦選擇到的資料不具有代表性的組合,誤差就沒有估計 的意義。為了避免這樣的限制,方法上我們可以使用重複取樣的方式來交叉驗 證。. 立. 政 治 大. 交叉驗證(Cross validation)是統計學上將數據樣本分割成較小子集的方法,. ‧ 國. 學. 可以在一個子集上做分析,剩下的子集用來做後續的比對與驗證。一開始的子集. ‧. 稱之為訓練集(Training Set)其他的子集稱為測試集(Testing Set) 。本研究中,. sit. y. Nat. 我們所採用的方法是 K 折交叉驗證(K-Fold Cross Validation)。K-Fold 是將資料. io. er. 分割成 K 個子集,其中一個子樣本被留作驗證模組使用,其餘 K-1 個子集被用 來訓練,如下圖 4 的 K 折交叉驗證示意圖。交叉驗證重複 K 次,每個子集都被. n. al. Ch. 驗證一次,平均 K 次的結果得到一個評估值。. engchi. 29. i n U. v.
(34) Total Experiment 1. Testing. Training. Experiment 2. Experiment 3. Experiment 4. Experiment 5. 立. 政 治 大. ‧. ‧ 國. 學. 圖 4、K 折交叉驗證示意圖. n. er. io. sit. y. Nat. al. Ch. engchi. 30. i n U. v.
(35) 3.8.6.. 績效評估. 資訊檢索領域中的文件自動分類的研究中,常見的績效評估指標有正確率 (Accuracy)、查準率(Precision)、查全率(Recall)、F 度量(F-measure)。是 以人工判斷與系統判斷做交叉分析,對每個類別分析的情形如下表所述: 系統判斷 相關. 不相關 false negative(fn). 人工. 相關. true positive(tp). 判斷. 不相關. false positive(fp). 政 治 大. 立. true negative(tn). tp:正確正例,屬於類別系統判斷為相關。. ‧ 國. 學. fn:錯誤負例,屬於類別系統判斷為不相關。. fp:錯誤正例,不屬於類別系統判斷為相關。. y. Recall =. n. Ch. 𝑡𝑝 𝑡𝑝 + 𝑓𝑛. sit. io. al. 𝑡𝑝 𝑡𝑝 + 𝑓𝑝. er. Nat. Precision =. ‧. tn:正確負例,不屬於類別系統判斷為不相關。. i n U. 𝑡𝑝 + 𝑡𝑛 Accuracy = 𝑡𝑝 + 𝑡𝑛 + 𝑓𝑝 + 𝑓𝑛. engchi. v. 如果單純使用查準率(Precision)、查全率(Recall),可能會因樣本數的變 化而有高查準率低查全率,或是低查準率高查全率的情形。而 F-measure 是一個 調和平均數,同時考慮了查準率與查全率,只有查準率和查全率都高的時候 F-measure 的值才會高,能夠作為客觀指標衡量整體的績效。. F − measure = 2 ×. 𝑃𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛 × 𝑅𝑒𝑐𝑎𝑙𝑙 𝑃𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛 + 𝑅𝑒𝑐𝑎𝑙𝑙. 在資訊檢索領域的文件自動分類研究裡,常因文件有多重分類(一篇文件可 31.
(36) 以同時分屬多種類別)以及類別的文件篇數分不均的情形,F 度量又細分為 Micro-F-measure 與 Macro-F-measure 兩種。Micro-F-measure 是全部文件一起累 加統計,不分類別,容易受到少量的大類別表現好壞的影響。Macro-F-measure 考慮每個類別的成效後再做平均,因此容易受到大量的小類別影響。. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. 32. i n U. v.
(37) 第四章 系統實作. 在本章中說明系統實作時的細部內容共分為四個部分,第一部分為個資料來源的 資料前處理實作方法,第二部分說明資料內容處理的經過和方法,第三部分為專 家分類的介面設計,第四部分為機器學習使用的工具,第五部分為分類器的驗證 方法。. 立. 4.1. 各資料來源前處理. 政 治 大. ‧ 國. 學. 由於研究使用的資料,來自於不同檔案格式和網路平台,最後儲存於資料庫中做 為分析用。在開始分析前,我們先進行資料的資料前處理,將不同的檔案格式、. ‧. 編碼內容整合為一,並移除不相關的干擾因素。資料內容的處理流程如下圖 5. 資料前處理. n. C h編碼轉換 engchi. er. io. al. sit. y. Nat. 所示:. i n U. v. 移除干擾值 中文斷詞處理 專家內容分類. 4.1.1. Twitter 資料轉換 圖 5、資料處理流程 Twitter API 的回傳資料型態在 2010 年 12 月開始,已經不提供 XML 格式的內容, 33.
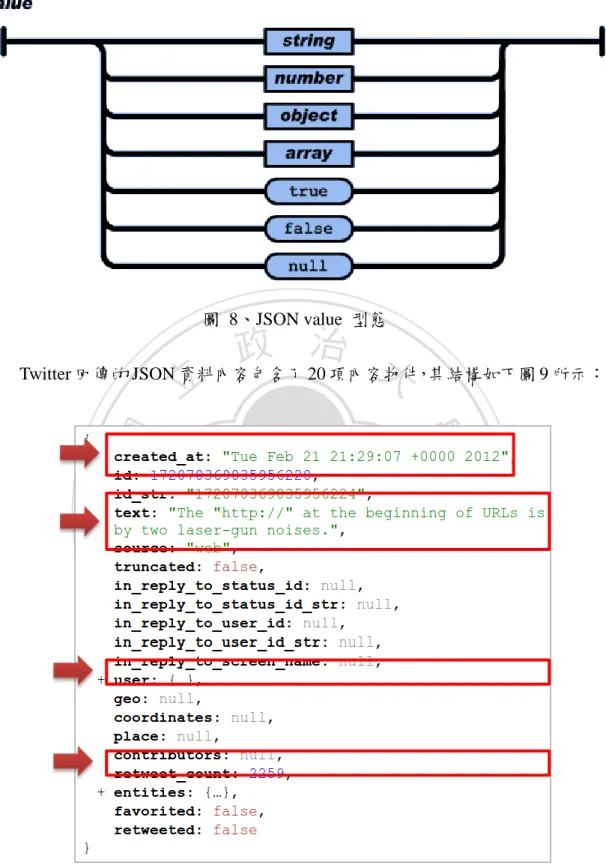
(38) 只提供 JSON(Javascript Object Notation)格式回傳資料,JSON 雖然是 Javascript 這個語言中的一的子集,但是是一個獨立於語言之外輕量級的資料交換文字格式, 而且易於讓人閱讀和撰寫。因獨立於語言之外,可以使用任何的程式語言來解讀 其內容。. We will end support for XML on all Streaming APIs on Dec 6th, 2010, after encouraging developers to use JSON-based output formats for some time now. This deprecation does not apply to the REST or Search APIs, but all clients requesting XML from stream.twitter.com, regardless of role and method (sample, filter, follow, etc) will be affected.. 政 治 大 圖 6、Twitter’s Taylor Singletary 宣布結束支援 XML 立. ‧ 國. 學. JSON 是一個簡單的結構,主要有兩個結構所構成: 物件(Object):每一個物件由一對大括號所構成({. ‧. }),一個 Object 包含. 一個以上非排序成對的名稱/值(name/value),每個成對之間以「,」分隔。每個. y. Nat. n. al. er. io. sit. 成對裡的名稱和值之間使用「:」隔開。其結構如下圖 7 所示:. Ch. engchi. i n U. v. 圖 7、JSON Object 結構圖 其中值(Value)的形態可以是 string、number、object、array、boolean、null, 如下圖 8 所示:. 34.
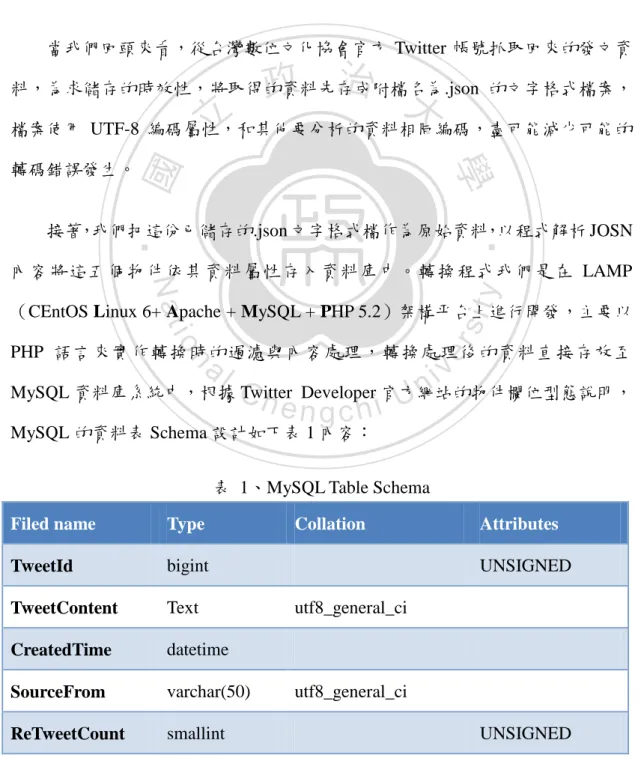
(39) 圖 8、JSON value 型態. 政 治 大 Twitter 回傳的 JSON 資料內容包含了 20 項內容物件,其結構如下圖 9 所示: 立 ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. v. 圖 9、Twitter Response JSON format data 其中,大部份的資料都不是這一次研究主題裡會用到的核心內容,因此在這 裡我們只擷取圖 9 中箭頭所指部分,如下述所列六點: 35.
(40) 1.. creat_at:發佈 tweet 的時間,格式為 UTC +0:00 時區的時間,轉為台北 時區 +8:00. 2.. id:每一則 tweet 的唯一編號. 3.. text:tweet 的內文. 4.. user::id:使用者物件中的編號. 5.. retweet_count:推文的數量. 6.. source:資料來自什麼程式. 當我們回頭來看,從台灣數位文化協會官方 Twitter 帳號抓取回來的發文資. 政 治 大. 料,為求儲存的時效性,將取得的資料先存成附檔名為.json 的文字格式檔案,. 立. 檔案使用 UTF-8 編碼屬性,和其他要分析的資料相同編碼,盡可能減少可能的. ‧ 國. 學. 轉碼錯誤發生。. ‧. 接著,我們把這份已儲存的.json 文字格式檔作為原始資料,以程式解析 JOSN. sit. y. Nat. 內容將這五個物件依其資料屬性存入資料庫中。轉換程式我們是在 LAMP. io. er. (CEntOS Linux 6+ Apache + MySQL + PHP 5.2)架構平台上進行開發,主要以 PHP 語言來實作轉換時的過濾與內容處理,轉換處理後的資料直接存放至. al. n. v i n MySQL 資料庫系統中,根據 C Twitter Developer 官方網站的物件欄位型態說明, hengchi U MySQL 的資料表 Schema 設計如下表 1 內容:. 表 1、MySQL Table Schema Filed name. Type. TweetId. bigint. TweetContent. Text. CreatedTime. datetime. SourceFrom. varchar(50). ReTweetCount. smallint. Collation. Attributes UNSIGNED. utf8_general_ci. utf8_general_ci UNSIGNED 36.
(41) bigint. TwitterUserId. UNSIGNED. 4.1.2. 文字辨識與檔案格式轉換 在資料集中的 Ricks 內容為災難發生時,透過使用者由螢幕擷取所保留的畫面資 料,我們先以文字辨識(Optical Character Recognition, OCR)將圖檔中的文字辨 識為文字檔,透過人力做文字的校稿確認和修正,再以程式整理為可以匯入資料 庫的內容格式。 屏東及台南兩個縣市的消防隊 119 報案電話記錄,是使用 Microsoft Excel. 政 治 大. 檔案格式儲存其內容,我們先依檔案中的欄位格式和內容特性,制定出資料庫中. 立. 的資料表結構(Table Schema),在完成轉換文字編碼後,即以程式匯入資料庫. ‧. ‧ 國. 學. 中儲存。. 4.1.3. 編碼轉換. y. Nat. io. sit. 文字編碼(Text Encoding)是一個複雜的議題,由於各國依據自己的語言特性,. n. al. er. 訂立了不同的文字編碼系統,即使我們在網頁中顯示中文文字,其背後可能為大. Ch. i n U. v. 五碼編碼(Big5) 、萬國碼(Unicode) 、簡字碼(GB2312)甚至有可能是日文編. engchi. 碼(Shift-JIS) 。為了減少分析發生問題,將收集的內容都轉換為相同的文字編碼 再進一步處理。另外也為了避免轉換過程中,因轉換的字集大小不同的問題而遺 失部分文字,我們選擇目前網頁上常見的 UTF-8(8-bit Unicode Transformation Format)編碼,UTF-8 可以用來表示 Unicode 標準中的任何字元,其編碼的第一 個位元組仍與 ASCII 相容。目前 UTF-8 已逐漸成為電子郵件、網頁及其他儲存 或傳送文字的應用中,優先採用的編碼。 編碼轉換實作在 Linux 環境中進行,主要以 Linux 中的 iconv 指令轉換編碼, 最後導出成為指定編碼的文字檔案。於終端機環境中輸入下面指令: 37.
(42) $ iconv -f old-encoding -t utf8 file.txt -o newfile_utf8.txt -f:from,來源編碼,原本的編碼格式 -t:to,轉換後的新編碼格式,這裡我們使用 utf8 -o:如果需要保留原檔案,使用 -o 新檔名,可以建立新編碼檔案。 4.1.4. 移除干擾雜訊 為了豐富文字中的情緒和趣味化,許多使用者會在文字段落中加入顏文字(表情 符號),表情符號原先只是一種網上次文化,隨著網際網路的普及和行動電話簡. 政 治 大. 訊普及,漸漸受到接受與使用。本研究所使用的資料內容部分來自於網路,內容. 立. 包含如 Σ( ° △ °|||)︴、( ̄. ̄)+、(= ̄ω ̄=)等等的顏文字,為了避免這些符號對. ‧ 國. 學. 分析的干擾,在文字前處理時我們將此類符號先由內容中移除。. ‧. 4.2. 中文斷詞處理. sit. y. Nat. 常見的中文斷詞工具有中央研究院 CKIP 中文斷詞與剖析系統、Yahoo 的斷章取. n. al. er. io. 義、MMSeg4j 等。其中 CKIP 系統使用的語料庫主要為新聞資料內容,對於網路. i n U. v. 上的文章,大都是未經過撰文訓練的內容,斷詞效果有限。Yahoo 的斷章取義雖. Ch. engchi. 然使用搜尋引擎詞庫,使用時需要經過網路送至 Yahoo 主機,每日使用上限為 2000 筆。考慮未來若發展為即時監測,需注意斷詞速度、使用的數量和具有擴 充性,因此在本研究中選擇了 mmseg4j 做為我們的斷詞工具。 中文斷詞工具 mmseg4j 為 Google Code 上的一個 Open Source 專案,目前版 本已經發展到 mmeeg4j-1.8.5。mmseg4j 是採用蔡志浩老師於 2000 年發表的一個 中文斷詞演算法 MMSeg[24],這個工具使用了兩套演算法和四個模糊解析規則, 在該文章末驗證了這個工具可以達到 98.41%的中文斷詞準確率。 Mmseg4j 這個工具是由中國大陸的 Bory.Chan 以 Java 語言實做出來的函式庫 套件,主要是用來替簡體中文斷詞,不過因為它的詞庫強制使用了 UTF-8 編碼 38.
(43) 且可以自行建立詞庫,所以我們在替換詞庫後,就可以使用 mmseg4j 來替正體 中 文 進 行 斷 詞 處 理 。 mmseg4j 預 設 使 用 的 詞 庫 來 源 為 大 陸 搜 狗 搜 尋 引 擎 (http://www.sogou.com)的詞庫,合併 Ruby 的中文斷詞套件詞庫而成。雖然我 們可以將詞庫檔由套件中取出,重新將簡體中文轉為繁體中文後儲存成新的詞庫 檔,但是,原來的詞庫主體為大陸地區的搜尋引擎,詞庫內容用語比較貼近大陸 地區的使用方式,並不適合用來做為台灣地區的中文文本斷詞使用。因此,我們 以國內教育部於 1997 年發行的「國語辭典簡編本編輯資料字詞頻統計報告」[25] 網路版中的〝字頻總表〞與〝詞頻總表〞 ,重新建立 mmseg4j 中的單一字對應頻. 政 治 大 中文斷詞的原則需要依賴詞庫,斷詞系統除了基本詞庫之外,使用者必須附 立. 率詞庫檔(chars.dic)和核心詞庫檔(words.dic)。. 加專屬領域詞庫。在災難發生的情境下,網路使用者在網路上發布的訊息文本,. ‧ 國. 學. 可能會異於平常使用的詞彙用語,也會包含大量的地點資訊內容。截至目前國內. ‧. 尚無針對災難發展相關領域的詞庫資料可直接運用,因此我們進行中文斷詞時需. io. y. sit. 建立災難詞庫. n. al. er. 4.2.1.. Nat. 自行建立災難相關的詞庫。. i n U. v. 此次研究的內容是針對災難發生狀況下的文本內容分析,災難詞庫建立之初將以. Ch. engchi. 選取災難新聞內容關鍵字,進行莫拉克八八風災收集的資料內容斷詞。在過程中, 透過不斷的隨機抽取斷詞後內容,挑出有意義的詞彙加入詞庫再斷詞,直至隨機 抽取的內容詞彙穩定。為了能更容易的挑選這些有意義的詞彙,在設計上,我們 撰寫詞彙收集的網路應用程式,以簡單的使用者介面設計,讓專家更容易的瀏覽 斷詞結果與挑選儲存,如下圖 10。. 39.
(44) 地理位置詞庫. sit. y. ‧. 圖 10、挑選災難詞彙應用程式介面. Nat. 4.2.2.. 學. ‧ 國. 立. 政 治 大. n. al. er. io. 災難事件發生時,災難相關的傳播訊息的最重要因素為事件的地理位置資訊,因. i n U. v. 此在斷詞過程中,地理位置資訊是需要重視和關注的內容。本研究中,斷詞使用. Ch. engchi. 的地理位置詞庫為自行建置,內容主體來自於我國「中華郵政有限公司」維護的 郵遞區號檔[26],抽取其中的縣市鄉鎮里鄰及街道等資訊,重新依字詞筆劃排序 而成。. 4.3. 移除停用字 中文檢索方面目前仍缺少標準的停用字詞表,在本研究中所使用的停用字集合是 參考「中央研究院平衡語料庫詞集及詞頻統計」(Word List with Accumulated Word Frequency in Sinica Corpus 3.0)資料。此統計是根據帶有標記的中央研 40.
(45) 究院平衡語料庫所計算出的詞頻統計資料,收錄有五百萬個詞。我們取統計資料 中頻率最高的前 100 個詞彙,建立本研究用的中文停用字集合。 有了中文停用字集合,我們將上個小節中已完成中文斷詞處理的文本由資料 庫中取出,將內容中的詞彙逐一掃描比對,符合中文停用字集合的詞彙,即由文 本中移除,再將去除停用詞後的斷詞文本存回資料庫中。. 4.4. 專家分類使用者介面設計 使用者介面(User Interface)是使用者與系統間進行互動和資訊交換的一個媒介, 可以說是硬體與使用者間的一個軟體設計思維,好的使用者介面設計,目的是在. 治 政 讓使用者能夠方便、有效率地去操作硬體來達成雙向的互動,所以這個領域中關 大 立 注的是創新性(Innovation)、易用性(Usability)和互動性(Interaction)。 ‧ 國. 學. 反觀傳統在文本分類設計,大都使用的工具程式為 Microsoft Office 系列中. ‧. 的 Excel 應用程式。運用 Excel 的優點是此軟體教育單位容易取得,使用者也已. sit. y. Nat. 經習慣此程式的操作介面。可是 Excel 實際上是歸類於試算應用類程式,它能方. n. al. er. io. 便於不同工作表和儲存格之間進行複雜的運算和儲存資料。對於我們進行資料分 類的應用,則會有下列幾個缺點:. 1.. Ch. engchi. i n U. v. 列高和換行:待分類內容有長有短,甚至部分發文中包含許多換行內容, Excel 這種定型表格的方式可能會遮蔽部分內容,造成閱讀上的視覺障 礙。. 2.. 多類別混淆:使用 Excel 分類時,不會將分類的項目名稱全部輸入,用 數字或英文字母等類別代號來代表某個分類,當類別項目很多時便難以 記憶,容易造成分類的誤差。. 3.. 受到其他資料干擾:Excel 表格呈現資料的方式集中,在同一頁中通常 會有數筆資料同時呈現,視覺上很難只聚焦在一筆資料上,眼睛餘光接 收其他筆資料的內容,容易造成思考上的干擾。 41.
(46) 基於上述幾點理由,我們使用網頁前端應用程式相關的技術(javascript 語 言和 jQuery 函式庫、ajax 非同步處理、HTML 網頁設計元素、CSS 樣式定義), 後端配合 MySQL 資料庫程式儲存,設計了新的專家分類使用者介面。我們在設 計時注意的原則有包含,直覺式的分類項目名稱、呈現較大的字型便於閱讀、按 鈕有明顯的顏色區別、互動後有明顯的顏色變化提示、更簡易的操作方式只用滑 鼠便可達成等。同時我們在後端 PHP 程式撰寫的設計上,讓分類時達到隨機抽 取未分類內容進行分類,以摒除分類項目與分類內容在時間上有相依性的問題。. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. 42. i n U. v.
(47) 立. 政 治 大. 圖 11、專家分類使用者介面(未選取). ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. v. 圖 12、專家分類使用者介面(已選取) 每個資料集完成專家分類的筆數如下: 台南 119 報案電話記錄:542 筆 屏東 119 報案電話記錄:512 筆 43.
(48) XDite:1056 筆 Ricks:1050 筆 ADCT 數位文化:1050 筆. 4.5. 機器學習與分類器 經過前面的資訊前處理過程,我們已經將莫拉克風災期間網路上的發文內容,完 成文字辨識、資料格式轉換、編碼轉換、移除干擾值、中文斷詞處理和專家文本 分類等繁複工作,在此小節中我們將說明機器學習實作情形,機器學習的步驟與. 政 治 大 再以卡方值排序後選擇適當的特徵數量,每一篇文章為一個向量使用特徵詞彙做 立. 流程,如下圖 13 所示。首先,我們將計算 TFIDF 後的詞彙與數值存在資料庫中,. ‧ 國. 學. 為維度 TFIDF 為向量維度內容,建置向量空間模型。最後透過 10 折交叉驗證 (10-fold Cross-validation)方式進行機器學習,與計算每一次的 F1-measure 平均. ‧. 值與 95%信賴區間做為績效驗證。. n. er. io. sit. y. Nat. al. Ch. engchi. 44. i n U. v.
數據

+4


相關文件
• Extension risk is due to the slowdown of prepayments when interest rates climb, making the investor earn the security’s lower coupon rate rather than the market’s higher rate.
• A delta-gamma hedge is a delta hedge that maintains zero portfolio gamma; it is gamma neutral.. • To meet this extra condition, one more security needs to be
Receiver operating characteristic (ROC) curves are a popular measure to assess performance of binary classification procedure and have extended to ROC surfaces for ternary or
Promote project learning, mathematical modeling, and problem-based learning to strengthen the ability to integrate and apply knowledge and skills, and make. calculated
Wang, Solving pseudomonotone variational inequalities and pseudocon- vex optimization problems using the projection neural network, IEEE Transactions on Neural Networks 17
Define instead the imaginary.. potential, magnetic field, lattice…) Dirac-BdG Hamiltonian:. with small, and matrix
• Adds variables to the model and subtracts variables from the model, on the basis of the F statistic. •
In the school opening ceremony, the principal announces that she, Miss Shen, t is going to retire early.. There will be a new teacher from
