A System for Taiwanese Teaching and Word Collection
16
0
0
全文
(2) A System for Taiwanese Teaching and Word Collection Hsiu-Chen Hsieh, I-Chiann Jiang, Neng-Huang Pan♣, Ming-Shing Yu Text-To-Speech System Laboratory Department of Applied Mathematics, National Chung-Hsing University, Taichung 40227, Taiwan {hchsieh, icjiang, nhpan, msyu}@amath.nchu.edu.tw. Abstract In this paper we proposed a system for Taiwanese teaching and word collection. The system can translate the input Chinese sentence or word into Taiwanese speech. Also we design a platform through which we can collect words and their pronunciation for Taiwanese lexicon by the help of users and some experts who participated in our project. The collection for words and speech through the collaboration of people is a new experiment. A high quality Text-to-Speech system is required for a system to teach Taiwanese speaking. We improve the quality of Taiwanese TTS system in the following ways: (a) We collect many synthesis units by finding more consonants (20), vowels (100), and tones (9). (b) We modify the general tone sandhi rules for entering tones to get higher intelligibility and naturalness of the synthesized speech. (c) With the help of CFSs, we get a better lexicon for Taiwanese. The output of word segmentation will be more suitable for Taiwanese TTS. Key words: Taiwanese, Min Nan, Taiwanese teaching, Text-to-Speech (TTS) system, word collection, and Chinese Frequent Strings (CFS). 1. Introduction We know that every culture or language is very precious. There is wisdom in it. They are the common property of human beings. In recent years, the government of Taiwan is devoted to the education of local culture. Taiwanese teaching is a very important task. We try to design a system for to teach people the speaking of Taiwanese. Such a system should be able to pronounce the word or sentence asked by the user. In the area of speech and language processing, it is related to the study of Text-to-Speech (TTS) systems [Jurafsky and Martin, 2000; Dutoit, 1997]. ♣. Correspondence author. TEL: +886-4-22856380 1.
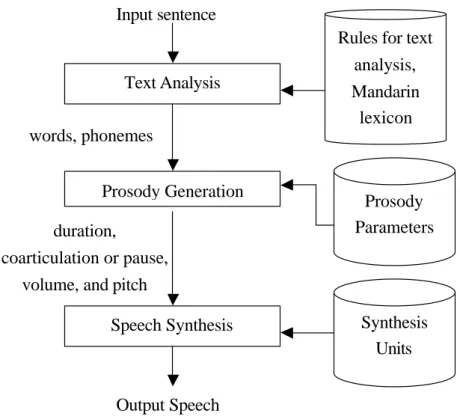
(3) Mandarin and Taiwanese (Min Nan) are two of the major languages in Taiwan, and they are also commonly used around the world. In the past, there are many papers proposed for Mandarin Text-to-Speech (TTS) Systems [Chen etc., 1998; Lee etc., 1989; Lee etc., 1993; Lin and Yu, 1998; Shih and Sproat, 1996] or related researches. In contrast to the large amount of researches in Mandarin, there are only a few papers dealing with Taiwanese [Lin and Chen, 1999; Wang etc., 1999; Lin, 2000; Fu, 2000]. A Mandarin TTS system can be described as in Figure 1. The input sentence is first passed to the Text Analysis module. In this module, word segmentation and character-to-phoneme conversion is done. Some text analysis module also outputs the part-of-speech (POS) information and parsing results. Then the words and phonemes are passed to the Prosody Generation module. In this module, the prosodic information of each syllable (corresponding to a character) is obtained. They are duration, coarticulation or pause, volume, and pitch contours. Finally the Speech Synthesis module extracts the required synthesis units and does some signal processing to get the desired speech.. Input sentence Rules for text analysis, Mandarin lexicon. Text Analysis words, phonemes Prosody Generation. Prosody Parameters. duration, coarticulation or pause, volume, and pitch. Synthesis Units. Speech Synthesis. Output Speech Fig. 1: A general architecture for Mandarin TTS system. We have many research results in Mandarin TTS systems. Also we have studied Taiwanese for a long time. Hence we have a good background in developing a Taiwanese TTS system. Some of our accomplishments in Mandarin TTS systems are: 2.
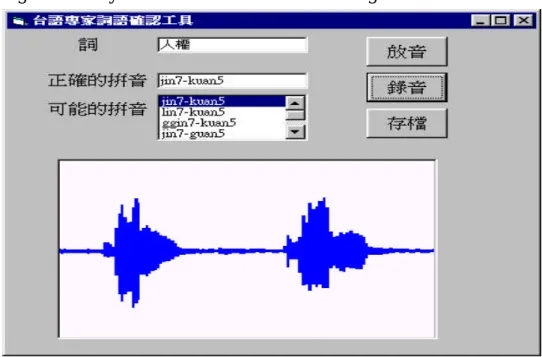
(4) (1) We have developed an efficient Mandarin TTS system in time domain [Lin and Yu, 1998]. (2) We have developed a good method to disambiguate the senses of non-text symbols [Yu and Huang, 2002]. For example, “3/4” may be “三月四日(san yue si ri)” or “四分之三(si fen jhi san)”. This is a difficult task. (3) We have developed techniques to do word segmentation, character-to-phoneme conversion, and phoneme-to-character conversion [Lin and Yu, 2001]. (4) We have designed a prosody generator with hierarchical structure, which can predict all the prosodic information for each syllable in a given sentence [Pan etc., 2000; Yu and Pan, 2002]. (5) We have designed a method for speech synthesis to get the desired output speech [Hwang etc., 1996; OuYang etc., 1996]. (6) We also have a method to evaluate the quality of synthetic speech [Wei, 1997], and a good method to segment speech [Chai, 1997], and good tools to find the pitches in speech. This paper is organized as follows. Section 2 describes the system function for Taiwanese teaching and word collection. Section 3 presents our Taiwanese TTS system. Section 4 focuses on the part of word and speech collection. Section 5 is the summary and future works.. 2. System Function for Taiwanese Teaching and Word Collection The function of our system is described as in Figure 2. The user can ask for the pronunciation of a Chinese sentence or word through an input box. When the user clicks [確定](Sure) button, the system responds with a list of the possible spellings. The user can listen to the speech of a spelling by clicking that spelling. Then the user is asked to mark the spellings, which he/she thinks are good through the check box associated with each spelling. Then he/she ends the teaching and feedback process of this word by clicking the [送出評語](Send Evaluation) button. When the system detected the [送出評語] action, it checks the evaluation of the user. If any choice is “好(Good)”, the system records those good spellings and the word in a database. If no “好(Good)” is selected, the system sends the question (the word asked) to an expert in Taiwanese through an email. This expert will answer the question by speaking the Taiwanese. The interface for a Taiwanese expert to answer the question is as in Figure 3. The word asked is displayed. The expert can start recording his speech by clicking the [錄 音](Record) button. The input speech is show in the window for the expert to check the recording quality of the speech. For instance, he can check whether the volume is 3.
(5) too large or small, and whether the speech is completed recorded. He can also listen to his speech by clinking the [放音](Play) button. It is even better if the expert can input the spelling. The system will supply a list of possible spellings for the expert to use. After the answering is completed. He clicks the [存檔](Save) button to send his answer. When the system received the answer from an expert. It sends the answer back to the user who asked the question. Also the answer will be recorded in our database.. Figure 2. The system function of Taiwanese teaching and word collection.. Figure 3. The interface for an expert to answer the question by speaking that word. 4.
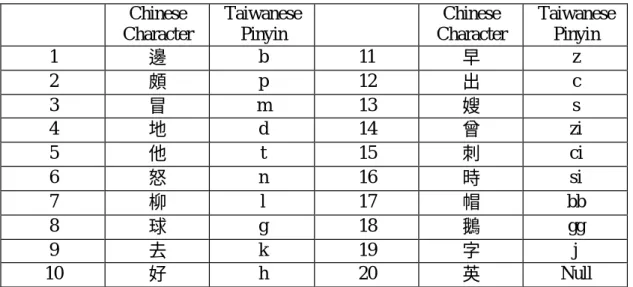
(6) 3. Taiwanese Text-to-Speech system We design a system that can teach Taiwanese speaking. Namely, people enter words or sentences into the system and the system responds with the pronunciation of the question. Hence, we need a high-quality Taiwanese TTS system. We will introduce our system in the order of speech synthesis, prosody generation, and text analysis modules. We think that synthesis units, tone-sandhi rules, and word segmentation are the most important factors in the above three modules, correspondingly. 3.1 Speech Synthesis Speech synthesis in TTS is the task to modify the synthesis units when needed. There are many approaches for speech synthesis [Dutoit, 1997]. The method PSOLA (Pitch Synchronous OverLap-Add) [Moulines and Charpentier, 1990; Hamon etc., 1989] is probably the most widely used synthesis method in TTS. Yet we also know that the more modification is made, the worse quality the synthetic speech is. Hence we try to record as many synthesis units as possible. Such a work can reduce the required modification on synthesis units. Taiwanese is a tonal language; each Taiwanese syllable is composed of consonant (optional), vowel, and tone. The numbers of consonant and vowel types between different systems are different. We combine the list of several systems to get a more complete list, as can be found in Tables 1 and 2. Table 1: The 20 consonant types in our Taiwanese TTS system. Chinese Taiwanese Chinese Character Pinyin Character 1 b 11 邊 早 2 p 12 頗 出 3 m 13 冒 嫂 4 d 14 地 曾 5 t 15 他 刺 6 n 16 怒 時 7 l 17 柳 帽 8 g 18 球 鵝 9 k 19 去 字 10 h 20 好 英. 5. Taiwanese Pinyin z c s zi ci si bb gg j Null.
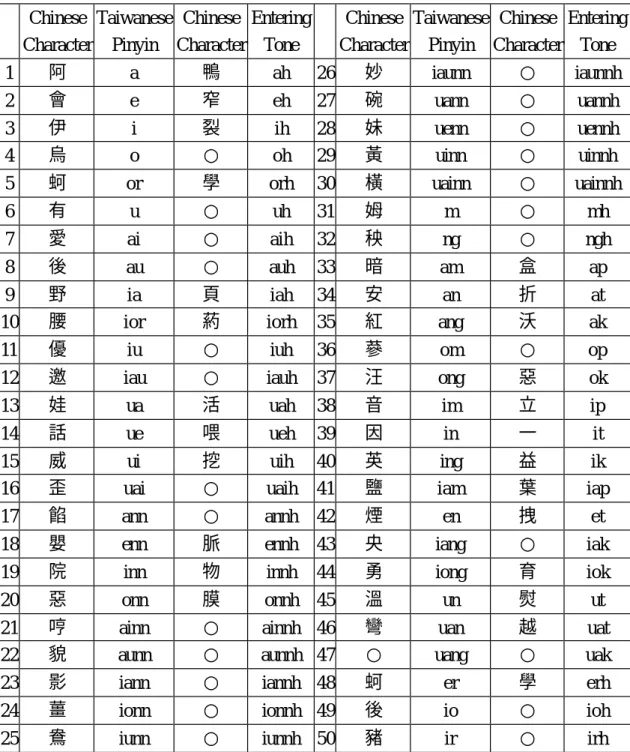
(7) Table 2: The 100 vowel types in our Taiwanese TTS system. (“○” means that there is no corresponding Chinese Character.) Chinese Taiwanese Chinese Entering Chinese Taiwanese Chinese Entering Character Pinyin Character Tone Character Pinyin Character Tone 阿 鴨 妙 ○ 1 a ah 26 iaunn iaunnh 會 窄 碗 ○ 2 e eh 27 uann uannh 3 4. 伊 烏. i o. 裂 ○. ih oh. 28 29. 妹 黃. uenn uinn. ○ ○. uennh uinnh. 5. 蚵. or. 學. orh. 30. 橫. uainn. ○. uainnh. 6. 有. u. ○. uh. 31. 姆. m. ○. mh. 7. 愛. ai. ○. aih. 32. 秧. ng. ○. ngh. 8. 後. au. ○. auh. 33. 暗. am. 盒. ap. 9 10. 野 腰. ia ior. 頁 葯. iah iorh. 34 35. 安 紅. an ang. 折 沃. at ak. 11. 優. iu. ○. iuh. 36. 蔘. om. ○. op. 12. 邀. iau. ○. iauh. 37. 汪. ong. 惡. ok. 13. 娃. ua. 活. uah. 38. 音. im. 立. ip. 14. 話. ue. 喂. ueh. 39. 因. in. 一. it. 15 16. 威 歪. ui uai. 挖 ○. uih uaih. 40 41. 英 鹽. ing iam. 益 葉. ik iap. 17. 餡. ann. ○. annh. 42. 煙. en. 拽. et. 18. 嬰. enn. 脈. ennh. 43. 央. iang. ○. iak. 19. 院. inn. 物. innh. 44. 勇. iong. 育. iok. 20. 惡. onn. 膜. onnh. 45. 溫. un. 熨. ut. 21 22. 哼 貌. ainn aunn. ○ ○. ainnh 46 aunnh 47. 彎 ○. uan uang. 越 ○. uat uak. 23. 影. iann. ○. iannh 48. 蚵. er. 學. erh. 24. 薑. ionn. ○. ionnh 49. 後. io. ○. ioh. 25. 鴦. iunn. ○. iunnh 50. 豬. ir. ○. irh. The recently designed Tong-Yuong spelling (通用拼音) is used in the column Taiwanese Pinyin. We use the second type of Tong-Yuong spelling for Taiwanese spelling. Namely, we use “bb” and “gg” instead of “v” and “q” that are used in the first type of Tong-Yuong spelling. There are two major differences between our and other system’s consonant types list. First, We don’t think that “ng” is a consonant. (Some systems think “ng” is a kind of consonant types, and it is also a kind of vowel types.) Secondly, We think “zi”, “ci”, and ”si” are three kinds of consonant types. They are not the same the combination of consonant “z” (or “c”, or “s”) and the vowel 6.
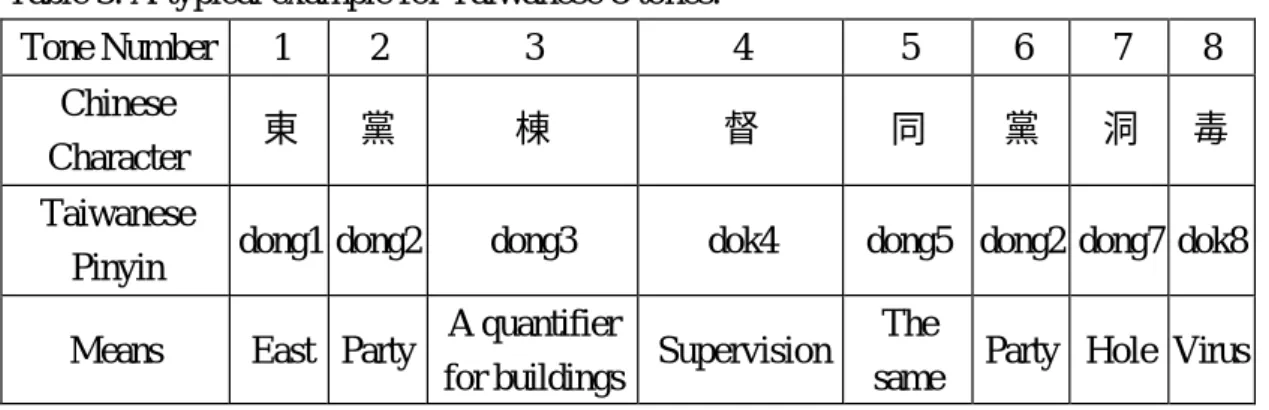
(8) “i”. Totally, we get the most consonants among all the other Taiwanese TTS systems we know. We get Table 2 by adding three kinds of vowel types, which are “er”, “io”, and “ir”, into the list of Taiwanese vowel types in Fu’s system [Fu, 2000]. Thus totally we have 100 vowel types. This is also the most we know. 3.2 Prosody Generation Traditionally we say that there are eight tones in Taiwanese [Yang, 1998]. They are upper even, high falling, upper departing, lower entering, lower departing, high falling, lower even, and upper entering. The 2nd and 6th tones are the same, and -p, -t, -k, -h are the four kinds of endings for the 4th and 8th tones. A typical example is show in Table 3. Table 3: A typical example for Taiwanese 8 tones. Tone Number. 1. 2. 3. 4. 5. 6. 7. 8. Chinese Character. 東. 黨. 棟. 督. 同. 黨. 洞. 毒. dong3. dok4. Taiwanese Pinyin. dong1 dong2. Means. East Party. A quantifier Supervision for buildings. dong5 dong2 dong7 dok8 The same. Party Hole Virus. Since tones 2 and 6 are the same, many people say that there are totally seven tones in Taiwanese. Each Taiwanese character has at lease one base tone. When we read a word in Taiwanese, all characters will read their sandhi tones except the last character in that word which will remain its base tone. The general Taiwanese tone sandhi rules in most system or documents are show in Fig. 4 [Lin and Chen, 1999]. 1. 2. 4h. 8p, t, k. 3. 8h. 4p, t, k. 5 7. Fig. 4: The general tone sandhi rules in most system and documents for Taiwanese. It means that the sandhi tone for syllable with base tone 5 is 7, and sandhi tone for a syllable with base tone 7 is 3, and so on. As an example, consider the word “電 腦”(computer) /den3-nau2/. The base tones are “電”/den7/ and “腦”/nau2/. The tone 7.
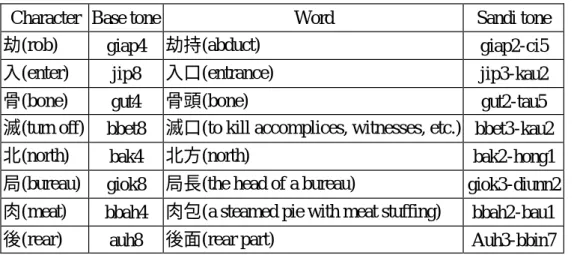
(9) of “腦” will be remain its base tone. However, we found that the sandhi tones of the 4th and 8th tones need more elaboration. Consider first the cases of 4p and 8p. An example of 4p is “劫”(rob) with base tone /giap4/. According to the tone sandhi rules in Fig. 4, it should read /giap8-ci5/ in “劫持”(abduct). Yet this reading is not correct. The correct reading is like /giap2-ci5/. This is indicated in the first row of Table 4. An example of 8p is “入”(enter) with base tone /jip8/. According to the tone sandhi rules in Fig. 4, it should read /jip4-kau2/ in “入口”(entrance). Yet the correct reading is like /jip3-kau2/. It is shown in the second row of Table 4. Similar cases for 4t, 8t, 4k,and 8k are shown in rows 3 to 6 of Table 4. Table 4: Some examples of 4th and 8th tones. Character Base tone 劫(rob) giap4 劫持(abduct) 入(enter) jip8 入口(entrance). Word. Sandi tone giap2-ci5 jip3-kau2. 骨(bone) 滅(turn off). gut4 bbet8. 北(north). bak4. 骨頭(bone) gut2-tau5 滅口(to kill accomplices, witnesses, etc.) bbet3-kau2 北方(north) bak2-hong1. 局(bureau). giok8. 局長(the head of a bureau). giok3-diunn2. 肉(meat). bbah4. 肉包(a steamed pie with meat stuffing). bbah2-bau1. 後(rear). auh8. 後面(rear part). Auh3-bbin7. Hence we know that there should be two more tones for the sandhi tones of -p, -t, -k. We call them 2p, 3p, 2t, 3t, 2k, and 3k. A similar idea is pointed out in [Huang, 2001] for the entering tones -h. Although the readings of tones 4h and 8h are very similar to tones 4 and 8. We adopted this idea and get a unified tone sandhi rule as shown in Fig. 5. Therefore we have totally nine tones in our Taiwanese TTS system. 1. 2. 4p, t, k,h. 8p, t, k,h. 3. 2p, t, k,h. 3p, t, k,h. 5 7. Fig. 5: The tone sandhi rules for Taiwanese in our system. Some characters have special tone sandhi rules. The spelling many even change too. Consider the example “仔” with base tone /a2/. It was mentioned in [Huang, 2001] that some characters preceding “仔” should change their tones. We found the phenomenon that when “仔” is preceded by a nasal ending , the pronunciation of “仔” will be nasalized. Some examples are “丸仔”(meat ball) /uan7-na2/, “鰹仔”(tuna) 8.
(10) /en7-na2/, “店仔”(shop) /diam1-ma2/, “金仔”(gold) /gim7-ma2/. When the tones and tone sandhi rules are set. We can use a prosody generator to get the prosody. We have a high accuracy prosody generator for Mandarin TTS system [Yu and Pan, 2002]. There are four levels in that model; they are syllable level, word level, prosodic phrase level, and utterance level. Each lower level is a subset of a high level. The prosodic information is first found in each level, and then they are combined to get the predicted prosody. Our structure has the advantage that it does not need a very large corpus in training. Besides, it can modify the emphasis easily. We will use its framework to develop a version for Taiwanese TTS system. 3.3 Text Analysis Our Taiwanese TTS system can translate the input Chinese sentence or word into its corresponding speech. We already have very high precision in word segmentation and character-to-phoneme conversion for Mandarin TTS [Lin and Yu, 2001; Lin, 2002]. Ye t text analysis in Taiwanese TTS has its own problems. The major problem we think is that the lexicon of Taiwanese is different from that of Mandarin. Our new concept CFS (Chinese Frequent Strings) [Lin and Yu, 2001; Lin, 2002] can help us in this issue. Word segmentation of a Taiwanese TTS system is more important than a Mandarin TTS system, because the tone sandhi problems in Taiwanese occur more than that in Mandarin, and tone sandhi is related to both the correctness and fluency in a Taiwanese TTS system. For example, ”網際網路” (the internet) is a CFS. Their base tones are /bbang7/, /ze3/, /bbang7/, /lo7/. It should be read continuously as /bbang3-ze2-bbang3-lo7/ in Taiwanese or else people can’t understand what you said. If we segment this word by using a traditional lexicon, this word will split into 3 words, namely “網” (net), “際” (border), ”網路” (network). This will result in the incorrect reading /bbang7/, /ze3/, /bbang3-lo7/. We can extract CFSs automatically from corpus. Many of them are the words (those satisfying tone sandhi rules) of Taiwanese. They are different from traditional words in Mandarin. Some examples are shown in Table 5. Our word segmentation tool can reduce the tone sandhi problems that are caused by wrong segmentation results. One reason is that many unknown words and proper nouns are in our CFS. Currently we have got more than 400,000 CFSs. A traditional Chinese dictionary may have about 100,000 words. We will design a tool to get more Taiwanese words from our CFSs.. 9.
(11) Table 5: Some examples that should be read continuously in a Taiwanese TTS [Lin, 2002]. The Chinese frequent string. Segmentation by using a traditional lexicon. Interpretation in English. 物理所. 物理 所. A research institute of physics. 化學系. 化學 系. Department of chemistry. 才開始. 才 開始. Being beginning. 工業化. 工業 化. Industrialization. 非常好. 非常 好. Very good. 一大串. 一 大 串. A long string of. 一句話. 一 句 話. A sentence. 已不再. 已 不再. Never again. 讓人感到. 讓 人 感到. Make one feel. 第二學期. 第 二 學期. The second semester. 網際網路. 網 際 網路. The internet. 我們學校. 我們 學校. Our school. We should also have good morphological rules. Atypical example in morphology is about the numbers and quantifiers. In Taiwanese there are two kinds of readings for digit: literal and speaking. They are listed in Table 6. Some problems should be resolved. For instance “一人”(a person) may read as /it2-jin5/ or /ji3-lang5/. Table 6: Pronunciations of Taiwanese digit. Digit. 0. Literal kong3 Speaking ling5. 1. 2. 3. 4. it4 zit4. ji7 nng7. sam1 sann1. su3 si3. 5. 6. ggonn2 liok8 ggo7 lak8. 7. 8. 9. cit4 cit4. bat4 beh4. giu2 gau2. 4. Word and Speech Collection In our system, the databases are very important. If we have more Taiwanese words and their associated speech, we can avoid many errors caused by word segmentation tone sandhi. We design a platform through which we can collect more Taiwanese words and their associated speech. The main idea is that when we detected that our TTS system cannot pronounce a word in Taiwanese correctly, we will trigger a mechanism to seek the help of an expert. There are three kinds of people in our system. One is that the common users who visit our web site to ask Taiwanese speaking. Another is some Taiwanese experts who answer the user’s question by recording the words. They will also record words and 10.
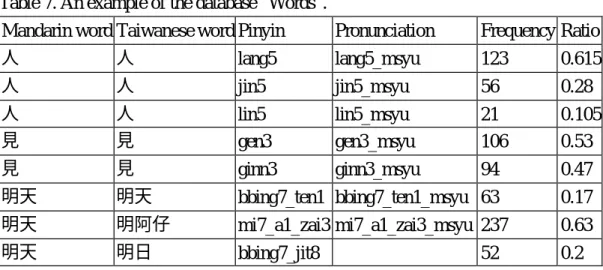
(12) sentences in our database. The other is that the system managers who maintain and update the databases by viewing the user judgments and expert answers. The programmers are also considered as system managers. There are five major databases in our system. They are modified by the above mentioned people. Following is a sketch of our databases. (1) “Words”: This is our main database. It stores the spelling and pronunciation of words. There are six fields in “Words”, as shown in Table 7. The field “Pinyin” is the Tong-Yuong spelling of the Taiwanese word. The field “Pronunciation” is the file name of the speech from an expert. The field “Frequency” is the occurrence times of the good spelling that adjudge by user. The field “Ratio” is the ratio of some spelling of a given word. Sometimes there are different words in Mandarin and Taiwanese. “明天”(tomorrow) is an example. Many entries, especially those words that are long or rarely used, may have no pronunciation. It will be synthesized from synthesis units. Table 7. An example of the database “Words”. Mandarin word Taiwanese word Pinyin 人 人 lang5. Pronunciation. Frequency Ratio. lang5_msyu. 123. 0.615. 人. 人. jin5. jin5_msyu. 56. 0.28. 人 見. 人 見. lin5 gen3. lin5_msyu gen3_msyu. 21 106. 0.105 0.53. 見. 見. ginn3. ginn3_msyu. 94. 0.47. 明天. 明天. bbing7_ten1 bbing7_ten1_msyu 63. 0.17. 明天. 明阿仔. mi7_a1_zai3 mi7_a1_zai3_msyu 237. 0.63. 明天. 明日. bbing7_jit8. 0.2. 52. (2) “Expert_Words”: It stores the words recorded by the experts. It has four fields, as shown in Table 8. Table 8. An example of the database “Expert_Words”. Mandarin word Taiwanese word Pinyin Prounciation 颱風 風颱 hong7_tai1 hong7_tai1_msyu (3) “Expert_Sentences”: It stores the sentences recorded by the experts. It has a structure similar to “Expert_Words”. This Table is mainly used to collect training data that can be used to get the prosodic parameters. (4) “User_Words”: It stores the words that are judged as good by the user. It has six 11.
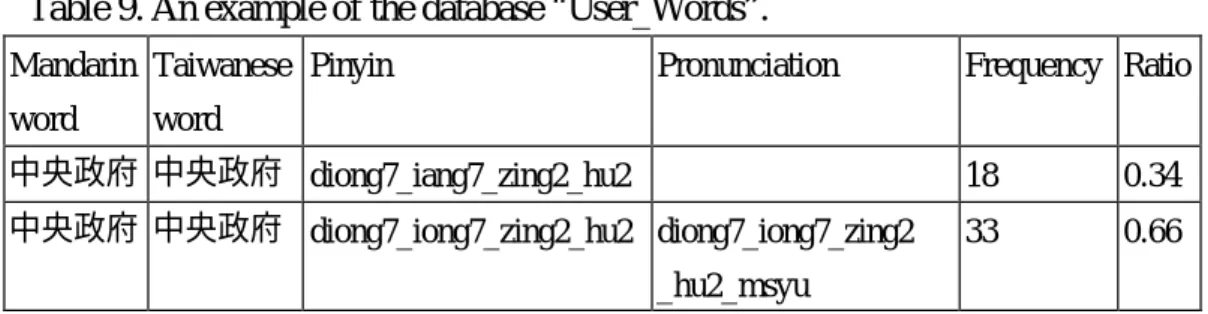
(13) fields as shown in Table 9. Table 9. An example of the database “User_Words”. Mandarin Taiwanese Pinyin word. Pronunciation. Frequency Ratio. word. 中央政府 中央政府 diong7_iang7_zing2_hu2. 18. 0.34. 中央政府 中央政府 diong7_iong7_zing2_hu2 diong7_iong7_zing2. 33. 0.66. _hu2_msyu. (5) “Experts_Emails”: It stores the names of the experts and their email addresses. Their available dates and times are also recorded. An example is shown in Table 10. Table 10. An example of the database “Expert_Emails”. Expert’s name Expert’s e-mail. Available date Available time. Ming-Shing Yu [email protected] 2002/7/13. 8:00_11:30. Ming-Shing Yu [email protected] 2002/7/24. 13:00_20:30. We have five major databases like above. When users input a sentence, system will search databases in the order “Words” and “User Words”. If it is found in any database, then the system output the searched pinyins and pronunciations. If we can’t find the input word in the above two databases, we do tone sandhi based on the pinyins in “Words”. For example, as user input “明天見“ which means see you tomorrow, the word will be spilt into two parts, namely “明天”(tomorrow), and ” 見”(see). System will output six pinyins to the user, since there are three spellings for “明天” and two pinyins for “見”. The combination with high probability will be put in the front. Sometimes we will only output a limited number of combinations. The system managers will add every record in “Expert_Words” to “Words”, unless there are obvious errors. Some pinyin may need checking since not every one is familiar with Tong-Yuong spelling. The system managers will also examine “User_Words”. They will add (some modification may be needed) the good records into “Words”, and discard the incorrect records. The system keeps the available times of the experts in “Expert_Emails”. It will dispatch the question to an available expert or the expert who will be available soon. The expert can update their available times. When an available time passed, its entry will be deleted.. 12.
(14) 5. Summary and Future Works In this paper we proposed a system for Taiwanese teaching and word collection. The system can translate the input Chinese sentence or word into Taiwanese speech. We improve the quality of Taiwanese TTS system in the following ways: (1) We collect many synthesis units by finding more consonants (20), vowels (100), and tones (9). (2) We modify the general tone sandhi rules for entering tones to get higher intelligibility and naturalness of the synthesized speech. (3) With the help of CFSs, we get a better lexicon for Taiwanese. The output of word segmentation will be more suitable for Taiwanese TTS. We also design a platform through which we can collect words and their pronunciation for Taiwanese lexicon by the help of users and some experts who participated in our project. At this stage our system is to teach Taiwanese speaking. After more words are collected, we can develop better system for Taiwanese, such as word segmentor and prosody generator for Taiwanese TTS system, speech recognizer for Taiwanese, and so on.. 6. Reference: 1.. 2.. 3. 4.. 5.. 6.. Chao-Lien Chai, “A Fast and Accurate Method for Segmenting Continuous Mandarin Speech”, Master Thesis of The Department of Applied Mathematics, National Chung-Hsing University, June 1997. Sin-Horng Chen, Shaw-Hwa Hwang, and Yih-Ru Wang, “An RNN-Based Prosodic Information Synthesizer for Mandarin Text-to-Speech”, IEEE Transactions on Speech and Audio Processing, Vol. 6, No. 3, pp. 226-239, 1998. Thierry Dutoit, “An Introduction to Text-to-Speech Synthesis”, Kluwer Academic Publishers, 1997. Zhen-Hong Fu, “Automatic Generation of Synthesis Units for Taiwanese Text-to-Speech System”, Master Thesis of the Department Electrical Engineering, Chang-Gung University, June 2000. C. Hamon, E. Moulines, and F.Charpentier, “A Diphone synthesis System Based on Time-Domain Prosodic Modification of Speech”, in Proc. ICASSP 1989, pp. 238-241, 1989. J. Y. Huang, “Implementation of Tone Sandhi Rules and Tagger for Taiwanese TTS”, Master thesis of the Institute of communication Engineering, National Chiao-Tung University, Tune 2001. 13.
(15) 7.. 8. 9.. 10.. 11.. 12.. 13.. 14.. 15.. 16.. 17.. 18.. Jun-Wen Hwang, Ming-Shing Yu, Shyh-Yang Hwang, and Ming-Jer Wu, “Coarticulation of two-syllable words in Mandarin Speech Synthesis”, Proc. ROCLING IX, pp.37-60, 1996. Daniel Jurafsky and James H. Martin, “Speech and Language Processing”, Prentice Hall, 2000. Lin-Shan Lee, Chiu-Yu Tseng, and Ching-Jiang Hsieh, “Improved Tone Concatenation Rules in a Formant-Based Chinese Text-to-Speech System”, IEEE Transactions on Speech and Audio Processing, Vol. 1, No. 3, pp. 287-294,1993. Lin-Shan Lee, Chiu-Yu Tseng, and M. Ouh-Young, “The Synthesis Rules in a Chinese Text-to-Speech System”, IEEE Transactions on Acoustics, Speech, and Signal Processing, Vol. 37, No. 9, pp. 1309-1320, 1989. Shun-Jie Lin, “Myna: A Development Tool for Mandarin-Taiwanese MT/TTS System”, Master Thesis of the Department of Computer Science and Information Engineering, National Cheng-Kung University, June 2000. Chuan-Jie Lin and Hsin-Hsi Chen, “A Mandarin to Taiwanese Min Nan Machine Translation System with Speech Synthesis of Taiwanese Min Nan”, Computational Linguistics and Chinese Language Processing, Vol. 4, No. 1, pp.59-84, February 1999. Yih-Jeng Lin, “Chinese Frequent Strings, A New Concept Over Traditional Language Models”, Ph. D. Thesis of The Department of Applied Mathematics, National Chung-Hsing University, June 2002. Yih-Jeng Lin and Ming-Shing Yu, “An Efficient Mandarin Text-to-Speech System on Time Domain,” IEICE Transactions of Information and Systems, Vol. E81-D, No. 6, pp. 545-555, June 1998. Yih-Geng Lin and Ming-Shing Yu, “Extracting Chinese Frequent strings without a Dictionary from a Chinese Corpus and Its Applications”, Journal of Information Science and Engineering 17, pp. 805-824, Sep. 2001. E. Moulines and F. Charpentier, “Pitch-Synchronous Waveform Processing Technique for Text-to-Speech Synthesis using Diphones”, Speech Communication 9, pp. 453-467, 1990. Roaul OuYoung, Ming-Shing Yu, Ming-Jer Wu, and Shyh-Yang Hwang, “Tone Modulation By using Pitch-Synchronous Nonlinear Resampling Techniques”, Proc. 1996 Workshop on Computer Vision, Graphics, and Image Processing, pp.267-274, 1996. Neng-Huang Pan, Wen-Tsai Jen, Shyr-Shen Yu, Ming-Shing Yu, Shyh-Yang Huang, and Ming-Jer Wu, “Prosody Model in a Mandarin Text-to-speech System Based on a Hierarchical Approach”, IEEE International Conference on Multimedia and Expo 2000, Vol. 1, pp. 448-451, 2000. 14.
(16) 19. Chilin Shih and Richard Sproat, “Issues in Text-to-Speech Conversion for Mandarin”, Computational Linguistics and Chinese Language Processing, Vol. 1, No. 1, pp. 37-86, 1996. 20. Jhing-Fa Wang, Bau-Jang Whang, Shun-Jie Lin, “A Study for Mandarin Text to Taiwanese Speech System”, Research on Computational Linguistics Conference XII (ROCLING XII), pp. 37-53,1999. 21. Hannin Wei, “An Approach to the Measurement of Fondness and Similarity on Speech”, Master Thesis of The Department of Applied Mathematics, National Chung-Hsing University, June 1997. 22. C.T. Yang(楊青矗), “Taiwanese-Manclarin Bilingual Dictionary(台華雙語辭 典)”, Dun-Li Publishing Co. (敦理出版社), Kaohsiung, Taiwan,7th edition, 1998. 23. Ming-Shing Yu and Fong-Long Huang, “Disambiguating the Senses of Non-Text Symbols for Mandarin TTS Systems with a Three-Layer Classifier”, Speech Communication, 2002. (Accepted for publication) 24. Ming-Shing Yu and Neng-Huang Pan, “A Statistical Model with Hierarchical Structure for Predicting Prosody in a Mandarin Text-to-Speech System”, International Symposium on Chinese Spoken Language Processing (ISCSLP) 2002, August 2002.. 15.
(17)
數據
+6
![Table 5: Some examples that should be read continuously in a Taiwanese TTS [Lin, 2002]](https://thumb-ap.123doks.com/thumbv2/9libinfo/8912555.260484/11.892.133.762.164.552/table-examples-read-continuously-taiwanese-tts-lin.webp)
相關文件
• When a system undergoes any chemical or physical change, the accompanying change in internal energy, ΔE, is the sum of the heat added to or liberated from the system, q, and the
• Teaching grammar through texts enables students to see how the choice of language items is?. affected by the context and how it shapes the tone, style and register of
Huang, A nonmonotone smoothing-type algorithm for solv- ing a system of equalities and inequalities, Journal of Computational and Applied Mathematics, vol. Hao, A new
Freely write an added part to the original motive, make sure your new part is of a different duration to the ostinato motive (say, more than two bars in length) so that they have
– Each listener may respond to a different kind of event or multiple listeners might may respond to event, or multiple listeners might may respond to
Skype provide better security than most VoIP system and PSTN. – Just because most VoIP system and PSTN do not provide any
“A Comprehensive Model for Assessing the Quality and Productivity of the Information System Function Toward a Theory for Information System Assessment.”,
In order to improve the aforementioned problems, this research proposes a conceptual cost estimation method that integrates a neuro-fuzzy system with the Principal Items
