透過分析資訊需求變動修正工作特徵檔以提供工作相關資訊
49
0
0
全文
(2) 透過分析資訊需求變動修正工作特徵檔 以提供工作相關資訊. Profile Adaptation for Providing Task-relevant Information by Variation of Task Needs. 研 究 生: 張 北 晨. Student: Pei-Cheng Chang. 指導教授: 劉 敦 仁. Advisor: Duen-Ren Liu. 國立交通大學 資訊管理研究所 碩士論文. A Thesis Submitted to Institute of Information Management College of Management National Chiao Tung University in Partial Fulfillment of the Requirements for the Degree of Master of Science in Information Management July 2006 Hsinchu, Taiwan, the Republic of China. 中華民國 九十五 年 七 月.
(3) 透過分析資訊需求變動修正工作特徵檔 以提供工作相關資訊 研究生:張北晨. 指導教授: 劉敦仁 博士. 國立交通大學資訊管理所. 摘要 在以工作為基礎的企業環境中,如何有效提供工作相關資訊以滿足知識工作 者的資訊需求為部署知識管理系統之重要課題。此外,知識密集工作環境中的工 作通常具有需要參閱大量文件資料的特性;因此,透過資訊過濾相關技術分析並 建構工作者的工作相關特徵檔,為有效提供工作相關知識之重要技術。本研究提 出需求特徵化修正方法來分析工作者的動態資訊需求,該方法主要是分析工作者 存取的文件及工作主題相關性,並考慮時間因素建構工作特徵檔。此外本研究分 析工作者在工作主題之需求變化以找出具相似主題需求變化的相似工作者,並進 一步依據相似工作者的主題需求變化進行合作式調整工作特徵檔並推論潛在資 訊需求。最後,本研究進行實驗評估,以比較所提方法在提供工作相關資訊之成 效。. 關鍵字:資訊過濾、工作需求、適性化技術、工作特徵檔、工作主題變動、合作 式工作特徵檔. i.
(4) Profile Adaptation for Providing Task-relevant Information by Variation of Task Needs Student: Pei-Cheng Chang. Advisor: Dr. Duen-Ren Liu. Institute of Information Management National Chiao Tung University. Abstract In task-based business environments, an important issue of deploying Knowledge Management System (KMS) is providing task-relevant information (codified knowledge) to fulfill the information needs of knowledge workers. In addition, workers need to access lots of textual documents in conducting knowledge-intensive tasks. Accordingly, effective knowledge management relies on using information filtering (IF) techniques to model worker's information needs as profiles and provide relevant information based on the modeled profiles. This research proposes a novel adaptive task-profiling technique to model worker's information needs on tasks, i.e., task-needs. The proposed technique adjusts task profiles to model worker's dynamic task-needs based on the documents accessed by workers and the relevance on the task-based topic taxonomy. Generally, the more recent the document accessed the more important it is to reflect a work's current task needs. Thus, the effect of time factor is considered in profile adaptation. In addition, the proposed profiling technique adopts a novel collaborative profile adaptation approach to adjust task profiles. We analyze the variations of workers' task needs on the topic taxonomy to identify workers with similar variations of task needs on topics (i.e., topic needs) over time. Similar workers' variations of topic needs are used to predict the target worker's future variations of topic needs, and are used to adjust the target worker's task profile. The codified knowledge that is relevant to the current task can be retrieved based on the adjusted task profile to fit the worker's dynamic task needs. Empirical experiments demonstrate that the proposed approach models workers' task-needs effectively and helps provide task-relevant knowledge. Keywords:Information filtering, task needs, adaptive profiling technique, self task profile, variation of task-needs on topics, collaborative profile ii.
(5) 誌. 謝. 佈滿回憶的暑夏悄然到來,兩年的學生生活即將隨著時間化作點滴成為這回 憶的一部份。下一段旅程! 首先感謝我的指導教授劉敦仁老師,這兩年來給予的許多指導與建議,讓我 能夠順利完成碩士學位。也感謝口試委員陳彥良博士與李永銘博士,在口試時提 供的許多寶貴意見,讓本論文得以更加完善。 感謝所有學長姐們在課業與生活上的照顧和幫忙;感謝同學們在課業上一同 學習和研究、在論文撰寫期間一起加油打氣;感謝學弟妹們為研究室帶來歡樂氣 氛。此外,特別感謝怡瑾學姐在研究過程中的指導,給了我很大的幫助與支持, 著實使我獲益良多。 最後要感謝我的家人與朋友們,謝謝你們的關懷、支持與鼓勵,讓我能一直 保有勇氣與希望。感謝所有幫助過我的人,願快樂常在你們心中。. iii.
(6) Table of Content 1. Introduction................................................................................................................1 2. Literature review........................................................................................................4 2.1. Task-based knowledge management and retrieval..........................................4 2.2. Information retrieval in a vector space model ................................................5 2.3. User modeling by information filtering technique..........................................6 2.4. Relevance feedback techniques ......................................................................7 3. Overview of methodology .........................................................................................9 4. Modeling task needs ................................................................................................12 4.1. Capturing users' access behavior ..................................................................12 4.2. Self profile adaptation...................................................................................12 5. Measuring variations of user topic needs over Time ...............................................16 5.1. Variation measurement for a specific topic...................................................16 5.2. Representation model: Topic-needs variation matrix ...................................17 6. Collaborative profile adaptation ..............................................................................19 6.1. Identifying similar workers...........................................................................19 6.2. Prediction of task needs ................................................................................22 6.3. Result demonstrations...................................................................................24 7. Experiments .............................................................................................................28 7.1. Experimental setup........................................................................................28 7.1.1. Experimental objective and design ....................................................28 7.1.2. Data and participants..........................................................................29 7.1.3. Evaluation metrics .............................................................................29 7.2. Experimental result and observations ...........................................................30 7.2.1. Experiment 1-1: parameter selection for TP-V method .....................30 7.2.2. Experiment 1-2: parameter selection for TP-D method.....................31 7.2.3. Experiment 2: comparisons of self profile adaptation methods.........32 7.2.4. Experiment 3: comparisons of various methods................................34 7.2.5. Case inspections.................................................................................35 7.2.6. Discussions ........................................................................................36 8. Conclusion and future research issues .....................................................................38 Reference .....................................................................................................................39. iv.
(7) List of Tables Table 4.1 Definitions of symbols and parameters used in the equations .....................13 Table 6.1 The definitions of symbols used in the identification algorithm..................19 Table 7.1 Effectiveness of TP-V method under various δ V values ...........................31 Table 7.2 Effectiveness of the TP-D method under various δ D values.....................32 Table 7.3 Comparison between self profile adaptation methods .................................33 Table 7.4 Comparison between methods .....................................................................34. v.
(8) List of Figures Fig. 3.1 Overview of proposed profile adaptation .........................................................9 Fig. 4.3 Example of modeling task needs ....................................................................15 Fig. 5.1 An example of topic-needs variation matrix...................................................18 Fig. 6.1 Algorithm of identifying similar workers.......................................................21 Fig. 6.2 Sample of trimming the variation matrix of the target worker.......................21 Fig. 6.3 Sample of calculating SimVM.........................................................................22 Fig. 6.4 Sample of calculating SimTP..........................................................................22 Fig. 6.5 Event information ...........................................................................................25 Fig. 6.6 Similarity with each topic...............................................................................25 Fig. 6.7 Variation of topic needs over time ..................................................................26 Fig. 6.8 Similar Workers ..............................................................................................26 Fig. 6.9 Prediction Result.............................................................................................27 Fig. 7.1 Result of knowledge support of TP-V under various δ V value....................31 Fig. 7.2 Result of knowledge support of TP-D under various δ D value ...................32 Fig. 7.3 Trends of retrieval effectiveness of the four methods under various top-N document support.........................................................................................................33 Fig. 7.4 Trends of retrieval effectiveness of the four methods under various top-N document support.........................................................................................................35 Fig. 7.5 Four experimental cases .................................................................................35 Fig. 7.6 Trends of retrieval effectiveness of the three cases (case 1, 2,3) under various top-N document support ..............................................................................................36. vi.
(9) 1. Introduction Knowledge management systems (KMSs) are important and useful tools for an enterprise to manage business knowledge effectively. In addition, KMSs provide adequate support for improving decision making and gaining competitive advantage. In an organization, workers are assigned to carry out various tasks, and workers need to apply their experience and professional knowledge to complete the tasks to achieve organizational goal [12][13]. For this reason, an organization has the urgency to make use of the knowledge assets which are emerging from organizational operations and management activities to increase its profitability and productivity with the support of KMSs. For KMSs, Information Technology (IT) plays the role of facilitating the access, reuse and sharing of knowledge assets within and across an organization to assist knowledge workers in executing their tasks [9][17]. In addition, workers need to access lots of textual documents in conducting knowledge-intensive tasks. Accordingly, Information Filtering (IF) techniques are often employed to model users’ information needs as profiles and provide relevant information based on the modeled profiles. Effective knowledge management relies on understanding workers’ information needs on tasks, for brevity, task-needs. As the operations and management activities of enterprises are mainly task-based, KMSs focus on providing task-relevant knowledge to workers engaged in knowledge-intensive tasks [1][2][11][12][13]. The Kabiria system supports knowledge-based document retrieval in office environments, allowing users to conduct document retrieval according to the operational context of task-associated procedures [8]. The KnowMore system maintains task specifications (profiles) to enumerate the process-context of tasks and associated knowledge items [1]. Context-aware delivery of task-specific knowledge can then be facilitated based on the task specifications and current execution context of the process. The above works provide an appropriate perspective for designing task-based knowledge support. However, they focus on specifying the process-context of a task to support context-aware or process-aware knowledge retrieval, rather than on a systematic method for constructing a task profile that models a worker’s task needs. Moreover, very few researches address the issue of profile adaptation to track workers’ dynamic information needs. This research proposes a novel adaptive task-profiling technique to model worker’s information needs on tasks, i.e., task-needs, as follows.. 1.
(10) First, a task profile specifies the key concept terms of a worker’s current task (task at hand), and models the information needs of the worker during the task’s execution. The proposed technique adjusts task profiles to model workers’ dynamic task-needs based on the documents accessed by workers without considering user feedback (positive or negative opinion). Second, in order to model users' task needs, a proper task-based topic taxonomy is used to conceptualize the domain information of organizational activities. Note that the main subjects of organizational activities defined by domain experts and previously (executed) representative tasks form the task-based topic taxonomy. The topics and their corresponding topic profiles are used as references to adjust task profiles according to their relevance (similarity) to the documents accessed by the workers. Third, generally, the more recent the document accessed the more important it is to reflect a work’s current task needs. Thus, the effect of time factor is considered in profile adaptation. Fourth, the proposed profiling technique adopts a novel collaborative profile adaptation approach to adjust task profiles. Knowledge workers usually require a substantial amount of time to accomplish knowledge-intensive tasks. For such long-term tasks, the information needs of the workers may vary according to their progress during the performance of tasks. For example, a graduate student is seeking adequate knowledge documents for her research. Her research topics may vary as the following: "Event detection" => "Mining event change" => "Mining Patent change" => "Patent Mining", where the symbol '=>' denotes that the left-hand side occurs before the right-hand side. Without explicitly specifying the change of information needs directly by workers, we try to capture the variations of workers’ information needs through those documents accessed by the workers. This work uses the variation of workers’ topic needs to model the variation of the workers’ information needs. Conventional user profiling approaches, which are based on relevance feedback on documents, can only reflect the information needs accumulated, and lack consideration of possible change of information needs. This work measures the variation of workers’ topic needs according to their knowledge activities (e.g. access documents). Workers with similar variations of topic needs over time are identified. A novel collaborative profile adaptation approach is proposed to adjust task profiles via. 2.
(11) using similar workers’ variations of topic needs to predict the target worker’s future possible variations of topic needs. The proposed approach enhances knowledge retrieval through collaboration from similar workers. The codified knowledge that is relevant to the current task can be retrieved based on the adjusted task profile to fit the worker’s dynamic task needs. Empirical experiments demonstrate that the proposed approach models workers’ task-needs effectively and helps provide task-relevant knowledge. The rest of this thesis is organized as follows. Section 2 surveys the related work. The overview of proposed methodology is described in Section 3. The approach of task needs modeling is detailed in Section 4. The details of measuring and maintaining variation of topic needs over time are presented in Section 5. Section 6 details how to identify similar workers with similar variations of topic needs and the proposed collaborative profile adaptation approach. The experiments of our proposed approaches are illustrated in Section 7. The conclusion and future works are concluded in Section 8.. 3.
(12) 2. Literature review 2.1. Task-based knowledge management and retrieval Managing knowledge within and across organizations is considered as an important tactic for gaining competitive advantages in nowadays business environments. Knowledge Management (KM) activities generally include creation, management and sharing and all the activities make up a cycle or repeated processes [9][24]. Organizations make use of the knowledge assets emerging from organizational operations and management activities to increase their profitability and productivity with the support of Knowledge Management Systems (KMSs) [16][24]. Contemporary KMSs employ Information technology (IT) such as document management and workflow management to facilitate the access, reuse and sharing of knowledge assets within and across organizations [9][17]. Generally, IT mainly focuses on explicit and tacit dimension in knowledge management to support knowledge management activities [17]. In order to manage the explicit knowledge, there are four primary resources being utilized: repositories, refineries, organization roles, information technologies [42]. The repository of structured and explicit knowledge, especially in document form, is a codified approach to manage knowledge [9][15]. Nevertheless, with the growing amount of information in an organization, KMSs face the challenge to fulfill users' information needs. In general, the operations in an organization are planned around tasks. As knowledge is embedded during the execution of tasks, providing task-relevant knowledge to fulfill the information needs of knowledge workers to complete their tasks is important. Knowledge retrieval is considered as a core component in supporting the workers to perform knowledge-intensive task in a business environment [11]. Recently, Information Retrieval (IR) technique has been greatly exploited in workflow management systems to support the knowledge workers to obtain task relevant knowledge. Furthermore, it is combined with workflow management systems to proactive deliver task-specific knowledge to users [2][11]. For complex and knowledge-intensive tasks, the collaboration among knowledge workers is helpful when there are some knowledge workers interested in similar problems or they share common interests. Sharing knowledge with peer groups is a 4.
(13) superior method in knowledge management [13]. The Computer-Supported Cooperative Work (CSCW) and Recommender Systems also give something additional splendor on collaboration [28][29]. CSCW emphasizes on the power of computer system to help groups of people perform the tasks in a shared environment [29]. Recommender systems employ content-based filtering and collaborative filtering to recommend web pages, movies, books and so on [14][26][28]. However, it is more difficult to provide task-relevant knowledge during the progress of execution of complex and knowledge-intensive tasks because such tasks often consist of several smaller tasks.. 2.2. Information retrieval in a vector space model The key contents of a codified knowledge item (document) can be represented as a term vector (i.e., a feature vector of weighted terms) in n-dimensional space, using a term weighting approach that considers the term frequency, inverse document frequency, and normalization factors [32]. The term transformation steps, including case folding, stemming, and stop word removal, are performed during text pre-processing (Salton et al., 1971; Poter, 1980; Witten et al., 1999). Then, term weighting is applied to extract the most discriminating terms [3]. Let d be a codified r knowledge item (document), and let d = <w(k1, d), w(k2, d), …, w(kn, d)> be the term vector of d, where w(ki, d) is the weight of a term ki that occurs in d. Note that the weight of a term represents its degree of importance in representing the document (codified knowledge). The well-known tf-idf approach, which is often used for term (keyword) weighting (Poter, 1980), assumes that terms with higher frequency in a document and lower frequency in other documents are better discriminators for representing the document. Let the term frequency tf (ki , d ) be the occurrence frequency of term ki in d, and let the document frequency df (ki ) represent the number of documents that contain ki. The importance of ki is proportional to the term frequency and inversely proportional to the document frequency, which is expressed as Eq. 2.1: w( ki , d ) =. 1. ∑ (tf (ki , d ) × log( N df (ki ) + 1) ). 2. tf ( ki , d ) × (log. N + 1) df (ki ). (2.1). i. where N is the total the number of documents. Note that the denominator on the right-hand side of the equation is a normalization factor that normalizes the weight of 5.
(14) a term. Similarity measure: The cosine formula is widely used to measure the degree of similarity between two items, x and y, by computing the cosine of the angle between r. r. their corresponding term vectors x and y , which is given by Eq. 2.2. The degree of similarity is higher if the cosine similarity is close to 1. r r r r x•y sim( x, y ) = cosine( x , y ) = r r x y. (2.2). 2.3. User modeling by information filtering technique Information retrieval (IR) and information filtering (IF) technologies applied to document management is generally the first step of knowledge management activities, since textual data such as articles, reports, manuals, know-how documents and so on are treated as the valuable and explicit knowledge within organizations [24]. In addition, IR and IF are considered as the core technologies to help organizations collect and process documents, to reduce the problem of information overload, and to provide relevant and needed information for knowledge workers to accomplish their tasks [6][19][34]. IF systems are similar to conventional IR ones, but rather than focusing on facilitating users' short-term information needs, IF systems lay emphasis on personalization to support long-term information needs of users [3][5][22][23][39]. Accordingly, maintaining and learning users' profiles is an important issue in order to support long-term information services. Various approaches for learning users' interests or preferences from textual documents or web pages have been proposed [4][21][22][23][27]. The well-known approaches in Information Retrieval or Information Theory are modified and then employed to model or capture user's dynamically changed interests, for example, Rocchio algorithm, information gain theory, Bayesian classifier. Sieg et al. (2004) integrate user profiles and concept hierarchies to infer users' information context to enhance original queries. Widyantoro et al. (2001) use a three-descriptor model to learn user's multiple interest dynamics, which maintains a long-term descriptor to capture the user's general interests and a short-term descriptor to keep track of the user's more recent, faster-changing interests. Moreover, an auto weight-adjusted mechanism is employed to adjust the weight of positive and negative descriptors to make the short-term descriptor react to a drastic change in interest faster. Notably, all 6.
(15) these approaches require users' relevance feedback, including explicit one (users' linguistic rating) and implicit one (users' access behavior) to reach this goal. Relevance feedback effectively improves search effectiveness through query reformulation. Various studies have demonstrated that relevance feedback applied in the vector model is an effective technique for information retrieval [30][33]. Consequently, the IF systems learn users' current information needs from the relevance feedback and update the model for information filtering in the future. Such kind of learning approaches can maintain the users' profiles adequately once the systems receive the feedback, hence the learning approaches are regarded as the incremental learning technique. In addition to relevance feedback, the characteristic of knowledge retrieval activities in the working environment is also needed to be taken into consideration to support the workers more precisely. The characteristic of knowledge retrieval activity is that the worker's information needs is always associated with the executing task at hand. Generally, a worker uses documents to understand a task, solve the encountered problem, or result in another search behavior to find a solution. Accordingly, several empirical studies focus on how documents are selected and used by workers during executing task [36][37]. Furthermore, K-Support System takes the characteristics of task stage into account and employs domain ontology to provide dynamic knowledge support [19]. Though the success of the IF techniques, few consider that the effect of variation processes of users' information needs and collaboration between the workers who have similar variation processes. So an enhanced profile adaptation approach taking the variations of topic needs over time of workers into account in advance and keeping them rather than just reflecting the information needs accumulated is required. Such can help the workers take advantage of the past experience of the other workers and enable them to have more chances to retrieve task-relevant knowledge.. 2.4. Relevance feedback techniques Relevance feedback (RF) improves the search effectiveness through query reformulation [33]. The RF technique reformulates or expands the original query based on partial relevance judgments, i.e., feedback on part of the evaluation set. Relevant documents with positive feedback have a positive influence on the weight of terms, while irrelevant documents with negative feedback have a negative influence 7.
(16) on the weight of terms. A refined query vector can be generated by adding the term weights of relevant documents and subtracting the term weights of irrelevant documents. Eq. 2.3 illustrates the Standard_Rocchio method designed by Rocchio. A r. modified query vector q m is derived using the relevance of documents (as feedback) r. to adjust the query vector q . r. r. Standard_Rocchio: q m = α q + β. 1 Dr. ∑. ∀d j ∈Dr. r. d j −γ. 1 Dn. ∑. ∀d j ∈Dn. r. dj. (2.3). where Dr denotes the set of relevant documents and Dn represents the set of irrelevant documents according to user assessments. Dr. and Dn represent the. number of documents in the sets Dr and Dn respectively; and α , β , γ are tuning constants.. 8.
(17) 3. Overview of methodology In this research, we propose a profile adaptation technique to adjust task profiles and enhance knowledge retrieval. Fig. 3.1 shows the proposed methodology.. user accesses the documents. Phase 2. Phase 1. Measuring variations of topic needs. Capturing user's behavior. Accessed documents Topic Variation Matrix Information of events. Topic Taxonomy. Accessed documents Relevant topics. Self-adapted Task Profile Identifying similar workers. Time effect. Similar workers Self profile adaptation. Collaborative profile adaptation. Self-adapted task profile. Collaborative profile. Integrating self task profile and collaborative profile. Fig. 3.1 Overview of proposed profile adaptation. The proposed adaptive task-profiling technique for modeling worker’s dynamic task-needs mainly comprises two phases, the self adaptation phase and collaborative adaptation phase. The self adaptation phase incrementally adjusts task profiles based on the documents accessed by workers, relevant topics and the time effect. The collaborative adaptation phase uses similar workers’ variations of topic-needs to adjust task profiles. The profiling approach uses an event-based approach to trigger the profile adaptation process, where an event occurs when a worker accesses a document at specific time. 9.
(18) (1)Phase 1:Self profile adaptation Whenever workers access a knowledge document, the information about the user's behavior is captured. The self adaptation phase considers the effect of time factor and the user's behavior (document accessed) to adjust the corresponding task profile with the aid of task-based topic taxonomy without considering user feedback (positive or negative opinion). In order to model users' task needs, a proper task-based topic-taxonomy is used to conceptualize the domain information of organizational activities. Some topics in the topic taxonomy are defined by the domain experts according to the main subjects of applied organizational activities. Some topics are defined using the previously executed tasks, which are considered as important tasks in an organization. Task-based topics play as important references of past experience to provide workers with task-relevant knowledge, since the task at hand is generally related to some previously executed tasks in an organization [9]. Our previous work shows that relevant topics play as points of reference and are very helpful to generate task profiles, especially when very few documents are accessed in the earlier phase of task executions. The topics and their corresponding topic profiles are used as references to adjust task profiles according to their relevance (similarity) to the documents accessed by the workers. Note that a topic profile specifies the weighted concept terms of a topic. Previous task profile is adjusted to generate a new self-adapted task profile that represents a worker’s future task needs according to the task-relevant topics and the accessed documents incrementally. Moreover, the adaptation takes the time factor into consideration. The rationale is that the more recent the document accessed the more important it is to reflect a work’s current task needs. Thus, the contribution of the user’s previous task needs (profile) towards adjusting the task profile needs to be reduced properly according to the proportion of passed time. The details of the proposed self profile adaptation approach are described in Section 4.2. (2)Phase 2:Collaborative profile adaptation Knowledge workers usually require a substantial amount of time to accomplish knowledge intensive tasks. For such long-term tasks, the information needs of the workers may vary according to their progress during the performance of tasks. Self-adapted task profiles can only reflect the information needs accumulated, and lack consideration of possible changes of information needs. The rationale of collaborative profile adaptation is that workers with similar changes of information needs in the 10.
(19) past are likely to have similar changes of information needs in the future; and thus a worker’s possible change of information needs can be derived from similar workers’ changes of information needs. Without explicitly specifying the change of information needs directly by workers, we try to capture the variations of workers’ information needs through those documents accessed by the workers. This work uses the variation of workers’ topic needs over time to model the variation of the workers’ information needs, as described in the following. The profiling approach uses an event-based approach to trigger the profile adaptation process. An event-based topic needs at specific time is modeled as weighted topics, where the weight of a topic is derived by considering the similarity between the topic profile and the document profile of the document accessed by the worker at that time. A worker’s topic-needs at specific time T is derived as weighted topics on the topic taxonomy by accumulating the event-based topic needs over time with the consideration of time decay. The derivation not only considers the event-based topic needs at time T, but also considers the event-based topic needs prior to time T. The variation of workers’ topic needs can then be measured according to the difference of topic weights between the two time points. Each worker’s variations of topic needs over time are expressed as a topic-needs variation matrix, i.e., a time-period by topic-needs matrix. A similar worker identifying approach is used to find workers with similar variations of topic needs according to the derived topic-variation matrix and self-adapted task profiles over a time window. Note that we focus on identifying similar workers with similar variations of topic needs and similar task needs. Thus, self-adapted task profiles are also considered in the identification process. Once similar workers are identified, similar workers’ task needs (at time T+1) are used to predict the target worker’s task needs at time T+1 that is modeled as a collaborative profile. The derived collaborative profile is then combined with the self-adapted task profile to generate a new task profile representing the target worker’s future task needs at time T+1. Two approaches are used to derive the collaborative profile. One is based on the variation of topic needs to derive the collaborative profile, in which similar workers’ variations of topic needs from time T to T+1 are used to predict the target worker’s possible variations of topic needs. The alternative is based on the documents accessed at time T+1, where similar workers’ documents accessed at time T+1 are used to derive the collaborative profile.. 11.
(20) 4. Modeling task needs Section 4.1 describes how our system captures and stores users' access behavior (document accessed). Section 4.2 illustrates the proposed self profile adaptation approach that considers the effect of time factor and the user's behavior (document accessed) to adjust the corresponding task profile with the aid of task-based topic taxonomy.. 4.1. Capturing users' access behavior Our K-support system records workers' knowledge activities during the execution of their works in previous research [19]. Whenever a worker performs an action about accessing any document, the system creates a new record to store the information of corresponding knowledge activity. In the following, an example is shown to explain how to capture and store users' access behavior. Example: Assuming that a worker "Mrkid" is searching for knowledge documents in K-support system, and he finds that a document "Learning User Interest Dynamics with a Three-Descriptor Representation" may help his task. "Mrkid" performs a "reading" action at time "2005-10-31 21:05:03" accordingly, and with the help of K-support system, the information about the "reading" action is recorded in the system. In the above example, the stored information is {"Mrkid", "2005-10-31 21:05:03", "reading", "Learning User Interest Dynamics with a Three-Descriptor Representation"}. All attributes are converted properly into identifiable number except the 'time' attribute. Hereafter, we use the word 'event' to denote an action performed by some user about accessing any document. In this research, only four kinds of event are adopted, including "download documents", "download reports of documents", "read documents on-line", and "upload documents".. 4.2. Self profile adaptation Whenever an event of worker's access behavior is detected, the system captures and records the document accessed by the worker. The event triggers the self profile adaptation process to adjust the worker's task profile according to the information of the corresponding event. 12.
(21) A document/task/topic profile specifies the weighted concept terms of the document/task/topic.. Vector-based. approach. is. adopted. to. represent. a. document/task/topic profile. A modified relevance feedback technique, adopted from the techniques proposed by Rocchio (1971), is used to adjust the workers' task profiles based on the profiles of documents accessed by the worker and the topic profiles of identified relevant topics. The adjustment considers the effect of time factor. The proposed profiling technique is given in E.q. 4.1, and E.q. 4.2. The associated definitions of symbols and parameters used in the equations are listed in Table 4.1. Let T denote the index of the actual time when the worker performs the latest r action of document access. S T +1 denotes the worker’s task profile generated at time T, which can be used to model his/her task-needs at time T+1. The equation includes the r. decay of previous task-profile S T , which models the worker’s task needs at time T, and the current information needs derived from the document accessed at time T. v Decay( S T ) represents the accumulated task needs from the beginning to the current time T by considering the time decay of previous task-profile. v v v v S T +1 = α × Decay ( S T ) + λOT + (1 − λ ) DT. [. v OT = β. 1 O Tpos. v ∑ Oi −γ. Oi ∈O Tpos. ]. 1 T Oneg. T O j ∈Oneg. [. T −1 v v v Decay ( ST ) = ∑ TWt ,T × λOt + (1 − λ ) Dt t =1. TWt ,T =. (4.1). v ∑Oj. ] (4.2). the actual time for t − ST the actual time for T − ST. Table 4.1 Definitions of symbols and parameters used in the equations. T r S T +1 v DT v OT. the index of the actual time when the worker performs the latest action of document access the task profile generated at time T, which can be used to model the worker’s task-needs at time T+1 the document profile of the document accessed by the worker at time T the aggregate topic profile derived from the topic profiles of relevant topics and irrelevant topics 13.
(22) Oi. the topic i in the topic taxonomy. O Tpos. the positive topic set derived at time T base on the relevance degrees of the topics to the document accessed at time T. O Tpos. the number of topics in O Tpos. T Oneg. the negative topic set derived at time T based on the relevance degrees of the topics to the document accessed at time T. T Oneg. T the number of topics in Oneg. the index of an actual time when the user performs an action of document access; t=0 denotes the time when the task starts. t. TWt ,T. the time weight of the event that occurred at time t (with respect to time T). ST. the starting time when the worker's task starts (in milliseconds). α. the tuning parameter used to adjust the weight of previous task profile. λ. the tuning parameter used to adjust the weights of topic profile OT and v document profile DT the tuning parameters used to adjust the weights of positive topic set and negative topic set. v. β,γ. r r The self-adapted task profile S T +1 is generated from previous task profile S T applied with a decay function and is refined by using the current information needs derived from the document accessed at time T. The current information needs consists of two parts: the document profile and the aggregate topic profile. The document v profile DT intuitively is the profile (feature vector) of the document accessed at time T. Task-based topics play as important references of past experience to adjust task profiles according to their relevance (similarity) to the document accessed by the workers. The relevance degree of a topic Oi to the document DT is obtained by v v calculating the similarity (cosine measure) between Oi and DT . The aggregate topic. profile is derived from the topic profiles of relevant topics in the positive topic set and irrelevant topics in the negative topic set. The positive topic set reflects the positive information needs of the worker, and is obtained by selecting the topics with relevance degree higher than a defined threshold. The negative topic set reflects the negative information needs of the worker on the topic taxonomy and is obtained by selecting the topics with relevance degree lower than a defined threshold. Our previous research shows that topic profiles are more important to adjust task profiles than document 14.
(23) profiles during the early phase of task executions [41], so a parameter λ is used here to adjust the weights of the document profile and the aggregate topic profile. Fig. 4.3 illustrates the given technique. The profile adaptation also takes the effect of time factor into consideration. v Decay( S T ) represents the accumulated task needs from the beginning to the current r time T by considering the time decay of previous task-profile, as given in E.q. 4.2. S T denotes the previous task profile generated at time T-1, and plays the role of previous r task needs. S T is the summation of aggregate topic profiles and document profiles derived from time ST to T-1. Generally, the more recent the document accessed the more important it is to reflect a work’s current task needs. Thus, a time weight is employed to reflect the decay of previous aggregate topic profiles and document profiles towards their contribution to worker’s current task needs. TWt ,T is the time weight of an event occurred at time t with respect to T, and is defined as the ratio of v time difference t-ST to T-ST. Thus, Decay( S T ) can reflect the effect of previous task r profile towards current task profile more accurately with TW than just using S T .. [. v v v v v v v S f +1 = α × Decay ( S f ) + λ[ β (O 2 + O7 + O5 ) / 3 − γO 4 ] + (1 − λ ) D 46 Time d. Time e. ]. Time f. accessed document: D0000000001. accessed document: D0000000547. accessed document: D0000000046. positive topic set: T0000000001 T0000000002 T0000000003. positive topic set: T0000000011 T0000000004 T0000000002. positive topic set: T0000000002 T0000000007 T0000000005. negative topic set: T0000000007. negative topic set: T0000000006. negative topic set: T0000000004. Fig. 4.3 Example of modeling task needs. 15.
(24) 5. Measuring variations of user topic needs over Time Section 5.1 describes the proposed approach to measure the variation of the worker's topic needs, i.e., information needs reflecting on the topic taxonomy. The worker’s variations of topic needs over time are represented as a topic-variation matrix, as described in Section 5.2.. 5.1. Variation measurement for a specific topic Herein, two factors are taken into account in measuring the variation of information needs on a specific topic i: one is the time factor, named the time weight TWt ,T , and the other is the relevance degree of topic. i in the topic taxonomy, namely. the topic-need weight NWt , for each event occurred at time t. The following shows i. the concepts of time weight and topic-need weight over time.. Time Weight :. Value ⎡ TW1,T ⎤ ⎢ ⎥ time 2 ⎢ TW2,T ⎥ ⎢ : ⎥ : ⎢ ⎥ time T - 1 ⎣TWT −1,T ⎦ time 1. Topic - Need Weight :. Topic 1 Topic 2 ‥ Topic q. [. Value NWt1. NWt2 ‥ NWtq. ]. where,. T. the index of an actual time when the latest event occurs. TWt ,T. the time weight of the event occurred at time t (with respect to time T). NWt i. the topic-need weight on topic i for the event occurred at time t. TWt ,T is the time weight of the event occurred at time t with respect to time T as described in Section 4.2. NWt i is the topic-need weight on topic i for the event occurred at time t and is obtained by calculating the similarity value (using vector-based cosine method) between the document accessed at time t and the profile of topic i. Whenever the worker performs an action of document access, the topic-need weight for the corresponding event is calculated.. 16.
(25) After obtaining all the task-need weights for the events of the worker, the variation of topic needs over time can be measured, as given in Eq. 5.1. Given two time index: d and e, where d < e. Let NVdi ,e denote the variation of the worker's information needs on a specific topic i between time d and time e. NVdi ,e is the difference of accumulated topic needs IN ei at time e and IN di at time d. The accumulated topic needs at time e is the summation of TWt ,e × NWti , for t = 1 to e. e. d. t =1. t =1. NV di ,e = IN ei − IN di = ∑ TWt ,e × NWti − ∑ TWt ,d × NWti. (5.1). where, NV di ,e. the variation of the worker's information needs on a specific topic i between time e and time d ( d < e ). IN di. the worker's accumulated information needs on topic i at time d. IN ei. the worker's accumulated information needs on topic i at time e The relevance degree of topic i is different at time d and e, and thus, NWt i is. exploited to take such situation into consideration. The time weight is used to reflect the effect of time decay of topic needs between time d and e. The measurement considers the accumulated topic needs over time; thus the events occurred before time d and time e are also considered.. 5.2. Representation model: Topic-needs variation matrix A representation model is defined to represent the variations of topic needs over time for the given target worker. A vector-based model is adopted to represent the variations of information needs on topics. Each worker’s variations of topic needs over time are expressed as a time-period by topics (in the topic taxonomy) matrix, i.e. topic-needs variation matrix, and the matrix consists of several topic-needs variation vectors. Given any two time indexes: d and e, where d < e. Let NV d ,e denote the variation vector of the worker’s topic needs between time e and d. NVd ,e are defined as E.q. 5.2. Notably, the measurement of the variation on a specific topic i, i.e., NVdi ,e is described in Section 5.1. Assume that there are q topics in the topic taxonomy.. 17.
(26) q NV d ,e = < NV d1,e , NV d2,e , …, NV di ,e ,.., NV d ,e >. (5.2). Eq 5.2 defines the topic-needs variation vector between two time points, i.e., a specific time period. The variations of topic needs over consecutive time indexes are expressed as a time-period by topic matrix VM. An element VMp,i in the matrix represents the variation on topic i during time-period p (e.g. from time d to e). A row of the matrix, VM[j] denotes a variation vector of topic needs. An example of topic-needs variation matrix is shown as follows:. topic 1 2003 - 09 - 24 09 : 57 : 00 ⎡ 0 .066 2003 - 10 - 07 18 : 25 : 42 ⎢ 0 .447 2003 - 10 - 13 14 : 13 : 00 ⎢ ⎢ 0 .06 2003 - 10 - 13 14 : 18 : 00 ⎢ 0 .04 2003 - 10 - 13 14 : 25 : 00 ⎢ ⎢ 0 .05 2003 - 10 - 14 14 : 49 : 30 ⎣. topic 2. topic 3. topic 4. topic 5. − 0 .013. − 0 .024. − 0 .066. 0 .328 0 .026 0 .015 − 0 .019. 0 .014 0 .031 0 .036 0 .019. 0 .074 0 .111 0 .109 0 .033. 0 .065 ⎤ 0 .078 ⎥⎥ 0 .080 ⎥ ⎥ 0 .044 ⎥ 0 .064 ⎥⎦. Fig. 5.1 An example of topic-needs variation matrix. The variation matrix shown in Fig. 5.1 is a 5x5 matrix. The variations of topic needs represented by this variation matrix spans from 2003-09-24 09:57:00 to 2003-10-14 14:49:30, and the value of each element in the variation matrix represents the variation on corresponding topic. For example, the value 0.447 represents the variation of topic needs on topic 1 from 2003-10-07 18:25:42 to 2003-10-13 14:13:00. Note that each time point shown in Fig. 5.1 represents the time when an event occurs, hence there are six events involved in the variation matrix of the worker. Let the time index of 2003-09-24 09:57:00 be denoted as t1, and the time index of 2003-10-07 18:25:42 be denoted as t2. NVt11,t 2 =0.066, which represents the variation of topic needs on topic 1 from time t1 to t2. NVt1,t 2 = <0.066, -0.013, -0.024, -0.066, 0.065>, which represents the variations of topic needs from time t1 to t2. The variations of topic needs over time are represented as set of topic-needs variation vectors.. 18.
(27) 6. Collaborative profile adaptation This section illustrates the proposed collaborative profile adaptation approach. Section 6.1 describes the approach to identify similar workers according to the derived topic-variation matrix and self-adapted task profiles over a time window. Section 6.2 explains how to use similar workers’ task needs to predict the target worker’s potential task needs modeled as a collaborative profile. Section 6.2 also describes the integration of the derived collaborative profile with the self-adapted task profile to generate a new task profile representing the target worker’s future task needs. The demonstrations of system implementation are described in Section 6.3.. 6.1. Identifying similar workers Each worker’s variations of topic needs over time are expressed as a topic-needs variation matrix, i.e., a time-period by topic-needs matrix. Similar workers of the target worker are identified according to the workers’ topic-needs variation matrices and self-adapted task profiles over a time window. Note that we focus on identifying similar workers with similar variations of topic needs and similar task needs. Thus, the self-adapted task profiles of the events involved in the variation process are considered to find workers with task needs similar to that of the target worker. The details of the identification approach are illustrated as follows. Figure 6.1 shows the algorithm to identify similar workers. Table 6.1 lists the definitions of symbols used in the algorithm. Table 6.1 The definitions of symbols used in the identification algorithm. q. the number of topics in the topic taxonomy. row(VM). the number of rows in a variation matrix VM. col(VM). the number of columns in a variation matrix VM; Apparently, col(VM)=q. VMT(ua). the variation matrix of the target worker ua generated at time T. VMT(ux). the variation matrix of the compared worker ux generated at time T. W. the sliding window whose size is w, where w ≤ row( VMT(ua)). WMT(ua). the w * q variation matrix generated from VMT(ua) which only keeps the latest w variation vectors of ua. WMT’(ux). the variation matrix of the compared worker ux generated according 19.
(28) to VMT(ux) and the sliding window W; T’ is the latest time index within the window W WMT’(ux)[j]/ WMT(ua)[j]. a variation vector of topic needs in WMT’(ux)/ WMT(ua). TP(ux)[k]/ TP(ua)[k]. a self-adapted task profile involved in WMT’(ux)/ WMT(ua). SimScore(ux) the similarity score of ux to the target worker ua the similarity calculated based on the variation matrix / task profile. SimVM / SimTP. T. Input:: VM (ua), W Output:: SimilarWorkerList. // the list of similar workers T. 1 2 3 4 5. 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24. function FindSimilarWorker(VM (ua), W){ Trim VMT(ua) to a w * q variation matrix WMT(ua) // which only keeps the last w variation vectors; foreach compared worker ux { Set SimScore(ux) = 0 Sliding the window W on VMT(ux) to derive WMT’(ux) T from row 1 to row (row( M y )-w+1), do { Let WMT’(ux) be the variation matrix of ux generated according to VMT(ux) and the sliding window W, when W is moving on VMT(ux); T’ is the latest time index within the window W for the variation matrix WMT’(ux) covered by W, do { Set SimVM =0, SimTP=0 foreach variation vector WMT’(ux)[j] of WMT’(ux) do { Let WMT(ua)[j] be the corresponding variation vector of MT(ua) SimVM = SimVM + simlarity(WMT’(ux)[j], WMT(ua)[j]) } SimVM = SimVM / w foreach self-adapted task profile TP(ux)[k] involved in WMT’(ux) do{ Let TP(ua)[k] be the corresponding task profile of WMT(ua) SimTP = SimTP + simlarity(TP(ux)[k], TP(ua)[k]) } SimTP = SimTP / (w+1) if ((η* SimVM +(1-η)* SimTP)> SimScore(ux)) then{ SimScore(ux)= η* SimVM +(1-η)* SimTP Set WMT’(ux) as the candidate (similar) variation matrix of ux } } } } Add the workers with top-N SimScore to SimilarWorkerList; return SimilarWorkerList; 20.
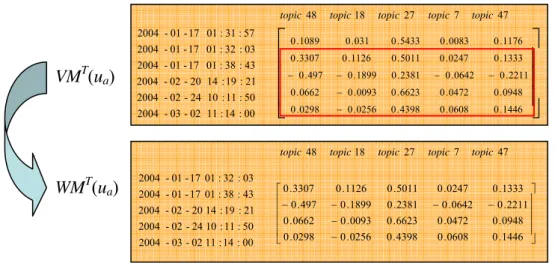
(29) 25. }. Fig. 6.1 Algorithm of identifying similar workers. First, the variation matrix VMT(ua) of the target worker is trimmed to a w*q variation matrix WMT(ua) which keeps only the latest w variation vectors to be employed to identify similar workers that have similar variation matrix and task profiles. For each compared worker ux, the sliding window W is employed accordingly to locate the part of variation matrix of ux that is similar to WMT(ua). WMT’(ux) is the variation matrix of ux generated according to VMT(ux) and the sliding window W. T’ is the latest time index within the window W. In line 3 ~ line 21, the detailed procedure to find the candidate similar variation matrix for each compared worker ux is described. The candidate variation matrix with the highest similarity score among all candidates of ux is selected as the most similar variation matrix of ux. The calculations (line 16 ~ line 19) of the similarity SimScore between ux and ua contains two parts, the calculation of similarity SimVM based on topic-needs variation vectors and the similarity SimTP based on the self-adapted task profiles. A parameter η is used here to balance the relative importance of SimVM and SimTP. In our application, we set η=1/2. That is, the similarity between variation vectors and self-adapted task profiles are equally important. The compared workers with top-N ranked similarity scores are selected as the similar workers of ua. The value of N should be properly set according to the application domain Figure 6.2 describes the trimming the variation matrix of the target worker according to the sliding window. Fig 6.3 and 6.4 illustrate the calculation of similarity score based on the variation matrices and task profiles within the sliding window. topic 48. 2004 - 01 - 17 01 : 31 : 57 2004 - 01 - 17 01 : 32 : 03. VMT(ua). 2004 - 01 - 17 01 : 38 : 43 2004 - 02 - 20 14 : 19 : 21 2004 - 02 - 24 10 : 11 : 50 2004 - 03 - 02 11 : 14 : 00. ⎡ 0 .1089 ⎢ 0 .3307 ⎢ − 0 .497 0662 ⎢ 00 ..0298 ⎣ topic 48. WMT(ua). 2004 - 01 - 17 01 : 32 : 03 2004 2004 2004 2004. - 01 - 17 01 : 38 : 43 - 02 - 20 14 : 19 : 21 - 02 - 24 10 : 11 : 50 - 03 - 02 11 : 14 : 00. ⎡ 0 . 3307 ⎢ − 0 . 497 ⎢ ⎢ 0 . 0662 ⎢ ⎣ 0 . 0298. topic 18. topic 27. topic 7. topic 47. 0 . 031. 0 . 5433. 0 . 0083. 0 . 1126. 0 . 5011. 0 . 0247. − 0 . 1899. 0 . 2381. − 0 . 0642. − 0 . 0093. 0 . 6623. 0 . 0472. − 0 . 0256. 0 . 4398. 0 . 0608. topic 18. topic 27. topic 7. ⎤ ⎥ − 0 . 2211 ⎥ 0 . 0948 ⎥ 0 . 1446 ⎦ 0 . 1176. 0 . 1333. topic 47. 0 . 1126. 0 . 5011. 0 . 0247. − 0 . 1899 − 0 . 0093 − 0 . 0256. 0 . 2381 0 . 6623 0 . 4398. − 0 . 0642 0 . 0472 0 . 0608. 0 . 1333 ⎤ − 0 . 2211 ⎥⎥ 0 . 0948 ⎥ ⎥ 0 . 1446 ⎦. Fig. 6.2 Sample of trimming the variation matrix of the target worker 21.
(30) topic 48 topic18 topic 27 topic 7 topic 47. 2004 - 01 - 17 01 : 32 : 03 T. WM (ua). 2004 - 01 - 17 01 : 38 : 43 2004 - 02 - 20 14 : 19 : 21 2004 - 02 - 24 10 : 11 : 50 2004 - 03 - 02 11 : 14 : 00. ⎡ 0.3307 0.1126 ⎢− 0.497 − 0.1899 ⎢ ⎢ 0.0662 − 0.0093 ⎢ ⎣ 0.0298 − 0.0256. 0.0247 0.1333 ⎤ 0.2381 − 0.0642 − 0.2211⎥⎥ 0.6623 0.0472 0.0948 ⎥ ⎥ 0.4398 0.0608 0.1446 ⎦ 0.5011. average value of similarity between variation vectors. topic 48 topic18 topic 27 topic 7 topic 47. 2003 - 04 - 07 16 : 20 : 09. T’. WM (ux). 0.4123 0.1145 0.0101 0.0098 ⎤ ⎡ 0.2072 ⎢ 0.0034 0 . 2345 − 0 . 1662 − 0 . 0912 0 .4127 ⎥⎥ 2003 - 06 - 17 17 : 08 : 58 ⎢ ⎢− 0.0834 − 0.0537 0.3812 − 0.4728 − 0.0043⎥ 2003 - 06 - 20 09 : 55 : 48 ⎢ ⎥ 0.4177 − 0.0023 0.4028 0.0987 0.0123 ⎦ 2003 - 06 - 24 11 : 31 : 22 ⎣. 2003 - 04 - 07 17 : 01 : 03. Fig. 6.3 Sample of calculating SimVM Self Task Profile involved in WMT(ua) 2004 - 01 - 17 01 : 32 : 03 2004 - 01 - 17 01 : 38 : 43. WMT(ua). 2004 - 02 - 20 14 : 19 : 21 2004 - 02 - 24 10 : 11 : 50 2004 - 03 - 02 11 : 14 : 00. ⎡ Self Task Profile(20 04 - 01 - 17 01 : 32 : 03) ⎤ ⎢ Self Task Profile(20 04 - 01 - 17 01 : 38 : 43) ⎥ ⎢ ⎥ ⎢ Self Task Profile(20 04 - 02 - 20 14 : 19 : 21)⎥ ⎢ ⎥ ⎢ Self Task Profile(20 04 - 02 - 24 10 : 11 : 50) ⎥ ⎢⎣ Self Task Profile(20 04 - 03 - 02 11 : 14 : 00) ⎥⎦. average value of similarity between self task profiles. Self Task Profile involved in WMT’(ux) 2003 - 04 - 07 16 : 20 : 09. WMT’(ux). 2003 - 04 - 07 17 : 01 : 03 2003 - 06 - 17 17 : 08 : 58 2003 - 06 - 20 09 : 55 : 48 2003 - 06 - 24 11 : 31 : 22. ⎡ Self Task Profile(20 03 - 04 - 07 16 : 20 : 09)⎤ ⎢ Self Task Profile(20 03 - 04 - 07 17 : 01 : 03) ⎥ ⎥ ⎢ ⎢ Self Task Profile(20 03 - 06 - 17 17 : 08 : 58)⎥ ⎥ ⎢ ⎢ Self Task Profile(20 03 - 06 - 20 09 : 55 : 48)⎥ ⎢⎣ Self Task Profile(20 03 - 06 - 24 11 : 31 : 22) ⎥⎦. Fig. 6.4 Sample of calculating SimTP. 6.2. Prediction of task needs Once the similar workers of the target worker have been identified, their variation matrixes, i.e., candidate similar variation matrixes identified by the algorithm, can be used to predict the target worker’s potential task needs. Note that time T’ux is the latest time index in the candidate similar variation matrix. The variation vectors right after time T’ux in the candidate similar variation matrixes can be regarded as the possible changes of topic needs that the target worker will experience in the near future. These variation vectors of similar workers are used to derive a vector-based variation profile, which can then be integrated with the 22.
(31) self-adapted task profile to predict the target worker's potential task needs accordingly. Alternatively, the documents accessed by similar workers right after time T’ux, i.e., T’ux+1, can also be regarded as the future potential information needs of the target worker. Thus, two approaches are proposed to predict the worker's potential task needs modeled as a collaborative profile which is derived according to the similar workers’ behaviors at time T’ux+1. One is based on the variation of topic needs to derive the collaborative profile, in which similar workers’ variations of topic needs from time T’ux to T’ux+1 are used to predict the target worker’s possible variations of topic needs at time T+1. The alternative is based on the documents accessed at time T’ux+1, where similar workers’ documents accessed at time T’ux+1 are used to derive the collaborative profile. A linear combination approach is used to integrate the derived collaborative profile with the self-adapted task profile to generate a new task v. profile PT +1 representing the target worker’s future task needs, as given below. The detailed approaches are as follows:. v PT +1. q v ⎧ i ∑ SimT (u a , u x ) × ∑ NVTux' ,Tux' +1 (u x ) * Oi ⎪ v i =1 ⎪ δ V × S T +1 + (1 − δ V ) × u x ∈U a ⎪ ∑ SimT (u a , u x ) ⎪ u x ∈U a =⎨ v ⎪ ∑ SimT (u a , u x ) × DTux' +1 (u x ) v ⎪ u x ∈U a ⎪ δ D × S T +1 + (1 − δ D ) × ∑ SimT (u a , u x ) ⎪ u x ∈U a ⎩. (TP-V method). (TP-D method). where, v S T +1. the self-adapted task profile generated at time T, described in Section 4.2. ua / ux. the target worker / similar worker. Ua. the set of similar workers of ua. δV / δ D. the tuning parameters used to adjust the relative weight between the self-adapted task profile and the collaborative profile. T’ux. the latest time index of candidate similar variation matrix WMT’(ux) of worker ux. SimT (u a , u x ). the similarity between the target worker ua and the worker ux at time T, which is obtained from the SimScore( ux ), described in Section 6.1. NVTi '. ' ux ,Tux +1. (u x ). the variation degree on topic i from time T’ux to time T’ux +1 of ux , as described in Section 5.2 23.
(32) v DTu. x. '+1 (u x ). v Oi. the document profile of the document D accessed at time T’ux +1 by the worker u x the topic profile of topic i in the topic taxonomy. For the TP-V method, the predicted profile of the target worker is the weighted combination of the self-adapted task profile and the accumulated collaborative topic-variation profile derived from similar workers’ variations of topic needs. A parameter δ V is used here to adjust their relative weights. Each worker’s topic-variation profile is obtained through the profiles of topics multiplied by the corresponding variation degrees NVTi '. '. ux ,Tux +1. (u x ) . The individual topic variation profile. represents the variation of topic needs of the corresponding worker, while the collaborative. topic-variation. profile. represents. similar. workers’. weighted. topic-variation profile by considering their similarity to the target worker. The collaborative topic-variation profile is integrated with the self-adapted task profile of the target worker to generate predicted task profile representing his potential task needs in the near future. The TP-D method is similar to the TP-V method, except that the documents accessed at time Tu x '+1 by similar workers are used to derive the. collaborative document profile. The comparisons of these two methods are described in Section 7.. 6.3. Result demonstrations For the purpose of reviewing and evaluation, an interface is implemented to show the detailed information after each operation of proposed methodology mentioned from Section 4. The individual operation is demonstrated respectively thereinafter. (1)Interface one: Information of task profile and variation process. Fig. 6.5 shows the event information during the adaptation process of the self-adapted task profile of worker "Nancy" from 2003-09-24 09:45:00 to 2005-04-21 13:27:00. For event 2, it shows that Nancy accessed the document labeled as D0000000339 at 2003-09-24 09:52:00. Fig 6.6 shows the similarity with all topics for each event. The topics are properly labeled and the similarity is obtained by calculating the cosine value between the topic profile and the document profile. From the figure, which topic is interesting for the worker can be grasped roughly.. 24.
(33) Fig. 6.5 Event information. Fig. 6.6 Similarity with each topic. Fig. 6.7 shows the information of the variation process of Nancy from 2003-09-24 09:45:00 to 2005-04-21 13:27:00. Each row with the preceding words "Variation X" represents a variation vector, and the string in bracket represents the variation degree on corresponding topic during some period. From the result, the trend of variations on topics can be understood in advance.. 25.
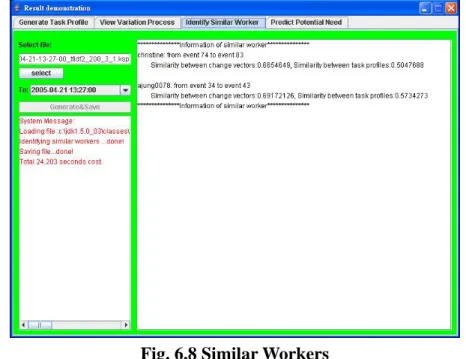
(34) Fig. 6.7 Variation of topic needs over time (2) Interface two: Identification of similar workers. Fig. 6.8 shows the information of similar workers after performing proposed identification approach. The top 2 similar workers are taken into account and are shown here. For the worker "Christine", the most similar variation process with what Nancy recently get interested around 2005-04-21 13:27:00 involves from event 74 to event 83 and it could be traced in advance to see the details by observing the variation process or event information mentioned above.. Fig. 6.8 Similar Workers. 26.
(35) (3) Interface three: Prediction of potential task needs. Fig. 6.9 shows the prediction result of three proposed prediction approaches in this research. In Fig. 6.9, twenty knowledge documents are chosen in the order of similarity to be recommended for Nancy. These documents could be reviewed on-line by checking the titles to see if there are some documents helpful for the execution of task, and then the user may choose some to read in advance.. Fig. 6.9 Prediction Result. 27.
(36) 7. Experiments Three experiments are conducted to evaluate the effectiveness of the proposed profile adaptation methods. Section 7.1 describes the experimental objective, design, resource and evaluation metrics. The experimental results and discussions are given in Section 7.2.. 7.1. Experimental setup 7.1.1. Experimental objective and design Experiments are conducted to evaluate the effectiveness of the proposed adaptive profiling techniques, including the TP method, TP-V method and the TP-D method. The TP method denotes the self profile adaptation method described in Section 4.2, which adjusts the worker’s task profile based on the document accessed by the worker and the relevance on topic taxonomy. The effect of time factor is also incorporated into the profile adaptation process, as given in E.q. 4.1 and E.q. 4.2. The TP-V method denotes the collaborative profile adaptation method described in Section 6.2, which adjust the task profile by a weighted combination of the self-adapted task profile and the collaborative profile (topic-variation profile) derived from similar workers. The TP-D method is similar to the TP-V method, except that the documents accessed at time Tu x '+1 by similar workers are used to derive the collaborative profile. Parameters δ V and δ D are used to adjust the relative weights of self profile and collaborative profile in TP-V and TP-D methods, respectively. Thereby, the parameters of δ V and δ D are determined in experiment one to select the best value of parameters in our application domain. Experiment two compares the TP method with a baseline method, which is called the PP method - primitive profiling method, and two self profile adaptation methods, PP-T and PP-P methods. The PP method generates and adjusts the target worker’s task profile based on the documents accessed, without considering topic profiles and the effect of time factor. The PP-T and PP-P methods act almost like the. PP method, but they consider the effect of time factor and topic profiles respectively. The equation of the PP, PP-T, and PP-P methods are given as follows:. 28.
(37) v v v ⎧ST +1 = αST + DT v v ⎪v = + S α Decay ( S ) D ⎨ T +1 T T v v v v ⎪S = αS +[λO + (1− λ)D T T T] ⎩ T +1. (PP method) (PP-T method) (PP-P method). where α is set to 1 in the experiments. Experiment three compares TP, TP-V, and TP-D methods with the baseline method, PP method.. 7.1.2. Data and participants Experiments are conducted using a real application domain on conducting research tasks in a laboratory of a research institute. Knowledge workers usually require a longer time (e.g. one year) to accomplish knowledge-intensive tasks, so the sample size of the data and participants is restricted in the experiments. In this work, the tasks concerned are writing research papers or conducting research projects. Thirteen workers were selected as the compared workers and ten workers were selected as the tested workers in the evaluation. Fifty five research tasks were collected, with 36 topics and 19 target tasks (the tasks at hand). Because the process of each task performance spans a long time period, the evaluation period of each target task is selected by the experts to examine the proposed methods. We evaluate the four methods by examining the effectiveness of the retrieval result based on documents accessed by conducting tasks. Over 600 documents are collected during the period of 2002~2005. Each document contains an average of ninety distinct terms after information extraction, and document pre-processing (e.g. stemming, removing stop words, and indexing).. 7.1.3. Evaluation metrics The effectiveness of each method is measured in terms of precision, recall and F-measure, which are widely used measures in information retrieval [3]. Precision and Recall: Precision is the fraction of retrieved documents that are. relevant, while recall is the fraction of known relevant documents that are retrieved. Known relevant documents of a worker u are those relevant documents selected by u in the test set. The definitions a given below:. 29.
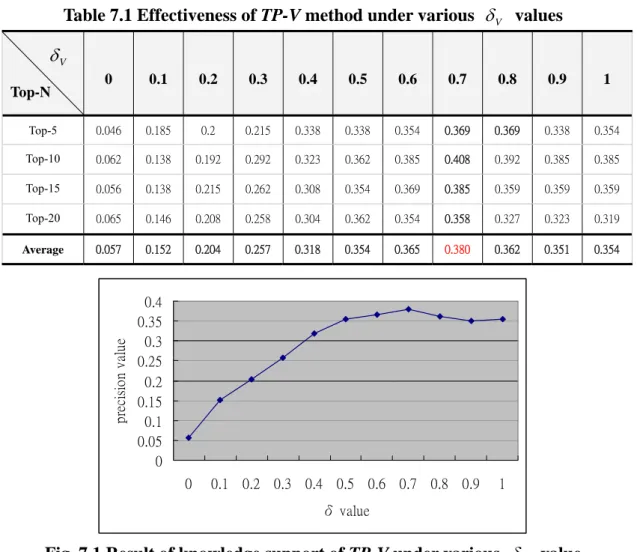
(38) precision =. recall =. number of retrieved documents that are relevant number of retrieved documents. number of relevant documents that are retrieved number of known relevant documents. F-Measure: For observing the relative importance of precision and recall, a. combination metric F1-metric [29] is used to adjust the relative weight of precision and recall to balance the trade-off between these two indicators.. (1 + β 2 ) × precision × recall Fβ = β 2 × precision + recall The function of β is to adjust the relative importance of the recall in comparison to the precision. If β=0, Fβ coincides with precision, and if β=∞, Fβ coincides with recall. In this experiment, we set β=1 (precision and recall are equally important).. 7.2. Experimental result and observations 7.2.1. Experiment 1-1: parameter selection for TP-V method This experiment aims to determine the value of parameter δ V in the TP-V method. TP-V method uses δ V to adjust the relative weight of self task profile and collaborative topic-variation profile. When δ V is set to 1, the TP-V method is equivalent to TP method, which takes only the self task profile into account. When. δ V is set to 0, it is equivalent to the collaborative topic-variation profile. The experiment was conducted by systematically adjusting the value of δ V in an increment of 0.1. The precision metric was chosen as the performance measure to evaluate the effectiveness of the methods. The optimal parameter values with the best results (the highest precision values) were chosen as the parameter settings of the proposed equations. Table 7.1 shows the performance of TP-V with different δ V value in terms of precision under various top-N supported documents. Observation: Table 7.1 shows that the average precision value of TP-V method with. δ V = 0.7 exceeds those with the other values. Meanwhile, while setting δ V = 0.7 in the given equation of TP-V method, it can achieve the best performance under Top-5, 30.
(39) Top-10, Top-15, or Top-20 document support. The TP-V method is increasing dramatically from δ V = 0 to 0.7 and is decreasing slightly from δ V = 0.7 to 1, as shown in Fig. 7.1. The experimental result reveals that self task profile is more important than the collaborative topic-variation profile in the TP-V method. Table 7.1 Effectiveness of TP-V method under various δ V values. δV 0. 0.1. 0.2. 0.3. 0.4. 0.5. 0.6. 0.7. 0.8. 0.9. 1. Top-5. 0.046. 0.185. 0.2. 0.215. 0.338. 0.338. 0.354. 0.369. 0.369. 0.338. 0.354. Top-10. 0.062. 0.138. 0.192. 0.292. 0.323. 0.362. 0.385. 0.408. 0.392. 0.385. 0.385. Top-15. 0.056. 0.138. 0.215. 0.262. 0.308. 0.354. 0.369. 0.385. 0.359. 0.359. 0.359. Top-20. 0.065. 0.146. 0.208. 0.258. 0.304. 0.362. 0.354. 0.358. 0.327. 0.323. 0.319. Average. 0.057. 0.152. 0.204. 0.257. 0.318. 0.354. 0.365. 0.380. 0.362. 0.351. 0.354. precision value. Top-N. 0.4 0.35 0.3 0.25 0.2 0.15 0.1 0.05 0 0. 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9. 1. δ value. Fig. 7.1 Result of knowledge support of TP-V under various δ V value. 7.2.2. Experiment 1-2: parameter selection for TP-D method This experiment aims to determine the value of parameter δ D in the TP-D method. TP-D method uses δ D to adjust the relative weight of self task profile and collaborative document profile. When δ D is set to 1, the TP-D method is equivalent to the TP method, which takes only the self task profile into account. When δ D is set to 0, it is equivalent to the collaborative document profile. The experiment was also conducted by systematically adjusting the value of δ D in an increment of 0.1. The. precision metric was chosen as the performance measure to evaluate the effectiveness of the methods. The optimal parameter values with the best results (the highest precision values) were chosen as the parameter settings of the proposed equations.. 31.
(40) Table 7.2 shows the performance of TP-D method with different δ D value in terms of precision under various top-N supported documents. Observation: Table 7.2 shows that the average precision value of TP-D method with. δ D = 0.5 has the best performance (i.e., precision value) than the other values. Interestingly, the result shows that if we set δ D = 0.5, δ D = 0.8, δ D = 0.9, or δ D = 1, they all have similar results. Thus, the curve of TP-D method shown in Fig. 7.2 is smooth and steady from δ V = 0.4 to 1. The result indicates the collaborative profile of. TP-D method has no significant influence to this experiment. We may take a further analysis in the Experiment 2. Table 7.2 Effectiveness of the TP-D method under various δ D values. δD 0. 0.1. 0.2. 0.3. 0.4. 0.5. 0.6. 0.7. 0.8. 0.9. 1. Top-5. 0.138. 0.231. 0.292. 0.323. 0.323. 0.338. 0.338. 0.338. 0.354. 0.354. 0.354. Top-10. 0.185. 0.262. 0.285. 0.346. 0.369. 0.385. 0.385. 0.392. 0.385. 0.385. 0.385. Top-15. 0.169. 0.231. 0.303. 0.354. 0.379. 0.369. 0.354. 0.354. 0.359. 0.359. 0.359. Top-20. 0.162. 0.25. 0.308. 0.331. 0.346. 0.331. 0.319. 0.319. 0.315. 0.315. 0.319. Average. 0.163. 0.243. 0.297. 0.338. 0.354. 0.356. 0.349. 0.351. 0.353. 0.353. 0.354. precision value. Top-N. 0.4 0.35 0.3 0.25 0.2 0.15 0.1 0.05 0 0. 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9. 1. δ value. Fig. 7.2 Result of knowledge support of TP-D under various δ D value. 7.2.3. Experiment 2: comparisons of self profile adaptation methods This experiment aims to compare the performance of task-relevant document support between the four methods: PP, PP-T, PP-P, and TP under various top-N supported documents. PP method is the baseline method as described in Section 7.1.1, which solely adjusts task profile based on the document profiles of documents accessed, but PP-T and PP-P methods consider the time factor and topic profiles respectively. The TP method is the self profile adaptation method which adjusts task 32.
(41) profile based on the document profile, topic profiles and time effect. Herein, Table 7.3 shows the performance of the four methods in terms of precision, recall and F-measure under various top-N documents. Observation 1: Table 7.3 and Fig. 7.3 shows that the average values of precision,. recall, and F-measure of proposed PP-T, PP-P, and TP methods are better than those of the baseline method, PP method, under various top-N retrievals. The result reveals that it is effective to consider the topic profiles and the time factor during the profile adaptation process. Observation 2: Fig. 7.3 shows the curve of each method under various top-N. supported documents. Notice that TP method is better than the PP-T and PP-P methods under various top-N supported documents. Consequently, the result implies that the TP method is more effective than the other three methods, by considering both the topic profiles and the time factor during the profile adaptation process. Table 7.3 Comparison between self profile adaptation methods method Top-N. PP method Pre. Re.. PP-T method. F.. Pre. Re.. PP-P method. TP method. F.. Pre.. Re.. F.. Pre.. Re.. F.. Top-5. 0.215. 0.030. 0.051. 0.246. 0.035. 0.060. 0.215. 0.022. 0.040. 0.354. 0.041. 0.073. Top-10. 0.215. 0.055. 0.085. 0.269. 0.068. 0.105. 0.262. 0.055. 0.090. 0.385. 0.092. 0.145. Top-15. 0.215. 0.083. 0.115. 0.277. 0.105. 0.146. 0.287. 0.097. 0.140. 0.359. 0.132. 0.186. Top-20. 0.204. 0.102. 0.129. 0.277. 0.138. 0.175. 0.277. 0.125. 0.166. 0.319. 0.155. 0.200. 0.212. 0.067. 0.095. 0.267. 0.086. 0.121. 0.260. 0.075. 0.109. 0.354. 0.105. 0.151. Average. 0.5 PP 0.4. PP-T PP-P. 0.3. TP 0.2. Top-5. Top-10. Top-15. Top-20. PP. 0.215. 0.215. 0.215. 0.204. PP-T. 0.246. 0.269. 0.277. 0.277. PP-P. 0.215. 0.262. 0.287. 0.277. TP. 0.354. 0.385. 0.359. 0.319. Fig. 7.3 Trends of retrieval effectiveness of the four methods under various top-N document support. 33.
數據




+7



相關文件
39 資訊與網路技術 佳作 李喬安 國立花蓮高級工業職業學校/勞動部勞動力發 展署桃竹苗分署. 39 資訊與網路技術 佳作
The underlying idea was to use the power of sampling, in a fashion similar to the way it is used in empirical samples from large universes of data, in order to approximate the
Context level: Teacher familiarizes the students with the writing topic/ background (through videos/ pictures/ pre- task).. Text level: Show a model consequential explanation
Using this formalism we derive an exact differential equation for the partition function of two-dimensional gravity as a function of the string coupling constant that governs the
Which of the following is used to report the crime of damaging the Great Wall according to the passage.
Proof. The proof is complete.. Similar to matrix monotone and matrix convex functions, the converse of Proposition 6.1 does not hold. 2.5], we know that a continuous function f
• Similar to futures options except that what is delivered is a forward contract with a delivery price equal to the option’s strike price.. – Exercising a call forward option results
• Similar to futures options except that what is delivered is a forward contract with a delivery price equal to the option’s strike price.. – Exercising a call forward option results
