國立高雄大學應用經濟學系研究所
碩士論文
央行干預下的匯率預測︰以美元兌新台幣與韓元為例
Exchange rate predictability under the central bank’s
intervention︰the cases of NTD and KRW
研究生︰曾靖尹 撰
指導教授︰柯秀欣 博士
央行干預下的匯率預測︰以美元兌新台幣與韓元為例
指導教授︰柯秀欣 博士 國立高雄大學應用經濟學系 學生︰曾靖尹 國立高雄大學應用經濟系研究所摘要
本文探討加入央行干預變數的匯率模型,是否能提升匯率變動的解釋能力與 預測能力。研究對象為美元兌新台幣與韓元,研究期間為1997 年 1 月到 2018 年 4 月共 256 筆月資料。並使用不同樣本外預測期間,以檢定加入央行干預變數的 匯率模型,對匯率變動的解釋能力是否提升。另外,利用Diebold–Mariano 檢定 加入央行干預變數的匯率模型其樣本外預測能力是否擊敗隨機漫步模型。 研究結果發現,加入央行干預變數的匯率模型,有助於提升以貨幣所得模型 為基礎之長期迴歸模型的解釋能力。一般情況下,隨機漫步模型的樣本外預測結 果優於其他模型,在部份情況下,考慮央行干預的匯率模型其樣本外預測結果能 優於隨機漫步模型,例如,美元兌韓元的匯率資料使用加入央行干預的貨幣所得 模型其預測能力較隨即漫步模型佳;美元兌新台幣的匯率資料使用加入央行干預 的隨機漫步模型其預測能力較其他匯率模型佳。 關鍵字︰央行干預、匯率預測、經濟基要、Diebold–Mariano 檢定Exchange rate predictability under the central bank’s
intervention︰the cases of NTD and KRW
Advisor︰Dr. Hsiu-Hsin Ko
Department of Applied Economics National University of Kaohsiung Student︰Ching-Yin Tseng
Department of Applied Economics National University of Kaohsiung
ABSTRACT
The goal of this study is to analyze whether adding the central bank intervention variable in the money-income model of the exchange rate will improve model’s explan-atory power and out-of-sample predictability against the random walk model. We use monthly data of USD/NTD and USD/KRW covering from 1997/1 to 2018/4. We test whether central bank intervention will improve explanatory power of exchange rate model at different forecast horizons. Also, we use Diebold–Mariano test to compare the out-of-sample predictability of the exchange rate model to that of the random walk model.
The results suggested that adding the central bank intervention variable in the long-run regression model based on the money-income model of the exchange rate improves model’s explanatory power. In most of the cases, the out-of-sample predictability of the random walk model is better than the other models. Only in few cases, the model’s of-sample predictability can beat that of the random walk model. Specifically, the out-of-sample predictability of the money-income model with the central bank intervention variable for the USD/KRW exchange rate could outperform the random walk model. In addition, the data of USD/NTD show that the out-of-sample predictability of the ran-dom walk model with the central bank intervention variable is better than the other models.
Keywords: Central Bank Intervention, Exchange Rate Forecast, Fundamentals,
i
目錄
目錄 ... i 表目錄 ... iii 第一章 緒論 ... 1 1.1 研究背景 ... 1 1.2 研究目的 ... 2 1.3 研究架構 ... 2 第二章 文獻回顧 ... 3 2.1 匯率預測 ... 3 2.2 央行干預 ... 7 第三章 研究方法 ... 9 3.1 資料恆定性檢定 ... 9 3.1.1 Augmented Dickey-Fuller 單根檢定 ... 9 3.1.2 Phillips-Perron 單根檢定... 10 3.2 貨幣所得模型(Money-Income Model) ... 11 3.3 匯率模型 ... 12 3.3.1 加入央行干預的隨機漫步模型 ... 12 3.3.2 加入央行干預的貨幣所得模型 ... 13 3.4 衡量模型的預測表現 ... 14 3.4.1 樣本外預測 ... 15 3.4.2 Diebold–Mariano 檢定 ... 16 第四章 研究結果 ... 18 4.1 資料說明 ... 18 4.2 單根檢定結果 ... 19 4.3 迴歸估計結果 ... 22 4.3.1 隨機漫步模型之迴歸估計結果 ... 22 4.3.2 貨幣所得模型之迴歸估計結果 ... 23 4.3.3 加入央行干預的隨機漫步模型之迴歸估計結果 ... 24 4.3.4 加入央行干預的貨幣所得模型之迴歸估計結果 ... 24 4.4 DM 檢定結果 ... 26 4.4.1 隨機漫步模型與貨幣所得模型之DM 檢定結果 ... 26 4.4.2 隨機漫步模型與加入央行干預的隨機漫步模型之DM 檢定結 果 ... 27 4.4.3 隨機漫步模型與加入央行干預的貨幣所得模型之DM 檢定結ii 果 ... 28 4.4.4 貨幣所得模型與加入央行干預的貨幣所得模型之DM 檢定結 果 ... 29 第五章 結論 ... 30 5.1 研究結果 ... 30 5.2 結果討論 ... 30 5.3 研究限制與建議 ... 32 參考文獻 ... 33 一. 國內文獻 ... 33 二. 國外文獻 ... 33
iii
表目錄
表4-2-1︰單根檢定結果 ... 20 表4-2-2︰一階差分後的單根檢定結果 ... 21 表4-3-1︰隨機漫步模型之迴歸估計結果 ... 22 表4-3-2︰貨幣所得模型之迴歸估計結果 ... 23 表4-3-3︰加入央行干預的隨機漫步模型之迴歸估計結果 ... 24 表4-3-4︰加入央行干預的貨幣所得模型之迴歸估計結果 ... 25 表4-4-1︰隨機漫步模型與貨幣所得模型之 DM 檢定結果 ... 26 表4-4-2︰隨機漫步模型與加入央行干預的隨機漫步模型之 DM 檢定結果 ... 27 表4-4-3︰隨機漫步模型與加入央行干預的貨幣所得模型之 DM 檢定結果 ... 28 表4-4-4︰貨幣所得模型與加入央行干預的貨幣所得模型之 DM 檢定結果 ... 291
第一章 緒論
1.1 研究背景自從1973 年布列敦森林體系(Bretton Woods System)瓦解之後,採取固定匯 率制度的國家也隨之減少,浮動匯率制度逐漸成為國際間的主流趨勢。在浮動 匯率制度下,匯率價格的決定取決於外匯市場的供給與需求,因此外匯市場具 備完全競爭市場的特徵,所有的市場參與者都為匯價接受者,單一參與者在外 匯市場中無足輕重,甚至就連一國也無法輕易地撼動匯率走勢。然而,看似運 作簡單的外匯市場,其匯率變動卻總讓外匯市場參與者們摸不著頭緒。
Meese and Rogoff(1983)比較多種模型的預測準確度後,發現隨機漫步模型 的預測能力優於經濟理論建構的模型,隱含匯率走勢無法預測。Obstfeld and Rogoff(2000)稱之為匯率分離謎題(Exchange Disconnect Puzzle),明確指出經濟 理論可以解釋匯率變動,卻無法預測匯率變動的脫鉤現象。Mark(1995)主張長 期匯率變動可以透過經濟理論來預測,但是短期仍沒有突破。從文獻回顧中我 們發現很可能有未考量到的干擾因素影響經濟基要在短期匯率預測的表現。 能夠影響短期匯率變動的因素眾多,舉凡近期的中美貿易戰、英國脫歐, 到前陣子的歐洲國債危機等發燒題材之外,還有重大經濟數據的公布、財政或 央行官員發表談話等等也能影響匯率走勢,其中最令我們感到好奇的就是央行 在外匯市場的干預政策,儘管如前段所述,央行身為外匯市場參與者之一,企 圖操作匯率走勢可謂蜉蝣撼樹之舉,但是與此同時,央行也身為一國貨幣供需 的掌控者,縱然沒有能夠與市場機制抗衡的力量,央行依然具備優於其他外匯 市場參與者的能力,因此我們認為將央行干預行為納入模型中考慮,不失為研 究匯率變動的一種方式。 央行干預常發生於開發中國家,特別是亞洲國家。依據美國《貿易便捷及 執行法》的定義,匯率操縱國須符合三項要件︰貿易逆差超過200 億美元、經 常帳順差超過GDP 三個百分比、單方面持續干預匯率。在美國財政部公布的
2 《美國主要貿易夥伴之外匯政策報告》中,中國、日本、南韓都常見於匯率操 縱國觀察名單中,而台灣也曾經在2016 年 4 月到 2017 年 10 月之間被列入觀察 名單中。 大部分國家的央行鮮少提供外匯干預的資料,這點跟央行的政策風格有所 關係。在1970 年代以前,國際主流的央行政策風格秉持不透明原則。1970 年 代到1990 年代間,由於理性預期理論的興起,學界開始提倡央行政策透明化 (Transpareny)。1990 年代至全球金融危機,國際主流的央行政策風格為央行應 具備可信度(Credibility)與獨立性(Independent),此期間以「通膨目標化」為政策 透明化的里程碑。爾後全球金融危機以來,儘管央行政策透明化後,依舊爆發 金融危機,促使國際反思央行應有限度的透明化,形成「前瞻性指引」等口頭 干預為現代主流的央行政策風格。 1.2 研究目的 由於在匯率預測文獻中鮮少將央行干預納入模型中考慮,所以本文參考 Levy-Yeyati(2013)估計央行干預變數的方式,探討在匯率模型中加入央行干預 變數是否能提升匯率變動的解釋能力與預測能力。此外,過往匯率預測文獻的 研究對象大多為已開發國家,然而央行干預盛行於開發中國家,因此我們選擇 台灣與韓國作為研究對象。 1.3 研究架構 第一章為緒論,說明本文的研究背景與目的。第二章為文獻回顧,分別針 對匯率預測與央行干預的文獻進行整理。第三章為研究方法,先透過單根檢定 檢查資料恆定性,再將央行干預變數納入模型後,使用最小平方法估計,並檢 定央行干預變是否具有解釋能力,以及利用DM 檢定衡量模型的樣本外預測準 確度是否具有優越性與統計顯著性。第四章為研究結果,第五章為本文之研究 結果與討論。
3
第二章 文獻回顧
2.1 匯率預測自1973 年布列頓森林體系(Bretton Woods System)瓦解,國際間盛行浮動匯 率制度後,匯率預測開始受到重視,可是學界普遍認為匯率是難以預測的,其 最主要原因為匯率與經濟基要(Fundamentals)的關聯性脫鉤,導致總體經濟變數 無法有效地用來預測匯率。此外,能夠影響匯率變動的因素與機制也過於複雜 以至於預測不易。
Meese and Rogoff(1983)比較各種匯率模型的樣本外預測準確度。利用隨機 漫步模型、遠期外匯模型、自我迴歸模型、貨幣結構模型等六種模型,資料期 間為1973 年 3 月到 1981 年 6 月的月資料,分別對美元兌英鎊、馬克、日幣、 美元貿易權重匯率共四種匯率,採取滾輪法(Rolling Regression)估計各模型的預 測值。將預測期數(Forecasting Horizon)劃分成 1、3、6、12 個月,並運用樣本 外預測計算出各期間的預測誤差作為衡量各模型的樣本外預測準確度的指標。 實證結果顯示隨機漫步模型的樣本外預測準確度優於其他以經濟理論為基礎的 模型,引申含意為匯率無法透過經濟變數來預測。由於該實證研究結果與經濟 理論相悖,Obstfeld and Rogoff(2000)稱此現象為匯率分離謎題(Exchange Discon-nect Puzzle)。
這促使後進學者為了解釋這項謎題而提出各方面的討論。一部分的文獻改 進計量方法來研究匯率變動的可預測性,Mark(1995)主張長期匯率可以透過經 濟基要來預測。運用長期迴歸檢定(Long-Horizon Regressions Test)1的概念,認
為匯率變動源自匯率與經濟基要的差異所致,當匯率偏離長期均衡時,將隨著 時間逐漸修正至由經濟基要所決定之長期均衡匯率。Mark(1995)建立向量誤差 修正模型(Vector Error Correction Model),資料期間為 1973 年 2 月到 1991 年 4 月的月資料,分別對美元兌法郎、馬克、日幣、加幣共四種匯率,使用拔靴重
1 長期迴歸檢定常用於金融領域中用來檢定市場是否具有效率。若檢定結果為缺乏效率的資產
4
抽法(Bootstrap Resampling Method)推論新的小樣本分配。將預測期數劃分成 1、4、8、12、16 個月,並使用 DM 檢定衡量模型的樣本外預測準確度。實證 結果顯示在長期匯率變動中包含著顯著的可預測部分,而短期匯率變動則為白 噪音(White Noise)。此外,向量誤差修正模型在更長期的樣本外預測準確度會 提高,且優於隨機漫步模型。這說明經濟基要在長期有助於預測匯率,但是在 短期則無幫助,短期匯率預測仍有待研究。 Kilian(1999)再度探討 Mark(1995)的研究,認為「向量誤差修正模型在更長 期的樣本外預測準確度會提高」這項結論有瑕疵,原因為長期迴歸檢定應用於 匯率變動的可預測性上可能存在由虛假迴歸(Spurious Regression)和小樣本偏誤 所產生嚴重的型Ⅰ誤差,進而無法拒絕短期匯率變動不可預測的虛無假設。然 而,此結果通常被解釋成長期匯率變動可以預測。Kilian(1999)主要依循 Mark(1995)的研究方法,另外採取新的拔靴重抽法來推論新的小樣本分配,最 後透過蒙地卡羅模擬(Monte Carlo Simulation)來衡量統計推論的穩健性(Robust-ness)。實證結果顯示向量誤差修正模型在更長期的樣本外預測準確度會保持不 變或降低。此外,實證研究中的向量誤差修正模型設定為線性模型,但是資料 生成過程(Data Generating Process)與線性模型卻出現不一致的檢定大小(Size)與 檢定力(Power),故 Kilian 認為應為非線性資料生成過程,且可能有模型假設錯 誤。若為非線性資料生成過程,則必須使用非線性模型和修改長期迴歸檢定來 推論匯率變動的可預測性。這結果暗示匯率變動或許呈現非線性走勢,匯率變 動的可預測性應以非線性模型和計量方法來研究。
另一部分的文獻則利用模型特性和統計性質來解釋匯率變動呈現隨機漫步 的可能原因,Engel and West(2005)主張匯率不能透過經濟基要來預測。利用資 產定價模型(Present-Value Asset Pricing Model),資料期間為 1974 年到 2001 年 的季資料,將經濟基要區分為可觀察之基要變數與不可觀察之衝擊變數,並透
5 過BN 分解2將匯率分解成當期與預期經濟基要的折現加總。實證結果顯示經濟 基要不可觀察之衝擊變數具有單根Ⅰ(1)的性質,且當經濟基要可觀察之基要變 數的折現因子趨近於一時,其恆常部分變動的變異數呈現發散,故恆常部分為 隨機趨勢,而短暫部分變動的變異數呈現收斂,故短暫部分為定態波動。由於 折現因子近似於一時,表示預期的經濟基要對匯率的解釋程度大於當期,也就 是經濟基要之恆常部分的重要度大於短暫部分,故匯率變動由恆常部分所決 定,呈現隨機漫步的走勢。 儘管支持匯率是可預測的相關文獻試圖找出突破匯率預測瓶頸的方法,如 Mark and Sul(2001),得到的結論為匯率在長期可以預測,在短期卻不能預 測。隱含經濟基要有助於長期匯率預測,但是在短期則效果不佳,凸顯出很可 能有未考量到的干擾因素影響經濟基要在短期匯率預測的表現。 為了探討潛在的干擾因素,我們必須先釐清匯率與經濟基要的關係。Engel and West(2005)提出匯率與經濟基要的關係為,經濟基要難以預測匯率,但是匯 率卻可以預測經濟基要。這項論點可由匯率與經濟基要的Granger 因果關係檢 定作為解釋,實證結果發現市場基要不會「Granger 影響」匯率,但是匯率 「Granger 影響」市場基要,其意涵為匯率的落後項可以為經濟基要的預測提供 所需要的資訊,表示現在的匯率變動是由未來的經濟基要變動所決定,且匯率 變動會領先經濟基要變動,所以匯率為經濟基要的領先指標,隱含匯率為影響 經濟基要的因素之一,這也是在現值資產定價模型中支持匯率可以用來預測經 濟基要的原理。由於匯率變動的速度較經濟基要快,才產生匯率似乎可以用來 預測經濟基要的結果,事實上在經濟理論中真正的因果關係是經濟基要會影響 匯率,隱含經濟基要為影響匯率的因素之一,這也是在誤差修正模型中支持經 濟基要可以用來預測長期匯率的原理。這項矛盾凸顯匯率與經濟基要之間缺乏 強力地關聯性,或者說兩者達到長期均衡狀態時所需的時間不一致,導致匯率 2
6
預測的困難度增加了。
除了變數之間的關聯性之外,模型設定也是值得探討的議題。傳統理論上 匯率模型多數為線性模型的討論,諸如上述文獻。匯率預測的研究亦朝向非線 性模型發展。Taylor and Peel(2000)研究匯率與經濟基要的長期均衡關係。使用 非線性的平滑轉換自我迴歸模型(Smooth Transition Autoregressive,STAR),研 究期間為1973 年第一季至 1996 年第四季,分別對美元兌英磅與馬克採用蒙地 卡羅模擬來建構擬真資料。實證結果顯示匯率偏離經濟基要所決定之均衡匯率 的修正過程中呈現非線性調整,且在非線性調整中均數復歸(Mean Reversion)3的
速度會隨著偏離均衡匯率的程度變大而增快。Taylor and Peel(2000)認為其原因 為投資者使用技術分析而不是總體經濟分析來預測匯率,將使匯率變動不會隨 著經濟基要變動而發生恆常性的調整,因此一般的線性模型觀察不到非線性的 動態調整。 傳統上的匯率模型通常只能針對單方面的因素提出解釋,例如購買力平 價、利率平價、國際收支、貨幣政策等由匯率決定理論所建立的匯率模型,發 展至今仍然沒有一個模型可以同時解釋各項影響匯率變動的因素。且研究對象 的選擇普遍以已開發國家為主,亦不足以概括解釋國際間的匯率走勢。此外, Cheung, Chinn, and Pascual(2005)也提到一個匯率模型或許可以完美解釋某一時 期的匯率走勢,但是可能並不適用於另一時期。諸多因素增加研究的侷限性, 更遑論精準地預測匯率的走勢。
3 均數復歸常見於金融領域中,由於資產價格不會無限制地上漲(下跌),當上漲(下跌)至一定幅
7
2.2 央行干預
依據《中央銀行年報》(2017 年版,頁 89)宣稱「本行採行管理浮動匯率制 度(managed floating regime),新台幣匯率原則上由外匯市場供需決定,如遇不 規則因素(如短期資金大量進出)及季節因素,導致匯率過度波動與失序變 動,而有不利於經濟與金融穩定之虞時,本行將本於職責維持外匯市場秩 序。」顯示央行將適時擔任協助修正匯率的角色,透過政策工具來縮小匯率變 動,以達成促進經濟成長與穩定物價的目標。 央行具有明顯地外匯干預行為,國內文獻的主流觀點認為央行主要採取逆 風干預且為偏好阻升的不對稱外匯干預政策(張興華,2013;陳旭昇,2016;柯 秀欣,2018)4。吳致寧等(2012)指出 1980 年到 1987 年採阻升政策,1987 年到 1997 年採阻貶政策,1997 年到 2010 年採均衡政策。陳旭昇(2019)認為 1998 年 到2010 年並非採均衡政策,應為阻升政策,因為對照外匯干預政策期間與外匯 存底變動,吳致寧等(2012)的結果無法解釋 1998 年以來外匯存底增加的現象, 而根據中央銀行損益表顯示造成外匯存底增加的主要原因是央行買匯。許嘉棟 (2015)亦指出 2000 年以後外匯存底增加的原因為央行沖銷不完全所致。 外匯干預政策對匯率波動的影響,文獻上並沒有共識。吳致寧等(2012)指 出1980 年到 1987 年的阻升政策與 1987 年到 1997 年的阻貶政策皆使匯率波動 加劇,1997 年到 2010 年與全樣本期間則使匯率波動縮小。陳旭昇與吳聰敏 (2008)提出阻升政策無法有效穩定匯率波動。柯秀欣(2018)亦發現央行逆風干預 對匯率波動無顯著的影響。 外匯干預政策對經濟成長的影響,文獻上分為兩派說法,一說為匯率低估 有利出口產業,進而促進經濟成長。王泓仁(2005)發現新台幣貶值對經濟成長 有正向影響。吳致寧等(2012)指出阻升政策對經濟成長有正向影響,阻貶政策 則不顯著。另一說為匯率低估不利產業升級,長期而言損害經濟成長。陳旭昇 4 阻升政策也稱為匯率貶值政策,亦是Levy-Yeyati et al.(2013)所稱的「害怕升值」現象。
8 與吳聰敏(2008)主張阻升政策對經濟成長無明顯影響。陳旭昇(2019)認為長期的 阻升政策對經濟成長為負向影響。 匯率預測的文獻指出考慮央行干預後有較好的預測表現。楊雅惠與許嘉棟 (2005)發現考慮央行干預的匯率模型具有較佳的匯率解釋與預測能力。然而, 將央行干預作為解釋變數的研究相對較少,主要由兩種原因所致,一方面為央 行通常不會公布有關外匯干預的相關資料,侷限匯率研究的發展;另一方面是 在缺乏實際資料的情況下,央行干預行為將難以衡量,文獻通常使用替代變數 (Proxy Variable)來估計央行干預行為,例如傳統文獻所使用的外匯存底與貨幣 供給,到近代受由於央行口頭干預(Verbal Intervention)興起而採用的媒體資料 等。 傳統文獻常將外匯存底視為央行干預替代變數,但是外匯存底的組成不全 然為央行干預而使用,使得如何透過外匯存底估計匯率變動更顯得重要。Levy-Yeyati(2013)為了去除外匯存底含有預防動機的成分,以及降低由央行干預方向 所引起的內生性問題,使用不含黃金的淨外國準備相對M2 貨幣供給的變動比 例作為央行干預的替代變數。Levy-Yeyati(2016)使用誤差修正模型,資料期間 為2003 年到 2011 年,分別對 18 個興新經濟體分析央行干預的有效性,實證結 果發現央行干預具有效性,能使實質匯率走勢趨向干預方向。 近代文獻亦使用媒體資料作為央行干預替代變數。張興華(2013)使用較簡 單的關鍵字搜尋有關央行干預的新聞。柯秀欣(2018)使用較嚴謹的關鍵字篩選 有關銀行業人士對央行干預外匯市場之觀點的新聞。兩者的研究結果均顯示央 行的干預方式主要為逆風干預且很少試圖扭轉走勢,表示干預目標為縮小匯率 變動幅度,符合《中央銀行年報》(2017 年版,頁 89)所宣稱。干預政策為偏好 阻升的不對稱干預,顯示央行意圖維持弱勢匯率以利出口產業發展。干預結果 大致與干預方向一致,顯示央行干預具有效性。
9
第三章 研究方法
本章分主要為四個部分,第一部分為單根檢定,檢驗資料是否具恆定性; 第二個部分為貨幣所得模型,由此模型推導出經濟基要與貨幣所得模型;第三 部分為匯率模型,將央行干預變數納入模型後,採用最小平方法(OLS)估計央行 干預變數,並檢定央行干預變數是否具有解釋能力;第四部分為DM 檢定,比 較模型的樣本外預測準確度否具優越性與統計顯著性。 3.1 資料恆定性檢定Granger and Newbold(1974)發現如果任意兩個不相干的變數皆具有隨機趨 勢,則估計時可能會產生相關性,稱其為虛假迴歸(surplus regression)。Nelson and Plosser(1982)進一步指出由於過去文獻認為去除固定趨勢後即為定態序列, 但是如果變數仍具有隨機趨勢,將導致研究產生模型設定錯誤,進而影響研究 結果的可信度。因此現今在實證研究前都必須優先檢查資料恆定性,務實作法 為透過單根檢定判斷資料是否具有單根。單根是指特性根方程式的其中一個特 性根為1,表示資料含有隨機趨勢。若資料具有單根,則為非定態序列,須要 差分後再分析;若不具有單根,則為定態序列,可以直接分析。下列介紹文獻 中常見的單根檢定,本文採用ADF 與 PP 兩種單根檢定。 3.1.1 Augmented Dickey-Fuller 單根檢定
Dickey and Fuller(1979)將一階自我迴歸模型重新參數化後,使用最小平方 法估計出參數,並對參數進行假設檢定,藉此判斷資料是否具有單根,稱之為 DF 檢定。然而,由於資料生成過程(Data Generating Process)的模式眾多,不只 有一階自我迴歸模型,如果迴歸估計後的誤差項具有序列相關,表示參數的迴 歸估計偏誤,此時DF 檢定的檢定力不足,以至於無法拒絕錯誤的虛無假設, 進而得出資料不具單根的錯誤結果。
10
為了改善DF 檢定的瑕疵,Said and Dickey(1984)在 DF 檢定的估計式中加 入被解釋變數的落後項後,使迴歸估計後的誤差項符合白噪音之性質,稱之為 ADF 檢定。下列為 ADF 檢定之模型︰ ∆𝑦𝑡 = 𝐶0+ 𝛼𝑡 + 𝛾𝑦𝑡−1+ ∑ 𝛿𝑖∆𝑦𝑡−𝑖+1 𝑝 𝑖=1 + 𝜀𝑡 (1) 𝐶0為截距項,𝑡為時間趨勢項,兩者須依照資料生成過程來決定是否加入。 Enders(2004,頁 213)建議先觀察資料的圖形走勢後,再透過他提供的步驟來決 定是否加入漂移項或時間趨勢項。∑𝑝𝑖=1𝛿𝑖∆𝑦𝑡−𝑖+1為增廣項,𝑝為落後期數,可 由AIC、SBC 或 HQC 等準則來協助判斷。𝜀𝑡為白噪音。 ADF 檢定的虛無假設為︰ 𝐻0︰𝛾 = 0 若檢定結果拒絕虛無假設,表示資料不具有單根,為定態序列;若無法拒 絕虛無假設,表示資料具有單根,為非定態序列,須要差分後再分析。 3.1.2 Phillips-Perron 單根檢定
儘管ADF 檢定改良 DF 檢定的瑕疵,但是 ADF 檢定亦有缺陷。由於 ADF 檢定利用增廣項來解決誤差項具有序列相關的問題,顯示ADF 檢定隱含迴歸估 計後的誤差項必須符合非序列相關與同質變異之基本假設,然而在未知資料性 質的情況下,不容易確保ADF 檢定結果的正確性。Phillips and Perron(1988)透 過無母數估計(Non-Parametric)來解決誤差項的潛在問題,並將誤差項具有序列 相關與異質變異納入考慮。此外,PP 檢定的估計式沿襲 DF 檢定所導出的分 配,因此具有相同臨界值,假設檢定之設定亦與DF 檢定、ADF 檢定相同。本 文使用ADF 檢定作為主要檢定依據,並使用 PP 檢定輔助說明檢定結果,屬於 文獻中較為務實的作法。
11 3.2 貨幣所得模型(Money-Income Model) 本節透過貨幣所得模型推導出經濟基要,下列為推導經濟基要的步驟︰ 步驟一. 考慮本國與外國的貨幣市場之供需函數︰ 𝑚𝑡 = 𝑝𝑡+ 𝛾𝑦𝑡− 𝛼𝑖𝑡 (2) 𝑚𝑡∗= 𝑝𝑡∗+ 𝛾𝑦𝑡∗− 𝛼𝑖𝑡∗ (3) 式(2)與式(3)分別為本國與外國貨幣市場之供需函數,本文假設本國為台灣 或韓國;假設外國為美國,並標記“ * ”以示區別。𝑚𝑡與𝑚𝑡∗分別為本國與外國貨 幣供給;𝑝𝑡與𝑝𝑡∗分別為本國與外國物價水準;𝑖 𝑡與𝑖𝑡∗分別為本國與外國的利率; 𝑦𝑡與𝑦𝑡∗分別為本國與外國的產出水準。𝛾為貨幣需求的所得彈性,且𝛾>0;𝛼為 貨幣需求之利率半彈性(semi-elasticity),且𝛼>0。 步驟二. 假設購買力平價成立︰ 𝑠𝑡= 𝑝𝑡− 𝑝𝑡∗ (4) 步驟三. 假設未拋補利率平價成立︰ 𝐸𝑡𝑠𝑡+1− 𝑠𝑡 = 𝑖𝑡− 𝑖𝑡∗ (5) 步驟四. 將式(2)與式(3)相減,並將式(4)與式(5)代入,可得到下列式(6)︰ 𝑠t = 1 1 + 𝛼[(𝑚𝑡− 𝑚𝑡 ∗) − 𝛾(𝑦 𝑡− 𝑦𝑡∗)] + 𝛼 1 + 𝛼[𝐸𝑡𝑠𝑡+1] (6) 式(6)為貨幣所得之匯率模型。其中,經濟基要可觀察的部分為(𝑚𝑡− 𝑚𝑡∗) 與(𝑦𝑡− 𝑦𝑡∗);經濟基要不可觀察的部分為𝐸𝑡𝑠𝑡+1。依據經濟直覺,當國內貨幣供 給高於國外時,本國貨幣將傾向貶值;當國內產出高於國外時,由於本國貨幣 需求相對增加,使本國貨幣購買力提升,本國貨幣將傾向升值。 步驟五. 假設貨幣需求的所得彈性𝛾為 1,可得到經濟基要為下列式(7)︰ 𝑓𝑡 = (𝑚𝑡− 𝑚𝑡∗) − (𝑦𝑡− 𝑦𝑡∗) (7)
12 3.3 匯率模型 本節考慮不具經濟意涵的隨機漫步模型,以及由經濟理論建構的貨幣所得 模型來代表解釋匯率變動的模型,分別加入央行干預變數後,檢定央行干預對 匯率變動的解釋能力與比較各模型的預測能力。 3.3.1 加入央行干預的隨機漫步模型 模型探討隨機漫步模型加入央行干預變數後,是否能影響匯率變動。下列 為加入央行干預的隨機漫步模型︰ 𝑠𝑡+𝑘− 𝑠𝑡= 𝐶𝑘+ ∅𝑘𝐼𝑁𝑇𝑡+ 𝜀𝑡+𝑘 (8) 𝐼𝑁𝑇𝑡= (𝑅 𝑀)𝑡− ( 𝑅 𝑀)𝑡−1 (9) 𝑘 ∈ { 1,3,6,12 } 𝑘為預測期數,設定為 1、3、6、12 個月。𝑠𝑡+𝑘為名目匯率在第𝑡 + 𝑘期的自 然對數值,𝑠𝑡為名目匯率在第𝑡期的自然對數值,故左式𝑠𝑡+𝑘− 𝑠𝑡為未來𝑘期後的 名目匯率變動。𝐶𝑘為漂移項。𝐼𝑁𝑇𝑡∗為央行干預變數,為當期與前1 期的國際準 備占貨幣供給比例之差異,其中R 為總外匯準備不含黃金,M 為 M2 貨幣供 給。𝜀𝑡+𝑘為誤差項。
採用最小平方法(The Method of Least Square, LS)估計央行干預之係數∅𝑘。 為了檢定央行干預是否能解釋匯率變動,下列為假設檢定︰ 𝐻0︰∅𝑘 = 0 𝐻1︰∅𝑘 ≠ 0 若無法拒絕虛無假設𝐻0,表示央行干預不會影響匯率變動,即央行干預不 能解釋匯率變動;若拒絕虛無假設𝐻0,則𝐻1成立時,表示央行干預會影響匯率 變動,即央行干預能解釋匯率變動。
13 3.3.2 加入央行干預的貨幣所得模型 模型探討加入央行干預變數後的貨幣所得模型,是否能影響匯率變動。下 列為加入央行干預的貨幣所得模型︰ 𝑠𝑡+𝑘− 𝑠𝑡 = 𝐶𝑘+ 𝛽𝑘𝑍𝑡+ ∅𝑘𝐼𝑁𝑇𝑡+ 𝜀𝑡+𝑘 (10) 𝑍𝑡 ≡ 𝑠𝑡− 𝑓𝑡且𝑓𝑡 = (𝑚𝑡− 𝑚𝑡∗) − (𝑦𝑡− 𝑦𝑡∗) (7) 𝐼𝑁𝑇𝑡= ( 𝑅 𝑀)𝑡 − (𝑅 𝑀)𝑡−1 (9) 𝑘 ∈ { 1,3,6,12 } 𝑘為預測期數,設定為 1、3、6、12 個月。𝑠𝑡+𝑘為名目匯率在第𝑡 + 𝑘期的自 然對數值,𝑠𝑡為名目匯率在第𝑡期的自然對數值,故左式𝑠𝑡+𝑘− 𝑠𝑡為未來𝑘期後的 名目匯率變動。𝐶𝑘為漂移項。𝑍𝑡為誤差修正項(Error Correction),為第𝑡期名目 匯率偏離其經濟基要的值;𝑓𝑡為兩國貨幣供給差異與產出缺口的差異比例,𝑚𝑡 為M2 貨幣供給,𝑦𝑡為工業生產指數。𝐼𝑁𝑇𝑡∗為央行干預變數,為當期與前1 期 的國際準備占貨幣供給比例之差異,其中𝑅為總外匯準備不含黃金,𝑀為 M2 貨 幣供給。𝜀𝑡+𝑘為誤差項。 誤差修正項的經濟意義為,當誤差修正項的係數為正時(𝑍𝑡> 0),表示當 期名目匯率高於其經濟基要所決定的均衡匯率(𝑠𝑡> 𝑓𝑡),則預期在未來𝑘期後, 當期名目匯率會下降修正到長期均衡匯率(𝑠𝑡→ 𝑠𝑡+𝑘 = 𝑓𝑡)。此時,當誤差修正 項增加時,將使匯率下降(本國貨幣升值,外國貨幣貶值)。
採用最小平方法(The Method of Least Square, LS)估計誤差修正項之係數 𝛽𝑘。為了檢定誤差修正項是否能解釋匯率變動,下列為假設檢定︰ 𝐻0︰𝛽𝑘= 0 𝐻1︰𝛽𝑘 ≠ 0 若無法拒絕虛無假設𝐻0時,表示誤差修正項不會影響匯率變動,匯率變動 將偏離經濟基要;若拒絕虛無假設𝐻0,則𝐻1成立時,表示誤差修正項會影響匯 率變動,即匯率變動將修正至由經濟基要決定的長期均衡匯率。
14 3.4 衡量模型的預測表現 本節介紹預測誤差作為衡量模型預測表現的指標。下列為計算模型預測誤 差的步驟與算法︰ 一. 給定預測值為從某一個時間序列模型的預測︰ 𝐸(𝑦𝑡+𝑘) = [1 0 ⋯ 0]Φ𝑘𝑌 𝑡 二. 定義預測損失(Forecasting Errors)為預測值與實際值之間的差異︰ 𝑒𝑡+𝑘,𝑡 = 𝑦𝑡+𝑘− 𝐸(𝑦𝑡+𝑘) 三. 定義預測損失函數為𝐿(𝑒𝑡+𝑘,𝑡),依照計算方法區分為下列三種函數形式︰ 𝐿(𝑒𝑡+𝑘,𝑡) = { (𝑒𝑡+𝑘,𝑡)2 二次函數法 |𝑒𝑡+𝑘,𝑡| 絕對函數法 𝑢(𝑒𝑡+𝑘,𝑡) 效用函數法 四. 預期預測損失函數為𝐸[𝐿(𝑒𝑡+𝑘,𝑡)],依照函數形式區分如下︰ A. 採用二次函數法計算的預期預測損失函數稱為均方差(MSE)和均方差 平方根(RMSE)︰ 𝑀𝑆𝐸 = 𝐸[𝐿(𝑒𝑡+𝑘,𝑡)] = 𝐸 [(𝑒𝑡+𝑘,𝑡)2] 𝑅𝑀𝑆𝐸 = √𝐸[𝐿(𝑒𝑡+𝑘,𝑡)] = √𝐸 [(𝑒𝑡+𝑘,𝑡)2] B. 採用絕對函數法計算的預期預測損失函數稱為絕對均差(MAE)︰ 𝑀𝐴𝐸 = 𝐸[𝐿(𝑒𝑡+𝑘,𝑡)] = 𝐸[|𝑒𝑡+𝑘,𝑡|] 假設有兩個時間序列模型A 與模型 B,可以分別計算出預期預測損失為 𝐸[𝐿(𝑒𝑡+𝑘,𝑡𝐴 )]與𝐸[𝐿(𝑒𝑡+𝑘,𝑡𝐵 )]。當模型預測損失越低,則該模型的預測準確度越 高,例如當𝐸[𝐿(𝑒𝑡+𝑘,𝑡𝐴 )] < 𝐸[𝐿(𝑒𝑡+𝑘,𝑡𝐵 )]時,則稱模型 A 相較於模型 B 具有較高 的預測準確度。一般而言最常使用的為均方差(MSE),故本文使用二次函數 法,也就是當𝑀𝑆𝐸𝐴 < 𝑀𝑆𝐸𝐵時,則稱模型A 相較於模型 B 具有較高的預測準確 度。
15 3.4.1 樣本外預測 在使用DM 檢定之前,需要先透過樣本外預測來重新分配樣本資料。樣本 外預測的操作方法為依照研究者選取的預測期數,將原始資料拆解成「樣本 內」與「樣本外」兩個部分,利用樣本內資料(拆解後的已知資料)在實證模型 中估計出預測值,再對比樣本外資料(拆解後假裝成的未知資料)計算出預測誤 差,藉此評估模型的預測準確度。樣本外預測有兩項優點,一方面可以提升研 究的速度,研究者不必確實地等待到預測時間發生就能透過實際資料來檢驗預 測成效,另一方面可以增加研究的嚴謹程度,避免模型出現過度配適(Over Fit) 的現象。 本文的原始資料共有256 筆月資料,將資料依照 5 年、10 年、15 年的期 間,分別選取60 筆、120 筆、180 筆月資料作為樣本外資料。扣除選取的資料 後,剩餘的資料則作為樣本內資料。由於模型設定1、3、6、12 個月的預測期 數,故樣本外資料的筆數會受到模型設定的預測期數影響,而分別再減少1、 3、6、12 筆資料。
16 3.4.2 Diebold–Mariano 檢定 本文採用DM 檢定來比較隨機漫步模型、加入央行干預的隨機漫步模型、 貨幣所得模型、加入央行干預的貨幣所得模型共四種模型的樣本外預測準確 度,由於DM 檢定只能選取兩個模型作為檢定對象,因此我們挑選任意兩種模 型進行檢定且不能重複檢定。為了清楚地呈現檢定結果,我們給定模型A 為隨 機漫步模型或貨幣所得模型,給定模型B 為貨幣所得模型或加入央行干預的隨 機漫步模型與貨幣所得模型,將DM 檢定分成四組進行,依序為隨機漫步模型 與貨幣所得模型、隨機漫步模型與加入央行干預的隨機漫步模型、隨機漫步模 型與加入央行干預的貨幣所得模型、貨幣所得模型與加入央行干預的貨幣所得 模型。 建立假設檢定︰ 𝐻0︰𝐸[𝐿(𝑒𝑡+𝑘,𝑡𝐴 )] − 𝐸[𝐿(𝑒𝑡+𝑘,𝑡𝐵 )] = 0 𝐻1︰𝐸[𝐿(𝑒𝑡+𝑘,𝑡𝐴 )] − 𝐸[𝐿(𝑒𝑡+𝑘,𝑡𝐵 )] ≠ 0 當𝐻0成立時,表示模型A 的預測準確度與模型 B 的預測準確度相等;當𝐻1 成立時,表示模型A 的預測準確度與模型 B 的預測準確度不相等,則出現兩種 結果,若𝑑𝑡 > 0,表示模型 A 的預測誤差大於模型 B,B 模型的預測能力較 佳;若𝑑𝑡 < 0,表示模型 A 的預測誤差小於模型 B,A 模型的預測能力較佳。 令︰ 𝑑𝑡 = 𝐿(𝑒𝑡+𝑘,𝑡𝐴 ) − 𝐿(𝑒 𝑡+𝑘,𝑡𝐵 ) = (𝑒𝑡+𝑘,𝑡𝐴 ) 2 − (𝑒𝑡+𝑘,𝑡𝐵 )2 其中𝑑𝑡為兩個模型的均方差之差(本文𝑑𝑡採用二次函數法計算)。 且 𝑑̅ = 1 𝑇∑ 𝑑𝑡 𝑇 𝑡=1 = 1 𝑇∑ 𝐿(𝑒𝑡+𝑘,𝑡 𝐴 ) − 𝐿(𝑒 𝑡+𝑘,𝑡𝐵 ) 𝑇 𝑡=1 = 1 𝑇∑(𝑒𝑡+𝑘,𝑡 𝐴 )2− (𝑒 𝑡+𝑘,𝑡𝐵 ) 2 𝑇 𝑡=1 其中𝑑̅為兩個模型的均方差之差的樣本平均。
17 Diebold–Mariano(1995)提出 DM 統計量,其作為評估兩種模型之間的預測 準確度是否具有統計顯著性,說明如下︰ 𝐷𝑀 = 𝑑̅ √ 𝐺̂ 𝑇 − 1 ~𝑡(𝑇 − 1), 𝐺̂ = 𝛾̂(0) + 2 ∑ 𝛾̂(𝑗) 𝑚 𝑗=1 , 其中𝛾̂(𝑗)為𝑗階自我共變異數,𝛾(𝑗) = 𝐶𝑜𝑣(𝑑𝑡, 𝑑𝑡−𝑗)的一致性估計式5。 當樣本很大時,DM 統計量的極限分配為標準常態分配。 𝐷𝑀→ 𝑁(0,1) 𝑑 陳旭昇(2013)在《時間序列分析》提到務實做法為將𝑑𝑡對常數項做簡單迴
歸,利用Newey and West(1987)提出的 HAC 標準差所得到的 t 統計量,即為
DM 統計量。 本研究使用eviews 軟體計算 DM 統計量,其算式如下︰ 𝐷𝑀𝑠𝑡𝑎𝑡𝑖𝑠𝑡𝑖𝑐 = 𝑑̅ √𝑉(𝑑) 𝑇 ~𝑁(0, 1), 其中𝑉(𝑑)為𝑑的變異數。 5 由於一致性估計式具有大樣本性質,因此當樣本增加時,估計值會趨近於母體參數真值的機 率提高。
18
第四章 研究結果
4.1 資料說明本文的資料期間為1997 年 1 月到 2018 年 4 月,共計 256 筆月資料。資料 選取的對象為台灣、韓國、及美國。資料來源為國際貨幣組織(International Monetary Fund,IMF) 所出版的國際金融統計資料庫(International Financial Statistics,IFS)與聖路易斯聯邦儲備銀行(Federal Reserve Bank of ST.Louis) 所 維護的美聯儲經濟數據庫(Federal Reserve Economic Data,FRED),絕大多數的 資料都可以從上述兩個資料庫中取得,除了一部分台灣的資料來源為行政院主 計總處所整理的中國民國統計資訊網之總體統計資料庫,與一部分韓國的資料 來源為南韓國家統計局(The Statistics Korea)。
本文所討論的名目匯率為直接匯率,表示以外國貨幣作為基準,計算一單 位的外國貨幣可以等價兌換成多少單位的本國貨幣。依據本文的實證模型與蒐 集資料所推導,將本國設定為台灣與韓國,外國設定為美國。其他變數的詳細 說明分別如下︰
A. 名目匯率(Nominal Exchange Rate)
資料來源為中華民國統計資訊網的我國與主要貿易對手通貨對美元之匯 率。將原始資料取自然對數再乘100%,以比率來表示。 B. 央行干預(Intervention) 央行干預參考Levy-Yeyati(2013)的估計方法,為𝐼𝑁𝑇𝑡 = ( 𝑅 𝑀)𝑡− ( 𝑅 𝑀)𝑡−1 C. 經濟基要(Fundamentals) 經濟基要從貨幣所得模型推導而來,為𝑓𝑡 = (𝑚𝑡− 𝑚𝑡∗) − (𝑦𝑡− 𝑦𝑡∗) D. 貨幣供給(Money) 本文使用M2 貨幣供給,資料來源為中華民國統計資訊網、ST.Louis FED、南韓國家統計局。將原始資料整理成百萬美元後,取自然對數再乘 100%,以比率來表示。
19
E. 工業生產指數(Industrial Production Index)
本文使用工業生產指數作為產出的替代變數。資料來源為中華民國統計資 訊網、ST.Louis FED、IFS。將原始資料取自然對數再乘 100%,以比率來 表示。
F. 總外匯準備不含黃金(Total Reserves excluding Gold)
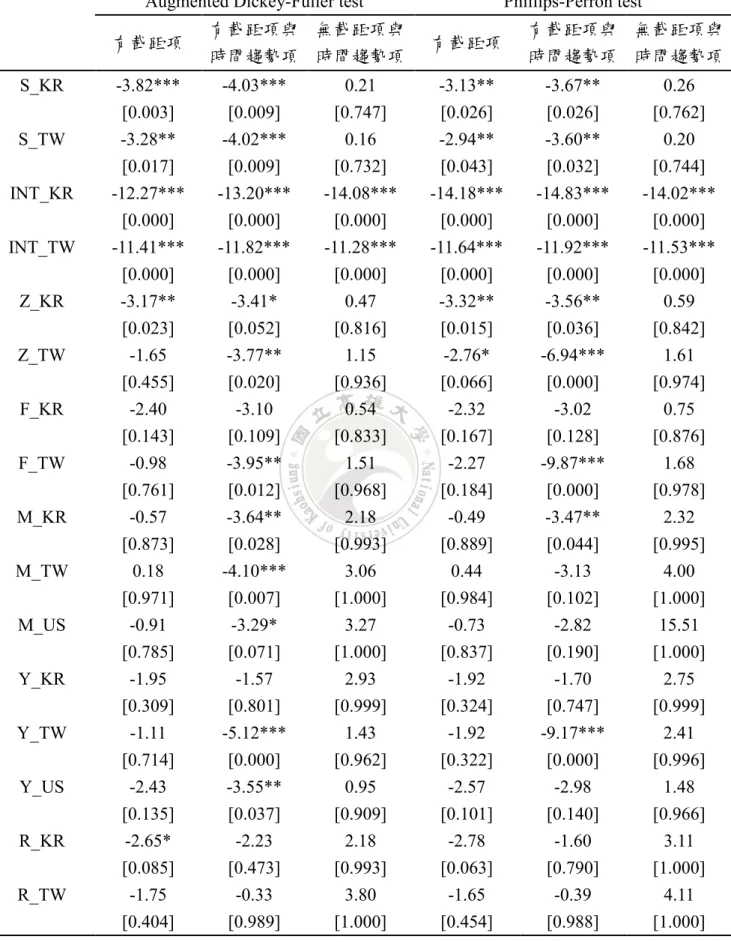
本文使用總外匯準備不含黃金作為外匯存底的替代變數。資料來源為中華 民國統計資訊網、ST.Louis FED、IFS。將原始資料整理成百萬美元後,取 自然對數再乘100%,以比率來表示。 4.2 單根檢定結果 表4-2-1 為單根檢定結果,ADF 檢定與 PP 檢定設定在有截距項的情況下, 除了台灣與韓國的名目匯率、央行干預,韓國的誤差修正項、總外匯準備不含 黃金,拒絕序列為非定態的虛無假設之外,其餘皆無法拒絕序列為非定態的虛 無假設。 表4-2-2 為一階差分後的單根檢定結果,ADF 檢定與 PP 檢定設定在有截距 項的情況下,所有變數皆能拒絕序列為非定態的虛無假設。
20
表4-2-1︰單根檢定結果
Augmented Dickey-Fuller test Phillips-Perron test 有截距項 有截距項與 時間趨勢項 無截距項與 時間趨勢項 有截距項 有截距項與 時間趨勢項 無截距項與 時間趨勢項 S_KR -3.82*** -4.03*** 0.21 -3.13** -3.67** 0.26 [0.003] [0.009] [0.747] [0.026] [0.026] [0.762] S_TW -3.28** -4.02*** 0.16 -2.94** -3.60** 0.20 [0.017] [0.009] [0.732] [0.043] [0.032] [0.744] INT_KR -12.27*** -13.20*** -14.08*** -14.18*** -14.83*** -14.02*** [0.000] [0.000] [0.000] [0.000] [0.000] [0.000] INT_TW -11.41*** -11.82*** -11.28*** -11.64*** -11.92*** -11.53*** [0.000] [0.000] [0.000] [0.000] [0.000] [0.000] Z_KR -3.17** -3.41* 0.47 -3.32** -3.56** 0.59 [0.023] [0.052] [0.816] [0.015] [0.036] [0.842] Z_TW -1.65 -3.77** 1.15 -2.76* -6.94*** 1.61 [0.455] [0.020] [0.936] [0.066] [0.000] [0.974] F_KR -2.40 -3.10 0.54 -2.32 -3.02 0.75 [0.143] [0.109] [0.833] [0.167] [0.128] [0.876] F_TW -0.98 -3.95** 1.51 -2.27 -9.87*** 1.68 [0.761] [0.012] [0.968] [0.184] [0.000] [0.978] M_KR -0.57 -3.64** 2.18 -0.49 -3.47** 2.32 [0.873] [0.028] [0.993] [0.889] [0.044] [0.995] M_TW 0.18 -4.10*** 3.06 0.44 -3.13 4.00 [0.971] [0.007] [1.000] [0.984] [0.102] [1.000] M_US -0.91 -3.29* 3.27 -0.73 -2.82 15.51 [0.785] [0.071] [1.000] [0.837] [0.190] [1.000] Y_KR -1.95 -1.57 2.93 -1.92 -1.70 2.75 [0.309] [0.801] [0.999] [0.324] [0.747] [0.999] Y_TW -1.11 -5.12*** 1.43 -1.92 -9.17*** 2.41 [0.714] [0.000] [0.962] [0.322] [0.000] [0.996] Y_US -2.43 -3.55** 0.95 -2.57 -2.98 1.48 [0.135] [0.037] [0.909] [0.101] [0.140] [0.966] R_KR -2.65* -2.23 2.18 -2.78 -1.60 3.11 [0.085] [0.473] [0.993] [0.063] [0.790] [1.000] R_TW -1.75 -0.33 3.80 -1.65 -0.39 4.11 [0.404] [0.989] [1.000] [0.454] [0.988] [1.000] 註1︰*表示 10%顯著水準之下顯著;**表示 5%顯著水準之下顯著;***表示 1%顯著水準之下顯著。 註2︰ADF 檢定之落後期採用 SBC 準則判斷出最適落後期;變數旁橫列為統計量;[ ]內為 P 值。
21
表4-2-2︰一階差分後的單根檢定結果
Augmented Dickey-Fuller test Phillips-Perron test 有截距項 有截距項與 時間趨勢項 無截距項與 時間趨勢項 有截距項 有截距項與 時間趨勢項 無截距項與 時間趨勢項 d(S_KR) -11.56*** -11.58*** -11.58*** -8.85*** -8.84*** -8.88*** [0.000] [0.000] [0.000] [0.000] [0.000] [0.000] d(S_TW) -10.69*** -10.77*** -10.71*** -10.47*** -10.50*** -10.49*** [0.000] [0.000] [0.000] [0.000] [0.000] [0.000] d(INT_KR) -10.29*** -10.30*** -10.31*** -135.89*** -134.63*** -136.73*** [0.000] [0.000] [0.000] [0.000] [0.000] [0.000] d(INT_TW) -10.60*** -10.59*** -10.63*** -98.28*** -98.74*** -98.70*** [0.000] [0.000] [0.000] [0.000] [0.000] [0.000] d(Z_KR) -12.19*** -12.20*** -12.19*** -11.29*** -11.31*** -11.29*** [0.000] [0.000] [0.000] [0.000] [0.000] [0.000] d(Z_TW) -4.72*** -4.75*** -4.57*** -29.21*** -30.10*** -27.98*** [0.000] [0.001] [0.000] [0.000] [0.000] [0.000] d(F_KR) -12.62*** -12.63*** -12.61*** -14.36*** -14.44*** -14.22*** [0.000] [0.000] [0.000] [0.000] [0.000] [0.000] d(F_TW) -4.37*** -4.36*** -4.03*** -41.05*** -41.58*** -37.32*** [0.000] [0.003] [0.000] [0.000] [0.000] [0.000] d(M_KR) -8.86*** -8.85*** -8.52*** -10.07*** -10.04*** -10.04*** [0.000] [0.000] [0.000] [0.000] [0.000] [0.000] d(M_TW) -11.05*** -11.06*** -10.44*** -10.64*** -10.60*** -10.40*** [0.000] [0.000] [0.000] [0.000] [0.000] [0.000] d(M_US) -3.53*** -3.61** -1.10 -16.33*** -16.33*** -13.07*** [0.008] [0.031] [0.247] [0.000] [0.000] [0.000] d(Y_KR) -15.79*** -15.87*** -15.29*** -15.80*** -15.87*** -15.40*** [0.000] [0.000] [0.000] [0.000] [0.000] [0.000] d(Y_TW) -4.08*** -4.07*** -3.78*** -34.18*** -34.23*** -33.61*** [0.001] [0.008] [0.000] [0.000] [0.000] [0.000] d(Y_US) -4.05*** -4.02*** -3.93*** -14.26*** -14.29*** -14.07*** [0.001] [0.009] [0.000] [0.000] [0.000] [0.000] d(R_KR) -6.08*** -6.40*** -5.56*** -9.39*** -9.62*** -8.82*** [0.000] [0.000] [0.000] [0.000] [0.000] [0.000] d(R_TW) -8.49*** -8.70*** -5.57*** -8.59*** -8.78*** -7.31*** [0.000] [0.000] [0.000] [0.000] [0.000] [0.000] 註1︰*表示 10%顯著水準之下顯著;**表示 5%顯著水準之下顯著;***表示 1%顯著水準之下顯著。 註2︰ADF 檢定之落後期採用 SBC 準則判斷出最適落後期;變數旁橫列為統計量;[ ]內為 P 值。
22 4.3 迴歸估計結果 4.3.1 隨機漫步模型之迴歸估計結果 表4-3-1 為隨機漫步模型的樣本內估計結果。不論在韓國或台灣方面,漂 移項對匯率變動的影響均不顯著。 表4-3-1︰隨機漫步模型之迴歸估計結果 國家 期數 變數 係數 標準差 t 統計量 P 值 R2 修正R2 韓國 1 C 0.09 0.22 0.40 0.688 0.000 0.000 3 C 0.25 0.49 0.51 0.611 0.000 0.000 6 C 0.49 0.69 0.71 0.481 0.000 0.000 12 C 0.79 0.94 0.84 0.401 0.000 0.000 台灣 1 C 0.03 0.08 0.32 0.747 0.000 0.000 3 C 0.08 0.18 0.41 0.680 0.000 0.000 6 C 0.16 0.27 0.60 0.549 0.000 0.000 12 C 0.21 0.39 0.54 0.588 0.000 0.000 註︰*表示 10%顯著水準之下顯著;**表示 5%顯著水準之下顯著;***表示 1%顯著水準之下顯著。
23 4.3.2 貨幣所得模型之迴歸估計結果 表4-3-2 為貨幣所得模型的樣本內估計結果。在韓國方面,當預測期數為 1、3、6、12 個月時,誤差修正項對匯率變動皆呈現顯著的負向影響,其經濟 意義為當期匯率低於由經濟基要所決定的均衡匯率,當期匯率在未來1、3、 6、12 個月將向上修正至均衡匯率,故匯率上升(韓元貶值、美元升值)。 在台灣方面,當預測期數為1、3、6、12 個月時,誤差修正項對匯率變動 呈現顯著的負向影響,其經濟意義為當期匯率低於由經濟基要所決定的均衡匯 率,在未來1、3、6、12 個月將向上修正至均衡匯率,故匯率上升(韓元貶值、 美元升值)。 表4-3-2︰貨幣所得模型之迴歸估計結果 國家 期數 變數 係數 標準差 t 統計量 P 值 R2 修正R2 韓國 1 Z -0.03*** 0.01 -3.27 0.001 0.040 0.037 C 24.08*** 7.35 3.28 0.001 3 Z -0.11*** 0.02 -6.12 0.000 0.130 0.127 C 93.32*** 15.20 6.14 0.000 6 Z -0.20*** 0.02 -8.63 0.000 0.231 0.228 C 174.49*** 20.17 8.65 0.000 12 Z -0.35*** 0.03 -12.42 0.000 0.389 0.387 C 304.97*** 24.51 12.44 0.000 台灣 1 Z -0.01*** 0.00 -2.79 0.006 0.030 0.026 C 4.67*** 1.67 2.80 0.006 3 Z -0.03*** 0.01 -4.66 0.000 0.080 0.076 C 16.61*** 3.55 4.67 0.000 6 Z -0.06*** 0.01 -6.69 0.000 0.153 0.150 C 34.37*** 5.12 6.72 0.000 12 Z -0.11*** 0.01 -8.31 0.000 0.222 0.219 C 58.81*** 7.06 8.33 0.000 註︰*表示 10%顯著水準之下顯著;**表示 5%顯著水準之下顯著;***表示 1%顯著水準之下顯著。
24 4.3.3 加入央行干預的隨機漫步模型之迴歸估計結果 表4-3-3 為加入央行干預的隨機漫步模型之樣本內估計結果。在隨機漫步 模型中加入央行干預的情況下,在韓國方面,當預測期數為1 個月時,央行干 預對匯率變動的影響不顯著。當預測期數為3、6、12 個月時,央行干預對匯率 變動呈現顯著的負向影響。 在台灣方面,當預測期數為1 個月時,央行干預對匯率變動呈現顯著的正 向影響。當預測期數為3、6 個月時,央行干預對匯率變動的影響不顯著。當預 測期數為12 個月時,央行干預對匯率變動呈現顯著的負向影響。 表4-3-3︰加入央行干預的隨機漫步模型之迴歸估計結果 國家 期數 變數 係數 標準差 t 統計量 P 值 R2 修正R2 韓國 1 INT -32.21 57.38 -0.56 0.575 0.001 -0.003 C 0.09 0.23 0.42 0.674 3 INT -393.85*** 122.28 -3.22 0.001 0.040 0.036 C 0.39 0.48 0.80 0.422 6 INT -504.09*** 173.83 -2.90 0.004 0.033 0.029 C 0.69 0.69 1.01 0.315 12 INT -598.73*** 224.92 -2.66 0.008 0.029 0.025 C 0.78 0.90 0.87 0.385 台灣 1 INT 39.39* 20.57 1.92 0.057 0.014 0.010 C 0.00 0.08 0.05 0.958 3 INT 45.10 45.18 1.00 0.319 0.004 0.000 C 0.05 0.18 0.26 0.795 6 INT -38.99 67.52 -0.58 0.564 0.001 -0.003 C 0.18 0.28 0.65 0.517 12 INT -172.66* 92.38 -1.87 0.063 0.014 0.010 C 0.23 0.38 0.60 0.551 註︰*表示 10%顯著水準之下顯著;**表示 5%顯著水準之下顯著;***表示 1%顯著水準之下顯著。 4.3.4 加入央行干預的貨幣所得模型之迴歸估計結果 表4-3-4 為加入央行干預的貨幣所得模型的樣本內估計結果。在貨幣所得 模型中加入央行干預的情況下,在韓國方面,當預測期數為1、3、6、12 個月
25 時,誤差修正項對匯率變動呈現顯著的負向影響。當預測期數為1 個月時,央 行干預對匯率變動的影響不顯著,當預測期數為3、6、12 個月時,央行干預對 匯率變動呈現顯著的負向影響。 在台灣方面,當預測期數為1、3、6、12 個月時,誤差修正項對匯率變動 呈現顯著的負向影響。當預測期數為1 個月時,央行干預對匯率變動呈現顯著 的正向影響。當預測期數為3、6 個月時,央行干預對匯率變動的影響不顯著。 當預測期數為12 個月時,央行干預對匯率變動呈現顯著的負向影響。 表4-3-4︰加入央行干預的貨幣所得模型之迴歸估計結果 國家 期數 變數 係數 標準差 t 統計量 P 值 R2 修正R2 韓國 1 Z -0.03*** 0.01 -3.17 0.002 0.040 0.032 INT -17.21 56.57 -0.30 0.761 C 23.96*** 7.52 3.18 0.002 3 Z -0.10*** 0.02 -5.92 0.000 0.158 0.152 INT -336.69*** 115.13 -2.92 0.004 C 90.95*** 15.31 5.94 0.000 6 Z -0.20*** 0.02 -8.53 0.000 0.254 0.248 INT -387.81** 153.61 -2.52 0.012 C 174.30*** 20.36 8.56 0.000 12 Z -0.33*** 0.03 -11.70 0.000 0.382 0.376 INT -401.98** 180.61 -2.23 0.027 C 283.01*** 24.12 11.73 0.000 台灣 1 Z -0.01*** 0.00 -2.61 0.010 0.040 0.033 INT 34.14* 20.43 1.67 0.096 C 4.42*** 1.69 2.61 0.010 3 Z -0.03*** 0.01 -4.59 0.000 0.082 0.074 INT 25.70 43.67 0.59 0.557 C 16.68*** 3.63 4.60 0.000 6 Z -0.07*** 0.01 -6.78 0.000 0.159 0.152 INT -75.65 62.34 -1.21 0.226 C 35.43*** 5.20 6.81 0.000 12 Z -0.11*** 0.01 -8.23 0.000 0.231 0.225 INT -231.34*** 82.07 -2.82 0.005 C 57.71*** 6.99 8.25 0.000 註︰*表示 10%顯著水準之下顯著;**表示 5%顯著水準之下顯著;***表示 1%顯著水準之下顯著。
26 4.4 DM 檢定結果 4.4.1 隨機漫步模型與貨幣所得模型之DM 檢定結果 表4-4-1 為不考慮央行干預的情況下,隨機漫步模型與貨幣所得模型之 DM 檢定結果,設定模型A 為隨機漫步模型,模型 B 為貨幣所得模型。 貨幣所得模型的預測準確度顯著優於隨機漫步模型的結果,只出現在韓國 方面。韓元在未來10 年間的匯率預測上,當預測期數為 3、6、12 個月時,貨 幣所得模型的預測能力顯著優於隨機漫步模型。 雖然大部分結果的𝑑𝑡呈現貨幣所得的預測準確度優於隨機漫步模型,然而 其DM 統計量不具統計顯著性,因此視為貨幣所得模型的預測能力無法擊敗隨 機漫步模型。呼應Meese and Rogoff(1983)主張的隨機漫步模型的預測能力優於 其他以經濟理論為基礎的模型。 表4-4-1︰隨機漫步模型與貨幣所得模型之 DM 檢定結果 樣本外資料數 韓國 台灣 預測期數 60 120 180 60 120 180 1 𝑑𝑡 0.440 1.005 0.129 -0.370 0.565 0.576 DM 統計量 0.660 0.315 0.897 0.711 0.572 0.565 3 𝑑𝑡 0.161 2.025 0.238 -0.448 0.445 0.986 DM 統計量 0.872 0.043 0.812 0.654 0.656 0.324 6 𝑑𝑡 -0.615 3.402 0.816 -0.899 0.672 1.455 DM 統計量 0.539 0.001 0.415 0.369 0.501 0.146 12 𝑑𝑡 -1.420 3.701 1.553 -1.169 0.720 0.878 DM 統計量 0.156 0.000 0.120 0.242 0.471 0.380 註︰*表示 10%顯著水準之下顯著;**表示 5%顯著水準之下顯著;***表示 1%顯著水準之下顯著。 註2︰𝑑𝑡為模型A 與模型 B 之間的預測誤差之差異;DM 統計量在表中以 P 值來表達。
27 4.4.2 隨機漫步模型與加入央行干預的隨機漫步模型之DM 檢定結果 表4-4-2 為隨機漫步模型與加入央行干預的隨機漫步模型之 DM 檢定結 果,設定模型A 為隨機漫步模型,模型 B 為加入央行干預的隨機漫步模型。 隨機漫步模型的預測準確度顯著優於加入央行干預的隨機漫步模型之結 果,只出現在韓國方面。韓元在未來5 年間的匯率預測上,當預測期數為 1 個 月時,呈現隨機漫步模型的預測能力顯著優於加入央行干預的隨機漫步模型。 加入央行干預的隨機漫步模型其預測準確度優於隨機漫步模型的結果,只 出現在台灣方面。新台幣在未來5 年間的匯率預測上,當預測期數為 1 個月 時,呈現加入央行干預的隨機漫步模型其預測能力顯著優於隨機漫步模型。在 未來15 年間的匯率預測上,當預測期數為 1 個月時,加入央行干預的隨機漫步 模型其預測能力仍然顯著優於隨機漫步模型。 雖然大部分結果的𝑑𝑡呈現加入央行干預的隨機漫步模型其預測準確度優於 隨機漫步模型,然而其DM 統計量不具統計顯著性,因此視為加入央行干預的 隨機漫步模型其預測能力無法擊敗隨機漫步模型。 表4-4-2︰隨機漫步模型與加入央行干預的隨機漫步模型之 DM 檢定結果 樣本外資料數 韓國 台灣 預測期數 60 120 180 60 120 180 1 𝑑𝑡 -1.992 -0.967 -0.775 2.563 1.326 1.725 DM 統計量 0.046 0.333 0.438 0.010 0.185 0.085 3 𝑑𝑡 -1.349 0.064 0.026 1.518 1.070 1.078 DM 統計量 0.177 0.949 0.979 0.129 0.285 0.281 6 𝑑𝑡 -0.618 -0.256 -0.186 -0.786 -0.242 0.083 DM 統計量 0.536 0.798 0.852 0.432 0.809 0.934 12 𝑑𝑡 -1.208 -0.071 0.042 -1.242 0.192 0.933 DM 統計量 0.227 0.944 0.967 0.214 0.847 0.351 註︰*表示 10%顯著水準之下顯著;**表示 5%顯著水準之下顯著;***表示 1%顯著水準之下顯著。 註2︰𝑑𝑡為模型A 與模型 B 之間的預測誤差之差異;DM 統計量在表中以 P 值來表達。
28 4.4.3 隨機漫步模型與加入央行干預的貨幣所得模型之DM 檢定結果 表4-4-3 為隨機漫步模型與加入央行干預的貨幣所得模型之 DM 檢定結 果,設定模型A 為隨機漫步模型,模型 B 為加入央行干預的貨幣所得模型。 加入央行干預的貨幣所得模型其預測準確度顯著優於隨機漫步模型的結 果,只出現在韓國方面。韓元在未來10 年間的匯率預測上,當預測期數為 6、 12 個月時,加入央行干預的貨幣所得模型其預測能力顯著優於隨機漫步模型。 在未來15 年間的匯率預測上,當預測期數為 12 個月時,加入央行干預的貨幣 所得模型其預測能力仍然顯著優於隨機漫步模型。 雖然大部分結果的𝑑𝑡呈現加入央行干預的貨幣所得模型其預測準確度優於 隨機漫步模型,然而其DM 統計量不具統計顯著性,因此視為加入央行干預的 貨幣所得模型的預測能力無法擊敗隨機漫步模型。 表4-4-3︰隨機漫步模型與加入央行干預的貨幣所得模型之 DM 檢定結果 樣本外資料數 韓國 台灣 預測期數 60 120 180 60 120 180 1 𝑑𝑡 0.339 0.793 -0.023 0.397 0.979 1.466 DM 統計量 0.734 0.428 0.982 0.691 0.328 0.143 3 𝑑𝑡 0.196 1.440 0.145 -0.386 0.534 1.096 DM 統計量 0.845 0.150 0.885 0.700 0.593 0.273 6 𝑑𝑡 -0.105 2.670 0.479 -0.876 0.686 1.452 DM 統計量 0.917 0.008 0.632 0.381 0.493 0.146 12 𝑑𝑡 -0.704 3.772 1.722 -1.142 0.998 1.346 DM 統計量 0.481 0.000 0.085 0.254 0.318 0.178 註︰*表示 10%顯著水準之下顯著;**表示 5%顯著水準之下顯著;***表示 1%顯著水準之下顯著。 註2︰𝑑𝑡為模型A 與模型 B 之間的預測誤差之差異;DM 統計量在表中以 P 值來表達。
29 4.4.4 貨幣所得模型與加入央行干預的貨幣所得模型之DM 檢定結果 表4-4-4 為貨幣所得模型與加入央行干預的貨幣所得模型之 DM 檢定結 果,設定模型A 為貨幣所得模型,模型 B 為加入央行干預的貨幣所得模型。 加入央行干預的貨幣所得模型其預測能力顯著優於貨幣所得模型的結果, 皆有出現在韓國與台灣方面。韓元在未來5 年間的匯率預測上,當預測期數為 6、12 個月時,加入央行干預的貨幣所得模型其預測能力顯著優於貨幣所得模 型。新台幣在未來5 年間的匯率預測上,當預測期數為 1 個月時,加入央行干 預的貨幣所得模型其預測能力顯著優於貨幣所得模型。 雖然大部分結果的𝑑𝑡呈現加入央行干預的貨幣所得模型其預測準確度優於 貨幣所得模型,然而其DM 統計量不具統計顯著性,因此視為加入央行干預的 貨幣所得模型的預測能力無法擊敗貨幣所得模型。 表4-4-4︰貨幣所得模型與加入央行干預的貨幣所得模型之 DM 檢定結果 樣本外資料數 韓國 台灣 預測期數 60 120 180 60 120 180 1 𝑑𝑡 -1.378 -0.919 -0.857 2.131 1.051 1.624 DM 統計量 0.168 0.358 0.392 0.033 0.293 0.104 3 𝑑𝑡 0.070 0.333 -0.012 0.566 0.677 0.813 DM 統計量 0.944 0.739 0.991 0.571 0.498 0.416 6 𝑑𝑡 1.653 0.088 -0.394 -0.009 0.133 0.188 DM 統計量 0.098 0.930 0.694 0.993 0.894 0.851 12 𝑑𝑡 2.932 -0.255 0.680 0.365 0.921 1.404 DM 統計量 0.003 0.799 0.497 0.715 0.357 0.160 註1︰*表示 10%顯著水準之下顯著;**表示 5%顯著水準之下顯著;***表示 1%顯著水準之下顯著。 註2︰𝑑𝑡為模型A 與模型 B 之間的預測誤差之差異;DM 統計量在表中以 P 值來表達。
30
第五章 結論
5.1 研究結果 比較迴歸估計結果發現,誤差修正項與央行干預都具有顯著的解釋能力。 對照貨幣所得模型與加入央行干預的貨幣所得模型發現,不論是韓元或新台 幣,當預測期數為1、3、6、12 個月時,誤差修正項對匯率變動皆呈現顯著的 負向影響。對照加入央行干預的隨機漫步模型與加入央行干預的貨幣所得模型 發現,在韓國方面,當預測期數為3、6、12 個月時,央行干預對匯率變動皆呈 現顯著的負向影響。在台灣方面,當預測期數為1 個月時,央行干預對匯率變 動皆呈現顯著的正向影響;當預測期數為12 個月時,央行干預對匯率變動皆呈 現顯著的負向影響。比較DM 檢定結果發現,加入央行干預的模型,儘管其預 測能力有所提升,仍僅有少數結果擊敗隨機漫步模型。 5.2 結果討論 一般來說在建立預測模型之前,為了提升模型的預測準確度,都會先參考 樣本內估計的配適度,再依結果建立適合的預測模型。由於文獻鮮少將央行干 預納入匯率模型中考慮,本文進一步探討後發現,儘管加入央行干預的匯率模 型具有顯著的解釋能力,其預測能力仍僅有少數結果能擊敗隨機漫步模型。這 意味著雖然加入央行干預對於解釋匯率變動有所幫助,但是用於匯率預測仍不 盡理想,呼應Meese and Rogoff(1983)的結論,也就是困擾經濟學界已久的六大 難題之一—匯率分離謎題。 此外,我們也發現幣別不同,加入央行干預的匯率模型其預測能力也不盡 相同。美元兌韓元的匯率資料使用加入央行干預的貨幣所得模型其預測能力較 隨即漫步模型佳;美元兌新台幣的匯率資料使用加入央行干預的隨機漫步模型 其預測能力較其他匯率模型佳。以美元兌新台幣為例,加入央行干預的隨機漫 步模型除了具有顯著的解釋能力之外,其預測能力在預測期數為1 個月時亦擊 敗隨機漫步模型。從這層關係上我們認為央行干預是影響匯率變動的重要因31 素,若研究對象是在外匯市場中實施央行干預政策的國家,將央行干預納入匯 率模型中有助於提升匯率的預測準確度,呼應楊雅惠與許嘉棟(2005)的結論。 本文發現加入央行干預有助於預測匯率變動,特別是預測期數為1 個月的 匯率模型其預測能力亦有所提升。由於央行干預的政策目標主要依循經濟基要 而制定,說明央行干預與經濟基要之間存在高度的關聯性,呼應《中央銀行年 報》(2017 年版,頁 89)所稱「…匯率過度波動與失序變動…本行將本於職責維 持外匯市場秩序。」表示央行干預之目的在於為了使短期匯率能正確反映出由 經濟基要所決定的均衡匯率,因此我們推論央行干預是影響短期匯率變動的因 素;至於長期匯率會自然地反映出由經濟基要所決定的均衡匯率,呼應 Mark(1995)主張影響長期匯率變動的因素為受經濟基要影響。另外一方面也呼 應Taylor and Peel(2000)認為匯率變動源自外匯市場參與者所採取的匯率預測方 式。由於央行是市場參與者之一,且央行干預依循經濟基要而制定,如果央行 與其他外匯市場參與者在短期的匯率預測亦跟隨央行干預的政策目標,將會導 致短期匯率逐漸修正至由經濟機要所決定的長期均衡匯率,因此匯率模型加入 央行干預變數後,能提升短期模型的預測準確度。 然而研究結果也發現,加入央行干預來提升短期匯率模型的預測準確度其 效果有限。以美元兌韓元為例,加入央行干預的貨幣所得模型其預測能力在預 測期數為6、12 個月時,顯著優於隨機漫步模型與貨幣所得模型,但是當預測 期數為1 個月時卻無法擊敗它們。我們認為由於央行干預的政策效果具有時間 落後(Time Lag),也就是從貨幣供給調控到實際影響市場運作所需的延遲時間, 例如成效落後(Effectiveness Lag);此外,外匯市場參與者也如理性預期理論 (Rational Expectation Hypothesis)所述,從解讀央行干預的訊息到形成理性預期 的決策並逐步修正外匯交易策略所需的延遲時間,例如數據資料落後(Data Lag)、認知落後(Recognition Lag),兩者皆使短期匯率預測具有侷限性。從研究 方法的層面來說,由於政府未公開央行干預方面的資料,難以估計央行干預造
32 成的落後效果;理性預期也難以客觀衡量,兩者亦強化短期匯率預測的困難 度。 5.3 研究限制與建議 本文模型的基本假設為外匯市場為均衡狀態且購買力平價與利率平價成 立。然而當經濟基要產生恆常性變動時,均衡匯率也將發生恆常的改變,即所 謂的結構性變動,將使本文模型之基本假設不成立或使誤差修正項所需的預測 時間大幅增加等模型設定錯誤之因素,進而影響研究結果的正確性。預測期數 的設定與樣本外資料的選取比例也對研究結果產生影響。根據本文設定的預測 期數會減少樣本數,且樣本外資料的選取比例在預測文獻中仍沒有一個定論, 因此兩者皆為影響模型預測能力的研究限制。 本文使用一般迴歸方法估計變數,即固定法(Fixed Scheme),只會估計出一 個參數,並且根據本文的模型設定會減少樣本數。然而樣本內估計的方法尚有 遞迴法(Recursive Scheme)與滾輪法(Rolling Scheme),兩者皆會估計出因時而變 的估計式,遞迴法會增加樣本數,滾輪法則會保持固定的樣本數。針對匯率文 獻採用的估計方法,通常資料經過單根檢定為定態後使用固定法估計變數,本 文亦採取相同作法,不過其他估計方法也值得參考。本文使用DM 檢定衡量模 型的預測能力,仍有其他檢定方法值得使用。 我們認為若研究對象為在外匯市場中實施央行干預政策的國家,將央行干 預納入模型中有助於預測匯率。然而國際間很少有央行開放完整的干預資料, 為匯率研究限制之一。此外,依據《中央銀行年報》(2017 年版,頁 89)「近年 國際短期資本大量且頻繁移動,已取代國際貿易或經濟基本面,成為短期左右 匯率變動的主要因素。」顯示除了本文考慮的央行干預因素之外,匯率研究上 仍有許多未衡量到的因素影響匯率變動,例如市場參與者的預期心理。
33 參考文獻 一. 國內文獻 王泓仁 (2005), “台幣匯率對我國經濟金融活動之影響”,《中央銀行季刊》, 27, 13-46。 吳致寧、黃惠君、汪建男、吳若瑋 (2012) , “再探臺灣匯率制度”,《經濟論文 叢 刊》, 40, 261-288。 柯秀欣 (2018), “台灣央行外匯市場干預對台美匯率之影響–媒體資料之應用”, 《經濟論文叢刊》, 46(2), 297-322。 徐千婷 (2006), “匯率與總體經濟變數之關係:台灣實證分析”,《中央銀行季 刊》, 28, 13-42。 張興華 (2013), “從央行干預新聞分析台灣央行外匯市場干預與台幣匯率之關 係” ,《證券市場發展季刊》, 25, 95–122。 陳旭昇 (2015), “央行「阻升不阻貶」? — 再探台灣匯率不對稱干預政策,” 《經 濟論文叢刊》, 44, 187–213。 陳旭昇與吳聰敏 (2008), “台灣匯率制度初探,”《經濟論文叢刊》, 36, 147– 182。 楊雅惠與許嘉棟 (2005), “新台幣匯率與央行干預行為”, 《台灣經濟預測與政 策》,35, 23- 41。 楊奕農 (2009),《時間序列分析:經濟與財務上之應用》, 臺灣:雙葉書廊。 陳旭昇 (2013),《時間序列分析:總體經濟與財務金融之應用》, 臺灣:東華書 局。 二. 國外文獻
Cheung, Yin-Wong., Menzie D. Chinn and Antonio G. Pascual (2005), “Empirical Ex-change Rate Models of the Nineties: Are Any Fit to Survive?” Journal of Interna-tional Money and Finance, 24, 1150-1175.
34
Daude, C., Levy-Yeyati, E., Nagengast, A.J., (2016), “On the effectiveness of ex-change rate interventions in emerging markets, ” Journal of International Money and Finance 64, 239–261.
Engel, C. and K. West (2005), “Exchange Rates and Fundamentals, ” Journal of Polit-ical Economy 113 (3), 485-517.
Kilian, L. (1999), “Exchange Rates and Monetary Fundamentals: What Do We Learn from Long-Horizon Regressions?” Journal of Applied Econometrics 14, 491-510.
Levy-Yeyati, E., Sturzenegger, F., Glüzmann, P.A., 2013. Fear of appreciation. J. Dev. Econ. 101, 233–247.
Mark, Nelson C. (1995), “Exchange Rate and Fundamentals: Evidence on LongHori-zon Predictability,” American Economimc Review, 85, 201-218.
Mark, N., and D. Sul (2001), “Nominal Exchange Rates and Monetary Fundamentals: Evidence from a Small Post-Bretton Woods Sample”, Journal of International Economics, 53, 29-52.
Meese, Richard A. and Kenneth Rogoff (1983), “Empirical Exchange Rate Models of the Seventies: Do They Fit Out of Sample?” Journal of International Economics, 14, 3-24.
Obstfeld, Maurice and Kenneth Rogoff (2000), “The Six Major Puzzles in Interna-tional Macroeconomics: Is There a Common Cause?” NBER Macroeconomics Annual, 15.
Taylor, M., and D. Peel (2000), “Nonlinear adjustment, long-run equilibrium and ex-change rate fundamentals”, Journal of International Money and Finance