國 立 交 通 大 學
資訊工程學系
博 士 論 文
高階視訊處理、擷取、特徵粹取及視訊
結構化計算之研究
Towards High-Level Content-Based Video
Retrieval and Video Structuring
研究生: 陳敦裕
指導教授: 李素瑛 教授
高階視訊處理、擷取、特徵粹取及視訊結構化計算之研究
Towards High-Level Content-Based Video Retrieval and
Video Structuring
研究生:陳敦裕 Student:Duan-Yu Chen
指導教授:李素瑛 博士 Advisor:Dr. Suh-Yin Lee
國 立 交 通 大 學
資 訊 工 程 學 系
博 士 論 文
A Dissertation
Submitted to
Department of Computer Science and Information Engineering
College of Electrical Engineering and Computer Science
National Chiao-Tung University
in Partial Fulfillment of the Requirements
for the Degree of
Doctor of Philosophy
in
Computer Science and Information Engineering
September 2004
Hsinchu, Taiwan, Republic of China
高階視訊處理、擷取、特徵粹取及視訊結構化計算之研究
學生:陳敦裕 指導教授:李素瑛 教授
國立交通大學資訊工程學系
摘要
隨著數位視訊在教育、娛樂、以及其它多媒體應用的發展下,造成數位視訊 資料大量且迅速增加。在此情況之下,對於使用者而言,需憑藉一個有效的工具 來快速且有效率地獲得所要的視訊資料。在搜尋視訊資料的方法中,對於使用者 而言以內容為基礎之方法最具有高階語意意義,也最為自然且友善。因此,以視 訊內容為基礎之搜尋、瀏覽以及擷取吸引各領域的學者研發各種粹取視訊資料中 的高階特徵,以提供有效率地搜尋並擷取資料。但另一方面,隨著視訊資料壓縮 法的成熟,愈來愈多的視訊資料以壓縮型態儲存,特別是 MPEG 格式。因此也 吸引了愈來愈多的學者投入在壓縮的視訊資料中粹取其高階特徵之研究。本論文 主旨在於研發粹取精簡且有效之視訊特徵,並達成具有語意之高階視訊資料結構 化。 首先,我們在壓縮視訊資料中偵測移動物體,並提出移動物體追蹤演算法, 以追蹤物體並產生物體軌跡,憑藉著物體軌跡,推測相對應之事件並產生事件之 標籤,最終建立以事件為基礎之視訊資料結構化瀏覽系統。 在建立高階視訊資料結構化當中,除了視覺資料之外,文字資料亦是更具有 語意意義的特徵,因此我們也提出了在壓縮視訊資料當中偵測文字字幕,並利用 字幕的長時間出現特性作為濾除雜訊之基礎以及文字字幕其梯度能量較高之特 性,以此獲得有意義的文字字幕,提供具語意之視訊結構化之計算。 為了提供有效的視訊資料相似性的比對,以利視訊資料擷取,我們也提出了兩個以移動物體為基礎之高階特徵(T2D-Histogram Descriptor 以及 Temporal MIMB Moments Descriptor)。與傳統方法在粹取視訊資料特徵僅考慮空間特性不
同,我們所提出的兩個 descriptor 利用了視訊資料之空間以及時間的特性。我們 以 Discrete Cosine Transform 之能量集中之特性,將各個影格之空間特性作為連 結,並大幅降低特徵值之資料量,達到高階視訊特徵精簡化但視訊資料相似性比 對高效率的目的。
我們進行了大規模完整的實驗以評估所提各方法的效能。在我們的實驗範圍
中,結果顯示,對於眾多的測試視訊資料,我們的視訊資料相似性比對的方法都 優於許多著名的方法。
Towards High-Level Content-Based Video Retrieval and
Video Structuring
Student: Duan-Yu Chen Advisor: Prof. Suh-Yin Lee
Department of Computer Science and Information Engineering
National Chiao-Tung University
Abstract
With the increasing digital videos in education, entertainment and other multimedia
applications, there is an urgent demand for tools that allow an efficient way for users
to acquire desired video data. Content-based searching, browsing and retrieval is more
natural, friendly and semantically meaningful to users. With the technique of video
compression getting mature, lots of videos are being stored in compressed form and
accordingly more and more researches focus on the feature extractions in compressed
videos especially in MPEG format. This thesis aims to investigate high-level semantic
video features in compressed domain for efficient video retrieval and video browsing.
We propose an approach for video abstraction to generate semantically meaningful
video clips and associated metadata. Based on the concept of long-term consistency of
spatial-temporal relationship between objects in consecutive P-frames, the algorithm
of multi-object tracking is designed to locate the objects and to generate the trajectory
of each object without size constraint. Utilizing the object trajectory coupled with
domain knowledge, the event inference module detects and identifies the events in the
application of tennis sports. Consequently, the event information and metadata of
accomplished.
A novel mechanism is proposed to automatically parse sports videos in compressed
domain and then to construct a concise table of video content employing the
superimposed closed captions and the semantic classes of video shots. The efficient
approach of closed caption localization is proposed to first detect caption frames in
meaningful shots. Then caption frames instead of every frame are selected as targets
for detecting closed captions based on long-term consistency without size constraint.
Besides, in order to support discriminate captions of interest automatically, a novel
tool – font size detector is proposed to recognize the font size of closed captions using
compressed data in MPEG videos.
For effective video retrieval, we propose a high-level motion activity descriptor,
object-based transformed 2D-histogram (T2D-Histogram), which exploits both spatial
and temporal features to characterize video sequences in a semantics-based manner.
The Discrete Cosine Transform (DCT) is applied to convert the object-based
2D-histogram sequences from the time domain to the frequency domain. Using this
transform, the original high-dimensional time domain features used to represent
successive frames are significantly reduced to a set of low-dimensional features in
frequency domain. The energy concentration property of DCT allows us to use only a
few DCT coefficients to effectively capture the variations of moving objects. Having
the efficient scheme for video representation, one can perform video retrieval in an
accurate and efficient way.
Furthermore, we propose a high-level compact motion-pattern descriptor, temporal motion intensity of moving blobs (MIMB) moments, which exploits both spatial invariants and temporal features to characterize video sequences. The energy concentration property of DCT allows us to use only a few DCT coefficients to precisely capture the variations of moving blobs. Compared to the motion activity
descriptors, RLD and SAH, of MPEG-7, the proposed descriptor yield 40% and 21 % average performance gains over RLD and SAH, respectively.
Comprehensive experiments have been conducted to assess the performance of the
proposed methods. The empirical results show that these methods outperform
誌 謝
在博士班在學期間,沒有指導教授 李素瑛老師的耐心指導,絕對無法成就 這本博士論文。老師嚴謹的治學態度,在研究與投稿的每個階段屢次再現,屢見 老師斟酌字句,費心審視。老師的指引、提攜與照顧,學生銘感於心。 博士論文口試委員之一的 廖弘源老師,在我面臨關鍵時刻,適時給予指導 與協助,特別是在論文的撰寫上,給予指導與鼓勵,讓學生深深受益,在此表示 由衷感激。 感謝所有口試委員,不吝於提供多年的寶貴研究經驗,充實了本論文的深度 與廣度。謝謝 廖弘源老師、陳稔老師、陳銘憲老師、陳良弼老師、楊熙年老師、 與吳家麟老師為豐富本論文內涵提供絕佳的意見,在方法適用範圍、方法評比、 研究結果的適切論述、方法的差異性等等見解,使本論文更臻完善。諸位口試委 員都是我學術研究的最佳典範。 資訊系統實驗室的學長、及學弟妹們,特別是林明言學長、學弟蕭銘和、陳 華總及陳漪紋等在研究的坦途上與我攜手並進,謝謝大家也祝福學弟、妹們早日 收穫豐碩的研究成果。在此特別感謝學長林明言博士的熱心及研究心得的分享, 增添許多研究的動力與樂趣。 家人給予我的關懷與支持讓我在博士求學過程中無後顧之憂,一路走來,父 母從不給我壓力,總是給予我溫暖的關懷,姊姊與哥哥對於弟的關心,以及對於 父母的照顧,更是給予我勇往直前的動力。沒有他們的犧牲與支持,絕對沒有今 日的我,感恩家人的支持,也謝謝姊夫、大嫂及其他親友對我的祝福與勉勵。 一直陪伴在我身旁、沒有怨言、不給我壓力、只有給我鼓勵的,就是我的太 太怡君。每當我身心俱疲的時候,她總是能夠化解我內心的焦慮,總是能夠給予 我綿綿不絕的支持,雖然她與我屬不同研究領域,但亦總是能激發我對研究的創 意與靈感。能夠順利完成博士學位,對於怡君,我有無盡的感謝。 要感謝的人真的很多,在此向所有曾經幫過我的人,致上我真切的謝意。 僅以此論文,獻給我摯愛的家人。Contents
摘要………...i Abstract………iii 誌謝………..….vi Contents………..vii List of Figures………..xi List of Tables………..……….xv Chapter 1. Introduction………...1Chapter 2. Automatic Content Parsing and Semantic Event Identification for Sports Video Abstraction and Description 2.1 Introduction………..4
2.2 Overview of The System Architecture……….7
2.3 Video Segmentation and Shots Selection……….9
2.3.1 GOP-Based Video Segmentation………9
2.3.2 Scene Identification………...10
2.4 Camera Motion Compensation………...12
2.4.1 Adaptive Threshold Decision………..12
2.4.2 Camera Motion Estimation………...13
2.5 Events Detection and Description………..16
2.5.1 Object Tracking Algorithm……….17
2.5.1.1 Object Localization………17
2.5.1.2 Object Tracking Forward and Backward………21
2.5.2 Events Inference Model………...23
2.5.3 Event Description Scheme………..28
2.7 Summary………35
Chapter 3. Automatic Closed Caption Detection and Filtering in MPEG Videos for Video Structuring……….38
3.1 Introduction………38
3.2 Shot Identification………..41
3.2.1 Video Segmentation………..41
3.2.2 Shot Identification……….41
3.3 Closed Caption Localization………..44
3.3.1 Caption Frame Detection………..45
3.3.2 Closed Caption Localization……….…48
3.3.3 Font Size Differentiation……….…..52
3.4 Experimental Results and Visualization System………57
3.4.1 Experimental Results……….…………57
3.4.2 The Prototype System of Video Content Visualization………….………63
3.5 Summary………66
Chapter 4. Motion Activity Based Shot Identification and Closed Caption Detection for Volleyball Video Structuring………..67
4.1 Introduction………67
4.2 Video Segmentation………...70
4.3 Shot Identification………..71
4.3.1 Moving Object Detection………..71
4.3.2 Motion Activity Descriptor – 2D Histogram……….73
4.3.3 Shot Identification Algorithm………75
4.4 Closed Caption Localization………..78
4.4.1 Localization of Superimposed Closed Captions………...78
4.5 Experimental Results and Analysis………83
4.6 Summary………88
Chapter 5. Robust Video Sequence Retrieval Using A Novel Object-Based T2D-Histogram Descriptor………90
5.1 Introduction………90
5.2 Overview of the Proposed Scheme………92
5.3 Characterization of Video Segments………..93
5.3.1 Moving Object Detection………..94
5.3.2 Describing Motion Activity in a Video Segment………..95
5.4 Video Sequence Matching………..97
5.4.1 Discrete Cosine Transform………97
5.4.2 Representation of Video Sequences………..97
5.4.3 Choice of Similarity Measure……….100
5.5 Experimental Results and Discussions……….102
5.5.1 Selecting Appropriate Number of DCT Coefficients………..103
5.5.2 Choosing an Appropriate Motion Activity Descriptor………106
5.5.3 Determining the Best Number of Histogram Bins………..108
5.5.4 Evaluation of Retrieval Performance………..109
5.6 Summary………..114
Chapter 6. Robust Video Similarity Retrieval Using Temporal MIMB Moments………115
6.1 Introduction………..115
6.2 Characterization of Video Segments………117
6.2.1 Detecting Moving Blobs in MPEG Videos……….117
6.2.2 MIMB Moments………..118
6.3 Experimental Results………120
6.3.1 Choice of Similarity Measure……….120
6.3.2 Evaluation of Retrieval Performance………..121
6.4 Summary………..123
Chapter 7. Conclusions and Future Work……….124
7.1 Conclusions………..124
7.2 Future Work………..124
List of Figures
Fig. 1-1. Overview of the proposed approaches………..………...2
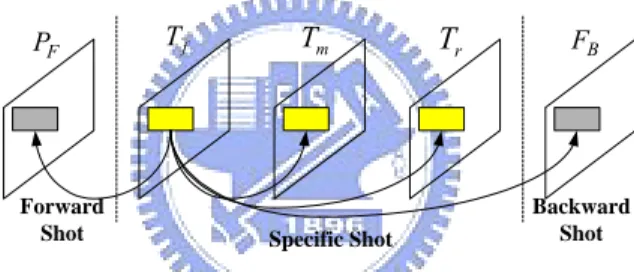
Fig. 2-1. Proposed system architecture of video abstraction and description…….…...7
Fig. 2-2. Structure of typical tennis video program………...9
Fig. 2-3. GOP-based scene change detection algorithm……….……….10
Fig. 2-4. Variation of I-frame DC value of a video sequence (frame0-frame1965).…12 Fig. 2-5. (a) original I-frame (b) result of tennis court region detection………….….13
Fig. 2-6. The approach of camera motion estimation……….………….….14
Fig. 2-7. An example of camera pan to the direction of left-bottom (frame 237)…....15
Fig. 2-8. Object localization algorithm………...……….19
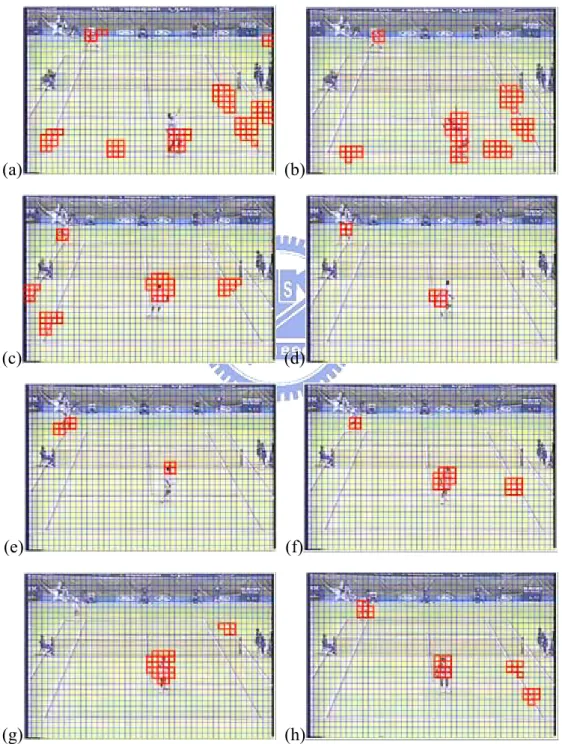
Fig. 2-9. Demonstration of the result of potential object localization, where frame(a) to frame(h) are numbered as 26, 38, 80, 89, 95, 110, 119 and 125………..20
Fig. 2-10. Three cases of tracking forward (a) object match in previous P-frame (b) object match in P-framePN−2(c) object match in P-framePN−3………22
Fig. 2-11. Three cases of tracking backward (a) object match in next P-frame (b) object match in 2nd P-frame (c) object match in 3rd P-frame………23
Fig. 2-12. Tennis events inference model……….………....24
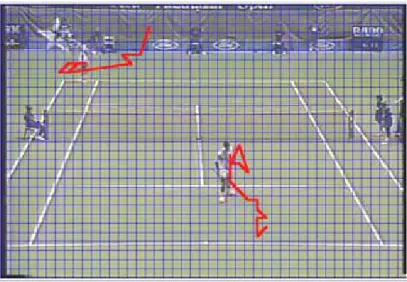
Fig. 2-13. An example of shape variation of server and receiver………....24
Fig. 2-14. Hierarchical Summary Description Scheme [17]……….…….…..28
Fig. 2-15. The system interface shows an example of tennis event detection…...…..31
Fig. 2-16. An example of baseline rally event…………..……….………..31
Fig. 2-17. An example of serve and volley event………..…….………..32
Fig. 2-18. An example of passing shot event….………..32
Fig. 2-19. Start-frame of a ball boy running clip………...…….………..33
Fig. 3-1. Overview of the system architecture……….41
Fig. 3-2. Variation of I-frame DC value (a) tennis; (b) football; (c) baseball…….….43
Fig. 3-3. The approach of closed caption localization……….44
Fig. 3-4. An original frame is divided into R regions (e.g. R = 6)………...46
Fig. 3-5. DCT AC coefficients used in text caption detection………..46
Fig. 3-6. Demonstration of caption frame detection: (a) small closed caption (b) large
closed caption………...48
Fig. 3-7. Illustration of intermediate results of closed caption localization (a) Original
frame (b) Closed caption detection (c) Result after applying morphological
operation (d) Result after long-term consistency verification………..49
Fig. 3-8. Potential caption regions are further verified based on the long-term
consistency……….. 51
Fig. 3-9. Examples of closed caption localization (a) baseball; (b) news; (c)
volleyball ……….51
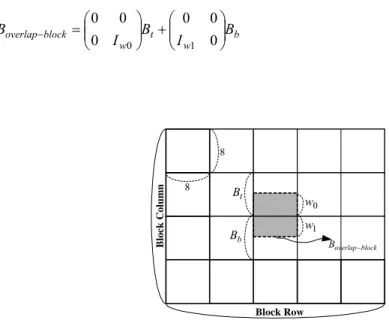
Fig. 3-10. Overlap-block is interpolated from its two neighboring blocks and
………...53
t
B
b
B
Fig. 3-11. The proposed approach of font size differentiation in compressed
domain………..53
Fig. 3-12. Localized closed captions (a) scoreboard (b) trademark……….55
Fig. 3-13. Variation of AC energy of the scoreboard in Fig. 3-12(a) (T=2.2, V =
0.05)………...56
Fig. 3-14. Variation of AC energy of the trademark in Fig. 3-12(b) (T=2.9, V=
0.8)………... 56
Fig. 3-15. Horizontal projection profile of DCT AC energy of the scoreboard and the
trademark in Fig.3-12(a) and Fig.3-12(b), respectively……….…..57
Fig. 3-17. Video Content Visualization System was composed of two areas –
“Playback” and “Visualization”………...65 Fig. 3-18. Hierarchical structure of the scoreboards was shown while the user clicks
the symbol “ ”………...………..65 Fig. 3-19. Video shots were presented in the detailed video hierarchy…...……..…...66
Fig. 4-1. System architecture of motion activity based video structuring……...…….69
Fig. 4-2. Moving objects detection; (a) anchor person; (b) football; (c) walking person;
(d) tennis; (e) volleyball game; (f) traffic monitoring………..72
Fig. 4-3. Workflow of motion activity descriptor……….74
Fig. 4-4. An example of 2D-histogram computation………..……….74
Fig. 4-5. Histograms of shots; (a) Service; (b) Full-court view; (c) Close-up……….76
Fig. 4-6. Closed caption localization in video frames……….…….78
Fig. 4-7. DCT AC coefficients used in localizing superimposed closed captions..….79
Fig.4-8. Demonstration of the localization of superimposed closed captions (a)
original I-frame; (b) result after filtering by using horizontal gradient energy; (c)
result after morphological operation; (d) result after filtering using SOM-based
algorithm; (e) result after dilation...80
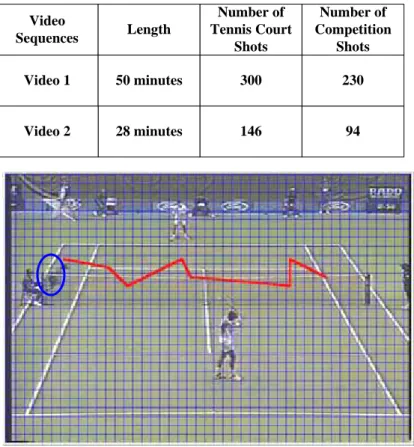
Fig. 4-9. Demonstration of testing videos: (a) Video I (b) Video II….………84
Fig. 4-10. Closed caption localization; (a) original I-frame; (b) result after filtering by
horizontal gradient energy; (c) result after morphological operation; (d) result
after filtering by SOM-based algorithm; (e) result after dilation ……...……… 86 Fig. 4-11. Video structure of caption frames as well as service, full-court view, and
close-up shots………...87 Fig. 4-12. The bottom of the interface shows full-court shots……….87
Fig. 4-13. The bottom of the interface presents close-up shots………88
Fig. 5-1. An overview of extracting the proposed T2D-Histogram descriptor –
low-dimensional DCT coefficients……….…..92
Fig. 5-2. Demonstration of moving object detection (a) anchor person (b) football (c) walking person (d) tennis competition……….95
Fig. 5-3. Demonstration of the computation of 2D-histogram………96
Fig. 5-4. Video sequences are characterized by the object-based T2D-Histogram descriptor and further represented by reduced low-dimensional DCT coefficients ...……….100
Fig. 5-5. Examples of the Close-Up (CUT), Bicycle Racing (BR), Walking Person (WP) and Anchorperson and Interview (API) shots………..104
Fig. 5-6. Average retrieval performance with different descriptors (β = 8, α∈ [1,5]) (a) X-histogram (b) Y-histogram (c) 2D-histogram (d) Weighted 2D-histogram…106 Fig. 5-7. Average retrieval performance (α=2) with different number of bins (β) (a) β = 4 (b) β = 6 (c) β = 8 (d) β = 10………..107
Fig. 5-8. Average retrieval performance with parameters:α=2, D: weighted 2D-histogram, β∈ {4,6,8,10}……….109
Fig. 5-9. Retrieval performance of the four shot classes (a) API Shots (b) CUT Shots (c) WP Shots (d) BR Shots and (e) Average………...111
Fig. 5-10. Demonstration of the query result for a CUT shot………112
Fig. 5-11. Demonstration of the query result for a BR shot………...113
Fig. 5-12. Demonstration of the query result for a WP shot………..113
Fig. 5-13. Demonstration of the query result for an API shot………114
Fig. 6-1. Demonstration of MVF noise reduction (a) MVF without filtering; (b) MVF smoothing with a cascaded filter………118
Fig. 6-2. Recall versus precision performance of the three shot classes (a) Interview Shots (b) Close-Up Tracking Shots (c) Walking Person Shots (d) Average...…122
List of Tables
Table 2-1. Ground truth of the testing video………....33
Table 2-2. Experimental Results of Tennis Event Inference……….……...35
Table 3-1. Performance of caption frame detection………...59
Table 3-2. Performance of closed caption localization after caption frame detected...67
Table 3-3. Experimental results of font size differentiation based on horizontal projection profile using vertical DCT AC coefficients……….62
Table 4-1. Result of shot identification (Video I: 163 shots)………...85
Table 4-2. Result of shot identification (Video II: 199 shots)………..85
Table 4-3. Result of closed caption localization………...85
Table 5-1. Performance using distinct α and four feature descriptors (β = 8)……...105
Table5- 2. The performance obtained of four descriptors with different β (α = 2)…108 Table 5-3. Comparison of performance using different numbers of histogram bins (β)………...109
Chapter 1. Introduction
Due to the tremendous growth in the number of digital videos, the development of video retrieval algorithms that can perform efficient and effective retrieval task is indispensable. In this proposal, as shown in the top of Fig. 1-1, we propose an object-based video content parsing and event understanding technique in MPEG compressed videos to support semantic content indexing and abstraction. Its aim is to reliably analyze the semantic video contents. Because moving objects and the corresponding trajectories are the important visual cues for content parsing, methods of object detection and object tracking are proposed using motion features. Therefore, a strategy of object-based event inference is introduced according to the spatio-temporal relationships between objects. Since high-level semantic events are domain dependent, the semantic events are detected and inferred from the long-term consistent spatio-temporal relationships between moving objects utilizing specific domain knowledge. Consequently, video content descriptions for MPEG-7 are generated automatically to support efficient content-based retrieval. Here, we use tennis sports videos as a demonstration of the system. Experimental results show the high accuracy of event detections and justify the effectiveness of the proposed mechanism.
Moreover, since object-based features are semantically more meaningful than other visual features, we propose a high-level motion activity descriptor – 2D histogram, as shown in the middle of Fig.1-1, that exploits both spatial and temporal features of moving objects characterize video sequences in a semantic manner. The Discrete Cosine Transform (DCT) is applied to convert the high-level features from the time domain to the frequency domain. Using this transform, the original high-dimensional time domain features used to represent successive frames are significantly reduced to
the low-dimensional features in frequency domain. The energy concentration property of DCT allows us to use only a few DCT coefficients to precisely represent the variations of moving objects. Having the proposed mechanism and the efficient scheme of video representation, one can perform video retrieval in an accurate and efficient way. Specific Domain Knowledge Semantic Events Object Detection Object Tracking Event Inference Object-Based Motion Activity Descriptor P-Frames MPEG-1/2 Videos
P-Frames Discrete Cosine Transform Selection of Low-Frequency Coefficients High-Level & Low Dimensional Feature Clustering-Based Shot Identification Superimposed Closed Caption Localization I-Frames Clustering-Based Noise Filtering Tracking-Based
Noise Filtering Differentiation inFont Size MPEG Videos
Video Structuring
Captions of Specific Font Size High-Level &
Compact Visualization
Fig. 1-1. Overview of the proposed approaches
In addition to employing visual features to characterize video shots, textual information in closed captions is also important for users to understand overall video content in a short time. Therefore, as shown in the bottom of Fig. 1-1, a novel approach of automatic closed caption detection and font size differentiation among localized text regions in MPEG videos. The tracking-based noise filtering is exploited to remove the noise of potential captions. When the general closed captions are localized, the designed tool – font size differentiation is used as a filter to assist in the discrimination of the specific and significant text captions, like scoreboards in sports videos.
step in video content analysis and is the process of extracting temporal structural information of video sequences. It involves detecting temporal boundaries, identifying meaningful segments of a video and then building a compact representation of video content. Therefore, we propose a novel approach to automatically parse MPEG sequences and then to construct a table of video content based on the textual information on superimposed closed captions and the semantic classes of video shots. First, video sequences are efficiently segmented into shots using the approach of GOP-based video segmentation. Each video shot is then characterized to be a novel feature – object-based motion activity, which takes into account the spatio-temporal motion activity among moving objects obtained from motion information of the compressed data. The shots are then classified into semantic classes when the specific domain-knowledge is employed. Finally, a clustering-based algorithm is exploited to distinguish the target captions – superimposed closed captions from the high-textured background regions in the shots of interest. Having the proposed video structuring approach, the system can allow users to browse video sequences at different levels of detail in an efficient way.
The rest of the thesis is organized as follows. Chapter 2 shows the algorithm of video event detection in compressed domains. Effective algorithm of closed caption detection and filtering is illustrated in Chapter 3. Semantic video structuring for volleyball games is introduced in Chapter 4. Two high-level compact video descriptors and their corresponding matching measurements are described in Chapter 5 and Chapter 6, respectively. Finally, Chapter 7 concludes this thesis.
Chapter 2. Automatic Content Parsing and Semantic Event
Identification for Sports Video Abstraction and Description
2.1 Introduction
The tremendous growth in the amount of digital videos is driving the need for more effective methods to access and acquire desired video data. Advances in automatic content analysis and feature extraction improve capabilities for effectively searching and filtering videos along perceptual features and semantics. Content-based indexing provides users natural and friendly query, searching, browsing and retrieving. In order to provide users more efficient and effective access methods, it is necessary to support high-level and semantic features for video content representation and indexing. The need of representation and indexing for high-level and semantic features motivates the emerging standard MPEG-7, formally called multimedia content description interface [1]. However, the methods that produce the desired features are non-normative part of MPEG-7 and are left open for research and future innovation.
In many practical queries of MPEG-7 database, high-level and semantic features can support users to acquire desired data more efficiently and effectively. Features of high-level semantics can be extracted and inferred from the closed caption streams [2], the edge information [3], the variation of camera motions and also from spatial-temporal relationship of object locations in uncompressed [4-7] or compressed domain [8-10]. In order to save computation cost and storage space, recently more researches extract features or segment video data directly in compressed video domain [11-13] instead of uncompressed raw data. To support semantic indexing of video content, domain specific knowledge is useful for content identification or annotation and is often applied accordingly. Some researches focus on classification
of video content by identifying significant camera operations [14-15] by using motion vectors of MPEG video streams with specific domain knowledge. In general, distinct camera operations would apply to different kinds of video events. For example, in a basketball game the slam-dunk may correspond to the zoom-in operation and the fast break may be with panning camera motion. However, shots of the same event may be regarded as different kinds of events when these shots are taken by various photographers. Babaguchi et al. [2] search the predefined keywords of American football games in closed caption streams to find out the possible time intervals, which contain the event-shots and subsequently apply the low-level color feature to discover shots similar to predefined events. However, this method would be confronted with some limitations. The target events would be lost due to the reason that the announcer or the commentator may not explain the whole game clearly enough. In addition, target event detection in sports videos based on simple color features would not work well while the court of games is in different colors.
Although these examples of semantic content analysis have achieved certain goals of interest, the features exploited are not general enough. Analyzing video content based on appearance of moving blobs or objects is more general and clearly advantageous since it can show the variation of objects in consecutive frames and even the relationship or event between objects while prior domain knowledge is applied. In addition, few researches focus on video abstraction based on event inference directly from compressed videos. Sports videos contain, besides game competition clips, many clips of commercials, close-up of players or clips that the competition is not actually ongoing. Hence, it is necessary to remove these insignificant clips from the large amount of video sequences so that users can browse or retrieve the desired relevant video data more efficiently.
semantically meaningful video clips and associated metadata. It exploits the efficient mechanism of scene change detection and the effective high-level features of spatial-temporal relationships between objects in MPEG compressed domain. In video segmentation, the proposed GOP-based scene change detection [16] is utilized to segment video streams into shots efficiently since video streams are examined GOP by GOP to detect scene cuts instead of frame by frame and the experimental results show the effectiveness of the approach. Generally, in sports videos, the clips of sports competition are the focus of interest. Shots identification mechanism is proposed to distinguish the interesting shots for further sports event detection. Moreover, objects should be located for event understanding. Based on the concept of long-term consistency of spatial-temporal relationship between objects in consecutive P-frames, the algorithm of multi-object tracking is designed to locate the objects and to generate the trajectory of each object without size constraint. Utilizing the object trajectory coupled with domain knowledge, the event inference module detects and identifies the events in the application of tennis sports. Consequently, the event information and metadata of associated video clips are extracted and the abstraction of video streams is accomplished. Furthermore, video content descriptions and description schemes based on the Hierarchical Summary Description Scheme [17] in MPEG-7 are generated automatically to support high-level video content indexing, retrieval and browsing.
The rest of the chapter is organized as follows. The overview of the proposed video abstraction approach is described in section 2.2 and the video segmentation and shots identification are presented in section 2.3. Section 2.4 presents the method of global motion estimation and section 2.5 describes the object-tracking algorithm. Experimental results and discussions are shown in section 2.6. Conclusion and future work are given in section 2.7.
2.2 Overview of The System Architecture
MPEG-1/2 Video Stream Semantic Video Clips and Information Description GOP-based Video Segmentation Scenes Identification Global Motion Estimation Event-based Video Clips Abstraction Event Infererence Moving Object Detection Domain KnowledgeFig. 2-1. Proposed system architecture of video abstraction and description
Fig. 2-1 shows the proposed system architecture for event-based semantic abstraction of videos. Video streams are first segmented into shots using the proposed GOP-based video segmentation and segmented shots are further classified using the color-based scene identification. In general, sports shots can be classified as two types according to the color features. The first type is the shot consisting of the competition court or field whose color variation is small throughout the whole shot and the second type is the shot including the commercials, close-up shots, the crowd, etc. in which the color variation is relatively significant. Significant video clips that contain competition court are usually the shots of interest and are thus selected for further event inference. In order to reduce computation cost, objects are detected using the motion information in P-frames. However, in sports videos, the camera is not static because it may pan or tilt to capture the players. To localize the positions of objects robustly, camera motion must be estimated. Instead of exploiting the motion estimation model such as affine motion model, the camera motion indicated by the dominant motion is characterized using the histogram-based method, in which motion vectors in P-frames are directly extracted and used for camera motion estimation.
obtained and be exploited to infer high-level semantic events of sports videos with the aid of domain knowledge. Video shots are distinguished into semantically meaningful clips based on the events inferred in the previous phase. After the thorough procedure, semantic video clips are obtained and the associated high-level metadata can be used for automatic generation of video descriptions, video indexing and video abstraction. For example, three major events in tennis games are: serve and volley, baseline rally and passing shot. Players always staying near baseline are considered as baseliners and thus the corresponding event is regarded as baseline-rally. When one of the players is a serve-and-volleyer, the event would be serve-and-volley or passing shot according to the final position of the serve-and-volleyer. These events are defined in terms of not only objects appearing in a time interval but also spatial relationships between the objects. Therefore, objects must be localized in a time point and further be tracked in a time interval.
In the experiments, we use tennis video streams formatted in MPEG-2 as testing sequences and its’ temporal tree structure for domain knowledge is shown in Fig. 2-2. A match can be played to the best of some sets (the player needs to win two sets out of three in order to win the match or to win three sets out of five in order to win the match). A set consists of several games (say six games) and a game is made up of some points (say four points) [18]. It is worth noting that such a tree can be constructed for any kind of sports games. The proposed object-based video analysis scheme can be applied to most kind of sports games and even the well-structured videos such as news because their video sequences can be structured as a tree and the video content can be modeled or described using objects. Therefore, given the structure and the domain knowledge, we are able to adapt the event detection scheme for specific application domain. The details of each module are explained in the following sections.
Tennis Video
Set Commercials Set
. . .
Game Commercials Game
. . . . . . . . . Point Point . . . . . .
Fig. 2-2. Structure of typical tennis video program
2.3 Video Segmentation and Shots Selection
2.3.1 GOP-Based Video Segmentation
Video data is segmented into clips to serve as logical units called “shots” or “scenes”. Fig. 2-3 illustrates our proposed GOP-based scene change detection approach [16]. In MPEG-II format [19-20], GOP layer is a random accessed point and contains GOP header and a series of encoded pictures including I, P and B-frames. The size of a GOP is about 10 to 20 frames, which is less than the minimum duration of two consecutive scene changes (about 20 frames) [21].
We first detect possible occurrences of scene change GOP by GOP (inter-GOP) instead of frame by frame to speed up the computation. The difference between each consecutive GOP-pair is computed by comparing the I-frames in each consecutive GOP-pair. If the difference of DC coefficients between these two I-frames is larger than the threshold, then there may have scene change in between these two GOPs. Hence, the GOP that contains the scene change frame is located. In the second step – intra GOP scene change detection, we further compute the ratio of forward to backward and the ratio of backward to forward motion vectors in B-frames. By
comparing the two ratios with predefined thresholds, the actual frame of scene change within a GOP can be located. The experimental results in [16] are convincing and justify that the efficiency and the effectiveness of video segmentation.
yes
no Step 1.
Step 2.
Inter-GOP scene change detection
Calculate the difference in each consecutive GOP-pair
If difference is more than threshold?
Intra-GOP scene change detection
Find out the actual scene change frame within the GOP
Fig. 2-3. GOP-based scene change detection algorithm
2.3.2 Scene Identification
While the boundary of each shot is detected, the video sequence is segmented into shots consists of various types of clips, which need further processing to identify the scenes. In order to detect and infer events, application domain of interest needs to be specified and knowledge model needs to be incorporated. Taking sports videos as an example, such as tennis, football and baseball, the clips might be commercials, close-up shots and competition court shots. However, commercials may not be interesting to clients and only the ongoing competition shots in sports games are clients’ concern. Hence, only the clips of interest are meaningful and need to be processed and analyzed further. Therefore, scene identification is to recognize the clips of the type desired (say competition court shots).
tennis court frame is very small through the whole clip and the value of intensity variation between consecutive frames is very similar. In contrast, the intensity of the commercial clips and close-up clips varies significantly in each frame and the difference of the intensity variance between two neighboring frames is relatively large. Therefore, the DC-image of each I-frame, which consists of DC coefficients of each block, is used to compute the intensity variation of I-frames. In addition to the intensity variance of each I-frame, the variance of each shot is also computed to be the shot feature. The definition of the frame variance and that of shot variance are shown in Eq. (2-1) and Eq. (2-2). means the jth block of the ith frame and N represents the total number of blocks in a frame. is the intensity variance of the frame i in shot s and the variance of shot s is expressed by , where M is the total number of frames in shot s. The variation of the intensity variance of each I-frame in a video sequence from frame-0 to frame-1965 is exhibited in Fig. 2-4. In the video sequence, four clips of tennis court are marked by the dotted ellipses and the close-up clips are marked by the dotted rectangles. The last clip of this sequence is an advertisement clip signed by the dotted circle. From Fig. 2-4, we can see that the intensity variance of the tennis court clips is very small and the intensity values of them are very similar through the whole clip. Thus, the clips of tennis court can be indicated and selected by the characteristic of the value of intensity variance being small in each frame and permanent through the shot.
j i DC, i s FVar, s SVar 2 1 , 1 2 , ,
∑
/ (∑
/ ) = = − = N j j i N j j i i s DC N DC N FVar (2-1) 2 1 1 2 , / (∑
/ )∑
= = − = M i i M i i s s FVar M FVar M SVar (2-2)Variation of I-frame DC values 0 50000 100000 150000 200000 250000 0 500 1000 1500 2000 2500 Frame Number Intensity Variance )
(FVarsDC,i : Tennis : Close-Up : Commercials
Fig. 2-4. Variation of I-frame DC value of a video sequence (frame0-frame1965)
2.4 Camera Motion Compensation
Camera motion estimation is a necessary and important step for object localization. To compute the camera motion of shots, generally motion vectors of all MBs in P-frames are used for estimation. However, most regions in consecutive frames of competition court clips are very similar and thus motion information of these regions cannot actually reflect the information of global motion. Therefore, the adaptive threshold decision scheme is proposed for camera motion estimation. In addition, the mechanism of dominant motion computation based on histogram is proposed to estimate the camera motion efficiently. Section 2.4.1 presents the approach of adaptive threshold decision and the approach of camera motion estimation is described in section 2.4.2.
2.4.1 Adaptive Threshold Decision
In order to select the threshold for the global motion estimation adaptively, we need to detect the outline regions that their intensity is different from the region of competition court. Hence, the DC coefficient of each block in the first I-frame of each competition court shot is extracted and used to represent the block intensity. The
adaptive threshold decision is defined in Eq. (2-3) where means the threshold for global motion estimation, N represents the number of macroblocks in an I-frame and α can be set to a half of the outline region or larger than that because most regions (say more than half) would have similar motion directions when the camera pans or tilts. global T [ ] ) ( , 1
∑
∑
∈ ∈ − = court j j N i i global MB MB T α (2-3) Outline Region Court Region (a) (b)Fig. 2-5. (a) original I-frame (b) result of tennis court region detection
An example of the outline region detection is demonstrated in Fig. 2-5. The largest region is the region of tennis court as marked in the bottom of Fig. 2-5 (b) and other unmarked regions in the top of Fig. 2-5(b) belonging to the outline regions are used for adaptive threshold decision.
2.4.2 Camera Motion Estimation
To correctly locate the position of players, camera motion should be estimated to compensate players for the camera motion. In this section, a fast and simplified camera motion detection approach is proposed. Fig. 2-6 shows the procedure of the camera motion detection. For the computation efficiency, only the motion vectors of P-frames are used for camera motion analysis since in general, in a 30 fps video consecutive P-frames separated by two or three B-frames, are still similar and would
not vary too much. Therefore, it is sufficient to use the motion information of P-frames only to detect camera motions.
Reliable Motion Vectors Selection Histogram-Based Dominant Motion Computation Camera Motion Detection Camera Motion Compensaton Motion Vectors of P-frame Compensated Motion Vectors
Fig. 2-6. The approach of camera motion estimation
However, the motion vectors of P-frames or B-frames in MPEG-2 compression standard are best match and may not actually represent correct motions in a frame because the motion estimation in MPEG videos is for the purpose of data compression. This problem in the sports video streams is more serious since consecutive frames in competition court clips are very similar. This will lead to the situation that for a macroblock in competition court, it is easy to find a good match around its neighbor in the reference frame. However, this motion estimation does not mean that the position of the macroblock is correctly located in its reference frame. Therefore, in order to achieve more robust analysis, it is necessary to select the regions that do not belong to the area of competition court for global motion estimation, since the motion vectors of the area of competition court cannot actually reflect the global motion. Taking the tennis court as an example, in Fig. 2-7, we can observe that motion vectors in the upper part of the frame are more reliable since these macroblocks are of similar motion vector magnitude and direction, but in most of the macroblocks within the area of tennis court, the magnitudes and directions are not consistent and are very noisy.
Fig. 2-7. An example of camera pan to the direction of left-bottom (frame 237) The histograms of magnitude and direction of motion vectors in the outline region, which are more reliable for camera motion estimation, are computed to acquire dominant motion direction and dominant motion magnitude to further identify whether camera motion, pan and tilt, happens or not. Using the approach of histogram-based dominant motion computation, we can avoid matrix multiplications, which are computationally inefficient when motion vectors are fit to affine motion models. Furthermore, pan and tilt are two major camera motions in most sports and can be detected fast and correctly by the proposed motion vector histogram-based approach. The threshold that is adaptively decided is used to identify the existence of camera motion in a frame. The magnitude and direction of camera motion are obtained by using Eq. (2-4) and Eq. (2-5).
global
) ( # ) ( # ) ( # DMH 1,i DMH,i DMH 1,i
i Bin Bin Bin
SDMH = − + + + (2-4) ) ( # ) ( # ) (
# DAH 1,i DAH,i DAH 1,i
i Bin Bin Bin
SDAH = − + + + (2-5)
DMH means the dominant magnitude of motion vector histogram, DAH the
dominant direction of motion vector histogram, the summation of three bins
( , and ) of magnitude histogram of the frame,
the summation of three bins ( , and ) of
direction histogram of the frame, and represents the value of the bin in the frame.
i
SDMH
i DMH
Bin −1, BinDMH,i BinDMH+1,i ith
i
SDAH BinDAH−1,i BinDAH,i BinDAH+1,i
th
i #(Binj,i) jth
th i
In the ideal situations, macroblocks in an object would have the same motion magnitude and direction. However, although the entire object moves toward the same direction, some regions in the object might have different but similar motion magnitudes and direction because objects in real world are not rigid in their shape and size. Consequently, to tolerate the error of motion estimations, the values of
, and of magnitude histogram
( , and of direction histogram) are summed to
examine whether the summation ( ) is larger than the threshold or
not. If and are both larger than the threshold , camera
motion happened, and DMH and DAH are identified as magnitude and direction of
camera motion in frame i. Moreover, motion vectors are compensated with the
magnitude and direction of camera motion for further player detections. i
DMH
Bin −1, BinDMH,i BinDMH+1,i
i DAH
Bin −1, BinDAH,i BinDAH+1,i
i
SDMH SDAHi
i
SDMH SDAHi
T
global2.5 Events Detection and Description
To infer events of sports games, we need to track the positions of players in consecutive frames and generate a trajectory for each player. However, the intrinsic
problem of motion estimation in MPEG-2 standard mentioned in the previous section makes players tracking difficult. Moreover, the difficulty is also due to the varied shape or size of players in consecutive frames. Therefore, in order to solve these problems, we propose a robust algorithm to track players in consecutive P-frames. Focusing on tennis videos, we have to recognize the server further by utilizing the proposed algorithm of server and receiver differentiation. The object-tracking algorithm is introduced in section 2.5.1 and the server-receiver differentiation algorithm is shown in section 2.5.2. The description scheme and descriptor in MPEG-7 for tennis game are presented in section 2.5.3.
2.5.1 Object Tracking Algorithm
2.5.1.1 Object
Localization
Object localization algorithm is to locate potential objects in video shots for subsequent object tracking. The overview of the algorithm of potential object localization is shown in Fig. 2-8. Initially, we verify if there is any camera motion of each P-frame and compensate motion vectors with global motion if camera motion happens. Otherwise, noisy motion vectors are eliminated directly without motion compensation. Subsequently, motion vectors that have similar magnitude and direction are clustered together and this group of associated macroblocks of similar motion vectors is regarded as a potential object. Details are presented in the object localization algorithm.
Object Localization Algorithm
Input: N P-frames of a video clip {P1, … ,PN}
Output: N object sets { }, { }, …, and { }, where N is total
number of P-frames and means the object of the P-frame. Each
object size is measured in terms of number of macroblocks.
1 , 1 n
Obj
2 , 2 nObj
N n NObj
, j n j Obj , th j n jth1. Analyze motion vector of inter-coded macroblocks in a P-frame to see if there is any camera motion.
2. If there is no camera motion, go to step 3. If camera motion is detected, motion vectors that are not noisy are compensated with camera motion magnitude and direction.
3. Cluster motion vectors that are of similar magnitude and direction into the same group with region growing approach.
3.1 Set search windows (W) size 3x3 macroblocks .
3.2 Search all macroblocks (MB) within W, and compute the difference
(diffMagkanddiffAngk) of motion vector magnitude ( MV ) and direction
( ) between center and its neighboring eight motion
vectors within W. MV ∠ MVcenter k MV ) ( center k k abs MV MV diffMag = − ) ( center k k abs MV MV
diffAng = ∠ −∠ , where k∈[1,8] and is the
motion vector in the center position of W
center MV
k
MV ∈ motion vectors within W except MVcenter For all k∈[1,8], flag
⎩ ⎨ ⎧ < < = otherwise T diffAng and T diffMag F k Mag k Ang k , 0 , 1
, where is the predefined threshold for motion vector magnitude and is the threshold for motion vector direction
Mag T
Ang T
If , mark f as 1, where is the flag of the center motion vector within W.
∑
= ≥ 8 1 6 k kF Fcentero MVcenter Fcenter
Otherwise, set all flags within W to 0.
1 MV MV2 MV3 4 MV MV5 6 MV MV7 MV8 Center
3.4 Group MBs that are marked as 1 into the same cluster.
3.5 Compute each object center and record its associated macroblocks. 3.6 Generate one object set for each P-frame.
4. Go to step 1 until all P-frames are processed.
Camera Motion Parameters > Threshold ? Camera Motion Detection No Noisy Motion Vector
Elimination Motion Vectors Clustering Potential Objects Camera Motion Compensation Yes No Last Frame in the
clip ? Yes
Tracking Forward and Backward
Fig. 2-8. Object localization algorithm
By applying the object localization algorithm, potential objects are located for each frame and the result is demonstrated in Fig. 2-9. Potential objects are marked by the bold-line rectangles. We can see that two players are localized except for the frame of Fig. 2-9(g), in which the top player is not detected. Since the top-player may turn and twist his body and its shape changes dramatically, therefore its associated macroblocks cannot find the matched macroblocks. Besides, some noisy objects also appear in these frames. However, our target is to locate the two players. In order to automatically recognize the two players and filter out noisy objects, long-term
consistency of the spatial-temporal relationship of objects in consecutive frames is employed as the measurement to check if two objects in successive frames are the same one. Therefore, the forward and backward object-tracking algorithm based on long-term consistency is proposed and is described in the following section.
(a) (b)
(c) (d)
(e) (f)
(g) (h)
Fig. 2-9. Demonstration of the result of potential object localization, where frame(a) to frame(h) are numbered as 26, 38, 80, 89, 95, 110, 119 and 125.
2.5.1.2 Object Tracking Forward and Backward
While potential objects are located, those objects that are not long-term consistent are regarded as noise and should be removed from the candidates. To compute the long-term consistency of each object, the motion information of each object in P-frames is used to track forward and backward. The forward and backward object-tracking algorithms are demonstrated in Fig. 2-10 and Fig. 2-11 respectively. In Fig.2-10(a), the first case is that object i of P-frame matches an object j
of P-frame by using the motion vector and object
continues to search if any object matched in the previous P-frame. However, if there
is no match for in , searches if any object matched in by
using the motion vector which is weighted by the frame distance between target and reference frames. While there is an object , which matches the object , the frame is set as the target frame and continues to find if any object matched in the previous P-frame. The concept of the third case is similar to the 2 i N Obj , PN j N Obj −1, PN−1 MVN,i ObjN−1,j i N Obj , PN−1 ObjN,i PN−2 i N MV , 2 j N Obj −2, i N Obj , PN−2 ObjN−2,j
nd case except that the weighted motion vector is . Furthermore,
if cannot find any matched object in the previous three P-frames, the procedure of object tracking for is terminated.
i N MV , 3 i N Obj , i N Obj ,
(a) N P i N MV , Target Reference 1 − N P j N MV −1, (b) N P i N MV , 2 Target Reference 1 − N P 2 − N P j N MV −2, I N P 1 − N P 2 − N P 3 − N P i N MV , 3 Target Reference j N MV −3,
Fig. 2-10. Three cases of tracking forward (a) object match in previous P-frame (b) object match in P-framePN−2(c) object match in P-framePN−3
The procedure of tracking backward is shown in Fig. 2-11 and the three cases are analogous to those of tracking forward. However, the reference direction of inter-coded macroblocks is forward reference and thus we can just use the motion information of objects of next frame to trace forward to previous frame while we want to realize backward tracking. Hence, in Fig. 2-11, the dotted line illustrates conceptually the backward object tracking from target frame to reference frame. In Fig. 2-11(a), all objects in frame are searched to see if any object matches the object . However, in Fig. 2-11(b), if there is no match in frame , the objects in are sought to find the matching object by using the weighted motion vector . The case in Fig. 2-11(c) is similar to the 2
1 + N P i N Obj , PN+1 2 + N P j N MV 2,
2 + nd case and the frame
distance 3 weights the motion vector and the procedure of backward object tracking is terminated when there is no match for in consecutive three P-frames. j N MV +3, i N Obj ,
(a) N P PN+1 j N MV+1, Target Reference (b) N P PN+1 PN+2 j N MV 2, 2 + Target Reference I N P PN+1 PN+2 PN+3 j N MV 3, 3 + Target Reference
Fig. 2-11. Three cases of tracking backward (a) object match in next P-frame (b) object match in 2nd P-frame (c) object match in 3rd P-frame
By applying the algorithm of forward and backward tracking, we may generate several trajectories of each object. However, based on the long-term consistency of objects, the longest trajectory is what we concern and hence other trajectories of the object are ignored. In addition, the longest two trajectories of objects are kept and these two objects are regarded as the two players.
2.5.2 Events Inference Model
While the object trajectory is acquired, we can infer video events from the object trajectory by applying some domain knowledge. Thus an event inference model, as shown in Fig. 2-12, is designed to infer events of tennis game from two trajectories of top and bottom players. In this chapter, three events of interest are identified: “serve and volley”, “baseline rallies” and “passing shot” since they are the major occurrences in tennis competitions. Notice that it is necessary to distinguish between server and receiver before event inferences. Server should be located for server related events, “serve and volley” and “passing shot”. Therefore, we propose an algorithm to differentiate between server and receiver based on the observation that the shape of
server varies more than receiver in consecutive P-frames from “two players ready” state to “one player serves” state.
Two Players Ready Start One Player Serves Two Players near Baseline Server Near Net Server Approaching Net Two Players Stay near Baseline Server Back to Baseline End of One Point
End of One Point
Server Near Service Line Server Approaching Service Line End of One Point
Two Players Stay near
Baseline
Fig. 2-12. Tennis events inference model
Diff = 0.5 Diff = 0.43 Diff = 1.6
Diff = 0.5 Diff = 0.25 Diff = 0.2 Server:
Receiver:
Algorithm: Server and Receiver Differentiation Algorithm
Input: Top player { } and bottom player { } in
consecutive P-frames { , … , } N TP TP TP1, 2,..., BP1,BP2,...,BPN 1 P PN
Output: {Server, Receiver}
1. Set i =0, Stop = 0, TPprob= 0 and BPprob= 0
2. Do until DistiTP−1,i ≧ Threshold or DistiBP−1,i≧ Threshold i = i + 1
Compute the center position of Top PlayerTPiand Bottom PlayerBPirespectively
∑
= = m j j i i TP x y m MB x y C 1 , , ( , ) 1 ( , ),∑
= = n j j i i BP x y n MB x y C 1 , , ( , ) 1 ( , ) , where{
MBi,1,MBi,2,...,MBi,m}
∈TPi and{
MBi,1,MBi,2,...,MBi,n}
∈BPi m is the number of MBs in TPi and n is the number of MBs in BPi 3. If DistiTP−1,i = CTP,i−1(x,y)−CTP,i(x,y) < Threshold and) , ( ) , ( , 1 , , 1 C x y C x y
DistiBP− i = BPi− − BPi < Threshold Then Compute TPi−1⊗TPi and BPi−1⊗BPi
If Norm(
∑
(TPi−1⊗TPi)) < Norm(∑
(BPi−1⊗BPi)) Then BPprob =BPprob +1Else IfNorm(
∑
(TPi−1⊗TPi))>Norm(∑
(BPi−1⊗BPi))Then TPprob =TPprob +14. If TPprob >BPprob Then Server = TP Else Server = BP
In the server and receiver differentiation algorithm, we first compute the center of top and bottom player. The distance of top player (bottom player) between consecutive P-frames is computed in the third step. If both the distance and
are smaller than β macroblocks (say three), it means that players do not actually move and are still in “two players ready” state. In order to obtain the shape variations of two players, we utilize the exclusion Boolean operation to compute the shape difference between consecutive P-frames. The center of and
( and ) are overlapped and macroblocks in and ( and
) are excluded ( and
TP i i Dist −1, BP i i Dist −1, ⊗ 1 − i TP TPi 1 − i BP BPi TPi−1 TPi BPi−1 i
BP TPi−1⊗TPi BPi−1⊗BPi). The exclusion results of each
macroblock-pair are summed to be the shape difference between frame i-1 and i. However, usually one player, either the server or receiver, is closer to the camera than the other one and the shape of the player closer to the camera would be larger in size. Therefore, to prevent the object size from being taken into account, the summation of the exclusive results should be normalized by the object size which is defined as the average of the minimum size between the object pair and . The equation of normalization is defined in Eq. (2-6) and Eq. (2-7). To manifest the size variation of objects between consecutive P-frames, the shape difference
1 − i TP TPi
(
)
∑
TPi−1⊗TPi oris normalized by the minimum value of the size of the object pair instead of normalizing by the average or maximum size.
(
∑
BPi−1⊗BPi)
) ) ( (∑
TPi−1⊗TPi Norm =∑
(TPi−1⊗TPi)/Min( TPi−1,TPi ) (2-6) ) ) ( (∑
BPi−1⊗BPi Norm =∑
(BPi−1⊗BPi)/Min( BPi−1, BPi ) (2-7)By applying the proposed server-receiver differentiation algorithm, bottom player is a potential server if its shape difference is larger than that of top player and hence