國立高雄大學資訊管理學系研究所
碩士論文
以應用程序權限與介面呼叫模型偵測 Android 惡意程式之
研究
A Study of Android Malware Detection Based on Permission
and API Calls Pattern
研究生:宋駿瑋 撰
指導教授:蕭漢威 博士
ii
以應用程序權限與介面呼叫模型偵測 Android 惡意程式之研究
國立高雄大學資訊管理學系 指導教授:蕭漢威 博士 國立高雄大學資管理學系研究所 學生:宋駿瑋 摘要 隨著資通訊基礎建設日趨完備,智慧型手機與行動裝置亦日漸普及,相關應用程 式也隨之蓬勃發展。智慧型手機之高實用度及易攜性,逐漸取代傳統對個人電腦的需 求。如此廣大之使用者族群,使得惡意程式如雨後春筍般出現於各行動裝置中。因此, 手機的安全性成為網路安全研究的重要議題。 在許多惡意程式中,我們發現惡意行為經常可透過觀察 Android 應用程式權限要 求、 Android 應用程式中的 API 函式呼叫以及 Android 應用程式中的 API 函式呼叫之 先後順序,三種特徵類別而辨識出。本研究使用盧森堡大學所提供之 Android 應用程 式樣本資料庫 Androzoo ,從中隨機挑選 2019 年裡各 500 隻正常及惡意程式為資料分 析樣本。並從樣本中,蒐集上述三種特徵類別資訊之組合,搭配資料探勘研究中五種 分類分析技術,分別為梯度提升(GBM)、極限梯度提升(XGBoost)、決策樹(Decision Tree),支援向量機(Support Vector Machine)以及單純貝氏分類(Naïve Bayes)。最後,以 Information Gain、Gain Ratio 以及 OneR 來篩選對於分類 Android 惡意程式效果較好之 特徵。實驗結果顯示,五種分類演算法中,當特徵數量在三十個時決策樹分類法具有 最佳效能。而在特徵類別中,以權限要求、API 函式呼叫以及 API 函式呼叫之先後順 序所組合而成的特徵,並使用 Information Gain 排名前三十個特徵數量時,即可擁有很 好的分類準確性 97.2% ,且精確率與召回率之表現亦屬優良。顯示決策樹演算法在我 們的實驗結果中,可以使用較少的特徵組合數量,達到優良的偵測率,此外本研究也 發現在三種特徵類別中,API 函式呼叫之先後順序具有最佳的判斷力。 關鍵詞:行動裝置安全、惡意程式偵測、網際網路安全、資料探勘iii
A Study of Android Malware Detection Based on Permission and API Calls
Pattern
Advisor: Dr. Han Wei Hsiao Department of Information Management
National University of Kaohsiung
Student: Jun Wei Song
Department of Information Management National University of Kaohsiung
ABSTRACT
With the popularity of mobile devices, applications developed based on these platforms are booming as well. The practicality and the portability of smartphones have replaced the need for traditional personal computers. Malware emerges on varieties of mobile devices since there is a vast user population. Hence, the mobile security issue has become important in the field of cybersecurity.
Normally, by observing features like Android permission requested, native Android API calls, and the sequence of calling native Android APIs, we tell if an application is a malware. In this paper, we use dataset Androzoo from the University of Luxembourg and picked 500 applications for normal and malicious applications respectively. We retrieved 3 features from the dataset and found every combination of the 3 features for training the classification techniques. We also select 5 classification techniques, GBM, XGBoost, Decision Tree, Support Vector Machine, Naïve Bayes classifier to train the model. Finally, we use Information Gain, Gain Ratio, and OneR to filter features that have the most effect on the classification of malware. The experiment shows, among 5 classifiers, the decision tree has the best outcome when the features are Android permission, native API calls, and the sequence of native API calls. The accuracy can be 97.2% if we use the first 30 features selected by using information gain. This has proved that in our experimental data, we can use fewer features to reach a good detection rate. In addition, this research also found that among the three feature categories, the sequence of Android API calls has the best performance.
iv 目錄 第一章 緒論... 1 1.1 研究背景... 1 1.2 研究動機... 3 1.3 研究目的... 4 第二章 文獻探討... 6 2.1 Android 惡意程式偵測特徵相關介紹 ... 6 2.2 Android 資料探勘之分類方法相關研究 ... 8 2.3 Android 惡意程式偵測方法之相關研究 ... 10 第三章 研究架構... 16 3.1 Android 惡意程式偵測系統架構 ... 16 3.2 實驗變數... 17 3.3 特徵篩選... 18 3.4 分類預測模組... 19 第四章 實證與評估... 21 4.1 實驗數據收集(Data set) ... 21 4.2 特徵變數集收集(Feature sets) ... 21 4.3 特徵挑選(Feature selection) ... 23 4.4 效能評比指標... 24 4.5 實驗結果... 25 第五章 結論與未來研究... 37 參考文獻... 39
v 圖目錄 圖 1 IDC 手機作業系統市佔率 ... 2 圖 2 McAfee 2020 年第一季手機惡意程式統計 ... 3 圖 3 支援向量機超平面示意圖... 10 圖 4 Android 惡意程式偵測系統架構 ... 16 表目錄 表 1 實驗變數... 17 表 2 混淆矩陣... 24 表 3 資訊獲利排名前十名之各個特徵類別組合之實驗結果... 26 表 4 資訊獲利排名前二十名之各個特徵類別組合之實驗結果... 27 表 5 資訊獲利排名前三十名之各個特徵類別組合之實驗結果... 28 表 6 資訊獲利排名前四十名之各個特徵類別組合之實驗結果... 29 表 7 資訊獲利排名前六十名之各個特徵類別組合之實驗結果... 30 表 8 資訊獲利排名前八十名之各個特徵類別組合之實驗結果... 31 表 9 資訊獲利排名前一百名之各個特徵類別組合之實驗結果... 32 表 10 三種特徵篩選方法排名前三十之特徵聯集... 34
1
第一章 緒論
1.1 研究背景
由於智慧型手機的普遍性和方便性,越來越多使用者會在手機上完成以往我們需 要一台電腦所能完成的事,如信用卡支付、銀行轉帳、社群媒體等等。市面上有著各 式各樣的應用程式,只要在 Google Play 商城輕輕一點,眾多方便的應用程式就會自動 幫我們安裝好,讓我們能藉由這些應用程式完成許多日常瑣事。例如想要在網路上購 物時,僅需下載相關的電子商務平台所製作的應用程式,帳號註冊完成後點選欲購買 的商品,最後再透過信用卡支付即可完成交易,同時也能指定取得商品的地點,既方 便又快速,且省去人們至實體門市及排隊等待的時間。而日常的金融轉帳、證券交易 也已經可以透過手機方便操作,不用前往金融機構也能處理個人帳務問題。以上案例 說明了手機的普及大幅提升我們日常生活的便利性。然而這些資訊已成為有心人士的 竊取目標,一旦惡意程式進入至我們的手機中,就有可能導致這些個資外洩。就上述 的例子而言,我們的個人資訊、社群媒體的登入帳號、信用卡卡號,以及銀行卡號都 可能在手機中留下足跡。若有有心人士想竊取,經常會透過各種惡意程式來進一步取 得這些資訊。人們對於行動裝置的依賴性日益漸增,對比以往的個人電腦,手機內所 擁有的個人資訊已遠超過個人電腦。根據國際數據資訊公司 (IDC, International Data Corporation) ,針對智慧型手機作業系統市佔率所做之調查 [1] ,自 2018 年開始,截至 2020 年 6 月 22 日止,明顯由 Google 公司的 Android 系統和 Apple 公司的 iOS 系統 佔 據了整個市場,且據 IDC 之預估,截至 2024 年 Android 的市佔率皆會維持在 85% 至 87% 之間,而 Apple 所推出的 iOS 則會維持在 13% 至 14% 。從中可看出 Android 系統 的市佔率約為 iOS 系統的六倍之多,也可看出此後數年 Android 系統仍會是智慧型手 機市場之主流。因此,本研究將探討以 Android 系統相關之應用程式為標的,萃取相 關特徵並佐以分類分析演算法,辨識出具惡意行為之應用程式。2 圖 1 IDC 手機作業系統市佔率 隨著智慧型手機深刻融入至我們的日常生活中,攻擊者也將目標從個人電腦轉向 手機使用者,以取得使用者手機中的資訊為目的,製作了各式各樣的惡意程式來攻擊 使用者。然而,一般手機使用者的安全意識並不高,經常疏忽手機上的惡意程式所潛 藏的風險,並且在下載應用程式時,僅依靠應用程式安裝前的權限檢查做為唯一的檢 核。但多數使用者並不完全清楚每一個權限所可能引發的安全議題,例如取得地理位 置權限,在旅遊類型的應用程式可能很常見,透過取得使用者的地理位置資訊,可以 做許多加值服務,提供導航資訊等等。但若此一權限出現在音樂類型的應用程式,可 能就需要多加謹慎,有可能此應用程式是一個惡意程式所偽裝,在背地裡偷偷竊取使 用者的位置資訊。除此之外,使用者在下載完應用程式後,也很少透過防毒軟體的掃 描來進一步清除惡意程式,導致惡意程式可以長時間駐留在使用者的手機中不斷影響 使用者而使用者無從得知。 手機上的惡意程式能夠竊取我們許多重要的個人隱私資訊,如信用卡帳戶、重要 密碼或是對手機系統造成損害,甚至讀取我們的網頁瀏覽資訊、簡訊內容、聯絡人資 料、監控我們的鍵盤輸入、監聽電話、影像等等。此外,惡意程式的偵測難度越趨困 難,惡意程式作者會利用許多規避技巧,藉以提高分析者的難度,以此躲避防毒軟體 或是 Google Play 商城的檢測,達到上架至 Google Play 商城之目的,並誘使使用者下 載。因此,即使是上架於 Google Play 商店的應用程式也仍有惡意程式威脅的風險。不 論是惡意程式的數量成長或是惡意程式的技術更新,速度皆相當驚人。根據防毒軟體 公司 McAfee 截至 2020 年第一季之行動裝置惡意程式統計 [2] 如圖 2 ,在 2018 年第一 季所統計到所偵測到的 Android 惡意程式的總數就高達兩千五百萬筆。而在 2019 年時 第四季時,所偵測到的惡意程式數量更是已經超過三千五百萬筆。可怕的是,這數字 仍在持續攀升。因此,如何在大量的應用程式快速篩選出潛在的惡意程式,是相當重 要的議題。
3 圖 2 McAfee 2020 年第一季手機惡意程式統計
1.2 研究動機
隨著 Android 惡意程式的數量持續增加且變化快速,傳統的特徵碼分析方法已無 法跟上惡意程式變種的速度。惡意程式之變種目的通常為 1. 躲避偵測 2. 功能強化。若 目的為躲避偵測,則惡意程式通常會透過更改函式名稱及部分程式碼區塊,使得惡意 程式之特徵產生變化,進而達成躲避特徵資料庫偵測之效果。若目的為功能強化,則 會修改或增加程式碼區段,達成駭客其他目的。而不論是何種類型之變種,亦會留下 許多線索,例如特徵改變,但功能類似,透過線索,便可將惡意程式歸納為特定惡意 程式家族。 由於特徵碼的分析需先建立特徵資料庫,並從已知惡意程式中提取二進制編碼作 為特徵。對駭客而言,只需簡單將惡意程式修改一小部分,特徵便可產生變化。然而, 這樣的變化,大多數仍須透過惡意程式分析人員檢查與確認才可建檔至特徵資料庫。 這也顯示,新特徵建檔速度,遠不及惡意程式的變種數度。因此有許多新的分析技巧 出現,現有的研究也已經能夠對於 Android 既有惡意程式偵測達到良好的準確率。但 若要達到非常準確的惡意行為判斷,需同時對程式進行靜態分析與動態分析,才能將 惡意程式之行為完整揭露。靜態分析方法會將惡意程式透過反組譯的方法,將可執行 程式轉換為原始程式碼或是組合語言。像是在 Android 的平台上的靜態分析方法,會 透過反組譯工具將 Android 的安裝檔案(APK, Android Application Package),轉換為原 始 Java 程式,並進一步分析。此種方法分析速度快,節省運算資源成本,但缺點是較 難以得知程式實際執行狀態。而動態分析則是需要將欲分析之惡意程式在一個隔離環 境中實際執行起來,同時記錄程式所執行的每一個行為,藉以瞭解惡意程式真實樣貌。 相較於靜態分析,動態分析需要耗費更多的執行時間與運算資源成本。4
本研究希望透過惡意行為來偵測 Android 惡意程式,惡意行為分析不同於特徵碼 分析,行為本身是一種動作,而動作則由一系列原生的 Android 的應用程式介面呼叫 (API, Application Programming Interface) 所構成,在本研究將簡稱 Android API 函式。 此研究所提之 Android API 為 Google 公司為提供 Android 程式開發者更加方便操作 Android 系統之程式介面,程式開發者僅需按照官方所提供之手冊,便可透過程式碼撰 寫,以函式組合各種 Android API 函式操控手機軟硬體功能。駭客通常透過混淆技術, 將組合各種 Android API 的函式名稱進行替換,使程式在邏輯或功能維持不變,但函式 名稱卻難以讓分析人員閱讀。以 Android API 函式組合分析惡意行為之優點,便是其本 身無法被混淆技術所影響。因為這些 Android 應用程式在執行時,若遇到混淆過後的 Android API 函式是無法被執行環境所辨識的,若經混淆,則會導致 Android API 函式 功能無法使用,進而使得惡意行為無法使用。例如竊取使用者地理位址,就必須呼叫 getCellLocation 這個 Android API 函式來取得使用者地理位置,並有可能透過網路或是 簡訊的方式傳送給攻擊者。我們發現許多惡意行為都會伴隨著危險的權限以及危險的 Android API 函式呼叫以及 Android API 函式呼叫的先後順序,因此如何從許多行為中 偵測出潛在惡意行為的發生,是有其必要性的。
1.3 研究目的
在本研究中所提出之 Android 惡意程式檢測方法,目的為提升偵測 Android 惡意程 式的準確性和效能,利用 Android 應用程式中的資訊,如安裝應用程式中的權限請求、 Android API 函式呼叫,以及 Android API 函式呼叫先後順序作為本研究的分析變數, 並使用五種資料探勘中的分類分析技術,分別為梯度提升、極限梯度提升、決策樹、 支援向量機以及單純貝氏分類,希望能夠藉由分類預測的方式,偵測出未知的 Android 應用程式是否為惡意程式。透過權限、 Android API 函式 和 Android API 函式呼叫先後 順序作為判斷依據,將三類不同性質之特徵組合作為特徵變數。利用惡意 Android API 函式的辨識,來找到更多有關惡意行為的證據,以此加強分析之準確性。本研究將會 對目標 Android 應用程式之 APK 檔案進行分析,建立分類預測模型,預期可以提升惡 意行為檢測的準確性與效能,提出新型態 Android 惡意程式偵測系統。
5 本論文的第一章說明本研究之時空背景以及本研究的研究動機與目的。在第二章 會討論先前既有之學者在偵測 Android 惡意程式相關的研究。第三章為本論文之研究 架構,在此章節本研究將會提出如何構建 Android 惡意程式分類預測模型。第四章則 是本論文的實證與評估,我們會實際收集訓練和測試樣本,建立我們的分類預測模型, 並在最後評估何種分類預測模組較為適合。第五章則是本研究之結論與未來可進一步 研究之方向。
6
第二章 文獻探討
本章節將探討與 Android 惡意程式之偵測研究相關文獻,第一節會介紹在 Android 應用程式中,經常被作為特徵分析之特徵,如應用程式權限、 Android API 函式呼叫。 第二節會介紹在資料探勘中常見的惡意程式分類方法,分別為梯度提升、極限梯度提 升、決策樹、支援向量機以及單純貝氏分類。第三節則探討過去有關 Android 惡意程 式偵測之相關研究,透過不同的特徵挑選以及偵測方法,評估各項 Android 特徵及惡 意程式偵測方法之優缺點。2.1 Android 惡意程式偵測特徵相關介紹
在許多 Android 惡意程式偵測研究中,常會以 Android 權限和 Android API 函式呼 叫作為分析變數,因為此兩種資訊是惡意行為發生的必要條件,例如上述竊取簡訊內 容之惡意程式,就需要在應用程式中請求讀取簡訊之 Android 權限,並且在程式碼中 呼叫讀取簡訊之 Android API 函式 ,方能完成此操作。在此章節將會簡介 Android 權限 機制和 Android API 函式呼叫。 Android 權限簡介 Android 權限設計的目的,是為了避免 Android 手機使用者隱私或手機資源被侵犯 的一個機制,Android 應用程式必須獲得相對應之訪問權限,才可以進行手機軟硬體操 作或資源讀寫。截至 2020 年七月,依據 Android 官方文件所示 [2],Android 權限共有 169 個,且主要可分為四大類,分別為:普通 (Normal)、簽章式 (Signature) 、危險 (Dangerous) 以及特殊 (Special) 四種權限類別。 普通類別之權限,即為對使用者而言,隱私損害風險極小之權限。例如:設定時 區之權限 (SET_TIME_ZONE),即為此類型權限。若應用程式在 AndroidManifest.xml 中要求訪問普通類別之權限,則系統會自動授權該權限予應用程式。簽章類別之權限, 即只有與該應用程式持有相同私鑰之其他應用程式,才能授予該權限。而危險類別之 權限,若被授予,則應用程式能訪問與使用者隱私相關之資訊或資源。例如:讀取使 用者簡訊之權限 (READ_SMS) ,或讀取手機聯絡人之權限 (READ_CONTACT)。與普
7 通類別權限之差異,即應用程式要求授予危險權限時,系統會主動跳出確認提示,經 使用者確認並同意後,系統才會授予該危險權限。另外,也有權限被 Android 官方歸 納在特殊權限類別,該類別可視為比危險權限更為敏感。其中,如顯示系統訊息視窗 (SYSTEM_ALERT_WINDOW) 與改寫系統設定 (WRITE_SETTINGS) 皆為極敏感之權 限。當應用程式要求訪問特殊權限類別時,則系統會跳出附有更多參考資訊之管理介 面,經使用者確認並同意後,系統才會授予該特殊權限。由於後兩種權限 (危險與特 殊),皆能獲取使用者高度敏感性資源或更改手機設定。因此,若在應用程式中發現有 對此兩類型權限之要求,則使用者應提高警覺,避免在大意中,使非必要之危害發生。 Android API 函式簡介 API 其原理是將複雜的運作方式或工作機制的細節隱藏,並用一簡潔易懂之介面 (Interface) 封裝起來。讓程式開發者,透過此一簡潔介面,在不必理解封裝內部之運 作原理或演算法情況下,即針對標的進行操控。而在 Android 中, Google 也為 Android 平台設計了一組 API 框架,給予程式開發者一組與 Android 系統底層互動的 機制,進而操控手機軟硬體的介面。開發者僅需按照官方文件說明,將對應之參數 放入正確位置,即可使用此 API 函式,來完成此對應之功能或是對於 Android 設備進 行操作。 通常,開發者會將不同 API 函式進行組合,以達成特地目的。例如惡意程式試 圖透過簡訊,將使用者地理位置傳送出去。則惡意程式中會呼叫 API getCellLocation 函式取得使用者地理位置,並透過呼叫 API sendTextMessage 函式將地理位置傳送出 去。也因此顯示出,不僅關鍵 API 函式是否被呼叫是重要的參考特徵變數,關鍵 API 函 式 被 呼 叫 的 順 序 , 更 是 具 重 要 參 考 價 值 之 特 徵 變 數 。 此 外 , 呼 叫 API getCellLocation 函 式 及 API sendTextMessage 函 式 皆 須 請 求 授 予 相 對 應 之 權 限 ACCESS_COARSE_LOCATION 、 ACCESS_FINE_LOCATION 以及 SEND_SMS , 方可執行 API 函式動作。這也顯示出,應用程式請求授予之權限與 Android API 函式 之使用,具高度連動關係,也因此,我們亦將權限請求納為重要特徵變數。
8
2.2 Android 資料探勘之分類方法相關研究
梯度提升(Gradient Boosting Machine)
GBM(Gradient Boosting Machine) [6],在 2001 年由 Jerome 所提出,又稱為梯度提 升,是基於 Boosting 原理來實現的一種機器學習演算法。Boosting 的概念是透過一群 弱學習機器演算法的集合來組成最佳的模型,例如使用一群的決策樹作為弱學習機器 演算法,並透過多個模型不斷迭代修正模型的學習效果,最後集成最佳學習模型,如 此一來便可有效解決傳統決策樹會遇到的擬合過度問題。GBM 在模型訓練期間將重點 擺在每一次訓練中預測錯誤的資料群,即預測錯誤的模型將有更高的權重值,以便模 型從過去的錯誤中學習。每一個模型的訓練階段彼此皆有順序性,每一個模型的訓練 基礎皆來自於前一個模型的訓練結果,藉由每一次從錯誤中不斷改進,最後集成最佳 的預測模型。
極限梯度提升(eXtreme Gradient Boosting)
XGBoost(eXtreme Gradient Boosting) [7],在 2014 年由陳天奇所提出,又稱為極限 梯度提升,常被用於回歸分析以及分類預測的機器學習方法,同是屬於 Boosting 方法 的其中一種機器學習演算法,在訓練速度和分類均有很好的效果。XGBoost 本身是基 於 GBM 中以回歸樹所建構的模型,透過集成眾多的回歸樹作為弱學習機器演算法,並 在此基礎上改良與優化,除了提升原有的速度和準確性以外,更加入了平行運算的功 能,使得 XGBoost 在訓練模型上能有更好的效能。此外,XGBoost 利用了許多方法來 解決過擬合的問題,例如 XGBoost 在每次迭代中會對每一個回歸樹的葉子節點給予一 個權重,並可以控制葉子的節點數量,使得每一個回歸樹對整體模型的影響不會太大, 進而不會造成預測偏差。並且 XGBoost 還能處理遺漏的特徵值,在效能以及準確度皆 有明顯優於 GBM。
9 決策樹(Decision Tree)
決策樹(Decision Tree) [4] ,是利用樹狀結構的方式,來處理分類的問題,決策樹 一般會包含根節點、分枝以及葉節點。透過樹中的每一個分枝中不同的屬性值來進行 分類,在每個樹葉節點則代表不同分類的類別標記。建立決策樹的依據是當下能獲得 的資訊獲利(Information Gain, 簡稱 IG),並透過演算法例如 ID3、C4.5 或 CART 等等, 來自動建構出樹中的每一個節點,由上至下分別為資訊獲利最大至最小。決策樹會藉 由分類現有訓練資料集,來建立一個樹狀結構,從中歸納出類別屬性和類別標記之間 的關係,而此結構能夠在未來成為一個分類預測模型。當下一個新資料進來時,即可 透過決策樹所預先建立好的分類模型,對資料進行分類預測,在分類速度上具有相當 大的優勢。但是決策樹容易有過適(Over-fitting)的問題,也就是當特徵數量越來越多, 導致樹的層數不斷增長,對於分類之效果反而會下降,此時就可以透過限制樹的層數, 在本研究中,因特徵數量相當多,因此我們會透過設置最大特徵數的方式,以此評估 最適當之特徵數量。
支援向量機(Support Vector Machine)
支援向量機(SVM, Support Vector Machine) [3] 是一種分類演算法,屬於資料探 勘中的分類技術,且被廣泛應用於統計分類與回歸分析。在支援向量機中,希望可 以找出在兩群資料中的決策邊界,並會讓此決策邊界與兩端邊界距離為最大,使其 可以完美區隔開來兩群資料,此決策邊界可以將兩群資料分為兩類如圖 3 所示。例 如就本篇研究的分類結果為惡意程式和正常程式。除此之外,當遇到無法進行線性 切割的資料群時,支援向量機也支援將原始資料轉換為高維度的向量空間,使用所 謂的核技巧能夠有效地進行非線性分類,使得兩群資料能夠在高維度的空間中,能 夠以一個超平面分割此兩群資料,以達到分類的目的。
10 圖 3 支援向量機超平面示意圖 單純貝氏分類(Naïve Bayes) 單純貝氏分類(Naïve Bayes)又被稱為貝氏分類器 [5] ,是基於貝氏條件機率理論,並假 設實驗變數之間彼此為獨立事件,藉由計算條件機率來決定該樣本的分類結果。 𝑃(𝐴|𝐵) = 𝑃(𝐵|𝐴)𝑃(𝐴) 𝑃(𝐵) P(A)代表發生 A 事件之機率, P(A|B)是指在事件 B 發生的情況下事件 A 發生的機 率,並以此計算各個特徵變數在訓練資料集中出現的條件機率下,計算可能各類別資 料發生的機率,最後評估何種類別發生之條件機率最大者。分類方法為透過機率統計 的分析,利用已知的事件發生機率來推測未知資料的類別,以此建立機率模型分類器, 屬於一個條件機率模型。以本篇研究的例子而言,將從訓練資料集中,運用單純貝氏 分類,計算每一個特徵變數在不同類別(惡意程式或正常程式)出現的條件機率,統計 出不同變數類別可能影響預測資料的機率,例如有請求極為敏感資料之權限如讀取簡 訊內容的應用程式,對於是惡意程式之機率為何,並以此推算各個特徵變數對於分類 之機率。如此一來,當新的樣本進來分析時,即可透過條件機率來計算此程式是惡意 程式的機率為多少。
2.3 Android 惡意程式偵測方法之相關研究
無論是 Android 權限要求或是 Android API 函式呼叫,在過去已經被許多研究作為 研究變數,因為這些資訊與惡意程式行為息息相關,例如惡意程式作者希望取得使用 者 之 地 理 位 置 , 並 透 過 簡 訊 回 傳 至 遠 端 伺 服 器 , 則 需 要 ACCESS_COARSE_LOCATION 和 SEND_SMS 兩個權限,並且在程式碼中實際呼叫此
11
兩權限所對應之 API 函式,分別為 getCellLocation 函式和 sendTextMessage 函式。因此, 在本節將針對現有之 Android 惡意程式偵測研究進行探討,以及回顧相關的文獻,討 論其所用到的分析技術和使用到的特徵變數,並以此作為本研究分析系統的基礎。 靜態分析
靜態分析 [8] 是將 Android 應用程式中的 APK 檔案,從 APK 中提取出所需的判斷 變數,進行比對。無論是權限、字串、和字節碼中的 API 函式呼叫等等。靜態分析的 優點在於不會被惡意程式所偵測,分析速度快,以及節省電腦計算資源。靜態分析的 方法,可再進一步依照提取的變數分成特徵分析、權限分析及 API 函式分析。 (1) 特徵分析 特徵分析會將程式碼中特定的模式或是一段程式指令提取出來,建立一個獨特的 特徵,並以此來比對現有的特徵資料庫,判斷是否有惡意特徵。然而這樣的分析方法 只能辨別出已知的惡意程式,無法識別未記錄特徵的惡意程式,因此需要不斷更新惡 意程式碼特徵資料庫。除此之外,大量的特徵比對也會消耗許多電腦運算資源。
Droid Analytics [9] 是基於特徵分析的系統,透過分析 Dalvik 字節碼 [10] ,將每一 個 Android 應用程式內所使用到的函式以及類別作為特徵變數,共有 47126 個特徵, 每個特徵將給予一個特定的十六進位編碼作為此特徵的編號,接著將每一個 Android APK 檔案反組譯後取得對應的特徵編號來與已知的惡意程式家族比對相似度。 Droid Analytics 與防毒軟體所使用 MD5 雜湊方式所建立的特徵相比更具優勢,因為 Droid Analytics 使用 Dalvik 字節碼作為特徵,因此能夠識別出惡意程式的程式碼區段,以及 惡意程式執行的程式邏輯,而 MD5 雜湊所建立的檔案特徵僅只限於單一檔案層級,無 法得知是哪段程式區段被辨認為惡意程式。但此研究也發現,有許多特徵同時出現在 惡意程式和非惡意程式中,代表這些重複的特徵對於辨別惡意程式與否為無效的特徵。 同時此研究只僅於辨認已知惡意程式,因為判別惡意程式與否均是仰賴與已知惡意程 式 家 族比 較, 而 如果 遇到未知惡意程 式則 無法辨識 。 Parvez 等人在 [11] 中提出 AndroSimilar,使用統計特徵的方式來偵測惡意程式,AndroSimilar 利用已知的惡意程
12 式特徵為基礎,來計算未知應用程式和惡意程式家族的相似度,判斷成功率為約為六 成。但使用特徵分析的缺點就是判斷準確率會根據惡意程式碼資料庫的特徵數量而有 不同的準確性,當特徵數量不足就無法準確判斷惡意程式。由上述研究可知,特徵分 析方式仍受限於特徵資料庫的大小,以及無法偵測未知的惡意程式。 (2) 權限分析 在每一個 Android 應用程式被安裝前,都需要授權同意程式所需要的權限,權限 要求會被列在 AndroidManifest.xml 檔案中,且 Google 將 Android 權限根據風險程度, 區分為一般權限和危險權限 [12] 。因此安全研究者可以根據危險權限的請求來進一步 分析是否有可能為惡意程式。 為了解決特徵分析的不足,而有了權限分析。 Ryo 等人在 [13] 中,提出一種輕量 化的檢測方法來分析 AndroidManifest.xml 檔案,來獲得 Android 的權限,並由此計算 惡意風險評分,若惡意風險評分超過閾值則認定為惡意程式。這樣的檢測方法非常節 省計算資源,且可以檢測出未被識別過的惡意程式。但僅有使用權限作為判斷依據的 準確度仍不高,很容易將非惡意的程式誤判為惡意程式,且權限也無法保護所有重要 的資訊,因為有些惡意行為不需要權限就能進行,例如在程式碼中執行 Linux 系統的 指令來取得手機系統之資訊。在 Enck 等人 [14] 和 Tang 等人 [15] 的研究中,提出以權 限為主要分析的變數,且均有使用權限分組作為新變數,並自訂了一些可能的惡意程 式規則,例如同時擁有接收簡訊和寫入簡訊內容權限的程式,就有可能為有風險的應 用程式,要求的權限同時符合所定義的組合規則時 才認定可能為惡意程式,例如 READ_PHONE_STATE 可以取得手機號碼和 IMEI 但是不能將資料移轉出去,若要竊 取出去可能需要 INTERNET 或是 SEND_SMS 的權限請求。因此使用組合的方式,能 夠更加確定惡意行為的發生。 針對權限要求所進行的研究已被認為是可行的,但誤判率較高,因為開發者有可 能會過度要求權限,一般的應用程式也會因為要求了高風險的權限而導致被判定為惡 意程式。之後 Wang 等人 [16] 提出具關聯的權限特徵,利用關聯法則將 APK 內的權限 進行資料探勘,找出潛在的權限關聯,再透過機器學習的方式進行分類預測。以及 Liang [17] 等人和 Liu [18] 等人也均有利用多種權限為組合特徵,將 Android 應用程式
13
的權限取出後,兩兩權限一組進行組合配對成新的屬性並再透過機器學習進行分類, 實驗結果顯示大幅提高了辨識率。由此可見,組合特徵可有效的提高判斷率。
(3) Android API 函式分析
在 Android 手機中所運行的程式,是程式開發者使用 Java 來撰寫的 Android 應用 程式,經過編譯之後會變成 Dalvik 字節碼,接著再透過 Dalvik 虛擬機來執行。API 函 式分析即是透過工具將 APK 反組譯成字節碼進行分析,從 Dalvik 字節碼中可以發現許 多有用的資訊,例如有使用到的 Android API 函式呼叫、程式碼中的字串等等。除了權 限外,另一派學者則將 API 函式呼叫作為主要變數,此處 API 所代表的是由 Google 所 提供的 Android SDK,為了使用手機特定功能,例如讀取簡訊、傳送簡訊、讀取聯絡 人、讀取定位等等功能,此類的 API 函式無法被程式碼混淆技術所混淆,因此可以從 靜態分析來找到是否有使用這樣的 API 函式呼叫。
DroidMat [19] 從 AndroidManifest.xml 提取權限、Intents 中傳遞的資料以及 API 函 式呼叫來分析惡意行為,並使用 K-means 來分群、KNN (K Nearest Neighbor)來分類。 對於惡意程式辨識率已有明顯提升,且花費計算資源少,缺點為無法檢測到有動態載 入以及加殼保護的惡意程式,這在靜態分析是一個常見的問題。之後有學者提出基於 權限和 Android API 函式呼叫作為判斷變數,DroidAPIMiner [20] 以及 Peiravian [21] 等 人,透過機器學習的方式來分類惡意程式,提高只有權限分析的準確性,已有穩定且 準確率高的結果。 (4) 函式呼叫圖(Call Graph)分析 函式呼叫圖是一個控制流程圖,代表程式中函式與函式之間呼叫的關係,通常 會用節點代表各個函式,以箭頭表示函式呼叫順序,並會搭配條件式控制函式呼叫 的路徑,以此構成函式呼叫圖。透過函式呼叫圖,我們可以很清楚瞭解一個程式中, 所有程式路徑的走向。函式呼叫圖可以是靜態也可以是動態,動態函式呼叫圖代表 式真實執行的路線,而靜態函式呼叫圖則代表程式所有可能的呼叫順序。 Jiawei 等 人在 [22] 中設計一個包含兩個步驟的檢測方法。首先將每一個 Android 應用程式中
14
的所有 Android API 函式繪製成靜態函式呼叫圖,稱為 API 函式控制流程圖。接著從 每個惡意程式家族中提取出不同的長度的 API 函式序列,因為惡意程式家族中的惡 意程式通常共享相似的行為模式。最後,將 Android API 函式序列作為輸入特徵,透 過支援向量機、單純貝氏分類以及決策樹分類方法建立 Android 惡意程式檢測模型。 並且評估不同長度的 Android API 函式序列的準確性,結果顯示,在支援向量機的分 類方法會有最佳的準確性,以及長度為二時,會有最好的效果。Apposcopy [23] 同樣 是透過靜態函式呼叫圖來檢測惡意程式,並從 Android API 函式中自定義目標以及動 作兩類型的 API 函式,以此建立資料流的分析。例如惡意程式中有 getDeviceId 函式 此 一 目標 API 函式 ,能夠取得目標手機的 IMEI(International Mobile Equipment Identity)號碼,並有透過 sendTextMessage 函式此一動作 API 函式傳送出去。將惡意 程式家族中以此方法建立所有可能的資料流特徵來檢測 Android 應用程式是否出現此 類特徵,若有則判斷為惡意程式。此種方法相較於單獨使用 Android API 函式更加精 準,但如同靜態分析會遇到的缺點,遇到程式碼混淆或加密即會提高分析的難度。 動態分析 不同於靜態分析,動態分析 [8] 是將所要分析的程式運行於虛擬機中後,才進一步 去分析程式的行為。動態分析的優點為可以看到一個程式完整的面貌,包括做了什麼 事、使用何種資料,若有什麼惡意行為可以很容易被檢測出來,而靜態分析則相對不 容易檢測;動態分析的缺點為有些程式路徑可能會沒有被執行到,且動態分析在分析 速度和計算資源使用度均比不上靜態分析,但是靜態分析遇到程式碼混淆、加密或者 是其他規避分析技巧時,便會使得分析更加複雜,因此遇到這樣的問題就需要透過動 態分析來解決以上問題。 (1) 函式執行順序分析
由於 Android 程式是在 Linux 作業系統中執行,因此在 Crowdroid [24] 提出一種動 態檢測程式行為的方法,藉由 strace [25]工具, strace 為在 Linux 作業系統環境下的一 套程式分析工具,能夠觀察程式在執行時,所使用到的所有系統呼叫,以此工具來收 集應用程式的 Linux 系統函式呼叫的詳細資訊,透過手機設備端傳送系統紀錄給遠端
15
的伺服器,而在伺服器端則是使用分群演算法來進行分析。這種架構是為了解決分析 需要大量資源,因此採取主從式架構。同樣基於 Linux , Isohara 等人 [26] 提出了一種 基於 Linux Kernel 的 Android 惡意程式行為分析,該系統由 Linux 層中的日誌收集器和 日誌分析應用程式組成。日誌收集器記錄所有系統呼叫並使用目標應用程式過濾事件, 而日誌分析器則是將活動與正規表達式進行匹配,以檢測惡意行為。 Canfora 等人 [27] 提出了一種基於 Linux 系統呼叫序列的 Android 惡意程式檢測方法,通過特定的系統呼 叫序列來實現惡意行為,例如,發送資費高的簡訊,為贖金提供密碼資料,殭屍網路 功能等。但分析者無法得知關於何種序列與惡意程式相關行為是有關連性的,特別是 在不斷出現新的惡意程式和非惡意程式生態系統中,因此需使用機器學習來自動學習 這些關聯。 從先前的文獻研究中發現到組合特徵能夠有效提升判斷準確率,像是地理位置權 限和傳送簡訊權限的組合或是透過取得使用者聯絡人資訊的 API 函式呼叫與網路傳輸 的 API 函式呼叫的 API 組合。此外,透過 Android API 函式呼叫先後順序可以更加確 定惡意行為的發生,對比於前人的研究,本研究所提出的研究方法是基於權限、API 函式呼叫的分析方法,並加入了 Android API 函式呼叫先後順序為新的變數,藉由找出 惡意程式使用 Android API 函式呼叫之潛在的順序關係,能夠更加確認惡意程式的行為 發生性,提升惡意程式偵測的準確性。
16
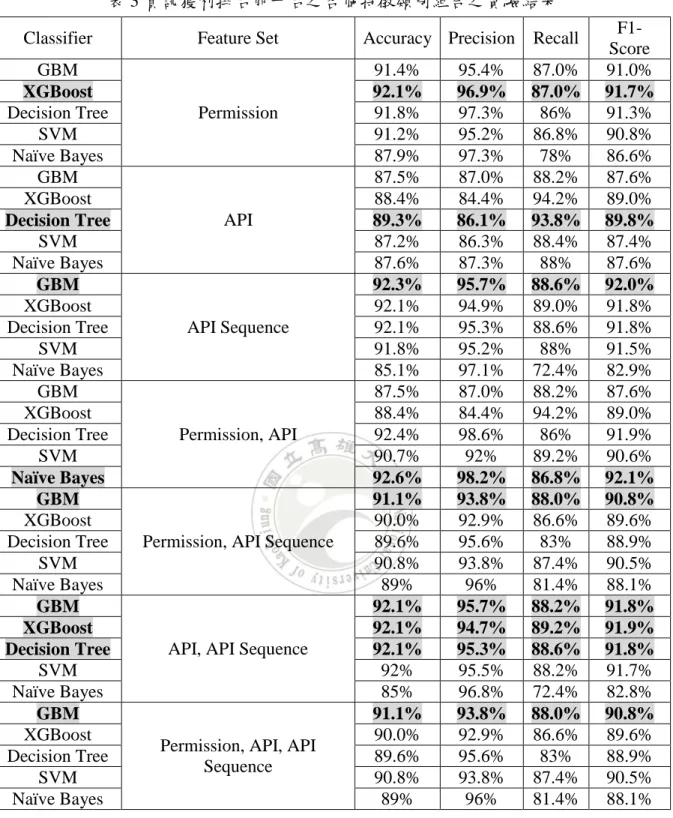
第三章 研究架構
在過去惡意程式分析的經驗,許多惡意行為會以順序性發生,比起以 Android API 函式呼叫進行分析,以順序性 API 函式呼叫分析可更加確認惡意行為的發生。因此根 據此一特性,本研究使用資料探勘中的分類分析技術,希望能夠藉由惡意程式和非惡 意程式之間順序性行為的差異,作為偵測未知惡意程式的分類條件。除此之外,本研 究也會評估使用 API 函式呼叫順序特徵有無的差異。在本研究中,將會從樣本中收集 Android APK 中的權限、 API 函式呼叫, API 函式呼叫順序資訊,讓預測模型進行學 習,此研究系統架構如圖 4 所示:圖 4 Android 惡意程式偵測系統架構
3.1 Android 惡意程式偵測系統架構
在此系統架構中,本研究將會分成兩個部份來說明。第一部分,將從定量的 Android 惡意程式與正常程式中提取出各程式之權限要求、Android API 函式,以及 Android API 函式呼叫先後順序作為原始資料。最後將應用程式權限、 Android API 函 式呼叫,以及 API 函式呼叫順序、各個特徵使用組合的方式合併成不同類別組合而成 的向量集,使用有或沒有代表每一項屬性值。第二部分,將第一部份所產生的訓練資 料集,利用五種資料探勘中的分類分析技術,分別為梯度提升、極限梯度提升、決策 樹、支援向量機以及單純貝氏分類,學習得到資料集中屬性與類別的關係。最後會評
17
估此五種分類分析技術,在本研究之 Android 惡意程式偵測中,何種效果最好。未來, 當本研究之 Android 惡意程式偵測系統接收到未知的 Android 應用程式時,便可依據之 前所學得之模型對其做分類預測,判斷此 Android 應用程式是否為惡意程式。
3.2 實驗變數
本研究使用 Android 權限、Android API 函式及 Android API 函式呼叫順序作為特 徵來源。在訪問特定資源或敏感性資料時,應用程式須先取得相關權限,隨後才能搭 配相對應之 Android API 函式執行相關動作。然而,通常應用程式之行為,皆由多個 API 函式所組合而成,且須依照特定順序呼叫,才能成功執行相關動作。例如:若惡 意 程 式 欲 持 續 探 測 藍 芽 裝 置 , 並 蒐 集 相 關 資 訊 。 應 用 程 式 得 先 呼 叫 API 函 式 BluetoothAdapter.isDiscovering 函式,檢查手機是否正在探測周圍環境中其他藍牙裝置。 若無,則呼叫 API 函式 BluetoothAdapter.startDiscovery 函式。也因此顯示出,不僅關 鍵 Android API 函式是否被呼叫為重要參考變數,其被呼叫之先後順序,更是具重要參 考價值之變數。此外,呼叫 API 函式 BluetoothAdpter.isDiscovering 函式 及 API 函式 BluetoothAdpter.startDiscovery 函 式 皆 須 請 求 授 予 相 對 應 之 權 限 BLUETOOTH 及 BLUETOOTH_ADMIN。這也顯示出,應用程式請求授予之 Android 權限與 Android API 函式之使用,具高度連動關係。也因此,我們將 Android 權限納為重要特徵變數。 其中,三種特徵變數內容之取得,皆來自 Androzoo 樣本資料集中之應用程式此三種重 要變數如表 1 所示。 表 1 實驗變數 變數類別名稱 說明 應用程式權限 資料集中應用程式所使用之權限
Android API 函式呼叫 資料集中應用程式所使用之 Android API 函式 Android API 函式呼叫順序
資料集中應用程式所使用之 Android API 函式呼叫先後 順序
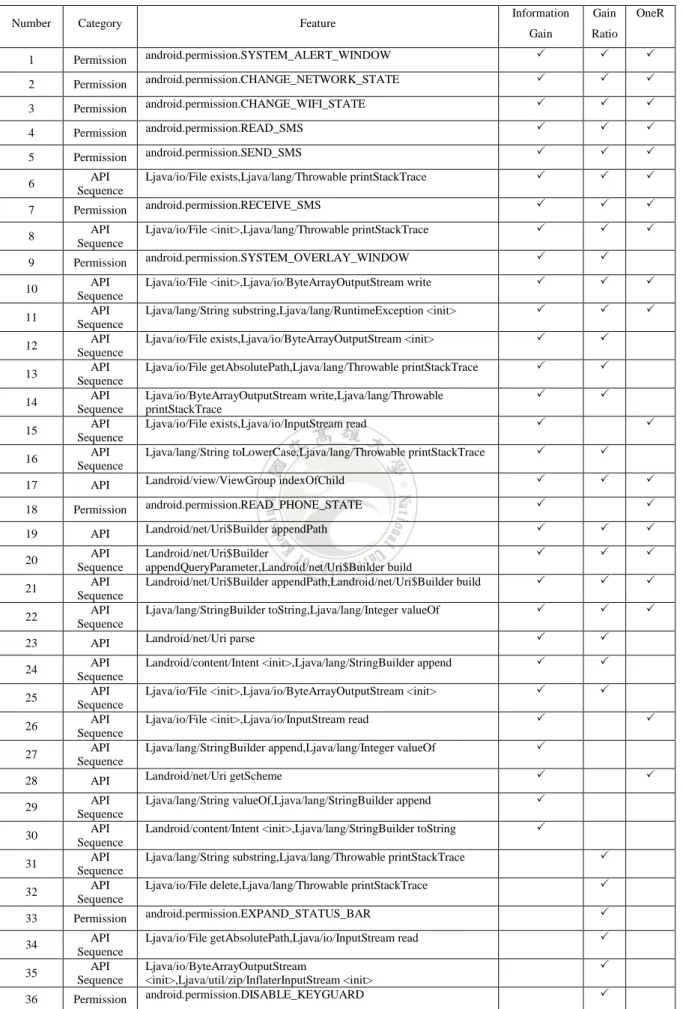
18 3.3 特徵篩選 由於在本研究中所蒐集到的特徵變數相當多,因此,在本研究中將會透過資訊獲 利、獲利比率以及單一規則此三種篩選特徵方法來挑選對於分類效果較好之特徵變 數,以此減少對於分類效果幫助不大之特徵變數。 資訊獲利(Information Gain) 資訊獲利為在資料探勘中被用於分類分析技術的決策樹篩選節點的衡量指標,決 策樹是透過建立一個樹狀結構的模型,藉由每一個特徵變數作為樹枝的節點,越上層 的節點則代表對於分類資料之效果越好,而這些決策樹節點的選擇,就是仰賴資訊獲 利的數值,資訊獲利是決策樹作為選擇該層之分類節點為何種特徵的指標,資訊獲利 越大,代表對於區分資料之效果越好,並以此來挑選最適合的特徵變數來作為當前樹 枝的節點。而資訊獲利的計算,則需透過對於資料集之熵值(Entropy)來取得,若一資 料集 S 中具有 C 個不同的類別,則此資料集之熵值計算公式為: Entropy(𝑆) = − ∑ 𝑝𝐶𝑖 𝑖 log2𝑝𝑖 其中 pi 則代表著該類別 i 在資料集 S 中出現的機率,如果一個資料群的屬性皆為 一致,則此資料群的熵值為零,反之,若一資料群可將資料一分為二,並且數量均等, 則資料群的熵值為一。而每一個節點的資訊獲利的計算方法,為資料集 S 的熵值減去 資料子集合的熵值,則為該節點之資訊獲利,並依此方法類推所有節點之資訊獲利。 而當前節點的挑選,則是選出資訊獲利最大之特徵變數。因此在挑選當前最好的分類 節點,為選擇目前資料集中之熵值最低的分類特徵變數,同時便可取得最大的資訊獲 利。 獲利比率(Gain Ratio) 獲利比率為基於資訊獲利方法的改良,在建構決策樹的模型時,我們會利用資訊 獲利的熵值來評估該節點該選何種特徵,然而這樣的方法當遇到決策樹分支過多的時 候,資訊獲利偏向選擇數值較多的特徵,使得原本的決策樹模型出現問題,導致一種
19 情況為雖然擁有很高的資訊獲利但卻使得分類出現不合理的情況。因此後續有學者提 出獲利比率,對比於資訊獲利,獲利比率加入了考量分支的數量,使得在建構決策樹 時,能有更佳客觀的衡量標準。 單一規則(One Rule) 單一規則是屬於一種簡單且有效的分類演算法,單一規則從資料中的每一個特徵 變數產生一個規則,並從中挑選分類誤差最小的規則作為單一規則。單一規則建立規 則的方法是統計所有特徵的每一個數值出現次數,依照資料中的特徵變數建立一個頻 率表格,從表中計算每一個特徵對於分類的總誤差率,並挑選總誤差率最小的特徵, 因為總誤差率最低意味著對於分類預測越有更高的可預測性。儘管準確度相對於目前 較新的分類演算法較為低,但產生的規則卻較容易使人理解,而本研究將會透過單一 規則計算總誤差率的方法,挑選排名較為前面的特徵變數。 3.4 分類預測模組 本研究所提出之 Android 惡意程式偵測系統中,使用目前資料探勘中較為常見的 五種分類分析技術作為建構自動學習分類預測模組。此五種分類分析技術分別為梯度 提升、極限梯度提升、決策樹、支援向量機以及單純貝氏分類進行分析。藉由此五種 資料探勘技術,並利用現有的樣本作為訓練資料集,分析 Android 應用程式各項資訊 屬性值與該類別之關係,以此建立一個分類預測系統,當未來有新的應用程式需要判 斷是否為惡意程式時,即可利用此預測系統進行類別判定。本研究挑選此五種分類分 析技術,其目的為在大量的 Android 惡意程式中,能夠在短時間內,即可快速判斷是 否為惡意程式。而此五種分類演算法也各有其優點,支援向量機能夠將分類惡意程式, 藉由二次函數分類模型的建立,在處理惡意程式此種二元分類之資料有良好的分類速 度。而決策樹則是訓練一個樹狀分支之分類模型,藉由各個變數對於分類效果之權重 高低來進行樹節點的安排,對於分類效果影響程度越高,則越在樹枝的上層。一旦模 型訓練完成後,當新的資料進來時,便不出需要龐大的運算即可快速完成預測結果。 而單純貝氏分類只需要根據少量的訓練資料,便可建立出一個條件機率模型,該條件 機率模型可使我們快速分類惡意程式。而梯度提升和極限梯度提升則是近年來較為被
20
分類預測廣泛使用之機器學習演算法,透過 Boosting 的技術,每一次的模型訓練皆會 基於前一個訓練的結果,並不斷修正整體模型,在訓練速度以及準確性皆有相當不錯 的效果,本研究亦將此兩類演算法加入此實驗中作為評估對於 Android 惡意程式分類 之效果。
21
第四章 實證與評估
本章將針對我們所提出之 Android 惡意程式偵測研究進行實證評估,以驗證本研 究所提出之以應用程序權限與介面呼叫模型偵測在分類 Android 惡意程式之準確性。 本評估將使用 Android 應用程式權限要求、Android API 函式呼叫以及 Android API 函 式呼叫順序,對本研究的偵測系統之分類分析模組中的梯度提升、極限梯度提升、決 策樹、支援向量機以及單純貝氏分類分別進行驗證。藉此評估本研究所提出之偵測系 統對於惡意程式之分類準確性。此外,本研究亦會將資料集依照不同的特徵類別進行 分組,探究 Android 應用程式權限要求、Android API 函式呼叫以及 Android API 函式 呼叫順序之間,在不同組合時對於分類惡意程式之準確性。
4.1 實驗數據收集(Data set)
為了萃取惡意程式與正常程式之特徵作為本實驗之訓練樣本,以此評估我們的分 類偵測模組準確度。我們從盧森堡大學所提供的應用程式樣本資料庫 (AndroZoo) [28] 收集應用程式樣本,此樣本資料庫之應用程式來源豐富,共計有 13 處 (Google Play, Anzhi, AppChina, 1mobile, AnGeeks, Slideme, torrents, freewarelovers, proandroid, HiApk, fdroid, genome, apk_bang),收集超過至少三百萬個 Android 應用程式,並透過可快速檢 測病毒、木馬、蠕蟲等惡意軟體服務平台 VirusTotal [29]分析,標籤是否為惡意程式以 確保惡意程式的標記為最新結果。截至 2020 年,AndroZoo 已經擁有千萬筆應用程式 之樣本。本實驗從中隨機收集並分析 2019 年裡各 500 隻正常及惡意程式作為資料分析 樣本共一千個 Android 應用程式。此外,我們將從 AndroZoo 所收集到的樣本再次透過 VirusTotal 此網站的服務進行標記惡意程式與正常程式,以確保最新檢測結果。 4.2 特徵變數集收集(Feature sets) 在完成樣本收集後,我們接著從 Android 應用程式中萃取我們所需之特徵變數, 包括應用程式要求權限、Android API 函式呼叫以及 Android API 函式呼叫先後順序, 以下將逐一介紹如何收集這三類特徵變數。
22 應用程式權限
每一個 Android 應用程式都需要在 Androidmanifest.xml 此檔案中宣告所需使用的 權限,才得以進行此操作。因此本研究將會把所收集到的一千個 Android 應用程式透過 Androguard 此工具讀取 Android 應用程式中的 Androidmanifest.xml ,解析出每一個 Android 應用程式要求之權限。在本次實驗中,共收集到 141 個應用程式中要求權限, 本研究會將此 141 個應用程式中的要求權限作為之後的特徵集。
Android API 函式呼叫
Android 應用程式中所有使用到的函式呼叫,都會被定義在 Android 應用程式套件 (APK)中檔案內的 classes.dex ,此檔案為用於在 Android Dalvik 虛擬機器上執行的程式 碼,又稱之為字節碼。每一個 Android 應用程式在執行前,都必須將原始的 Java 程式 碼透過工具轉換為 classes.dex,此檔案包含了 Android 中所有的類別與函式呼叫程式碼, 並 已 轉 成 Android Dalvik 虛 擬 機 器 所 能 直 接 執 行 的 字 節 碼 。 在 本 研 究 中 會 透 過 Androguard 進行取得字節碼中全部的原生 Android API 函式呼叫,在本實驗共收集到 17246 組 Android API 函式呼叫,每一個 Android API 函式呼叫特徵變數集都會由一個 類別搭配一個 Android API 函式呼叫名稱。
Android API 函式呼叫順序
在 本 研 究 中 , 為 取 得 Android 應 用 程 式 中 的 函 式 呼 叫 順 序 , 我 們 會 利 用 Androguard 其中的建立函式呼叫圖功能,來獲得所需之 Android API 函式呼叫先後順序 之特徵。Androguard 能夠解析 Android 應用程式中,每一個函式之間的呼叫先後順序 關係,以節點代表 Android 中所使用的函式、以線條代表每兩個節點之間的先後呼叫關 係,依此方法建立完整的程式邏輯。在本實驗中,本研究會將每兩個節點作為一組特 徵,即蒐集兩兩一組函式之間的先後順序特徵,以此作為本實驗之特徵變數集。在本 實驗共收集到約 99 萬組 Android API 函式呼叫,每一個 Android API 函式呼叫順序特徵 變數皆會由兩個 Android API 函式呼叫,第一欄為第一順序所呼叫之 Android API 函式, 第二欄為第二順序所呼叫之 Android API 函式。
23
4.3 特徵挑選(Feature selection)
在本研究中,所收集之 Android 權限要求、Android API 函式呼叫以及 Android API 函式呼叫順序此三類特徵類別之特徵變數之數量就已接近一百萬筆特徵。然而如此多 的特徵數量除了會提高分類分析模組之學習與訓練時間成本外,同時也會對於分類效 果造成反效果導致過適(over-fitting),即因過多的特徵使得分類效果不增反減。因此本 研究將使用資訊獲利、獲利比率,以及單一規則來取得對於分類 Android 惡意程式效 果較好之特徵。並分別針對各個組合之特徵向量集共七組來篩選,此七組特徵向量集 分別為: 應用程式權限(Permission) Android API 函式呼叫(API)
Android API 函式呼叫順序(API Sequence)
應用程式權限 + Android API 函式呼叫(Permission, API)
應用程式權限 + Android API 函式呼叫順序(Permission, API Sequence) Android API 函式呼叫 + Android API 函式呼叫順序(API, API Sequence)
應用程式權限 + Android API 函式呼叫 + Android API 函式呼叫順序(Permission, API, API Sequence) 並取資訊獲利、獲利比率,以及單一規則排名前一百名、八十名、六十名、四十 名、三十名、二十名以及十名之特徵變數,此處所透過特徵篩選方法取其特徵數量, 為先按照不同組合類別先合併特徵向量集,接著再透過特徵篩選的計算來取得排名。 例如要計算第一組資訊組合之資訊獲利前十名,方法為在僅有應用程式權限之特徵向 量集中,從中挑選對於分類效果之好之前十名。若要計算第七組資訊組合之資訊獲利 前十名,方法則為在應用程式權限、Android API 函式呼叫,以及 Android API 函式呼 叫順序之合併特徵向量集中,從中挑選對於分類效果之好之前十名。依此方法類推總 共會有 147 組特徵組合資料集,以此評估不同特徵篩選方法以及不同數量之特徵變數 對於分類預測之效果。
24 4.4 效能評比指標 為求實驗評估準確,本研究將所使用到的特徵變數皆採用十摺交叉驗證法(10-Fold-Cross-Validation)在各個分析模組中加以驗證。十摺交叉驗證法會將本研究所收集 到的資料隨機分成十組資料,每次實驗會取其中一組資料做為測試資料,其餘九組作 為訓練資料,如此形成一摺實驗資料組,並依序將十組資料做為測試資料,最後將會 把十次資料之數值平均值作為本研究之實驗結果。 在本研究中,我們使用分類分析常使用的四項指標,準確率(Accuracy)、精確率 (Precision)、召回率(Recall)以及 F1-Score 作為本研究之效能評估之指標,而此四項指 標可由表 2 的混淆矩陣中的條件構成,混淆矩陣為一個二維的表格,分別由真實資料 與分類預測結果所組成,並由四個數值 (TP, FN, FP, TN) 分別對應真實資料與分類預測 結果的配對。在表 2 中,真陽性 (TP, True Positive) 代表實際資料中應用程式為惡意程 式,經由本研究的分類偵測也被判斷為是惡意程式。偽陰性(FN, False Negative)表示實 際資料中應用程式為惡意程式,卻被本研究的分類預測模組判斷為正常程式。偽陽性 (FP, False Positive)代表實際資料中應用程式為正常程式,但經由本研究的分類預測模 組卻被判斷為惡意程式。真陰性(TN, True Negative)表示實際資料中應用程式為正常程 式,經由本研究的分類預測也被判斷為正常程式的應用程式。從上述實際資料與分類 結果的相互比較可以得到此四種指標的數值, 此四項指標定義如下: 表 2 混淆矩陣 真實資料 預測結果 惡意程式 非惡意程式 惡意程式 TP FP 非惡意程式 FN TN Accuracy = 𝑇𝑃+𝑇𝑁 𝑇𝑃+𝑇𝑁+𝐹𝑃+𝐹𝑁 Precision = 𝑇𝑃 𝑇𝑃+𝐹𝑃 Recall = 𝑇𝑃 𝑇𝑃+𝐹𝑁 F1-Score = 2∗𝑃𝑅 𝑃+𝑅
25 準確率(Accuracy)之定義為真陽性和真陰性的總和除以總數,在本研究的偵測結果 中,準確率代表本研究之偵測分類分析模組能夠正確分辨惡意與非惡意程式的比率, 準 確 率 代 表 整 體 分 類 模 型 之 判 斷 率 , 通 常 數 值 越 高 表 示 分 類 效 果 愈 好 。 精 確 率 (Precision)為真陽性與陽性總數(包括可能被誤認為陽性的偽陽性)之比率,代表所有被 本研究之偵測分類分析模組預測為是惡意程式中,實際為惡意程式之比率,即所有被 判定為是惡意程式中的程式有多少比例為真的惡意程式。召回率(Recall)是真陽性與實 際陽性總數之比率,代表所有被本研究之偵測分類分析模組預測判定正確的程式中, 有多少比例為惡意程式,也就是在被正確判斷為惡意程式和非惡意程式中,正確被判 斷為惡意程式佔了多少的比率。F1-Score 則為精確率和召回率的調和平均值,能夠綜 合評估精確率和召回率的數值。本研究將同時使用此四種效能評估指標,來評估本研 究之 Android 惡意程式偵測系統。 4.5 實驗結果 在本研究之實驗中,將會評估 1. 利用五個分類演算法分別為梯度提升、極限梯度 提升、決策樹、支援向量機以及單純貝氏分類,何種分類演算法對於分類 Android 惡 意程式具有較好之效果。 2. 在不同的特徵資訊類別(應用程式權限請求、Android API 函式呼叫、Android API 函式呼叫順序)組合中,何種特徵資訊的組合對於分類 Android 惡意程式具有較好的分類效果。3. 在不同的特徵資訊類別組合下,利用資訊獲利、獲 利比率,單一規則所取得的何種特徵數量對於分類 Android 惡意程式具有較佳的分類 效果。 在本研究實際透過資訊獲利、獲利比率,以及單一規則此三種特徵篩選方法篩選 完後,結果顯示在三者所篩選出來的特徵中,以資訊獲利中的變數與其他兩者特徵篩 選方法之交集變數最多,因此本研究認為以資訊獲利之方法較具代表性。以下將根據 資訊獲利篩選特徵後,分別挑選排名前十個特徵、排名前二十個特徵、排名前三十個 特徵、排名前四十個特徵、排名前六十個特徵、排名前八十個特徵以及排名前一百個 特徵,對於各個特徵資訊組合在不同的分類演算法之分類結果進行說明。為了方便說 明,在表格中分別以 Permission 代表應用程式權限,API 代表 Android API 函式呼叫, API Sequence 代表 Android API 函式呼叫順序。
26
表 3 資訊獲利排名前十名之各個特徵類別組合之實驗結果
Classifier Feature Set Accuracy Precision Recall F1-Score GBM Permission 91.4% 95.4% 87.0% 91.0% XGBoost 92.1% 96.9% 87.0% 91.7% Decision Tree 91.8% 97.3% 86% 91.3% SVM 91.2% 95.2% 86.8% 90.8% Naïve Bayes 87.9% 97.3% 78% 86.6% GBM API 87.5% 87.0% 88.2% 87.6% XGBoost 88.4% 84.4% 94.2% 89.0% Decision Tree 89.3% 86.1% 93.8% 89.8% SVM 87.2% 86.3% 88.4% 87.4% Naïve Bayes 87.6% 87.3% 88% 87.6% GBM API Sequence 92.3% 95.7% 88.6% 92.0% XGBoost 92.1% 94.9% 89.0% 91.8% Decision Tree 92.1% 95.3% 88.6% 91.8% SVM 91.8% 95.2% 88% 91.5% Naïve Bayes 85.1% 97.1% 72.4% 82.9% GBM Permission, API 87.5% 87.0% 88.2% 87.6% XGBoost 88.4% 84.4% 94.2% 89.0% Decision Tree 92.4% 98.6% 86% 91.9% SVM 90.7% 92% 89.2% 90.6% Naïve Bayes 92.6% 98.2% 86.8% 92.1% GBM
Permission, API Sequence
91.1% 93.8% 88.0% 90.8% XGBoost 90.0% 92.9% 86.6% 89.6% Decision Tree 89.6% 95.6% 83% 88.9% SVM 90.8% 93.8% 87.4% 90.5% Naïve Bayes 89% 96% 81.4% 88.1% GBM
API, API Sequence
92.1% 95.7% 88.2% 91.8% XGBoost 92.1% 94.7% 89.2% 91.9% Decision Tree 92.1% 95.3% 88.6% 91.8% SVM 92% 95.5% 88.2% 91.7% Naïve Bayes 85% 96.8% 72.4% 82.8% GBM
Permission, API, API Sequence 91.1% 93.8% 88.0% 90.8% XGBoost 90.0% 92.9% 86.6% 89.6% Decision Tree 89.6% 95.6% 83% 88.9% SVM 90.8% 93.8% 87.4% 90.5% Naïve Bayes 89% 96% 81.4% 88.1% 以表 3 資訊獲利排名前十名之各個特徵類別組合之實驗結果顯示,以特徵組合為 應用程式權限要求和 Android API 函式呼叫所組合而成之特徵類別,在單純貝氏分類之 分類效果表現最為良好,準確率可達 92.6% ,且精確率和召回率分別為 98.2% 和 86.8% ,而 F1-Score 則有 92.1% 。亦即在 100 筆資料中,若使用單純貝氏分類,則有 92.6 筆應用程式可正確判斷其為惡意程式或非惡意程式。其次為決策樹分類法,其準 確率為 92.4%,其精確率和召回率為 98.6% 和 86% ,而 F1-Score 則為 91.9% 。表現較
27 差者為梯度提升,準確率為 87.5% ,其精確率和召回率為 87% 和 88.2% ,而 F1-Score 為 87.6% 。從此結果中,以三種特徵類別個別來比較,我們發現以 Android API 函式呼 叫順序之單一資料集的準確率明顯高於應用程式權限類別以及 Android API 函式呼叫類 別,然而以三種類別組合而成的資料集之準確率略低於僅有應用程式權限和 Android API 函式呼叫類別此兩種特徵所組合而成之資料集。由此可推論,僅以資訊獲利排前 十為特徵數量,還不足以顯示出 Android API 函式呼叫順序對於分類效果的權重之高。 但整體準確率與其他組合差距不大。因此我們推測在特徵數的數量選擇,只取排名前 十個的代表性還不足夠。除此之外,我們已經可以看到,有使用組合特徵與沒有使用 組合特徵,確實有使用組合之資訊特徵有較高的準確率,且由此可見,在排名前十特 徵中,順序之特徵權重並不佔有太前面的排名。 表 4 資訊獲利排名前二十名之各個特徵類別組合之實驗結果
Classifier Feature Set Accuracy Precision Recall F1-Score GBM Permission 91.8% 96.0% 87.2% 91.4% XGBoost 92.1% 96.9% 87.0% 91.7% Decision Tree 92% 97.1% 86.6% 91.5% SVM 91.1% 95.4% 86.4% 90.7% Naïve Bayes 86.9% 98.4% 75% 85.1% GBM API 87.3% 86.8% 88.0% 87.4% XGBoost 88.7% 85.0% 94.0% 89.3% Decision Tree 90.4% 88% 93.6% 90.7% SVM 87.1% 86% 88.6% 87.3% Naïve Bayes 84.4% 91.5% 75.8% 82.9% GBM API Sequence 94.0% 94.4% 93.6% 94.0% XGBoost 94.1% 95.7% 92.4% 94.0% Decision Tree 94.9% 96.7% 93% 94.8% SVM 92.8% 93.5% 92% 92.7% Naïve Bayes 92.9% 94.4% 91.2% 92.8% GBM Permission, API 87.3% 86.8% 88.0% 87.4% XGBoost 88.7% 85.0% 94.0% 89.3% Decision Tree 96.2% 96.4% 96% 96.2% SVM 95.1% 94.1% 96.2% 95.2% Naïve Bayes 94.7% 94.6% 94.8% 94.7% GBM
Permission, API Sequence
95.3% 96.3% 94.2% 95.2% XGBoost 94.8% 95.3% 94.2% 94.8% Decision Tree 94.8% 95.5% 94% 94.8% SVM 95.4% 94.5% 96.4% 95.4% Naïve Bayes 92.3% 98.4% 86% 91.8% GBM
API, API Sequence
94.1% 94.0% 94.2% 94.1% XGBoost 93.0% 93.2% 92.8% 93.0% Decision Tree 94.2% 93.8% 94.6% 94.2%
28
Naïve Bayes 93.3% 94.1% 92.4% 93.2%
GBM
Permission, API, API Sequence 94.6% 96.1% 93.0% 94.5% XGBoost 94.5% 96.8% 92.0% 94.4% Decision Tree 94.4% 96.6% 92% 94.3% SVM 94% 95.3% 92.6% 93.9% Naïve Bayes 89.4% 97.3% 80.8% 88.3% 以表 4 資訊獲利排名前二十名之各個特徵類別組合之實驗結果顯示,各個特徵組 合類別皆在決策樹的分類法下,皆提升至 90% 以上,其中仍以應用程式權限要求和 Android API 函式呼叫所組合而成之特徵類別,在決策樹之分類效果表現最為良好,準 確率可達 96.2%,且精確率和召回率分別為 96.4% 和 96% ,而 F1-Score 則有 92.1% , 此四項指標之結果皆屬優異。顯示在此特徵數量下,對於判斷惡意程式已有相當的穩 定性和準確性。此外,我們發現,有使用組合之特徵類別之準確率上升幅度皆明顯大 於只有單獨單一特徵類別。 表 5 資訊獲利排名前三十名之各個特徵類別組合之實驗結果
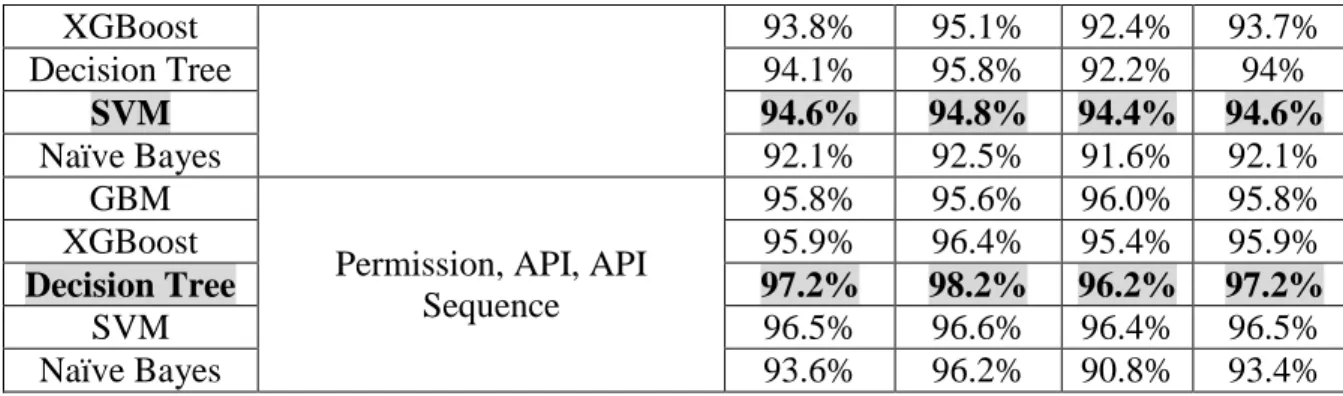
Classifier Feature Set Accuracy Precision Recall F1-Score GBM Permission 92.3% 96.1% 88.2% 92.0% XGBoost 91.6% 95.4% 87.4% 91.2% Decision Tree 93.0% 97.8% 88.0% 92.6% SVM 92.6% 96.9% 88.0% 92.2% Naïve Bayes 87.6% 97.5% 77.2% 86.2% GBM API 87.3% 87.1% 87.6% 87.3% XGBoost 88.7% 85.0% 94.0% 89.3% Decision Tree 91.0% 89.1% 93.4% 91.2% SVM 86.6% 85.6% 88.0% 86.8% Naïve Bayes 83.4% 90.7% 74.4% 81.8% GBM API Sequence 93.9% 94.0% 93.8% 93.9% XGBoost 93.3% 93.7% 92.8% 93.3% Decision Tree 93.9% 95.1% 92.6% 93.8% SVM 93.8% 94% 93.6% 93.8% Naïve Bayes 92.2% 93.6% 90.6% 92.1 GBM Permission, API 87.3% 87.1% 87.6% 87.3% XGBoost 88.7% 85.0% 94.0% 89.3% Decision Tree 96.1% 96.4% 95.8% 96.1% SVM 95.4% 94.5% 96.4% 95.4% Naïve Bayes 93.1% 94.3% 91.8% 93% GBM
Permission, API Sequence
95.9% 95.8% 96.0% 95.9% XGBoost 95.9% 96.4% 95.4% 95.9%
Decision Tree 97% 97.8% 96.2% 97%
SVM 96.7% 96.8 96.6% 96.7%
Naïve Bayes 93.4% 95.6% 91% 93.2% GBM API, API Sequence 94.1% 95.1% 93.0% 94.0%
29 XGBoost 93.8% 95.1% 92.4% 93.7% Decision Tree 94.1% 95.8% 92.2% 94% SVM 94.6% 94.8% 94.4% 94.6% Naïve Bayes 92.1% 92.5% 91.6% 92.1% GBM
Permission, API, API Sequence 95.8% 95.6% 96.0% 95.8% XGBoost 95.9% 96.4% 95.4% 95.9% Decision Tree 97.2% 98.2% 96.2% 97.2% SVM 96.5% 96.6% 96.4% 96.5% Naïve Bayes 93.6% 96.2% 90.8% 93.4% 以表 5 資訊獲利排名前三十名之各個特徵類別組合之實驗結果顯示,以特徵組合 為應用程式權限要求和 Android API 函式呼叫以及 Android API 函式呼叫順序所組合而 成之特徵類別,在決策樹之分類效果表現最為良好,準確率已達 97.2%,且精確率和 召回率分別為 98.2%和 96.2%,而 F1-Score 則有 97.2%。此外,該組合也已超過由應用 程式權限要求和 Android API 函式呼叫所組合而成之特徵類別之各項指標。代表在特徵 數量取至三十個時,由三項特徵類別所組合而成之特徵資料集能有最佳的分類效果。
表 6 資訊獲利排名前四十名之各個特徵類別組合之實驗結果
Classifier Feature Set Accuracy Precision Recall F1-Score GBM Permission 92.1% 96.3% 87.6% 91.7% XGBoost 91.5% 95.2% 87.4% 91.1% Decision Tree 93.3% 98% 88.4% 93% SVM 92.5% 97.1% 87.6% 92.1% Naïve Bayes 90.7% 97.7% 83.4% 90% GBM API 87.0% 86.6% 87.6% 87.1% XGBoost 88.9% 84.9% 94.6% 89.5% Decision Tree 91.9% 90.4% 93.8% 92.1% SVM 87.3% 87.2% 87.4% 87.3% Naïve Bayes 83.6% 90.6% 75% 82.1% GBM API Sequence 93.7% 93.8% 93.6% 93.7% XGBoost 93.4% 93.8% 93.0% 93.4% Decision Tree 94.4% 94.9% 93.8% 94.4% SVM 94% 94.4% 93.6% 94% Naïve Bayes 93.3% 94.3% 92.2% 93.2% GBM Permission, API 87.0% 86.6% 87.6% 87.1% XGBoost 88.9% 84.9% 94.6% 89.5% Decision Tree 95.8% 96.5% 95% 95.8% SVM 94.2% 93.3% 95.2% 94.3% Naïve Bayes 92% 93.4% 90.4% 91.9% GBM
Permission, API Sequence
95.6% 95.4% 95.8% 95.6% XGBoost 95.9% 96.2% 95.6% 95.9%
Decision Tree 96.8% 97.8% 95.8% 96.8%
SVM 96.4% 96.6% 96.2% 96.4%
30 GBM
API, API Sequence
94.4% 95.1% 93.6% 94.4% XGBoost 94.6% 95.3% 93.8% 94.6% Decision Tree 93.8% 95.1% 92.4% 93.7% SVM 95.6% 96% 95.2% 95.6% Naïve Bayes 92.4% 93.3% 91.4% 92.3% GBM
Permission, API, API Sequence 96.1% 96.6% 95.6% 96.1% XGBoost 95.4% 95.4% 95.4% 95.4% Decision Tree 96.9% 97.6% 96.2% 96.9% SVM 97% 97.6% 96.4% 97% Naïve Bayes 94.1% 94.9% 93.2% 94% 當本研究之特徵數量取至前四十名時如表 6,仍以由三項特徵類別所組合而成之 特徵資料集有最佳的分類效果,準確率為 97%,且精確率和召回率分別為 97.6%和 96.4%,而 F1-Score 則有 97%。我們發現當特徵數量取到四十個時,各項指標已經與三 十個特徵數量時差異不大。 表 7 資訊獲利排名前六十名之各個特徵類別組合之實驗結果
Classifier Feature Set Accuracy Precision Recall F1-Score GBM Permission 92.0% 95.5% 88.2% 91.7% XGBoost 91.7% 95.8% 87.2% 91.3% Decision Tree 93.0% 96.1% 89.6% 92.8% SVM 93.2% 98.0% 88.2% 92.8% Naïve Bayes 90.9% 97.7% 83.8% 90.2% GBM API 87.5% 87.0% 88.2% 87.6% XGBoost 89.3% 86.5% 93.2% 89.7% Decision Tree 91.1% 90.1% 92.4% 91.2% SVM 87.2% 84.8% 90.6% 87.6% Naïve Bayes 83.2% 90.3% 74.4% 81.6% GBM API Sequence 93.7% 93.8% 93.6% 93.7% XGBoost 93.4% 93.6% 93.2% 93.4% Decision Tree 94.8% 95.5% 94.0% 94.8% SVM 94.0% 94.9% 93.0% 93.9% Naïve Bayes 92.6% 94.6% 90.4% 92.4% GBM Permission, API 87.5% 87.0% 88.2% 87.6% XGBoost 89.3% 86.5% 93.2% 89.7% Decision Tree 91.1% 90.1% 92.4% 91.2% SVM 87.2% 84.8% 90.6% 87.6% Naïve Bayes 83.2% 90.3% 74.4% 81.6% GBM
Permission, API Sequence
96.0% 96.4% 95.6% 96.0% XGBoost 95.6% 95.2% 96.0% 95.6% Decision Tree 97.3% 98.2% 96.4% 97.3% SVM 96.5% 97.0% 96.0% 96.5% Naïve Bayes 93.8% 94.9% 92.6% 93.7% GBM
API, API Sequence 94.1% 94.0% 94.2% 94.1% XGBoost 94.2% 95.7% 92.6% 94.1%
31
Decision Tree 93.9% 94.7% 93.0% 93.8%
SVM 95.1% 95.9% 94.2% 95.1%
Naïve Bayes 91.3% 93.8% 88.4% 91.0% GBM
Permission, API, API Sequence 96.1% 96.6% 95.6% 96.1% XGBoost 96.2% 97.0% 95.4% 96.2% Decision Tree 97.0% 97.6% 96.4% 97.0% SVM 97.4% 98.0% 96.8% 97.4% Naïve Bayes 93.6% 94.7% 92.4% 93.5% 而當本研究之特徵數量取至前六十名時如表 7,仍以由三項特徵類別所組合而成 之特徵資料集有最佳的分類效果,準確率為 97.4%,且精確率和召回率分別為 98%和 96.8%,而 F1-Score 則有 97.4%。雖然在各項指標比起四十個時有些許上升,但仍然差 距不大。 表 8 資訊獲利排名前八十名之各個特徵類別組合之實驗結果
Classifier Feature Set Accuracy Precision Recall F1-Score GBM Permission 91.9% 95.4% 88.0% 91.6% XGBoost 91.7% 95.8% 87.2% 91.3% Decision Tree 93.0% 96.1% 89.6% 92.8% SVM 92.9% 97.6% 88.0% 92.5% Naïve Bayes 90.9% 97.7% 83.8% 90.2% GBM API 87.7% 87.2% 88.4% 87.8% XGBoost 89.6% 86.4% 94.0% 90.0% Decision Tree 91.1% 90.4% 92.0% 91.2% SVM 89.5% 86.6% 93.4% 89.9% Naïve Bayes 82.9% 89.6% 74.4% 81.3% GBM API Sequence 93.9% 94.0% 93.8% 93.9% XGBoost 94.0% 95.3% 92.6% 93.9% Decision Tree 95.1% 96.5% 93.6% 95.0% SVM 94.5% 95.1% 93.8% 94.5% Naïve Bayes 91.2% 94.0% 88.0% 90.9% GBM Permission, API 87.7% 87.2% 88.4% 87.8% XGBoost 89.6% 86.4% 94.0% 90.0% Decision Tree 91.1% 90.4% 92.0% 91.2% SVM 89.5% 86.6% 93.4% 89.9% Naïve Bayes 82.9% 89.6% 74.4% 81.3% GBM
Permission, API Sequence
96.1% 96.4% 95.8% 96.1% XGBoost 95.8% 95.4% 96.2% 95.8% Decision Tree 97.5% 98.2% 96.8% 97.5% SVM 97.1% 97.2% 97.0% 97.1% Naïve Bayes 93.6% 94.7% 92.4% 93.5% GBM
API, API Sequence
94.8% 95.3% 94.2% 94.8% XGBoost 95.1% 96.7% 93.4% 95.0% Decision Tree 94.3% 95.7% 92.8% 94.2%