台灣花卉批發市場整合關係的探討-變動門檻共整合之應用
67
0
0
全文
(2) 謝辭 中山是一個很美的地方,兩年前從未到過高雄的我帶著這個模糊的印象來到中山 展開研究所生涯。轉眼間,我已經結束碩士班課程並且完成屬於自己的著作,碩 士論文。這當中要感謝許多人的幫助。首先,碩士論文得以順利完成,我要感謝 我的指導教授李慶男老師。老師不僅教導我學術上的知識外,也常與我分享人生 經歷及為人處事的道理,讓我獲益良多。在論文寫作上,老師總是在繁忙的課務 中抽空指正我論文內容上的缺失,對於本論文的完成有莫大的幫助。還要感謝口 試委員,翁銘章教授及許永河教授,為學生的論文費心審查,並給予許多寶貴的 意見,使本論文更加完備。此外感謝所有老師的諄諄教誨,以及秀燕姐、育萍姐 和麗霜姐的協助,讓我可以專心致力於課業上的學習。 在求學過程中,特別感謝大為學長在我懵懂無知、徬徨無助的時候給我指引並鼓 勵我努力。還有地下室成員:沛翰、長富、政揚、建翔、怡君。謝謝你們陪我度 過兩年來的喜、怒、哀、樂。另外也要感謝同組戰友,于翔,祥凱,在論文寫作 期間,給予我諸多意見並幫助我解決論文排版的問題。以及所有的同學,謝謝你 們豐富了我碩士班的生活,祝你們一切順利。 最後,我要感謝我們家人,父親、母親、大哥、大姐和二姐。你們總是在生活上 及精神上給予我鼓勵,使我得以全心全意在求學的路途中前進。還有小青,總是 在我最累的時候陪著我。謝謝你們陪我度過這段求學的歲月,如果沒有你們的支 持,我想我沒有辦法完成碩士學位。若我有任何小小的成就,我願獻給你們。 中山真的很美,讓我有許多回憶,我會永遠記得的。. 王崇維 謹誌於 中山大學經濟研究所 中華民國九十七年六月.
(3) 摘要 本文主要以 Park (2007)的模型為架構,探討台灣花卉批發市場共整合關係。欲探 討市場整合情形,其概念是由單一價格法則延伸而來。單一價格法則的意義為, 若不考慮交易成本時,產品會從價格低的市場流向價格高的市場,直到各地市場 的價格達到一致。然而,在交易成本存在的情況下,單一價格法則的假設卻是有 問題的。兩市場間的價差超過交易成本時,套利行為有可能會發生。因此本文利 用門檻共整合方法分析台灣花卉批發市場間的整合關係。結果顯示,台灣花卉批 發市場間長期存在共移關係且具有明顯的門檻效果。除此之外,本文還利用 Park (2007)提出變動門檻值的觀點,嘗試分析台灣花卉批發市場間是否可能存在季節 性套利的行為。結果發現,由於門檻值的變動,即使批發市場間相同的價差,在 不同的季節會落在不同的門檻區域內,導致季節性的套利現象。. 關鍵字:單一價格法則,花卉批發市場,單根檢定,門檻共整合,變動門檻值.
(4) Abstract In the purpose of this study we examine the long run relationship between the flower wholesale markets in Taiwan by the theory of Park (2007). The market integration is analyzed from the viewpoint of the Law of One Price (LOP). The LOP means that the products flow from the lower price markets to the higher price ones without transaction cost utill everywhere have the same price.However, in a situation that the transaction cost exists, the assumption of LOP is questionable. When the price difference between two markets exceeds the transaction cost, there is an arbitrage opportunity. This study examine the relationship between the flower wholesale markets in Taiwan by threshold cointegration theory. The result is that there indeed exists long run relationship and threshold effects. In addition, we consider a timevaring threshold cointegration model in Park (2007), to see whether there are different arbitrage behavious depending on the season between the flower wholesale markets. Finally, we have a result that the same price gap between markets in different season will be in different regime because of the change of the value of threshold. And it causes the seasonal arbitrage behavious. Keywords : Law of One Price, Flower Wholesale Markets, Unit Root Test, Threshold Cointegration, Time-varing Threshold Cointegration..
(5) 目錄. 1 緒論. 1. 1.1. 前言 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 1. 1.2. 研究動機與目的 . . . . . . . . . . . . . . . . . . . . . . . . . . .. 3. 1.3. 研究架構 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 4. 2 經濟理論與文獻回顧. 5. 2.1. 經濟理論 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 5. 2.2. 文獻回顧 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 5. 3 研究方法 3.1. 10. 單根檢定 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12 3.1.1. Dickey-Fuller檢定 (DF 檢定) . . . . . . . . . . . . . . . 13. 3.1.2. Augmented Dickey-Fuller 檢定 (ADF 檢定) . . . . . . . 15. 3.1.3. Phillips-Perron檢定 (PP 檢定) . . . . . . . . . . . . . . 19. 3.1.4. DF-GLS檢定 . . . . . . . . . . . . . . . . . . . . . . . . 20. i.
(6) 3.2. 3.3. 3.4. 傳統共整合檢定 . . . . . . . . . . . . . . . . . . . . . . . . . . . 21 3.2.1. Engle and Granger 兩階段估計法 . . . . . . . . . . . . . 23. 3.2.2. Johansen最大概似估計法 . . . . . . . . . . . . . . . . . . 25. 門檻共整合模型 . . . . . . . . . . . . . . . . . . . . . . . . . . . 29 3.3.1. 模型 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30. 3.3.2. 估計 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33. 3.3.3. 檢定 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34. 變動門檻值的估計 . . . . . . . . . . . . . . . . . . . . . . . . . . 34. 4 實證結果分析. 36. 4.1. 資料來源說明 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36. 4.2. 單根檢定結果 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36. 4.3. 共整合檢定結果 . . . . . . . . . . . . . . . . . . . . . . . . . . . 38. 4.4. 4.3.1. Engle and Granger 兩階段估計法檢定結果 . . . . . . . . 39. 4.3.2. Johansen最大概似估計法檢定結果 . . . . . . . . . . . . . 40. 門檻向量誤差修正模型 . . . . . . . . . . . . . . . . . . . . . . . 46. ii.
(7) 4.5. 變動門檻值估計結果 . . . . . . . . . . . . . . . . . . . . . . . . 48. 5 結論與建議. 51. 5.1. 結論 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51. 5.2. 建議 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52. 參考文獻. 53. 附錄. 57. iii.
(8) 1 緒論. 1. 緒論. 1.1. 前言. 近年來, 隨著國民所得增加及生活水準提升在食物方面日益講求精緻與品質; 作物方 面, 亦由過去水稻為主的糧食生產, 轉向蔬菜、 水果、 花卉等園藝作物生產。 其中, 花 卉是政府農業產業結構調整方案下的一項重點產業, 農業政策白皮書中指出, 台灣地 區未來農作物生產, 在園藝作物產銷結構的調整方面, 發展策略作法的第一項是: 園 藝作物之生產朝向企業化、 專業化、 精緻化與多樣化發展, 建立本土特色, 未來將以種 苗、 蔬菜、 熱帶、 水果、 花卉、新興菇類等為發展重點。 可見花卉產業在未來農業產業 中將扮演重要角色。 以農業條件而言, 台灣非常適合經營花卉作物生產。 因為台灣氣候適宜, 具有熱帶 及亞熱帶兩種類型的氣候帶, 同時又擁有高低海拔不同高度的坡地, 使得種類及品種繁 多的花卉作物, 在台灣都能全年性的生長並供應市場需求。 根據行政院農業委員會之 統計, 台灣地區之花卉生產從 1980 年代以來即逐年成長, 從 1983 年栽培面積僅 2996 公頃, 產值16億, 到2004年已成長至栽培面積12579公頃, 總產值125.3億,22年來栽 培面積成長 4 倍, 產值成長高達 8 倍。 直至今日, 全體花卉的產值每年可達上百億, 花 卉成為具有高利潤產值的農產作物, 花卉產業發展的潛力指日可待。 談到台灣花卉產業, 台灣地區的花卉批發市場扮演一個重要的角色。 在花卉批發市 場成立之前, 花卉的交易制度屬於自產自銷及行口交易的方式, 由傳統市場花商直接 向產地尋求貨源進行交易, 或由花農直接在市場販賣, 這樣的交易模式花商必須費時 尋求貨源, 而花農在進行生產時則須擔心能否順利銷售, 由於難以兼顧產銷, 造成產品 品質提升不易; 且雖有交易功能, 但在價格形成及結價機制上, 因缺乏中間仲裁而易產 生糾紛。 因此政府農政單位一方面為解決上述問題, 另一方面為健全花卉運銷體制, 自. 1.
(9) 1.1 前言 民國 77 年起陸續輔導花卉運銷者、 生產者和農民團體興建花卉批發市場, 以批發市場 為運銷體制的中心, 負擔花卉集中、 均衡與分散的運銷職能工作。 花卉批發市場以公 開競價的拍賣方式進行交易, 價格形成較為公開、 公平及公正, 也能適切地反應市場供 需狀況。 此外, 交易相關資料由電腦資料庫系統的彙總, 能迅速精確的計算出市場交易 統計資料, 再藉由農產品行情報導系統傳遞給花卉生產和運銷相關人員, 做為相關決 策的參考資料。 台灣目前共有5家花卉拍賣市場: 台北花卉產銷股份有限公司 (台北花 市)、 台灣區花卉運銷合作社 (台中花市)、 彰化縣花卉批發市場 (彰化花市)、 台南市綜 合農產品批發市場 (台南花市) 及高雄國際花卉股份有限公司 (高雄花市)。 各花卉市 場成立時間表如下: 表 1: 花卉批發市場組織 批發市場. 台北花市. 台中花市. 彰化花市. 台南花市. 高雄花市. 成立時間. 西元 1989 年. 西元 1995 年. 西元 1994 年. 西元 1995 年. 西元 2003 年. 藉由花卉批發市場的設立, 不僅使花商、 花農專業分工, 有助花卉產品的品質提升, 亦 使以花卉批發市場為中心的運銷體系更加穩定健全, 目前台灣花卉產業大部分的花卉 物流是由產地花農透過農會、 產銷班、 合作社等組織單位或自行向花卉批發市場申請 供應代號, 供貨到花卉批發市場進行拍賣, 再由承銷商競價拍賣後購得貨品, 零售商 (花店等) 再向承銷商購買, 然後到達消費者手中。 而承銷商也可由花卉批發市場透過 訂貨交易直接與供應人媒介交易, 另外目前也還有經由販賣商或出口商直接與花農接 洽購買者。 未來台灣花卉產業應會朝向市場與物流中心概念結合之交易制度發展, 結合現代 化科技及高速資訊網路之運用, 追求高品質高效率之產品運銷體系。. 2.
(10) 1.2 研究動機與目的. 1.2. 研究動機與目的. 僅管台灣地區花卉批發市場的作業和交易方式已漸趨現代化, 但由於各個批發市場所 地處的區位不同, 地理位置、 氣候的差異皆會影響花卉的產量, 加上各市場創設和經營 方式不盡相同, 導致各批發市場之相同花卉的價格有所差異, 批發市場間的花卉交易 價格是否存在長期均衡的共移現象, 值得深入探討。 回顧過去相關研究, 有關花卉的文 獻, 較少有實證研究著重於市場整合的探討; 有關時間序列的文獻, 較少有實證研究應 用在花卉議題上。 欲探討市場整合情形, 其概念是從單一價格法則的角度出發, 但由於 市場間存在空間距離, 交易成本也變成影響花卉交易價格的因素之一。 交易成本可視 為商品物流的阻力, 就台灣花卉物流而言, 目前已被解釋的交易成本包括資訊成本與 運輸成本。 由於花卉批發資訊分享熱線的建立代表花卉交易資訊的流通, 拍賣資訊的 透明化, 使得非對稱資訊因素消除, 資訊成本已大幅下降, 故一般在進行花卉市場相關 研究時, 交易成本常以運輸成本為主。 考慮交易成本的問題, 若市場間存在價差, 當價 差小於交易成本, 利潤無法產生, 套利的行為不會進行, 造成市場間非連續性的調整。 因此門檻共整合模型 (Threshold Cointegration) 是最合適分析考慮交易成本存在 時, 市場間長期均衡共移現象的模型。 以台灣的花卉批發市場而言, 台北花市是最早成 立, 其規模和交易量為各市場之最, 所以全台灣是以台北花市為中心市場運作, 其他市 場為地方市場。 本文試著以門檻共整合模型分析考慮交易成本下, 中心市場對各地方 市場的整合情形。 由於高雄花市是 2003 年才開市, 市場組織尚未發展成熟, 能收集到 的訊息也有限, 所以在此不納入研究對象。 此外, 本研究嘗試引用 Park (2007) 提出 的變動門檻值的論點, 藉由隨時間變動的門檻值, 試著分析門檻值是否存在季節性的 變化, 而在本文中門檻值代表的經濟意義是成本, 因此本研究更進一步探討市場間是 否可能存在季節性套利行為的現象。. 3.
(11) 1.3 研究架構 具體而言, 本研究之目的為:. 1. 以實證分析台灣地區花卉批發市場之中心市場與地方市場是否存在共整合關係。 2. 以實證分析台灣地區花卉批發市場之中心市場與地方市場是否存在門檻共整合 關係。 3. 藉由變動的門檻值, 研究花卉批發市場之中心市場與地方市場間是否可能存在 季節性套利行為的現象。. 1.3. 研究架構. 本文的架構共分為五章。 第一章為緒論, 說明本文的研究背景、 研究動機、 研究目的及 簡述本文的內容架構。 第二章為經濟理論與文獻回顧, 首先先介紹單一價格法則, 接著 介紹國內外學者研究有關農產品的相關文獻。 第三章為研究方法, 介紹本文所用的相 關計量理論模型, 包括單根檢定、 共整合檢定模型及門檻向量誤差修正模型等。 第四 章為實證結果, 利用計量模型所得到的實證結果作一整理與呈現。 第五章為結論, 對本 文的實證研究結果做總結說明。. 4.
(12) 2 經濟理論與文獻回顧. 2. 經濟理論與文獻回顧. 2.1. 經濟理論. 1. 單一價格法則: 所謂單一價格法則是指同質性的商品在不考慮運輸成本、 關稅、 貿易障礙、 及蒐集 資訊成本下, 經由商品套利的行為, 將使市場上同質性的商品只存在單一價格。 因為地 區間同質性商品的價格如果存在差異性的話, 套利者會在價格低的地區買商品, 然後 在價格高的地區販售商品。 如此一來, 透過市場機制的運作最終會使地區間商品的價 格趨於一致。. 2.2. 文獻回顧. 本節主要是描述過去學者的相關研究。 回顧有關共整合檢定的實證研究文獻, 屬於財 務、 金融方面 (股價、 匯率、 期貨...等) 的文獻相當豐富, 而應用在農產品市場的實 證研究文獻相對而言比較少。 在此, 僅就所搜集有關農產品市場整合文獻分國外及國 內兩部份作一簡單的敘述。 1. 國外農產品市場相關文獻: Ardeni (1989) 以 Engle and Granger (1987) 的共整合檢定法, 針對美國、 加 拿大、 澳洲及英國四個國家的小麥、 茶、 牛肉、 糖、 羊毛、 鋅和錫七種產品, 檢定單一 定價法則。 首先先對單一變數進行單根檢定, 以便確認變數的性質。 由結果得知, 除了 英國錫的價格無法拒絕單根外, 其他產品的價格皆可拒絕單根檢定, 所以確認了大部 分變數皆為非定態的序列。 接著再進行共整合檢定, 發現除了小麥和茶以外, 其他產品. 5.
(13) 2.2 文獻回顧 不具有共整合關係, 即無法支持單一價格法則。 Baffes (1991) 沿用 Ardeni (1989) 的樣本資料, 惟修正檢定模型, 同樣研究美 國、 加拿大、 澳洲及英國四個國家的七種產品。 由單根檢定結果顯示, 除了英國和美國 的錫的價格是 I(0) 數列外, 其他產品的價格皆為 I(1) 數列。 接著進行共整合檢定, 發 現大部分產品具有共整合關係, 得到了與 Ardeni (1989) 相異的結果, 驗證了單一價 格的存在。 Alexander and Wyeth (1994) 使用 Engle Granger (1987) 的共整合檢定法 及 Johansen (1998)、(1991) 共整合檢定法分析1979年1月到1990年12月印尼七個 稻米市場的共整合關係。 結果顯示所有各別市場的稻米價格皆為 I(1) 數列。 進而做共 整合檢定, 發現除了雅加達和 Ujung Pandang兩個市場沒有共整合關係外, 其餘市 場皆具有共整合關係。 B.H. Ling、Leung and Shang 等人 (1998) 同樣以 Engle Granger (1987) 的 共整合檢定法探討 1990 年 6 月至 1993 年 12 月泰國、 印度及日本草蝦產品市場的共整 合關係。 結果顯示市場間皆存在共整合的關係。 Goodwin and Piggott (2001) 運用門檻共整合分析北卡羅萊州 (North Carolina) 玉米以及大豆的四個市場的共整合性。 在該研究中, 玉米是以最大交易量的 Williamston 市場為中心市場, 其餘3個市場為地方市場 (Candor、Cofield、Kingston); 大豆則是以 Fayetteville 市場為中心市場, 其餘3個市場為地方市場 (Raleigh、Greenville、 Kingston)。 分析資料是日均價格, 以中心市場分別對地方市場進行門檻共整合檢定。 指出門檻共整合比傳統共整合更適合探討考慮交易成本下的市場整合情形, 並且指”非 對稱的門檻”比”對稱的門檻”更有解釋能力。 另外, 研究中拿各市場的相對距離做比 較, 說明因為較遠的市場有較大的交易成本, 所以兩市場相對距離大則門檻值也大。 距離較遠的市場其回到均衡區間的速度較慢也驗證了市場較遠則整合性比較差。 最後,. 6.
(14) 2.2 文獻回顧 研究結果顯示, 除了大豆市場中的 Candor 及 Williamston 兩市場有較不明顯的整 合關係, 其餘市場皆有共整合關係。 Sephton (2003) 將 Goodwin and Piggott (2001) 做進一步的延伸, 認為門檻 的數目應該內生決定, 而不是直接假設門檻的數目進行估計, 所以採用 Hansen 門檻 數目檢定法取代 Tsay 檢定門檻顯著性的方法。 以此門檻數目檢定法發現: 大豆市場中 的 Fayetteville市場及 Kingston 市場應為單一門檻。。 而玉米市場各地方市場對中心 市場皆為單一門檻。 確認門檻數目之後再一次進行各市場的共整合檢定, 與 Goodwin and Piggott (2001) 的研究結果一致, 除了大豆市場中的 Candor 及 Williamston 兩市場有較不明顯的整合關係, 其餘市場皆有共整合關係。 Park (2007) 運用非線性調整的門檻共整合來探討北美汽油市場的單一價格法則, 更指出門檻值應該會隨著時間的變動而變動。 這個論點有別於以往門檻值一旦決定後 就不再變動, 作者也以這種變動的門檻值來說明一些季節性的套利行為。 2. 國內農產品市場相關文獻: 涂旭志 (1994) 「臺灣產地蔬菜批發市場決價效率之研究」, 利用單根檢定及共整合 檢定, 以溪湖、 永靖、 西螺三個產地蔬菜批發市場為對象, 研究市場間價格是否存在共 整合關係。 最後研究結果顯示, 大部份的市場蔬菜價格間皆存在共整合關係。 即表示產 地批發市場間的價格長期下彼此有一定程度的影響。 陳慧秋和陳玄宗 (1994) 「台灣毛豬批發價格空間均衡分析-共整合方法之應用」, 同樣利用單根檢定及共整合檢定台灣地區十個毛豬批發市場價格之共整合關係。 蔡月香 (1997) 「台蕉與菲蕉在日本市場上之價格行為分析-共整合法之應用」, 則 是以 Engle Granger (1987) 的共整合檢定法探討台蕉與菲蕉在日本市場上的關係。 實證結果指出台蕉與菲蕉在日本市場上的價格都具有單根, 顯示台蕉價格數列及菲蕉 7.
(15) 2.2 文獻回顧 價格數列皆有非定態的現在。 共整合檢定發現台蕉價格與菲蕉價格長期下存在均衡穩 定的正向關係。 郭如秀 (1998) 對台灣玉米現貨價格與美國玉米期貨價格進行共整合研究, 發現玉 米現貨價格序列與期貨價格序列具有共整合關係。 何彩華 (2002) 研究台灣台北、 台中、 彰化以及台南四個花卉批發市場之共整合關 係。 以八種花卉在四個批發市場的平均週價格為資料做分析。 選定一個批發市場為中 心市場, 其餘三個市場為地方市場, 分別探討各地方市場與中心市場間的關係。 研究結 果顯示不論以台北或彰化化市為中心市場做分析, 中心市場的價格皆會影響其餘三個 地方市場的價格, 而且大致上地方市場與中心市場長期下呈現整合關係。 賴瀚棠 (2004) 以向量自我迴歸模型分析台北花市與彰化花市多種花卉的相依性, 並以共整合檢定探討多條花卉供應鏈的市場整合關係。 黃致穎 (2005) 進一步以門檻共整合模型探討考慮交易成本下台灣四個花卉批發 市場多條花卉供應鏈的共整合關係。 其研究結果證明了台灣花卉批發市場是以台北市 場為中心在運作的供應鏈體系, 台北市場花卉的拍賣價格將影響台中、 彰化、 台南市場 的價格。 總觀前述實證研究文獻, 學者們以不同的模型及不同的計量方法討論有關各種農 產品的單一價格法則。 由於各學者使用的資料及研究方法皆不同, 所以得到的結果不 盡相同, 但皆是以討論市場長期均衡狀態為宗旨。 欲探討套利行為的實證分析, 我們 不能忽略交易成本的因素。 考慮交易成本的情況下, 使用傳統的線性方法不盡合理, 為 了能得到正確的估計結果, 門檻共整合是最適合的方法。 根據 Goodwin and Piggot (2001) 指出門檻共整合比傳統共整合更適合探討考慮交易成本下的市場整合情形。 因 此本文主要是以 Park (2007) 為架構, 依據黃致穎 (2005) 以門檻共整合模型分析台. 8.
(16) 2.2 文獻回顧 灣花卉批發市場的實證研究, 同樣以門檻共整合模型對台灣花卉批發市場做實證研究, 由於花卉深受季節氣候自然條件的影響, 進而影響花卉的價格, 花價的波動亦會影響 交易成本, 在門檻共整合模型中, 交易成本為區分區域的門檻值, 交易成本的改變意謂 著門檻值的變動, 因此季節性因素顯得不可忽視, 本文更進一步嘗試引用 Park (2007) 提出的變動門檻值的論點, 探討市場間是否可能存在季節性套利行為的現象。. 9.
(17) 3 研究方法. 研究方法. 3. 自從 Nelson and Plosser (1982) 利用 Dickey-Fuller 檢定法對美國資料進行檢定 分析後, 發現大部份總體經濟變數普遍存在單根的現象, 即時間序列具有非恆定的特性 (non-stationary)。 因此大體上學術界普遍接受多數總體經濟變數為非恆定的時間序 列。 而在傳統的實證研究中, 多採用迴歸估計的方式來解釋變數間的關係。 當我們在做 迴歸分析時, 若討論的變數為非定態的時間序列, 會有虛偽迴歸 (spurious regrssion) 的問題產生,1 得到錯誤的結果。 為了避免虛偽迴歸的情況發生, 在利用時間序列變數進 行實證分析之前, 判定變數是否具恆定性已成為實證分析中必要的一項步驟。 以下我 們先簡單的介紹何謂恆定。 時間序列資料的特性區分為恆定性(stationary) 與非恆定 性 (non-stationary), 恆定性又可分為強恆定性 (strongly stationary) 與弱恆定性 (weakly stationary 或 covariance ststionary)。 一般的恆定性是指弱恆定性, 因此 以下我們僅定義弱恆定性。 如果一時間序列 yt 滿足下列的三個條件, 且對於所有的 t 、 t − s 、 t − j 而言: E(yt ) = E(yt−s ) = µ E(yt − µ)E(yt − µ) = E(yt−s − µ)E(yt−s − µ) = σy2 E(yt − µ)E(yt−s − µ) = E(yt−j − µ)E(yt−j−s − µ) = γs. 則我們稱此時間序列 yt 具有弱恆定性, 其中 µ 為期望值, σy2 為變異數, γs 為 s 期自我 共變異數。 由上述的定義, 我們可以發現期望值 µ 、 變異數 σy2 皆為有限的常數, 而自 我共變異數 γs 則取決於期數的差距, 亦為一有限常數, 三者皆不隨著時間的變動而改 變。 反之, 對於一個非恆定的數列而言, 外在的干擾並不會隨時間的變動而逐漸消失, 其變異數也不再只隨著期數差距的不同而不同。 欲分析一個非恆定的的時間數序, 有 1. 以迴歸方法檢定或估計實證模型的時候, 如果所採用的時間序列變數不是定態, 則迴歸結果很有可 能使原本毫無線性關係的變數間, 出現假的線性關係。. 10.
(18) 3 研究方法 兩種方法可以使其變為得具有恆定性, 一為差分穩定, 一為趨勢穩定。 以下分別對差分 穩定及趨勢穩定做簡單的描述。 1. 差分穩定 (Differencing-Stationary): 所謂的差分穩定是指非恆定數列可經由差分轉換成恆定的數列。 若一非恆定數列 只需差分一次即可達到恆定性, 則稱此數列的整合階次為 1 (integrated of order 1), 也稱此數列具有單根, 記為 I(1) , 若需差分 d 次才能達到恆定性, 則其整合階次為 d , 記為 I(d) 。 一個數列 Yt 經過 d 次差分後, 即 (1 − L)d Yt , 可被表示成一個穩定且可逆 的 ARM A(p, q) 如下: (1 − φ1 L − φ2 L2 − . . . − φp Lp )(1 − L)d Yt = c + (1 + θ1 L + θ2 L2 + . . . + θq Lq )εt (3.1a) 或 φ(L)(1 − L)d Yt = c + θ(L)εt. (3.1b). 其中 φ(L) = 0 及 θ(L) = 0 的所有根皆位於單位圓外 (outside the unit circle), 且 εt 為一白噪音 (white noise), 則稱 Yt 是一個 ARIM A(p, d, q) 數列。 若 d = 1 , 即有單根的情況下,(3.1b) 式可改寫為 (1 − L)Yt = c∗ + ψ(L)εt. (3.2). 其中 c∗ = φ−1 (L)c , ψ(L) = φ−1 (L)θ(L) 且係數為絕對可加, 經過替代運算後, 則 (3.2) 式可表示成: ∗. Yt = Yo + c t + ψ(L). t−1 X i=0. 11. εt−i. (3.3).
(19) 3.1 單根檢定 其中 c∗ t 為固定趨勢, ψ(L). Pt−1 i=0. εt−i 為隨機趨勢。. 2. 趨勢穩定 (Trend-Stationary): 若有一數列為 Xt = µ + ct + ψ(L)εt. 其中 ψ(L) 的係數為絕對可加, E(Xt ) = µ + ct , V ar(Xt ) = (1 + ψ12 + ψ22 + . . .)σ 2 , 因為 V ar(Xt ) < ∞ , 因此只要從 Xt 數列中去掉 ct , Xt 則可轉成恆定的數列, 此稱 為趨勢穩定過程。. 單根檢定. 3.1. 時間序列資料應具有恆定性, 才能避免分析時產生虛偽迴歸的問題。 要判斷資料是否 具有恆定性, 在計量方法上, 我們常使用單根檢定來判斷。 以下簡單介紹何謂單根檢 定。 考慮存在一個 AR(1) 過程: yt = ρyt−1 + ut , 其中 ut 為白噪音。 在不考慮所謂 的分數單根的情形下, 若 ρ > 1 時將會使數列發散, 唯有 ρ = 1 是最容易探討的情形。 而當 ρ = 1 時, 我們稱為單根過程 (unit root process), 檢定 ρ 是否等於 1 則為單根 檢定。 本文將介紹一般實證研究常使用的單根檢定法: Dickey-Fuller檢定 (DF 檢定)、 Augmented Dickey-Fuller(ADF 檢定)、 Phillips-Perron(PP檢定)、 DF-GLS 檢 定。 在 DF 單根檢定中, 誤差項假設為白噪音, 至於 ADF 檢定與 PP 檢定則是將誤 差項的限制逐漸放寬。. 12.
(20) 3.1 單根檢定. 3.1.1. Dickey-Fuller檢定 (DF 檢定). 此檢定由 Dickey and Fuller 於1979年提出, 考慮殘差項為白噪音的 AR(1) 模型去 檢定是否具有單根特性。 在給定樣本觀察值的情況下, Dickey and Fuller 證明利用 OLS 法所估出 ρ 的估計值 ρˆ 具有一致性; 同時, 在具有單根的虛無假設下, 檢定統計 量的漸進分配不再為常態家族分配, 而是兩個布朗運動 (Brownian Motion) 相除的 形式, 以下便進一步說明。 假設母體迴歸式為一個 AR(1) 模型如下: Yt = ρYt−1 + ut ρ=1. 在此令起始值 Y0 = 0 且 ut 為 i.i.d(0, σ 2 ) 為一白噪音。 而根據迴歸式是否包含常數項 (constant term) 或時間趨勢項 (timetrend term) 又可分為下列三種模型: 模型一: 迴歸式中沒有常數項及時間趨勢項 yt = ρyt−1 + ut. (3.4). 假設檢定為 H0 : ρ = 1 , H1 : ρ < 1 , 在虛無假設成立之下 Dickey and Fuller 導出檢定統計量的極限分配: 1/2{[W (1)]2 − 1} T (ˆ ρ − 1) −→ R1 W (r)2 dr 0 L. ρˆ − 1 L 1/2{[W (1)]2 − 1} t= −→ R 1 σ ˆρˆ { 0 W (r)2 dr}1/2 13.
(21) 3.1 單根檢定 其中 σ ˆρˆ = [s2 ÷. PT. t=1. 2 yt−1 ]1/2 且 s2 =. PT. t=1. (yt − ρˆyt−1 )/(T − 1)2 , 而 ρˆ 是由. (3.4) 式用 OLS 估計法得到的估計值。 模型二: 迴歸式中有常數項但無時間趨勢項 yt = θ + ρyt−1 + ut. (3.5). = x0 t p + ut. 其中 θ 為迴歸式中之常數項, p = [ θ ρ ]0 , xt = [ 1 yt−1 ]0 。 假設檢定為 H0 : ρ = 1 (且 θ = 0 ), H1 : ρ < 1 , 在虛無假設成立之下 Dickey and Fuller 導出檢定統計 量的極限分配: R1 1/2{[W (1)]2 − 1} − W (1) · 0 W (1)dr T (ˆ ρθ − 1) −→ R1 R1 2 W (r) dr − [ W (r)dr]2 0 0 R1 2 ρˆθ − 1 L 1/2{[W (1)] − 1} − W (1) · 0 W (1)dr −→ tθ = R1 R1 σ ˆρˆθ { 0 W (r)2 dr − [ 0 W (r)dr]2 }1/2 L. P 其中 σ ˆρˆθ = [s2 e0 2 ( xt x0 t )−1 e2 ]1/2 , e2 = [ 0. 1 ]0 且 s2 =. PT. t=1 (yt. − θˆ −. ρˆθ yt−1 )2 /T − 2 而 ρˆθ 是由 (3.5) 式利用 OLS 估計法得到的估計值。 模型三: 迴歸式中有常數項及時間趨勢項 yt = θ + ρyt−1 + δt + ut. (3.6). = x0 t p + ut. θ 為迴歸式中之常數項, δ 為迴歸式中之時間趨勢項, p = [θ ρ δ]0 , xt = [1 yt−1 t]0 。 假設檢定為 H0 : ρ = 1 (且 δ = 0 ), H1 : ρ < 1 , 在虛無假設成立之下 Dickey and. 14.
(22) 3.1 單根檢定 Fuller 導出檢定統計量的極限分配: R1 R1 R1 1/2{[W (1) − 2 0 W (r)dr][W (1) + 6 0 W (r)dr − 12 0 rW (r)dr] − 1} T (ˆ ρτ − 1) −→ R 1 R R R R 2 dr − 4[ 1 W (r)dr]2 + 12 1 rW (r)dr 1 W (r)dr − 12[ 1 rW (r)dr]2 [W (r)] 0 0 0 0 0 ρˆτ − 1 tτ = σ ˆρˆτ L. P 其中 σ ˆρˆτ = [s2 e0 3 ( xt x0 t )−1 e3 ]1/2 , e3 = [ 0. 1. 0]0 且 s2 =. PT. t=1 (yt. − θˆ −. ˆ 2 /T − 3 , 而 ρˆτ 是由 (3.6) 式利用 OLS 估計法得到的估計值。 ρˆθ yt−1 − δt) 若檢定結果無法拒絕虛無假設, 則 yt 為一非恆定性序列, 具有單根; 反之, yt 為一 恆定性序列。 上述三種模型的檢定統計量之極限分配並非屬於一般的常態家族分配, 而是為布朗運動 (Brownian Motion) 形式, 所以臨界值無法參考常態家族分配表, 是要參考 Dickey and Fuller (1979) 的臨界表。. 3.1.2. Augmented Dickey-Fuller 檢定 (ADF 檢定). 前一小節介紹的 DF 檢定是把模型設定為 AR(1) 且誤差項為白噪音, Dickey and Fuller (1979) 進一步放鬆誤差項的假設, 考慮誤差項具有序列相關 (serial correlation) 的情形。 在此情形下,DF 檢定法已不再適用, 為了消除序列相關, 需加入 p 期落 後項, 才能把誤差項修正為白噪音, 因此提出以 AR(p) 為模型進行單根檢定, 稱為擴 充的或修正後的 DF 檢定 (Augmented Dickey-Fuller檢定)。 假設母體迴歸式為一個 AR(p) 模型如下: yt = φ1 yt−1 + φ2 yt−2 + . . . + φp yt−p + εt. 其中 εt 為 i.i.d(0, φ2 ) 。. 15. (3.7).
(23) 3.1 單根檢定 定義 ρ ≡ φ1 + φ2 + . . . + φp ζj ≡ −(φj+1 + φj+2 + . . . + φp ). f or j = 1, 2, . . . , p − 1. 經過數學式的轉換後, 可將 (3,7) 式整理成: yt = ζ1 4yt−1 + ζ2 4yt−2 + . . . + ζp−1 4yt−p+1 + ρyt−1 + εt. (3.8). 同樣地, 根據迴歸式是否包含常數項或時間趨勢項又可分為下列三種型態, 其模型表 示如下: 模型一: 迴歸式中沒有常數項及時間趨勢項 yt = ζ1 4yt−1 + ζ2 4yt−2 + . . . + ζp−1 4yt−p+1 + ρyt−1 + εt. (3.9). = x0 t p + εt. p = [ ζ1 ζ2 . . . ρ ]0 , x0 t = [ 4yt−1 4yt−2 . . . yt−1 ]0 。 假設檢定為 H0 : ρ = 1 , H1 : ρ < 1 , 在虛無假設成立之下 Dickey and Fuller 導出檢定統計量的極限分 配: R1 2 1/2{[W (1)] − 1} − W (1) · W (1)dr 0 T (ˆ ρ∗ − 1) −→ (σ/λ) · R1 R1 2 W (r) dr − [ 0 W (r)dr]2 0 L. 其中 (σ/λ) 為序列相關的校正因子。 且經過調整後 R1 1/2{[W (1)]2 − 1} − W (1) · 0 W (1)dr T (ˆ ρ∗ − 1) =⇒ R1 R1 1 − ζˆ1 − ζˆ2 − . . . − ζˆp−1 W (r)2 dr − [ 0 W (r)dr]2 0 R1 1/2{[W (1)]2 − 1} − W (1) · 0 W (1)dr T (ˆ ρ∗θ − 1) ∗ P t = 2 0 =⇒ R1 R1 [s e p+1 ( xt x0 t )−1 ep+1 ]1/2 { 0 W (r)2 dr − [ 0 W (r)dr]2 }2 16.
(24) 3.1 單根檢定 其中 ep+1 = [ 0 0 . . . 0 1 ]0 , s2 =. PT. t=1 (yt. − x0 t ρˆ∗ )2 /T − p , 而 ρˆ∗ 是由 (3.9) 式. 利用 OLS 估計法得到的估計值。 模型二: 迴歸式中有常數項但無時間趨勢項 yt = ζ1 4yt−1 + ζ2 4yt−2 + . . . + ζp−1 4yt−p+1 + α + ρyt−1 + εt. (3.10). = x0 t p + εt. 其中 α 為迴歸式中之常數項, p = [ζ1 ζ2 . . . α ρ]0 , x0 t = [4yt−1 4yt−2 . . . 1 yt−1 ]0 。 假設檢定為 H0 : ρ = 1 (且 α = 0 ), H1 : ρ < 1 , 在虛無假設成立之下 Dickey and Fuller 導出檢定統計量的極限分配: T (ˆ ρα − 1) 及 tα = (ˆ ρα − 1)/ˆ σρˆα 。 其 P 中 ep+1 = [ 0 0 . . . 0 1 ]0 , s2 = Tt=1 (yt − x0 t ρˆα∗ )2 /T − p − 1 。 而 ρˆα∗ 是由 (3.10) 式利用 OLS 估計法得到的估計值。 模型三: 迴歸式中有常數項及時間趨勢項 yt = ζ1 4yt−1 + ζ2 4yt−2 + . . . + ζp−1 4yt−p+1 + α + δt + ρyt−1 + εt. (3.11). = x0 t p + εt. α 為迴歸式中之常數項, δ 為迴歸式中之時間趨勢項, p = [ζ1 ζ2 . . . α δ ρ]0 , x0 t = [ 4yt−1 4yt−2 . . . 1 t yt−1 ]0 。 假設檢定為 H0 : ρ = 1 (且 δ = 0 ), H1 : ρ < 1 , 在虛無假設成立之下 Dickey and Fuller 導出檢定統計量的極限分配: T (ˆ ρ∗τ − P 1) 及 t∗τ = (ˆ ρ∗τ −1)/[s2 e0 p+2 ( xt x0 t )−1 ep+2 ]1/2 。 其中 e0 p+2 = [ 0 0 . . . 0 1 ]0 , s2 = PT 0 ˆτ ∗ )2 /T − p − 2 。 而 ρˆτ ∗ 是由 (3.11) 式利用 OLS 估計法得到的估計 t=1 (yt − x t ρ 值。 ADF檢定中修正後 T (ˆ ρ∗ )−1 統計量與 DF 檢定中 T (ˆ ρ)−1 統計量具有相同的極 限分配, 而 ADF 檢定 tρˆ∗ 統計量亦與 DF 檢定中 tρˆ 具有相同的極限分配, 因此 ADF 17.
(25) 3.1 單根檢定 的臨界值表是參考 DF 的臨界值表。 隨後,Said and Dickey (1984) 將原先 AR(p) 模型更進一步擴展為: 差分後的 ARM A(p, q) 模 型, 模型表示如下: (1 − φ1 L − φ2 L2 − . . . − φp Lp )4Yt = (1 + θ1 L + θ2 L2 + . . . + θq Lq )εt (3.12). 假設起始值 y0 = 0 , εt 是 i.i.d(0, σ 2 ) 為白噪音, 而 p和 q 為未知數 (unknown)。 我 們可將 (3.12) 式改寫成: η(L)4yt = εt. 其中, η(L) = (1 − η1 L − η2 L − . . .) = (1 + θ1 L + θ2 L2 + . . . + θq Lq )−1 (1 − φ1 L − φ2 L2 − . . . − φp Lp ). 因此, 一 ARM A(p, q) 的模型可以轉換為一 AR(∞) 的模型: 母體迴歸式為: yt = yt−1 + η1 4yt−1 + η2 4yt−2 + η3 4yt−3 + . . . + εt. (3.13). 而迴歸模型為: yt = α + ρyt−1 + η1 4yt−1 + η2 4yt−2 + . . . + ηk 4yt−k + etk. 其中, etk = ζk+1 4yt−k−1 + ζk+2 4yt−k−2 + . . . + εt 18. (3.14).
(26) 3.1 單根檢定 在此 etk 不為白噪音。 若 k → ∞ , 且 k 增加的速度小於 T , 則 p. etk − εt = ζk+1 4yt−k−1 + ζk+2 4yt−k−2 + . . . −→ 0. 如果 k 值夠大, 則 ARIM A(p, 1, q) 序列在虛無假設之下的檢定統計量與 ARIM A(p, 1, 0) 序 列在虛無假設之下的檢定統計量有相同的極限分配。. 3.1.3. Phillips-Perron檢定 (PP 檢定). 此檢定方法是由 Phillips and Perron 於1987及1988提出的。 Phillips and Perron 指出, 雖然 ADF 檢定法已考慮殘差項具有序列相關的可能性, 但並未考慮有可能存 在異質性 (heteroscedasticity) 的問題, 因此他們更進一步放鬆殘差項的設定, 把具 有單根的 AR(1) 模型延伸至更一般話的設定, 考慮殘差項 ut 為一個 mixing process, 即允許 ut 有一定程度的相依性及異質性。 假設母體迴歸式為一個 AR(1) 模型如下: Yt = ρYt−1 + ut. (3.15). ρ=1. 在此令起始值 Y0 = 0 且 ut 為一個 mixing process。 迴歸模型表示如下: yt = α + ρyt−1 + ut. (3.16). 利用 OLS 法估計係數 ρˆT 時,Phillips and Perron建議所使用的修正統計量為: 1 ˆ 2 − γˆ0 ) Zρ ≡ T (ˆ ρT − 1) − (T 2 σ ˆρ2ˆT ÷ ST2 )(λ 2 2 1/2 ˆ ) · tT − { 1 (λ ˆ 2 − γˆ0 )/λ} ˆ × {T · σ Zt ≡ (ˆ γ0 λ ˆρ2ˆT ÷ ST } 2 19. (3.17) (3.18).
(27) 3.1 單根檢定 其中 ˆ 2 = γˆ0 + 2 λ. l X. [1 − j/(l + 1)] · γˆj. j=1. γˆj = T. −1. ·. T X. uˆt uˆt−j. t=j+1. uˆt = yt − α ˆ − ρˆyt−1 uˆt−j = yt−j − α ˆ − ρˆyt−j−1. T 為總樣本數, ρˆT 為用 OLS 法估計的 ρ 值, σ ˆρ2ˆT 為 ρˆT 的變異數, ST2 亦是利用 OLS 法求得的殘差項變異數。 因此, 經過修正後的檢定統計量亦與 DF 檢定、ADF 檢定 有相同的極限分配, 故使用 PP 檢定時, 其臨界值表同樣參考 Dickey and Fuller (1979) 的臨界值表。. 3.1.4. DF-GLS檢定. DF-GLS檢驗是由 Elliott,Rothenberg and Stock (1996) 提出的。 他們建議不直接 將一時間序列 yt 以 AR(p) 的模型進行迴歸分析, 而是先對時間序列 yt 進行差分, 處 理方式如下: yα = (y1 , y2 − αy1 , . . . , yT − αyT −1 ) zα = (z1 , z2 − αz1 , . . . , zT − αzT −1 ). 其中, 在只有常數項的模型中, z 為一單位向量; 在有趨勢項的模型中, z = (1, t) 。 而常數 α = 1 + c · T −1 與樣本數 T 及 c 有關, 且根據ERS (1996), 僅有常數項 的模型中 c = −7 ; 在有趨勢項的模型中 c = −13.5 。 經過上述的差分處理後, 在 20.
(28) 3.2 傳統共整合檢定 將 yα 對 zα 做迴歸分析, 可以估出 βˆ , 則 ytd = yα − βˆ0 zα , ytd 為一差分且去掉趨勢 (GLS detrending) 的時間序列。 最後在以 AR(p) 的模型建構迴歸式: d d d 4ytd = α4yt−1 + β1 4yt−1 + . . . + β4yt−p + εt. 當模型只有常數項時, 其檢定統計量與只有常數項的 DF 檢定統計量相同, 臨界值參 考 DF 的臨界值表。 當模型有常數及趨勢項時, 其檢定統計量的極限分配和 DF 檢定 統計量不相同相同, 臨界值參考 ERS(1996) 模擬出來的臨界值表。. 3.2. 傳統共整合檢定. 時間序列的計量方法在 1980 年代以來, 研究重點已從原本的恆定性時間序列變數的 研究, 擴展到非恆定性時間序列研究方法的探討。 最重要的突破, 可是說是 Granger and Newbold (1974) 發現非恆定變數間可能存在虛偽迴歸的現象。 為了解決虛偽迴 歸的問題, 於是學者們提出一些解決之道, 例如本節之前介紹的將非恆定性的時間序 列變數進行差分 (difference) 或去掉趨勢部份 (detrend)。 在進行非恆定性的時間序 列分析時, 較常使用的方式為差分的方法, 此法亦比較合理, 即以差分後的恆定性序 列進行迴歸分析。 差分的方法雖然有效的解決計量上的問題, 卻也引起其他的經濟問 題: 其一, 將時間序列的變數差分後, 代表的是一種變動量的型態, 以變動量進行迴 歸分析時, 參數代表的經濟意涵已經與原本迴歸分析之參數經濟意涵完全不同, 會產 生經濟解釋上的問題。 其二, 若將時間序列的變數差分後, 雖然能清楚地瞭解短期的 變化, 卻也使得變數間長期特性消失, 以致無法探討變數間是否存在著長期均衡的關 係, 產生模型設定錯誤的問題。 有鑑於此,Engle and Granger (1987) 提出共整合理 論 (cointegration), 他們發現非恆定變數之間的迴歸關係, 如果出現共整合, 即一組 非恆定時間序列變數的線性組合變成具有恆定性, 則這樣的迴歸關係仍然有經濟意義, 且代表兩變數間存在著穩定的長期均衡關係。 以下為 Engle and Granger (1987) 對 21.
(29) 3.2 傳統共整合檢定 共整合的定義。 定義: 若向量 yt 的所有組成元素皆為 I(d) 之非恆定性的時間序列, 且存在一向 量 a(6= 0) 使得 zt = a0 yt ∼ I(d − b) , 其中 b > 0 , 則稱向量 yt 的組成元素間存 在 d − b 階共整合關係, 記為 yt ∼ CI(d − b) , 而向量 a 則稱為共整合向量 (cointegration vector)。 Engle and Granger (1987) 提出 Granger Representation Theorem, 考慮一 個 (n × 1) 的向量 yt , 且 4yt 具有 Wold representation: (1 − L)yt = δ + ψ(L)εt. 其中, εt 為 i.i.d.(0, Ω) 且 {s·Ψs }∞ s = 0 滿足絕對可加性 (absolutely summable)。 假設向量 yt 的組成元素間存在 h 個共整合關係, 則會存在一個 (h × n) 的矩陣 A0 , 且 矩陣 A0 中的每一列為線性獨立, 則一 (h × 1) 的向量 zt 可定義成: zt = A0 yt. 所以 zt 是一個具恆定性的序列。 另外, 矩陣 A0 有一特性: A0 Ψ(1) = 0. 若可將序列表示成一個 p 階的 V AR 模型: yt = a + Φ1 yt−1 + Φ2 yt−2 + . . . + Φp yt−p + εt. 或可表示為: Φ(L)yt = a + εt 22.
(30) 3.2 傳統共整合檢定 其中, Φ(L) ≡ Ik − Φ1 L − Φ2 L2 − . . . − Φp Lp. 則會存在一個 (n × n) 矩陣 B , 以滿足: Φ1 = BA0. 其中, Φ1 = Ik − Φ1 − Φ2 − . . . − Φp 。 所以, 會存在 (n × n) 矩陣 ζ1 , ζ2 , . . . , ζp−1 , 迴歸模型可表示如下: 4yt = ζ1 4yt−1 + ζ2 4yt−2 + . . . + ζp−1 4yt−p−1 + a − Bzt−1 + εt. (3.19). (3.19) 式即為一個誤差修正模型 (vector error correction model ,VECM), 而 (zt−1 ) 為均衡誤差。 由上述, 可透過 Granger Representation Theorem得知共整 合關係必與誤差修正模型相對應。 共整合常被解釋為經濟變數具有長期均衡關係, 隱 含了這些變數長期而言, 具有往長期均衡方向調整的特性, 亦即短期時, 變數間可能會 存在偏離的現象, 但隨著時間的增長, 此偏離會逐漸縮小, 逐漸往長期均衡調整; 這個 造成偏離長期均衡得以縮小的機制, 即是誤差修正機能。. 3.2.1. Engle and Granger 兩階段估計法. 考慮一個估計法: 假設有一模型如下: yt = βxt + ut. 先經由單根檢定確定了序列 yt 及 xt 皆為 I(1) 。 檢定步驟如下: 23.
(31) 3.2 傳統共整合檢定 步驟一: 利用 OLS 估計法估出殘差 uˆt 。 先利用 OLS 估計法估出 βˆ , 進而可求得殘差 uˆt , 若 yt 和 xt 存在共整合關係, 則 uˆt ∼ √ I(0) , 即具有恆定性。 在大樣本的情況下, βˆ 收斂到真實值 β 並非以一般的速度 T , 而是以大於一般的速度 T 收斂, 因此由OLS 法估出的 βˆ 值具有超一致性 (superconsistency)。 步驟二: 檢定 ut 是否為 I(1) 序列, 可得知 yt 與 xt 是否存在共整合關係。 假設檢定為虛無假設 H0 : ut ∼ I(1) , 表示 yt 與 xt 不存在共整合關係, 對立假設 為 H1 : ut ∼ I(0) , 可利用 DF 或 ADF 單根檢定法做上述的檢定較佳, 模型表示如 下: ∗. ∆ˆ ut = ψ uˆt−1 +. p−1 X. ψ ∗ ∆ˆ ut−i + ωt. i=1. 其中, ωt 為 i.i.d(0, σ 2 ) 。 ψ ∗ 顯著異於零, 則拒絕虛無假設, 表示 ut ∼ I(0) , yt 與 xt 兩 變數存在共整合關係, 亦可利用誤差修正模型表示: 4yt = a1 + ay (yt−1 − βxt−1 ) + A(L)4yt−1 + B(L)4xt−1 + ω1t. (3.20). 4xt = a2 + ax (yt−1 − βxt−1 ) + C(L)4yt−1 + D(L)4xt−1 + ω2t. (3.21). ˆ t−1 為 其中, A(L) 、 B(L) 、 C(L) 和 D(L) 均為有限期的落後多項式, 且 εt−1 = yt−1 −βx 誤差修正項。 可利用 εˆt−1 = yt−1 − βˆt−1 帶入此模型中, 模型表示如下: 4yt = a1 + ay · εˆt−1 + A(L)4yt−1 + B(L)4xt−1 + ω1t. (3.22). 4xt = a2 + ax · εˆt−1 + C(L)4yt−1 + D(L)∆xt−1 + ω2t. (3.23). 模型中的 ∆yt 、 ∆xt−1 、 ∆yt−1 和 εˆt−1 所有變數皆為 I(0) 序列, 故可用 OLS 法來估 計參數, 求出變動間的短期動態調整過程。 24.
(32) 3.2 傳統共整合檢定 雖然 Engle and Granger 兩階段估計法簡單易懂, 卻存在幾個不可忽略的缺點: 1.此方法是假定變數間只有一個共整合關係, 即共整合向量只有一個。 當變數為兩個 以上時, 存在的共整合關係可能不只一個, 若檢定結果為沒有共整合關係, 並不表示變 數間不存在共整合關係, 此法便不適用。 2.存在有限樣本偏差的問題。 雖然用 OLS 法估出的 βˆ 具有超一致性, 但如果樣本數 過少時, 會使偏差的問題無法忽略。 3. 在 Phillips and Durlauf (1986) 中明白指出 βˆ 的極限分配不為常態分配 (nonnormal), 且 t 檢定統計量並非服從 t 分配, 故利用此 t 檢定統計量進行假設檢定是 無意義的。. 3.2.2. Johansen最大概似估計法. 由於 Engle and Granger (1987) 兩階段估計法有上述的缺失, 經濟學者陸續提出許 多不同的檢定方法以克服上述的缺失, 其中最具代表性的即是 Johansen (1988)、(1991) 提出的最大概似估計法, 也是目前為止, 最被廣泛使用的共整合檢定法。 Johansen最大概似估計法是由 Johansen (1988) 及 Johansen (1991) 提出以 檢定變數間的共整合關係。 在 Johansen 最大概似估計法中, 模型是假設為向量自我 迴歸模型 (vector autoregression model; VAR), 且可估計與檢定共整合向量的個 數, 因此, 相較於 Engle and Granger兩階段估計法, 更能處理兩個以上的變數問題。 假設有一個 (n×1) 的向量 yt , 且向量 yt 中的每一要素均為 I(1) 序列, 以 V AR(p) 表 示如下: yt = µ + Π1 xt−1 + Π2 xt−2 + . . . + Πp xt−p + εt 25. t = 1, 2, . . . , T. (3.24).
(33) 3.2 傳統共整合檢定 其中, µ 是常數項且 εt 為 i.i.d. N (0, Ω) 。 可將 (3.24) 式以誤差修正模型表示為: 4yt = µ + ξ1 4yt−1 + ξ2 4yt−2 + . . . + ξp−1 4yt−p+1 + ξyt−1 + εt. (3.25). 其中, ξ = −(In − Π1 − Π2 − . . . − Πp ) = −Π(1) ξi = −(In − Π1 − Π2 − . . . − Πi ). t = 1, 2, . . . , p − 1. 假設向量 yt 中的每一個別變數 yit 均為 I(1) , 且變數之間具有 h 個共整合關係, 則 ξ = αβ 0 , α , β 皆為 (h × n) 的矩陣, β 稱為共整合矩陣, α 則為調整係數矩陣。 而矩陣 ξ 的 秩 (rank) 可指出變數間存在長期均衡關係的數目, 即共整合向量的個數, 有三種可能 的情形: 1. rank(ξ) = n 。 ξ 矩陣為完全訊息矩陣, 即滿秩 (full rank), 表示向量 yt 中的各變 數皆為恆定性的時間序列。 2. 0 < rank(ξ) = h < n 。 表示向量 yt 中的變數之間存在 h 個共整合向量。 3. rank(ξ) = 0 。 ξ 矩陣為空矩陣, 即零秩 (null rank), 表示向量 yt 中並不存在任何 共整合關係。 因此, 檢定過程主要在於確定 ξ 矩陣的秩, 即對 (3.25) 式進行假設檢定, 虛無假設 為 H0 : rank(ξ) = h , 以確定 rank(ξ) 共整合向量的個數。 Johansen最大概似估計法步驟如下: 步驟一: 計算代理迴歸 (Auxiliary Regression). 26.
(34) 3.2 傳統共整合檢定 將 4yt , yt−1 分別對 4yt−1 , . . . , 4yt−p+1 作迴歸模型, 可將 (3.25) 式改寫成: Zot = ΓZ1t + ξZpt + εt. 其中, Zot = 4yt Z1t = (1, 4yt−1 , . . . , 4yt−p+1 )0 Zpt = yt−p Γ = (µ, ξ1 , . . . , ξp−1 ). 利用 OLS 估計法可得到殘差項 R0t 及 Rpt , 且殘差的平方和為: Sij = Mij − Mi1 M−1 11 M1j. (i, j = 0, p). 其濃縮的概似函數 (concentrated likelihood function) 表示成: T. −T /2. L(α, β, Ω) = |Ω|. 1X (R0t − ξRpt )0 Ω−1 (R0t − ξRpt )} exp{− 2 t=1. (3.26). 步驟二: 計算正交相關 (Canonical Correlation) 欲求最大概似估計式, 先求解下式: |λSpp − Sp0 S−1 00 S0p | = 0. ˆ1 > λ ˆ2 > . . . > λ ˆ n > 0 , 及標準化後的特性 因此可以求得特徵根 (eigenvalues): λ ˆ = (ˆ ˆ 0 Spp V ˆ = I。 向量 (eigenvectors) 為 V v1 , vˆ2 , . . . , vˆn ) , 且 V 27.
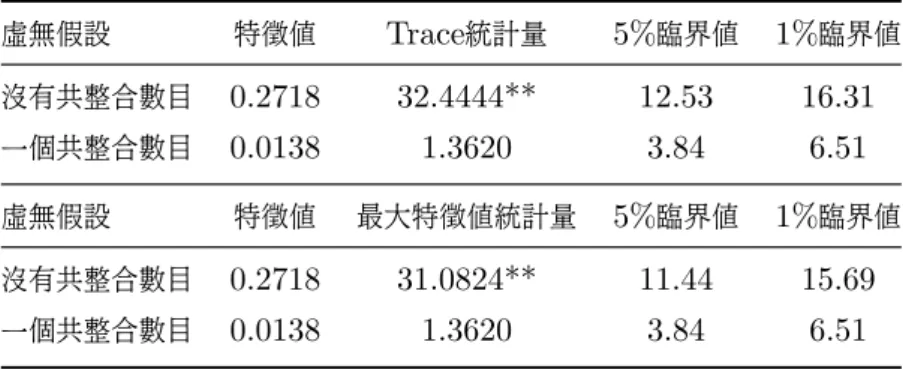
(35) 3.2 傳統共整合檢定 步驟三: 計算概似函數的估計參數 (MLE Estimation of Parameters) 若存在 h 個共整合關係, 則 β 之估計即為前 h 個特性根所對應的前 h 個特性向量 所組成的矩陣, 及 β = (ˆ v1 , vˆ2 , . . . , vˆh ) 且 ξ = α0 β , 則可將 (3.26) 改寫如下: T. L(α, β, Ω) = |Ω|−T /2 exp{−. 1X (R0t − αβ 0 Rpt )0 Ω−1 (R0t − αβ 0 Rpt )} (3.27) 2 t=1. 當 β 值固定下, 可以得到下式: ˆ = S0p β( ˆ βˆ0 Skk β) ˆ −1 α ˆ(β) ˆ = S00 − S0p (βˆ0 Skk β) ˆ −1 βˆ0 S0k ˆ β) Ω( ˆ = (M01 − ξMp1 )M−1 Γ 11. Johansen提出兩種檢定法來檢定共整合向量的個數: 1.軌跡檢定 (Trace Test): 在尚未確定存在幾組共整合關係之前, 由上述所得到的特性根可以被用來檢定模 型中最多存在 h 個共整合向量是否成立。 假設檢定如下: H0 : rank(ξ) ≤ h. (至多有h個共整合向量). H1 : rank(ξ) > h. (有大於h個共整合向量). 檢定統計量為: −2ln(H0 |H1 ) = −T. n X. ˆi) ln(1 − λ. i=t+1. 其漸進分配可以表達為一個 (n − h) 維度的布朗運動 (Brownian Motion), 且檢定統 計量的極限分配會等於 Q 矩陣的軌跡。 28.
(36) 3.3 門檻共整合模型. 2.最大特性根檢定 (Maximum Eigenvalues Test): H0 : 有h個共整合向量 H1 : 有h + 1個共整合向量. 檢定統計量為: ˆ h+1 ) −2ln(H0 |H1 ) = −T ln(1 − λ. 相同地, 其漸進分配亦可表達為一個 (n − h) 維度的布朗運動 (Brownian Motion), 且檢定統計量的極限分配會等於 Q 矩陣的最大特性根。. 3.3. 門檻共整合模型. 傳統的共整合只考慮了變數之間存在線性共整合關係, 接著我們考慮經濟變數間之共 整合現象以非連續的機制來進行調整。 將其擴充為非線條的模型, 不僅能使檢定力上 升, 對經濟現象的解釋能力也大為提升。 門檻共整合模型是由 Balke and Fomby (1997) 提出, 他們認為在達到長期均衡 過程中, 時間序列會有非連續性的調整, 當時間序列在脫離長期均衡太遠時, 共整合關 係較為強烈; 然而當時間序列離長期均衡比較近的時候, 則共整合關係較為薄弱。 他們 指出由於政府單位在調控經濟時, 必需付出一定的調整成本, 所以變數在不同期間, 向 長期均衡調整的過程會呈現不一致的現象, 因此調整過程要在調整後的效益大於成本 時, 也就是偏離長期均衡較大時才會出現。 Lo and Zivot (2001) 進一步利用門檻向量誤差模型 (TVECM) 進行檢定, 檢 定的重點在於是否存在門檻效果, 而其中的門檻變數為誤差修正項。 即研究當誤差修. 29.
(37) 3.3 門檻共整合模型 正項大於門檻值與誤差修正項小於門檻值的時候, 變動在到達長期均衡過程中的調整 行為是否相同。. 3.3.1. 模型. 線性向量誤差修正模型 假設 xt 為一 p 維的 I(1) 時間序列, 若 xt 存在一組 (p × 1) 的向量 β , 則 wt (β) = β 0 xt 為 I(0) 的誤差修正項。 若以向量誤差修正模型表示, 可寫成下式: 4xt = A0 Xt−1 (β) + ut. (3.29). 其中, 4xt 為 xt 的一次差分, Xt−1 (β) = [1, wt−1 , 4xt−1 , 4xt−2 , . . . , 4xt−l ]0 為 (k × 1) 矩陣, 且 l 為最適落後期數 (lag length)。 A 為 (k × p) 之係數矩陣, 其中 k = p × l + 2 。 誤差項 ut 為 i.i.d(0, Σ) 且符合 Gaussian 假設, 則參數 (β, A, Σ) 可由 e A, e Σ) e 表示之, 則 u e t = 4xt − LS(least square) 法估計而求得。 其估計值以 (β, e 為殘差向量。 e 0 Xt−1 (β) A 門檻共整合模型 門檻共整合將交易成本納入模型加以考慮, 認為無法進行連續調整的原因是來自 於交易成本, 因此以交易成本為模型的門檻值。 門檻的存在指出並非所有的差價都會 向長期均衡調整, 只有當價差偏離長期均衡超過某一門檻值時, 經濟個體才會進行運 作使得經濟體系恢復均衡。 本文主要是探討雙向套利的情形, 以中心市場為主體, 分別 對地方市場進行分析, 在此僅考慮兩個門檻值的門檻共整合模型。 兩門檻的模型將樣 本區分為三個區域: 最上區域表示中心市場花價相對高於地方市場花價, 相對價差大 於交易成本, 有套利行為的發生, 即存在共整合特性; 最下區域則表示地方市場花價相 對高於中心市場, 相對價差亦大於交易成本, 亦有套利的情況發生, 同樣具有共整合特 30.
(38) 3.3 門檻共整合模型 性; 在上下門檻中間的區域, 中心市場花價與地方市場花價的相對價差小於交易成本, 套利不會產生利潤, 故無共整合關係。 在此簡單介紹門檻共整合模型, 假設 xt 、 yt 兩變 數符合:. yt = αxt + zt. (u) µ(u) + ρ(u) (L) + εt if θ(u) ≤ zt−d zt = µ(m) + ρ(m) (L) + ε(m) if θ(l) < zt−d < θ(u) t µ(l) + ρ(l) (L) + ε(l) if θ(l) ≥ zt−d t (i). 其中, α 為係數, zt 為均衡誤差, ρ(i) (L) 為遞延多項式 (i = l, m, u) , εt 為白噪音 (i = l, m, u) , 整數 d 代表誤差調整過程的遞延時間, θ(u) 和 θ(l) 分別代表上門檻值和下門 檻值。 由上述的模型可以發現, 若市場中有交易成本的存在, zt 會依照上述模型做非線 性的調整。 Chan et al., (1985) 提供了一項充分且必要的條件來判斷 xt 、 yt 是否具 有門檻共整合, 令 ρ(i) (L) = ρ(i) 且 d = 1 , 若 µ(l) , µ(u) , ρ(l) , ρ(u) 滿足下列條件之一, 即具有門檻共整合的關係。. (1)ρ(l) < 1, ρ(u) < 1, 且ρ(l) ρ(u) < 1 (2)ρ(l) = 1, ρ(u) < 1, 且µ(l) > 0 (3)ρ(l) < 1, ρ(u) = 1, 且µ(u) < 0 (4)ρ(l) = ρ(u) = 1, 且µ(u) < 0 < µ(l) (5)ρ(l) ρ(u) = 1, ρ(l) < 0, 且µ(u) + ρ(u) µ(l) > 0. 31.
(39) 3.3 門檻共整合模型 Chan所提供的條件在說明, 若兩變數有門檻共整合關係, 則允許均衡誤差在中間區域 有單根的存在, 而在上下區域無單根的存在, 可以下圖簡單表示:. I(0). ݁ᘝ. Ղ॰ា. I(1). Հ॰ា I(0) 圖 1: 門檻共整合概念說明圖 兩門檻三區域向量誤差修正模型 考慮一個兩門檻三區域向量誤差修正模型, 模型表示如下: A0 1 Xt−1 (β) + u1 if wt−1 (β) ≤ γ1 4xt = A0 2 Xt−1 (β) + u2 if γ1 < wt−1 (β) < γ2 A0 X (β) + u if w (β) ≥ γ 3 t−1 3 t−1 2 其中 γ1 為下門檻值, γ2 為上門檻值。 假設 E(u1 u0 1 ) = E(u2 u0 2 ) = E(u3 u0 3 ) , 則上 述模型亦可改寫為: 4xt = A0 1 Xt−1 (β)d1t (β, γ1 , γ2 )+A0 2 Xt−1 (β)d2t (β, γ1 , γ2 )+A0 3 Xt−1 (β)d3t (β, γ1 , γ2 )+ut (3.30) (3.30) 式中 d1t (β, γ1 , γ2 ) = 1 (wt−1 (β) ≤ γ1 ) 、 d2t (β, γ1 , γ2 ) = 1 (γ1 < wt−1 (β) < γ2 ) 、 d3t (β, γ1 , γ2 ) = 1 (wt−1 (β) ≥ γ2 ) ; 當 wt−1 (β) ≤ γ1 時, d1t (β, γ1 , γ2 ) = 1 , 其他情況下, d1t (β, γ1 , γ2 ) = 0 ; 而當 γ1 < wt−1 (β) < γ2 時, d2t (β, γ1 , γ2 ) = 1 , 32.
(40) 3.3 門檻共整合模型 其他情況下, d2t (β, γ1 , γ2 ) = 0 , 而當 wt−1 (β) ≥ γ2 時, d3t (β, γ1 , γ2 ) = 1 , 其他 情況下, d3t (β, γ1 , γ2 ) = 0 。. 3.3.2. 估計. 估計的方法則是根據 Lo and Zivot (2001) 延伸 Hansen (1996) 循序最小平方 法 (sequential least squares ), 採用循序條件最小平方法 (sequential conditonal least squares ), 其基本原理是將門檻變數的所有觀察值都當作可能的門檻值, 據以 分割樣本並進行最小平方估計, 再以對應最小殘差平方和之分割點作為估計的門檻值。 以下分兩步驟簡單說明: 步驟一: 給定所有可能的 (γ1 , γ2 , l) 條件下用 LS 法估計出所有可能的 (A0 1 , A0 2 , A0 3 ) 根據 (3.30) 式, 利用 LS 估計法可求得 b = (X0 X)−1 (X0 4xt ) A. 其中, Xt−1 d1t (β, γ1 , γ2 ). . X = Xt−1 d2t (β, γ1 , γ2 ) Xt−1 d3t (β, γ1 , γ2 ). . . . b0 A 1. . b = b0 A A 2 b0 A 3 此外亦可求出所有可能的 b 0 X)0 (4xt − A b 0 X) ˆ 1 , γ2 , l) = (4xt − A S(γ 33.
(41) 3.4 變動門檻值的估計 步驟二: 選出使 S 最小的 (ˆ γ1 , γˆ2 , ˆl) 在所有可能的 S(γ1 , γ2 , l) 裡, 選出使 S 最小之門檻值 (ˆ γ1 , γˆ2 ) 及落後期 ˆl , 即 ˆ 1 , γ2 , l) (ˆ γ1 , γˆ2 , ˆl) = argmin S(γ. 3.3.3. 檢定. 門檻效果的檢定, Hansen (1996,1999) 提出以 sup-F 統計量來檢定虛無假設為 H0 : 一區域的T AR模型 及對立假設為 H1 : m區域的T AR模型 的問題。 隨後Lo and Zivot (2001) 將模型擴展為多元的 TVECM 模型, 本研究即以 Lo and Zivot (2001) 提出 的統計量為準則, 其漸近分配與拒絕域是由 bootstrap 模擬產生的。 虛無假設 H0 為 (3.29) 式的線性向量誤差修正模型, 對立假設 H1 為 (3.30) 式的三區域門檻向量誤差 修正模型。 檢定統計量如下: ˆ − ln(det(Σ ˆ 3 (ˆ sup − LR = T (ln(det(Σ)) γ1 , γˆ2 , ˆl)))). ˆ 為線性向量誤差修正模型的共變異數矩陣, Σ ˆ 3 (ˆ 其中, Σ γ1 , γˆ2 , ˆl) 為三區域門檻向量誤 差修正模型的共變異數矩陣。 由於 sup-LR 統計量的分配非一般標準分配, 且計算不 易。 於是, 我們採用 Hansen (1999) 建議的拔靴法 (bootstrap) 來計算 p-value, 以 檢定模型之門檻效果。. 3.4. 變動門檻值的估計. 在傳統的門檻共整合中, 一旦門檻值決定了就固定不變。 Park (2007) 提出一個新的 看法, 認為固定不變的門檻值在現實生活中有時並不合理。 他以北美的 gas 市場為例, 認為應將影響汽油價格的因素根據 Frisch-Waugh 理論以迴歸模型的方式去除, 以求 34.
(42) 3.4 變動門檻值的估計 得淨影響。 本文研究對象為花卉。 花卉對自然條件選擇嚴密及對環境反應敏銳, 影響花 卉生長的環境因素包括溫度、 雨量、 土壤、 濕度等, 然而許多相關文獻及農業期刊在研 究的過程中, 皆著重於溫度對花卉的影響, 對其他環境因子的討論少有著墨, 所以在此 僅考慮氣溫的影響。 本研究嘗試以簡單迴歸的方式, 建構以下的迴歸式: (i). (i). pt = ϕ(i) + Φ(i) tept−1 + et. (i). 其中 pt. (i). t = 1, 2, . . . , 100 ; i = 1, 2, 3, 4. (3.31). (i). = lnPt , Pt 為花價, ϕ(i) 為常數項, Φ(i) 為係數, tep 為溫度 (tempera-. (i) (i) ˆ (i) tept−1 , 此 eˆt(i) 即是去掉氣溫因素的花 ture)。 經由估計可得 eˆt = pt − ϕˆ(i) − Φ. 價(filtered price)。 由前面模型的介紹可知, 分析套利行為的門檻共整合方法是以交 易成本為區分區域的門檻值。 另外由中間區域的條件可得: (1). (2). γ 1 ≤ eˆt − eˆt ≤ γ 2. (3.32). (1) (1) (2) ˆ (1) tept−1 , eˆ(2) ˆ (2) tept−1 , 代入 (3.32) 其中, eˆt = pt − ϕˆ(1) − Φ ˆ(2) − Φ t = pt − ϕ. 式可得: ˆ (1) tept−1 − ϕˆ(2) − Φ ˆ (2) tept−1 ) γt1 = γ 1 + (ϕˆ(1) + Φ. (3.33). ˆ (1) tept−1 − ϕˆ(2) − Φ ˆ (2) tept−1 ) γt2 = γ 2 + (ϕˆ(1) + Φ. (3.34). γt1 即為變動的下門檻值, γt2 即為變動的上門檻值。 接著, 我們發現了一個可能可以延伸的問題。 變動門檻值是否會使原本固定門檻劃分 的樣本產生改變, 即當門檻發生變動時, 是否會使某些樣本在固定門檻時, 落在某一區 域, 因門檻值的變動, 而落在另一區域裡, 如此一來, 會產生不同的調整過程。 從估計 的觀點而言, 誤差修正係數是由循序條件最小平方法估計求得, 與門檻值有關, 當門檻 發生變動是否會影響誤差修正係數的估計值得探討。 Park (2007) 亦沒有提到相關的 問題, 在此僅提出可以思考的可能性, 本文還是依照 Park (2007) 的架構。 35.
(43) 4 實證結果分析. 4. 實證結果分析. 4.1. 資料來源說明. 本研究資料為台灣地區四個花卉批發市場, 台北花卉產銷股份有限公司, 台灣區花卉 運銷合作社, 彰化縣花卉批發市場和台南市綜合農產品批發市場, 每日花卉拍賣交易 價格, 資料取自農產品交易行情站資料電腦檔。 樣本期間為民國 88 年 10 月 1 日至民國 97 年 1 月 31 日。 因考慮各個批發市場的休市日並不相同, 乃採平均月資料進行分析, 樣本資料共計100個觀察值。 然而, 花卉批發市場中每天有上百種花完成拍賣交易, 若 將每一種花卉都做分析則會耗費相當長的時間, 且有些冷門花種並不是一年四季都有 生產, 亦無法每天或每週進行交易, 若進行分析可能會出現偏誤的情形。 因此, 在此僅 討論花卉生產中產值最大的切花類, 而切花類中, 又以菊花、 百合、 玫瑰為前幾大宗, 所以本研究之花卉品項為菊花、 百合及玫瑰。 在簡單迴歸的部份, 氣溫的資料則是取自於中央氣象局各地觀測站的資料庫檔案。 樣本期間依舊為民國 88 年 10 月 1 日至民國 97 年 1 月 31 日, 同樣取每月平均溫度進行 分析, 樣本資料共計100個觀察值。 本文欲討論的市場對象為台北, 台中, 彰化及台南, 然而氣象局只有在台北, 台中及台南架設觀測站, 由於台中及彰化距離不遠且同屬中 部地區, 氣溫差異不大, 因此, 在本研究中, 彰化市場花卉價格與氣溫的迴歸分析中, 氣溫亦採用台中觀測站的氣溫資料。. 4.2. 單根檢定結果. 在進行時間序列變數關連性的探討之前, 必須先以單根檢定進行恆定性的檢定, 確認 變數是否具恆定性, 以避免虛偽迴歸的問題產生。 本文使用 ADF 檢定法、PP 檢定法. 36.
(44) 4.2 單根檢定結果 及 DF-GLS 檢定法分別對四個批發市場的三個花卉品項進行恆定性的確認。 單根檢 定之實證結果如表: 表 2: 台北花市花卉價格單根檢定表 H0 : 水準值為單根行程. H0 : 一階差分為單根行程. 花卉品項. ADF. PP. DF-GLS. ADF. PP. DF-GLS. 菊花. -2.05. -2.39. -1.53. -3.78***. -6.83***. -2.95***. 百合. -2.41. -2.16. -1.16. -6.07***. -5.97***. -3.41***. 玫瑰. -1.42. -2.51. -0.76. -3.46***. -7.61***. -2.68***. 附註: 1.***代表在 1% 顯著水準下, 可以拒絕具單根的虛無假設。 2.所使用的模型為包含常數項但沒有趨勢項的模型。 3.ADF, PP臨界值參考 Fuller (1979);DF-GLS 臨界值則參考 ERS (1996)。. 表 3: 台中花市花卉價格單根檢定表 H0 : 水準值為單根行程. H0 : 一階差分為單根行程. 花卉品項. ADF. PP. DF-GLS. ADF. PP. DF-GLS. 菊花. -2.27. -2.33. -1.33. -4.38***. -6.29***. -2.99***. 百合. -1.80. -2.27. -1.11. -6.11***. -5.71***. -2.94***. 玫瑰. -1.44. -2.48. -1.07. -5.78***. -7.23***. -2.71***. 附註: 1.***代表在 1% 顯著水準下, 可以拒絕具單根的虛無假設。 2.所使用的模型為包含常數項但沒有趨勢項的模型。 3.ADF, PP臨界值參考 Fuller (1979);DF-GLS 臨界值則參考 ERS (1996)。. 表 4: 彰化花市花卉價格單根檢定表 H0 : 水準值為單根行程. H0 : 一階差分為單根行程. 花卉品項. ADF. PP. DF-GLS. ADF. PP. DF-GLS. 菊花. -2.28. -2.21. -1.39. -4.48***. -5.34***. -2.91***. 百合. -2.23. -2.04. -1.00. -5.92***. -4.65***. -3.05***. 玫瑰. -1.91. -2.45. -0.99. -6.60***. -6.96***. -3.12***. 附註: 1.***代表在 1% 顯著水準下, 可以拒絕具單根的虛無假設。 2.所使用的模型為包含常數項但沒有趨勢項的模型。 3.ADF, PP臨界值參考 Fuller (1979);DF-GLS 臨界值則參考 ERS (1996)。. 37.
(45) 4.3 共整合檢定結果 表 5: 台南花市花卉價格單根檢定表 H0 : 水準值為單根行程. H0 : 一階差分為單根行程. 花卉品項. ADF. PP. DF-GLS. ADF. PP. DF-GLS. 菊花. -2.21. -2.19. -1.46. -3.91***. -5.54***. -3.59***. 百合. -1.60. -2.36. -1.38. -5.95***. -4.63***. -4.27***. 玫瑰. -1.09. -2.08. -1.09. -4.81***. -6.51***. -2.97***. 附註: 1.***代表在 1% 顯著水準下, 可以拒絕具單根的虛無假設。 2.所使用的模型為包含常數項但沒有趨勢項的模型。 3.ADF, PP臨界值參考 Fuller (1979);DF-GLS 臨界值則參考 ERS (1996)。. 檢定結果指出, 四個批發市場的三種花卉品項之價格時間序列無論在1%、5%或10% 的顯著水準之下, 皆具有單根特性, 且經過一次差分之後皆呈現定態, 亦即四個批發市 場的三種花卉品項之價格時間序列皆為 I(1) 之時間序列。 故需進一步使用共整合檢定 分析花卉品項在不同市場是否存在共移均衡的關係。. 4.3. 共整合檢定結果. 在前一節中, 本研究對四個批發市場的三種花卉品項之價格進行單根檢定, 檢定結果顯 示均為非恆定的時間序列, 確定變數皆為 I(1) 後, 進一步考慮變數間可能存在共整合 關係。 本研究中是以台北花市為中心市場, 台中花市、 彰化花市及台南花市為地方市場, 分析相同花卉下, 各地方市場與中心市場是否存在共移均衡的關係。 共整合檢定的方 法常見的是 Johansen 檢定法 (1988), 但 Balke and Fomby (1997) 認為 Johansen (1988) 檢定方法在有門檻效果的情況下檢定力不佳,2 而 Engle and Granger兩階段 估計法仍有不錯的檢定績效。 故若是兩個結果產生不一致時, 以 Engle and Granger 兩階段估計法的結果為準。 2. Balke and Fomby (1997) 認為 Johansen 共整合檢定法之常態性假設, 將因門檻效果存在時殘 差為非標準分配, 而造成模型誤設的情況發生. 38.
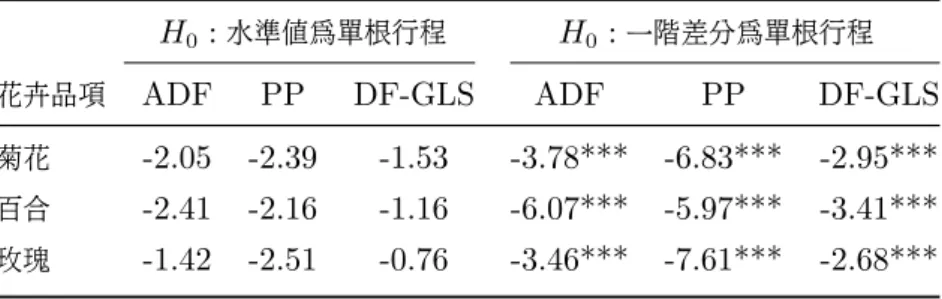
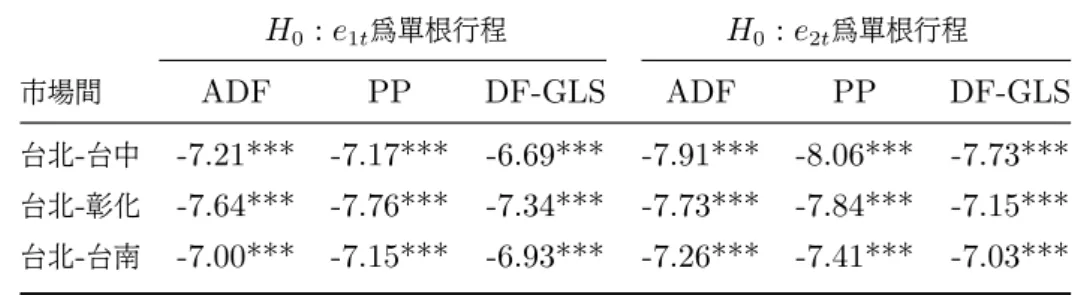
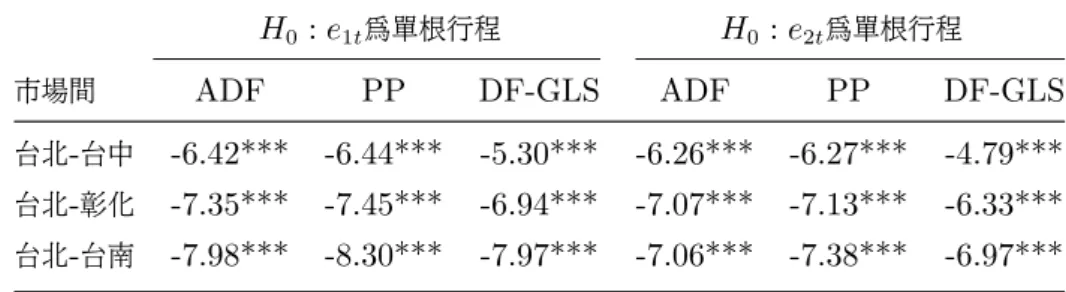
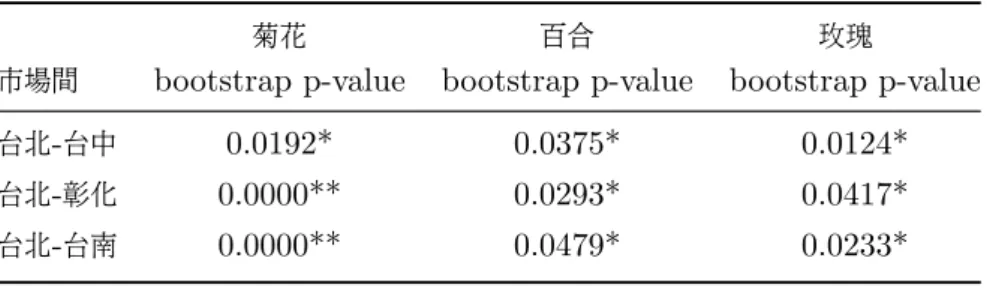
(46) 4.3 共整合檢定結果. 4.3.1. Engle and Granger 兩階段估計法檢定結果. 在此先做 Engle and Granger 兩階段估計法。 步驟一: 先分別以 p1t 以及 p2t 為自變數對彼此進行最小平方迴歸可得下列兩條迴 歸式: p1t = α1 + β1 p2t + e1t p2t = α2 + β2 p1t + e2t. 步驟二: 在分別對殘差項 e1t 與 e2t 進行單根檢定。 檢定結果如下表:. 表 6: 菊花Engle and Granger 共整合檢定表 H0 : e1t 為單根行程 市場間. H0 : e2t 為單根行程. ADF. PP. DF-GLS. ADF. PP. DF-GLS. 台北-台中. -7.21***. -7.17***. -6.69***. -7.91***. -8.06***. -7.73***. 台北-彰化. -7.64***. -7.76***. -7.34***. -7.73***. -7.84***. -7.15***. 台北-台南. -7.00***. -7.15***. -6.93***. -7.26***. -7.41***. -7.03***. 附註: 1.***代表在 1% 顯著水準下, 可以拒絕具單根的虛無假設。 2.ADF,PP臨界值參考 Phillips and Quliaris (1990);DF-GLS臨界值則參考 ERS (1996)。. 39.
(47) 4.3 共整合檢定結果 表 7: 百合Engle and Granger 共整合檢定表 H0 : e1t 為單根行程 市場間. H0 : e2t 為單根行程. ADF. PP. DF-GLS. ADF. PP. DF-GLS. 台北-台中. -8.13***. -8.12***. -8.11***. -8.32***. -8.34***. -8.24***. 台北-彰化. -8.23***. -8.20***. -8.01***. -7.93***. -8.00***. -7.57***. 台北-台南. -6.67***. -6.60***. -4.63***. -6.34***. -6.30***. -4.61***. 附註: 1.***代表在 1% 顯著水準下, 可以拒絕具單根的虛無假設。 2.ADF,PP臨界值參考 Phillips and Quliaris (1990);DF-GLS臨界值則參考 ERS (1996)。. 表 8: 玫瑰Engle and Granger 共整合檢定表 H0 : e1t 為單根行程 市場間. H0 : e2t 為單根行程. ADF. PP. DF-GLS. ADF. PP. DF-GLS. 台北-台中. -6.42***. -6.44***. -5.30***. -6.26***. -6.27***. -4.79***. 台北-彰化. -7.35***. -7.45***. -6.94***. -7.07***. -7.13***. -6.33***. 台北-台南. -7.98***. -8.30***. -7.97***. -7.06***. -7.38***. -6.97***. 附註: 1.***代表在 1% 顯著水準下, 可以拒絕具單根的虛無假設。 2.ADF,PP臨界值參考 Phillips and Quliaris (1990);DF-GLS臨界值則參考 ERS (1996)。. 由表可知, 無論是以 ADF 檢定、PP 檢定或 DF-GLS 檢定, 在顯著水準為 1% 、5% 或10% 下, 皆拒絕迴歸式中之殘差項具有單根的虛無假設, 可依此推斷相同花卉 在不同市場間存在共整合關係, 共移趨勢亦得到模型的確認。. 4.3.2. Johansen最大概似估計法檢定結果. 鑑於 Engel and Granger (1987) 的檢定存在如 (3.2.1) 節所提之不足之處, 本小 節繼續使用 Johansen (1991) 之共整合檢定法來探討市場間長期均衡的關係。 在進 行 Johansen 最大概似估計法檢定共整合關係之前, 必須先確定使用的 VAR 模型所 選取的落後期數, 在此以 SIC 的準則來選取落後期數, 並使殘差項通過 Ljung and Box (1979) 之獨立性檢定, 檢定至殘差項不具自我相關為止。 另外, 採用 Jarque and 40.
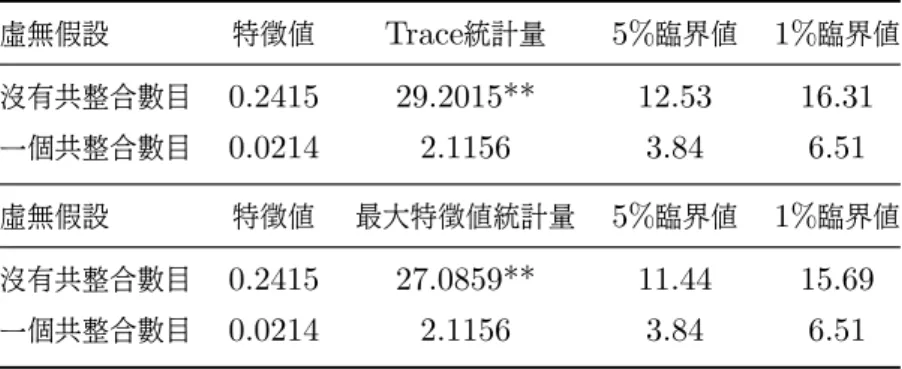
(48) 4.3 共整合檢定結果 Bera (1980) 的常態性檢定, 檢驗殘差項是否為常態分配。 根據 SIC 的準則所得到的 結果如表 9, 其結果顯示三種花卉三市場間的最適落後期皆為一期。 由於 SIC 值隨著 落後期數的增加而逐漸變大, 在此只做出落後六期的結果: 表 9: 菊花市場最適落後期之選取 市場間. Lag 0. Lag 1. Lag 2. Lag 3. Lag 4. Lag 5. Lag 6. 台北-台中. 13.793. 13.726*. 13.893. 13.755. 13.847. 13.878. 13.974. 台北-彰化. 12.841. 12.763*. 12.949. 13.172. 13.289. 13.436. 13.688. 台北-台南. 12.831. 12.810*. 12.896. 13.108. 13.241. 13.408. 13.558. 表 10: 百合市場最適落後期之選取 市場間. Lag0. Lag 1. Lag 2. Lag 3. Lag 4. Lag 5. Lag 6. 台北-台中. 16.482. 16.461*. 16.476. 16.576. 16.658. 16.787. 16.902. 台北-彰化. 15.808. 15.716*. 15.813. 15.818. 16.039. 16.280. 16.410. 台北-台南. 16.286. 16.244*. 16.271. 16.422. 16.631. 16.826. 16.999. 表 11: 玫瑰市場最適落後期之選取 市場間. Lag 0. Lag 1. Lag 2. Lag 3. Lag 4. Lag 5. Lag 6. 台北-台中. 17.658. 17.486*. 17.878. 17.799. 17.791. 17.577. 17.743. 台北-彰化. 16.761. 16.636*. 16.703. 16.921. 16.652. 16.829. 17.043. 台北-台南. 16.557. 16.416*. 16.480. 16.694. 16.439. 16.587. 16.778. 決定最適落後期數為一期後, 進一步做 Ljung and Box (1979) 的獨立性檢定, 在顯著水準為5%及顯著水準為1%下, 三種花卉市場間的Var 模型在一期落後期之下 的殘差皆通過獨立性檢定, 即皆呈現無自我相關。 而在最適落後期數為一之下檢定殘 差是否服從常態分配, 檢定結果顯示只有少數通過常態檢定。 在此情況之下用常態假 設去估計和檢定共整合向量可能會產生一些問題。 不過有文獻指出即使殘差項不服從 常態分配, 對共整合分析結果不會產生顯著的影響 (Cheung and Lai (1993))。 選定落後期數, 便可進行 Johansen (1988),(1991) 所提出的軌跡檢定以及最大 特徵值檢定法, 檢定結果如表: 41.
數據

+7



Outline
相關文件
172, Zhongzheng Rd., Luzhou Dist., New Taipei City (5F International Conference Room, Teaching Building, National Open University)... 172, Zhongzheng Rd., Luzhou Dist., New
We are not aware of any existing methods for identifying constant parameters or covariates in the parametric component of a semiparametric model, although there exists an
In this paper, we evaluate whether adaptive penalty selection procedure proposed in Shen and Ye (2002) leads to a consistent model selector or just reduce the overfitting of
Robinson Crusoe is an Englishman from the 1) t_______ of York in the seventeenth century, the youngest son of a merchant of German origin. This trip is financially successful,
• Content demands – Awareness that in different countries the weather is different and we need to wear different clothes / also culture. impacts on the clothing
Now, nearly all of the current flows through wire S since it has a much lower resistance than the light bulb. The light bulb does not glow because the current flowing through it
O.K., let’s study chiral phase transition. Quark
In addition, to incorporate the prior knowledge into design process, we generalise the Q(Γ (k) ) criterion and propose a new criterion exploiting prior information about
