多重全域樣版匹配引導AdaBoost演算法學習之人形偵測系統
97
0
0
全文
(2) I.
(3) 誌謝 研究生涯即將結束了,也代表從小到大在高雄漫長的求學生涯將劃下階段性的句點, 進而進入人生的下一階段。回首各種不同的求學階段,直至就讀研究所時才開始接受真 正的磨練與訓練,也因此擁有更成熟的心態,心中也充滿了感謝。 首先,我要先感謝我的指導教授蕭培墉 教授,老師認真負責的教學態度使我受益良 多,能夠在我就讀研究所生涯期間,指導正確的研究方法與態度,並且培養我學習新的 知識時所應要有的觀念。也是讓我經過研究所就讀後,成長最多、收獲最大的主因。 另外感謝我的研究所同學王威淵,在碩班的求學路上,於課業與研究方面;我們總 是相互討論及幫忙,於生活方面;我們也是互相提醒進度與體諒,在這邊我先預祝你能 夠順利發展,得到理想的工作。以及感謝國立高雄第一科技大學電腦與通訊工程學系黃 世勳 博士,能夠不嫌麻煩的提點我一些研究上的盲點與相關的知識,多次拜訪請教時 也是傾囊相授。也感謝口試委員陳春堯 博士,能夠提出更好的研究修改方向,讓我的 論文更趨完整,非常謝謝你們。 最後我要特別感謝在這段求學時間中,一路無條件的支持我與相信我的家人,真的 很感謝你們的關心與陪伴;在學校中能夠忍受我壞脾氣的壘球隊的學弟翊成、仁芳與家 驊;不時就為我加油打氣的高中同學紡安、岳宏與婉真;在實驗室中幫忙我處理大小事 務的鈞彥、世育,能夠提供新的看法與一起討論的冠安、冠穎與雲翔。感謝大家一路上 的關心、支持與陪伴。. II.
(4) 多重全域樣版匹配 多重全域樣版匹配引導 匹配引導 AdaBoost 演算法學習之 人形偵測系統. 指導教授:蕭培墉 博士(教授) 國立高雄大學電機工程學系. 學生:顏履安 國立高雄大學電機工程學系. 摘要. 本研究提出以多重全域人形樣版引導 AdaBoost 演算法學習並建立三種分類強分類 器,其研究方法於訓練階段自動選擇適當的參數,以能夠適應不同場景的人形偵測系統 為目的。全域特徵使用 ADM 邊緣偵測演算法計算邊緣強度值,並二值化得出全身正背 面人形樣版及頭肩人形樣版。測試影像則是經二值化後,藉由計算距離轉換演算法與樣 版進行樣版比對。經由比對結果判斷其分類效果,用以調整全域分類門檻,給予全域特 徵分類的功能。區域特徵則使用 HOG 向量搭配線性 SVM 分類器做為弱分類器,結合 AdaBoost 演算法學習,建立強分類器。再引入全域特徵分類,引導 AdaBoost 演算法學 習分別選擇不同類別的影像,額外建立最適用該類影像的強分類器。最後於偵測階段以 全域特徵分辨影像類別,使用適合該類別的強分類器進一步分類,以達到適應不同場景 人形偵測系統功能之目的。. 關鍵字: 關鍵字:HOG、SVM、Adaboost、人形偵測系統、全域特徵、區域特徵。. III.
(5) Multiple global templates matching for guiding the AdaBoost learning of human detecting system Advisor:Dr.(Professor) Pei-Yung Hsiao Institute of Electronic Engineering National University of Kaohsiung. Student:Lu-An Yen Institute of Electronic Engineering National University of Kaohsiung. Abstract We proposes multiple global human templates guiding AdaBoost algorithm to learning and build three different classes strong classifier, The research method to automatically select the appropriate parameters in the training stage, in order to be able to adapt to different scenarios of human detection system for the purpose. Global features using edge detection algorithm to calculate ADM edge strength values and thresholding Front-Back humanoid body template and Head-Shoulders template. And the testing images after the thresholding to calculating the distance transform algorithm performed template matching. Judged by comparing the results of the classification results to adjust the global classification threshold, given the global detector of functional classification. Local feature are used HOG vectors with linear SVM classifier as the weak classifier, and combined by AdaBoost learning algorithm. Reintroduction global feature classification guide AdaBoost algorithm to select the image to learn different classes respectively, and additional establish the most suitable class of strong classifier. The last, global feature in order to detecting stage distinguish image to their classes. And use appropriate for the class of strong classifier further classified in order to achieve the purpose to adapt to different scenarios of human detection system functions.. key word: :HOG, SVM, Adaboost, human detection system, local feature, global feature. IV.
(6) 目錄 口試委員審定書………………………………………………………………………………i 口試委員審定書 誌 謝 ……………………………………………………………………………………ii 中文摘要……………………………………………………………………………………iii 中文摘要 英文摘要……………………………………………………………………………………iv 文摘要 第一章 緒論.... 緒論 .. .. .. .. ... .. .. .. .. .. .. .. .. .. .. .. .. .. ... .. .. .. .. .. .. .. .. .. .. .. .. .. ... .. .. .. .. .. .. .. .. .1 1.1 研究背景與動機..............................................................................................1 研究背景與動機 1.2 研究目的與演算法選用............................................................................................3 研究目的與演算法選用 1.3 研究問題與挑戰.....................................................................................5 研究問題與挑戰 1.3.1 攝影高度與視角的影響.................................................................................5 攝影高度與視角的影響 1.3.2 人形遮蔽現象................................................................................................6 人形遮蔽現象 1.3.3 背景複雜度影響.....................................................................................7 背景複雜度影響 1.4 論文章節組織架構...................................................................................8 論文章節組織架構 第二章 相關研究與文獻探討....................................................................................8 相關研究與文獻探討 2.1 人形與人群的區域特徵......................................................................10 人形與人群的區域特徵 2.2 人形與人群的全域特徵......................................................................11 人形與人群的全域特徵 2.3 區域與全域特徵整合與應用方向...............................................................11 區域與全域特徵整合與應用方向 2 . 3 . 1 單 一 人 形 偵測. 偵測 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1 2 2 . 3 . 2 人 群 偵 測 與切割 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1 3 第三章 演算法技術模組.................................................................14 3.1 絕對差值遮罩(ADM)邊緣偵測 邊緣偵測.....................................................................14 絕對差值遮罩 邊緣偵測 3.2 距離轉換(DT)演算法 演算法...........................................................................19 距離轉換 演算法 3.3 梯度方向直方圖(HOG)......................................................................................21 梯度方向直方圖 第四章 GDguiding AdaBoost 演算法....................................................................29 演算法 4.1 建立全域偵測器階段 建立全域偵測器 階段流程 階段 流程......................................................................29 流程. V.
(7) 4.1.1 建立多重樣版與樣版比對...........................................................34 建立多重樣版與樣版比對 4.1.2 雙重樣板比對分數與轉換權重係數..................................................36 雙重樣板比對分數與轉換權重係數 4.1.3 調整最佳門檻值.......................................................................37 調整最佳門檻值 4.2 全域偵測器引導 AdaBoost 學習訓練階段............................................................39 學習訓練階段 4.2.1 三類弱分類器訓練階段選用規則..........................................................46 三類弱分類器訓練階段選用規則 4.2.2 弱分類器的權重更新....................................................................................49 弱分類器的權重更新 4.2.3 GDguiding AdaBoost 三種強分類器訓練結果...........................................50 三種強分類器訓練結果 4.3 GDguiding AdaBoost 人形偵測系統之即時偵測階段 人形偵測系統之即時偵測階段..................................51 4.3.1 Non-Maximum Suppression 與 Mean-Shift 後處理演算法……………..53 後處理演算法 第 五 章 實 驗 與 結 果比 較 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5 7 5 . 1 實驗設備. 實驗設備 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5 7 5.2 訓練與測試影像資料庫........................................................58 5.2.1 靜態資料庫..............................................................................58 靜態資料庫 5.2.2 動態資料庫..................................................................................58 動態資料庫 5.3 實驗結果與分析............................................................................63 實驗結果與分析 5.3.1 靜態資料庫.......................................................................................64 靜態資料庫 5.3.2 動態資料庫.............................................................................................66 動態資料庫 第六章 結論與未來改善方向........................................................80 參考文獻...................................................................................82. VI.
(8) 圖目錄 圖 1-1. 監視主要出入口畫面視角 監視主要出入口畫面視角,人物被遮蔽 人物被遮蔽的情形 遮蔽的情形........................... 的情形...........................3 ...........................3. 圖 1-2. 攝影高度 h、 、攝影俯視角 三者相互關係的示意圖............6 攝影俯視角 θ 與攝影位置(x,y)三者相互關係的示意圖 與攝影位置 三者相互關係的示意圖. 圖 1-3.. 不同的攝影角度,人物的比例也不同...................................6. 圖 1-4.. 遮蔽現象發生時, 遮蔽現象發生時,可能造成的現象............................................................7 可能造成的現象. 圖 1-5.. 前景人物與背景過於相近...................................7. 圖 3-1. ADM 演算法流程及其各階段結果影像圖 演算法流程及其各階段 結果影像圖............................................15 結果影像圖. 圖 3-2. 半高斯模糊遮罩...................................................................................15 半高斯模糊遮罩. 圖 3-3. 計算邊緣強度及方向值的遮罩.......................................................................16 計算邊緣強度及方向值的遮罩. 圖 3-4. ADM 邊緣定位遮罩....................................................................................16 緣定位遮罩. 圖 3-5. Canny 演算法將梯度角度分為四個角度區間示意圖............................17 演算法將梯度角度分為四個角度區間示意圖. 圖 3-6. OpenCV 中 Canny 演算法所使用的高斯模糊遮罩...................................18 演算法所使用的高斯模糊遮罩. 圖 3-7. 由灰階圖片計算出 ADM Strength 邊緣, 邊緣,而後計算出 而後計算出 DT 影像......................20 影像. 圖 3-8. 距離轉換遮罩.....................................................................20. 圖 3-9. DT 距離轉換流程示意圖......................................................................21 距離轉換流程示意圖. 圖 3-10 測試影像、 測試影像 、 偵測視窗、 偵測視窗 、 區塊與 HOG 關係示意圖............................22 關係示意圖 圖 3-11 不 同 長 寬 比 例 的 特 徵 區 塊 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2 2 圖 3-12 計算 36D HOG 向量步驟流程圖.................................................23 向量步驟流程圖 圖 3-13 9D 直方圖與 36D 直方圖示意圖..................................................24 直方圖示意圖 圖 3-14 HOG 向量的 9 個分量的產生流程................................................25 個分量的產生流程 圖 3-15 計算一個 36D HOG 向量輸出入流程圖.........................................27 向量輸出入流程圖 圖 3-16 計算 H O G 模組函式階層圖. 模組函式階層圖 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2 8 圖 4-1. 全域偵測器模組切割三階段完整訓練流程...........................................29 全域偵測器模組切割三階段完整訓練流程. 圖 4-2. 全 域 偵 測 器 訓 練 虛 擬碼 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3 4. 圖 4-3. M o d u l e 1 演 算 及 模組 切 割流 程圖 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3 5. VII.
(9) 圖 4-4. 樣版比對及計算比對分數方法示意圖..................................................35 樣版比對及計算比對分數方法示意圖. 圖 4-5. Module 2 模組演算細部流程圖....................................................36 模組演算細部流程圖. 圖 4-6. Module 3 模組演算細部流程圖..................................................................37 模組演算細部流程圖. 圖 4-7. 訓練樣本與雙重樣版比對數分佈以及類別門檻值範例示意圖.....................38 訓練樣本與雙重樣版比對數分佈以及類別門檻值範例示意圖. 圖 4-8. 條件判斷分類品質後調整門檻值示意圖.........................................................39 條件判斷分類品質後調整門檻值示意圖. 圖 4-9. 展開主模組及子模組輸出訓練流程圖....................................................40 展開主模組及子模組輸出訓練流程圖. 圖 4-10 GDguiding AdaBoost 訓練階段虛擬碼............................................46 訓練階段虛擬碼 圖 4-11 模組一細部流程圖.......................................................................47 模組一細部流程圖 圖 4-12 模組二細部流程圖.... 模組二細部流程圖 ... .. ... .. .. ... .. .. ... .. .. ... ... .. ... .. .. ... .. .. ... .. .. ... ... .. ..48 圖 4-13 模組三細部流程圖...........................................................................48 模組三細部流程圖 圖 4-14 總樣本數量被全域偵測器分類為三類, 總樣本數量被全域偵測器分類為三類,並包含 並包含不同的樣本數量..................49 不同的樣本數量 圖 4-15 弱分類器權重 αt 更新次 更新次數與數值改變曲線 數與數值改變曲線圖 變曲線圖................................................50 圖 4-16 三種強分類器不同弱分類器位置與數量示意圖...................................50 三種強分類器不同弱分類器位置與數量示意圖 圖 4-17 GDguiding AdaBoost 人形偵測系統偵測流程 人形偵測系統偵測流程.......................................51 流程 圖 4-18 偵測階段流程模組化 偵測階段流程模組 化 階層關係示意圖.....................................................52 階層關係示意圖 圖 4-19 後處理期望 後處理期望結果示意圖 期望結果示意圖……………………………….......................................53 結果示意圖 圖 4-20 NMS 演算法計算範圍 演算法計算範圍示意圖……………….................................................54 示意圖 圖 4-21 NMS 演算法計算流程 演算法計算流程示意圖 流程示意圖.............................................................................55 示意圖 圖 4-22 Mean-Shift 演算法計算流程 .....................56 演算法計算 流程示意圖 流程 示意圖....................... 示意圖 圖 4 -2 3 人形偵測系統 後處理階段 性 結果示意圖. 結果示意圖 .. . . .. . .. . .. . .. . . ... . . .. . . .. . .. . .. . .. . 5 7 圖 5-1. Caviar 資料庫測試場 資料庫測試 場 景 .......................................................................59. 圖 5-2. 2007 AVSS 資料庫測試場 資料庫測試場景....................................................................60. 圖 5-3. 自行拍攝的資料庫測試 自行拍 攝的資料庫測試場 攝的資料庫測試 場 景 ..............................................................60. 圖 5-4. 測試結果之間的相互關聯性...................................................64. 圖 5-5. CVC 及 CBCL 全身正背面樣版及 身正背面樣版及頭肩 背面樣版及頭肩樣版 頭肩樣版................................................65 樣版. 圖 5-6. 動態資料庫統計計算示意圖..........................................................................66 動態資料庫統計計算示意圖. VIII.
(10) 圖 5-7. Caviar Test Video 1 TPR 比較圖 比較圖.......................................................................68. 圖 5-8. TPR 比較圖組成示意圖 比較圖組成示意圖.............................................................................69 圖組成示意圖. 圖 5-9. AVSS Test Video 1 TPR 比較圖 比較圖 ...........................................................72. 圖 5-10 AVSS Test Video 2 TPR 比較圖 比較圖............................................................72 圖 5-11 AVSS Test Video 3 TPR 比較圖 比較圖.....................................................................73 圖 5-12 AVSS Test Video 4 TPR 比較圖 比較圖...............................................................73 圖 5-13 Ours Test Video 1 TPR 比較圖 比較圖.....................................................................75 圖 5-14 Ours Test Video 2 TPR 比較圖 比較圖..................................................................76 圖 5-15 AVSS 資料庫兩 資料庫兩種方法測試影片比較結果圖.................................................77 種方法測試影片比較結果圖 圖 5-16 Caviar 資料庫兩 資料庫 兩種方法測試影片比較結果圖..........................................78 種方法測試影片比較結果圖 圖 5-17 Ours 資料庫兩 資料庫兩種方法測試影片比較結果圖.................................................79 種方法測試影片比較結果圖. IX.
(11) 表目錄 表 1.1. 全域及區域特徵選用的演算法.................................................5. 表 3.1. 原始 ADM 與 OpenCV Canny 演算步驟特性 演算步驟特性 差異 ...............................19. 表 3.2. ADM 演算法與 OpenCV Canny 演算過程中間結果比較圖.....................19 演算過程中間結果比較圖. 表 5.1. 系統平台.......................................................................57. 表 5.2. 靜態影像資料庫.............................................................................58 靜態影像資料庫. 表 5.3. 動態影像資料庫相關資訊 動態影像資料庫相關資訊...........................................................................59. 表 5.4. Caviar 影 片 資料庫詳 資料庫 詳 細資訊 細資 訊 ..............................................................62. 表 5.5. AVSS 及我們的 我們的影片資料庫詳 資料庫詳細資訊 細資訊............................................................63. 表 5.6. 靜態資料庫測試結果........................................................64. 表 5.7. Caviar 資料庫測試影片總 Frame 平均數 平均數據比較表 比較表.................................67. 表 5.8. AVSS 資料庫測試影片總 Frame 平均數 平均 數據 比較表 比較表 .................................71. 表 5.9. Ours 資料庫測試影片總 Frame 平均數 平均 數 據 比較表 比較 表 .................................75. X.
(12) 第一章 緒論 1.1 研究背景與動機 近年來人形偵測(Human Detection)及人群偵測(Crowd Detection)系統應用於智慧型 監視系統(Intelligent Surveillance System , ISS)需求與趨勢的技術開始受到國內外研究人 員的重視,其中,人群偵測的部份包含了人群切割(Crowd Segmentation)與計數(Counting) 的功能,是乃達到智慧型監視系統的重要門檻與技術基石。在傳統的影像監視方式中, 監看人員需同時監看數個螢幕,除了注意人員進出狀況外,還需監看每個個人是否有異 常的行為,或者是否在該場所遺留了可疑的物體。在公共室內空間(Public Indoor Space) 中,例如:火車站(Rail Station)、機場(Airport)、餐廳(Restaurant)與圖書館(Library)等等, 監看人員都需要去觀看眾多的畫面,再從這些畫面中去自行分析上述的各個可能會發生 的情形。這種做法會因為長時間以人眼監看,造成監看人員的眼睛與身心的疲勞,有可 能因為疲勞時疏忽,而造成重大的損失。國際上對 ISS 有廣泛的迫切需求,例如美國芝 加哥市在全市的各種公共地點,包括地鐵站(Subway Station)、學校(School)、公車站(Bus Station)與住宅區(Residential Area)等,皆有高密度的監視系統運作以防止犯罪或意外發 生,其中,使用包含智慧型偵測系統的約有 15000 隻監視器(Camera) 統一由市中心少 數人來監看系統[1]。如此大量的畫面若能夠由智慧型偵測系統於適當的時機主動觸發 提醒或警示(Reminding or Warning)監看人員,以及提供即時或事件的資料分析與系統, 不但能夠避免因疏忽所造成的意外發生,也能夠更有效的節省人力成本。 英國從 2002 年開始持續進行稱為城市之眼(Urban Eye)的安全監控計畫,目前在英 國境內由官方監控的就有超過 400 萬支的監視器[2],而英國首都倫敦市內的監視器已 經超過了 50 萬支[3]。這些監視器都依據應用的地點不同而分別加入了各式各樣的智慧 型監視功能,例如用於高速公路(Freeway)的監視器,加入了車牌辨識功能(License Plate Recognition);在交通運輸系統(Transit System)中人群擁擠的地點,則加入了異常行為辨 識的功能以防止犯罪與恐怖攻擊(Crime and Terrorism)等。另外,近年中國大陸也開始執 行了一個名為金盾計畫(Golden Shield Project)的工程[4],這個計畫以中國大陸的深圳地. 1.
(13) 區進行實驗,目前監視器數量已經達到了 20 萬支,並且加入了視訊內容分析(Video Content Analysis , VCA)與臉部辨識功能(Facial Recognition)。同時,這個計畫預期在未 來三年內,深圳地區的監視器總數將會達到 200 萬支。 上述這些監視器的後端平台(Backend Platform)都是統一由監控站來匯集資訊,但若 是有數量眾多的監視器畫面同時傳輸至後台處理,計算量就會變的非常龐大,甚至無法 即時處理,因此,計算量大而複雜的系統便不適合應用於全面性監控的系統上。而面對 如此龐大的資料量,若能在攝影機端就預先處理,得到有效的資訊後回報,那麼後台主 機就可以更快速的取得需要的事件資訊,並且對突發事件做出即時的反應。如此更能突 顯出智慧型監視系統具備了人群切割與計數功能後附加價值的提升包含了:即時軟體的 開發與晶片模組的設計。 一般而言,關於廣泛的人形偵測相關的研究領域涵蓋非常廣,其中行為辨識 (Behavior Recognition)、警戒區侵入偵測(Warning Area Invading Detection)、人物動向追 蹤(Human Tracking)[5]、人群切割與計數[6,7]、行人流量預測(Pedestrian Flows Prediction) 與人群疏散路線規劃(Evacuation Control)[8,9]為較常見的研究項目。這些研究所面對的 場景大致可分為室內(Indoor)空間與室外(Outdoor)空間的兩類應用,這兩類的應用方式 所需的技術與內容其差異性很大。室內空間的應用大多為監視警戒區的侵入(Intrusion) 狀況,另外也有機場大廳中是否有被遺留的可疑爆裂物的研究,以及發生火警時辨識人 群(Crowds)位置並找出適當的逃生路線[9]等;而室外的應用方式則常見的有人數的監控 [10],人物流量的紀錄[11]。此外,室外空間的應用研究實施於公共交通運輸系統上[12,13] 也很常見,例如文獻[14]中,就有於各個公車站(Bus Stop)控管人物動向與人流的應用方 式。以上室內外兩種不同的應用空間,需要考量的環境因素也不相同,如:攝影的視角 (View Point)差異、環境光影的變化(Light Condition)及複雜的背景(Background Cluster) 等等。 ISS 應用的範圍若設定過大,並且不能夠明確聚焦指出應用於何種場景及如何應用, 將會導致系統過於複雜,精準度與穩定度不足,使得該系統無法真正成為被廣泛使用的 商品。本論文針對論文主題分析與規劃明確的應用,目的在提升所提出的智慧型人群切. 2.
(14) 割與計數系統其切割學理與演算法的成功率與計數的正確性,以確保本系統在 ISS 中產 生應有的價值。. 1.2 研究目的與演算法選用 我們以人群切割及計數的智慧型偵測系統做為主要研究目標,由於會影響智慧型偵 測系統研究的環境影響因子非常多,每一個影響因子都會造成研究方法的不同,所以我 們必須先設立研究限制(Limitation)。因為人體的多變的外形(Appearance)和姿勢(Pose), 因此衍生出許多不同的相關研究。我們將主要的研究對象設定為行走中的人群,行人擁 有大多為行走姿勢的特點,整體研究方向與廣泛的多變人形姿勢相比之下變得明確了許 多。人群在移動時,可能會因為人物互相重疊(Overlapped)或被其他物件阻擋(Shield)而 造成整體人形產生某種程度的被遮蔽(Occluded)。此時,我們必須定義出能夠接受到某 種程度的遮蔽(Occlusion)做為我們的研究條件。而人體的頭部(Head)與肩膀(Shoulder)具 有強大代表性的人體特徵形狀,一般在人們被遮蔽的情形下,其遮蔽程度至一半的頭與 肩膀時,代表人體的特徵形狀已經低於 50%。因此,我們要求一個人形至少要顯現較完 整的頭部與肩膀,才能夠被我們的方法偵測切割及正確的計數出來。. 圖1-1 監視主要出入口畫面視角,人物被遮蔽的情形 (a)頭與肩膀完全被遮蔽 (b)頭與肩膀被遮蔽程度高於50% (c)人物雖然被遮蔽,但頭部與肩膀有完整顯現. 3.
(15) 人形特徵分為全域特徵(Global Feature)與區域特徵(Local Feature),全域特徵代表一 個人整體的形狀輪廓(Contour),而區域特徵則為人體某一個部份或是一個部位的特徵。 本論文中,將全域特徵與區域特徵整合以達到較高人群切割率與計數的研究目的。在全 域 特 徵 的 選 擇 上 , 我 們 使 用 建 立 人 形 樣 板 (Human Template) 及 樣 板 比 對 (Template Matching)、絕對差值遮罩(Absolute Difference Mask , ADM)邊緣偵測演算法[15]計算前 景邊緣。區域特徵則是選擇使用梯度方向直方圖(Histograms of Oriented Gradients , HOGs)[16]搭配線性支持向量機(Linear Support Vector Machine , LSVM)做為分類器使用, 並且使用 AdaBoost 演算法(Adaptive Boosting)[17,18]學習(Learning)挑選出辨識效果較 好的一些區域特徵位置;構成一個更有效的強分類器。 樣板建立與樣板比對的演算法選定,我們以 ADM 邊緣偵測演算法中的邊緣強度 (Edge Strength)建立多種人形樣板(Multiple Template),再以距離轉換演算法(Distance Transform)計算輸入人形邊緣全域特徵後,將兩者進行樣板比對(Template Matching) [19,20,21] ,以此種方式做為其中一個階段性的行人確認(Verification)。經過我們的觀察, 監視影像畫面中的行人方向最主要可分為三類:其一為向右行走,也就是我們會看到行 人的右邊側面(Right Side,+90 度);其二為向左行走,我們會看到行人的左邊測面(Left Side,-90 度);最後則為向前及向後行走,我們會看到行人的正面或背面(Front View,0 度或 Back View,180 度),由於正面及背面的特徵相似,所以將他們歸屬至同一類中。 我們分別利用上述這三類的行人角度,及人形特有的頭肩形狀,建立出兩種代表人形的 樣版(Two Template)。目前與人形樣板相關的研究中分為 2D 樣板[18]與 3D 樣板[22]兩 類,我們選擇使用的樣板建立方法則屬於 2D 樣板。與本論文特徵有關的技術模組演算 法的選定經由整理後如表 1.1 所示。 本研究選用這些演算法,並將演算法轉變為技術模組,這些技術模組都能夠單獨以 嵌入式即時軟體模組執行,並於未來研究中能夠進一步成為硬體模組,藉由技術模組的 相互組合達到即時人群切割計數的目的,同時也能夠達到高辨識率與低誤判率(False Positive Rate)的效果。. 4.
(16) 表 1.1 全域及區域特徵選用的演算法. 1.3 研究問題與挑戰 在研究的過程中,我們整理歸納出幾種遇到的問題,分別是攝影機視角所帶來的影 響、人形相互重疊遮蔽的程度、背景複雜度的影響以及行人多樣的不同角度外形與姿態。 每一種問題都具有其一定的挑戰性,這些問題也同樣是在人形偵測與人群切割相關的研 究中常常被提出來探討的,對於解決問題的方式(Approach or Method)不同,所衍生的解 決方法(Solution)也不會相同。. 1.3.1 攝影高度與視角的影響 在一般的攝影架設的情形中,我們考慮三種架設變數,分別為攝影的位置(Location)、 攝影的視角(View Angle)與攝影的高度(Height)。針對同樣的一幅場景,攝影機的位置不 同所拍攝到的畫面與內含物件就會不同。而攝影的視角則是以拍攝的位置相同時為前提 的情況下,從不同的角度去拍攝,而其角度的變化又可分為以水平變化不同幅角(Pan Angle)拍攝或以垂直變化的不同及仰俯角(Tile Angle)拍攝。通常攝影的位置會影響攝影 的高度,而攝影的視角也會因為攝影的高度而決定不同的角度,三種不同的變數各有著 相互影響的關係。如圖 1-2 所示,我們將攝影機架設在左上方,攝影的高度以符號 h 表 示,攝影的位置則是以二維平面座標(x,y)表示,而攝影的視角則是以拍攝的角度與二維 座標 Y 方向夾角 θ 的俯視夾角作為代表。. 5.
(17) 圖 1-2 攝影高度 h、攝影俯視角 θ 與攝影位置(x,y)三者相互關係的示意圖 若我們預先設定攝影的位置不再改變,當攝影高度伴隨視角改變時,畫面中人物的 全身比例就會出現很大的差異。人物比例的改變對於我們如何建立出與畫面中的人物相 符合的人形樣版會造成很大的影響。攝影的高度與視角對於人物全身比例的影響如圖 1-3 所示。. 圖 1-3. 不同的攝影角度,人物的比例也不同. 1.3.2 人形遮蔽現象 當觀看的空間中有兩個以上的物體(Object),物體與物體之間便會出現遠近的相對關 係,此時,就可能會發生遮蔽現象(Occlusion)。若是人物(Human)與人物相互的遮蔽關 係,則會有身體互相上下遮蔽及左右遮蔽的情形發生。當靜止物體被視為背景時,移動 中的人物則為前景。前景與背景間的遮蔽關係,需要仔細觀察再加以判斷,倘若背景遮 蔽程度過大時,則可能是攝影機地點或視角選擇不當所造成。圖 1-4 分別表示人物上下 遮蔽、左右遮蔽、前景與背景半身遮蔽及前景與背景遮蔽範圍甚大的四種情況。. 6.
(18) 圖 1-4. 遮蔽現象發生時,可能造成的現象 (a) 人物互相上下遮蔽 (b)人物互相左右遮蔽 (c)人物下半身被前方物件遮蔽 (d)人物被前方物體遮蔽範圍甚大. 1.3.3 背景複雜度影響 受限於拍攝地點與人類物理活動範圍廣泛,靜止的背景可能會出現桌子、櫃子或椅 子等家具。越複雜的背景就越有機會因造成遮蔽而遺失前景資訊,這類影像經過邊緣提 取後,常常出現過多背景物件的邊緣。而我們以建立背景模型(Background Model)及背 景相減法能夠有效的解決背景邊緣被提取資訊過多的問題,但是剩下的背景因其顏色或 形狀仍很有可能與前景人物相近,此時我們還是會遺失有效的前景資訊。圖 1-5 為監視 圖書館門口出入狀況的畫面,綠色框即為前景人物與背景相仿之處。. 圖 1-5. 前景人物與背景過於相近. 7.
(19) 1.3.4 行人多樣化姿勢與外形 行人的外形(Appearance)和姿勢(Pose)有著不同的意義。當兩個人同樣做出高舉左手 的動作時,他們的姿勢是相同的,但不同的兩個人會因為身高、體形、衣著或樣貌有所 差異,導致他們的外形不相同。我們選擇行人前景資訊切割的方法,可以有效的解決大 多數人物不同外形造成的問題,但對於行人出現特殊的姿勢時,就可能會與我們訂定的 人形樣版產生分岐。本論文於 1.2 章節中提到,我們建立了四種不同樣版,而這些樣版 是依照大多數的行人姿勢所建立出來的,所以當畫面中的行人出現特殊的姿勢時,便會 無法符合我們針對大多數行人所建立出那幾種人形樣版。頭部與肩膀的樣板對於樣板比 對特殊姿勢的行人,能夠有很大的幫助,但如果行人攜帶特殊的物品或穿著特殊的服裝 以致改變頭部與肩膀的輪廓時,對我們來說這類型的行人辨識難度就提高很多。. 1.4 論文章節組織架構 本論文於第一章述說基本的研究背景與動機、研究目的及選用的演算法之後,第二 章將會開始探討關於人形偵測、行人偵測、人群切割及人群計數國內外的相關研究成果 與文獻,分析目前研究所使用的方法優缺點。並以相關的研究來驗證我們選用的演算法 應用於監控式人形偵測系統的可靠性,藉以預先估測使用各個選用的演算法階段性的效 果。 在第三章一開始將會先敘述我們的人形偵測系統中所會用到的演算法技術模組。因 為加入了學習型演算法,之後於第四章會將其系統分為全域偵測器訓練階段與全域引導 AdaBoost 學習訓練階段兩個子章節分別解說及將每一個階段的演算結果組合使用的概 念。於訓練階段子章節中包含了建立全域人形樣版、計算樣版比對分數轉換係數、調整 全域偵測器門檻、AdaBoost 強分類器訓練以及全域引導 AdaBoost 學習強分類器訓練的 流程與做法。 第五章實驗將會比較我們的方法與一般 AdaBoost 的實驗結果。比較的資料庫分為 靜態資料庫與動態資料庫。靜態資料庫為一般只有偵測視窗大小的樣本影像,如: CBCL[44]、CVC[45]。動態資料庫則是影片類型,我們將影片分割出多張 Frame,進行. 8.
(20) 測試與計算最後的辨識率等。動態資料庫則使用 Caviar[46]及 2007 年 AVSS[47]所提供 的監視器畫面以及我們自行拍攝位於一般室內走廊場景的監視器畫面。 最後,第六章則是探討我們方法在往後能夠改進的方向與空間,分析系統式的偵測 方式與影響結果的原因。. 9.
(21) 第二章 相關研究與文獻探討 2.1 人形與人群的區域特徵 區域特徵為一個人形中的某個部份(Part)或某個部位(Block)的特徵向量,藉由蒐集多 個向量來代表一個人形。在 2000 年時,Papageorgiou 與 Poggio [23]提出了由 Haar Wavelet 轉變為使用於人臉偵測的區域特徵 Haar-Like,該特徵用以代表一個人形在各種位置 (Location)、大小(Scales)和梯度方向(Orientations)的區域強度差異,Haar-Like 在目前都 還是人臉辨識的研究非常熱門的區域特徵。而 Viola 等人[ 18] 於 2005 年時的研究中, 提出加入了正負 45 度的梯度方向等類似 Haar-Like 的區域特徵搭配 AdaBoost 演算法, 並首次將 Haar-Like 區域特徵的概念應用於人形偵測。Monteiro 等人[24]於 2006 年時, 提出將原始的 Haar-Like 區域特徵搭配 AdaBoost 演算法應用於行人偵測。因為人形姿勢 多變與複雜的輪廓,導致 Haar-Like 區域特徵的辨識效果有限,而在後幾年的人形或行 人偵測的相關研究中,Cui 等人[25]則是因應人形的複雜度而提出增強與修改 Haar-Like 的區域特徵。 Dalal 與 Triggs[16]於 2005 年時,提出了梯度方向直方圖(Histograms of Oriented Gradients,HOG) 的方法,以邊緣或梯度結構的區域形狀特徵,描述身體各不同位置與 大小的區塊部位(Block),其效果非常好,所以在之後人形偵測與人群切割的相關研究中 被其他研究者廣泛的使用[26][ 27]。Zhu 等人[17]在 2006 年時,將 HOG 搭配 AdaBoost 演算法,而且還更進一步的引用串級(Cascade)方式加以改善效能。Enzweiler 與 Gavrila[28]的研究將 Haa-Like 與 HOG 兩種特徵分別加入 AdaBoost 演算法來比較兩種區 域特徵間的計算速度與辨識效果,同時也證明了 AdaBoost 能夠有效的提升系統的辨識 效能。 Wojek 與 Schiele[27]所提出的方法不同於使用 AdaBoost 改善區域特徵的方法,而是 將 HOG 加入物體了外形辨識描述的形狀內涵(Shape Context , SC),這種方法的目的也 是可以降低計算成本,但因為人體外形過於複雜導致結果不如單純使用 AdaBoost 來的 有效。還有一些不同於上述而較為常見的區域特徵,如 Shapelet[29]、Edgelet[30]、. 10.
(22) Adaptive Contour Features[31]與 Local Binary Patterns(LBPs)[ 32]等。此外,Tuzel 等人[33] 則是於 2008 年時提出了新型態的特徵,這個特徵仍以區塊(Block)為基本,而進一步計 算出影像特徵的協方差(Covariance),但其被廣泛使用的程度尚不及 HOG 來的多。. 2.2 人形與人群的全域特徵 全域特徵通常為代表一個人整體的外形或輪廓(Contour Shape or Silhouette),使用這 種特徵對於人體被遮蔽(Occluded)的情況比區域特徵通常會有更好的效果。在毛君[19] 的研究中是以平均梯度大小(Mean Magnitude)的方式建立出一個代表整體人形的樣板, 其藉由大量站立正面的行人樣本影像(Image Sample),分別計算所有樣本影像其梯度大 小後,再相加並除以樣本影像總數,得到平均梯度大小,最後給定一個門檻值(Threshold) 操作以獲得站立正面行人的樣板。蔡君[34]與張君[7]也是使用相同的方法建立樣板,但 蔡君只以人形的頭肩部做為其研究中的全域特徵;張君則是建立出三種不同行人方向的 樣板,分別為正面樣板、面左側 45 度與面右側 45 度,其三種行人方向中分別又有三種 不同大小的樣板,共有九種樣板。上述三人的研究皆以距離轉換演算法(Distance Transform)[35]進行樣板比對,其比對的方式最早是由 Gavrila 與 Philomin 於 1999 年時 提出[36],用在汽車偵測應用方面。 近幾年的許多研究為了改善人體被遮蔽的情況,採用了基於多重部位(Multiple Part-Based or Part-Based)的樣板分別代表人體的各個部位。如文獻[21],[28],[37],[38] 與[39]皆使用多重部位的樣板來改善人體被遮蔽的情形,其中[21]與[37]更是將其樣板細 分至不同方向的人形對應到不同部位的肢體形狀。文獻[22]與[6]則是採用了 3D 樣板, 對應至畫面中行人不同方向的姿勢與行人與鏡頭之間的距離遠近,藉由行人與鏡頭的遠 近不同便可分辨出前後行人間的相互遮蔽關係。. 2.3 區域與全域特徵整合與應用方向 目前許多人形偵測與人群切割相關的研究已經將區域及全域特徵整合使用,以提高 辨識效果與其系統的效能。我們將這些相關的文獻分為單一人形偵測(Single Human Detection)及人群偵測與切割(Crowd Detection and Segmentation)兩個單元,分別描述它. 11.
(23) 們的使用方法及應用方向。單一人形偵測的研究大多因為沒有完全解決人物重疊時相互 遮蔽的問題,因此無法直接有效的引用在人群切割的領域上。對於人群偵測與切割來說, 大多數方法使用身體的某一部分做為偵測器(Detector)以便能找出不完整的人形或行人 部位,如此對於人群中的相互遮蔽現象具有較高的適應性。. 2.3.1 單一人形偵測 Wojek與Schiele提出Shape Context(SC)與HOGs相互結合[27],將影像邊緣做隨機取 樣,以直方圖統計取樣點與其他取樣點之間的距離與角度,評估相似程度(Similarity)做 為全域特徵。再透過結合HOGs區域特徵偵測器,以便最終取得一個權重(Weight)關係進 行辨識人形。蔡君[34]以全域特徵驅動區域特徵分類器的基本構想,將全域特徵以人形 特有的頭肩部輪廓作為單一樣板,再以距離轉換演算法進行樣板比對。而後進一步觀察 出於訓練樣本中被全域特徵分類出人(Human)與非人(Non Human)的分數分佈,找出兩 者間樣板比對後分數相似的數學模型,以便順利的選出分類的門檻值。如此藉由全域特 徵的分類,驅動改變AdaBoost中的HOGs向量SVM弱分類器的分類標準。當頭肩資訊非 常可靠的時候放寬所有弱分類器的標準,反之則是讓標準更加嚴格,以此達到全域與區 域特徵整合的概念。 採用與[34]相同的概念來整合全域及區域特徵,毛君[19]進一步加強以全域特徵驅動 區域特徵分類器的研究。該研究以全身行人的正面樣板做為全域特徵,而後以距離轉換 演算法(DT)進行樣板比對,並手動設立一個辨識全域特徵的門檻值用以區分為人或非人。 當全域特徵分類為人時,將會驅動區域特徵的HOGs向量SVM弱分類器於某個區間中找 出最佳的降低分類標準,意即提高被分類為人的機會;反之,若全域特徵分類為非人時, 則會於HOGs向量SVM弱分類器的某個區間中找出最佳的提高分類標準,意即降低被分 類為人的機會。如此以全域與區域特徵相互搭配驅動的方式達到更精準的弱分類器效果, 進而提高AdaBoost演算法學習(Learning)的功效。. 12.
(24) 2.3.2 人群偵測與切割 對於人群偵測來說,大多數方法使用身體的某一部分做為偵測器(Detector),用以解 決人群中人與人重疊時發生的相互遮蔽現象。Lin 與 Davis [21]的研究中使用的區域特 徵為 HOGs 向量以搭配 AdaBoost 演算法,而全域特徵為將身體部位樣板分為多層次身 體部位樣版比對(Hierarchical Part-Template Matching);由單一頭肩樣板開始向下分支, 接著分為側面及正背面的身體軀幹樣板,再個別從兩種身體軀幹樣板分支出多種行人腳 部樣板的不同角度與姿勢,以這種多層次身體部位的樣版比對方式找出正確的行人姿勢 與角度。Lin 與 Davis 的全域與區域特徵整合的概念是藉由區域特徵偵測(Detection)人形 所在位置,再以多層次身體部位樣版比對的全域特徵,將人形正確的姿勢輪廓切割 (Segmentation)出來。Hao 等人[40]則是與 zhu 等人使用相同的 Cascade 架構做為區域特 徵的驗證偵測,並且加入使用大量的人形樣本(Sample)圖片建立出機率頭肩樣板,再以 DT 進行樣板比對找出人形或行人與機率頭肩樣板相似程度最高的部位。利用此種方式 結合區域特徵與全域特徵,來達到正確的標示人形或行人的效果。 不同於[40],[27],[21],[34]與[19]的研究,Wu 與 Nevatia[30]使用了 Edgelet 做為 區域特徵。但全域特徵的部份與[21]使用相同的概念,將人形分為多個部位的階層式樣 板個別比對。這種身體部位樣板(Part-Template)的概念是為了有效的解決人體遮蔽的問 題,並且共通點都在於必須要求人形顯現完整的頭肩部份。Leibe 等人[41]相對於上述 文獻中區域特徵的使用概念,反而是以局部的身體外觀做為區域特徵解決人群相互遮蔽 的問題,並且與全域行人的外觀輪廓(Silhouette)相結合,藉由行人外觀輪廓的比對方式, 正確的切割出人群畫面中的各個行人。而在參考文獻[42]中,Ramanan 以大量的樣本圖 片建立人形的輪廓遮罩樣板,再以輪廓遮罩樣板進行全域分割(Global Segmentation)找 出偵測區域,並於驗證階段過程中將輪廓遮罩樣板與區域特徵結合進行分類。. 13.
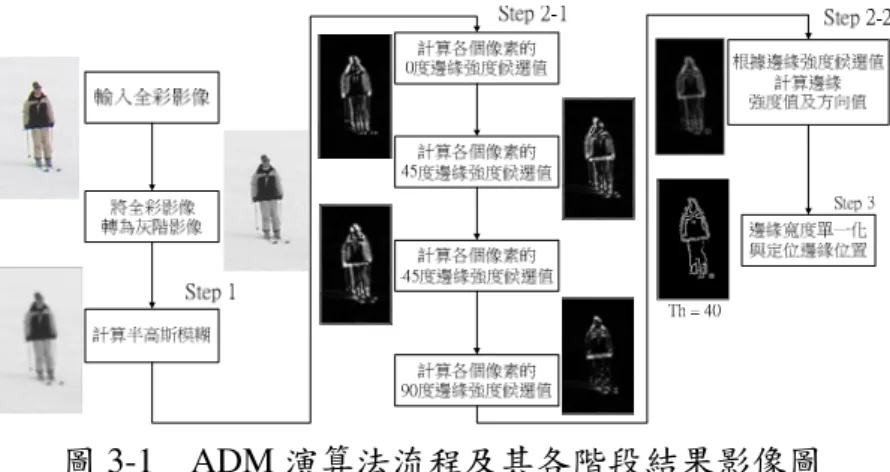
(25) 第三章 演算法技術模組 3.1 絕對差值遮罩(ADM) 邊緣偵測 絕對差值遮罩 絕對差值遮罩(Absolute Difference Mask , ADM)是由 Alzahrani 與 Chen[15]於 1997 年所提出的邊緣偵測演算法(Edge Detection)。ADM 演算法是承襲 Canny 邊緣偵測演算 法[43],但主要改善目的是以能夠達成更有效的硬體電路模組設計為考量基礎,因此在 該演算法的流程中盡量避免使用浮點數的運算。ADM 的第一步驟提出了適合硬體實作 的影像模糊化方法(Smoothing),這種用以符合硬體設計的影像模糊化取代原先 Canny 演算法中,計算較複雜的高斯模糊遮罩,而稱為半高斯模糊(Semi-Gaussian Smooth)。半 高斯模糊以 2 的 1 次方遞減至負數次方實現高斯分佈曲線,2 的負數次方在實作時,能 以二進位移位的方式取代浮點數乘法的運算,達到有效硬體電路模組化的設計概念。而 ADM 計算邊緣(Edge)的遮罩,計算流程除了半高斯遮罩迴旋運算外,還有以下兩個步 驟。第一步驟先計算出像素的邊緣強度(Strength)及方向值(Direction),而方向則是決定 出該像素的邊緣是屬於 0 度、90 度、+45 度或-45 度等四個方向的其中之一。而第二步 驟會將邊緣的寬度單一化,並且定位(Localization)出邊緣正確的位置。由此,其 ADM 完整演算流程配合可圖 3-1 說明如下: 1.. Semi-Gaussian smoothing:半高斯模糊迴旋運算將影像模糊化。. 2.. Pixels strength and direction calculation:計算方向值以及邊緣強度。 2-1. 計算每個像素的 4 個方向邊緣強度候選值。 2-2. 根據邊緣強度候選值計算出邊緣強度值及方向值。. 3.. One-pixel edge and localization:將邊緣寬度單一像素化並定位出其所在位置。. 14.
(26) 圖 3-1. ADM 演算法流程及其各階段結果影像圖. 半高斯模糊迴旋運算的遮罩數值如圖 3-2 所示。假定像素 P 的影像強度(Intensity) 位於影像的座標(x,y)上將其表示為 P(x,y)。若以 Semi-Gaussian 最外圍角落的權值 0.25 來說,迴旋乘積(Convolution)的做法應為 P(x-2,y-2)*0.25,此時我們可將其改為 P(x-2,y-2) >> 2。意即,將 P(x-2,y-2)的影像強度以二進位的方式直接往右移兩位即可得到相同結 果,最後再把各像素的移位後影像強度進行加總。而 Gaussian 分佈又稱常態分佈 (Normal Distribution),其所有的權值加起來應為 1。依循這個定理,Semi-Gaussian 必須 將加總值除以 16,這個操作也可將其改為往右移 4 位即可得相同結果。. 1 × 16. 圖 3-2 半高斯模糊遮罩 經過半高斯模糊的計算之後,開始對各個像素分別計算 4 個方向的邊緣強度,其計 算邊緣強度及方向的遮罩如圖 3-3 所示。計算 0 度方向候選計算值以 Hu、Hl 為表示符 號;90 度方向候選計算值則是使用 Vu、Vl 符號為代表;而正負 45 度則分別以 Pdu、Pdl 與 Ndu、Ndl 為符號代表。演算法中依序計算出 4 個方向的方向候選計算值如公式(3.1) 所示,而後將 4 個方向計算出來的方向候選計算值相減並取絕對值,以得到 4 個方向邊 緣強度候選值(V , H , Pd , Nd),如公式(3.2)所示。最後挑選出 4 個方向候選值中最大的. 15.
(27) 邊緣強度候選值並除以 2,成為代表這個像素的邊緣強度值(Se),而方向值則是根據邊 緣強度候選值挑選出最小的做為代表方向值(dire),如公式(3.3)所示。. 圖 3-3. 計算邊緣強度及方向值的遮罩. Vu = Vu (1) + Vu (2), Vl = Vl (1) + Vl (2) H u = H u (1) + H u (2), H l = H l (1) + H l (2) Pdu = Pdu (1) + Pd u (2), Pdl = Pdl (1) + Pd l (2). (3.1). Ndu = Nd u (1) + Nd u (2), Nd l = Ndl (1) + Ndl (2). V = Vu − Vl , H = H r − H l. Se = max{V , H , Pd , Nd } / 2. Pd = Pdu − Pdl , Nd = Ndu − Ndl. dire = dir (min{V , H , Pd , Nd }). (3.2). (3.3). 經過計算出影像中所有像素的邊緣強度值與方向後,再採用寬高大小 3*3 的遮罩來 比對出真正的邊緣位置,遮罩如圖 3-4 所示。計算邊緣位置的方式是以遮罩中心像素(P5) 所計算出的方向為基準,給定一個門檻值,並判斷該像素方向前後像素的邊緣強度(Se) 是否符合條件或大於門檻值。若條件皆符合時,即判定該邊緣存在於影像中。. 圖 3-4. ADM 邊緣定位遮罩. 我們將 ADM 與 Canny 兩種演算兩者的演算步驟與邊緣偵測結果圖進行分析與比較。 Canny 演算法的結果圖是以 OpenCV 2.0 的 cvCanny()函式進行計算所得到,所以在演算 法的分析與比較中,我們也會將 OpenCV 的計算步驟加入比較。原始 Canny 的演算步. 16.
(28) 驟上共分為四個階段,分別為: 1. Gaussian Smoothing: 以 σ = 1.0 至 2.0 之間的高斯模糊遮罩,計算出模糊化影像。 2. Compute Gradients component、Magnitude and Orientation: 計算各個像素的梯度分量、梯度大小及梯度角度,如公式(3.4)所示。. Mag = g x 2 + g y 2. θ = arctan. gx gy. (3.4). 3. Non-Maximum Suppression: 將角度分為四個角度區間,分別為-22.5~22.5 度、22.5~67.5 度、67.5~112.5 度與 112.5~157.5 度,如圖 3-6 所示。而後根據各個像素的梯度角度找出符合的 角度區間,並比對該像素鄰近的梯度大小,藉此標記出候選的邊緣所在之處。. 圖 3-5. Canny 演算法將梯度角度分為四個角度區間示意圖. 其比對的方式為,與符合自己像素梯度角度區間方向的鄰近像素比較其梯 度大小。若 P5(中心點)與鄰近像素相比後,梯度大小值不是最大時,則判斷為 非邊緣點,反之,當 P5 是鄰近像素中梯度大小值為最大時,則判斷該點為邊緣 點,其梯度角度區間與比對的鄰近點如下: 3-1.. -22.5 ~ 22.5 : P4、P5 與 P6 三者比較梯度大小。. 3-2.. 22.5 ~ 67.5 : P3、P5 與 P7 三者比較梯度大小。. 3-3.. 67.5 ~ 112.5 : P2、P5 與 P8 三者比較梯度大小。. 3-4.. 112.5 ~ 157.5 : P1、P5 與 P9 三者比較梯度大小。. 4. Hysteresis Thresholding: 設立兩個門檻值(Threshold),其一門檻值較數值小(Thlow),另一則較大. 17.
(29) (Thhigh)。Thlow 用於判斷附近的邊緣是否為連接的線,若無連接則該點可能為雜 訊,Thhigh 則是用於判斷該點的梯度大小強度是否足以成為邊緣。兩個門檻值的 判斷式如下: 4-1.當像素(x, y)的梯度大小低於 Thlow 時,該候選邊緣點則被捨棄(標記為黑 色)。 4-2.當像素(x, y)的梯度大小高於 Thhigh 時,該候選邊緣點則確定強度足夠成為邊 緣點(標記為白色)。 4-3.當像素(x, y)的梯度大小介於 Thlow 與 Thhigh 之間時,則會判斷一個範圍的遮 罩內相連接的像素梯度大小是否高於 Thhigh,若是高於 Thhigh 則判斷該候選 邊緣點為邊緣點(標記為白色)。 4-4.當像素(x, y)與鄰近的像素皆無高於 Thhigh 時,則會判斷一個範圍的遮罩內相 連接的像素是否有某一像素的梯度大小介於 Thlow 與 Thhigh 之間,若存在, 則判斷該候選邊緣點為邊緣點(標記為白色)。 4-5.其他情況則皆判斷非邊緣點(標記為黑色)。 OpenCV 中的 Canny 演算法修改了些許步驟中的細節,其中第一步驟修改為使用 σ 約等於 1.4 的固定數值的高斯模糊化遮罩,其遮罩數值如圖 3-6 所示;第二步驟使用 Sobel 演算法計算梯度分量藉以計算梯度大小及梯度角度;而於第三步驟中,判斷邊緣的鄰近 大小範圍固定使用 3*3 Pixels 的遮罩;第四步驟則是於 4-3 與 4-4 判斷式中的大小範圍 的遮罩固定使用 3*3 Pixels 的遮罩。. 1 × 159. 圖 3-6. OpenCV 中 Canny 演算法所使用的高斯模糊遮罩. 18.
(30) 我們將原始與 OpenCV 的 Canny 演算法以及 ADM 演算法的各個演算步驟差異製作 於表 3.1 中。我們使用本研究所製作的 ADM 模組程式與 OpenCV Canny 演算法演算步 驟結果差異相互比較,並製作於表 3.2 中。 表 3.1. 表 3.2. 原始 ADM 與 OpenCV Canny 演算步驟特性差異. ADM 演算法與 OpenCV Canny 演算過程中間結果比較圖. 3.2 距離轉換(DT)演算法 演算法 距離轉換 我們引用距離轉換演算法(Distance Transform,DT)與多重樣板進行比對[4],以實現 估算行人樣板與行人影像之差異。DT 是將二值化邊緣影像轉換為距離影像,經由轉換 後的 DT 距離值可以表現出由邊緣開始向背景擴展後的距離,其距離代表邊緣與週遭物 體的遠近,如圖 3-7 所示。. 19.
(31) 圖 3-7 由灰階圖片計算出 ADM Strength 邊緣,而後計算出 而後計算出 DT 影像。 DT 的計算方式類似於一般影像套用遮罩的迴旋運算(Convolution) 的計算方式類似於一般影像套用遮罩的迴旋運算(Convolution)方式,其差異之處 為,將遮罩中心點套入至邊緣像素後 將遮罩中心點套入至邊緣像素後,依據遮罩值依序累加至 DT 影像中,若遇到已計 影像中 算過像素則選擇較小的距離做為 過像素則選擇較小的距離做為 DT 距離代表,如公式(3.5)所示。在公式 在公式(3.5) 中,i 為 邊緣影像 IADMstr 中的一個像素,j 中的一個像素 則是對應至 3*3 Pixels 的遮罩內位置。我們希望 的遮罩內位置 DT 轉 換後的距離能夠接近原本的邊緣的形狀 換後的距離能夠接近原本的邊緣的形狀,因此使用由[35]所推導出的 所推導出的 Chamfer 距離,將 遮罩數值套用 a = 3 與 b = 4 進行 DT 轉換,如圖 3-8 所示。. DT (i ) =. min. i∈I ADMstr , j∈mask. +b. +a. +b. +a. 0. +a. +b. +a. +b. d (i, j ). (3.5). 圖 3-8 距離轉換遮罩. DT 會一直重覆計算,直至整張影像都填入距離值時 直至整張影像都填入距離值時。圖 3-9 是距離轉換流程示意 圖,圖中黑色部分代表特徵點 圖中黑色部分代表特徵點,並以遮罩參數設定 a = 3 與 b = 4 進行 DT 轉換運算, 經過四回合的計算即可得到距離轉換圖 經過四回合的計算即可得到距離轉換圖,原本是特徵點的位置都以 0 來取代,從特徵點 來取代 向外延展,距離越遠則數值越大 距離越遠則數值越大。. 20.
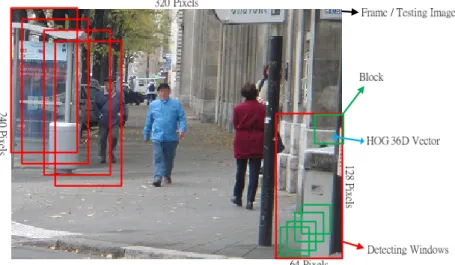
(32) 0. 0. 0. 0. 0. 4. 3. 3. 3. 4. 4. 3. 0. 0. 0. 3. 4. 3. 3. 0. 3. 4. 4. 3. 0. 3. 4. 3. 0. 3. 0. 0. 3. 0. 3. 4. 0. 0. 3. 0. 3. 3. 0. 3. 0. 0. 3. 0. 3. 3. 0. 3. 0. 0. 3. 0. 3. 4. 4. 3. 0. 3. 4. 3. 0. 3. 3. 3. 0. 3. 4. 4. 3. 0. 0. 0. 3. 4. 4. 3. 3. 3. 4. 0. 0 0. 0. 0. 8. 7. 4. 3. 3. 3. 4. 7. 8. 11 8. 7. 4. 3. 3. 3. 4. 7. 8. 8. 7. 4. 3. 0. 0. 0. 3. 4. 7. 8. 7. 4. 3. 0. 0. 0. 3. 4. 7. 7. 4. 3. 0. 3. 3. 3. 0. 3. 4. 7. 4. 3. 0. 3. 3. 3. 0. 3. 4. 6. 3. 0. 3. 4. 6. 4. 3. 0. 3. 6. 3. 0. 3. 4. 6. 4. 3. 0. 3. 6. 3. 0. 3. 6. 8. 6. 3. 0. 3. 6. 3. 0. 3. 6. 8. 6. 3. 0. 3. 6. 3. 0. 3. 6. 8. 6. 3. 0. 3. 6. 3. 0. 3. 6. 8. 6. 3. 0. 3. 6. 3. 0. 3. 4. 6. 4. 3. 0. 3. 6. 3. 0. 3. 4. 6. 4. 3. 0. 3. 7. 4. 3. 0. 3. 3. 3. 0. 3. 4. 7. 4. 3. 0. 3. 3. 3. 0. 3. 4. 8. 7. 4. 3. 0. 0. 0. 3. 4. 7. 8. 7. 4. 3. 0. 0. 0. 3. 4. 7. 8. 7. 4. 3. 3. 3. 4. 7. 8. 11 8. 7. 4. 3. 3. 3. 4. 7. 8. 圖 3-9 DT 距離轉換流程示意圖. 3.3 梯度方向直方圖(HOG) 梯度方向直方圖 梯度方向直方圖(Histogram of Oriented Gradients , HOG)是由 Dalal 與 Triggs[16]於 2005 年所提出,其概念是以 36 個維度向量來代表一個影像區塊(Block)內物體的輪廓與 外觀的資訊。在該文獻中也提出了測試影像圖(Testing Image)、偵測視窗(Detecting Window)、區塊(Block)與 HOG 間的關係,其測試影像即為一張待辨識人形解析度為 320*240 的畫面(Frame),或其他解析度也可以,而該畫面中則會有許多個,經依序掃描 產出而寬高為 64*128 的偵測視窗,其中一個偵測視窗中就包含了許多個經第二層不同 掃描產出的區塊,而每一個區塊就會有一個 36 維度向量的 HOG。此外,在訓練階段沒 有偵測視窗存在,而是以正負樣本(Positive / Negative Samples)取代這個角色。四者的關 係如圖 3-10 所示。. 21.
(33) 圖 3-10 測試影像、偵測視窗、區塊與 HOG 關係示意圖 區塊的形狀分為兩種,分別為圓形區塊(C-HOG)與矩形區塊(R-HOG),矩形區塊與 圓形區塊效果差不多,但實作較方便,且在 Zhu 等人的研究中[17]提到多變的矩形特徵 區塊(Feature Block)有助於描述人體部位,因此我們採用矩形區塊 HOG 向量來描述人體 外觀與輪廓,而特徵區塊長寬可以介於 12*12 到 64*128 之間。寬高比例為(1:1)、(1: 2)或(2:1),如圖 3-11 所示。一個偵測視窗中的矩形特徵區塊數量會受到第二層掃描時, 區塊與區塊間的像素步進採樣間隔(Step)所影響,如 Dalal 的研究中採用固定寬高大小 為 16*16 的矩形特徵區塊,而像素採樣間隔則定為 8 Pixels。如此,一個偵測視窗中共 可掃描取出 105 個 16*16 的矩形特徵區塊。而 Zhu 等人的研究中則是同時使用了三種 寬高比例的區塊,並有 4、6、8 Pixels 三種不同的像素採樣間隔,此時,一個偵測視窗 中共可掃描取出 3705 個三種不同尺寸的矩形特徵區塊。. 圖 3-11 不同長寬比例的特徵區塊. 22.
(34) 在一般情形中,輸入的影像為一張彩色的影像,在計算 HOG 特徵向量之前會先經 過將彩色影像轉換為灰階影像的前處理步驟,而後才開始計算 HOG 特徵向量,運算過 程共有四個步驟,各步驟配合圖 3-12 分別說明如下: 1.. 2.. 3.. 計算影像區塊內各像素的梯度分量(Vector Component)。 1-1.. 計算水平方向的梯度分量 gx。. 1-2.. 計算垂直方向的梯度分量 gy。. 根據梯度分量計算出梯度大小與方向。 2-1.. 計算每一個像素的梯度大小 M(x,y)。. 2-2.. 計算每一個像素的梯度方向 θ(x,y)。. 將區塊分為四等份,每一等份中利用梯度方向角度平分為九個區間,每一 個區間的梯度大小進行累計,九個區間便可獲得一個直方圖,如此,一個 區塊共有四個直方圖。. 4.. 每個直方圖各有九個區間,每個區間存有一個梯度大小的累計值,因此, 一個特徵區塊中共會有 36 個累計值,稱之為一個 36 維度的 HOG 向量。. 圖 3-12 計算 36D HOG 向量步驟流程圖 第一步驟只要將特徵區塊像素與遮罩[-1, 0, 1]或[-1, 0, 1]T 進行迴旋運算,便可計算 出影像水平與垂直方向的梯度向量之分量 gx 與 gy,如公式(3.6)表示。接著第二步驟使 用水平與垂直方向的梯度分量(gx,gy)求得梯度大小(Magnitude)與梯度方向(Orientation),. 23.
(35) 運算如公式 3.7 表示。. ∇I origin ( x , y ). ∂I origin ( x , y ) g x ∂x = grad ( I origin ( x , y ) ) = = ∂ I g origin ( x , y ) y ∂y . (3.6). M ( x, y ) = mag (∇I origin ( x , y ) ) = g x 2 + g y 2 (3.7). gy gx . θ ( x, y ) = tan −1 . 經過上述兩個步驟計算之後,進行第三步驟利用分割梯度方向為九個等份區間進行 其內各像素的梯度大小的累計值計算。梯度方向共 0~180 度以每 20 度為一個等份區間, 稱之為票箱(Bin)。一個直方圖對應 9 個等份區間(票箱)。一個特徵區塊會分為四個區塊 單元(Cell),每個區塊單元計算出一個直方圖,該直方圖也可稱為一個 9 維的向量(9D Vector)或 9 維的直方圖(9D Histogram),如圖 3-13 所示。最後第四步驟,將 4 個 9 維度. 的向量資訊合併,因此,一個特徵區塊之中即會有一個 36 維度的 HOG 特徵向量(36D Feature Vector),也可稱之為一個 36 維的直方圖,如圖 3-14 所示。. 圖 3-13. 9D 直方圖與 36D 直方圖示意圖. 24.
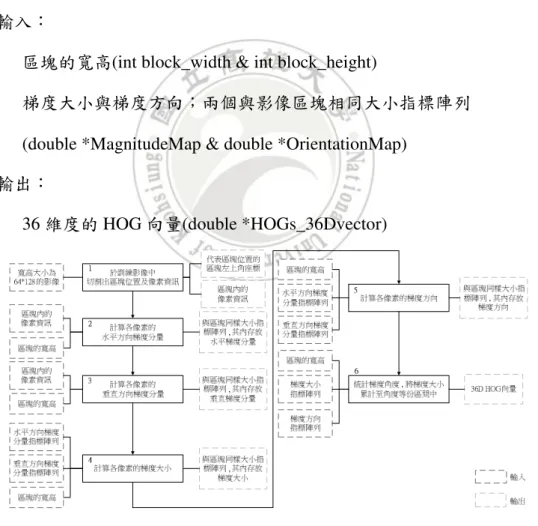
(36) 圖 3-14. HOG 向量的 9 個分量的產生流程. 我們藉由模組化程式設計的方式,將 HOG 演算流程轉化為程式設計模組,並要求 每一個模組(步驟)都能夠獨立進行運算,如同圖 3-12 各個流程中的階段都會有自己的輸 出結果。模組化程式設計著重於每一個模組與模組之間輸出入參數的銜接,如此即可確 保 HOG 模組化程式設計流程中,每一個階段的計算結果都是正確的。 輸入一張訓練影像(與偵測視窗相同寬高大小)並將訓練影像轉為灰階影像,接著進 入計算一個 HOG 向量計算模組(oneHOG)的流程,經由我們的模組化程式設計規劃後, 配合圖 3-15 說明步驟如下: 1. 於訓練影像中,切割出符合我們要求的影像區塊座標與內含的像素資訊。. 模組函式名稱:oneHOG_ImageIntensity_to_Block() 輸入: 一張寬高大小為 64*128 的影像。 輸出: 代表影像區塊位置的左上角座標 (int block_startX & int block_startY). 影像區塊內的像素資訊(unsigned char *block_pixel) 2. 計算水平方向梯度分量 gx. 模組函式名稱:oneHOG_IntensityMap_to_GradientMap(),與 gy 使用相同模組 函式計算。 輸入:. 25.
(37) 影像區塊內的像素資訊(unsigned char *block_pixel) 區塊的寬高(int block_width & int block_height) 輸出: 與影像區塊相同大小指標陣列,其內容存放水平方向梯度分量 (int *gradientComponentMap_x) 3. 計算垂直方向梯度分量 gy. 模組函式名稱:oneHOG_IntensityMap_to_GradientMap(),與 gx 使用相同模組 函式計算。 輸入: 影像區塊內的像素資訊(unsigned char *block_pixel) 區塊的寬高(int block_width & int block_height) 輸出: 與影像區塊相同大小指標陣列,其內容存放垂直方向梯度分量 (int *gradientComponentMap_y) 4. 以 gx 與 gy 計算出影像區塊內該梯度向量的梯度大小. 模組函式名稱:oneHOG_GradientMap_to_MagnitudeMap() 輸入: 區塊的寬高(int block_width & int block_height) 水平與垂直方向梯度分量;兩個與影像區塊相同大小指標陣列 (int *gradientComponentMap_x & int *gradientComponentMap_y). 輸出: 與影像區塊相同大小指標陣列,其內容存放該梯度向量的梯度大小值 (double *MagnitudeMap) 5. 以 gx 與 gy 計算出影像區塊內該梯度向量的梯度方向. 模組函式名稱:oneHOG_GradientMap_to_ OrientationMap() 輸入:. 26.
(38) 區塊的寬高(int block_width & int block_height) 水平與垂直方向梯度分量;兩個與影像區塊相同大小指標陣列 (int *gradientComponentMap_x & int *gradientComponentMap_y). 輸出: 與影像區塊相同大小指標陣列,其內容存放該梯度向量的梯度方向值 (double *OrientationMap) 6. 統計梯度角度,並將梯度大小個別累加至角度等份區間,最後成為 4 個 9 bins. 的直方圖,完成一個 36 維度的 HOG 向量。 模組函式名稱:oneHOG_Block_Histograms_voting() 輸入: 區塊的寬高(int block_width & int block_height) 梯度大小與梯度方向;兩個與影像區塊相同大小指標陣列 (double *MagnitudeMap & double *OrientationMap). 輸出: 36 維度的 HOG 向量(double *HOGs_36Dvector). 圖 3-15. 計算一個 36D HOG 向量輸出入流程圖. 27.
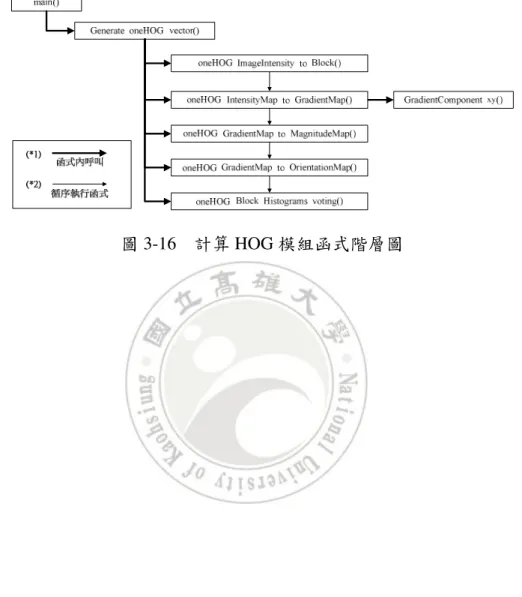
(39) 模組化程式設計會規劃出 oneHOG 主要模組函式,該主要模組函式目的在於呼叫各 個步驟的模組函式,以完成 HOG 向量計算的流程,該主要模組函式則命名為 Generate_oneHOG_vector(),其主要模組與各步驟的模組函式階層關係如圖 3-16 所示。. 圖 3-16. 計算 HOG 模組函式階層圖. 28.
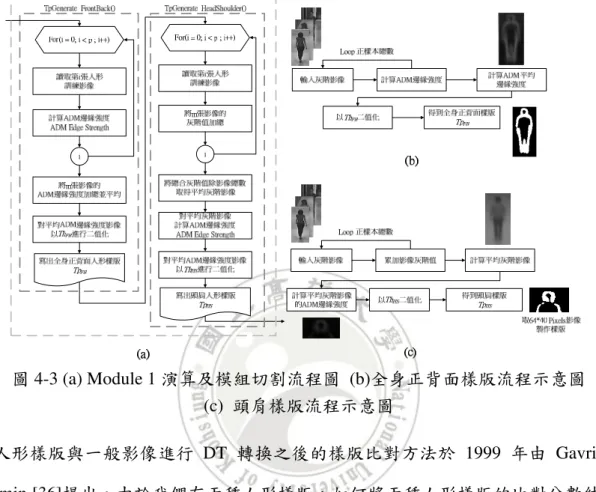
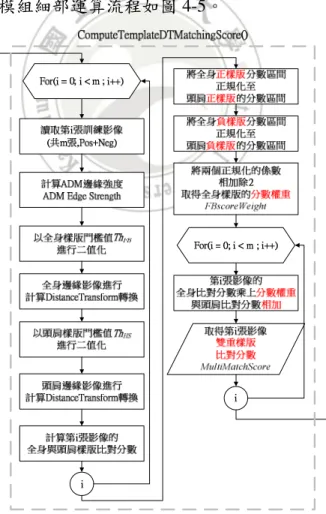
(40) 第四章 GDguiding AdaBoost 演算法 4.1 建立全域偵測器 建立全域偵測器階段 全域偵測器階段流程 階段流程 全域偵測器(Global Detector)是經由三個模組的循序計算,組合成一個完整的建立階 段流程,也因此才具備分類的功能。整體建立流程以階段性的輸出為基準,劃分為三個 模組,如圖 4-1 所示。圖中包含了代表各個模組階段性的輸出與內含步驟的子模組名稱, 在後面的子章節中,將會進一步切割出詳細模組計算步驟並加以說明。. 圖 4-1 全域偵測器模組切割三階段完整訓練流程 三個模組在整個建立流程中是串列進行的。由程式開始執行至模組一(Module 1) 執行結束後,輸出一張全身正背面人形樣版影像(FrontBack Template)及一張頭肩人形樣 版影像(HeadShoulder Template)。而後進入模組二(Module 2)的計算,模組二會使用模組 一所輸出的兩張樣版影像與各張訓練樣本影像經過 DT 轉換之後,進行樣版比對取得樣 板比對分數,最後在模組中計算出將兩種樣版比對結合的分數轉換權重係數及雙重樣版 比對分數。 模組三(Module 3)則承接模組二所輸出的雙重樣版比對分數,分別計算正樣本、負 樣本與所有樣本的平均值做為分類是人(+1)、非人(-1)與不明(0)的門檻值,再以該門檻. 29.
(41) 值對全域分類器的分類品質(Quality)進行評估。根據評估的結果來決定目前的門檻值是 否需要被調整,以及被調整的門檻類別。 全域偵測器經過三個模組的計算之後,由模組一所輸出的兩張人形樣版影像、模 組二所輸出的分數轉換權重係數及模組三輸出的分類門檻值,將會分別被使用在偵測階 段計算的流程中,以達到對測試影像進行全域特徵分類的效果。三個模組的詳細計算步 驟與模組切割拆解將會分別於 4.1.1、4.1.2 及 4.1.3 章節說明。 Global Detector Generation Stage Given:. p. is total number of positive training samples.. n. is total number of negative training samples.. m. is total number of training samples, m = p + n .. Module 1 建立多重樣版影像 TpFB 及 TpHS 。 Step 1:計算全身正背面樣版影像, TpFB 。 1.1 將 p 張灰階影像 I grey 計算轉換至 ADM 邊緣強度影像 I ADMstr 。 1.2 累加 p 張 ADM 邊緣強度影像 I iADMstr ,...., I pADMstr 並除 p,取得 ADM 平均邊緣影像 I AvgStr 。 p. ∑ (I I AvgStr (x, y) = 1.3. ADMstr i. (x, y)). i =1. p. 對 ADM 平均邊緣影像 I AvgStr 進行二值化,得全身正背面樣版影像 TpFB 。. 1, if I AvgStr (x, y) ≥ Th FB TpFB (x, y) = 0, otherwise Step 2:計算頭肩樣版影像, TpHS 。 2.1 累加 p 張灰階影像 I igrey ,..., I pgrey ,並除以 p 取得平均灰階影像 I AvgGrey 。. 30.
(42) p. ∑ (I I AvgGrey (x, y) =. grey i. (x, y)). i =1. p. 2.2 對平均灰階影像 I AvgGrey 計算 ADM 邊緣強度,取得 I ADMstr 。 2.3 對 I ADMstr 進行二值化,得頭肩樣版影像 TpHS 。. 1, if I ADMstr (x, y) ≥ Th HS TpHS (x, y) = 0, otherwise Module 2 計算雙重樣版比對分數 MultiMatchScore 及分數轉換係數 FBscoreWeight 。 Step 1:計算共 m 張訓練樣本影像全身正背面及頭肩樣版比對分數,. FBscore 、 HSscore 。 For. i = 1,.....,m. { 1.1 計算第 i 張訓練影像的 ADM 邊緣強度影像 I iADMstr 。 1.2 以 ThFB 二值化 I iADMstr 得到全身正背面邊緣影像 FBedgei 。 1.3 使用 chamfer 4-3 距離 DT 轉換 FBedgei ,得到 DT 影像 DTi chamfer ( FBedgei ) 。 1.4 以 ThHS 二值化 I iADMstr 得到頭肩邊緣影像 HSedgei 。 1.5 使用 chamfer 4-3 距離 DT 轉換 HSedgei ,得到 DT 影像 DTi chamfer ( HSedgei ) 。 1.6 DTi chamfer ( FBedgei ) 與全身正背面樣版 TpFB 比對,得到全身正背面比對分數. FBscorei 。 1.7 DTi chamfer ( HSedgei ) 與全身正背面樣版 TpHS 比對,得到全身正背面比對分數. HSscorei 。 } Step 2:找出各類的比對分數的最大值, PosFBmax 、 PosHSmax 、 NegFBmax 、 NegHSmax 。. 31.
(43) 2.1 於 p 個 FBscorei 中找出正樣本的全身正背面比對分數最大值 PosFBmax 。 2.2 於 p 個 HSscorei 中找出正樣本的頭肩比對分數最大值 PosHSmax 。 2.3 於 n 個 FBscorei 中找出負樣本的全身正背面比對分數最大值 NegFBmax 。 2.4 於 n 個 FBscorei 中找出負樣本的頭肩比對分數最大值 NegHSmax 。 Step 3:計算全身正背面比對分數正規化至頭肩比對分數的轉換係數 FBscoreWeight 。 PosHS max NegHS max + PosFB max NegFB max FBscoreWeight = 2 Step 4: FBscorei 乘上 FBscoreWeight 再與 HSscorei 相加,得到雙重樣版比對分數 MultiMatchScorei 。. MultiMatchScorei = FBscorei * FBscoreWeight + HSscorei Module 3 調整全域偵測器分類門檻值並紀錄調整後的分類門檻值, HumanTh 、. UnknowTh 、 NonHumanTh 。 Step 1:計算三種分類結果(+1,0,-1)的門檻值, HumanTh 、UnknowTh 、 NonHumanTh 。 1.1 計算正樣本影像 p 張的 MultiMatchScore 平均值,並紀錄為是人(+1)全域分類門. 檻值 HumanTh 。 p. ∑ ( MultiMatchScore ) i. HumanTh = 1.2. i =1. p. 計算所有樣本影像 m 張的 MultiMatchScore 平均值,並紀錄為不明(0)全域分 類門檻值 UnknowTh 。 m. ∑ (MultiMatchScore ) i. UnknowTh = 1.3. i =1. m. 計算負樣本影像 n 張的 MultiMatchScore 平均值,並紀錄為非人(-1)全域分類 門檻值 NonHumanTh 。. 32.
(44) n. ∑ (MultiMatchScore ) i. NonHumanTh =. Step 2. i =1. n. 以全域分類門檻值分類正樣本影像,計算對正樣本的分類品質 PosQuality 。. 2.1 計算樣本 MultiMatchScorei 與三個門檻值的距離,類別間最小距離者為分類結. 果 GlobalResult i 。. Scoredistance +1 =| MultiMatchScorei − HumanTh |, Scoredistance0 =| MultiMatchScorei − UnknowTh |, Scoredistance −1 =| MultiMatchScorei − NonHumanTh |, GlobalResult i = argmin Scoredistance x x∈[ +1,0, −1]. 2.2 若正樣本分類為人(+1),則 PosQuality 加 1,不明(0)則減 0.5,非人(-1)則減 1,. 最後再正規化至 0~100 之間。 For i=1,....,p { PosQuality + 1, if GlobalResulti = +1 PosQuality = PosQuality − 0.5, if GlobalResulti = 0 PosQuality − 1, if GlobalResult = −1 i }. PosQuality = Step 3. PosQuality ∗100 p. 以全域分類門檻值分類負樣本影像,計算對負樣本的分類品質 NegQuality 。. 3.1 計算樣本 MultiMatchScorei 與三個門檻值的距離,類別間最小距離者為分類結. 果 GlobalResult i 。. Scoredistance +1 =| MultiMatchScorei − HumanTh |, Scoredistance0 =| MultiMatchScorei − UnknowTh |, Scoredistance −1 =| MultiMatchScorei − NonHumanTh |, GlobalResult i = argmin Scoredistance x x∈[ +1,0, −1]. 33.
(45) 3.2 若負樣本分類為人(-1),則 NegQuality 加 1,不明(0)則減 0.5,是人(+1)則減 1,. 最後再正規化至 0~100 之間。 For i=1,....,n { NegQuality + 1, if GlobalResulti = −1 NegQuality = NegQuality − 0.5, if GlobalResulti = 0 NegQuality − 1, if GlobalResult = +1 i } NegQuality =. NegQuality ∗100 n. Step 4 若 PosQuality 大於 NegQuality ,則遞減 UnknowTh 與 NonHumanTh 後重複計算 Step 2 及 Step 3,直到在不變動 PosQuality 的情況下,將 NegQuality 提升到最好。 Step 5 若 NegQuality 大於 PosQuality ,則遞增 UnknowTh 與 HumanTh 後重複計算 Step 2. 及 Step 3,直到在不變動 NegQuality 的情況下,將 PosQuality 提升到最好。 圖 4-2 全域偵測器訓練虛擬碼. 4.1.1 建立多重樣版與樣版比對 在模組一建立樣版的流程中,我們最後會建立出兩張不同的樣版,分別是全身正背 面人形樣版(TpFB)與頭肩人形樣版(TpHS)。兩種樣版的建立過程雖然都是以 ADM 邊緣強 度影像(IADMstr)為基礎加以運算,但細部的流程不同,如圖 4-2 中 Module 1 的 Step 1 及 Step 2,詳細演算流程及模組切割則如圖 4-3(a)所示。 Step 1 為全身正背面人形樣版的建立流程,將正樣本灰階影像(Igrey)個別計算出其 ADM 邊緣強度影像,待所有正樣本都計算完後,相加並除以正樣本總數,得到平均邊. 緣強度影像(IAvgStr)。然後再以觀察的方式設立一個門檻值(ThFB),進行二值化後得全身 正背面人形樣版,如圖 4-3(b)所示。. 34.
(46) Step 2 為頭肩人形樣版的建立流程,將所有正樣本灰階影像(Igrey)的灰階值累加,並. 計算出平均灰階影像(IAvgGrey)。而後對平均灰階影像計算 ADM 邊緣強度影像,再以觀 察的方式設立一個門檻值(ThHS),進行二值化後得頭肩人形樣版,如圖 4-3(c)所示。. 圖 4-3 (a) Module 1 演算及模組切割流程圖 (b)全身正背面樣版流程示意圖 (c) 頭肩樣版流程示意圖. 人形樣版與一般影像進行 DT 轉換之後的樣版比對方法於 1999 年由 Gavrila 與 Philomin [36]提出。由於我們有兩種人形樣版,如何將兩種人形樣版的比對分數結合將. 於 4.1.2 章節說明。在本章節中是以範例的方式來說明 DT 影像與樣版比對的方法。 一般影像在經過由 3.2 章節中所講述的 DT 距離演算法轉換之後,便可以開始與樣 版進行比對,並計算比對分數。其比對的方法是將樣版中的特徵點座標(Tp(x,y))對應至 DT 影像中的相同座標(DTchamfer(x,y)),並依 DT 影像 (x,y)座標中的距離值進行累加,直. 至樣版所有的特徵點都對應並累加完成後,便為比對分數。比對的示意圖如圖 4-4 所示。. 圖 4-4 樣版比對及計算比對分數方法示意圖. 35.
數據



+7

相關文件
Krishnamachari and V.K Prasanna, “Energy-latency tradeoffs for data gathering in wireless sensor networks,” Twenty-third Annual Joint Conference of the IEEE Computer
Cheng-Chang Lien, Cheng-Lun Shih, and Chih-Hsun Chou, “Fast Forgery Detection with the Intrinsic Resampling Properties,” the Sixth International Conference on Intelligent
Godsill, “Detection of abrupt spectral changes using support vector machines: an application to audio signal segmentation,” Proceedings of the IEEE International Conference
[16] Goto, M., “A Robust Predominant-F0 Estimation Method for Real-time Detection of Melody and Bass Lines in CD Recordings,” Proceedings of the 2000 IEEE International Conference
Jones, "Rapid Object Detection Using a Boosted Cascade of Simple Features," IEEE Computer Society Conference on Computer Vision and Pattern Recognition,
Dragan , “Provably good global buffering using an available buffer block plan”, IEEE International Conference on Computer-Aided Design, pp.. Cong, “Interconnect performance
programming, logic/reasoning, signal processing, computer vision, pattern recognition, mechanical structure, psychology, and cognitive science, to well control or to represent
Kyunghwi Kim and Wonjun Lee, “MBAL: A Mobile Beacon-Assisted Localization Scheme for Wireless Sensor Networks”, the 16th IEEE International Conference on Computer Communications
