On Mining General Temporal Association Rules in a Publication Database
Chang-Hung Lee, Cheng-Ru Lin, and Ming-Syan Chen
Department of Electrical Engineering
National Taiwan University
Taipei, Taiwan, ROC
E-mail: mschen@cc.ee.ntu.edu.tw, {chlee, owenlin}@arbor.ee.ntu.edu.tw
Abstract
In this paper, we explore a new problem of mining gen-eral temporal association rules in publication databases. In essence, a publication database is a set of transactions where each transaction T is a set of items of which each item contains an individual exhibition period. The cur-rent model of association rule mining is not able to handle the publication database due to the following fundamental problems, i.e., (1) lack of consideration of the exhibition period of each individual item; (2) lack of an equitable sup-port counting basis for each item. To remedy this, we pro-pose an innovative algorithm Progressive-Partition-Miner (abbreviatedly as PPM) to discover general temporal asso-ciation rules in a publication database. The basic idea of PPM is to first partition the publication database in light of exhibition periods of items and then progressively accu-mulate the occurrence count of each candidate 2-itemset based on the intrinsic partitioning characteristics. Algo-rithm PPM is also designed to employ a filtering threshold in each partition to early prune out those cumulatively infre-quent 2-itemsets. Explicitly, the execution time of PPM is, in orders of magnitude, smaller than those required by the schemes which are directly extended from existing methods.
1 Introduction
The discovery of association relationship among a huge database has been known to be useful in selective market-ing, decision analysis, and business management [4, 9]. A popular area of applications is the market basket analysis, which studies the buying behaviors of customers by search-ing for sets of items that are frequently purchased together (or in sequence). For a given pair of confidence and sup-port thresholds, the problem of mining association rules is to identify all association rules that have confidence and support greater than the corresponding minimum support
threshold (denoted as min_supp) and minimum confidence threshold (denoted as min_conf).
Since the early work in [1], several efficient algorithms to mine association rules have been developed in recent years. These studies cover a broad spectrum of topics in-cluding: (1) fast algorithms based on the level-wise Apri-ori framework [2, 13] and partitioning [11]; (2) FP-growth algorithms [8]; (3) incremental updating [6, 10]; (4) min-ing of generalized and multi-level rules [7, 14]; (5) minmin-ing of quantitative rules [15]; (6) mining of multi-dimensional rules [18]; (7) constraint-based rule mining [16] and mul-tiple minimum supports issues [12, 17]; and (8) temporal association rule discovery [3, 5].
While these are important results toward enabling the integration of association mining and fast searching algo-rithms, e.g., BFS and DFS which are classified in [9], we note that these mining methods cannot effectively be ap-plied to the mining of a publication-like database which is of increasing popularity recently. In essence, a publication database is a set of transactions where each transaction T is a set of items of which each item contains an individ-ual exhibition period. The current model of association rule mining is not able to handle the publication database due to the following fundamental problems, i.e., (1) lack of consideration of the exhibition period of each individ-ual item; (2) lack of an equitable support counting basis for each item. Note that the traditional mining process takes the same task-relevant tuples, i.e., the size of transaction set D, as a counting basis. Recall that the task of support speci-fication is to specify the minimum transaction support for each itemset. However, since different items have different exhibition periods in a publication database, only consider-ing the occurrence count of each item might not lead to a fair measurement. This problem can be further explained by the illustrative example below.
Example 1.1: In a bookstore transaction database as
shown in Figure 1, the minimum transaction support and confidence are assumed to be min_supp = 30% and min_conf = 75%, respectively. A set of time series
Date TID Item Publication Date Jan-01 t1 B D A Jan-95 P1 t2 B C D B Apr-96 t3 B C C Jul-97 t4 A D D Aug-00 D Feb-01 t5 B C E db1,3 E Feb-01 P2 t6 D E F Mar-01 t7 A B C t8 C D E db2,3 Mar-01 t9 B C E F P3 t10 B F db3,3 t11 A D t12 B D F
Transaction Database Item Information Itemset
Figure 1. An illustrative transaction database and the corresponding item information
database indicates the transaction records from January 2001 to March 2001. The publication date of each trans-action item is also given. Based on the traditional min-ing techniques, the absolute support threshold is denoted as SA = d12 ∗ 0.3e = 4 where 12 is the size of
transac-tion set D. It can be seen that only {B, C, D, E, BC} can be termed as frequent itemsets since the amounts of their oc-currences in this transaction database are respectively larger than the absolute value of support threshold. Thus, only rule C =⇒ B is termed as a frequent association rule with sup-port s = 41.67% and confidence c = 83.33%. However, some phenomena are observed when we take the “item
in-formation” in Figure 1 into consideration.
1. An early publication intrinsically possesses a higher
likelihood to be determined as a frequent itemset.
For example, the sales volume of an early product, such as A, B, C or D, is likely to be larger than that of a newly exhibited product, e.g., E or F , since an early product has a longer exhibition period. As a result, the association rules we usually get will be those with long-term products such as “milk and bread are fre-quently purchased together”, which, while being cor-rect by the definition, is of less interest to us in the association rule mining. In contrast, some more recent products, such as new books, which are really “fre-quent” and interesting in their exhibition periods are less likely to be identified as frequent ones if a tradi-tional mining process is employed.
2. Some discovered rules may be expired from users’
interest. Considering the generated rule C =⇒ B,
both B and C were published from the very early dates of this mining transaction database. This information is very likely to have been explored in the previous mining database, such as the one from January 1996 to December 1997. Such mining results could be of less
interest to our on-going mining works. For example, most researchers tend to pay more attention to the lat-est published papers.
Note that one straightforward approach to addressing the above issues is to lower the value of the minimum support threshold required. However, this naive approach will cause another problem, i.e., those interesting rules with smaller supports may be overshadowed by lots of less important information with higher supports. As a consequence, we introduce the notion of exhibition period for each transac-tion item in this paper and develop an algorithm,
Progres-sive Partition Miner (abbreviatedly as PPM), to address this
problem. It is worth mentioning that the application do-main of this study is not limited to the mining of a publica-tion database. Other applicapublica-tion domains include bookstore transaction databases, video and audio rental store records, stock market data, and transactions in electronic commerce, to name a few.
Explicitly, we explore in this paper the mining of
gen-eral temporal association rules, i.e., (X =⇒ Y )t,n, where
t is the latest-exhibition-start time of both itemsets X and Y , and n denotes the end time of the publication database. In other words, (t, n) is the maximal common
exhibition period of itemsets X and Y . An association
rule X =⇒ Y is termed to be a frequent general tem-poral association rule (X =⇒ Y )t,n if and only if its
probability is larger than minimum support required, i.e., P (Xt,n∪ Yt,n) > min_supp, and the conditional
prob-ability P (Yt,n|Xt,n) is larger than minimum confidence
needed, i.e., P (Yt,n|Xt,n) > min_conf . Instead of using
the absolute support threshold SA
= d|D| ∗ min_suppe as a minimum support threshold for each item in Figure 1, a relative minimum support, denoted by SR
X = d|DX|∗
min_suppe where |DX| indicates the amount of partial
transactions in the exhibition period of itemset X, is given to deal with the mining of temporal association rules.
To deal with the mining of general temporal association rule (X =⇒ Y )t,n, an efficient algorithm, Progressive
Par-tition Miner, is devised. The basic idea of PPM is to first
partition the publication database in light of exhibition pe-riods of items and then progressively accumulate the occur-rence count of each candidate 2-itemset based on the in-trinsic partitioning characteristics. Algorithm PPM is also designed to employ a filtering threshold in each partition to early prune out those cumulatively infrequent 2-itemsets. The feature that the number of candidate 2-itemsets gen-erated by PPM is very close to the number of frequent 2-itemsets allows us to employ the scan reduction technique by generating Cks from C2directly to effectively reduce the
number of database scan. Experimental results show that
PPM produces a significantly smaller amount of candidate
Apri-ori algApri-orithm. In fact, the number of the candidate itemsets
Cks generated by PPM approaches to its theoretical
mini-mum, i.e., the number of frequent k-itemsets, as the value of the minimal support increases. Explicitly, the execution time of PPM is, in orders of magnitude, smaller than those required by Apriori+. Sensitivity analysis on various
pa-rameters of the database is also conducted to provide many insights into algorithm PPM. The advantage of PPM over
Apriori+ becomes even more prominent as the size of the
database increases. This is indeed an important feature for
PPM to be practically used for the mining of a time series
database in the real world.
It is worth mentioning that the problem of mining
gen-eral temporal association rules will be degenerated to the
one of mining temporal association rules explored in prior works [3, 5] if the exhibition period (t, n) of association rule (X =⇒ Y )t,nis applied to a non-maximal exhibition
pe-riod of X =⇒ Y , such as (j, n) where j > t. Consider for example the database in Figure 1 where (C =⇒ B)1,3and
(C =⇒ E)2,3are two general temporal association rules in database D while the temporal subset of (C =⇒ B)1,3,
e.g., (C =⇒ B)2,3, can also be a temporal association rule
as defined in [3, 5], showing that the model we consider can be viewed as a general framework of prior studies. This is the reason we use the term “general temporal association rule” in this paper.
We mention in passing that the Frequent Pattern growth (FP-growth), which constructs a highly compact data struc-ture (an FP-tree) to compress the original transaction database, is a method of mining frequent itemsets with-out candidate generation [8]. However, in our opinion, FP-growth algorithms do not have obvious extensions to deal with this publication database problem. Further, some methodologies were proposed to explore the problem of dis-covering temporal association relationship in the partial of database retrieved [3, 5], i.e., to determine association rules from a given subset of database specified by time. These works, however, do not consider the individual exhibition period of each transaction item, and are thus not applicable to solving the mining problems in a publication database. On the other hand, some techniques were devised to use multiple minimum supports for frequent itemsets genera-tion [12, 17]. However, it remains unclear for how the techniques in [12, 17] to be coupled with the correspond-ing minimum confidence thresholds when general temporal association rules we consider in this paper in a publication database are being generated.
The rest of this paper is organized as follows. Prob-lem description is given in Section 2. Algorithm PPM is described in Section 3. Performance studies on various schemes are conducted in Section 4. This paper concludes with Section 5.
2 Problem Description
Let n be the number of partitions with a time granularity, e.g., business-week, month, quarter, year, to name a few, in database D. In the model considered, dbt,ndenotes the part
of the transaction database formed by a continuous region from partition Ptto partition Pn, and |dbt,n|=Ph=t,n|Ph|
where dbt,n⊆ D. An item xx.start,nis termed as a
tempo-ral item of x, meaning that Px.start is the starting partition
of x and n is the partition number of the last database parti-tion retrieved.
Example 2.1: Consider the database in Figure 1. Since
database D records the transaction data from January 2001 to March 2001, database D is intrinsically segmented into three partitions P1, P2 and P3 in accordance with the
“month” granularity. As a consequence, a partial database db2,3⊆ D consists of partitions P
2and P3. A temporal item
E2,3denotes that the exhibition period of E2,3is from the
beginning time of partition P2 to the end time of partition
P3.
As such, we can define a maximal temporal itemset Xt,n
as follows.
Definition 1: An itemset Xt,nis called a maximal
tem-poral itemset in a partial database dbt,n if t is the latest
starting partition number of all items belonging to X in
database D and n is the partition number of the last parti-tion in dbt,nretrieved.
For example, as shown in Figure 1, itemset DE2,3 is
deemed a maximal temporal itemset whereas CD2,3is not.
In view of this, the exhibition period of an itemset is ex-pressed in terms of Maximal Common exhibition Period (MCP) of the items that appear in the itemset. Let MCP (x) denote the MCP value of item x. The MCP value of an item-set X is the shortest MCP among the items in itemitem-set X. Consider three items C, E and F in Figure 1 for example. Their exhibition periods are as follows: MCP (C) = (1, 3), MCP (E) = (2, 3) and MCP (F ) = (3, 3). Since itemset CEF is termed to be CEF3,n = (CEF )3,nwith
consid-ering the exhibition of CEF , we have MCP (CEF ) = (3, 3).
In addition, |dbt,n| is the number of transactions in
the partial database dbt,n. The fraction of
transac-tion T supporting an itemset X with respect to par-tial database dbt,n is called the support of Xt,n, i.e.,
supp(XM CP (X)) = |{T ∈dbM CP (X)|X⊆T }|
|dbM CP (X)| . The support of
a rule (X =⇒ Y )MCP (XY )is defined as supp((X =⇒
Y )MCP (XY )) = supp((XSY )MCP (XY )). The
con-fidence of this rule is defined as conf((X =⇒
Y )MCP (XY )) = supp((X
S
Y )M CP (XY ))
supp(XM CP (XY )) . Consequently, a
which holds in the transaction set D can be defined as fol-lows.
Definition 2: An association rule (X =⇒ Y )MCP (XY )
is called a general temporal association rule in the trans-action set D with conf((X =⇒ Y )MCP (XY )) = c and
supp((X =⇒ Y )M CP (XY )) = s if c% of transactions in
dbM CP (XY )that contain X also contain Y and s% of
trans-actions in dbMCP (XY )contain XSY while XTY = φ.
For a given pair of min_conf and min_supp as the min-imum thresholds required in the maximal common exhibi-tion period of each associaexhibi-tion rule, the problem of min-ing general temporal association rules is to determine all frequent general temporal association rules, e.g., (X =⇒
Y )MCP (XY )∈ dbMCP (XY )which transaction itemsets X
and Y have “relative” support and confidence greater than the corresponding thresholds. Thus, we have the following definition to identify the frequent general temporal associa-tion rules.
Definition 3: A general temporal association rule
(X =⇒ Y )MCP (XY ) is termed to be frequent if and
only if supp((X =⇒ Y )M CP (XY )) > min_supp and
conf ((X =⇒ Y )MCP (XY )) > min_conf .
Consequently, this rule mining of general temporal asso-ciation can also be decomposed into to three steps:
(1) generate all frequent maximal temporal itemsets (T Is) with their support values.
(2) generate the support values of all corresponding tempo-ral sub-itemsets (SIs) of frequent T Is.
(3) generate all temporal association rules that satisfy min_conf using the frequent T Is and/or SIs.
Example 2.2: Recall the illustrative general temporal
as-sociation rules, e.g., (C =⇒ E)2,3 with relative
sup-port 37.5% and confidence 75%, of the bookstore trans-action database as shown in the Figure 1. In accor-dance with Definition 3, the implication (C =⇒ E)2,3 is
termed as a general temporal association rule if and only if supp((C =⇒ E)2,3) > min_supp and conf ((C =⇒
E)2,3) > min_conf . Consequently, we have to
deter-mine if supp(CE2,3) > min_supp and supp(C2,3) >
min_supp for discovering the newly identified association rule (C =⇒ E)2,3. It is worth mentioning that though
CE2,3 has to be a maximal temporal itemset, called T I,
C2,3may not be a T I. We call C2,3is one of
correspond-ing temporal sub-itemsets, i.e., SI, of itemset CE2,3.
For better readability, a list of symbols used is given in Table 1. Then, the definition of a frequent maximal tem-poral itemset and the property of its corresponding sub-itemsets are given below.
Definition 4: A maximal temporal itemset XMCP (X)
is termed to be frequent when the occurrence frequency
of XM CP (X) is larger than the value of min_supp
re-quired, i.e., supp(XM CP (X)) > min_supp, in transaction
set dbMCP (X).
Property 1: When a maximal temporal k-itemset
XM CP (Xk)
k is frequent in data set dbM CP (Xk), each of its
corresponding sub-itemset XM CP (Xk)
i (1 ≤ i < k) is also
frequent in dbM CP (Xk).
|dbi,n| Number of transactions in dbi,n
Xi,n A temporal itemset in partial database dbi,n
T I A maximal temporal itemset
SI A corresponding temporal sub-itemset of T I Table 1: Meanings of symbols used
Once, F = { XMCP (X) ⊆ I | XMCP (X) is
f requent}, the set of all frequent T Is and SIs to-gether with their support values is known, deriving the desired association rules is straightforward. For ev-ery XMCP (X)
∈ F, check the confidence of all rules (X =⇒ Y )MCP (XY ) and drop those that do not
sat-isfy s(XYMCP (XY ))/s(XMCP (XY )) ≥ min_conf. This
problem can also be reduced to the problem of finding all frequent maximal temporal itemsets first and then generat-ing their correspondgenerat-ing frequent sub-itemsets for the same support threshold. Therefore, in the rest of this paper we concentrate our discussion on the algorithms for mining fre-quent T Is and SIs. In fact, the process steps of generating frequent T Is and SIs can be further merged to one step in our proposed algorithm P P M.
As explained, we have to find all maximal temporal item-sets that satisfy min_supp first and then to calculate the oc-currences of their corresponding sub-itemsets for producing all temporal association rules hidden in database D. How-ever, if we use an existing algorithm to find all frequent T Is for this new problem, the downward closure property, which Apriori-based algorithms are based on, no longer holds. In addition, the candidate generation process is not intuitive at all. Note that, even though itemset Xt,n is not a
fre-quent itemset, it does not imply that Xt+1,n, i.e., a
tem-poral sub-itemset of Xt,n, is not a frequent itemset. In
other words, even knowing Xt,n is not frequent in dbt,n
where MCP (X) = (t, n), we are not able to assert whether
XYt+1,nis frequent or not when MCP (Y ) = (t + 1, n).
Specifically, to determine whether a general temporal as-sociation rule (X =⇒ Y )t+1,n is frequent, we have to
find out the support values of Xt+1,nand XYt+1,nwhere
MCP (XY ) = MCP (Y ) = (t + 1, n).
Example 2.3: Consider MCP (x1) = (1, n), M CP (x2) =
(2, n) and MCP (x3) = (3, n). If we find that item x1 is
not frequent at exhibition period (1, n), then it does not sat-isfy min_supp requirement at level 1. Under a conventional
Partition database based on exhibition periods
Produce candidate 2-TIs
Use candidate 2-TIs to produce candidate k-TIs and k-SIs
Generate frequent k-TIs and k-SIs
Rule generation 2nd Scan database 1st Scan database
Figure 2. The flowchart of PPM
Apriori-based association rule mining algorithm, this item-set is discarded since it will not be frequent. The potentially frequent itemsets x1x2and x1x3will then not be generated
at level 2 for consideration. Clearly, this disposition is in-correct in mining general temporal association rules since x1 is still possible to be frequent at (2, n) and (3, n),
in-dicating that the downward property is not valid in mining general temporal association rules.
It is worth mentioning that since the downward level-wise property, which holds for Apriori-like algorithms, is not valid in this general temporal association rule mining problem, the second method is to expand each transaction item to be its combination with different exhibition peri-ods. For instance, all temporal sub-itemsets of Xt,n
k at
level k with different exhibition periods, i.e., Xt,n
k , X
t+1,n
k ,
Xkt+2,n, ..., Xn,n
k , are taken as “temporal candidate
k-itemsets” for producing any possible combination of
gen-eral temporal association rules. Using this approach, the problem of mining temporal association rules can be imple-mented on an anti-monotone Apriori-like heuristic. As in most previous works, the essential idea is to iteratively gen-erate the set of candidate itemsets of length (k + 1), i.e., Xk+1r,n, from the set of frequent itemsets of length k, i.e., Xkr,n, (for k ≥ 1), and to check their corresponding occur-rence frequencies in the database dbr,n. This is the basic
concept of an extended version of Apriori-based algorithm, called Apriori+, whose performance will be comparatively evaluated with algorithm PPM in our experimental studies later.
3 General Temporal Association Rules
An overview of progressive partition miner is given in Section 3.1. We present an illustrative example of algorithm
PPM in Section 3.2.
3.1 An overview of Progressive Partition Miner
As explained above, a naive adoption of conventional methods to mine general temporal association rules will be
prohibitively expensive. To remedy this, by partitioning a transaction database into several partitions, algorithm PPM is devised to employ a filtering threshold in each partition to deal with the candidate itemset generation and process one partition at a time. For ease of exposition, the processing of a partition is termed a phase of processing. Explicitly, a progressive candidate set of itemsets is composed of the following two types of candidate itemsets, i.e., (1) the can-didate itemsets that were carried over from the previous pro-gressive candidate set in the previous phase and remain as candidate itemsets after the current partition is included into consideration (Such candidate itemsets are called type α candidate itemsets); and (2) the candidate itemsets that were not in the progressive candidate set in the previous phase but are newly selected after only taking the current data parti-tion into account (Such candidate itemsets are called type β candidate itemsets). Under PPM, the cumulative informa-tion in the prior phases is selectively carried over toward the generation of candidate itemsets in the subsequent phases. After the processing of a phase, algorithm PPM outputs a
progressive screen, denoted by P S, which consists of a
pro-gressive candidate set of itemsets, their occurrence counts and the corresponding partial supports required.
3.2 Algorithm of PPM
The operation of algorithm PPM can be best understood by an illustrative example described below and its corre-sponding flowchart is depicted in Figure 2. Recall the trans-action database shown in Figure 1 where the transtrans-action database db1,3is assumed to be segmented into three
par-titions P1, P2and P3, which correspond to the three time
granularities from January 2001 to March 2001. Suppose that min_supp = 30% and min_conf = 75%. Each par-tition is scanned sequentially for the generation of candi-date 2-itemsets in the first scan of the database db1,3. After
scanning the first segment of 4 transactions, i.e., partition P1, 2-itemsets {BD, BC, CD, AD} are sequentially
gen-erated as shown in Figure 3. In addition, each potential can-didate itemset c ∈ C2has two attributes: (1) c.start which
contains the partition number of the corresponding starting partition when c was added to C2, and (2) c.count which
contains the number of occurrences of c since c was added to C2. Since there are four transactions in P1, the partial
minimal support is d4 ∗ 0.3e = 2. Such a partial mini-mal support is called the filtering threshold in this paper. Itemsets whose occurrence counts are below the filtering threshold are removed. Then, as shown in Figure 3, only {BD, BC}, marked by “ ° ”, remain as candidate item-sets (of type β in this phase since they are newly generated) whose information is then carried over to the next phase P2
of processing.
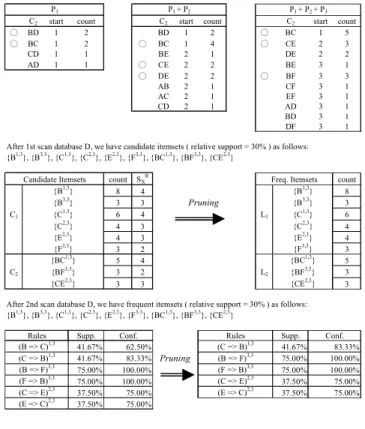
C2 start count C2 start count C2 start count ○ BD 1 2 BD 1 2 ○ BC 1 5 ○ BC 1 2 ○ BC 1 4 ○ CE 2 3 CD 1 1 BE 2 1 DE 2 2 AD 1 1 ○ CE 2 2 BE 3 1 ○ DE 2 2 ○ BF 3 3 AB 2 1 CF 3 1 AC 2 1 EF 3 1 CD 2 1 AD 3 1 BD 3 1 DF 3 1 count SXR count 8 4 8 3 3 3 C1 6 4 L1 6 4 3 4 4 3 4 3 2 3 5 4 5 C2 3 2 L2 3 3 3 3 Supp. Supp. 41.67% 41.67% 41.67% 75.00% 75.00% 75.00% 75.00% 37.50% 37.50% 37.50% 37.50% 75.00% 75.00% After 2nd scan database D, we have frequent itemsets ( relative support = 30% ) as follows:
{B1,3}, {B3,3}, {C1,3}, {C2,3}, {E2,3}, {F3,3}, {BC1,3}, {BF3,3}, {CE2,3} Conf. 83.33% 100.00% 100.00% 100.00% 100.00% 75.00% 75.00% Pruning 62.50% Conf. 83.33% {C2,3} {E2,3} {F3,3} {CE2,3} (E => C)2,3 (F => B)3,3 (C => E)2,3 Freq. Itemsets {B1,3} {B3,3} {C1,3} (C => E)2,3 (E => C)2,3 (F => B)3,3 (C => B)1,3 (B => F)3,3 (B => C)Rules1,3 {B1,3}, {B3,3}, {C1,3}, {C2,3}, {E2,3}, {F3,3}, {BC1,3}, {BF3,3}, {CE2,3} P1 P1 + P2 P1 + P2 + P3
After 1st scan database D, we have candidate itemsets ( relative support = 30% ) as follows:
{F3,3} {BC1,3} {BF3,3} {CE2,3} Candidate Itemsets {B1,3} {B3,3} {C1,3} {C2,3} {E2,3} {BC1,3} {BF3,3} Pruning Rules (C => B)1,3 (B => F)3,3
Figure 3. Frequent temporal itemsets genera-tion for mining general temporal associagenera-tion rules by PPM
counts of potential candidate 2-itemsets are recorded (of type α and type β). From Figure 3, it is noted that since there are also 4 transactions in P2, the filtering
thresh-old of those itemsets carried out from the previous phase (that become type α candidate itemsets in this phase) is d(4 + 4) ∗ 0.3e = 3 and that of newly identified candidate itemsets (i.e., type β candidate itemsets) is d4 ∗ 0.3e = 2. It can be seen that we have 3 candidate itemsets in C2after
the processing of partition P2, and one of them is of type α
and two of them are of type β.
Finally, partition P3is processed by algorithm PPM. The
resulting candidate 2-itemsets are C2= {BC, CE, BF } as
shown in Figure 3. Note that though appearing in the pre-vious phase P2, itemset {DE} is removed from C2 once
P3is taken into account since its occurrence count does not
meet the filtering threshold then, i.e., 2 < 3. However, we do have one new itemset, i.e., BF , which joins the C2 as
a type β candidate itemset. Consequently, we have 3 can-didate 2-itemsets generated by PPM, and two of them are of type α and one of them is of type β. Note that only 3 candidate 2-itemsets are generated by PPM.
After generating C2from the first scan of database db1,3,
we employ the scan reduction technique [13] and use C2to
generate Ck (k = 2, 3, ..., m), where Cmis the candidate
last-itemsets. Instead of generating C3from L2? L2, a C2
generated by PPM can be used to generate the candidate 3-itemsets and its sequential C0
k−1can be utilized to
gener-ate C0
k. Clearly, a C30 generated from C2? C2, instead of
from L2? L2, will have a size greater than |C3| where C3is
generated from L2? L2. However, since the |C2| generated
by PPM is very close to the theoretical minimum, i.e., |L2|,
the |C0
3| is not much larger than |C3|. Similarly, the |Ck0| is
close to |Ck|. Since C2 = {BC, CE, BF }, no candidate
k-itemset is generated in this example where k ≥ 3. Thus, Ck0 = {BC, CE, BF } and all Ck0 can be stored in main memory. Then, we can find Lks (k = 1, 2, ..., m) together
when the second scan of the database db1,3 is performed.
Note that those generated itemsets C0
k = {BC, CE, BF }
are termed to be the candidate maximal temporal itemsets (T Is), i.e., BC1,3, CE2,3and BF3,3, with a maximal
ex-hibition period of each candidate.
Before we process the second scan of the database db1,3 to generate L
ks, all candidate SIs of candidate
T Is can be propagated based on Property 1, and then added into C0
k. For instance, as shown in Figure 3, both
candidate 1-itemsets B1,3 and C1,3 are derived from
BC1,3. Moreover, since BC1,3, for example, is a candidate
2-itemset, its subsets, i.e., B1,3and C1,3, should potentially
be candidate itemsets. As a result, 9 candidate itemsets, i.e., {B1,3, B3,3, C1,3, C2,3, E2,3, F3,3, BC1,3, BF3,3, CE2,3}
as shown in Figure 3, are generated. Note that since there is no candidate T I k-itemset (k ≥ 2) containing A or D in this example, Ai,3and Di,3(1 ≤ i ≤ 3) are not necessary
to be taken as SI itemsets for generating general temporal association rules. In other words, we can skip them from the set of candidate itemsets C0
ks. Finally, all occurrence
counts of C0
ks can be calculated by the second database
scan. Note that itemsets BC1,3, BF3,3 and CE2,3 are
termed as frequent T Is, while B1,3, B3,3, C1,3, C2,3, E2,3
and F3,3are frequent SIs in this example.
As shown in Figure 3, after all frequent T I and SI item-sets are identified, the corresponding general temporal as-sociation rules can be derived in a straightforward man-ner. Explicitly, the general temporal association rule of (X ⇒ Y )MCP (XY )holds if conf((X ⇒ Y )MCP (XY )) ≥
min_conf.
4 Experimental Studies
To assess the performance of algorithm PPM, we per-formed several experiments on a computer with a CPU clock rate of 450 MHz and 512 MB of main memory. The methods used to generate synthetic data are described in Section 4.1. The performance comparison of PPM and
Apriori+ is presented in Section 4.2. Results on scaleup
4.1 Generation of synthetic workload
For obtaining reliable experimental results, the method to generate synthetic transactions we employed in this study is similar to the ones used in prior works [2, 13]. These transactions mimic the publication items in a publication database. Each database consists of |D| transactions, and on the average, each transaction has |T | items. To simu-late the characteristic of the exhibition period in each item, transaction items are uniformly distributed into database D with a random selection. In accordance with the exhibition periods of items, database D is divided into n partitions. Ta-ble 2 summarizes the meanings of various parameters used in the experiments. The mean of the correlation level is set to 0.25 for our experiments. Without loss of generality, we use the notation T x − Iy − Dm to represent a database in which D = m thousands, |T | = x, and |I| = y. We compare relative performance of Apriori+and PPM.
|D| Number of transactions in the database |T | Average size of the transactions
|I| Average size of the maximal frequent itemsets |L| Number of maximal potentially frequent itemsets N Number of items
|Pi| Number of transactions in the partition database Pi
Table 2: Meanings of various parameters
4.2 Relative performance
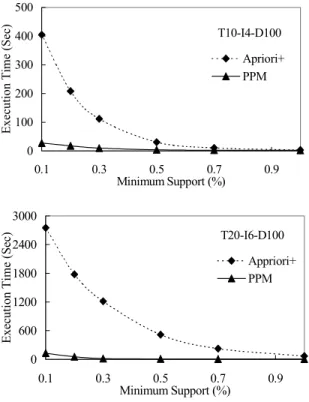
We first conducted several experiments to evaluate the relative performance of Apriori+ and PPM. Since the
ex-perimental results are consistent for various values of n, |L| and N, for interest of space, we only report the results on |L| = 2000 and N = 10000 in the following experiments. Figure 4 shows the relative execution times for both two algorithms as the minimum support threshold is decreased from 1% support to 0.1% support. When the support thresh-old is high, there are only a limited number of frequent item-sets produced. However, as the support threshold decreases, the performance difference becomes prominent in that PPM significantly outperforms Apriori+. Explicitly, PPM is in
orders of magnitude faster than Apriori+, and the margin
grows as the minimum support threshold decreases.
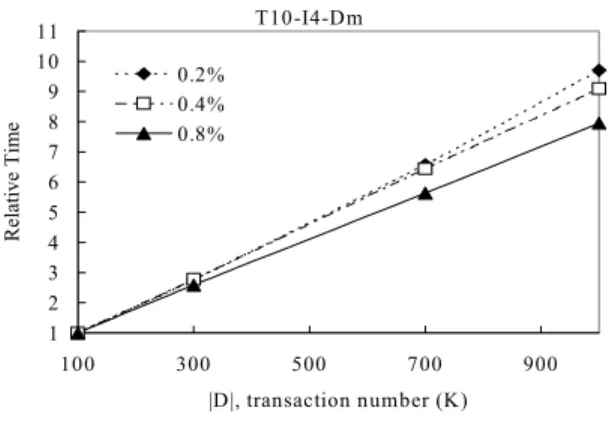
4.3 Scaleup performance
In this experiment, we examine the scaleup performance of algorithm PPM. The scale-up results for different se-lected datasets are obtained. Figure 5 shows the scaleup per-formance of algorithm PPM as the values of |D| increase.
T10-I4-D100 0 100 200 300 400 500 0.1 0.3 0.5 0.7 0.9 Minimum Support (%) E xecut ion T
ime (Sec) Apriori+
PPM T20-I6-D100 0 600 1200 1800 2400 3000 0.1 0.3 0.5 0.7 0.9 Minimum Support (%) Execut ion Ti m e ( Sec) Appriori+ PPM
Figure 4. Relative performance studies
Three different minimum supports are considered. We ob-tained the results for the dataset T 10 − I4 − Dm when the number of customers increases from 100, 000 to one mil-lion. The execution times are normalized with respect to the times for the 100, 000 transactions dataset in the Fig-ure 5. Note that, as shown in FigFig-ure 5 the execution time only slightly increases with the growth of the database size, showing good scalability of PPM.
5 Conclusion
In this paper, we not only explored a new model of mining general temporal association rules, i.e., (X ⇒
Y )MCP (XY ), in a publication database but also developed
algorithm PPM to generate the temporal association rules as well as conducted related performance studies. Un-der PPM, the cumulative information of mining previous partitions is selectively carried over toward the generation of candidate itemsets for the subsequent partitions. Algo-rithm PPM is particularly powerful for efficient mining for a publication-like transaction database, such as bookstore transaction databases, video rental store records, library-book rental records, and transactions in electronic com-merce. One extension to our proposed model in this paper is to mine general temporal association rules with different
T10-I4-Dm 1 2 3 4 5 6 7 8 9 10 11 100 300 500 700 900 |D|, transaction number (K) R ela tive T ime 0.2% 0.4% 0.8%
Figure 5. Scaleup performance of PPM
start and end points of items. This is an interesting yet chal-lenging issue, and will be a matter of future research.
6 Acknowledgment
The authors are supported in part by the Ministry of Ed-ucation Project No. 89-E-FA06-2-4-7 and the National Sci-ence Council, Project No. NSC 89-2219-E-002-028 and NSC 89-2218-E-002-028, Taiwan, Republic of China.
References
[1] R. Agrawal, T. Imielinski, and A. Swami. Mining Association Rules between Sets of Items in Large Databases. Proc. of ACM SIGMOD, pages 207–216, May 1993.
[2] R. Agrawal and R. Srikant. Fast Algorithms for Min-ing Association Rules in Large Databases. Proc. of
the 20th International Conference on Very Large Data Bases, pages 478–499, September 1994.
[3] J.M. Ale and G. Rossi. An Approach to Discovering Temporal Association Rules. ACM Symposium on
Ap-plied Computing, 2000.
[4] M.-S. Chen, J. Han, and P. S.Yu. Data Mining: An Overview from Database Perspective. IEEE
Transac-tions on Knowledge and Data Engineering, 8(6):866–
883, December 1996.
[5] X. Chen and I. Petr. Discovering Temporal Associa-tion Rules: Algorithms, Language and System. Proc.
of 2000 Int. Conf. on Data Engineering, 2000.
[6] D. Cheung, J. Han, V. Ng, and C.Y. Wong. Main-tenance of Discovered Association Rules in Large Databases: An Incremental Updating Technique.
Proc. of 1996 Int’l Conf. on Data Engineering, pages
106–114, February 1996.
[7] J. Han and Y. Fu. Discovery of Multiple-Level Asso-ciation Rules from Large Databases. Proc. of the 21th
International Conference on Very Large Data Bases,
pages 420–431, September 1995.
[8] J. Han, J. Pei, and Y. Yin. Mining Frequent Patterns without Candidate Generation. Proc. of 2000
ACM-SIGMOD Int. Conf. on Management of Data, pages
486–493, May 2000.
[9] J. Hipp, U. Güntzer, and G. Nakhaeizadeh. Algo-rithms for association rule mining – a general survey and comparison. SIGKDD Explorations, 2(1):58–64, July 2000.
[10] C.-H. Lee, C.-R. Lin, and M.-S. Chen. Sliding-Window Filtering: An Efficient Algorithm for Incre-mental Mining. Proc. of the ACM 10th Intern’l Conf.
on Information and Knowledge Management,
Novem-ber 2001.
[11] J.-L. Lin and M.H. Dunham. Mining Association Rules: Anti-Skew Algorithms. Proc. of 1998 Int’l
Conf. on Data Engineering, pages 486–493, 1998.
[12] B. Liu, W. Hsu, and Y. Ma. Mining Association Rules with Multiple Minimum Supports. Proc. of 1999 Int.
Conf. on Knowledge Discovery and Data Mining,
Au-gust 1999.
[13] J.-S. Park, M.-S. Chen, and P. S. Yu. Using a Hash-Based Method with Transaction Trimming for Mining Association Rules. IEEE Transactions on Knowledge
and Data Engineering, 9(5):813–825, October 1997.
[14] R. Srikant and R. Agrawal. Mining Generalized As-sociation Rules. Proc. of the 21th International
Con-ference on Very Large Data Bases, pages 407–419,
September 1995.
[15] R. Srikant and R. Agrawal. Mining quantitative asso-ciation rules in large relational tables. Proc. of 1996
ACM-SIGMOD Conf. on Management of Data, 1996.
[16] A. K. H. Tung, J. Han, L. V. S. Lakshmanan, and R. T. Ng. Constraint-Based Clustering in Large Databases.
Proc. of 2001 Int. Conf. on Database Theory, January
2001.
[17] K. Wang, Y. He, and J. Han. Mining Frequent Itemsets Using Support Constraints. Proc. of 2000 Int. Conf. on
Very Large Data Bases, September 2000.
[18] C. Yang, U. Fayyad, and P. Bradley. Efficient dis-covery of error-tolerant frequent itemsets in high di-mensions. The Seventh ACM SIGKDD International
Conference on Knowledge Discovery and Data Min-ing, 2001.