A new fuzzy clustering menthod with adjustable membership characteristics
5
0
0
全文
(2) From ∂∂L v i = 0, we have Pn m xk − v i k2 )x xk k=1 uki (a1 + 2a2 kx vi = P , ∀i n m 2 xk − v i k ) k=1 uki (a1 + 2a2 kx. ternating procedure consists of two steps: (1) fix cluster centers and find the fuzzy partition matrix, and (2) fix the fuzzy partition matrix and update cluster centers. Steps (1) and (2) are alternately executed until convergence is achieved. Note that the algorithm may converge to a local minimum or even a saddle point.. Substituting Eq. (9) into Eq. (7), one obtains Ã. 3. THE NEW FUZZY CLUSTERING METHOD WITH ADJUSTABLE MEMBERSHIP CHARACTERISTICS. αk = −. 4. min U ,V. U,V ) = J(U. c X n X. uki. subject to. uki = 1, ∀k. 2. Update the fuzzy partition matrix using Eq. (12). (6). 3. Update the cluster centers using Eq. (10).. (7). 4. Check for convergence. Usually this is done by U (k+1) − U (k) k ≤ ε. If not yet conchecking kU verged, go to Step 2 and proceed.. i=1. where U is the fuzzy partition matrix, V is the collection of cluster centers, n is the number of data samples, c is the number of clusters, m is the weighting exponent, and uki is the membership value of x k with respect to cluster i, for k = 1, · · · , n and i = 1, · · · , c. The necessary conditions for this optimization problem can be found using the method of Lagrange multipliers. First we define the corresponding Lagrangian function as L. 4. =. c X n X i=1 k=1 n X. αk. +. k=1. 4. ANALYSIS OF MEMBERSHIP FUNCTIONS In accordance with Eq. (12) one can define the membership function by −1 1 ¶ m−1 c µ 2 4 X x x a kx − v k + a kx − v k 1 i 2 i , ∀i x) = fi (x x − v j k2 + a2 kx x − v j k4 a kx 1 j=1. xk − v i k2 + a2 kx xk − v i k4 ) um ki (a1 kx à c X. ! uki − 1. −1 1 ¶ m−1 c µ 2 4 X xk − v i k + a2 kx xk − v i k a1 kx , ∀k, i = xk − v j k2 + a2 kx xk − v j k4 a kx 1 j=1. 1. Initialize cluster centers. Usually this is performed by random assignment.. i=1 k=1 c X. 1. (12) The alternating algorithm of the conventional fuzzy cmeans method can also be applied to the new fuzzy clustering method with different updating functions for the cluster centers and fuzzy partition matrix. We summarize the solution algorithm as follows:. (5). xk − v i k2 um ki (a1 kx. xk − v i k4 ) +a2 kx. !−m+1. 1. xk − v i k2 + a2 kx xk − v i k4 )] m−1 [m(a1 kx (11) Eqs. (11) and (9) together yield. where x k is the kth input datum, v i is the ith cluster center, and a1 and a2 are two parameters specified by the user. With this new definition of distance measure, the fuzzy clustering problem can be reformulated as a new optimization problem 4. c X i=1. In convectional fuzzy c-means algorithm, the distance xk − v i k2 . We now extend this measure is defined by kx definition to include an additional higher-order term, namely, let us define the new distance measure by xk − v i k2 + a2 kx xk − v i k4 dki = a1 kx. (10). (13) where v i and v j are the centers for cluster i and j respectively. To gain more insight regarding how the parameters a1 and a2 affect the membership fuctions, let us focus on a specific situation with only two clusters where the feature vector possesses a single dimension and m = 2. Let the cluster centers of these two clusters be denoted by v 1 and v 2 respectively, and let x denote the Euclidean distance between the input datum and v 1 . Here we consider two different scenarios: (1) the input datum is located between v 1 and v 2 ; (2) v 1 is. (8). i=1. where αk is the corresponding Lagrange multiplier. At the optimal points of solutions, the partial derivatives of L with respect to all related variables should be equal ∂L = 0, we obtain to zero. From ∂u ki xk − v i k2 + a2 kx xk − v i k4 ) + αk = 0, ∀k, i mum−1 (a1 kx ki (9) 2. , ∀k.
(3) Inter−Center Distance (r) = 1. Inter−Center Distance (r) = 1. 1. 1. 0.9. 0.98. 0.8. 0.96. a2/a1 = 0 a /a = 1 2 1 a2/a1 = 10 a2/a1 = 100. 0.6. 0.94. Membership Value. Membership Value. 0.7. 0.5. 0.4. 0.92. 0.9. 0.88. 0.3. 0.86. 0.2. 0.84. 0.1. 0.82. 0. 0. 0.1. 0.2. 0.3. 0.4. 0.5. 0.6. 0.7. 0.8. 0.9. 0.8. 1. Euclidean Distance (x). a2/a1 = 0 a2/a1 = 1 a /a = 10 2 1 a2/a1 = 100. 0. 0.1. 0.2. 0.3. 0.4. 0.5. 0.6. 0.7. 0.8. 0.9. Fig. 1. The membership vs. Euclidean distance curve. Shown in this figure is the first scenario where the input datum is located between v 1 and v 2 .. Fig. 2. The membership vs. Euclidean distance curve. Shown in this figure is the second scenario where v 1 is located between the input datum and v 2 .. located between the input datum and v 2 . For the first scenario, we have. 5. EXAMPLES. ½ f1 (x) = =. 1+[. 1 a1 x2 + a2 x4 ] m−1 a1 (r − x)2 + a2 (r − x)4 (r − x)2 + aa21 (r − x)4. [x2 + (r − x)2 ] +. a2 4 a1 [x. + (r − x)4 ]. In this study we used an artificially synthesized data set for experimentation. This data set with 2000 data points comprises three non-overlapped clusters. Since the clusters are separable, the clustering task can be easily accomplished. However, with different fuzzy clustering strategies, varying fuzzy partition matrices can be generated. Figs. 3 through 6 show the experimental results. Prior to clustering, the data set went through a linear normalization operation so that each component of the feature vector is scaled to be in the range [0, 1]. In each figure, the scatter plot of input data are drawn with cluster centers and iso-membership contours overlaid. Each figure possesses a different combination of a1 and a2 values. From these figures, it is seen that cluster centers change slightly with varying combinations of a1 and a2 ; however, the iso-membership contours exhibit distinct changes. In principle, the larger the a2 /a1 ratio is, the higher the membership value is observed around the same neighborhood of a cluster center. Refer to Figs. 3 through 6 for the detailed contour plots.. ¾−1. (14). where r is the Euclidean distance between v 1 and v 2 . Similarly, for the second scenario we easily obtain ½ f1 (x) = =. 1+[. 1 a1 x2 + a2 x4 ] m−1 a1 (r + x)2 + a2 (r + x)4 (r + x)2 + aa21 (r + x)4. [x2 + (r + x)2 ] +. a2 4 a1 [x. + (r + x)4 ]. 1. Euclidean Distance (x). ¾−1. (15). From Eqs. (14) and (15) it is clearly seen that in both scenarios the memberships are affected by r and the ratio a2 /a1 . Figs. 1 and 2 show the membership vs. x curves. For the first scenario, with an increasing a2 /a1 ratio, the clustering gradually changes from soft partition toward harder partitions, as illustrated by Fig. 1. For the second scenario, we also observe that with an increasing a2 /a1 ratio, the clustering gradually changes from soft partition toward harder partitions, which is illustrated by Fig. 2. However, in the latter scenario, the changes occur at a slower pace.. 6. CONCLUSION Clustering plays a very important role in almost all branches of science and engineering. The conventional k-means and fuzzy c-means algorithms have been most popular methods for solving separable and non-separable clustering tasks. Based on a new definition of distance 3.
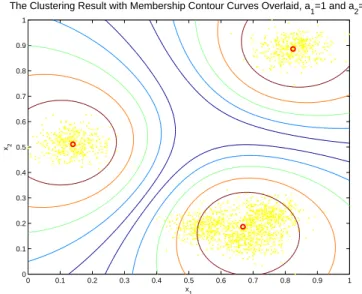
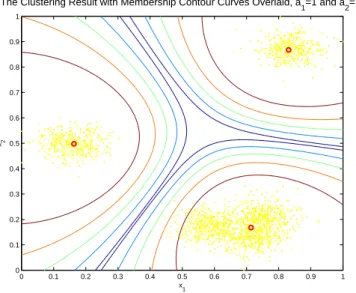
(4) measure, we propose a new form of fuzzy clustering method. The key distinct property of this new fuzzy clustering scheme is that it is capable of controlling the membership curve through adjusting the values of a1 and a2 . Further research will be necessary in order to characterize the choice of a1 and a2 values in a practical setting.. The Clustering Result with Membership Contour Curves Overlaid, a1=1 and a2=0 1. 0.9. 0.8. 0.7. 0.6 x2. 7. REFERENCES [1] A. Jain and R. Dubes, Algorithms for Clustering Data, Englewood Cliffs, NJ: Prentice-Hall, 1988.. 0.5. 0.4. 0.3. [2] J. bezdek, Pattern Recognition with Fuzzy Objective Function Algorithms, New York: Plenum, 1981.. 0.2. 0.1. 0. [3] R. Krishnapuram and J. Keller, “A Possibilistic Approach to Clustering,” IEEE Tr. Fuzzy Systems, Vol. 1, pp. 98-110, May 1993.. 0. 0.1. 0.2. 0.3. 0.4. 0.5 x1. 0.6. 0.7. 0.8. 0.9. 1. Fig. 3. An example to demonstrate the fuzzy clustering result. In this figure, a1 = 1 and a2 = 0, and cluster centers are shown as small red circles. For each cluster, five iso-membership contours are illustrated, which correspond to membership values of 0.9, 0.8, 0.7, 0.6 , and 0.5.. [4] R. N. Dave, “Characterization and Detection of Noise in Clustering,” Pattern Recognition Letters, Vol. 12, pp. 657-664, 1991. [5] D. Tran and M. Wagner, “Fuzzy Entropy Clustering,” Proc. IEEE 2000 Int’l Conf. Fuzzy Systems, pp. 152-157. [6] K. K. Chintalapudi and M. Kam, “A NoiseResistant Fuzzy c-Means Algorithm for Clustering,” Proc. IEEE 1998 Int’l Conf. on Fuzzy Systems, pp. 1458-1463.. The Clustering Result with Membership Contour Curves Overlaid, a1=1 and a2=1 1. 0.9. 0.8. [7] I. H. Suh, J.-H. Kim, and F. C.-H. Rhee, “ConvexSet-Based Fuzzy Clustering,” IEEE Tr. Fuzzy Systems, Vol. 7, No. 3, pp. 271-285, June 1999.. 0.7. 0.6 x2. [8] J. M. Leski, “Generalized Weighted Conditional Fuzzy Clustering,” IEEE Tr. Fuzzy Systems, Vol. 11, No. 6, pp. 709-715, Dec. 2003.. 0.5. 0.4. 0.3. 0.2. 0.1. 0. 0. 0.1. 0.2. 0.3. 0.4. 0.5 x1. 0.6. 0.7. 0.8. 0.9. 1. Fig. 4. An example to demonstrate the fuzzy clustering result. In this figure, a1 = 1 and a2 = 1, and cluster centers are shown as small red circles. For each cluster, five iso-membership contours are illustrated, which correspond to membership values of 0.9, 0.8, 0.7, 0.6 , and 0.5.. 4.
(5) The Clustering Result with Membership Contour Curves Overlaid, a1=1 and a2=10 1. 0.9. 0.8. 0.7. x2. 0.6. 0.5. 0.4. 0.3. 0.2. 0.1. 0. 0. 0.1. 0.2. 0.3. 0.4. 0.5 x1. 0.6. 0.7. 0.8. 0.9. 1. Fig. 5. An example to demonstrate the fuzzy clustering result. In this figure, a1 = 1 and a2 = 10, and cluster centers are shown as small red circles. For each cluster, five iso-membership contours are illustrated, which correspond to membership values of 0.9, 0.8, 0.7, 0.6 , and 0.5.. The Clustering Result with Membership Contour Curves Overlaid, a1=1 and a2=100 1. 0.9. 0.8. 0.7. x2. 0.6. 0.5. 0.4. 0.3. 0.2. 0.1. 0. 0. 0.1. 0.2. 0.3. 0.4. 0.5 x. 0.6. 0.7. 0.8. 0.9. 1. 1. Fig. 6. An example to demonstrate the fuzzy clustering result. In this figure, a1 = 1 and a2 = 100, and cluster centers are shown as small red circles. For each cluster, five iso-membership contours are illustrated, which correspond to membership values of 0.9, 0.8, 0.7, 0.6 , and 0.5.. 5.
(6)
數據

相關文件
Reading Task 6: Genre Structure and Language Features. • Now let’s look at how language features (e.g. sentence patterns) are connected to the structure
"Extensions to the k-Means Algorithm for Clustering Large Data Sets with Categorical Values," Data Mining and Knowledge Discovery, Vol. “Density-Based Clustering in
The research proposes a data oriented approach for choosing the type of clustering algorithms and a new cluster validity index for choosing their input parameters.. The
Chen, The semismooth-related properties of a merit function and a descent method for the nonlinear complementarity problem, Journal of Global Optimization, vol.. Soares, A new
Then, it is easy to see that there are 9 problems for which the iterative numbers of the algorithm using ψ α,θ,p in the case of θ = 1 and p = 3 are less than the one of the
(Another example of close harmony is the four-bar unaccompanied vocal introduction to “Paperback Writer”, a somewhat later Beatles song.) Overall, Lennon’s and McCartney’s
Biases in Pricing Continuously Monitored Options with Monte Carlo (continued).. • If all of the sampled prices are below the barrier, this sample path pays max(S(t n ) −
The fuzzy model, adjustable with time, is first used to consider influence factors with different features such as macroeconomic factors, stock and futures technical indicators..
