A Novel Method for Discovering Fuzzy Sequential
Patterns Using the Simple Fuzzy Partition Method
Ruey-Shun Chen, Yi-Chung Hu
Institute of Information Management, National Chiao Tung University, Hsinchu 300, Taiwan, ROC. E-mail address: rschen@bis03.iim.nctu.edu.tw (R. -S. Chen)
Sequential patterns refer to the frequently occurring patterns related to time or other sequences, and have been widely applied to solving decision problems. For example, they can help managers determine which items were bought after some items had been bought. However, since fuzzy sequential patterns described by natural language are one type of fuzzy knowledge representation, they are helpful in building a prototype fuzzy knowledge base in a business. Moreover, each fuzzy sequential pattern consisting of several fuzzy sets described by the natural language is well suited for the thinking of human subjects and will help to increase the flexibility for users in making decisions. Additionally, since the comprehensibility of fuzzy rep-resentation by human users is a criterion in designing a fuzzy system, the simple fuzzy partition method is preferable. In this method, each attribute is partitioned by its various fuzzy sets with pre-specified member-ship functions. The advantage of the simple fuzzy par-tition method is that the linguistic interpretation of each fuzzy set is easily obtained. The main aim of this paper is exactly to propose a fuzzy data mining tech-nique to discover fuzzy sequential patterns by using the simple partition method. Two numerical examples are utilized to demonstrate the usefulness of the pro-posed method.
1. Introduction
Data mining is the exploration and analysis of data in order to discover meaningful patterns (Berry & Linoff, 1997). Thus knowledge acquisition can be easily
achieved for users by checking these patterns discovered from databases, and association rule is an important type of knowledge representation. Agrawal et al. (Agrawal, Imielinski, & Swami, 1993) initially proposed a method to find association rules, later proposing the well-known Apriori algorithm (Agrawal, Mannila, Srikant, Toivonen, &Verkamo, 1996). In addition to association rules, se-quential patterns are another important type of knowl-edge representation, and effective algorithms (i.e. Apri-oriSome and AprioriAll) for mining sequential patterns were proposed by Agrawal and Srikant (1995). In addi-tion, sequential patterns have been widely applied to solve decision problems. For example, they can help managers determine which items were bought after some items had (already) been bought (Han & Kamber, 2001), or realize browsing orders of homepages in a web site (Myra, 2000).
Sequential pattern mining is the mining of frequently occurring patterns related to time or other sequences (Han & Kamber, 2001), where a sequence is an ordered list of itemsets (Agrawal & Srikant, 1995). Specially, if there are
k itemsets (kⱖ 1) in a frequent sequence whose support is
larger than or equal to the user-specified minimum support, then we call it a frequent k-sequence. Moreover, a sequen-tial pattern is a frequent sequence but it is not contained in another sequence (Agrawal & Srikant, 1995). For example, a 2-sequence具{Banana} , {Apple, Orange}典 may represent items Apple and Orange being bought together after item Banana had been bought, where {Banana} and {Apple, Orange} are itemsets. Whereas 具{Banana} , {Apple, Or-ange}典 is not contained in the 1-sequence 具{Banana, Apple, Orange}典 since the latter sequence is shorter than the former sequence.
However, since fuzzy sequential patterns described by natural language are one type of fuzzy knowledge represen-tation, they are helpful to build a prototype fuzzy knowledge base in business. Moreover, fuzzy sequential patterns de-scribed by the natural language are well suited for the thinking of human subjects and will help to increase the flexibility for users in making decisions. Actually, each Nomenclature K, number of partitions in each quantitative attribute;
k, length of a fuzzy sequence; d, degree of a given relation, where dⱖ 1; AK,im
xm , i
m-th linguistic value of K fuzzy partitions defined in quantitative
attribute xm, 1ⱕ im ⱕ K;K,im
xm , membership function of A K,im xm ; n, total
number of customers; cr, r-th customer, where 1ⱕ r ⱕ n;␣r, number of
consecutive transactions ordered by transaction-time for cr;, total number
of frequent fuzzy grids; tp共r兲, p-th transaction corresponding to cr, where tp共r兲
⫽ 共tp1 共r兲, t p2 共r兲, …, t pd 共r兲), and 1ⱕ p ⱕ␣
r; Lj, j-th frequent fuzzy grid, where 1
ⱕ jⱕ.
fuzzy sequential pattern is composed of several fuzzy sets that can be described by the natural language. For example, a fuzzy sequence 具A2,1
Product 1
, A2,2 Product 2
典 discovered from a transaction database in summer may represent that large purchase amounts of product 2 were bought by customers after they had bought small purchase amounts of product 1, where A2,1
Product 1
and A2,2 Product 2
are fuzzy sets defined in pur-chase amounts of product 1 (i.e., Product 1) and purpur-chase amounts of product 2 (i.e., Product 2), respectively. In other words, a fuzzy sequence expresses the temporal relation between purchase behaviors described by fuzzy sets. In addition, if one customer bought product 1 on August 1, and bought product 2 on August 6, then we say that the corre-sponding transaction record supports具A2,1
Product 1
, A2,2 Product 2
典. Since the comprehensibility of fuzzy representation by human users is a criterion in designing a fuzzy knowledge-based system (Ishibuchi et al., 1999), easy linguistic inter-pretations of fuzzy sets must be taken into account. The simple fuzzy partition method is thus preferable (Ishibuchi et al., 1999). In this method, each attribute is partitioned by its various fuzzy sets with pre-specified membership func-tions. For example, the m-th axis denoted by xm is
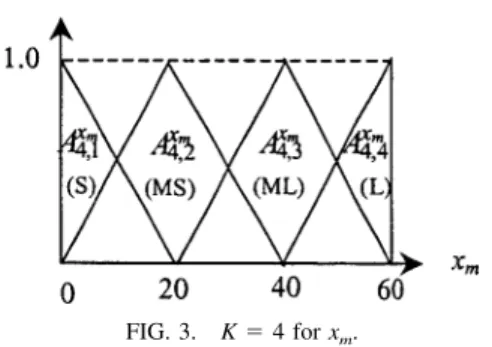
parti-tioned by 2, 3, 4 linguistic values with linguistic interpre-tations as shown in Figures 1–3, respectively. For example,
A3,1
x1 and A 3,3
x2 are interpreted as “small” and “large”,
respec-tively. That is, the simple fuzzy partition method provides a comprehensible expression for interpreting fuzzy sets.
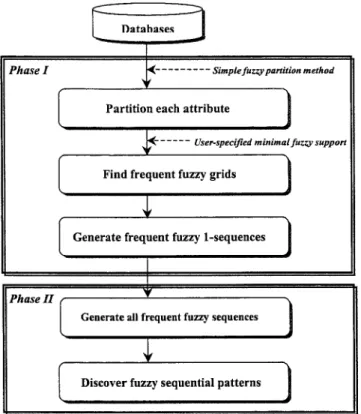
The main aim of this paper is to propose a fuzzy data mining technique to discover fuzzy sequential patterns by using the simple partition method. The first phase is to find purchase behaviors (e.g., A2,1
Product 1
, A2,2 Product 2
) that frequently occurred for a period of time, and the second phase is to discover fuzzy sequential patterns by analyzing the tempo-ral relation between those purchase behaviors (e.g., 具A2,1 Product 1 , A2,2 Product 2 典 or 具A2,2 Product 2 , A2,1 Product 1 典) found in the first phase.
The rest of this paper is organized as follows. The simple fuzzy partition method is introduced in Section 2. The determinations of purchase behaviors that frequently oc-curred (i.e., frequent fuzzy grids) and fuzzy sequential pat-terns are presented in Section 3 in detail. The framework of the proposed method consisting of two phases is also illus-trated in this section. The real implementation of the pro-posed method is described in Section 4. In Section 5, two numerical examples are used to demonstrate the usefulness of the proposed method. We end this paper with discussions and conclusions in Section 6.
2. Simple Fuzzy Partition Method
The concepts of a linguistic variable were proposed by Zadeh (1976), who initially proposed the fuzzy sets (Zadeh, 1965). A linguistic variable is a variable whose values are linguistic terms or sentences in a natural language. We view both quantitative and categorical attributes, which are used to describe each sample data, as linguistic variables (Zadeh, 1976; Chen & Jong, 1997; Zimmermann, 1996; Pedrycz & Gomide, 1994). For example, the values of the linguistic variable “Purchase amount of Product 1” may be “medium” or “very close to 50.” Here, “medium” or “very close to 50” are called linguistic values. Then, each linguistic variable can be partitioned by its linguistic values with pre-specified membership functions, so-called the simple fuzzy partition method. Simple fuzzy grids or grid partitions in a pattern space (Ishibuchi , Nozaki, Yamamoto, & Tanaka, 1995; Ishibuchi et al, 1999; Jang & Sun, 1995) are thus generated. The simple fuzzy partition method has been widely used in pattern recognition and fuzzy reasoning. For example, there are the applications to classification rule discovery for pattern classification problems (Ishibuchi et al, 1995; Ishi-buchi et al, 2001; Hu, Tzeng, & Chen, 2002; IshiIshi-buchi et al, 1999; Ravi & Zimmermann, 2000), and to the fuzzy rule generation for control problems (Wang & Mendel, 1992; Homaifar & McCormick, 1995; Jang, 1993). In addition, several fuzzy approaches for partitioning a pattern space were discussed by Sun (1994) and Bezdek (1981). From the above-mentioned studies, we can find that it should be quite feasible to discover useful fuzzy knowledge from business databases by utilizing the simple fuzzy partition method. Moreover, as we have mentioned above, the simple fuzzy partition method provides a comprehensible expression to interpret fuzzy sets. Additionally, data mining techniques
FIG. 3. K⫽ 4 for xm.
FIG. 1. K⫽ 2 for xm.
can ease the knowledge acquisition bottleneck in building prototype knowledge base systems (Hong, Wang, Wang, & Chien, 2000). Fuzzy data mining techniques using the sim-ple fuzzy partition method are thus helpful to build a com-prehensibly prototype fuzzy knowledge base in a business. In the simple fuzzy partition method, K (K⫽ 2, 3, 4,…) various linguistic values are defined in each quantitative attribute. K is also pre-specified before executing the pro-posed method. It is clear that if K is very small (e.g., K⫽ 2), then the resultant partition is too coarse; otherwise (e.g., K ⫽ 10), the resultant partition is too fine. It is also suggested that K should not exceed 9, since it is difficult for us to simultaneously judge or distinguish from the items whose number is larger than 9 (Ravi & Zimmermann, 2000).
Triangular membership functions, which are usually used for the linguistic values, are the default value in our method. In fact, Pedrycz (1994) had pointed out the useful-ness and effectiveuseful-ness of the triangular membership func-tions in the fuzzy modeling. It is noted that, in addition to the simple fuzzy partition method, decision-makers can also specify membership functions and the number of partitions in each attribute depending on professional knowledge they have or subject perception.
Specifically, we use AK,im
xm
to denote a candidate 1-dim fuzzy grid. And,K,im
xm (x) is defined as follows: K,im xm 共x兲 ⫽ max{1 ⫺x ⫺ a im K/bK , 0} (1) where aim
K⫽ mi ⫹ 共ma ⫺ mi兲 䡠 共i
m⫺ 1兲/共K ⫺ 1兲 (2)
bK⫽ 共ma ⫺ mi兲/共K ⫺ 1兲
(3) where ma is the maximum value of attribute domain, and mi is the minimum value.
If we partition both x1and x2into three fuzzy partitions,
then a pattern space is divided into 3⫻ 3 2-dim fuzzy grids, as shown in Figure 4. For the shaded 2-dim fuzzy grid shown in Figure 4, we use linguistic values, A3,1
x1 ⫻ A 3,3
x2
(i.e. small AND large), to represent it. In this paper, each fuzzy
grid is treated as a purchase behavior. The next important task is how to use these candidate 1-dim fuzzy grids to generate frequent fuzzy sequences and fuzzy sequential patterns. The framework of the proposed method is further described in following section.
3. Determine Frequent Fuzzy Grids and Fuzzy Sequential Patterns
In this section, the concrete meanings of frequent fuzzy grids and fuzzy sequential patterns are described in detail. At first, the computational steps of the proposed method are briefly introduced as follows.
After candidate 1-dim fuzzy grids have been generated, we must determine how to find frequent fuzzy grids, fre-quent fuzzy k-sequences (kⱖ 1) and fuzzy sequential pat-terns from those candidate 1-dim fuzzy grids. Frequent fuzzy grids with a small dimension, say m, are used to construct candidate (m⫹ 1)-dim fuzzy grids accompanied by a fuzzy support. A candidate (m ⫹ 1)-dim grid can be determined to be frequent or not by comparing its fuzzy support with the user-specified minimum fuzzy support (min FS). At the end of phase I, each frequent fuzzy grid, say Lj, can be transformed into a frequent fuzzy 1-sequence
Lj. Frequent fuzzy grid may stand for purchase behaviors
that frequently occurred for a period of time.
We define that a fuzzy sequence is an ordered list of frequent fuzzy grids, and the length of a fuzzy sequence is the number of frequent fuzzy grids in the fuzzy sequence. That is, a fuzzy sequence expresses the temporal relation between frequent fuzzy grids. Thus, if there are k fuzzy grids (kⱖ 1) in a fuzzy sequence, then we call it a fuzzy
k-sequence. For example, 具A2,1
Product 1
, A2,2
Product 2典 is a fuzzy
2-sequence.
The main purpose of phase II is to discover fuzzy se-quential patterns by analyzing the temporal relation between those frequent grids found in phase I. In phase II, frequent fuzzy sequences with a shorter length, say k, are used to construct candidate fuzzy sequences with a longer length (i.e. fuzzy (k ⫹ 1)-sequences) accompanied by a fuzzy support. A candidate fuzzy (k⫹1)-sequence can also be determined to be frequent or not by comparing its fuzzy support with the min FS used in phase I. At the end of phase II, all fuzzy sequential patterns are generated from those frequent fuzzy sequences.
From the above-mentioned operations, the framework for discovering fuzzy sequential patterns is illustrated in Figure 5. Below, the Apriori algorithm is briefly introduced in Subsection 3.1 since the concept of support is originated from this well-known algorithm. The determinations of frequent fuzzy 1-sequences and fuzzy sequential patterns are described in Subsections 3.2 and 3.3, respectively.
3.1 The Apriori Algorithm
Association rules are one type of knowledge representa-tion, having been widely applied to analyze market baskets FIG. 4. Both attributes x1and x2are partitioned into three partitions.
to help managers realize which items are likely to be bought at the same time (Han & Kamber, 2001, Berry & Linoff, 1997). The Apriori algorithm proposed by Agrawal et al. (1996) is an influential algorithm that can be used to find association rules. In this algorithm, all frequent itemsets are found from databases in the first phase. A candidate itemset is frequent if its support is larger than or equal to the user-specified minimum support. Generally, a frequent itemset means that this set is useful for decision makers. In the second phase, frequent itemsets are used to generate association rules.
Example 1. Any set of fruits, say {Apple, Orange}, sold
in one supermarket is a candidate itemset. The support of {Apple, Orange} is computed by dividing the number of transactions that buy apples and oranges by the total number of transactions. That is, if Apple and Orange were bought at the same time in one transaction, then this transaction record supports {Apple, Orange}. If the support of {Apple, Or-ange} is larger than or equal to the user-specified minimum support, then {Apple, Orange} is a frequent itemset. This means that “Apple and Orange are likely to be bought together” frequently occurred.
Furthermore, the larger minimum support is specified by users, the smaller number of frequent itemsets will be gen-erated. Therefore, if the user-specified minimum support is set to zero, then all itemsets will be frequent. Additionally, the Apriori property (Han & Kamber, 2001) for mining association rules shows that any subset of a frequent itemset must also be frequent. This property can be also applied to show that any superset (i.e., sequence of length above k) of
an infrequent k-sequence is not frequent (Han & Kamber, 2001).
Example 2. From the Apriori property, if {Banana,
Ap-ple, Orange} is frequent, then {Banana} , {Apple} , {Or-ange} , {Banana, Apple} , {Banana, Or{Or-ange} and {Apple, Orange} must be frequent.具{Banana} , {Apple, Orange}典 is an infrequent 2-sequence if either 具{Banana}典 or {Apple, Orange} is infrequent.
3.2 Frequent Fuzzy 1-Sequences
In phase I, the main work is to generate frequent fuzzy grids, and then transform those grids to frequent fuzzy 1-sequences. Now, given a candidate l-dim (l ⱕ d) fuzzy grid AK,i1 x1 ⫻ A K,i2 x2 ⫻ . . . ⫻ A K,il⫺1 xl⫺1 ⫻ A K,il xl
, the degree to which
tp共r兲belongs to this fuzzy grid can be computed as follows
(Ishibuchi et al., 2001; Hu, Chen, & Tz, 2002) : AK,i1x1 ⫻AK,i2
x2 ⫻ . . . ⫻AK,il⫺1 xl⫺1⫻A K,il xl共t p 共r兲兲 ⫽K,i1 x1 共t P1 共r兲兲 䡠 K,i2 x2 共t P2 共r兲兲 䡠 . . . 䡠 K,il⫺1 xl⫺1 共t Pl⫺1 共r兲 兲 䡠 K,il xl 共t Pl 共r兲兲 (7)
where “ 䡠 ” is a fuzzy intersection operator, namely the algebraic product (Zimmermann, 1996; Hu et al., 2002). It should be noted that in comparison with the other fuzzy intersection operators such as the minimum operator or the drastic product, the algebraic product “gently” performs the fuzzy intersection. To check whether this fuzzy grid is frequent or not, we define its fuzzy support, FS共AK,i1
x1 ⫻ AK,i2 x2 ⫻ . . . ⫻ AK,il⫺1 xl⫺1 ⫻ A K,il xl ), as follows: FS共AK,i1 x1 ⫻ A K,i2 x2 ⫻ . . . ⫻ A K,il⫺1 xl⫺1 ⫻ A K,il xl 兲 ⫽
冘
r⫽1 nAK,i1x1 ⫻AK,i2 x2 ⫻ . . . ⫻AK,il⫺1 xl⫺1 ⫻A K,il xl 共cr兲/n ⫽
冘
r⫽1 n max p⫽1. . . ar冤
冘
r⫽1 n AK,i1 x1 ⫻AK,i2 x2⫻. . .⫻A K,il⫺1 xl⫺1⫻A K,il xl 共t p 共r兲兲冥
Ⲑ
n (8)whereAK,i1x1 ⫻AK,i2x2 ⫻. . . ⫻ AK,i
l⫺1 xl⫺1 ⫻A
K,il
xl (c
r) is the degree to which cr
supports AK,i1 x1 ⫻ A K,i2 x2 ⫻ . . . ⫻ A K,il⫺1 xl⫺1 ⫻ A K,il xl . Since sequen-tial pattern mining mainly analyzes the customer behaviors, the fuzzy support is obtained by computing AK,i1x1 ⫻AK,i2x2 ⫻. . .⫻ AK,i
l⫺1 x2 ⫻A K,il xl (c r). If FS共AK,i1 x1 ⫻ A K,i2 x2 ⫻ . . . ⫻ AK,il⫺1 xl⫺1 ⫻ A K,il xl
) is larger than or equal to the user-specified minimum fuzzy support (i.e. min FS), then AK,i1
x1 ⫻ AK,i2 x2 ⫻ . . . ⫻ A K,il⫺1 xl⫺1 ⫻ A K,il xl
is a frequent l-dim fuzzy grid. The fuzzy support also indicates the degree of importance of one fuzzy grid. Of course, if the user-specified minimum fuzzy support is set to zero, then all l-dim fuzzy grid (1ⱕ l ⱕ d) will be frequent. Actually, AK,i1
x1 ⫻ A K,i2 x2 ⫻ . . . ⫻ A K,il⫺1 xl⫺1 ⫻ AK,il xl
is a fuzzy subset and can be represented as a Zadeh fuzzy notation (Zimmermann, 1996; Pedrycz & Gomide, 1998):
AK,i1 x1 ⫻ A K,i2 x2 ⫻ . . . ⫻ A K,il⫺1 xl⫺1 ⫻ A K,il xl ⫽
冘
r⫽1 nAK,i1x1 ⫻AK,i2 x2 ⫻ . . . ⫻AK,il⫺1 xl⫺1⫻A K,il xl 共c r兲/cr (9)
It is clear that AK,i1
x1 ⫻ A K,i2 x2 ⫻ . . . ⫻ A K,il⫺1 xl⫺1 ⫻ A K,il⫺1 xl 債 A K,i1 x1 ⫻ AK,i2 x2 ⫻ . . . ⫻ A K,il⫺1
xl⫺1 holds. From Eqs. (8) and (9), we can
observe that if a m-dim fuzzy grid, say AK,i1
x1 ⫻ A K,i2 x2 ⫻ . . . ⫻ AK,im⫺1 xm⫺1 ⫻ A K,im xm
, that participates in the construction of a frequent l-dim fuzzy grid, say AK,i1
x1 ⫻ AK,i2 x2 ⫻ . . . ⫻ AK,im⫺1 xm⫺1 ⫻ AK,im xm ⫻ AK,im⫹1 xm⫹1 ⫻ . . . ⫻ A K,il⫺1 xl⫺1 ⫻ A K,il xl
, then that m-dim fuzzy grid must also be frequent since min FSⱕ FS共AK,i1
x1 ⫻ AK,i2 x2 ⫻ . . . ⫻ AK,im⫺1 xm⫺1 ⫻ A K,im xm ⫻ . . . ⫻ AK,il⫺1 xl⫺1 ⫻ A K,il xl ) ⱕ FS共AK,i1 x1 ⫻ AK,i2 x2 ⫻ . . . ⫻ AK,im⫺1 xm⫺1 ⫻ A K,im xm
) holds. That is, any subset of a frequent fuzzy grid must also be frequent. Finally, AK,i1 x1 ⫻ AK,i2 x2 ⫻ . . . ⫻ AK,il⫺1 xl⫺1 ⫻ A K,il xl can be trans-formed into a frequent fuzzy 1-sequence denoted by具AK,i1
x1 ⫻ AK,i2 x2 ⫻ . . . ⫻ A K,il⫺1 xl⫺1 ⫻ A K,il xl .
Example 3. Any two fuzzy grids in兵A3,2
x1 ⫻ A 3,1 x2 , A 3,2 x1 ⫻ A3,3 x3, A 3,1 x2 ⫻ A 3,3
x3} can be used to generate A 3,2 x1 ⫻ A 3,1 x2 ⫻ A 3,3 x3 since A3,2 x1 ⫻ A 3,1 x2 債 A 3,2 x1 ⫻ A 3,1 x2 ⫻ A 3,3 x3, A 3,2 x1 ⫻ A 3,3 x3 債 A 3,2 x1 ⫻ A3,1 x2 ⫻ A 3,3 x3, and A 3,1 x2 ⫻ A 3,3 x3 債 A 3,2 x1 ⫻ A 3,1 x2 ⫻ A 3,3 x3 hold. If A 3,2 x1 ⫻ A3,1 x2 ⫻ A 3,3 x3 is frequent, then A 3,2 x1 ⫻ A 3,1 x2 , A 3,2 x1 ⫻ A 3,3 x3 and A3,1 x2 ⫻ A 3,3
x3 are also frequent. Therefore, the
above-men-tioned fuzzy grids will be transformed into 具A3,2
x1 ⫻ A 3,1 x2典, 具A3,2 x1 ⫻ A 3,3 x3典, 具A 3,1 x2⫻ A 3,3 x3典, and 具A 3,2 x1 ⫻ A 3,1 x2 ⫻ A 3,3 x3典, respec-tively.
3.3 Fuzzy Sequential Patterns
Based on frequent fuzzy 1-sequence found in phase I, the next step for us is to find frequent fuzzy k-sequences (2ⱕ k ⱕ). As we have mentioned in the previous section, each frequent fuzzy grid, say Lj, can be transformed into a frequent fuzzy 1-sequence denoted by Lj. The fuzzy support of a fuzzy k-sequence is the average degree of total cus-tomers who support this sequence. Here, we take a fuzzy
k-sequence L1, L2,. . ., Lk, which may represent L1, L2,. . .,
Lkbeing bought sequentially, to be an example to compute its fuzzy support. For the r-th customer (i.e., cr) with ␣r transactions, there are␣rCk(␣rⱖ k) different combinations 共ts1 共r兲, t s2 共r兲, . . . , t sk 共r兲) (1ⱖ s 1⬍ s2⬍ . . . ⬍ skⱕ ␣r) ordered by transaction-time. Since 共ts1 共r兲, t s2 共r兲, . . . t sk 共r兲) supports 具L 1, L2, . . . , Lk典, the degree FS(具L1, L2, . . . , Lk典r) to which cr
supports L1, L2, . . . , Lkis described as follows:
FS共具L1, L2, . . . ,Lk典r兲 ⫽ max (ts1(r), ts2(r), . . . , tsk(r)) [L1共ts1共r兲兲 䡠 L2共ts2共r兲兲 䡠 . . . 䡠 Lk共tsk共r兲兲], for␣rCkdifferent共ts1共r兲, ts2共r兲, . . . , tsk共r兲兲 (10) whereLk共tsk
共r兲兲 represents the degree which t
sk
共r兲 belongs to Lk, and can be computed by Eq. (7). Of course, if␣r⬍ k,
then FS具L1, L2, . . . , Lk典r ⫽ 0.
Example 4. Assume that the number of transactions of c2
is␣2⫽ 3 (i.e., t1共2兲, t2共2兲, and t3共2兲), and all possible
combina-tions of transaccombina-tions ordered by transaction-time is共t1共2兲, t2共2兲兲,
共t1共2兲, t3共2兲兲, and 共t2共2兲, t3共2兲兲. Let L1and L2be A3,2 Product 2 and A3,2 Product 3 , respectively, FS共具A3,2 Product 2 , A3,2 Product 3典) 2 (i.e., k ⫽ 2) is
ob-tained by computing max兵L1共t1共2兲兲 䡠 L2共t2共2兲兲, L1共t1共2兲兲 䡠
L2共t3共2兲兲,L1共t2共2兲兲 䡠 共t3共2兲兲} since each combination may
sup-port具A3,2 Product 2
, A3,2
Product 3典 and␣
2ⱖ k. However, if the number
of transactions of c1is␣1⫽ 1, then FS共具A3,2 Product 2
, A3,2 Product 3典)
1
is equal to zero since␣1⬍ k.
The fuzzy support FS(具L1, L2, . . . , Lk典) of 具L1, L2, . . . , Lk典 is further described as follows:
FS共具L1, L2, . . . , Lk典兲 ⫽
冘
r⫽1 nFS共具L1, L2, . . . , Lk典r兲/n (11)
Example 5. Following Example 4, if the total number of
customers is 2 (i.e., n⫽ 2), then FS共具A3,2 Product 2 , A3,2 Product 3典) ⫽ 关FS共具A3,2 Product 2 , A3,2 Product 3典) 1⫹ FS共具A3,2 Product 2 , A3,2 Product 3典) 2]/2. The
fuzzy support also indicates the degree of importance of one fuzzy sequence.
If FS具L1, L2, . . . , Lk典 is larger than or equal to the
aforementioned min FS, then具L1, L2, . . . , Lk典 is a frequent
fuzzy k-sequence. From Eqs. (10) and (11), it is clear that FS(具L1, L2, . . . , Lk⫹1典) ⱕ FS(具L1, L2, . . . , Lk典) since FS(具L1, L2, . . . , Lk⫹1典r)ⱕ FS(具L1, L2, . . . , Lk典r) (1ⱕ r ⱕ n) holds.
In addition, any fuzzy (k⫹1)-sequence, say 具L1, L2, . . . , Lk⫹1典, cannot be frequent if fuzzy k-sequence 具L1, L2, . . . , Lk典 is infrequent since FS(具L1, L2, . . . , Lk⫹1典) ⱕ FS(具L1, L2, . . . , Lk典) ⱕ min FS holds. Example 6. 具A2,1 Product 1 , A2,2 Product 2
典 is not frequent if either 具A2,1
Product 1典 or 具A 2,2
Product 2典 is not frequent since FS共具A 2,1 Product 1 , A2,2 Product 2典 r) ⱕ FS共A2,1 Product 1典
r) ⱕ min FS and FS共具A2,1 Product 1 , A2,2 Product 2典 r)ⱕ FS共具A2,2 Product 2典
r)ⱕ min FS hold. In other words,
if具A2,1 Product 1
, A2,2
Product 2典 is a frequent sequence, then 具A 2,1 Product 1典
and具A2,2
Product 2典 are frequent.
As for 具A2,1 x1 , A2,2 x1 , A2,1 x1 ⫻ A 2,2 x1典, it can be generated by
using any two fuzzy sequences in兵具A2,1
x1 , A2,2 x1 典, 具A2,1 x1 , A2,1 x1 ⫻ A2,2 x1 典, 具A2,2 x1 , A2,1 x1 ⫻ A2,2 x1 典}. If 具A2,1 x1 , A2,2 x1 , A2,1 x1 ⫻ A2,2 x1 典 is frequent, then具A2,1
x1 , A2,2 x1典, 具A 2,1 x1 , A2,1 x1 ⫻ A 2,2 x1典, and 具A 2,2 x1 , A2,1 x1 ⫻ A2,2
x1 典 must be also frequent.
As we have mentioned above, a sequential pattern is a frequent sequence but it is not contained in another se-quence. Formally, a frequent z1-sequence, say a, denoted by 具La,1, La,2, . . . , La,z1典 is contained in another frequent
z2-sequence, say b, denoted by 具Lb,1, Lb,2, . . . , Lb,z2典, if z1
ⱕ z2 and there exist integers 1 ⱕ j1 ⬍ j2 ⬍ . . . ⬍ jz1 ⱕ z2 such that La,1債 Lb,j1, La,2債 Lb,j2, . . . , La,z1債 Lb,jz1. Then,
a is not a sequential pattern but b is if it is not contained in
the other frequent sequences. A detailed example is shown as follows.
Example 7. The 2-sequence 具{Banana} , {Apple}典
de-noted by a is contained in 具{Banana} , {Apple, Orange}典 since {Banana}債 {Banana} and {Apple} 債 {Apple, Or-ange} . Because {Banana} 債 {Banana} and {Apple} 債 {Apple,} ,具{Banana} , {Apple}典 is also contained in
具{Ba-nana} , {Apple} , {Orange}典. From the aforementioned definition, we can find that a is not contained in the 1-se-quence 具{Banana, Apple, Orange}典 denoted by b since the latter sequence (i.e., b with length 1) is shorter than the former sequence (i.e., a with length 2).
Similarly, we define that a fuzzy sequential pattern is a frequent fuzzy sequence, but it is not contained in any other frequent fuzzy sequence. That is, not all frequent fuzzy sequences are desirable. For measuring the importance of a fuzzy sequence, in addition to the fuzzy support, the amount or type of information contained in it is the other criterion. Formally, a frequent fuzzy z1-sequence, say a, denoted by 具La,1, La,2, . . . , La,z1典 is contained in another frequent fuzzy
z2-sequence, say b, denoted by具Lb,1, Lb,2, . . . , Lb,z2典, if z1
ⱕ z2 and there exist integers 1 ⱕ j1 ⱕ j2 ⬍ . . . ⬍ jz1 ⱕ z2 such that Lb,j1債 La,1, Lb,j2債 La,2, . . . , Lb,jz1債 La,z1. Then,
a is not a fuzzy sequential pattern but b is if it is not
contained in the other frequent fuzzy sequences. In com-parison with b, it seems that a is not valuable for decision makers.
Example 8. Assume that 具La,1, La,2典 ⫽ 具A2,1 Product 1
,
A2,2
Product 1典 (i.e., z1 ⫽ 2) and 具L
b,1, Lb,2, Lb,3典 ⫽ 具A2,1 Product 1 , A2,2 Product 1 ⫻ A 2,1 Product 2 , A2,1 Product 1 ⫻ A 2,2
Product 2典 (i.e., z2 ⫽ 3) are
frequent fuzzy sequences.具A2,1 Product 1
, A2,2
Product 1典 is not a fuzzy
sequential pattern, since z1ⱕ z2 and there exist j1 ⫽ 1 and
j2⫽ 2 such that Lb,j1債 La,1 (i.e., A2,1
Product 1 債 A 2,1 Product 1 ) and Lb,j2 債 La,2 (i.e., A2,2 Product 1 ⫻ A 2,1 Product 2 債 A 2,2 Product 1 ). That is, 具A2,1 Product 1 , A2,2
Product 1典 is contained in 具A 2,1 Product 1 , A2,2 Product 1 ⫻ A2,1 Product 2 , A2,1 Product 1 ⫻ A 2,2
Product 2典. There is no doubt that the
information contained in the latter sequence (i.e.,具A2,1 Product 1 , A2,2 Product 1 ⫻ A 2,1 Product 2 , A2,1 Product 1 ⫻ A 2,2
Product 2典) is more than that
contained in the former sequence (i.e.,具A2,1 Product 1
, A2,2 Product 1典).
We note that 具A2,1 Product 1 , A2,2 Product 1 ⫻ A 2,1 Product 2 , A2,1 Product 1 ⫻ A2,2
Product 2典 is a fuzzy sequential pattern if it is not contained in
the other frequent fuzzy sequences.
Example 9. In this example, we demonstrate the possible
application of fuzzy sequential pattern. We assume that 具A2,2
Product 2
, A2,1
Product 1典 is a fuzzy sequential pattern. If product 1
is orange juices, and product 2 is apple juices, then a piece of useful information extracted from this pattern demon-strates that small purchase amounts of orange juices are likely to be bought by customers next time after they bought large purchase amounts of apple juices. This information can help decision makers (e.g., retailers) plan marketing strategy. For example, those customers, who have ever bought large purchase amounts of apple juices, may be attracted to buy more orange juice on sale.
4. Implementation of the Proposed Method
Based on the framework illustrated in Section 3, we present the real implementation of the proposed method in detail. As we have mentioned above, the first phase is to find frequent fuzzy sequences, and the second phase is to dis-cover fuzzy sequential patterns by those frequent fuzzy sequences. Phases I and II are described in Sections 4.1 and 4.2, respectively.
4.1 Phase I: Frequent Fuzzy 1-Sequence Mining
Table FGTTFS is used to generate frequent fuzzy grids, and consists of the following substructures:
(a) Fuzzy Grids table (FG): FG is a two-valued matrix. In FG, each row represents a fuzzy grid, while each col-umn represents a linguistic value AK,ixmm.
(b) Transaction table (TT): each column represents tp共r兲,
while each element records the membership degree
which tp共r兲belongs to the corresponding fuzzy grid.
(c) Column FS: stores the fuzzy support corresponding to the fuzzy grid in FG.
An initial tabular FGTTFS is shown in Table 1 as an example. From Table 1, we can see that there are two transaction records, t1共1兲and t2共1兲(i.e.,␣1⫽ 2), corresponding
to customer 1, and two quantitative attributes x1and x2in a
given database relation. Each attribute is partitioned into 2 partitions (i.e., K⫽ 2). We can see that each element of FG is assigned to 0 or 1. Thus, we can apply Boolean operations on FG[u] ⫽ (FG[u,1], FG[u,2], FG[u,3], FG[u,4]) and FG[v]⫽ (FG[v,1], FG[v,2], FG[v,3], FG[v,4]) (i.e., u-th row and v-th row of FG). For example, if we apply the OR operation on two rows, say FG[1]⫽ (1, 0, 0, 0) and FG[3] ⫽ (0, 0, 1, 0), then (FG[1] OR FG[3]) ⫽ (1, 0, 1, 0) corresponding to a candidate 2-dim fuzzy grid A2,1
x1 ⫻ A 2,1
x2
, is generated. Then, FS共A2,1
x1 ⫻ A 2,1 x2 ) ⫽ TT[1] 䡠 TT[3] ⫽ max兵2,1 x1 共t 11 共1兲兲 䡠 2,1 x2 共t 12 共1兲兲, 2,1 x1共t 21 共1兲兲 䡠 2,1 x2共t 22 共1兲兲} is obtained
to compare with the min FS. If A2,1
x1 ⫻ A 2,1
x2
is frequent, then the data (i.e. FG[1] OR FG[3], TT3[1]䡠 TT3[3], and FS(A2,1
x1
⫻ A2,1
x2
)) will be inserted to corresponding data structures (i.e., FG, TT, and FS).
In the Apriori algorithm, two frequent (l⫺ 1)-itemsets are joined to be a candidate l-itemset (3ⱕ l ⱕ d), and these two frequent itemsets share (l ⫺ 2) items Agrawal et al., 1993; Jang & Sun, 1995). Similarly, a candidate l-dim fuzzy grid, say AK,i1
x1 ⫻ A K,i2 x2 ⫻ . . . ⫻ A K,il⫺1 xl⫺1 ⫻ A K,il xl , is also derived TABLE 1. An initial table FGTTFS for an example.
Fuzzy grid FG TT FS A2,1x1 A2,2x1 A2,1x2 A2,2x2 t1(1) t2(1) A2,1x1 1 0 0 0 2,1x1(t11 (1)) 2,1 x1(t 21 (1)) FS(A 2,1 x1) A2,2x1 0 1 0 0 2,2x1(t11 (1)) 2,2 x1(t 21 (1)) FS(A 2,2 x1) A2,1x2 0 0 1 0 2,1x2(t12 (1)) 2,1 x2(t 22 (1)) FS(A 2,1 x2) A2,2x2 0 0 0 1 2,2x2(t12 (1)) 2,2 x2(t 22 (1)) FS(A 2,2 x2)
by joining two frequent (l–1)-dim fuzzy grids (e.g., AK,i1 x1 ⫻ AK,i2 x2 ⫻ . . . ⫻ A K,il⫺2 xl⫺2 ⫻ A K,il xl and AK,i1 x1 ⫻ A K,i2 x2 ⫻ . . . ⫻ A K,il⫺2 xl⫺2 ⫻ AK,il⫺1
xl⫺1 ), and these two frequent grids share a frequent (l
⫺ 2)-dim fuzzy grid (i.e., AK,i1
x1
⫻ AK,i2
x2
⫻ . . . ⫻ AK,il⫺2
xl⫺2 ). For
example, we can use two frequent fuzzy grids A3,2
x1 ⫻ A 3,1 x2 and A3,2 x1 ⫻ A 3,3 x3
to generate the candidate 3-dim fuzzy grid
A3,2 x1 ⫻ A3,1 x2 ⫻ A3,3 x3 because A3,2 x1 ⫻ A3,1 x2 and A3,2 x1 ⫻ A3,3 x3 share the same 1-dim fuzzy grid A3,2
x1 . However, A3,2 x1 ⫻ A 3,1 x2 ⫻ A 3,3 x3
can also be generated by joining A3,2 x1 ⫻ A3,1 x2 with A3,1 x2 ⫻ A3,3 x3 since A3,2 x1 ⫻ A3,1 x2 ⫻ A3,3 x3 is a subset of A3,1 x2 ⫻ A 3,3 x3 , and A3,2 x1 ⫻ A 3,1 x2 and A3,1 x2 ⫻ A 3,3 x3 share A3,1 x2
. This means that we must select one of many possible combinations to avoid redundant computations. To resolve this problem, we consider that if there exist l inte-gers number e1, e2, . . . , el⫺1, elwhere 1ⱕ e1⬍ e2⬍ . . . ⬍ el⫺1⬍ elⱕ d, such that FG[u, e1]⫽ FG[u, e2]⫽ . . . ⫽ FG[u, el⫺2]⫽ FG[u, el⫺1]⫽ 1 and FG[v, e1]⫽ FG[v, e2]
⫽ . . . ⫽ FG[v, el⫺2]⫽ FG[v, el]⫽ 1, where FG[u] and
FG[v] correspond to individual frequent (l⫺ 1)-dim fuzzy grids, then FG[u] and FG[v] can be merged to generate a candidate l-dim fuzzy grid. It should be noted that any two 1-dim fuzzy grids defined in the same attribute cannot be simultaneously contained in a candidate l-dim fuzzy grid (l ⱖ 2). Thus (1, 1, 0, 0) or (0, 0, 1, 1) are invalid. We describe the detailed procedure of phase I as follows.
Algorithm: The proposed method for discovering fuzzy
sequential patterns (phase I)
Input: a. A specified database;
b. Minimum fuzzy support.
Output: Frequent fuzzy 1-sequences (i.e., frequent fuzzy
grids)
Method:
Step 1. Perform the simple fuzzy partition method Step 2. Scan the database and then construct the initial
FGTTFS
Step 3. Generate frequent fuzzy grids 3-1. Generate frequent 1-dim fuzzy grids
Set l⫽ 1 and eliminate the rows of initial FGTTFS corre-sponding to candidate 1-dim fuzzy grids that are not fre-quent.
3-2. Generate frequent l-dim fuzzy grids
Set l⫹ 1 to l. If there is only one frequent (l ⫺ 1)-dim fuzzy grid, then go to phase II.
For two unpaired rows, FGTTFS[u] and FGTTFS[v] (u⫽
v), corresponding to frequent (l⫺ 1)-dim fuzzy grids do
Compute (FG[u] OR FG[v]) corresponding to a candidate
l-dim fuzzy grid c.
3-2-1. Examine the validity of c
If any two 1-dim fuzzy grid defined in the same attribute, then discard c and skip Steps 3-2-2, 3-2-3 and 3-2-4. That is,
c is invalid.
3-2-2. If any two 1-dim fuzzy grids defined in the same attribute for c, then discard c and skip Steps 3-2-3 and 3-2-4.
3-2-3. Examine whether or not FG[u] and FG[v] share (l⫺ 2) 1’s
If there exist integers 1ⱕ e1⬍ e2⬍ . . . ⬍ el⫺1⬍ elⱕ d
such that FG[u, e1]⫽ FG[u, e2]⫽ . . . ⫽ FG[u, el⫺2] ⫽
FG[u, el⫺1]⫽ 1 and FG[v, e1]⫽ FG[v, e2]⫽ . . . ⫽ FG[v, el⫺2]⫽ FG[v,el]⫽ 1, then compute (TT[e1] ( TT[e2]䡠 . . . 䡠
TT[el]) and fuzzy support denoted by fs of c.
3-2-4. Examine the fuzzy support of the newly gener-ated candidate fuzzy grid Insert (FG[u] OR FG[v]) to FG, (TT[e1] ( TT[e2]䡠 . . . 䡠 TT[el])
to TT and fs to FS when fs is larger than or equal to min FS; otherwise, discard c.
End
3-3. Check whether any frequent l-dim fuzzy grid is generated or not
If any frequent l-dim fuzzy grid is generated, then go to Step 3-2; otherwise go to phase II. It is noted that the final FGTTFS stores only frequent fuzzy grids.
4.2 Phase II: Fuzzy Sequential Pattern Mining
Table FSEFS is used to generate fuzzy sequences and consists of two substructures including the fuzzy sequences table (FSE) and the column FS. FSE is an integer matrix and each row represents a fuzzy sequence, while each column represents a frequent fuzzy grid. FSE can allow us to easily determine which fuzzy sequence is generated and which frequent fuzzy grids are contained in this sequence.
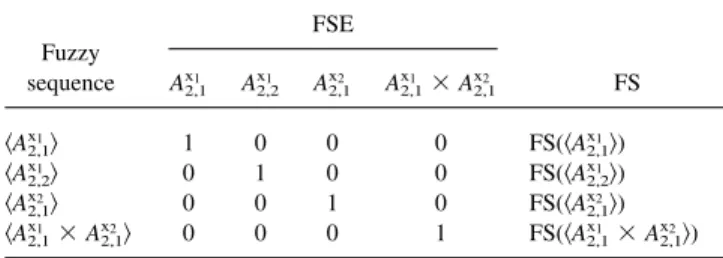
We assume that the initial FSEFS is generated as Table 2, where we can see that four frequent fuzzy 1-sequences are generated. By using the asymmetric aggregation opera-tor 䊝 for FSE[u] and FSE[v] (i.e., FSE[u] 䊝 FSE[v] or FSE[v] 䊝 FSE[u]), we can obtain a candidate fuzzy se-quence. FSE[u]䊝 FSE[v] is computed as follows: FSE[u, j]Q FSE[v, j]
⫽
冦
FSE[u, j]⫹ 1, if 0 ⱕFSE[v, j] ⱕ FSE[u, j], FSE[u, j]⫽ 0
1, if FSE[u, j]⬍ FSE[v, j] 0, if 0⫽ FSE[u, j] ⫽ FSE[v, j]
冧
(12)
Example 10. (2, 1, 0, 0) corresponding to a candidate
fuzzy 2-sequence 具A2,1
x1
, A2,2
x1典 is generated by FSE[1] 䊝
FSE[2] (i.e. (1, 0, 0, 0) 䊝 (0, 1, 0, 0)) in Table 2, since TABLE 2. Table FSEFS for an example.
Fuzzy sequence FSE FS A2,1x1 A2,2x1 Ax2,12 A2,1x1 ⫻ A2,1x2 具A2,1x1典 1 0 0 0 FS(具A2,1x1典) 具A2,2x1典 0 1 0 0 FS(具A2,2x1典) 具A2,1x2典 0 0 1 0 FS(具A2,1x2典) 具A2,1x1 ⫻ A2,1x2典 0 0 0 1 FS(具A2,1x1 ⫻ A2,1x2典)
FSE[2, 1]ⱕ FSE[1, 1], FSE[1, 2] ⬍ FSE[2, 2], FSE[1, 3] ⫽ FSE[2, 3] ⫽ FSE[1, 4] ⫽ FSE[2, 4] ⫽ 0. The frequent fuzzy grid corresponding to the largest number (i.e., 2) in FSE[1]䊝 FSE[2] is the first item (i.e. first occurrence) of this sequence, the frequent fuzzy grid corresponding to the next-to-the-largest number (i.e., 1) is the second item (i.e., second occurrence) of this sequence, and so on. If 具A2,1
x1
,
A2,2
x1典 is frequent, then corresponding data (i.e., FSE[1] 䊝
FSE[2] and FS共具A2,1
x1
, A2,2
x1典) will be inserted to
correspond-ing data structures (i.e., FSE and FS).
A candidate fuzzy k-sequence (kⱖ 3) can be derived by joining two frequent fuzzy (k⫺ 1)-sequences, and these two sequences share a frequent fuzzy (k ⫺ 2)-sequence. For example, we can use two frequent fuzzy sequences, say 具A2,1 x1 , A2,2 x1典 and 具A 2,1 x1 , A2,1 x1 ⫻ A 2,1 x2典, to generate a candidate
fuzzy 3-sequence具A2,1
x1 , A2,2 x1 , A2,1 x1 ⫻ A 2,1 x2典 because 具A 2,1 x1 , A2,2 x1典 and 具A2,1 x1 , A2,1 x1 ⫻ A 2,1
x2 典 share the same fuzzy 1-sequence
具A2,1
x1典. Actually, another candidate fuzzy 3-sequence 具A 2,1 x1 , A2,1 x1 ⫻ A 2,1 x2 , A2,2 x1典 can be generated. However,具A2,1 x1 , A2,2 x1 , A2,1 x1 ⫻ A 2,1
x2典 can also be generated
by combining具A2,1 x1 , A2,2 x1典 with 具A 2,2 x1 , A2,1 x1 ⫻ A 2,1 x2典 since 具A 2,1 x1 , A2,2 x1典 and 具A 2,2 x1 , A2,1 x1 ⫻ A 2,1 x2典 share 具A 2,2 x1 典. To resolve this
problem, we consider that that if there exist (k⫺ 2) (k ⱖ 3) integers numbers e1, e2, . . . , ek⫺3, ek⫺2 where 1 ⱕ e1, e2, . . . , ek⫺2ⱕ , such that FSE[u, e1]⫽ FSE[v, e1]⫽ 2,
FSE[u, e2]⫽ FSE[v, e2]⫽ 3, . . . , FSE[u, ek⫺3]⫽ FSE[v, ek⫺3]⫽ k ⫺ 2 and FSE[u, ek⫺2]⫽ FSE[v, ek⫺2]⫽ k ⫺ 1,
where FSE[u] and FSE[v] correspond to individual frequent fuzzy (k ⫺ 1)-sequences, then we can employ (FSE[u] 䊝 FSE[v]) and (FSE[v]䊝 FSE[u]) to generate various candi-date fuzzy k-sequences.
Example 11. FSE[u]䊝 FSE[v] ⫽ (1, 0, 0, 2) (i.e., 具A2,1
x1 ⫻ A2,1 x2 , A2,1 x1典) 䊝 (0, 1, 0, 2) (i.e., 具A 2,1 x1 ⫻ A 2,1 x2 , A2,2 x1典) ⫽ (2, 1, 0, 3) (i.e.,具A2,1 x1 ⫻ A 2,1 x2 , A2,1 x1 , A2,2
x1典) can be obtained since
there exist (3⫺ 2) (i.e., k ⫽ 3) integers numbers e1⫽ 3 such
that FG[u, 4] ⫽ FG[v, 4] ⫽ 2. As we mentioned above, FSE[v]䊝 FSE[u] ⫽ (0, 1, 0, 2) 䊝 (1, 0, 0, 2) ⫽ (1, 2, 0, 3) (i.e., 具A2,1 x1 ⫻ A 2,1 x2 , A2,2 x1 , A2,1
x1典) can be also obtained.
However, for FSE[u] ⫽ (2, 1, 0, 0) (i.e., 具A2,1
x1
, A2,2
x1 典) and
FSE[v]⫽ (0 , 2, 0, 1) (i.e., 具A2,2
x1
, A2,1
x1 ⫻ A 2,1
x2 典), (2, 1, 0, 0)
䊝 (0 , 2, 0, 1) is invalid since FSE[u, j] ⫽ FSE[v, j] (j ⫽ 1, 2, 3, 4).
Additionally, we can observe that if a candidate fuzzy
k-sequence is generated by FSE[u]䊝 FSE[v], then FSE[u]
䊝 FSE[v] must contain k positive and consecutive positive integer numbers (i.e., 1, 2, . . . , k⫺ 1, k). For example, (1, 2, 3, 0) contain 3 various integer numbers (i.e., 1, 2, 3). We describe the detailed procedure of phase II as follows.
Algorithm: The proposed method for discovering fuzzy
sequential patterns (phase II)
Input: a. Frequent fuzzy 1-sequences (initial FSEFS)
b. Minimum fuzzy support.
Output: Fuzzy sequential patterns Method:
Step 0. Initialization
Set 1 to k.
Step 1. Generate frequent fuzzy k-sequences (2 < k
<)
Set k ⫹ 1 to k. If there is only one frequent fuzzy (k ⫺ 1)-sequence, then go to Step 2. For two unpaired rows,
FSEFS[u] and FSEFS[v] (u &neq; v), corresponding to frequent fuzzy (k⫺ 1)- sequences do
1-1. Examine the validity of FSE[u] ( FSE[v] If there exist (k⫺ 2) integers numbers e1, e2, . . . , ek⫺3, ek⫺2
where 1 ⱕ e1, e2, . . . , ek⫺2ⱕ , such that FSE[u,
e1]⫽ FSE[v, e1]⫽ 2, FSE[u, e2]⫽ FSE[v, e2] ⫽
3, . . . , FSE[u, ek⫺3]⫽ FSE[v, ek⫺3]⫽ k ⫺ 2 and
FSE[u, ek⫺2]⫽ FSE[v, ek⫺2]⫽ k ⫺ 1, then compute
FSE[u]䊝 FSE[v] and FSE[v] 䊝 FSE[u] to generate candidate fuzzy k-sequences s⬘ and s⬙, respectively 1-2. Examine the fuzzy support of the newly generated
fuzzy sequences
Insert FSE[u] 䊝 FSE[v] or FSE[v] 䊝 FSE[u] to FSE, and FS(s⬘) or FS(s⬙) to FS when FS(s⬘) or FS(s⬙) is larger than or equal to min FS.
End
Step 2. Check whether or not any frequent fuzzy k-sequence is generated
If any frequent fuzzy k-sequence is generated, then repeat by going to Step 1, else go to Step 3.
Step 3. Find fuzzy sequential patterns
For any two rows of FSEFS, say FSE[u] and FSE[u], if the fuzzy sequence corresponding to FSE[u] is contained in the fuzzy sequence corresponding to FSE[v] by using the method introduced in Subsection 3.3, then eliminate FSE[u]. It is noted that the final FSEFS stores only fuzzy sequential patterns.
The analysis of the computational complexity is some-what difficult. We roughly analyze the proposed method in the worst case (i.e., minimum fuzzy support⫽ 0) since an appropriate minimum fuzzy support is determined by deci-sion makers. As we have mentioned above, the smaller minimum fuzzy support is specified by users, the larger number of frequent fuzzy 1-sequences will be generated. It is thus clear that the more frequent fuzzy 1-sequences are generated, the more computational steps will be used in phase I. For example, in Figure 4, there are 15 possible frequent fuzzy grids (i.e., 6 1-dim grids and 9 2-dim grids) in the worst case. It is also clear that 15 is larger than 31 ⫹ 32. In a similar manner, if each of the d quantitative attributes is partitioned into K linguistic values, then the total number of frequent fuzzy grids would be larger than K1 ⫹ K2⫹ . . . ⫹ Kd
in the worse case. That is, it is possible that the number of processing computational steps in phase I will increase exponentially for databases with high degree. If let be equal to K1⫹ K2⫹ . . . ⫹ Kd, then C2iterations
of the for-loop in Step 1 of phase II would be performed. In the following section, two numerical examples are utilized to demonstrate the usefulness of the proposed method.
5. Numerical Examples
The main purpose of this section is to show the useful-ness of the proposed method. Two possible applications relating to analyze purchase behaviors are demonstrated as follows: one to analyze general purchase behaviors, and the other to analyze purchase behaviors of one group.
A. Analysis of General Purchase Behaviors
In a supermarket or a mart, a table named BOUGHT with 10 transactions is extracted from transaction databases as shown in Table 3, where the asterisk denotes that one product was not purchased in that transaction. We can see that␣1⫽ 2,␣2⫽ 3,␣3⫽ 1,␣4⫽ 3,␣5⫽ 1.
There are nine quantitative attributes, and each quantita-tive attribute ranging from zero to twenty is partitioned into three linguistic values (i.e., K ⫽ 3), which are similar to partitions depicted in Figure 2, by the simple fuzzy partition method. Therefore, fuzzy subsets defined in individual par-titions can be linguistically interpreted, such as for the product m (m ⫽ 1 . . . 9): A3,1 Product m : small A3,2 Product m : medium A3,3 Product m : large
Then, we employ the proposed method to find fuzzy se-quential patterns from BOUGHT by specifying min FS to be 0.20. The detailed computation process is omitted for simplicity. At the end of phase II, 10 fuzzy sequential patterns with individual fuzzy supports can be discovered (i.e.,具A3,2
Product 5典 with 0.20, 具A 3,1
Product 9典 with 0.20, 具A 3,2 Product 2 ⫻ A3,2
Product 3典 with 0.29, 具A 3,1 Product 3⫻ A 3,2 Product 9典 with 0.20, A 3,2 Product 3 ⫻ A3,2
Product 7典 with 0.30, 具A
3,2 Product 2 , A3,2 Product 3典 with 0.21, 具A3,2 Product 3 , A3,1
Product 3典 with 0.22, 具A 3,2 Product 7 , A3,1 Product 3典 with 0.20, 具A3,2 Product 7 , A3,2
Product 9典 with 0.20, and 具A 3,3 Product 7
, A3,2
Product 9典 with
0.21). It is suggested that decision makers should pay more attention on those patterns with larger fuzzy support.
The aforementioned patterns can help decision makers plan marketing strategies. For example, 具A3,2
Product 3 , A3,1 Product 3典 and 具A3,2 Product 7 , A3,1
Product 3典 demonstrate that small purchase
amounts of product 3 are likely to be bought by customers next time after they bought medium purchase amounts of product 3 or medium purchase amounts of product 7. Those customers, which can be found from databases by a query language such as SQL, may be attracted to buy more prod-uct 3 on sale. Decision makers should further analyze the possible reasons why small purchase amounts of product 3 are likely to be bought.
Another interesting patterns are 具A3,2 Product 2 , A3,2 Product 3典 and 具A3,2 Product 3 , A3,1
Product 3典. That is, we find that 具A 3,2 Product 2 , A3,2 Product 3 , A3,1
Product 3典 is not generated. Those customers who bought
medium purchase amounts of product 2 may feel that me-dium purchase amounts of product 3 can sufficiently satisfy their requirement. Maybe, they can be also attracted to buy more product 3 on sale. It is possible that A3,3
Product 3
will be generated in the next pattern mining by performing an appropriate marketing strategy.
B. Analysis of Purchase Behaviors of One Group
It is possible that one group is very significant for a business. The analysis of purchase behaviors of one group is thus meaningful. If we treat Table 3 as transaction records of one group, say a group of high salary (GHS), then a new table sorted by transaction time for GHS is generated as shown in Table 4. It is also reasonable that we view GHS as customer 1 such that ␣1⫽ 10. Each quantitative attribute
ranging from zero to twenty is still partitioned into three linguistic values. Then, we employ the proposed method to find fuzzy sequential patterns from BOUGHT by specifying min FS to be 0.90.
At the end of phase II, 4 fuzzy sequential patterns with individual fuzzy supports can be found (i.e., 具A3,2
Product 2 ⫻ A3,2
Product 3
, A3,2
Product 5典 with 0.90, 具A 3,2 Product 2 ⫻ A 3,2 Product 3 , A3,3 Product 7典 with 0.90,具A3,2 Product 2 , A3,3 Product 7 , A3,2 Product 5⫻ A 3,2 Product 7典 with 0.90, and 具A3,2 Product 2 , A3,3 Product 7 , A3,2 Product 5 , A3,1
Product 3典 with 0.90).
Deci-sion-makers should make use of these patterns to plan appropriate marketing strategies for GHS. The possible analysis of fuzzy sequential patterns is omitted here. TABLE 3. Table BOUGHT sorted by transaction time for each customer.
Record
Transaction
time Product 1 Product 2 Product 3 Product 4 Product 5 Product 6 Product 7 Product 8 Product 9
t1(1) 04/10/02 * * 5 * * * * * * t2(1) 05/11/02 * * * * * * * * 8 t1(2) 04/12/02 6 10 9 * * * * * * t2(2) 04/25/02 * * 8 * * * 14 * * t3(2) 06/01/02 * * 1 9 * 12 6 * 6 t1(3) 05/02/02 * 8 7 * 10 * 9 * * t1(4) 04/05/02 * * 15 * * * 12 * * t2(4) 04/29/02 * 6 * 10 * * 10 * * t3(4) 06/02/02 * * 4 * * * * * 12 t1(5) 05/20/02 * * * * * * * * 5
6. Discussions and Conclusions
As we have mentioned above, the main aim of this paper is to propose a fuzzy data mining technique to discover fuzzy sequential patterns by using the simple partition method. The first phase is to find purchase behaviors that frequently occurred for a period of time (i.e., frequent fuzzy grids), and the second phase is to discover fuzzy sequential patterns by analyzing the temporal relation among those purchase behaviors found in the first phase. Two numerical examples can demonstrate the usefulness and possible ap-plications of the proposed method. Several improvements or suggestions of the proposed method are discussed as fol-lows. Some issues are left for future works.
The rough analysis of the computational complexity in the worst case is described in Section 4. Since it is possible that the number of processing computational steps in phase I will increase exponentially for databases with high degree, the computational time and the storage requirement will be enlarged. The usefulness of the proposed method for data-bases with high degree is more or less deteriorated. There-fore, it is possible to remove the unimportant attributes to reduce the dimensions. In reducing the feature space dimen-sions, several feature selection methods can be used such as the principal component analysis (Sharma, 1996), which is a useful multivariate analysis technique. Additionally, var-ious linguistic interpretations of a fuzzy set can be obtained by linguistic hedges (Zimmermann, 1991, 1996; Ishibuchi & Nii, 2001; Pedrycz & Gomide, 1998) for AK,im
xm
such as “very AK,im
xm
” denoted by 共AK,im
xm
兲⬘ or “more or less AK,im
xm
” denoted by 共AK,im
xm 兲⬙ as follows: 共AK,im xm 兲⬘ ⫽ very A K,im xm ⫽ 共A K,im xm 兲2 (13) 共AK,im xm 兲⬙ ⫽ more or less A K,im xm ⫽ 共A K,im xm 兲1/2 (14) The membership functions of 共AK,im
xm 兲⬘ and 共A K,im xm 兲⬙ can be stated as 关K,im xm (x)]2 and 关K,im xm (x)]1/2, respectively. There-fore, there are three different linguistic terms defined in each partition, such as AK,im
xm
, “very AK,im
xm
” and “more or less AK,im
xm
.” Therefore, there are 3K different linguistic values defined in
xm. It is possible that the proposed method uses these
linguistic values simultaneously to discover fuzzy
sequen-tial patterns. We believe that such extensions will make fuzzy sequential patterns to be more versatile and more useful for users.
As we have mentioned in Section 2, the decision makers can subjectively determine the number, locations and shapes of fuzzy sets in each quantitative attribute depending on their preferences, past experiences, or prior knowledge. The advantage is that the fuzzy sequential patterns are more comprehensible for the decision-makers. That is, it is not necessary to provide methods to find general or optimal parameter specifications (i.e., number, locations, and shapes) of membership functions in each quantitative at-tribute.
Acknowledgements
We are very grateful to the anonymous referees for their valuable comments and constructive suggestions.
References
Agrawal, R., Imielinski, T., & Swami, A. (1993). Mining association rules between sets of items in frequent databases. In Proceedings of the ACM SIGMOD International Conference on Management of Data, 1993, (pp. 207-216). Washington D.C.
Agrawal, R., Mannila, H., Srikant, R., Toivonen, H., & Verkamo, A.I. (1996). Fast discovery of association rules. In U.M. Fayyad, G. Pia-tetsky-Shapiro, P. Smyth, & R. Uthurusamy (Eds.). Advances in knowl-edge discovery and data mining, Menlo Park: AAAI Press, 1996, pp. 307–328.
Agrawal, R., & Srikant, R. (1995). Mining sequential patterns. In Proceed-ings of the Eleventh International Conference on Data Engineering, 1995, (pp. 3–14). Taipei, Taiwan.
Berry, M., & Linoff, G. (1997). Data mining techniques: for marketing, sales, and customer support. New York: John Wiley & Sons. Bezdek J.C. (1981). Pattern recognition with fuzzy objective function
algorithms, New York: Plenum.
Chen, S.M., & Jong, W.T. (1997). Fuzzy query translation for relational database systems. IEEE Transactions on Systems, Man, and Cybernet-ics, 27(4), 714 –721.
Han J.W., & Kamber M. (2001). Data mining: concepts and techniques. San Francisco: Morgan Kaufmann.
Homaifar, A., & McCormick, E. (1995). Simultaneous design of member-ship functions and rule sets for fuzzy controllers using genetic algo-rithms. IEEE Transactions on Fuzzy Systems, 3(2), 129 –139. TABLE 4. Table BOUGHT sorted by transaction time for one group.
Transaction time Product 1 Product 2 Product 3 Product 4 Product 5 Product 6 Product 7 Product 8 Product 9
04/05/02 * * 15 * * * 12 * * 04/10/02 * * 5 * * * * * * 04/12/02 6 10 9 * * * * * * 04/25/02 * * 8 * * * 14 * * 04/29/02 * 6 * 10 * * 10 * * 05/02/02 * 8 7 * 10 * 9 * * 05/11/02 * * * * * * * * 8 05/20/02 * * * * * * * * 5 06/01/02 * * 1 9 * 12 6 * 6 06/02/02 * * 4 * * * * * 12
Hong T.P., Wang T.T., Wang, S.L., & Chien, B.C. (2000). Learning a coverage set of maximally general fuzzy rules by rough sets. Expert Systems with Applications, 19(2), 97–103.
Hu, Y.C., Chen, R.S., & Tzeng, G.H. Generating learning sequences for decision makers through data mining and competence set expansion. IEEE Transactions on Systems, Man, and Cybernetics, Part B, 32(5), 679 – 686.
Hu Y.C., Tzeng G.H., & Chen R. S. (2002). Mining fuzzy association rules for classification problems. Computers and Industrial Engineering, 43(4), 735–750.
Ishibuchi, H., Nakashima, T., Murata, T. (1999). Performance evaluation of fuzzy classifier systems for multidimensional pattern classification problems. IEEE Transactions on Systems, Man, and Cybernetics, 29(5), 601– 618.
Ishibuchi, H., Nakashima T., & Murata, T. (2001). Three-objective genet-ics-based machine learning for linguistic rule extraction. Information Sciences, 136, 109 –133.
Ishibuchi, H., Nozaki K., Yamamoto N., & Tanaka H. (1995). Selecting fuzzy if-then rules for classification problems using genetic algorithms. IEEE Transactions on Fuzzy Systems, 3(3), 260 –270.
Ishibuchi H., & Nii, M. (2001). Numerical analysis of the learning of fuzzified neural networks from fuzzy if-then rules. Fuzzy Sets and Systems 120, 281–307.
Ishibuchi, H., Yamamoto, T., & Nakashima, T. (2001). Fuzzy data mining: effect of fuzzy discretization. In Proceedings of the 1st IEEE International Conference on Data Mining, San Jose, CA, 2001, pp.241–248.
Jang, J.S.R. (1993). ANFIS: adaptive-network-based fuzzy inference systems. IEEE Transactions on Systems, Man, and Cybernetics, 23(3), 665– 685.
Jang, J.S.R., & Sun, C.T. (1995). Neuro-fuzzy modeling and control. Proceedings of the IEEE, 83(3), 378 – 406.
Myra, S. (2000). Web usage mining for web site evaluation. Communica-tions of the ACM, 43(8), 127–134.
Pedrycz, W. (1994). Why triangular membership functions? Fuzzy Sets and Systems 64, 21–30.
Pedrycz, W., & Gomide, F. (1998). An Introduction to Fuzzy Sets: Anal-ysis and Design, Cambridge: MIT Press.
Ravi, V., Zimmermann, H. -J. (2000). Fuzzy rule based classification with
FeatureSelector and modified threshold accepting. European Journal of
Operational Research, 123(1), 16 –28.
Saaty, T.L. (1980). The analytic hierarchy process: planning, priority setting, resource allocation. New York: McGraw-Hill.
Sharma, S. (1996). Applied multivariate techniques. Singapore: John Wiley & Sons.
Sun, C.T. (1994). Rule-base structure identification in an adaptive-net-work-based fuzzy inference system. IEEE Transactions on Fuzzy Sys-tems, 2(1), 64 –73.
Zadeh, L.A. (1965). Fuzzy sets. Information Control, 8(3), 338 –353. Zadeh, L.A. (1975, 1976) The concept of a linguistic variable and its
application to approximate reasoning, Information Science, 8(3), 199 – 249(part 1); 8(4) 301–357(part 2); 9(1), 43– 80(part 3).
Zimmermann, H.-J. (1991). Fuzzy sets, decision making, and expert sys-tems. Boston: Kluwer.
Zimmermann, H.-J. (1996). Fuzzy set theory and its applications. Boston: Kluwer.
Wang, L.X., & Mendel, J.M. (1992). Generating fuzzy rules by learning from examples. IEEE Transactions on Systems, Man, and Cybernetics, 22(6), 1414 –1427.