國立臺灣大學電機資訊學院資訊工程學研究所 碩士論文
Department of Computer Science and Information Engineering College of Electrical Engineering and Computer Science
National Taiwan University Master Thesis
跨語言與可解釋語義表徵之學習 Learning Crosslingual and Explainable
Sense-Level Word Representations
季大中 Ta-Chung Chi
指導教授:陳縕儂博士 Advisor: Yun-Nung Chen, Ph.D.
中華民國 108 年 1 月 January, 2019
Acknowledgements
In the two-year master program, I gain knowledge and cultivate my re- search skills significantly, which will not come true without help from the people around me. First and foremost, I would like to thank my advisor, pro- fessor Yun-Nung Chen, for her invaluable advice and suggestions regarding my research plans and future career. I really appreciate her help. Secondly, I would like to thank all the members in lab 524 for discussions when I encoun- tered research difficulties. Moreover, I would like to thank my roommates for always supplying me with food and snack, which is inspirational. Last but not least, I would like to thank my girlfriend and my parents for their uncondi- tional love and support.
摘要
本篇論文主要目的在於解決詞義表徵的問題,因為詞義才是最精確 的意思單位。解決的問題主要有二,第一是學習在向量空間中有良好 對齊的詞義表徵,因為這樣可以作為下游工作譬如無監督機器翻譯很 好的初始化。第二是提供詞義表徵的解釋,可以讓我們更知道複雜的 表徵向量代表的意思。
本篇論文的第一部分提出模組化的詞義選擇以及表徵學習模型,並 且可以同時學習在向量空間中有良好對齊性質的雙語詞義表徵。模型 利用了句子層級平行的語料庫以捕捉語言對的特性。模型在 SCWS 上 以及 BCWS 上皆得到很好的效果,而 BCWS 是本篇論文提出的第一個 高品質測試資料用於衡量跨語言的詞義表徵質量。
本篇論文的第二部分嘗試解決詞義表徵的可解釋問題,包括維度上 以及產生的文字解釋。給定前後文以及預訓練的詞義表徵,模型先將 其投射到高維度的向量空間並選出最適合前後文的維度,使得目標字 的意思可以被最近鄰表示。最後,模型使用遞迴神經網路產生人類可 讀的文字解釋以增進可解釋性。同時提出一個高品質的資料集用於訓 練多義字表徵以及銷歧義問題。實驗結果顯示模型在 BLEU 分數以及 人類評分上都有良好的表現。
在未來工作方面,可以嘗試使用隱含前後文句義的向量來表示句 子,以得到更好的詞義選擇能力以及詞義表徵,也可以比較其與本篇 論文提出之詞義表徵之差異。除此之外,嘗試解釋模型根據前文的某 些字才做出當前字的字義選擇是另一種可解釋性的方向。
關鍵字:跨語言, 語義表徵, 強化學習, 消歧義字, 可解釋性
Abstract
The main purpose of this thesis is to solve problems related to sense rep- resentations, for they being the basic and fine-grained semantic unit. Firstly, we try to align a set of cross-lingual sense representations in the vector space, which may serve as a good initialization point for downstream tasks such as unsupervised machine translation. Secondly, we aim to provide interpretabil- ity for sense representations based on their contexts such that we can explain the inherently dense and complicated embeddings.
The first part of this thesis proposes a modularized sense induction and representation learning model that jointly learns bilingual sense embeddings that align well in the vector space, where the cross-lingual signal in the English- Chinese parallel corpus is exploited to capture the collocation and distributed characteristics in the language pair. The model is evaluated on the Stanford Contextual Word Similarity (SCWS) dataset to ensure the quality of monolin- gual sense embeddings. In addition, we introduce Bilingual Contextual Word Similarity (BCWS), a large and high-quality dataset for evaluating cross- lingual sense embeddings, which is the first attempt of measuring whether the learned embeddings are indeed aligned well in the vector space. The pro- posed approach shows the superior quality of sense embeddings evaluated in both monolingual and bilingual spaces.1
The second part of this thesis focuses on interpreting the sense representa- tions for various aspects, including sense separation in the vector dimensions and definition generation. Specifically, given a context together with a tar-
1The code and dataset are available at http://github.com/MiuLab/CLUSE.
get word, our algorithm first projects the target word embedding to a high- dimensional sparse vector and picks the specific dimensions that can best ex- plain the semantic meaning of the target word by the encoded contextual infor- mation, where the sense of the target word can be indirectly inferred. Finally, our algorithm applies an RNN to generate the textual definition of the target word in the human readable form, which enables direct interpretation of the corresponding word embedding. We also introduces a large and high-quality context-definition dataset that consists of sense definitions together with mul- tiple example sentences per polysemous word, which is a valuable resource for definition modeling [1] and word sense disambiguation. The conducted experiments show the superior performance in BLEU score and the human evaluation test.
As for future work, contextualized representations can be used to encode sentence information for better sense induction and representations. More- over, the difference between them and our proposed sense representations is also worth exploring. Finally, endow the model capacity to explain on which words it focuses such that it decide to induce the sense for current word is another potential research direction.
Keywords: cross-lingual, word embedding, reinforcement learning, word sense disambiguation, interpretability
Contents
Acknowledgements iii
摘要 v
Abstract vii
1 Introduction 1
1.1 Motivation . . . 1
1.2 Problem Description . . . 2
1.3 Main Contributions . . . 3
1.4 Thesis Structure . . . 3
2 Related Work 5 2.1 Cross-Lingual Sense Representations . . . 5
2.2 Explainable Sense Representations . . . 7
3 Background 9 3.1 Word Representation Learning . . . 9
3.2 Reinforcement Learning . . . 10
3.2.1 Markov Decision Process (MDP) . . . 10
3.2.2 Value-Based Reinforcement Learning . . . 10
3.2.3 Exploration and Exploitation . . . 10
3.3 Recurrent Neural Models . . . 10
3.3.1 Recurrent Neural Network (RNN) . . . 10
3.3.2 Gated Recurrent Unit (GRU) . . . 11
3.4 Optimization . . . 12
3.4.1 Sparsity Loss . . . 12
3.4.2 Cross Entropy . . . 12
3.4.3 Teacher Forcing . . . 13
4 Datasets 15 4.1 BCWS - Bilingual Contextual Word Similarity . . . 15
4.1.1 Dataset Construction . . . 17
4.1.2 Data Analysis . . . 19
4.2 Oxford . . . 20
5 Cross-Lingual Sense Representations 23 5.1 Notations . . . 23
5.2 Bilingual Sense Induction Module . . . 24
5.3 Monolingual Sense Induction Module . . . 25
5.4 Monolingual Sense Representation Learning Module . . . 26
5.5 Bilingual Sense Representation Learning Module . . . 26
5.6 Optimization . . . 27
5.7 Experiments . . . 28
5.7.1 Experimental Setup . . . 28
5.7.2 Hyperparameters . . . 29
5.7.3 Evaluation Metrics . . . 30
5.7.4 Baselines . . . 30
5.7.5 Bilingual Embedding Evaluation . . . 31
5.7.6 Monolingual Embedding Evaluation . . . 31
5.7.7 Sensitivity of Bilingual Contexts . . . 32
5.7.8 Downstream Evaluation . . . 32
5.7.9 Qualitative Analysis . . . 33
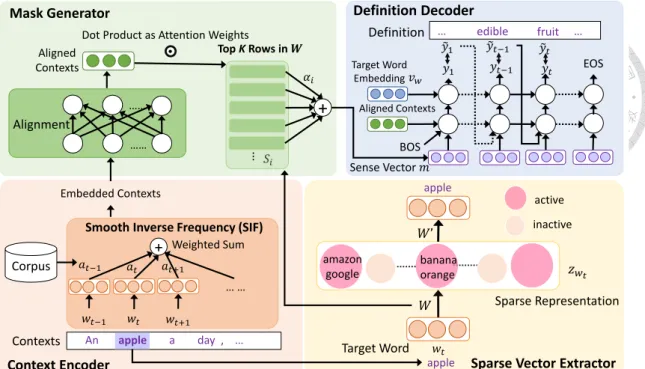
6 Explainable Sense Representations 35
6.1 Context Encoder . . . 36
6.2 Sparse Vector Extractor . . . 37
6.3 Mask Generator . . . 38
6.4 Definition Decoder . . . 39
6.5 Optimization . . . 41
6.6 Experiments . . . 41
6.6.1 Experimental Setup . . . 41
6.6.2 Hyperparameters . . . 42
6.6.3 Evaluation Metrics . . . 42
6.6.4 Baselines . . . 42
6.6.5 Proposed Variants . . . 42
6.6.6 Results . . . 43
6.6.7 Human Evaluation . . . 44
6.6.8 Sense Selection Capability . . . 46
6.6.9 Qualitative Analysis . . . 46
7 Conclusion and Future Work 49
Bibliography 51
List of Figures
4.1 Illustration of the workflow. . . 16 4.2 The distribution of the annotated Spearman’s rank correlation computed
by leave-one-out. . . 20 5.1 Sense induction modules decide the senses of words, and two sense rep-
resentation learning modules optimize the sense collocated likelihood for learning sense embeddings within a language and between two languages.
Two languages are treated equally and optimized iteratively. . . 24 6.1 Illustration of the proposed model. Encoder does not have parameters to
train. The sparse extractor is pretrained and fixed during the training of mask generator and the decoder. . . 36
List of Tables
4.1 Sentence pair examples and average annotated scores in BCWS. . . 15 4.2 An erroneous example, which is the second instance in the training set.
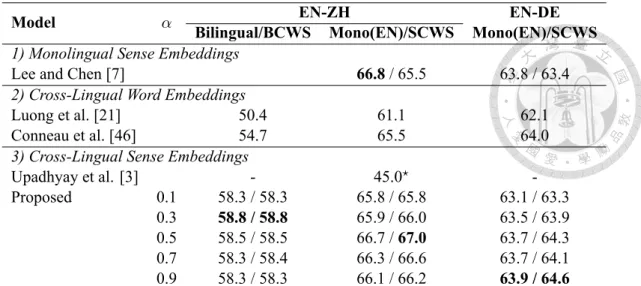
Note that the example sentence cannot be found on the oxford dictionary website and is entirely irrelevant to both the target word and the definition. 20 4.3 Part of content for the word “bass” in the proposed Oxford dataset. . . . . 21 4.4 The dataset comparison between the prior work [2] and the proposed one. 21 5.1 Contextual similarity results evaluated on the SCWS/BCWS dataset, where
the reported numbers indicate Spearman’s rank correlation ρ× 100 on AvgSimC / MaxSimC.⋆ indicates that [3] trained the sense embeddings using a different parallel dataset. . . 29 5.2 Accuracy on cross-lingual document classification (%). . . 31 5.3 Words with similar senses obtained by kNN. . . 33 6.1 BLEU and ROUGE-L scores for baselines and various proposed architec-
tures. (BLEU / ROUGE-L:F1). . . 43 6.2 Human evaluation results on randomly sampled 100 single and 100 multi-
sense questions from the small datasets. . . . 45 6.3 The analysis of the generated definition and the highest value of a single
dimension in a sparse vector. . . 45 6.4 The results on Word-in-Context (WiC) dataset. . . 45 6.5 Error analysis of common mistakes made by the proposed model. . . 46
Chapter 1 Introduction
1.1 Motivation
Word embeddings have recently become the basic component in most NLP tasks for its ability to capture semantic and distributed relationships learned in an unsupervised man- ner. The higher similarity between word vectors can indicate similar meanings of words.
Therefore, embeddings that encode semantics have been shown to serve as the good ini- tialization and benefit several NLP tasks.
However, word embeddings do not allow a word to have different meanings in different contexts, which is a phenomenon known as polysemy. For example, “apple” may have different meanings in fruit and technology contexts. Several attempts have been proposed to tackle this problem by inferring multi-sense word representations [4, 5, 6, 7]. Therefore, the main topic of this theses is about sense-level word representations.
Cross-lingual Considering that different senses of a word may be translated into dif- ferent words in a foreign language, [8] and [9] proposed to learn multi-sense embeddings using this additional signal. For example, “bank” in English can be translated into banc or banque in French, depending on whether the sense is financial or geographical. Such information allows the model to identify which sense a word belongs to. However, the drawback of these models is that the trained foreign language embeddings are not aligned well with the original embeddings in the vector space.
We addresses these limitations by proposing a bilingual modularized sense induction and representation learning system. Our learning framework is the first pure sense rep- resentation learning approach that allows us to utilize two different languages to disam- biguate words in English. To fully use the linguistic signals provided by bilingual language pairs, it is necessary to ensure that the embeddings of each foreign language are related to each other (i.e., they align well in the vector space). We solve this by proposing an algorithm that jointly learns sense representations between languages.
Interpretability Machine learning models utilizing deep learning methodologies have achieved huge success on various tasks. However, state-of-the-art models are often ex- tremely complex and have a huge amount of parameters such that transparency or inter- pretability are compromised. Researchers cannot tell why or how the model makes a spe- cific decision, which is particularly problematic when predictions are related to decision- critical applications such as medical applications. Considering that understanding the un- derlying phenomenon in the model is critical, interpretability [10] has therefore arisen as a key desideratum of machine learning models.
In natural language processing (NLP), word embeddings are dense representations that human finds difficult to interpret, which can be summarized in three main reasons:
1. Polysemy: Word embeddings mix different meanings into a single vector, which is also known as the polysemy issue [4].
2. Dimension understanding: The higher and lower values in the dimensions of an embedding vector are difficult to interpret and analyze for human [11].
3. Semantic analysis: We can only indirectly check the nearest neighbors to inspect the semantic meaning of a word embedding [1].
1.2 Problem Description
Based on the above discussion, concretely, we want to address these two challenges:
1. How to train a set of cross-lingual sense-level word representations that aligned well in the embedding space?
2. How to provide explainable network for each sense of word representations given different context?
1.3 Main Contributions
Cross-lingual
• We propose the first system that maintains purely sense-level cross-lingual repre- sentation learning with linear-time sense decoding.
• We are among the first to propose a single objective for modularized bilingual sense embedding learning.
• We are the first to introduce a high-quality dataset for directly evaluating bilingual sense embeddings.
• Our experimental results show the state-of-the-art performance for both monolin- gual and bilingual contextual word similarities.
Interpretability
• Given a (context, word) pair, our proposed system can explicitly pin down the di- mension in the sparse word representation that represents the sense of the word under a given context.
• Our system is able to interpret the value of a specific dimension in the transformed sparse representation.
• Our system provides the human understandable textual definition for a particular sense of a word embedding given its context.
• We release a large and high-quality context-definition dataset that consists of abun- dant example sentences and the corresponding definitions for a variety of words.
1.4 Thesis Structure
The thesis is organized as below.
• Chapter 2 - Related Work
This chapter summarizes related work and discusses current challenges of the field.
• Chapter 3 - Background
This chapter reviews background knowledge utilized in the proposed methods.
• Chapter 4 - Datasets
This chapter details the proposed datasets and how it is built.
• Chapter 5 - Cross-Lingual Sense Representations
This chapter focuses on inducing a cross-lingual representation learning model and shows the conducted experiments for evaluation. Part of this research work has been presented in the following publication [12]:
– Ta-Chung Chi and Yun-Nung Chen, “CLUSE: Cross-Lingual Unsupervised Sense Embeddings,” in Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 271-281, 2018.
• Chapter 6 - Explainable Sense Representations
This chapter focuses on introducing a explainable sense representation learning framework and examines the effectiveness of sense disambiguation and interpreta- tion. Part of this research work has been presented in the following publication [13]:
– Ta-Chung Chi, Ting-Yun Chang, Shang-Chi Tsai, and Yun-Nung Chen, “xSense:
Learning Sense-Separated Sparse Representations and Textual Definitions for Explainable Word Sense Networks,” in arXiv preprint arXiv:1809.03348, 2018.
• Chapter 7 - Conclusion and Future Work
This chapter concludes the contributions and describes the potential future research directions.
Chapter 2
Related Work
2.1 Cross-Lingual Sense Representations
There are a lot of prior works focusing on representation learning, while the first part of this thesis mainly focuses on bridging the work about sense embeddings and cross-lingual embeddings and introducing a newly collected bilingual data for better evaluation.
Sense Embeddings [4] first proposed multi-prototype embeddings to address the lexical ambiguity when using a single embedding to represent multiple meanings of a word. [14, 5, 6, 15] utilized neural networks as well as the Bayesian non-parametric method to learn sense embeddings. [7] first utilized a reinforcement learning approach and proposed a modularized framework that separates learning of senses from that of words. However, none of them leverages the bilingual signal, which may be helpful for disambiguating senses.
Cross-Lingual Word Embeddings [16] first pointed out the importance of learning cross-lingual word embeddings in the same space and proposed the cross-lingual docu- ment classification (CLDC) dataset for extrinsic evaluation. [17] trained directly on mono- lingual data and extracted a bilingual signal from a smaller set of parallel data. [18] used a probabilistic model that simultaneously learns alignments and distributed representations for bilingual data by marginalizing over word alignments. [19] learned word embeddings
by minimizing the distances between compositional representations between parallel sen- tence pairs. [9] reconstructed the bag-of-words representation of semantic equivalent sen- tence pairs to learn word embeddings. [20] proposed a training algorithm in the form of matrix decomposition, and induced cross-lingual constraints for simultaneously factoriz- ing monolingual matrices. [21] extended the skip-gram model to bilingual corpora where contexts of bilingual word pairs were jointly predicted. [22] proposed a variational autoen- coding approach that explicitly models the underlying semantics of the parallel sentence pairs and guided the generation of the sentence pairs. Although the above approaches aimed to learn cross-lingual embeddings jointly, they fused different meanings of a word in one embedding, leading to lexical ambiguity in the vector space model.
Cross-Lingual Sense Embeddings [8] adopted the heuristics where different meanings of a polysemous word usually can be represented by different words in another language and clustered bilingual word embeddings to induce senses. [9] proposed an encoder, which uses parallel corpora to choose a sense for a given word, and a decoder that predicts context words based on the chosen sense. [23] proposed an unsupervised method for clustering the translations of a word, such that the translations in each cluster share a common semantic sense. [3] leveraged cross-lingual signals in more than two languages. However, they ei- ther used pretrained embeddings or learned only for the English side, which is undesirable since cross-lingual embeddings shall be jointly learned such that they aligned well in the embedding space.
Evaluation Datasets Several datasets can be used to justify the performance of learned sense embeddings. [14] presented SCWS, the first and only dataset that contains word pairs and their sentential contexts for measuring the quality of sense embeddings. How- ever, it is a monolingual dataset constructed in English, so it cannot evaluate cross-lingual semantic word similarity. On the other hand, while [24] proposed a cross-lingual seman- tic similarity dataset, it ignored the contextual words but kept only word pairs, making it impossible to judge sense-level similarity. In contrast, we present an English-Chinese contextual word similarity dataset in order to benchmark the experiments about bilingual
sense embeddings.
2.2 Explainable Sense Representations
The second part of this thesis can be viewed as a bridge that connects sparse embeddings and sense embeddings together for better interpretability via definition modeling.
Sparse embedding Several works have shown that introducing sparsity in word em- bedding dimensions improves dimension interpretability [25, 26] and the benefit of word embeddings as features in downstream tasks [27]. They focused on investigating the inter- nal characteristics of word embeddings, making it hard to perform real-world applications such as word sense disambiguation (WSD). In addition, they cannot provide explicit tex- tual definitions of word embeddings.
Sense-level embedding In literature, most of the prior works assigned a vector represen- tation for each sense of a word. The work often assumed a large training corpus to facilitate the training of multi-sense embeddings in an unsupervised manner [4, 6, 7]. Note that the sense embeddings in our framework are disentangled internally by a sparse autoencoder.
In this paper, the additional training data is not required. Also, unlike the prior work, our model can provide human-readable definitions for better interpretability.
Dictionary definition task There are several works that utilized dictionary definitions to perform the ranking task or learn word embeddings. In the ranking tasks, the models are evaluated by how well they rank words for given definitions [28] or definitions for words [1]. Aside from ranking tasks, [29] suggested using definitions to compute embed- dings for out-of-vocabulary words. Different from them, this thesis focuses on utilizing the textural definitions to provide the capability of explaining the embeddings via human understandable natural language.
Chapter 3 Background
In this chapter, we will give some background knowledge about models, training algo- rithms, and evaluation metrics.
3.1 Word Representation Learning
The underlying idea of learning word representations is knows as ”a word is characterized by the company it keeps [30]. Concretely, every word is represented by a continuous vector, where the learning target is to maximize the collocation likelihood of the target word wi and the context word wj:
p(wj | wi) = exp(UwTiVwj)
∑
wkexp(UwT
iVwk), (3.1)
this is the skip-gram objective for training word representations. Note that U is the matrix for target word embedding and V is the matrix for context word embedding. However, the partition function is impractical to calculate due to the large vocabulary size. Therefore, we approximate the above objective by negative sampling [31]:
log p(wj | wi) = log σ(UwT
iVwj) +
∑N k=1
Ewk∼pneg(w)[σ(−UwTiVwk)], (3.2)
We choose N words in the vocabulary as negative samples.
3.2 Reinforcement Learning
3.2.1 Markov Decision Process (MDP)
We use the simplest one-step markov decision process in this thesis, which can be for- mulated as a 4-tuple. (S, A, Pa, Ra), where S is a set of finite states, A is a finite set of actions, Pais the probability transition function between states, and Rais the immediate reward obtained after taking an action. The state space is often too large to fill in a table, so we use the neural network to approximate.
3.2.2 Value-Based Reinforcement Learning
To provide a learning algorithm for the MDP process, our model outputs several values for each a ∈ A in the finite action space, which indicates the goodness of taking that action given the current state s∈ S. We then train the one-step Pa using the immediate reward Ra.
3.2.3 Exploration and Exploitation
To obtain data for training the MDP, our model has to explore in the environment and generate trajectories for training. There are several ways to explore the environment while we use the ϵ-greedy strategy in this thesis, which means our model randomly pick another action other than the predicted a with a predefined probability ϵ.
3.3 Recurrent Neural Models
In this section, we will introduce standard recurrent neural network (RNN) and gated re- current unit(GRU) we used for generating explainable textual definitions.
3.3.1 Recurrent Neural Network (RNN)
The idea behind RNN [32] is to capture information of time dimension of a sequential observations (x1, x2, . . . , xT). The network outputs a sequence of learned hidden repre-
sentations (h1, h2, . . . , hT), where ht encodes observations (x1, x2, . . . , xt). The hidden representation is generated in a recursive way:
ht= σ(Whxt+ Uhht−1+ bh) (3.3)
where σ is a non-linear activation function applied element-wise(e.g., sigmoid) and Wh, Uhand bh are matrices and vector to be learned. The hidden state htis used to predict a target output ot. For example, if we want to predict the next word in a sentence, the target output otwill be a vector of probabilities across the vocabulary size.
ot= sof tmax(Wyht+ by) (3.4)
where Σioit= 1, and Wy and by are learned parameters.
3.3.2 Gated Recurrent Unit (GRU)
As the observations become longer and longer, the model introduced in Sec. 3.3.1 will encounter the gradient vanish problem. The problem is that: network uses back propaga- tion to compute gradients. After multiplying numbers smaller than one several times, the
“front” time step may receive very small gradient which makes it untrainable. To avoid this problem, LSTM cell [33] is introduced. However, its training speed is relatively slow so we choose the GRU cell [34] since it runs faster than LSTM and achieves similar per- formance. The internal structure of a GRU cell is:
rt= σ(Wr· [ht−1, xt]), (3.5)
zt= σ(Wz· [ht−1, xt]), (3.6)
h˜t= tanh(W˜h· [rt∗ ht−1, xt]), (3.7) ht= (1− zt)∗ ht−1+ zt∗ ˜ht. (3.8)
where Wr is the parameter for reset gate, and Wz is the parameter for update gate. The new hidden state ht is updated by the linear interpolation of original hidden state and
transformed hidden state ˜htweighted by update gate.
3.4 Optimization
3.4.1 Sparsity Loss
Sparse coding technique is used in this thesis. In particular, we want every element of the sparse representation generated by our model to be either 0 or 1. This is easily achieved by minimizing:
∑
h
vw,h(1− vw,h) (3.9)
where vw,h is the hth dimension of the word embedding of the word w. This loss is used to train the sparse vector extractor in section 6.2.
3.4.2 Cross Entropy
The module in section 6.4 is trained by maximizing the likelihood with standard decoder architecture. At every time step t, the conditional probability p(yt|y1, y2,· · · , yt−1) is modeled as a parametric function of RNN(Eq. 3.4). In particular, the softmax function in Eq. 3.4 is applied after the RNN layer to get the probability distribution over all words in the vocabulary.
Given a target sentence {y1∗,· · · , yT∗}, the output distribution p(yt|y1, y2,· · · , yt−1) is optimized toward the true distributionp(y∗t|y∗1, y2∗,· · · , yt−1∗ ) by minimizing the cross entropy loss:
Loss =− log p(y∗1,· · · , yT∗) (3.10)
=− log
∏T t=1
p(yt∗|y∗1,· · · , y∗t−1) (3.11)
=−
∑T t=1
log p(yt∗|y∗1,· · · , y∗t−1) (3.12)
Note that in this thesis, since our true distribution is an one-hot representation, this objective is the same as maximizing the log-likelihood of the ground truth token at time step t.
3.4.3 Teacher Forcing
Teacher forcing [35] is proposed for training RNN models efficiently . Models are trained to maximize the likelihood of generating a sequence of ground truth tokens which are given as the input during training time. Concretely, the ground truth token y∗t−1is fed into the model as input at time step t to predict the output yt. During testing time, since ground truth tokens are not available, the inputs for RNN are replaced by tokens generated by the model itself at each time step. We used this technique when generating textual definitions in section 6.4.
Chapter 4 Datasets
We proposed two datasets for training and testing in this thesis.
4.1 BCWS - Bilingual Contextual Word Similarity
This new dataset is constructed to measure the bilingual contextual word similarity. En- glish and Chinese are chosen as our language pair for three reasons:
1. They are the top widely used languages in the world.
2. English and Chinese belong to completely different language families, making it interesting to explore syntactic and semantic difference among them.
3. Chinese is a language that requires segmentation, this dataset can also help re- searchers experiment on different segmentation levels and investigate how segmen-
English Sentence Chinese Sentence Score
Judges must give both sides 我非常喜歡這個故事,它 < 告訴 > 我們 7.00
an equal opportunity to 一些重要的啟示。(I like this story a lot,
<state> their cases. which<tells> us some important inspiration.)
It was of negligible <importance> 黃斑部病變的預防及早期治療是相當 < 重要 > 6.94 prior to 1990, with antiquated 的。(The prevention and early treatment of
weapons and few members. macular lesions is very <important>.)
Due to the San Andreas Fault 水果攤老闆似乎很意外真有人買這 < 冷 > 貨 3.70
bisecting the hill, one side has ,露出「你真內行」的眼神與我聊了幾句。
<cold> water, the other has hot. (The owner of the fruit stall seemed surprised that someone bought this <unpopular> product, talking me few words about “you are such a pro”.) Table 4.1: Sentence pair examples and average annotated scores in BCWS.
Chinese Wordnet
English Wikipedia Chinese
Sentence
English Sentence
Words(EN) hyponyms hypernyms holonyms Words(ZH)
Noun Adjective 制服 Verb
學生必須穿制服上學
(Students have to wear uniforms to school.)
subjugate,uniform
subjugate, uniform, livery, enslave clothing, repress, dominate, dragoon enslave
Tyrants rise and enslave the spirit of freedom.
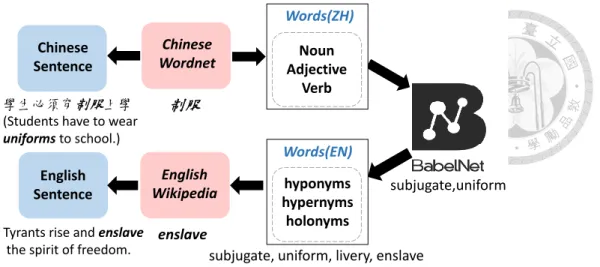
Figure 4.1: Illustration of the workflow.
tation affects the sense similarity.
This dataset also provides a direct measure to determine whether the two language em- beddings align well in the vector space. Note that we focus on word-level, and this is different from [16], which also measured the cross-lingual embedding similarity but rely on the ambiguous document-level classification.
Our dataset contains 2091 question pairs, where each pair consists of exactly one En- glish and one Chinese sentence; note that they are not parallel but with their own sentential contexts shown in Table 4.1. Eleven raters1 were recruited to annotate this dataset. Each rater gives a score ranging from 0.0 (different) to 10.0 (same) for each question to indi- cate the semantic similarity of bilingual word pairs based on sentential clues. The anno- tated dataset shows very high intra-rater consistency; we leave one rater out and calculate Spearman correlation between the rater and the average of the rest, and the average num- ber is about 0.83, indicating the human-level performance (the average number in SCWS is 0.52).
We describe the construction of BCWS below.
4.1.1 Dataset Construction
To establish the bilingual contextual word similarity (BCWS) dataset, we collect the data by a five-step procedure as illustrated in Figure 4.1.
Chinese Multi-Sense Word Extraction
First, we to extract the most frequent 10,000 Chinese words from Chinese Wikipedia dump. Considering the common part-of-speech (PoS), we then select the words that are nouns, adjective, and verb based on Chinese Wordnet [36]. In order to test the sense-level representations, we remove words with only a single sense to ensure that the selected words are polysemous. Also, the words with more than 20 senses are deleted, since those senses are too fine-grained and even hard for the human to disambiguate. We denote the list of Chinese words lc.
English Candidate Word Extraction
Second, the goal is to find an English counterpart for each Chinese word in lc. We utilize BabelNet [37], a free and open-sourced knowledge resource, to serve as our bilingual dictionary. Specifically, we first query the selected Chinese word using the free API call provided by Babelnet to retrieve all WordNet senses. For example, the Chinese word “制 服” has two major meanings:
• uniform: a type of clothing worn by members of an organization
• subjugate: force to submit or subdue
Hence, we can obtain two candidate English words, “uniform” and “subjugate”. Each word in lc retrieves its associated English candidate words, and then a dictionary D is formed.
Enriching Semantic Relationship
Note that D is merely a simple translation mapping between Chinese and English words.
It is desirable that we have more complicated and interesting relationships between bilin-
1They are all Chinese native speaker whose scores are at least 29 in the TOEFL reading section or 157 in the GRE verbal section.
gual word pairs. Hence, for each English word in D, we find its hyponyms, hypernyms, holonyms and attributes, and add the additional words into D. In our example, we may ob- tain {制服: [uniform, subjugate, livery, clothing, repress, dominate, enslave, dragoon...]}.
We sample 2 English words if the number of English candidate words is more than 5, 3 English words if more than 10, and 1 English word otherwise to form the final bilingual pair.
For example, a bilingual word pair (制服, enslave) can be formed accordingly. After this step, we obtain 2,091 bilingual word pairs P .
Adding Contextual Information
Given the bilingual word pairs P , appropriate contexts should be found in order to form the full sentences for human judgment. For each Chinese word, we randomly sample one example sentence in Chinese WordNet that matches the PoS tag we selected in 4.1.1.
For each English word, we find all sentences containing the target word from the English Wikipedia dump. We then sample one sentence where the target word is tagged as the matched PoS tag2.
Human Labeling
In order to associate a similarity measure with a collected bilingual word pair with their contexts, we recruit 11 human annotators for annotating the semantic scores. To ensure the workers’ proficiency, all recruited annotators are Chinese native speakers whose scores are at least 29 in the TOEFL reading section or 157 in the GRE verbal section. All pairs will be scored by all 11 annotators in a random order. To ensure consistency of labeling, the annotators are highly encouraged to look up a given dictionary, the English Oxford dictionary3, due to its plentiful example sentences. Note that they are asked not to rely solely on dictionary definitions but should consider the contextual information given in questions.
The annotators are asked to determine the sense similarity of these two target words
2We use the NLTK PoS tagger to obtain the tags.
3https://www.oxforddictionaries
based on their contexts in the sentences. Each question is given a score between 0.0 and 10.0 depending on how semantic related they are.
• 0.0 indicates that the semantic meanings of the two target words are entirely differ- ent.
• 10.0 indicates that the semantic meanings of two target words are entirely the same.
If a particular question is difficult to answer; for example, for the questions with terribly missing words that prevent them from understanding the meaning, the annotators can mark them with 0.0. To ensure the same grading standard, the annotators are asked to finish all questions within 3 days, and we also retest some previously answered questions to make sure they receive similar scores.
4.1.2 Data Analysis
Our collected BCWS dataset includes 2,091 questions, each of which contains exactly one Chinese sentence and one English sentence. Moreover, each sentence contains exactly one target word that is surrounded by < and > shown in Table 4.1. After finishing labeling, the inter-annotator consistency is then calculated. Specifically, we leave one annotator out and calculate the Spearman’s rank correlation between the scores from the annotator who is left out and the average of the remaining annotators. The average score can be viewed as the human performance, the upper bound of the embedding models. The average agreement of BCWS is 0.83, while the agreement of previously similar dataset SCWS [14] is about 0.52. The distribution of the correlation scores for two datasets is shown in Figure 4.2.
It can be found that our BCWS dataset has much higher consistency among annotators compared to SCWS, demonstrating the better quality for evaluating sense embeddings.
From the prior work on SCWS, the current state-of-the-art score is around 0.7 [38], and most work cannot further improve the performance significantly, because they have already surpassed human-labeled performance on SCWS. This observation is also pointed out by [39]. Moreover, note that a merely 300-dimensional word-level skip-gram model can achieve a score of 0.65 [15] on SCWS. In contrast, our baseline word-level skip-gram model can only obtain a score of 0.49, indicating that our dataset provides a larger room
0.0 0.2 0.4 0.6 0.8 1.0
1 2 3 4 5 6 7 8 9 10 11
Spearman's Correlation
Annotator ID
SCWS BCWS
Figure 4.2: The distribution of the annotated Spearman’s rank correlation computed by leave-one-out.
Word Definition Example Sentence
picture imagine; conceive of; see in one’s mind. I can see a risk in this strategy.
Table 4.2: An erroneous example, which is the second instance in the training set. Note that the example sentence cannot be found on the oxford dictionary website and is entirely irrelevant to both the target word and the definition.
of improvement for the follow-up work.
4.2 Oxford
There are lots of lexical resources containing example sentences (gloss) [40, 37], but only few or no example sentences are provided per definition. In contrast, the oxford dictio- nary4 is the one that contains abundant example sentences. This is particularly useful for the machine learning models. [2] recently released a dataset based on this resource. How- ever, their dataset does not contain complete information achievable online, which hinders the usage for diverse tasks. Some findings are described here:
1) It is reasonable to assume that every example sentence should contain the target word, but there are about 16% instances that are not the case as demonstrated in Table 4.2 (considering both training and testing splits).
2) It is unreasonable that they only proposed ONE example sentence per definition,
4https://en.oxforddictionaries.com/
Word Definition & Example Sentence
bass
Def 1: The lowest adult male singing voice.
His bass voice rings out attractively.
These are the opening words of the play, sung as a bass solo.
Def 2: The common European freshwater perch.
Only leisure anglers are allowed to fish bass in Irish waters.
I did manage a couple of hours fishing a bass pool the next morning.
Table 4.3: Part of content for the word “bass” in the proposed Oxford dataset.
Attribute Theirs Ours
#words 36,767 31,798
Avg. #sent. per def. 1 27
POS tag N Y
Total sentences 122,319 1,299,821 Total tokens 3,516,066 18,484,401
Table 4.4: The dataset comparison between the prior work [2] and the proposed one.
which makes no difference from traditional resources.
These concerns lead us to build a high-quality dataset with more example sentences per definition. A word example along with its multiple definitions and associated example sentences are shown in Table 4.3.
To be more specific, our dataset provides the following guarantees:
• Each example sentence contains the target word it defines.
• We include all example sentences of a specific definition available in the online dictionary.
• We also include the corresponding POS tag of each word sense for further research usage.
The statistics of the proposed dataset is summarized in Table 4.4, where it is obvious that our dataset contains much more example sentences, and the size is about 5 times larger than one provided by [2]. The high-quality and rich dataset can be leveraged in different NLP tasks, and this thesis utilizes it for explainable sense representations.
Chapter 5
Cross-Lingual Sense Representations
Our proposed model borrows the idea about modularization from [7], which treats the sense induction and representation modules separately to avoid mixing word-level and sense-level embeddings together.
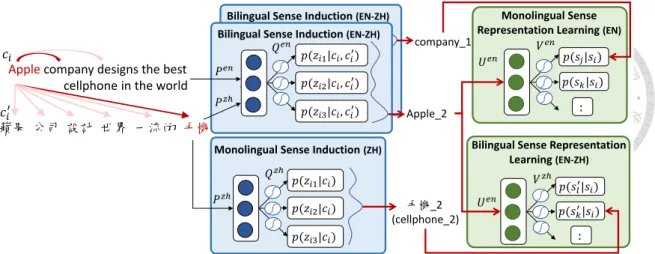
Our model consists of four different modules illustrated in Figure 5.1, where sense in- duction modules decide the senses of words, and two sense representation learning mod- ules optimize the sense collocated likelihood for learning sense embeddings within a lan- guage and between two languages in a joint manner. All modules are detailed below.
5.1 Notations
We denote our parallel corpus without word alignment C, where Cen is for the English part and Czh is for the Chinese part. Our English vocabulary is Wen and Chinese vo- cabulary is Wzh. Moreover, Ctenand Ctzhare the t-th sentence-level parallel sentences in English and Chinese respectively. In the following sections, we treat English as the major language and Chinese as an additional bilingual signal, while their roles can be mutu- ally exchanged. Specifically, English and Chinese iteratively become the major language during the training procedure.
Bilingual Sense Induction (EN-ZH)
蘋果 公司 設計 世界 一流的 手機
𝑝(𝑧𝑖1|𝑐𝑖, 𝑐𝑖′) 𝑄𝑒𝑛
𝑃𝑒𝑛
𝑝(𝑧𝑖2|𝑐𝑖, 𝑐𝑖′) 𝑝(𝑧𝑖3|𝑐𝑖, 𝑐𝑖′) 𝑃𝑧ℎ
𝑐𝑖
𝑐𝑖′
Bilingual Sense Induction (EN-ZH)
𝑝(𝑧𝑖1|𝑐𝑖) 𝑄𝑧ℎ
𝑝(𝑧𝑖2|𝑐𝑖) 𝑝(𝑧𝑖3|𝑐𝑖) 𝑃𝑧ℎ
Monolingual Sense Induction (ZH)
Apple_2 :
𝑝(𝑠𝑗|𝑠𝑖) 𝑝(𝑠𝑘|𝑠𝑖) 𝑉𝑒𝑛 𝑈𝑒𝑛
Monolingual Sense Representation Learning (EN)
: 𝑝(𝑠𝑙′|𝑠𝑖) 𝑝(𝑠𝑘′|𝑠𝑖) 𝑉𝑧ℎ 𝑈𝑒𝑛
Bilingual Sense Representation Learning (EN-ZH)
手機_2 (cellphone_2)
company_1 Applecompany designs the best
cellphone in the world
Figure 5.1: Sense induction modules decide the senses of words, and two sense repre- sentation learning modules optimize the sense collocated likelihood for learning sense embeddings within a language and between two languages. Two languages are treated equally and optimized iteratively.
5.2 Bilingual Sense Induction Module
The bilingual sense induction module takes a parallel sentence pair as input and determines which sense identity a target word belongs to given the bilingual contextual information.
Formally, for the t-th English sentence Cten, we aim to decode the most probable sense zik ∈ Zi for the i-th word wi ∈ Wen in Cten, where Zi is the set of sense candidates for wi and 1 ≤ k ≤ |Zi|. We assume that the meaning of wi can be determined by its surrounding words, or the so-called local context, ci = {wi−m,· · · , wi+m}, where m is the size of context window.
Aside from monolingual information, it is desirable to exploit the parallel sentences as additional bilingual contexts to enable cross-lingual embedding learning. Note that word alignment is not required in this work, so we consider the whole parallel bilingual sen- tence during training. Considering training efficiency, we sample M words in the parallel bilingual sentence with their original relative order or pad it to M for those shorter than M . Formally, given the t-th parallel bilingual sentence Ctzh, the bilingual context of wiis therefore c′i ={w′0,· · · , w′M−1} and w′ ∈ Wzh.
To ensure efficiency, continuous bag-of-words (CBOW) model is applied, where it takes word-level input tokens and outputs sense-level identities. Specifically, given an English word embedding matrix Pen, the local context can be modeled as the average of
word embeddings from its context,|c1
i|
∑
wj∈ciPjen. Similarly, we can model the bilingual contextual information given Chinese word embedding matrix Pzhusing the CBOW for- mulation and obtainM1 ∑
w′j∈c′iPjzh. We linearly combine the contextual information from different languages as:
C = α¯ · 1
|ci|
∑
wj∈ci
Pjen+ (1− α) · 1 M
∑
wj′∈c′i
Pjzh. (5.1)
The likelihood of selecting each sense identity zikfor wican be formulated in the form of Bernoulli distribution with a sigmoid function σ(·):
p(zik | ci, c′i) = σ((Qenik)TC),¯ (5.2)
where Qenis a 3-dimensional tensor with each dimension denotes Wen, zik for a specific word i in Wen, and the corresponding latent variable, respectively. Therefore, Qenik will retrieve the latent variable of k-th sense of i-th English word. Finally, we can induce the sense identity, z∗ik, given the contexts of a word wi from different languages, ci and c′i.
zik∗ = arg max
zik
p(zik | ci, c′i) (5.3)
In order to allow the module to explore other potential sense identities, we apply an ϵ- greedy algorithm [41] for exploration in the training procedure.
5.3 Monolingual Sense Induction Module
This module is the degraded version of bilingual sense induction module when α = 1, which occurs where no parallel bilingual signal exists. In other words, every bilingual sense induction module will experience the degradation during the training process pre- sented in Algorithm 1. The only difference is that it cannot access the bilingual infor- mation. The purpose of this module is to maintain the stability of sense induction and to decode the sampled bilingual sense identity which will later be used in the bilingual sense
representation learning module. As shown in Figure 5.1, given the monolingual context of a word, this module selects its sense identity using (5.2) and (5.3) with α = 1.
5.4 Monolingual Sense Representation Learning Module
Given the decoded sense identities from the sense induction module, the skip-gram archi- tecture [42] is applied considering that it only requires two decoded sense identities for stochastic training. We first create an input English sense representation matrix Uenand an English collocation estimation matrix Venas the learning targets. Given a target word wiand its collocated word wjin the t-th English sentence Cten, we map them to their sense identities as zik∗ = siand zjl∗ = sj by the sense induction module and maximize the sense collocation likelihood. The skip-gram objective can be formulated as p(sj | si):
p(sj | si) = exp((Usen
i )TVsen
j )
∑
skexp((Usen
i )TVsen
k ), (5.4)
where sk iterates over all possible English sense identities in the denominator. This for- mulation shares the same architecture as skip-gram but extends to rely on senses. Note that the Chinese sense representation learning module is built similarly.
5.5 Bilingual Sense Representation Learning Module
To ensure sense embeddings of two different languages align well, we hypothesize that the target sense identity si not only predicts the sense identity sj of wj in Cten but also one sampled sense identity s′l of wl′ from the parallel sentence Ctzh, where s′l is decoded by the Chinese monolingual sense induction module. Specifically, the bilingual skip- gram objective can be formulated using the English sense embedding matrix Uenand the bilingual collocation estimation matrix Vzhas:
p(s′l| si) = exp((Useni )TVszh′ l )
∑
s′kexp((Useni )TVszh′
k ), (5.5)
where s′kiterates over all possible Chinese sense identities in the denominator.
5.6 Optimization
In this learning framework, the gradient cannot be back-propagated from the representa- tion module to the induction module due to the usage of arg max operator. It is therefore desirable to connect these two modules in a way such that they can improve each other by their own estimations. In one direction, forwarding the prediction of the sense induction module to the sense representation learning module is trivial, while in another direction, we treat the estimated collocation likelihood as the reward for the induction module.
First note that calculating the partition function in the denominator of (5.4) and (5.5) is intractable since it involves a computationally expensive summation over all sense identi- ties. In practice, we adopt the negative sampling strategy technique [42] and rewrite (5.4) and (5.5) as:
log p(sj | si) = log σ((Useni )TVsenj )+
∑N k=1
Esk∼pneg(s)[σ(−(Useni )TVsen
k )], (5.6)
log p(s′l | si) = log σ((Usen
i )TVszh′
l )+
∑N k=1
Es′k∼pneg(s′)[σ(−(Useni )TVszh′
k )], (5.7)
where pneg(s) and pneg(s′) is the distribution over all English senses and all Chinese senses for negative samples respectively, and N is the number of negative sample. The rewritten objective for optimizing two sense representation learning modules is the same as maxi- mizing (5.6) and (5.7). Moreover, we can utilize the probability of correctly classifying the skip-gram sense pair as the reward signal. The intuition is that a correctly decoded sense identity is more likely to predict its neighboring sense identity compared to incorrectly decoded ones.
This learning framework can now be viewed as a reinforcement learning agent solv-
ing one-step Markov Decision Process [43, 7]. For bilingual modules, the state, action, and reward correspond to bilingual context ¯C, sense zik, and σ((Usen
i )TVszh′
l ) respectively.
As for the monolingual modules, the state, action, and reward correspond to monolingual context ct, sense zik, and σ((Usen
i )TVsen
j )). Finally, we can optimize both bilingual and monolingual sense induction modules (P and Q from (5.2) by minimizing the cross en- tropy loss between decoded sense probability and reward. We also include an entropy regularization term as suggested in [9] to let the sense induction module converge faster and make more confident predictions. Formally,
min H(σ((Usen
i )TVszh′
l ), p(zik | ci, c′i))
+ λE(p(zik | ci, c′i)) (5.8) min H(σ((Useni )TVsenj ), p(zik | ci))
+ λE(p(zik | ci)) (5.9)
E is the entropy of selection probability weighted by λ. Note that the major language is switched iteratively among two languages. Algorithm 1 presents the full learning proce- dure.
5.7 Experiments
We present the experiments of our proposed model for cross-lingual sense representations in the first part of this section.
5.7.1 Experimental Setup
Two sets of parallel data are used in the experiments, one for English-Chinese (EN-ZH) and another for English-German (EN-DE). UM-corpus [44] is used for EN-ZH training, while Europarl corpus [45] is used for EN-DE training. UM-corpus contains 15,764,200 parallel sentences with 381,921,583 English words and 572,277,658 unsegmented Chinese