國立臺灣大學電機資訊學院電信工程學研究所 碩士論文
Graduate Institute of Communication Engineering College of Electrical Engineering and Computer Science
National Taiwan University Master Thesis
運用超像素的即時互動式影像切割
Real-Time Interactive Image Segmentation with Superpixel Pre-segmentation
林家蓉 Chia-Jung Lin
指導教授:丁建均 博士 Advisor: Jian-Jiun Ding, Ph.D.
中華民國 103 年 7 月
July, 2014
誌謝
首先感謝我的父母,一直以來包容我的幼稚及任性,並持續支持我走我選擇 的路,即使我仍並不十分確定自己想要的是什麼。感謝我的弟妹時常幫我分憂,
未來幾年分別的日子我會很想念很想念你們的。
碩一上忙著實習,碩一下出國交換,這一年沒有和實驗室的同學和學長姐們 有太多交流,十分遺憾。感謝實驗室的同屆同學,盈柔、思維、胡豪,感謝有你 們一起修課一同耍廢抱怨和表人。感謝柏宏和信慧,一直以來你們用很不同的風 格帶領著這個實驗室。感謝學弟妹們,浩軒、士昌、景文、麒偉、奕帆、品萱,
這一年與你們相處愉快,祝福你們未來一年也能在彼此扶持之下順利度過。
感謝哲勳將近四年的陪伴,是你讓我成為了現在的我。感謝為碩,我很懷念 與你談心的時光。感謝李鎬,你總是不談心,但是在課業上給了我許多幫助,也 很大程度地影響了我大三之後走的方向。感謝圈圈陪我走過碩二的這段時光,認 識你多年才突然覺得我們如此相似,祝我們都幸福。感謝逸祥這麼好約,每次都 分享身旁友人幼稚的舉動,讓我覺得自己十分成熟(?)順便暫時忘記煩憂。
謝謝威昇,你是我唯一不後悔這兩年的原因,你讓我看見不曾奢望過的美好 風景。希望此去經年,仍是我陪著你追夢。
感謝其他以上未曾提到,但曾影響我或幫助過我的人。抱歉環境破壞已經很 嚴重了我還浪費這麼多紙(哭),整本最有價值的就是這一頁,看完請直接闔起來,
謝謝大家。
中文摘要
影像切割一直是計算機視覺中一個重要的研究課題。這是因為電腦很難完全 自動地從背景分割出目標,這也導致了互動式影像分割研究的興起 互動式影像分 割藉由使用者的引導及修正來切割出理想的結果。然而,雖然稱為“互動”式影 像切割,近期的許多研究仍未做到能即時回饋。
在本篇論文中,我們著重於縮短切割系統的反應時間。為了產生即時的結果,
我們提出充分利用使用者仍在與系統互動的時間(例如正在標記前景或背景的大概 位置),我們將演算法分為兩部份,其中只有第二部分會造成使用者可能察覺到的 系統延遲。我們也提出採用的紋理特徵以降低切割的錯誤率,尤其當前景和背景 具有相似的顏色的時候。實驗結果表明,在人眼的反應系統下,我們的演算法和 框架可以達到視為“即時”的反應時間,這樣的框架同時也可以被其他演算法拿 來應用。
關鍵字:互動式影像切割、超像素、像切割、即時系統
ABSTRACT
Image segmentation has been a major research topic in computer vision. It is hard to segment the object from the background fully automatically, and solving the problem leads to the researches in interactive image segmentation, which incorporates user intervention to guide the segmentation process and to correct anomalies in the segmentation results. Although called “interactive,” real-time response is not yet reachable by many recent methods.
In this thesis, we focus on shorten the response time of the segmentation system.
To produce real-time result, we propose making use of the time when user interacts with the system. We separate our algorithm into two parts, where the response time is only contributed by the later part. We adopt texture feature to enhance the results in images where foreground and background have similar colors. Experimental results show that our implementation achieves short response time that could be perceived as “instant.”
The framework can also be applied by other different algorithms to shorten the response time.
Index terms: Interactive Image Segmentation, Superpixel, Graph Cut, Real-Time
SystemCONTENTS
口試委員會審定書 ... #
誌謝 ...i
中文摘要 ... ii
ABSTRACT ... iii
CONTENTS ...iv
LIST OF FIGURES ... vii
LIST OF TABLES ... x
Chapter 1 Introduction ... 1
1.1 Motivation... 1
1.2 Main Contribution ... 2
1.3 Organization ... 2
Chapter 2 Interactive Image Segmentation ... 3
2.1 Image Segmentation ... 3
2.2 Interactive Segmentation ... 5
2.3 Prior Works on Interactive Segmentation ... 6
2.3.1 Graph Cut ... 6
2.3.2 Random Walker ... 7
2.3.3 Shortest Path (Geodesic) ... 7
Chapter 3 Graph Cut Method ... 9
3.1 Preliminaries ... 9
3.2 Max-Flow/Min-Cut Theorem ... 10
3.3 Graph Cut... 11
3.4 Graph Cut Segmentation... 12
3.4.1 Basic Ideas and Background Information ... 12
3.4.2 Hard Constraints ... 16
3.5 Issues in Graph Cut Algorithm ... 19
3.5.1 The Shrinking Bias ... 19
3.5.2 Efficiency ... 21
3.5.3 Vulnerability to Noise ... 21
3.6 Prior Works ... 22
3.6.1 Speed-up based graph cut ... 22
3.6.2 Interactive-based graph cut ... 23
3.6.3 Shape prior-based graph cut ... 23
3.7 Lazy Snapping[5]... 25
Chapter 4 Overview of Superpixel Methods ... 29
4.1 Introduction... 29
4.2 Gradient-Ascent-Based Algorithms ... 31
4.3 Graph-Based Algorithms ... 33
4.4 Remarks ... 34
4.5 Benchmark and Comparison... 35
4.5.1 Benchmark ... 35
4.5.2 Comparison Results ... 37
Chapter 5 Proposed Interactive Image Segmentation Method ... 43
5.1 Observation ... 43
5.2 User Interface (UI) Design ... 44
5.3 Framework ... 45
5.4 Desired Properties of Superpixel Segmentation ... 46
5.5 Proposed Segmentation Algorithm ... 48
5.5.1
The Regional Term ... 48
5.5.2
The Boundary Term ... 50
5.5.3
Max-Flow/Min-Cut Algorithm ... 50
5.6 Summary ... 51
Chapter 6 Experimental Results and Discussion ... 53
6.1 Grabcut Benchmark ... 53
6.2 Discussion ... 65
6.2.1 Processing Time ... 65
6.2.2 Achievable Segmentation Error ... 70
6.2.3 Graph Cut Segmentation Issues Revisited ... 71
6.3 Summary ... 72
Chapter 7 Conclusion and Future Work... 73
7.1 Conclusion ... 73
7.2 Future Work ... 74
Appendix A
A.1 Simple Linear Iterative Clustering Superpixel (SLIC) ... 75REFERENCE ... 81
LIST OF FIGURES
Fig. 2.1 Example of medical image segmentation. [1] (a) Magnetic resonance heart image; (b) image after segmented into three classes ... 4 Fig. 3.1 An example of a flow network ... 10 Fig. 3.2 Illustration of s-t graph. The image pixels correspond to the neighbor nodes in the graph(except s and t nodes). The orange lines in the graph are n-links and the black lines are t-links. ... 12 Fig. 3.3 Illustration of graph cut for image segmentation. The cut is corresponding to the minimal energy of (3.1) ... 15 Fig. 3.4 The optimal object segment (red tinted area in (c)) finds a balance between
“region” and “boundary” terms in (2). The solution is computed using graph cuts as explained in Section 2.5. Some ruggedness of the segmentation boundary is due to metrication artifacts that can be realized by graph cuts in textureless regions.[3] ... 17 Fig. 3.5 Illustration of shrinking bias. A12 and A0 are some homogeneous areas.
Graph-cut methods may short-cut across the desired object along B1 instead of following the true edge B2 because less cost is accrued traversing the shorter path. ... 21 Fig. 3.6 Lazy Snapping is an interactive image cutout system, consisting of two steps:
a quick object marking step and a simple boundary editing step. In (b), only 2 (yellow) lines are drawn to indicate the foreground, and another (blue) line to indicate the background. All these lines are far away from the true object boundary. In (c), an accurate boundary can be obtained by simply clicking and dragging a few polygon vertices in the zoomed-in view. In (d), the
cutout is composed on another Van Gogh painting. ... 25 Fig. 3.7 (a) A small region by the pre-segmentation. (b) The nodes and edges for the graph cut algorithm with pre-segmentation. (c) The boundary output by the graph cut segmentation. ... 27 Fig. 4.1 An superpixel segmentation example. The input image (a) is segmented into 25 (middle part, top-left corner) and 250 (middle part, bottom-right) superixels in (b). The segmentation result is shown with mean colors of each region in (c)... 29 Fig. 4.2 Visual comparison of superpixels produced by various methods. The average superpixel size in the upper left of each image is 100 pixels, and 300 in the lower right. Alternating rows show each segmented image followed by a detail of the center of each image. [48] ... 34 Fig. 4.3 Illustration of undersegmentation error. A ground truth segment (green) is covered by three superpixels (A,B,C), that can flood over the groundtruth segment border.[43] ... 36 Fig. 4.4 Runtime of segmentation algorithms (log-scale) [43]. ... 40 Fig. 4.5 Boundary recall of segmentation algorithms on Neubert and Protzel’s benchmark( top-left is better).[43] ... 41 Fig. 4.6 Undersegmentation error of segmentation algorithms on Neubert & Protzel’s benchmark( bottom-left is better). [43] ... 41 Fig. 4.7 Visual Comparison of superpixel segmentation results. The bumbers on the left side indicate the number of superpixels in one image... 42 Fig. 5.1 Prototype of user interface. ... 44 Fig. 5.2 Flowchart of our system. ... 45 Fig. 6.1 Example of GrabCut dataset. Left column: original image. Middle column:
the trimap image with user defined foreground (white) background (dark
grey) and unknown (light grey). Right column: ground truth. ... 54
Fig. 6.2 Visual comparison on dataset [2]. ... 59
Fig. 6.3 Visual comparison on dataset [2]. The error rate of (c)-(h) are 5.19%, 4.39%, 9.15%, 15.06%, 14.20% and 9.42% respectively. ... 60
Fig. 6.4 Visual comparison on dataset [2]. ... 61
Fig. 6.5 Visual comparison on dataset [2]. ... 62
Fig. 6.6 Visual comparison on dataset [2]. ... 63
Fig. 6.7 Visual comparison on dataset [2]. ... 64
Fig. 6.8 Response time with respect to different number of ERS superpixels. ... 66
Fig. 6.9 Processing time of computing energy term with respect to different number of ERS superpixels. ... 66
Fig. 6.10 Processing time of with respect to different number of ERS superpixels. .... 67
Fig. 6.11 Response time of 50 images with different node ratio. (ERS) ... 67
Fig. 6.12 Response time with respect to different number of SLICO superpixels. ... 68
Fig. 6.13 Processing time of computing energy term with respect to different number of SLICO superpixels. ... 68
Fig. 6.14 Processing time of with respect to different number of SLICO superpixels. 69 Fig. 6.15 Response time of 50 images with different node ratio. (SLICO) ... 69
Fig. 6.16 Visual comparison of our failure case. ... 71
Fig. A.1 Reducing the superpixel search regions. (a) standard k-means searches the entire image. (b) SLIC searches a limit region. ... 76
Fig. A.2 Segmentation results of SLIC and SLICO. ... 79
LIST OF TABLES
Table 3.1 Weight of the s-t graph. P represent all the pixels in the original image and
, :{p,q} N
1 max p q
p P q
K B
. ... 17Table 3.2 Manually assigned regional values. ... 18
Table 3.3 Definitions of
R
i(l )
i ... 26Table 3.4 Core algorithm of first step in Lazy Snapping ... 28
Table 4.1 Summary of existing superpixel algorithms. ... 34
Table 4.2 Runtime (in seconds) of segmentation algorithms[43]. ... 40
Table 5.1 Definitions of regional term. ... 49
Table 5.2 Algorithm of ur interactive segmentation framework ... 51
Table 5.3 Algorithm of ur interactive segmentation framework ... 51
Table 6.1 Performance evaluation Microsoft GrabCut Database [3]. ... 56
Table 6.2 Algorithms of Calculating ASE ... 58
Table 6.3 Preprocessing time of two superpixel methods (in second). ... 70
Table 6.4 Error rate of two superpixel methods and various node ratio. ... 70
Table 6.5 Error Rate of segmentation results on noisy dataset. ... 72
Table A.1 Algorithm of SLICO superpixel segmentation. ... 80
Chapter 1 Introduction
1.1 Motivation
Photo editor is probably the most popular application on PCs or smart devices, since photo sharing has become such an important part of social life. At the same time, users have become stricter than ever with the response time of applications. Image segmentation is an important part of photo editing, because it is usually a pre-step for other local editing. We look through recent researches on interactive segmentation;
almost all methods need users to do further correction. In terms of user behavior, we think giving timely response is more important than the accuracy. That means we are willing to sacrifice a few percent of accuracy for a real-time system without any delay.
Since 4% of error rates needs further correction as much as 7 % of error rates. To note that the system we discuss here is more suitable for single image segmentation.
Interactive video segmentation (segment through a series of continuous frames with only key frame marked by the user) demands higher accuracy and thus has different priority with us. Therefore, in this thesis, we focus on designing a real-time interactive segmentation system that generates result instantly while retain high accuracy.
1.2 Main Contribution
In this thesis, we review the researches in interactive image segmentation and superpixel segmentation. Based on superpixel segmentation and graph cut segmentation, we propose a novel framework that focuses on improving user experience by shortening the response time of the system. Experimental results show that the response time of our system can be perceived as “instant.” Additionally, we propose using texture information to retain the segmentation accuracy. Our results do not achieve the lowest error rate among recent methods, but are visually comparable to state-of-the-art methods in most of the test images.
1.3 Organization
This thesis is organized as follows: in Chapter 2, an overview of interactive image segmentation is presented. A detailed introduction of graph cut segmentation, including the original method and the extended ones in recent years, is given in Chapter 3. In Chapter 4, we give an overview of superpixel methods, both for conventional methods and modern approaches. In Chapter 5, we propose a novel framework, which enables the segmentation system to produce real-time result. Experimental results and discussion are given in Chapter 6. Finally, the conclusion and future work are given in Chapter 7.
Chapter 2 Interactive Image Segmentation
Interactive segmentation is one of the research subfields in image segmentation. In this chapter, we first introduce the concept and possible applications of image segmentation. Then, we explain the difficulties in image segmentation, which lead to the research in interactive image segmentation. Next, we cover the basic ideas of interactive segmentation. In the end, we briefly review three of the popular approaches to interactive image segmentation.
2.1 Image Segmentation
In computer vision, image segmentation is the process of partitioning an image into
“meaningful” regions. More precisely, image segmentation is the process of assigning a label to every pixel in an image such that pixels with the same label share certain characteristics. The result of image segmentation is a set of segments that collectively cover the entire image, or a set of contours extracted from the image. Each of the pixels in a region is similar with respect to some characteristic or computed property, such as color, intensity, or texture. Adjacent regions are significantly different with respect to the same characteristic(s).
Image segmentation is a fundamental task in a large number of applications in computer vision. More generally, effective image segmentation is a key to better scene understanding and object recognition. For instance, in medical imaging, the resulting contours after image segmentation can be used to locate tumors, measure tissue volumes or do virtual surgery simulation. Fig. 2.1 shows an example of medical image segmentation. The image is roughly segmented into three regions by their difference in texture and intensity.
There are three main segmentation categories: fully automatic methods, semi-supervised (also called interactive or seeded) methods, and completely manual ones. The results produced by fully automatic methods are still far from matching human performance, especially for natural images. The difficulty of the task at hand and the limitations of the input data (real images differ from their models because of noise, occlusion, clutter, etc.) often lead to ill-posed problems. The segmentation process itself is in general ill-defined without additional prior knowledge: Homogeneity in some a priori feature space such as color or texture is not a sufficient criterion to define a meaningful, unambiguous image partition. People probably rely on a combination of low-level information (e.g., color, texture, contours) and high-level knowledge (e.g., shape priors, semantic cues) to resolve these ambiguities. Even with prior knowledge, automatic segmentation remains a challenging and active research area.
On the other hand, interactive segmentation allows some form of human intervention to guide the segmentation process and to correct anomalies in the segmentation results.
Fig. 2.1 Example of medical image segmentation. [1] (a) Magnetic resonance heart image; (b) image after segmented into three classes
2.2 Interactive Segmentation
A practical interactive segmentation algorithm usually contents these four qualities:
1. Fast computation 2. Fast editing
3. An ability to produce an arbitrary segmentation with enough interaction 4. Intuitive segmentations.
Many forms of interaction have been proposed, ranging from loosely tracing the desired boundary (e.g., [9],[10],[11],[13],[14]) to loosely marking parts of the desired object and/or background (e.g., [3],[4],[5],[21],[22],[23],[26]) to loosely placing a bounding box around the desired object (e.g., [2], [16]). In all forms, the goal is to allow the user to accurately select objects of interest with minimal effort.
We focus here on approaches where the user marks “scribbles” on parts of the desired foreground and background regions to seed the segmentation. Such approaches are popular because they generally require less precise input from the user, allowing them to loosely mark broader interior regions instead of more finely tracing near object boundaries, though each approach can sometimes be advantageous. Allowing the user to draw a bounding box [2] is simpler in many cases, though may not provide sufficient control in all cases, in which scribble-based corrections are often employed to refine the results.
Many methods for seeded segmentation expand outward from the seeds to selectively fill the desired region, either explicitly [22], [23], [24] or conceptually [21].
Because these approaches work from the interior of the selected object outwards and do not explicitly consider the object boundary, they are particularly useful for selecting objects with complex boundaries such as those with long, thin parts. However, because
these expansions are monotonic, these approaches suffer from a bias that favors shorter paths back to the seeds. As a result, they can be sensitive to seed placement, as illustrated for geodesic segmentation in Figure 2. Because they lack an explicit edge component, these methods may also fail to accurately localize object boundaries. The stronger the image edges are, the more likely these methods are to make these transitions here, but this is not guaranteed, as illustrated for geodesic segmentation in Figure 3.
2.3 Prior Works on Interactive Segmentation
The algorithms reviewed in this section view an image as a graph where each pixel corresponds to a node and the weighting of edges reflect changes in image intensity, color or other features.
2.3.1 Graph Cut
Our proposed algorithm is based on graph cut. Thus, we only give a brief introduction here, and we will give a more thorough review in Chapter 3. The labeling produced by the graph cut algorithm is determined by finding the minimum cut between the foreground and background seeds via a maximum flow computation. The original work on graph cut for interactive image segmentation was produced by Boykov and Jolly[3], and this work has been subsequently extended by several groups to employ different features [9] or user interfaces [2], [5]. Although graph cut is relatively new, the use of minimal surfaces in segmentation has been a common theme in computer vision for a long time [28], [27] and other boundary-based user interfaces have been previously employed [29], [30], [31].
2.3.2 Random Walker
The random walker algorithm of Grady [22] is also formulated on a weighted graph and determines labels for the unseeded nodes by assigning the pixel to the seed for which it is most likely to send a random walker. This algorithm may also be interpreted as assigning the unlabeled pixels to the seeds for which there is a minimum diffusion distance [13], as a semi-supervised transduction learning algorithm [17] or as an interactive version of normalized cuts [33], [23]. Additionally, popular image matting algorithms based on quadratic minimization with the Laplacian matrix may be interpreted as employing the same approach for grouping pixels, albeit with different strategies to determine the edge weighting function [26]. Diffusion distances avoid segmentation leaking and the shrinking bias, but the segmentation boundary may be more strongly affected by seed location than with graph cuts [34].
2.3.3 Shortest Path (Geodesic)
The shortest path algorithm assigns each pixel to the foreground label if there is a shorter path from that pixel to a foreground seed than to any background seed, where paths are weighted by image content in the same manner as with the GC and RW approaches. This approach was recently popularized by Bai and Sapiro [5], but variants of this idea have appeared in other sources [16], [3], [18]. The primary advantage of this algorithm is speed and prevention of a shrinking bias. However, it exhibits stronger dependence on the seed locations than the Random Walker approach [34], is more likely to leak through weak boundaries (since a single good path is sufficient for connectivity) and exhibits metrication artifacts on a 4-connected lattice.
Chapter 3 Graph Cut Method
In this chapter, we focus on Graph Cut approaches. First, we cover the background in graph theory in section 3.1-3.3. Then, we introduce the core algorithm of Graph Cut segmentation in section 3.4. In section 3.5, we discuss the weakness in this popular approach. Then, in section 3.6, we review the three main extensions based on Graph Cut segmentatioin. Finally, we give a thorough introduction to Lazy Snapping [5], which is one of the classic work aiming at improving processing time.
3.1 Preliminaries
Graph representation: We useG
(V, E) to denote an undirected graph where V is the vertex set and E is the edge set. The vertices and edges are denoted byv
i ande respectively. The edge weights are denoted
i j,w . In an
ij undirected graph, the edge weights are symmetric, that is,w
ij w
ji.
Cut: In a graphG
(V, E), a cut is a set of edgesC E
such that the two terminals become separated on the induced graphG
'
(V, E\ C).3.2 Max-Flow/Min-Cut Theorem
Graph cut segmentation is solved by the max-flow/min-cut theorem. However, we do not have to look too deep into the theorem to understand the concept of graph cut segmentation. Thus, here we first cover a few definitions related to the flow network, and then we state the max-flow/min-cut theorem.
Fig. 3.1 An example of a flow network
A flow network is defined as a directed graph where an edge has a nonnegative capacity. The capacity of an edge is denoted by
c
uv. It represents the maximum amount of flow that can pass through an edge. We denote a source terminal as s and a sink terminal as t. A cut (S,T) of graph G is a partition of V into S andT V S \
such thatt T
ands S
. A flow is denoted byf
uv , subject to the following two constraints:1.
f
uv c
uv for each (u, v)
E (capacity constraint) 2.:(u,v) E :(v,u) E
uv vu
u u
f f
for eachv V
\ {s, t} (conservation of flows).The value of flow is defined by sv
v V
f f
, where s is the source of G
. It
represents the amount of flow passing from the source to the sink. The maximum flow
problem is to maximize | f |, that is, to route as much flow as possible from s to t. An s-t
cut C = (S,T) is a partition of V such that s S
andt T
. When we remove C, no flow is able to pass from the source to the sink. The capacity of an s-t cut is defined as(u,v) S T
(S,T) uv
c c
. The minimum s-t cut problem is minimizing (S,T)c
, that is, todetermine S and T such that the summed capacity of the S-T cut is minimal.
The max-flow min-cut theorem proves that the maximum network flow and the sum of the cut-edge weights of any minimum cut that separates the source and the sink are equal.
With the basic ideas of a flow network, we can now move on to build the graph cut algorithm on top of it.
3.3 Graph Cut
Let an undirected graph be denoted as
G
(V, E). The vertex V is composed of two different kinds of nodes (vertices). The first kind of vertices is neighborhood nodes, which are composed of pixels in the image. The second kind of vertices is called terminal node. There are two terminal nodes added for applying max-flow/min-cut algorithm: an “object” terminal (a source S) and a “background” terminal (a sink). This kind of graph is also called s-t graph. In s-t graph, there are also two types of edges.The first type of edges is called n-links which connect the neighboring pixels within the image (Here we adopt 4-connected system in the 2D image). And the second type of edge is called t-links which connect the terminal nodes with the neighborhood nodes. In this kind of graph, each edge is assigned with a non-negative weight denoted as e w which is also named as cost. The cost of the cut | C | is the sum of the weights on edges C, which is expressed as e
e C
C w
.
A minimum cut is the cut that have the minimum cost called min-cut and it can be achieved by finding the maximum flow which is verified in [12, 13, 23] that the min-cut
is equivalent to max-flow. The max-flow/min-cut algorithm developed by Boykov and Kolmogorov [23] can be used to get the minimum cut for the s-t graph. Thus, the graph is divided by this cut and the nodes are separated into two disjoint subsets S and T where s∈S , t∈T and S ∪T = V . The two subsets correspond to the foreground and background in the image segmentation. This kind of graph can be depicted in Figure 3-1.
Fig. 3.2 Illustration of s-t graph. The image pixels correspond to the neighbor nodes in the graph(except s and t nodes). The orange lines in the graph are n-links and the black lines are t-links.
3.4 Graph Cut Segmentation
3.4.1 Basic Ideas and Background Information
Image segmentation can be regarded as pixel labeling problems. The label of the object (s-node) is set to be 1 while that of the background (t-node) is given to be 0 and this process can be achieved by minimizing the energy-function through minimum graph cut. In order to make the segmentation reasonable, the cut should be occurred at the boundary between object and the background. Namely, at the object boundary, the energy (cut) should be minimized. Let the labeled pixel set be L= {l1
, l
2, l
3, ⋅ ⋅ ⋅ , l
i,⋅ ⋅ ⋅,
l
n} where n is the number of the pixels in the image and li ∈{0,1} . Thus, the set L is divided into 2 parts and the pixels labeled with 1 belong to object while others are grouped into background.Greig et al. [8] first proposed that the min-cut/max-flow algorithms from combinatorial optimization can be used to minimize certain important energy functions in vision. The energies addressed by Greig et al. and by most later graph-based methods can be represented as
( ) ( ) ( )
E L R L B L
. (3.1)R(L) is called the regional term, while B(L) is the boundary term. The coefficient 0
specifies a relative importance of R(L) versus B(L). The regional term R(l) represents the individual penalties for assigning pixel p to “object” or “background”. It can be defined as( ) p( )p
p
R L R l
(3.2)where lp is the label for foreground or background. Rp
(l
p) is the weight on a t-link edge.
It can be obtained by comparing the intensity of pixel p with the given histogram of the object and background. Other features might as well be used to replace the intensity. We are designing a term that will be minimized in later computation process. Therefore, we should let the penalty of a pixel grouping into an area, e.g. Rp
(l
p), be smaller when p has
some quality similar to the area. For instance, the weight of the t-links can be defined as following equations.R (1) = -ln Pr(I |1)p p (3.3)
R (0) = -ln Pr(I |0)p p (3.4)
where Pr(I |1)p is the conditional probability given the intensity information of pixel p
and the object. When Pr(I |1)p is larger than Pr(I |0)p ,
R
p 1
will be smaller than 0
R
p . This means when the pixel is more likely to be the object, the penalty for grouping that pixel into object should be smaller which can reduce the energy in (3.1).Thus, when all of the pixels have been correctly separated into two subsets, the regional term would be minimized.
On the other hand, the boundary term B(L) comprises the “boundary” properties of segmentation. B(L) can be defined as
, { , }
( ) p q ( , )p q
p q N
B A B l l
, (3.5)where p, q are adjacent pixels and
(l , l )p q is defined as:(l , l ) 1 0
p q
p q
p q
if l l if l l
(3.6)Each pair of neighboring pixels {p, q} in N is connected by an n-link. Coefficient
, 0
B
p q
is the weight on an n-link edge. It could be interpreted as a penalty for a discontinuity between p and q. Normally, Bp,qis large when pixels p and q are similar
(e.g. in their intensity) and Bp,qis close to zero when the two are very different. The
penalty Bp,qcan also decrease as a function of distance between p and q. Costs B
p,qmay
be based on local intensity gradient, Laplacian zero-crossing, gradient direction or other criteria. Often, it is sufficient to set the boundary penalties from a simple function like2
, 2
( ) 1
exp( )
2 ( , )
p q
p q
I I
B c
dist p q
(3.7)where c is an arbitrary constant and σ can be estimated as “camera noise”.
With (3.2) and (3.5), we can rewrite (3.1) into
, { , }
( ) p( )p p q ( , )p q
p p q N
E L R l B l l
(3.8)In order to get a reasonable segmentation result, the assignment of the weight in the s-t graph is very important. Here we sum up the “design guideline” of the regional and boundary term:
1. For every pixel: when the feature of the pixel is inclined to be the object, the regional term between this pixel and s-node will be larger than that between pixel and t-node which means the cut is more likely occurred at the edge with smaller weight.
2. For the neighboring pixels, when their intensity is very similar, the boundary term should be large so that they are not likely to be separated by the cut.
Fig. 3.3 Illustration of graph cut for image segmentation. The cut is corresponding to the minimal energy of (3.1)
3.4.2 Hard Constraints
So far we have covered the basic ideas of graph cuts as well as the essence of the energy function. Now we step back a little to combine the concept above with our user interaction.
In real examples, objects may not have sufficiently distinct regional properties. In such cases it becomes necessary to further constraint the search space of possible solutions before computing an optimal one. Boykov et al. proposed using topological (hard) constraints as an important source of “high level” contextual information about the object of interest in real images.
Assume that O and B denote the subsets of pixels p priori known to be a part of
“object” and “background”, correspondingly. Naturally, the subsets O ⊂ P and B ⊂ P are such that
O B . Our goal is to compute the global minimum of (3.1) among all
segmentations L satisfying “hard constraints”: p 1
p O l
(3.9): p 0
p B l
(3.10)The hard constraints can be used to initialize the algorithm and to edit the results. It can be set either automatically or manually depending on an application. Manually controlled seed is the most likely way to enter hard constraints in many generic applications. On the other hand, automatically set hard constraints can be used to initialize the algorithm in highly specialized applications such as organ segmentation from medical images or volumes.
In interactive segmentation framework, the user provides seeds to indicate foreground and background regions. The seeded regions are viewed as hard constraints, that is, they will be labeled accordingly. In addition, the information provided by seeded
region will be viewed as prior knowledge to help generate edge weights in graph cut segmentation.
In Boykov and Jolly’s method, the weight of the s-t graph is given in Table 3-1.
Table 3.1 Weight of the s-t graph. P represent all the pixels in the original image and
, :{p,q} N
1 max p q
p P q
K B
.edge weight For
{p, q} Bp,q {p, q}
{p, S}
R
p(0)
K 0
,
p P p O B
(unknown)p O
p B
{p, T}
R
p(1)
0 K
,
p P p O B
(unknown)p O
p B
At the end of this subsection, we use a simple example to demonstrate a more detailed process of graph cut segmentation.
Fig. 3.4 The optimal object segment (red tinted area in (c)) finds a balance between
“region” and “boundary” terms in (2). The solution is computed using graph cuts as explained in Section 2.5. Some ruggedness of the segmentation boundary is due to metrication artifacts that can be realized by graph cuts in textureless regions.[3]
In Fig. 3.4 illustrates some interesting properties of the cost function(3.1). The object of interest is a cluster of black dots in Fig. 3-3(a) that we would like to segment as one blob. We combine boundary term (3.5) and region term (3.2) and take λ > 0 in (3.1). The penalty for discontinuity in the boundary cost is defined manually as:
,
1 0.2
p q
p q
p q
if I I
B if I I
(3.11)To describe regional properties of segments we use a priori known intensity histograms (Fig. 3-3(b)). Note that the background histogram concentrates exclusively on bright values while the object allows dark intensities observed in the dots. If these histograms are used in (3.2, 3.5) then we get the following regional penalties Rp
(l
p) for pixels of
different intensities.Table 3.2 Manually assigned regional values.
I
pR
p(1) R
p(0)
dark
2.3 +∞bright
0.1 0The optimal segmentation in Fig. 2.2(c) finds a balance between the regional and the boundary term of energy (2.1). Individually, bright pixels slightly prefer to stay with the background (see Table 3.2). However, boundary term forces some of them to agree with nearby dark dots.
Note that a fast implementation of graph cut algorithms can be an issue in practice.
The most straight-forward implementations of the standard graph cut algorithms, e.g.
max-flow or push-relabel, can be slow. The experiments conducted by Boykov and Kolmogorov [4] compared several well-known “tuned” versions of these standard algorithms in the context of graph based methods in vision. The same paper also describes a new version of the max-flow algorithm that significantly outperformed the standard techniques. We adopted this algorithm as the base of our segmentation scheme.
3.5 Issues in Graph Cut Algorithm
3.5.1 The Shrinking Bias
The shrinking bias refers to the tendency of graph cut algorithm towards shorter paths. (This length bias predates graph-cut methods and is present in earlier least-cost path approaches [13].) The tendency is caused by the boundary term, which consists of a summation over the boundary of the segmented regions.
This can be especially noticeable when these methods shortcut across the interior of an object to avoid segmenting an appendage as illustrated in Fig. 3.5. This is offset somewhat by the region term, which tries to penalize shortcuts through areas where the labeling is clear from the coloring. However, this is not without tradeoffs—overweighting the region term to compensate for the boundary term’s shrinking bias can result in discontinuous objects with coloring similar to the user’s respective scribbles being incorrectly selected (as also illustrated in Fig. 3.5). This leads to a delicate balance between the weighting of the two terms and the resulting strengths and limitations of each.
Most approaches for otherwise avoiding the shrinking bias in graph-cut and similar approaches involve variations on normalizing the cost of the cut by the size of the
resulting object(s). This may be done for grey-level images for which flux may be defined along the boundary of the region [15], but as noted in [16], this does not readily extend to color images. Optimizing general normalized cost functions directly is NP-hard but may be approximated [17]. Alternatively, a subspace of solutions may be explored by varying the relative weighting of the boundary and region terms [18]. (The authors of [18] note, however, that this method is not fast enough for interactive color image segmentation.) More recent work in [19] uses a curvature-minimizing rather than length-minimizing regularization term to smooth the resulting boundaries while avoiding shortcutting, but this does not use an edge component to localize edges, nor does it run in interactive time.
Because of the complementary strengths and weaknesses of seed-expansion and graph-cut approaches, some have suggested combining them. Work in [20] showed that graph-cuts and random-walkers [21] (a form of seed expansion), along with a new method similar in principle to geodesic segmentation [22], could be placed in a common framework in which the three methods differ by only the (integer) selection of a single parameter. The idea is further expanded in [25] by varying a second parameter. They also showed empirically that of these three approaches the new method (analagous to geodesic segmentation) is most sensitive to seed placement while “because of the ’small cut’ phenomenon, the Graph Cuts segmentation is the least robust to the quantity of seeds.” More recent work [26] has explored a way to blend the respective strengths of these methods using non-integer selections for the free parameter in [20], determining a suitable parameter selection empirically over a set of sample images with known ground truth.
Fig. 3.5 Illustration of shrinking bias. A12 and A0 are some homogeneous areas.
Graph-cut methods may short-cut across the desired object along B1 instead of following the true edge B2 because less cost is accrued traversing the shorter path.
3.5.2 Efficiency
Mean reaction time for college-age individuals is approximately 190 milliseconds to detect visual stimulus. To our knowledge, the technique proposed by Boykov et al.[3]
is the most efficient implementation of max-flow/min-cut algorithm to date.
Unfortunately, as shown in the last column of Table 1[5], the max-flow algorithm fails to provide interactive visual feedback for real life image cutouts. To improve efficiency, [5] proposed building the graph cut formulation on a pre-segmented image instead of image pixels. Because our framework is inspired by [5], we will introduce the algorithm in details in 3.7.
3.5.3 Vulnerability to Noise
A small amount of noise (adjusting even a single pixel) could cause the contour returned by the algorithm to change drastically. This is caused by the same nature that causes the shrinking bias.
3.6 Prior Works
The graph cuts segmentation algorithm has been extended in three different directions in order to address issues of different factors. We briefly introduce the three directions in this section.
3.6.1 Speed-up based graph cut
The first type of extension to the graph cuts algorithm has focused on increasing speed. In order to speed up the computation of graph cut algorithm, implementation based on GPU with CUDA code is proposed in [53]. This kind of methods increase speed with the parallel computing, which perform well compared tp sequentially computing. However, the most used method for reducing the computational time for the graph cut related algorithms is coarsening the graph before applying the graph cuts algorithm. This coarsening has been accomplished in two manners: 1) by applying a standard multilevel approach and solving subsequent, smaller graph cuts problems in a fixed band to produce the final, full-resolution segmentation [12]. 2) by applying a watershed algorithm to the image and treating each watershed basin as a “supernode” in a coarse graph to which graph cuts in applied [5]. The primary goal of these two approaches is to increase the computational speed of graph cuts by intelligently reducing the number of nodes in the graph. As stated in [12], the objective is to produce the same segmentation result as regular graph cuts by introducing a heuristic that greatly speeds the computation. Therefore, the benefits and difficulties of the graph cuts algorithm listed above also apply to these approaches, with an added uncertainty about the role of the coarsening operator in the final result (i.e., the final segmentation is no longer guaranteed to be the minimum cut).
3.6.2 Interactive-based graph cut
The second direction of extension started from an iterative estimation of a color model with the graph cuts algorithm in [9]. This iterative color model was later coupled with an alteration of the user interface to create the GrabCut algorithm [2]. The GrabCut approach asks the user to draw a box around the object to be segmented and employs the color model as priors (“t-links”) to obviate the need for explicit specification of foreground seeds. The added color model is of clear value in the application of color image segmentation and the “boxinterface” requires less user interaction. Although the approach does perform well in the domain of color image segmentation, the iterative nature of the algorithm does increase the computational burden of the algorithm (requiring a solution to the max-flow/min-cut problem in every iteration). In addition, there is no longer a guarantee of optimality (the algorithm is terminated when the iterations stagnate). The “box-interface” is not always sufficient to capture the desired object, since further editing of the results with standard graph cuts is often required.
3.6.3 Shape prior-based graph cut
Due to noise, diffuse edge or occluded objects, conventional graph cut which only incorporate regional and edge information cannot get ideal segmented object. Even though the interactive-based graph cut can reduce these problems to some extent, many rounds of interaction will be needed and this will affect the segmentation efficiency.
Thus, the shape prior-based graph cut algorithms are widely researched. They incorporate the shape information of the object into the energy function to improve the segmentation result [32]-[36]. Especially for the images with known prior information, shape prior-based graph cut can work well when the shape is described appropriately. In
most of the cases [32]-[36], the energy of the shape prior is combined into the energy function. The energy function for the shape prior-based graph cut is usually defined as following equation:
shape
E(L) = R(L)+ B(L)+ E
(3.12)Where, R(L) is the regional term, B(L) is the boundary term and Eshape
is the prior shape
term. The energy for the regional and boundary term can be described as that in section 3.4. For the energy in the shape term, the aim is to make it smaller for the pixels around the object boundary and bigger for that far away from the boundary of object. There are two kinds of energy representation for the shape prior. The first one computes the weights of n-links with the gradient and shape prior information, while the weights of the t-links are obtained as the traditional way in section 3.4. The second one, on the opposite, reflects the shape prior information in the regional term (t-links), while the boundary term (n-links) are obtained by the way in section 3.4.For the shape prior-based graph cut, the establishment of the shape template is very important. Many pre-segmented object will be adopted to be the training set to build the shape template. Furthermore, the alignment of the training set is also inevitable for making the shape template fit the segmented image better.
3.7 Lazy Snapping[5]
We would spend some time introducing Lazy Snapping[5] because our work is primarily based on it. Fig. 3.6 shows how the interactive image cutout system works.
(a) Input image (b) Object Marking (c) Boundary editing (d) Output composition
Fig. 3.6 Lazy Snapping is an interactive image cutout system, consisting of two steps:
a quick object marking step and a simple boundary editing step. In (b), only 2 (yellow) lines are drawn to indicate the foreground, and another (blue) line to indicate the background. All these lines are far away from the true object boundary. In (c), an accurate boundary can be obtained by simply clicking and dragging a few polygon vertices in the zoomed-in view. In (d), the cutout is composed on another Van Gogh painting.
Lazy Snapping consists of two steps: an object marking step and a boundary
editing step. The first step, object marking, works at a coarse scale, which specifies the
object of interest by a few marking lines. The second step, boundary editing, works at a finer scale or on the zoomed-in image, which allows the user to edit the object boundary by clicking and dragging polygon vertices.Here we only introduce the first step in details. As introduced earlier in section 3.4,
the general energy form we try to minimize is i, j
{i, j}
( ) i( )i ( , )i j
i N
E L R l B l l
, where Ri(l
i) is the regional term, encoding the cost when the label of node i is l
i, andi, j ( , )i j
B l l
is the boundary term, encoding the cost when the labels of adjacent nodes i and j are li and lj respectively.To compute R, first the colors in foreground seeds and background seeds (marked by the user) are clustered by the K-means method. The mean colors of the foreground and background clusters are denoted as
KnF and KmB respectively. The K-means
method is initialized to have 64 clusters. Then, for each node i, we compute the
minimum distance from its color C(i) to foreground clusters as iF min (i) K
nF
min (i) K
nFn
d C
,and to background clusters as iB
min (i) K
Bmm
d C
. Therefore,R
i(l )
i is defined as follows:Table 3.3 Definitions of
R
i(l )
il
i= 1 l
i= 0
i F
0 ∞i B
∞ 0i U
Fi
F B
i i
d d d
B i
F B
i i
d d d
where F and B denote foreground and background respectively, and
U V
\ {F B}
(the uncertain region).We define B as a function of the color gradient between two nodes i and j:
B(i, j)
l
il
jg
(C )ij (3.13)where 1
( ) 1
g
, andC
ij C
(i)
C(j)2 is the L2-Norm of the RGB color difference of two pixels i and j. Again, the boundary term B represents the penalty forboundaries. It is larger when adjacent pixels have similar color. With all definitions in place, we then minimize the energy
E
(X) using the max-flow/min-cut algorithm[3].To improve efficiency, Li et al. introduced a novel graph cut formulation which is built on a pre-computed image over-segmentation instead of image pixels. They chose the watershed algorithm [37] as their pre-segmentation algorithm. As shown in Figure 3, we can use the same notation G = (V, E) for the new graph, while the nodes V are the set of all small regions from pre-segmentation, and the edges E are the set of all arcs connecting adjacent regions.
Fig. 3.7 (a) A small region by the pre-segmentation. (b) The nodes and edges for the graph cut algorithm with pre-segmentation. (c) The boundary output by the graph cut segmentation.
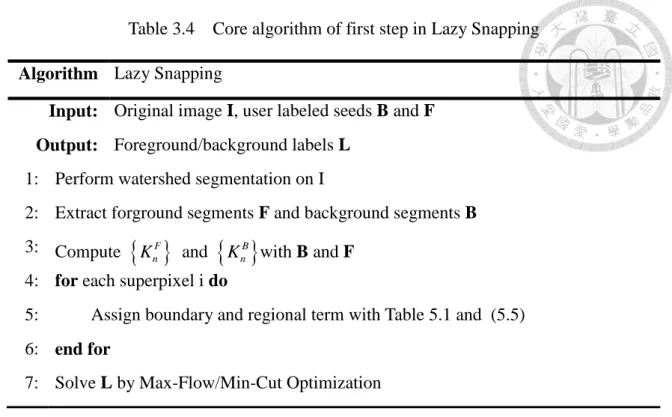
Li et al. did not release source code or software of their work, so we are unclear of their exact framework. Nevertheless, we present a complete algorithm in Table 3.4 for reference.
Table 3.4 Core algorithm of first step in Lazy Snapping
Algorithm Lazy Snapping
Input: Original image I, user labeled seeds B and F Output: Foreground/background labels L
1: Perform watershed segmentation on I
2: Extract forground segments F and background segments B 3: Compute
KnF and KnB with B and F
4: for each superpixel i do
5:
Assign boundary and regional term with Table 5.1 and (5.5)
6: end for7: Solve L by Max-Flow/Min-Cut Optimization
Chapter 4 Overview of Superpixel Methods
In this chapter, we first introduce the concept and possible applications of superpixels in section 4.1. Two main categories of prior works are reviewed in section 4.2 and section 4.3. Then, we give a summary of superpixel methods in section 4.4.
Finally, we introduce the benchmark proposed by Neubert and Protzel[43] and present the evaluation results of methods we introduced in section 4.2 and section 4.3.
4.1 Introduction
A superpixel is commonly defined as a perpetually uniform region in the image.
The major advantage of using superpixels is computational efficiency—a superpixel representation greatly reduces the number of image primitives compared to the pixel representation. It has been proved useful for applications such as depth estimation, image segmentation, body model estimation and object localization.
(a) (b) (c)
Fig. 4.1 An superpixel segmentation example. The input image (a) is segmented into 25 (middle part, top-left corner) and 250 (middle part, bottom-right) superixels in (b).
The segmentation result is shown with mean colors of each region in (c).
Generally, superpixel contains the following properties [38]:
Every superpixel should ov erlap with only one object.
The set of superpixel boundaries should be a superset of object boundaries.
The mapping from pixels to superpixels should not reduce the achievable performance of the intended application.
The above properties should be obtained with as few superpixels as possible.We can broadly classify superpixel algorithms into graph-based and gradient-ascent-based methods. In graph-based algorithms, each pixel is treated as a node in a graph, and edge weight between two nodes are set proportional to the similarity between the pixels. Superpixel segments are extracted by minimizing a cost function defined on the graph. Gradient-ascent-based methods start from an initial rough clustering, and then refine the clusters from the previous iteration with gradient ascent methods to obtain better segmentation until convergence.
4.2 Gradient-Ascent-Based Algorithms
1. Watershed (WS)
The watershed approach [44] performs a gradient ascent starting from local minima to produce watersheds, lines that separate catchment basins. The resulting superpixels are often highly irregular in size and shape, and do not exhibit good boundary adherence.
The approach of [44] is relatively fast (O(NlogN) complexity), but does not offer control over the amount of superpixels or their compactness.
2. Meanshift (MS)
Mean-shift [47] (MS) is a mode-seeking algorithm that generates image segments by recursively moving to the kernel smoothed centroid for every data point in the pixel feature space, effectively performing a gradient ascent [46]. The generated segments/superpixels can be large or small based on the input kernel parameters, but there is no direct control over the number, size, or compactness of the resulting superpixels.
3. Quickshift (QS)
Quick shift [46] is also a mode-seeking segmentation scheme like Mean-shift, but is faster in practice. It moves each point in the feature space to the nearest neighbor that increases the Parzen density estimate. While it has relatively good boundary adherence, QS is quite slow, with an O(dN2
) complexity (d is a small constant [47]). QS does not
allow for explicit control over the size or number of superpixels.4. Turbopixel (TP)
The Turbopixel method progressively dilates a set of seed locations using level-set based geometric flow [47]. The geometric flow relies on local image gradients, aiming to regularly distribute superpixels on the image plane. Unlike WS, TP superpixels are constrained to have uniform size, compactness, and boundary adherence. TP relies on algorithms of varying complexity, but in practice, as the authors claim, has approximately O(N) behavior [47]. However, it is among the slowest algorithms examined and exhibits relatively poor boundary adherence.
5. Simple Linear Iterative Clustering (SLIC)
The SLIC algorithm begins with sampling K regularly spaced cluster centers and moving them to seed locations corresponding to the lowest gradient position in a 3x3 neighborhood [48]. The clustering is based on superpixels’ color similarity and proximity in the image plane (5-diminsional space [labxy]). Since the spatial distance in the xy plane depends on the image size, Achanta et al. propose a new distance measure to normalize the distance term. This measure ensures superpixels have similar cluster sizes and also regular shapes. SLIC achieves O(N) complexity and is among the fastest algorithms.
4.3 Graph-Based Algorithms
1. Normalized Cuts (NC)
The Normalized cuts algorithm [49] recursively partitions a graph of all pixels in the image using contour and texture cues, globally minimizing a cost function defined on the edges at the partition boundaries. It produces very regular, visually pleasing superpixels. However, the boundary adherence of NC is relatively poor and it is the slowest among the methods (particularly for large images), although attempts to speed up the algorithm exist [50]. NC has a complexity of
3
(N )
2O
[49], where N is the number of pixels.2. Felzenszwalb and Huttenlocher (FH)
Felzenszwalb and Huttenlocher [51] propose an alternative graph-based approach that has been applied to generate superpixels. It performs an agglomerative clustering of pixels as nodes on a graph, such that each superpixel is the minimum spanning tree of the constituent pixels. FH adheres well to image boundaries in practice, but produces superpixels with very irregular sizes and shapes. It is O(NlogN) complex and fast in practice. However, it does not offer an explicit control over the amount of superpixels or their compactness.
3. Entropy Rate Superpixel (ERS)
Liu et al. propose solving the superpixel segmentation problem by maximizing an objective function on the graph topology [52]. The objective function consists of an entropy rate and a balancing term for obtaining superpixels with similar sizes. They also present a greedy optimization scheme to reduce the complexity of the algorithm to
O(NlogN) [52]. ERS offers control over the amount of superpixels and also their compactness.
4.4 Remarks
Table 4.1 Summary of existing superpixel algorithms.
Graph-based Gradient-ascent-based
NC [49]
FH [51]
SLIC [48]
WS [44]
MS [45]
QS [46]
TP [47]
ERS [52]
Complexity 3
N
2N
logN
N NlogN
N
2dN
2 N NlogNParameters 1 2 1 1 3 2 1 2
Superpixel number control a
Yes No Yes No No No Yes Yes
Superpixel compactness
control
No No Yes No No No No Yes
Fig. 4.2 Visual comparison of superpixels produced by various methods. The average superpixel size in the upper left of each image is 100 pixels, and 300 in the lower right.
Alternating rows show each segmented image followed by a detail of the center of each image. [48]
![Fig. 2.1 Example of medical image segmentation. [1] (a) Magnetic resonance heart image; (b) image after segmented into three classes](https://thumb-ap.123doks.com/thumbv2/9libinfo/9607888.633566/15.892.251.680.746.995/example-medical-image-segmentation-magnetic-resonance-segmented-classes.webp)

![Fig. 4.5 Boundary recall of segmentation algorithms on Neubert and Protzel’s benchmark( top-left is better).[43]](https://thumb-ap.123doks.com/thumbv2/9libinfo/9607888.633566/52.892.196.786.116.578/boundary-recall-segmentation-algorithms-neubert-protzel-benchmark-better.webp)
