行政院國家科學委員會專題研究計畫成果報告
大型資料庫中概括性的知識擷取技術之研究 Mining Generalized Knowledge in Large Databases
計畫編號:NSC90-2213-E-011-046 執行期限:90 年 8 月 1 日至 91 年 7 月 31 日
主持人:呂永和 {[email protected]} 國立台灣科技大學資訊管理系 計畫參與人員:洪振洲、廖珠惠、陳怡靜、邱士軍
一、中文摘要
資 料 探 勘 的 目 的 是 從 大 量 資 料 中 找出潛在的、有用的知識。目前已有很 多 有 效 的 資 料探勘方法;然而,這些方 法普遍存在一個問題,那就是它們所產 出的知識過多,使用者無法輕易地找出 所需的知識。本研究使用分類階層的概 念,找出較具一般性的知識,以方便使 用者找的他所需的知識。本研究的主要 成果有二。一為開發一個在關聯式資料 庫中,探勘具有概念階層的關聯規則演 算法;二為開發一個在交易資料庫中探 勘具概念階層的序列型樣演算法。這兩 個方法均有實作,並已在第七屆人工智 慧與應用研討會發表。
關鍵詞:概念階層、多階層關聯規則、多 階層序列型樣
A b s t r a c t
The purpose of data mining is to dredge implicit and useful patterns from large databases. Many efficient data mining algorithms have been developed. However, they all face with the same dilemma. That is, too many patterns discovered such that users are drowned in the sea of the discovered patterns. To help users to discover related patterns, we include concept hierarchies in data mining algorithms. The multilevel association rule mining algorithm can discover generalized association rules from relational databases. The multilevel sequential pattern mining algorithm can discover generalized multilevel sequential
patterns from a transactional database. Both algorithms have been published in the seventh conference on artificial intelligence and applications.
Keywords: Concept Hierarchy 、Multilevel Association Rules、Multilevel Sequential Patterns
二、緣由與目的
一般的資料探勘演算法所找出來的型 樣都太多,使用者不易發現他真正想要的 型樣。本研究將概念階層的概念,融入資 料探勘演算法之中,使的所找出的型樣較 具一般性,使用者更可以找到他所想要的 型樣。
三、結果與討論
(一) 多階層關聯規則演算法
在多 階 層 關 聯 規 則 演 算 法 方 面,主 要 的 議 題 是 關 聯 式 資 料 庫 表 格 中 數 值 欄位內容值的切割問題。由於所切割的 區段(interval) 需具代表性,且其支持 度要夠大;因此,我們採用由使用者提 出 一 個 初 步 切 割 , 當 作 一 個 參 考 (hints), 再 由 動 態 切 割 找 出 具 有 足 夠 支持度的區間,再用這些區間來調整參 考區間的大小。所找出的區間則具有代 表性及足夠的支持度。另外,我們將數 值 欄 位 所 對 應 的 概 念 階 層 樹 轉 化 為 一 個概念階層表,及一個欄位記錄表,用 來 記 錄 資 料 內 容 的 父 子關 係 以 及 哪 些
資料內容是屬於同一棵階層樹;父子關 係 資 料 是 用 來 累 加 子 節 點 的 支 持 度 到 父節點之中,而欄位記錄表是用來避免 同 一 欄 位 的 不 同 值 所 對 應 的 資 料 項 出 現在同一個關聯規則中,因為這樣產出 的規則是沒有意義的。最後,我們記錄 支 持 的 方 式是 如 果 有 一 筆 資 料 的 值 是 落在某一數值資料的區段中,這筆資料 對 該 區 段 所 對 應 的 項 目 的 支 持 度 的 貢 獻 度 為 1 ;對於類別性欄位,若一筆資 料的值為該欄位的某一特定值,則這筆 資 料 對 該 值 所 對 應 的 資 料 項 的 支 持 度 的 貢 獻度 為 1。本演算法的其它部份則 是 沿 用 我 們 之 前 所 開 發 的 布 林 演 算 法 [1] , 將 項 目 組 及 交 易 資 料 編 碼 ; 利 用 兩 個 項目 組編碼後 的項目 作 邏輯的 OR 運算,求得新的項目組;而新項目組的 支 持 度 是 由 原 兩 項 目 組 所 對 應 的 交 易 資 料 作邏 輯 A N D 運算而得。詳細方法 請 參 考 [2] 。 資 料 表 、 概 念 階 層 樹 、 概 念階層表及欄位記錄表如所示:
表 1:資料表
表 2:概念階層表
表 3:欄位記錄表
(二) 多階層序列型樣
所 謂 多 階 層 序 列 型 樣 是 指 在 項 目 概念階層中所存在的序列型樣。例如可 以從顧客的購買行為上,找出大部份顧 客 在 其 不 同 交 易 中 採 購 物 品 的 先 後 順 序行為。而這些商品是建立在一個既定 的項目概念階層架構中。
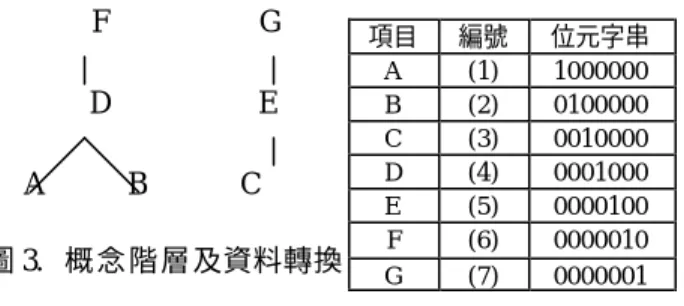
在 銷 售 資 料 庫 的 每 一 筆 交 易 中 每 一 個 商 品 項 目 及 其 所 屬 類 別 都 有 個 唯 一編號。如下圖 3,此概念階層架構共 有三層,第三層(最 底 層)為 Product,第 二 層 為 C lass , 第 一 層 ( 最 頂 層 ) 為 Category,例如產品 A 的 上 層 Class 為 D,再上一層為 F。編號的順序則是由
Name Area Age John Taipei 18 Mary Kaohsiung 26 Amy Taoyuan 48 Jane I-lan 46 Alex Taichung 25 Chery Chiayi 35
圖 1: Age 的概念階層
S e q _ n o N o d e P a r e n t L e v e l
1 Taipei 北部 0
2 Taoyuan 北部 0
3 I_lan 北部 0
4 Taichung 中部 0
5 Chiayi 中部 0
6 Kaohsiung 南部 0
7 北部 Area 1
8 中部 Area 1
9 南部 Area 1
10 0,18 Age 0
11 18,30* Age 0
12 22,35* Age 0
13 44,60* Age 0
14 61,100 Age 0
F i e l d _ n a m e
S e q _ n o ( s t a r t )
S e q _ n o ( e n d )
T r e e _ n o A t t r i b u t e t y p e
Area 1 9 1 2
Age 10 14 2 1
圖 2 : Area 欄位的概念階層樹
最底層的 Product 開始,給予每一商品 項 目 唯 一 編 號 , 接 著 再 對 Class 以 及 Category 層級項目依序編號,完成後並 將其轉換成位元字串。
項目 編號 位元字串
A (1) 1000000 B (2) 0100000 C (3) 0010000 D (4) 0001000 E (5) 0000100 F (6) 0000010 G (7) 0000001
我 們 將 商 品 分 類 的 資 訊 轉 換成 位 元 資 料 型 態 , 形 成 表 格 TP(Table of Parent)。TP 分 成 TP1 與 TP2 兩個部份,
TP1 代 表 為 儲 存 項 目 的 資 料 表 格(包括 概念階層的上層項目), 並 用 TP2 來 記 錄 某 一項 目的上層 資訊, 也 就是以 TP 表 格 中 的 的 一 列 (TP1∪TP2) 代 表 了 一 個項目與其階層資訊 。 TP1 及 TP2 的 欄 數 都 為 所 有 項 目 總 數 ( 包 含 上 層 分 類 項目) , 在 TP1 中 若 第 i 個 位 元 為 1 代 表此項目為項目 i;而 TP2 中 若 第 j 個 位 元 為 1, 代 表 項 目 i 的 Parent 為第 j 個 項 目。我 們 將 圖 3 的 項 目 的 各 分 類 階 層編號轉成表 4 的 TP 表格。
表 4.TP 表格 TP1 TP2
項目
編號 1 2 3 4 5 6 7 1 2 3 4 5 6 7 (1) 1 0 0 0 0 0 0 0 0 0 1 0 1 0 (2) 0 1 0 0 0 0 0 0 0 0 1 0 1 0 (3) 0 0 1 0 0 0 0 0 0 0 0 1 0 1 (4) 0 0 0 1 0 0 0 0 0 0 0 0 1 0 (5) 0 0 0 0 1 0 0 0 0 0 0 0 0 1 (6) 0 0 0 0 0 1 0 0 0 0 0 0 0 0 (7) 0 0 0 0 0 0 1 0 0 0 0 0 0 0
由 於 在 商 品 的 概 念 性 階 層 架 構 下,若消費者購買了商品項目 A,同時 也 代 表 了 購 買 D Class 以 及 F Category 的商品。為能表現出這些資訊,我們只 要 將 第 i 項的 TP2 與 第 j 項 的 TP1 進 行 A N D 運算,即可判定第 j 項 是 否 為 第 i 項的上層,用以表現出上層商品類別被 購買的交易資訊。
本 研 究計 劃中,對於多階層序列型 樣 的 探 勘 發 展 了 一 套 以 布 林 演 算 法 為 基礎的探勘技術。此探勘技術可以在大
型 資 料 中 有 效 率 找 出 具 有 階 層 概 念 的 序列型樣。演算法進行的步驟主要為:(1) 資 料 轉 換 與 表 格 的 建 立 ; (2) 高 頻 項 目 組的產生;(3)高頻序列的產生。
由於序列型樣是以顧客為主,因此 由 使 用 者 輸 入 的 最 小 支 持 度 必 須 乘 於 總顧客數,得到最小支持顧客數,且一 顧 客 的 交 易 對 於 每 一 項 商 品 的 支 持 度 最 多 僅 貢 獻 一 次 。 此 部 份 支 持 度 的 計 算 , 我 們 可 以 透 過 布 林 運 算 方 法 來 達 成。之後尋找高頻 k- 項目組時,因為我 們的項目組有階層關係,為避免找到太 多重覆的規則,合併的項目組必須排除 具有階層關係的組合,我們修改布林演 算法 , 尋找高 頻項目組[3]。 以 TP1 及 TP2 檢 查 兩 個 項 目 組 是 否 有 階 層 關 係,以避免產生一個項目組中包含多個 具有階層關係的項目。當高頻項目組產 生之後,將之重新編碼,並以之當作高 頻- 1 序列;最後,使用位元串列運算的 概 念 [4] , 結 合 我 們 所 設 計 的 資 料 結 構,找尋多階層的序列型樣。
四、計劃結果自評
1、研究內容與原計畫相符程度
本研究內容與原提案計畫內容相符。
2、預計達成目標狀況
本計畫所列的項目均順利完成。
3、研究成果的學術或應用價值
演算法有實作,且都能順利執行;因 此,具有實用價值。其在學術上亦多所 突破。
4、是否適合在學期刊上發表
適合在期刊上發表,其中多階層關聯規 則演算法機會較大。
五、參考文獻
1. S.Y. Wur and Y. Leu, "An Effective Boolean Algorithm for Mining Association Rules in Large Databases," 6th International Conference on Database Systems for Advanced Applications (DASFAA), Hsinchu, Taiwan, F G
D E
A B C
圖 3. 概念階層及資料轉換
2. 呂 永 和, 張 淑 貞“ 關 聯 式 資 料 庫 中 多 階 層 數 值 關 聯 規 則 之 探 勘,” Seventh Conference on Artificial Intelligence and Applications, 2002
3. 呂永和, 賴瓊惠,劉佳灝, 吳素英 ,”以布林演算 法 為 基 礎 的 多 階 層 序 列 型 樣 探 勘 技 術 ,”
Seventh Conference on Artificial Intelligence and Applications, 2002.
4. 顏 秀 珍, 何 仁 傑, 邱 鼎 穎, ”從 大 型 資 料 庫 中 挖 掘 感 興 趣 的 型 樣 ,” Fifth Conference on Artificial Intelligence and Applications, pages 84-91, 2000.
行政院國家科學委員會補助專題研究計畫成果報告
※※※※※※※※※※※※※※※※※※※※※※※※※※
※ ※
※ 大型資料庫中概括性的知識擷取技術之研究 ※
※ ※
※※※※※※※※※※※※※※※※※※※※※※※※※※
計畫類別:□個別型計畫 □整合型計畫 計畫編號:NSC 90-2213-E-011-046
執行期間:90 年 8 月 1 日 至 91 年 7 月 31 日
計畫主持人: 呂永和 共同主持人:
計畫參與人員:洪振洲、廖珠惠、陳怡靜、邱士軍
本成果報告包括以下應繳交之附件:
□赴國外出差或研習心得報告一份
□赴大陸地區出差或研習心得報告一份
□出席國際學術會議心得報告及發表之論文各一份
□國際合作研究計畫國外研究報告書一份
執行單位: 國立台灣科技大學資訊管理系
中 華 民 國 91 年 10 月 31 日 ˇ