國 立 交 通 大 學
電 機 與 控 制 工 程 研 究 所
碩 士 論 文
根據法則於人類正常與異常動作辨識
Rule Based Human Normal and Abnormal Activity Recognition
研 究 生 : 陳 冠 廷
指 導 教 授: 張 志 永
根據法則於人類正常與異常動作辨識
Rule Based Human Normal and Abnormal Activity Recognition
學 生 : 陳冠廷 Student : Kuan-Ting Chen
指導教授 : 張志永 Advisor : Jyh-Yeong Chang
國立交通大學
電機與控制工程學系
碩士論文
A Thesis
Submitted to Department of Electrical and Control Engineering
College of Electrical Engineering and Computer Science
National Chiao Tung University
in Partial Fulfillment of the Requirements
for the Degree of Master in
Electrical and Control Engineering
June 2008
Hsinchu, Taiwan, Republic of China
Rule Based Human Normal and Abnormal
Activity Recognition
STUDENT: Kuan-Ting Chen ADVISOR: Dr. Jyh-Yeong Chang Institute of Electrical and Control Engineering
National Chiao-Tung University
ABSTRACT
Human activity recognition plays an essential role in applications such as automatic surveillance systems, human-machine interface, home care system and smart home applications. It is in-sufficient that a human activity recognition system uses only the posture of an image frame to classify an activity. On the other hand, transitional relationships of postures embedded in the temporal sequence are important information for human activity recognition.
In the thesis, we combine temple posture matching and fuzzy rule reasoning to recognize an action. Firstly, a foreground subject is extracted and converted to a binary image by a statistical background model based on frame ratio. The binary image is then transformed to a new space by eigenspace and canonical space transformation, and recognition is done in canonical space. A three image frame sequence, 5:1 down sampling from the video, is converted to a posture sequence by template matching. The posture sequence is classified to an action by fuzzy rules inference. Fuzzy rule approach can not only combine temporal sequence information for recognition but also be tolerant to the variation of action done by different people. During the training of image sequences, we can compute the mean and standard deviation of each pre-defined activity. These numbers can be employed to determine whether an input image belongs to one of the pre-defined actions or an unknown
action. Lastly, we will also use Unsupervised Clustering Algorithm to generate some key postures for unknown activities. Our action recognition system not only can recognize an pre-defined action but also can signal an unknown action, which enhance the capability and recognition accuracy of activity recognition.
ACKNOWLEDGEMENTS
I would like to express my sincere gratitude to my advisor, Dr. Jyh-Yeong Chang for valuable suggestions, guidance, support and inspiration he provided. Without his advice, it is impossible to complete this research. Thanks are also given to all of my lab members for their suggestion and discussion. Finally, I would like to express my deepest gratitude to my family for their concern, supports and encouragements.
Content
摘要 ...………... i
ABSTRACT ……….…... ii
ACKNOWLEDGEMENTS ……….. iv
Content ………...…. v
List of Figures ………... vii
List of Tables ……….. ix
Chapter 1 Introduction ………1
1.1 Motivation of this research ………...1
1.2 Foreground Subject Extraction ……….4
1.3 Eigenspace and Canonical Space Transformation ………4
1.4 Image Frame Classification and Activity Recognition ……….5
1.5 Thesis Outline ………..7
Chapter 2 Basic Concept ……….8
2.1 Fundamentals of Eigenspace and Canonical Space Transform ………8
2.1.1 Eigenspace Transformation (EST) ………9
2.1.2 Canonical Space Transformation (CST) ………..11
Chapter 3 Human Activity Recognition System ………..16
3.1 Object Extraction ………16
3.1.1 Background Modeling by Frame Ratio ………...16
3.1.2 Extraction of Foreground Object ……….18
3.2 Activity Template Selection ………...21
3.3 Construction of Fuzzy Rules from Video Streams ……….23
3.4 Classification Algorithm ………....27
Chapter 4 Experimental Results ...30
4.1 Background Model and Object Extraction ……….31
4.2 Fuzzy Rule Construction for Action Recognition ………..34
4.3 The Recognition Rate of Activities Using Fuzzy Rule Base Approach ….42 4.4 Extract the New Key Postures ………44
Chapter 5 Conclusion ……….48
List of Figures
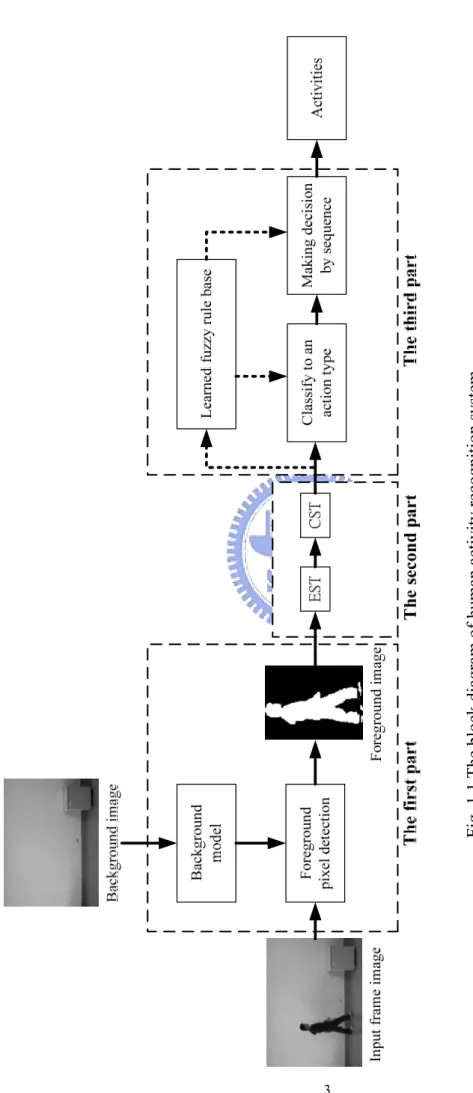
Fig. 1.1. The block diagram of human activity recognition system ………...3
Fig. 3.1. Histogram of binary image projection in X and Y direction ………..20
Fig. 3.2. The binary image of extracted foreground region .………20
Fig. 3.3. One image frame is selected as template with an interval ……….21
Fig. 3.4. Common states of two different activities ……….23
Fig. 3.5. The structure of the human activity recognition algorithm ………29
Fig. 4.1. The environment of the classroom ……….30
Fig. 4.2. An example of foreground region extraction at different threshold, k, values. (a) An image frame, (b) k=1.0, (c) k=1.1, (d) k=1.2, (e) k=1.3, (f) k=1.4………...32
Fig. 4.3. An example of foreground region extraction. (a) An image frame, (b) binary image after background analysis, (c) project of (b) onto X direction, (d) projection of (b) onto Y direction, (e) foreground region extracted….33 Fig. 4.4. Some “essential templates of posture” of person 1……….35
Fig. 4.5. Some “essential templates of posture” of person 5……….36
Fig. 4.6. Two examples of fuzzy rules. (a) Walking from left to right, (b) Climbing down………...41
Fig. 4.8. “The new key postures,” of person 5………..46 Fig. 4.9. “The final new key postures,” of person 1………..46 Fig. 4.10. “The final new key postures,” of person 5………47
List of Tables
TABLE I. THE RULE NUMBERS AT DIFFERENT THRESHOLD………...38
TABLE II. THE OBTAINED FUZZY RULE BASE GENERATED FROM THE TRAINING DATA
EXCEPT PERSON 5………...39
TABLE III. THE RECOGNITION RATES OF KEY POSTURES SELECTED MANUALLY….40
TABLEIV. THE RECOGNITION RATES OF KEY POSTURES SELECTED BY UNSUPERV- ISED CLUSTERING ALGORITHM………..40
TABLE V. THE MEANS AND STANDARD DEVIATIONS OF SIX ACTIVITIES’MATCHING
DEGREE OF TRAINING MODEL EXCEPT PERSON 5……….41 TABLE VI. THE RECOGNITION RATE OF PERSON 5 WITH DIFFERENT STARTING
FRAME……….43 TABLE VII. THE RECOGNITION RATES OF EACH ACTIVITY………...44 TABLE VIII. THE DETECTION ACCURACY OF REAL-TIME NEW KEY POSTURES
BELONGING TO THE UNKNOWN ACTION VIDEO………...47 TABLE IX. THE DETECTION ACCURACY OF FINAL NEW KEY POSTURES BELONGING TO THE UNKNOWN ACTION VIDEO………47
Chapter 1 Introduction
1.1 Motivation of this research
Human activity recognition plays an important role in applications such as automatic surveillance systems, human-machine interface, home care system and smart home applications. For example, an automatic system will trigger an alarm condition when the automated surveillance system detect and recognize suspicious human activities. Human activity recognition can also be used in extracting semantic descriptions from video clips to automate the process of video indexing. However, there is no rigid syntax and well-defined structure as that of the gesture and sign language which can be used for activity recognition. Therefore, this makes human activity recognition become a more challenging task.
Several human activity recognition methods have been proposed in the past few years. Most of human activity recognition methods can be classified into two categories depending on the features being used. The first one makes use of motion-based features [1], [2]. In [1], Bobick and Davis recognized the human activities by comparing motion-energy and motion-history of template images with temporal images. In [2], R. Hamid et al. extracted spatio-temporal features such as the relative distance between two hands and their velocities; furthermore they used dynamic Bayesian networks to recognize human activities such as writing, drawing and erasing on a white board. On the other hand, 2-D and 3-D shape features were used to recognize activities [3], [4]. In [3], shape was represented by edge data obtained from canny edge detector, and key frames were defined for each activity. In [4], the authors presented a view-independent 3-D shape description for classifying
and identifying human activity using SVM.
If we only adopt the motion-based and shape-based features to recognize an activity, many activities remain unidentified since the temporal information is discarded. Hence, this motivates us to design a robust method that uses temporal information, which is implicitly inherent in the human activity recognition. People have the same postures and posture sequences when they perform a specific activity. Therefore, we use shape features to classify each image frame into postures we defined. Then, we use the frame sequences of key postures to recognize which activity one does. Besides, a human body has almost constant natural frequency when one performs an action. It is the congenital restrictions of people. There are few differences between two image frames if they are captured in a short period. Hence, we can down sample the video frame instead of using all the thirty frames per second. Down sampling can also ease the intensive computational and memory loads encountered in a video signal processing.
The system flowchart is illustrated in Fig 1.1. Our system can be separated into three components. The first component is foreground subject extraction. The second component is transformation of image data into a space that is smaller and easier for posture recognition. The third component is automatic key posture frame selection of the video frames for activity classification. Using this key frame selection technique, we can discriminate a new, namely unknown, activity from the previous defined activities. A certain amount of unknown activity detected will signal us to request update learning of the activity recognition rule base. Note that the proposed key posture selection scheme can also generate the new key postures for unknown activities, which accelerates the update learning of our activity recognition rule base.
Fig. 1.1
The block diagram of hu
man activity rec
1.2 Foreground Subject Extraction
Background subtraction is widely used for detecting moving objects from image frames of static cameras. The rationale of this approach is to detect the moving objects by the difference between the current frame and a reference frame, often called the “background image,” or “background model.” A review is given in [5] where many different approaches were proposed in recent years. These approaches are all based on background subtraction. Basically, the background image is a representation of the scene with no moving objects; besides, background images are usually kept regularly update so as to adapt to the varying luminance conditions.
In order to solve the effect of varying luminance conditions, we develop a method which is robust to the illumination changes. The method use frame ratio rather than frame difference. After building a background model, we can extract foreground subject from video frames by subtracting each pixel value of background model from that of current image frame. The resulting image is converted to a binary one by setting a threshold. The binary image mainly contains foreground subject with only little noise. Therefore, we can set a threshold in the histogram of the binary image to extract a rectangle image, which is the most resemble shape of a person, of the target subject. The rectangle image is resized to the same measurements.
1.3 Eigenspace and Canonical Space Transformation
In most of video and image processing, the size of frame is usually very large and it usually exists some redundancy. The redundancy possesses little information of an image. Hence, some space transformations are introduced to reduce redundancy of
an image by reducing the data size of the image. The first step of redundancy reduction often transforms an image from spatiotemporal space to another data space. The transformation can use fewer dimensions to approximate the original image. There are many well-known transformation methods such as Fourier transformation, wavelet transformation, Principal Component Analysis and so on. Our transformation method combines eigenspace transformation and canonical space transformation which are described as follows.
Eigenspace transformation (EST), based on Principal Component Analysis, has been demonstrated to be a potent scheme used below: automatic face recognition proposed in [7], [8]; gait analysis proposed in [9]; and action recognition proposed in [10]. The subsequent transformation, Canonical space transformation (CST) based on Canonical Analysis, is used to reduce data dimensionality and to optimize the class separability and improve the classification performance. Unfortunately, CST approach needs high computation efforts when the image is large. Therefore, we combine EST and CST in order to improve the classification performance while reducing the dimension, and hence each image can be projected from a high-dimensional spatiotemporal space to a single point in a low-dimensional canonical space. In this new space the recognition of human activities becomes much simpler and easier.
1.4 Image Frame Classification and Activity Recognition
In this thesis, images are transformed into an image feature vector by extracting features from images. We utilize eigenspace and canonical space transformation method which is used to extract image features. We group three feature consecutive vectors from three contiguous images. Consequently, the time-sequential images are
converted to a posture sequence by using these three feature vectors. The posture sequence is dignified by the number of the templates. In the learning phase, we build a transition model in terns of three consecutive posture sequences which is the category symbol of the posture template. For human action recognition, the model which best matches the observed posture sequence is chosen as the recognized action category.
After transforming image frames to eigenspace and canonical space domain, some data information have been omitted. By using fuzzy rule-base techniques, the activity analysis task is tolerant to uncertainty, ambiguity and irregularity. Relevant articles using the fuzzy theory are described as follows. Wang and Mendel proposed that fuzzy rules to be generated by learning from examples in [11]. Su [12] presented a fuzzy rule-based approach to spatio-temporal hand gesture recognition. This approach employs a powerful method based on hyperrectangular composite neural networks (HRCNNs) for selecting templates. Ushida and Imura [13] introduced a real-time human-motion recognition method by means of Fuzzy Associative Memories Organizing Units System.
In our system, we propose a fuzzy rule-base approach for human activity recognition. Training data of each activity is represented in the form of crisp IF-THEN rules that is extracted from the posture sequences of the training data. Each crisp IF-THEN rule is then fuzzified by employing an innovative membership functions in order to represent the degree indicating the similarity between a pattern and the corresponding antecedent part in the training data. When an unknown activity is to be classified, each sample of the unknown activity is tested by each fuzzy rule. The accumulated similarity measure associated with three consecutive samples of the input image frame is to match the posture sequence representing an activity model of the training database, and the unknown activity is classified to the activity yielding the
highest accumulative similarity.
In classifying an action in the video frames, we compute the smallest dissimilarity membership degree among the IF-THEN rules. In the training phase, we compute the rule’s mean and standard deviation of each pre-defined activity. If the dissimilarity of the testing video frames, which is greater than the pre-defined activity to be performing a new action. Then, these three images frames will be input to the unsupervised clustering algorithm for possible new key posture selection.
1.5 Thesis Outline
The thesis is organized as follows. The theory of eigenspace transform, canonical space transform and unsupervised clustering algorithm is firstly introduced in Chapter 2. In Chapter 3, we describe our human activity recognition system in detail. In this chapter, we also use 5:1 down sampled video frames to build a fuzzy rule database for activity recognition. We collect three consecutive images as a feature vector. Then by training from the known data, we can extract transitional rules of templates for activity recognition. The fuzzy rules play an important role in our activity recognition system. Likewise, we also use action’s dissimilarity to the learned rule bases to find new activity. Last, we use unsupervised clustering algorithm to obtain the new key postures. In Chapter 4, the experiment results of our recognition system are shown. At last, we conclude this thesis with a discussion in Chapter 5.
Chapter 2 Basic Concept
In this chapter, we briefly explain the basic concepts of eigenspace and canonical space transform. Then unsupervised clustering algorithm concept is introduced.
2.1 Fundamentals of Eigenspace and Canonical Space
Transform
In video and image processing, the dimensions of image data are often extremely large. There are many well-known transformation methods to reduce the size of data such as Fourier transformation, wavelet, principal component analysis (PCA), eigenspace transformation (EST) and so on. However, PCA based on the global covariance matrix of the full set of image data is not sensitive to the class structure existent in the data. In order to increase the discriminatory power of various activity features, Etemad and Chellappa [14] used linear discriminant analysis (LDA), also called canonical analysis (CA), which can be used to optimize the class separability of different activity classes and improve the classification performance. The features are obtained by maximizing between-class and minimizing within-class variations. Here we call this approach canonical space transformation (CST). Combining EST with CST, our approach reduces the data dimensionality and optimizes the class separability among classes.
Image data in high-dimensional space are converted to low-dimensional eigenspace using PCA. The obtained vector thus is futher projected to a smaller canonical space using CST. Action Recognition is accomplished in the canonical space.
Assume that there are c classes to be learned. Each class represents a specific posture, which assumes of testers various forms existing in the training image data.
i, j
′
x is the j-th image in class i, and Ni is the number of images in the i-th class. The
total number of images in training set isNT = N1+N2 + +Nc. This training set can
be written as
[
x′1,1 , ,x1′,N1 , ,x′2,1 , ,x′c,Nc]
, (1)where each x′ is an image with n pixels. i,j
At first, the intensity of each sample image is normalized by
. , , , j i j i j i x x x ′ ′ = (2)
Then we can get the mean pixel value for training image as
. 1 1 1 , x
∑∑
= = = c i N j j i T i N x m (3)The training set can be rewritten as a n×NT matrix X. And each image xi,j forms
a column of X, that is
X=
[
x1,1−mx , ,x1,N1 −mx , ,xc,Nc −mx]
. (4)2.1.1 Eigenspace Transformation (EST)
Basically EST is widely used to reduce the dimensionality of an input space by mapping the data from a correlated high-dimensional space to an uncorrelated
information loss. EST uses the eigenvalues and eigenvectors generated by the data covariance matrix to rotate the original data coordinates along the direction of maximum variance.
If the rank of the matrix XXT is K, then K nonzero eigenvalues of XXT,
K
λ λ
λ1, 2, , , and their associated eigenvectors, e1 ,e2 , ,eK , satisfy the
fundamental relationship , 1 2 i i i i , , , K λ e =R e = (5) where T XX
R= and R is a square, symmetric matrix. In order to solve Eq. (5), we
need to calculate the eigenvalues and eigenvectors of of the n×n matrix XX . But T
the dimensionality of T
XX is the image size, it is too large to be computed easily.
Based on singular value decomposition theory, we can get the eigenvalues and eigenvectors by computing the matrix R~ instead, that is
T , data matrix
=
R X X X: (6)
in which the matrix size of R~ is NT ×NT which is much smaller than n×n of
R . Assume that the matrix R~ has K nonzero eigenvalues K ~ , , ~ , ~ λ λ λ1 2 and K
associated eigenvectors ~e1,~e2, ,~eK which are related to those in R by
( )
i i i K i i i , , 2 , 1 ~ ~ ~ 2 1 = ⎪⎩ ⎪ ⎨ ⎧ = = − e X e λ λ λ (7)These K eigenvectors are used as an orthogonal basis to span a new vector space. Each image can be projected to a point in this K-dimensional space. Based on the theory of PCA, each image can be approximated by taking only the k ≤K largest
eigenvalues λ1 ≥ λ2 ≥ ≥ λk and their associated eigenvectors e1 ,e2 , ,ek .
This partial set of k eigenvectors spans an eigenspace in which yi,j are the points
that are the projections of the original images xi,j by the equation
[
]
T, 1, , , 2 , , 1 2 ; 1 2
i j = k i j i= , , , c j= , , , Nc
y e e e x (8)
We called this matrix
[
e1,e2, ,ek]
T the eigenspace transformation matrix. Afterthis transformation, each original image xi,jcan be approximated by the linear
combination of these k eigenvectors and yi,j is a one-dimensional vector with k
elements which are their associated coefficients.
2.1.2 Canonical Space Transformation (CST)
Based on canonical analysis in [15], we suppose that
{
φ1,φ2, ,φc}
represents the classes of transformed vectors by eigenspace transformation and yi,j
is the j-th vector in class i. The mean vector of entire set can be written as
y 1 i j, , 1 2 ; 1 2 i i j T i , , , c j , , , N N =
∑∑
= = m y (9)The mean vector of the i-th class can be presented by
1 . Φ ,
∑
∈ = i i,j j i i i N y y m (10)Let Sw denote the within-class matrix and Sb denote the between-class matrix,
(
) (
)
(
) (
)
, T , , 1 φ T 1 1 1 i j i c i j i i j i i T c i i y i y i T N N N = ∈ = = − − = − −∑ ∑
∑
y S y m y m S m m m m w bwhere Sw represents the mean of within-class vectors distance and Sb represents the
mean of between-class distance vectors distance. The objective is to minimize Sw and
maximize Sb simultaneously, which is known as the generalized Fisher linear
discriminant function and is given by
( )
T . T W S W W S W W J w b = (11)The ratio of variances in the new space is maximized by the selection of feature transformation W if . 0 = ∂ ∂ W J (12)
Suppose that W* is the optimal solution where the column vector * i
w is a
generated eigenvector corresponding to the i-th largest eigenvalues λi. According to the theory presented in [15], we can solve Eq. (12) as follows
* * i i i S w w Sb =λ w . (13)
After solving Eq. (11), we will obtain c–1 nonzero eigenvalues and their corresponding eigenvectors
[
v1,v2, ,vc]
that create another orthogonal basis andspan a (c–1)-dimensional canonical space. By using these bases, each point in eigenspace can be projected to another point in canonical space by
[
c]
i j j i , T 1 2 1 , v ,v , ,v y z = − , (14)where zi,j represents the new point and the orthogonal basis
[
v1,v2, ,vc−1]
T iscalled the canonical space transformation matrix. By merging equation (8) and (14), each image can be projected into a point in the new (c-1)-dimensional space by
i,j j i H x z, = ⋅ , (15) in which H
[
, , ,] [
T 1, 2, ,]
T. 1 2 1 v vc e e ek v − =2.2 Unsupervised Clustering Algorithm
To further automatize in key frame selection of action recognition sysrem, we will propose an automatic clustering scheme for this purpose. Clustering is a powerful technique used in various disciplines such as pattern recognition [16], speech analysis [17], and information retrieval [18], etc. In [19], an unsupervised clustering based approach was introduced to determine key frames within a shot boundary. In this section, we introduce a new clustering approach to key frames extraction in video sequences [20].
Given a video shot s=
{
f1, f2, …, fN}
obtained from a shot foregroundextraction algorithm [6], we cluster the N frames into M clusters of center similarity, say σ1, σ2, …, σM . The similarity of two frames is defined as the similarity of their visual content, where the visual content could be color, texture, shape of the salient object of the frame, or the combination of the above. In this thesis, we select the binary values of our foreground detected frames as our visual content, although
other visual contents are readily integratable into the algorithm. The size of each frame we used is 128×96, raster-scanned to become 1×12288 vector. The similarity between frames i and j is thus defined as:
12288
( )
( )
1 2 1, 1, i j y B y B y = −∑
(16)Any clustering algorithm has a threshold parameter δ to determine whether a new frame will be classified into a certain cluster which in turns control the density of clustering. The similarities between the new frame node and the centroid of the existing cluster must be computed first. If the smallest similarity is less than δ , it means this node is close enough to be a member representing the cluster; otherwise, this node is not close enough to be a member representing the cluster. So we need to create a new cluster to represent the current image frame. The unsupervised clustering algorithm can be summarized as follows:
1. Initialization: σ1← f1, f1 → the centroid of σ1 (denoted as c ), 1σ1 → NumClu;
2. Get the next frame f . If the frame pool is empty, Goto 6; i
3. Calculate the similarities between f and existing clusters i
(
)
(
i k)
k k NumClu Sim f σ
σ =1,2,…, : , , based on Eq. 16;
4. Determine which cluster is the closest to f by clustering MinSim. Let i
NumClu
(
i k)
k Sim f MinSim=min =0 ,σ .If MinSim>δ , it means that f is not close enough to be put in any of the i
clusters, goto 5; otherwise, put f into the cluster which has MinSim, and i
Goto 6.
6. End the clustering algorithm.
It is natural that a big enough cluster would be qualified to be a representative of a dataset. In this thesis we say a clustering is big enough if its size is bigger than N/M (N:training data numbers; M:clustering numbers ), the average size of clusters. With above constraint in mind, we use Eq. (17) to compute the representative key frames which can represent its cluster.
⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ − =
∑
∈CluMem j j i i M M 2 min keyframes tive Representa , (17)Chapter 3 Human Activity Recognition System
The first step of human activity recognition system is foreground subject extraction. We have to construct a background model for sbject extraction. There are many well-known background models. The most common one is that applies frame difference with a threshold. W4 is such a typical example with some modifications [6]. It records the maximum and minimum grayscale and the maximum inter-frame difference of each pixel in a background video. Then each image frame subtracts the maximum and minimum grayscale of each pixel. If the pixel’s absolute value of the subtraction operation is larger than the maximum inter-frame difference, the pixel is classified to a foreground one. W4 admits some rules make the background model to be adaptive to varying environment. In our approach, we describe the background scene as a statistical model. We obtain a background model from background only video by calculating the maximum, minimum gray level and frame ratio of each pixel in the images.
3.1 Object Extraction
3.1.1 Background Modeling by Frame Ratio
We assume the image captured by a camera can be described as
( )
x y S( ) ( )
x y r x yIi , = i , i , , (18)
illumination, ri is the distribution of scene reflectance,
( )
x,y is the location of apixel in the image and i is the image sequence index. If the camera is fixed stationary and moving objects are not permitted to show up in the scene, the reflectance of the background may remain the same at any time. That is,
( ) ( )
x y r x yri , = , . (19)
Although the reflectance is not changed, the effect of illumination is still going on. The frame ratio between two consecutive frames can respectively be written as
( )
( )
( ) ( )
( ) ( )
( )
( )
( )
(
,)
log(
( )
,)
, log , , log , , , , log , , log 1 1 1 1 y x S y x S y x S y x S y x r y x S y x r y x S y x I y x I i i i i i i i i − − − − − = ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ = ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ = ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ (20)where I is the intensity of captured images, S is the spatial distribution of source illumination.
We propose to utilize the frame ratio to build the background model. Each pixel of background scene is characterized by three statistics: minimum intensity value
( )
x yn , , maximum intensity value m
( )
x ,y and maximum inter-frame ratio d( )
x ,yof a background video. Because these three values are statistical, we need a background video, without any moving objects, for background model training. Let I be an image frame sequence and contains N consecutive images. Ii
( )
x,y be theintensity of a pixel which is located at
( )
x,y in the i-th frame of I. The background( )
( )
( )
( )
{
}
( )
{
}
( )
( )
{
}
( )
( )
( )
{
}
( )
{
}
( ) ( )
{
}
1 1 1 max , min , if , , 1 , max , , , max , , min , otherwise max , , i i i i i i i i i i i i i i i i I x y I x y I x y I x y m x y I x y I x y n x y I x y d x y I x y I x y I x y − − − ⎧ ⎡ ⎤ ⎪ ⎢ ⎥ ⎪ ⎢ ⎥ ≥ ⎪ ⎢ ⎥ ⎡ ⎤ ⎪ ⎢ ⎥ ⎪ ⎣ ⎦ ⎢ ⎥ = ⎨ ⎢ ⎥ ⎡ ⎤ ⎪ ⎢ ⎥ ⎣ ⎦ ⎪ ⎢ ⎥ ⎢ ⎥ ⎪ ⎢ ⎥ ⎪ ⎢ ⎥ ⎪ ⎣ ⎦ ⎩ (21) . , ... 2, , 1 N i=3.1.2 Extraction of Foreground Object
Foreground objects can be segmented from every frame of the video stream. Each pixel of the video frame is classified to either a background or a foreground pixel by the difference between the background model and a captured image frame. We utilize the maximum intensity m
( )
x ,y , minimum intensity n( )
x ,y andmaximum inter-frame ratio d
( )
x ,y of the training background model to segment aforeground by ⎪ ⎪ ⎩ ⎪ ⎪ ⎨ ⎧ = ) , (x y B (22)
where Ii
( )
x ,y be the intensity of a pixel which is located at( )
x,y , B( )
x ,y is thegray level of a pixel in a binary image and k is a threshold. Threshold k is determined by experiments according to difference environments. The value of k affects the
otherwise. pixel foreground a , 255 ) , ( ) , ( ) , ( or ) , ( ) , ( ) , ( if pixel background a , 0 ⎪ ⎩ ⎪ ⎨ ⎧ < < y x kd y x n y x I y x kd y x m y x I i i
mount of information retained in binary image B.
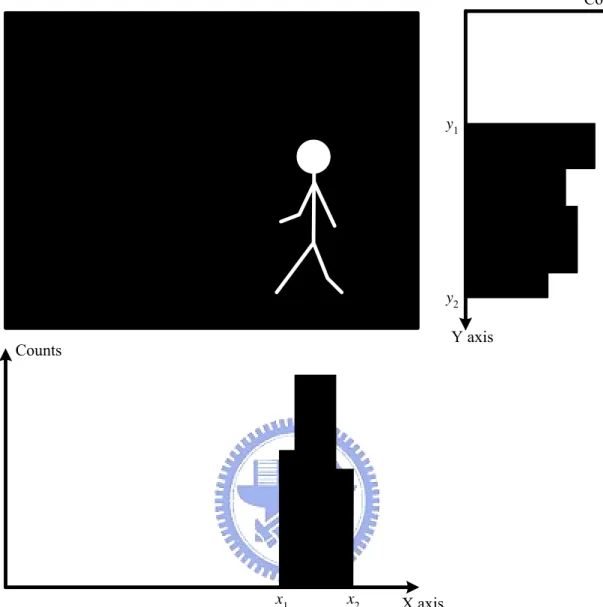
According to binary image B, we extract the region of foreground object to minimize the image size. Foreground region extraction can be accomplished by simply introducing a threshold on the histograms in X and Y direction. Fig. 3.1 shows an example of foreground region extraction. We utilize the binary image and project it to X and Y directions. The interested section has higher counts in the histogram. We obtain the boundary coordinates x1, x2 of X axis and y1, y2 of Y axis from the
projection histogram. We can use these boundary coordinates as the corner of a rectangle to extract foreground region. Fig. 3.2 is the extracted foreground region.
X axis Counts Counts Y axis x1 x2 y1 y2
Fig. 3.1 Histogram of binary image projection in X and Y direction.
3.2 Activity template selection
A human body is a rigid body, thus has its natural frequency. It has restriction on action speed when doing some specific actions. Because cameras usually capture image frames in a high frequency, i.e., 30 frames /sec, there is little difference between two consecutive postural image frames in such a short interval. In the following, we develop an automatic key posture frame selection of the video frames for activity classification. Firstly, we need to determine how many key posture frames we want in this video sequence. These images frames will be inputted to the unsupervised clustering algorithm for possible key posture selection and the key frames usually should pass the mean number of constituent of member support for enough representative. Namely, we will delete the clusters whose constituent member number is too small. After the above clustering procedure, if the clustering number is not larger than the predefined threshold (threshold=28 the suitable key postures for six actions), we will delete clusters that are not representative enough; otherwise, we will find the first 28 cluster centers whose mutual distances are farthest in distance each other. After the clustering steps, we call them as the essential template image, or equivalently, key posture frame. An example is shown in Fig. 3.3. After the template selection, each activity is represented by several essential templates.
These essential templates are transformed to a new space by eigenspace transformation (EST) and canonical space transformation (CST). The approximation can decrease data dimension, but it would also lose slight information of image with few differences. However, two similar image frames will converge to two near points after eigenspace and canonical space transformation. The images of similar postures done by difference people also barely converge to one point. Consequently, we select only essential templates rather than use all sequences for human activity recognition.
As described in Chapter 2, each image frame is transformed to a (c–1)-dimensional vector by EST and CST methods. Assume that there are n training models and c clusters in the system. Therefore, we have Nt templates, where Nt is
equal to n multiplied by c. Let gi,j be a vector of template image of the j-th training
model and the i-th category and ti,j be the transformed vector of gi,j.Vector ti,j
is computed by n j c i j i j i, =H⋅g, , =1 ,2 , , ; =1 ,2 , , t (23)
where H denote the transformation matrix combing EST and CST and n is the total number of posture images in the i-th cluster. ti,j is a (c–1)-dimensional vector and
each dimension is supposed to be independent. Hence,vector ti,j is rewritten as
T 1 2 1 , , , , , , , . c i j ti j ti j ti j − ⎡ ⎤ = ⎣ ⎦ t (24)
3.3 Construction of Fuzzy Rules from Video Streams
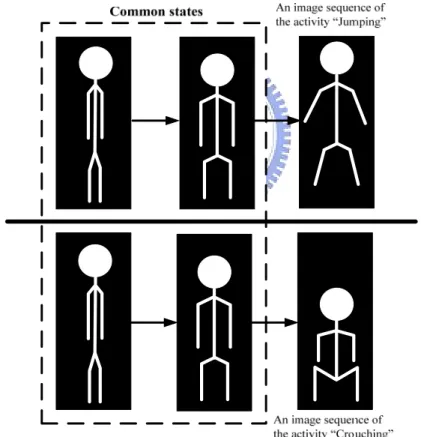
Transitional relationships of postures in a temporal sequence are important information for human activity classification. If we only utilize one image frame to classify the action, classification result may be failed easily because human’s actions may have similar postures in two different activity sequences. For example, the action of “jumping” and “crouching” both have the same postures called common states as shown in Fig. 3.4. Besides, the posture sequence of each activity is dissimilar in different people.
Fig. 3.4 Common states of two different activities.
Hence, we propose a method which not only combines temporal sequence information for recognition but also is tolerant to variations of different people. We
use the fuzzy rule-base approach to design our system. The fuzzy rule-base approach also has been proposed in gesture recognition in [12]; it is capable of absorbing the data difference by learning.
We use the Euclidean distance between the image frames of CST transformed feature vector to indicate the chance to be belonging to the modeling clusters of key posture.Firstly, when the k-th training image frame xk is inputted, the feature vector ak
is extracted by
ak =H⋅xk. (25) As same as ti,j in Eq. (24), ak can be rewritten as
1, , , 2 c 1 T k ak ak ak − ⎡ ⎤ = ⎣ ⎦ a . (26)
If we assume the dimensions of the feature vectors are independent, a local measure of similarity between the input image frame and each modeling key postures can be computed. The class index as well as the distance between the input image frame and the best matched key posture frames can be computed as
= ⎜⎝⎛
(
−)
⎟⎠⎞ 2 , min min arg ˆ j i k j i k a t i , (27) = ⎜⎝⎛(
−)
⎟⎠⎞ 2 , , ˆ min min k ij j i k i a t r , (28)where j is the training model number. Number riˆ,k denotes the distance between the
k-th image frame and most resembled key frame posture iˆ.
Moreover, we collect three consecutive image frames to integrate the temporal information. If we use too many images to form a basis, we could contain too many images to be processed and reduce the throughput rate. If we use too few images, it may not have enough timing information to represent an activity.
Using minimal distance criterion, we can determine the belonging key posture of the input image. Namely, each image frame can be represented by one of 28 key postures. To employ the temporal relation existing among the video frames, we combine three contiguous 5:1 down-sampled images to a group ( , , )I I I1 2 3 . The
transformation through CST of the image group will result in a feature vector [a1,a2,a3]. Using Eqs. (27) and (28), we can classify a to i P , i i=1, 2, and 3. Thus
classify [a1,a2,a3] to [P1,P2,P3]. There are c3 combinations of the feature vector to
form a clue for action identification. Each combination represents the possible transition states of the three images that compile part of an action. Naturally, an image sequence with [P1,P2,P3] sequence will be associated with its output of corresponding activity.
As developed by Wang and Mendel [11], fuzzy rules can be generated by learning from examples. Such image sequence constitutes an input-output pair to be learned in the fuzzy rule base. In this setting, the generated rules are a series of associations of the form
“IF antecedent conditions hold, THEN consequent conditions hold.”
The number of antecedent conditions equals the number of features. Note that antecedent conditions are connected by “AND.”
[ 1 1 3 1 2 1 1,P ,P ;D P ] (29)
For example, suppose that Image 1, Image 2 and Image 3 belong to key posture 1, key posture 2 and key posture 3 respectively. Therefore, we assign the image sequences, whose CST transformed feature vector is [ 1
1
a ,a12,a13], to the key posture sequence
Posture 1, Posture 2 and Posture 3 respectively; i.e, [P1,P2,P3]. Finally, according to
the feature-target association implies this image sequence to support the rule of
Rule 1. IF the activity’s I1 is P11 AND its I2 is P AND its 21 I is 3 P , 31
THEN the activity is D1. (30)
Similarly, for the second
[ 2 2 3 2 2 2 1 ,P ,P ;D P ] (31)
where i 1 a , i 2 a , and i 3
a denote the identified key postures of Image 1, Image 2, and
Image 3 of the activity, respectively, and Di is the corresponding belonging object
category of the activity.
[ 2 2 3 2 2 2 1 ,P ,P ;D
P ] can imply the rule of
Rule 2. IF the activity’s I1 is P12 AND its I2 is P22 AND its I is 3 P32,
THEN the activity is D2. (32)
After the learning steps of action video, some rules that obtained enough member of supporting fire strength may be representative to describe an action in video. In this thesis, a rule with at least four supporting input image frames is selected and compiled to constitute the knowledge rule base of our action recognition system. During the training of image sequences, we can compute the mean and standard deviation of each pre-defined activity. In this thesis, we have six pre-defined activities, thus we can compute six activity group’s means and standard deviations and use them to determine whether the input image belongs to one of the pre-defined actions or an unknown action. Lastly, we will also generate some extra key postures for unknown actions.
3.4 Classification Algorithm
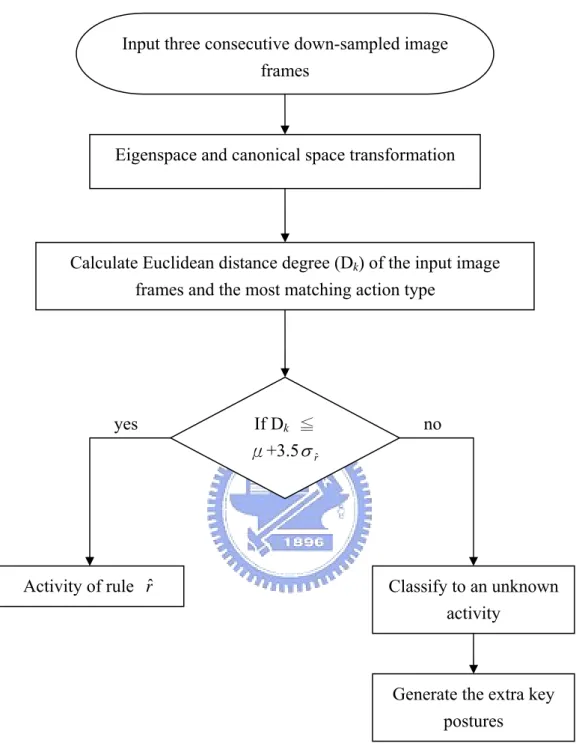
After constructing the rule base, we can match the input image sequence to each fuzzy rule by calculating their matching degrees. The distance between the input image sequence and a rule base is the sum of distance between three corresponding key postures in Eq. (28). The consequence of the rule having smallest key posture
difference is identified to be the action of the current image sequence. However, if this posture difference sum falls outside 3.5 times standard deviations of this action type, then the current image frame is not similar enough to this action, and we will identify it to be an unknown action instead. Moreover, we can also generate the extra key postures for unknown action. Fig. 3.5 shows the structure of human activity recognition algorithm.
Fig. 3.5 The structure of the human activity recognition algorithm.
yes no
Eigenspace and canonical space transformation
Calculate Euclidean distance degree (Dk) of the input image
frames and the most matching action type
If Dk ≦
μ+3.5σrˆ
Activity of rule rˆ Classify to an unknown activity
Generate the extra key postures
Input three consecutive down-sampled image frames
Chapter 4 Experimental Results
In our experiment, we test our system on video sequence containing a subject action. There are eight model actions, which are demonstrated by the research members of our Intelligence Technology Lab of the Department of Electrical and Control Engineering at National Chiao Tung University (NCTU). The video is taken in a classroom at the 5th Engineering Building in NCTU. The light source is fluorescent lamps and is stable. The background is not complex and we equip a table in the scene. The camera is set up at a fixed location and kept stationary. The camera has a frame rate of thirty frames per second and the image resolution is 320×240 pixels. The environment of the classroom is shown in Fig. 4.1.
Fig. 4.1 The scene environment of our system.
Each member performed eight actions: “walking from left to right,” “walking from right to left,” “jumping,” “crouching,” “climbing up,” “climbing down,” “cavorting ” and “sitting.” The action “climbing up” is to climb up on the table from the ground. The action “climbing down” is to climb down to the ground from the table. Hence we have eight model actions as described above. First six actions are the
pre-defined, or called known, actions and the last two actions, “cavorting” and “sitting,” are not defined, or called unknown, actions. Five lab members did these eight actions at their pleasure. Besides, a video of pure background with no subject in the scene is adopted in our experiment and this is used as a background model. One video chosen randomly from the five model actions is used for testing, i.e.,
recognition and the rest four are used for training. The video of each subject model is used for testing in turn.
4.1 Background Model and Object Extraction
A background model is used for segmenting the foreground subject or object. If the background model is affected by the illumination change, there will be some noise or wrong segmented region left in the extracted image. From our experience, the frame ratio method can eliminate the influence of illumination variations.
A threshold k is applied in frame ratio approach to obtain binary image B
( )
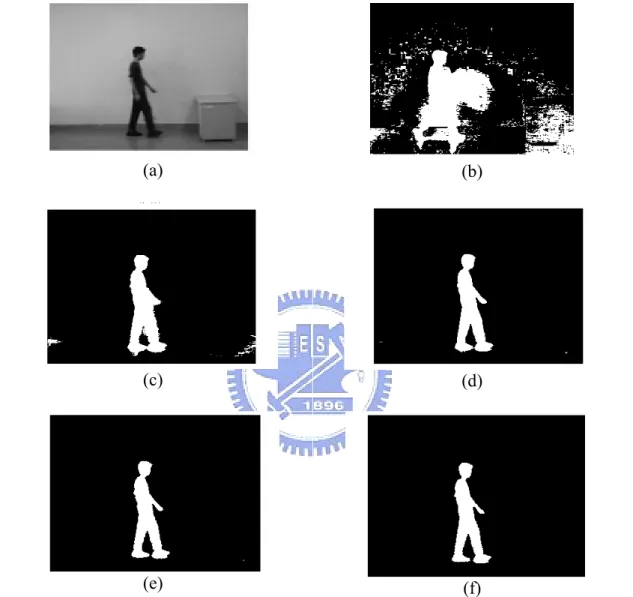
x ,yin Eq. (22) described in Section 3.1.2. The value of k is chosen by experiment and varies with different environment. Hence, we ran a series of experiments to determine the optimal threshold k and the corresponded binary images are shown in Fig. 4.2. The threshold value k =1.3 was adopted in our experiment.
Foreground object region is extracted from binary image B
( )
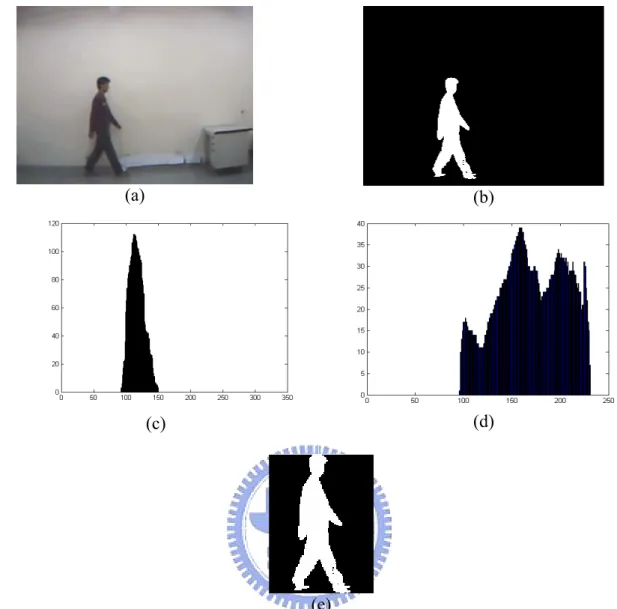
x ,y in order tominimize the size of images. Foreground region extraction is accomplished by simply taking a threshold along X and Y directions. Fig. 4.3 shows an example of foreground region extraction. Fig. 4.3(a) is a image frame of the video stream. Fig. 4.3(b) is the binary image after performing background model analysis. Figs. 4.3(c) and 4.3(d) show the projection of Fig. 4.3(b) onto the X and Y directions, respectively. We can
find the boundary coordinates of X and Y directions by observing the projection histogram. We used these boundary coordinates to define a rectangle to extract foreground region from Fig. 4.3(b). Fig. 4.3(e) is the extracted foreground region.
(a) (b)
(c) (d)
(e) (f)
Fig. 4.2 An example of foreground region extraction at different threshold, k, values. (a) An image frame, (b) k = 1.0, (c) k = 1.1, (d) k = 1.2, (e) k = 1.3, (f) k = 1.4.
(a) (b)
(c) (d)
(e)
Fig. 4.3 An example of foreground region extraction. (a) An image frame, (b) binary image after background analysis, (c) projection of (b) onto X direction, (d) projection of (b) onto Y direction, (e) foreground region extracted.
4.2 Fuzzy Rule Construction for Action Recognition
For activity recognition, we use the key frame selection technique to
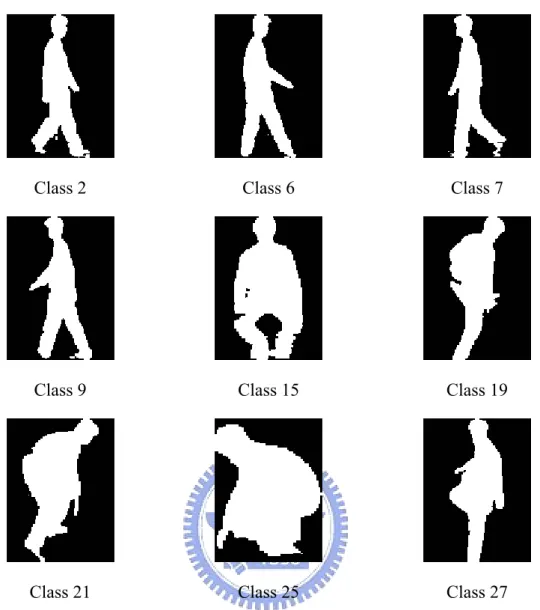
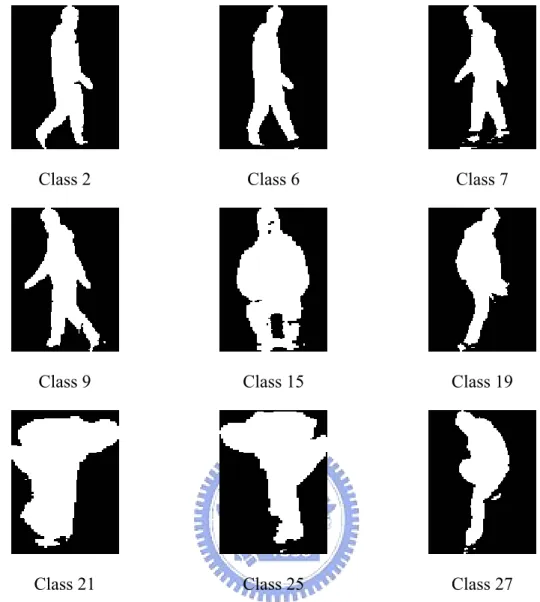
automatically select essential templates of the video frames for activity clustering. We chose six essential templates for “walking from right to left,” “walking from left to right” and “climbing down,” respectively; five for “climbing down,” three for “crouching” and two for “jumping.” There are totally 28 essential templates, and comprising 28 classes. The essential template numbers of each activity depend on how long the activity takes for a complete cycle. Each essential template is a representative cluster center around every five images, which are extracted from five different training persons and have similar postures. Figs. 4.4 and 4.5 are two examples of some templates of two training models.
As shown in Figs. 4.4 and 4.5, if a model bend down or squat down, the bodies in template images are wider than others. For normalization purpose, every segmented image is resized until its height equals to 128 pixels or width equals to 96 pixels. Images of stand posture usually resize to its height to be the ratio of 96 to 128 pixels. On the contrary, when the height of body shape is small, the magnifying factor of the image becomes large.
Class 2 Class 6 Class 7
Class 9 Class 15 Class 19
Class 21 Class 25 Class 27 Fig. 4.4 Some “essential templates of posture” of person 1.
Class 2 Class 6 Class 7
Class 9 Class 15 Class 19
Class 21 Class 25 Class 27 Fig. 4.5 Some “essential templates of posture” of person 5.
The template images are transformed to canonical space by the methods described in Chapter 2. Each essential template image of a training model was treated as a center. Hence, there were 112 center vectors because of four subject models and 28 class centers of essential templates of each subject models. Using leave-one-out strategy, there were five test subject models to be tested.
In the testing phase, the training video frames are inputted for activity recognition. The smallest essential template to each image frame is calculated by using Eq. (28) in Section 3.4. We gathered three consecutive 5:1 sub-sampled images
as a group in order to include temporal information. Training is accomplished in off-line manner. Therefore, we gathered three images from different start points to train for constructing fuzzy rules. For examples: the first frame, the 6-th frame and the 11-th frame are gathered together as an input training data; the second frame, the 7-th frame and 12-th frame are gathered together as another input training data; and the third frame, the 8-th frame and the 13-th frame are gathered together as an other input training data, etc. Different start points of image frames, as described above, are used for training fuzzy rules in our experiment, in corresponding to the starting testing video frame may not be the same, either. By utilizing different starting images, the system will be robust to be insignificant to the starting position of the video frames.
The group of the threes images is converted to the posture sequence which has the summation of the three minimal Euclidean distances to the essential templates by Eq. (28). Each posture sequence will support the corresponding rule once. If the corresponding rule is not existent, a new rule is generated in the IF-THEN form as represented in Section 3.4.
A threshold has to be set after all training patterns have been learned. The threshold is used to abandon the IF-THEN rule whose cumulative occurrence times are relative few. The numbers of rules being selected varies with different threshold selection. Table I shows the rule numbers versus different threshold values. Five model excluding one subject are chosen from the training data be utilized for rule construction. Obviously, the higher the threshold we choose, the fewer rules we will obtain. Although higher threshold can reduce rules, fewer rules will lose the tolerance for small difference observed even for the same activity. If some conflicting rules are generated, we choose the rule that is supported by a maximum number of training instances.
TABLE I
THE RULE NUMBERS AT DIFFERENT THRESHOLD
Training models
except Threshold = 3 Threshold = 4 Threshold = 5
Person 1 200 137 92
Person 2 190 138 104
Person 3 184 126 94
Person 4 185 128 91
Person 5 210 150 107
The test images are similarly 5:1 down-sampled of video frames. An activity should appear in a proper order directly perceived through our sense. For example, P1
through P6 are the six linguistic labels of the activity “walking from left to right.” The
activity of “walking from left to right” should have the rules with the posture sequence directly perceived through the senses: (P1, P2, P3), (P2, P3, P4), (P3, P4, P5),
(P4, P5, P6), (P5, P6, P1), (P6, P1, P2). With the threshold was set at four, a set of fuzzy
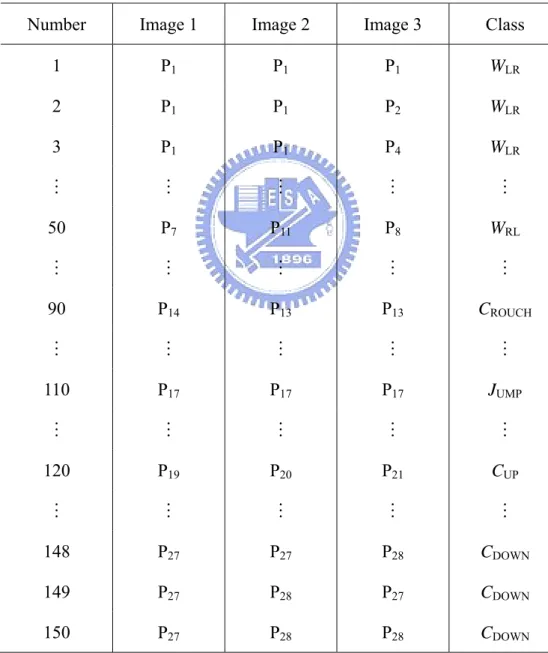
rules generated from the training data except person 5 are listed in Table II. Two of the learned fuzzy rules of above are represented together with template images are shown in Fig. 4.6. After training all of image sequences, we can compute each the mean and standard deviation of pre-defined activity’s matching degree. In this thesis, we have six pre-defined activities, this we can compute these six activities means and standard deviations and use them to determine whether a input image is belonging to one of pre-defined activity or an unknown activity. In Section 3.2, we discuss the key postures selected by manually and unsupervised clustering algorithm. Table III is the
recognition rates of key postures selected manually. Table IV is the recognition rates of key postures selected by unsupervised clustering algorithm. Table V is the means and standard deviations of person 5.
TABLE II
THE OBTAINED FUZZY RULE BASE GENERATED FROM THE TRAINING DATA EXCEPT
PERSON 5
Number Image 1 Image 2 Image 3 Class
1 P1 P1 P1 WLR 2 P1 P1 P2 WLR 3 P1 P1 P4 WLR 50 P7 P11 P8 WRL 90 P14 P13 P13 CROUCH 110 P17 P17 P17 JUMP 120 P19 P20 P21 CUP 148 P27 P27 P28 CDOWN 149 P27 P28 P27 CDOWN 150 P27 P28 P28 CDOWN
TABLE III
THE RECOGNITION RATES OF KEY POSTURES SELECTED MANUALLY
Recognition rate (%) Testing data
WLR WRL CROUCH JUMP CUP CDOWN
Person 1 100 100 100 100 100 62.26 Person 2 100 94.62 100 100 100 93.33 Person 3 99.11 100 100 100 100 72.61 Person 4 97.06 100 71.70 100 83.54 100 Person 5 100 100 100 100 82.61 100 Average 96.21 TABLE IV
THE RECOGNITION RATES OF KEY POSTURES SELECTED BY UNSUPERVISED CLUSTERING
ALGORITHM
Recognition rate (%) Testing data
WLR WRL CROUCH JUMP CUP CDOWN
Person 1 100 95.74 100 100 100 83.02 Person 2 100 89.25 100 100 100 95.56 Person 3 99.11 100 100 100 87.16 32.88 Person 4 97.06 98.78 85.85 97.17 81.01 91.38 Person 5 100 89.66 100 100 89.86 100 Average 94.79
(a)
(b) Fig. 4.6 Two examples of fuzzy rules. (a) Walking from left to right, (b)
Climbing down.
TABLE V
THE MEANS AND STANDARD DEVIATIONS OF SIX ACTIVITIES’MATCHING DEGREE OF
TRAINING MODEL EXCEPT PERSON 5
Activity Mean Standard deviation (
σ
)WLR 7060.04 1819.92 WRL 7043.74 1870.61 CROUCH 5227.48 1332.18 JUMP 3630.96 1168.53 CUP 6282.87 2544.87 CDOWN 7131.24 2804.25
4.3 The Activity Recognition Using Fuzzy Rule Base
Approach
The activity recognition system in our experiment is off-line presented and tested; therefore, the testing video is not done in real time phase. We input the testing video from different starting frames which is similar to the way for the training phase. Namely, we recognize the video from the first frame, the second frame, the third frame and the fourth frame, etc. with the down sampling intervals of five frames. The testing video was not used for constructing templates and fuzzy rules. Hence, there are five video databases for training and testing.
An example of recognition rate of a testing video start from different frames is shown in Table VI. In this table, WLR is the activity “walking form left to right,” WRL
is the activity “walking from right to left,” JUMP is the activity “jumping,” CROUCH is
the activity “crouching,” CUP is the activity “climbing up,” CDOWN is the activity
“climbing down,” CAVORT is the activity “cavorting” and SIT is the activity “sitting.”
The threshold selected for this model is four and we also employ mean plus 3.5 standard deviations as matching degree a boundary to differentiate between the predefined and unknown activities.
TABLE VI
THE RECOGNITION RATE OF PERSON 5 WITH DIFFERENT STARTING FRAME
Recognition rate (%) Starting frame
WLR WRL CROUCH JUMP CUP CDOWN CAVORT SIT
From the 1st, 6th, … frame 100 94.44 100 100 85.71 100 64.71 89.66 From the 2nd, 7th, … frame 100 83.33 100 100 78.57 100 52.94 87.93 From the 3rd, 8th, … frame 100 88.24 100 100 78.57 100 47.06 91.23 From the 4th, 9th, … frame 100 88.24 100 100 64.29 100 68.75 89.47 From the 5th, 10th, … frame 100 94.12 100 100 61.54 100 87.50 85.96
Table VII shows the recognition rate of our system on the five testing subject models. The threshold used to construct fuzzy rules is four. For each activity, the recognition are obtained from different frame and then averaged.
TABLE VII
THE RECOGNITION RATES OF EACH ACTIVITY
Recognition rate (%) Testing data
WLR WRL CROUCH JUMP CUP CDOWN CAVORT SIT
Person 1 100 95.74 74.34 100 100 83.02 17.54 96.65 Person 2 100 89.25 94.03 87.04 95.96 68.89 14.42 94.74 Person 3 78.57 97.25 100 100 83.49 32.88 84.56 100 Person 4 97.06 98.78 59.43 70.75 49.37 91.38 4.85 100 Person 5 100 89.66 100 100 73.91 100 63.86 88.85 Average 84.63
4.4 Extract the New Key Postures
After the recognition scheme is complete, we can generate some unknown image frames from unknown activities of cavorting and sitting. We input these image frames not belonging to the essential templates to unsupervised clustering algorithm. Moreover, we can then generate the extra key postures for unknown action. After generate the key postures, we will compute the distances between the newly found key postures 112 pre-defined key postures. If this distance is greater than the threshold, Th=8500, then the key posture is not similar enough to the pre-defined key postures, and we will thus identify it to be the extra key posture instead. Figs. 4.7 and 4.8 are two obtained extra key postures of two testing models. Then, imposing at least having Th=8500 deviation from a pre-defined key postures on these key postures. Figs. 4.9 and 4.10 are obtained the final key postures of these two testing model. The
detection accuracies of real-time and final new key postures belonging to the unknown action video are summarized in Tables VIII and IX.
Fig. 4.8 “The new key postures,” of person 5.
Fig. 4.10 “The final new key postures,” of person 5.
TABLE VIII
THE DETECTION ACCURACY OF REAL-TIME NEW KEY POSTURES BELONGING TO THE
UNKNOWN ACTION VIDEO
Person 1 Person 2 Person 3 Person 4 Person 5 Average Key posture
detection accuracy (%)
100.00 88.00 78.38 91.30 90.91 87.90
TABLE IX
THE DETECTION ACCURACY OF FINAL NEW KEY POSTURES BELONGING TO THE
UNKNOWN ACTION VIDEO
Person 1 Person 2 Person 3 Person 4 Person 5 Average Key posture
detection accuracy (%)
Chapter 5 Conclusion
In this thesis, we have presented a fuzzy rule base approach to human activity recognition. In our approach, the effect of illumination variation is decreased by adopting frame ratio method. Moreover, CST and EST are used to reduce data dimensionality and optimize the class separability simultaneously, and each frame of video sequence is then converted to one of 28 key frame postures. At last, fuzzy rule base is reasoned for activity recognition. We also employ unsupervised clustering algorithm to on-line obtain the new key postures of unknown action.
Experiment results have shown that the recognition rate for eight activity classification is 84.63%. Besides, the detection accuracies of finding new key postures, that belonging to the unknown action, are 87.90% on-line, and 89.56% off-line, respectively.
To investigate further, we will further automize the update learning of activity recognition rule base. In addition, recognition from a different viewing direction, extension of test environment, and more complicated activities are our future work.
References
[1] F. Bobick and J. W. Davis, “The recognition of human movement using temporal templates,” IEEE Trans. Pattern Anal. Machine Intell., vol. 23, no. 3,
2001.
[2] R. Hamid, Y. Huang, and I. Essa, “ARGMode–Activity recognition using graphical models”, in Proc. Conf. Comput. Vision Pattern Recog., vol. 4, pp. 38–45, Madison, Wisconsin, 2003.
[3] S. Carlsson and J. Sullivan, “Action recognition by shape matching to key frames,"in Proc. IEEE Comput. Soc. Workshop Models versus Exemplars in
Comput. Vision, pp. 263–270, Miami, Florida, 2002.
[4] I. Cohen and H. Li, “Inference of human postures by classification of 3D human body shape," in Proc. IEEE Int. Workshop on Anal. Modeling of Faces
and Gestures, pp. 74–81, 2003.
[5] M. Piccardi, “Background subtraction techniques: a review,” in Proc. IEEE Int.
Conf. SMC., vol. 4, pp. 3099–3104, 2004.
[6] I. Haritaoglu, D. Harwood, and L. S. Davis, “W4: Real-time surveillance of people and their activities,” IEEE Trans. Pattern Anal. Machine Intell., vol. 22, no. 8, pp. 809–830, August 2000.
[7] H. Saito, A Watanabe, and S Ozawa, “Face pose estimating system based on eigenspace analysis,” in Proc. Int. Conf. Image Processing, vol. 1, pp. 638–642, 1999.
[8] J. Wang, G. Yuantao, K. N. Plataniotis, and A. N. Venetsanopoulos, “Select eigenfaces for face recognition with one training sample per subject,” 8th Cont.,
[9] P. S. Huang, C. J. Harris, and M. S. Nixon, “Canonical space representation for recognizing humans by gait or face,” in Proc. IEEE Southwest Symp. Image Anal.
Interpretation, pp. 180–185, 1998.
[10] M. M. Rahman and S. Ishikawa, “Robust appearance-based human action recognition,” in Proc. the 17th Int. Conf. Pattern Recog., vol. 3, pp. 165–168, 2004.
[11] L. X. Wang and J. M. Mendel, “Generating fuzzy rules by learning from examples,” IEEE Trans. Syst., Man Cybern, vol. 22, no. 6, pp. 1414–1427, 1992. [12] M. C. Su, “A fuzzy rule-based approach to spatio-temporal hand gesture
recognition,” IEEE Trans. Syst., Man Cybern, vol. 30, no. 2, pp. 276–281, 2000. [13] H. Ushida and A. Imura, “Human-motion recognition by means of fuzzy
associative inference,” in Proc. Fuzzy Syst., 1994. IEEE World Congress Comput.
Intell., vol. 2, pp. 813–818, 1994.
[14] K. Etemad and R. Chellappa, “Discriminant analysis for recognition of human face images,” in Proc. ICASSP, pp. 2148–2151, 1997.
[15] K. Fukunaga, Introduction to Statistical Pattern Recognition, 2nd edition, 1300 Boylston Street Chestnut Hill, Massachusetts USA: Academic Press, 1990.
[16] R. O. Duda and P. E. Hart, Pattern Classification and Scene Analysis, ch. 6. John Wiley and Sons, Inc.
[17] L. Rabiner and B. H. Juang, Fundamentals of Speech Recognition, ch. 5. Englewood Cliffs, New Jersey:Prentice Hall, 1993.
[18] G. Salton and M. J. McGill, Introduction to Modern Information Retrieval. McGraw-Hill Book Company, 1983.
[19] A. M. Ferman and A. M. Tekalp, “Multiscale content extraction and representation for video indexing, ” in Multimedia Storage and Archival Systems, (Dallas, TX), Nov. 1997.
[20] Y. Zhuang, Y. Rui, T. S. Huang, and S. Mehrotra, “Adaptive key frame extraction using unsupervised clustering, ” in Proc. Conf. Image Processing., vol. 1, pp. 866-870, 1998.