里德所羅門碼之信念傳遞解碼演算法研究
71
0
0
全文
(2) 里德所羅門碼之信念傳遞解碼演算法研究 A Study on Belief-Propagation Based Decoding Algorithms for Reed-Solomon Codes 研 究 生:謝郁民. Student:Yu-Min Hsieh. 指導教授:王忠炫. Advisor:Chung-Hsuan Wang 國立交通大學 電信工程學系碩士班 碩 士 論 文 A Thesis. Submitted to Department of Communication Engineering College of Electrical and Computer Engineering National Chiao Tung University in Partial Fulfillment of the Requirements for the Degree of Master of Scince in Communication Engineering July 2007 Hsinchu, Taiwan, Republic of China. 中. 華. 民. 國 九十六 年 七 月.
(3) 里德所羅門碼之信念傳遞解碼演算法研究. 研究生:謝郁民. 指導教授:王忠炫 博士. 國立交通大學 電信工程學系碩士班. 摘. 要. 里德所羅門碼 (Reed-Solomon codes) 目前已被使用於許多先進的通訊和儲 存系統上。眾所皆知,里德所羅門碼的軟式決策解碼相較於傳統的硬式決策解碼 能夠提供明顯的效能改善,但由於其軟式決策解碼的高複雜度,目前大部分的系 統仍然使用傳統的硬式決策解碼器。Jiang 和 Narayanan 於 2006 年提出了一種 利用適應性校驗矩陣,對里德所羅門碼進行軟式輸出輸入解碼的演算法 (JN 演 算法)。JN 演算法能夠避免校驗節點飽和化以及低信任度位置之錯誤傳遞等問 題,然而其潛在的問題在於過度信任高信任度位置的訊息。於本篇論文中,我們 首先將討論造成 JN 演算法解碼失敗的因素,並提出適當的演算法來避免 JN 演 算法中高信任度位置錯誤所造成的影響,並增進其解碼效能。.
(4) A Study on Belief-Propagation Based Decoding Algorithms for Reed-Solomon Codes. Student:Yu-Min Hsieh. Advisor:Dr. Chung-Hsuan Wang. Department of Communication Engineering National Chiao Tung University. Abstract. Recently, Reed-Solomon (RS) codes have been used in many state-of-the art communication and recording systems. It is known that soft-decision decoding (SDD) of RS codes provides significant performance gain over hard decision decoding (HDD), but most systems still are based on HDD because of the high complexity of SDD. In 2006, Jiang and Narayanan presented an iterative soft-in soft-out decoding algorithm of RS codes by adapting the parity check matrix. JN algorithm can avoid the problem of check node saturation and the error propagation from the least reliable positions, but the drawback of JN algorithm is to over believe the message from the most reliable positions. In this thesis, we first discuss the cause of decoding failure in traditional JN algorithm. Based on our discussion, we present a proposed algorithm to avoid the influence of the high reliable errors in JN algorithm and improve the decoding performance..
(5) 誌. 謝. 本篇論文得以完成,首先要感謝指導教授王忠炫博士的栽培,在兩年的過程 中,教導我研究的態度和方法,並且適時地給予建議和方向。也感謝同學、學弟、 學長們的鼓勵和幫助。 特別想感謝在最後這段時間裡支持我的朋友們,小毛、軒哥、阿傑、冠霖, 還有電工系的毛大學長,蘭友會的朋友們,在精神上給予極大的支持和幫助。最 後想謝謝我的家人,讓我能夠專心在研究過程中,謝謝大家。. 民國九十六年七月 研究生謝郁民謹識於交通大學.
(6) 目錄 目錄........................ ……………………………………………………………………I 圖目錄..........................................................................................................................III. 第一章 概論 .................................................................................................................1 第二章 梯度下降解碼演算法之理論基礎 .................................................................4 2-1 符號定義 .............................................................................................................4 2.1.1 傳送信號符號定義......................................................................................4 2-1.2 通道環境符號定義 .....................................................................................5 2-1.3 里德所羅門碼之符號定義 .........................................................................6 2-2 里德所羅門碼之二位元映射.............................................................................6 2-2.1 二位元映射基底 .........................................................................................6 2-2.2 代數加法之二位元映射 .............................................................................7 2-2.3 代數乘法之二位元映射 .............................................................................7 2-2.4 里德所羅門碼二位元奇偶校驗矩陣之生成 .............................................8 2-3 梯度下降法之理論基礎.....................................................................................9 2-3.1 函數定義 .....................................................................................................9 2-3.2 梯度下降法理論基礎 ...............................................................................10 2-3.3 梯度下降法解碼步驟 ...............................................................................13 2.4 梯度下降法之圖形化運作方式 .......................................................................13 第三章 JN 解碼演算法及 ABP-OSD(1)解碼演算法 ..............................................17 3-1 JN 解碼演算法 ..................................................................................................17 3-1.1 JN 解碼演算法簡介...................................................................................17 3-1.2 JN 演算法解碼步驟...................................................................................19 3-1.3 JN 演算法解碼範例...................................................................................19 3-1.4 JN 解碼演算法之改善方式.......................................................................21 3-2 ABP-OSD(1) 解碼演算法 ................................................................................23 3-2.1 ABP-OSD(1) 解碼演算法簡介.................................................................23 3-2.2 OSD ( w ) 解碼演算法步驟......................................................................24 3-2.3 OSD(1) 解碼演算法範例..........................................................................26 3-2.4 JN-OSD(1) 解碼演算法步驟....................................................................28 第四章 抑制 JN 演算法中高信任度錯誤之演算法 ................................................30 4-1 JN 演算法之探討 ..............................................................................................30 4-1.1 JN 演算法之優勢.......................................................................................30 I.
(7) 4-1.2 JN 演算法之潛在問題...............................................................................35 4-2 提出之演算法...................................................................................................36 4-2.1 提出之演算法概念說明 ...........................................................................36 4-2.2 提出之演算法解碼步驟 ...........................................................................38 4-2.3 提出演算法之 OSD(1) 回授機制討論....................................................39 4-2.4 提出之演算法數據觀察 ...........................................................................44 4-3 結合里德所羅門碼之內插特性之方式 ...........................................................47 第五章 模擬結果與討論 ...........................................................................................51 第六章 結論 ...............................................................................................................59 參考文獻 .....................................................................................................................61. II.
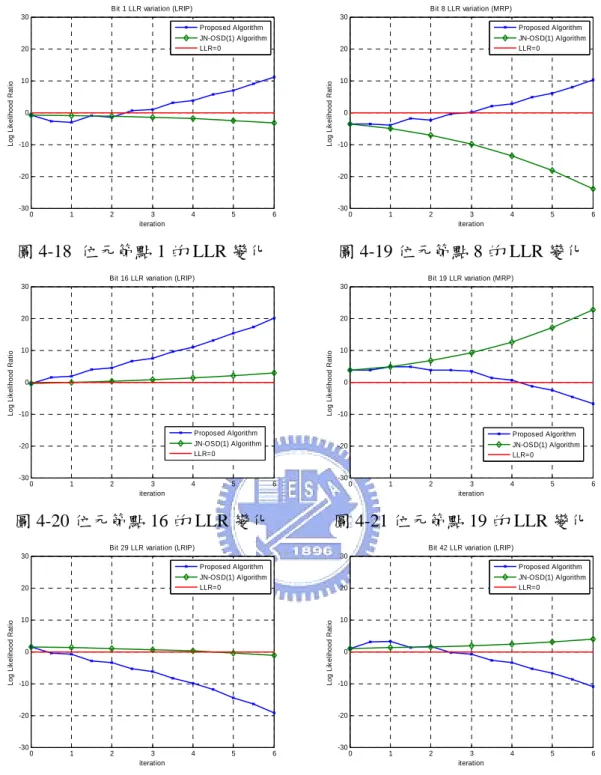
(8) 圖目錄 圖 2-1 使用 TANNER 圖表示二位元奇偶校驗矩陣 .............................................................................14 圖 2-2 給予每個位元節點初始 LLR 示意圖.......................................................................................14 圖 2-3 計算校驗節點給予位元節點之額外消息量示意圖.................................................................15 圖 2-4 更新每個位元之 LLR 值示意圖...............................................................................................15 圖 2-5 和積演算法由位元節點給予校驗節點消息量示意圖.............................................................16 圖 3-1 經高斯消去法後,二位元奇偶校驗矩陣內的低密度位置及高密度位置.............................18 圖 3-2 過多低信任度位置造成梯度下降演算法無法提供位元節點保護能力 ................................18 圖 3-3 JN 演算法之初始化範例 ...........................................................................................................20 圖 3-4 JN 演算法之排序範例 ...............................................................................................................20 圖 3-5 JN 演算法之高斯消去動作範例 ...............................................................................................20 圖 3-6 JN 演算法之 LLR 更新範例......................................................................................................21 圖 3.7 OSD(W) 演算法運作過程 ..........................................................................................................26 圖 3-8 OSD(1)演算法之初始化範例....................................................................................................27 圖 3-9 OSD(1)演算法之排序範例........................................................................................................27 圖 3-10 OSD(1)演算法之初始化範例..................................................................................................27 圖 3-11 OSD(1)演算法之重新編碼範例 ..............................................................................................28 圖 3-12 ABP-OSD(1) 機制運作方式 ....................................................................................................29 圖 4-1 位元節點 3 和位元節點 6 為低信任度位置 ............................................................................31 圖 4-2 當高密度位置 (位元節點 3) 發生一個錯誤時........................................................................32 圖 4-3 高密度位置發生一個錯誤 (位元節點 3) 時的訊息傳遞情況................................................32 圖 4-4 經過 JN 演算法高斯消去動作後的 TANNER 圖.......................................................................33 圖 4-5 發生一個錯誤 (位元節點 3)時,經高斯消去動作後的額外消息量傳遞情形......................33 圖 4-6 當高密度位置發生兩個錯誤時 (位元節點 3、位元節點 4)...................................................34 圖 4-7 當高密度位置發生兩個錯誤時,額外消息量的傳遞情形 ....................................................34 圖 4-8 兩個錯誤下,經 JN 演算法高斯消去動作後的 TANNER 圖...................................................35 圖 4-9 發生兩個錯誤時,經高斯消去法作用後的訊息傳遞情形 ....................................................35 圖 4-10 JN 演算法解碼失敗分布圖......................................................................................................36 圖 4-11 所提供演算法之概念圖 ..........................................................................................................38 圖 4-12 (15,7)里德所羅門碼配合回授機制(1)於不同 A 值下的情況 ................................................41 圖 4-13 (15,7)里德所羅門碼配合回授機制(2)於不同 A 值下的情況 ................................................42 圖 4-14 (15,7)里德所羅門碼配合回授機制(3)於不同 A 值下的情況 ................................................42 圖 4-16 (15,7)里德所羅門碼配合回授機制(3)於不同 A 值下的情況 ................................................43 圖 4-17 (15,7)里德所羅門碼比較不同回授機制於最好 A 值下的情況 .............................................43 圖 4-18 位元節點 1 的 LLR 變化.........................................................................................................45. III.
(9) 圖 4-19 位元節點 8 的 LLR 變化 .........................................................................................................45 圖 4-20 位元節點 16 的 LLR 變化 .......................................................................................................45 圖 4-21 位元節點 19 的 LLR 變化 .......................................................................................................45 圖 4-18 位元節點 29 的 LLR 變化.......................................................................................................45 圖 4-19 位元節點 42 的 LLR 變化.......................................................................................................45 圖 4-22 位元節點 53 的 LLR 變化.......................................................................................................46 圖 4-23 位元節點 56 的 LLR 變化.......................................................................................................46 圖 4-24 三種演算法之解碼失敗情況之比較圖 ..................................................................................47 圖 4-25 所提出演算法結合里德所羅門碼之未知位置解碼器之運作方式。 ..................................48 圖 4-26 (15,7)里德所羅門碼利用未知位置解碼器在不同內部疊代時的效能改善........................50 圖 5-1 (15,7) 里德所羅門碼於提出之演算法在不同 A 值時的表現 ...............................................52 圖 5-2 (15,9) 里德所羅門碼於提出之演算法在不同 A 值時的表現 ...............................................52 圖 5-3 (31,15) 里德所羅門碼於提出之演算法在不同 A 值時的表現 .............................................53 圖 5-4 (31,23) 里德所羅門碼於提出之演算法在不同 A 值時的表現 .............................................53 圖 5-5 (31,25) 里德所羅門碼於提出之演算法在不同 A 值時的表現 .............................................54 圖 5-6 (15,7) 里德所羅門碼在不同演算法間表現 ..............................................................................55 圖 5-7 (15,9) 里德所羅門碼在不同演算法間表現 ..............................................................................55 圖 5-8 (31,15) 里德所羅門碼在不同演算法間表現 ............................................................................56 圖 5-9 (31,23) 里德所羅門碼在不同演算法間表現 ............................................................................56 圖 5-10 (31,25) 里德所羅門碼在不同演算法間表現 ..........................................................................57. IV.
(10) 第一章. 概論 里德所羅門碼 (Reed-Solomon codes) [1] 為最大距離分離碼 (maximum distance separable code,簡稱 MDS 碼),目前已被大量應用於數位通訊系統和儲 存系統上。對一個 ( N , K ) 里德所羅門碼而言,使用傳統的硬式決策 (hard-decision) 解碼器能夠更正碼字中個數為 t = ⎣⎢ d min / 2 ⎦⎥ 以內的錯誤,其中 d min = N − K + 1 為. ( N , K ) 里德所羅門碼的最小距離. (minimum distance)。由於里德所羅門碼本身的. 碼字為非二位元符元 (non-binary symbol) 所組成,因此有可能在更正一個符元 的同時,更正了數個連續的錯誤位元,故其極適合用於處理突發錯誤 (burst errors) 的情況。 大部分的使用上,由於高速和低複雜度的需求,里德所羅門碼的解碼方式多 採用硬式決策解碼器,其利用代數結構的特性得到一組解碼方程式,並且使用有 限場 (finite field) 的數學運算來解出方程式的未知數。然而眾所皆知,里德所羅 門碼的最大概似解碼器 (maximum likelihood decoder) 相較於傳統的硬式解碼器 能夠提供顯著的效能改善,但最大概似解碼器的高複雜度問題,仍然沒有一個較 為有效的處理方式。 面對這樣的問題,於軟式決策解碼方面 (soft-decision decoding),Forney [2] 和 Chase [3] 曾提出基於信任度的解碼方式,利用翻轉碼字中的最小信任位置 (least reliable positions,簡稱 LRPs) ,試圖尋找和接收信號相關性最大的合法碼 字。同樣地,利用信任度解碼的方式,Fossorier 和 Lin [4] 利用尋找最大獨立信 任位置 (most reliable independent positions,簡稱 MRIPs),並重新編碼以尋找和. 1.
(11) 接收信號相關性最大的碼字,這種方法稱為排序統計解碼演算法 (ordered statistic decoding algorithm,簡稱 OSD)。Vardy 和 Ber’ey [5] 利用里德所羅門碼 代數上的特性,將其生成矩陣 (generator matrix) 經二位元映射後,拆解為數個 BCH 碼為其子場域子碼 (subfield subcode),並以連接碼 (glue code) 作為其之間 的連繫。僅管這種方式降低了使用柵欄解碼 (trellis decoding) 的複雜度,然而整 體複雜度還是會隨著碼長和 d min 變大時快速增加。 而於疊代解碼 (iterative decoding) 方面,Ponnampalam 和 Grant [6] 利用和 Vardy 和 Ber’ey 相同的原理,將里德所羅門碼拆解為數個子柵欄 (sub-trellis),並 且利用之間連接碼的關係互相傳送消息量而進行疊代解碼。Liu 和 Lin [7] 則同 樣是利用子場域子碼的拆解原理,將生成矩陣拆為數個大小較小的生成矩陣,並 利用之間連接碼的關連性進行渦輪 (turbo) 編碼和解碼。同樣為疊代解碼的信念 傳遞 (belief propagation) 演算法於低密度奇偶校驗碼 (LDPC codes) 提出後,廣 泛受到討論。自然於里德所羅門碼的軟式決策解碼上,亦有相關的演算法被提 出。2004 年 Jiang 和 Narayann 就提出了隨機平移解碼演算法 (stochastic shifting based iterative decoding scheme,簡稱 SSID) [8]。其利用里德所羅門碼經二位元 映射後的二位元奇偶校驗矩陣 (binary parity check matrix) 和其為循環碼的特 性,在每次疊代進行信念傳遞演算法中的梯度下降演算法 (gradient descent algorithm) 時,亦進行二位元奇偶校驗矩陣的隨機平移動作,以減少錯誤傳遞所 造成的影響。Halford [9] 於此提出了延伸方向,其利用自同構 (automorphism) 的 特性來增加冗餘二位元奇偶校驗矩陣 (redundant binary parity check matrix) 的個 數,於每次疊代中隨機選擇一自同構冗餘奇偶校驗矩陣來進行梯度下降演算法。 Hehn、Huber、Laendner 和 Milenkovic [10] 則是利用循環群產生器 (cyclic group generator) 生成數個二位元奇偶校驗矩陣後,平行進行信念傳遞演算法,從中選 擇和接收信號相關性最大的碼字輸出。 2004 年 Jiang 和 Narayan [11] 提出了 JN 演算法,其方式為對二位元奇偶校 驗矩陣依照信任度進行高斯消去動作,而減少未知位置 (erasure positions) 對於 2.
(12) 梯度下降演算法所造成的影響。而 Kothiyal、Takeshita 和 Fossorier [12] 提出了 結合 OSD(1) 演算法和適應性信念傳遞 (adaptive belief propagation,簡稱 ABP) 的機制來相互輔助,稱為 ABP-OSD(1)演算法,其 ABP 的動作可為 JN 演算法或 [13]。 本研究主要針對 JN 演算法進行討論,利用修正 ABP-OSD(1)的機制,以解 決 JN 演算法的潛在問題,並利用數據觀察說明提出之演算法對於原有的 JN 解 碼演算法所帶來的效應,最後呈現經由提出之演算法所帶來的效能增益和複雜度 考量。本論文之架構如下:第二章中將會介紹相關的符號定義、里德所羅門碼的 二位元映射方法,以及梯度下降演算法之理論基礎。第三章中將簡介 JN 解碼演 算法的解碼步驟和相關的改善方式,並且介紹 ABP-OSD(1) 的解碼機制和運作 方式。第四章中,一開始將討論 JN 解碼演算法的潛在問題,並且針對其問題來 說明本研究所提出之演算法,最後佐以數據觀察經提出之演算法作用後,對於原 有 JN 解碼演算法之影響。第五章將呈現提出之演算法的效能表現並進行複雜度 討論。最後於第六章中提出本論文之結論。. 3.
(13) 第二章. 梯度下降解碼演算法 之理論基礎 於本章中將定義相關的符號標示法和所處之系統環境,並介紹里德所羅門碼 之二位元映射法,接下來將說明梯度下降解碼演算法的理論基礎,此理論基礎將 使用於接下來的章節,最後以圖形化說明其運作方式。接下的說明中,於字母下 方加一底線代表一個向量,如 c ;粗體的字母代表一個矩陣,如 Η 。向量或矩陣 中的元素以下標來表示,如 ci 表示向量 c 中的第 i 個元素,H ij 表示矩陣 Η 中第 i 列 第 j 行的元素。. 2-1 符號定義 2.1.1 傳送信號符號定義 首先定義一個二位元碼字 (binary codeword) c = [ c1 , c2 ,… , cn ] ,碼字長度為 n,碼字空間的維度 (dimension) 以 k 來表示。向量中每個元素 ci 均屬於 GF (2) 中. 的元素。本研究以 Η 來表示這個碼字空間 (codeword space) 的奇偶校驗矩陣. (parity check matrix),並以 μ 代表 Η 的列數, n 為 H 的行數; hi 則表示矩陣中第 i 個奇偶校驗方程式 (parity check equation),亦為 Η 的第 i 列向量。 一個合法的碼字必須要滿足 Η 中每一個奇偶校驗方程式偶校驗 (even parity. check) 的特性。所謂的偶校驗,是指當選取奇偶校驗方程式 hi ,並從 hi 中為 1 的位置取出對應位置的 ci ,則這些 ci 的值在 GF (2) 的加法下,必須總和為 0。如. 4.
(14) 下列之說明: ⎡1 1 0 1 1 0 0 ⎤ H = ⎢⎢1 1 1 0 0 1 0 ⎥⎥ ,而 c = [1 1 0 1 1 0 0] ,符合所有的 Η 中的 ⎢⎣1 0 1 1 0 0 1 ⎥⎦ ⎧1 + 1 + + 1 + 1 + + = 0 ⎪ 奇偶校驗方程式 ⎨1 + 1 + 0 + + + 0 + = 0 ,故 c 為一合法碼字。 ⎪1 + + 0 + 1 + + + 0 = 0 ⎩. 2-1.2 通道環境符號定義 在本論文中假設所使用的通道環境均為可加性高斯白雜訊 (additive white. Gaussian noise) 通道,以下均簡稱為 AWGN 通道;調變方式為二位元移鍵 (binary phase shift keying) 調變,以下均簡稱為 BPSK。BPSK 調變將 0 映射至+1 且 1 映 射至-1 後,最後傳送於 AWGN 通道的過程可以由 (2.1) 式所表示: y = ( −2 c + 1) + n .. (2.1). 其中 y = [ y1 , y2 ,......, yn ] 表示經過 BPSK 調變和 AWGN 通道後的接收信號,而 n = [ n1 , n2 ,......, nn ] 表示 AWGN 通道上的雜訊,且其雙邊雜訊功率為 N 0 / 2 。. 獲得接收信號後,即可計算碼字中每個元素的對數概似比例 (log likelihood. ratio,以下均簡稱為 LLR),計算的方式為 (2.2) 式: L(ci ) = log. Pr ( ci = 0 | yi ) . Pr ( ci = 1| yi ). (2.2). 於 AWGN 通道,可將 (2.2) 式化簡為 (2.3) 式:. L(ci ) = log. Pr ( ci = 0 | yi ) = log Pr ( ci = 1| yi ). − 1 e π N0. 1 e π N0. ( yi −1)2 N0. ( y +1)2 − i N0. =. 4 yi . N0. 在接下來的討論中,演算法所使用的初始 LLR,均以 (2.3) 式計算之。 5. (2.3).
(15) 2-1.3 里德所羅門碼之符號定義 ( N , K ) 里德所羅門碼運作於 GF (2m ) 之下時,則長度為 N = 2m − 1 ,維度為. K ,則可求得其最小距離為 d min = N − K + 1 。而奇偶校驗矩陣可用 (2.4) 式的形 式來表示: ⎡1 β ⎢ 1 β2 HS = ⎢ ⎢ ⎢ ( d min −1) ⎣1 β. … … …. β ( N −1) ⎤ ⎥ β 2( N −1) ⎥. ⎥ ⎥ … β ( dmin −1)( N −1) ⎦. (2.4). .. H S 為 M 列 N 行之矩陣,在這裡 β 為 GF (2m ) 中的質元素 (primitive element)。. 2-2 里德所羅門碼之二位元映射 [14] 2-2.1 二位元映射基底 本研究中,以 GF (2m ) 中的符元 (symbol) 1, β , β 2 ,. , β m −1 做為符元映射至. 二位元向量之基底。如 Α ∈ GF (2m ) 為一符元,其可投影在 1, β , β 2 , m −1. 的基底上,而以 A = ∑ Ab( i ) β i 或 A vector = ⎡⎣ Ab(0) i =0. Ab(1). , β m −1 所組成. Ab( m −1) ⎤⎦ 的形式來表. 示,其中 Ab(i ) ∈ GF (2) 。 範例 於 GF ( 23 ) 時,使用的質多項式 (primitive polynomial) 為 1 + x + x3 ,則. GF ( 23 ) 中的每個元素均可用 GF ( 2 ) [ x ] mod (1 + x + x3 ) 的方式表示如下,其中. β = x:. 6.
(16) 0 = 0 + 0 ⋅ x + 0 ⋅ x 2 = [ 0, 0, 0] , 1 = 1 + 0 ⋅ x + 0 ⋅ x 2 = [1, 0, 0] ,. β = 0 + 1 ⋅ x + 0 ⋅ x 2 = [ 0,1, 0] , β 2 = 0 + 0 ⋅ x + 1⋅ x 2 = [ 0, 0,1] , β 3 = 1 + 1⋅ x + 0 ⋅ x 2 = [1,1, 0] , β 4 = 0 + 1⋅ x + 1⋅ x 2 = [ 0,1,1] , β 5 = 1 + 1⋅ x + 1⋅ x 2 = [1,1,1] , β 6 = 1 + 0 ⋅ x + 1⋅ x 2 = [1, 0,1] .. 2-2.2 代數加法之二位元映射 每個符元映射為二位係數的向量後,仍然需要滿足在 GF (2m ) 中的加法特 性。由於先前選取的基底 1, β , β 2 ,. , β m −1,其在加法上可直接由向量的 GF ( 2 ) 二. 位元加法取代原有的符元加法計算,因此經過二位元映射後,加法仍然滿足原有 的代數特性。 範例 於 GF ( 23 ) 中. β + β 5 = ( 0 + 1⋅ x + 0 ⋅ x 2 ) + (1 + 1⋅ x + 1⋅ x 2 ) = [ 0,1, 0] + [1,1,1] = [1, 0,1] = 1 + 0 ⋅ x + 1⋅ x 2 = β 6 .. 2-2.3 代數乘法之二位元映射 符元映射為二位元向量後,亦需要滿足在 GF (2m ) 中的乘法特性。而在乘法 上,每個符元經二位元映射後的二位元向量乘上另一符元的動作,在這裡需要以 乘上一矩陣的動作來取代,以維持原有的代數特性。我們藉由原先選擇的基底則 可如範例中的方式推得每個符元在乘法上所代表的矩陣。 範例 於 GF ( 23 ) 中 ⎡A B β ⋅1 = ⎢⎢ D E ⎢⎣ G H 5. C⎤ T T T F ⎥⎥ [1, 0, 0] = [ A, D, G ] = β 5 =[1,1,1] . I ⎥⎦. 7.
(17) ⎡A B β ⋅ β = ⎢⎢ D E ⎢⎣ G H 5. ⎡A B β ⋅ β = ⎢⎢ D E ⎢⎣ G H 5. 2. C⎤ T T T F ⎥⎥ [ 0,1, 0] = [ B, E , H ] = β 6 =[1, 0,1] . I ⎥⎦ C⎤ T T T F ⎥⎥ [ 0, 0,1] = [C , F , I ] = β 7 = 1 =[1, 0, 0] . I ⎥⎦. ⎡1 1 1 ⎤ 故我們可知 β 在經過二位元映射後,乘法上可用 ⎢⎢1 0 0 ⎥⎥ 來取代。 ⎢⎣1 1 0 ⎥⎦ 5. 而由以上的推論,可得到 GF ( 23 ) 中所有符元所代表的乘法矩陣如下:. ⎡0 0 0 ⎤ ⎡1 ⎢ ⎥ 0 = ⎢ 0 0 0 ⎥ , 1 = ⎢⎢ 0 ⎢⎣ 0 0 0 ⎥⎦ ⎢⎣ 0 ⎡1 0 1⎤ ⎡0 ⎢ ⎥ 3 4 β = ⎢1 1 1⎥ , β = ⎢⎢1 ⎣⎢1 0 1⎦⎥ ⎣⎢1. 0 0⎤ ⎡0 ⎥ 1 0 ⎥ , β = ⎢⎢ 1 ⎢⎣ 0 0 1 ⎥⎦ 1 1⎤ ⎡1 ⎥ 5 1 0 ⎥ , β = ⎢⎢1 ⎢⎣1 1 1 ⎥⎦. 0 1⎤ ⎡0 ⎥ 2 0 1 ⎥ , β = ⎢⎢ 0 ⎢⎣ 1 1 0 ⎥⎦ 1 1⎤ ⎡1 ⎥ 6 0 0 ⎥ , β = ⎢⎢ 0 1 0 ⎦⎥ ⎣⎢1. 1 0⎤ 1 1 ⎥⎥ , 0 1 ⎥⎦ 1 0⎤ 0 1 ⎥⎥ . 0 0 ⎥⎦. 2-2.4 里德所羅門碼二位元奇偶校驗矩陣之生成 H s 可藉由 GF (2m ) 中選擇的基底 1, β , β 2 ,. , β m −1,由原有的符元奇偶校驗矩. 陣映射成大小為 (n − k ) × n 的二位元奇偶校驗矩陣 H b ,在這裡 n = m ⋅ N 且 k = m ⋅ K 。經過二位元映射後,我們可以將里德所羅門碼的解碼問題,看待成大. 小為 (n − k ) × n 的二位元線性區塊碼 (binary linear block code) 之解碼問題。 範例 於 GF ( 23 ) 中,考慮一里德所羅門碼其 N = 23 − 1 = 7, K = 5, d min = N − K + 1 = 3 , 且奇偶校驗矩陣 H S 為. 8.
(18) ⎡1 β HS = ⎢ 2 ⎣1 β. β2 β4. β3 β6. β4 β. β5 β6⎤ ⎥. β3 β5⎦. 經過乘法映射後,則可以得到對應的二位元奇偶校驗矩陣 H b ,其 n = 21 且 k = 15 。 ⎡1 ⎢0 ⎢ ⎢0 Hb = ⎢ ⎢1 ⎢0 ⎢ ⎣0. 0 1 0 0 1. 0 0 1 0 0. 0 1. 0 1 0 0 0. 0 0 1 1 1. 1 1 0 0 1. 1 0 1. 0 0 1 0 1. 1 1 0 1 1. 0 1 1 1 0. 1 1 1. 1 1 1 1 0. 0 1 0 1 0. 1 1 1 0 1. 1 0 0. 0 1 0 0 1. 1 1 1 0 0. 1 0 1 1 1. 0 1 0. 1 1 1 1 1. 1 0 1 0 1. 1 0 0 1 1. 0 1 1. 0⎤ 1 ⎥⎥ 0⎥ ⎥. 1⎥ 0⎥ ⎥ 1 1 0⎦. 1 0 1 1 1. 1 0 0 1 0. 2-3 梯度下降法之理論基礎 以下將介紹 SSID 演算法和 JN 解碼演算法等演算法所使用的梯度下降法, 其理論基礎 [12] 和執行步驟。在進行梯度下降法前,我們可以由式 (2.3) 得到 接收信號中每個位置的 LLR ( L(ci ) ),並且預備二位元奇偶校驗矩陣 H b ,以進行 梯度下降法之解碼。. 2-3.1 函數定義 接下來定義兩個函數以說明梯度下降演算法 函數定義 2-1 函數 ν : [ −∞, +∞ ] → [ −1, +1] 為將 L(ci ) 自 LLR 域映射至 tanh 域之函數 : ⎛L⎞ ⎝ ⎠. eL − 1. ν ( L ) = tanh ⎜ ⎟ = L . 2 e +1 此為一對一 (one-to-one) 且映成 (onto) 函數。. 函數定義 2-2. 9. (2.5).
(19) ν 之反函數 ν −1 : [ −1, +1] → [ −∞, +∞ ] : ⎛1+ t ⎞ ⎟ , t ∈ [ −1, +1] . ⎝ 1− t ⎠. ν −1 ( t ) = ln ⎜. (2.6). 此亦為一對一且映成函數。. 2-3.2 梯度下降法理論基礎 從接收信號求得每個位置的 LLR( L(ci ) )後,首先將其利用式 (2.5) 將每個位 置的 LLR 轉換至 tanh 域表示,如式 (2.7):. T = [T1 , T2 ,. , Tn ] = ⎡⎣ν ( L(c1 ) ) ,. ,ν ( L(cn ) ) ⎤⎦ .. (2.7). 其中 T 為經過轉換後的 tanh 域向量。接下來,利用式 (2.7) 定義 H b 中第 j 個校 驗方程式 (即 H b 中的第 j 列 ) 的決策信任度 γ j (decision reliability) 於式 (2.8) 中:. γ j = ∏ ν ( L (c p ) ) . n. (2.8). p∈Γ j. 其中 Γ j ∈ {a | ∀ 1 ≤ a ≤ n, H b ja = 1} 。 γ j 於此所代表的意義有兩項 (1) 若將 LLR 經 過硬式決策後,則可計算 LLR 相對於 H b 的徵狀 (syndrome) 。當 γ j > 0 時,表 示徵狀中第 j 個位置為 0。若 γ j < 0 ,則表示徵狀中第 j 個位置為 1。 (2) 依一般 信任度解碼的思考,若 H b 中第 j 個校驗方程式所校驗到的位元位置 (即 H b 的第. j 列於該位置之值為 1),其 LLR 的絕對值較大時,會認為該位置的硬式決策較 不易發生錯誤,若所校驗到位元位置其 LLR 之絕對值較小時,會認為該位元位 置的硬式決策較易發生錯誤。同樣的概念應用於此處的決策信任度上,當 γ j 愈 大時,會認為徵狀中第 j 個位置的決策(為 1 或 0)較不易發生錯誤,而當 γ j 愈小 時,會認為該決策較易發生錯誤。由式 (2.5) 和式 (2.6) 可知, γ j 必定界於. 10.
(20) [ −1, +1] 間。因此若. LLR 經過 H b 中第 j 個校驗方程式校驗為一合法碼字,則. γ j > 0 ,且 γ j 愈大表示我們能夠愈信任這個校驗的決策,反之 γ j 愈小,則表示 這個校驗的決策愈容易發生錯誤。 接下來以式 (2.9) 定義一位能函數 (potential function) J 定義 2.1 : 定義位能函數 J 為. ( n−k ). ( n−k ). J ( Hb , T ) = − ∑ γ j = − ∑ j =1. ∏T. j =1 p∈Γ j. p. .. (2.9). 其中 Γ j ∈ {a | ∀ 1 ≤ a ≤ n, H b ja = 1} ,且 J 是一個同時受 H b 和 T 所影響的函數。 由以上的討論可知,若一個校驗方程式對於 LLR 的校驗結果一定為正確時,我 們會認為其 γ j 為 1。而當 γ j > 0 且 γ j = 1 時,則表示我們認為該校驗方程式對. LLR 所做的校驗結果必定徵狀為 0,也就是該校驗方程式認為其一定為合法的碼 字。 以一個合法的碼字而言,其必定滿足所有的校驗方程式,而徵狀必定均為. 0。因此在校驗合法碼字的情況下,每個校驗方程式的 γ j 必定為 1,且此時所有 校驗方程式的 γ j 總合為 ( n − k )。由式 (2.9) 可知此時位能函數值 J 會到達最小 值 − ( n − k ) 。故若能由通道所得到信任度 T 為初始起點,使接收信號的 LLR 往位 能函數最低點的方向前進,並收斂於位能函數的最低點時,則被認為此過程成功 找到了傳送的碼字而成功解碼。 因此基於這樣的想法,梯度下降法適合進行這樣的運作過程。 首先對位能 函數進行偏微分後,得到式 (2.10) ∂J ( H b , T ) ⎞ ⎛ ∂J ( H b , T ) ∂J ( H b , T ) ∇J ( H b , T ) = ⎜ , ,… , ⎟. ∂T1 ∂T2 ∂Tn ⎝ ⎠. 11. (2.10).
(21) 其中每個對應 Ti 的偏微分元素可以表示成式 (2.11) 的形式 ∂J ( H b , T ) = −∑ ∂Ti j∈Λ i. ∏T. p∈Ω j. p. .. (2.11). 此時 Λ i = {q | ∀1 ≤ q ≤ n − k , H bqi = 1} 且 Ω j = {s | ∀1 ≤ s ≤ n, H b js = 1, s ≠ i} 。 最後以式 (2.12) 來描述梯度下降法搜尋位能函數最低點的過程. T. (l ). − α∇J ( H b , T ( l ) ) → T. ( l +1). .. (2.12). 這裡 α 為一抑制係數,如同梯度下降法中控制每次疊代的步距 (step size) 係數, 上標 ( l ) 表示目前為第 l 次疊代。由於信任度 Ti 以 tanh 域表示時,其被定義在. [ −1, +1] 的區間內,因此需修正原來的梯度下降法的疊代函數,以保證信任度 Ti 始 終於 [ −1, +1] 的區間內。經過最後經過修正後,可得到式 (2.13) 的形式。 ⎡. ⎛ ⎜ p∈Ω ⎝ j. ⎞⎤ ⎟⎥ ⎠⎦. ν −1 (Ti (l ) ) − α ⎢ − ∑ ν −1 ⎜ ∏ Tp(l ) ⎟ ⎥ → ν −1 (Ti (l +1) ) . ⎢⎣. j∈Λi. (2.13). 此時 Λ i = {q | ∀1 ≤ q ≤ n − k , H b qi = 1} 且 Ω j = {s | ∀1 ≤ s ≤ n, H b js = 1, s ≠ i} , Tp(l ) 和. Ti (l ) 之上標 ( l ) 表示目前為第 l 次疊代。 實際運作上,由式 (2.5) 和 (2.13) 式,每個位置的 LLR ( L(ci ) )在第 l 次疊 代過程中所接收到的額外消息量 (extrinsic information) 總值 L(extl ) (ci ) 可以表示如 式 (2.14) 所示:. ⎛ ⎞ L (ci ) = ∑ ν ⎜ ∏ Tp(l ) ⎟ = ⎜ p∈Ω ⎟ j∈Λ i ⎝ j ⎠ (l ) ext. −1. ⎛ ⎛ L(l ) (c p ) ⎞ ⎞ 2 tanh ⎜ ∏ tanh ⎜ . ∑ ⎜ 2 ⎟⎟ ⎟⎟ ⎜ p∈Ω j∈Λ i ⎝ ⎠⎠ ⎝ j −1. (2.14). 其中 Λ i = {q | ∀1 ≤ q ≤ n − k , H b qi = 1} 且 Ω j = {s | ∀1 ≤ s ≤ n, H b js = 1, s ≠ i} , Tp(l ) 和 L(l ) (c p ) 之上標 ( l ) 表示目前為第 l 次疊代。而由式 (2.14) 可知,額外消息量總值. 中,由第 j 個校驗方程式所提供的消息量可用式 (2.15) 來表示,這裡以上標. 12.
(22) ( l )( j ) 來表示額外消息量 L(extl )( j ) (ci ) 由第 j 個校驗節點所提供。 ( l )( j ) ext. L. ⎛ ⎛ L(l ) (c p ) ⎞ ⎞ (ci ) = 2 tanh ⎜ ∏ tanh ⎜ . ⎜ 2 ⎟⎟ ⎟⎟ ⎜ p∈Ω j ⎝ ⎠ ⎝ ⎠ −1. (2.15). 其中 Ω j = {s | ∀1 ≤ s ≤ n, H b js = 1, s ≠ i} 。. 2-3.3 梯度下降法解碼步驟 經由前一節之介紹,接下來我們將梯度下降法的解碼執行步驟陳述如下: 步驟 1、 設定抑制係數 α , 最大疊代次數 lmax ,並計算接收信號中每個元素的 初始的 LLR 為 L(0) (ci ) = ( 4 yi / N 0 ) ,並以初始 LLR ( L(0) (ci ) ) 開始進行 解碼。 步驟 2、 利用梯度下降法於每次疊代中,計算每個位元位置所得到的額外消息 量 L(extl ) (ci ) ,計算方式前一小節之式 (2.14)。 步驟 3 、 經由方程式 L( l +1) (ci ) = L(l ) (ci ) + α L(extl ) (ci ) ,將每個位元位置的 LLR. ( L( l ) (ci ) ) 進行更新,此過程即前一小節中式 (2.13) 的運作。解碼過程 中,若已達預設的最大疊代次數 lmax ,或著疊代過程中經硬式決策後能 得到一個合法碼字時,則停止解碼並輸出目前的解碼結果。若未達預 設最大疊代次數且未得到合法碼字時,則以更新後的 LLR ( L( l +1) (ci ) ), 回到步驟 2 進行下一次疊代。. 2.4 梯度下降法之圖形化運作方式 經過二位元映射後的奇偶校驗矩陣均可用以下的 Tanner 圖來表示,如. 13.
(23) ⎡1 1 0 1 1 0 0 ⎤ H b = ⎢⎢1 1 1 0 0 1 0 ⎥⎥ ⎢⎣1 0 1 1 0 0 1 ⎥⎦ 校驗節點1 校驗節點2 校驗節點3. 位元節點. 1. 2. 3. 4. 5. 6. 7. 圖 2-1 使用 Tanner 圖表示二位元奇偶校驗矩陣. Η b 上的每一列,在 Tanner 圖上是使用校驗節點 (check node) 表示;而碼 字上的每個元素 ci ,在 Tanner 圖上則是用相對應的位元節點 (bit node) 來表 示。當 Η b 中的第 i 列第 j 行的位置為 1 時,則將則第 i 列所代表的校驗節點和 第 j 行的位元節點在圖形上以相連來表示。則原有的梯度下降法對應至 Tanner 圖上時,可利用簡單的圖形化動作來表示其運作過程。 圖 2-2 表示梯度下降法的初始過程,即前一小節中的步驟一。每個位元節 點均可經由接收信號得到一初始的 LLR 值: L(0) (ci ) = ( 4 yi / N 0 ) ,並且傳送給相 連的校驗節點。. L(0) (c1 ). L(0) (c1 ) L(0) (c2 ) L(0) (c3 ) L(0) (c4 ) L(0) (c5 ) L(0) (c6 ) L(0) (c7 ). 圖 2-2 給予每個位元節點初始 LLR 示意圖 圖 2-3 為梯度下降法計算第 l 次疊代時,校驗節點提供位元節點額外消息量 的表示圖,即式 (2.15) 的過程。以校驗節點 1 為範例,計算其給予位元節點 5 之額外消息量時,其消息來源分別來自位元節點 1、位元節點 2 和位元節點 4。. 14.
(24) ⎛ ⎛ L(l ) (c1 ) ⎞ ⎛ L(l ) (c2 ) ⎞ ⎛ L(l ) (c4 ) ⎞ ⎞ L(extl )(1) (c5 ) = 2 tanh −1 ⎜ tanh ⎜ ⎟ ⋅ tanh ⎜ ⎟ ⋅ tanh ⎜ ⎟⎟ ⎝ 2 ⎠ ⎝ 2 ⎠ ⎝ 2 ⎠⎠ ⎝. L( l ) (c1 ) L(l ) (c2 )L(l ) (c ) 4. 圖 2-3 計算校驗節點給予位元節點之額外消息量示意圖 圖 2-4 則為梯度下降法更新位元節點 LLR 的動作,即式 (2.14) 的過程。以 位元節點 1 為範例,其於該次疊代中得到校驗節點 1、校驗節點 2 和校驗節點 3 所提供的額外消息量 L(extl )(1) (ci ) 、 L(extl )( 2) (ci ) 和 L(extl )( 3) (ci ) 。. Lext( ) (c1 ) (l ) 2. ( l )(1) ext. L. (c1 ) L(extl )( 3) (c1 ). L( l +1) (c1 ) = L( l ) (c1 ) + α ⋅ ⎡⎣ L(extl )(1) (c1 ) + L(extl )( 2) (c1 ) + L(extl )(3) (c1 ) ⎤⎦. 圖 2-4 更新每個位元之 LLR 值示意圖 而梯度下降法和傳統的和積演算法 (sum-product algorithm) 不同之處在於 位元節點給予校驗節點消息量時,梯度下降法由同一個位元節點給予其相連所有 校驗節點的消息量均為 L( l ) (ci ) ,而和積演算法則是由圖 2-5 的方式計算給予校驗 節點消息量,其中 Q(1) ( c1 ) 表示由第 1 個位元節點給予第一個校驗節點之消息量。 而在計算位元節點給予校驗節點之消息量時,其中由位元節點本身所提供的 LLR 值,在梯度下降法時為前一次疊代時位元節點的 LLR ( L( l ) (ci ) ),在和積演算法時 則均為該位元節點的初始 LLR ( L(0) (ci ) )。. 15.
(25) Lext( ) (c1 ) (l ) 2. ( l )( 2 ) ext. Q(1) (c1 ) = L (c1 ) + α ⋅ ⎡⎣ L (0). ( l )( 3) ext. (c1 ) + L. (c1 ) ⎤⎦. Lext( ) (c1 ) (l ) 3. 圖 2-5 和積演算法由位元節點給予校驗節點消息量示意圖 在本研究接下來的數章中,將會利用到以上圖形化表示的方式來方便說明梯 度下降演算法相關的應用。. 16.
(26) 第三章. JN 解碼演算法及 ABP-OSD(1)解碼演算法 本章將介紹 JN 解碼演算法和 ABP-OSD(1) 解碼演算法的解碼方式。. 3-1 JN 解碼演算法 3-1.1 JN 解碼演算法簡介 首先我們將里德所羅門碼經由二位元映射後得到二位元奇偶校驗矩陣 H b , 再利用此 H b 進行接下來的解碼動作。 解碼過程中,每次的疊代動作主要可分為兩個階段如下:. (1) 更新奇偶校驗矩陣階段 於此階段,首先將所有位元節點的 LLR 依照其信任度排序,其後按照 信任度由小至大的對應位置進行高斯消去法,使 H b 成為一簡化梯式 (row. reduced echelon form) 矩陣。此動作由最小信任度的位置開始,利用列運算 將該位置正規化後,再對信任度次高的位置進行同樣的動作,若發現該位置 無法正規化,則略過該位置進行信任度次高的下一個位置,直到得到 H b 的 簡化梯式矩陣 H b′ 和 (n − k ) 個成功正規化的位置,稱為最小信任獨立位置. ( least reliable independent positions,簡稱 LRIPs),這些位置可以經由重新排 序而成為一正規化矩陣 (identity matrix)。而非最小信任獨立位置的部分於本 論文中則稱為最大信任度位置 (most reliable positions ,簡稱 MRPs) ,由於. H b′ 中對應到這些 LRIPs 的行向量,均只有一個 1,因此這些部分亦稱為 H b′ 17.
(27) 的低密度位置,反之這些位置以外則稱為 H b′ 的高密度位置,如圖 3-1 所示。. ⎡0 ⎢0 ⎢ H b′ = ⎢0 ⎢ ⎢0 ⎢⎣1. ... 1 ... 0 0 ... 0 ... ...⎤ ... 0 ... 0 1 ... 0 ... ...⎥⎥ ... 0 ... 0 0 ... 1 ... ...⎥ ⎥ ... 0 ... 1 0 ... 0 ... ...⎥ ... 0 ... 0 0 ... 0 ... ...⎥⎦. 圖 3-1 經高斯消去法後,二位元奇偶校驗矩陣內的低密度位置及高密度位置. (2) 更新位元節點之 LLR 階段 接下來利用經過高斯消去法作用後的簡化梯式矩陣 H b′ ,使用梯度下降 法求得每個位元節點的額外消息量後更新原有的 LLR,即前式 (2.13) 之動 作。. Jing Jiang 和 Narayanna 於 [15]中提出,一般的梯度下降法運作時,若一個 校驗節點相連至多個低信任度的位元節點,則受這些低信任度的位元節點的影 響,校驗節點傳送給位元節點的訊息量大部分會近似為 0,因此造成梯度下降法 無法提供位元節點足夠的額外消息量以更正錯誤,此現象稱為校驗節點飽和化. (check node saturation) ,如圖 3-2 所示。因此使用 JN 解碼演算法,則可使一個 校驗節點僅連接至一個低信任度的位元節點,減少校驗節點飽和化所帶來的影 響,以增進其效能。. L ( c1 ). L ( c5 ) L ( c6 ) L ( c7 ). L ( c2 ). 圖 3-2 過多低信任度位置造成梯度下降演算法無法提供位元節點保護能力 18.
(28) 3-1.2 JN 演算法解碼步驟 於本節中,將 JN 演算法執行的詳細步驟說明如下: 步驟一、 設定抑制係數 α , 最大疊代次數 lmax ,並計算每個位元節點的初始的. LLR 為 L(0) (ci ) = ( 4 yi / N 0 ) ,並以初始 LLR ( L(0) (ci ) ) 開始進行解碼。. (. 步驟二、更新奇偶校驗矩陣: H b(l ) = φ H b , L. (a) 依據 LLR 絕對值 L. (l ). (l ). ) , φ 表示更新 H 的動作。 b. 的大小將每個位元位置進行排序,並且記錄排. 序後的順序。. (b) 利用高斯消去法,按照信任度由小至大的位置將 H b(l ) 消為簡化梯式矩 陣,並得到 (n − k ) 個 LRIPs。 步驟三、 利用高斯消去法正規化後的 H b(l ) ,進行梯度下降法得到每個位元節. (. 點的額外消息量: L ext = ϕ H b(l ) , L (l ). (l ). ) ,即式 (2.14) 的過程。 ϕ 表示計. 算額外消息量之動作。 步驟四、 更新每個位元節點的 LLR: L. ( l +1). = L + α L ext ,即式 (2.13) 的過程。 (l ). (l ). 在這裡 0 < α ≤ 1 。 ( l +1) ⎪⎧0, L ( ci ) > 0 步驟五、 硬式決策: ci = ⎨ ( l +1) ⎪⎩1, L ( ci ) < 0. 步驟六、 終止條件:若所有的校驗節點均被滿足,或當到達最大的預設疊代次 數時,則停止疊代並且輸出目前經硬式決策後每個位元的決策值。若 未達最大疊代次數,則令 l = l + 1 ,回到步驟二進行下一次的疊代。. 3-1.3 JN 演算法解碼範例 使用(7,4)漢明碼作為範例,原始的二位元奇偶校驗矩陣 H b 和相對應每個位. 19.
(29) 元位置的初始 LLR 如圖 3-3 所示。. ⎡1 0 1 0 1 0 1⎤ H b = ⎢⎢0 1 1 0 0 1 1⎥⎥ ⎢⎣0 0 0 1 1 1 1⎥⎦ 位元1. 位元2. 位元3. 位元4. 位元5. 位元6. 位元7. 1.2. -0.01. 10.0. 4.3. -5.2. -6.6. -7. 圖 3-3 JN 演算法之初始化範例 首先經過排序,由小至大的順序分別為圖 3-4 所示。 位元1. 位元2. 位元3. 位元4. 位元5. 位元6. 位元7. 1.2. -0.01. 10.0. 4.3. -5.2. -6.6. -7. 順序2. 順序1. 順序7. 順序3. 順序4. 順序5. 順序6. 圖 3-4 JN 演算法之排序範例. 接下來將二位元奇偶校驗矩陣,依信任度排序由小至大進行高斯消去動作後,得 到對應的簡化梯式矩陣 H b′ 、LRIP 的位置和相對應的 Tanner 圖,如圖 3-5 所示。. ⎡0 1 1 0 0 1 1⎤ H b′ = ⎢⎢1 0 1 0 1 0 1⎥⎥ ⎢⎣0 0 0 1 1 1 1⎥⎦. 圖 3-5 JN 演算法之高斯消去動作範例 接下來利用經高斯消去動作後的簡化梯式矩陣 H b′ 進行梯度下降演算法,並得到 每個位元節點的額外消息量,更新原有之 LLR,如圖 3-6 所示。. 20.
(30) ⎛ ⎛ L(l ) (c3 ) ⎞ ⎛ L(l ) (c5 ) ⎞ ⎛ L( l ) (c7 ) ⎞ ⎞ (l ) 2 Lext( ) (c1 ) = 2 tanh −1 ⎜ tanh ⎜ ⎟ ⋅ tanh ⎜ ⎟ ⋅ tanh ⎜ ⎟⎟ ⎝ 2 ⎠ ⎝ 2 ⎠ ⎝ 2 ⎠⎠ ⎝ ⎛ ⎛ 10.0 ⎞ ⎛ −5.2 ⎞ ⎛ −7.0 ⎞ ⎞ = 2 tanh −1 ⎜ tanh ⎜ ⎟ ⋅ tanh ⎜ ⎟ ⋅ tanh ⎜ ⎟⎟ ⎝ 2 ⎠ ⎝ 2 ⎠ ⎝ 2 ⎠⎠ ⎝ = 5.04. L(l +1) (c1 ) = L(l ) (c1 ) + α ⎡⎣ Lext( ) (c1 ) ⎤⎦ = 1.2 + 1 ⋅ [5.04] (l ) 2. α. 圖 3-6 JN 演算法之 LLR 更新範例. 接下來以更新後的 LLR 進行下一次的疊代過程。. 3-1.4 JN 解碼演算法之改善方式 Jing Jiang 和 Narayanna 於[15]提出了三種改進原有 JN 演算法效能的方式, 接下來將介紹此三種方法。. 21.
(31) (1) 階段-2 隨機相連方式 由於經過高斯消去法作用後,位於 H b 低密度位置的位元節點均只相連至一 個校驗節點,因此其只會收到該校驗節點所傳送的額外消息量。若該校驗節點相 連的其他高密度位置之位元節點發生錯誤時,則此低密度位置的位元節點容易收 到錯誤的額外消息量而翻轉其 LLR 的正負號,整個解碼過程也容易受此影響而 收斂到錯誤的碼字。因此提出以下的方式,於更新奇偶校驗矩陣階段修正這個問 題。 階段-2 隨機相連演算法 步驟一、 按照原有的方式對每個位元節點的 LLR 進行排序,並且由信任度小 至大進行高斯消去法得到 H b 的低密度位置和高密度位置。 步驟二、 將 H b 的列 1 至列 (n − k ) 間進行隨機的排序,並記錄排序後的索引 值為 p 1 , p 2 , p 3 ,...., p n − k 。 如 [1 2 3 4] → [ 2 4 1 3] = [ p1. p2. p3. p4 ] 。. 步驟三、 將高斯消去法後得到的 H b ,按照以下的方式進行修正: 將列 pi +1 加至列 pi ,自 i = 1 至 i = n − k − 1 。. 經過此演算法作用後,除了 p 1 行仍然只相連至一個校驗節點外,所有的低 密度部分的位元節點均相連至兩個校驗節點,而抑制了上述問題的影響。. (2) 平行選擇不同的位元節點作為低密度位置 按照 LLR 排序進行高斯消去法後,某些高密度位置的位元節點,其信任度 相當接近低密度位置的位元節點,而這些高密度部分的位元節點實際上由於信任 度不大,因此也較容易發生錯誤的情況,因此在 [15] 中針對此種情況提出了改 進的方式。 其平行進行數個原有的 JN 演算法,然而每個 JN 演算法於一開始均使用不. 22.
(32) 同低密度位置的位元節點,也就是將部分位於高信任度和低信任度交界處的低信 任度位置和高信任度位置進行交換,再依交換後的順序進行高斯消去法和梯度下 降法的疊代過程。這些平行處理的數個 JN 演算法由於初始時為不同的排序而在 初始時有不同的 H b。每個 JN 演算法於每次疊代中均會經過硬式決策而得到一組 解碼輸出,假設經過 l 次疊代,則會產生 l 個解碼輸出,若現在共有 A 組 JN 演算 法使用不同的排序平行處理,則總共會有 Al 個解碼輸出,則在這 Al 個解碼輸出 中,最後將選擇和接收信號相關性最高的解碼輸出作為最終的解碼輸出。. (3) 合併代數解碼 (algebraic decoding) 方式 此方式為對 JN 演算法每次疊代的解碼輸出再予以進行代數解碼,因此在每 次疊代中解碼器均會得到一個代數解碼的輸出。由於代數解碼所輸出的碼字有可 能非為與接收信號相關性最大的碼字,因此 JN 演算法在每次解碼時,將執行至 最大的疊代次數後,選擇代數解碼輸出的所有碼字中和接收信號間相關性最大的 碼字做為最後的解碼輸出。 在此特別說明,以下於本研究中所提及之 JN 演算法,皆為原始之 JN 演算 法,並未使用以上三種方式。. 3-2 ABP-OSD(1) 解碼演算法 3-2.1 ABP-OSD(1) 解碼演算法簡介 ABP-OSD(1) 解碼演算法 [12] 結合了兩種使用信任度排序的解碼法。其中 ABP 的過程是利用二位元奇偶校驗矩陣由信任度小至大的位置進行高斯消去法 得到 LRIPs 和相對應的簡化梯式奇偶校驗矩陣後,再計算每個位元節點額外消息 量的動作。OSD(1) 則是利用二位元生成矩陣由信任度大至小的位置進行高斯消 去法得到 k 個最大信任獨立位置 (most reliable independent positions,簡稱 MRIPs ) 23.
(33) 和簡化梯式生成矩陣後,再以這些位置配合測試錯誤樣本 (test error patterns,以 下簡稱為 TEPs) 重新編碼來來進行解碼。TEP 為長度 k 的向量,若預設第 i 個. MRIP 為錯誤的位置時,TEP 的該位置即為 1,否則為 0,並以 w 來表示 TEP 中 1 的個數。我們可以利用 TEP 加上 MRIPs 來獲得更新的 MRIPs 後,再利用更新 後的 MRIPs 重新編碼,若錯誤的確均發生在 TEP 所預測的位置上時,則可以編 碼出正確的碼字。以下關於 OSD 的討論中,碼字的非 MRIPs 部分,稱為最小信 任位置 (least reliable positions,簡稱 LRPs)。於下一節中,我們將說明 OSD 之運 作方式。. 3-2.2 OSD ( w ) 解碼演算法步驟 於說明 OSD(w)之解碼步驟前,我們先介紹解碼中所使用到的判斷原則和數 學表示,其相關說明如下: 首先由碼字 c 和接收信號定義兩個集合於式 (3.1) 和式 (3.2): D0 ( c ). {i : ci = zi , 1 ≤ i ≤ n}. (3.1). D1 ( c ). {i : ci ≠ zi , 1 ≤ i ≤ n} .. (3.2). 其中 zi 為接收信號經硬式決策後所得的 0 或 1 之值。 另外定義 D1 ( c ) 中的個數於式 (3.3):. n ( c ) = D1 ( c ) .. (3.3). 接下來定義接收信號和碼字間的相關性差異 (correlation discrepancy) 為 λ ,而 其計算方式為式 (3.4)。. λ ( r, c) =. ∑. i∈D1 ( c ). ri .. (3.4). 而接收信號和碼字間的相關性 (correlation) θ 可定義為式 (3.5). θ ( r, c). n. ∑ r ⋅ (1 − 2c ) . i =1. i. 24. i. (3.5).
(34) 在 D0 ( c ) 中,信任度最小的前 d min − n ( c ) 個位置,我們以集合 D0A ( c ) 來表示。 若 d min < n ( c ) 時,則定義 D0A ( c ) 為空集合。 由以上的定義,我們最後定義一比較係數 G ( c ) 於式 (3.6). G(c). ∑. i∈D0A ( c ). ri .. (3.6). 由[16]可知,當式 (3.7) 成立時,則表示 c 為和接收信號相關性 θ 最大的碼字, 即最大概似碼字。. λ ( r, c) ≤ G (c ).. (3.7). 以下為 OSD(w)演算法之詳細執行步驟,運作過程可以圖 3.7 表示: 步驟一、 依據信任度大小進行位元節點的排序。 步驟二、 依排序的結果,依信任度由大至小的位置對二位元生成矩陣 G b 進行高 斯消之動作而得到簡化梯式生成矩陣。若該位置無法經列運算正規 化,則跳過該位置至信任度次大的下一個位置,直到得到 k 個 MRIPs 後停止。 步驟三、 製作測試錯誤樣本:假設此 k 個 MRIPs 中分別有 0、1、2、…….、 w 個錯誤,( w < k ),此於演算法之標示為 OSD( w ),則表示此演算 法於該 MRIPs 中,最多測試至發生 w 個錯誤。接下來分別產生 0、1、. 2、…….、 w 個錯誤的所有測試錯誤樣本,若該位置發生錯誤,則在 樣本中給予 1 的值,否則給 0 的值,而在 OSD( w )的情況下,總共產 生. w. ⎛k ⎞. i =0. ⎝ ⎠. ∑⎜ i ⎟. 個 TEPs。. 步驟四、 將原來的 MRIPs 向量加上 TEP 向量後,根據高斯消去法所得到的梯 式簡化生成矩陣進行編碼,當所有的 TEP 配合 MRIPs 均被重新編碼 後,選擇和接收信號相關性最大碼字的做為解碼輸出。或當某個 TEP 25.
(35) 配合 MRIPs 所得到的碼字為最大概似碼字時,則直接輸出該碼字。. L(c1 ), L(c2 ), L(c3 ),..., L(cn ). 依輸入LLR之信任度進行排序 將TEP加至MRIPs後利用高斯消 去法所得之簡化梯式生成矩陣 重新編碼. 依照排序信任度大至小的位置 進行高斯消去法的動作,將生 成矩陣經列運算後得到簡化梯 式生成矩陣和k個MRIPs。. 若編碼後所得的碼字為最大概 似碼字則直接輸出解碼結果, 否則輸出所有TEPs經編碼後和 接收信號相關性最大的碼字. 製作測試OSD(w)之測試錯誤樣本 w= 0. w=1. w= 2. 0000000 1000000 1100000 0100000 1010000 ...... ....... ....... 解碼輸出. 0000001 0000011. 圖 3.7 OSD(w) 演算法運作過程. 而在 ABP-OSD(1)解碼演算法中,使用 w 為 1 的情況。. 3-2.3 OSD(1) 解碼演算法範例 使用(7,4)漢明碼作為範例,原始的二位元生成矩陣和相對應每個位元位置的 初始 LLR 如下:. 26.
(36) ⎡1 ⎢1 Gb = ⎢ ⎢0 ⎢ ⎣1. 1 0 1 1. 位元1. 位元2. 位元3. 位元4. 位元5. 位元6. 位元7. 1.2. -0.01. 10.0. 4.3. -5.2. -6.6. -7. 1 0 0 0. 0 1 1 1. 0 1 0 0. 0 0 1 0. 0⎤ 0 ⎥⎥ 0⎥ ⎥ 1⎦. 圖 3-8 OSD(1)演算法之初始化範例 首先經過排序 位元1. 位元2. 位元3. 位元4. 位元5. 位元6. 位元7. 1.2. -0.01. 10.0. 4.3. -5.2. -6.6. -7. 順序2. 順序1. 順序7. 順序3. 順序4. 順序5. 順序6. 圖 3-9 OSD(1)演算法之排序範例. 則將生成矩陣由高信任度位置由大至小開始做高斯消去動作後,得到對應的簡化 梯式生成矩陣和最大獨立信任度位置,如圖 3-11. ⎡1 ⎢1 G=⎢ ⎢0 ⎢ ⎣1. 1 1 0 0 0 0⎤ 1 0 1 0 0 1 ⎥⎥ 1 0 1 0 1 0⎥ ⎥ 0 0 1 1 0 0⎦ MRIPs. 圖 3-10 OSD(1)演算法之初始化範例. 將 LLR 經過硬式決策後,得到每個位置的決策值,接下來設定 k + 1 個 TEPs, 加至決策值後的向量,再將此向量經由高斯消去動作後的生成矩陣重新編碼產生 碼字,如圖 3-11。. 27.
(37) MRIP = 0111. 例. TEP = 0000 0001 0010. MRIP + TEP = 0111 + 0001 = 0110. 0100 1000. 重新編碼後得到碼字. ⎡1 ⎢1 MRIPiG′ = [ 0 1 1 0]i ⎢ ⎢0 ⎢ ⎣1. 1 1 0 0 0 0⎤ 1 0 1 0 0 1 ⎥⎥ = [1 0 0 0 0 1 1] 1 0 1 0 1 0⎥ ⎥ 0 0 1 1 0 0⎦. 圖 3-11 OSD(1)演算法之重新編碼範例 最後計算該碼字和接收信號間的相關性,若其為最大概似碼字則直接輸出, 否則保留目前相關性最大的碼字,最後以相關性最大的碼字作為最終的解碼輸 出。. 3-2.4 JN-OSD(1) 解碼演算法步驟 於 ABP-OSD(1)演算法中,本研究於 ABP 的部分使用以梯度下降法為基礎 的 JN 演算法,以下簡稱為 JN-OSD(1)解碼演算法。. JN-OSD(1)解碼演算法的詳細步驟如下: 步驟一、設定抑制係數 α , 最大疊代次數 lmax ,並計算每個位元節點的初始的. LLR 為 L(0) (ci ) = ( 4 yi / N 0 ) ,並以初始 LLR ( L(0) (ci ) ) 開始進行解碼。 步驟二、 OSD(1)演算法階段:. (1) 依據 LLR 絕對值 L. (l ). 的大小將每個位元位置進行排序,並且記錄排序後的順. 序。. (2) 依排序的結果,依信任度由大至小的位置對二位元生成矩陣 G b 進行高斯消 之動作而得到簡化梯式生成矩陣。若該位置無法經列運算正規化,則跳過該 位置至信任度次大的下一個位置,直到得到 k 個 MRIPs 後停止。. (3) 此時假設此 k 個 MRIPs 中僅有一個錯誤,因此生成 w 為 0 和 w 為 1 的 k + 1 個 TEPs。並按照此 k + 1 個 TEPs 以高斯消去動作後的生成矩陣進行編碼得到 k + 1 組候選碼字 (candidate codewords)。 28.
(38) (4) 若找到最大概似碼字,則停止解碼並輸出結果。若到達最大預定疊代次數 lmax 時,則停止解碼並輸出最目前所存相關性最大的碼字。未停止解碼則進行步 驟三。 步驟三、 JN 演算法階段。. (. (1) 更新奇偶校驗矩陣: H b(l ) = φ H b , L. (l ). ) , φ 表示更新 H 的動作。利用高斯消 b. 去法,按照信任度由小至大的位置將 H b(l ) 消為簡化梯式矩陣,並得到 (n − k ) 個. LRIPs。 (2) 利用高斯消去法正規化後的 H b(l ) ,進行梯度下降法得到每個位元節點的額外. (. 消息量: L ext = ϕ H b(l ) , L (l ). (l ). ) ,即式 (2.14) 的過程。 ϕ 表示計算額外消息量之. 動作。. (3) 更新每個位元節點的 LLR: L. ( l +1). = L + α L ext ,即式 (2.13) 的過程。在這 (l ). (l ). 裡 0 < α ≤ 1。. (4) 回到步驟二。. ABO-OSD(1)之機制可以用圖 3-12 來表示. 圖 3-12 ABP-OSD(1) 機制運作方式. 29.
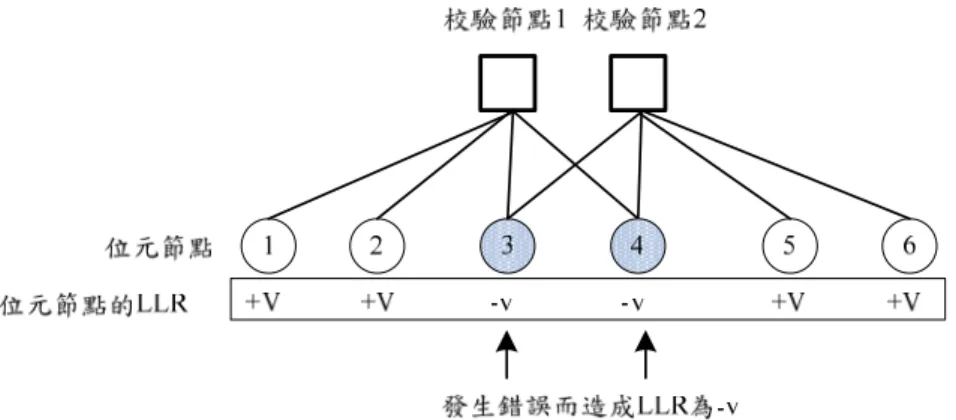
(39) 第四章. 抑制 JN 演算法中高信任度 錯誤之演算法 於本章中首先將指出原有 JN 演算法的潛在問題,並說明本研究中如何於提 出之演算法中改善此潛在問題,並且佐以數據分析以證明此潛在問題受到了抑 制。於最後一節中,再提出利用里德所羅門碼的內插特性,輔助解碼器改善效能 之概念。. 4-1 JN 演算法之探討 4-1.1 JN 演算法之優勢 於信念傳遞解碼中,通常希望錯誤不要發生在二位元奇偶校驗矩陣的高密度 位置中,以免由於錯誤相連至過多的校驗節點,而造成錯誤傳遞的問題。基於信 任度解碼的概念,在 AWGN 通道之下,接收信號的 LLR 絕對值 (信任度) 愈小 的位置,會被認定較有可能發生錯誤。因此於 JN 演算法中,其利用高斯消去得 到 LRIPs 的動作,使得每個低信任度位元節點僅相連至一個校驗節點,每個校驗 節點也只相連至一個低信任度的位元節點。這個動作除了於前一章所提到防止校 驗節點飽和化的作用外,也同樣的抑制了低信任度錯誤所造成的錯誤傳遞問題。 接下來我們利用以下的分析方式來說明這個現象。 若現有二位元奇偶校驗矩陣之 Tanner 圖如圖 4-1 所示,圖中週期 4 (cycle 4) 的部分所代表的是二位元奇偶校驗矩陣中的高密度位置。在以下的討論中,假設. 30.
(40) 正確的 LLR 值為一正值 (+),而錯誤的 LLR 值為一負值 (-)。我們假設在沒有發 生錯誤的情況下,高信任度位置 LLR 的絕對值為 V ,低信任度位置的 LLR 的 絕對值為 v,且 V>v。若高信任度位置發生錯誤,則我們令其 LLR 值為-V,若 低信任度位置發生錯誤,我們令其 LLR 值為-v。在圖 4-1 中,我們同時假設位元 節點 3 和位元節點 4 為低信任度位置,其他位元節點為高信任度位置。 接下來我們假設為低信任度位於高密度位置的位元節點 3 發生錯誤並給予 其-v 的 LLR 值,如圖 4-2 所示。利用梯度下降法的運作,每個位元節點可分別 自校驗節點 1 或校驗節點 2 得到計算後的額外消息量。由於目前假設正確的 LLR 為一正值,因此當校驗節點給予某個位元節點正確的額外消息量時,此額外消息 量我們以+E (E>0) 來表示,而當校驗節點給予某個位元節點錯誤的額外消息量 時,此額外消息量則以-E 來表示。 因此利用以上的假設,我們可以得到每個位元節點所收到的額外消息量,以 及更新後的 LLR 值,如圖 4-3 所示。從訊息的傳遞過程中發現,圖 4-3 中除了錯 誤的位元節點外,所有其他的位元節點均接收到了錯誤的額外消息量。這種錯誤 額外消息量的大量傳播容易造成其他位元的錯誤。因此若錯誤發生於高密度位置 時,往往造成梯度下降法收斂至錯誤的碼字,甚至無法收斂的現象。. 圖 4-1 位元節點 3 和位元節點 6 為低信任度位置. 31.
(41) 圖 4-2 當高密度位置 (位元節點 3) 發生一個錯誤時. 圖 4-3 高密度位置發生一個錯誤 (位元節點 3) 時的訊息傳遞情況 若是利用 JN 演算法同樣考慮發生一個錯誤的情況,我們首先可以利用前一 章中所提到的高斯消去動作,得到簡化梯式校驗矩陣和相對應的 Tanner 圖。這 個動作能夠使得低信任度的位元節點僅連接到一個校驗節點,每個校驗節點也僅 連結至一個低信任度的位元節點,因此校驗矩陣高密度的位置此時會均為高信任 度之位元節點。利用這個動作,我們將上例中低信任度的位元節點 3 和 4 移至低 密度位置,而位元節點 1 和 6 轉移至高密度位置,如圖 4-4 所示。再利用此 Tanner 圖計算每個位元節點的額外消息量,圖 4-5 所示。圖 4-5 中可以發現,相較於圖. 4-3,錯誤傳遞的情況大量減少,僅有一個高信任度位置會收到錯誤的額外消息 量。. 32.
(42) 圖 4-4 經過 JN 演算法高斯消去動作後的 Tanner 圖. 圖 4-5 發生一個錯誤 (位元節點 3)時,經高斯消去動作後的額外消息量傳遞情形. 接下來考慮兩個低信任度位置 (位元節點 3 和位元節點 4) 同時發生錯誤的 情況,我們依照前例中所做的假設,給予位元節點 3 和位元節點 4 為-v 的 LLR 值,如圖 4-6 所示。而此時的訊息傳遞情形表示於圖 4-7。從圖 4-7 中我們可以 發現,由於錯誤間互相影響,本來錯誤的位置不斷收到錯誤的額外消息量,這個 現象在解碼上亦容易造成解碼失敗。. 33.
(43) 圖 4-6 當高密度位置發生兩個錯誤時 (位元節點 3、位元節點 4) 校驗節點1 校驗節點2. 位元節點. 1. 2. 3. 4. 5. 6. +V. +V. -v. -v. +V. +V. 由校驗節點1所提供的額外消息量. +E. +E. -E. -E. 0. 0. 由校驗節點2所提供的額外消息量. 0. 0. -E. -E. +E. +E. +V+E. -v-2E. +V+E. +V+E. 位元節點的LLR. 經過疊代後每個位元節點之LLR +V+E. +v-2E. 圖 4-7 當高密度位置發生兩個錯誤時,額外消息量的傳遞情形. 若在同樣的情況下,使用 JN 演算法中高斯消去法的動作,使得低信任度位 置自高密度位置改至低密度位置,則經此動作後的 Tanner 圖和訊息傳遞情況可 以圖 4-8 和圖 4-9 呈現。由圖 4-9 可以發現,在此例中雖然也出現了大量的錯誤 傳遞情形,但若在信任度 V 夠大的情況下,在此次疊代過程中較能不被錯誤的 額外消息量影響而改變其正負號,並且低信任度的位置有機會在這次疊代中被更 正,相較於圖 4-7 的情況,高斯消去動作仍然較能抑制解碼失敗的發生。. 34.
(44) 校驗節點1 校驗節點2. 位元節點 位元節點的LLR. 3. 2. 1. 6. 5. 4. -v. +V. +V. +V. +V. -v. 移至低密度位置. 移至低密度位置. 圖 4-8 兩個錯誤下,經 JN 演算法高斯消去動作後的 Tanner 圖. 圖 4-9 發生兩個錯誤時,經高斯消去法作用後的訊息傳遞情形 由以上的分析可知,JN 演算法的高斯消去動作能夠抑制低信任度錯誤所造 成的問題,此為其優勢。. 4-1.2 JN 演算法之潛在問題 在前一小節的討論中,雖然 JN 演算法利用高斯消去動作將低信任度的位元 節點置於二位元奇偶校驗矩陣的低密度位置,使其僅影響到一個校驗節點以減少 錯誤傳遞的情況,然而這個動作建立在相信高信任度位置均為正確的假設之下, 實際上卻並非如此。因此 JN 演算法的潛在問題便在於過於相信高信任度位置為 正確的假設,而將其置於二位元奇偶校驗矩陣的高密度位置,若高信任度位置發 生錯誤的情況,僅管錯誤的個數不多,卻往往會造成嚴重的錯誤傳遞現象,使得 35.
(45) 解碼器收斂至錯誤的碼字,甚至無法收斂。 圖 4-10 為統計上 JN 演算法於(15,7)里德所羅門碼解碼失敗分布圖,橫軸代 表若無法成功解碼時,於第一次高斯消去動作執行時,被置於高密度位置的錯誤 位元節點個數,而縱軸代表所有測試碼字中,發生此個數情況的次數,此時所使 用的最大疊代次數 lmax 為 20 次, α 為 0.1。 RS (15,7) ; the distribution of error frames ; SNR=4.0 ; total frame number=100,000 200 180. 164. decoding failure number. 160. 133. 140 120 100 80 60 40 20 0. 5 0. 1 2 Number of Error in MRPs. 3. 圖 4-10 JN 演算法解碼失敗分布圖 由圖 4-10 可以觀察到,若於第一次的高斯消去動作中,錯誤的發生均落於 低密度位置 (即橫軸坐標為 0 )時,則均可順利解碼成功。由前一小節的討論可 知,JN 演算法於此時提供了良好的保護能力。但當第一次的高斯消去動作中高 密度位置的錯誤個數增加時,JN 演算法卻由於過度相信這些高密度位置為正確 的位置,造成解碼失敗的結果。於下一小節中,我們將提出適當的改善機制來避 免這個問題。. 4-2 提出之演算法 4-2.1 提出之演算法概念說明 當 JN 演算法執行時,其所需要擔心的問題為錯誤傳遞的現象。若要抑制錯 36.
(46) 誤傳遞的現象,則需要於疊代過程中即進行處理,否則當碼字已逐漸收斂到錯誤 的碼字時,再進行補救則為時已晚。然而 JN 演算法本身的特性在於相信錯誤均 落於 LRIPs 上而進行解碼,因此若要幫助 JN 演算法解決前一小節中所提到的問 題,我們傾向於利用額外的機制來提供 JN 演算法足夠的訊息量來進行改善。這 些訊息量能夠快速使得 LRIPs 的錯誤被更正,並且加強其信任度後,使得 MRPs 和 LRIPs 進行交換。此時 MRPs 若發生錯誤,有可能在幾次疊代後即落入為. LRIPs,而使得解碼過程得以不受到原來 MRPs 錯誤的影響而收斂到正確的碼字。 於本論文中希望使用額外的機制為 OSD(1) 解碼演算法。該演算法能夠利用 測試錯誤樣本 (TEP) 和 MRIPs 進行重新編碼的動作,再自這些重新編碼的碼字 中選擇和接收信號相關性較大的碼字。這些和接收信號相關性較大的碼字,其於. LRPs 的正確性也會和正確的碼字較為接近。因此若以 OSD(1)的解碼結果提供適 當的消息量給予 JN 演算法的 LRIPs,則能夠協助 JN 演算法解決前述的潛在問題。 在此說明提出之演算法和 JN-OSD(1)解碼演算法之差別在於,JN-OSD(1)並 未提供適當的機制來解決 JN 演算法面對高信任度錯誤的問題,僅管 OSD(1) 本 身對於碼字中能夠提供高信任度位置中一個錯誤位置的更正,然而在多個高信任 度錯誤發生的情況下,其並不能協助 JN 演算法進行妥善的處理。 因此本論文提出之演算法其能夠提供 JN 演算法以下的兩項協助:. (1) 加速 LRIPs 錯誤位置之更正,和 LRIPs 正確位置之信任度提昇。 (2) 藉由使 MRPs 和 LRIPs 之交換,抑制 MRPs 錯誤的影響。 提出之演算法的解碼疊代過程可以表示如圖 4-11 所示。. 37.
(47) 圖 4-11 所提供演算法之概念圖. 4-2.2 提出之演算法解碼步驟 以下將說明於 ( n, k ) 線性區塊碼時,提出之演算法的解碼步驟: 步驟一、設定抑制係數 α , 最大疊代次數 lmax ,並計算每個位元節點的初始 的 LLR 為 L(0) (ci ) = ( 4 yi / N 0 ),並以初始 LLR ( L(0) (ci ) ) 開始進行解碼。 步驟二、 OSD(1)演算法階段:. (1) 依據 LLR 絕對值 L. (l ). 的大小將每個位元位置進行排序,並且記錄. 排序後的順序。. (2) 依排序的結果,依信任度由大至小的位置對二位元生成矩陣 G b 進 行高斯消之動作而得到簡化梯式生成矩陣。若該位置無法經列運 算正規化,則跳過該位置至信任度次大的下一個位置,直到得到 k 個 MRIPs 後停止。. (3) 此時假設此 k 個 MRIPs 中僅有一個以下的錯誤。因此生成 1 的個. 38.
(48) 數為 0,和 1 的個數為 1 的 TEPs。接下來按照此 k + 1 個 TEPs 以 高 斯 消 去 動 作 後 的 生 成 矩 陣 進 行 編 碼 得 到 k +1 組 候 選 碼 字. (candidate codewords)。 (4) 若自候選碼字中找到最大概似碼字,則停止解碼並輸出結果。若 到達最大預定疊代次數 lmax 時,則停止解碼並輸出最目前所存相關 性最大的碼字。否則保留此次疊代中和接收信號相關性最大的碼 字,並進行步驟三。 步驟三、 回授機制:回授機制將說明於 4-2.3 節中。 步驟四、 JN 演算法階段。. (. (1) 更新奇偶校驗矩陣: H b(l ) = φ H b , L 依據回授機制後的 LLR 絕對值 L. (l ). (l ). ) , φ 表示更新 H 的動作。 b. 的大小將每個位元位置進行排. 序,並且記錄排序後的順序。利用高斯消去法,按照信任度由小 至大的位置將 H b(l ) 消為簡化梯式矩陣,並得到 (n − k ) 個 LRIPs。. (2) 利用高斯消去法正規化後的 H b(l ) ,進行梯度下降法得到每個位元. (. 節點的額外消息量: L ext = ϕ H b(l ) , L (l ). (l ). ),即式 (2.14) 的過程。ϕ 表. 示計算額外消息量之動作。. (3) 更新每個位元節點的 LLR: L. ( l +1). = L + α L ext ,即式 (2.13) 的過 (l ). (l ). 程。在這裡 0 < α ≤ 1 。. (4) 回到步驟二。. 4-2.3 提出演算法之 OSD(1) 回授機制討論 於回授機制的討論中,本論文使用四種方式進行模擬以選擇回授機制:. 回授機制(1): 於每次疊代過程中,儲存 OSD(1)機制中所得到與接收信號相關性最大的碼 39.
(49) 字。若於 OSD(1)機制結束後,該碼字於某 LRP 的位置判斷為 0,則於該位置的. LLR 加上 + A 的額外消息量,若該碼字於某 LRP 的位置判斷為 1,則於該位置的 LLR 加上 − A 的額外消息量,其中 A 為可調整之係數,且 A > 0 。. 回授機制(2): 於每次疊代過程中,儲存 OSD(1)機制中所得到與接收信號相關性最大的兩 個碼字。若於 OSD(1)機制結束後,該兩個碼字於某 LRP 的位置判斷同為 0,則 於該位置的 LLR 加上 + A 的額外消息量,若該兩個碼字於某 LRP 的位置判斷為 同為 1,則於該位置的 LLR 加上 − A 的額外消息量,其中 A 為可調整之係數,且 A>0。. 若此兩個碼字的判斷不相同時,則分別計算該兩個碼字的事後機率,將該位 置為判斷為 0 的碼字事後機率( p0 )置於分子,而該位置判斷為 1 的碼字事後機率 置於分母( p1 ),最後將該位置原有的 LLR 加上 log ( p0 / p1 ) 的額外消息量,若 log ( p0 / p1 ) 超過 + A 或小於 − A 時,該位置原有的 LLR 僅加上 + A 或 − A 之值。. 回授機制(3): 首先於每次疊代過程中,首先計算 OSD(1) 所有生成碼字的事後機率。我們 定義於生成碼字中第 i 個位置為 0 的碼字集合為 C0i ,而生成碼字中第 i 個位置為. 1 的碼字集合為 C1i 。則接下來我們將 LRPs 中位元節點 i 原有的 LLR 加上 log ( Pr ( c 0 max | r ) / Pr ( c1max | r ) ) 的額外消息量值,其中 c 0max 為 C0i 中事後機率最大. 的碼字, c1max 為 C1i 中事後機率最大的碼字。若 log ( Pr ( c 0 max | r ) / Pr ( c1max | r ) ) 超 過 + A 或小於 − A 時,該位置原有的 LLR 僅加上 + A 或 − A 之值。. 回授機制(4): 於每次疊代過程中,首先計算 OSD(1) 所有生成碼字的事後機率。我們定義於 生成碼字中第 i 個位置為 0 的碼字集合為 C0i ,而生成碼字中第 i 個位置為 1 的碼字 集 合 為 C1i 。 則 接 下 來 我 們 將 LRPs 中 位 元 節 點 i 原 有 的 LLR 加 上. 40.
(50) ⎛ ⎞ ⎛ ⎞ log ⎜ ∑ Pr ( c | r ) / ∑ Pr ( c | r ) ⎟ 的額外消息量值。若 log ⎜ ∑ Pr ( c | r ) / ∑ Pr ( c | r ) ⎟ c∈C1i c∈C1i ⎝ c∈C0 i ⎠ ⎝ c∈C0 i ⎠ 超過 + A 或小於 − A 時,該位置原有的 LLR 僅加上 + A 或 − A 之值。 接下來利用 (15,7) 里德所羅門碼對於以上四種回授機制進行模擬,抑制參數. α = 0.10 ,最大疊代次數為 20 次,在不同的 A 值情況下,模擬結果分別於圖 4-12 至圖 4-17。 10. feedback(1) feedback(1) feedback(1) feedback(1) feedback(1) feedback(1). -3. A=1.00 A=2.00 A=3.00 A=4.00 A=5.00 A=6.00. BER. 10. RS (15,7); AW GN channel; BPSK ; feedback scheme (1). -2. 10. 10. -4. -5. 3. 3.2. 3.4. 3.6. 3.8. 4 4.2 E b/N0 (dB). 4.4. 4.6. 4.8. 5. 圖 4-12 (15,7)里德所羅門碼配合回授機制(1)於不同 A 值下的情況. 41.
(51) 10. feedback(2) feedback(2) feedback(2) feedback(2) feedback(2) feedback(2). -3. A=1.00 A=2.00 A=3.00 A=4.00 A=5.00 A=6.00. BER. 10. RS (15,7); AW GN channel; BPSK ; feedback scheme (2). -2. 10. 10. -4. -5. 3. 3.2. 3.4. 3.6. 3.8. 4 4.2 E b/N0 (dB). 4.4. 4.6. 4.8. 5. 圖 4-13 (15,7)里德所羅門碼配合回授機制(2)於不同 A 值下的情況 10. feedback(3) feedback(3) feedback(3) feedback(3) feedback(3) feedback(3). -3. A=1.00 A=2.00 A=3.00 A=4.00 A=5.00 A=6.00. BER. 10. RS (15,7); AW GN channel; BPSK ; feedback scheme (1). -2. 10. 10. -4. -5. 3. 3.2. 3.4. 3.6. 3.8. 4 4.2 E b/N0 (dB). 4.4. 4.6. 4.8. 5. 圖 4-14 (15,7)里德所羅門碼配合回授機制(3)於不同 A 值下的情況. 42.
(52) 10. feedback(4) feedback(4) feedback(4) feedback(4) feedback(4) feedback(4). -3. A=1.00 A=2.00 A=3.00 A=4.00 A=5.00 A=6.00. BER. 10. RS (15,7); AW GN channel; BPSK ; feedback scheme (4). -2. 10. 10. -4. -5. 3. 3.2. 3.4. 3.6. 3.8. 4 4.2 E b/N0 (dB). 4.4. 4.6. 4.8. 5. 圖 4-16 (15,7)里德所羅門碼配合回授機制(3)於不同 A 值下的情況 10. RS (15,7); AW GN channel; BPSK; compare feedback scheme. -2. feedback(1) feedback(2) feedback(3) feedback(4) -3. BER. 10. A=2.00 A=2.00 A=2.00 A=2.00. 10. 10. -4. -5. 3. 3.2. 3.4. 3.6. 3.8. 4 4.2 E b/N0 (dB). 4.4. 4.6. 4.8. 5. 圖 4-17 (15,7)里德所羅門碼比較不同回授機制於最好 A 值下的情況. 43.
數據



+7





Outline
相關文件
Real Schur and Hessenberg-triangular forms The doubly shifted QZ algorithm.. Above algorithm is locally
Then, we tested the influence of θ for the rate of convergence of Algorithm 4.1, by using this algorithm with α = 15 and four different θ to solve a test ex- ample generated as
In this chapter we develop the Lanczos method, a technique that is applicable to large sparse, symmetric eigenproblems.. The method involves tridiagonalizing the given
For the proposed algorithm, we establish a global convergence estimate in terms of the objective value, and moreover present a dual application to the standard SCLP, which leads to
The temperature angular power spectrum of the primary CMB from Planck, showing a precise measurement of seven acoustic peaks, that are well fit by a simple six-parameter
For the proposed algorithm, we establish its convergence properties, and also present a dual application to the SCLP, leading to an exponential multiplier method which is shown
This thesis applied Q-learning algorithm of reinforcement learning to improve a simple intra-day trading system of Taiwan stock index future. We simulate the performance
• When this happens, the option price corresponding to the maximum or minimum variance will be used during backward induction... Numerical
