Submitted manuscript
Mining Weighted Browsing Patterns with Linguistic
Minimum Supports
Tzung-Pei Hong†*, Ming-Jer Chiang‡ and Shyue-Liang Wang‡
†Department of Electrical Engineering
National University of Kaohsiung Kaohsiung, 811, Taiwan, R.O.C.
‡Graduate School of Information Engineering
I-Shou University Kaohsiung, 840, Taiwan, R.O.C.
ndmc893009@ yahoo.com.tw, slwang@ isu.edu.tw
Abstract
World-wide-web applications have grown very rapidly and have made a significant impact on computer systems. Among them, web browsing for useful information may be most commonly seen. Due to its tremendous amounts of use, efficient and effective web retrieval has become a very important research topic in this field. Techniques of web mining have thus been requested and developed to achieve this purpose. All the web pages are usually assumed to have the same importance in web mining. Different web pages in a web site may, however, have different importance to users in real applications. Besides, the parameters set in most conventional data-mining algorithms are numerical. This paper thus attempts to propose a weighted web-mining technique to discover linguistic browsing patterns from log data in web servers. Web pages are first evaluated by managers as linguistic terms to reflect their importance, which are then transformed as fuzzy sets of weights. Linguistic minimum supports are assigned by users, showing a more natural way of human reasoning. Fuzzy operations including fuzzy ranking are then used to find linguistic weighted large sequences. An example is also given to clearly illustrate the proposed approach.
Keywords: browsing pattern, fuzzy set, web mining, weight.
--- * Corresponding author
1. Introduction
Knowledge discovery in databases (KDD) has become a process of considerable interest
in recent years as the amounts of data in many databases have grown tremendously large.
KDD means the application of nontrivial procedures for identifying effective, coherent,
potentially useful, and previously unknown patterns in large databases[17]. The KDD process
generally consists of three phases: pre-processing, data mining and post-processing [16, 29].
Among them, data mining plays a critical role to KDD. Depending on the classes of
knowledge derived, mining approaches may be classified as finding association rules,
classification rules, clustering rules, and sequential patterns [8], among others.
Recently, world-wide-web applications have grown very rapidly and have made a
significant impact on computer systems. Among them, web browsing for useful information
may be most commonly seen. Due to its tremendous amounts of use, efficient and effective
web retrieval has thus become a very important research topic in this field. Techniques of web
mining have thus been requested and developed to achieve this purpose. Cooley et. al. divided
web mining into two classes: web-content mining and web-usage mining [13]. Web-content
mining focuses on information discovery from sources across the world-wide-web. On the
from web servers [14]. In the past, several web-mining approaches for finding sequential
patterns and interesting user information from the world-wide-web were proposed [7, 9, 12,
13].
The fuzzy set theory has been used more and more frequently in intelligent systems
because of its simplicity and similarity to human reasoning [38, 39]. The theory has been
applied in fields such as manufacturing, engineering, diagnosis, and economics, among others
[19, 26, 28, 38]. Several fuzzy learning algorithms for inducing rules from given sets of data
have been designed and used to good effect with specific domains [2, 4, 15, 18, 20-24, 32-34].
Strategies based on decision trees were proposed in [6, 10-11, 30-32, 35-36], and based on
version spaces were proposed in [27]. Fuzzy mining approaches were proposed in [5, 25, 27,
37].
In the past, all the web pages were usually assumed to have the same importance in web
mining. Different web pages in a web site may, however, have different importance to users in
real applications. For example, a web page with merchandise items on it may be more
important than that with general introduction. Also, a web page with expensive merchandise
items may be more important than that with cheap ones. Different importance for web pages
confidence values in most conventional data-mining algorithms were set numerical. In [22],
we proposed a weighted mining algorithm for association rules using linguistic minimum
support and minimum confidence. In this paper, we further extend it to mining weighted
sequential browsing patterns from log data on web servers. The linguistic minimum support
values are given, which are more natural and understandable for human beings. The browsing
sequences of users on web pages are used to analyze the overall retrieval behaviors of a web
site. Web pages may have different importance, which is evaluated by managers or experts as
linguistic terms. The proposed approach transforms linguistic importance of web pages and
minimum supports into fuzzy sets, then filters out weighted large browsing patterns with
linguistic supports using fuzzy operations.
The remaining parts of this paper are organized as follows. Several mining approaches
related to this paper are reviewed in Section 2. Fuzzy sets and operations are introduced in
Section 3. The notation used in this paper is defined in Section 4. The proposed web-mining
algorithm for weighted browsing patterns with linguistic minimum supports are described in
Section 5. An example to illustrate the proposed web-mining algorithm is given in Section 6.
2. Review of related mining approaches
Agrawal and Srikant proposed a mining algorithm to discover sequential patterns from a
set of transactions [1]. Five phases are included in their approach. In the first phase, the
transactions are sorted first by customer ID as the major key and then by transaction time as
the minor key. This phase thus converts the original transactions into customer sequences. In
the second phase, the set of all large itemsets are found from the customer sequences by
comparing their counts with a predefined support parameter α. This phase is similar to the
process of mining association rules. Note that when an itemset occurs more than one time in a
customer sequence, it is counted once for this customer sequence. In the third phase, each
large itemset is mapped to a contiguous integer and the original customer sequences are
transformed into the mapped integer sequences. In the fourth phase, the set of transformed
integer sequences are used to find large sequences among them. In the fifth phase, the
maximally large sequences are then derived and output to users.
Besides, Cai et al. proposed weighted mining to reflect different importance to different
items [3]. Each item was attached a numerical weight given by users. Weighted supports and
weighted confidences were then defined to determine interesting association rules. Yue et al.
In this paper, we proposed a weighted web-mining algorithm to mine browsing patterns
with linguistic supports from log data on a web server. Different web pages have different
importance, which is evaluated by managers or experts. The fuzzy concepts are used to
represent importance of web pages and minimum supports. These parameters are expressed in
linguistic terms, which are more natural and understandable for human beings.
3. Review of related fuzzy set concepts
Fuzzy set theory was first proposed by Zadeh and Goguen in 1965 [39]. Fuzzy set theory
is primarily concerned with quantifying and reasoning using natural language in which words
can have ambiguous meanings. This can be thought of as an extension of traditional crisp sets,
in which each element must either be in or not in a set.
Formally, the process by which individuals from a universal set X are determined to be
either members or non-members of a crisp set can be defined by a characteristic or
discrimination function [39]. For a given crisp set A, this function assigns a value µA( )x to
∉ ∈ = . A x if only and if 0 A x if only and if 1 ) (x Aµ
Thus, the function maps elements of the universal set to the set containing 0 and 1. This
kind of function can be generalized such that the values assigned to the elements of the
universal set fall within specified ranges, referred to as the membership grades of these
elements in the set. Larger values denote higher degrees of set membership. Such a function is
called the membership function,
µ
A( ) , by which a fuzzy set A is usually defined. This xfunction is represented by
µ
A:X→[ , ]0 1 ,where [0, 1] denotes the interval of real numbers from 0 to 1, inclusive. The function can also
be generalized to any real interval instead of [0,1].
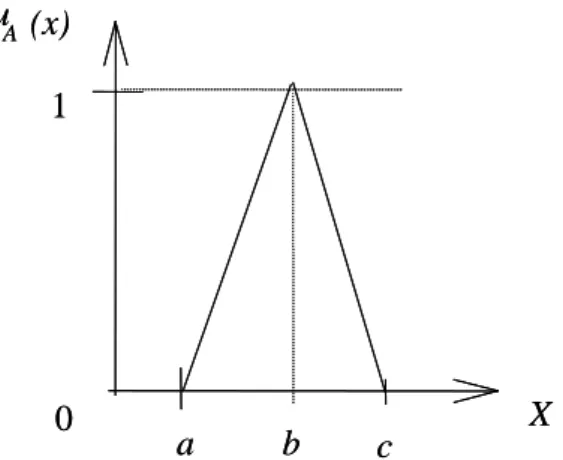
Triangular membership functions are commonly used and can be denoted by A=(a, b, c),
where a≤ ≤b c (Figure 1). The abscissa b represents the variable value with the maximal
grade of membership value, i.e.
µ
A(b)=1; a and c are the lower and upper bounds of theFigure 1: A triangular membership function
There are a variety of fuzzy set operations. Among them, three basic and commonly used
operations are complement, union and intersection, defined as follows.
(1) The complement of a fuzzy set A is denoted by
¬
A and the membership function of¬
A is given by: ) ( 1 ) (x x A Aµ
µ
¬ = −∀ ∈
x X
.(2) The intersection of fuzzy sets A and B is denoted by A I B and the membership
function of A I B is given by:
} ) ( , ) ( { ) (x Min A x B x B A
µ
µ
µ
I =∀ ∈x X . a b c X 1 0 u A (x) a b c X 1 0 u A (x)
(3) The union of fuzzy sets A and B is denoted by A U B and the membership function of A U B is given by: } ) ( , ) ( { ) (x Max x x B A B A
µ
µ
µ
U = ∀ ∈x X .Besides, fuzzy ranking is usually used to determine the order of fuzzy sets and is thus
quite important to actual applications. Several fuzzy ranking methods have been proposed in
the literature. The ranking method using gravities is introduced here. Note that other ranking
methods can also be used in our fuzzy algorithm.
The abscissa of the gravity of a triangular membership function (a, b, c) is stated as
follows.
)
(
3
1
)
(
)
(
)
(
)
(
)
(
)
)
(
(
c
b
a
dx
a
b
a
x
dx
a
b
a
x
xdx
b
c
x
c
xdx
a
b
a
x
dx
x
dx
x
x
gravity
c b b a c b b a A A=
+
+
−
−
+
−
−
×
−
−
+
×
−
−
=
×
=
∫
∫
∫
∫
∫
∫
µ
µ
.Let A and B be two triangular fuzzy sets. A and B can then be represented as follows:
B = (aB, bB, cB). Let g(A) = 3 1 (aA + bA + cA), and g(B) = 3 1 (aB + bB + cB).
Using the gravity ranking method, we say A > B if g(A) > g (B).
4. Notation
The notation used in this paper is defined as follows.
n: the total number of log records;
n’: the total number of browsing sequences;
m: the total number of web pages;
i
A : the i-th web page, 1≤i≤m;
k: the total number of managers;
j i
W, : the transformed fuzzy weight for importance of PageAi, evaluated by the j-th
ave i
W : the fuzzy average weight for importance of PageAi;
s
W : the fuzzy weight for importance of sequential sequence s;
connti: the count of PageAi;
α
: the predefined linguistic minimum support value; Ij : the j-th membership function of importance;ave
I : the fuzzy average weight of all possible linguistic terms of importance;
wsupi: the fuzzy weighted support of Page Ai;
minsup: the transformed fuzzy set from the linguistic minimum support value
α
;wminsup: the fuzzy weighted set of minimum supports;
Cr: the set of candidate sequences with r web pages;
r
L : the set of large sequences with r web pages;.
5. The proposed algorithm for linguistic weighted web mining
Log data in a web site are used to analyze the browsing patterns on that site. Many fields
exist in a log schema. Among them, the fields date, time, client-ip and file name are used in
the mining process. Only the log data with .asp, .htm, .html, .jva and .cgi are considered web
pages and used to analyze the mining behavior. The other files such as .jpg and .gif are
thus reduced. The log data to be analyzed are sorted first in the order of client-ip and then in
the order of date and time. The web pages browsed by a client can thus be easily found. The
importance of web pages are considered and represented as linguistic terms. Linguistic
minimum support value is assigned in the mining process.
The proposed web-mining algorithm then uses the set of membership functions for
importance to transform managers’ linguistic evaluations of the importance of web pages into
fuzzy weights. The fuzzy weights of web pages from different mangers are then averaged.
The algorithm then calculates the weighted counts of web pages from browsing sequences
according to the average fuzzy weights of web pages. The given linguistic minimum support
value is also transformed into a fuzzy weighted set. All weighted large 1-sequences can thus
be found by ranking the fuzzy weighted support of each web page with fuzzy weighted
minimum support. After that, candidate 2-sequences are formed from weighted large
1-sequences and the same procedure is used to find all weighted large 2-sequences. This
procedure is repeated until all weighted large sequences have been found. Details of the
proposed mining algorithm are described below.
The weighted web-mining algorithm:
managers, two sets of membership functions respectively for importance and
minimum support, and a pre-defined linguistic minimum support value
α
.OUTPUT: A set of weighted linguistic browsing patterns.
STEP 1: Select the records with file names including .asp, .htm, .html, .jva, .cgi and closing
connection from the log data; keep only the fields date, time, client-ip and file-name.
STEP 2: Transform the client-ips into contiguous integers (called encoded client ID) for
convenience, according to their first browsing time. Note that the same client-ip with
two closing connections is given two integers.
STEP 3: Sort the resulting log data first by encoded client ID and then by date and time.
STEP 4: Form a browsing sequence for each client ID by sequentially listing the web pages.
STEP 5: Transform each linguistic term of importance for web page Ai, 1≤i≤m, which is
evaluated by the j-th manager into a fuzzy set Wi,j of weights, using the given
membership functions of the importance of web pages.
STEP 6: Calculate the fuzzy average weight Wiave of each web page Ai by fuzzy addition as:
ave i W =
∑
= ∗ k j j i W k 1 , 1 .STEP 7: Count the occurrences (counti) of each web page Ai appearing in the set of browsing
sequences; if Ai appears more than one time in a browsing sequence, its count
addition is still one; set the support (supporti) of Ai as counti / n’, where n’ is the
STEP 8: Calculate the fuzzy weighted support wsupi of each web page Ai as: wsupi = ' n W counti × iave .
STEP 9: Transform the given linguistic minimum support value
α
into a fuzzy set minsup,using the given membership functions of minimum supports.
STEP 10: Calculate the fuzzy weighted set (wminsup) of the given minimum support value as:
wminsup = minsup × (the gravity of ave
I ), where m I I m j j ave ∑ = = 1 ,
with Ij being the j-th membership function of importance. Iave represents the fuzzy
average weight of all possible linguistic terms of importance.
STEP 11: Check whether the weighted support (wsupi) of each web page Ai is larger than or
equal to the fuzzy weighted minimum support (wminsup) by fuzzy ranking. Any
fuzzy ranking approach can be applied here as long as it can generate a crisp rank. If
wsupi is equal to or greater than wminsup, put Ai in the set of large 1-sequences L1.
STEP 12: Set r=1, where r is used to represent the number of web pages kept in the current
large sequences.
STEP 13: Generate the candidate set Cr+1 from Lr in a way similar to that in the aprioriall
algorithm [1]. Restated, the algorithm first joins Lr and Lr, under the condition that
permutations represent different candidates. The algorithm then keeps in Cr+1 the
sequences which have all their sub-sequences of length r existing in Lr.
STEP 14: Do the following substeps for each newly formed (r+1)-sequence s with web
browsing pattern
(
s1→s2→...→sr+1)
in Cr+1:(a) Calculate the fuzzy weight W of sequence s as: s
ave s ave s ave s s W1 W 2 W r 1 W + = Λ ΛKΛ , where ave si
W is the fuzzy average weight of web page s , calculated in STEP 6. i
If the minimum operation is used for the intersection, then:
ave s r i s MinWi W 1 1 + = = .
(b) Count the occurrences (counts) of sequence s appearing in the set of browsing
sequences; if s appears more than one time in a browsing sequence, its count
addition is still one; set the support (supports) of s as counts / n’, where n’ is the
number of browsing sequences.
(c) Calculate the weighted support wsup of sequence s as: s
' n count W
wsups = s × s .
(d) Check whether the weighted support wsup of sequence s is greater than or equal s
to the fuzzy weighted minimum support wminsup by fuzzy ranking. If wsup is s
greater than or equal to wminsup, put s in the set of large (r+1)-sequences Lr+1.
STEP 16: For each large r-sequence s (r > 1) with weighted support wsups, find the linguistic
minimum support region Si with wminsupi≤ wsups < wminsupi+1 by fuzzy ranking,
where:
wminsupi = minsupi × (the gravity of Iave),
minsupi is the given membership function for Si. Output sequence s with linguistic
support value Si.
The linguistic sequential browsing patterns output after Step 16 can serve as
meta-knowledge concerning the given log data.
6. An example
In this section, an example is given to illustrate the proposed web-mining algorithm. This
is a simple example to show how the proposed algorithm can be used to generate weighted
linguistic browsing sequential patterns for clients' browsing behavior according to the log data
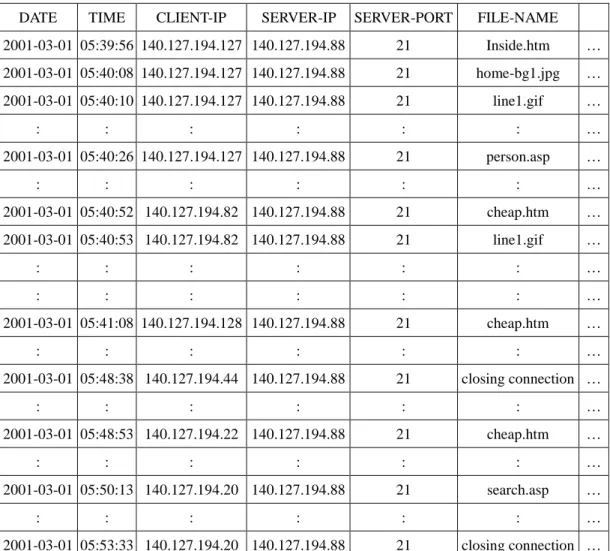
Table 1: A part of the log data used in the example
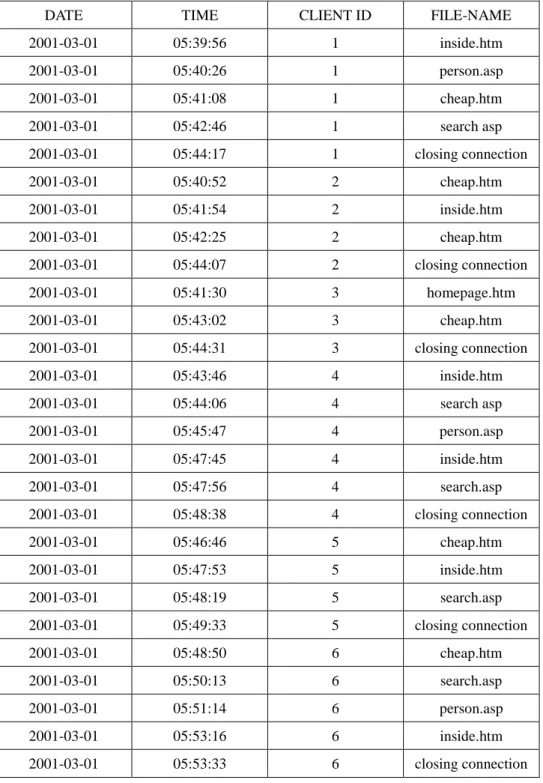
DATE TIME CLIENT-IP SERVER-IP SERVER-PORT FILE-NAME 2001-03-01 05:39:56 140.127.194.127 140.127.194.88 21 Inside.htm … 2001-03-01 05:40:08 140.127.194.127 140.127.194.88 21 home-bg1.jpg … 2001-03-01 05:40:10 140.127.194.127 140.127.194.88 21 line1.gif … : : : : : : … 2001-03-01 05:40:26 140.127.194.127 140.127.194.88 21 person.asp … : : : : : : … 2001-03-01 05:40:52 140.127.194.82 140.127.194.88 21 cheap.htm … 2001-03-01 05:40:53 140.127.194.82 140.127.194.88 21 line1.gif … : : : : : : … : : : : : : … 2001-03-01 05:41:08 140.127.194.128 140.127.194.88 21 cheap.htm … : : : : : : … 2001-03-01 05:48:38 140.127.194.44 140.127.194.88 21 closing connection … : : : : : : … 2001-03-01 05:48:53 140.127.194.22 140.127.194.88 21 cheap.htm … : : : : : : … 2001-03-01 05:50:13 140.127.194.20 140.127.194.88 21 search.asp … : : : : : : … 2001-03-01 05:53:33 140.127.194.20 140.127.194.88 21 closing connection …
Each record in the log data includes fields date, time, client-ip, server-ip, server-port and
file-name, among others. Only one file name is contained in each record. For example, the
user in client-ip 140.127.194.127 browsed the file inside.htm at 05:39:56 on March 1st, 2001.
For the log data shown in Table 1, the proposed web-mining algorithm proceeds as follows.
Step 1: The records with file names being .asp, .htm, .html, .jva, .cgi and closing
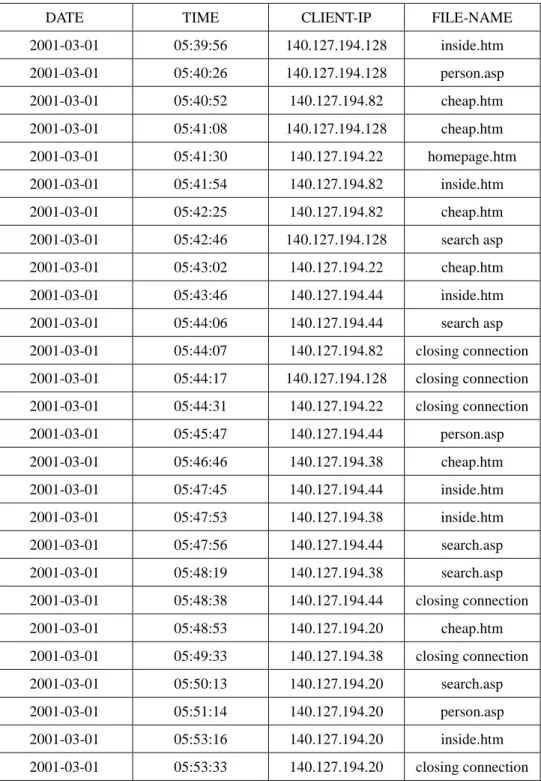
kept. Assume the resulting log data from Table 1 are shown in Table 2.
Table 2: The resulting log data for web mining.
DATE TIME CLIENT-IP FILE-NAME
2001-03-01 05:39:56 140.127.194.128 inside.htm 2001-03-01 05:40:26 140.127.194.128 person.asp 2001-03-01 05:40:52 140.127.194.82 cheap.htm 2001-03-01 05:41:08 140.127.194.128 cheap.htm 2001-03-01 05:41:30 140.127.194.22 homepage.htm 2001-03-01 05:41:54 140.127.194.82 inside.htm 2001-03-01 05:42:25 140.127.194.82 cheap.htm 2001-03-01 05:42:46 140.127.194.128 search asp 2001-03-01 05:43:02 140.127.194.22 cheap.htm 2001-03-01 05:43:46 140.127.194.44 inside.htm 2001-03-01 05:44:06 140.127.194.44 search asp 2001-03-01 05:44:07 140.127.194.82 closing connection 2001-03-01 05:44:17 140.127.194.128 closing connection 2001-03-01 05:44:31 140.127.194.22 closing connection 2001-03-01 05:45:47 140.127.194.44 person.asp 2001-03-01 05:46:46 140.127.194.38 cheap.htm 2001-03-01 05:47:45 140.127.194.44 inside.htm 2001-03-01 05:47:53 140.127.194.38 inside.htm 2001-03-01 05:47:56 140.127.194.44 search.asp 2001-03-01 05:48:19 140.127.194.38 search.asp 2001-03-01 05:48:38 140.127.194.44 closing connection 2001-03-01 05:48:53 140.127.194.20 cheap.htm 2001-03-01 05:49:33 140.127.194.38 closing connection 2001-03-01 05:50:13 140.127.194.20 search.asp 2001-03-01 05:51:14 140.127.194.20 person.asp 2001-03-01 05:53:16 140.127.194.20 inside.htm 2001-03-01 05:53:33 140.127.194.20 closing connection
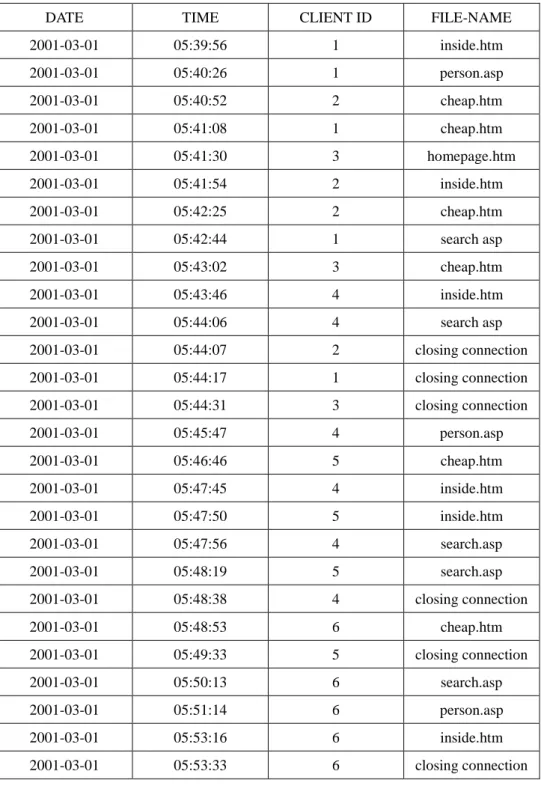
each client’s first browsing time. The transformed results for Table 2 are shown in Table 3.
Totally six clients logged on the web server and five web pages including homepage.htm,
longin.htm, search.asp, cheap.htm and person.asp were browsed in this example.
Table 3: Transforming the values of field client-ip into contiguous integers.
DATE TIME CLIENT ID FILE-NAME
2001-03-01 05:39:56 1 inside.htm 2001-03-01 05:40:26 1 person.asp 2001-03-01 05:40:52 2 cheap.htm 2001-03-01 05:41:08 1 cheap.htm 2001-03-01 05:41:30 3 homepage.htm 2001-03-01 05:41:54 2 inside.htm 2001-03-01 05:42:25 2 cheap.htm 2001-03-01 05:42:44 1 search asp 2001-03-01 05:43:02 3 cheap.htm 2001-03-01 05:43:46 4 inside.htm 2001-03-01 05:44:06 4 search asp 2001-03-01 05:44:07 2 closing connection 2001-03-01 05:44:17 1 closing connection 2001-03-01 05:44:31 3 closing connection 2001-03-01 05:45:47 4 person.asp 2001-03-01 05:46:46 5 cheap.htm 2001-03-01 05:47:45 4 inside.htm 2001-03-01 05:47:50 5 inside.htm 2001-03-01 05:47:56 4 search.asp 2001-03-01 05:48:19 5 search.asp 2001-03-01 05:48:38 4 closing connection 2001-03-01 05:48:53 6 cheap.htm 2001-03-01 05:49:33 5 closing connection 2001-03-01 05:50:13 6 search.asp 2001-03-01 05:51:14 6 person.asp 2001-03-01 05:53:16 6 inside.htm 2001-03-01 05:53:33 6 closing connection
Step 3: The resulting log data in Table 3 are then sorted first by encoded client ID and
then by date and time. Results are shown in Table 4.
Table 4. The resulting log data sorted first by client ID and then by date and time
DATE TIME CLIENT ID FILE-NAME
2001-03-01 05:39:56 1 inside.htm 2001-03-01 05:40:26 1 person.asp 2001-03-01 05:41:08 1 cheap.htm 2001-03-01 05:42:46 1 search asp 2001-03-01 05:44:17 1 closing connection 2001-03-01 05:40:52 2 cheap.htm 2001-03-01 05:41:54 2 inside.htm 2001-03-01 05:42:25 2 cheap.htm 2001-03-01 05:44:07 2 closing connection 2001-03-01 05:41:30 3 homepage.htm 2001-03-01 05:43:02 3 cheap.htm 2001-03-01 05:44:31 3 closing connection 2001-03-01 05:43:46 4 inside.htm 2001-03-01 05:44:06 4 search asp 2001-03-01 05:45:47 4 person.asp 2001-03-01 05:47:45 4 inside.htm 2001-03-01 05:47:56 4 search.asp 2001-03-01 05:48:38 4 closing connection 2001-03-01 05:46:46 5 cheap.htm 2001-03-01 05:47:53 5 inside.htm 2001-03-01 05:48:19 5 search.asp 2001-03-01 05:49:33 5 closing connection 2001-03-01 05:48:50 6 cheap.htm 2001-03-01 05:50:13 6 search.asp 2001-03-01 05:51:14 6 person.asp 2001-03-01 05:53:16 6 inside.htm 2001-03-01 05:53:33 6 closing connection
Step 4: The web pages browsed by each client are listed as a browsing sequence. For
convenience, simple symbols are used here to represent web pages. Let A, B, C, D and E
respectively represent homepage.htm, inside.htm, search.asp, cheap.htm and person.asp. The
resulting browsing sequences from Table 4 are shown in Table 5.
Table 5: The browsing sequences formed from Table 4.
CLIENT ID BROWSING SEQUENCES
1 B, E, D, C 2 D, B, D 3 A, D 4 B, C, E, B, C 5 D, B, C 6 D, C, E, B
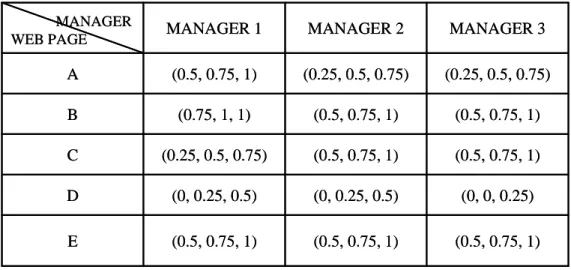
Step 5: Assume the importance of the five web pages (A, B, C, D, and E) is evaluated by
three managers as shown in Table 6.
Table 6: The importance of the web pages evaluated by three managers
MANAGER Important Important Important E Very Unimportant Unimportant Unimportant D Important Important Ordinary C Important Important Very Important B Ordinary Ordinary Important A MANAGER 3 MANAGER 2 MANAGER 1 WEB PAGE MANAGER Important Important Important E Very Unimportant Unimportant Unimportant D Important Important Ordinary C Important Important Very Important B Ordinary Ordinary Important A MANAGER 3 MANAGER 2 MANAGER 1 WEB PAGE
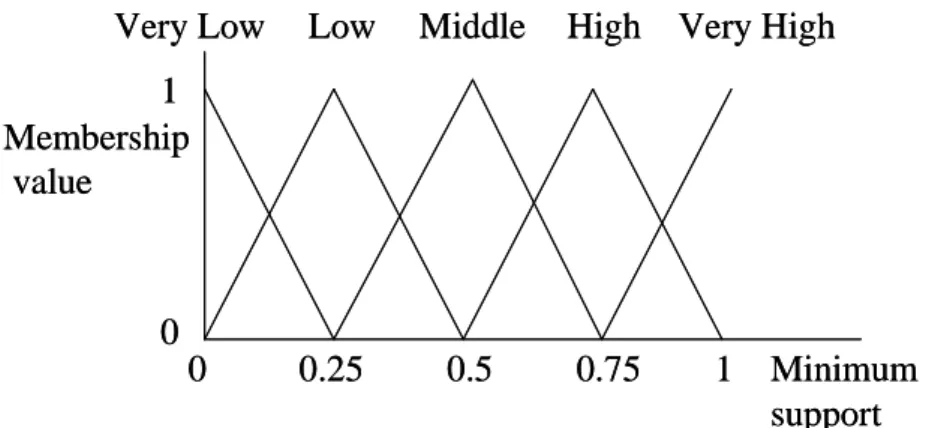
Also assume the membership functions for importance of the web pages are given in
Figure 2.
Figure 2: The membership functions of importance of the web pages in this example
In Figure 2, the importance of the web pages is divided into five fuzzy regions: Very
Unimportant, Unimportant, Ordinary, Important and Very Important. Each fuzzy region is
represented by a membership function. The membership functions in Figure 2 can be
represented as follows:
Very Unimportant (VU): (0, 0, 0.25),
Unimportant (U): (0, 0.25, 0.5),
Ordinary (O): (0.25, 0.5, 0.75),
Important (I): (05, 075, 1), and
Very Important (VI): (0.75, 1, 1).
Weight Membership value 1 1 0.5 0.25 0.75 Very Unimportant Unimportant Important Very Important Ordinary 0 0 Weight Membership value 1 1 0.5 0.25 0.75 Very Unimportant Unimportant Important Very Important Ordinary 0 0
MANAGER WEB PAGE (0.5, 0.75, 1) (0.5, 0.75, 1) (0.5, 0.75, 1) E (0, 0, 0.25) (0, 0.25, 0.5) (0, 0.25, 0.5) D (0.5, 0.75, 1) (0.5, 0.75, 1) (0.25, 0.5, 0.75) C (0.5, 0.75, 1) (0.5, 0.75, 1) (0.75, 1, 1) B (0.25, 0.5, 0.75) (0.25, 0.5, 0.75) (0.5, 0.75, 1) A MANAGER 3 MANAGER 2 MANAGER 1 MANAGER WEB PAGE (0.5, 0.75, 1) (0.5, 0.75, 1) (0.5, 0.75, 1) E (0, 0, 0.25) (0, 0.25, 0.5) (0, 0.25, 0.5) D (0.5, 0.75, 1) (0.5, 0.75, 1) (0.25, 0.5, 0.75) C (0.5, 0.75, 1) (0.5, 0.75, 1) (0.75, 1, 1) B (0.25, 0.5, 0.75) (0.25, 0.5, 0.75) (0.5, 0.75, 1) A MANAGER 3 MANAGER 2 MANAGER 1
The linguistic terms for the importance of the web pages given in Table 6 are
transformed into fuzzy sets by the membership functions in Figure 2. For example, Page A is
evaluated to be important by Manager 1. It can then be transformed as a triangular fuzzy set
(0.5, 0.75, 1) of weights. The transformed results for Table 6 are shown in Table 7.
Table 7: The fuzzy weights transformed from the importance of the web pages in Table 6.
Step 6: The average weight of each web page is calculated by fuzzy addition. Take Page
A as an example. The three fuzzy weights for A are respectively (0.5, 0.75, 1), (0.25, 0.5, 0.75)
and (0.25, 0.5, 0.75). The average weight is then ((0.5+0.25+0.25)/3, (0.75+0.5+0.5)/3,
(1+0.75+0.75)/3), which is derived as (0.33, 0.58, 0.83). The average fuzzy weights of all the
Table 8: The average fuzzy weights of all the web pages
WEB PAGE AVERAGE FUZZY WEIGHT
A (0.333, 0.583, 0.833)
B (0.583, 0.833, 1)
C (0.417, 0.667,0.917)
D (0, 0.167, 0.417)
E (0.5, 0.75, 1)
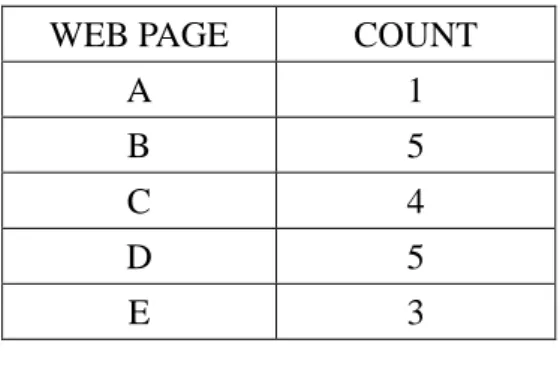
Step 7: The appearing number of each web page is counted from the browsing sequences
in Table 5. If a web page occurs more than one time in a sequence, it is counted once for this
sequence. Results for all the web pages are shown in Table 9.
Table 9: The counts of all the web pages
WEB PAGE COUNT
A 1
B 5
C 4
D 5
E 3
Step 8: The weighted support of each web page is calculated. Take Page A as an example.
The average fuzzy weight of A is (0.333, 0.583, 0.833) and the count is 1. Its weighted
support is then (0.333, 0.583, 0.833) * 1/ 6, which is (0.056, 0.097, 0.139). Results for all the
Table 10: The weighted supports of all the web pages
WEB PAGE WEIGHTED SUPPORT
A (0.056, 0.097, 0.139)
B (0.486, 0.694, 0.833)
C (0.278, 0.444, 0.611)
D (0, 0.139, 0.347)
E (0.25, 0.375, 0.5)
Step 9: The given linguistic minimum support value is transformed into a fuzzy set of
minimum supports. Assume the membership functions for minimum supports are given in
Figure 3.
Figure 3: The membership functions of minimum supports
Also assume the given linguistic minimum support value is “Middle”. It is then
transformed into a fuzzy set of minimum supports, (0.25, 0.5, 0.75), according to the given
membership functions in Figure 3.
Minimum support Membership value 1 1 0.5 0.25 0.75
Very Low Low Middle High Very High
0 0 Minimum support Membership value 1 1 0.5 0.25 0.75
Very Low Low Middle High Very High
0 0
Step 10: The fuzzy average weight of all possible linguistic terms of importance in
Figure 2 is first calculated as:
Iave = [(0, 0, 0.25) + (0, 0.25, 0.5) + (0.25, 0.5, 0.75) + (0.5, 0.75, 1) +(0.75, 1, 1)]/5
= (0.3, 0.5, 0.7).
The gravity of Iave is then (0.3+0.5+0.7)/3, which is 0.5. The fuzzy weighted set of
minimum supports for “Middle” is then (0.25, 0.5, 0.75) × 0.5, which is (0.125, 0.25, 0.375).
Step 11: The weighted support of each web page is compared with the fuzzy weighted
minimum support by fuzzy ranking. Any fuzzy ranking approach can be applied here as long
as it can generate a crisp rank. Assume the gravity ranking approach is adopted in this
example. Take Page B as an example. The average height of the weighted support for Page B
is (0.486 + 0.694 + 0.833)/3, which is 0.671. The average height of the fuzzy weighted
minimum support is (0.125 + 0.25 + 0.375)/3, which is 0.25. Since 0.671 > 0.25, B is thus a
large weighted 1- sequences. Similarly, C and E are large weighted 1-sequences. These
1-sequences are put in L1.
large sequences.
Step 13: The candidate set Cr+1 is generated from Lr. C2 is then first generated from L1 as
follows: (B, B), (B, C), (B, E), (C, B), (C, C), (C, E), (E, B), (E, C) and (E, E).
Step 14: The following substeps are done for each newly formed candidate 2-sequence in
C2.
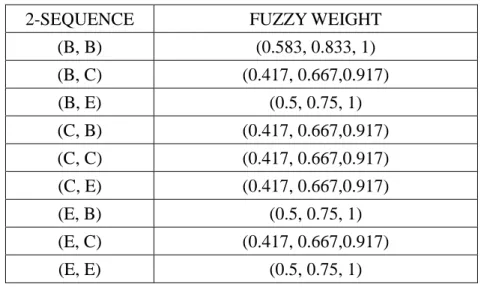
(a) The fuzzy weights of all the 2-sequences in C2 are calculated. Here, the minimum
operator is used for intersection. Take the 2-sequence (B, C) as an example. Its fuzzy weight is
calculated as min((0.583, 0.833, 1), (0.417, 0.667, 0.917)), which is (0.417, 0.667, 0.917). The
results for all the 2-sequences are shown in Table 11.
Table 11: The fuzzy weights of the 2-sequences in C2.
2-SEQUENCE FUZZY WEIGHT
(B, B) (0.583, 0.833, 1) (B, C) (0.417, 0.667,0.917) (B, E) (0.5, 0.75, 1) (C, B) (0.417, 0.667,0.917) (C, C) (0.417, 0.667,0.917) (C, E) (0.417, 0.667,0.917) (E, B) (0.5, 0.75, 1) (E, C) (0.417, 0.667,0.917) (E, E) (0.5, 0.75, 1)
(b) The count of each candidate 2-sequence is found from the browsing sequences. If a
2-sequence occurs more than one time in a browsing sequence, it is counted once for this
browsing sequence. Results for this example are shown in Table 12.
Table 12: The counts of the 2- sequences
2-SEQUENCE COUNT (B, B) 1 (B, C) 3 (B, E) 2 (C, B) 2 (C, C) 1 (C, E) 2 (E, B) 2 (E, C) 2 (E, E) 0
(c) The weighted support of each candidate 2-sequence is calculated. Take the sequence
(B, C) as an example. The minimum fuzzy weight of (B, C) is (0.417, 0.667, 0.917) and the
count is 3. Its weighted support is then (0.417, 0.667, 0.917) * 3 / 6, which is (0.208, 0.333,
Table 13: The weighted supports of the 2-sequences
2-SEQUENCE WEIGHTED SUPPORT
(B, B) (0.097, 0.139, 0.167) (B, C) (0.208, 0.333, 0.458) (B, E) (0.167, 0.25, 0.333) (C, B) (0.139. 0.222, 0.306) (C, C) (0.069, 0.111, 0.153) (C, E) (0.139, 0.222, 0.306) (E, B) (0.167, 0.25, 0.333) (E, C) (0.139, 0.222, 0.306) (E, E) (0, 0, 0)
(d) The weighted support of each candidate 2-sequence is compared with the fuzzy
weighted minimum support by fuzzy ranking. As mentioned above, assume the gravity
ranking approach is adopted in this example. (B, C), (B, E) and (E, B) are then found to be
large weighted 2-sequences. These 2-sequences are put in L2.
Step 15: Since L2 is not null in the example, r = r + 1 = 2. Steps 13 to 15 are repeated to
find L3. C3 is then generated from L2. There are no large 3-sequences in the example. L3 is
thus an empty set.
STEP 16: The linguistic support value is found for each large r-sequence s (r > 1). Take
the sequential browsing pattern (E, B) as an example. Its weighted support is (0.167, 0.25,
(0.25, 0.5, 0.75) and for “High“ is (0.5, 0.75, 1). The weighted fuzzy set for these two regions
are (0.125, 0.25, 0.375) and (0.25, 0.375, 0.5). Since (0.125, 0.25, 0.375) ≤ (0.167, 0.25, 0.333)
< (0.25, 0.375, 0.5) by fuzzy ranking, the linguistic support value for sequence (E, B) is then
“Middle”. The linguistic supports of the other two large 2-sequences can be similarly derived.
All the three large sequential browsing patterns are then output as:
1. B -> C with a middle support,
2. B -> E with a middle support,
3. E -> B with a middle support.
The three linguistic sequential patterns above are thus output as the meta-knowledge
concerning the given log data.
7. Conclusion and future work
In this paper, we have proposed a new weighted web-mining algorithm, which can
process web-server logs to discover useful sequential browsing patterns with linguistic
supports. The web pages are evaluated by managers as linguistic terms, which are then
are used to find weighted sequential browsing patterns. Compared to previous mining
approaches, the proposed one has linguistic inputs and outputs, which are more natural and
understandable for human beings.
Although the proposed method works well in weighted web mining from log data, and
can effectively manage linguistic minimum supports, it is just a beginning. There is still much
work to be done in this field. Our method assumes that the membership functions are known
in advance. In [20-21, 23], we proposed some fuzzy learning methods to automatically derive
the membership functions. In the future, we will attempt to dynamically adjust the
membership functions in the proposed web-mining algorithm to avoid the bottleneck of
References
[1] R. Agrawal, R. Srikant: “Mining Sequential Patterns”, The Eleventh International
Conference on Data Engineering, 1995, pp. 3-14.
[2] A. F. Blishun, “Fuzzy learning models in expert systems,” Fuzzy Sets and Systems, Vol. 22,
1987, pp. 57-70.
[3] C. H. Cai, W. C. Fu, C. H. Cheng and W. W. Kwong, “Mining association rules with
weighted items,” The International Database Engineering and Applications Symposium,
1998, pp. 68-77.
[4] L. M. de Campos and S. Moral, “Learning rules for a fuzzy inference model,” Fuzzy Sets
and Systems, Vol. 59, 1993, pp. 247-257.
[5] K. C. C. Chan and W. H. Au, “Mining fuzzy association rules,” The 6th ACM
International Conference on Information and Knowledge Management, 1997, pp.10-14.
[6] R. L. P. Chang and T. Pavliddis, “Fuzzy decision tree algorithms,” IEEE Transactions on
Systems, Man and Cybernetics, Vol. 7, 1977, pp. 28-35.
[7] M. S. Chen, J. S. Park and P. S. Yu, “Efficient Data Mining for Path Taversal Patterns”
IEEE Transactions on Knowledge and Data Engineering, Vol. 10, 1998, pp. 209-221.
[8] M. S. Chen, J. Han and P. S. Yu, “Data mining: an overview from a database perspective,”
[9] Liren Chen and Katia Sycara, “WebMate: A Personal Agent for Browsing and searching,”
The Second International Conference on Autonomous Agents, ACM, 1998.
[10] C. Clair, C. Liu and N. Pissinou, “Attribute weighting: a method of applying domain
knowledge in the decision tree process,” The Seventh International Conference on
Information and Knowledge Management, 1998, pp. 259-266.
[11] P. Clark and T. Niblett, “The CN2 induction algorithm,” Machine Learning, Vol. 3, 1989,
pp. 261-283.
[12] Edith Cohen, Balachander Krishnamurthy and Jennifer Rexford, ” Efficient Algorithms
for Predicting Requests to Web Servers,” The Eighteenth IEEE Annual Joint Conference
on Computer and Communications Societies, Vol. 1, 1999, pp. 284 –293.
[13] R. Cooley, B. Mobasher and J. Srivastava, “Grouping Web Page References into
Transactions for Mining World Wide Web Browsing Patterns,” Knowledge and Data
Engineering Exchange Workshop, 1997, pp. 2 –9.
[14] R. Cooley, B. Mobasher and J. Srivastava, “Web Mining: Information and Pattern
Discovery on the World Wide Web,” Ninth IEEE International Conference on Tools with
Artificial Intelligence, 1997, pp. 558 -567
[15] M. Delgado and A. Gonzalez, “An inductive learning procedure to identify fuzzy
systems,” Fuzzy Sets and Systems, Vol. 55, 1993, pp. 121-132.
data analysis," Intelligent Data Analysis, Vol. 1, No. 1, 1997.
[17] W. J. Frawley, G. Piatetsky-Shapiro and C. J. Matheus, “Knowledge discovery in
databases: an overview,” The AAAI Workshop on Knowledge Discovery in Databases,
1991, pp. 1-27.
[18] A.Gonzalez, “A learning methodology in uncertain and imprecise environments,”
International Journal of Intelligent Systems, Vol. 10, 1995, pp. 57-371.
[19] I. Graham and P. L. Jones, Expert Systems – Knowledge, Uncertainty and Decision,
Chapman and Computing, Boston, 1988, pp.117-158.
[20] T. P. Hong and J. B. Chen, "Finding relevant attributes and membership functions," Fuzzy
Sets and Systems, Vol.103, No. 3, 1999, pp. 389-404.
[21] T. P. Hong and J. B. Chen, "Processing individual fuzzy attributes for fuzzy rule
induction," Fuzzy Sets and Systems, Vol. 112, No. 1, 2000, pp.127-140.
[22] T. P. Hong, M. J. Chiang and S. L. Wang, ”Mining from quantitative data with linguistic
minimum supports and confidences”, The 2002 IEEE International Conference on Fuzzy
Systems, Honolulu, Hawaii, 2002, pp.494-499.
[23] T. P. Hong and C. Y. Lee, "Induction of fuzzy rules and membership functions from
training examples," Fuzzy Sets and Systems, Vol. 84, 1996, pp. 33-47.
[24] T. P. Hong and S. S. Tseng, “A generalized version space learning algorithm for noisy
No. 2, 1997, pp. 336-340.
[25] T. P. Hong, C. S. Kuo and S. C. Chi, "Mining association rules from quantitative data",
Intelligent Data Analysis, Vol. 3, No. 5, 1999, pp. 363-376.
[26] A. Kandel, Fuzzy Expert Systems, CRC Press, Boca Raton, 1992, pp. 8-19.
[27] C. M. Kuok, A. W. C. Fu and M. H. Wong, "Mining fuzzy association rules in
databases," The ACM SIGMOD Record, Vol. 27, No. 1, 1998, pp. 41-46.
[28] E. H. Mamdani, “Applications of fuzzy algorithms for control of simple dynamic plants,
“ IEEE Proceedings, 1974, pp. 1585-1588.
[29] H. Mannila, “Methods and problems in data mining,” The International Conference on
Database Theory, 1997, pp.41-55.
[30] J. R. Quinlan, “Decision tree as probabilistic classifier,” The Fourth International
Machine Learning Workshop, Morgan Kaufmann, San Mateo, CA, 1987, pp. 31-37.
[31] J. R. Quinlan, C4.5: Programs for Machine Learning, Morgan Kaufmann, San Mateo,
CA, 1993.
[32] J. Rives, “FID3: fuzzy induction decision tree,” The First International symposium on
Uncertainty, Modeling and Analysis, 1990, pp. 457-462.
[33] C. H. Wang, T. P. Hong and S. S. Tseng, “Inductive learning from fuzzy examples,” The
fifth IEEE International Conference on Fuzzy Systems, New Orleans, 1996, pp. 13-18.
for modular rules,” Fuzzy Sets and Systems, Vol.103, No. 1, 1999, pp. 91-105.
[35] R.Weber, “Fuzzy-ID3: a class of methods for automatic knowledge acquisition,” The
Second International Conference on Fuzzy Logic and Neural Networks, Iizuka, Japan,
1992, pp. 265-268.
[36] Y. Yuan and M. J. Shaw, “Induction of fuzzy decision trees,” Fuzzy Sets and Systems, 69,
1995, pp. 125-139.
[37] S. Yue, E. Tsang, D. Yeung and D. Shi, “Mining fuzzy association rules with weighted
items,” The IEEE International Conference on Systems, Man and Cybernetics, 2000, pp.
1906-1911.
[38] L. A. Zadeh, “Fuzzy logic,” IEEE Computer, 1988, pp. 83-93.