行政院國家科學委員會專題研究計畫 成果報告
多語言複合式文件自動摘要之研究(3/3)
計畫類別: 個別型計畫 計畫編號: NSC94-2213-E-009-013- 執行期間: 94 年 08 月 01 日至 95 年 07 月 31 日 執行單位: 國立交通大學資訊科學學系(所) 計畫主持人: 楊維邦 計畫參與人員: 柯皓仁教授, 葉鎮源, 謝佩原, 梁;哲瑋, 鄭佳彬, 劉;政璋, 顧世彥, 王瓊婉, 林;昕潔, 張家 寧; 報告類型: 完整報告 處理方式: 本計畫可公開查詢中 華 民 國 95 年 10 月 31 日
行政院國家科學委員會補助專題研究計畫
□ 成 果 報 告
□期中進度報告
多語言複合式文件自動摘要之研究
計畫類別:□ 個別型計畫 □ 整合型計畫
計畫編號:
(1/3) NSC-92-2213-E-009-126-
(2/3) NSC-93-2213-E-009-044-
(3/3)
NSC-94-2213-E-009-013-執行期間: 92 年 08 月 01 日至 95 年 07 月 31 日
計畫主持人:楊維邦 教授
共同主持人:
計畫參與人員: 柯皓仁 教授, 葉鎮源, 謝佩原, 梁哲瑋, 鄭佳彬,
劉政璋, 顧世彥, 王瓊婉, 林昕潔, 張家寧
成果報告類型(依經費核定清單規定繳交):□精簡報告 □完整報告
本成果報告包括以下應繳交之附件:
□赴國外出差或研習心得報告一份
□赴大陸地區出差或研習心得報告一份
□出席國際學術會議心得報告及發表之論文各一份
□國際合作研究計畫國外研究報告書一份
處理方式:除產學合作研究計畫、提升產業技術及人才培育研究計畫、
列管計畫及下列情形者外,得立即公開查詢
□涉及專利或其他智慧財產權,□一年□二年後可公開查詢
執行單位:國立交通大學資訊科學學系(所)
9
9
9
中文摘要
自動化文件摘要(Automated Text Summarization)之研究,探討如何分析、統 整與萃取文件中重要的資訊,並以簡明的形式呈現,可作為使用者或其他資訊系 統的判斷與決策依據。過去關於文件摘要的研究,大多著眼於單文件摘要。近來, 多文件摘要愈顯得重要。多文件摘要與單文件摘要最大的差異,在於過濾重複的 資訊(Anti-redundancy),同時須避免重要資訊的流失。
本計畫為三年期研究案,目的在於研究多文件自動摘要(Multidocument Summarization)、跨語言多文件摘要(Cross-Language Multidocument Summarization) 與使用者問答導向摘要(Query-Focused Multidocument Summarization)技術。 z 第一年計畫: 多文件摘要技術之研究
計畫目的在於研究並發展多文件自動摘要的技術,探討如何導出文件的結 構、如何組織文件的內容及如何表示所抽取出文件抽象涵義等議題。我們考量相 關文獻所提多文件摘要的方法之優缺點,並以先前我們所發展之單文件摘要方法 為基礎,加以改進以適用於多文件摘要。
我們利用潛在語意分析(Latent Semantic Analysis, LSA)與主題關係地圖(Text Relationship Map)作為多文件分析模型。此模型將每個語句視為圖(Graph)中的一 個點,兩兩語句若相似度大於臨界值,則彼此間具有一連結,其中語句相似度的
計算採用 LSA 所倒出的概念空間模型,以達到具有語意判別的相似度計算。根
據主題關係地圖模型,我們提出兩種段落重要性評估模型,分別為 1) Global
Bushy Path;2) Aggregate Similarity。依據上述兩種計算重要性的模型,我們修改 Maximal Marginal Relevance,提出新的摘要段落挑選方式,以達到多文件中去除 重複性(Redundancy)的要求。
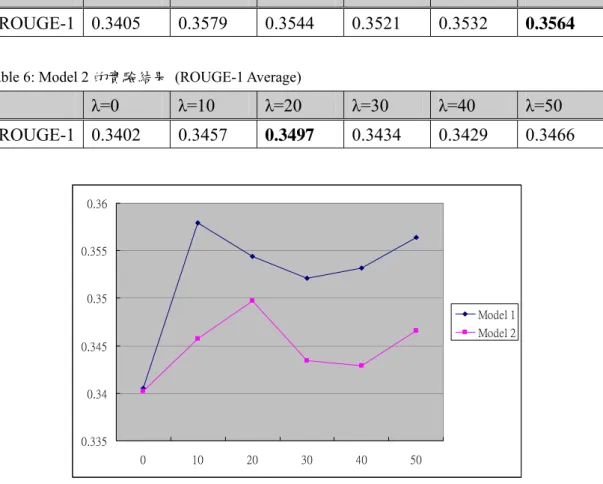
實驗評估採用ROUGE 來計算專家所產出的摘要與機器所產出摘要中,平均
包含有多少個相同的字。我們以ROUGE-1 為評估標準,實驗結果顯示 Model 1
獲得平均ROUGE-1 分數為 0.3564,Model 2 獲得平均 ROUGE-1 分數為 0.3497。
比較DUC 2003 的比賽結果,我們的方法亦有不錯的表現,約在中等以上。
z 第二年計畫: 中英文多文件摘要技術之研究
計 畫 目 的 在 於 發 展 多 語 多 文 件 摘 要 (Multilingual Multidocument Summarization)技術。研究內容著重於中英文混合式多文件摘要,研究議題為如 何跨越語言型態及結構的障礙,提出計算中英文語句相似度的方法。
我 們 提 出 一 套 中 英 概 念 空 間 擷 取 的 方 法 。 基 於 中 英 雙 語 平 行 語 料 庫 (Chinese-English Parallel Corpus),進行中英文詞分群(Word Clustering),以建立階 層式概念空間(Hierarchical Concept Space)。接著,將中英文語句對應至該階層式 概念空間中,透過此對應關係,可將關鍵詞向量空間表示式(Keyword-Level Vector Representation) 轉 換 至 概 念 向 量 空 間 表 示 式 (Concept-Level Vector Representation)。最後,於相同的概念空間中,便可計算任兩中中、中英及英英 語句的概念相似度。 中英混合式詞分群可抽取出中文詞與英文詞間的關連。當分群的群數目越多 時,位於詞群中的中英文詞可互為翻譯;當分群的群數目越少時,位於詞群中的 中英文詞可視為相關。透過階層式概念空間相似度的組合,可得不錯的中英語句 對應。實驗結果顯示,考慮Top 10 組中英對應段落,平均 Precision 約 57%為相 關。摘要內容的評估,則由專家進行評比。平均而言,資訊量涵蓋度為7.06,可 讀性為6.04。(其中,1 代表最差,5 代表普通,10 代表最好。) z 第三年計畫: 問答式多文件摘要技術之研究 第三年的研究內容著重於參考使用者給定的自然語言查詢問題及設定檔 (Profile)1, 以產生可以回答使用者問題的摘要。 我們提出一套計算文件集中每個語句與使用者所下的查詢間的相關度計算 方式。考量傳統Vector Space Model 與 Latent Semantic Analysis 的優缺點,我們 提出以線性方式結合上述兩種模型的相似度。此外,我們亦研究過去應用於文件
摘要的shallow features 是否依然於問答摘要環境下扮演重要角色。於本計畫中,
我們考慮以下五個語句特徵,分別為 1) Sentence Position; 2) Sentence TF-IDF Weight; 3) Sentence’s Similarity to the Title; 4) Sentence’s Similarity to the Document; 5) Sentence’s Similarity to the Topic Cluster。
針對我們所提出的語句與查詢相似度計算方法,並結合五個語句特徵值,我 們修改Maximum Marginal Relevance,提出新的摘要段落挑選方式,以達到多文 件中去除重複性(Redundancy)的要求。 實驗中,我們以 DUC 2005 的資料集測試,該年度評估以 ROUGE-2 及 ROUGE-SU4 為官方標準。實驗結果顯示,我們所提出的方法有不錯的表現,在 最佳的情況下,獲得ROUGE-2 的分數為 0.0757,ROUGE-SU4 的分數為 0.1299。 1 該設定檔定義摘要內容為 specific 或 general。
英文摘要
Automated text summarization investigates the process of extracting the most important information from a source (or sources), and presenting a summary to the user. In the past, much related work only focuses on single-document summarization. Multi-document summarization obtains increasing attentions in recent years. The distinction between single and multi-document summarization is that the latter has to handle anti-redundancy and to keep salient information meanwhile.
This project is composed of three parts and was conducted in the past three years. The goal of this research is to investigate and develop the techniques focusing on multidocument summarization, cross-language multidocument summarization, and query-focused multidocument summarization.
z The First-Year Project: A Study on Multidocument Summarization
This principal objective of this project is to develop new approaches to address multi-document summarization. The research includes 1) Conceptual Modeling and Representation for Multiple Documents, 2) Paragraph Significances Measurement, and 3) Content Ordering for the summary.
We exploit latent semantic analysis and text relationship map to derive conceptual model (or a graph model) for multiple documents. Based on the model, we propose two approaches to measure the significance of a paragraph. They are 1) Global Bushy Path, and 2) Aggregate Similarity. Moreover, we propose a novel paragraph re-ranking approach on the basic foundation of Maximal Marginal Relevance to extract salient paragraphs.
The evaluation metric used in this project is ROUGE, which is the official evaluation tool at DUC 2004. We report ROUGE-1 as the official score for each proposed models. Model 1 obtained a value of 0.3564 while Model 2 obtained a value of 0.3497 for ROUGE-1. When compared with the official results at DUC 2003, our proposed methods are at the average position and obtained competitive results.
z The Second-Year Project: A Study on Cross-Language Multidocument Summarization
The principal objective of this project is to develop novel techniques to address multilingual, multidocument summarization. The main issue is to propose a method to compute the similarity between two short passages which are written in different languages.
With a Chinese-English parallel corpus, we propose a framework to derive a hierarchical concept space by word clustering. On the basis of the concept space, a Chinese or an English paragraph can be mapped into the space and represented as a concept-level vector representation. Since a Chinese or an English paragraph is mapped into the same concept space, it becomes easy to compute the similarity between two paragraphs. Once the similarity between a Chinese and an English passage is obtained, the summary is generated using the techniques developed in the first-year project.
The preliminary results show that the larger the number of concept clusters, words in the same concept can be regarded as corresponding translations; while the smaller the number of concept clusters, words in the same concept are loosely-related. In the set of Chinese-English paragraph pairs with Top 10 similarities, approximately 57% are judged as related by humans. Regarding the quality of the summary, in average, a score of 7.06 and 6.04 was obtained in terms of information coverage and readability respectively, in which 1 the worst, 5 good, and 10 the best.
z The Third-Year Project: A Study on Query-Focused Multidocument Summarization
The principal objective of this project is to develop a summarization method to answer user-specific questions. In this report, we try to merge techniques of multidocument summarization and question-answering to generate a brief, well-organized fluent summary to provide more relevant information for the purpose of answering real-world complicated questions. The problem is addressed as a query-biased sentence retrieval task.
We propose a hybrid relevance analysis to evaluate sentence relevance to the query. This is achieved by combining similarities computed from the vector space model and the latent semantic analysis. Surface features are also examined to know the impacts of low-level features for query-focused multidocument summarization. In other words, the summary is created by including sentences with the topmost significances which are measured in terms of sentence relevance and surface feature salience. In addition, a modified Maximal Marginal Relevance is proposed to reduce redundancy by taking into account sentence shallow feature scores.
The experimental results showed the proposed method obtained competitive results when evaluated with the DUC 2005 corpus. Regarding ROUGE-2 and ROUGE-SU4, the proposed method obtained a value of 0.0757 and 0.1299 respectively.
目錄
中文摘要 ………... I 英文摘要 ………... III 目錄 ………... V 圖目錄 ………... VI 表目錄 ………... VII 計畫概述 …………..…..………... 1 執行成果 ………... 2 參與人員 ………... 4 計畫分年報告 第一年計畫報告 ………... 5 第二年計畫報告 ………... 37 第三年計畫報告 ………... 60 著作發表 ………... 80圖目錄
Figure 1: PERSIVAL 使用者介面 ... 11
Figure 2: Columbia Summarizer 系統架構...12
Figure 3: GLEANS 系統架構圖 ...12 Figure 4: GISTexter 系統架構 ...14 Figure 5: XDoX 系統架構 ...14 Figure 6: MEAD 運作原理示意圖 ...16 Figure 7: 文件圖形模型範例 ...19 Figure 8: LSA 工作原理 ...21 Figure 9: 主題關係地圖的範例 ...21 Figure 10: 本研究所提之多文件摘要架構 ...23
Figure 11: 計算 Aggregate Similarity 的概念圖示 ...26
Figure 12: Model 1 與 Model 2 的 ROUGE-1 比較 ...29
Figure 13: 多語言多文件摘要系統架構 ...41 Figure 14: 中英文混合語句分群架構 ...42 Figure 15: 策略二單一字詞相似比對示意圖 ...43 Figure 16: 策略三單一字詞相似比對示意圖 ...43 Figure 17: 策略四單一字詞相似比對示意圖 ...43 Figure 18: 策略五單一字詞相似比對示意圖 ...44
Figure 19: Columbia Newsblaster 多語言摘要系統架構 ...44
Figure 20: 中英雙語混合式文件自動摘要架構 ...46
Figure 21: 中英詞混合之 Word-by-Paragraph 矩陣 ...47
Figure 22: (a) 詞分群概念空間建構; (b) 段落對應於概念空間示意圖...48
Figure 23: 計算不同階層概念空間相似度示意圖 ...51
表目錄
Table 1: 參與人員及執行工作列表...4
Table 2: 研究項目與相關技術...10
Table 3: MMR-MD 中 Sim1及Sim2的計算方式...18
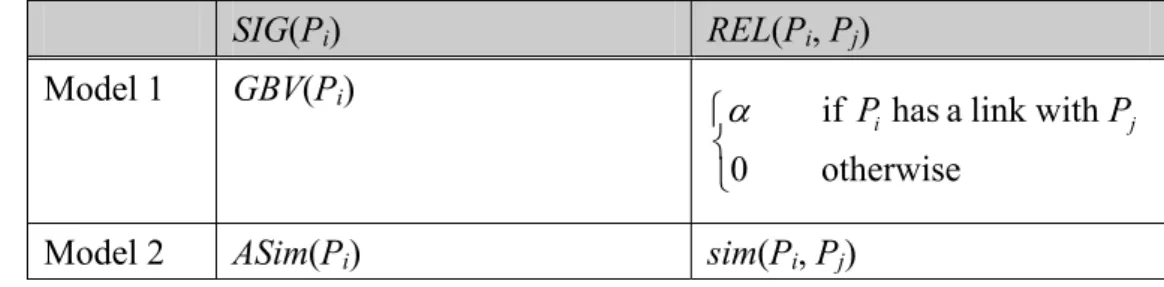
Table 4: SIG 與 REL 的計算方式 ...27
Table 5: Model 1 的實驗結果 (ROUGE-1 Average) ...29
Table 6: Model 2 的實驗結果 (ROUGE-1 Average) ...29
Table 7: DUC 2003 的部分 Official Results ...30
Table 8: General 詞群結果舉例...52 Table 9: Specific 詞群結果舉例...53 Table 10: 測試集文件群分析...53 Table 11: 測試集中相異詞數目及其於平行語料庫中的涵蓋比例...54 Table 12: Top10 相似度高之中英段落中正確對應數目...54 Table 13: 中英對照例一...55 Table 14: 中英對照例二...55 Table 15: 中英對照例三...55 Table 16: 摘要資訊量涵蓋度及可讀性評估...56 Table 17: 事件群 6 之摘要內容範例...56
Table 18: DUC 2005 example queries ...63
Table 19: Settings of different models ...75
Table 20 Parameter settings ...75
計畫概述
本計畫主要目的在於研究多文件自動摘要(Multidocument Summarization)、 跨語言多文件摘要(Cross-Language Multidocument Summarization)與使用者問答 導向摘要(Query-Focused Multidocument Summarization)技術。
本計畫共分為三年期計畫,研究範疇及目的分述如下: z 第一年:多文件摘要技術研究 研究範疇包含:1) 文件模型建構(Modeling)及表示(Representation)的方 法,主要分析文件的主題、判斷主題的重要性及排序(Ordering)等,將抽取 出的主題結構化及組織化;2) 偵測多個文件主題模型間的相關性,並透過 相關結構的連結,以得到完整的資訊模型;3) 探討由文件模型導出摘要的 方法。 z 第二年:跨語言、多媒體摘要技術研究 研究範疇包含:1)中英文文件內容的轉譯及相似度的評量;2)探究中英 文轉譯應用在自動摘要的可能性,並基於語意的連結來評估中英文的相似 度。研究內容著重於中英文混合式多文件摘要,研究議題為如何跨越語言型 態及結構的障礙,提出計算中英文語句相似度的方法。 z 第三年:客製化摘要呈現技術研究 研究範疇包含:1) 參考使用者給定的自然語言查詢問題及設定檔 (Profile)2, 以產生可以回答使用者問題的摘要;2) 偵測自然語言問題與文件 集中相關語句;3) 研究過去應用於文件摘要的 shallow features 是否依然於 問答摘要環境下扮演重要角色。 2 該設定檔定義摘要內容為 specific 或 general。
執行成果
第一年成果 第一年的研究內容著重於如何判別文件主題及抽取具有代表性的語句作為 候選摘要語句。 我們考量相關文獻所提多文件摘要的方法之優缺點,並以先前我們所發展之 單文件摘要方法為基礎,加以改進以適用於多文件摘要。首先,我們利用潛在語 意分析(Latent Semantic Analysis, LSA)與主題關係地圖(Text Relationship Map)作 為多文件分析模型。此模型將每個語句視為圖(Graph)中的一個點,兩兩語句若相似度大於臨界值,則彼此間具有一連結,其中語句相似度的計算採用 LSA 所
倒出的概念空間模型,以達到具有語意判別的相似度計算。
根據主題關係地圖模型,我們提出兩種段落重要性評估模型,分別為 1)
Global Bushy Path;2) Aggregate Similarity。其中 Global Bushy Path 以圖中各個點 所具有的連結數當作其重要性(Significance);Aggregate Similarity 類似於 Global Bushy Paht,不同之處在於其計算所有連結的相似度總合,作為每個點重要性。 根據上述兩種計算重要性的模型,我們修改Maximal Marginal Relevance,提出 新的摘要段落挑選方式,以達到多文件中去除重複性(Redundancy)的要求。
實驗評估採用ROUGE 來計算專家所產出的摘要與機器所產出摘要中,平均
包含有多少個相同的字。我們以ROUGE-1 為評估標準,實驗結果顯示 Model 1
獲得平均ROUGE-1 分數為 0.3564,Model 2 獲得平均 ROUGE-1 分數為 0.3497。
比較DUC 2003 的比賽結果,我們的方法亦有不錯的表現,約在中等以上。
第二年成果
第二年的研究內容著重於中英文混合式多文件摘要,研究議題為如何跨越語 言型態及結構的障礙,提出計算中英文語句相似度的方法。
我 們 提 出 一 套 中 英 概 念 空 間 擷 取 的 方 法 。 基 於 中 英 雙 語 平 行 語 料 庫 (Chinese-English Parallel Corpus),進行中英文詞分群(Word Clustering),以建立階 層式概念空間(Hierarchical Concept Space)。接著,將中英文語句對應至該階層式 概念空間中,透過此對應關係,可將關鍵詞向量空間表示式(Keyword-Level Vector Representation) 轉 換 至 概 念 向 量 空 間 表 示 式 (Concept-Level Vector Representation)。最後,於相同的概念空間中,便可計算任兩中中、中英及英英 語句的概念相似度。
中英混合式詞分群可抽取出中文詞與英文詞間的關連。當分群的群數目越多 時,位於詞群中的中英文詞可互為翻譯;當分群的群數目越少時,位於詞群中的 中英文詞可視為相關。透過階層式概念空間相似度的組合,可得不錯的中英語句 對應。 實驗結果顯示,考慮Top 10 組中英對應段落,平均 Precision 約 57%為相關。 摘要內容的評估,則由專家進行評比。平均而言,資訊量涵蓋度為7.06,可讀性 為6.04。(其中,1 代表最差,5 代表普通,10 代表最好。) 第三年成果 第三年的研究內容著重於參考使用者給定的自然語言查詢問題及設定檔 (Profile)3, 以產生可以回答使用者問題的摘要。 我們提出一套計算文件集中每個語句與使用者所下的查詢間的相關度計算 方式。考量傳統Vector Space Model 與 Latent Semantic Analysis 的優缺點,我們 提出以線性方式結合上述兩種模型的相似度。此外,我們亦研究過去應用於文件
摘要的shallow features 是否依然於問答摘要環境下扮演重要角色。於本計畫中,
我們考慮以下五個語句特徵,分別為 1) Sentence Position; 2) Sentence TF-IDF Weight; 3) Sentence’s Similarity to the Title; 4) Sentence’s Similarity to the Document; 5) Sentence’s Similarity to the Topic Cluster。
針對我們所提出的語句與查詢相似度計算方法,並結合五個語句特徵值,我 們修改Maximum Marginal Relevance,提出新的摘要段落挑選方式,以達到多文 件中去除重複性(Redundancy)的要求。 另外,摘要的產出方式必須符合使用者所給定的 Profile 限制。目前我們僅 考量摘要內容的豐富性,分別為Specific 與 General。Specific 主要著重在回答使 用者的問題;General 則除了回答問題外,還會提供相關的背景資訊。為了達到 提供Specific 的要求,我們認為當使用者要求 Specific 的摘要內容時,實則要求 具有較多人、地、時的資訊,因此挑選候選語句時,會依據其涵蓋的人、地、實 資訊給予不同的權重。 實驗中,我們以 DUC 2005 的資料集測試,該年度評估以 ROUGE-2 及 ROUGE-SU4 為官方標準。實驗結果顯示,我們所提出的方法有不錯的表現,在 最佳的情況下,獲得ROUGE-2 的分數為 0.0757,ROUGE-SU4 的分數為 0.1299。 3 該設定檔定義摘要內容為 specific 或 general。
參與人員
Table 1: 參與人員及執行工作列表 計畫項目 參與人員 服務單位 職稱 擔任工作 第一年計畫 第二年計畫 第三年計畫 楊維邦 國立交通大學 資訊科學學系 國立東華大學 資訊管理學系 教授 計畫主持人 第一年計畫 第二年計畫 第三年計畫 柯皓仁 國立交通大學 資訊管理研究所 教授 計畫參與人員 第一年計畫 第二年計畫 第三年計畫 葉鎮源 國立交通大學 資訊科學學系 博士生 文獻蒐集研讀、理論分 析、演算法設計及評估 方法設計 第一年計畫 謝佩原 國立交通大學 資訊科學學系 碩士生 文獻蒐集研讀、協助演 算法設計與實作 第一年計畫 梁哲瑋 國立交通大學 資訊科學學系 碩士生 文獻蒐集研讀、協助演 算法設計與實作 第一年計畫 鄭佳彬 國立交通大學 資訊科學學系 碩士生 文獻蒐集研讀、協助演 算法設計與實作 第二年計畫 劉政璋 國立交通大學 資訊科學學系 碩士生 文獻蒐集研讀、協助演 算法設計與實作 第二年計畫 顧世彥 國立交通大學 資訊科學學系 碩士生 文獻蒐集研讀、協助演 算法設計與實作 第二年計畫 王瓊婉 國立交通大學 資訊科學學系 碩士生 文獻蒐集研讀、協助演 算法設計與實作 第三年計畫 林昕潔 國立交通大學 資訊科學學系 碩士生 文獻蒐集研讀、協助演 算法設計與實作 第三年計畫 張家寧 國立交通大學 資訊科學學系 碩士生 文獻蒐集研讀、協助演 算法設計與實作多語言複合式文件自動摘要之研究 (1/3)
計畫類別: 個別型計畫
計畫編號: NSC-92-2213-E-009-126-
執行期間: 2003/08/01 – 2004/07/31
計畫主持人: 楊維邦 教授
計畫參與人員: 柯皓仁 教授, 葉鎮源, 謝佩原, 梁哲瑋, 鄭佳彬
中文摘要
自動化文件摘要(Automated Text Summarization)之研究,探討如何分析、統 整與萃取文件中重要的資訊,並以簡明的形式呈現,可作為使用者或其他資訊系 統的判斷與決策依據。過去關於文件摘要的研究,大多著眼於單文件摘要。近來, 多文件摘要愈顯得重要。多文件摘要與單文件摘要最大的差異,在於過濾重複的 資訊(Anti-redundancy),同時須避免重要資訊的流失。另外,摘要內容排序(Content Ordering),亦是多文件摘要必須探討的議題。 本計畫為三年期研究案『多語言複合式文件自動摘要之研究』之第一年計 畫。本年度計畫之目的,在於研究並發展多文件自動摘要的技術,將探討如何導 出文件的結構、如何組織文件的內容及如何表示所抽取出文件抽象涵義等相關議 題。研究範疇包含:1) 文件模型的建構及表示;2) 文件主題偵測及重要性評估;
3) 摘要內容組織及排序。我們利用潛在語意分析(Latent Semantic Analysis)與主 題關係地圖(Text Relationship Map)作為多文件分析模型,提出兩種段落重要性評 估模型,分別為1) Global Bushy Path;2) Aggregate Similarity。根據上述模型, 我們採用Maximal Marginal Relevance,提出新的摘要段落挑選方式。
實驗評估採用ROUGE 來計算專家所產出的摘要與機器所產出摘要中,平均
包含有多少個相同的字。我們以ROUGE-1 為評估標準,實驗結果顯示 Model 1
獲得平均ROUGE-1 分數為 0.3564,Model 2 獲得平均 ROUGE-1 分數為 0.3497。
比較DUC 2003 的比賽結果,我們的方法亦有不錯的表現,約在中等以上。
英文摘要
Automated text summarization investigates the process of extracting the most important information from a source (or sources), and presenting a summary to the user. In the past, most related work on text summarization focuses on single-document summarization. Multi-document summarization obtains increasing attentions in recent years. The distinction between single and multi-document summarization is that the latter has to handle anti-redundancy as well as to keep salient information meanwhile. Moreover, content ordering, which is to provide a cohesive and coherent summary, is an important issue to be examined.
As the first part of the project “The Research on Cross-Language, Composite and Multi-Document Automated Text Summarization”, the principal objective is to develop new approaches to address multi-document summarization. Our researches include 1) Conceptual Modeling and Representation for Multiple Documents, 2) Topic Detection and Paragraph Significances Measurement, and 3) Content Ordering for the summary.
We exploit latent semantic analysis and text relationship map to derive conceptual model for multiple documents. Based on the model, we propose two approaches to measure the significance of a paragraph. They are 1) Global Bushy Path, and 2) Aggregate Similarity. Besides, we propose a novel paragraph re-ranking approach on the basic foundation of Maximal Marginal Relevance to extract salient paragraphs.
The evaluation metric used in this project is ROUGE which is the official evaluation tool at DUC 2004. In the experiment, we report ROUGE-1 as the official score for each proposed models. Model 1 obtained a value of 0.3564 while Model 2 obtained a value of 0.3497 for ROUGE-1. When compared with the official results at DUC 2003, our proposed methods are at the average position and obtained competitive results.
Keywords: Multi-document Summarization; Latent Semantic Analysis; Text
1. 研究背景及目的
今日電腦與資訊技術蓬勃發展的數位時代,網際網路已成為現代生活中不可 或缺的重要角色,更帶動人類文明往新的資訊紀元(Information Era)推進。拜科技 之賜,各種媒體資料的數位化;透過網際網路管道,大量且豐富的數位內容(Digital Content)得以無遠弗屆地傳播。就現況而言,各式各樣的資訊於網際網路中流通, 資訊的傳播不再單純藉由傳統平面媒體,人們亦漸漸習慣經由網路找尋所要的資 料。資訊的蒐集變得方便,然而亦衍生相關問題,如「資訊爆炸(Information Explosion)」。 龐大的資訊量,使得搜尋及辨別有用資訊的困難度大幅提昇,如何快速且有 效地獲得真正符合自身需求的資訊,亦是目前熱門的研究議題。為解決此類問 題,使用者藉由輔助工具的幫助,得以快速獲知資料的意涵,期能正確地判斷是 否符合自身的需求。相關的輔助工具有:1) 搜尋引擎(Search Engine)及 2) 自動 摘 要 系 統(Automated Summarization) 。 其 中 , 搜 尋 引 擎 扮 演 『 資 訊 過 濾 器 (Information Filter)』的角色,其功用乃是分析檢索條件(Query),搜尋與檢索條件 相關的資料;自動摘要系統則扮演『資訊監督者(Information Spotter)』的角色, 其功用在於分析、統整相關的資料,以簡明的形式呈現,以幫助使用者在最短時 間得知資料內容的意義[20]。 自動摘要系統依原始資料之性質可分為: z 文件摘要(Text Summarization) – 原始資料為純文字。 z 多媒體摘要(Multimedia Summarization) – 原始資料為影像及聲音。 z 複合性摘要(Hybrid Summarization) – 原始資料綜合純文字和多媒體。 本年度研究計畫主要著重於文件摘要技術的研發。以下深入針對何謂文件自 動化摘要,技術起源與發展,與摘要類型等作一詳盡介紹。1.1. 文件摘要介紹
根據Mani 與 Maybury 為文件自動摘要所下的定義[34],自動化文件摘要乃 是從原始資料中精鍊出最重要資訊的過程,其結果即為該原始資料的精簡化版 本,且可作為人們或其他資訊系統的判斷與決策依據。Text summarization is the process of distilling the most important information from a source (or sources) to produce an abridged version for a particular user (or users) and task (or tasks).
文件摘要研究起源於1950 年代,所使用的技術可大致分為下列幾種: z 1950至1960年代,研究方法著重於寫作格式(Genre)的分析。相關研究,如
[16][32]。舉例來說,語句中含有提示片語(Cue Phrase),如『In Summary』 或『In Conclusion』,則該語句可視為摘要語句。此類技術之優點在於簡單 容易,然而卻與文件類型相關,技術重複利用性並不高。 z 1970至1980年代初期,研究方法轉而利用人工智慧來建構知識的表示法 (Knowledge Representation),藉以達到分析文件主題及涵義的目的。相關研 究,如[53][14]。此類技術以模板(Template)來辨認人物、地點及時間等事件 基本要素(Entity),並透過知識模型的推演偵測主題及產生摘要。其缺點在於 模板的定義不夠詳盡,容易導致摘要意義上與原內容可能有所出入,且模板 的定義必須依賴專家,耗時又耗人力。
z 1990年代開始,資訊擷取(Information Retrieval, IR)技術被廣泛應用。相關研 究,如[4][8][20][24][27][45][48]。然其分析只著重於字詞層面(Word-level), 並 沒 有 考 慮 同 義 詞(Synonymy) 、 一 詞 多 義 (Polysemy) 及 字 詞 依 屬 (Term Dependency)關係等語意層面(Semantic-level)分析。資訊擷取技術的應用,發 展至今已經越來越多人朝著語意層面深入研究。 由摘要系統的輸入來看,文件摘要可分為單文件摘要(Single Document Summarization)及多文件摘要(Multdocument Summarization)。單文件摘要將文件 精 簡 化 、 重 點 化 , 著 重 於 從 單 一 文 件 中 刪 減 無 用 資 料 。 相 關 研 究 , 如 [1][2][4][20][24][27][30][40][48][52]。多文件摘要則處理多篇探討相似主題的文 件(Topically-related Documents),著重於刪減、過濾無用且重複的資料。相關研 究,如[7][19][23][31][33][37][45][46]。一般來說,理想的多文件摘要系統必須滿 足以下要求[19]: 1. Clustering – 具有將相似的文件或段落群集成相關資訊的能力。 2. Coverage – 摘要應涵蓋不同文件中所有主題的能力。 3. Anti-redundancy – 刪減摘要中各段落間重複資料的能力。
4. Summary Cohesion Criteria – 將各項資料結合成一致性高且適合閱讀的摘 要,包含各段落的排序。
5. Quality – 摘要結果須具有高可讀性,並具有相關性高且內容豐富的資訊。 6. Identification of Source Inconsistence – 辨認不同文件所提供不同資訊、錯誤
及不一致性的能力。
7. Summary Updates – 追蹤時間性事件發展能力,以提供使用者最新的資訊。 8. Effective User Interface – 提供與使用者互動的介面,如個人化摘要及呈現。
由 語 言 的 角 度 來 看 , 文 件 摘 要 亦 可 分 為 單 語 言 文 件 摘 要(Mono-lingual Summarization)與多語言文件摘要(Multi-lingual Summarization)。多語言文件摘 要,如[55][10][57][29]。多語言摘要係指文件來源可能為不同語言或單文件中包 含不同語言等,此類摘要著重於克服各語言在型態、結構及用語習慣的差異,並 提供各語言間互相轉譯的能力。
1.2. 研究目的與範疇
本計畫為三年期研究案『多語言複合式文件自動摘要之研究』之第一年計 畫。本年度計畫之目的,在於研究並發展多文件自動摘要的技術,將探討如何導 出文件的結構、如何組織文件的內容及如何表示所抽取出文件抽象涵義等相關議 題。研究範疇包含: 1. 文件模型的建構及表示 2. 文件主題偵測及重要性評估 3. 摘要內容組織及排序 針對以上所述研究項目,我們採用先前研究單文件摘要所提出的方法 – LSA-based T.R.M. Approach [52]為基礎,加以改良以適用於多文件摘要的研究, 同時提出兩種評估段落(或語句)重要性的模型。同時,考慮到多文件摘要必須去 除重複性(Redundancy)的議題,我們利用 Maximum Marginal Relevance (MMR) [8] 來達成此目的。於第三章中,將對我們所提的摘要技術作詳盡的介紹。以下僅就 上述研究項目,整理所對應的採用方法。Table 2: 研究項目與相關技術
研究項目 相關技術
文件模型的建構及表示 1) Latent Semantic Analysis 2) Text Relationship Map 文件主題偵測及重要性評估 1) Global Bushy Path
2) Average Similarity
摘要內容組織及排序 MMR
2. 相關研究
近年來網際網路興起後,文件摘要從 80 年代的蟄伏期復甦又蓬勃發展起
來。總括而言,大部分文件摘要之研究著重於單文件摘要。目前的研究涵蓋資訊 擷取(Information Retrieval)與自然語言處理(Natural Language Processing)等技 術,除詞性分析、詞組分析,更運用WordNet [39]等領域知識(Domain Knowledge)
輔助,進行資訊萃取(Information Extraction)等較複雜的語意分析。
相 關 的 研 究 單 位 很 多 , 著 名 的 有 卡 內 基 美 濃 大 學(Carnegie-Mellon University)、康乃爾大學(Cornell University)、南加州大學(Southern California University) 、 密 西 根 大 學 (Michigan University) 及 哥 倫 比 亞 大 學 (Columbia University)等;國內大學,如台灣大學、清華大學都有相關的研究。除此之外, 美 國 國 防 部 高 等 研 究 計 畫 機 構(DARPA) 亦 舉 辦 大 型 的 文 件 摘 要 比 賽 , 如 SUMMAC [50]與 DUC [15],皆有詳細的介紹文件摘要方法及評估的標準。 由此可知,文件自動摘要是具有實際運用價值與挑戰性的研究,以下我們介 紹幾個著名的相關研究成果,然後針對相關的文獻作深入的討論。 Figure 1: PERSIVAL 使用者介面 [43] 哥倫比亞大學發展PERSIVAL 系統[43],將病人就醫紀錄與資料庫中相關的 醫學影像和聲音作關聯,並透過適當的版面設計將結果以摘要的形式呈現出來。 如Figure 1 所示,文件摘要不再只侷限於純文字資訊摘取,更包括內容上下文中 影 像 與 聲 音 的 關 聯 及 呈 現 。 該 系 統 亦 建 置 個 人 化 環 境(Personalized Environment),提供不同層面的摘要內容。舉例而言,病人及親屬所看到的摘要 內容與醫療人員所看到的摘要內容,其深度及廣度皆有所不同。該系統更提供專 業術語(Terminology)的轉換,使摘要的內容與使用詞彙,隨使用者背景知識與興 趣的差異而有所不同。同時,提供文件的視覺化(Visualization)摘要,以方便使用 者快速了解各文件所提及的主題與各文件的差異性。
哥倫比亞大學亦針對新聞文章發展Columbia Summarizer [36]。該系統依據
不同類型的文件整合不同的摘要技術,定義文件類型分為 1) 單一事件(Single
Event);2) 相關多事件(Multiple Related Event);3) 傳記(Biography);4) 相關事 件的討論議題(Discussion Issue)等。Figure 2 為該系統的系統架構圖,共分為三個 部分:Preprocessing、Routing 及 Summarizer Module。Preprocessing 將輸入的文
件轉換成統一的 XML 格式;Router 則依據輸入文件的類型轉送給適當的摘要
器;MultiGen [37]處理具有相同事件的文件集;DEMS (Dissimilarity Engine for Multi-document Summarization) [49]則依據輸入文件的特徵分析,處理多事件及傳
記等類型的摘要。目前,該系統已整合於線上新聞摘要系統 NewsBlaster [11],
提供每日新聞主題偵測、追蹤及摘要服務。
Figure 2: Columbia Summarizer 系統架構[36]
南加州大學發展一套摘要系統GLEANS [13],Figure 3 為其系統架構。該系 統將文件集中所有文件所描述的物件(Entity)及物件間關聯(Relationship)抽取出 來,並以資料庫表格的表示法儲存。同時,利用分類技術將文件集分為四種不同 的類別,分別為1) 單人物(Single Person);2) 單事件(Single Event);3) 多事件 (Multiple Event);4) 天然災害(Natural Disaster)。根據不同的類別,依據事先定 義好的模板(Template)產生長度較短的內容提要。最後,依照不同的類別,考慮 內容一致性(Coherence)的關係以產生最後的摘要內容。GLEANS 之特點在於利 用模板產生品質較佳的摘要(Abstract)。
南加州大學同時發展 NeATS (Next Generation Automated Summarization) [31]。該系統分析字詞的重要性,包含單字詞(Unigram)、二字詞(Bigram)及三字 詞(Trigram),利用 log likelihood ratio 計算字詞與主題的相關性,自動擷取出文件 集中與主題相關的部分(即 Topic Signature)。NeATS 系統可產生一般性摘要 (Generic Summary),且其結果會依照使用者喜好的主題有所調整。其運作步驟如 下:1) 擷取主題特徵(Topic Signature) [24]及主題語句[24],並依照語句的重要性 排序(Ranking);2) 利用 OPP (Optimal Position Policy) [24]將不具重要性之語句移 除;3) 強化一致性(Cohesion)及連貫性(Coherent);4) 利用 MMR [8]篩選語句以 減 少 重 複 性 , 並 保 留 下 固 定 的 摘 要 語 句 數 目 的 語 句 ;5) 強 化 時 間 順 序 (Chronological)的一致性;6) 將摘要結果格式化並輸出。
密西根大學對於多文件摘要提出各種不同的摘要技術,包含 Centroid-based
Approach [45]、Cross-Document Structure Theory [54]、Revision-based Approach [42] 及Event-based Approach [12]。同時,亦實作三個不同類型之線上摘要系統,分 別為MEAD [38]、NewsInEssence [41]及 WebInEssence [44]。目前,MEAD 已經
發展為適用於一般領域的多文件摘要模組,其研究目的為1) 發展中英文的多文
件摘要模組;2) 發展單/多文件摘要系統的評估工具;3) 實驗並評估四種不同的
摘要標準,包含Co-Selection、Content-based、Relative Utility 及 Rank Preservation。 NewsInEssence 為應用於新聞領域的摘要系統,提供新聞文章的主題群集(Topic Clustering) 、 即 時 搜 尋 、 文 章 摘 要 及 使 用 者 互 動 (User Interaction) 等 功 能 。 WebInEssence 則整合文件摘要技術於搜尋技術中。
德州大學開發GISTexter 摘要系統[21],Figure 4 為 GISTexter 的系統架構圖。 該系統利用資訊萃取(Information Extraction, IE)系統 – CICERO [22]與外在的知
識,如WordNet [39],抽取文件中所提到的物件與事件,並且建構物件與事件的
關聯模型。摘要的產生方式則是套用既有的模板來產生內容連貫性與一致性高的 摘要。對單文件來說,主要是透過語句抽取(Sentence Extraction)的方式;對多文 件來說,則是將分散於多文件中的相同主題(Shared Topics)抽取出來。
Figure 4: GISTexter 系統架構[21]
馬里蘭大學發展適用於大型文件集(Large Corpus)的摘要系統,名為 XDoX [23],其處理的文件集大小約為 50-500 篇文章。該系統利用分群技術(Clustering) 將文件集分為幾個有意義的主題,接著以段落為單位,依據段落與主題群集的相 關程度作分類,最後依據不同的群集產生摘要,其流程如Figure 5 所示。另外, XDoX 提供使用者兩種不同的摘要結果,一為詳細的摘要,提供較豐富的資訊; 另一個則依據使用者的需求,如壓縮比等等,提供資訊量較少的摘要。 Figure 5: XDoX 系統架構[23]
微軟劍橋研究中心利用語彙鏈結(Lexical Bonds)技術產生摘要[25]。其方法 共分為三個步驟,分別為 1) 分析(Analysis);2) 轉換(Transformation);3) 合成 (Synthesis)。首先,將文件的特徵抽取出來;共考慮 12 種文件的特徵,如語句在 文件中的位置等。接著,利用SVM (Support Vector Machine)將文件中的重要語 句挑選出來。最後,依照語句出現在文件中的順序排序以產生摘要。該方法的好 處在於利用統計與機器學習的技術,並且透過語彙鏈結將文字的語意納入考量, 可產生連貫性較佳的摘要。
其他相關研究,如[46]針對同一事件的新聞文件作摘要。他們利用專有名詞 識別技術(Named Entity Identification)擷取人名、地名及組織名等資訊,並由新聞 摘要的語料庫中學習摘要的產生方式;同時,利用事先定義好的摘要模板來產生 摘要。McKeown et al. [37]將機器學習與統計的技術整合應用於多文件摘要的研 究。他們的方法可分為三個部分:1) 主題辨識(Theme Identification) [18]: 透過分 群技術將文件中的主題(Theme)抽取出來,同時辨識文件間相似及差異的部分; 2) 資訊融合(Information Fusion) [5]: 將討論相關主題的段落融合,並去除重複的 資訊;3) 摘要生成(Text Reformulation) [37]: 利用 FUF/SURGE [17][47]將所摘錄 出來的重要字詞重新組合以產生流暢的摘要。 國內相關研究,如台灣大學[56],將中文新聞文件拆解成長度較短的句子 (Sub-sentence),同時萃取名詞與動詞關鍵詞。接著,利用關鍵詞計算任兩小句間 關聯強度,將關聯度大於門檻值之小句作成連結,最後評估小句連結並將重要的 小句取出作為摘要。清華大學[55],提出一個可調式中文文件摘要系統,該系統 包含三個部分,分別為 1) 文件分群;2) 文件內容分析;3) 摘要呈現。其概念 乃是將語句分群,以抽取出代表某事件的重要語句;接著,去除重複的資訊,同 時標示重點後將新聞摘要呈現給使用者。 本計畫研究團隊亦對於單文件摘要進行相關研究,提出兩種新的文件摘要方 法,以摘錄文件中重要語句,分別為Modified Corpus-based Approach (MCBA) [52] 及LSA-based T.R.M. Approach (LSA+T.R.M.) [52]。
MCBA 基於統計模型與特徵分析,以評估語句的重要性。考慮的特徵,分 別為語句位置(Position)、正面關鍵詞(Positive Keyword)、負面關鍵詞(Negative Keyword)、向心性(Centrality)及與標題相關度(Resemblance to the Title)。我們提 出三個新的想法:1) 利用語句位置重要性分級提高不同語句位置的重要性;2) 利用詞彙關聯(Word Co-occurrence)分析文件中新詞,並將新詞加入關鍵詞的重要 性計算;3) 利用基因演算法(Genetic Algorithm)找出適合之語句權重計算方式 (Score Function)。實驗結果顯示,我們所提的方法有良善的表現。當壓縮比 (Compression Ratio)為 30%時,平均而言,F-measure 為 0.5151。
LSA+T.R.M.利用潛在語意分析(Latent Semantic Analysis)技術,以擷取文件 概念結構(Conceptual Structure),即語意矩陣(Semantic Matrix),可達到進行語意 層面分析之目的。同時,利用語意矩陣導出語句表示式(Sentence Representation), 以建構主題相關地圖(Text Relationship Map)。最後,透過主題相關地圖,篩選重 要的語句成為摘要。針對語意矩陣的建構,我們考量單文件層面(Single-document Level)及文件集層面(Corpus Level),並比較兩種模式之適用性。實驗收集 100 篇 關於政治類的中文文件。實驗結果顯示,我們所提的方法有良善的表現。當壓縮 比(Compression Ratio)為 30%時,平均而言,F-measure 為 0.4242。
2.1. 文獻探討
2.1.1. MEAD[38]
MEAD [38]接受分群過後的文件集4,以語句(Sentence)為單位,針對每個文
件群(Document Cluster)抽取出具有代表性的語句為摘要。方法如 Figure 6 所示。 MEAD 考慮文件群中每個語句與群中心(Centroid)的相關度、語句的位置及該語 句與所屬文件中首句的相似度,以評估每個語句的重要性。同時對每個文件群抽 取出ni*r 個語句,以組成摘要;其中,ni代表Clusteri中語句的總數,r 代表壓縮 比。 Figure 6: MEAD 運作原理示意圖 評估語句的重要性,MEAD 考慮以下三個特徵,分別為 1) 語句所在的文件 群;2) 語句於文件中的位置,通常出現在文件中的首句可視為代表整篇文章, 因此加重這些語句的重要性;3) 語句如果與首句有關的話,亦加重該語句的重 要性。最後,MEAD 以線性組合(Linear Combination)綜合地評估語句的重要性, 如Eq. (1):
4 MEAD 接受相關的文件集,以產生摘要。然此處所提及之相關文件集,實為考慮 loosely-related
documents。
… Cluster1 Cluster2 Cluster3
n1*r n2*r n3*r #(Sentence):
i i i i w C w F w L S = 1× + 2× + 3× Eq. (1) 其中,Ci 代表語句所在文件群的群中心(Centroid)的相關度,Fi 代表跟所屬文件 之首句的相似度,Li代表該語句是否為所屬文件的首句。一般而言,MEAD 使用 的首句加重計分法,比較適用於藝術類的文章或是新聞文章5;如果文件集是為 其他領域,例如技術類的文件,則首句加重計分法要再調整才合適。 2.1.2. Theme Recognition [37] McKeown et al. [37]認為主題相關的文件集中,存在有許多不同的主題 (Theme);依著此假設將機器學習與統計的技術整合應用於多文件摘要的研究。 他們的方法,分為三個部分:1) 主題辨識(Theme Identification) [18]: 透過分群技 術將文件中的主題(Theme)抽取出來,同時辨識文件間相似及差異的部分;2) 資 訊融合(Information Fusion) [5]: 將討論相關主題的段落融合,並去除重複的資 訊;3) 摘要生成(Text Reformulation) [37]: 利用 FUF/SURGE [17][47] 將所摘錄 出來的重要字詞重新組合以產生流暢的摘要。
首先,考慮以下特徵以決定兩段落的相似度,進而利用分群法將找出主題, 即相似段落的集合。
z Word co-occurrence:假如段落中有許多相似的字,則兩個段落可視為相似。 z Matching noun phrases:利用 LinkIt [51]判斷是否互相關聯的名詞片語群組。 z WordNet synonyms:使用 WordNet [39]找出同義詞組。
z Common semantic classes for verb:判斷具有同一語意的動詞詞組。
接著,利用Information Fusion 的技術,從主題中萃取出具有代表性的詞組
或片語。接著,依照出現在文章中的次序,對片語排序。最後,藉由FUF/SURGE
自 然 語 言 產 生 器 生 成 完 整 語 句 。FUF(Functional Unification Formalism) 利 用 SURGE 產出句法樹(Parsing Tree),接著,藉由句法樹的轉換,以產生新的語句。 2.1.3. MMR[8]及 MMR-MD[19]
MMR (Maximal Marginal Relevance) [8]適用於單文件摘要,可用於降低摘要
中具有相同涵義的語句,即減少重複性資訊。其概念乃是對所挑選出與Query 相
關的語句重新排序,以符合具有最大相關度及最大差異度的特性。排序方式如 Eq. (2):
)] , ( max ) 1 ( ) , ( [ max 1 2 \S i S S i j R S def S S Sim Q S Sim Arg MMR j i∈ ∈ − − = λ λ Eq. (2) 其中,S 代表以挑選出的語句集合,Si代表某個語句,Q 代表 Query,Sim1(Si,Q) 計算Si與Q 的相似度,Sim2(Si,Sj)計算 Si與Sj的相似度。
Table 3: MMR-MD 中 Sim1及Sim2的計算方式[19]
MMR-MD [19]延伸 MMR 的概念,針對多文件摘要提出適合的排序方式。
主要目標是使摘要語句對文件的主題和Query 有極高的相似度,同時能夠降低摘
要中具有重覆意思的段落數目。MMR-MD 同時考慮到時間順序、專有名詞、對
)] , , , ( max ) 1 ( ) , , ( 1 [ max 2 / S C P P Sim C Q P Sim Arg MD MMR nm ij S P ij ij S R P def ij ij ∈ ∈ − − = − λ λ Eq. (3) 其中,Sim1(Pij,Q,Cij)計算 Pij與 Q 的相似度,同時衡量與段落所在的文件群的相 關度;Sim2(Pij,Pnm,C,S)計算 Pij與Pnm的相似度,其中Pnm為一以挑選出之段落。 上述兩相似度的計算方式,整理於Table 3。 MMR-MD 希望能使的摘要中的段落儘可能的相似於 Query,但其所選到的 段落間要儘可能的不相似。λ 則是用來控制要取與 Query 相似度高的段落,但彼 此之間的重複性可能也高,或是要與段落相似度稍低的段落,但彼此之間的重複 性也低。適當的λ 值可以找到兼具主題但又不會有過多重複性段落為摘要。 2.1.4. Graph Matching [33]
Mani et al. [33]將文件表示成圖形(Graph),其中,每個節點代表一個關鍵詞 (Term),節點與節點間用不同的關係連接起來,包含 1) 片語關係(PHRASE);2) 形容詞關係(ADJ);3) 同義關係(SAME);4) 關聯關係(COREF)。文件圖形模型, 如Figure 7 所示。
Figure 7: 文件圖形模型範例
首先,賦予每個節點一權重(Weight),權重值初始為該關鍵詞的 TF-IDF [3] 值。接著,利用Spreading Activation [9]演算法,透過節點間相連的連結權重變
更節點的權重值,以找出與Query 相關的節點。接著,比較兩兩文件圖形模型的
相似度(Commonality)及差異性(Difference)。他們提出 FSD (Find Similarities and Differences)演算法,以找出兩圖形中相似或差異的節點。透過以下演算法,將節 點分成兩群,一群為相似的節點,另外一群則為具有差異的節點。 COREF NAME NAME ADJ ADJ ADJ ADJ
1) Common = {c | concept_match(c, G1) & concept_match(c, G2)} 2) Differences = (G1 ∪ G2) – Common
concept_match(c, G) is true iff c1 ∈ G such that c1 is a topic term or c and c1 are synonyms. 最後,透過分析Common 及 Difference 中的關鍵詞,計算語句的重要性,並 挑選出重要的語句當成摘要結果。語句重要性的計算方式,如Eq. (4):
∑
= = ∈ ∩ = | ( |) 1 ( ), ( ) { | } | ) ( | 1 ) ( c si weight wi wherec s w w Common s
s c s score Eq. (4)
3. 研究方法
我們以先前研究單文件摘要所提出的方法 – LSA-based T.R.M. Approach [52]為基礎,加以改良以適用於多文件摘要的研究,同時提出段落重要性評估的 三種模型。本節中,首先介紹潛在語意分析(Latent Semantic Analysis) [28]與主題 關係地圖(Text Relationship Map) [48],最後說明我們所提出的多文件摘要技術模 型 – LSA-based MD-T.R.M. Approach。3.1. 潛在語意分析 (Latent Semantic Analysis)
潛在語意分析 (Latent Semantic Analysis) [28]為以數學統計為基礎的知識模 型,其運作方式與類神經網路(Neural Net)相似。不同的是類神經網路以權重的傳 遞(Propagation)與回饋(Feedback)修正本身的學習;潛在語意分析則以奇異值分解 (Singular Value Decomposition, SVD)與維度約化(Dimension Reduction)為核心作
為邏輯推演的方式,其原理如Figure 8 所示。 潛在語意分析將文件或文件集表示為矩陣,透過SVD 將文件所隱含的知識 模型,抽象轉換到語意空間(Semantic Space),再利用維度約化萃取文件知識於語 意空間中重要的意涵。整個過程除可以將隱含的語意顯現出來外,更能將原本輸 入的知識模型提升到較高層次的語意層面。 潛在語意分析的應用非常廣泛,包含資訊擷取、同義詞建構、字詞與文句相 關性判斷標準、文件品質優劣的判別標準及文件理解與預測等各方面的研究。
Figure 8: LSA 工作原理
做 法 上 , 首 先 將 文 件 集(Corpus) 中 所 有 文 件 的 Context 6建 構 為 Word-by-Context 矩陣(A)。矩陣中的每個元素(ai,j),即某關鍵詞(Wi)在某 Context (Cj)
中的權重或出現頻率。接著,透過奇異值分解將A 分解轉換成三個矩陣乘積,即
A=USVT。其中,S 代表語意空間(Semantic Space),U 代表關鍵詞於此語意空間
中的表示法,VT則代表Context 於此語意空間中的表示法。再利用維度約化可更 精 確 地 描 述 語 意 空 間 的 維 度 , 並 重 建 矩 陣 A’=U’S’V’T, 可 更 進 一 步 導 出 Word-Word、Word-Context 或 Context-Context 的關聯強度。值得一提的是,潛在 語意分析具有知識推演的能力;如果將原始矩陣中的任一數值改變,其結果會影 響到最後重建的矩陣,且影響的範圍不單為原先經過改變的數值,更會影響到矩 陣中的其他數值。
3.2. 主題關係地圖 (Text Relationship Map)
Figure 9: 主題關係地圖的範例[48]
主題關係地圖(Text Relationship Map) [48]將文件集中文件間關聯度表示成 關係地圖。作法上將每篇文件以關鍵詞的向量表示法(Vector)表示,計算兩兩文 件的相似度(Similarity);當相似度大於臨界值時,表示此兩篇文件存在連結關係 6 Context 可視需求定義為語句(Sentence),段落(Paragraph),或文件(Document)的層面來考量。 Surface Information Deeper Abstraction SVD Dimension Reduction LSA 22387—Thermonuclear Fusion 19199—Radioactive Fallout 17016—Nuclear Weapons 17012—Nuclear Energy 11830—Hydrogen Bomb 8907—Fission, Nuclear
Links below 0.01 ignored
0.57 0.24 0.54 0.49 0.50 0.33 0.38 0.09 0.23 17016 17012 11830 19199 22387 8907
(Semantic Related Link)。依此原則可以建構出所有文件間的關係地圖。舉例來 說,Figure 9 中編號 17012 及 17016 的文章,二者的相似程度約 0.57,大於臨界 值0.01,所以存在連結關係;而 8907 與 22387 的相似度則低於臨界值,因此於 主題關係地圖中並不存在連結。一般來說,具有連結的文章,可說它們之間具有 關聯性。 [48]將主題關係地圖的概念應用於單文件摘要研究。以每個段落(Paragraph) 為單位計算兩兩段落的相似度,建構主題關係地圖7。當某個節點具有的連結數 愈多,則代表該節點所對應的段落和整篇文件中主題的相關度愈高。[48]依據連 結數目的多寡來決定摘錄段落順序,並提出以下三種方法以產生單文件摘要: 1. Global Bushy Path
首先定義任一節點的Bushiness 為該節點與其他節點的連結數目;擁有
越多關聯連結的節點,表示該節點所對應的段落與其他段落所討論的主題相 似,因此,該段落可視為討論文件主題的段落。Global Bushy Path 將段落依 照原本出現在文件中的順序以及其連結個數由大而小的排列。接著,挑選排 名前K 個段落(Top-K),即為該文件的摘要。 2. Depth-first Path Depth-first Path 選取某個節點 – 可能為第一個節點或是具有最多連結 的節點,接著每次選取於原始文件中順序與該節點最接近且與該節點相似度 最高的節點當作下一個節點,依此原則選取出重要而且連續的段落以形成文 件摘要。
3. Segmented Bushy Path
Segmented Bushy Path 分為兩個步驟,首先分析文件結構進行文件結構 切割(Text Segmentation)。接著針對每個 Segmentation 個別利用 Global Bushy Path 來 選 取 重 要 的 段 落 。 為 了 保 留 所 有 Segmentation 的 內 容 , 每 個 Segmentation 至少要挑選出一個段落納入最後的摘要。
Topically Related Documents Feature Selection Feature Extraction Preprocessing W-by-P Matrix Construction Singular Value Decomposition Dimension Reduction Semantic Matrix Reconstruction Semantic Modeling Semantic Similarity Computation Semantic Related Paragraph Link
Text Relationship Map Construction
Model 1:
Global Bushy Path Traversing Model 2: Average Similarity Computation Model 3: Spread Activation Significance Measurement Postprocessing MMR-based Paragraph Selection Paragraph Ordering Summary Topically Related Documents Feature Selection Feature Extraction Preprocessing Feature Selection Feature Extraction Feature Selection Feature Extraction Preprocessing W-by-P Matrix Construction Singular Value Decomposition Dimension Reduction Semantic Matrix Reconstruction Semantic Modeling W-by-P Matrix Construction Singular Value Decomposition Dimension Reduction Semantic Matrix Reconstruction W-by-P Matrix Construction Singular Value Decomposition Dimension Reduction Semantic Matrix Reconstruction Semantic Modeling Semantic Similarity Computation Semantic Related Paragraph Link
Text Relationship Map Construction Semantic Similarity Computation Semantic Related Paragraph Link Semantic Similarity Computation Semantic Related Paragraph Link
Text Relationship Map Construction
Model 1:
Global Bushy Path Traversing Model 2: Average Similarity Computation Model 3: Spread Activation Significance Measurement Model 1:
Global Bushy Path Traversing Model 2: Average Similarity Computation Model 3: Spread Activation Significance Measurement Postprocessing MMR-based Paragraph Selection Paragraph Ordering Postprocessing MMR-based Paragraph Selection Paragraph Ordering MMR-based Paragraph Selection Paragraph Ordering Summary Figure 10: 本研究所提之多文件摘要架構
3.3. Proposed LSA-based MD-T.R.M. Approach
本節以我們先前對於單文件摘要所提出的方法LSA-based T.R.M. Approach [52]為基礎,加以改進以適用於多文件摘要,並提出段落重要性評估的三種模 型。系統架構如Figure 10 所示8,共包含五個模組,分別為前處理(Preprocessing)、 語意模型建立(Semantic Modeling)、主題關係地圖建構(Text Relationship Map Construction) 、 段 落 重 要 性 評 估 (Significance Measurement) 及 後 處 理 (Post-processing)。以下分別說明各個模組之功用。 3.3.1. 前處理(Preprocessing) 前處理包含兩個步驟,分別為特徵選取(Feature Selection)及特徵擷取(Feature Extraction)。 特徵選取 我們以段落(Paragraph)為單位,考慮所有的單字詞(Unigram)、二字詞(Bigram) 及三字詞(Trigram)。針對二字詞及三字詞,利用 Mutual Information [35]計算其代
8 本計畫所提之多文件摘要架構,乃延伸先前研究所提出適用於單文件摘要之 LSA-based T.R.M.
Approach [52],利用潛在語意分析(LSA) [28]與主題相關地圖(Text Relationship Map) [48]作為文 件分析模型。
表性,以篩選不具代表性之特徵,計算方式如Eq. (5)9: ) ( ) ( ) , ( ) , ( y p x P y x P y x MI = Eq. (5) 其中,x 與 y 為相鄰之兩個單字詞10,P(x)為 x 出現於文件集的個數,P(y)為 y 出現於文件集的個數,P(x, y)則為 x 與 y 共同出現的個數。為了更進一步篩選
出具有代表性的特徵,針對每個特徵計算其 IDF (Inverse Document Frequency) [3],其計算如 Eq. (6)所示:
n N w
IDF( j)=log Eq. (6)
其中,wj為一特徵關鍵詞,N 為文件集中段落的總數,n 為 wj出現的段落總數。 當IDF 值大於預設的臨界值,則表示該特徵具有代表性。 特徵擷取 每個特徵的重要性,除了考慮每個特徵關鍵詞於段落出現的頻率外,亦考慮 每個特徵關鍵詞於文件集中的重要程度。定義其權重為Kij,其計算如Eq. (7): ij i ij G L K = * Eq. (7) 假設文件集中段落的集合為P = {Pj | Pj代表某一Pk,l,即文件Dl中Pk段落}, Gi代表特徵關鍵詞 Wi於 P 集合中的分佈權重,Lij代表 Wi在 Pj中的分佈權重。 假設cij為Wi出現在Pj中的次數,tj為Wi出現在P 集合中的次數,則 Wi在Pj中 的相對頻率計算方式如Eq. (8): i ij ij t c f = Eq. (8) 接著,考慮P 集合中 Wi的資訊分佈量(Entropy),計算方式如 Eq. (9):
( )
∑
=( )
− = N j ij j i fi f N E 1 log * log 1 Eq. (9)由Eq. (9)可知當 fij等於1 的時候,Ei的值為0;當 fij等於1/N 的時候,Ei的
值為1。當 Ei的值越接近於1 的時候,表示 Wi在P 集合中的分佈越平均,Wi的
重要性便會降低;相反地,如果Ei的值越接近0 的時候,表示 Wi只出現在某些
9計算三字詞之MI 值則為 MI(x, y, z)。
段落, Wi的重要性便比平均分布在P 集合中的特徵關鍵詞來得高。最後,定義 Wi於P 中的總體權重 Gi,如Eq. (10): i i E G = 1− Eq. (10) 另外,定義Wi於Pj中的權重Lij,如Eq. (11),其中 nj 代表 Pj中所含的特徵關鍵 詞總數。 ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ + = j ij ij n c L log2 1 Eq. (11) 3.3.2. 語意模型建立(Semantic Modeling) 我們以建構 Word-by-Paragraph 的矩陣作為代表文件集之語意模型。假設該 矩陣為A,其中 aij代表Wi於Pj的權重值11。接著,將矩陣A 作奇異值分解(SVD),
使得 A=USVT。對於 S 進行維度約化(Dimension Reduction),同時取適當的維度
後重新建構矩陣A’=U’S’V’T。此時,便得到具有語意的Word-by-Paragraph 矩陣 表示法,其中,每個列向量(Row-Vector)代表該關鍵詞在每個段落中的權重,而 每個行向量(Column-Vector)代表該段落由各個關鍵字所組成的意義。
先前提及潛在語意分析(LSA) [28]能將文章中的隱性語意(Latent Semantic) 表現出來。若以潛在語意分析所導出之段落表示式計算任兩段落的相似度,其結 果會比單純使用關鍵字出現頻率權重的表示法來得好。基於這個想法,我們以潛 在語意分析所得到的段落表示式 – 行向量(Column Vector)套用在主題相關地圖 (Text Relationship Map) [48],並衡量潛在語意分析對於摘要結果的影響。 3.3.3. 主題關係地圖建構(Text Relationship Map Construction)
以潛在語意分析重建之後得到的行向量當作段落的表示法,並計算任兩向量 的Cosine 值來衡量計算任兩段落的相似度。建構主題相關地圖時,只保留約 1.5 倍語句數目的連結;亦即,若有n 個段落的話,那麼總共的連結數目 C(n, 2)個, 而最後只保留相似度高的前1.5*n 個連結。 3.3.4. 重要性評估(Significance Measurement) 我們提出兩種評估方式,以評估主題相關地圖上節點(即段落)的重要性。分 別敘述如下: 11 a ij的值可透過Eq. (7)的公式計算。
Model 1: Global Bushy Value
Global Bushy Value (GBV)12為主題相關地圖上任一節點與其他節點間
的連結數目;定義如Eq. (12)所示,其中,Pi為主題地圖上一節點。由此可 知,擁有越多關聯連結的節點,表示該段落與其他段落的寫作與用字方式相 似,並且討論的主題也相似,因此,該段落視為討論主題的段落。
∑
∀ = i j jP P P i P GBV link with a has , 1 ) ( Eq. (12) Model 2: Average Similarity
相較於Model 1 只考慮到主題相關地圖上每個節點的連結個數,我們參
考[26],並考慮每個連結權重的方式,以 Aggregate Similarity 計算每個節點 的重要性,Aggregate Similarity 的示意圖如 Figure 11:
Figure 11: 計算 Aggregate Similarity 的概念圖示[26]
圖中的每個節點代表某個段落的向量表示法,每個連結代表兩個語句間 的相似度,任兩個語句的相似度即是計算相對應向量間的內積值。Aggregate Similari 之計算如 Eq. (13):
( )
∑
(
)
≠ ∀ = i link with a has , P P P P i j i j i j P P sim P AvgSim Eq. (13) 其中,sim(Pi, Pj)為兩個節點間的相似度,即是計算相對應向量間 Cosine 值。 計算每個節點的Aggregate Similarity,其好處在於除了考慮到每個節點的連 結個數,同時亦考慮到每個連結的權重值。 12 即[48]中定義之 Bushiness 值。3.3.5. 後處理(Post-processing)
後處理包含兩個步驟,分別為段落選取(Paragraph Selection)及段落排序 (Paragraph Ordering)。
段落選取
我們參考Maximal Marginal Relevance (MMR)13 [8]的概念,提出段落選取的 方法,如Eq. (14)所示: ] ) , ( max * ) ( [ max \S i P S i j R P def P P REL P SIG Arg PS j i∈ ∈ − = λ Eq. (14) 其中,S 代表已被選到之段落的集合,SIG(Pi) 代表 Pi的重要性,REL(Pi, Pj) 代 表Pi與Pn的關聯強度。 做法上,PS 依序選取出組成摘要的段落,同時評估目前衡量的段落與先前 取出的段落間相關程度;此機制乃是為了去除重複性(Anti-redundancy),以提供 使用者更多的資訊。Table 4 整理針對前一步驟所提出的兩個模型中 SIG 與 REL 的計算方式。
Table 4: SIG 與 REL 的計算方式
SIG(Pi) REL(Pi, Pj) Model 1 GBV(Pi) ⎩ ⎨ ⎧ otherwise 0 link with a has if Pi Pj α
Model 2 ASim(Pi) sim(Pi, Pj)
段落排序 段 落 排 序 之 目 的 , 將 挑 選 出 來 的 段 落 依 據 內 容 一 致 性(Cohesion) 及 連 貫 性 (Coherent)重新排序,以提供使用者適合閱讀的摘要。本研究中,我們的重點在 於探討如何有效的評估段落或語句的重要性,以作為挑選摘要語句的依據。因 此 , 本 研 究 中 有 關 段 落 排 序 的 方 法 , 僅 將 段 落 依 其 所 屬 文 章 的 發 佈 日 期 (Publication Date)排序。 13 請參考相關研究工作中所提及之 MMR [8]及 MMR-MD [19]。
4. 結果與討論
4.1. 測試資料集
實驗中以DUC (Document Understanding Conference)的 DUC 2003 資料為測 試對象,該年度的評比共分為四個項目:1) Task 1 – Very short summaries; 2) Task 2 – Short summaries focused by events; 3) Task 3 – Short summaries focused by viewpoints; 4) Task 4 – Short summaries in response to a question。其中 Task 2 及 Task 3 為多文件摘要評比,然而因為我們所發展的摘要技術針對新聞事件多文件
摘要而設計,因此,我們使用Task 2 的資料作為評估演算法好壞的資料集。
Task 2 所提供的資料共有 30 個文件群(Document Clusters),每個文件群中各
有約10 篇新聞文章,且這 10 篇新聞文件皆是討論相同的新聞事件發展。Task 2
要求每個參與比賽的系統針對這30 個文件群各產生約 100 字的摘要14。
4.2. 評估方法
DUC 從 DUC 2004 起採用 ROUGE (Recall-Oriented Understudy for Gisting Evaluation)[58]為評估工具,因此我們亦已該工具來評估演算法的好壞。DUC 2003 的資料中,每個文件群皆由四個專家閱讀過所有文章後,針對該文件群所
討論的事件主題等資訊,以人工方式產出約100 字的短摘要。ROUGE 以專家所
產出的摘要當參考答案,對照機器所產出的摘要內容,主要計算有平均有多少個 Word 被專家與機器所產生的摘要所共同包含。
ROUGE 的評估主要有 ROUGE-1, ROUGE-2, …, ROUGE-N, ROUGE-L, ROUGE-WL。ROUGE-N 以 N 個字為單位計算 Recall 值, 如 ROUGE-2 為以 Bigram 為單位時所得到的 Recall。ROUGE-L 以 common string 為單位計算 Recall,ROUGE-WL 則為加權過後的 ROUGE-L。目前已經證明 ROUGE-1 的評
估分數比較接近專家所給定的評估分數,因此我們僅列出ROUGE-1 的分數。
4.3. 實驗結果
實驗的參數設定,Model 1 的 α 值(亦即 Table 4 中的 α 值)動態設定為該 Pi 與目前所產生摘要段落集合中具有連結的Pj個數。Eq. (14)中的 λ 值則設定為 0 到50,以比較各種不同 λ 值下對於摘要好壞的影響。 14 小於 100 字不予加分;多於 100 字則需先縮減為 100 字後再由評估工具計算分數。Table 5 列出 Model 1 的 ROUGE-1 平均值;Table 6 則列出 Model 2 的 ROUGE-1 平均值。Figure 12 則將 Table 5 與 Table 6 整合製圖。由圖中可知,當 λ=0 時(亦即沒有考慮到 Anti-Redundancy),此時的結果最差。另外,Model 1 不
管在任何λ 值的設定下,皆比 Model 2 有較佳的表現。這是因為 Model 2 考慮語
句與其他語句的平均相似度值,導致失去了連結個數的表現。因而使得結果變得 較差。
Table 5: Model 1 的實驗結果 (ROUGE-1 Average)
λ=0 λ=10 λ=20 λ=30 λ=40 λ=50
ROUGE-1 0.3405 0.3579 0.3544 0.3521 0.3532 0.3564
Table 6: Model 2 的實驗結果 (ROUGE-1 Average)
λ=0 λ=10 λ=20 λ=30 λ=40 λ=50 ROUGE-1 0.3402 0.3457 0.3497 0.3434 0.3429 0.3466 0.335 0.34 0.345 0.35 0.355 0.36 0 10 20 30 40 50 Model 1 Model 2
Figure 12: Model 1 與 Model 2 的 ROUGE-1 比較
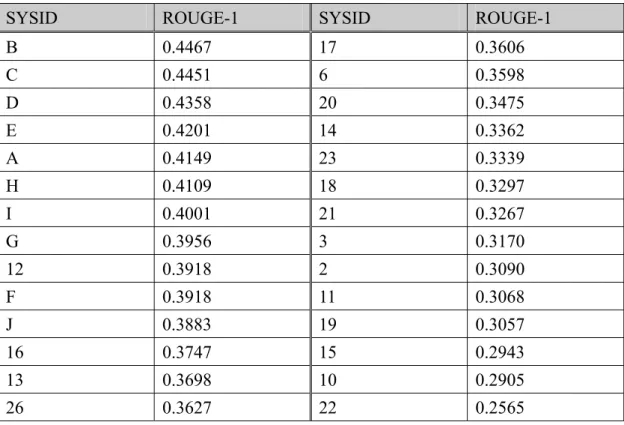
Table 7 中列出 DUC 2003 年的比賽結果,其中 SYSID 代表不同的系統,且
字母A-J 為專家所作的摘要與其他專家的摘要比較結果,數字代表當年度參加比
賽的系統代號。由此表並比較我們的所提出的演算法結果,可知我們的方法亦有 不錯的結果,評估所獲得的分數約為中等以上。
Table 7: DUC 2003 的部分 Official Results
SYSID ROUGE-1 SYSID ROUGE-1
B 0.4467 17 0.3606 C 0.4451 6 0.3598 D 0.4358 20 0.3475 E 0.4201 14 0.3362 A 0.4149 23 0.3339 H 0.4109 18 0.3297 I 0.4001 21 0.3267 G 0.3956 3 0.3170 12 0.3918 2 0.3090 F 0.3918 11 0.3068 J 0.3883 19 0.3057 16 0.3747 15 0.2943 13 0.3698 10 0.2905 26 0.3627 22 0.2565
![Figure 2: Columbia Summarizer 系統架構[36]](https://thumb-ap.123doks.com/thumbv2/9libinfo/8402190.179270/21.892.210.684.401.664/Figure2ColumbiaSummarizer系統架構36.webp)
![Figure 4: GISTexter 系統架構[21]](https://thumb-ap.123doks.com/thumbv2/9libinfo/8402190.179270/23.892.190.705.112.503/Figure4GISTexter系統架構21.webp)
![Table 3: MMR-MD 中 Sim 1 及 Sim 2 的計算方式[19]](https://thumb-ap.123doks.com/thumbv2/9libinfo/8402190.179270/27.892.138.766.369.907/Table3MMRMD中Sim1及Sim2的計算方式19.webp)

![Figure 9: 主題關係地圖的範例[48]](https://thumb-ap.123doks.com/thumbv2/9libinfo/8402190.179270/30.892.179.704.701.959/Figure9主題關係地圖的範例48.webp)
![Figure 11: 計算 Aggregate Similarity 的概念圖示[26]](https://thumb-ap.123doks.com/thumbv2/9libinfo/8402190.179270/35.892.249.681.510.753/Figure11計算AggregateSimilarity的概念圖示26.webp)