國立台中教育大學教育測驗統計研究所理學碩士論文
指導教授: 楊 志 堅 教授
因素負荷量之測量恆等性檢測
模擬研究
研究生: 陳 冠 志 撰
中 華 民 國 九 十 五 年 七 月
A Monte-Carlo Study of
Measurement Equivalence/Invariance
between Factor Loadings
謝 辭
能完成這篇論文,首先我要感謝指導教授楊志堅教授的悉心指導,在研究學 習的過程中耐心的鞭策我、鼓勵我,給予我許許多多的幫助和資源。除了在學術 的領域上受到了楊老師的教誨,在做人處世、待人接物上,更深深受到楊老師的 薰陶,使我更加成熟與堅強。在此,深深獻上我最誠摯的敬意與感謝。再來,我 要感謝的是口試委員:吳齊殷博士,楊志強博士和呂淑妤博士百忙之中撥冗閱讀 論文,並給予我許多專業的知識與建議,使得此論文能更臻於完善。 在研究所中,除了感謝所上所有老師對我的指導,更要感謝與我一同學習、 相互扶植的同學們:感謝佳峯、俊宏在生活上給予我許多幫助;雅云、平梓在課 業上給予我許多協助;慶麟助教在行政上給予許多協助;以及其他同學對我的許 多幫助。更要感謝研究室的良庭學長、秀玉學妹、玉玲學妹、才恬學妹、幸彧學 妹與我一同討論並適時給我建議與協助。在生活中,感謝好友柏仲、益宏對我的 關心與照顧。在低潮中,更要感謝佳峰同學、才恬學妹陪我一同度過。這些日子, 能有你們這群好同學、好朋友的協助,對我來說,是莫大的恩惠,在此致上我最 真摯的謝意。 最後,我要感謝我的父母,不斷的鼓勵我、用心的栽培我、毫不保留的付出, 讓我深深的感動。在此,謹獻此論文給我的父母與親友們,並在一次獻上最誠摯 的謝意,謝謝您們。陳冠志
謹致於 國立台中教育大學教育測驗統計研究所 中華民國九十五年七月十日摘 要
在多組群確認性因素分析的組群間之模式恆等性檢測的過程中,因素負荷量 的恆等性檢測步驟是整體測量恆等性檢測上的一個關鍵步驟。本研究針對此一步 驟上所使用的統計方法,探討其在不同實驗情境下的正確性表現。本研究採用電 腦模擬實驗的方式進行,將分析的模式設定為傳統的確認性因素分析模式(一個 潛在因子與六個觀測變項),並在本研究所設立的 10 種樣本數條件與 15 種因素 負荷量差距條件交互下的 150 種情境進行因素負荷量之恆等性檢測上的統計方法 的正確性表現比較。而在因素負荷量之恆等性檢測步驟上,本研究將其分為「逐 條檢測」和「同時檢測」二種,透過上述的模擬研究設計來探討其差異。 本研究主要的研究結果如下: 1. 於本研究範圍內,在因素負荷量差距小於 0.10 時,「逐條檢查」比「同 時檢查」更能檢測出因素負荷量是否有差異。 2. 樣本數 500 以下時,本研究建議使用「逐條檢查」的方式來檢測因素負 荷量的測量恆等性。當樣本數 500 以上時,本研究建議可採用「同時檢 查」的方式來檢測因素負荷量的測量恆等性,發現不滿足測量恆等性 時,可再使用「逐條檢查」的方法來判斷各題目的測量恆等性。 關鍵字: 測量恆等性、卡方差異檢定、多組群驗證性因素分析、結構方程模式Abstract
In the process of testing measurement equivalence of confirmatory factor analysis between multiple groups, one of the most critical steps is to test the equivalences between factor loadings. This study is focus on this step to discuss the steadiness of test the equivalences between factor loadings. This study is use the Monte Carlo method that is design the 10 types of sample size and 15 types of factor loading difference. And this study is design two methods to test the equivalences between factor loadings. One is the “one by one”, and the other is “all in one”.
The results of this study are as follows:
In this study, use the “one by one” method to test the equivalences between factor loadings is better then the “all in one” method when the factor loading difference less then 0.1.
When sample size less then 500, this study is suggest to use the “one by one” method to test the equivalences between factor loadings. When sample size more then 500, this study is suggest to use the “all in one” method to test the equivalences between factor loadings before use the “one by one” method to test the equivalences between factor loadings.
Keywords:
Measurement Equivalence/Invariance, Chi-square Different Test,
目 錄
第一章 緒論 ...1 第一節 研究動機...1 第二節 研究目的...3 第三節 名詞定義...4 壹、「因素負荷量相同檢驗-逐條檢查」步驟 ...6 貳、「因素負荷量相同檢驗-同時檢查」步驟 ...7 第二章 文獻探討 ...9 第一節 測量恆等性...9 壹、測量恆等性的意義 ...9 貳、測量恆等性與結構方程模式 ...10 參、檢測測量恆等性的步驟 ...11 第二節 卡方差異檢定...14 第三章 研究設計 ...17 第一節 研究流程...17 第二節 實驗設計...19 第四章 結果與討論 ...25 第一節 逐條檢查的結果...25 第二節 同時檢查的結果...32 第五章 結論與建議 ...39 第一節 研究結論...39 第二節 研究特點...41 第三節 未來研究建議...41 參考文獻 ...43表 目 錄
表 4. 1 卡方差異檢定顯著次數表(A)...29
表 4. 2 卡方差異檢定檢定力表(A)...30
表 4. 3 卡方差異檢定顯著次數表(B) ...35
圖 目 錄
圖 1. 1 Model A設定圖 ...4 圖 1. 2 Model B設定圖 ...5 圖 1. 3 「逐條檢查」Model B設定圖 ...6 圖 1. 4 「同時檢查」Model B設定圖 ...7 圖 2. 1 結構方程模式模型圖 ...11 圖 3. 1 研究流程圖 ...18 圖 3. 2 資料產生模式設計圖 ...20 圖 3. 3 「逐條檢查」卡方差異檢定設定圖 ...21 圖 3. 4 「同時檢查」卡方差異檢定設定圖 ...22 圖 4. 1 樣本數檢定力折線圖(A) ...31 圖 4. 2 因素負荷量差距檢定力折線圖(A) ...31 圖 4. 3 樣本數檢定力折線圖(B) ...37 圖 4. 4 因素負荷量差距檢定力折線圖(B) ...37第一章 緒論
本章共分為三節,前二節將對本研究的研究動機與研究目的進行闡述,第三 節定義本研究所採用的「逐條檢查」與「同時檢查」二種方法。
第一節 研究動機
不同群組間的比較在教育或心理研究上是一個相當重要的課題,如 Hilton, Schau, & Olsen(2004)便針對性別的不同與監督時間的長短來探討學生在 SATS (Survey of Attitudes Toward Statistics)表現上的差異比較。欲進行此類研究的學 者必須要注意其研究所採用的測量工具或測驗在其研究將比較的各群組間必須 要有等價性(Equivalence),也就是說該測量工具或測驗必須滿足測量恆等性 (Measurement Equivalence/Invariance, ME/I)。所謂測量恆等性是指一份測量工具 或測驗對於不同的對象或時間點上使用,評量的結果或測驗的分數應該具有等同
性(Reise, Widaman, & Pugh, 1993)。舉例來說,假設一份具有測量恆等性的數學
能力測驗,代表該測驗對於具有相同數學能力,卻來自於不同樣本群組(如:不 同種族、不同性別)之受試者在該測驗上的反應必須一致,並不會受到種族或性 別的影響,則研究者便可以放心的去比較不同樣本群組的數學能力差異。於是在 進行跨樣本的研究時,所採用的測驗工具或量表是否具有測量恆等性是值得研究 者注意。如果其研究所採用的測量工具或測驗不滿足測量恆等性,則研究者便無 法知道其組間差異是否為各組間的真正差異或是該測量工具或測驗所造成的差 異,因此在該測量分數上進行組間比較便顯得沒有意義。 檢測測量工具或測驗是否具有測量恆等性的方法有許多種,如結構方程模式
(Structural Equation Mosel, SEM)、項目反應理論(Item Response Theory, IRT) 等方法都可以來檢驗測量恆等性(Raju, Laffitte, & Byrne, 2002)。近年來,使用結 構方程模式中的多組群驗證性因素分析(Multiple Group Confirmatory Factor Analysis, Multiple Group CFA)來進行測量恆等性的檢定是相當常見的(Meade, &
Lautenschlager, 2004)。利用結構方程模式來檢驗測量恆等性的方法,最早由 Byrne
在 1989 年提出,其後陸續有許多學者提出相關的研究(如:Steenkamp & Baumgartner, 1998; Jöreskog & Sörbom, 1993 等)。在 2000 年,Vandenberg & Lance 便針對在結構方程模式中使用驗證性因素分析檢驗測量恆等性的方法做了一系 列的回顧而並提出檢定測量恆等性的建議流程。其所建議的流程主要是建立出不 同條件限制的模型,以進行模型間的競爭比較,進而判斷該測驗工具是否滿足測 量恆等性。
在結構方程模式的相關研究中,研究者在處理有二組或二組以上的競爭模式 時,通常會使用卡方差異檢定(Chi-square Different Test)來比較各競爭模式 (Alternative Models)對於資料的適配程度,進而幫助研究者選擇資料較符合的 模式(Schermelleh-Engel, Moosbrugger, & Müller, 2003)。Vandenberg & Lancey 在 2000 年所建議的檢測測量恆等性流程便是利用卡方差異檢定來進行模型間的競 爭比較。其主要概念是先假設在不同樣本群組間其因素結構是相等的,並以此為 基本模式。之後在這此基本模式下加上不同的限制條件(如:因素負荷量相等、 潛在因子變異數相等),形成不同的對立模式。利用這些對立模式與基本模式進 行卡方差異檢定,進而判斷資料是否符合條件較限制的模式。若資料皆通過這些 卡方差異檢定(檢定結果為不顯著),則可以推論測驗工具具有測量恆等性。 關於檢測測量恆等性步驟中所需設定的模型,有許多的學者都提出建議,如 Byrne(1989)、Steenkamp & Baumgartner(1998)、Jöreskog & Sörbom(1993)等。 Vandenberg & Lance 在 2000 年針對結構方程模式檢測測量恆等性的方法作了詳 細的回顧,並根據這些回顧整理成流程圖供研究者進行檢測測量恆等性使用。
Meade & Lautenschlager 於 2004 年針對 Vandenberg & Lance 在 2000 年所建議的 測量恆等性流程進行模擬研究。在其研究結果中,大部分不滿足測量恆等性的模 型都是在「因素負荷量相同檢驗」的步驟中被檢測出來,研究者由此推論,「因 素負荷量相同檢驗」的檢測步驟在檢測測量恆等性的流程上,是一個相當關鍵的 步驟。本研究便針對此一步驟並簡化 Meade & Lautenschlager 的模式設計進行模 擬研究。探討在「因素負荷量相同檢驗」步驟中,卡方差異檢定在資料樣本數的 大小以及因素負荷量差距大小影響的穩定性表現。 在本研究中將「因素負荷量相同檢驗」步驟分為「逐條檢查」與「同時檢查」 二種方式。這二種方式會於本章第三節中加以定義並於第三章中詳細說明。利用 此二種設定方式,來探討檢測「因素負荷量相同檢驗」上不同的設定方法是否對 於卡方差異檢定存有差異。
第二節 研究目的
本研究目的為針對測量恆等性下的「因素負荷量相同檢驗」步驟,探討樣本 數大小及因素負荷量差距大小來探討卡方差異檢定的穩定性,並架構出其檢定力 表。本研究將將「因素負荷量相同檢驗」步驟分「逐條檢查」與「同時檢查」二 種檢驗方式,探討這二種檢驗方式的差別。將本研究的目的條列如下: 1. 在因素負荷量之測量恆等性檢測中,卡方差異檢定是否會受到樣本數大 小影響? 2. 在因素負荷量之測量恆等性檢測中,卡方差異檢定可檢測出因素負荷量 差距為何? 3. 在因素負荷量之測量恆等性檢測中,採用「逐條檢查」的方式進行檢驗與採用「同時檢查」的方式進行檢驗,二者是否有差異?
第三節 名詞定義
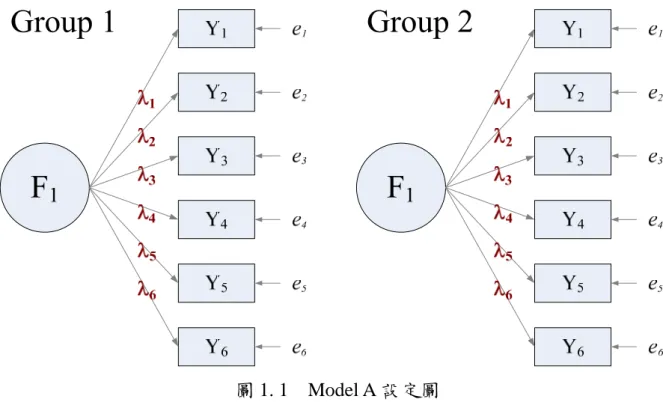
本研究主要針對測量恆等性下的「因素負荷量相同檢驗」模型進行卡方差異 檢定的穩定性探討。在進行卡方差異檢定時,主要將資料設定為二種模式(Model A 和 Model B),說明如下: 圖 1.1 為 Model A 設定圖,為假設二群組的模式結構、因素負荷量、殘差是 相同的。也就是說 Group 1 的模式是等同於 Group 2 的模式。Group 2 的參數估計 值是根據 Group 1 的參數估計值而來,並以此當作 Group 2 的參數估計值。圖 1. 1 Model A 設定圖
異的,而其餘條件(模式結構、殘差)是相同的。也就是說 Group 1 的模式和 Group 2 的模式在因素負荷量的參數估計上是 Group 1 和 Group 2 個別去估計, 其餘的 參數估計值則根據 Group 1 的參數估計值而來,並以此當作 Group 2 的參數估計 值。
1
Y
1Y
2Y
3Y
4Y
5Y
6e
1e
2e
6e
5e
4e
31
Y
1Y
2Y
3Y
4Y
5Y
6e
1e
2e
6e
5e
4e
3 1 2 4 3 5 6 1'
2'
4'
3'
5'
6'
圖 1. 2 Model B 設定圖本研究利用 Model A 和 Model B 分別對資料進行適配,求得資料在 Model A 設定下與 Model B 設定下的卡方值,利用這二個卡方值來進行卡方差異檢定,進 而判斷因素負荷量之測量恆等性。本研究在進行卡方差異檢定上針對 Model B 分 為「逐條檢查」與「同時檢查」二種方式設定,利用此二種 Model B 和 Model A 進行卡方差異檢定,其二種方式的定義如下二小節所示:
壹、「因素負荷量相同檢驗-逐條檢查」步驟
在此步驟下,Model A 如上一小節所定義。而 Model B 進一步定義為二群組 的模式是在其中一題因素負荷量是存在有差異的,而其餘的因素負荷量和其他條 件(結構、殘差等)是相同的(如圖 1.3)。也就是說 Group 1 的模式和 Group 2 的模式在其中一題的因素因素負荷量的參數估計上是 Group 1 和 Group 2 個別去 估計, 其餘的因素負荷量和其他參數估計值則根據 Group 1 的參數估計值而來, 並以此當作 Group 2 的參數估計值。依此設定,本研究希望能夠逐一檢查出各題 是否滿足測量恆等性。 圖 1. 3 「逐條檢查」Model B 設定圖貳、「因素負荷量相同檢驗-同時檢查」步驟
在此步驟下,Model A 和 Model B 如上一小節所定義。但在設定上,本研究 假定在 Model B 中,Group 1 和 Group 2 在其中一題的因素負荷量是相同的,而其
他題目上因素負荷量是不相同(如圖 1.4)。這是為了在比較二群組的模式時,能 有一條因素負荷量當作基準,來比較其他各題的因素負荷量在這二群組資料上的 差異。也就是說 Group 1 的模式和 Group 2 的模式在其餘各題的因素因素負荷量 的參數估計上是 Group 1 和 Group 2 個別去估計, 設定為相同的因素負荷量和其 他參數估計值則根據 Group 1 的參數估計值而來,並以此當作 Group 2 的參數估 計值。依此設定,本研究希望能夠檢查出該份測驗工具是否滿足測量恆等性。
1
Y
1Y
2Y
3Y
4Y
5Y
6e
1e
2e
6e
5e
4e
31
Y
1Y
2Y
3Y
4Y
5Y
6e
1e
2e
6e
5e
4e
3 1 1 2'
4'
3'
5'
6'
2 4 3 5 6 圖 1. 4 「同時檢查」Model B 設定圖第二章 文獻探討
本章共分二節闡述。第一節將介紹測量恆等性的意義與測量恆等性的檢驗步 驟。第二節將介紹卡方差異檢定的原理與條件。第一節 測量恆等性
壹、測量恆等性的意義
測量恆等性的概念大約在 1980 年代被提出來。Drasgow 在 1984 年利用項目 反映理論提出測量恆等性的概念,他認為當一份測驗工具的觀測變項與其所要測 量潛在變項之間的關係在相比較的各樣本群組間相等的時候,則此測驗工具便具 有測量恆等性。進一步解釋為:當來自不同群組但具有相同潛在變項能力程度的 受試者,其在觀測分數上的表現也應該要一致。舉例來說:當研究者施測一份數 學測驗,其中有二位數學能力相等但背景(如性別、社經地位等)不同的學生, 他們在這份測驗題目上的得分表現應該要一致。如果表現不一致,代表該題目會 受到不同背景變數的影響,而不是單純的只受到數學能力影響。這時該題目便不 具有測量恆等性。Drasgow 在 1987 更進一步提出測驗工具的測量恆等性應該包括 測量恆等(Measurement equivalence)和關係恆等(Relational equivalence)兩個 部分。測量恆等是指觀測分數和潛在特質在相比較的各組之間等價;而關係恆等 是指潛在特質得分之間的關係在相比較的各組之間等價。測量恆等性對於測驗工具的要求是觀測分數和潛在特質、潛在特質得分之間 的關係在相比較的各組之間等價,但並不要求反映群體特徵的參數,如平均數、
能力層次的個體,因而其特徵也就不同。但是只要滿足在相比較的群體中,能力 相同的個體其得分也相等,則測驗工具就具備了測量恆等性。 在進行不同樣本群組比較時,一份測驗工具是否具有測量恆等性是非常重要 的前提。當研究者的研究結果發現在不同的樣本群組有顯著差異,其推論會因為 測驗工具是否具有測量恆等性而受到影響。研究結果的顯著差異可能來自於兩種 情況:一種研究結果是在不同的樣本群組真的是存在差異;另一種是研究結果是 在不同的樣本群組並沒有存在差異,但因為測驗工具不具有測量恆等性,造成研 究結果的差異。也就是說,當所採用測驗工具具有測量恆等性時,在進行不同樣 本群組比較時,便能在同一測量尺度上進行比較。所得到的結果也較正確。
貳、測量恆等性與結構方程模式
結構方程模式包含了測量模型(Measurement model)與結構模型(Structural model)兩部分,前者指觀測變項(Observed Variable)與潛在變項(Latent Variable) 的相互關係,後者說明潛在變項之間的關係(Bollen, 1989)。觀測變項是指研究 者可直接觀察得到的變項,如學生的數學期中考成績;潛在變項是指研究者無法 直接觀察得到但可以利用觀測變項來推估的變項,如利用學生的數學期中考成績 和期末考成績來推斷學生的數學能力,數學能力便是潛在變項。圖 2-1 便是一個標準的結構方程模式模型,圖中二邊的實線框各自代表為一
個測量模型,它說明一個潛在變項與三個觀測變項間(如F1和I1、I2、I3,F2和I4、
I5、I6)的關係;圖中間的虛線框代表為一個結構模式,說明潛在變項之間(F1和
圖 2. 1 結構方程模式模型圖 在上一小節,本研究了回顧 Drasgow(1987)提出了測量工具的測量恆等性 應該包括測量恆等和關係恆等兩個部分。而結構方程模型的結構也分為測量模型 和結構模型兩個部分。受這一概念的啟發,Byrne(1989)亦認為測量恆等性應 包含「測量模型恆等」和「結構模型恆等」兩部分,並將測量恆等性導入結構方 程模型之中。他認為「測量模型恆等」是指觀測變項與潛在變項之間的關係在相 比較的各樣本群組間相等;而「結構模型恆等」是指當潛在變項不只一個的時候, 其潛在變項與潛在變項之間的關係在相比較的各樣本群組間相等。
參、檢測測量恆等性的步驟
檢測測量不變性的方法一般來說有結構方程模式與項目反應理論兩種方 法,而這兩種方法各有其優劣之處。主要的差異為結構方程模式認為潛在變項與 觀測變項之間的關係為線性關係;而項目反應理論則認為潛在變項與觀測變項之 間的關係為非線性關係。當觀測變項為二分變項時,項目反應理論的非線性關係 假設便符合此一情境。但是隨著觀測變項的尺度增加,結構方程模式的線性關係 假設便叫符合此一情境。因此以結構方程模式來進行因素恆等性評估會較佳在結構方程模式上檢驗測量恆等性的方法上,通常是採用多組群驗證性因素 分析,此一方法最早由 Byrne 在 1989 年提出,其後更有許多學者提出相關的研 究(如:Steenkamp, & Baumgartner, 1998; Jöreskog, & Sörbom, 1993; Vandenberg, & Lance, 2000; Cheung, & Rensvold, 2002; Raju, Laffitte, & Byrne, 2002 等)。在這些 文獻中,檢驗測量恆等性通常是透過一系列的檢定來達成檢驗測量恆等性的目 的。Byrne(1989)首先提出了測量恆等性條件和檢驗步驟是: 1. 不同群組間的觀測變數之變異數與共變異數矩陣是否相等? 2. 不同群組間的因素負荷量矩陣是否相等? 3. 不同群組間的殘差矩陣和變異數與共變異數矩陣是否相等? 當資料滿足上面三者時,便可以稱測量工具滿足測量恆等性。Vandenberg 和
Lance(2000)、Raju 和 Lafitte(2002)分別提出了相似的方法,但進一步把涵義
和步驟闡述得很清楚。本文主要依據 Vandenberg & Lance 在 2000 年所建議的流 程圖,將檢驗測量恆等性的步驟簡述如下。 在他們建議的檢定流程下,其流程分為五個步驟: 1. 不同群組間的觀測變項的變異數與共變異數矩陣相同檢驗(Σg=Σg’)。 2. 不同群組間的因素結構相同檢驗。 3. 不同群組間的因素負荷量相同檢驗(Λg=Λg’)。 4. 不同群組間的項目截距相同檢驗(τg=τg’)。 5. 不同群組間的潛在變項平均數相同檢驗(Κg=Κg’)。 第一個步驟主要是檢測群組間的觀測變項的變異數與共變異數矩陣是否相 等(Variance-Covariance Matrix)。此為總體檢測,如果兩群組的觀測變項的變異 數與共變異數矩陣相等假設成立,則可以推論該測驗工具在兩群組上測量不變性 成立。 第二個步驟是檢測群組間的因素結構(Factor Structural)是否相同。也就是 兩群組的潛在變項個數與觀測變項屬於哪一個潛在變項的模型架設是相同的。滿
足此條件的模型,將其作為基線模型(Baseline Model),接下來的檢測步驟都是 為此基線模型的巢套模型(Nested Model)。 第三個步驟是檢測群組間的因素負荷量(Factor Loading)是否相同。其模式 是建立在第二個步驟中的基線模型下,加上兩群組因素負荷量相同的假設。若滿 足此一假設,則代表不同樣本群組的個體,在潛在變項上的得分相等,則其潛在 變項所對應的觀測變項得分也會相等。 第四個步驟是檢測群組間的項目截距(Item Intercepts)是否相同。項目截距 是指當潛在變項為 0 時,觀測變項的分數。其模式是建立在第二個步驟中的基線 模型下,加上兩群組的項目截距相同的假設。 第五個步驟是檢測群組間的潛在變項平均數是否相同。其模式是建立在第二 個步驟中的基線模型下,加上兩群組的潛在變項平均數相同的假設。 上述的第四個步驟與第五個步驟通常會以「潛在變項的變異數與共變異數矩 陣相同檢驗(Φg=Φg’)」與「觀測變項的殘差矩陣相同檢驗(Θg=Θg’)」來代替。 因為在很多時候,項目截距通常是假設為 0。而檢測觀測變項的殘差矩陣是否相 等,可進一步說明測驗工具的信度是否相等。 上述的檢驗步驟,主要是依據各步驟所設定的巢套模型與第二個步驟的基線 模型來進行模型間的卡方差異性檢定。藉由卡方差異檢定,可以來選定資料適合 的模型,進而檢測測量恆等性。Meade & Lautenschlager 於 2004 年針對此測量恆 等性流程進行模擬研究,在其研究結果中,大部分不滿足測量恆等性的模型都在 「因素負荷量相同檢驗」的步驟中被檢測出來。研究者由此推論,「因素負荷量 相同檢驗」的檢測步驟在檢測測量恆等性的流程上,是一個相當關鍵的步驟。 針對上述的文獻回顧,本研究採用多組群驗證性因素分析針對「因素負荷量 相同檢驗」的檢驗步驟進行探討。
第二節 卡方差異檢定
卡方差異檢定的先決條件是兩個模型必須為巢套模型(Nested Model) (Schermelleh-Engel, Moosbrugger, & Muller,2003)。所謂的巢套關係,是指一個 模式是另一個模式的簡約模型。也就是說,一個模式是另一個模式加以限制而 來。更進一步的說,當一個模型將其中的某些自由參數(free parameter)加以限 制,例如等同於其他的自由參數或等同於某一參數後所得到的這些被限制的模型 對於一開始未受限制模型會形成一種包含關係,則稱此包含關係為巢套關係,滿 足此種關係的模型便稱作為巢套模型。以檢驗測量恆等性的步驟為例,在第二個 步驟中所設立的「因素結構相同的模式」加上一些限制,如群組間因素負荷量相 同,成為第三步驟中的「因素結構相同且因素負荷量相同的模式」。「因素結構相 同的模式」和「因素結構相同且因素負荷量相同的模式」彼此的關係就是巢套關 係。在本研究中將具有巢套關係的二個模型分為未受限模型(nonrestrictive model) 和受限模型(restrictive model)。以檢驗測量恆等性的步驟為例,「因素結構相同 的模式」與「因素結構相同且因素負荷量相同的模式」相比較,「因素結構相同 的模式」可以看成未受限模型;而「因素結構相同且因素負荷量相同的模式」可 以看成受限模型。 卡方差異檢定是在比較非受限模型與受限模型的概似函數的對數值差異。在 結構方程模式中,比較常見的參數估算法有三種方法:最大概似估算法(Maximum likelihood estimation, MLE)、廣義最小平方法(Generalized least squares, GLS)和 未加權最小平方法(Unweighted least squares, ULS),對應的離差函數(discrepancy function)為:最大概似離差函數(Maximum likelihood fitting function, FML)、廣
義最小平方法離差函數(Generalized least squares fitting function, FGLS)和未加權
形式如下(Bollen, 1989): 1 1 2 2 log ( ) log ( ) 1 [( ) ] 2 1 [( ) ] ML GLS ULS F tr S S T F tr I S F tr S − − = Σ + Σ − − + = − Σ = − Σ 2 q 而卡方差異檢定主要是利用最大概似估算法來進行參數的估算。對於未受限 模型求得其參數估算值 ˆ u θ ;對於受限模型求得其參數估算值 ˆ r θ 。利用下面的公式 可以求出卡方差異檢定的 LR 值: ˆ ˆ 2[log ( ) log ( )]r u LR= − Lθ − Lθ 接著將最大概似離差函數的通式帶入,可以得到新的 LR 值計算公式: ( 1) ( 1) ( 1)( ) r u r u LR N F N F N F F = − − − = − − 在上面的式子,Fr是指估計受限模型所得的參數θ 代入的最大概似離差函ˆr 數;Fu是指估計受限模型所得的參數θ 代入的最大概似離差函數。而在單一模型ˆu 中,如未受限模型,(N−1)Fu的理論分配為卡方分配。同理,在受限模型下,(N−1)Fr 的理論分配也為卡方分配。根據卡方分配的性質:兩個卡方分配的差也為卡方分 配,其自由度為兩個卡方分配自由度相減。所以,LR值的理論分配也為卡方分配, 其自由度為受限模型的卡方自由度減去未受限模型的卡方自由度。 2 2 LR r u 2 LR r u df df df χ =χ −χ = − 利用 LR 值及其卡方分配,可以來作下列的檢定:
H0:受限模式為真 H1:受限模式為偽 也就是說,當卡方差異顯著時,拒絕虛無假設而認定受限模式為偽。以檢驗 測量恆等性的步驟為例,「因素結構相同的模式」為未受限模型;而「因素結構 相同且因素負荷量相同的模式」為受限模型。則虛無假設為「因素結構相同且因 素負荷量相同的模式」是成立的,對立假設為「因素結構相同且因素負荷量相同 的模式」是不成立。當卡方差異檢定顯著時,則拒絕「因素結構相同且因素負荷 量相同的模式」成立,也就是說,認為這二群組的因素負荷量是不相等的。
第三章 研究設計
本章分為二部分。第一部份介紹本研究的進行流程,第二部份則針對本研究 所設定的模型加以描述。第一節 研究流程
本研究流程如圖 3.1 所示:首先針對過往的相關研究文獻來設定本研究所要 探討的模型,依此模型與所要探討的條件來產生模擬資料進行模擬研究,並將模 擬研究的結果整理並加以分析解釋。根據 Meade & Lautenschlager 在 2004 年針對測量恆等性檢驗的模擬研究的 研究結果,可以發現因素負荷量檢測是整體測量恆等性檢測中的一個關鍵步驟且 大部分不滿足測量恆等性的資料都在此步驟中被檢驗出來。而測量恆等性也有嚴 格與寬鬆之分。根據寬鬆的標準,當滿足因素負荷量檢測步驟,也就是說觀測變 項與潛在變項之間的關係等價時,就可以認為該量表具有測量恆等性。 基於上述,本研究的重心便針對測量恆等性檢測中的因素負荷量檢測步驟進 行探討在不同樣本數與不同的因素負荷量差距下,對卡方差異檢定是否造成影 響? 本研究使用 Mplus 程式針對不同的實驗情境產生模擬資料。並使用 Mplus 程 式計算這些資料在「因素結構相同的模式」(Model B)與「因素結構相同且因素
負荷量相同的模式」(Model A)的卡方值,之後利用 Matlab 撰寫程式來進行卡方
第二節 實驗設計
本研究的實驗設計採用傳統驗證性因素分析的模型。主要探討在一個潛藏因 子與六個觀測變項的模型設定下,其中一項因素負荷量(如λ )在這二群組資料6 中具有差異。進而討論在不同因素負荷量差距及不同樣本數下,對卡方差異性檢 定造成的影響? 模擬資料的產生主要依據圖 3.2 而來。首先二組資料是都是產生y1到y6的觀測 變項,這六個觀測變項是依據相同的潛在變項(F)而來。這潛在變項的分配為 標準常態分配,然後依據所設定的因素負荷量產生六個觀測變項。在Group 1 時, 本研究所設定的因素負荷量皆為 1(λ , 1 λ , 2 λ , 3 λ ,4 λ , 5 λ 皆為 1)6 。而在Geoup 2 時,前五個因素負荷量與Group 1 相同(λ , 1 λ , 2 λ , 3 λ ,4 λ 皆為 1),改變第六個5 觀測變項的因素負荷量(λ )。Group 1 與Geoup 2 在第六個因素負荷量差距分別6 設定為:0、0.01、0.02、0.03、0.04、0.05、0.06、0.07、0.08、0.09、0.10、0.20、 0.30、0.40、0.50 共 15 種。依據所設立的 15 種模式,分別產生樣本數為 100、200、 300、400、500、600、700、800、900、1000 筆共 10 種樣本數情境。依據第六個 觀測變項的因素負荷量差距與樣本數的設定,總共設定了 150 種情境。針對這 150 種情境分別模擬 500 筆資料集來進行「檢測群組間的因素負荷量是否相同」的模 擬研究。 在「檢測群組間的因素負荷量是否相同」所使用的卡方差異檢定的顯著水準 設定為 0.05。也就是說,本研究所使用的卡方差異檢定其型一誤差(Type 1 Error) 設定為 0.05。在此條件下,討論每一情境上,所使用的卡方差異檢定其穩定性為 何?並進一步探討其檢定力(Power)為何?圖 3. 2 資料產生模式設計圖 本研究中將「因素負荷量相同檢驗」步驟分為「逐條檢查」與「同時檢查」 二種方式。這二種方式的卡方差異檢定設定如下: 在「逐條檢查」方式下,本研究所設立的巢套模型為:「因素結構相同且因 素負荷量相同的模式」和「因素結構相同且因素負荷量相同,但在某一題上的因 素負荷量具有差異的模式」。換句話說,本研究假設的第一個模式與這二群組的
模型為完全相同;第二個模式為二群組模式的差異為其中一條因素負荷量不同, 剩下的條件二群組皆相同。 在圖 3.3 中, Model 1 下,二群組的因素負荷量皆相等(分別為λ , 1 λ , 2 λ , 3 4 λ ,λ , 5 λ )6 。而在 Model 2 下,二群組的前五個因素負荷量為相同(分別為λ , 1 λ , 2 3 λ , λ ,4 λ ),但在第六個因素負荷量是不相同的(群組一為5 λ ;群組二為61 λ )。62 在此設定下,Model 1 和 Model 2 為一巢套模型,彼此的自由度差異為 1。依此設 定,進行「逐條檢查」的卡方差異檢定模擬研究。 圖 3. 3 「逐條檢查」卡方差異檢定設定圖
1 6 1 6 1 61 1 62 圖 3. 4 「同時檢查」卡方差異檢定設定圖 在「同時檢查」方式下,本研究所設立的巢套模型為:「因素結構相同且因 素負荷量相同的模式」和「因素結構相同但因素負荷量具有差異的模式」。換句 話說,本研究假設的第一個模式為這二群組的模型為完全相同;第二個模式為二 群組模式的差異為因素負荷量不同,剩下的條件二群組皆相同。但第二個模式在 進行模式參數估計時,必須設定二群組其中一題的因素負荷量相同,才能有所基 準進行二群組間的比較。於是,將第二個模式修正「因素結構相同且其中一題因 素負荷量相同但其餘因素負荷量具有差異的模式」。 在圖 3.4 中,在 Model 1 下,二群組的因素負荷量皆相等(分別為λ , 1 λ , 2 λ , 3 4 λ ,λ , 5 λ )。而在 Model 2 下,二群組在第一題的因素負荷量為相同(6 λ ),但1
在後五個因素負荷量是不相同的(群組一為λ 、21 λ 、31 λ 、41 λ 、51 λ ;群組二為61 λ 、22 32 λ 、λ 、42 λ 、52 λ )。Model 1 和 Model 2 為巢套模型,彼此的自由度差異為 5。62 依此設定,進行「同時檢查」的卡方差異檢定模擬研究。 本研究利用圖 3.2 所設定的模式產生不同樣本數及不同因素負荷量差距大小 的模擬資料,分別使用圖 3.3 和圖 3.4 所設定的卡方差異檢定模型進行檢驗,進 而分析不同樣本數及不同因素負荷量差距大小對於卡方差異的影響,並討論採用 「逐條檢查」與「同時檢查」二種方式來檢測「檢測群組間的因素負荷量是否相 同」是否有差異。其結果將於第四章詳細列出。
第四章 結果與討論
在本章中,將依據第三章所提出的研究架構逐步進行實驗。依據不同的樣本 數與因素負荷量差距來進行「檢測群組間的因素負荷量是否相同」的卡方差異檢 定。本研究中,將「檢測群組間的因素負荷量是否相同」步驟分為「逐條檢查」 與「同時檢查」二種方式。第一種模式為針對因素負荷量差距進行逐條檢驗。第 二種模式為針對因素負荷量差距進行全面檢測。本章共分為二節:第一節說明第 一種模式的結果,第二節說明第二種模式的結果。第一節 逐條檢查的結果
在本節中,將進行測量恆等性中「檢測群組間的因素負荷量是否相同」的「逐 條檢查」。在此所設立的巢套模型為:「因素結構相同且因素負荷量相同的模式」 和「因素結構相同且因素負荷量相同,但在某一題上的因素負荷量具有差異的模 式」。換句話說,本研究假設的第一個模式為這二組群的模型為完全相同;第二 個模式為二組群模式的差異為其中一條因素負荷量不同,剩下的條件二組群皆相 同,其模式設計如第三章的圖 3.3 所示。在此設定下,針對本研究所產生的模擬 資料進行的卡方差異檢定結果如表 4.1 所示。 表 4.1 中數字代表在 500 份的資料集中,卡方差異檢定結果為顯著的筆數。 橫列代表在固定因素負荷量差距下,在不同的樣本數間,卡方差異檢定結果為顯 著的筆數的情形。直列代表固定樣本數下,在不同的因素負荷量差距間,卡方差 異檢定結果為顯著的筆數的情形。在此表中,本研究發現在因素負荷量差距在 0.20 以上時,被檢測出不滿足測量恆等性的筆數大都在 479 以上(除了當因素負荷量差距 0.20 與樣本數 100 時),代表當因素負荷量大於 0.20 時,不管樣本數為多少, 卡方差異檢定皆有不錯的表現。而當因素負荷量差距在 0.03 以上時,隨著樣本數 的增加,其被檢測出不滿足測量恆等性的筆數也隨之增加(如因素負荷量差距為 0.07 時,被檢測出不滿足測量恆等性的筆數會隨樣本數的增加,由 69 筆增加至 383 筆)。 進一步將表 4.1 的數值轉換成檢測出不滿足測量恆等性的筆數的百分比,如 表 4.2 所示。因為卡方差異檢定在本研究中主要是要檢測模擬資料是否滿足「檢 測群組間的因素負荷量是否相同」。其虛無假設為「檢測群組間的因素負荷量相 同」;對立假設為「檢測群組間的因素負荷量不相同」。在本研究設計下,在因 素負荷量差距在 0.01 以上時所產生的模擬資料,其真實情形為「檢測群組間的因 素負荷量不相同」,代表對立假設為真。所以,在表 4.2,當因素負荷量差距在 0.01 以上時,表格內的數值代表卡方差異檢定檢測出不滿足測量恆等性的比例, 也就是說卡方差異檢定的檢定力(虛無假設為偽時,拒絕虛無假設的機率)。而 在本研究設計下,在因素負荷量差距在 0 時所產生的模擬資料,其真實情形為「檢 測群組間的因素負荷量相同」。所以在表 4.2,當因素負荷量差距在 0 時,表格 內的數值代表卡方差異檢定檢測出不滿足測量恆等性的比例,也就是說卡方差異 檢定的型一誤差(虛無假設為真時,拒絕虛無假設的機率)。 在表 4.2 中,當因素負荷量差距為 0 時,其數值介於 2.8%到 7.0%之間,與 本研究所設定顯著水準 5%相近,代表本研究所設立的實驗並沒有偏差。若以檢 定力 80%為標準,因素負荷量差距在 0.01~0.07,在本研究樣本數設定下,並沒 有一個樣本數條件達到此一標準。但在因素負荷量差距在 0.03 以上時,檢定力會 隨著樣本數的增加而有所改善(如因素負荷量差距為 0.07 時,檢定力隨樣本數的 增加,由 13.8%增加至 76.6%)。所以,當因素負荷量差距在 0.07 時,試著將樣 本數擴大到 1000 以上,或許可滿足檢定力 80%的標準。當因素負荷量差距在 0.08 時,樣本數 900 便可以有不錯的檢定力(86.4%);當因素負荷量差距在 0.09 時,
樣本數 700 能有不錯的檢定力(86.2%);當因素負荷量差距在 0.10 時,樣本數 600 便可以有不錯的檢定力(86.8%);當因素負荷量差距在 0.20 時,樣本數 200 就能有不錯的檢定力(95.8%);當因素負荷量差距在 0.30 以上時,樣本數 100 便可以有不錯的檢定力(97.4%~100.0%)。其中當因素負荷量差距在 0.20 時, 樣本數 400 以上,便能有 100%的檢定力;因素負荷量差距在 0.30 時,樣本數 300 以上,便能有 100%的檢定力;因素負荷量差距在 0.40 和 0.50 時,樣本數 100 以 上,就能有 100%的檢定力。所以當要檢測的因素負荷量差距越大時,所需的樣 本數便越小。當要檢測的因素負荷量差距在 0.4 以上時,樣本數只要 100 便能有 100%的檢定力。 根據表 4.2 的數值,按照樣本數的不同,將其繪製檢定力折線圖如圖 4.1。圖 中 X 軸代表因素負荷量的差距,Y 軸代表檢定力,每一條曲線代表一種樣本數, 共有 10 條曲線依序代表 100 到 1000 的樣本數。在此圖中,樣本數 100 的檢定力 曲線在因素負荷量 0.10 到 0.20 間開始向上爬升,樣本數 100 的檢定力曲線由 22.2%提升到 70.0%。而其餘的樣本數曲線(樣本數 200 到 1000),會隨著檢測 的因素負荷量差距變大而穩定增加。在每一種樣本數分組下,當因素負荷量差易 大時(0.20 以上),檢定力皆很高(70%以上)。在樣本數 100 的情形下,檢定 力在因素負荷量 0.10 前和因素負荷量 0.10 後有一段明顯的落差。而在其他的樣 本數分組下,隨著因素負荷量差距的增加,會有穩定的成長。 根據表 4.2 的數值,按照因素負荷量差距的不同,將其繪製檢定力折線圖如 圖 4.2。圖中 X 軸代表樣本數,Y 軸代表檢定力,每一條曲線代表一種因素負荷 量差距,共有 15 條曲線依序代表 0 到 0.50 的因素負荷量差距。在此圖中,最下 面的一條曲線為因素負荷量差距為 0 的曲線,依據樣本數的不同,大至在 0.05 擺 動,代表本研究設計大致滿足所設定的型一誤差 0.05 標準。而因素負荷量差距 0.01 到 0.03 的曲線大致隨樣本數的增加而水平成長,代表因素負荷量差距小時,
曲線,大致上隨著樣本數的增加而有所爬升,代表而因素負荷量差距 0.04 到 0.10 時,會隨著樣本數的增加,檢定力也會有所增加。因素負荷量差距在 0.20 以上的 曲線在圖形的上半部,代表在各樣本數下,因素負荷量差距在 0.20 以上有不錯的 檢定力表現。在因素負荷量差距為 0 這一組,各樣本數的檢定力皆在 0.05 左右, 代表本研究的各樣本數設計下,皆滿足型一誤差 5%的假設。而因素負荷量差距 為 0.01 到 0.03 這三組,各樣本數的檢定力大致上算一致(因素負荷量差距為 0.01 時檢定力介於 4.4%到 7.4%、因素負荷量差距為 0.02 時檢定力介於 5.8%到 12.4%、 因素負荷量差距為 0.03 時檢定力介於 7.2%到 21.0%),代表在因素負荷量差距 小於 0.03 時,檢定力並不會隨著樣本數增加而明顯增加。因素負荷量差距 0.04 到 0.10 的這七組,其檢定力會隨著樣本數增加而加大,代表當因素負荷量差距 0.04 到 0.10 時,檢定力會隨著樣本數增加而增加。因素負荷量差距 0.20 以上的 這四組,其檢定力在各樣本數皆很大(70%~100%),代表當因素負荷量差距大 於 0.20 時,檢定力會不管在哪種樣本數皆有不錯的數值。
表 4. 1 卡方差異檢定顯著次數表(A) Sample Size Factor Loading Difference 100 200 300 400 500 600 700 800 900 1000 0.00 17 25 24 35 26 21 23 22 14 23 0.01 23 26 34 37 30 22 31 26 33 33 0.02 29 37 39 52 43 34 54 48 59 62 0.03 36 50 52 71 64 63 94 80 105 102 0.04 45 65 64 103 98 101 143 129 168 158 0.05 47 75 95 140 143 160 194 204 237 239 0.06 57 93 130 178 182 212 268 276 323 317 0.07 69 121 175 218 233 275 343 337 383 383 0.08 75 161 214 286 303 330 397 394 432 440 0.09 92 195 260 329 354 378 431 435 467 470 0.10 111 233 305 368 391 434 469 469 490 491 0.20 350 479 494 500 500 500 500 500 500 500 0.30 487 499 500 500 500 500 500 500 500 500 0.40 500 500 500 500 500 500 500 500 500 500 0.50 500 500 500 500 500 500 500 500 500 500
表 4. 2 卡方差異檢定檢定力表(A) Sample Size Factor Loading Difference 100 200 300 400 500 600 700 800 900 1000 0.00 3.4% 5.0% 4.8% 7.0% 5.2% 4.2% 4.6% 4.4% 2.8% 4.6% 0.01 4.6% 5.2% 6.8% 7.4% 6.0% 4.4% 6.2% 5.2% 6.6% 6.6% 0.02 5.8% 7.4% 7.8% 10.4% 8.6% 6.8% 10.8% 9.6% 11.8% 12.4% 0.03 7.2% 10.0% 10.4% 14.2% 12.8% 12.6% 18.8% 16.0% 21.0% 20.4% 0.04 9.0% 13.0% 12.8% 20.6% 19.6% 20.2% 28.6% 25.8% 33.6% 31.6% 0.05 9.4% 15.0% 19.0% 28.0% 28.6% 32.0% 38.8% 40.8% 47.4% 47.8% 0.06 11.4% 18.6% 26.0% 35.6% 36.4% 42.4% 53.6% 55.2% 64.6% 63.4% 0.07 13.8% 24.2% 35.0% 43.6% 46.6% 55.0% 68.6% 67.4% 76.6% 76.6% 0.08 15.0% 32.2% 42.8% 57.2% 60.6% 66.0% 79.4% 78.8% 86.4% 88.0% 0.09 18.4% 39.0% 52.0% 65.8% 70.8% 75.6% 86.2% 87.0% 93.4% 94.0% 0.10 22.2% 46.6% 61.0% 73.6% 78.2% 86.8% 93.8% 93.8% 98.0% 98.2% 0.20 70.0% 95.8% 98.8% 100.0% 100.0% 100.0% 100.0% 100.0% 100.0% 100.0% 0.30 97.4% 99.8% 100.0% 100.0% 100.0% 100.0% 100.0% 100.0% 100.0% 100.0% 0.40 100.0% 100.0% 100.0% 100.0% 100.0% 100.0% 100.0% 100.0% 100.0% 100.0% 0.50 100.0% 100.0% 100.0% 100.0% 100.0% 100.0% 100.0% 100.0% 100.0% 100.0%
圖 4. 1 樣本數檢定力折線圖(A)
第二節 同時檢查的結果
在本節中,本研究將進行測量恆等性中「檢測群組間的因素負荷量是否相同」 的「同時檢查」。在此本研究所設立的巢套模型為:「因素結構相同且因素負荷 量相同的模式」和「因素結構相同且其中一題因素負荷量相同但其餘因素負荷量 具有差異的模式」。其模式設計如第三章的圖 3.4 所示。在此設定下,針對本研究 所產生的模擬資料進行的卡方差異檢定結果如表 4.3 所示。 表 4.3 中數字代表在 500 份的資料集中,卡方差異檢定結果為顯著的筆數。 橫列代表在固定因素負荷量差距下,在不同的樣本數間,卡方差異檢定結果為顯 著的筆數的情形。直列代表固定樣本數下,在不同的因素負荷量差距間,卡方差 異檢定結果為顯著的筆數的情形。在此表中,本研究發現在因素負荷量差距在 0.10 以下時(除了因素負荷量差距為 0),被檢測出不滿足測量恆等性的筆數介於 18 ~167,代表當因素負荷量差距小於 0.10 時,其卡方差異檢定結果並不理想。當 因素負荷量差距在 0.20 以上時,卡方差異檢定結果為顯著的筆數,會隨著樣本數 的增加而增加(如因素負荷量差距 0.30 時,檢測出來的筆數由 150 增加到 500)。 進一步將表 4.3 的數值轉換成檢測出不滿足測量恆等性的筆數的百分比,如 表 4.4 所示。在表 4.4,當因素負荷量差距在 0.01 以上時,表格內的數值代表卡 方差異檢定檢測出不滿足測量恆等性的比例,也就是說卡方差異檢定的檢定力 (虛無假設為偽時,拒絕虛無假設的機率)。當因素負荷量差距在 0 時,表格內 的數值代表卡方差異檢定檢測出不滿足測量恆等性的比例,也就是說卡方差異檢 定的型一誤差(虛無假設為真時,拒絕虛無假設的機率)。 在表 4.4 中,當因素負荷量差距為 0 時,其數值介於 3.4%到 6.8%之間,與 本研究所設定顯著水準 5%相近,代表本研究所設立的實驗並沒有偏差。若以檢 定力 80%為標準,因素負荷量差距在 0.01~0.10,在本研究樣本數設定下,並沒有一個樣本數條件達到此一標準。當因素負荷量差距在 0.20 時,樣本數 700 便可 以有不錯的檢定力(86.8%);當因素負荷量差距在 0.30 時,樣本數 300 便能有 不錯的檢定力(81.2%)。當因素負荷量差距在 0.40 以上時,樣本數 200 便有不 錯的檢定力(90%~99.4%)。 根據表 4.4 的數值,按照樣本數的不同,將其繪製檢定力折線圖如圖 4.3。圖 中 X 軸代表因素負荷量的差距,Y 軸代表檢定力,每一條曲線代表一種樣本數, 共有 10 條曲線依序代表 100 到 1000 的樣本數。在此圖中,每一種樣本數的檢定 力曲線在因素負荷量 0.10 到 0.20 間開始明顯向上爬升,樣本數 100 的檢定力曲 線由 6.2%提升到 14.0%;樣本數 200 的檢定力曲線由 11.4%提升到 30.8%;樣本 數 300 的檢定力曲線由 9.8%提升到 38.4%;樣本數 400 的檢定力曲線由 19.8%提 升到 56.0%;樣本數 500 的檢定力曲線由 18.4%提升到 62.8%;樣本數 600 的檢 定力曲線由 20.0%提升到 77.4%;樣本數 700 的檢定力曲線由 25.8%提升到 86.8%;樣本數 800 的檢定力曲線由 25.0%提升到 86.8%;樣本數 900 的檢定力曲 線由 33.4%提升到 92.8%;樣本數 1000 的檢定力曲線由 32.8%提升到 93.6%。代 表在因素負荷量 0.10 以下時,不管在何種樣本數設計,皆沒有很好的檢定力。而 在因素負荷量 0.20 以上,檢定力會有大幅增加。在每一種樣本數分組下,當因素 負荷量差易大 0.20 以上,檢定力才會有明顯的增加,當因素負荷量差易 0.10 以 下時,檢定力並沒有很高的表現。而樣本數 100 時,在各種因素負荷量差距下, 檢定力皆不高(4.8%~76.2%),代表在採用「同時檢查」的方法時,樣本數不 適用 100。 根據表 4.4 的數值,按照因素負荷量差距的不同,將其繪製檢定力折線圖如 圖 4.4。圖中 X 軸代表樣本數,Y 軸代表檢定力,每一條曲線代表一種因素負荷 量差距,共有 15 條曲線依序代表 0 到 0.50 的因素負荷量差距。在此圖中,最下 面的一條曲線為因素負荷量差距為 0 的曲線,依據樣本數的不同,大至在 0.05 擺
0.01 到 0.10 的曲線大致隨樣本數的增加而水平成長,代表因素負荷量差距在 0.01 ~0.10 時,隨著樣本數的增加,檢定力並無明顯的成長。而因素負荷量差距 0.20 到 0.50 的曲線,大致上隨著樣本數的增加而有所爬升,代表而因素負荷量差距 0.20 到 0.50 時,會隨著樣本數的增加,檢定力也會有所增加。其中因素負荷量差 距在 0.40 和 0.50 曲線在樣本數 200 後有不錯的檢定力表現(90%~100%)。在 因素負荷量差距為 0 這一組,各樣本數的檢定力皆在 0.05 左右,代表本研究的各 樣本數設計下,皆滿足型一誤差 5%的假設。而因素負荷量差距為 0.01 到 0.06 這 六組,各樣本數的檢定力大致上算一致(因素負荷量差距為 0.01 時檢定力介於 3.6%到 6.6%、因素負荷量差距為 0.02 時檢定力介於 4.2%到 7.0%、因素負荷量差 距為 0.03 時檢定力介於 4.8%到 8.4%、因素負荷量差距為 0.04 時檢定力介於 5.2% 到 9.8%、因素負荷量差距為 0.05 時檢定力介於 5.4%到 13.2%、因素負荷量差距 為 0.06 時檢定力介於 5.6%到 14.8%),代表在因素負荷量差距小於 0.06 時,檢 定力並不會隨著樣本數增加而明顯增加。因素負荷量差距 0.06 到 0.10 的這四組, 其檢定力會隨著樣本數增加而加大,代表當因素負荷量差距 0.04 到 0.10 時,檢 定力會隨著樣本數增加而增加,但增加的幅度不大。因素負荷量差距 0.20 以上的 這四組,其檢定力在各樣本數的影響下,有很明顯的增加。
表 4. 3 卡方差異檢定顯著次數表(B) Sample Size Factor Loading Difference 100 200 300 400 500 600 700 800 900 1000 0.00 24 32 20 22 17 25 34 22 25 31 0.01 24 33 23 21 18 25 33 24 25 31 0.02 24 34 21 24 22 25 34 29 30 35 0.03 27 32 24 25 26 28 37 32 36 42 0.04 26 33 27 31 30 31 43 39 45 49 0.05 27 38 27 38 35 34 47 45 51 66 0.06 28 41 27 42 41 43 56 51 73 74 0.07 28 47 33 51 51 54 72 75 86 92 0.08 29 48 38 60 62 64 85 86 105 113 0.09 30 51 42 74 75 76 105 96 132 134 0.10 31 57 49 99 92 100 129 125 167 164 0.20 70 154 192 280 314 387 434 433 464 468 0.30 151 318 406 459 482 492 499 498 500 500 0.40 260 450 488 500 500 500 500 500 500 500 0.50 381 497 500 500 500 500 500 500 500 500
表 4. 4 卡方差異檢定檢定力表(B) Sample Size Factor Loading Difference 100 200 300 400 500 600 700 800 900 1000 0.00 4.8% 6.4% 4.0% 4.4% 3.4% 5.0% 6.8% 4.4% 5.0% 6.2% 0.01 4.8% 6.6% 4.6% 4.2% 3.6% 5.0% 6.6% 4.8% 5.0% 6.2% 0.02 4.8% 6.8% 4.2% 4.8% 4.4% 5.0% 6.8% 5.8% 6.0% 7.0% 0.03 5.4% 6.4% 4.8% 5.0% 5.2% 5.6% 7.4% 6.4% 7.2% 8.4% 0.04 5.2% 6.6% 5.4% 6.2% 6.0% 6.2% 8.6% 7.8% 9.0% 9.8% 0.05 5.4% 7.6% 5.4% 7.6% 7.0% 6.8% 9.4% 9.0% 10.2% 13.2% 0.06 5.6% 8.2% 5.4% 8.4% 8.2% 8.6% 11.2% 10.2% 14.6% 14.8% 0.07 5.6% 9.4% 6.6% 10.2% 10.2% 10.8% 14.4% 15.0% 17.2% 18.4% 0.08 5.8% 9.6% 7.6% 12.0% 12.4% 12.8% 17.0% 17.2% 21.0% 22.6% 0.09 6.0% 10.2% 8.4% 14.8% 15.0% 15.2% 21.0% 19.2% 26.4% 26.8% 0.10 6.2% 11.4% 9.8% 19.8% 18.4% 20.0% 25.8% 25.0% 33.4% 32.8% 0.20 14.0% 30.8% 38.4% 56.0% 62.8% 77.4% 86.8% 86.6% 92.8% 93.6% 0.30 30.2% 63.6% 81.2% 91.8% 96.4% 98.4% 99.8% 99.6% 100.0% 100.0% 0.40 52.0% 90.0% 97.6% 100.0% 100.0% 100.0% 100.0% 100.0% 100.0% 100.0% 0.50 76.2% 99.4% 100.0% 100.0% 100.0% 100.0% 100.0% 100.0% 100.0% 100.0%
圖 4. 3 樣本數檢定力折線圖(B)
第五章 結論與建議
本章將本研究的結果作最後的結論,並說明本研究的限制和提出若干建 議,以供未來相關研究的探討。因此本研究分成三節:第一節為研究結論, 第二節為研究限制,第三節為未來研究建議。以下就這三部分加以說明。第一節 研究結論
經過以上的研究,本文歸納了以下結論: 1. 卡方差異檢定會隨著樣本數增加,其檢定力會逐步上升,且在本研 究設計內,其型一誤差皆控制在 0.05 左右。 2. 在本研究設計中,使用「逐條檢查」的方式,在樣本數 900 時,因 素負荷量差異為 0.07 時,卡方差異檢定能有 70%以上檢定力;使 用「同時檢查」的方式,在樣本數 600 時,因素負荷量差異為 0.2 時,卡方差異檢定能有 70%以上檢定力。由此判斷,使用「逐條檢 查」能檢測到因素負荷量差異為 0.07,使用「逐條檢查」能檢測到 因素負荷量差異為 0.2。 3. 於本研究設計內,因素負荷量差距小於 0.10 時,「逐條檢查」比「同 時檢查」更能檢測出因素負荷量是否有差距。在因素負荷量差距 0.10 時,使用「逐條檢查」的方式,建議需要 600 以上的樣本數。 在因素負荷量差距 0.09 時,使用「逐條檢查」的方式,建議需要 700 以上的樣本數。在因素負荷量差距 0.08 時,使用「逐條檢查」 的方式,建議需要 900 以上的樣本數。4. 於本研究設計內,因素負荷量差距大於 0.20 時,「逐條檢查」和「同 時檢查」都能檢測出因素負荷量是否有差距。在因素負荷量差距 0.20 時,使用「逐條檢查」的方式,建議需要 200 以上的樣本數, 使用「同時檢查」的方式,建議需要 700 以上的樣本數。在因素負 荷量差距 0.30 時,使用「逐條檢查」的方式,建議需要 100 以上的 樣本數,使用「同時檢查」的方式,建議需要 300 以上的樣本數。 在因素負荷量差距 0.40 以上時,用「逐條檢查」的方式,建議需要 100 以上的樣本數,使用「同時檢查」的方式,建議需要 200 以上 的樣本數。 5. 在樣本數 500 以下時,本研究建議使用「逐條檢查」的方式來檢測 因素負荷量的測量恆等性。當樣本數 500 以上時,本研究建議可採 用「同時檢查」的方式來檢測因素負荷量的測量恆等性,發現不滿 足測量恆等性時,可再使用「逐條檢查」的方法來判斷各題目的測 量恆等性。 6. 研究者認為採用「同時檢查」的方式來進行因素負荷量的測量恆等 性檢測,當二組群因素負荷量差距小(λ 和61 λ 的差異)時,其檢62 定力不高的原因為在分析時被其他條的因素負荷量(λ 和21 λ 、22 λ31 和λ 、32 λ 和41 λ 、42 λ 和51 λ )的估計誤差所影響,進而造成卡方差52 異檢定上的誤差。
第二節 研究特點
本研究主要針對傳統驗證性因素分析的模型進行探討,其模型為一個潛 藏因子與六個觀測變項的設定。另外,本研究所設定的為二群組樣本的測量 恆等性檢測,並將其兩組的樣本數設為相等。本研究的樣本數設計為 100 到 1000,可供實務研究者在進行預試時,進行參考。第三節 未來研究建議
本研究對於後續相關研究,有以下四點建議: 1. 本次研究報告所設定的分析模型為一較簡單的模型,未來將把分析 模型擴展為較複雜的模型來進行研究,如加入另一潛藏變數、或使 用平均數結構方程模式(Mean Structural Equation Model)、或使用 多層次模型(Multilevel Model)來探討。2. 將各群組的樣本數設定不相同,討論不同樣本比率的影響。 3. 本研究所設定的觀測變項為常態分配的連續變數,未來可將觀測變
參考文獻
Bollen, K. A. (1989). Structural equations with latent variables: Wiley New York.
Bollen, K. A., & Long, J. S. (1993). Testing structural equation models: Sage Publications.
Byrne, B. M., Shavelson, R. J. & Muthén, B. (1989). Testing for the equivalence of factor covariance and mean structures: the issue of partial measurement invariance. Psychological Bulletin, 105(4), 456-466..
Cheung, G. W., & Rensvold, R. B. (2002). Evaluating Goodness-of-Fit Indexes for Testing Measurement Invariance. Structural Equation Modeling, 9(2), 233-255.
Drasgow, F. (1982). Biased test items and differential validity. Psychological
Bulletin, 92, 526-531.
Drasgow, F. (1984). Scrutinizing psychological tests: Measurement equivalence and equivalent relations with external variables are the central issues:
Psychological Bulletin, 95, 34-135.
Drasgow, F., & Kanfer, R. (1985). Equivalence of psychological measurement in heterogeneous populations. Journal of Applied Psychology, 72(1), 19-29. Drasgow, F. (1987). Study of the measurement bias of two standardized
psychological tests. Journal of Applied Psychology, 70(4), 662-680.
Hilton, S. C., Schau, C., & Olsen, J. A. (2004). Survey of Attitudes Toward Statistics: Factor Structure Invariance by Gender and by Administration Time. Structural Equation Modeling, 11(1), 92-109.
Little, T. D. (1997). Mean and Covariance Structures (Macs) Analyses of Cross-Cultural Data: Practical and Theoretical Issues. Multivariate
Behavioral Research, 32(1), 53-76.
Mantel, N. (1963). Chi-Square Tests with One Degree of Freedom; Extensions of the Mantel-Haenszel Procedure. Journal of the American Statistical
Association, 58(303), 690-700.
Meade, A. W., & Lautenschlager, G. J. (2004). A Monte-Carlo Study of Confirmatory Factor Analytic Tests of Measurement Equivalence/Invariance. Structural Equation Modeling, 11(1), 60-72.
Meredith, W. B. (1993). Measurement invariance, factor analysis and factorial invariance. Psychometrika, 58(4), 525-543.
Raju, N. S., Laffitte, L. J., & Byrne, B. M. (2002). Measurement equivalence: A comparison of methods based on confirmatory factor analysis and item response theory. Journal of Applied Psychology, 87(3), 517-529.
Raykov, T., & Marcoulides, G. A. (2000). A Method for Comparing Completely Standardized Solutions in Multiple Groups. Structural Equation Modeling,
7(2), 292-308.
Reise, S. P., Widaman, K. F., & Pugh, R. H. (1993). Confirmatory factor analysis and item response theory: two approaches for exploring measurement invariance. Psychol Bull, 114(3), 552-566.
Schermelleh-Engel, K., Moosbrugger, H., & Muller, H. (2003). Evaluating the Fit of Structural Equation Models: Tests of Significance and Descriptive Goodness-of-Fit Measures. Methods of Psychological Research Online,
8(3), 23-74.
asymptotic distribution of sequential chi-square statistics. Psychometrika,
50(3), 253–264.
Vandenberg, R. J., & Lance, C. E. (2000). A review and synthesis of the measurement invariance literature: Suggestions, practices, and recommendations for organizational research. Organizational Research