A Diagnosis System Based on the Fractal Characteristics of Retinal Images of Diabetics
21
0
0
全文
(2) A Diagnosis System Based on the Fractal Characteristics of Retinal Images of Diabetics Shu-Chen Cheng1. Yueh-Min Huang2. Department of Engineering Science National Cheng Kung University E-mail:. 1. [email protected] 2. [email protected] Abstract. A novel diagnostic scheme to develop quantitative indexes of diabetes is introduced in this paper. The fractal dimension of the vascular distribution is estimated because we discovered that the fractal dimension of a severe diabetic patient’s retinal vascular distribution appears greater than that of a normal human’s. The issue of how to yield an accurate fractal dimension is to use high quality of images. To achieve a better image-processing result, an appropriate image-processing algorithm is adopted in this work. Another important fractal feature introduced in this paper is the measure of lacunarity, which describes the characteristics of fractals that have the same fractal dimension but different appearances. For those vascular distributions in the same fractal dimension, further classification can be made using the degree of lacunarity. As for the classification of diagnosis results, four different approaches are compared to achieve higher accuracy. In this study, the fractal dimension and the measure of lacunarity.
(3) have shown their significance in the classification of diabetes and are adequate for use as quantitative indexes. Keywords: Fractal Dimension, Lacunarity, Image-Processing, Back-propagation Algorithm, Radial Basis Function Network, Genetic Algorithm, Voting Scheme, Classification, Diagnosis System. 1. Introduction Clinically, the incidence of diabetic retinopathy (DR) is prevalent in patients diagnosed as having diabetes. DR has features of both micro vascular occlusion and leakage. The consequence of retinal capillary non-perfusion is retinal hypoxia, which, in turn, causes blindness. The fluorescein angiogram of a diabetic patient’s eye shows retinal vascular lesions caused by ischaemia. [1]. Relatively, severe retinal vascular disorders reflect higher degrees of diabetes. Therefore, an effective diagnostic scheme to develop quantitative indexes for diabetes is required. With these quantitative indexes, diabetics can maintain good metabolic control to retard the development of DR. Based on the aforementioned, this work is dedicated to the effort of establishing meaningful quantitative indexes. Due to the invariance when the scale is changed, the fractal dimension is adequate to quantify the degree of complexity [6]. Thus, the fractal dimension of the vascular distribution is estimated because we discovered that the fractal dimension of a severe diabetic patient’s retinal vascular distribution appears greater than that of a normal.
(4) human’s. Based on the fractal characteristics of a fluorescein angiogram, a diagnosis model can be derived to help a diabetic with metabolic or medication control. Because the fractal dimension is a quantitative index in this context, it is very important to implement appropriate image-processing procedures to obtain sound image results for accuracy. To reduce all possible noise, an appropriate image-processing algorithm is adopted in this work. In addition to the image-processing technique, the threshold of the original image resolution is also examined in this paper. In the past, the resolution factor was never involved when estimating the fractal dimension. From our experiments, a low-resolution image cannot yield an accurate fractal dimension. Therefore, we present a new scheme for checking whether the resolution of the source image is high enough. Because high image resolution cannot improve the accuracy of the fractal dimension, improving the image resolution for this process simply wastes disk space and computation time. Another important fractal feature introduced in this paper is the measure of lacunarity, which describes the characteristics of fractals that have the same fractal dimension but with different appearances [5] [6]. In the past, lacunarity has rarely been discussed in any kind of application, especially in biomedical applications. Actually, for those vascular distributions in the same fractal dimension, further classification can be made using the degree of lacunarity. Four different approaches, the back-propagation algorithm, the radial basis function network, the genetic algorithm and the voting scheme, are compared for diagnosis.
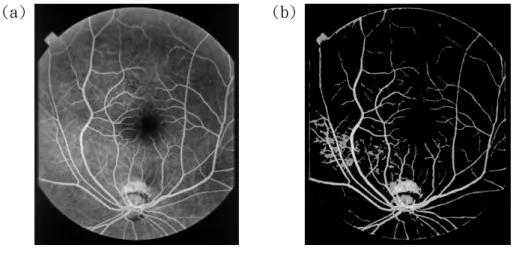
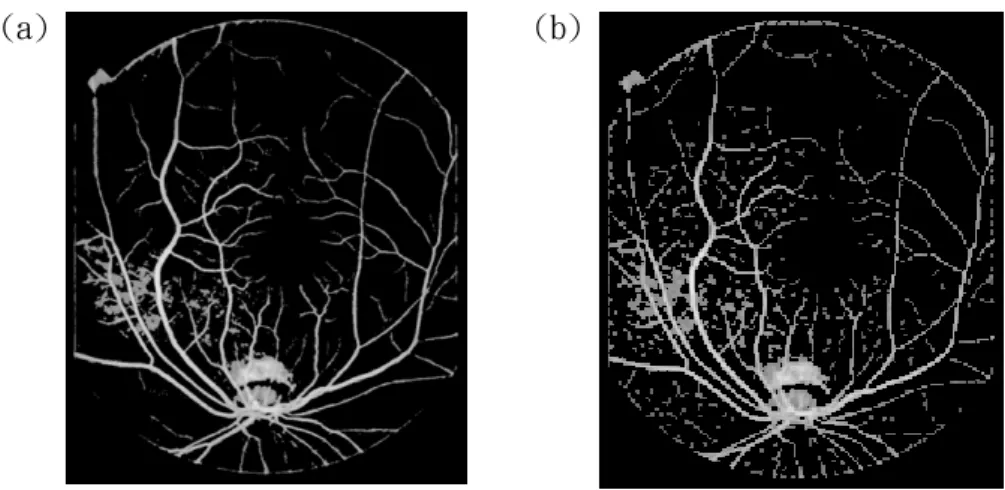
(5) classification results to achieve higher accuracy. 2. Image Processing To yield an accurate fractal dimension, an appropriate image-processing algorithm is very important to generate a high-quality result. The algorithm adopted is described as follows: (a). Divide the original image into small blocks and estimate a local threshold for each block depending on the corresponding gray-level histogram. In this case, the gray-level value of the brightest 20% of the pixels is assigned as a local threshold. The global threshold approach is not suitable for this case because it generates too much noise. (b). An edge detecting technique is adopted to reduce the noise from the previous procedure. In this case, pixels with gradients greater than 10 are defined as edges [2]. (c). Remove the remaining isolated points. Figure 1.(b) shows the segmented image vascular distribution for Fig. 1.(a) after processing using our approach. (a). (b). Figure 1: (a) Original image of a human retina; (b) Segmented result after image processing..
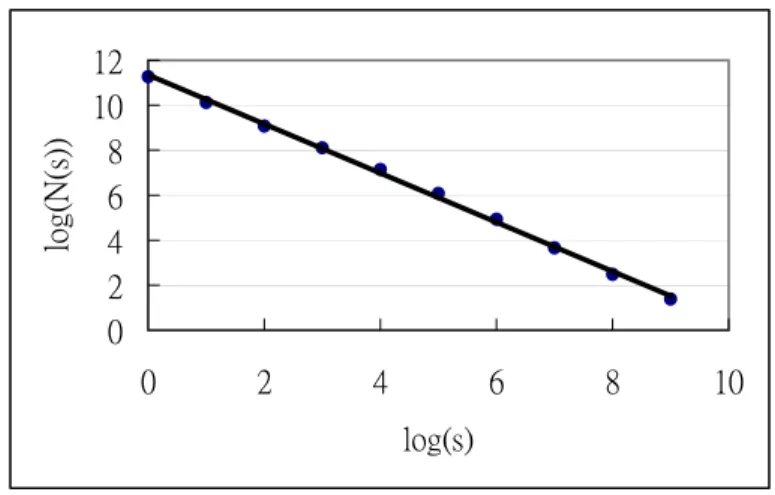
(6) 3. Fractal Dimension Demonstrating the fractal characteristics of a medical image is valuable, for it provokes the development of new ways to discover a new order in the world of complex phenomena and structures. In this work, not only the fractal dimension of the vascular distribution is estimated but the influence of the image resolution on the fractal dimension is also explored. The fractal dimension is calculated using the box-counting method [3]. First, the image is divided into regular meshes with mesh size s. The number N(s) of grid boxes containing any vessel parts are then counted. The number N(s) depends on the choice for s. In this case, we changed size s from 1 to 2k pixels and counted the corresponding number N(s), where k = 0, 1, 2,…. and 2k < image size. Second, the measurement in a log2 (N(s))/log2(s)-diagram is plotted. A straight line is then fitted to the plotted points in the diagram using the least square method [4]. As Mandelbrot suggested, a fractal set with the number N of boxes of size s obeys the power law [6]: N ( s ) = Ks − D. (1). where K is a constant and D denotes the dimension of the fractal set. Hence, the slope of the line is measured as (–Db) and Db is the box-counting dimension of the image. Figure 2 illustrates the above procedure and we find Db is approximately equal to 1.092..
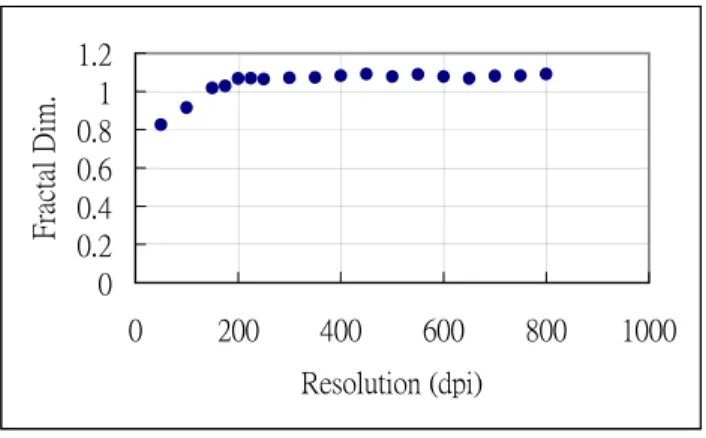
(7) log(N(s)). 12 10 8 6 4 2 0 0. 2. 4. 6. 8. 10. log(s). Figure 2: Box-counting dimension for Fig. 1.(b). (Db = 1.092) So far, we calculated the fractal dimension regardless of the image resolution. However, if the resolution of the original image is low beyond a certain degree, regardless what kind of image processing approach is implemented, it will be impossible to yield an accurate fractal dimension. Therefore, the appropriate resolution should be investigated before estimating the fractal dimension. In this case, we scanned an original image at different resolutions varying from 800 dpi to 50 dpi and then computed the corresponding fractal dimensions of the image. Figure 3 shows the results. We found that the fractal dimension would drop at 200 dpi resolution. This proves that a low-resolution image cannot yield an accurate fractal dimension. The fractal dimensions of images at a resolution higher than the lower bound all appear steady in value, that is, raising the resolution too high would simply waste the disk space and computation time. The fractal dimension accuracy cannot be improved using higher resolution of images..
(8) Fractal Dim.. 1.2 1 0.8 0.6 0.4 0.2 0 0. 200. 400. 600. 800. 1000. Resolution (dpi). Figure 3: Different resolutions and the corresponding fractal dimensions for Fig. 1.(b). 4. Lacunarity In this paper, the term lacunarity is introduced to describe the characteristic offractals that have the same fractal dimension but with different appearances. As suggested by Fender [5] and Mandelbrot [6], two data sets could look different in spite of the fact that they have the same fractal dimension.. This is because they have different lacunarity. The degree of. lacunarity is deduced from the gap size distribution. A distribution with a higher degree of lacunarity gives the impression of having definitely larger gaps and more clusters in the geometry. Conversely, a lower degree of lacunarity appears to have a more homogeneous distribution. For those vascular distributions in the same fractal dimension, further classification can be made using the lacunarity feature. Let P(m,L) be the probability that there are m intensity points within a box of size L. For any value of L,. N. ∑ P ( m, L ) = 1. (2). m =0. where N is the number of possible points in the box of size L. (N is equal to the number of pixels the box contains.).
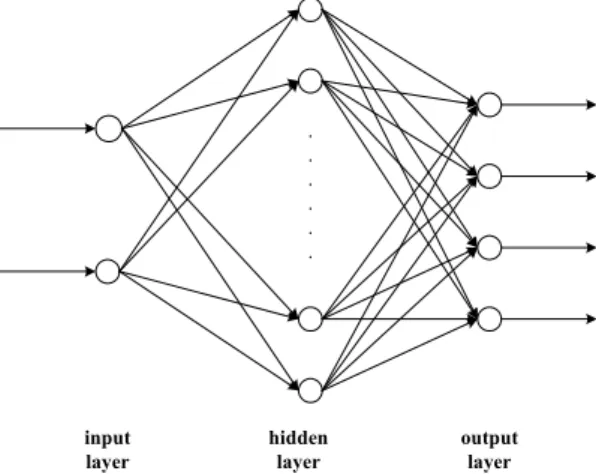
(9) N. M ( L) = ∑ mP(m, L). (3). N. (4). m =0. M 2 ( L ) = ∑ m 2 P ( m, L ) m=0. The definition of lacunarity is [16] Λ ( L) =. (5). M 2 ( L) − [ M ( L)]2 [ M ( L)]2. 5. Classification In this study, four different strategies are presented to accomplish classifying the degree of seriousness of the diabetes. Each of these strategies is described as follows: 5.1 Back-propagation algorithm The back-propagation algorithm is one of the most popular and widely used network-learning algorithms [7] [8] [9] [10]. The network architecture is illustrated in Fig. 4. The input layer consists of two nodes, which are the fractal dimension of the vascular distribution in the retinal image and its lacunarity, respectively. There are four nodes in the output layer, which indicate the degree of seriousness of the diabetes.. . . . . . .. input layer. hidden layer. output layer. Figure 4. The design of network architecture Consider a single neuron j, the output yj of this neuron at iteration n is a function (called.
(10) the activation function) of the total input vj fed to neuron j, (6). y j ( n) = f (v j (n)). Thus, vj is defined as m. (7). v j (n) = ∑ w ji (n) y i (n) + b j (n) i =1. where m is the total number of inputs applied to neuron j, wji(n) is the synaptic weight of the connection from neuron i to neuron j at iteration n, and bj(n) is the bias applied to neuron j. To satisfy the requirement of differentiability [8], the following activation function is chosen: f ( x) =. 1 1 + e −x. (8). To train the network, the synaptic weights are modified according to the error-correction learning rule. The error signal E to be minimized at the output of neuron j at iteration n is defined by E (n) =. 1 2. ∑[d (n) − y (n)] j. j. j∈C. 2. =. 1 2. ∑ e (n) 2 j. (9). j∈C. where the set C contains all of the neurons in the output layer of the network, dj(n) denotes the desired response for neuron j, and yj(n) refers to the function signal appearing at the output of neuron j at iteration n. The correction Δwji(n) applied to the synaptic weight is determined by the delta-rule: ∆w ji (n) = −η. ∂E (n) ∂w ji (n). where η is the learning-rate parameter.. (10).
(11) According to the chain rule, the gradient can be expressed as ∂E (n) ∂E (n) ∂e j ( n) ∂y j (n) ∂v j ( n) = ∂w ji ( n) ∂e j (n) ∂y j (n) ∂v j (n) ∂w ji ( n). = −e j (n) f ′(v j (n)) yi ( n). (11) (12). Hence, the correction Δwji(n) can be computed by: (13). ∆w ji (n) = ηδ j (n) yi ( n). where δj(n) denotes the local gradient and depends on whether neuron j is an output node or a hidden node [8]. For all of the neurons in the output layer, (14). δ j ( n ) = e j ( n ) f ′( v j ( n )). For all of the neurons in the hidden layer, j =l. δ k (n) = f ′(v k ( n))∑ δ j (n) w jk (n). (15). j. where δk(n) requires the sum of δj(n) computed for the neurons connected to neuron k in the next hidden or output layer, assuming that the output layer consists of l neurons. 5.2 Radial Basis Function Network Generally, classification tasks are more amenable to the radial basis function network than the back-propagation network [10]. A radial basis function network involves three layers. The higher the dimension of the hidden space, the more accurate the approximation will be [8]. The output units form a linear combination of the basis functions computed by the hidden units..
(12) Correspondingly, the number of nodes in the hidden layer is equal to the number of training data, while the input and the output layers are the same as in the back-propagation network. To make sure the interpolation matrix is nonsingular [8] [9] [10], the most common basis function chosen is a Gaussian function: Φ ( r ) = exp( −. r2 ) 2σ 2. (16). Hence, the output of hidden neuron j is calculated using O j = exp[ −. ( X − W j )2 2σ 2j. ]. (17). where X is the input vector, Wj is the weight vector associated with the hidden neuron j, and σj is the normalization factor. The closer the input to the center of the basis function, the greater the response of the neuron will behave [10]. For an output neuron j, its value yj is determined by (18). y j = f (v j ). Thus, vj is defined as m. vj =. ∑w. ji. yi + b j. (19). i =1. f ( x) =. 1 1 + e −x. (20). where m is the total number of inputs applied to neuron j, wji is the synaptic weight of the connection from neuron i to neuron j, and bj is the bias applied to neuron j. The normalization factor σj is determined by the average distance between the cluster center and the training data:.
(13) σ 2j =. 1 M. ∑( X − W ) j. (21). 2. where M is the total number of training data. Similar to back-propagation algorithm, the correction Δwji(n) can be computed by: ∆w ji = ηδ j y i. (22). where δj denotes the local gradient and is computed by δ j = ( d j − y j ) f ′( v j ). (23). where dj denotes the desired response for neuron j, and yj refers to the function signal appearing at the output of neuron j. 5.3 Genetic Algorithm It appears that implementing genetic algorithms to find a set of weights instead of applying gradient-based methods may be advantageous for supervised learning classification problems [12] [13]. The third strategy we proposed is a novel approach, which makes classification based on a neural network that implements the genetic algorithm for network learning. The input and the output layers are the same as in the back-propagation network. Inspired by the back-propagation network, the chromosome for the solution consists of six genes: (w1, w2, th1, th2, th3, th4) where w1 and w2 are the weight factors for the input 1 and 2, and th1, th2, th3 and th4 are the corresponding thresholds for the output 1,2,3 and 4..
(14) With some drawbacks when applied to high-precision numerical problems, the binary representation traditionally used in genetic algorithms is replaced by floating point representation [11]. The output yj is determined by yi = f(w1*x1+w2*x2)-thi-i where f(x) is defined by f ( x) =. 1 1 + e −x. (24). The solution for classification is the class i that has the minimum value of yi. The fitness function is calculated by summing errors between the desired output and the computed output over all the training examples. N. fitness = ∑ [d ( n ) − s( n )]2. (24). n =1. where N is the number of training samples, d(n) denotes the desired output and s(n) denotes the calculated result. Because each chromosome consists of six genes, the crossover operator may be performed on five positions of the crossing points randomly according to probability of crossover pc. The next operator, mutation, is performed on gene-by-gene basis according to probability of mutation pm. 5.4 Combining Multiple Classifiers based on a Voting Scheme As is often the case, for a specific application, each classifier could attain a different degree of accuracy, but none of them is totally optimal [14]. Some previous works have.
(15) shown that the combination of several complementary classifiers will improve the accuracy. The voting approach exhibits better performance independent of the fault distribution [15]. Accordingly, a voting scheme based on majority-voting rule is applied to the above three classifiers. Denote a pattern space P containing M mutually exclusive sets: P=C1∪ C2∪ ….∪ CM And Λ={1,2,…,M} Given the events e1(x), e2(x),…, eK(x), we must generate a new event E(x). A common rule to resolve this kind of situation is voting by majority. The majority-voting rule can be expressed using the following formula: K. if TE (x∈Ci ) = maxi∈Λ TE (x∈Ci ) > j, 2 E(x) = otherwise . M +1,. (25) where e ( x) = i. 1, when k and i ∈ Λ Tk ( x ∈ Ci ) = otherwise. 0, K. TE ( x ∈ C i ) =. ∑ T ( x ∈ C ), i = 1,2,..., M k. i. (26) (27). k =1. and E(x)=M+1 denotes that E(x) has no idea about which class x belongs to. 6. Experimental Results In this study, we investigated the influence of image resolution on the fractal dimension. As we can see in Fig. 3, fractal dimensions at resolutions lower than 200 dpi deviate from the.
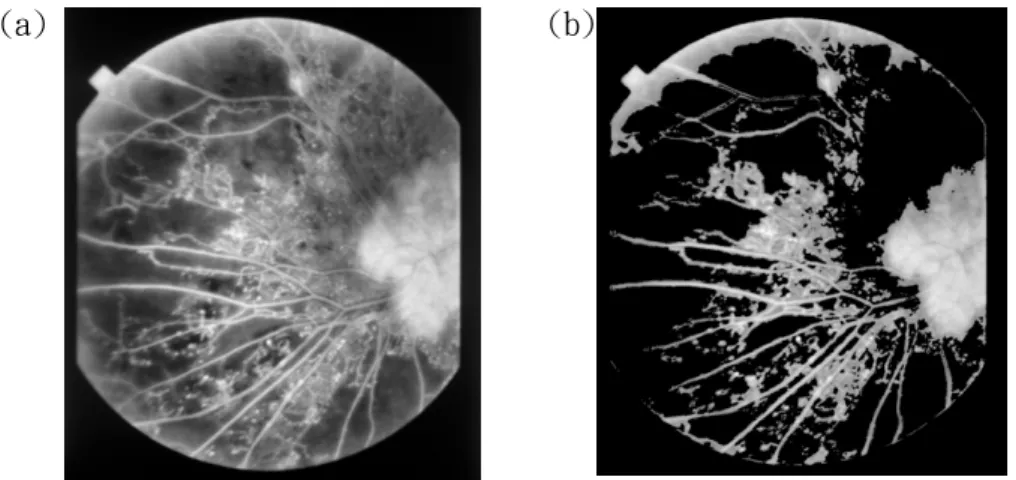
(16) steady values. When comparing the segmented results, we find that results at resolutions from 800 dpi to 225 dpi all appear to have the same quality. However, the segmented result at resolution 200 dpi shows a lot more noise than the other resolutions. Figure 5 illustrates a comparison of the results from different qualities. Therefore, 225 dpi would be recommended as the lower bound instead of 200 dpi. (a). (b). Figure 5: (a) Segmented result for Fig. 1.(a) at 800 dpi; (b) Segmented result for Fig. 1.(a) at 200 dpi. We also discovered that the fractal dimension of a severe diabetic patient’s retinal vascular distribution appears greater than that of a normal human’s. Figure 6.(b) shows the segmented image vascular distribution in Fig. 6.(a). using the same approach as implemented on Fig. 1.(a). The fractal dimension in Fig. 1.(b) is equal to 1.092 while that in Fig. 6.(b) is equal to 1.192. A greater fractal dimension indicates a more complicated structure. As we compare Fig. 1.(b) and Fig.6.(b), the vascular distribution of a diabetic patient’s retina appears more complicated than that of a normal individual’s..
(17) (a). (b). Figure 6: (a) Original image of a diabetic patient’s retina; (b) Segmented result after image processing. To make further classification, we investigated the lacunarity of each retinal vascular distribution image. Because the degree of lacunarity decreases when the gap size increases, a smaller gap size is obviously a better choice. In this study, the gap size chosen was 1 pixel to make the most distinction of lacunarity. In this study, 92 image samples were analyzed and 75 of them were used as the training data set. Figure 7 illustrates the results of all study samples. As we can see in Fig. 7, diabetic patients are divides into four groups, “normal”, “slight”, “medium”, and “severe”.. 10. Lacunarity. 8 normal 6. slight. 4. medium severe. 2 0 1.05. 1.1. 1.15. 1.2. 1.25. Fractal Dimension. Figure 7: The fractal dimension and corresponding lacunarity of study samples..
(18) BPN, RBF and GA classifiers converged after 100, 50 and 300 learning cycles respectively. In this case, the correctness remained stable when using different numbers of nodes, such as 2,4,6,12 and 18, in the hidden layer for BPN. The comparison of the correctness for different classifiers is illustrated in Fig. 8. BPN provided the highest correctness when the number of the training data exceeded 35, but its correctness dramatically descended with fewer training data. The correctness of the RBF network deviated firstly when the number of the training data was smaller than 60. The genetic algorithm can provide the highest correctness with the least amount of training data. The voting scheme did not always provide the highest correctness as supposed to, because sometimes there might be a majority of classifiers obtained the wrong solution concurrently. The best classification result was 89.2%. correctness. correctness. 1 0.9 0.8. BPN RBF. 0.7. GA. 0.6. Voting. 0.5 0.4 0. 10. 20. 30. 40. 50. 60. 70. 80. number of training data. Figure 8. The comparison of the correctness for different classifiers 7. Conclusions A novel diagnostic scheme to develop quantitative indexes for diabetes was introduced in this paper. The fractal dimension of the vascular distribution was estimated because we.
(19) discovered that the fractal dimension of a severe diabetic patient’s retinal vascular distribution appears greater than that of a normal human’s. The issue of how to yield an accurate fractal dimension is to use high quality of images. Another important fractal feature introduced in this paper was the measure of lacunarity, which describes the characteristics of fractals that have the same fractal dimension but different appearances. For those vascular distributions in the same fractal dimension, further classification can be made using the degree of lacunarity. In this paper, the influence of the image resolution on the fractal dimension was explored. We found that a low-resolution image cannot yield an accurate fractal dimension. The fractal dimensions of images at the resolution higher than the lower bound all appear steady in values. Using extraordinarily high-resolution images is simply a waste of disk space and computation time and cannot achieve higher accuracy of fractal dimension. As for the classification of diagnosis results, four different approaches, the back-propagation algorithm, the radial basis function network, the genetic algorithm and the voting scheme, were compared to achieve higher accuracy. In this study, the fractal dimension and the measure of lacunarity have shown to be so successful for the classification of diabetes that they are adequate for use as quantitative indexes. Acknowledgment We would like to thank Prof. Sung-Huei Tseng, MD, and Shih-Chin Lin, MD,.
(20) Department of Ophthalmology at National Cheng Kung University Hospital, for providing the fluorescein angiograms and their professional help. Reference [1] Kanski, “Clinical Ophthalmology”, Third Edition, Butterworth-Heinemann International. Editions, pp. 344-347, 1993. [2] R. C. Gonzales and R. E. Woods, “Digital Image Processing”, Addison-Wesley Publishing. Company, pp. 455-456, 1992. [3] H. O. Peitgen, H. Jurgens and D. Saupe, “Chaos and Fractals : New Frontiers of Science”,. Springer-Verlag, pp. 202-213, 1992. [4] S. Nakamura, “Applied Numerical Methods in C”, Prentice Hall International Editions, pp.. 294-296, 1993. [5] J. Fender, “Fractals”, Plenum Press, pp. 62-65, 1988. [6] B. B. Mandelbrot, “The Fractal Geometry of Nature”, New York, pp. 14-19, pp. 310-318,. 1983. [7] R. Rojas, “Neural Networks: A Systematic Introduction”, Springer, pp. 149-162, 1996. [8] Simon Haykin, “Neural Networks”, Second Edition, Prentice Hall International Editions,. pp. 161-175, 1999. [9] James A. Anderson, “An Introduction to Neural Networks”, The MIT Press, pp. 255-277, pp.. 454-459, 1995..
(21) [10] LiMin Fu, “Neural Networks in Computer Intelligence”, McGraw-Hill, pp. 80-96, 1994. [11] Zbigniew Michalewicz, “Genetic Algorithms + Data structures = Evolution Programs”,. Third Edition, Springer, pp. 97-106, 1999. [12] G. Winter, J. Periaux, M. Galan, and P. Cuesta “Genetic Algorithms in Engineering and. Computer Science”, Wiley, pp. 203-213, 1995. [13] Melanie Mitchell, “An Introduction to Genetic Algorithms”, Third Edition ,The MIT Press,. pp. 65-79, 1997. [14] L. Xu, A. Krzyzak, and C. Y. Suen, “Methods of Combining Multiple Classifiers and Their. Applications to Handwriting Recognition”, IEEE Transactions on Systems, Man, and Cybernetics, Vol.22, No.3, pp. 418-435, 1992. [15] J. Y. Lee, H. Y. Youn, and A. D. Singh, “Adaptive Unanimous Voting (UV) Scheme for. Distributed Self-Diagnosis”, IEEE Transactions on Computers, Vol.44, No.5, pp.730-735, 1995. [16] R. Candela, G. Mirelli, and R. Schifani, “PD Recognition by Means of Statistical and. Fractal Parameters and a Neural Network”, IEEE Transactions on Dielectrics and Electrical Insulation, Vol.7, No.1, pp. 87-94, 2000..
(22)
數據
+4

相關文件
Each unit in hidden layer receives only a portion of total errors and these errors then feedback to the input layer.. Go to step 4 until the error is
Keywords: pattern classification, FRBCS, fuzzy GBML, fuzzy model, genetic algorithm... 第一章
3 Distilling Implicit Features: Extraction Models Lecture 14: Radial Basis Function Network. RBF
A multi-objective genetic algorithm is proposed to solve 3D differentiated WSN deployment problems with the objectives of the coverage of sensors, satisfaction of detection
Moreover, this chapter also presents the basic of the Taguchi method, artificial neural network, genetic algorithm, particle swarm optimization, soft computing and
This study proposed the Minimum Risk Neural Network (MRNN), which is based on back-propagation network (BPN) and combined with the concept of maximization of classification margin
Keywords: light guide plate, stamper, etching process, Taguchi orthogonal array, back-propagation neural networks, genetic algorithms, analysis of variance, particle
Therefore, this study based on GIS analysis of road network, such as: Nearest Neighbor Method, Farthest Insertion Method, Sweep Algorithm, Simulated Annealing
